OSD – コンピューティングUCS 240M4の交換 – vEPC
ダウンロード オプション
偏向のない言語
この製品のドキュメントセットは、偏向のない言語を使用するように配慮されています。このドキュメントセットでの偏向のない言語とは、年齢、障害、性別、人種的アイデンティティ、民族的アイデンティティ、性的指向、社会経済的地位、およびインターセクショナリティに基づく差別を意味しない言語として定義されています。製品ソフトウェアのユーザインターフェイスにハードコードされている言語、RFP のドキュメントに基づいて使用されている言語、または参照されているサードパーティ製品で使用されている言語によりドキュメントに例外が存在する場合があります。シスコのインクルーシブ ランゲージの取り組みの詳細は、こちらをご覧ください。
翻訳について
シスコは世界中のユーザにそれぞれの言語でサポート コンテンツを提供するために、機械と人による翻訳を組み合わせて、本ドキュメントを翻訳しています。ただし、最高度の機械翻訳であっても、専門家による翻訳のような正確性は確保されません。シスコは、これら翻訳の正確性について法的責任を負いません。原典である英語版(リンクからアクセス可能)もあわせて参照することを推奨します。
内容
はじめに
このドキュメントでは、StarOS Virtual Network Functions(VNF)をホストするUltra-Mセットアップで、障害のあるオブジェクトストレージディスク(OSD)コンピューティングサーバを交換するために必要な手順について説明します。
背景説明
Ultra-Mは、VNFの導入を簡素化するために設計された、パッケージ済みで検証済みの仮想化モバイルパケットコアソリューションです。 OpenStackは、Ultra-M向けの仮想化インフラストラクチャマネージャ(VIM)であり、次のノードタイプで構成されています。
- 計算
- OSD – コンピューティング
- コントローラ
- OpenStackプラットフォーム – ディレクタ(OSPD)
Ultra-Mの高度なアーキテクチャと関連するコンポーネントを次の図に示します。
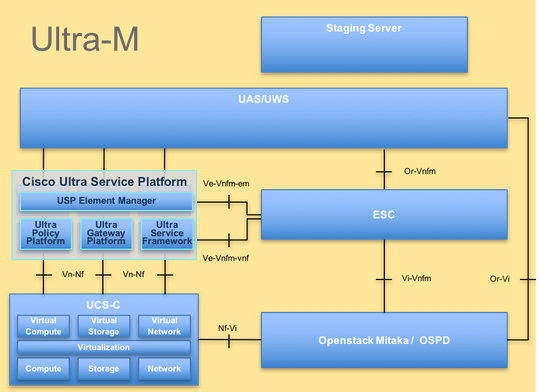
このドキュメントは、Cisco Ultra-Mプラットフォームに精通しているシスコの担当者を対象とし、コンピューティングサーバの交換時にOpenStackおよびStarOS VNFレベルで実行する必要のある手順について詳しく説明しています。
注:このドキュメントでは、手順を定義するためにUltra M 5.1.xリリースを考慮しています。
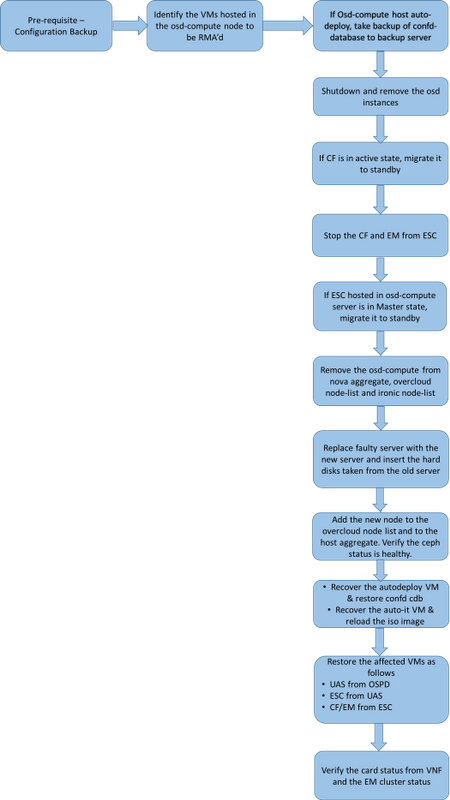
MoPのワークフロー
略語
| VNF | 仮想ネットワーク機能 |
| CF | 制御機能 |
| SF | サービス機能 |
| ESC | 柔軟なサービスコントローラ |
| MOP | 手順の方法 |
| OSD | オブジェクトストレージディスク |
| HDD | ハードディスクドライブ |
| SSD | ソリッドステートドライブ |
| VIM | 仮想インフラストラクチャマネージャ |
| 仮想マシン | 仮想マシン |
| エム | エレメント マネージャ |
| UAS | Ultra 自動化サービス |
| UUID | ユニバーサル一意識別子 |
前提条件
バックアップOSPD
OSD-Computeノードを交換する前に、Red Hat OpenStack Platform環境の現在の状態を確認することが重要です。コンピュータの交換プロセスがオンの場合の複雑さを避けるために、現在の状態を確認することをお勧めします。この交換の流れによって実現できます。
リカバリの場合は、次の手順を使用してOSPDデータベース(DB)をバックアップすることをお勧めします。
[root@director ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql
[root@director ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql
/etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack
tar: Removing leading `/' from member names
このプロセスにより、インスタンスの可用性に影響を与えずにノードを確実に交換できます。 また、特に交換するコンピュートノードがCF VMをホストしている場合は、StarOS設定をバックアップすることをお勧めします。
OSDコンピューティングノードでホストされるVMの特定
コンピューティングサーバでホストされているVMを特定します。次の2つの可能性があります。
OSD-Computeサーバには、VMのEM/UAS/Auto-Deploy/Auto-ITの組み合わせが含まれます。
[stack@director ~]$ nova list --field name,host | grep osd-compute-0
| c6144778-9afd-4946-8453-78c817368f18 | AUTO-DEPLOY-VNF2-uas-0 | pod1-osd-compute-0.localdomain |
| 2d051522-bce2-4809-8d63-0c0e17f251dc | AUTO-IT-VNF2-uas-0 | pod1-osd-compute-0.localdomain |
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-osd-compute-0.localdomain |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-osd-compute-0.localdomain |
コンピューティングサーバには、VMのCF/ESC/EM/UASの組み合わせが含まれています。
[stack@director ~]$ nova list --field name,host | grep osd-compute-1
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-compute-8.localdomain |
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229 | pod1-compute-8.localdomain |
| 75528898-ef4b-4d68-b05d-882014708694 | VNF2-ESC-ESC-0 | pod1-compute-8.localdomain |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-compute-8.localdomain |
注:ここに示す出力では、最初の列がUUIDに対応し、2番目の列がVM名、3番目の列がVMが存在するホスト名です。この出力のパラメータは、以降のセクションで使用します。
1台のOSDサーバを取り外せるようにCephに空き容量があることを確認します。
[root@pod1-osd-compute-1 ~]# sudo ceph df
GLOBAL:
SIZE AVAIL RAW USED %RAW USED
13393G 11804G 1589G 11.87
POOLS:
NAME ID USED %USED MAX AVAIL OBJECTS
rbd 0 0 0 3876G 0
metrics 1 4157M 0.10 3876G 215385
images 2 6731M 0.17 3876G 897
backups 3 0 0 3876G 0
volumes 4 399G 9.34 3876G 102373
vms 5 122G 3.06 3876G 31863
OSD-Computeサーバでceph osd treeステータスがupになっていることを確認します。
[heat-admin@pod1-osd-compute-1 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod1-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-3 4.35999 host pod1-osd-compute-2
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
-4 4.35999 host pod1-osd-compute-1
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
CephプロセスがOSD-Computeサーバでアクティブになっている。
[root@pod1-osd-compute-1 ~]# systemctl list-units *ceph*
UNIT LOAD ACTIVE SUB DESCRIPTION
var-lib-ceph-osd-ceph\x2d11.mount loaded active mounted /var/lib/ceph/osd/ceph-11
var-lib-ceph-osd-ceph\x2d2.mount loaded active mounted /var/lib/ceph/osd/ceph-2
var-lib-ceph-osd-ceph\x2d5.mount loaded active mounted /var/lib/ceph/osd/ceph-5
var-lib-ceph-osd-ceph\x2d8.mount loaded active mounted /var/lib/ceph/osd/ceph-8
ceph-osd@11.service loaded active running Ceph object storage daemon
ceph-osd@2.service loaded active running Ceph object storage daemon
ceph-osd@5.service loaded active running Ceph object storage daemon
ceph-osd@8.service loaded active running Ceph object storage daemon
system-ceph\x2ddisk.slice loaded active active system-ceph\x2ddisk.slice
system-ceph\x2dosd.slice loaded active active system-ceph\x2dosd.slice
ceph-mon.target loaded active active ceph target allowing to start/stop all ceph-mon@.service instances at once
ceph-osd.target loaded active active ceph target allowing to start/stop all ceph-osd@.service instances at once
ceph-radosgw.target loaded active active ceph target allowing to start/stop all ceph-radosgw@.service instances at once
ceph.target loaded active active ceph target allowing to start/stop all ceph*@.service instances at once
各Cephインスタンスを無効および停止し、OSDから各インスタンスを削除し、ディレクトリをアンマウントします。各Cephインスタンスに対して繰り返します。
[root@pod1-osd-compute-1 ~]# systemctl disable ceph-osd@11
[root@pod1-osd-compute-1 ~]# systemctl stop ceph-osd@11
[root@pod1-osd-compute-1 ~]# ceph osd out 11
marked out osd.11.
