AI Inferencing on Cisco UCS X-Series for Intel OpenVINO Based RAG Deployments
Available Languages
Bias-Free Language
The documentation set for this product strives to use bias-free language. For the purposes of this documentation set, bias-free is defined as language that does not imply discrimination based on age, disability, gender, racial identity, ethnic identity, sexual orientation, socioeconomic status, and intersectionality. Exceptions may be present in the documentation due to language that is hardcoded in the user interfaces of the product software, language used based on RFP documentation, or language that is used by a referenced third-party product. Learn more about how Cisco is using Inclusive Language.
- US/Canada 800-553-2447
- Worldwide Support Phone Numbers
- All Tools
 Feedback
Feedback
 Feedback
Feedback

In partnership with:

About the Cisco Validated Design Program
The Cisco Validated Design (CVD) program consists of systems and solutions designed, tested, and documented to facilitate faster, more reliable, and more predictable customer deployments. For more information, go to: http://www.cisco.com/go/designzone.
Enterprises across various industries are actively embracing the power of Large Language Models (LLMs) and generative AI to revolutionize their operations, streamline their processes, and enhance customer experiences. As businesses explore the best opportunities to integrate generative AI into their workflows and processes that would lead to a significant ROI, they recognize the significant computational resources needed to train or fine-tune an LLM to gain domain- or company-specific knowledge, incorporate the most current information, and reduce the chances of generating inaccurate or irrelevant content. Specifically for AI models with billions of parameters, organizations often face a requirement to invest in costly computing power to be able to efficiently train state-of-the-art LLMs.
Retrieval Augmented Generation (RAG) is a technique that presents a viable alternative for enterprises to benefit from the generative AI capabilities of LLMs without having to incur in all the costs required to train or fine-tune an LLM, while at the same time ensuring the generative model uses current and pertinent information to create superior content that aligns more closely with the organization's business policies and priorities.
Unlike LLM training, which usually requires the parallel processing power of multiple high-end GPUs, inference tasks can often be run efficiently on CPUs when using a pre-trained LLM to generate content using RAG, especially if models are properly optimized to benefit from the AI acceleration capabilities built into hardware architectures. OpenVINO is a robust open-source toolkit that accelerates AI workloads and enables enterprises to take advantage of the AI acceleration features built into the 5th Gen Intel Xeon Scalable Processors to easily optimize embedding models and LLMs, both of which are critical to RAG deployments. These optimizations present organizations with an effective option to start their journey on the path to the integration of generative AI into their internal processes, without sacrificing efficiency, while also meeting application latency requirements, and enhancing the relevance and accuracy of the generated content.
Cisco UCS X-Series Servers, equipped with 5th Generation Intel Xeon Scalable Processors and managed via Cisco Intersight, deliver a robust solution for optimizing AI workloads, especially those requiring heavy inferencing. This integrated ecosystem enhances management efficiency through the user-friendly Cisco Intersight interface, simplifying the deployment, scaling, and operation of AI workloads. By harnessing the power of AMX-accelerated 5th Gen Intel Xeon processors, organizations can tackle demanding AI tasks with greater speed, scalability, and reliability, making this infrastructure well-suited for high-performance applications across various industries.
This Cisco Validated Design demonstrates the deployment of an Intel AMX-accelerated OpenVINO-based question-answering RAG pipeline on a Cisco UCS X-Series X210C M7 node. This utilizes the Llama-3-8B-instruct LLM model to assess the performance of the question-answering LangChain pipeline to generate human-like responses from documents retrieved from a Qdrant vector database. The evaluation focuses on optimizing the performance of the RAG pipeline through OpenVINO, which enhances the model's inference efficiency and speed. The integration of OpenVINO in this solution is based on the LLM Chatbot Demo notebook developed by the Intel OpenVINO team. Performance results indicate that these optimizations significantly improve overall system performance, enabling faster and more scalable AI-driven responses suitable for real-world applications.
This chapter contains the following:
● Audience
This chapter provides a rationale for the selection of the hardware and software stack utilized in this solution, spanning from the infrastructure layer to the software layer.
This document is intended for, but not limited to, sales engineers, technical consultants, solution architecture and enterprise IT, and machine learning teams interested in design, deployment, and life cycle management of generative AI systems.
This document outlines a reference architecture featuring Cisco UCS X210c M7 Compute Nodes equipped with 5th Gen Intel Xeon Scalable processors. It illustrates the performance validation on OpenVINO based RAG deployments. The performance improvements with the OpenVINO toolkit demonstrate a notable enhancement in system efficiency, allowing for quicker and more scalable AI-driven responses that are well-suited for practical, real-world use.
This solution showcases the performance of an AI application leveraging OpenVINO™ and LangChain to implement an efficient RAG pipeline on a single Cisco UCS X-Series X210C M7 node, managed through Cisco Intersight. The RAG pipeline can work as a chatbot application that can access a company’s internal knowledge database while answering customer queries. By deploying a complex RAG pipeline on a single Cisco UCS X-Series node powered by 5th Gen Intel® Xeon® processors, this solution highlights the exceptional capability of Cisco UCS X-Series infrastructure to seamlessly run AI-driven applications alongside traditional and modern workloads within the same chassis. The result is outstanding performance, scalability, and efficiency, making Cisco UCS X-Series the ideal platform for running diverse, high-demand workloads without compromise.
Key benefits of the Intel OpenVINO™ framework, integrated into this solution, include:
● Exceptional performance for large language models (LLMs) on Intel® Core™ and Intel® Xeon® processors.
● Broad support for various LLM architectures across multiple frameworks.
● Model weight compression and optimization through the Neural Network Compression Framework (NNCF).
● Access to pre-converted and optimized models for faster deployment.
This Cisco Validated Design (CVD) offers comprehensive guidance on the integration of these technologies, including code examples and links to end-to-end deployment guides. Whether deploying locally or using OpenVINO™ Model Server, the solution highlights the efficiency, scalability, and operational excellence of Cisco UCS X-Series servers, delivering a seamless, high-performance experience for AI-driven applications.
This chapter contains the following:
● Cisco UCS X-Series Modular System
● Cisco UCS 6500 Series Fabric Interconnect
● Intel Xeon Scalable Processor Family
Cisco UCS X-Series Modular System
The Cisco Unified Computing System X-Series (Cisco UCSX) is a modular, next-generation data center platform that builds upon the unique architecture and advantages of the previous Cisco UCS 5108 system. The Cisco UCS X-Series is a standards-based open system designed to be deployed and automated quickly in a hybrid cloud environment. The following key enhancements in Cisco UCS X-Series simplify IT operations:
● Cloud-managed infrastructure: With Cisco UCS X-Series, the management of the network infrastructure is moved to the cloud, making it easier and simpler for IT teams to respond quickly and at scale to meet the needs of your business. The Cisco Intersight cloud-operations platform allows you to adapt the resources of the Cisco UCS X-Series Modular System to meet the specific requirements of a workload. Additionally, you can seamlessly integrate third-party devices such as Pure Storage and VMware vCenter. This integration also enables global visibility, monitoring, optimization, and orchestration for all your applications and infrastructure.
● Adaptable system designed for modern applications: Today's cloud-native and hybrid applications are dynamic and unpredictable. Application and DevOps teams frequently deploy and redeploy resources to meet evolving requirements. To address this, the Cisco UCS X-Series provides an adaptable system that doesn't lock you into a fixed set of resources. It combines the density, manageability, and efficiency of blade servers with the expandability of rack servers, allowing you to consolidate multiple workloads onto a single platform. This consolidation results in improved performance, automation, and efficiency for both hybrid and traditional data center applications.
● Platform engineered for the future: The Cisco UCS X-Series is designed to adapt to emerging technologies with minimal risk. It is a modular system that can support future generations of processors, storage, nonvolatile memory, accelerators, and interconnects. This eliminates the need to purchase, configure, maintain, power, and cool separate management modules and servers. Cloud-based management through Intersight ensures automatic updates and access to new capabilities delivered through a software-as-a-service model.
● Broad support for diverse workloads: The Cisco UCS X-Series supports a broad range of workloads, reducing the need for different products which lowers support costs, training costs, and gives you more flexibility in your data center environment.
The Cisco UCS X-Series chassis is engineered to be adaptable and flexible. With a midplane-free design, I/O connectivity for the Cisco UCS X9508 chassis is accomplished with front-loading vertically oriented computing nodes that intersect with horizontally oriented I/O connectivity modules in the rear of the chassis. A unified Ethernet fabric is supplied with the Cisco UCS 9108 IFMs. Cisco UCS X9508 Chassis’ superior packaging enables larger compute nodes, thereby providing more space for actual compute components, such as memory, GPU, drives, and accelerators. Improved airflow through the chassis enables support for higher power components, and more space allows for future thermal solutions (such as liquid cooling) without limitations.
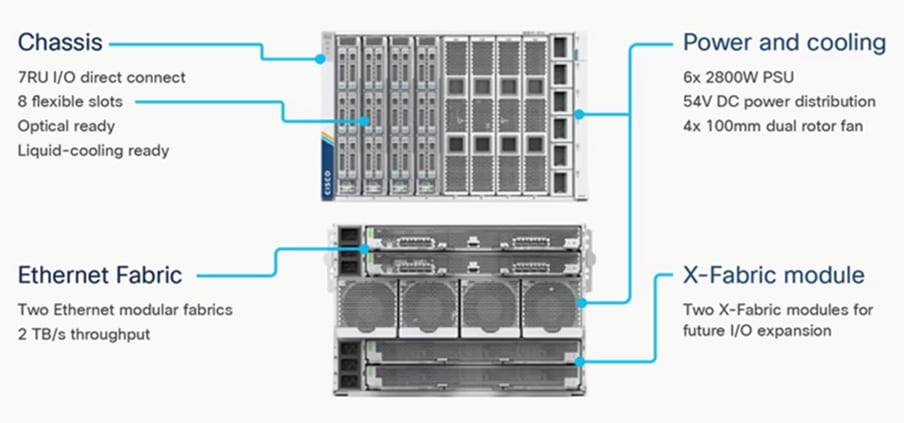
The Cisco UCS X9508 Chassis (Figure 1) provides the following features and benefits:
● The 7RU chassis has 8 front-facing flexible slots. These slots can house a combination of computing nodes and a pool of future I/O resources, which may include graphics processing unit (GPU) accelerators, disk storage, and nonvolatile memory.
