NVIDIA 認定 Cisco Nexus HyperFabric AI エンタープライ ズ リファレンス アーキテクチャ
偏向のない言語
この製品のドキュメントセットは、偏向のない言語を使用するように配慮されています。このドキュメントセットでの偏向のない言語とは、年齢、障害、性別、人種的アイデンティティ、民族的アイデンティティ、性的指向、社会経済的地位、およびインターセクショナリティに基づく差別を意味しない言語として定義されています。製品ソフトウェアのユーザインターフェイスにハードコードされている言語、RFP のドキュメントに基づいて使用されている言語、または参照されているサードパーティ製品で使用されている言語によりドキュメントに例外が存在する場合があります。シスコのインクルーシブ ランゲージの取り組みの詳細は、こちらをご覧ください。
翻訳について
このドキュメントは、米国シスコ発行ドキュメントの参考和訳です。リンク情報につきましては、日本語版掲載時点で、英語版にアップデートがあり、リンク先のページが移動/変更されている場合がありますことをご了承ください。あくまでも参考和訳となりますので、正式な内容については米国サイトのドキュメントを参照ください。
Cisco Nexus® Hyperfabric フル スタック AI インフラストラクチャは、クラウドでホストされているコントローラによって管理されるオンプレミスの AIクラスターであり、NVIDIA HGX H200 および Spectrum-X の NVIDIA Enterprise Reference Architecture(エンタープライズ RA)に準拠しています。AI イニシアチブを強化および簡素化し、包括的な統合クラウド管理型ソリューションにより AI のデプロイメントを促進します。
ソリューションの重要コンポーネントを図 1 に示します。クラスタで使用される主要なハードウェア コンポーネントについては、次のセクションで説明します。
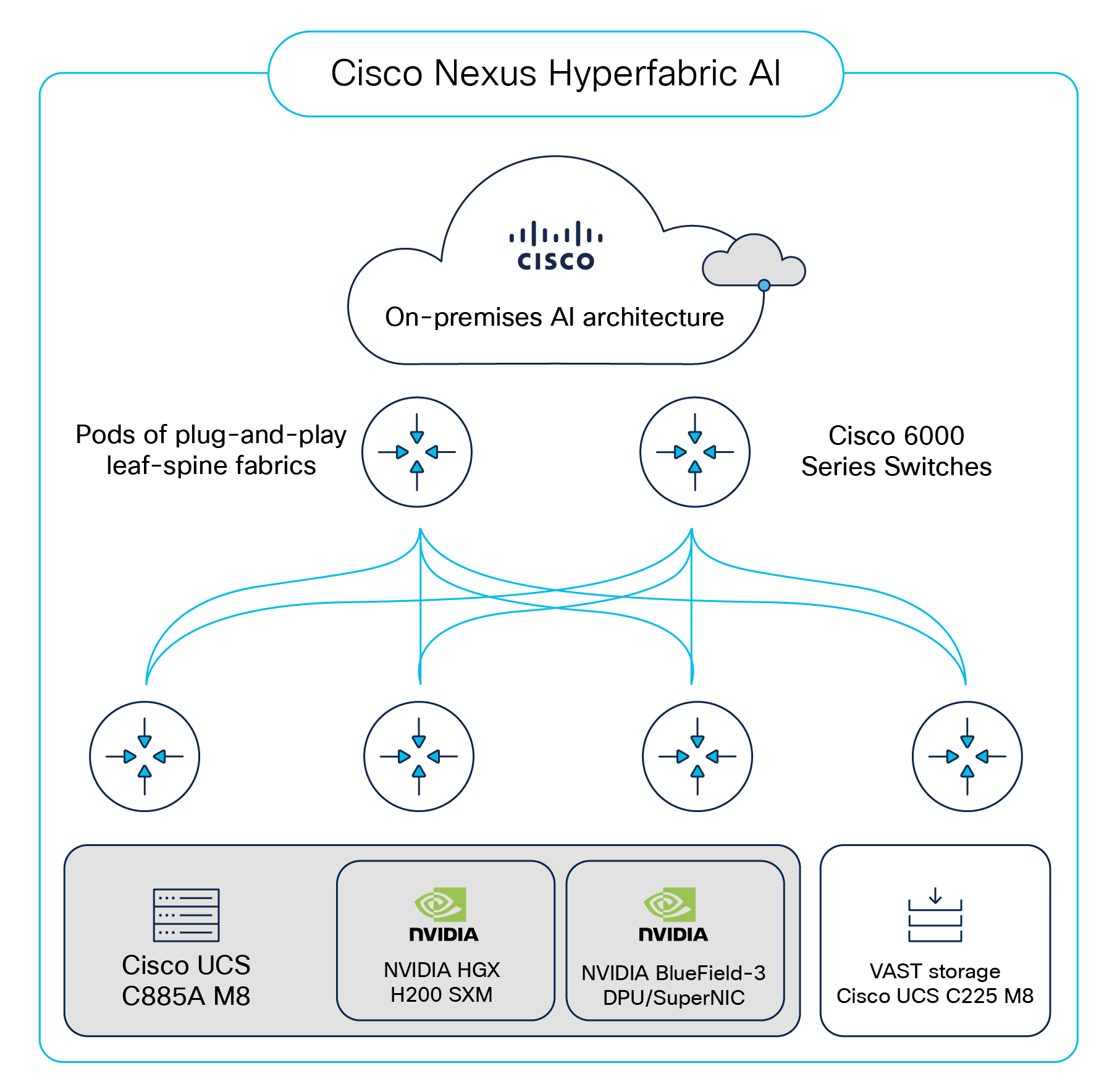
Cisco Nexus Hyperfabric フル スタック AI インフラストラクチャの主要なコンポーネント
Cisco UCS C885A M8 ラック サーバは、大規模言語モデル(LLM)トレーニング、ファインチューニング、大規模モデル推論、取得拡張生成(RAG)などの AI ワークロード向けに、大規模でスケーラブルなパフォーマンスを提供する 8RU であり、高密度 GPU サーバです。C-G-N-B 命名規則は、2-8-10-40(C-G-N-B)内の NVIDIA HGX リファレンス アーキテクチャに基づいてが次のように定義されています:
● C:ノード内の CPU の数
● G:ノード内の GPU の数
● N:以下のように分類されているネットワーク アダプタ(NIC)の数
◦ North-south:ノードと外部システムの間の通信。
◦ East-west:クラスタ内の通信。
● B:GPU あたりの平均ネットワーク帯域幅(ギガビット/秒(GbE)単位)
サーバ内の 8x NVIDIA H200 SXM GPU は、高速 NVLink インターコネクトを使用してインターコネクトされています。east-west トラフィック は、8x NVIDIA BlueField-3 B3140H SuperNIC、そして、north/south トラフィックは、VIDIA BlueField-3 B3240 DPU NIC(1x400G モード内)を使用して、他の物理サーバに GPU 接続します。コンピューティング用に、各サーバには 2 つの AMD EPYC CPU、最大 3 TB の DDR DRAM、30 TB の NVMe ローカル ストレージ、およびホットスワップ可能なファン トレイと電源が含まれます。サーバの詳細な仕様については、付録 A を参照してください。

