Cisco Nexus Dashboard Insights ホワイトペーパー、リリース 6.0.1
偏向のない言語
この製品のドキュメントセットは、偏向のない言語を使用するように配慮されています。このドキュメントセットでの偏向のない言語とは、年齢、障害、性別、人種的アイデンティティ、民族的アイデンティティ、性的指向、社会経済的地位、およびインターセクショナリティに基づく差別を意味しない言語として定義されています。製品ソフトウェアのユーザインターフェイスにハードコードされている言語、RFP のドキュメントに基づいて使用されている言語、または参照されているサードパーティ製品で使用されている言語によりドキュメントに例外が存在する場合があります。シスコのインクルーシブ ランゲージの取り組みの詳細は、こちらをご覧ください。
翻訳について
このドキュメントは、米国シスコ発行ドキュメントの参考和訳です。リンク情報につきましては、日本語版掲載時点で、英語版にアップデートがあり、リンク先のページが移動/変更されている場合がありますことをご了承ください。あくまでも参考和訳となりますので、正式な内容については米国サイトのドキュメントを参照ください。
 フィードバック
フィードバック
可視性、トラブルシューティング、根本原因の分析、およびネットワークの問題の修復は、日常のネットワーク運用に共通する課題です。レガシー ネットワーキング運用ツールを使用すると、これらのタスクは手動で行われ、時間がかかり、リアクティブになります。そのため、ネットワーク運用者は、長年の経験、ドメインに関する広範な専門知識、および複雑な IT 環境における異なるイベントを相互に関連付ける能力を有し、インフラストラクチャの稼働時間を維持して最小限の中断で問題を防止または修正できる必要があります。
最新のネットワーキング運用サービスである Cisco Nexus Dashboard Insights は、これらの運用タスクを簡素化し、自動化することを目的としています。すべてのデバイスからリアルタイムにストリーミングされたネットワーク テレメトリを取り込むことで、広範なインフラストラクチャの可視性を提供します。6.0 リリース以降、Nexus Dashboard Insights には統合サービスの一部として Cisco Network Assurance Engine(NAE)アプリケーションが組み込まれています。強力な保証および分析エンジンにより、ネットワークの動作状態を継続的に検証および確認しながら、運用者の意図からのあらゆる逸脱を事前に検出し、ネットワーク全体のさまざまな種類の異常を検出し、異常の根本原因を特定し、修復方法を特定します。これは、ネットワークの運用を最新化するためのツールであり、ネットワーク チームがトラブルシューティング作業を削減し、運用効率を向上させ、ネットワークの停止を予防的に防止するのに役立ちます。
注: この製品のマニュアルセットは、偏向のない言語を使用するように配慮されています。このドキュメントセットでの偏向のない言語とは、年齢、障害、性別、人種的アイデンティティ、民族的アイデンティティ、性的指向、社会経済的地位、およびインターセクショナリティに基づく差別を意味しない言語として定義されています。製品ソフトウェアのユーザインターフェイスにハードコードされている言語、RFP のドキュメントに基づいて使用されている言語、または参照されているサードパーティ製品で使用されている言語によりドキュメントに例外が存在する場合があります。
最新のデータセンターは、Cisco ACI™ や Cisco DCNMなどのコントローラを介して管理され、データセンター全体で自動化された一貫性のあるポリシー フレームワークを提供するためにネットワークの意図をキャプチャします。同じインテント ベースのポリシーを複数のデータセンター サイト、ブランチ、およびパブリック クラウドに拡張して、集中管理を実現できます。Cisco Nexus Dashboard Insights は、これらのネットワークサイトのDay2フェーズの運用を支援し、可視性、保証、相関ネットワークの異常のプロアクティブな検出、およびアプリケーション ビューを提供します。これにより、問題の特定、トラブルシューティングの迅速化、その後のこれらのサイトでの問題の修復に役立ちます。Cisco Nexus Dashboard Insights は、次のネットワーク特性とアーキテクチャを考慮して設計されています。
組み込みの自動化:ネットワーク設定はコントローラによって一元的に管理されるため、ネットワーク オペレータはデバイス設定をボックス単位で管理する必要がなくなります。中央集中型コントローラ方式を使用すると、ネットワーク全体で機能と設定の一貫性を維持しやすくなります。
スケーラブルなアーキテクチャ:規模、災害回避、ディザスタ リカバリなどのさまざまな理由により、最新のデータセンターは、単一のサイトから地理的に分散した複数の場所に、場合によってはパブリック クラウドにまで拡張されます。データセンターの規模が拡大すると、ネットワークの運用状態を把握するためのデータの収集と分析の複雑さが増します。同時に、アプリケーション ワークロードの分散が増加しているため、データセンター インフラストラクチャは、一度に数千から数百万のフローで実行できます。また、毎秒数百のメッセージまたはイベントがログに記録されることがあります。問題をトラブルシューティングするために、これらのフロー、ログ、スイッチを手動で関連付けることは、非常に困難で時間がかかる場合があります。
運用上の課題:オペレータが直面する課題は、ファブリック内の各スイッチから収集されたデータを把握し、Webアプリケーションの速度低下などの特定の問題に関連付けることです。これは、オペレータが必要とする知識と専門知識(通常は構築に時間がかかる)を持っているという厳しい期待を意味します。
Cisco Nexus Dashboard Insights は、これらの課題に対処し、次のような利点をもたらします。
● 予防的モニタリングとアラートによる運用効率とネットワーク可用性の向上:Cisco Nexus Dashboard Insightsは、ネットワークの動作を学習および分析してエンドユーザより先に異常を認識し、停止を防ぐのに役立つ予防的アラートを生成します。また、Cisco Nexus Dashboard Insights は、既知のデフォルト、PSIRT、または Field Notice に対するネットワークの脆弱性の影響をプロアクティブに特定し、プロアクティブな修復に最適なコースを推奨します。
