QvPC-DIでのiftaskおよびNPUパフォーマンスの監視
ダウンロード オプション
偏向のない言語
この製品のドキュメントセットは、偏向のない言語を使用するように配慮されています。このドキュメントセットでの偏向のない言語とは、年齢、障害、性別、人種的アイデンティティ、民族的アイデンティティ、性的指向、社会経済的地位、およびインターセクショナリティに基づく差別を意味しない言語として定義されています。製品ソフトウェアのユーザインターフェイスにハードコードされている言語、RFP のドキュメントに基づいて使用されている言語、または参照されているサードパーティ製品で使用されている言語によりドキュメントに例外が存在する場合があります。シスコのインクルーシブ ランゲージの取り組みの詳細は、こちらをご覧ください。
翻訳について
シスコは世界中のユーザにそれぞれの言語でサポート コンテンツを提供するために、機械と人による翻訳を組み合わせて、本ドキュメントを翻訳しています。ただし、最高度の機械翻訳であっても、専門家による翻訳のような正確性は確保されません。シスコは、これら翻訳の正確性について法的責任を負いません。原典である英語版(リンクからアクセス可能)もあわせて参照することを推奨します。
はじめに
このドキュメントでは、QvPC-DIでiftask/NPUのパフォーマンスを監視する方法について説明します。
また、 iftaskの主な概念についても説明します。
使用するコンポーネント
このドキュメントの情報は、QvPC-DIに基づくものです。
このドキュメントの情報は、特定のラボ環境にあるデバイスに基づいて作成されました。このドキュメントで使用するすべてのデバイスは、クリアな(デフォルト)設定で作業を開始しています。本稼働中のネットワークでは、各コマンドによって起こる可能性がある影響を十分確認してください。
Iftaskアーキテクチャ
iftaskはQvPC-DIのプロセスです。DIネットワークポートおよびサービスポート用のサービス機能仮想カード(SF)および制御機能仮想カード(CF)で、データプレーン開発キット(DPDK)機能を有効にします。DPDKは、仮想化環境で入出力を処理するためのより効率的な方法です。
高性能ネットワークインターフェイスコントローラ(NIC)のデバイスドライバがユーザ空間に移行されたため、高価なコンテキストスイッチ(ユーザ空間/カーネル空間)が不要になります。
ドライバはユーザ空間の割り込み不可モードで動作し、スレッドはこれらのNICドライバ内のHWキュー/リングバッファに直接アクセスできます。
アーキテクチャに関するドキュメントは、で入手できます。
Ultra Gateway Platform System Administration GuideのUltra Services Platform(USP)の概要
詳細は、次の図に(SFの)タスクアーキテクチャを示します。
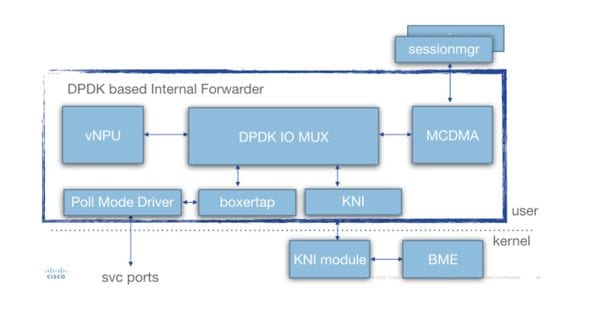
さまざまなコンポーネントが存在します。
Poll Mode Driver(PMD):これは、NIC(SR-IOVの場合)またはSWリングバッファ(仮想/vmxnetタイプのインターフェイスの場合)からハードウェアキューを継続的にポーリングする機能です。 このため、これらのPMDに関連付けられたCPUは100 %で継続的にペギングされます。
配備時に、 iftaskおよびiftask内のさまざまな関数に割り当てられたCPUのnrは、 param.cfgファイルを使用して静的に割り当てることができます。
Boxertap:パケットの送信元(例:Diポート/サービスポート)、および送信先(例:ローカルvNPU)に基づいて、starosメタデータ(MEHヘッダー)をパケットに追加/削除
IOMUX:すべての宛先(sessmgr/ports/vNPU/..)を含むBIAライブラリがあります。 この機能は、基本的にBIA
vNPU:フロー分類/ルックアップ。これは、ハードウェアベースシステム(ASR5000/ASR5500)のNPUに相当します。
vNPUのフローは、vNPUからアクセス可能な共有メモリ内でNPUmgr(demuxmgr/sessmgrなどから情報を取得するユーザ)によって引き続きプログラムされます。
– さらに、npumgr/sessmgrが統計/設定のためにvNPUをポーリングできるようにAPIが作成されます。
MCDMA:sessmgr宛てのパケットは、(使用可能なさまざまなMCDMAコア/スレッドを介して)MCDMAインターフェイスに書き込まれます。 これらのパケットは、DMAを介してsessmgrで使用できるようになります。カーネルは限られた方法でしか使用されないため、これにより実際のパフォーマンスが向上します。これについては、この記事で詳しく説明します。
MCDMAは、バッチ機能も提供しています(1つのシステムコールで多数のパケットを処理する)。
KNI:Linuxカーネルに向かう必要があるパケットのインターフェイス(DI control/ARP/icmp/routing/...)