NVIDIA HGX を搭載した Cisco UCS C885A M8 ラック サーバ
Cisco HF6100-60L4D は、1RU シリコン ワン NPU ベースの高密度スイッチで、1/10/25/50GE の速度に対応する 60 個の SFP56 ポートと、ブレークアウトをサポートする 400 QSFPDD の 4 個のポートをサポートしています。このスイッチは、管理ネットワーク、アプリケーションやサポート サーバーへの接続などのさまざまな役割を果たします。

Cisco HF6100-60L4D スイッチ
Cisco HF6100-32D は、32 ポートの QSFPDD をサポートする、1RU シリコン ワン NPU ベースの高密度 400G-port–capable スイッチです。このスイッチは、クラスタの要件に応じて、リーフまたはスパイン ロールで使用できます。

Cisco HF6100-32D スイッチ
Cisco HF6100-64E は、Silicon One NPU ベースの 2RU スイッチで、64 個の OSFP 800G ポートをサポートし、64 個の 800GE または 128 個の 400G GE ポートに対応します。これは、リーフとスパインの両方のロールで使用されます。

Cisco HF6100-64ED スイッチ
Cisco N9164E-NS4-O は、64 個の 800G OSFP モジュールをサポートし、64 個の 800GE または 128 個の 400GE ポートに対応する、NVIDIA Spectrum-4 NPU ベースの 2RU スイッチです。このスイッチは、HF6100-64ED スイッチの代替として、イーストウェスト コンピューティング ネットワークにおいて、リーフとスパインの両方のロールで使用できます。

Cisco N9164E-NS4-O スイッチ
Cisco UCS C225 M8 ラック サーバは 1RU の汎用サーバーで、アプリケーション サーバー、サポート サーバー、Kubernetes(K8s)や Slurm などの制御ノードなど、さまざまなロールで使用できます。これらのサーバーは RA 内で、以下の「ストレージ アーキテクチャ」セクションで説明されている VAST ストレージ ソリューションを実行するためにも使用されます。
Cisco UCS C225 M8 ラック サーバ
表 1 に示されている次のシスコのオプティクスとケーブルが、リストされているデバイスで使用されています。
表 1 さまざまなデバイスでサポートされるオプティクスおよびケーブルのリスト
| デバイス |
オプティクスおよびケーブル |
| B3220、B3140H、B3240 |
CB-M12-M12-SMF ケーブル付き QSFP-400G-DR4 |
| B3220L |
CB-M12-M12-MMF ケーブル付き QSFP-200G-SR4 |
| HF6100-64ED N9164E-NS4-O |
デュアル CB-M12-M12-SMF ケーブル付き OSFP-800G-DR8 |
| HF6100-32D |
CB-M12-M12-SMF ケーブル付き QDD-400G-DR4 CB-M12-M12-MMF ケーブル付き QSFP-200G-SR4 |
| HF6100-60L4D |
CB-M12-M12-SMF ケーブル付き QDD-400G-DR4 CAT5E ケーブルを使用した 1G 用の SFP-1G-T-X CAT6A ケーブルを使用した 10G 用 SFP-10G-TX |