● トラブルシューティングのための平均解決時間(MTTR)の短縮:Cisco Nexus Dashboard Insights は、パケット ドロップ、遅延、ワークロードの移動、ルーティングの問題、ACL のドロップなど、データプレーンの異常の根本原因分析を自動化することで、重要なトラブルシューティング時間を最小限に抑えます。さらに、Cisco Nexus Dashboard Insights は、時系列形式で表示される検索可能な履歴データを使用して、監査およびコンプライアンス チェックを支援します。
● キャパシティ プランニングのスピードと俊敏性の向上:Cisco Nexus Dashboard Insightsは、リソース使用率と履歴トレンドのファブリック全体の可視性により、キャパシティしきい値を超えるコンポーネントを検出して強調表示します。キャプチャしたリソース利用率によって時系列に基づくキャパシティの有効利用率が傾向としてわかるため、ネットワーク運用チームはサイズ調整や再構築、用途変更の計画が可能になります。
● 構成変更管理やソフトウェア アップグレードなどのネットワーク運用における効率性を高め、リスクを軽減します。6.0 リリース以降、Nexus Dashboard Insights は、ネットワーク運用者が実際のネットワークのスナップショットに対して意図した設定変更をテストおよび検証し、ネットワークへの変更の影響を把握し、変更内容を実稼働ネットワークに入力する前に修正してください。ネットワーク設定変更のリスクを最小限に抑えます。
Cisco Nexus Dashboard Insights の概要
Cisco Nexus Dashboard Insights は、ネットワーク運用のためのマイクロサービスベースの最新サービスです。Cisco Nexus Dashboard でホストされ、Cisco ACI および Cisco DCNM サイトがオンボーディングされ、これらのサイトからのそれぞれのデータが Cisco Nexus Dashboard Insights によって取り込まれ、関連付けられます。
Cisco Nexus Dashboard Insights は、トラブルシューティング、モニタリング、監査、計画、脆弱性など、当面のタスクに関連する重要事項にオペレータの注意を向けます。Cisco Nexus Dashboard Insights のすべての異常および分析結果には、 REST API 経由の外部システム、またはユーザが関連トピックにサブスクライブできる Kafka を使用してエクスポートされます。ユーザは、シビラティ(重大度)とリズムとともに表示する異常タイプをカスタマイズするオプションを使用して、異常に関する電子メール通知を受信することもできます。
ネットワーク モニタリング、分析、および保証は、Nexus Dashboard Insights のコア機能ですが、ネットワーク運用の効率を高め、ネットワーク運用のリスクを軽減するためのその他の多くの機能とツールを提供します。以下に、Nexus Dashboard Insights の主要コンポーネントを示します。
ネットワーク テレメトリによるデータセンターの完全可視化と分析
Nexus Dashboard Insights は、ネットワーク デバイスからネットワーク テレメトリ データを受信します。コントロール プレーンとデータ プレーンの操作とパフォーマンスの両方を含むテレメトリ データを通じて、きめ細かい可視性を取得します。ネットワークのベースライン動作を分析して学習し、ネットワークの異常を検出します。異常は、Insights UI または電子メール通知を介してネットワーク運用チームに報告され、Kafka エクスポートや直接 API コールなどのプログラムによる方法で他のツールに送信できます。
数学的モデリングによるスナップショット ベースのネットワーク保証
6.0 のリリースでは、Nexus Dashboard Insights は元の Network Assurance Engine(NAE)アプリケーションから保証分析エンジンを継承しました。保証エンジンは、定期的にネットワークの完全なスナップショットを継続的に取得し、ネットワークとその時点での動作を表す各スナップショットの数学モデルを構築します。次に、このモデルに対するネットワークの動作を分析します。ネットワーク設定のエラーをチェックし、ネットワーク設定と実際の動作状態との整合性を検査します。構成の問題、構成と動作状態の不一致、またはネットワーク コンポーネントの不正な動作は、ネットワーク異常として報告されます。ネットワーク設定、ポリシースペース、接続性、およびエンドポイント スペースを保証します。アシュアランス機能は、自動化されたトラブルシューティング プロセスの包括的なコレクションであり、長年のネットワーク設計、導入、およびサポート エクスペリエンスを通じて蓄積された深い知識ベースに基づいて開発されています。
One View による集中型ネットワーク インサイト
組織は、多くの場合、地理的に分散した複数のデータセンター サイトを展開することで、データセンターを拡張します。これにより、ネットワークイン フラストラクチャのフラグメント化されたビューが作成され、2 日目の運用チームにとって課題が発生し、インシデントの検出、相関、および解決が遅くなります。Nexus Dashboard 2.1 リリース以降、ユーザは複数の Nexus ダッシュボード クラスタをリンクして、この1つの中央ポイントからネットワーク サイトを操作し、すべてのネットワーク サイトの操作の集約ビューを取得できます。Nexus ダッシュボードの「One View」機能により、Insights サービス自体が、リンクされた Nexus ダッシュボード上のすべてのネットワーク サイトを一元化して可視化し、同じInsights UI で異なるサイト間をスムーズに移動できるようになりました。
リスクのない構成変更管理のための変更前の分析
ネットワーク構成変更管理は、リスクを伴う運用と見なされてきました。これは、ネットワーク チームが、製品ネットワークに変更を実装する前に変更を完全に認定するための優れたツールを持っていなかったためです。変更前分析は、Cisco Network Assurance Engine(NAE)が元々提供していた機能で、意図した設定変更を完全にテストするためのツールをネットワーク チームに提供することで、この課題に対処します。Cisco NAE は、Cisco Nexus Dashboard Insights リリース 6.0 に統合されています。Insights ユーザは、同じ変更前検証機能を最大限に活用して、ネットワークの最新のスナップショットに対して設定の変更をプロアクティブに検証できます。これは、ネットワーク運用チームが待ち望んでいた機能です。これで、目的の変更を Insights サービスに送信するだけで済みます。Insights サービスは、ネットワークへの変更の影響を分析し、エラーまたは潜在的な問題がある場合はそれらを呼び出します。ネットワーク チームは、エラーを確認して修正し、完全修飾された設定変更のみをネットワークに実装する機会を得ます。この変更前分析機能は、ネットワーク設定変更管理から推測作業を排除し、変更管理のリスクを最小限に抑え、ネットワーク全体の可用性を向上させます。