[root@pod1-osd-compute-1 ~]# ceph osd crush remove osd.11
removed item id 11 name 'osd.11' from crush map
[root@pod1-osd-compute-1 ~]# ceph auth del osd.11
updated
[root@pod1-osd-compute-1 ~]# ceph osd rm 11
removed osd.11
[root@pod1-osd-compute-1 ~]# umount /var/lib/ceph.osd/ceph-11
[root@pod1-osd-compute-1 ~]# rm -rf /var/lib/ceph.osd/ceph-11
または
Clean.shスクリプトは、次のタスクを実行するために使用できます。
[heat-admin@pod1-osd-compute-0 ~]$ sudo ls /var/lib/ceph/osd
ceph-11 ceph-3 ceph-6 ceph-8
[heat-admin@pod1-osd-compute-0 ~]$ /bin/sh clean.sh
[heat-admin@pod1-osd-compute-0 ~]$ cat clean.sh
#!/bin/sh
set -x
CEPH=`sudo ls /var/lib/ceph/osd`
for c in $CEPH
do
i=`echo $c |cut -d'-' -f2`
sudo systemctl disable ceph-osd@$i || (echo "error rc:$?"; exit 1)
sleep 2
sudo systemctl stop ceph-osd@$i || (echo "error rc:$?"; exit 1)
sleep 2
sudo ceph osd out $i || (echo "error rc:$?"; exit 1)
sleep 2
sudo ceph osd crush remove osd.$i || (echo "error rc:$?"; exit 1)
sleep 2
sudo ceph auth del osd.$i || (echo "error rc:$?"; exit 1)
sleep 2
sudo ceph osd rm $i || (echo "error rc:$?"; exit 1)
sleep 2
sudo umount /var/lib/ceph/osd/$c || (echo "error rc:$?"; exit 1)
sleep 2
sudo rm -rf /var/lib/ceph/osd/$c || (echo "error rc:$?"; exit 1)
sleep 2
done
sudo ceph osd tree
すべてのOSDプロセスが移行/削除された後、ノードをオーバークラウドから削除できます。
注:Cephを取り外すと、VNF HD RAIDは縮退状態になりますが、HDディスクにアクセスできる必要があります。
グレースフルパワーオフ
Case 1.OSDコンピュートノードはCF/ESC/EM/UASをホスト
CFカードのスタンバイ状態への移行
StarOS VNFにログインし、CF VMに対応するカードを特定します。「OSDコンピュートノードでホストされるVMの識別」セクションで識別されたCF VMのUUIDを使用し、UUIDに対応するカードを探します。
[local]VNF2# show card hardware
Tuesday might 08 16:49:42 UTC 2018
<snip>
Card 2:
Card Type : Control Function Virtual Card
CPU Packages : 8 [#0, #1, #2, #3, #4, #5, #6, #7]
CPU Nodes : 1
CPU Cores/Threads : 8
Memory : 16384M (qvpc-di-large)
UUID/Serial Number : F9C0763A-4A4F-4BBD-AF51-BC7545774BE2
<snip>
カードのステータスを確認します。
[local]VNF2# show card table
Tuesday might 08 16:52:53 UTC 2018
Slot Card Type Oper State SPOF Attach
----------- -------------------------------------- ------------- ---- ------
1: CFC Control Function Virtual Card Standby -
2: CFC Control Function Virtual Card Active No
3: FC 4-Port Service Function Virtual Card Active No
4: FC 4-Port Service Function Virtual Card Active No
5: FC 4-Port Service Function Virtual Card Active No
6: FC 4-Port Service Function Virtual Card Active No
7: FC 4-Port Service Function Virtual Card Active No
8: FC 4-Port Service Function Virtual Card Active No
9: FC 4-Port Service Function Virtual Card Active No
10: FC 4-Port Service Function Virtual Card Standby -
カードがアクティブ状態の場合は、カードをスタンバイ状態に移行します。
[local]VNF2# card migrate from 2 to 1
ESCからのCFおよびEM VMのシャットダウン
VNFに対応するESCノードにログインし、VMのステータスを確認します。
[admin@VNF2-esc-esc-0 ~]$ cd /opt/cisco/esc/esc-confd/esc-cli
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229</vm_name>
<state>VM_ALIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c3_0_3e0db133-c13b-4e3d-ac14-
<state>VM_ALIVE_STATE</state>
<deployment_name>VNF2-DEPLOYMENT-em</deployment_name>
<vm_id>507d67c2-1d00-4321-b9d1-da879af524f8</vm_id>
<vm_id>dc168a6a-4aeb-4e81-abd9-91d7568b5f7c</vm_id>
<vm_id>9ffec58b-4b9d-4072-b944-5413bf7fcf07</vm_id>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea</vm_name>
<state>VM_ALIVE_STATE</state>
<snip>
VM名を使用して、CFとEM VMを1つずつ停止します。セクション「OSDコンピュートノードでホストされるVMの特定」からメモされたVM名。
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli vm-action STOP VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli vm-action STOP VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea
停止した後、VMはSHUTOFF状態になる必要があります。
[admin@VNF2-esc-esc-0 ~]$ cd /opt/cisco/esc/esc-confd/esc-cli
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229</vm_name>
<state>VM_SHUTOFF_STATE</state>
<vm_name>VNF2-DEPLOYM_c3_0_3e0db133-c13b-4e3d-ac14-
<state>VM_ALIVE_STATE</state>
<deployment_name>VNF2-DEPLOYMENT-em</deployment_name>
<vm_id>507d67c2-1d00-4321-b9d1-da879af524f8</vm_id>
<vm_id>dc168a6a-4aeb-4e81-abd9-91d7568b5f7c</vm_id>
<vm_id>9ffec58b-4b9d-4072-b944-5413bf7fcf07</vm_id>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea</vm_name>
VM_SHUTOFF_STATE
<snip>
ESCをスタンバイモードに移行
コンピュートノードでホストされているESCにログインし、マスターステートになっているかどうかを確認します。表示されている場合は、ESCをスタンバイモードに切り替えます。
[admin@VNF2-esc-esc-0 esc-cli]$ escadm status
0 ESC status=0 ESC Master Healthy
[admin@VNF2-esc-esc-0 ~]$ sudo service keepalived stop
Stopping keepalived: [ OK ]
[admin@VNF2-esc-esc-0 ~]$ escadm status
1 ESC status=0 In SWITCHING_TO_STOP state. Please check status after a while.
[admin@VNF2-esc-esc-0 ~]$ sudo reboot
Broadcast message from admin@vnf1-esc-esc-0.novalocal
(/dev/pts/0) at 13:32 ...
The system is going down for reboot NOW!