Hyperfabric は、任意のタイプのファブリック設計に使用できる柔軟な多目的ファブリック設計ツールです。AI クラスタの展開を容易にするために、Hyperfabric for AI には、さまざまな「T レイヤー」サイズの AI クラスタ用の事前構成済みテンプレートが付属しています。お客様は「現状のまま」のテンプレートを使用するか(デバイスの接続に必要な光ファイバおよび関連する光ファイバの長さ以外の選択肢やカスタマイズはありません)、または独自のカスタム ネットワークを設計することを選択できます。テンプレート化された設計のみが、NVIDIA エンタープライズ リファレンス アーキテクチャ(ARA)と密接に連携するリファレンス アーキテクチャの一部と見なされます。以下に示すように、Cisco® のデザインの特定の側面に対応するために、マイナーな変更が加えられています:
● NVIDIA HGX を搭載した Cisco UCS C885A M8 ラック サーバには、NVIDIA の 2x200G ポートではなく、2x400G のフロント エンド ポートが含まれています。また、x86 管理ポートでは 1G ではなく 10G の速度が使用されます。
● VAST ストレージ ソリューションには、ストレージ ネットワークに最低 8x400G が必要です
● NVIDIA BlueField-3 SuperNIC の BMC ポートは接続されず、x86 ホストから管理されます。ただし、NVIDIA BlueField-3 DPU の BMC ポートは接続されます。
NVIDIA HGX を搭載した Cisco UCS C885A M8 ラック サーバのトポロジ
図 8 に、NVIDIA HGX を使用した最大 12 の Cisco UCS C885A M8 ラック サーバ のクラスタ トポロジを示します。

NVIDIA HGX を搭載した 12 台の Cisco UCS C885A M8 ラック サーバ用エンタープライズ RA(96 GPU)
表 2 に NVIDIA HGX サーバを搭載した 12 ノード Cisco UCS C885A M8 ラック サーバ クラスタの BOM を示します。
表 2 NVIDIA HGX (96 GPU)を搭載した 12 ノード Cisco UCS C885A M8 ラック サーバ クラスタの BOM
| PID |
説明 |
数量 |
| UCSC-885A-M8-HC1 |
NVIDIA HGX を搭載した Cisco UCS C885A M8 ラック サーバ |
12 |
| HF6100-64ED N9164E-NS4-O |
Cisco ハイパーファブリック スイッチ、64x800Gbps OSFP |
2 |
| HF6100-60L4D |
Cisco Hyperfabric スイッチ 60x50G SFP28 4x400G QSFP-DD |
1 |
| HF6100-32D |
Cisco Hyperfabric スイッチ、32x400Gbps QSFP-DD |
2 |
| OSFP-800G-DR8 |
OSFP、800GBASE-DR8、SMF デュアル MPO-12 APC、500m |
114 |
| QDD-400G-DR4-S |
400G QSFP-DD トランシーバ、400GBASE-DR4、MPO-12、500m パラレル |
10 |
| QSFP-400G-DR4 |
400G QSFP112 トランシーバ、400GBASE-DR4、MPO-12、500 m パラレル |
120 |
| SFP-1G-TX |
1G SFP |
36 |
| SFP-10G-T-X |
10G SFP |
24 |
| CB-M12-M12-SMF |
MPO-12 ケーブル |
204 |
| CAT6A |
10G 用銅ケーブル |
24 |
| CAT5E |
1G 用銅ケーブル |
36 |
800G から 400G への接続では、以下に示すように、スイッチ側にデュアル 2x400G MPO-12 コネクタを備えたオプティクスを使用します。
Cisco OSFP-800G-DR8 トランシーバ モジュール
