|
hv_user_0
|
Hypervisor username. This is the username of a user with root access to the VMware host/blade. If installing CPS to multiple
blade servers, it is assumed that the same username and password can be used for all blades.
This parameter is optional1.
|
|
hv_passwd_0
|
Hypervisor Password for Hypervisor User. User can also use special (non-alpha numeric) characters in the password.
This parameter is optional.
|
Note
|
To pass special characters in the hv_passwd_0, they need to be replaced with its “% Hex ASCII”. For example, “$” would be
“%24” or “hello$world” would be “hello%24world”.
|
|
|
vcenter_hostname
|
vCenter hostname.
Example: qps-vcenter.cisco.com
|
|
vcenter_user
|
vCenter user2.
Example: administrator@vsphere.local
|
|
vcenter_passwd
|
vCenter password3. You need to add the encrypted password.
To encrypt the password,
cd /var/qps/bin/support
./encrypt_pass.sh vcenter <vcenter_passwd>
where, <vcenter_passwd> is the vCenter password in plain text format.
|
Note
|
The ./encrypt_pass.sh vcenter <vcenter_passwd> command must be run on every Cluster Manager and the Configuration.csv file should have the password generated for the respective Cluster Manager. The encrypted passwords cannot be reused on other
Cluster Managers or setups.
|
|
Note
|
The encrypted password must be added in the Configuration.csv spreadsheet. To make the new password persisent, execute import_deploy.sh.
|
|
|
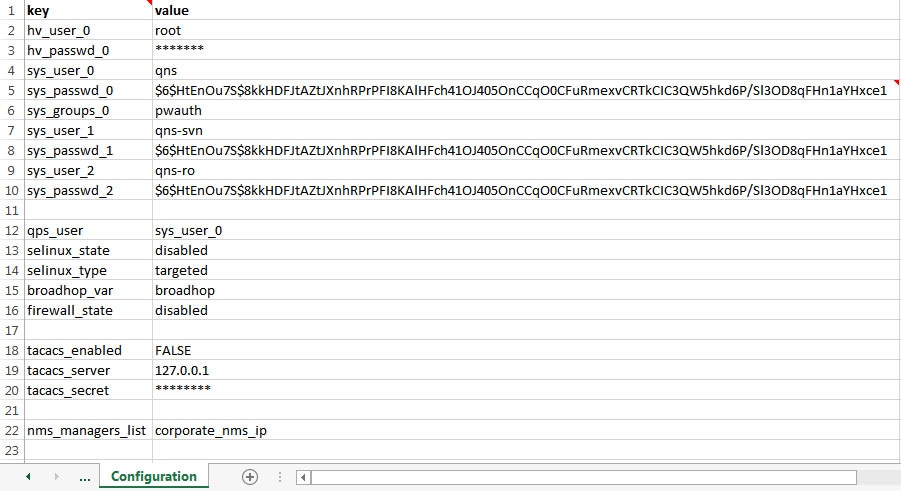
sys_user_0
|
The CPS System user (qns) is the main user set up on the VMs. By default, this is qns.
|
|
sys_passwd_0
|
Encrypted System Password for System User 0. Refer to System Password Encryption to generate an encrypted password.
For High Availability (HA) environments or Geographic Redundancy (GR) environments, the password entered here in the spreadsheet
is not used even if you specify one. You must set the password for the user prior to first access by connecting to the Cluster
Manager after deployment and running the change_passwd.sh command.
|
|
sys_group
|
Group for the previous System User.
|
Note
|
User group can be qns-svn, qns-ro, qns-su, qns-admin and pwauth.
pwauth group is valid only for qns username and no other username.
|
|
|
sys_user_1
|
The qns-svn system user is the default user that has access to the Policy Builder subversion repository.
Default: qns-svn
|
|
sys_passwd_1
|
By default, the encrypted password for qns-svn is already added in Configuration.csv spreadsheet.
If you want to change the password for qns-svn user after CPS is deployed, you can use change_passwd.sh script. You also need to generate an encrypted password. To generate an encrypted password, refer to System Password Encryption.
|
Note
|
The encrypted password must be added in the Configuration.csv spreadsheet. To make the new password persisent, execute import_deploy.sh. If the encrypted password is not added in the spreadsheet and import_deploy.sh is not executed, then after running reinit.sh script, the qns-svn user takes the existing default password from Configuration.csv spreadsheet.
|
|
|
qps_user
|
-
|
|
selinux_state
selinux_type
|
By default, Security Enhanced Linux (SELinux) support is disabled.
|
Note
|
Cisco recommends not to change this value.
|
|
|
firewall_state
|
Enables or disables the linux firewall on all VMs (IPtables).