Nova AggregateリストからOSD-Computeノードを削除
Nova集計をリストし、ホストされているVNFに基づいてコンピューティングサーバに対応する集計を特定します。通常は、<VNFNAME>-EM-MGMT<X>および<VNFNAME>-CF-MGMT<X>の形式です。
[stack@director ~]$ nova aggregate-list
+----+-------------------+-------------------+
| Id | Name | Availability Zone |
+----+-------------------+-------------------+
| 29 | POD1-AUTOIT | mgmt |
| 57 | VNF1-SERVICE1 | - |
| 60 | VNF1-EM-MGMT1 | - |
| 63 | VNF1-CF-MGMT1 | - |
| 66 | VNF2-CF-MGMT2 | - |
| 69 | VNF2-EM-MGMT2 | - |
| 72 | VNF2-SERVICE2 | - |
| 75 | VNF3-CF-MGMT3 | - |
| 78 | VNF3-EM-MGMT3 | - |
| 81 | VNF3-SERVICE3 | - |
+----+-------------------+-------------------+
この場合、OSD-ComputeサーバはVNF2に属しています。したがって、対応する集約はVNF2-CF-MGMT2とVNF2-EM-MGMT2になります。
特定された集約からOSD-Computeノードを削除します。
nova aggregate-remove-host
[stack@director ~]$ nova aggregate-remove-host VNF2-CF-MGMT2 pod1-osd-compute-0.localdomain
[stack@director ~]$ nova aggregate-remove-host VNF2-EM-MGMT2 pod1-osd-compute-0.localdomain
[stack@director ~]$ nova aggregate-remove-host POD1-AUTOIT pod1-osd-compute-0.localdomain
OSD-Computeノードが集約から削除されているかどうかを確認します。次に、ホストが集約の下にリストされていないことを確認します。
nova aggregate-show
[stack@director ~]$ nova aggregate-show VNF2-CF-MGMT2
[stack@director ~]$ nova aggregate-show VNF2-EM-MGMT2
[stack@director ~]$ nova aggregate-show POD1-AUTOIT
Case 2.OSD – コンピューティングノードのホストの自動導入/自動IT/EM/UAS
自動展開のCDBのバックアップ
autodeploy confd cdbデータを定期的にまたはアクティブ化/非アクティブ化のたびにバックアップし、ファイルをバックアップサーバに保存します。自動展開は冗長ではなく、このデータが失われると、展開を非アクティブ化するのが困難になります。
Auto-Deploy VM and backup confd cdbディレクトリにログインします。
ubuntu@auto-deploy-iso-2007-uas-0:~$sudo -i
root@auto-deploy-iso-2007-uas-0:~#service uas-confd stop
uas-confd stop/waiting
root@auto-deploy-iso-2007-uas-0:~# cd /opt/cisco/usp/uas/confd-6.3.1/var/confd
root@auto-deploy-iso-2007-uas-0:/opt/cisco/usp/uas/confd-6.3.1/var/confd#tar cvf autodeploy_cdb_backup.tar cdb/
cdb/
cdb/O.cdb
cdb/C.cdb
cdb/aaa_init.xml
cdb/A.cdb
root@auto-deploy-iso-2007-uas-0:~# service uas-confd start
uas-confd start/running, process 13852
注:autodeploy_cdb_backup.tarをバックアップサーバにコピーします。
Auto-ITからのsystem.cfgのバックアップ
system.cfgファイルのバックアップをbackup-serverに作成します。
Auto-it = 10.1.1.2
Backup server = 10.2.2.2
[stack@director ~]$ ssh ubuntu@10.1.1.2
ubuntu@10.1.1.2's password:
Welcome to Ubuntu 14.04.3 LTS (GNU/Linux 3.13.0-76-generic x86_64)
* Documentation: https://help.ubuntu.com/
System information as of Wed Jun 13 16:21:34 UTC 2018
System load: 0.02 Processes: 87
Usage of /: 15.1% of 78.71GB Users logged in: 0
Memory usage: 13% IP address for eth0: 172.16.182.4
Swap usage: 0%
Graph this data and manage this system at:
https://landscape.canonical.com/
Get cloud support with Ubuntu Advantage Cloud Guest:
http://www.ubuntu.com/business/services/cloud
Cisco Ultra Services Platform (USP)
Build Date: Wed Feb 14 12:58:22 EST 2018
Description: UAS build assemble-uas#1891
sha1: bf02ced
ubuntu@auto-it-vnf-uas-0:~$ scp -r /opt/cisco/usp/uploads/system.cfg root@10.2.2.2:/home/stack
root@10.2.2.2's password:
system.cfg 100% 565 0.6KB/s 00:00
ubuntu@auto-it-vnf-uas-0:~$
注:OSD-Compute-0でホストされるEM/UASをグレースフルシャットダウンするために実行する手順はどちらも同じです。その場合はCase.1を参照してください。
OSD – コンピュートノードの削除
このセクションで説明する手順は、コンピューティングノードでホストされるVMに関係なく共通です。
サービスリストからのOSD-Computeノードの削除
サービスリストからコンピューティングサービスを削除します。
[stack@director ~]$ source corerc
[stack@director ~]$ openstack compute service list | grep osd-compute-0
| 404 | nova-compute | pod1-osd-compute-0.localdomain | nova | enabled | up | 2018-05-08T18:40:56.000000 |
openstack compute service delete
[stack@director ~]$ openstack compute service delete 404
中性子エージェントを削除
関連付けられている古いneutronエージェントを削除し、コンピューティングサーバのvswitch agentを開きます。
[stack@director ~]$ openstack network agent list | grep osd-compute-0
| c3ee92ba-aa23-480c-ac81-d3d8d01dcc03 | Open vSwitch agent | pod1-osd-compute-0.localdomain | None | False | UP | neutron-openvswitch-agent |
| ec19cb01-abbb-4773-8397-8739d9b0a349 | NIC Switch agent | pod1-osd-compute-0.localdomain | None | False | UP | neutron-sriov-nic-agent |
openstack network agent delete
[stack@director ~]$ openstack network agent delete c3ee92ba-aa23-480c-ac81-d3d8d01dcc03
[stack@director ~]$ openstack network agent delete ec19cb01-abbb-4773-8397-8739d9b0a349
Nova and Ironicデータベースから削除
novaリストとironicデータベースからノードを削除し、確認します。
[stack@director ~]$ source stackrc
[stack@al01-pod1-ospd ~]$ nova list | grep osd-compute-0
| c2cfa4d6-9c88-4ba0-9970-857d1a18d02c | pod1-osd-compute-0 | ACTIVE | - | Running | ctlplane=192.200.0.114 |