● Two Cisco UCS 9108 IFMs at the top of the chassis connect the chassis to upstream Cisco UCS 6400 Series Fabric Interconnects (FIs). Each IFM offers these features:
◦ The module provides up to 100 Gbps of unified fabric connectivity per computing node.
◦ The module provides eight 25-Gbps Small Form-Factor Pluggable 28 (SFP28) uplink ports.
◦ The unified fabric carries management traffic to the Cisco Intersight cloud-operations platform, Fibre Channel over Ethernet (FCoE) traffic, and production Ethernet traffic to the fabric interconnects.
● At the bottom of the chassis are slots used to house Cisco UCS X9416 X-Fabric Modules which enables GPU connectivity to the Cisco UCS X210c Compute Nodes.
● Six 2800-watt (W) power supply units (PSUs) provide 54 volts (V) of power to the chassis with N, N+1, and N+N redundancy. A higher voltage allows efficient power delivery with less copper wiring needed and reduced power loss.
● Efficient, 4 x 100-mm, dual counter-rotating fans deliver industry-leading airflow and power efficiency. Optimized thermal algorithms enable different cooling modes to best support the network environment. Cooling is modular, so future enhancements can potentially handle open- or closed-loop liquid cooling to support even higher-power processors.
The Cisco UCS X210 M7 server is a high-performance and highly scalable server designed for data centers and enterprise environments. Some of the key benefits of this server are:
● Performance: The Cisco UCS X210 M7 server is built to deliver exceptional performance. It features the latest Intel Xeon Scalable processors, providing high processing power for demanding workloads such as virtualization, database management, and analytics. The server's architecture is designed to optimize performance across a wide range of applications.
● Scalability: The Cisco UCS X210 M7 server offers excellent scalability options, allowing organizations to easily scale their computing resources as their needs grow. With support for up to eight CPUs and up to 112 DIMM slots, the server can accommodate large memory configurations and high core counts, enabling it to handle resource-intensive applications and virtualization environments.
● Memory Capacity: The server supports a large memory footprint, making it suitable for memory-intensive workloads. It can accommodate a vast amount of DDR4 DIMMs, providing a high memory capacity for applications that require significant data processing and analysis.
● Enhanced Virtualization Capabilities: The Cisco UCS X210 M7 server is designed to optimize virtualization performance. It includes features such as Intel Virtualization Technology (VT-x) and Virtual Machine Device Queues (VMDq), which improve virtual machine density and network performance in virtualized environments. These capabilities enable organizations to consolidate their workloads and achieve efficient resource utilization.
● Simplified Management: The Cisco Unified Computing System (Cisco UCS) management software provides a unified and streamlined approach to server management. The Cisco UCS Manager software allows administrators to manage multiple servers from a single interface, simplifying operations and reducing management complexity. Additionally, the server integrates with Cisco's ecosystem of management tools, providing enhanced visibility, automation, and control.
● High Availability and Reliability: The Cisco UCS X210 M7 server is built with redundancy and fault tolerance in mind. It includes features such as hot-swappable components, redundant power supplies, and redundant fans, ensuring high availability and minimizing downtime. The server's architecture is designed to support mission-critical applications that require continuous operation.
● Energy Efficiency: Cisco UCS servers are designed to be energy-efficient. The Cisco UCS X210 M7 server incorporates power management features that optimize power usage and reduce energy consumption. This not only helps organizations reduce their carbon footprint but also lowers operating costs over time.

Cisco UCS Virtual Interface Cards (VICs)
Cisco UCS X210c M7 Compute Nodes support multiple Cisco UCS VIC cards. This design uses the Cisco UCS VIC 15000 adapter.
● Cisco UCS X210c M7 Compute Nodes support the following Cisco UCS VIC cards:
◦ Cisco UCS VIC 15231
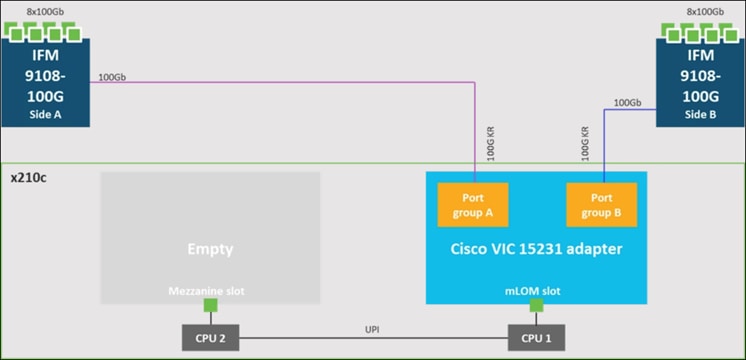
Cisco UCS VIC 15231 fits the mLOM slot in the Cisco UCS X210c Compute Node and enables up to 100 Gbps of unified fabric connectivity to each of the chassis IFMs for a total of 200 Gbps of connectivity per server. Cisco UCS VIC 15231 connectivity to the IFM and up to the fabric interconnects is delivered through 100Gbps. Cisco UCS VIC 15231 supports 512 virtual interfaces (both FCoE and Ethernet) along with the latest networking innovations such as NVMeoF over FC or TCP, VxLAN/NVGRE offload, and so forth.
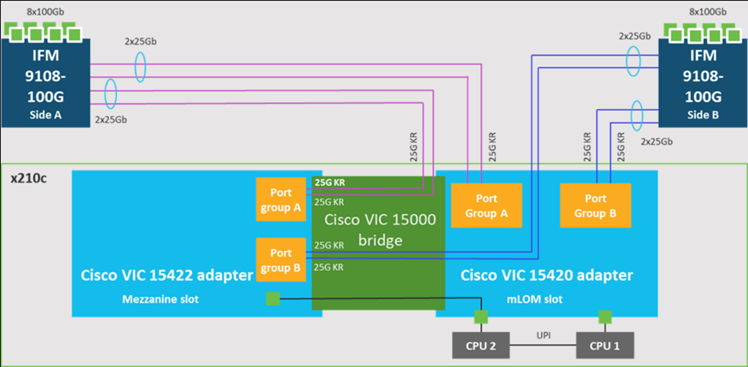
Cisco UCS VIC 15420
Cisco UCS VIC 15420 fits the mLOM slot in the Cisco UCS X210c Compute Node and enables up to 50 Gbps of unified fabric connectivity to each of the chassis IFMs for a total of 100 Gbps of connectivity per server. Cisco UCS VIC 15420 connectivity to the IFM and up to the fabric interconnects is delivered through 4x 25-Gbps connections, which are configured automatically as 2x 50-Gbps port channels. Cisco UCS VIC 15420 supports 512 virtual interfaces (both Fibre Channel and Ethernet) along with the latest networking innovations such as NVMeoF over RDMA (ROCEv2), VxLAN/NVGRE offload, and so on.

Cisco UCS VIC 15422
The optional Cisco UCS VIC 15422 fits the mezzanine slot on the server. A bridge card (UCSX-V5-BRIDGE) extends this VIC’s 2x 50 Gbps of network connections up to the mLOM slot and out through the mLOM’s IFM connectors, bringing the total bandwidth to 100 Gbps per fabric for a total bandwidth of 200 Gbps per server.
Cisco UCS 6500 Series Fabric Interconnect
The Cisco UCS Fabric Interconnects (FIs) provide a single point of connectivity and management for the entire Cisco UCS system. Typically deployed as an active/active pair, the system’s FIs integrate all components into a single, highly available management domain controlled by the Cisco UCS Manager or Cisco Intersight. Cisco UCS FIs provide a single unified fabric for the system, with low-latency, lossless, cut-through switching that supports LAN, SAN, and management traffic using a single set of cables.
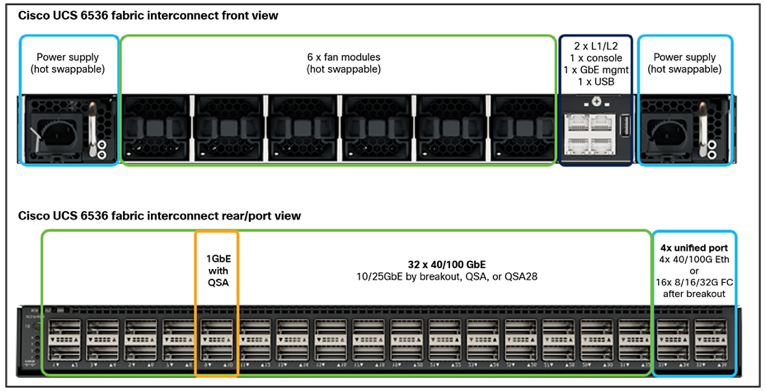
The Cisco UCS 6536 Fabric Interconnect utilized in the current design is a One-Rack-Unit (1RU) 1/10/25/40/100 Gigabit Ethernet, FCoE, and Fibre Channel switch offering up to 7.42 Tbps throughput and up to 36 ports. The switch has 32 40/100-Gbps Ethernet ports and 4 unified ports that can support 40/100-Gbps Ethernet ports or 16 Fiber Channel ports after breakout at 8/16/32-Gbps FC speeds. The 16 FC ports after breakout can operate as an FC uplink or FC storage port. The switch also supports two ports at 1-Gbps speed using QSA, and all 36 ports can breakout for 10- or 25-Gbps Ethernet connectivity. All Ethernet ports can support FCoE.