Iftaskパケットフロー
次の図は、コントロールプレーンパケットのパケットフローを示しています。例:GTPv2 Create session Request
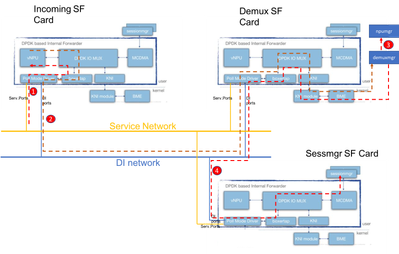
ステップ1:GTPv2 CSRパケットが、使用可能な任意のSFのサービスポート経由で着信します。サービスインターフェイスNICのRxキューに入れられ、iftaskプロセスのPMDコアの1つによって選択されます。BoxertapはMEHヘッダーを配置し、パケットはIOMux経由でローカルvNPUに転送されてフロールックアップを行います。
これは新しいセッションであるため、vNPUには専用のフローがプログラムされておらず、demuxカードのdemux mgrにパケットをルーティングする必要があります。
ステップ2:vNPUはMEHヘッダーを変更します(関連するdemuxプロセス用の新しいBIAを使用)。 IOMUXは、これをDIネットワーク経由でdemuxカードに送信する必要があることを認識しています。Demuxカード上のタスクプロセスが着信パケットを処理し、IOMuxはパケットをKNIモジュール(カーネルへのインターフェース)にルーティングします。 カーネルを通して、最終的にはdemuxmgrプロセス(この場合はegtpinmgr)で終了します。
ステップ3: Demuxmgrがそのタスクを実行します。sessmgrを選択し、後続のGTPv2パケットのフローでnpumgrをプログラムします
すべてのカードのvNPUは、npumgrがこれらのフローをプログラムするために使用する共有メモリにアクセスできます。
ステップ4:選択したsessmgrにGTPv2 CSRが転送されます。MEHが再度変更され、DemuxカードからDIネット上でSessmgr SFカードに転送されます。そのカード上のIOMUXプロセスは、MCDMAインターフェイスを介して、選択されたsessmgrにパケットを転送します。これ以降、sessmgrはこのセッションのすべてのGTPv2トラフィックを処理します。GTPU TEIDがネゴシエートされると、NPUmgrを介してフローがプログラムされ、後続のGTPUパケットも着信SFカードからsessmgr SFカードに直接送信できるようになります。
iftask内のvCPU
展開時に、一定量の仮想中央処理装置(vCPU)がiftaskプロセスに静的に割り当てられます。これにより、ユーザスペースアプリケーション(sessmgrなど)のコア数は削減されますが、I/Oのパフォーマンスは大幅に向上します。
この割り当ては、配備時に各SF/CFに関連付けられているparam.cfgテンプレート内の次のパラメータによって行われます。
- IFTASK_CORES ( iftaskで割り当てられる使用可能なコアの割合)
- (IFTASK_CRYPTO_CORES - (暗号化処理(EPDGの場合)に割り当てられる使用可能なコアの割合)
- (IFTASK_MCDMA_CORES - (MCDMA機能に割り当てられたコア数をさらに調整するため)
- SFでは、iftaskプロセスが内部的に割り当てられたコアを次の場所に分散します。
- ポールモードドライバ(PMD)vCPU(tx/rx/vnpuアクティビティを実行)
- MCDMA vCPU、 iftaskからsessmgrへのパケット転送と返送
- CFでは、SFがsessmgrプロセスをホストしていないため、MCDMA vCPUは必要ありません。
コマンド「show cloud hardware iftask」を実行すると、QVPC-DI環境での問題の詳細が表示されます。
[local]UGP# show cloud hardware iftask Card 1: Total number of cores on VM: 8 Number of cores for PMD only: 0 Number of cores for VNPU only: 0 Number of cores for PMD and VNPU: 2 <-- CF: 2 out of 8 cores are assigned to iftask PMD/VNPU Number of cores for MCDMA: 0 <-- CF: no cores allocated to MCDMA as there is no sessmgr process on CF Number of cores for Crypto: 0 Hugepage size: 2048 kB Total hugepages: 3670016 kB NPUSHM hugepages: 0 kB CPU flags: avx sse sse2 ssse3 sse4_1 sse4_2 Poll CPU's: 1 2 KNI reschedule interval: 5 us ... Card 3: Total number of cores on VM: 8 Number of cores for PMD only: 0 Number of cores for VNPU only: 0 Number of cores for PMD and VNPU: 2 <-- SF: 2 out of 8 core are assigned to iftask PMD/VNPU
Number of cores for MCDMA: 1 <-- SF: 1 out of 8 cores is assigned to iftak MCDMA
Number of cores for Crypto: 0
Hugepage size: 2048 kB
Total hugepages: 4718592 kB
NPUSHM hugepages: 0 kB
CPU flags: avx sse sse2 ssse3 sse4_1 sse4_2
Poll CPU's: 1 2 3