自動継続的コンプライアンス保証
ほとんどの組織には、ネットワークに関するいくつかのタイプのコンプライアンス要件があります。これは、業界の規制コンプライアンス要件、またはセキュリティまたはビジネス機能に関する組織の内部要件です。さらに、ネットワーク チームには、確立されたベスト プラクティス、標準設定、または標準化された命名規則があり、それらを継続的なネットワーク運用中に実装または適用することがよくあります。これらの要件はすべて、Nexus Dashboard Insights のコンプライアンス保証機能によって保証されます。これらの機能は、当初は Cisco NAE アプリケーションに含まれていましたが、6.0 リリース以降、Insights サービスの一部になりました。
Insights サービスのコンプライアンス保証機能により、ネットワーク チームは、ネットワークのインテントを直接記述して送信することができ、ネットワークのインテントを自動的かつ継続的に検証および検証できます。インテントからの逸脱はコンプライアンス違反の異常としてキャプチャされ、ネットワーク チームにただちに報告されます。自動化された継続的なセキュリティと設定コンプライアンス分析により、Nexus Dashboard Insights は真のインテントベースのネットワーク運用を実現します。
自然言語を使用したデータベースのようなデータベースのクエリ
Explorer は、元々は Cisco NAE アプリケーションでしたが、6.0 リリース以降、Nexus Dashboard Insights の一部になりました。これは、ネットワーク チームが自然言語ベースのクエリを使用して、データベースのようにネットワーク全体を便利に探索するためのツールです。Explorer は、「EPG A が EPG B と通信できるか」などの質問に答えることができます。「どのように話せますか」「テナント スペース X に導入されている VRF」「リーフ スイッチ 101 ポート 1/1 に接続されているエンドポイント」これは、オブジェクトを検索し、オブジェクトがネットワーク内でどのように関連付けられているかを検出するための非常に効率的な方法です。
ネットワーク オペレータは、自然言語クエリを簡単に作成して、検出タスクを効率的に実行できます。たとえば、ネットワーク全体の何千もの特定のエンドポイントなど、特定のオブジェクトをすばやく特定したり、単にネットワーク内の特定のネットワーク オブジェクト タイプのデバイスごとまたはネットワーク全体のインベントリを取得したり、ネットワークの過去または現在のスナップショットを使用して通信できるか、または互いに分離されているネットワーク全体のさまざまなオブジェクト間の通信関係を示します。
Explorer は、ネットワーク設定、動作状態、およびネットワーク変更計画などのトラブルシューティングに役立つ効果的なツールです。
ネットワーク ソフトウェアのアップグレードを簡単かつ安全に
Nexus Dashboard Insights は、6.0 リリース以降、ソフトウェア アップグレード分析を提供し、ソフトウェア アップグレード ワークフローのリスクを軽減します。ネットワーク チームがアップグレードに適したターゲット ソフトウェア バージョンを選択するのに役立ちます。アップグレード前の分析結果に基づいて、ネットワーク チームは、ネットワーク内の特定された問題または障害(存在する場合)をクリアすることでアップグレードの準備を行い、更新によってどのような問題が解決されるかを明確に予測し、ターゲット バージョンは、新しい警告を導入します。アップグレード後の分析では、アップグレード前とアップグレード後のネットワーク状態(エンドポイント、ルート、インターフェイス ステータスなど)の違いがネットワーク チームに示されるため、ネットワークが問題なくアップグレードされたかどうかをすばやく確認できます。不足している場合。アップグレード前後の分析により、ソフトウェアアップ グレードの操作が簡単かつ安全になります。
Cisco Nexus Dashboard Insights の重要なコンポーネント
以下のセクションでは、Cisco Nexus Dashboard Insights の主要コンポーネントについて説明します。これらのオプション(およびサブ カテゴリ)は、サービスの左側のパネルで使用できます。
Cisco Nexus Dashboard Insights サイトの概要
これは、注意が必要なサイト レベルの異常(問題)を直接表示します。これらはすべて Cisco Nexus Dashboard Insights によって計算されます。異常は [概要(Overview)] 画面に統合され、カテゴリとシビラティ(重大度)でソートされます。Insights サービスは、上位ノード、タイムライン ビュー、サイト ヘルス スコア、およびアドバイザリによって異常をさらにグループ化します。最後に、ロール別のノード インベントリ、および対応するヘルス スコアにより、ノードレベルの詳細な可視性へのクリック アクセスが可能になり、観察された異常の傾向など、ノードに関するすべての詳細情報が得られます。
Cisco Nexus Dashboard Insights では、サービスに表示されるチャートのカスタム ダッシュボードを作成することもできます。
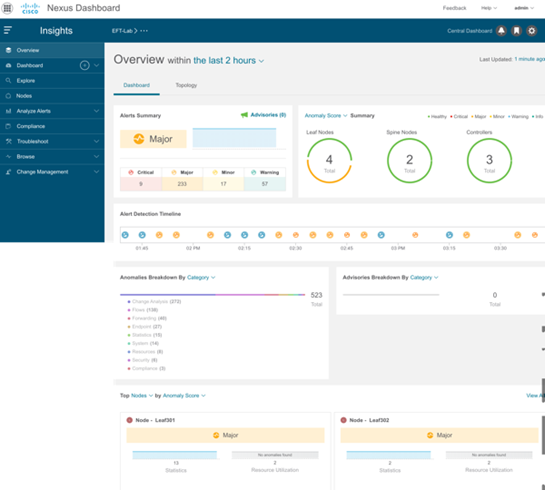
動作状態がオーバーレイされたインタラクティブ ネットワーク トポロジ
ファブリックとノードの接続方法をグラフィカルに表示します。ユーザは、スイッチのロール、ノードのスコア、VRF、EPG、BD などに基づいてフィルタを選択し、トポロジ ビューで問題を特定できます。
アラート分析
異常とアラートの要約サマリー表示に加えて、Nexus Dashboard Insights ユーザは、サービスによって生成された異常とアドバイザリ アラートをインタラクティブに参照、検索、および分析することもできます。
異常とは、次のネットワーク操作に関する問題です。