The Cisco UCS 6536 Fabric Interconnect (FI) is a core part of the Cisco Unified Computing System, providing both network connectivity and management capabilities for the system. The Cisco UCS 6536 Fabric Interconnect offers line-rate, low-latency, lossless 10/25/40/100 Gigabit Ethernet, Fibre Channel, NVMe over Fabric, and Fibre Channel over Ethernet (FCoE) functions.
The Cisco UCS 6536 Fabric Interconnect provides the communication backbone and management connectivity for the Cisco UCS X-Series compute nodes, Cisco UCS X9508 X-Series chassis, Cisco UCS B-Series blade servers, Cisco UCS 5108 B-Series server chassis, and Cisco UCS C-Series rack servers. All servers attached to a Cisco UCS 6536 Fabric Interconnect become part of a single, highly available management domain. In addition, by supporting a unified fabric, Cisco UCS 6536 Fabric Interconnect provides both LAN and SAN connectivity for all servers within its domain.
From a networking perspective, the Cisco UCS 6536 uses a cut-through architecture, supporting deterministic, low-latency, line-rate 10/25/40/100 Gigabit Ethernet ports, a switching capacity of 7.42 Tbps per FI and 14.84 Tbps per unified fabric domain, independent of packet size and enabled services. It enables 1600Gbps bandwidth per X9508 chassis with X9108-IFM-100G in addition to enabling end-to-end 100G ethernet and 200G aggregate bandwidth per X210c compute node. With the X9108-IFM-25G and the IOM 2408, it enables 400Gbps bandwidth per chassis per FI domain. The product family supports Cisco low-latency, lossless 10/25/40/100 Gigabit Ethernet unified network fabric capabilities, which increases the reliability, efficiency, and scalability of Ethernet networks. The Cisco UCS 6536 Fabric Interconnect supports multiple traffic classes over a lossless Ethernet fabric from the server through the fabric interconnect. Significant TCO savings come from the Unified Fabric optimized server design in which network interface cards (NICs), Host Bus Adapters (HBAs), cables, and switches can be consolidated.
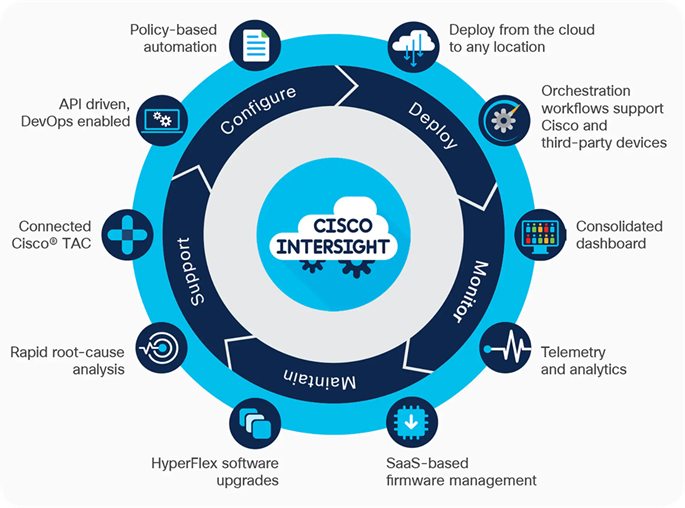
Cisco Intersight is a lifecycle management platform for your infrastructure, regardless of where it resides. In your enterprise data center, at the edge, in remote and branch offices, at retail and industrial sites—all these locations present unique management challenges and have typically required separate tools. Cisco Intersight Software as a Service (SaaS) unifies and simplifies your experience of the Cisco Unified Computing System (Cisco UCS).
As applications and data become more distributed from core data center and edge locations to public clouds, a centralized management platform is essential. IT agility will be struggle without a consolidated view of the infrastructure resources and centralized operations. Cisco Intersight provides a cloud-hosted, management and analytics platform for all Cisco UCS and other supported third-party infrastructure across the globe. It provides an efficient way of deploying, managing, and upgrading infrastructure in the data center, ROBO, edge, and co-location environments.
Cisco Intersight API can help you to programmatically:
● Simplify the way they manage their infrastructure.
● Automate configurations and provision for their data center.
● Save long provisioning time.
Intel Xeon Scalable Processor Family
The Intel® Xeon® Scalable processors come with built-in accelerators and featured technologies that help optimize workload-specific performance, accelerate AI capabilities, reduce data center latency, reduce data bottlenecks, and balance resource consumption. Intel® Accelerator Engines are purpose-built integrated accelerators on Intel® Xeon® Scalable processors that deliver performance and power efficiency advantages across today’s fastest-growing workloads.
Intel Xeon Scalable processors are designed to meet your organization's computing needs whether it is empowering solid foundations for AI innovation and HPC, supporting critical workloads at the edge, or building a secure cloud. They offer optimized performance, scale, and efficiency across a broad range of data center, edge, and workstation workloads.
5th Gen Intel Xeon Scalable Processors
5th Gen Intel Xeon Scalable processors are designed to help boost performance, reduce costs, and improve power efficiency for today’s demanding workloads, enabling you to achieve greater business outcomes.
These processors deliver impressive performance-per-watt gains across all workloads, with higher performance and lower total cost of ownership (TCO) for AI, databases, networking, storage, and high-performance computing (HPC). They offer more compute, larger shared last-level cache, and faster memory at the same power envelope as the previous generation. They are also software- and platform compatible with the 4th Gen Intel Xeon processors, so you can minimize testing and validation when deploying new systems for AI and other workloads.

Some of the key features of 5th Gen Intel Xeon Scalable processors include[1]:
● Built-in AI accelerators on every core, Intel® Advanced Matrix Extensions (Intel®AMX) for a big leap in DL inference and training performance.
● Intel AI software suite of optimized open-source frameworks and tools.
● Out-of-the-box AI performance and E2E productivity with 300+ DL models validated.
● The 5th Gen Intel Xeon processor provides higher core count, better scalability for training and inferencing parallel tasks.
● 5th Gen Intel Xeon processor supports 5600MT/s DDR5 memory speed -16% increase over 4th Gen.
● Boost performance for memory-bound and latency-sensitive workloads with faster memory.
● Up to 320 MB last-level cache shared across all cores — an up to 2.7x increase in last-level cache[2].
Intel Advanced Matrix Extensions (Intel AMX)
Intel Advanced Matrix Extensions (Intel AMX) enables Intel Xeon processors to boost the performance of deep-learning training and inferencing workloads by balancing inference, which is the most prominent use case for a CPU in AI applications, with more capabilities for training. Customers can experience up to 14x better training and inference versus 3rd Gen Intel Xeon processors[3].
Primary benefits of Intel AMX include:
● Improved performance
CPU-based acceleration can improve power and resource utilization efficiencies, giving you better performance for the same price.
For example, 5th Gen Intel Xeon Platinum 8592+ with Intel AMX BF16 has shown up to 10.7x higher real-time speech recognition inference performance (RNN-T) and 7.9x higher performance/watt vs. 3rd Gen Intel Xeon processors with FP32.4.
● Reduced Total Cost of Ownership (TCO)
Intel Xeon processors with Intel AMX enable a range of efficiency improvements that help with decreasing costs, lowering TCO, and advancing sustainability goals.
As an integrated accelerator on Intel Xeon processors, Intel AMX enables you to maximize the investments you have already made and get more from your CPU, removing the cost and complexity typically associated with the addition of a discrete accelerator.
Intel Xeon processors with Intel AMX can also provide a more cost-efficient server architecture compared to other available options, delivering both power and emission reduction benefits.
● Reduced development time
To simplify the process of developing deep-learning applications, Intel works closely with the open-source community, including the TensorFlow and PyTorch projects, to optimize frameworks for Intel hardware, upstreaming Intel’s newest optimizations and features so they are immediately available to developers. This enables you to take advantage of the performance benefits of Intel AMX with minimal code changes, reducing overall development time.
For more information, see: https://www.intel.com/content/www/us/en/products/docs/accelerator-engines/advanced-matrix-extensions/overview.html
Intel OpenVINO
OpenVINO is an open-source toolkit that can be used for optimizing and deploying AI models for video, audio, and text applications. With OpenVINO, developers and data scientists can easily convert and optimize models from popular machine learning frameworks such as PyTorch, TensorFlow, and ONNX, to automatically accelerate inference and deployments across Intel platforms from PC to cloud. The following are some of the key features found in OpenVINO:
● Easy integration with models from popular machine learning frameworks as well as easy extensibility to add new features specific to users’ projects.
● Easy deployment to run inference locally or remotely through the OpenVINO model server.
● Easy scalability that enables a “write once - deploy anywhere” paradigm to enable developers to take advantage of their hardware setup, be it CPU, GPU, or XPU. OpenVINO is optimized to work with Intel hardware.
● Easy integration with Hugging Face models and pipelines.
● Easy model optimization that exposes multiple model compression algorithms that can make AI models smaller and faster.
Intel Neural Compression Framework (NNCF)
NNCF (Neural Network Compression Framework) is a Python package that implements multiple optimization algorithms to make AI models smaller and faster. NNCF enables developers to apply the following types of optimizations to existing models in PyTorch, TensorFlow , ONNX, and OpenVINO IR formats:
● Weight Compression: A technique to increase the efficiency of AI models by reducing their memory footprint through the quantization of model weights only, while keeping activation values unmodified. Weight compression is recommended for use only with LLMs and other GenAI models that require large amounts of memory during inference, such as models larger than one billion parameters.
● Post-training quantization: A quantization technique that doesn't require retraining the model. It utilizes a small subset of the initial dataset to calibrate quantization constants.
● Training-time optimization: In training-time quantization, the compression algorithms are applied during the training process. Since this technique can keep track of the drops in accuracy incurred during training, it provides more control for developers and data scientists to set a minimum acceptable accuracy value for the model.
● NNCF implements Quantization and Filter pruning algorithms, as well as other experimental methods, for training-time optimization. Training-time optimizations typically deliver better results than post-training quantization.