Valid Options: enabled/disabled
Default: enabled (This field is case sensitive)
|
Note
|
An alternate parameter ‘firewall_disabled’ can be used with true/false options to control the IPtables functionality.
|
|
Note
|
In case the firewall is disabled, mongo authentication functionality for Policy Server (QNS) read-only users is also disabled.
When firewall is enabled, mongo authentication functionality for read-only users is enabled by default.
|
|
Note
|
If the firewall is enabled/disabled, ICMP should not be blocked. If ICMP is blocked between VMs many of the dependent scripts
and underlying framework fails to work. For example, blocking of ICMP can result in upgrade or migration failure, replica
creation failure, and so on.
|
|
|
broadhop_var
|
Default: broadhop
|
|
tacacs_enabled
|
Enter true to enable TACACS+ authentication.
For more information related to TACACS+, refer to TACACS+.
|
|
tacacs_server
|
Enter the IP address of the TACACS+ server.
|
Note
|
If configured TACACS server is not reachable, Installation gets interrupted. To avoid interruption, make sure that the TACACS
server is reachable and working before it makes part of the configuration.
|
|
|
tacacs_secret
|
Enter the password/secret of the TACACS+ server.
|
|
tacacs_on_ui
|
This parameter is used to enable the TACACS+ authentication for Policy Builder and Control Center.
Default value is false.
Possible values are true or false.
|
|
allow_user_for_cluman
|
This parameter is used to update the /etc/sudoers with CPS entries on cluman.
Default value is false.
Possible values are true or false.
|
|
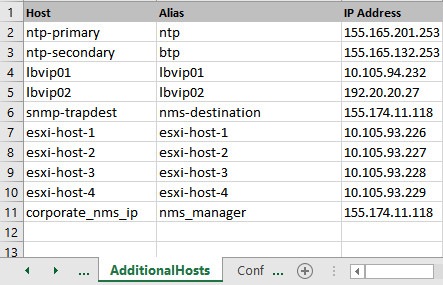
nms_managers_list
|
Define the SNMP Network Management Station (NMS) address or hostname by replacing corporate_nms_ip with the hostname or IP address of your NMS.
To add Multiple SNMP NMS destinations, replace corporate_nms_ip with a space separated list of hostnames or IP addresses of your NMS managers. For example:
10.105.10.10 10.202.10.10
or 10.105.10.10 10.202.10.10 2003:3041::22:22
or nms_main nms_bck
To change the NMS trap receiver port, update nms_managers_list
<nms_manager_list:port_num>
For example, nms_managers_list
corporate_nms_ip:6100
|
Note
|
Any hostnames defined should also be defined in the Additional Hosts tab of the deployment spreadsheet.
|
|
|
free_mem_per_alert
|
By default, a low memory alert is generated when the available memory of any CPS VM drops below 10% of the total memory.
To change the default threshold, enter a new value (0.0-1.0) for the alert threshold. The system generates an alert trap whenever
the available memory falls below this percentage of total memory for any given VM. Default: 0.10 (10% free).
|
|
free_mem_per_clear
|
Enter a value (0.0-1.0) for the clear threshold. The system generates a low memory clear trap whenever available memory for
any given VM is more than 30% of total memory. Default: 0.3 (30% of the total memory).
|
|
syslog_managers _list
|
Entries are space separated tuples consisting of protocol:hostname:port. Currently, only UDP is supported.
Default: 514
For example:
udp:corporate_syslog_ip:514
udp:corporate_syslog_ip2:514
|
|
syslog_managers _ports
|
A comma separated list of port values. This must match values in the syslog_managers_list.
|
|
logback_syslog_ daemon_port
|
Port value for the rsyslog proxy server to listen for incoming connections, used in the rsyslog configuration on the Policy
Director (LB) and in the logback.xml on the OAM (PCRFCLIENT).
Default: 6515
|
|
logback_syslog_ daemon_addr
|
IP address value used in the /etc/broadhop/controlcenter/logback.xml on the OAM (PCRFCLIENT).