[stack@al01-pod1-ospd ~]$ nova delete c2cfa4d6-9c88-4ba0-9970-857d1a18d02c
nova show| grep hypervisor
[stack@director ~]$ nova show pod1-osd-compute-0 | grep hypervisor
| OS-EXT-SRV-ATTR:hypervisor_hostname | 4ab21917-32fa-43a6-9260-02538b5c7a5a
ironic node-delete
[stack@director ~]$ ironic node-delete 4ab21917-32fa-43a6-9260-02538b5c7a5a
[stack@director ~]$ ironic node-list (node delete must not be listed now)
雲マークから削除
次に示す内容で、delete_node.shという名前のスクリプトファイルを作成します。 記載されているテンプレートが、スタック展開に使用されるdeploy.shスクリプトで使用されているテンプレートと同じであることを確認します。
delete_node.sh
openstack overcloud node delete --templates -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml -e /home/stack/custom-templates/layout.yaml --stack
[stack@director ~]$ source stackrc
[stack@director ~]$ /bin/sh delete_node.sh
+ openstack overcloud node delete --templates -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml -e /home/stack/custom-templates/layout.yaml --stack pod1 49ac5f22-469e-4b84-badc-031083db0533
Deleting the following nodes from stack pod1:
- 49ac5f22-469e-4b84-badc-031083db0533
Started Mistral Workflow. Execution ID: 4ab4508a-c1d5-4e48-9b95-ad9a5baa20ae
real 0m52.078s
user 0m0.383s
sys 0m0.086s
COMPLETE状態に移行するため、OpenStackスタックの動作を待機します。
[stack@director ~]$ openstack stack list
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| ID | Stack Name | Stack Status | Creation Time | Updated Time |
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| 5df68458-095d-43bd-a8c4-033e68ba79a0 | pod1 | UPDATE_COMPLETE | 2018-05-08T21:30:06Z | 2018-05-08T20:42:48Z |
+--------------------------------------+------------+-----------------+----------------------+----------------------
新しいコンピューティングノードのインストール
- 新しいUCS C240 M4サーバをインストールする手順と初期設定の手順については、次のドキュメントを参照してください。
Cisco UCS C240 M4サーバインストレーションおよびサービスガイド
- サーバのインストール後、ハードディスクを古いサーバとして各スロットに挿入します
- CIMC IPを使用してサーバにログインします
- ファームウェアが以前に使用した推奨バージョンと異なる場合は、BIOSアップグレードを実行します。BIOSアップグレードの手順は次のとおりです。
Cisco UCS CシリーズラックマウントサーバBIOSアップグレードガイド
- 物理ドライブのステータスを確認します。迷惑でない良好な状態である必要があります
- RAIDレベル1の物理ドライブから仮想ドライブを作成する
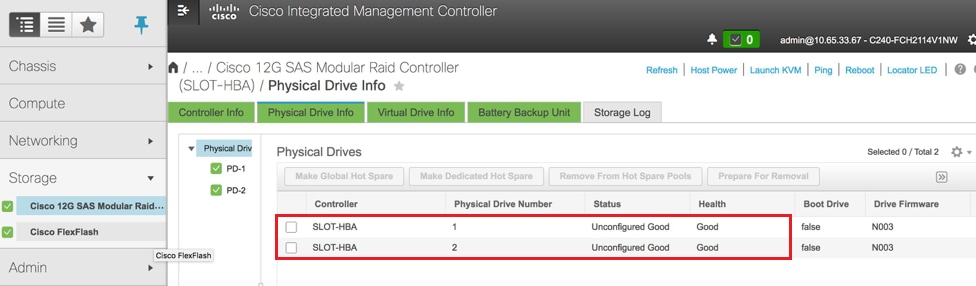 ストレージ> Cisco 12G SASモジュラRaidコントローラ(SLOT-HBA) >物理ドライブ情報
ストレージ> Cisco 12G SASモジュラRaidコントローラ(SLOT-HBA) >物理ドライブ情報
注:この図は説明のみを目的としており、実際のOSD-Compute CIMCでは、スロット(1、2、3、7、8、9、10)内の7台の物理ドライブから仮想ドライブが作成されていないため、スロットは未構成の良好な状態になっています。
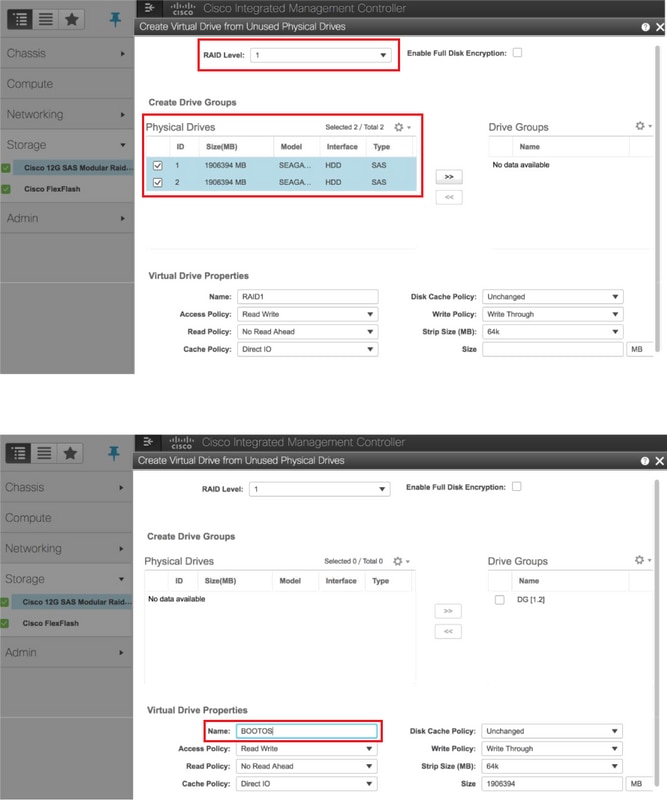 [ストレージ]>[Cisco 12G SASモジュラRaidコントローラ(SLOT-HBA)]>[コントローラ情報]>[未使用の物理ドライブから仮想ドライブを作成]
[ストレージ]>[Cisco 12G SASモジュラRaidコントローラ(SLOT-HBA)]>[コントローラ情報]>[未使用の物理ドライブから仮想ドライブを作成]
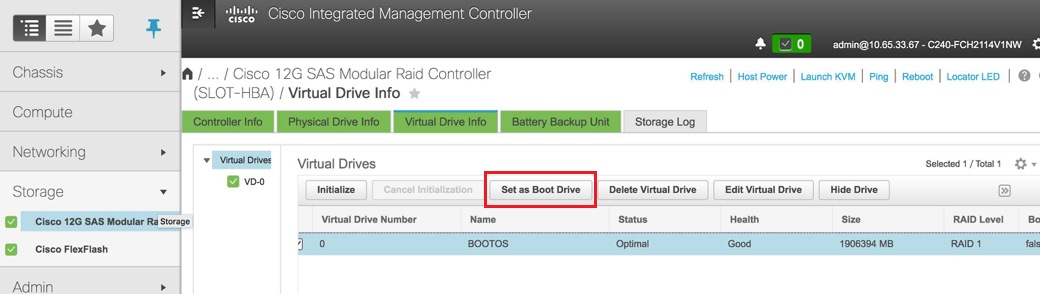 VDを選択し、「Set as Boot Drive」を設定します
VDを選択し、「Set as Boot Drive」を設定します
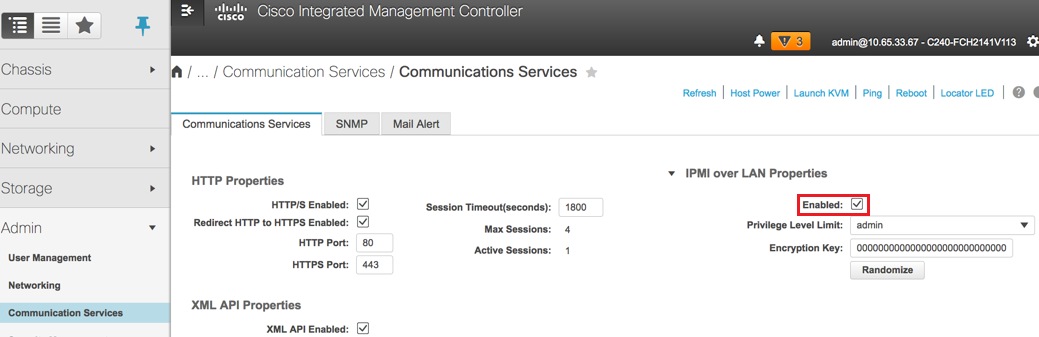 IPMI over LANの有効化: Admin > Communication Services > Communication Services
IPMI over LANの有効化: Admin > Communication Services > Communication Services
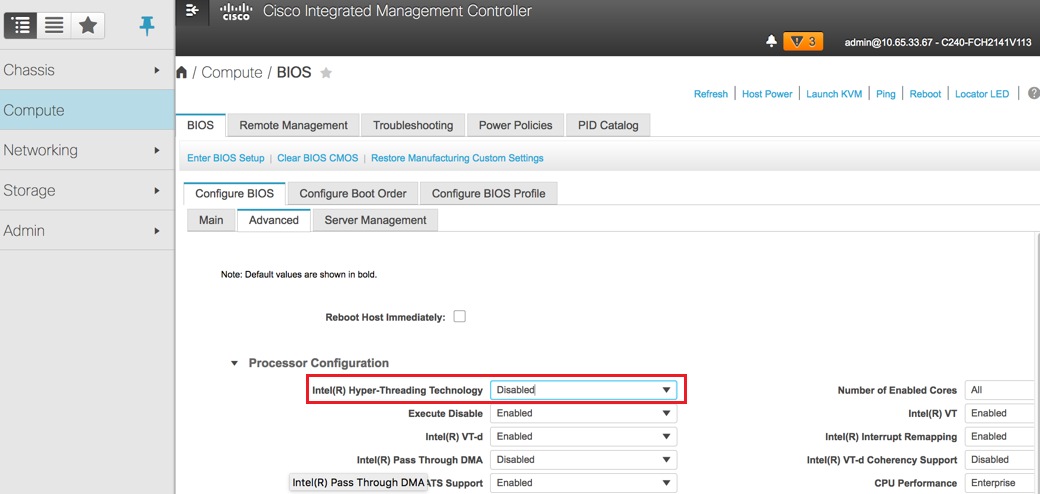 ハイパースレッディングの無効化:コンピューティング> BIOS > BIOSの設定> Advanced > Processor Configuration
ハイパースレッディングの無効化:コンピューティング> BIOS > BIOSの設定> Advanced > Processor Configuration
- 物理ドライブ1および2で作成されたBOOTOS VDと同様に、次のように4つの仮想ドライブを作成します
ジャーナル>物理ドライブ番号3から
OSD1 >物理ドライブ番号7から
OSD2 >物理ドライブ番号8から
OSD3 >物理ドライブ番号9から
OSD4 >物理ドライブ番号10 - 最後に、物理ドライブと仮想ドライブは図に示すような構成にする必要があります。
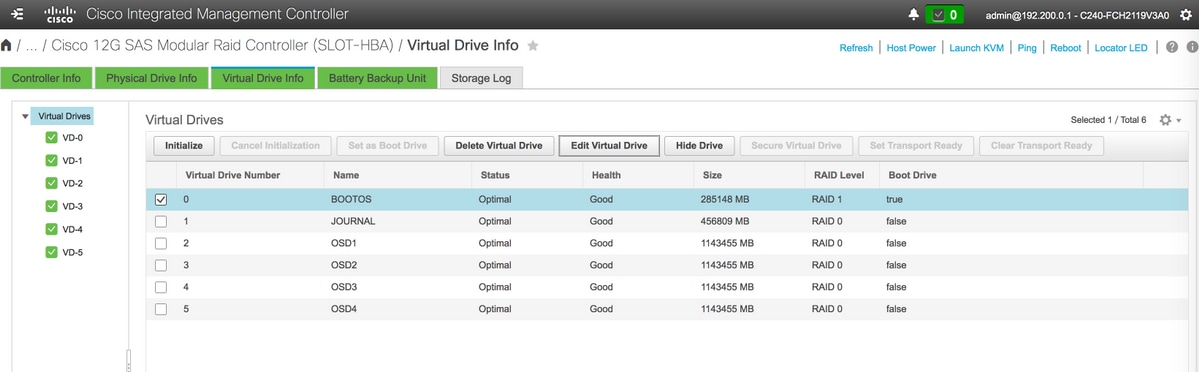 仮想ドライブ
仮想ドライブ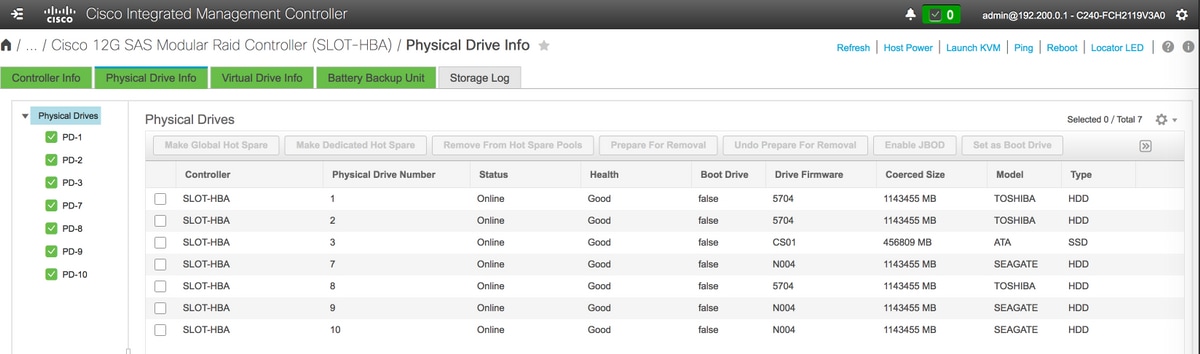 物理ドライブ
物理ドライブ
注:ここに示すイメージとこのセクションで説明する設定手順はファームウェアバージョン3.0(3e)を基準としているため、他のバージョンを操作する場合は多少バリエーションがある可能性があります。
新しいOSD-ComputeノードをOvercloudに追加
このセクションで説明する手順は、コンピューティングノードによってホストされるVMに関係なく共通です。
別のインデックスを使用してコンピューティングサーバを追加します。
追加する新しいコンピューティングサーバの詳細だけを含むadd_node.jsonファイルを作成します。新しいOSD-Computeサーバのインデックス番号が以前に使用されていないことを確認します。通常は、次に高い計算値を増やします。
例:以前の最高位はOSD-Compute-0であったため、2-vnfシステムの場合にOSD-Compute-3が作成されました。
注:json形式に注意してください。
[stack@director ~]$ cat add_node.json
{
"nodes":[
{
"mac":[
"<MAC_ADDRESS>"
],
"capabilities": "node:osd-compute-3,boot_option:local",
"cpu":"24",
"memory":"256000",
"disk":"3000",
"arch":"x86_64",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"<PASSWORD>",
"pm_addr":"192.100.0.5"
}
]
}
jsonファイルをインポートします。
[stack@director ~]$ openstack baremetal import --json add_node.json
Started Mistral Workflow. Execution ID: 78f3b22c-5c11-4d08-a00f-8553b09f497d
Successfully registered node UUID 7eddfa87-6ae6-4308-b1d2-78c98689a56e
Started Mistral Workflow. Execution ID: 33a68c16-c6fd-4f2a-9df9-926545f2127e
Successfully set all nodes to available.
前の手順でメモしたUUIDを使用して、ノードのイントロスペクションを実行します。