This chapter contains the following:
● Hardware and Software Components
The reference architecture proposed in this solution leverages a Cisco Intersight managed Cisco UCS X-Series X210c M7 node, powered by 5th Generation Intel® Xeon® Scalable 8568Y+ processors with 48 cores to evaluate the performance of a RAG pipeline based on the Llama-3-8B-instruct LLM model. The RAG pipeline is built using the Intel optimization toolkit OpenVINO™ designed to accelerate deep learning model inferencing, and the LangChain framework for RAG applications that use the Llama-3-8B-instruct LLM model and chains together different components, such as prompts, data retrieval, and external tools.
Solution Topology
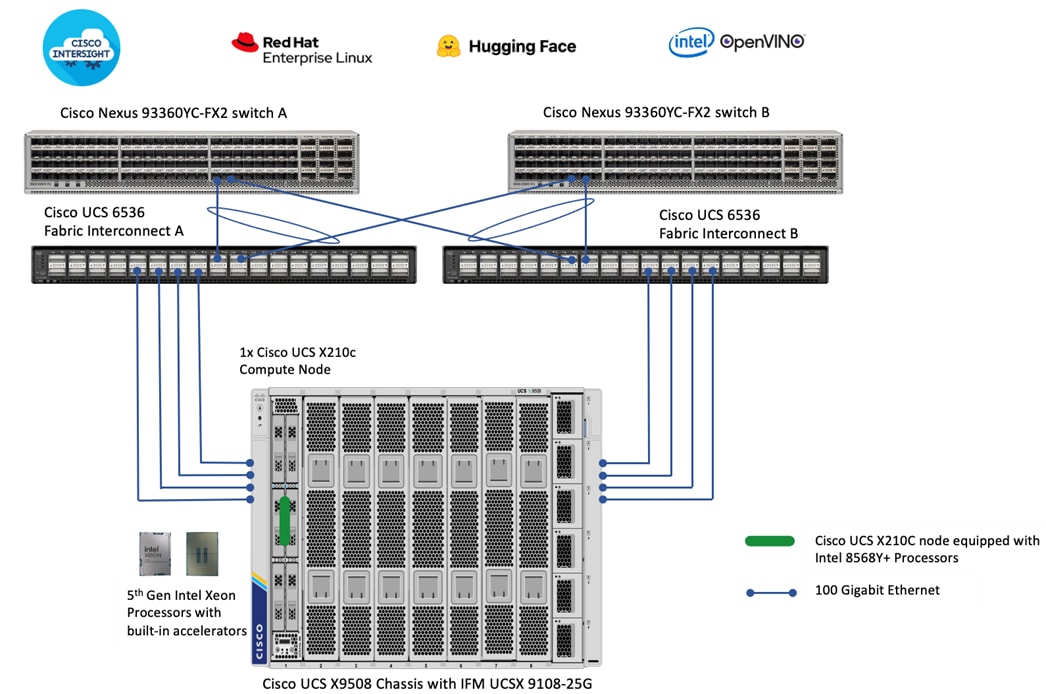
As shown in Figure 9, we leveraged a single Cisco UCS X210c M7 compute node powered by 5th Gen Intel Xeon Scalable processors to demonstrate this solution.
A Cisco UCS 9508 chassis with 1x Cisco UCS X210 M7 node is connected using 100GbE IFM modules to Cisco UCS Fabric Interconnects, deployed in Intersight Managed Mode (IMM). 1 x 100GbE links from each IFM connect are bundled in a port-channel and connected to each Fabric Interconnect to provide an aggregate bandwidth of 200Gbps to the chassis, which can house up to 8 Cisco UCS compute nodes. Cisco Nexus Switches ensure high-bandwidth and lossless communication. Cisco UCS X210 M7 compute node is equipped with a Cisco UCS VIC 15231 that provides 2 x 100GbE ports for 200Gbps of bandwidth from each server to the chassis. Two Cisco Nexus 9000 Series Switches in Cisco NX-OS mode provide top-of-rack switching. The fabric interconnects use multiple 100GbE links to connect to the Nexus switches in a VPC configuration. At least two 100 Gigabit Ethernet ports from each FI, in a port-channel configuration are connected to each Nexus 9000 Series Switch.
Hardware and Software Components
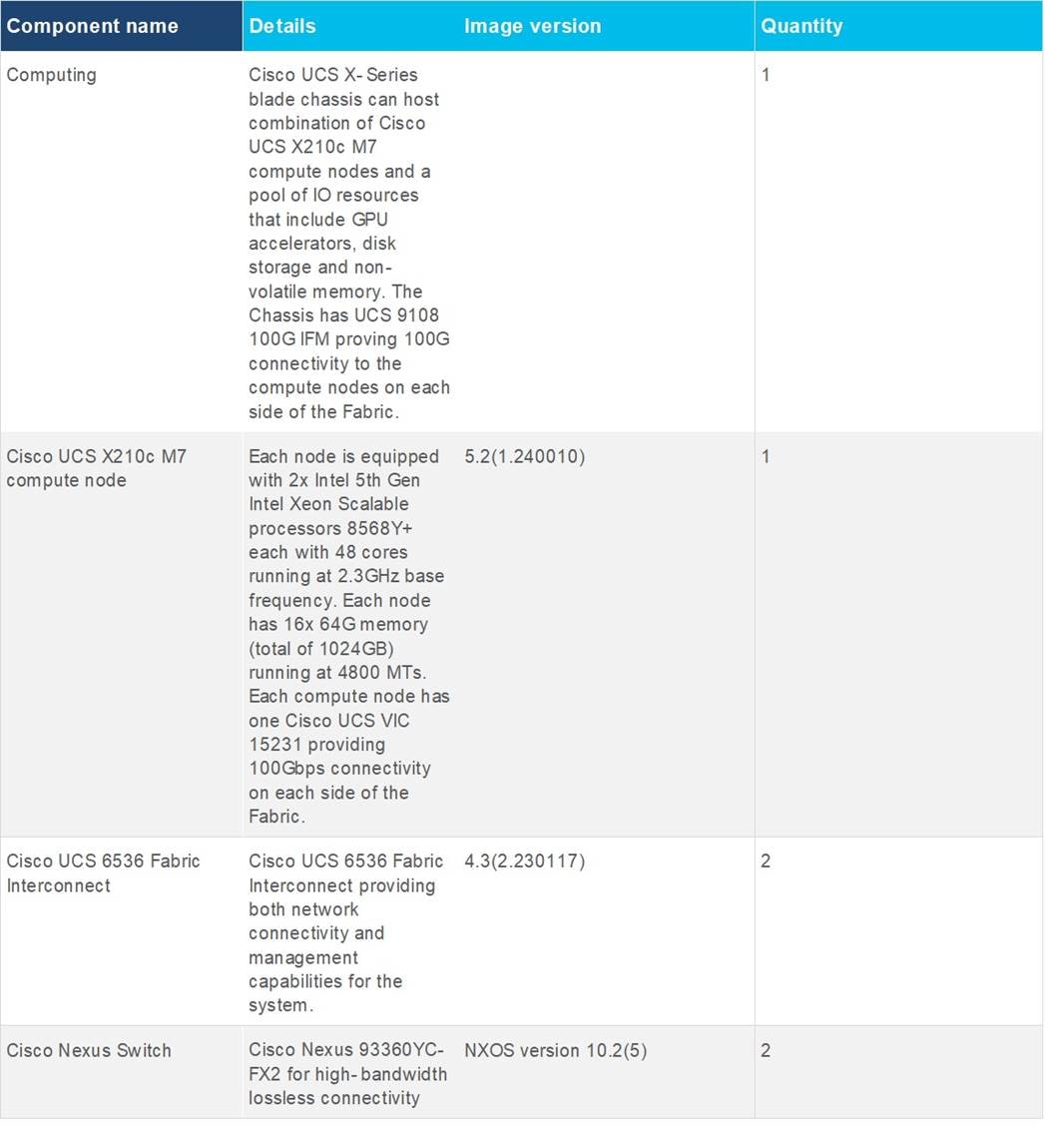
Table 1 lists the details about the hardware and software components used in this solution.
Table 1. Hardware and Software components
This chapter contains the following:
● Configure Cisco UCS X-Series Servers using Cisco Intersight
● Implementation of RAG-enhanced question-answering applications using OpenVINO
● Run Performance Tests on OpenVINO RAG Pipeline
Configure Cisco UCS X-Series Servers using Cisco Intersight
Cisco Intersight Managed Mode is illustrated in Figure 10.
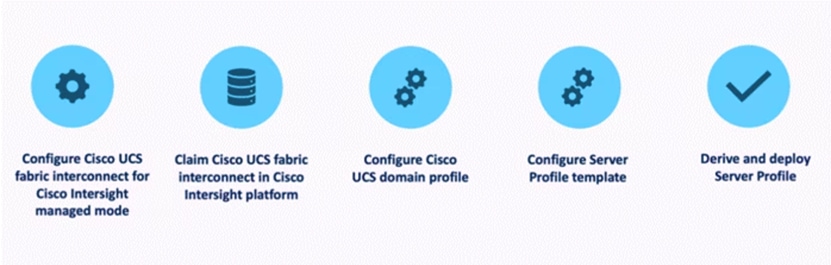
The stages are as follows:
1. Set Up Cisco UCS Fabric Interconnect for Cisco Intersight Managed Mode.
During the initial configuration, for the management mode the configuration wizard enables customers to choose whether to manage the fabric interconnect through Cisco UCS Manager or the Cisco Intersight platform. Customers can switch the management mode for the fabric interconnects between Cisco Intersight and Cisco UCS Manager at any time; however, Cisco UCS FIs must be set up in Intersight Managed Mode (IMM) for configuring the Cisco UCS X-Series system.
2. Claim a Cisco UCS Fabric Interconnect in the Cisco Intersight Platform.
After setting up the Cisco UCS 6536 Fabric Interconnect for Cisco Intersight Managed Mode, FIs can be claimed to a new or an existing Cisco Intersight account. When a Cisco UCS Fabric Interconnect is successfully added to Cisco Intersight, all future configuration steps are completed in the Cisco Intersight portal.
