はじめに
このドキュメントでは、Cisco Real-Time Monitoring Tool(RTMT)アラートについて説明し、一般的なアラートのトラブルシューティング方法を示します。
前提条件
要件
Cisco Call Manager Web Administrationに関する知識があることが推奨されます。
使用するコンポーネント
このドキュメントの情報は、Cisco CallManager サーバ 11.0 に基づいています。
このドキュメントの情報は、特定のラボ環境にあるデバイスに基づいて作成されました。このドキュメントで使用するすべてのデバイスは、クリアな(デフォルト)設定で作業を開始しています。対象のネットワークが実稼働中である場合には、どのようなコマンドについても、その潜在的な影響について確実に理解しておく必要があります。
背景説明
クライアント側のアプリケーションとして実行されるRTMTは、HTTPSおよびTCPを使用して、システムパフォーマンス、デバイスステータス、デバイス検出、コンピュータテレフォニーインテグレーション(CTI)アプリケーション、およびボイスメッセージングポートをモニタします。RTMTを使用して、監視対象のクラスタのアラートを設定できます。
システムは、アクティブ化されたサービスがアップからダウンに移行したときなど、事前に定義された条件が満たされたときに管理者に通知するためにアラートメッセージを生成します。システムは、電子メール/電子ページとしてアラートを送信できます。
アラートの定義、設定、表示をサポートするRTMTには、事前設定されたアラートとユーザ定義のアラートが含まれています。両方のタイプの設定タスクを実行できますが、事前設定されたアラートは削除できません。
RTMTアラート
Unified RTMTは、図に示すように、事前設定されたアラートとカスタムアラートの両方をAlert Centralに表示します。
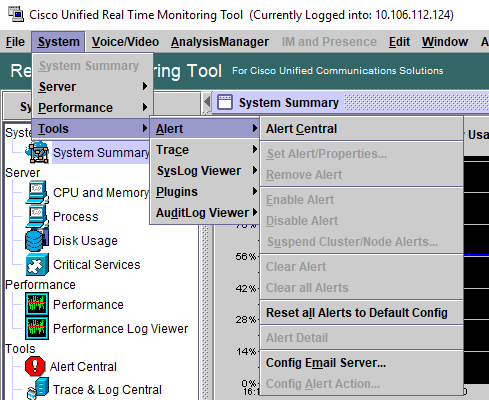
[システム]ドロワーの階層ツリーで[Alert Central]アイコンをクリックして、Alert Centralにアクセスすることもできます。
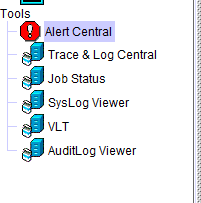
設定
Unified RTMTでは、System、CallManager、Cisco Unity Connection、およびCustomの該当するタブの下にアラートが編成されます。
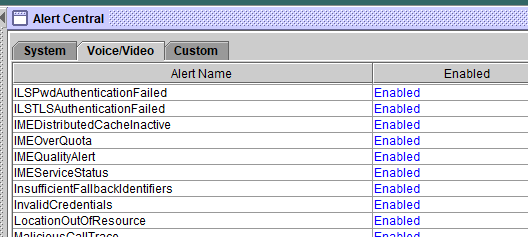
Alert Centralでは、事前設定されたアラートとカスタムアラートを有効または無効にすることができますが、事前設定されたアラートを削除することはできません。
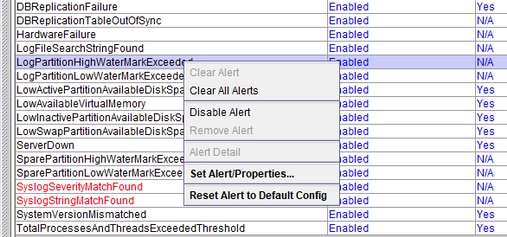
RTMTのアラートは次のように分類されます。
システムアラート
このリストは、事前設定されたシステムアラートで構成されています。
-
認証の失敗
-
CiscoDRFFailure
-
CoreDumpFileFound
-
Cpuペギング
-
重要な監査イベント生成
-
重要なサービス停止
-
ハードウェア障害
-
LogFileSearchStringFound
-
LogPartitionHighWaterMarkExceeded
-
LogPartitionLowWatermarkExceeded
-
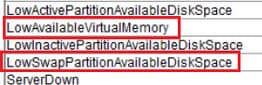
LowActivePartitionAvailableDiskSpace
-
低可用性仮想メモリ
-
LowInactivePartitionAvailableDiskSpace
-
LowSwapPartitionAvailableDiskSpace
-
ServerDown(Unified Communications Manager(CUCM)クラスタに適用)
-
SparePartitionHighWaterMarkExceeded
-
SparePartitionLowWaterMarkExceeded
-
SyslogSeverityMatchFound
-