各接続は、ブレークアウト ケーブルを必要とせずに独立して 400G をサポートします。
Cisco OSFP-800G-DR8 プラグホール ビュー
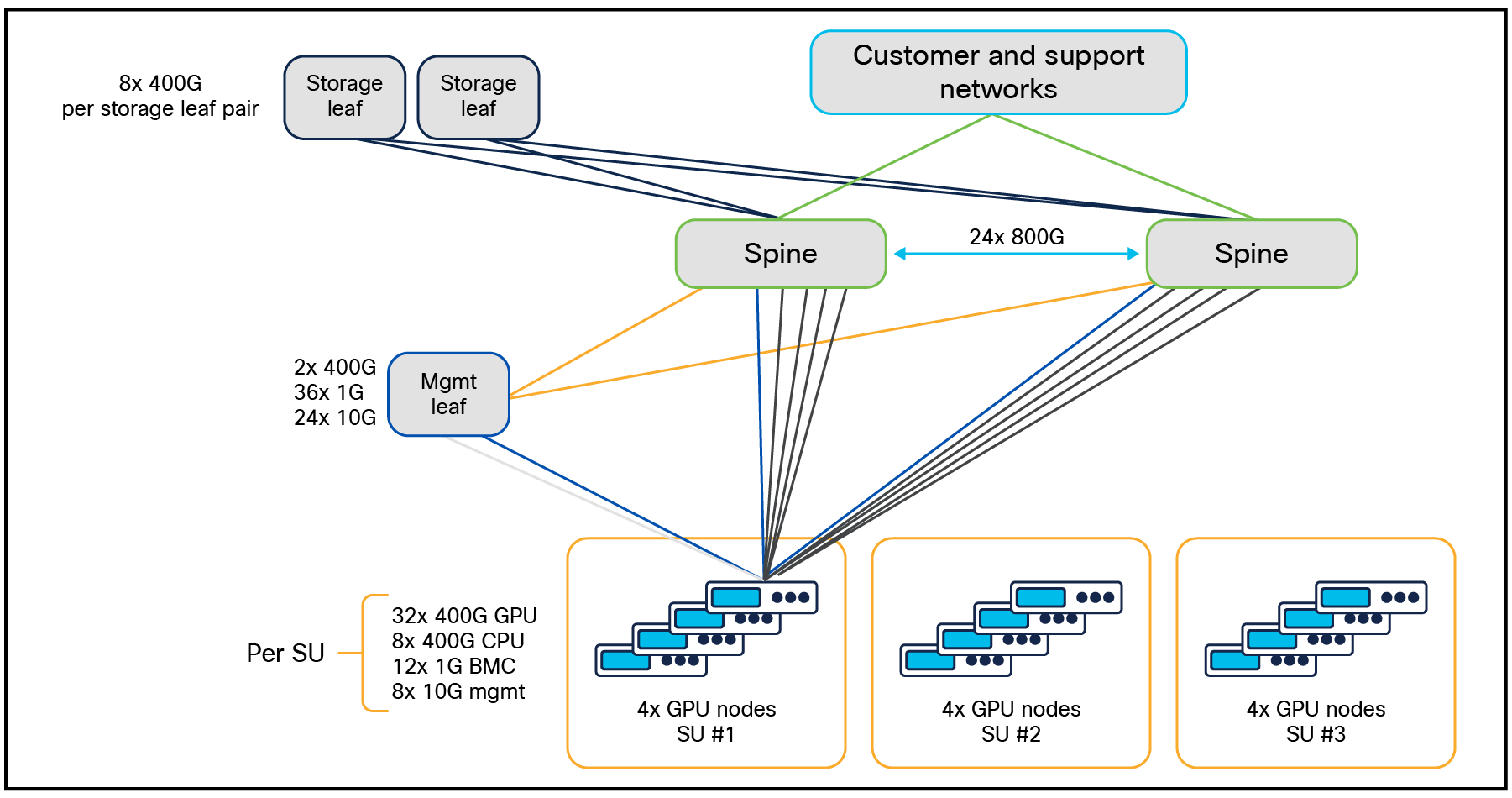
図 11 に、NVIDIA HGX を使用した最大 16 の Cisco UCS C885A M8 ラック サーバ のクラスタ トポロジを示します。East-West(EW)ネットワークは、左側の東西スパイン上に 4 本のレール、右側の東西スパイン上に 4 本のレールが配置されています。
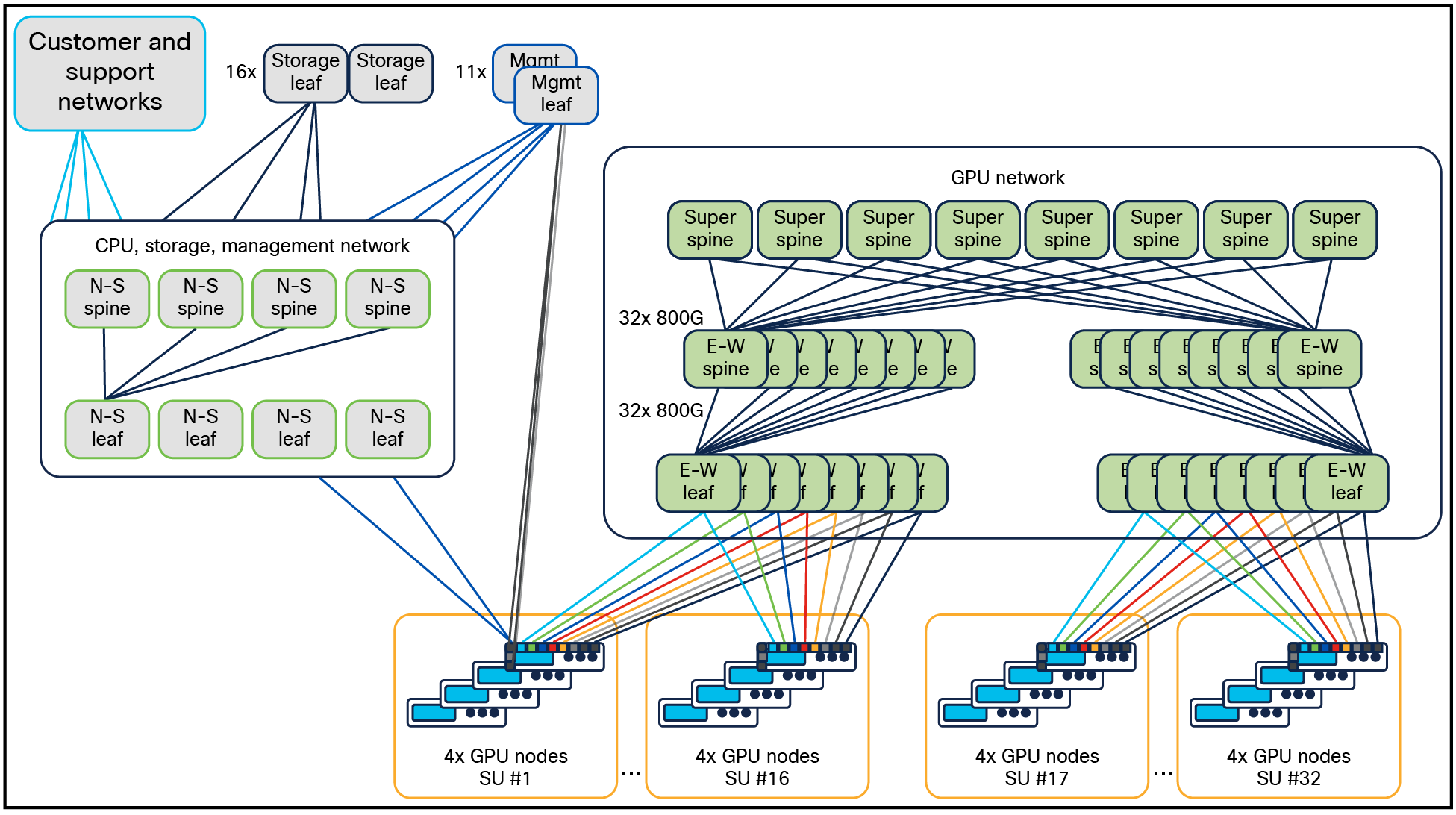
NVIDIA HGX を搭載した 16 台の Cisco UCS C885A M8 ラック サーバ用エンタープライズ RA(128 GPU)
表 3 に NVIDIA HGX サーバを搭載した 16 ノード Cisco UCS C885A M8 ラック サーバ クラスタの BOM を示します。
表 3 NVIDIA HGX (128 GPU)を搭載した 16 ノード Cisco UCS C885A M8 ラック サーバ クラスタの BOM
| PID |
説明 |
数量 |
| UCSC-885A-M8-HC1 |
NVIDIA HGX を搭載した Cisco UCS C885A M8 ラック サーバ |
16 |
| HF6100-64ED N9164E-NS4-O |
Cisco ハイパーファブリック スイッチ、64x800Gbps OSFP |
4 |
| HF6100-60L4D |
Cisco Hyperfabric スイッチ 60x50G SFP28 4x400G QSFP-DD |
2 |
| HF6100-32D |
Cisco Hyperfabric スイッチ、32x400Gbps QSFP-DD |
2 |
| OSFP-800G-DR8 |
OSFP、800GBASE-DR8、SMF デュアル MPO-12 APC、500m |
144 |
| QDD-400G-DR4 |
400G QSFP-DD トランシーバ、400GBASE-DR4、MPO-12、500m パラレル |
12 |
| QSFP-400G-DR4 |
400G QSFP112 トランシーバ、400GBASE-DR4、MPO-12、500 m パラレル |
160 |
| SFP-1G-TX |
1G SFP |
48 |
| SFP-10G-T-X |
10G SFP |
32 |
| CB-M12-M12-SMF |
MPO-12 ケーブル |
198 |
| CAT6A |
10G 用銅ケーブル |
32 |
| CAT5E |
1G 用銅ケーブル |
48 |
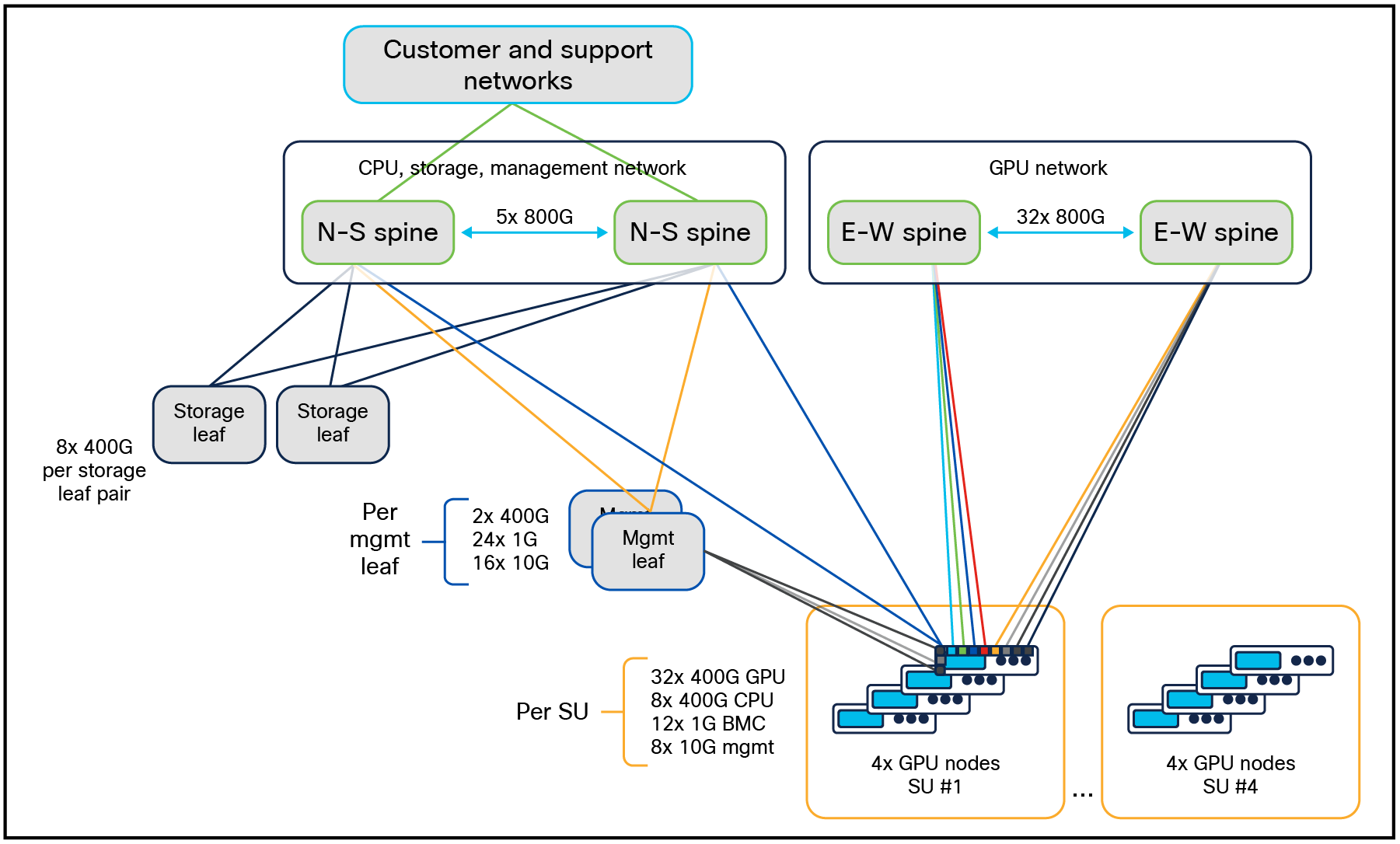
クラスタ サイズが 16 を超える場合、East-West(E-W)コンピューティング ネットワークはスパイン リーフ ファブリックに拡張されます。クラスタ サイズが最大の場合、128 Cisco UCS C885A M8 ラック サーバ クラスタの図 12 に示すように、ノース/サウス(N-S)ネットワークもスパイン-リーフになります。E-W ネットワークは、各 EW リーフ 1〜8 にある各レール 1〜8 とレールに沿っています。
NVIDIA HGX を搭載した 128 台の Cisco UCS C885A M8 ラック サーバ用エンタープライズ RA(1024 GPU)
Cisco UCS C885A M8 ラック サーバでサイジング
表 4 と表 5 は、NVIDIA HGX を搭載した Cisco UCS C885A M8 ラック サーバ システム、8 EW B3140H NVIDIA BlueField-3 基の SuperNIC と 2 NS B3240 NVIDIA BlueField-3 DPU NIC を使用したさまざまなクラスタ サイズに必要なさまざまなユニットの数量を示しています。