o リソース使用率
o 電源障害、メモリ リーク、プロセス クラッシュ、ノードのリロード、CPU、メモリ スパイクなどの環境問題
o CRCエラー、DOM 異常、インターフェイスのドロップ、既存のネイバーとの接続の切断などの BGP の問題、PIM、IGMP フラップ、LLDP フラップ、CDP の問題などのインターフェイスおよびルーティング プロトコルの問題。
o ハードウェア テレメトリおよび直接ハードウェア エクスポートを使用した、フローのドロップの場所と理由、異常な遅延スパイク。ハードウェア テレメトリのもう1つの形式であるフロー テーブル イベント(FTE)を使用した、スイッチに似たバッファ、ポリサー、転送ドロップ、ACL またはポリシー ドロップなどのイベントによって影響を受けるフロー
o エンドポイントの重複、迅速なエンドポイントの移動、不正なエンドポイント
o ネットワーク設定の問題:変更分析の異常として検出および報告
o コンプライアンス保証のコンプライアンス要件への違反:コンプライアンス異常として検出および報告
o ネットワーク転送分析および保証で検出された問題:転送異常として検出および報告
o AppDynamics および Cisco Nexus Dashboard Insights で計算されたアプリケーションの問題(AppD の統合が必要)
また、既知のシスコの警告およびノードレベルでのベスト プラクティス違反の影響を受けていることも示されます。
アドバイザリ:Nexus Dashboard Insights は、Field Notice、ソフトウェア/ハードウェア製品の EOL / EOS アナウンスメント、およびモニタリングしているネットワーク サイトに影響を与える可能性のある PSIRT を特定し、ネットワーク運用チームにアドバイザリ アラートを生成します。アラートは、特定された Field Notice、EOL / EOS、または PSIRT の関連する影響、およびネットワーク内の影響を受けるデバイスから構成されます。また、Nexus Dashboard Insights は、ハードウェア/ソフトウェアのバージョン、ネットワークで有効になっている機能、およびネットワーク設定に基づいて、特定のネットワーク環境に関連する既知の不具合について、ネットワーク運用チームにアラートを出すためのターゲット バグ スキャンも実行します。これにより、ネットワーク チームは、影響を受けるスイッチで迅速に修復アクションを実行したり、ソフトウェアまたはハードウェアのアップグレード計画を作成したりできます。
ネットワーク デルタ分析
6.0 リリース以降、Nexus Dashboard Insights はネットワーク デルタ分析を実行できます。これは、Cisco NAE アプリケーションから継承された機能です。Insights サービスのユーザは、ネットワーク サイトの任意の 2 つのスナップショットを選択し、設定の違いや、ネットワークの 2 つの時間ポイントにおけるネットワークの動作の違いを明らかにする異常やアドバイザリの違いなど、それらの間の違いを分析するようInsightsに依頼できます。
ネットワークの設定と操作の違いを理解することは、多くの異なるシナリオで重要であり、非常に役立ちます。ネットワークの問題のトラブルシューティングを行う場合、ネットワークの設定や運用の違いが問題の原因を特定するのに役立つことがよくあります。設定の変更、ソフトウェアのアップグレード、ハードウェアの交換などのネットワーク メンテナンスを実行する場合は、メンテナンス タスクの前後にネットワークの違いを確認すると役立ちます。ネットワークがタスクの終了後の状態に収束または回復したかどうか、タスクが解決すべき問題を解決したかどうか、または新しい問題が発生したかどうかを判断できます。差分分析機能は、これらのメンテナンス タスクのネットワーク運用効率を向上させ、トラブルシューティングの平均解決時間(MTRR)の短縮に役立ちます。
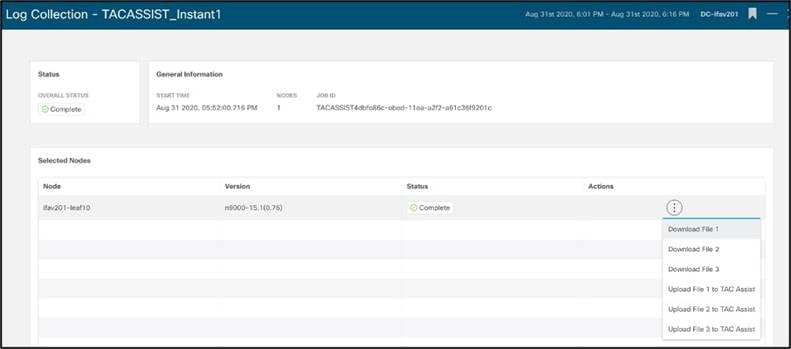
ログ コレクタ
Nexus Dashboard Insights は、ネットワーク チームがノードごとにテクニカル サポート ログを収集するのに役立ちます。これにより、退屈なタスクがシンプルなワンステップの自動化されたジョブに変わります。これらのログはローカルでダウンロードでき、オプションで Cisco Cloud にアップロードして、サービス リクエスト(SR)を開くときに Cisco Support で使用できるようにすることもできます。
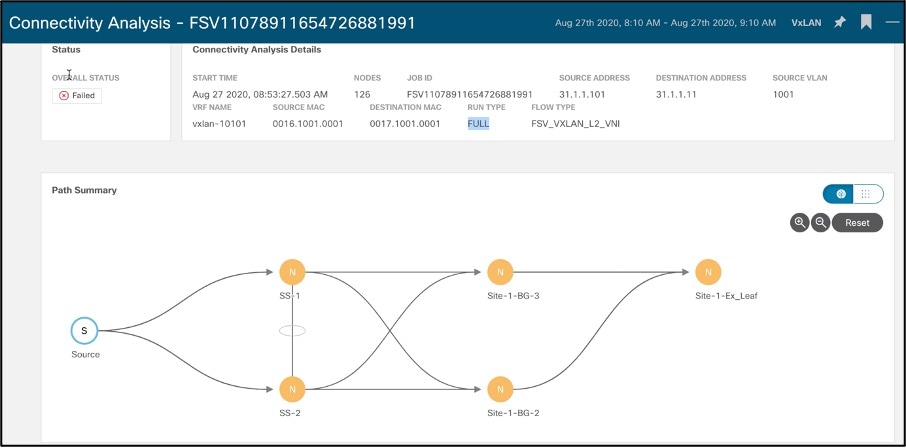
接続の分析
ユーザは、1 つの NX-OS ネットワーク サイト内のフローまたは複数の NX-OS ネットワーク サイトにまたがるフローについて、迅速または完全な分析を実行できます。
o 送信元から宛先エンドポイントまでの特定のフローで考えられるすべての転送パスをトレースする
o 問題のある問題のデバイスを特定し、フローがドロップする
o フォワーディング パス チェックの実行、整合性チェッカによるソフトウェアおよびハードウェア状態のプログラミングの一貫性、パケット ウォークスルーやパケット キャプチャによるルックアップ結果に関する詳細など、問題の根本原因を絞り込むのに役立ちます。
次のスクリーンショットは、完全な整合性チェックの実行中にフローが通過できるパスの例を示しています。これらの問題はデバッグに時間がかかり、接続分析はユーザ主導の方法でこれらの問題の迅速な分析を提供します。
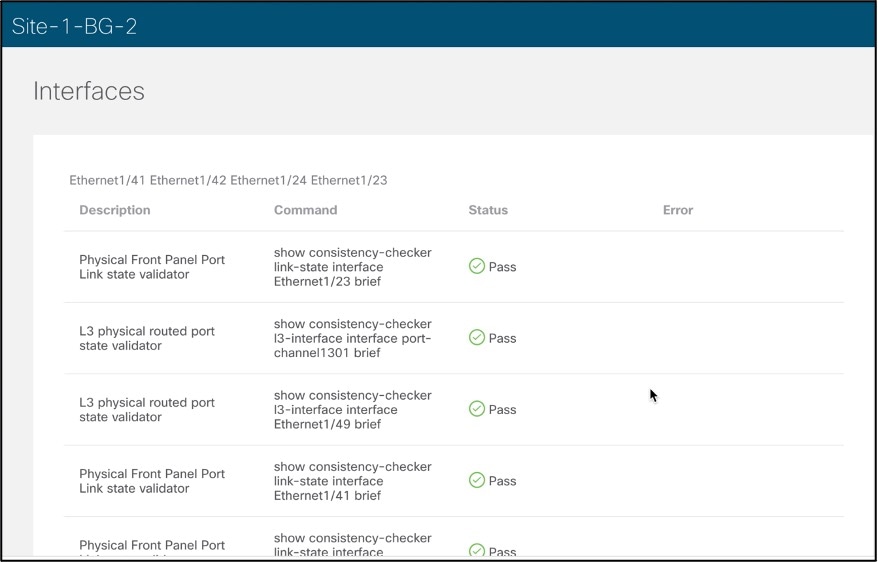
Cisco Nexus Dashboard Insights の参照
Cisco Nexus Dashboard Insights で利用できる参照機能について詳しく見てみましょう。以下のデータ セットのいずれかで観察されたすべての異常は、注意を引くために、それぞれのサイトのダッシュボードビューに展開されます。
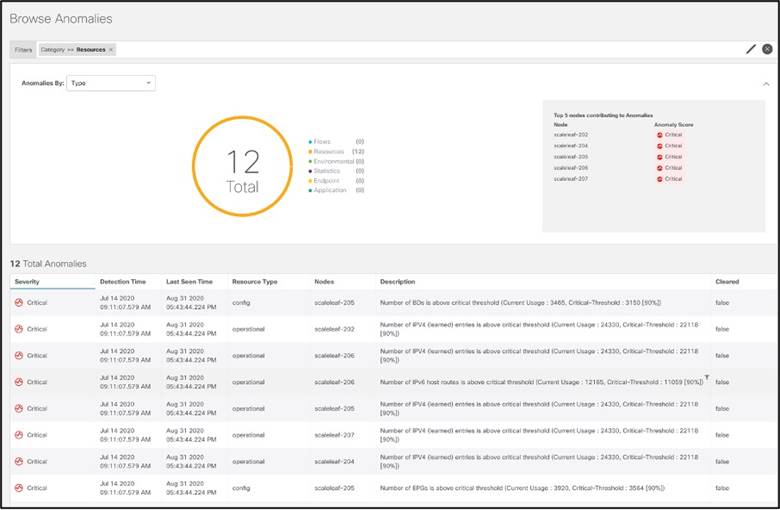
リソース
リリースごと、リソースごと、およびネットワーク内のハードウェアがサポートするスケールごとに、ソフトウェアで検証された規模を追跡するのは面倒です。さらに、ノードごとのリソース使用率を経時的に追跡し、これらのリソースに違反時に通知されるように静的しきい値を設定しても、動的に成長するネットワークには対応できません。これを解決するために、Cisco Nexus Dashboard Insights はリソースの使用率をベースライン化し、傾向をモニタし、ノード全体のリソースの異常な使用に関する異常を生成して、ユーザがネットワークのキャパシティを計画できるようにします。