KNI reschedule interval: 5 us
コマンド「show cloud configuration」を実行すると、使用されているパラメータの詳細が表示されます。
[local]UGP# show cloud configuration Card 1: Config Disk Params: ------------------------- CARDSLOT=1 CPUID=0 CARDTYPE=0x40010100 DI_INTERFACE=BOND:TYPE:ixgbevf-1,TYPE:ixgbevf-2 DI_INTERFACE_VLANID=2111 VNFM_INTERFACE=MAC:fa:16:3e:23:aa:e9 VNFM_PROXY_ADDRS=172.16.180.3,172.16.180.5,172.16.180.6 MGMT_INTERFACE=MAC:fa:16:3e:87:23:9b VNFM_IPV4_ENABLE=true VNFM_IPV4_DHCP_ENABLE=true Local Params: ------------------------- CARDSLOT=1 CARDTYPE=0x40010100 CPUID=0 ... Card 3: Config Disk Params: ------------------------- CARDSLOT=3 CPUID=0 CARDTYPE=0x42030100 DI_INTERFACE=BOND:TYPE:ixgbevf-1,TYPE:ixgbevf-2 SERVICE1_INTERFACE=BOND:TYPE:ixgbevf-3,TYPE:ixgbevf-4 SERVICE2_INTERFACE=BOND:TYPE:ixgbevf-5,TYPE:ixgbevf-6 DI_INTERFACE_VLANID=2111 VNFM_INTERFACE=MAC:fa:16:3e:29:c6:b7 IFTASK_CORES=30 VNFM_IPV4_ENABLE=true VNFM_IPV4_DHCP_ENABLE=true Local Params: ------------------------- CARDSLOT=3 CARDTYPE=0x42010100 CPUID=0
設計上の考慮事項:
iftaskにvCPUを割り当てる際には、考慮する必要のある要素がいくつかあります。
-total vCPU's available to the SF vs iftask vCPU's:デフォルト設定では、param.cfgファイルのIFTASK_CORESパラメータを介してiftaskに関連付けられたvCPUの30 %が指定されます。ただし、これはアプリケーション(MMEとSPGWとePDG)によって異なります – >エンジニアリングと相談する必要があります。
-iftask vCPUがPMDに割り当てられているのに対し、iftask vCPUはMCDMAに割り当てられている。このバランスが取れているかどうかを確認するには、後述の「iftaskのパフォーマンス」のセクションを参照してください。
-iftask MCDMA vCPUと、すべてのアプリケーションの残りのvCPUの比較。通常は、アプリケーション(sessmgr/aaamgr/...)用の残りのvCPUに対して、iftask MCDMA vCPUを1/xに分散させるのが良いでしょう。
例:
SFで使用可能なコアの合計38:
-14 iftaskに割り当て(6 PMD、8 MCDMA)
– 他のプロセスに24を割り当て済み
つまり、3つのアプリケーションvCPUごとに1つのMCDMA vCPUがあります。
これにより、各MCDMA vCPUの負荷を均等にすることができます。
タスク・パフォーマンスの監視
iftaskプロセスは、いくつかの方法で監視できます。
showコマンドのリストを統合します。
show subscribers data-rate show npumgr dinet utilization pps show npumgr dinet utilization pps show cloud monitor di-network summary show cloud hardware iftask show cloud configuration show iftask stats summary show port utilization table show npu utilization table show npumgr utilization information show processes cpu
コマンド#show cpu info verboseはiftaskコアに関する情報を提供しません。常に100 %の使用率で表示される
次の例では、core 1,2,3がiftaskに関連付けられ、使用率100%にリストされています。これは正常です。
Card 3, CPU 0:
Status : Standby, Kernel Running, Tasks Running
Load Average : 3.12, 3.12, 3.13 (3.95 max)
Total Memory : 16384M
Kernel Uptime : 4D 21H 56M
Last Reading:
CPU Usage All : 1.9% user, 0.3% sys, 0.0% io, 0.0% irq, 97.8% idle
Core 0 : 5.8% user, 0.2% sys, 0.0% io, 0.0% irq, 94.0% idle
Core 1 : Not Averaged (Poll CPU)
Core 2 : Not Averaged (Poll CPU)
Core 3 : Not Averaged (Poll CPU)