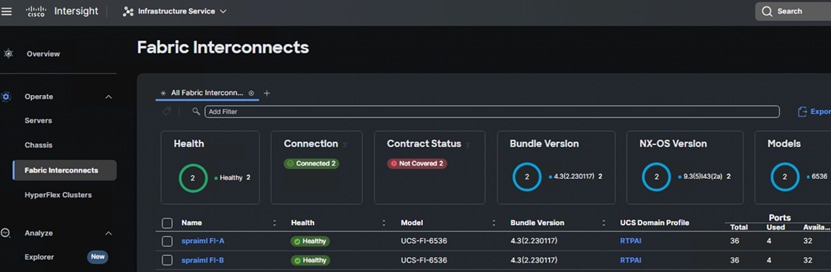
3. You can verify whether a Cisco UCS Fabric Interconnect is in Cisco UCS Manager managed mode or Cisco Intersight Managed Mode by clicking on the fabric interconnect name and looking at the detailed information screen for the FI.
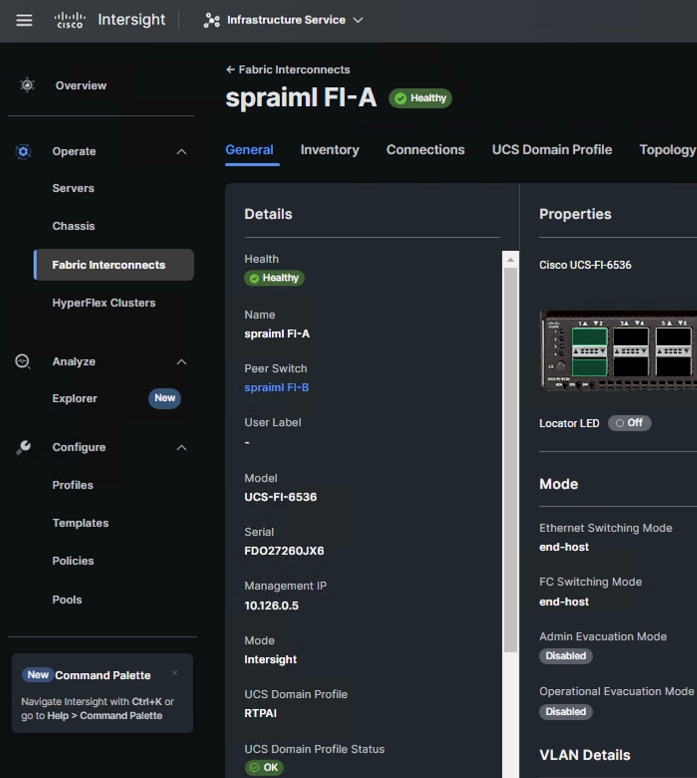
4. Cisco UCS Domain Profile.
A Cisco UCS domain profile configures a fabric interconnect pair through reusable policies, allows configuration of the ports and port channels, and configures the VLANs and VSANs to be used in the network. It defines the characteristics of and configures the ports on the fabric interconnects. One Cisco UCS domain profile can be assigned to one fabric interconnect domain.
Some of the characteristics of the Cisco UCS domain profile are:
● A single domain profile is created for the pair of Cisco UCS fabric interconnects.
● Unique port policies are defined for the two fabric interconnects.
● The VLAN configuration policy is common to the fabric interconnect pair because both fabric interconnects are configured for the same set of VLANs.
● The Network Time Protocol (NTP), network connectivity, and system Quality-of-Service (QoS) policies are common to the fabric interconnect pair.
The Cisco UCS X9508 Chassis and Cisco UCS X210c M7 Compute Nodes are automatically discovered when the ports are successfully configured using the domain profile as shown below:
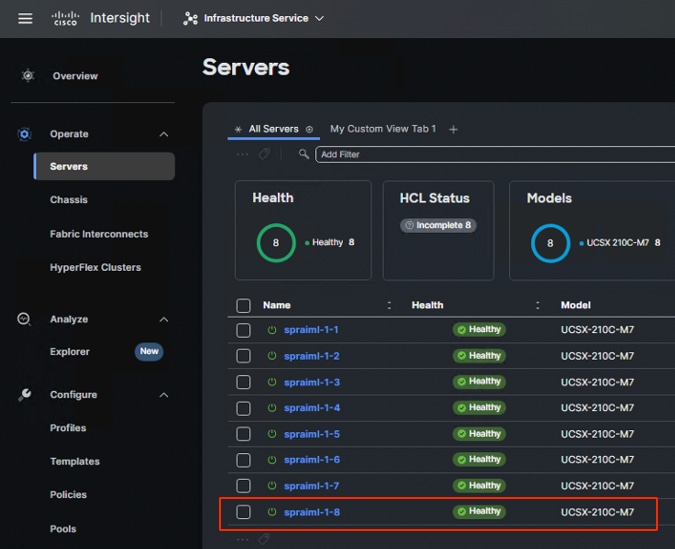
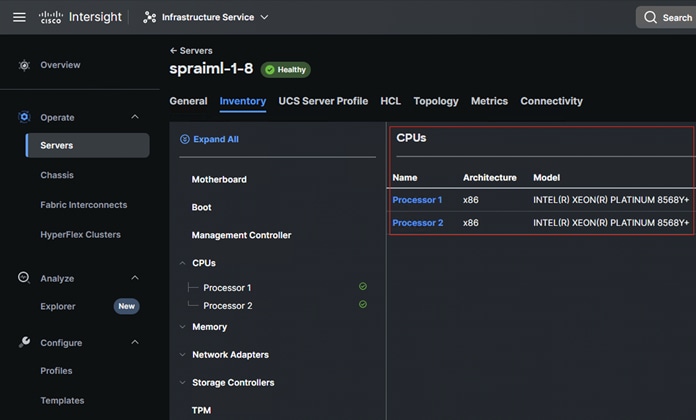
Note: For this solution, Cisco UCS x210c M7 Compute node spraiml-1-8 was used. This node is equipped with Intel Xeon Platinum 8568Y+ processors with 48 cores.

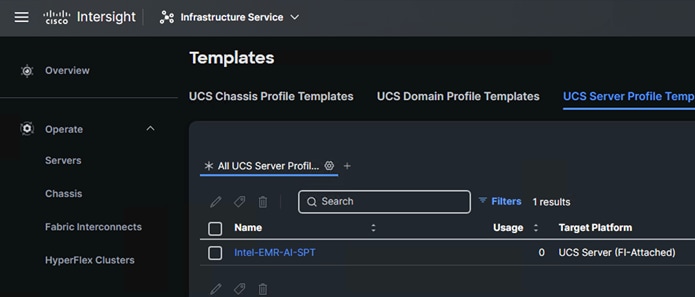
5. Server Profile Template.
A server profile template enables resource management by simplifying policy alignment and server configuration. A server profile template is created using the server profile template wizard.
The server profile template wizard groups the server policies into the following four categories to provide a quick summary view of the policies that are attached to a profile:
● Compute policies: BIOS, boot order, and virtual media policies.
● Network policies: adapter configuration and LAN connectivity. The LAN connectivity policy requires you to create Ethernet network policy, Ethernet adapter policy, and Ethernet QoS policy.
● Storage policies: configuring local storage for application.
● Management policies: device connector, Intelligent Platform Management Interface (IPMI) over LAN, Lightweight Directory Access Protocol (LDAP), local user, network connectivity, Simple Mail Transfer Protocol (SMTP), Simple Network Management Protocol (SNMP), Secure Shell (SSH) and so on.
● Some of the characteristics of the server profile template for our solution are:
● Boot order policy defines virtual media (KVM mapper DVD), local storage and UEFI Shell.
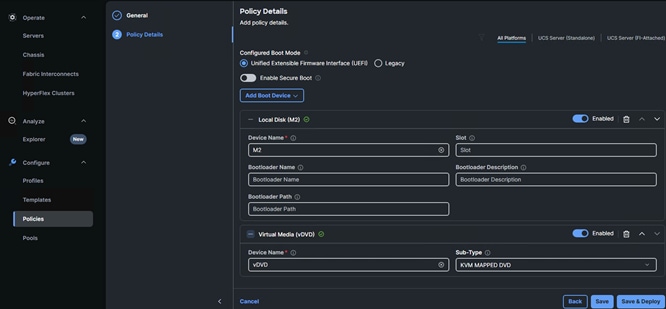
● IMC access policy defines the management IP address pool for KVM access.
● Local user policy is used to enable KVM-based user access.
● LAN connectivity policy is used to create virtual network interface cards (vNICs) — Various policies and pools are also created for the vNIC configuration.
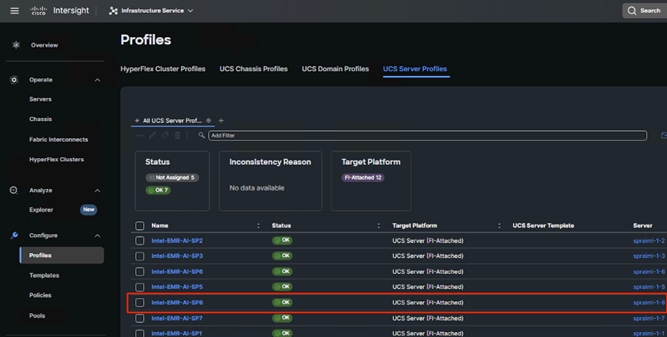
6. Derive and deploy Server Profiles.
Server profiles are derived from server-profile templates and applied on baremetal UCS servers that are claimed in Cisco Intersight. When the server profiles are applied successfully, you can see the profile status as shown in the screenshot below:
7. Once the server profile is successfully applied, you can proceed with Red Hat Enterprise Linux 9.4 installation. You can choose to install RHEL 9.4 OS manually or automatic OS install. For automatic OS install you would need an Advantage license.