リソース使用率は、各サイトのノードから収集されたソフトウェア テレメトリ データを相関させることで、キャパシティ使用率の時系列ベースの傾向を示します。一貫した傾向があれば、負荷の高いインフラストラクチャを特定し、リソースのサイズ変更、再構築、転用を計画することができます。
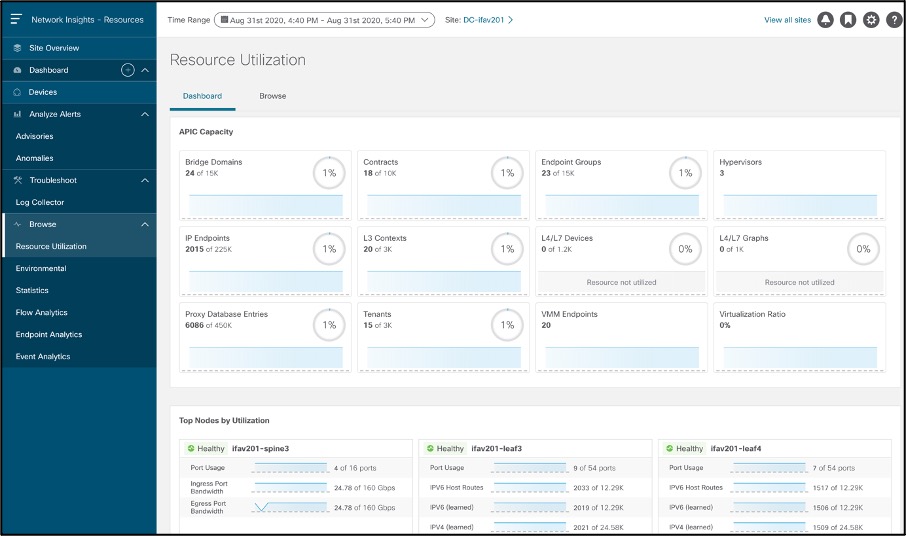
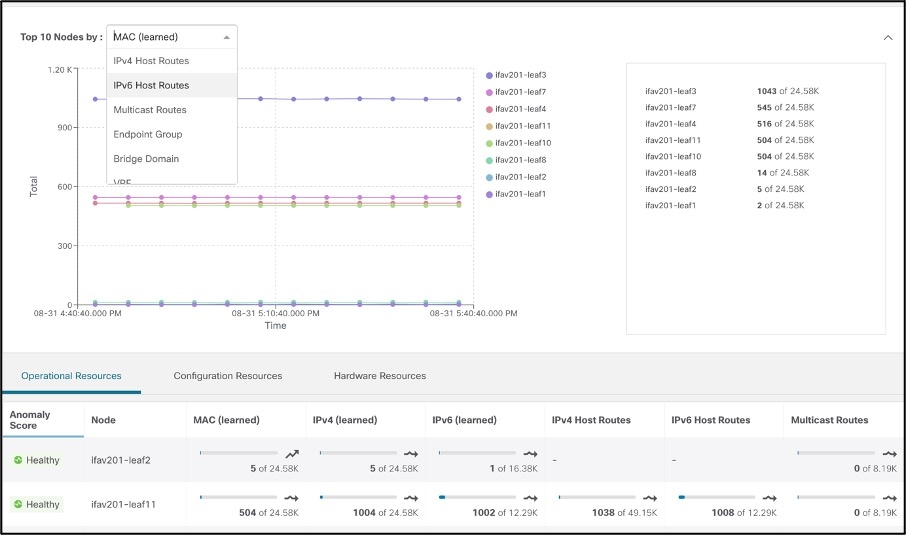
リソース使用率では、キャパシティの使用率が次のように分類されます。
● 運用リソース:短い間隔で使用率が変化することが想定される一時的なリソースのキャパシティを示します。例としては、ルート、MAC アドレス、セキュリティ TCAM などがあります。
● 設定リソース:VRF、ブリッジドメイン、VLAN、EPG の数など、設定によって異なるリソースのキャパシティ使用率を示します。
● ハードウェア リソース:ディスプレイ ポートと帯域幅容量の使用率を示します。
デバイスをドリル ダウンすると、リソースを大量に消費しているプロセスの詳細が表示されます。リソース使用率が 70% の容量しきい値を超えると、黄色で色分けされます。 80% を超えるとオレンジ色に、90% を超えると赤色に色分けされます。これにより、注意を必要とする特定のリソースについて、ネットワーク運用者に予防的に警告します。
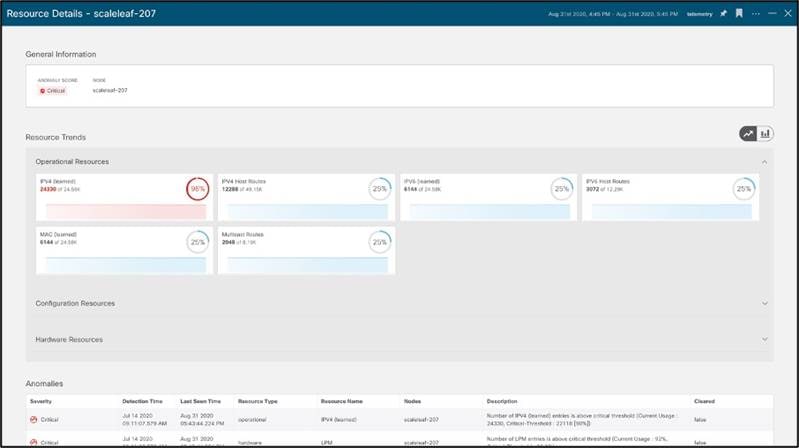
これは、履歴の傾向と変化率に基づいて異常を予測し、リソース不足を予測するのにも役立ちます。例については、次のスクリーンショットを参照してください。
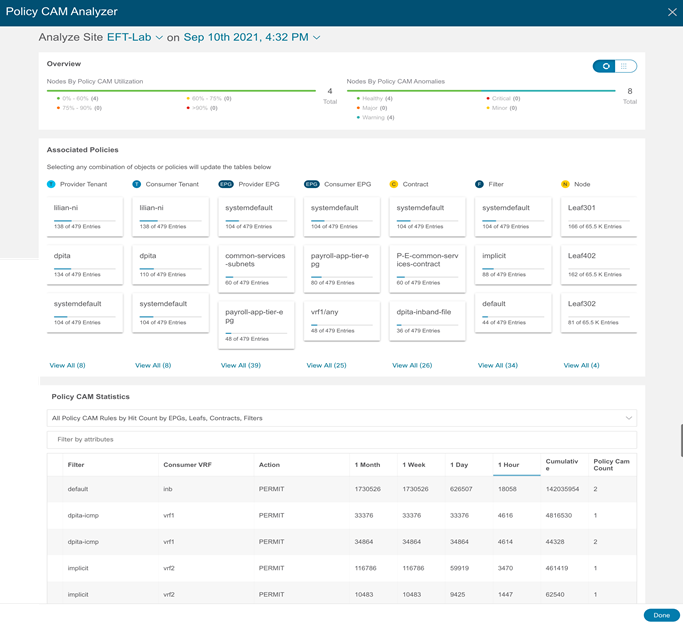
ACI ネットワーク サイトのポリシー TCAM 分析に関しては、Nexus Dashboard Insights はそれをモニタするだけでなく、ネットワーク チームがサイトまたはスイッチ レベルでコントラクトごとまたはフィルタごとの使用状況を分析できるようにします。これにより、ネットワーク チームは、最も多くの TCAM を使用しているコントラクト(グローバルまたはスイッチ レベル)を簡単に理解でき、実際のトラフィックでコントラクトがどれだけ使用されているかを把握できます。これにより、ネットワーク チームは未使用のコントラクトを削除したり、高 TCAM 消費コントラクトを最適化したりできます。
環境
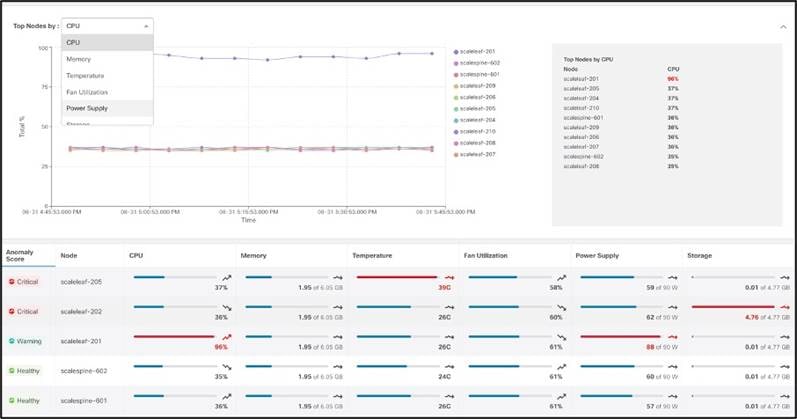
ほとんどの場合、環境データは SNMP、CLI などの従来のアプリケーションを使用してモニタされます。これらのアプリケーションからのデータは、後処理が難しく、デバイス固有であり、本質的に履歴ではなく、手動によるチェックが必要です。したがって、環境の異常のモニタリングは非常に反応的で扱いにくいものになります。Cisco Nexus Dashboard Insights は、ストリーミング ソフトウェア テレメトリを使用して環境データを消費し、使用率が事前に設定されたしきい値を超えるたびに傾向をベースライン化します。これにより、ユーザは完全な可視性を持ちながら、どのプロセスが CPU を消費しているか、メモリを占有しているか、ストレージがいっぱいになったか、プロセスがクラッシュしたか、またはメモリ リークがあるかどうかを判断できます。
環境データ分析機能によって、CPU、メモリ、温度、ファン速度、温度、電力、ストレージなどのハードウェア コンポーネントにおける異常を検出できます。他の画面と同様に、しきい値を超えるコンポーネントが強調表示され、運用者の注意が促されます。
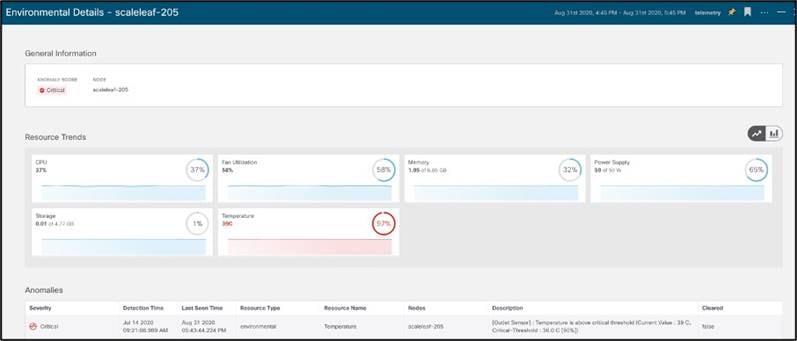
より詳細な画面では、ハードウェア コンポーネントの異常をより詳細に確認できます。
統計情報
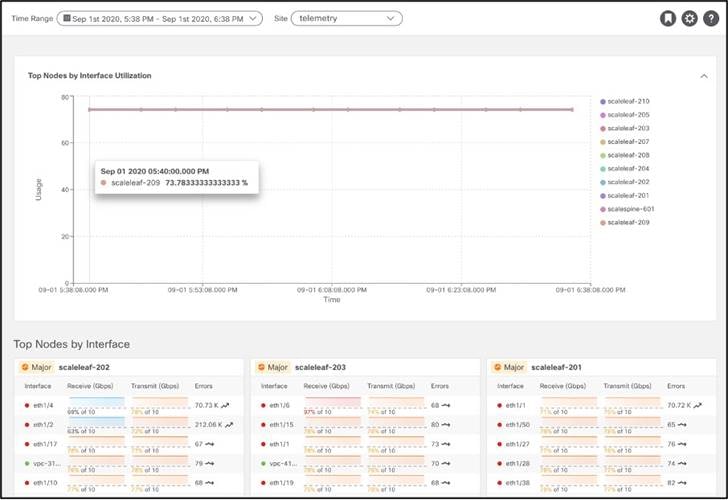
統計情報は、インターフェイスとルーティング プロトコルに関するものです。Cisco Nexus Dashboard Insights は、ストリーミング ソフトウェア テレメトリを使用して、ファブリック内の各ノードからデータを取り込みます。その後、データをベースライン化して傾向を導き出し、これらのデータ セットのいずれかがインターフェイス使用率の急激な低下(たとえば、時間の経過に伴うドロップまたは CRC エラーの急激な増加)を示すタイミングを特定します。
ダッシュボード ビューには、インターフェイスの使用率とエラー別に上位ノードが表示されるため、ユーザはインターフェイスをすばやく特定してエラーを調査できます。
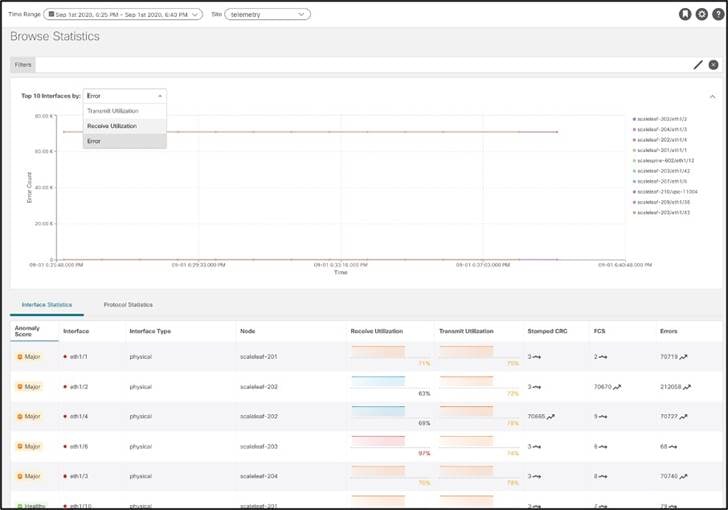
[参照(Browse)] ビューでは、インターフェイスおよびプロトコルの統計情報を詳しく調べることができます。
インターフェイス統計情報は、CRC、FCS、ストンプ CRC などの使用率の傾向を表示します。
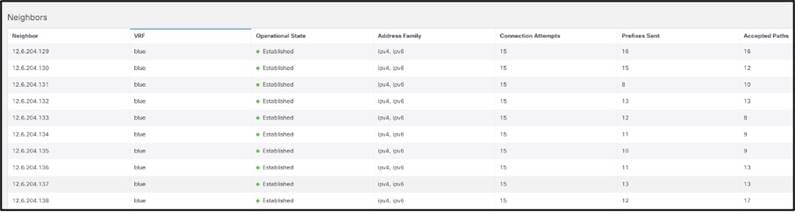
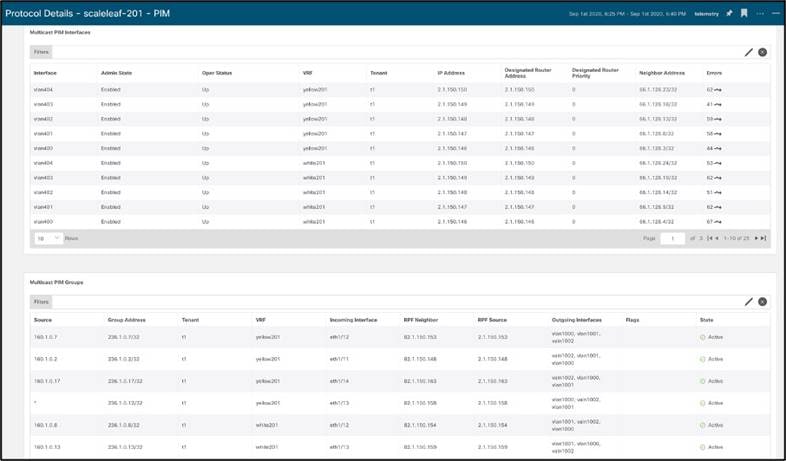
プロトコル統計情報は、CDP、LLDP、LACP、BGP、PIM、IGMP、IGMP スヌープなどのプロトコルがアクティブであるインターフェイス、ネイバー、着信、OIF などのプロトコルの詳細を(*,G)、(S,G)エントリに表示します失われた接続またはネイバー、OIF フラップ、無効なパケットなどのエラーの傾向
BGP ネイバーの例:
PIM インターフェイスとグループの例:
統計データは、Cisco Nexus Dashboard Insights の相互関係にも使用されます。たとえば、CRC エラーが発生した場合、Cisco Nexus Dashboard Insights は他のデータ セットを使用して推定影響(影響を受けるエンドポイントなど)を検出し、その時点で確認された他の異常(DOM 異常など)に基づいて推奨を提供します。 CRC エラーが発生する可能性があります)。
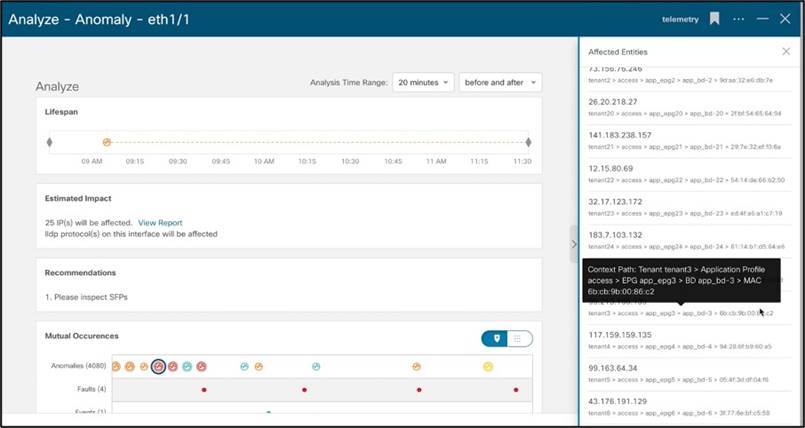
Flows