[stack@director ~]$ openstack baremetal node manage 7eddfa87-6ae6-4308-b1d2-78c98689a56e
[stack@director ~]$ ironic node-list |grep 7eddfa87
| 7eddfa87-6ae6-4308-b1d2-78c98689a56e | None | None | power off | manageable | False |
[stack@director ~]$ openstack overcloud node introspect 7eddfa87-6ae6-4308-b1d2-78c98689a56e --provide
Started Mistral Workflow. Execution ID: e320298a-6562-42e3-8ba6-5ce6d8524e5c
Waiting for introspection to finish...
Successfully introspected all nodes.
Introspection completed.
Started Mistral Workflow. Execution ID: c4a90d7b-ebf2-4fcb-96bf-e3168aa69dc9
Successfully set all nodes to available.
[stack@director ~]$ ironic node-list |grep available
| 7eddfa87-6ae6-4308-b1d2-78c98689a56e | None | None | power off | available | False |
IPアドレスをOsdComputeIPsの下のcustom-templates/layout.ymlに追加します。この場合、OSD-Compute-0を置き換える際に、各タイプのリストの最後にそのアドレスを追加します。
OsdComputeIPs:
internal_api:
- 11.120.0.43
- 11.120.0.44
- 11.120.0.45
- 11.120.0.43 <<< take osd-compute-0 .43 and add here
tenant:
- 11.117.0.43
- 11.117.0.44
- 11.117.0.45
- 11.117.0.43 << and here
storage:
- 11.118.0.43
- 11.118.0.44
- 11.118.0.45
- 11.118.0.43 << and here
storage_mgmt:
- 11.119.0.43
- 11.119.0.44
- 11.119.0.45
- 11.119.0.43 << and here
以前にスタックの導入に使用したdeploy.shスクリプトを実行して、新しいコンピューティングノードをオーバークラウドスタックに追加します。
[stack@director ~]$ ./deploy.sh
++ openstack overcloud deploy --templates -r /home/stack/custom-templates/custom-roles.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml --stack ADN-ultram --debug --log-file overcloudDeploy_11_06_17__16_39_26.log --ntp-server 172.24.167.109 --neutron-flat-networks phys_pcie1_0,phys_pcie1_1,phys_pcie4_0,phys_pcie4_1 --neutron-network-vlan-ranges datacentre:1001:1050 --neutron-disable-tunneling --verbose --timeout 180
…
Starting new HTTP connection (1): 192.200.0.1
"POST /v2/action_executions HTTP/1.1" 201 1695
HTTP POST http://192.200.0.1:8989/v2/action_executions 201
Overcloud Endpoint: http://10.1.2.5:5000/v2.0
Overcloud Deployed
clean_up DeployOvercloud:
END return value: 0
real 38m38.971s
user 0m3.605s
sys 0m0.466s
OpenStackスタックのステータスがCOMPLETEになるまで待機します。
[stack@director ~]$ openstack stack list
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| ID | Stack Name | Stack Status | Creation Time | Updated Time |
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| 5df68458-095d-43bd-a8c4-033e68ba79a0 | pod1 | UPDATE_COMPLETE | 2017-11-02T21:30:06Z | 2017-11-06T21:40:58Z |
+--------------------------------------+------------+-----------------+----------------------+----------------------+
新しいOSD-ComputeノードがActive状態であることを確認します。
[stack@director ~]$ source stackrc
[stack@director ~]$ nova list |grep osd-compute-3
| 0f2d88cd-d2b9-4f28-b2ca-13e305ad49ea | pod1-osd-compute-3 | ACTIVE | - | Running | ctlplane=192.200.0.117 |
[stack@director ~]$ source corerc
[stack@director ~]$ openstack hypervisor list |grep osd-compute-3
| 63 | pod1-osd-compute-3.localdomain |
新しいOSD-Computeサーバにログインし、Cephプロセスを確認します。最初は、Cephが回復すると、ステータスはHEALTH_WARNになります。
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_WARN
223 pgs backfill_wait
4 pgs backfilling
41 pgs degraded
227 pgs stuck unclean
41 pgs undersized
recovery 45229/1300136 objects degraded (3.479%)
recovery 525016/1300136 objects misplaced (40.382%)
monmap e1: 3 mons at {Pod1-controller-0=11.118.0.40:6789/0,Pod1-controller-1=11.118.0.41:6789/0,Pod1-controller-2=11.118.0.42:6789/0}
election epoch 58, quorum 0,1,2 Pod1-controller-0,Pod1-controller-1,Pod1-controller-2
osdmap e986: 12 osds: 12 up, 12 in; 225 remapped pgs
flags sortbitwise,require_jewel_osds
pgmap v781746: 704 pgs, 6 pools, 533 GB data, 344 kobjects
1553 GB used, 11840 GB / 13393 GB avail
45229/1300136 objects degraded (3.479%)
525016/1300136 objects misplaced (40.382%)
477 active+clean
186 active+remapped+wait_backfill
37 active+undersized+degraded+remapped+wait_backfill
4 active+undersized+degraded+remapped+backfilling
ただし、短い時間(20分)が経過すると、CephはHEALTH_OK状態に戻ります。
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
monmap e1: 3 mons at {Pod1-controller-0=11.118.0.40:6789/0,Pod1-controller-1=11.118.0.41:6789/0,Pod1-controller-2=11.118.0.42:6789/0}
election epoch 58, quorum 0,1,2 Pod1-controller-0,Pod1-controller-1,Pod1-controller-2
osdmap e1398: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v784311: 704 pgs, 6 pools, 533 GB data, 344 kobjects
1599 GB used, 11793 GB / 13393 GB avail
704 active+clean
client io 8168 kB/s wr, 0 op/s rd, 32 op/s wr