表 4 NVIDIA HGX を搭載した Cisco UCS C885A M8 ラック サーバの East-west コンピューティング ファブリック テーブル:コンピューティング、スイッチ、トランシーバ、ケーブル数
| コンピューティング数 |
スイッチ数 |
トランシーバ数 |
ケーブル数 |
||||||
| ノード |
GPU |
リーフ |
スパイン |
SuperSpine |
ノードからリーフ |
スイッチ間(800G) |
ノードからリーフ |
スイッチとスイッチ |
|
| ノード (400G) |
リーフ (800G) |
||||||||
| 12 |
96 |
2 |
なし |
N/A |
96 |
48 |
48 |
96 |
48 |
| 16 |
128 |
2 |
なし |
N/A |
128 |
64 |
64 |
128 |
64 |
| 32 |
256 |
4 |
2 |
N/A |
256 |
128 |
256 |
256 |
256 |
| 64 |
512 |
8 |
8 |
該当なし |
512 |
256 |
1024 |
512 |
1024 |
| 128 |
1024 |
16 |
16 |
8 |
1024 |
512 |
2048 |
1024 |
2048 |
表 5 NVIDIA HGX を搭載した Cisco UCS C885A M8 ラック サーバの North-south コンピューティング ファブリック テーブル:コンピューティング、スイッチ、トランシーバ、ケーブル数
| コンピューティング数 |
スイッチ数 |
トランシーバ数 |
ケーブル数 |
|||||||||||||||||
| ノード |
GPU |
リーフ |
スパイン |
管理リーフ |
ストレージ リーフ |
ノードからコンピューティング リーフ |
ISL ポート |
ノードから管理リーフ(1/10G) |
リーフからスパインへの管理 |
ストレージ リーフからスパイン |
スパインからお客様およびサポートへのスパイン |
|||||||||
| ノード |
リーフ |
800G |
ノード |
リーフ |
リーフ(400G) |
スパイン(800G) |
リーフ(400G) |
スパイン(800G) |
お客様(800G) |
サポート(800G) |
SMF |
CAT6A + CAT5E |
||||||||
| 12 |
96 |
East-west でコンバージド |
1 |
2 |
24 |
12 |
なし |
N/A |
60 |
2 |
2 |
8 |
4 |
8 |
4 |
60 |
60 |
|||
| 16 |
128 |
2 |
N/A |
2 |
2 |
32 |
16 |
10 |
なし |
80 |
4 |
2 |
8 |
4 |
8 |
4 |
78 |
80 |
||
| 32 |
256 |
2 |
N/A |
3 |
繰り返します。 |
64 |
32 |
16 |
N/A |
160 |
6 |
4 |
16 |
8 |
16 |
4 |
144 |
160 |
||
| 64 |
512 |
2 |
N/A |
6 |
4 |
128 |
64 |
30 |
なし |
320 |
12 |
6 |
32 |
16 |
32 |
4 |
274 |
320 |
||
| 128 |
1024 |
4 |
4 |
11 |
8 |
256 |
128 |
256 |
なし |
640 |
44 |
22 |
64 |
32 |
64 |
4 |
756 |
640 |
||
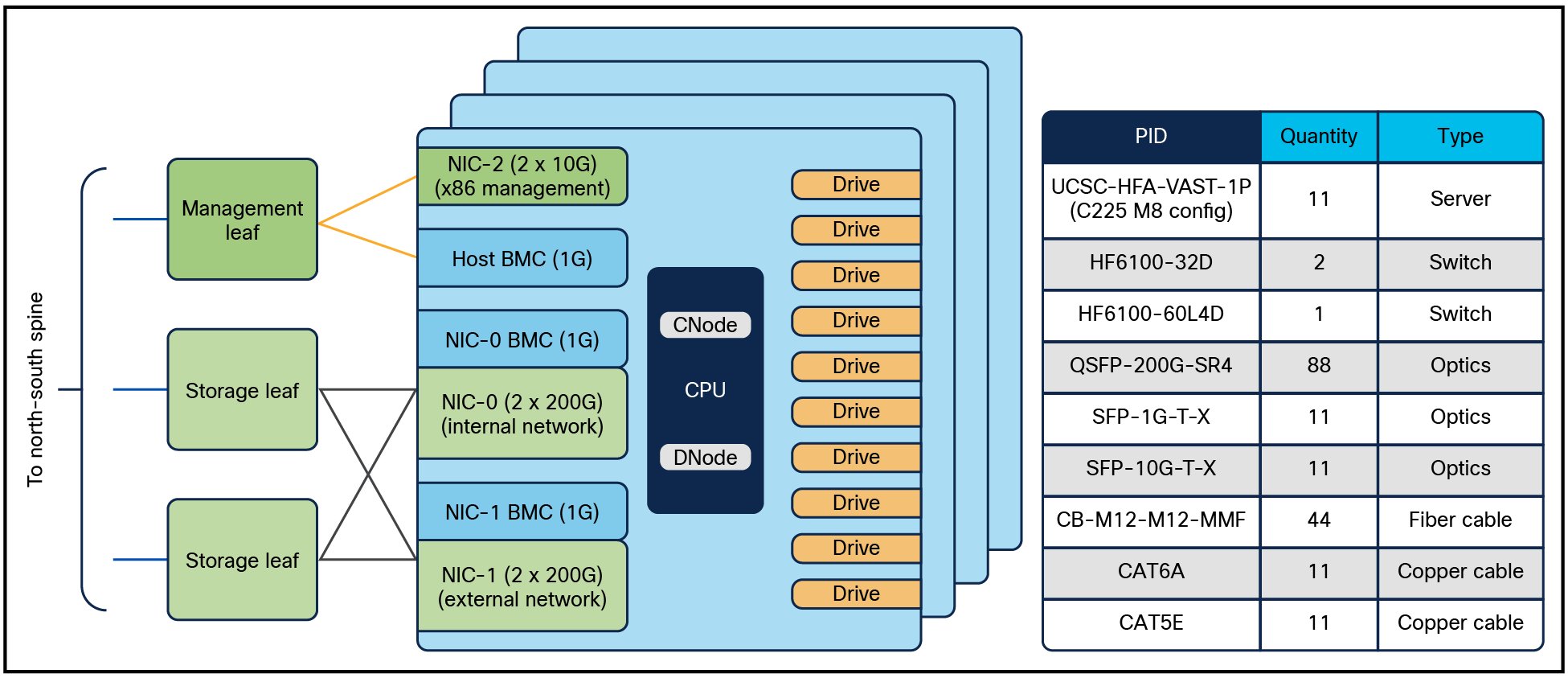