アプリケーションの問題ですか、それともネットワークの問題ですか? これは、データセンターの世界でよく寄せられる質問です。どちらかといえば、常にネットワークから始まります。データセンターでビジネス クリティカルなアプリケーションを扱う場合、無害化までの時間と解決までの平均時間が不可欠になります。今日のネットワーク運用のツールでは、データ プレーン カウンタ、フロー、遅延、ドロップに関するインサイトが非常に限られています。ネットワーク スイッチからデータプレーン フロー データを取得できたとしても、個々のスイッチからのデータをつなぎ合わせて、ネットワークを通過するフローのエンドツーエンド ビューを形成するにはどうすればよいでしょうか。フロー データからフローのエンドツーエンド ネットワーク遅延を抽出するにはどうすればよいですか。以前は、限られた支援ツールでこれらの複雑なフロー分析タスクをすべて実行する必要があったネットワーク チームでした。つまり多くの労力を意味します。Cisco Nexus Dashboard Insights では、フロー テレメトリを使用して、サービスがフロー レコードとそれぞれのカウンタを消費し、このデータを経時的に関連付けて、エンドツーエンドのフロー パスと遅延を提供します。Cisco Nexus Dashboard Insights は、各フローの「通常の」遅延を認識します。遅延がこの正常値を超えると、ユーザに警告が表示され、異常な遅延の増加がダッシュボードに異常として示されます。
フロー分析ダッシュボードでは、インフラストラクチャ データ プレーンの状態に関する重要な指標が管理者に提示されます。時系列データによって、過去の傾向、特定のパターン、過去の問題に関する情報が得られるため、管理者は、監査、コンプライアンス、キャパシティ プランニング、インフラストラクチャ評価に関するケースを構築できます。フロー分析ダッシュボードには、次に示すように時系列ベースのサマリー データが表示されます。グラフをクリックすると、特定の機能でドリル ダウンできます。
● 平均ノード別の上位ノード:上位ノードの平均エンドツーエンド遅延を表示します。これにより、エンドツーエンドの遅延が最大のフローを持つ出力ノードが生成されます。
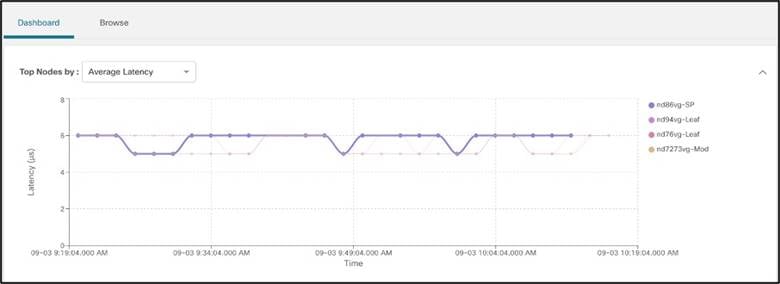
ノードをクリックすると、そのノードを出力ノードとするすべてのフローが生成されるため、ユーザは特定の出力ノードを通過する高遅延の上位フローにドリル ダウンできます。
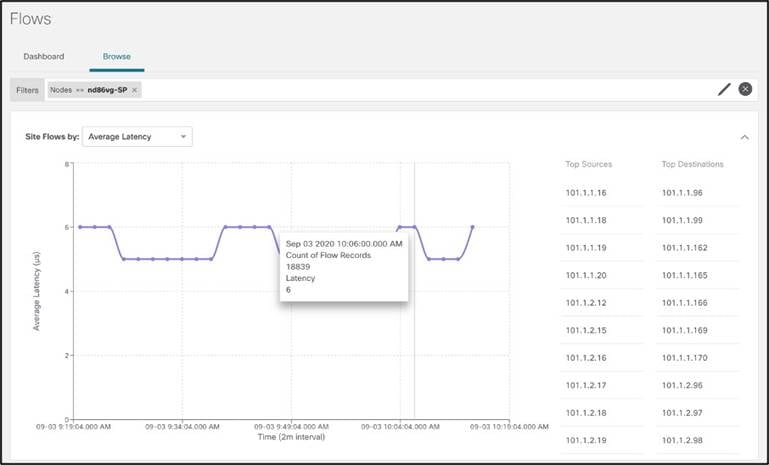
● 平均遅延別の上位フロー:時系列ベースの遅延統計を表示します。特定のフローをクリックすると、遅延数、ファブリック内のフローの正確なパス、エンドツーエンドの遅延など、詳細なフロー データにドリル ダウンします。これにより、インフラストラクチャの遅延ホットスポットを特定するために必要な、試行錯誤と手動の手順が不要になります。これにより、オペレータは遅延の根本原因に焦点を当て、それらを修正します。履歴トレンドは、オペレータが永続的な問題を特定し、インフラストラクチャのキャパシティを再評価するのに役立ちます。
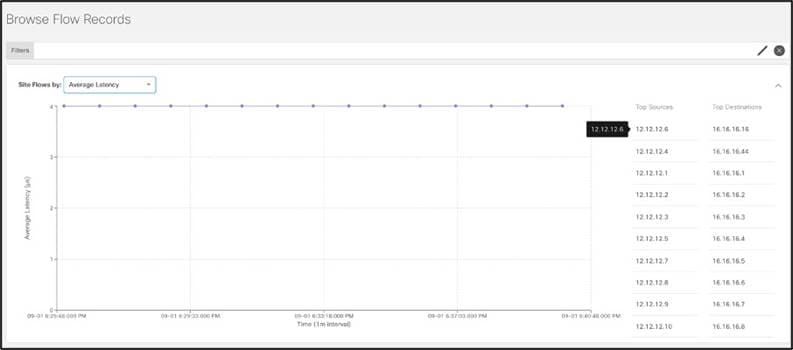
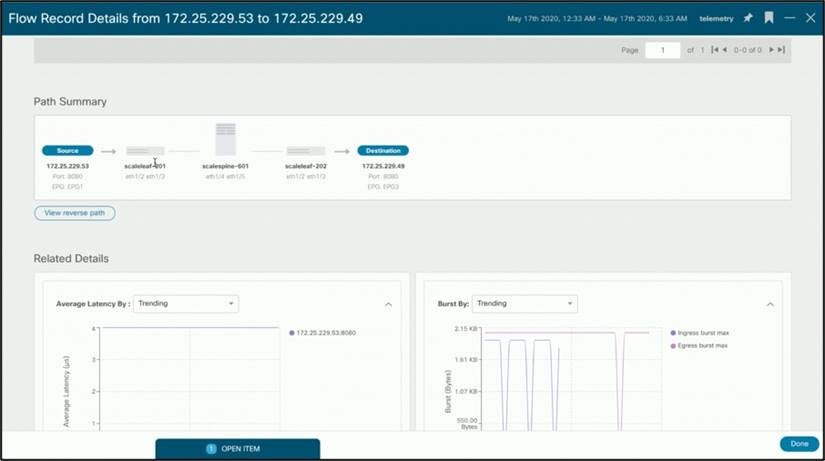
フローをダブルクリックすると、フローレベルの詳細が表示されます。
バースト性などのフローの詳細は、帯域幅の問題を特定して修正したり、適切な Quality of Service(QoS)レベルを適用したりするのに役立ちます。
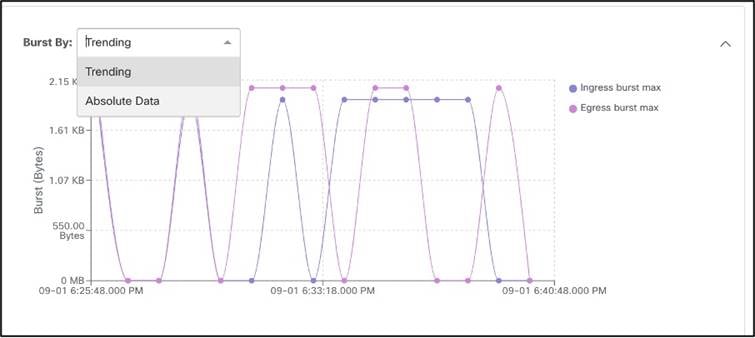
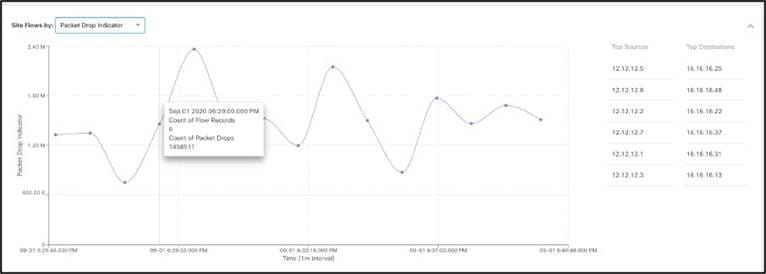
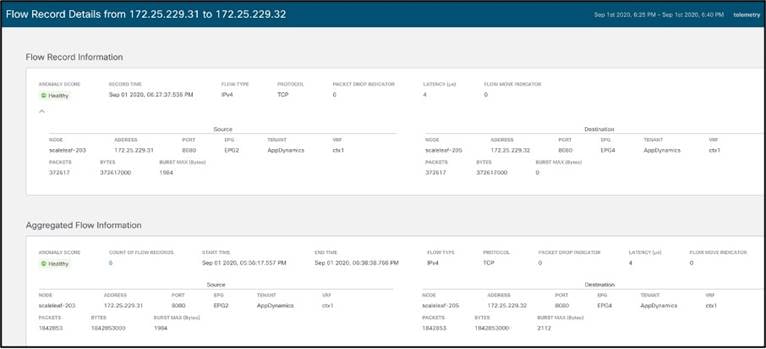
● [Top Flows by Packet] ドロップ インジケータ:時系列ベースのパケット ドロップ統計情報を表示します。特定のフローをクリックすると、次の 2 つの図に示すように、ファブリック内のドロップが発生した正確なポイントとドロップが発生した理由など、詳細なフロー データにドリルダウンします。これにより、トラブルシューティングの時間を節約でき、オペレータはインフラストラクチャ内の特定の潜在的な問題点を迅速に特定して特定できます。
エンドポイント
ファブリック内の時系列ベースのエンドポイントの移動、エンドポイントの詳細、および重複する IP を持つエンドポイントを表示します。仮想化されたデータ センター環境では、仮想マシンの移動を追跡します。これは、ファブリック内の現在の場所と履歴の移動を識別するのに非常に役立ちます。これは、仮想マシンの動作を確立するための証拠となるため、他の IT チームと協力しながら問題解決を積極的に支援します。次のスクリーンショットを参照してください。

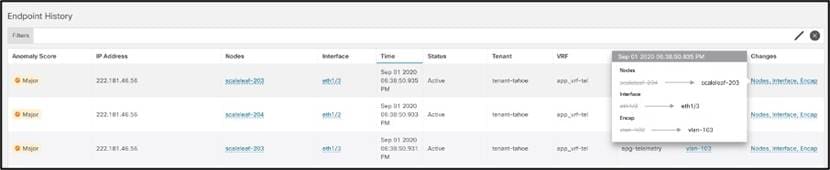
エンドポイントの健全性と一貫性は、Nexus Dashboard Insights によっても監視されます。
- エンドポイントが重複していますか?問題を修正しました。Insights サービスはそれらを迅速に検出し、重複が存在するスイッチとポートをユーザに示します。
- 古いエンドポイントですか? Insights サービスは、ワンクリックでこの状況を修復する組み込みの自動化を提供します。
アプリケーション
Cisco AppDynamics と Cisco Nexus Dashboard Insights の統合により、ユーザはアプリケーションとネットワークの統計情報と異常を一元管理できます。Cisco Nexus Dashboard Insights は、AppDynamics コントローラからストリーミングされたデータを使用し、アプリケーション、階層、ノードの状態、およびメトリックを表示するほか、TCP 損失、ラウンド トリップ時間、遅延、スループット、パフォーマンス影響イベント(PIE)など、これらのアプリケーションのネットワーク統計情報のベースラインを取得し、しきい値違反の異常を生成します。AppDynamics のフローについて、Cisco Nexus Dashboard Insights は、エンドパスの詳細なエンドポイント、遅延、ドロップ(存在する場合)、およびドロップの理由も提供し、アプリケーションの遅延や問題がネットワークの問題によるものかどうかをユーザが特定できるようにします。
すべてのアプリケーションとそれぞれの統計情報を表示するアプリケーション ダッシュボード
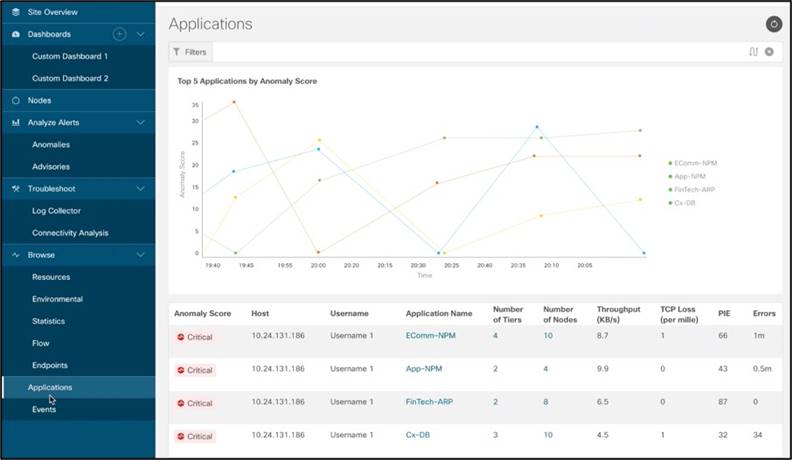
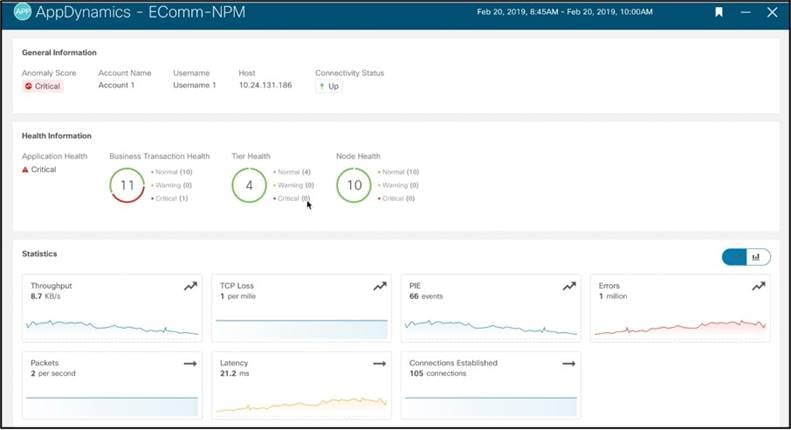
アプリケーションの詳細を調べて、健全性、各層、およびノードを確認します。