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 0 host pod1-osd-compute-0
-3 4.35999 host pod1-osd-compute-2
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
-4 4.35999 host pod1-osd-compute-1
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
-5 4.35999 host pod1-osd-compute-3
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
サーバー交換後の設定
サーバをオーバークラウドに追加した後、以下のリンクを参照して、以前のサーバに存在していた設定を適用してください。
VMの復元
Case 1.CF、ESC、EM、およびUASをホストするOSDコンピュートノード
Nova Aggregateリストへの追加
OSD-Computeノードをaggregate-hostsに追加し、ホストが追加されたかどうかを確認します。この場合、OSD-ComputeノードをCFとEMの両方のホスト集約に追加する必要があります。
nova aggregate-add-host
[stack@director ~]$ nova aggregate-add-host VNF2-CF-MGMT2 pod1-osd-compute-3.localdomain
[stack@director ~]$ nova aggregate-add-host VNF2-EM-MGMT2 pod1-osd-compute-3.localdomain
[stack@direcotr ~]$ nova aggregate-add-host POD1-AUTOIT pod1-osd-compute-3.localdomain
nova aggregate-show
[stack@director ~]$ nova aggregate-show VNF2-CF-MGMT2
[stack@director ~]$ nova aggregate-show VNF2-EM-MGMT2
[stack@director ~]$ nova aggregate-show POD1-AUTOITT
UAS VMのリカバリ
novaリストのUAS VMのステータスを確認し、削除します。
[stack@director ~]$ nova list | grep VNF2-UAS-uas-0
| 307a704c-a17c-4cdc-8e7a-3d6e7e4332fa | VNF2-UAS-uas-0 | ACTIVE | - | Running | VNF2-UAS-uas-orchestration=172.168.11.10; VNF2-UAS-uas-management=172.168.10.3
[stack@director ~]$ nova delete VNF2-UAS-uas-0
Request to delete server VNF2-UAS-uas-0 has been accepted.
autovnf-uas VMを回復するには、uas-checkスクリプトを実行して状態を確認します。ERRORを報告する必要があります。次に、—fixオプションを指定して再度実行し、欠落しているUAS VMを再作成します。
[stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts/
[stack@director scripts]$ ./uas-check.py auto-vnf VNF2-UAS
2017-12-08 12:38:05,446 - INFO: Check of AutoVNF cluster started
2017-12-08 12:38:07,925 - INFO: Instance 'vnf1-UAS-uas-0' status is 'ERROR'
2017-12-08 12:38:07,925 - INFO: Check completed, AutoVNF cluster has recoverable errors
[stack@director scripts]$ ./uas-check.py auto-vnf VNF2-UAS --fix
2017-11-22 14:01:07,215 - INFO: Check of AutoVNF cluster started
2017-11-22 14:01:09,575 - INFO: Instance VNF2-UAS-uas-0' status is 'ERROR'
2017-11-22 14:01:09,575 - INFO: Check completed, AutoVNF cluster has recoverable errors
2017-11-22 14:01:09,778 - INFO: Removing instance VNF2-UAS-uas-0'
2017-11-22 14:01:13,568 - INFO: Removed instance VNF2-UAS-uas-0'
2017-11-22 14:01:13,568 - INFO: Creating instance VNF2-UAS-uas-0' and attaching volume ‘VNF2-UAS-uas-vol-0'
2017-11-22 14:01:49,525 - INFO: Created instance ‘VNF2-UAS-uas-0'
autovnf-uasにログインします。数分待つと、UASが良好な状態に戻る必要があります。
VNF2-autovnf-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.17.181.101
INSTANCE IP STATE ROLE
-----------------------------------
172.17.180.6 alive CONFD-SLAVE
172.17.180.7 alive CONFD-MASTER
172.17.180.9 alive NA
注:uas-check.py —fixが失敗した場合、このファイルをコピーして再実行する必要があります。
[stack@director ~]$ mkdir –p /opt/cisco/usp/apps/auto-it/common/uas-deploy/
[stack@director ~]$ cp /opt/cisco/usp/uas-installer/common/uas-deploy/userdata-uas.txt /opt/cisco/usp/apps/auto-it/common/uas-deploy/
ESC VMのリカバリ
novaリストからESC VMのステータスを確認し、削除します。
stack@director scripts]$ nova list |grep ESC-1
| c566efbf-1274-4588-a2d8-0682e17b0d41 | VNF2-ESC-ESC-1 | ACTIVE | - | Running | VNF2-UAS-uas-orchestration=172.168.11.14; VNF2-UAS-uas-management=172.168.10.4 |
[stack@director scripts]$ nova delete VNF2-ESC-ESC-1
Request to delete server VNF2-ESC-ESC-1 has been accepted.
AutoVNF-UASからESC導入トランザクションを探し、トランザクションのログでboot_vm.pyコマンドラインを探して、ESCインスタンスを作成します。
ubuntu@VNF2-uas-uas-0:~$ sudo -i
root@VNF2-uas-uas-0:~# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on VNF2-uas-uas-0
VNF2-uas-uas-0#show transaction
TX ID TX TYPE DEPLOYMENT ID TIMESTAMP STATUS
-----------------------------------------------------------------------------------------------------------------------------
35eefc4a-d4a9-11e7-bb72-fa163ef8df2b vnf-deployment VNF2-DEPLOYMENT 2017-11-29T02:01:27.750692-00:00 deployment-success
73d9c540-d4a8-11e7-bb72-fa163ef8df2b vnfm-deployment VNF2-ESC 2017-11-29T01:56:02.133663-00:00 deployment-success
VNF2-uas-uas-0#show logs 73d9c540-d4a8-11e7-bb72-fa163ef8df2b | display xml
<config xmlns="http://tail-f.com/ns/config/1.0">
<logs xmlns="http://www.cisco.com/usp/nfv/usp-autovnf-oper">
<tx-id>73d9c540-d4a8-11e7-bb72-fa163ef8df2b</tx-id>
<log>2017-11-29 01:56:02,142 - VNFM Deployment RPC triggered for deployment: VNF2-ESC, deactivate: 0
2017-11-29 01:56:02,179 - Notify deployment
..