Default: lbvip02
|
|
cpu_usage_alert_ threshold
|
The following cpu_usage settings are related to the High CPU Usage Alert and High CPU Usage Clear traps that can be generated for CPS VMs. Refer
to CPS SNMP and Alarms Guide, Release 9.1.0 and prior releases or CPS SNMP, Alarms and Clearing Procedures Guide, Release 10.0.0 and later releases for more details about these SNMP traps.
Set the higher threshold value for CPU usage. System generates an Alert trap whenever the CPU usage is higher than this value.
|
|
cpu_usage_clear_ threshold
|
Set the lower threshold value for CPU usage. System generates a Clear trap whenever the CPU usage is lower than this value
and alert trap already generated.
|
|
cpu_usage_trap_ interval_cycle
|
This value is used as an interval period to execute the CPU usage trap script. The interval value is calculated by multiplying
5 with the given value. For example, if set to 1 then the script is executed every 5 sec.
The default value is 12, which means the script is executed every 60 seconds.
|
|
snmp_trap_community
|
This value is the SNMP trap community string.
Default: broadhop
|
|
snmp_ro_community
|
This value is the SNMP read-only community string.
Default: broadhop
|
|
monitor_replica_timeout
|
This value is used to configure timeout value.
The default value is 540 sec considering four replica sets. The customer can set timeout value according to the number of
replica sets in their network.
To recover single session replica-set, it takes approx 120 sec and adding 20% buffer to it; we are using 540 sec for default
(for four replica sets).
Without any latency between sessionmgr VMs, one replica-set recovers in ~135 sec. If latency (40 -100 ms) is present between
sessionmgr VMs we can add 10% buffer to 135 sec and set the timeout value for the required number of replica sets in customer’s
network.
|
|
snmpv3_enable
|
This value is used to enable/disable the SNMPv3 support on CPS. To disable the SNMPv3 support, set this value to FALSE.
Default: TRUE
|
|
v3User
|
User name to be used for SNMPv3 request/response and trap.
Default: cisco_snmpv3
|
|
engineID
|
This value is used for SNMPv3 request/response and on which NMS manager can receive the trap. It should be a hex value.
Default: 0x0102030405060708
|
|
authProto
|
This value specifies the authentication protocol to be used for SNMPv3. User can use MD5/SHA as the authentication protocol.
Default: SHA
|
|
authPass
|
This value specifies the authentication password to be used for SNMPv3 requests. It should have minimum length as 8 characters.
Default: cisco_12345
|
|
privProto
|
This value specifies Privacy/Encryption protocol to be used in SNMPv3 request/response and SNMP trap. User can use AES/DES
protocol.
Default: AES
|
|
privPass
|
This value specifies Privacy/Encryption password to be used in SNMPv3. It is an optional field. If it is blank then value
specified in authPass is used as privPass.
Default: <blank>
|
|
sctp_enabled
|
By default, SCTP support is enabled. For more information about enabling/disabling this functionality, refer to SCTP Configuration.
Default: TRUE
|
|
corosync_ping_hosts
|
Moving corosync resources (like VIPs) when the connectivity is lost between lb01 or lb02 (or pcrfclient01/02) to hosts configured
in this field. So if lb01 cannot connect to sessionmgr01 and sessionmgr02 then corosync resources (like VIPs) are moved from
lb01 to lb02.
Example: key = corosync_ping_hosts and Value = sessionmgr01 sessionmgr02
|
|
avoid_corosync_split_brain
|
If this field is not defined or value is 0, and when both nodes fail to connect to the configured corosync_ping_hosts, then
the resources stay on the last active node. If value is 1, and both nodes fail to connect to configured corosync_ping_hosts,
then the resources are not available on any nodes.
|
Remember
|
A split brain scenario (that is, VIPs are up on both nodes) can still occur when there is connectivity loss between lb01 and
lb02 and not with other hosts.
|
|
|
rsyslog_tls
|
This field is used to enable or disable encryption for rsyslog.
Default: TRUE
|
|
rsyslog_cert
|
This field is used to define the path for trusted Certificate of server.
|
|
rsyslog_ca
|
This field is used to define the Path of certifying authority (CA).
Default: /etc/ssl/cert/quantum.pem
|
|
rsyslog_key
|
This field is used to define the path of private key.
|
|
haproxy_stats_tls
|
This field is used to enable or disable the encryption for HAproxy statistics (including diameter statistics).
Default: TRUE
|
|
redis_authentication
_enabled
|
This field is used to enable or disable Redis authentication.