ネットワーク リンクは、階層間の通信です。Cisco Nexus Dashboard Insights は、ファブリックを通過するそれぞれのフローへのリンクをマッピングします。これにより、ユーザはフローの詳細とドロップがある場合はパスを確認できます。
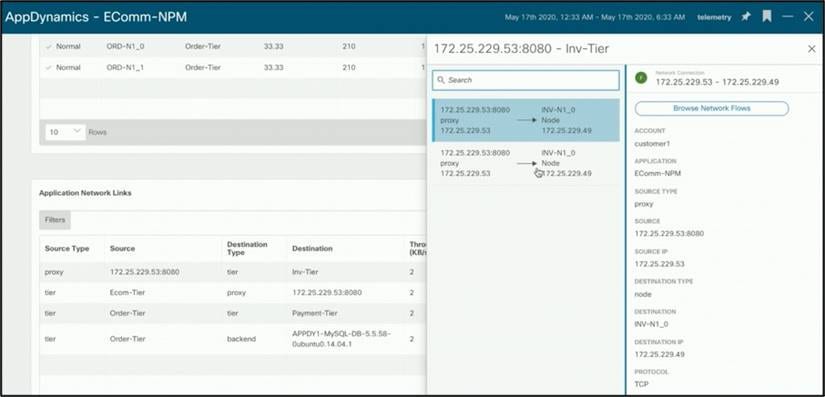
上記のフローをクリックすると、異常な遅延またはドロップ(存在する場合)を分析するための詳細なフロー ページが表示されます。
この統合は、組織内のサイロの境界をあいまいにし、オペレータがアプリケーションの観点からネットワークを確認できるようにするために不可欠です。オペレータは、どの IP がどのアプリケーションに関連付けられているか、どのアプリケーションフローがどのノードをどの時点で通過するかを知る必要はありません。Cisco Nexus Dashboard Insights は、これらすべての情報を提供し、データを強化し、全体的な統合運用ビューに関連付けます。
イベント分析
イベント分析機能は、インフラストラクチャ内のコントロール プレーン イベントに合わせて調整されます。以下の機能があります。
● データ収集:設定の変更およびコントロール プレーンのイベントと障害に関するデータを収集します。
● 分析:AI と ML(機械学習)アルゴリズムによって、すべての変更、イベント、障害の相関関係を判断します。
● 異常検出:AI および ML アルゴリズムによって異常(想定外のイベント、またはダウンタイムを引き起こすイベント)を検出します。
イベント分析ダッシュボードには、障害、イベント、監査ログが時系列で表示されます。履歴内でこれらのポイントをクリックすると、過去の状態と詳細情報が表示されます。さらに、これらのすべてが相互に関連付けられて、設定の削除が障害を引き起こしたかどうかを識別します。
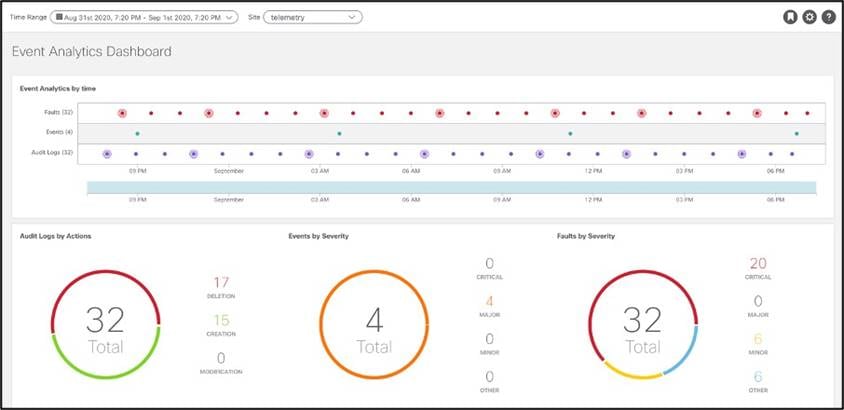
● 監査ログ:Cisco ACI のオブジェクトの作成、削除、および変更を示します。たとえば、サブネット、IP アドレス、ネクストホップ、EPG、VRF などです。これは、予期しない動作の潜在的な原因である可能性がある最近の変更を識別するのに役立ちます。変更を安定した状態に戻すのに役立ち、アカウンタビリティの割り当てに役立ちます。フィルタの機能により、シビラティ(重大度)、アクション、説明、オブジェクトなどによって特定の変更に焦点を絞ることができます。監査ログをドリル ダウンすると、各ログの詳細が表示されます。
● イベント:インフラストラクチャの運用イベントを表示します。たとえば、IP デタッチ/アタッチ、仮想スイッチのポート アタッチ/デタッチ、インターフェイス ステートの変更などです。
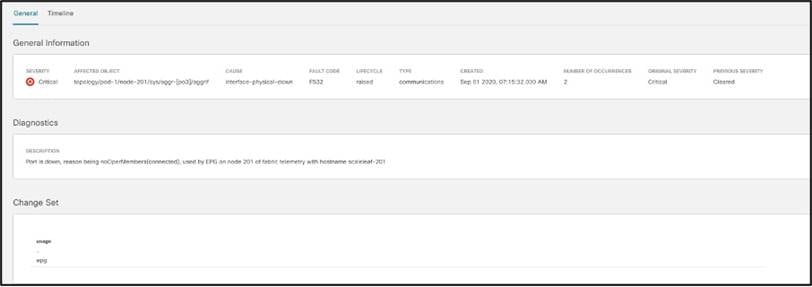
● 障害:可変、ステートフル、および永続的な管理対象オブジェクトであり、インフラストラクチャの問題を示します。たとえば、無効な設定です。この機能により、問題の修正に向けたオペレータのアクションが迅速化されるため、根本原因の分析と修正にかかる時間を短縮できます。通常は、複数の手順、専門知識、症状の関連付け、および場合によっては多少の試行錯誤が必要になります。
タイムライン バーのズームインおよびズームアウト機能を使用すると、調査中のタイムラインをすばやく縮小または拡張できます。
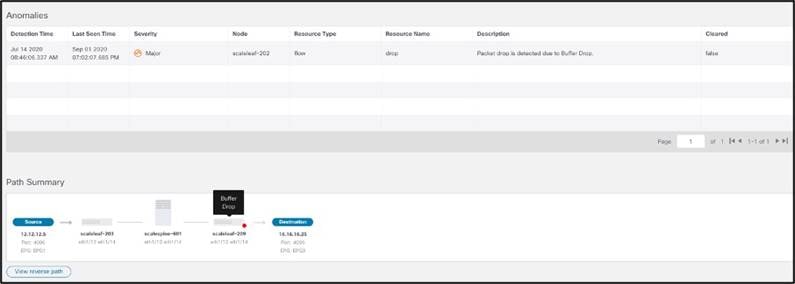
Cisco Nexus ダッシュボード インサイトは、ファブリック内のすべてのノードからのさまざまなデータ セットをモニタし、データを基準にして「正常な」動作を識別します。この正常からの逸脱は、サービス ダッシュボードに異常として表示されます。これにより、オペレータはネットワーク内のどこで問題が実際に発生したかを見つけるのではなく、問題の解決に時間を費やすことができます。Cisco Nexus Dashboard Insights に用意されている相関アルゴリズムを使用すると、異常に加えて、この異常の影響の推定値を示すこともできるため、ユーザは問題の潜在的な影響を特定できます。この影響により、サービスは異常の性質に応じて推奨事項を生成し、平均トラブルシューティング時間と解決策を削減します。
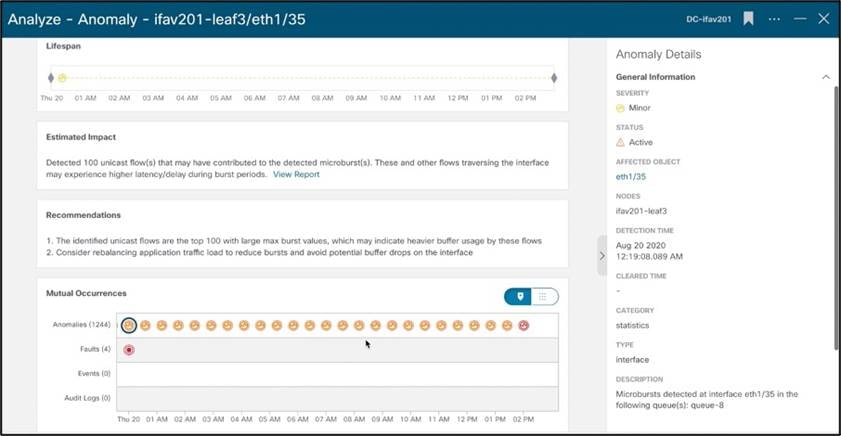
たとえば、このマイクロバーストの異常を見てみましょう。マイクロバーストは、複雑であり、無数のネットワークの問題を特定して引き起こします。信頼性が高く低遅延のネットワークを必要とするアプリケーションでは、マイクロバーストが重大な問題を引き起こす可能性があります。マイクロバーストはマイクロ秒のオーダーで発生するため、全体的な 1 秒あたりのパケット数のグラフを見ると、全体的な伝送がスムーズに見えます。Cisco Nexus Dashboard Insightsは、データを迅速に収集するためにこれらのマイクロバーストを検出し、これらのバーストによって影響を受ける可能性のあるフローを詳細に示します。これにより、特定のノード、インターフェイス、およびキューでバーストが発生したことをオペレータが検出できるだけでなく、この異常を修正するための推奨事項が影響するフローも容易になります。
マイクロバースト異常の例:
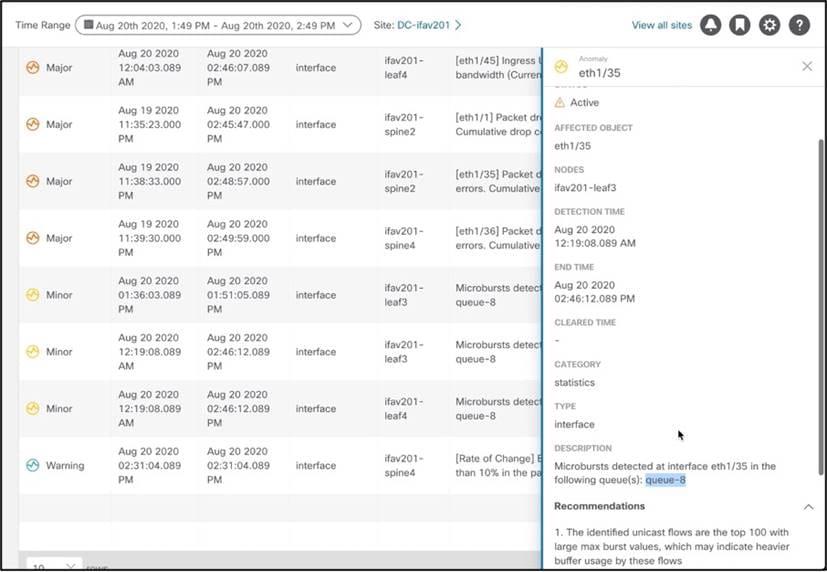
この特定の期間にマイクロバーストが発生したために、高遅延が発生する可能性があるフローの例:
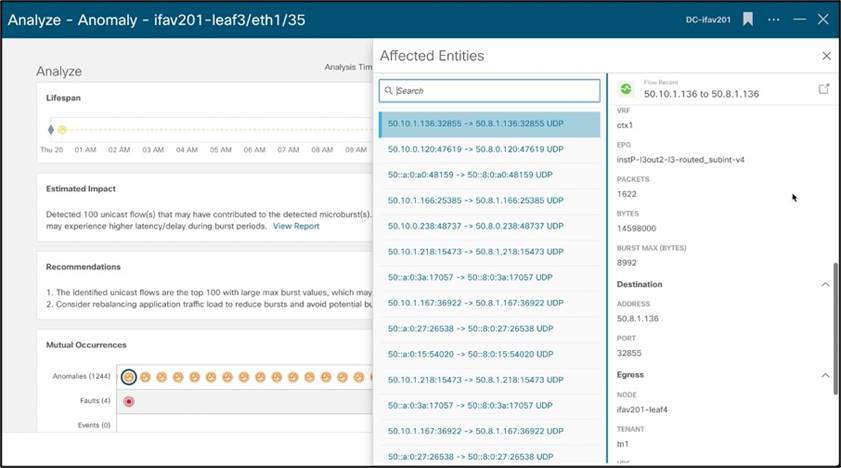
Nexus Insight に記載されているように、このノードの他の問題の相互発生とともに、この異常を修復する方法に関する推奨事項。また、監査ログ、イベント、障害も表示され、すべての情報を 1 つのページに保持して迅速なトラブルシューティングを可能にします。
データセンター ネットワークの可用性を維持し、ダウンタイムを最小限に抑えるには、ネットワーク運用者がネットワーク インフラストラクチャを最新のスイッチ プラットフォームで構築し、適切なバージョンのソフトウェアを実行していることを確認することが重要です。これは、インフラストラクチャ全体の定期的かつ詳細な監査を必要とします。Cisco Nexus Dashboard Insights は、このタスクを自動化されたプロセスに変換し、ボタンをクリックするだけで、デジタル化されたシグニチャを使用してネットワーク インフラストラクチャの脆弱性を特定します。