シスコは VAST Data とのパートナー関係により、EBox アーキテクチャの Cisco UCS C225 M8N ラック サーバ上に AI OS をオンボードできるようにしています。これによって、この RA 向けのストレージ サブシステムを提供します。この製品は Cisco EBox と呼ばれ、NVIDIA および Cisco Enterprise Secure AI factory の両方に対応する、NVIDIA の認定を受けた高性能ストレージです。VAST Data は、サーバを単一のネームスペースに段階的に追加することでストレージ容量と読み取り/書き込みパフォーマンスを水平方向にスケーリングできる、「非集約全共有(Disaggregated Shared Everything、DASE)」アーテクチャをサポートします。その他の機能には、マルチテナントのネイティブサポート、マルチプロトコル(NFS、S3、SMB)、データ削減、データ保護、クラスターの高可用性、障害が発生したハードウェア コンポーネントのサービス対応などが含まれます。
図 13 は、12 台のストレージ サーバを備えたネットワーク全体の接続性と BOM を示しています。データ パスの場合、各サーバは 2 つの NVIDIA BlueField-3 B3220L 2x200G NICを使用します:NIC0 はサーバ内の内部ネットワークに使用され、他のサーバからストレージ ドライブにアクセスできるようにします。 そして NIC1 は、NFS、S3、および SMB などのクライアント トラフィックをサポートする外部ネットワークに使用されます。1G BMC および 10G x86 管理ポートは管理リーフ スイッチに接続されます。
ストレージ サブシステムのブロック図と BOM
Cisco EBox 以外に、他の NVIDIA 認定ストレージ パートナーもこのリファレンス アーキテクチャで使用できます。
Hyperfabric は、クラウドホスト型のマルチテナント コントローラであり、主な機能はネットワーク ファブリックを制御することです。Hyperfabric スイッチの構成ターゲット状態、ソフトウェア バージョンなどを完全に管理します。
ネットワーク コントローラは、接続されているデバイスによって観察されるネットワークの動作をより詳細に可視化できるというメリットを利用できます。Cisco UCS ベースのコンピューティングおよびストレージ サーバーの場合、ハイパー ファブリックは IPM テレメトリを提供し、パケットの順序変更、バッファの調整、IPG の調整などのいくつかのポート レベルのオプションを最小限に管理します。それ以外の場合は、サーバーと NIC は可視性のみのデバイスです。
そのため、Hyperfabric は次のことを行いません。
● 何らかの方法でコンピューティングまたはストレージを構成する
● サーバの BMC またはホスト CPU ソフトウェア ライフサイクルを管理する
● NVIDIA BlueField-3 NIC でカーネルおよびディストリビューションを管理する
サーバの構成および管理機能は、他の方法で管理する必要があります(Cisco Intersight® は、オプションです)。これらのツールの展開および使用は、お客様側で全責任を負います。ネットワーク コントローラの適切な範囲であることに加えて、この懸念事項の分離は、ネットワーク運用をコンピューティングとストレージからセグメント化するという主要な運用パラダイムに合致しています。
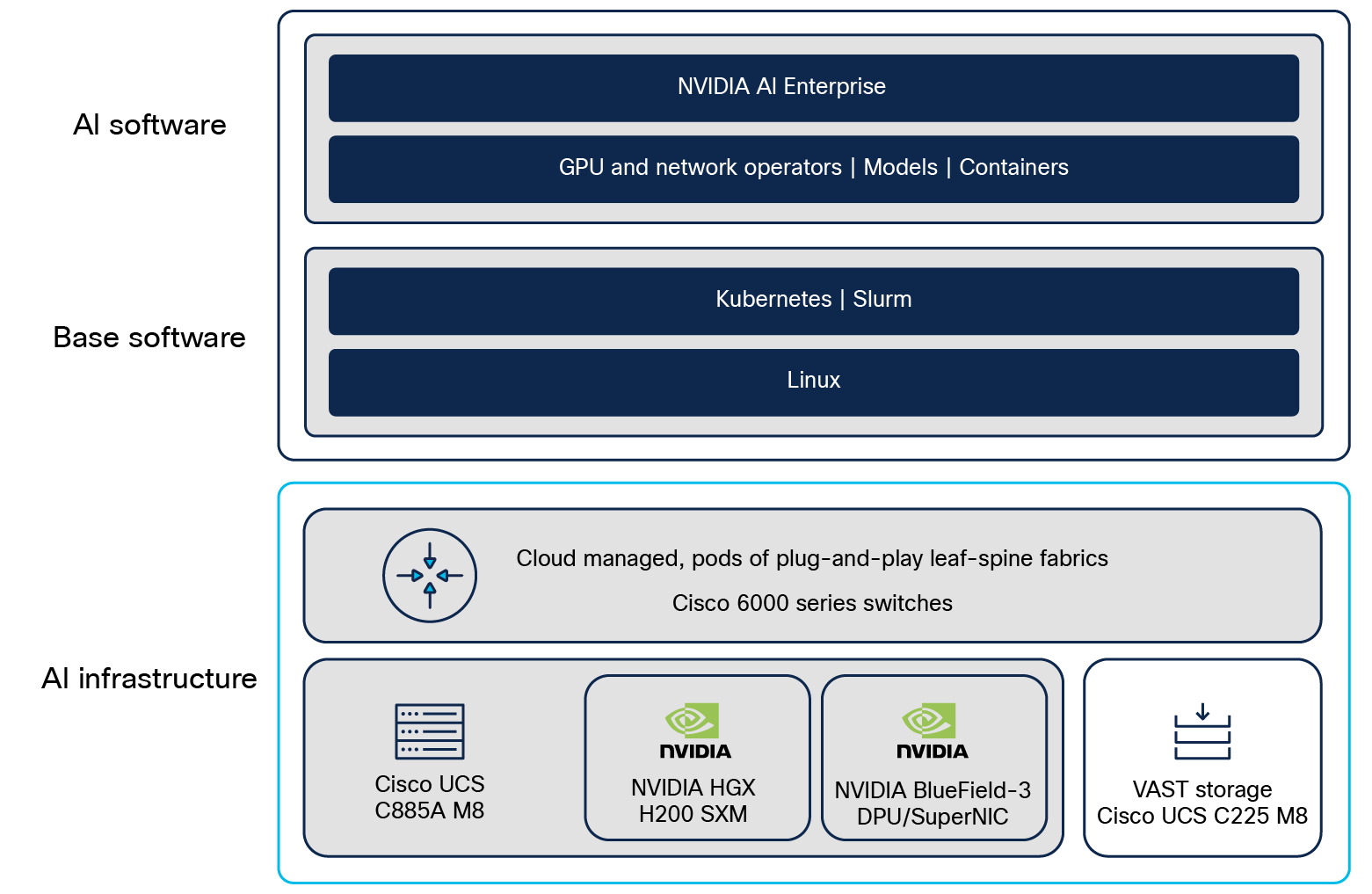