Default: TRUE (For fresh installations)
To enable or disable redis authentication for upgrade and migration, refer to Redis Authentication for Upgrading/Migrating Systems.
|
|
redis_authentication
_passwd
|
This field is used to add an encrypted password for Redis. For more information on about generating encrypted password, refer
to Redis Authentication.
|
|
redis_server_count
|
This value specifies the number of redis server instances running on each policy director (lb) VM. For more information on
redis functionality, refer to Configure Multiple Redis Instances.
Redis can be enabled with the number of instances as defined in redis_server_count. If the value for redis server count is not provided, default value of 3 for redis_server_count is considered.
To disable redis explicitly, redis server count should have value 0.
Default: 3
Value range: 0 to 64
|
|
remote_redis_server_count
|
This value can be added for Geographic Redundancy (GR) deployments only.
This value specifies the number of redis server instances running on each remote policy director (lb) VM.
If this value is not configured, remote redis server instances are not added for GR deployments.
|
|
snmpRouteLan
|
This field contains the value of a VLAN name which can be used to access the KPIs value provided by SNMP.
Default: Oam
|
|
redis_for_ldap_required
|
This parameter is used only when dedicated LDAP instance is required.
Default: false
Possible Values: true, false
If you configure LDAP instance explicitly, first redis instance on policy director (lb) VMs running on port 6379 is used for
LDAP and the remaining are used for diameter.
|
Note
|
If you configure redis_for_ldap_required parameter, then the following changes are automatically added in configuration files.
In /etc/broadhop/qns.conf file, an additional parameter -DldapRedisQPrefix=ldap is added.
/etc/broadhop/redisTopology.ini file has the following content if redis_for_ldap_required=true and redis_server_count=3:
ldap.redis.qserver.1=lb01:6379
policy.redis.qserver.2=lb01:6380
policy.redis.qserver.3=lb01:6381
ldap.redis.qserver.4=lb02:6379
policy.redis.qserver.5=lb02:6380
policy.redis.qserver.6=lb02:6381
If a dedicated LDAP instance is required, you many also want to consider increasing the total redis servers to accomodate
the diameter traffic.
For example, if redis_for_ldap_required property was not configured, and redis_server_count=3 then after configuring redis_for_ldap_required as true, you want to increase total redis server count to 4 by setting redis_server_count=4.
|
|
|
database_nics
|
This parameter allows user to provide interface names on which firewall must be opened for replica-set on a VM.
If database_nics is not configured, firewall is opened only for internal interface for a replica-set.
If database_nics is configured, then firewall is opened for configured interfaces and internal interface as well (even if it is not mentioned
in database_nics). This field has semicolon (;) separated interface names for firewall ports to be opened for a replica-set on a VM.
|
Note
|
This field is effective only when the firewall is enabled.
|
|
|
db_authentication_
enabled
|
This field is used to enable or disable MongoDB authentication.
Possible Values: TRUE, FALSE
|
Note
|
You must configure db_authentication_ enabled parameter. This parameter cannot be left empty. To disable the authentication, the parameter value must be set as FALSE.
To enable, the value should be TRUE, and admin and readonly passwords must be set. This is applicable only for new installs
and not for upgrades.
|
For more information, refer to MongoDB Authentication.
|
|
db_authentication_
admin_passwd
|
This parameter is the encrypted password for admin user and is applicable only when db_authentication_enabled is set to TRUE. The following command is used to generate encrypted password from Cluster Manager:
/var/qps/bin/support/mongo/encrypt_passwd.sh <Password>
For more information, refer to MongoDB Authentication.
|
|
db_authentication_
readonly_passwd
|
This parameter is the encrypted password for readonly user. The following command is used to generate encrypted password from
Cluster Manager:
/var/qps/bin/support/mongo/encrypt_passwd.sh <Password>
For more information, refer to MongoDB Authentication.
|
|
remote_site_ip
|
This parameter is used to update the remote site Cluster Manager IP address.
|
Note
|
This parameter is used only for GR and multi-cluster setups.
|
|
|
enable_ssh_login_security
|
This parameter allows user to enable or disable SSH login security.
Default: disabled
Possible Values: enabled, disabled
|
|
cps_admin_user_cluman
|
This parameter is used to configure Cluster Manager administrator user.
|
|
cps_admin_password_
cluman
|
This parameter is the encrypted password for administrator user.
|
|
whitelisted_hosts_for_ssh
|
Valid values are colon separated host names/IP addresses of the machine for which SSH access needs to be allowed.