Core 4 : 2.2% user, 0.2% sys, 0.0% io, 0.0% irq, 97.6% idle
Core 5 : 0.8% user, 0.5% sys, 0.0% io, 0.0% irq, 98.7% idle
Core 6 : 0.4% user, 0.5% sys, 0.0% io, 0.0% irq, 99.1% idle
Core 7 : 0.1% user, 0.3% sys, 0.0% io, 0.0% irq, 99.6% idle
Poll CPUs : 3 (1, 2, 3)
Core 1 : 100.0% user, 0.0% sys, 0.0% io, 0.0% irq, 0.0% idle
Core 2 : 100.0% user, 0.0% sys, 0.0% io, 0.0% irq, 0.0% idle
Core 3 : 100.0% user, 0.0% sys, 0.0% io, 0.0% irq, 0.0% idle
Processes / Tasks : 143 processes / 16 tasks
Network mcdmaN : 0.002 kpps rx, 0.001 mbps rx, 0.002 kpps tx, 0.001 mbps tx
File Usage : 1504 open files, 1627405 available
Memory Usage : 7687M 46.9% used
Memory Details:
Static : 330M kernel, 144M image
System : 10M tmp, 0M buffers, 54M kcache, 79M cache
Process/Task : 6963M (120M small, 684M huge, 6158M other)
Other : 104M shared data
Free : 8696M free
Usable : 5810M usable (8696M free, 0M reclaimable, 2885M reserved by tasks)コマンド#show npu utilization tableは、(各カードの)iftaskプロセスに関連付けられた各コアの使用率に関する優れた要約を提供します。
注:ここで重要なのは、一部のコアの使用率が他のコアよりも常に高いかどうかを特定することです。
[local]UGP# show npu utilization table
-------iftask-------
lcore now 5min 15min
-------- ------ ------ ------
01/0/1 0% 0% 0%
01/0/2 0% 0% 0%
02/0/1 0% 0% 0%
02/0/2 2% 1% 0%
03/0/1 0% 0% 0%
03/0/2 0% 0% 0%
03/0/3 0% 0% 0%
04/0/1 0% 0% 0%
04/0/2 0% 0% 0%
04/0/3 0% 0% 0%
05/0/1 0% 0% 0%
05/0/2 0% 0% 0%
05/0/3 0% 0% 0%コマンド#show npumgr utilization information(隠しコマンド)
このコマンドは、各iftaskコアの詳細と、これらのコアでCPUを消費している内容を表示します。
注:PMDコアでは、PortRX、PortTX、KNI、CipherでCPUが消費されています。MCDMAコアのCPUがMCDMAによって消費されています。
PMDとMCDMAの両方のコアの負荷は均等である必要があります。
そうでない場合は、いくつかの調整が必要になります(たとえば、より多くの/少ないMDMAコアを割り当てる)。
******** show npumgr utilization information 3/0/0 *******
5-Sec Avg: lcore01| lcore02| lcore03| lcore04| lcore05| lcore06| lcore07| lcore08| lcore09| lcore10| lcore11| lcore12| lcore13| lcore14| lcore15| lcore16|
Idle: 31%| 37%| 32%| 35%| 41%| 48%| 47%| 38%| 57%| 56%| 55%| 56%| 46%| 56%| 54%| 52%|
PortRX: 28%| 26%| 27%| 26%| 0%| 0%| 0%| 0%| 12%| 14%| 11%| 11%| 0%| 0%| 0%| 0%|
PortTX: 5%| 5%| 6%| 5%| 8%| 8%| 8%| 14%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%|
KniRX: 6%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%|
Kni: 1%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%|
McdmaRX: 0%| 0%| 0%| 0%| 34%| 29%| 29%| 32%| 0%| 0%| 0%| 0%| 35%| 28%| 28%| 28%|
Mcdma: 0%| 0%| 0%| 0%| 11%| 7%| 4%| 6%| 0%| 0%| 0%| 0%| 14%| 7%| 7%| 7%|
Vnpu: 28%| 29%| 28%| 32%| 0%| 0%| 0%| 0%| 30%| 28%| 33%| 28%| 0%| 0%| 0%| 0%|
McdmaFlush: 0%| 0%| 0%| 0%| 6%| 8%| 12%| 10%| 0%| 0%| 0%| 0%| 6%| 10%| 11%| 14%|
Cipher: 1%| 2%| 6%| 2%| 0%| 0%| 0%| 0%| 1%| 2%| 1%| 5%| 0%| 0%| 0%| 0%|