2017-11-29 01:57:30,385 - Creating VNFM 'VNF2-ESC-ESC-1' with [python //opt/cisco/vnf-staging/bootvm.py VNF2-ESC-ESC-1 --flavor VNF2-ESC-ESC-flavor --image 3fe6b197-961b-4651-af22-dfd910436689 --net VNF2-UAS-uas-management --gateway_ip 172.168.10.1 --net VNF2-UAS-uas-orchestration --os_auth_url http://10.1.2.5:5000/v2.0 --os_tenant_name core --os_username ****** --os_password ****** --bs_os_auth_url http://10.1.2.5:5000/v2.0 --bs_os_tenant_name core --bs_os_username ****** --bs_os_password ****** --esc_ui_startup false --esc_params_file /tmp/esc_params.cfg --encrypt_key ****** --user_pass ****** --user_confd_pass ****** --kad_vif eth0 --kad_vip 172.168.10.7 --ipaddr 172.168.10.6 dhcp --ha_node_list 172.168.10.3 172.168.10.6 --file root:0755:/opt/cisco/esc/esc-scripts/esc_volume_em_staging.sh:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc_volume_em_staging.sh --file root:0755:/opt/cisco/esc/esc-scripts/esc_vpc_chassis_id.py:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc_vpc_chassis_id.py --file root:0755:/opt/cisco/esc/esc-scripts/esc-vpc-di-internal-keys.sh:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc-vpc-di-internal-keys.sh
boot_vm.py行をシェルスクリプトファイル(esc.sh)に保存し、すべてのユーザ名*****とパスワード*****行を正しい情報(通常はcore/<PASSWORD>)に更新します。 -encrypt_keyオプションも削除する必要があります。 user_passとuser_confd_passには、username: passwordの形式を使用する必要があります(例:admin:<PASSWORD>)。
このURLを見つけて、bootvm.pyをrunning-configから外さないようにし、bootvm.pyファイルをautovnf-uas VMに取得します。この場合、10.1.2.3は自動IT VMのIPです。
root@VNF2-uas-uas-0:~# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on VNF2-uas-uas-0
VNF2-uas-uas-0#show running-config autovnf-vnfm:vnfm
…
configs bootvm
value http:// 10.1.2.3:80/bundles/5.1.7-2007/vnfm-bundle/bootvm-2_3_2_155.py
!
root@VNF2-uas-uas-0:~# wget http://10.1.2.3:80/bundles/5.1.7-2007/vnfm-bundle/bootvm-2_3_2_155.py
--2017-12-01 20:25:52-- http://10.1.2.3 /bundles/5.1.7-2007/vnfm-bundle/bootvm-2_3_2_155.py
Connecting to 10.1.2.3:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 127771 (125K) [text/x-python]
Saving to: ‘bootvm-2_3_2_155.py’
100%[=====================================================================================>] 127,771 --.-K/s in 0.001s
2017-12-01 20:25:52 (173 MB/s) - ‘bootvm-2_3_2_155.py’ saved [127771/127771]
/tmp/esc_params.cfgファイルを作成します。
root@VNF2-uas-uas-0:~# echo "openstack.endpoint=publicURL" > /tmp/esc_params.cfg
シェルスクリプトを実行して、UASノードからESCを導入します。
root@VNF2-uas-uas-0:~# /bin/sh esc.sh
+ python ./bootvm.py VNF2-ESC-ESC-1 --flavor VNF2-ESC-ESC-flavor --image 3fe6b197-961b-4651-af22-dfd910436689
--net VNF2-UAS-uas-management --gateway_ip 172.168.10.1 --net VNF2-UAS-uas-orchestration --os_auth_url
http://10.1.2.5:5000/v2.0 --os_tenant_name core --os_username core --os_password <PASSWORD> --bs_os_auth_url
http://10.1.2.5:5000/v2.0 --bs_os_tenant_name core --bs_os_username core --bs_os_password <PASSWORD>
--esc_ui_startup false --esc_params_file /tmp/esc_params.cfg --user_pass admin:<PASSWORD> --user_confd_pass
admin:<PASSWORD> --kad_vif eth0 --kad_vip 172.168.10.7 --ipaddr 172.168.10.6 dhcp --ha_node_list 172.168.10.3
172.168.10.6 --file root:0755:/opt/cisco/esc/esc-scripts/esc_volume_em_staging.sh:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc_volume_em_staging.sh
--file root:0755:/opt/cisco/esc/esc-scripts/esc_vpc_chassis_id.py:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc_vpc_chassis_id.py
--file root:0755:/opt/cisco/esc/esc-scripts/esc-vpc-di-internal-keys.sh:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc-vpc-di-internal-keys.sh
新しいESCにログインし、バックアップの状態を確認します。
ubuntu@VNF2-uas-uas-0:~$ ssh admin@172.168.11.14
…
####################################################################
# ESC on VNF2-esc-esc-1.novalocal is in BACKUP state.
####################################################################
[admin@VNF2-esc-esc-1 ~]$ escadm status
0 ESC status=0 ESC Backup Healthy
[admin@VNF2-esc-esc-1 ~]$ health.sh
============== ESC HA (BACKUP) ===================================================
ESC HEALTH PASSED
ESCからのCFおよびEM VMの回復
NovaリストからCFおよびEM VMのステータスを確認します。これらはERROR状態である必要があります。
[stack@director ~]$ source corerc
[stack@director ~]$ nova list --field name,host,status |grep -i err
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | None | ERROR|
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229 |None | ERROR
ESCマスターにログインし、影響を受けるEMおよびCF VMごとにrecovery-vm-actionを実行します。しばらくお待ちください。ESCはリカバリアクションをスケジュールし、数分間発生しない可能性があります。yangesc.logを監視します。
sudo /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli recovery-vm-action DO
[admin@VNF2-esc-esc-0 ~]$ sudo /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli recovery-vm-action DO VNF2-DEPLOYMENT-_VNF2-D_0_a6843886-77b4-4f38-b941-74eb527113a8
[sudo] password for admin:
Recovery VM Action
/opt/cisco/esc/confd/bin/netconf-console --port=830 --host=127.0.0.1 --user=admin --privKeyFile=/root/.ssh/confd_id_dsa --privKeyType=dsa --rpc=/tmp/esc_nc_cli.ZpRCGiieuW
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="1">
<ok/>
</rpc-reply>
[admin@VNF2-esc-esc-0 ~]$ tail -f /var/log/esc/yangesc.log
…
14:59:50,112 07-Nov-2017 WARN Type: VM_RECOVERY_COMPLETE
14:59:50,112 07-Nov-2017 WARN Status: SUCCESS
14:59:50,112 07-Nov-2017 WARN Status Code: 200
14:59:50,112 07-Nov-2017 WARN Status Msg: Recovery: Successfully recovered VM [VNF2-DEPLOYMENT-_VNF2-D_0_a6843886-77b4-4f38-b941-74eb527113a8]
新しいEMにログインし、EMの状態がアップであることを確認します。
ubuntu@VNF2vnfddeploymentem-1:~$ /opt/cisco/ncs/current/bin/ncs_cli -u admin -C
admin connected from 172.17.180.6 using ssh on VNF2vnfddeploymentem-1
admin@scm# show ems
EM VNFM
ID SLA SCM PROXY
---------------------
2 up up up
3 up up up
StarOS VNFにログインし、CFカードがスタンバイ状態であることを確認します。
Case 2.自動IT、自動導入、EM、およびUASをホストするOSDコンピューティングノード
自動導入VMのリカバリ
OSPDから、自動展開VMが影響を受けたがACTIVE/Runningと表示される場合は、最初にそれを削除する必要があります。自動導入が影響を受けなかった場合は、「自動VMのリカバリ:
[stack@director ~]$ nova list |grep auto-deploy
| 9b55270a-2dcd-4ac1-aba3-bf041733a0c9 | auto-deploy-ISO-2007-uas-0 | ACTIVE | - | Running | mgmt=172.16.181.12, 10.1.2.7 [stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts