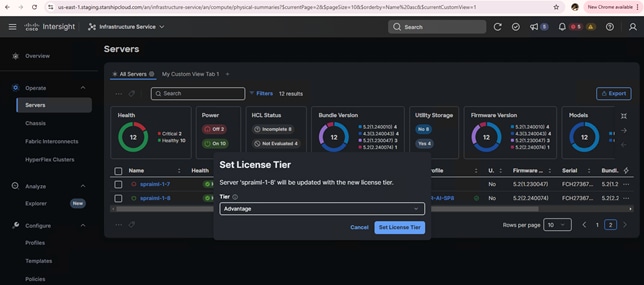
8. Automatic RHEL 9.4 installation using Cisco Intersight.
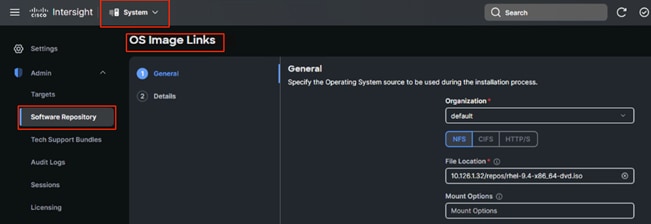
Navigate to the Systems tab > Software Repository > OS Image Links as highlighted in the screenshot. Select the FTP type based the protocol you want to use to share the OS image and SCU image, provide the details as required and click Next.
Note: For more information about the automated OS installation and the type of file shares supported, go to: https://intersight.com/help/saas/resources/adding_OSimage#about_this_task
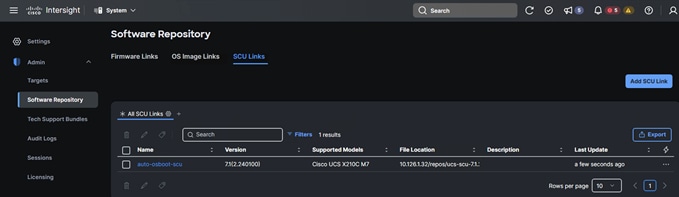
9. Once submitted, the added OS image link displays as shown below. Click SCU Links.
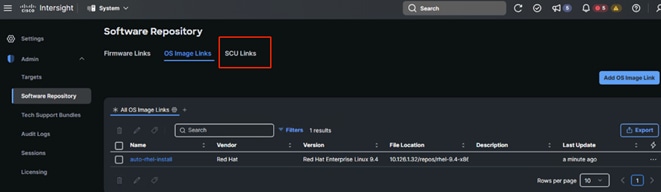
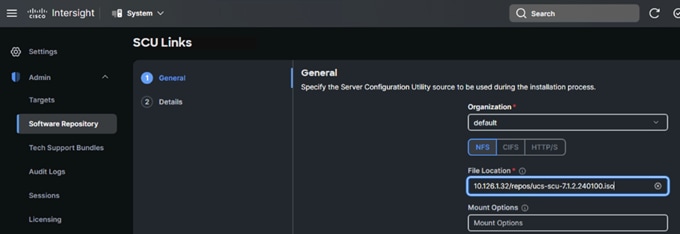
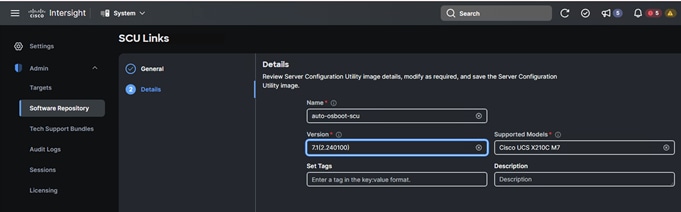
10. Choose the FTP type and location for sharing your SCU image and click Next. You can download the SCU image for the type of server you are using from https://software.cisco.com/download/home. Once submitted, the added SCU link displays as shown in the screenshot below:
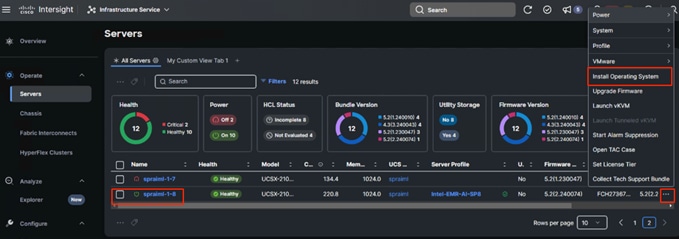
11. To install RHEL 9.4, right-click on the server and click Install Operating System as shown below:
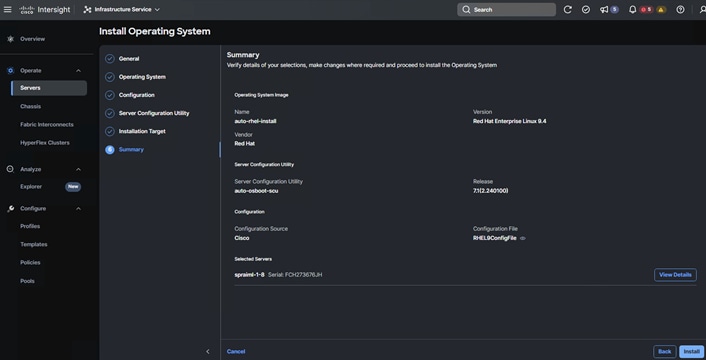
12. Upon clicking Install Operating System, a wizard opens. Ensure the desired server is selected, click Next and complete the wizard navigation by entering all the details as shown in the following screenshots:
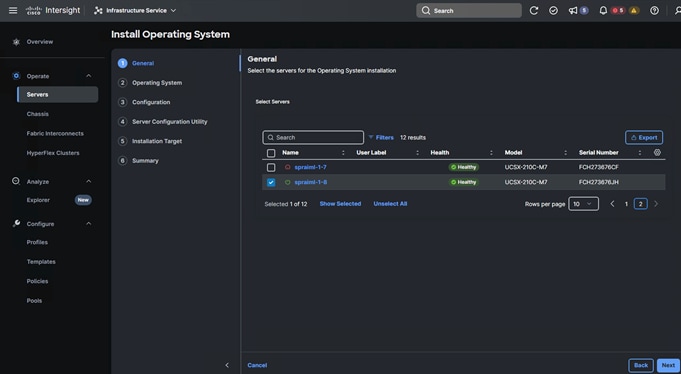
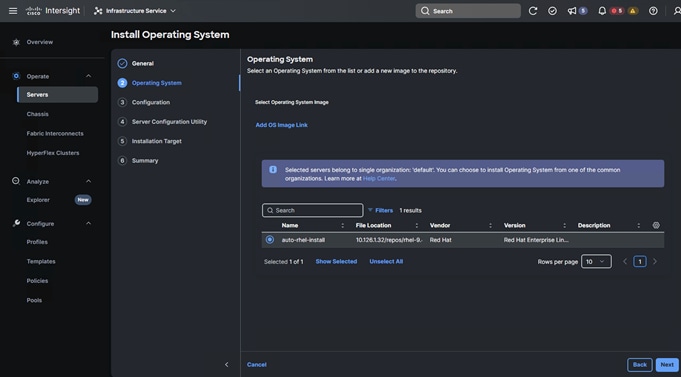
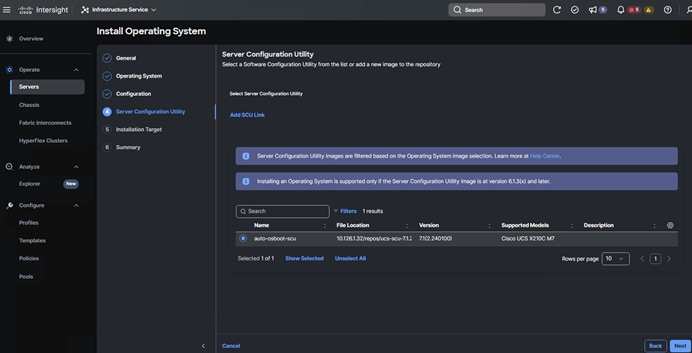
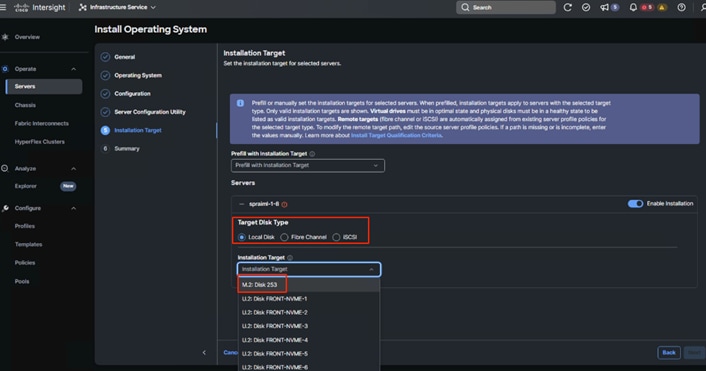
13. Review the Install summary and click Install to complete the automatic RHEL 9.4 installation.
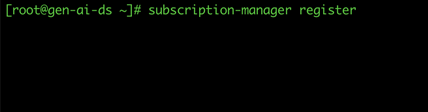
14. Once the installation is complete, ensure you can ssh into the node and then register the node using subscription-manager register command.
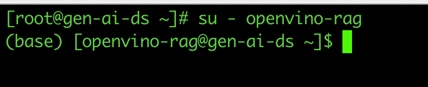
15. Once the node is available for post OS installation procedure, create a new user. For this solution we created openvino-rag as the user.
16. Create a conda environment to keep the packages required for the OpenVINO based RAG deployment together without tampering into the RHEL 9.4 auto installed software package versions.