このリファレンス アーキテクチャには、NVIDIA 認定の Cisco UCS C885A M8 ラック サーバーで展開およびサポートされている NVIDIA AI Enterprise が含まれています。NVIDIA AI Enterprise は、実稼働対応の AI エージェント、生成 AI、コンピュータ ビジョン、音声 AI などの開発と展開を合理化するクラウドネイティブなソフトウェア プラットフォームです。エンタープライズ レベルのセキュリティ、サポート、および API の安定性により、プロトタイプから実稼働へのスムーズな移行が保証されます。
NVIDIA NIM™ マイクロサービスは、オープンソース コミュニティ モデル、カスタム モデル、および NVIDIA AI Foundation モデルの実稼働展開のための完全な推論スタックを提供します。スケーラブルで最適化された推論エンジンと使いやすさにより、モデルが加速し、TCO が改善され、実稼働展開が迅速化されます。
NVIDIA Spectrum-X ネットワーキング テクノロジーは、イーサネットベースの GPU およびストレージ ネットワークのパフォーマンスと効率を大幅に向上させます。この長所は、NVIDIA BlueField-3 SuperNIC に接続し、Fine Grain Load Balancing(FGLB)ライセンスが有効になっている場合、Cisco SiliconOne ベースの Hyperfabric スイッチで利用できます。N9164E-NS4-O スイッチを使用してイースト-ウェスト コンピューティング ネットワークを展開する場合、Spectrum-X ライセンスは必要ありません。
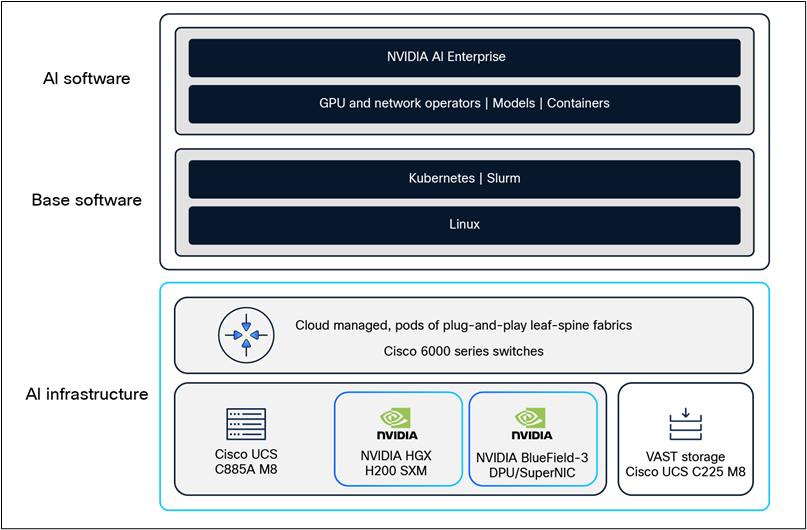
コンピューティング サーバー ソフトウェア スタック
お客様は、NVIDIA が公開している NVIDIA AI Enterprise、ドライバ、および CNS 互換性マトリックスに従って、OS ディストリビューションとソフトウェア バージョンを選択して実行できます。
AI インフラストラクチャにおけるセキュリティは、堅牢なアクセス制御とホストとネットワークの分離を実装して不正アクセスや不正操作を防止することによって、敵対的な攻撃に対する機密性、完全性、および高可用性を確保するために非常に重要です。以下に列挙する多くのシスコのセキュリティ技術は、企業がこれらの技術を展開することで、アプリケーションからインフラストラクチャ全体までエンドツーエンドのセキュリティを設定、監視、および適用することができます。これらのテクノロジーをエンドツーエンドのワークフローに完全に統合することは、この RA の範囲外です。
可観測性は、継続的な可視性と信頼性を確保し、調整と適切なインフラストラクチャのスケーリングで高いパフォーマンスを提供するための AI インフラストラクチャの重要な要素です。また、デバッグを促進し、セキュリティを支援し、信頼性の高い効果的な AI システムを維持するのにも役立ちます。Cisco Splunk® は、企業が大量のテレメトリを取り込み、詳細な可視性を実現できるようにする、業界をリードするオブザーバビリティ ソリューションです。これをエンドツーエンドのワークフローに統合することは、この RA の範囲を超えています。
管理プレーン、コントロール プレーン、およびコンピューティング、ストレージとネットワーキングを組み合わせたデータ プレーンのあらゆる側面で全体的なソリューションを徹底的にテストしています。コンピューティング ノードは NVIDIA-Certified Systems™ です。Cisco EBox 高性能ストレージ ソリューションは、NCP レベルで NVIDIA 認定ストレージの検証を取得しています。また、HPC Benchmark、IB PerfTest、NCCL Test、MLCommons Training、Inference ベンチマークなど、多数のベンチマークテストスイートを実行して、パフォーマンスを評価し、調整を支援しています。NVIDIA AI エンタープライズ エコシステムのさまざまな要素とエンティティが投入およびテストされ、微調整、推論、および RAG に関する多数の企業中心のお客様のユース ケースを評価します。