[stack@director ~]$ ./auto-deploy-booting.sh --floating-ip 10.1.2.7 --delete
自動展開を削除したら、同じfloatingipアドレスで再度作成します。
[stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts
[stack@director scripts]$ ./auto-deploy-booting.sh --floating-ip 10.1.2.7
2017-11-17 07:05:03,038 - INFO: Creating AutoDeploy deployment (1 instance(s)) on 'http://10.84.123.4:5000/v2.0' tenant 'core' user 'core', ISO 'default'
2017-11-17 07:05:03,039 - INFO: Loading image 'auto-deploy-ISO-5-1-7-2007-usp-uas-1.0.1-1504.qcow2' from '/opt/cisco/usp/uas-installer/images/usp-uas-1.0.1-1504.qcow2'
2017-11-17 07:05:14,603 - INFO: Loaded image 'auto-deploy-ISO-5-1-7-2007-usp-uas-1.0.1-1504.qcow2'
2017-11-17 07:05:15,787 - INFO: Assigned floating IP '10.1.2.7' to IP '172.16.181.7'
2017-11-17 07:05:15,788 - INFO: Creating instance 'auto-deploy-ISO-5-1-7-2007-uas-0'
2017-11-17 07:05:42,759 - INFO: Created instance 'auto-deploy-ISO-5-1-7-2007-uas-0'
2017-11-17 07:05:42,759 - INFO: Request completed, floating IP: 10.1.2.7
バックアップサーバからAutodeploy.cfgファイル、ISO、およびconfd_backup tarファイルをコピーして、VMを自動導入し、バックアップtarファイルからconfd cdbファイルを復元します。
ubuntu@auto-deploy-iso-2007-uas-0:~# sudo -i
ubuntu@auto-deploy-iso-2007-uas-0:# service uas-confd stop
uas-confd stop/waiting
root@auto-deploy-iso-2007-uas-0:# cd /opt/cisco/usp/uas/confd-6.3.1/var/confd
root@auto-deploy-iso-2007-uas-0:/opt/cisco/usp/uas/confd-6.3.1/var/confd# tar xvf /home/ubuntu/ad_cdb_backup.tar
cdb/
cdb/O.cdb
cdb/C.cdb
cdb/aaa_init.xml
cdb/A.cdb
root@auto-deploy-iso-2007-uas-0~# service uas-confd start
uas-confd start/running, process 2036
以前のトランザクションをチェックして、confdが正しくロードされたことを確認します。autodeploy.cfgを新しいOSD-Compute名で更新します。 詳細については、セクション「最後のステップ:AutoDeploy設定の更新」を
root@auto-deploy-iso-2007-uas-0:~# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on auto-deploy-iso-2007-uas-0
auto-deploy-iso-2007-uas-0#show transaction
SERVICE SITE
DEPLOYMENT SITE TX AUTOVNF VNF AUTOVNF
TX ID TX TYPE ID DATE AND TIME STATUS ID ID ID ID TX ID
-------------------------------------------------------------------------------------------------------------------------------------
1512571978613 service-deployment tb5bxb 2017-12-06T14:52:59.412+00:00 deployment-success
auto-deploy-iso-2007-uas-0# exit
自動IT VMのリカバリ
OSPDから、自動IT VMが影響を受けていてもACTIVE/Runningと表示される場合は、これを削除する必要があります。auto-itが影響を受けなかった場合は、次のVMに進みます。
[stack@director ~]$ nova list |grep auto-it
| 580faf80-1d8c-463b-9354-781ea0c0b352 | auto-it-vnf-ISO-2007-uas-0 | ACTIVE | - | Running | mgmt=172.16.181.3, 10.1.2.8 [stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts
[stack@director ~]$ ./ auto-it-vnf-staging.sh --floating-ip 10.1.2.8 --delete
auto-it-vnfステージングスクリプトを実行し、auto-itを再作成します。
[stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts
[stack@director scripts]$ ./auto-it-vnf-staging.sh --floating-ip 10.1.2.8
2017-11-16 12:54:31,381 - INFO: Creating StagingServer deployment (1 instance(s)) on 'http://10.84.123.4:5000/v2.0' tenant 'core' user 'core', ISO 'default'
2017-11-16 12:54:31,382 - INFO: Loading image 'auto-it-vnf-ISO-5-1-7-2007-usp-uas-1.0.1-1504.qcow2' from '/opt/cisco/usp/uas-installer/images/usp-uas-1.0.1-1504.qcow2'
2017-11-16 12:54:51,961 - INFO: Loaded image 'auto-it-vnf-ISO-5-1-7-2007-usp-uas-1.0.1-1504.qcow2'
2017-11-16 12:54:53,217 - INFO: Assigned floating IP '10.1.2.8' to IP '172.16.181.9'
2017-11-16 12:54:53,217 - INFO: Creating instance 'auto-it-vnf-ISO-5-1-7-2007-uas-0'
2017-11-16 12:55:20,929 - INFO: Created instance 'auto-it-vnf-ISO-5-1-7-2007-uas-0'
2017-11-16 12:55:20,930 - INFO: Request completed, floating IP: 10.1.2.8
ISOイメージをリロードします。この場合、自動IPアドレスは10.1.2.8です。ロードには数分かかります。
[stack@director ~]$ cd images/5_1_7-2007/isos
[stack@director isos]$ curl -F file=@usp-5_1_7-2007.iso http://10.1.2.8:5001/isos
{
"iso-id": "5.1.7-2007"
}
to check the ISO image:
[stack@director isos]$ curl http://10.1.2.8:5001/isos
{
"isos": [
{
"iso-id": "5.1.7-2007"
}
]
}
OSPD自動導入ディレクトリから自動VMにVNF system.cfgファイルをコピーします。
[stack@director autodeploy]$ scp system-vnf* ubuntu@10.1.2.8:.
ubuntu@10.1.2.8's password:
system-vnf1.cfg 100% 1197 1.2KB/s 00:00
system-vnf2.cfg 100% 1197 1.2KB/s 00:00
ubuntu@auto-it-vnf-iso-2007-uas-0:~$ pwd
/home/ubuntu
ubuntu@auto-it-vnf-iso-2007-uas-0:~$ ls
system-vnf1.cfg system-vnf2.cfg
注:EMとUAS VMの回復手順はどちらも同じです。詳細については、「ケース1」のセクションを参照してください。
ハンドルESC回復エラー
予期しない状態が原因でESCによるVMの起動が失敗する場合は、マスターESCをリブートしてESCスイッチオーバーを実行することをお勧めします。ESCスイッチオーバーには約1分かかります。新しいマスターESC上でスクリプトhealth.shを実行して、ステータスがアップであるかどうかを確認します。マスターESCを押して、VMを起動し、VMの状態を修正します。このリカバリタスクの完了には、最大5分かかります。
/var/log/esc/yangesc.logおよび/var/log/esc/escmanager.logをモニタできます。5 ~ 7分経過してもVMがリカバリされない場合は、影響を受けるVMの手動リカバリを実行する必要があります。
自動展開構成の更新
AutoDeploy VMから、auto-deploy.cfgを編集して、古いOSD-Computeサーバを新しいサーバで置き換えます。次に、confd_cliでreplaceをロードします。この手順は、後で展開を正常に非アクティブ化するために必要です。
root@auto-deploy-iso-2007-uas-0:/home/ubuntu# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on auto-deploy-iso-2007-uas-0
auto-deploy-iso-2007-uas-0#config
Entering configuration mode terminal
auto-deploy-iso-2007-uas-0(config)#load replace autodeploy.cfg
Loading. 14.63 KiB parsed in 0.42 sec (34.16 KiB/sec)
auto-deploy-iso-2007-uas-0(config)#commit
Commit complete.
auto-deploy-iso-2007-uas-0(config)#end
設定の変更後、uas-confdサービスとAuto-Deployサービスを再起動します。
root@auto-deploy-iso-2007-uas-0:~# service uas-confd restart
uas-confd stop/waiting
uas-confd start/running, process 14078
root@auto-deploy-iso-2007-uas-0:~# service uas-confd status
uas-confd start/running, process 14078
root@auto-deploy-iso-2007-uas-0:~# service autodeploy restart
autodeploy stop/waiting
autodeploy start/running, process 14017
root@auto-deploy-iso-2007-uas-0:~# service autodeploy status
autodeploy start/running, process 14017
Syslogの有効化
UCSサーバ、OpenStackコンポーネント、およびリカバリされたVMのsyslogを有効にするには、次のセクションに従ってください
次のリンクの「Re-Enable syslog for UCS and Openstack components」および「Enable syslog for the VNFs」
更新履歴
| 改定 | 発行日 | コメント |
|---|---|---|
1.0 |
10-Jul-2018
|
初版 |
シスコ エンジニア提供
- パルテエバンラジャゴパルシスコアドバンスドサービス
- パドマラージラマヌードジャムシスコアドバンスドサービス
 フィードバック
フィードバックシスコに問い合わせ
- サポート ケースをオープン

- (シスコ サービス契約が必要です。)