This configuration is effective only when the SSH login security is enabled.
If the hostname is mentioned then it should be resolvable by CPS VM's. No validation on hostname/IP addresses is provided.
You can specify both IPv4/IPv6 address.
|
Note
|
New whitelisted host list overwrites the old list. If the new whitelist host configuration is empty then all old additional
whitelisted hosts (apart from standard local CPS VM's host ) are deleted.
|
|
|
LDAP SSSD Configuration
|
For more information, refer to LDAP SSSD Configuration.
|
|
enable_prometheus
|
This parameter is used to enable/disable Prometheus in CPS.
Default: disabled
Possible Values: enabled, disabled
For more information, refer to Prometheus and Grafana chapter in CPS Operations Guide.
|
|
stats_granularity
|
This parameter is used to configure statistics granularity in seconds.
Default: 10 seconds
Possible Values: Positive Number
For more information, refer to Prometheus and Grafana chapter in CPS Operations Guide.
|
|
restrict_access_http_port
|
When set to true, the http port (80) on pcrfclient and Cluster Manager VMs listen only on internal guest NIC and loopback
interface.
By default, this parameter is not present in Configuration.csv file.
Possible Values: true, false
|
|
service_log_tmpfs_enabled
|
This parameter is used to enable or disable service log on tmpfs.
Currently, this is supported only on Policy Director (LB), Policy Server (QNS) and UDC VMs.
Default: false
Possible Values: true, false
If this parameter is not configured, then by default, the value is false.
|
|
pcrf_proc_mon_list
|
This parameter is used to configure additional processes on OAM (pcrfclient) VMs. Multiple processes need to be semicolon
separated. By default, the following processes are monitored:
|
|
lb_proc_mon_list
|
This parameter is used to configure additional processes on Policy Director (LB) VMs. Multiple processes need to be semicolon
separated. By default, the following processes are monitored:
|
|
qns_proc_mon_list
|
This parameter is used to configure additional processes on Policy Server (QNS) VMs. Multiple processes need to be semicolon
separated. By default, the following processes are monitored:
|
|
sm_proc_mon_list
|
This parameter is used to configure additional processes on sessionmgr VMs. Multiple processes need to be semicolon separated.
By default, the following processes are monitored:
|
|
udc_proc_mon_list
|
This parameter is used to configure additional processes on UDC VMs. Multiple processes need to be semicolon separated. By
default, the following processes are monitored:
|
|
lwr_proc_mon_list
|
This parameter is used to configure additional processes on LWR VMs. Multiple processes need to be semicolon separated. By
default, the following processes are monitored:
|
|
perf_mod
|
1 or undefined: CPS java processes are run by Zulu on Policy Server (QNS), Policy Director (LB), and UDC VMs.
|
Note
|
Zing is only supported on Policy Server (QNS), Policy Director (LB), UDC, and LWR VMs. It is not supported on pcrfclient and
session manager VMs.
|
|
Note
|
In CPS 21.2 release and later releases, Zing package is no longer installed on Policy Director (LB) abd UDC VMs.
By default (1), CPS java process is run by Zulu on Policy Server (QNS), Policy Director (LB), and UDC VMs.
|
If 2: CPS java processes are run by Zing on Policy Server (QNS), Policy Director (LB), and UDC VMs in the VMware. To disable
Zing, refer to Disable Zing.
|
|
gc_alarm_state
|
This parameter is used to enable or disable the GC alarm.
Default: false
Possible Values: true, false
|
|
gc_alarm_
trigger_count
|
This parameter is used to configure the value of continous GCs after which the GC alarm is generated from the system.
Default: 3
|
|
gc_alarm_
trigger_interval
|
This parameter is used to indicate the interval under which the gc_alarm_trigger_count occurs to generate the GC alarm.
Default: 600 (10 mins)
|
|
gc_clear_
trigger_interval
|
This parameter is used to indicate the interval under which the there is no GC event and GC clear notofication is generated.
Default: 900 (15 mins)
|
|
oldgen_
alarm_state
|
This parameter is used to enable or disable the Old generation alarm.
Default: false
Possible Values: true, false
|
|
oldgen_alarm_
trigger_thr_per
|
This parameter is used to indicate the threshold in percentage for Old Generation post GC event to generate the Old Generation
alarms.