このように、Cisco Nexus Hyperfabric AI は、完全に統合された、エンドツーエンドのテスト済み AI クラスタ ソリューションであり、AI インフラストラクチャの展開ニーズに対応するワンストップ ショップをお客様に提供します。
Cisco UCS C885A M8 ラック サーバ
表 6 Cisco UCS C885A M8 8RU ラック サーバ
| エリア |
詳細 |
| フォーム ファクタ |
8RU ラック サーバ(空冷) |
| コンピューティング + メモリ |
第 5 世代 AMD EPYC 9575F X 2(400W、64 コア、最大 5GHz) 24x 96GB DDR5 RDIMM、最大 6,000 MT/S(推奨メモリ構成) 24x 128GB DDR5 RDIMM、最大 6,000 MT/S(サポートされる最大メモリ構成) |
| ストレージ |
RAID サポート付きデュアル 1 TB M.2 NVMe(ブート デバイス) 最大 16 台の PCIe5 x4 2.5 インチ U.2 1.92 TB NVMe SSD(データキャッシュ) |
| GPU |
8x NVIDIA H200 GPU(各 700W) |
| ネットワーク カード |
8 PCIe x16 HHHL NVIDIA BlueField-3 B3140H East-West NIC 2 PCIe x16 FHHL NVIDIA BlueField-3 B3240 North-South NIC 1 つのホスト管理用の OCP 3.0 X710-T2L |
| 冷却 |
システム冷却用の 16 ホットスワップ可能(N+1)ファン |
| 前面 IO |
2xUSB 2.0、1xID ボタン、1x電源ボタン |
| 背面 IO |
1x USB 3.0 A、1x USB 3.0 C、mDP、1x ID ボタン、1x 電源ボタン、1x USB 2.0 C、1x RJ45 |
| 電源装置 |
6 X 54V 3kW MCRPS(4+2 冗長性)および 2 X 12V 2.7kW CRPS(1+1 冗長性) |
汎用性の高い Cisco UCS C225 M8 1RU ラック サーバは、Slurm および Kubernetes(K8)、等のサポート サーバと制御ノードサーバとして使用されます。表 7 は、サーバの最小仕様を表示します。
表 7 Cisco UCS C225 M8 1RU ラック サーバ
| エリア |
詳細 |
| フォーム ファクタ |
1RU ラック サーバ(空冷) |
| コンピューティング + メモリ |
1x第 4 世代 AMD EPYC 9454P(48 コア) 32GB DDR5 RDIMM X 12(4800MT/s) |
| ストレージ |
RAID 搭載デュアル 1 TB M.2 SATA SSD(ブート デバイス) 最大 10 台の 2.5 インチ PCIe Gen4 NVMe PCIe SSD(それぞれ容量 1.9 〜 15.3 TB):オプション |
| ネットワーク カード |
1 PCIe x16 FHHL NVIDIA BlueField-3 B3220L(DPU モードで構成) x86 ホスト管理用の 1 OCP 3.0 X710-T2L(2 x 10G RJ45) |
| 冷却 |
システム冷却用の 8 ホットスワップ可能(N+1)ファン |
| 電源装置 |
2x 1.2KW MCRP PSU N+1 冗長構成 |
| BMC |
ホスト管理用の 1G RJ45 |
2 ソケット CPU を使用する展開では、B3220 DPU NIC とともに Cisco UCS C245 M8 2RU ラック サーバ バリアントを使用できます。