SyslogStringMatchFound
-
SystemVersionMismatched
-
TotalProcessesAndThreadsExceededThreshold
CallManagerアラート
このリストは、事前設定されたCallManagerアラートで構成されます。
- BeginThrottlingCallListBLFSubscriptions
- CallAttemptBlockedByPolicy
- コール処理ノードCPUペギング
- CARIDSEngine緊急
- CARIDSEngine障害
- CARSchedulerJobFailed
- CDRAgentSendFileFailed
- CDRFileDeliveryFailed
- CDRHighWaterMarkExceeded
- CDRMaximumDiskSpaceの超過
- コードイエロー
- DBChangeNotifyFailure
- DBReplicationFailure
- DBReplicationTableOutofSync
- DDRBlockPrevention
- DDRD所有
- EMCCFailedInLocalCluster
- EMCCFailedInRemoteCluster
- ExcessiveVoiceQualityレポート
- IMEDistributedCacheInactive
- IMEOverQuota
- IMEQualityAlert
- 不十分なフォールバック識別子
- IMEサービス状態
- 無効な資格情報
- LowTFTPServerHeartbeatRate
- MaliciousCallTrace(ベータ版)
- メディアリスト枯渇
- MgcpDChannelOutOfService
- NumberOfRegisteredDevicesの超過
- 登録済みゲートウェイ数の減少
- 登録ゲートウェイ数の増加
- 登録済みメディアデバイス数の減少
- 登録済みメディアデバイス数の増加
- 登録電話数ドロップ
- RouteListExhausted エラー
- SDLLinkOutOfService
- TCPSetupToIMEFailed
- TLSConnectionToIMEFailed(デフォルト)
- UserInputFailure
LowAvailableVirtualMemoryおよびLowSwapPartitionAvailableDiskSpace
Linuxサーバでは、ある期間の仮想メモリの使用量を「クリア」しない傾向があり、それが累積して、これらのアラートが発生することが確認されています。
Linuxはオペレーティングシステムとして少し異なる動作をします。
あるプロセスにメモリが割り当てられると、他のプロセスが利用可能なメモリよりも多くのメモリを要求しない限り、そのメモリはプロセッサから取り戻されません。
これにより、仮想メモリの使用量が増加します。
より上位のバージョンのCall Managerでアラームのしきい値を増やす要求は、不具合で文書化されています。https://bst.cloudapps.cisco.com/bugsearch/bug/CSCuq75767/?reffering_site=dumpcr
スワップパーティションの場合、このアラートは、スワップパーティションの空き領域が少なく、システムによって頻繁に使用されていることを示します。スワップパーティションは通常、必要に応じて物理RAM容量を拡張するために使用されます。通常の状況では、RAMが十分な場合、スワップをあまり使用しないでください。
また、一時ファイルの蓄積によって発生するRTMTアラートがスローされる場合があります。不要な一時ファイルを消去するために、サーバを再起動することをお勧めします。
LogPartitionHighWaterMarkExceededおよびLogPartitionLowWaterMarkExceeded