rx kbits/sec: 728563| 736103| 647535| 626595| 811362| 698724| 717147| 799281| 617199| 595268| 623670| 633132| 819270| 672732| 790849| 719498|
rx frames/sec: 94409| 95586| 91107| 84997| 109526| 97466| 98557| 107690| 81122| 82076| 86959| 87960| 114114| 96198| 108108| 100259|
tx kbits/sec: 715038| 722181| 634227| 614221| 827124| 712740| 731329| 814782| 605373| 583318| 611001| 620328| 835692| 686575| 806395| 733924|
tx frames/sec: 94310| 95491| 90969| 84896| 109526| 97466| 98557| 107690| 81002| 81986| 86858| 87859| 114114| 96198| 108108| 100259|
5-Min Avg: ...
15-Min Avg: ...詳細:
CPUは、サービスポートまたはDIポート経由でiftaskプロセスに着信するパケットに対して、次のように考慮されます。
Vnpuルックアップは、CPUに最も大きな負荷がかかる部分です。
Vnpuルックアップの後:
パケットがMCDMAコアに送信されると、関連するMCDMAコアのMcdmaRxでCPU時間が課金されます。
– パケットは別のiftaskコアに送信され、CPU時間はVnpu
– パケットは同じiftaskコアに送信され、CPU時間はPortRx
– パケットは同じiftaskコアに送信され、CPU時間はunderKniRxに計上されます。
PortRxには、受信キューからパケットを取り出し、必要な場所にディスパッチ/キューイングするための大きな一般的オーバーヘッドも含まれます
コマンド#show npumgr dinet utilization pps、#show npumgr dinet utilization bbps、および#show port utilization table
これらは、DIポートの負荷とサービスポートに関する情報を提供します。
実際のパフォーマンスは、NIC/CPUおよびiftaskへのCPU割り当てに依存します。
[local]UGP# show npumgr dinet utilization pps
------ Average DINet Port Utilization (in kpps) ------
Port Type Current 5min 15min
Rx Tx Rx Tx Rx Tx
----- ------------------------ ------- ------- ------- ------- ------- -------
1/0 Virtual Ethernet 0 0 0 0 0 0
2/0 Virtual Ethernet 0 0 0 0 0 0
3/0 Virtual Ethernet 0 0 0 0 0 0
4/0 Virtual Ethernet 0 0 0 0 0 0
5/0 Virtual Ethernet 0 0 0 0 0 0
[local]UGP# show npumgr dinet utilization bps
------ Average DINet Port Utilization (in mbps) ------
Port Type Current 5min 15min
Rx Tx Rx Tx Rx Tx
----- ------------------------ ------- ------- ------- ------- ------- -------
1/0 Virtual Ethernet 1 1 1 1 1 1
2/0 Virtual Ethernet 1 0 1 0 1 0
3/0 Virtual Ethernet 0 0 0 0 0 0
4/0 Virtual Ethernet 0 0 0 0 0 0
5/0 Virtual Ethernet 0 0 0 0 0 0
[local]UGP# show port utilization table
------ Average Port Utilization (in mbps) ------
Port Type Current 5min 15min
Rx Tx Rx Tx Rx Tx
----- ------------------------ ------- ------- ------- ------- ------- -------
1/1 Virtual Ethernet 0 0 0 0 0 0
2/1 Virtual Ethernet 0 0 0 0 0 0
3/10 Virtual Ethernet 0 0 0 0 0 0
3/11 Virtual Ethernet 0 0 0 0 0 0
4/10 Virtual Ethernet 0 0 0 0 0 0
4/11 Virtual Ethernet 0 0 0 0 0 0
5/10 Virtual Ethernet 0 0 0 0 0 0
5/11 Virtual Ethernet 0 0 0 0 0 0コマンド#show cloud monitor di-network summary
このコマンドは、DIネットワークの状態を監視します。カードは相互にハートビートを送信し、損失が監視されます。正常なシステムでは、損失は報告されません。