Default: 50
|
|
oldgen_clear_
trigger_thr_per
|
This parameter is used to indicate the threshold in percentage for Old Generation post GC event to generate the Old Generation
clear notification.
Default: 40
|
|
no_of_cont_
fullgc_for_oldgen
|
This parameter is used to indicate the number of continuous GC events under which the Old generation value is more than oldgen_alarm_trigger_thr_per
to generate the Old generation alarm.
Default: 2
|
|
alarm_resync_enabled
|
This parameter is used to store and forward the alarms based on NMS availability.
Default: false
Possible Values: true, false, TRUE, FALSE, True, False
alarm_resync_enabled should start at the first characer in the line and there must be no additional characters after true/false.
|
Restriction
|
When NMS comes up, it takes almost 5 mins for system to start sending the stored alarms to NMS. In between if any alarm gets
generated by the system, it is sent to NMS. So there is possibility that NMS may receive latest alarms first and all the older
alarms later. This happens only when NMS is unreachable and comes back to rechable state.
-
Multiple NMSs are configured: If few NMS servers are down, then the alarm resync feature will not store the alarms to be sent
to NMS.
-
Multiple NMSs are configured: If all NMS servers are down, then the alarm resync feature stores the alarms in Admin database
and sends them to NMS when it is reachable.
-
Single NMS is configured: If NMS server is down, then the alarm resync feature stores the alarms in Admin database and sends
them to NMS when it is reachable.
-
Single NMS is configured: If NMS server is up, then the alarm resync feature does not not store the alarms but just forwards
the alarms to NMS.
|
|
|
autoheal_qns_enabled
|
autoheal_qns_enabled parameter helps app_monitor.sh script (application monitor script) to take the decision to restart the QNS process or not.
-
FALSE: To disable the restart QNS process in case of the MongoDB health monitor failed to reset the MongoDB client connection.
-
TRUE: To enable the restart QNS process in case of the MongoDB health monitor failed to reset the MongoDB client connection.
For installing platform script, refer to Installing Platform Scripts for MongoDB Health Monitoring - VMware.
|
|
prevent_primary_
flapping_enabled
|
This parameter is used to prevent primary flapping from impacting the remote sites.
Default: false
|
Restriction
|
-
When the local site is handling traffic, during local site reboot scenario, if the latency is more between the local and remote
sites, then there may be some timeout or high response time from remote site since the PRIMARY is shifted to remote site.
-
If the member state is not stable within the stipulated 300 seconds time, then the priority level is retained as 1 for those
members until it becomes stable for minimum 300 seconds.
-
If mon_db* is enabled, make sure not to enable the prevent_primary_flapping_enabled flag. If both the parameters are enabled in a setup, it creates conflicts in MongoDB operations.
|
|
|
auto_haproxy_
balancing_list
|
This parameter is used to add the list of diameter endpoints that are enabled for Policy Director (LB) HAProxy Balancing.
For example:
$ cat /var/qps/config/deploy/csv/Configuration.csv |
grep auto_haproxy_balancing_list
auto_haproxy_balancing_list,diameter-int1-vip diameter-int2-vip,
To disable the HAProxy balancing, auto_haproxy_balancing_list is set to empty.
For example:
$ cat /var/qps/config/deploy/csv/Configuration.csv |
grep auto_haproxy_balancing_list
auto_haproxy_balancing_list, ,
|
|
gx_alarm_ccr_i
_avg_threshold
|
This parameter is used to specify the threshold value for Gx CCR-I response time in Gx Average Message processing Dropped alarm.
Default: 20 millisec
For alarm information, refer to Gx Average Message processing Dropped in CPS SNMP, Alarms, and Clearing Procedures Guide.
|
|
gx_alarm_ccr_u_
avg_threshold
|
This parameter is used to specify the threshold value for Gx CCR-U response time in Gx Average Message processing Dropped alarm.
Default: 20 millisec
For alarm information, refer to Gx Average Message processing Dropped in CPS SNMP, Alarms, and Clearing Procedures Guide.
|
|
gx_alarm_ccr_t_
avg_threshold
|
This parameter is used to specify the threshold value for Gx CCR-T response time in Gx Average Message processing Dropped alarm.
Default: 20 millisec
For alarm information, refer to Gx Average Message processing Dropped in CPS SNMP, Alarms, and Clearing Procedures Guide.
|
|
ldap_alarm_retry_
threshold
|
This parameter is used to specify the threshold value for Percentage of LDAP retry threshold Exceeded alarm.