CUCMサーバのCLIでshow statusを実行すると、CUCMディスクスペース内のロギングパーティションの占有率と空き率を指定する値が表示されます。これらの値は共通パーティションとも呼ばれ、ログ/トレースとサーバのCDRファイルが占有する領域を指定します。この値は無害ですが、時間の経過とともに領域が不足するため、インストール/アップグレード手順で問題が発生する可能性があります。これらのアラートは、管理者に対する警告として機能し、時間の経過とともにクラスタ/サーバに蓄積された可能性があるログをクリアします。
LogPartitionLowWaterMarkExceeded:このアラートは、塗りつぶされた領域がアラートに設定されたしきい値に達したときに生成されます。このアラートは、ディスク使用率のチェック前インジケータとして機能します。
LogPartitionHighWaterMarkExceeded:このアラートは、塗りつぶされた領域がアラートに設定されたしきい値に達したときに生成されます。アラートが生成されると、サーバは最も古いログの自動パージを開始し、HighWaterMarkしきい値を満たすスペースを削除します。
ベストプラクティスは、LogPartitionLowWaterMarkExceededアラートを受信したらすぐに手動でログを消去することです。
これを行う手順は次のとおりです。
ステップ 1:RTMTを起動します。
ステップ 2:Alert Centralを選択してから、次のタスクを実行します。
LogPartitionHighWaterMarkExceededを選択し、その値をメモして、しきい値を60%に変更します。
LogPartitionLowWaterMarkExceededを選択し、その値をメモして、しきい値を50 %に変更します。
ポーリングは5分ごとに行われるため、5 ~ 10分待ってから、必要なディスク領域が使用可能であることを確認します。共通パーティションの空きディスク領域を増やす場合は、LogPartitionHighWaterMarkExceededスレッドとLogPartitionLowWaterMarkExceededスレッドの値を、より低い値(30%や20%など)に変更します。
15 ~ 20分かけて、共通パーティション内のスペースをクリアします。CLIからshow statusコマンドを実行すると、ディスク使用量の減少を監視できます。
これにより、共通のパーティションがダウンします。
Cpuペギング
CpuPeggingアラートは、設定されたしきい値に基づいてCPU使用率を監視します。
CPUペギングアラートを受信すると、最も高いCPUを占有しているプロセスは、左側のシステムドロワー、つまりプロセスに移動して占有できます。
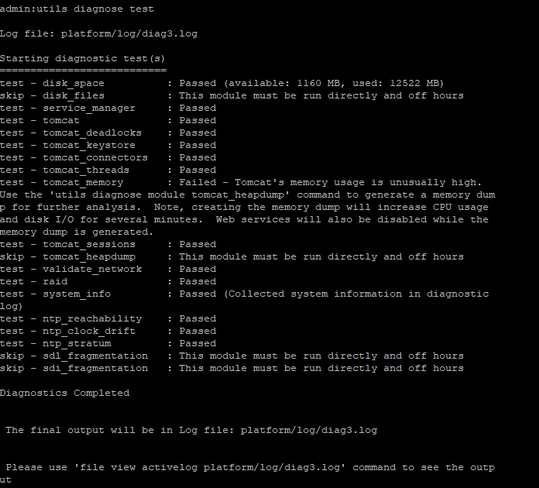
関連するサーバのCLIから、これらの出力は洞察に役立ちます。
- utils diagnose test
- show process load cpu sorted(プロセス負荷cpuのソート済み表示)
- show status
- utils core activeリスト
CPUスパイクが特定の時間に発生するか、ランダムに発生するかを確認することをお勧めします。これがランダムに発生する場合、必要な詳細なCUCMトレースとRisDC perfmonログを確認して、CPU使用率の急増の原因を調べます。アラートが特定の時刻に発生する場合は、ディザスタリカバリシステム(DRS)のバックアップ、CDRのロードなどのスケジュール済みアクティビティが原因である可能性があります。
また、どのプロセスが最もCPUを占有しているかについての情報に基づいて、詳細な調査のために特定のログが取得されます。たとえば、原因がTomcatの場合は、Tomcat関連のログが必要です。
確認
ここでは、設定が正常に機能しているかどうかを確認します。
ここで提示されている回避策を実行してもアラートが解除されない場合、またはアラートがサービスにすぐに影響を与えると思われる場合は、Cisco TACに連絡して、Call Managerのバージョン、クラスタ内のノードの数、アラートの時間と期間、およびCPUペギングの場合に必要なプロセスを絞り込むことについて、必要な詳細情報を入手してください。
トラブルシュート
現在、この設定に関する特定のトラブルシューティング情報はありません。
 フィードバック
フィードバック