[local]UGP# show cloud monitor di-network summary Card 3 Heartbeat Results: ToCard Health 5MinLoss 60MinLoss 1 Good 0.00% 0.00% 2 Good 0.00% 0.00% 4 Good 0.00% 0.00% 5 Good 0.00% 0.00% Card 4 Heartbeat Results: ToCard Health 5MinLoss 60MinLoss 1 Good 0.00% 0.00% 2 Good 0.00% 0.00% 3 Good 0.00% 0.00% 5 Good 0.00% 0.00% Card 5 Heartbeat Results: ToCard Health 5MinLoss 60MinLoss 1 Good 0.00% 0.00% 2 Good 0.00% 0.00% 3 Good 0.00% 0.00% 4 Good 0.00% 0.00%
コマンド#show iftask stats summary
NPUの負荷が高いと、トラフィックがドロップされる可能性があります。
これを評価するには、コマンド#show iftask stats summaryの出力を取得します。
注:DISCARDSはゼロ以外の値になる可能性があるため、他のすべてのカウンタは理想的には0のままにしておきます。
[local]VPC# show iftask stats summary Thursday January 18 16:01:29 IST 2018 ----------------------------------------------------------------------------------------------- Counter SF3 SF4 SF5 SF6 SF7 SF8 SF9 SF10 SF11 SF12 ___TOTAL___ ------------------------------------------------------------------------------------------------ svc_rx 32491861127 16545600654 37041906441 37466889835 32762859630 34931554543 38861410897 16025531220 33566817747 32823851780 312518283874 svc_tx 46024774071 14811663244 40316226774 39926898585 40803541378 48718868048 35252698559 1738016438 4249156512 40356388348 312198231957 di_rx 42307187425 14637310721 40072487209 39584697117 41150445596 44534022642 31867253533 1731310419 4401095653 40711142205 300996952520 di_tx 28420090751 16267050562 36423298668 36758561246 32731606974 30366650898 35201117980 16009902791 33536789041 32815316570 298530385481 __ALL_DROPS__ 1932492 252 17742 790473 11228 627018 844812 60402 0 460830 4745249 svc_tx_drops 0 0 0 0 0 0 0 0 0 0 0 di_rx_drops 0 1 0 0 49 113 579 30200 0 4888 35830 di_tx_drops 0 0 0 0 0 0 0 0 0 0 0 sw_rss_enq_drops 0 0 0 0 0 0 0 0 0 0 0 kni_thread_drops 0 0 0 0 0 0 0 0 0 0 0 kni_drops 0 1 0 0 0 0 124 30200 0 0 30325 mcdma_drops 0 0 0 168 80 194535 758500 0 0 11628 964911 mux_deliver_hop_drops 0 0 0 0 0 0 0 0 0 1019 1019 mux_deliver_drops 0 0 0 0 0 0 0 0 0 0 0 mux_xmit_failure_drops 0 3 0 0 0 0 7 2 0 0 12 mc_dma_thread_enq_drops 0 0 0 0 49 113 580 0 0 3457 4199 sw_tx_egress_enq_drops 1904329 0 0 787971 9004 429214 85022 0 0 429810 3645350 cpeth0_drops 0 0 0 0 0 0 0 0 0 0 0 mcdma_summary_drops 28163 247 17742 2334 2046 3043 0 0 0 10028 63603 fragmentation_err 0 0 0 0 0 0 0 0 0 0 0 reassembly_err 0 0 0 0 0 0 0 0 0 0 0 reassembly_ring_enq_err 0 0 0 0 0 0 0 0 0 0 0 __DISCARDS__ 20331090 9051092 23736055 23882896 23807520 24231716 24116576 8944291 22309474 20135799 20135799
SW-RSSとHW-RSS
RSSは、NICからの着信トラフィックを複数のDPDKプロセッサに分散できる機能です。通常、NICはHWでRSSをサポートし、複数のiftaskコアにトラフィックを分散できるようにします。