Cisco Nexus Dashboard Insights は、ネットワーク全体をスキャンして、ハードウェア、ソフトウェア バージョン、およびアクティブな設定に関する完全な情報を収集します。次に、既知の障害、PSIRT、フィールド通知のデジタル化されたデータベースに対して分析を実行し、特定のネットワーク環境に影響を与える可能性のある関連するものを特定し、そのハードウェアとソフトウェアのバージョン、機能、およびトポロジを照合します。識別された脆弱性のオペレータは、修復のための適切なハードウェアおよび/またはソフトウェアのバージョンにそれらをアドバイスします。また、シスコ製品の EoL(サポート終了)または EoS(販売終了)のアナウンスとスケジュールに基づいて、ネットワークが古いハードウェアまたはソフトウェアを実行しているかどうかを分析し、アドバイスします。検出された問題のいずれかについて、Cisco Nexus Dashboard Insights には、影響を受けるデバイス、脆弱性の詳細、および緩和手順(アドバイザリ)がリストされます。アドバイザリでは、解決に最適なソフトウェア バージョンと、シングルステップ アップグレードまたは中間ソフトウェア バージョンによるアップグレード パスが推奨されます。また、アップグレードの影響(破壊的または非破壊的)が明らかになるため、運用者はそれに応じて積極的にアップグレードを計画できます。
自動スキャン、ネットワークコンテキスト認識型脆弱性分析、および実用的な推奨事項により、Cisco Nexus Dashboard Insights のアドバイザリ機能により、運用チームはネットワーク全体の正確な監査を維持し、予防的なアラートを取得して予防的な修復アクションを実行することにより、製品の欠陥や PSIRTS に起因するダウンタイムを回避します。
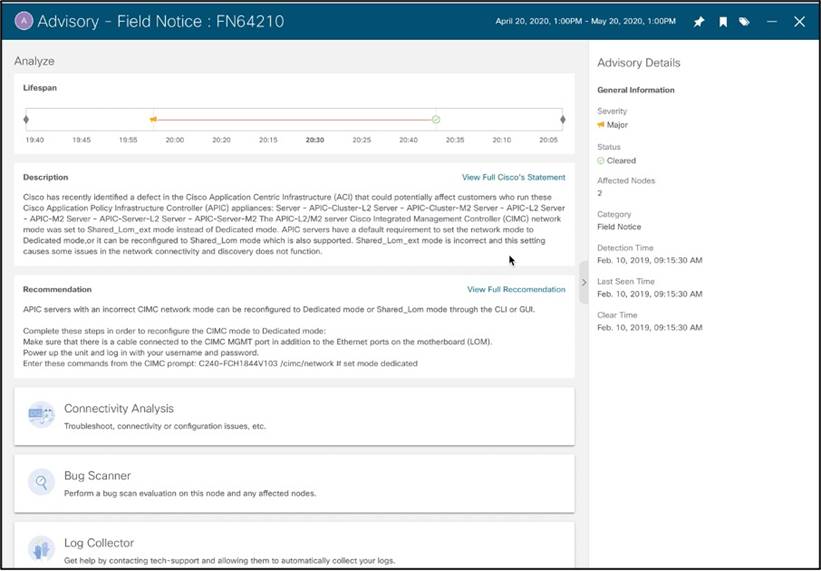
Field Notice に関するアドバイザリの例:
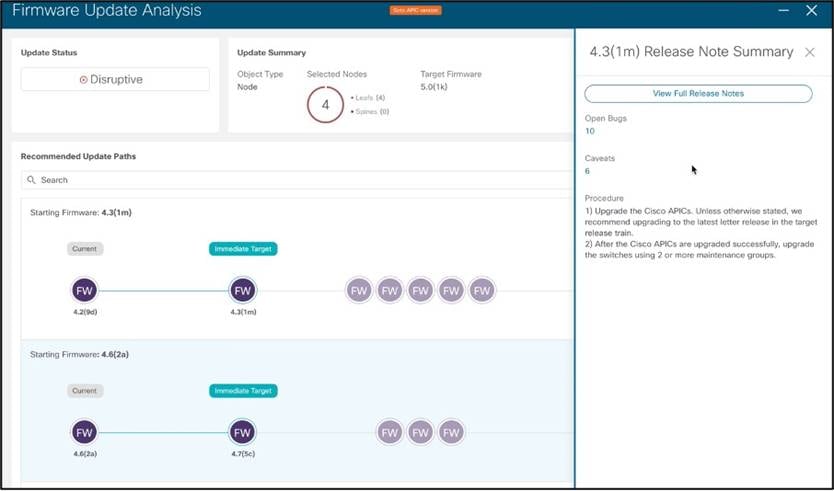
Cisco Nexus Dashboard Insights が推奨するファームウェア アップグレードの例:
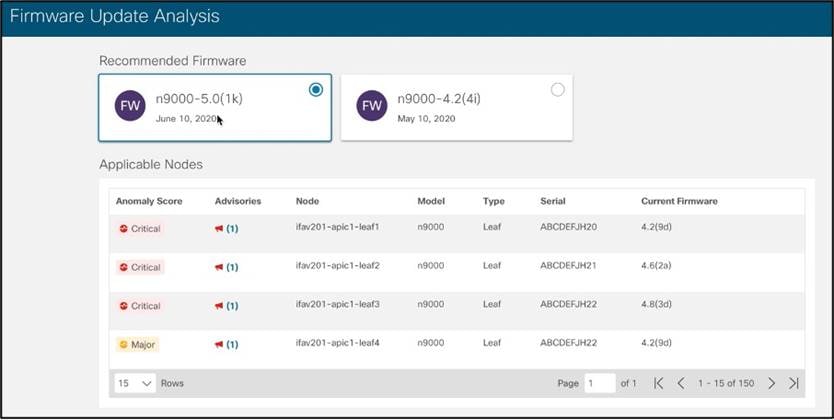
アップグレード分析の例:宛先ソフトウェアに到達するための断続的なアップグレードのリスト、アップグレードの影響、Cisco Nexus Dashboard Insights に直接リンクされている各リリースのリリースノート
シスコは、すべてのオンボーディング データセンター サイトの中央管理コンソールとして、また Cisco Nexus Dashboard Insights などのデータセンター運用サービスの中央ホスティング プラットフォームとして Cisco Nexus Dashboard を導入しました。さまざまなアプリケーションの運用とライフ サイクル管理を簡素化し、共通のプラットフォームとアプリケーション インフラストラクチャを提供することで、さまざまなアプリケーションを実行するためのインフラストラクチャ オーバーヘッドを削減します。また、Cisco Nexus ダッシュボードでホストされるサービスを使用して、API 主導のサードパーティ アプリケーションの中央統合ポイントを提供します。
Cisco Nexus Dashboard Insights は、Cisco Nexus Dashboard でホストされるように設計されたマイクロサービス ベースのサービスです。Nexus ダッシュボードは、水平方向に拡張可能なコンピューティング ノードのクラスタを提供します。Cisco Nexus Dashboard でネイティブにホストされるサービスとして、Cisco Nexus Dashboard Insights に必要なサイジングとコンピューティング ノードの数は、ファブリックの数、各ファブリック内のスイッチの数、およびユーザがサービスでサポートする必要があるフロー/秒によって異なります。
詳細については、次のドキュメントを参照してください。
● Cisco Nexus Dashboard Insights データシート
● Cisco Nexus Dashboard Insights ユーザ ガイド、リリース 6.0(1) (Cisco ACI 用)
● Cisco Nexus Dashboard Insights ユーザ ガイド、リリース 6.0(1) (Cisco DCNM 用)
● Cisco Nexus Dashboard Insights FAQ
● Cisco Nexus Dashboard FAQ
Nexus Dashboard Insights サービスは、Cisco ACIおよびCisco DCNMでサポートされます。最新のソフトウェア互換性情報については、 『Cisco Nexus Dashboard and Services Compatibility Matrix』を参照してください。
Cisco Nexus Dashboard Insights サービス ライセンスは、Cisco ACI または NX-OS Premium ライセンスの一部として含まれています。Cisco ACI または NXOS Essentials ライセンス、または Advantage ライセンスをお持ちのお客様は、Cisco Nexus Dashboard Insights を含むアドオン DCN Day2Ops を購入できます。
上記のライセンスはどちらもサブスクリプション専用のスマート ライセンスです。シスコ ライセンスの詳細については、https://www.cisco.com/go/licensingguide を参照してください。
必要なデバイス ライセンスの数は、Cisco ACI ファブリック内のリーフ スイッチの総数および/または Cisco DCNM ベースのファブリック内のノードの総数です。
価格および発注:
注文情報については、こちらをクリックしてください。今後の価格および詳細については、シスコのアカウント チームにお問い合わせください。
Cisco Nexus Dashboard Insights は、予測分析、ネットワーク保証、および AIOps を使用した実用的なインサイトを提供します。膨大な情報を使用し、インフラストラクチャに関するデータを追跡し、新しいイベントを学習してその原因を特定し、ネットワークでの予期しない発生を強調すると同時に、ネットワーク運用者が事前に計画し、ポリシーと監査を遵守し、インフラストラクチャのキャパシティと稼働時間を追跡します。Cisco Nexus Dashboard Insights は、運用者の知識の延長線上にあり、ネットワークの障害を防止したり、障害発生時に迅速な復旧に向けた修復作業に集中するためのものです。