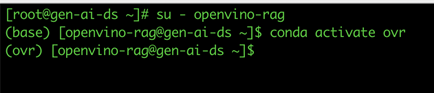
To create a conda environment, refer to Miniconda here: https://docs.anaconda.com/miniconda/
Implementation of RAG-enhanced question-answering applications using OpenVINO
A question-answering RAG pipeline is implemented in this solution to highlight the capabilities of OpenVINO to seamlessly speedup the execution of Generative AI workloads on Intel Xeon processors.
To demonstrate the power of OpenVINO for model optimization, the Llama-3-8B instruct pre-trained model from the Hugging Face Transformers library is used. To simplify the user experience, the Hugging Face Optimum Intel library is used to convert the models to OpenVINO™ IR format and the Langchain framework is used to create the inference pipeline depicted in Figure 11. The RAG pipeline consists of the following main components: A vector database, an embedding model, a large language model, and a reranker . OpenVINO is used to optimize the embeddings and LLM performance.
Figure 11 presents a diagram of the question-answering RAG pipeline implemented in this solution where users submit queries, and an answer is extracted from a set of documents previously stored in a vector database.
Firstly, when the user submits a query, the system computes its embedding and uses it to extract an initial set of the top_k[1] most relevant documents that may contain the answer to the question from a vector database. This process is done through a similarity search of the query against the documents stored in the vector database. The vector database may contain millions of records of unstructured or semi-structured data. Next, the list of the top_k documents is further refined through a re-ranking process that selects a set of the top_n[2] documents most relevant to the query from the list of top_k documents. Finally, the LLM is prompted to effectively answer the question received from the user based on the content found on the top N documents selected during the re-ranking process.
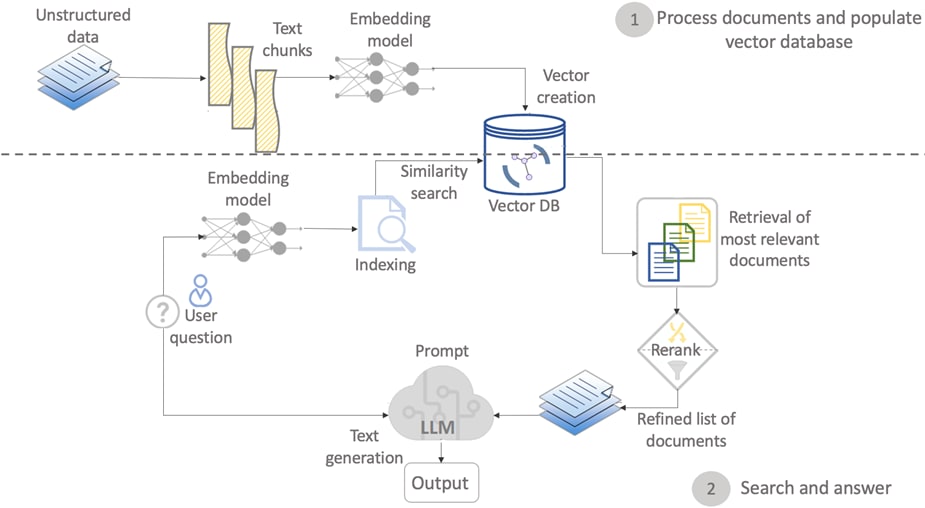
See the Appendix for the complete Python code samples used to implement a RAG pipeline similar to the one presented in Figure 11. At a high level, using OpenVINO for the implementation of a question-answering RAG pipelines based on HuggingFace, Langchain, and Qdrant requires the completion of the following steps:
Step 1. (Optional) Create a Python virtual environment with Conda or the python venv module to avoid any potential conflicts with other libraries. For example, the following instruction uses the venv module to create a Python virtual environment named openvino_env:
python -m venv openvino_env
Step 2. Install the OpenVINO runtime and verify it’s correctly installed. Similarly, install HuggingFace, Torch, NNCF, Langchain, optimum, and any other dependencies required for your application.
openvino_env\Scripts\activate
pip install openvino nncf optimum langchain_community …
Step 3. Download the LLM model you want to use for text generation in its original format. For example, the following command uses the huggingface-cli tool to download the Llama-3-8B-Instruct:
huggingface-cli download meta-llama/Meta-Llama-3-8B-Instruct
Step 4. (Optional) Convert models from Hugging Face to the OpenVINO IR format and use Optimum Intel to perform model optimization through weight compression using NNCF. The optimum-cli tool enables users to easily perform post-training model optimization on HuggingFace LLM models by applying 8-bit or 4-bit weight compression using NNCF. OpenVINO’s model compression features significantly improve the model’s memory requirements and inference latency with a minimal impact in accuracy. The compressed models can easily be used with the OpenVINO tools and libraries.
For instance, the following bash command creates an 8-bit compressed version of the Llama-3-8B-Instruct model and stores it into a directory named ov_llama3_8b:
optimum-cli export openvino --model meta-llama/Meta-Llama-3-8B-Instruct -- weight-format int8 ov_llama3_8b
Step 5. Create the Python dictionaries with the respective OpenVINO configurations for Embeddings and LLM. The preferred way to configure performance in the OpenVINO Runtime is using performance hints. Settings such as the number of execution streams, cache directory, dynamic quantization options, and whether the execution should be optimized for latency or throughput can be specified in a configuration dictionary. For example, the following Python instruction creates a dictionary with configurations optimized for low latency, one stream, and cache directory named .cache that could be used for both Embeddings and LLM:
ov_config = {"PERFORMANCE_HINT": "LATENCY", "NUM_STREAMS": "1", "CACHE_DIR": ".cache"}
Step 6. Load the LLM model using the OVModelForCasualLM class from the Optimum Intel library, and provide its configuration dictionary, along with any other additional settings, such as the preferred device to run the LLM model. The following Python instruction is an example of how to load an LLM model from a directory named ov_llama3_8b and with the configurations stored in a Python dictionary named ov_config. It also specifies that the LLM model will be run on the CPU of the system.
model = OVModelForCausalLM.from_pretrained(ov_llama3_8b, device=”CPU”, ov_config=ov_config, export=True)
Step 7. Load the Tokenizer from the LLM model that is going to be used for text generation. For instance, the following Python instruction creates a tokenizer object from the directory named ov_llama3_8b.
tokenizer = AutoTokenizer.from_pretrained(ov_llama3_8b)
Step 8. Create a Python dictionary with the appropriate settings for text-generation on Langchain, including the OpenVINO model and the tokenizer, as well as other additional settings such as the maximum number of tokens allowed for each text generation request, and the text generation strategy (example: bean search, sampling, greedy search, etc.).
generate_kwargs = dict(model=ov_model, tokenizer=tok, max_new_tokens=256, streamer=streamer, )
pipe = pipeline("text-generation", **generate_kwargs)
llm = HuggingFacePipeline(pipeline=pipe)
Step 9. Load the embeddings model and provide its configuration dictionary. The embeddings model must be the same that was used during the population of the vector database. In RAG-based question answering systems the embeddings model is used to perform a similarity search between the question and the possible documents previously stored in the vector database that may contain the answer to the question. The following Python instructions shows how to load the embeddings model using its name or the name of a directory where it was previously saved.
embeddings = OpenVINOEmbeddings( model_name_or_path=model_dir )
Step 10. Setup an instance of the vector database to access the documents previously stored and use it to create a retriever responsible for finding the top_k most relevant documents to the user query in the vector database (top_k is a positive integer). The following Python instructions create an instance of an ephemeral Qdrant vector database that resides in memory, stores all the texts from the list of Langchain documents docs into a collection named my_documents, uses embeddings model to compute 768-dimensional embeddings of the texts, and that is then configured as a document retriever that uses the dot product of vectors to compute their distance:
qdrant = Qdrant.from_documents(
docs,
embeddings,
location=":memory:",
collection_name="my_documents",
embedding_dim=768,
similarity="dot_product",
recreate_index=True )
retriever = vectordb.as_retriever(search_kwargs={"k": top_k})
Step 11. Create a HuggingFace cross-encoder (re-ranker) that uses a model to further refine the initial list of top_k documents retrieved from the vector database. The following three Python instructions show how a re-ranker that is attached to a retriever can be created. The reranker is configured to return the top_n documents most relevant to the user’s query from a list of the top_k most relevant documents returned by the retriever.
reranker_model = HuggingFaceCrossEncoder(model_name=<cross_encoder_model_id>)
reranker = CrossEncoderReranker(model=reranker_model, top_n=args.topN_retriever_docs)
reranking_retriever = ContextualCompressionRetriever( base_compressor=reranker, base_retriever=retriever)
Step 12. Create a HuggingFace text generation pipeline and create a Langchain retrieval chain that connects the inputs and outputs of the LLM model, the tokenizer, the retriever, the re-ranker, and the vector database in a way that effectively results in an answer to the query submitted by the user.
chain_type_kwargs = {"prompt": QA_CHAIN_PROMPT}
rag_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=reranking_retriever,
chain_type_kwargs=chain_type_kwargs,
)
Step 13. Invoke the Langchain retrieval chain using the user’s query. For instance, the following instruction shows how to run the Langchain chain using a query q as the input.
rag_chain.run(q)
Run Performance Tests on OpenVINO RAG Pipeline
The repository used for this solution contains an implementation of a question-answering RAG pipeline, designed to showcase how OpenVINO accelerates the execution of generative AI workloads on Intel® Xeon® processors.
For the first time when an LLM model or an embedding model is used, the script downloads the model from the huggingface hub. In addition, when the precision parameter is specified, the script will check whether the compressed model already exists. If it does not exist, then it will automatically create the compressed model before running the pipeline.
During the execution of the pipeline, the Questions and Answers along with all the relevant documents selected from the vector DB are printed (if the *-\-print* parameter is set to *yes*). After the execution of the pipeline, additional execution details are printed, including the time-to-first-token (TTFT), second-token latencies (TPOT), and number of tokens generated for each QA session. The tests run close to 2 hours as it is retrieving and processing large amounts of textual data to answer the questions.