Starosのiftaskプロセスには、次の場合に有効にできるrssのソフトウェアバージョンが実装されています。
-nicはHW rssをサポートしていません(したがって、すべてのtx/rxトラフィックは単一のiftask CPUに送られます)。
-nicに十分なtx/rxキューがない(iftaskに割り当てられた利用可能なtx/rx CPUより少ないキュー)。 この場合、SW-RSS(comprehensive)を使用すると、rx/txに割り当てられた使用可能なすべてのiftaskコアに対して適切な配信が可能になります。
この機能は、サービスポート経由で着信するトラフィックに対してのみ機能します。DIトラフィックは考慮されません。
次の3つの設定モードがあります。
-no iftask sw-rss - sw-rssが無効です。システムはハードウェアのRSSに依存しています。
-iftask sw-rss comprehensive – すべてのトラフィックにsw rssを使用します。ソフトウェアRSSは、ハードウェアRSSと一緒に実行できます。ハードウェアRSSを無効にする必要はありません。ただし、SW RSSは、iftaskコアへのSERVICEトラフィックの実際のロードバランシングを行います。
-iftask sw-rss supplemental - hw-rssでサポートされていないトラフィック(例:MPLSトラフィック)だけにsw rssを使用
ハードウェアとソフトウェアの両方のRSSでは、トラフィックがさまざまなiftask/dpdkプロセッサにどのようにハッシュされるかを理解することが重要です。
ハードウェアRSS:ハッシュはハードウェアによって異なります。次に例を示します。
[root@host]# ethtool -n enp10s0f1
4 RX rings available
Total 0 rules
[root@host] # ethtool -n enp10s0f0 rx-flow-hash udp4
UDP over IPV4 flows use these fields for computing Hash flow key:
IP SA
IP DA
SW RSS:Staros 21.6以降、SW RSSバージョンのハッシュは次のように動作します。
1. In case of IPV6
we only support L3( IP src/dst ) based hashing (same as the old behaviour).
2. In case of IPV4
a. For TCP we support IP src/dst + tcp ports src/dst
b. For UDP fragmented - only IP src/dst
c. For UDP non-fragmented not gtpu ( I.e. Port !=2152) ? IP src/dst + udp port src/dst
d. For UDP non-fragmented and gtpu ( I.e. Port ==2152) - IP src/dst + udp port src/dst + gtp tunnel id
e. Any other protocol ? we default back to IP src/dst
重要:暗号化DIトラフィックのRSS:
SW-RSS(supplemental/comprehensive)がない場合、iftaskですべての暗号化されたDIトラフィックがハッシュされて1つのコアになる可能性があります。
これにより、このコアの使用率が他のコアよりも常に高くなります。
CSCvi06080以降  この問題は、次の設定コマンドで緩和できます。
この問題は、次の設定コマンドで緩和できます。
iftask di-net-encrypt-rss
CSCvm41257の統合後 このオプションはデフォルトになります。
ソフトウェアRSSの詳細情報:
sw-rssの目的は、PMDコアのロードバランシングを行い、あるPMDコアが他のコアの使用可能な容量が非常に大きい場合に最大になるスループット制限シナリオを回避することです。
サービスポートの入力パケットはすべてNICから取り出され、到着したRxキューを処理するPMDコアによってMEHカプセル化が指定されます。
この時点で、iftaskはパケットの送信先を認識していません。内部宛先を決定するには、パケットをVNPUで処理する必要があります。これらのパケットのほぼすべてが、VNPUに渡されたときにIOC/フロールックアップを通過します。例外は、vlanが設定されていない/無効になっている、または宛先MACが無効であるなどの理由による廃棄に関係します(L3転送のシナリオもありますが、これはまれです)。
sw-rssが設定されていない場合、MEHカプセル化の直後に同じコアでVNPU IOC/フロールックアップ処理が発生します。sw-rssが設定されている場合、パケットはハッシュに基づいてVNPU処理のためにコアにキューイングされます。VNPU IOC/flow lookup操作は、最もコストのかかる単一のiftask機能です。sw-rssを使用すると、すべてのPMDコア間でワークロードを分散できます。
VNPU IOC/flowルックアップの後、パケットはDINet送信を介して別のSFに送信されるか、MCDMA転送を介してローカルアプリケーションにキューイングされます(繰り返しますが、例外はありますが、この説明に関連はないと思います)。
別のSFに送信されたパケットは、DINet Rxに続く宛先カードの適切なMCDMAチャネルに直接キューイングされます。(2番目の)VNPUパスは必要ありません。
TX/RXキュー
iftaskのログには、次のようなログが表示されます。
Tue May 7 15:26:48 2019 PID:8188 APP: max rx queues supported 16 ...