Default: 10 %
For alarm information, refer to Percentage of LDAP retry threshold Exceeded in CPS SNMP, Alarms, and Clearing Procedures Guide.
|
|
ldap_alarm_ccr_i_
req_threshold
|
This parameter is used to specify the threshold value for LDAP Requests as percentage of CCR-I Dropped alarm.
Default: 25 %
For alarm information, refer to LDAP Requests as percentage of CCR-I Dropped in CPS SNMP, Alarms, and Clearing Procedures Guide.
|
|
ldap_alarm_result_
threshold
|
This parameter is used to specify the threshold value for LDAP Query Result Dropped alarm.
Default: 0 (recommended)
For alarm information, refer to LDAP Query Result Dropped in CPS SNMP, Alarms, and Clearing Procedures Guide.
|
|
ldap_alarm_request_
threshold
|
This parameter is used to specify the threshold value for LDAP Requests Dropped alarm.
Default: 0
For alarm information, refer to LDAP Requests Dropped in the CPS SNMP, Alarms, and Clearing Procedures Guide.
|
|
client_Alive_Interval
|
This parameter represents SSH idle timeout. This value is configured in seconds.
For example: client_Alive_Interval, 500
Default value is 0 (zero).
|
|
MongoDB Replication Health Monitoring
|
For more information, refer to MongoDB Replication Health Monitoring.
|
|
pcrfclient_memcache_
memory_size
|
This parameter is used to change the memcached memory size on pcrfclients.
This parameter doesn't change memcached memory on other VMs.
For example: pcrfclient_memcache_memory_size,8192
Default: 2048
|
Note
|
You can change the value as per your deployment requirements. Make sure you have enough memory on pcrfclients to support the
change in memcached memory size.
|
If you are adding pcrfclient_memcache_memory_size parameter to an existing installation, execute the following:
/var/qps/install/current/scripts/import/import_deploy.sh
/var/qps/install/current/scripts/build/build_all.sh
/var/qps/install/current/scripts/upgrade/reinit.sh
|
|
balance_mgmt_
fragmentation_threshold
|
This parameter is used to specify the threshold value for balance_mgmt MongoPrimaryDB fragmentation that exceeded the threshold value alarm.
Default: 40
|
|
diameter_
fragmentation_threshold
|
This parameter is used to specify the threshold value for diameter MongoPrimaryDB fragmentation that exceeded the threshold value alarm.
Default: 40
|
|
session_cache_
fragmentation_threshold
|
This parameter is used to specify the threshold value for session_cache MongoPrimaryDB fragmentation that exceeded the threshold value alarm.
Default: 40
|
|
sk_cache_
fragmentation_threshold
|
This parameter is used to specify the threshold value for sk_cache MongoPrimaryDB fragmentation that exceeded the threshold value alarm.
Default: 40
|
|
spr_fragmentation_
threshold
|
This parameter is used to specify the threshold value for spr MongoPrimaryDB fragmentation that exceeded the threshold value alarm
Default: 40
|
|
db_fragmentation_
alarm_enable
|
This parameter is to enable or disable MongoPrimaryDB fragmentation that exceeded the threshold value alarm.
Default: false
|
|
WT_CACHESIZEGB
|
This parameter configures wiredtiger cache in GB on Session Manager VMs. The configured WT_CACHESIZEGB reflects in mongo processes as --wiredTigerCacheSizeGB parameter. This is an optional parameter.
Default value: 2 GB
|
Note
|
With WiredTiger, MongoDB utilizes both the WiredTiger internal cache and the filesystem cache. The default WiredTiger internal cache size
is the larger of either 50% of (RAM - 1 GB), or 256 MB.
For example, on a system with a total of 4 GB of RAM the WiredTiger cache can use 1.5GB of RAM (0.5 * (4 GB - 1 GB) = 1.5
GB). Conversely, a system with a total of 1.25 GB of RAM can allocate 256 MB to the WiredTiger cache because that is more
than half of the total RAM minus one gigabyte (0.5 * (1.25 GB - 1 GB) = 128 MB < 256 MB).
|
|
|
WT_CACHEARBSIZEGB
|
This parameter configures wiredtiger cache in GB on arbiter VMs. The configured WT_CACHEARBSIZEGB will be reflected in mongo processes --wiredTigerCacheSizeGB parameter. This is an optional parameter.
Default value: 1 GB
|



 Feedback
Feedback