Tue May 7 15:26:48 2019 PID:8188 APP: max tx queues supported 8 ...
Tue May 7 15:26:48 2019 PID:8188 APP: hw rx requested 2 ...
Tue May 7 15:26:48 2019 PID:8188 APP: hw tx requested tx 5
この値は、iftaskが要求したtx/rxキューの数に対して、実際のハードウェアがサポートするrxおよびtxキューのサポート数に関連しています。
iftask要求の内容は、 iftaskに割り当てられたプロセッサの数と密接に関連しています。
注意:ドライバはそれぞれ異なります。一部のクエリホストはハードコードされています。
hw tx requested countは、dpdkが使用しているコアの数です。dpdkには制御/ipcスレッドが実行されるコアが含まれるため、通常はiftaskに割り当てられる合計コア数よりも1つ多くなります。このコアはboxerと共有され、汎用cpuとしてスケジューリングされます(dpdk制御/ipcスレッドはcpuを大量に使用しません)。
通常、hw rx requested countはPMDコアの数です。
Iftaskは各ポートに最小(要求、最大)を割り当て、コア全体に分散します。分散アルゴリズムは少し複雑です。目標は、すべてのコアにできるだけ均等にワークロードを分散させることです。
Iftask txbatch
リリース21.9以降、starosにはバッチ処理(トラフィックの集約)に重要な次のiftask設定オプションがデフォルトで用意されています。 これは、ノードが単一(または少数)のサブスクライバでテストされている場合に、パフォーマンスに悪影響を及ぼします。
# iftask mcdmatxbatch burst size 32 # iftask mcdmatxbatch latency 200 # iftask txbatch burst size 32 # iftask txbatch latency 200
これについての詳細な説明は、次のリンクに記載されています。
バルク統計
iftask/dinetに関連するQPVC-DIパフォーマンス用にbulkstatスキームが開発されました。これは、パフォーマンス/負荷の観点からdinet、サービスポート、およびnpu使用率を監視する場合に便利です。
card schema iftask-dinet format EMS,IFTASKDINET,%date%,%time%,%dinet-rxpkts-curr%,%dinet-txpkts-curr%,%dinet-rxpkts-5minave%,%dinet-txpkts-5minave%,%dinet-rxpkts-15minave%,%dinet-txpkts-15minave%,%dinet-txdrops-curr%,%dinet-txdrops-5minave%,%dinet-txdrops-15minave%,%npuutil-now% file 2 port schema iftask-port format EMS,IFTASKPORT,%date%,%time%,%util-rxpkts-curr%,%util-txpkts-curr%,%util-rxpkts-5min%,%util-txpkts-5min%,%util-rxpkts-15min%,%util-txpkts-15min%,%util-txdrops-curr%,%util-txdrops-5min%,%util-txdrops-15min% file 3 card schema npu-util format EMS,NPUUTIL,%date%,%time%,%npuutil-now%,%npuutil-5minave%,%npuutil-15minave%,%npuutil-rxbytes-5secave%,%npuutil-txbytes-5secave%,%npuutil-rxbytes-5minave%,%npuutil-txbytes-5minave%,%npuutil-rxbytes-15minave%,%npuutil-txbytes-15minave%,%npuutil-rxpkts-5secave%,%npuutil-txpkts-5secave%,%npuutil-rxpkts-5minave%,%npuutil-txpkts-5minave%,%npuutil-rxpkts-15minave%,%npuutil-txpkts-15minave%
更新履歴
| 改定 | 発行日 | コメント |
|---|---|---|
1.0 |
09-Jun-2018
|
初版 |
 フィードバック
フィードバック