The data extraction to querying process follows this procedure:
● Data Extraction from Wikipedia: Over 300,000 articles were extracted from an XML dump of the English-language Wikipedia. This XML dump contains the full content of Wikipedia articles.
● Converting Articles into text files: These extracted articles are converted into 1MB plain text files. Each file contains:
◦ Article titles
◦ Main content (the body of the article)
◦ Some basic metadata (such as publication date, author, or categories)
● Text segmentation with Langchain: Using Langchain’s text splitters, the 1MB plain text files are split into over one million smaller segments, usually referred to as text chunks. Each chunk preserves the meaning (semantic content) of the original text, so even when split, the smaller pieces still make sense on their own.
● Storing in the Qdrant vector database: These text chunks are then stored in a Qdrant vector database. Qdrant is a database designed for efficiently searching and retrieving text or data based on similarity (such as finding relevant information for a query).
● Query processing and latency measurement: Finally, multiple queries are submitted to the RAG pipeline, which processes the query by retrieving relevant text chunks from the database and using them to generate an answer. The time it takes for the system to process these queries and generate responses (called token latencies) was measured to assess the performance of the system.
A sample Python code that implements a RAG-based question-answering pipeline is similar to the one presented in Figure 11 is provided in the Appendix. To run the sample code, some Python modules need to be installed. The code presented in the Appendix provides a way for readers to explore the benefits of RAG pipelines and the AI acceleration features provided by the OpenVINO toolkit to accelerate generative AI workloads.
Note: This sample code is not intended to be run on production systems as is, as it may contain references to older versions of Python modules that may have included additional optimizations in later releases.
To run a set of performance tests for RAG pipelines using OpenVINO toolkit, follow these steps:
Step 1. Clone the OpenVINO GenAI repository: https://github.com/openvinotoolkit/openvino.genai/
Step 2. Create a folder with all the sample python files and the requirements.txt file provided in the Appendix.
Note: These python files are used for running performance tests on the OpenVINO toolkit based RAG deployment. These sample Python files are based on the OpenVINO Notebook example.
Step 3. To run the tests on your system you'll need to install the Python modules listed on the requirements.txt file included in the Appendix using the following command:
pip install --no-cache-dir --extra-index-url https://download.pytorch.org/whl/cpu -r requirements.txt
Step 4. To run the benchmark script, run the command:
python benchmark-OV_noOV.py -p INT8 -l llama-3-8b-instruct -e all-mpnet-base-v2 --dataset_path /home/openvino-rag/ov-rag/rag-wikipedia/raw_data -ds qdrant --hooks yes -f OV
The workload parameters definition is as follows:
● **-\-dataset_path:** Path to the input dataset directory that will be stored in the Vector DB. The input dataset is expected to be a set of *.txt* files.
● **-f:** Deep learning framework to use. Can be *OV* for OpenVINO or *PT* for Pytorch.
● **-p:** Model precision to use when running with *OpenVINO*. Can be one of *BFloat16*, *INT8*, or *INT4*.
● **-l:** LLM model to use. Currently the following values are supported: *llama-3-8b-instruct* and *llama-2-chat-7b*.
● **-e:** Embeddings model to use during the population and querying of the vector DB. Currently the following values are supported:* all-mpnet-base-v2*, *text2vec-large-chinese*, and*bge-large-en-v1.5*.
● **-ds:** Type of vector DB to use in the tests. Currently the following values are supported: *qdrant* and *chromadb*.
● **-k:** Top *k* documents to select from the vector DB that are relevant to the question being asked. The default value is 10.
● **-n:** Top *n* documents to select by the reranker. The default value is 3.
● **-\-print:** Whether to print the *top k* and *top n* documents selected from the vector DB. Can be either *yes* or *no*. The default value is *yes*.
● **-\-hooks:** Whether to print the token latencies after running the workload. Can be either *yes* or *no*. The default value is *no*.
Step 5. You can run the above command for INT8, INT4 and BFloat16 precisions.
Note: We restricted our tests for various precisions (INT8, INT4 and BFloat16) and fixed the other parameters like vector DB to “qdrant”, embeddings to “all-mpnet-base-v2”, LLM model to “llama-3-8b-instruct” and Deep learning framework to “OV” (OpenVINO).
Step 6. To compare the performance of BFloat16 with Pytorch “PT” as the deep learning framework vs OpenVINO “OV”, the benchmark script is run as follows:
python benchmark-OV_noOV.py -l llama-3-8b-instruct -e all-mpnet-base-v2 --dataset_path /home/openvino-rag/ov-rag/test_wikidump_data/800 -ds qdrant --hooks yes -f PT
python benchmark-OV_noOV.py -l llama-3-8b-instruct -e all-mpnet-base-v2 --dataset_path /home/openvino-rag/ov-rag/test_wikidump_data/800 -ds qdrant --hooks yes -f OV
OpenVINO RAG Performance Validation
To evaluate the optimizations provided by OpenVINO, we used Langchain to implement the RAG question answering pipeline depicted in Figure 11. This pipeline leverages the Llama3-8B-instruct language model to generate human-like responses based on documents retrieved from a Qdrant vector database. The integration of OpenVINO in this application is inspired by the LLM Chatbot Demo notebook developed by the OpenVINO team (https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/notebooks/llm-chatbot/llm-chatbot.ipynb).
To populate the vector database, we extracted over 300,000 articles from an XML dump of the English-language Wikipedia database. These articles were then converted into multiple 1MB plain text files, containing only the articles' titles, main content, and some basic metadata. Using Langchain’s text splitters, we created more than one million semantic preserving text segments, also called text chunks, from 1MB plain text files and stored them in the Qdrant vector database. We then submitted multiple queries to be processed by the RAG pipeline and measured the token latencies.
The following are some of the important parameters (limited to those used in assessing performance test results):
● TTFT (Time to First Token): Time to start generating a response (first token) after receiving a query.
● TPOT (Time per Output Token): Time to generate each subsequent token after the first. Also called inter-token latency.
● Latency: Total time delay from query submission to the full response being generated (includes TTFT and TPOT). Latency = TTFT + (TPOT) * (the number of tokens to be generated)
● Throughput: The number of queries or tokens the system can process per unit of time, indicating scalability and efficiency.
For chatbot question-answering systems, achieving low latency and TPOT while maintaining high throughput ensures both fast and efficient performance, which is crucial for providing a seamless and responsive user experience.
Figure 12 shows the inter-token latencies (TPOT) obtained from running a question answering RAG pipeline with OpenVINO using 8-bit and 4-bit weight compression compared to a non-compressed model. The inter-token latency measures the average time between consecutive tokens being generated and it’s typically required to be less than 0.2 seconds based on the average English reading speed of 200 words per minute. In our tests, the average inter-token latency is less than 0.07 seconds when an uncompressed model is used with OpenVINO. That is a significantly better value than the typically required inter-token latency. Furthermore, the test results show that by using Optimum Intel to apply weight compression, a speedup of 1.4x can be obtained when using INT8 compared to an uncompressed model. Furthermore, INT4 weight compression provides an additional 1.3x performance boost compared to INT8. Thus, a total of 1.8x speedup can be obtained when using INT4 weight compression compared to an uncompressed model using OpenVINO.

Even though in the results presented in Figure 12, the BFloat16 model is not using any weight-compression techniques, it still uses other optimizations provided by OpenVINO that take full advantage of the Intel 5th Gen Xeon Scalable processor features to accelerate AI applications. These optimizations make the OpenVINO model give — even before applying any weight compression techniques — a performance boost of 3x compared to the stock Pytorch model, see Figure 13.
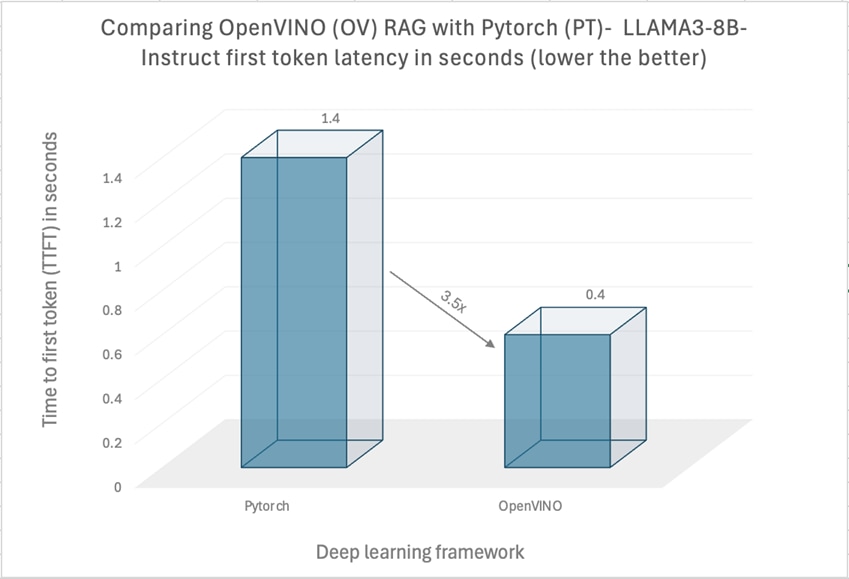
We also measured the average TTFT latency which is the time taken by the model to generate the first token. It is an important metric, especially in interactive applications, because a lower first token latency leads to a better user experience by making interactions feel more immediate and natural. In general, a first token latency of less than 2 seconds is considered acceptable. In our tests the average TTFT was always less than or equal to 0.4 seconds when using OpenVINO. In contrast, using the stock Pytorch model resulted in an average TTFT of 1.4 seconds, hence showing a 3.5x performance boost in TTFT when using OpenVINO as presented in Figure 13. These results show that by leveraging OpenVINO’s LLM inference optimization features, along with NNCF and Optimum Intel, users can obtain a total of more than 3.5x speedup in TTFT latency for a question answering RAG pipeline compared to stock Pytorch.
In addition to improving the token latencies, OpenVINO also enables you to gain significant performance boost when populating a vector database using the OpenVINOEmbeddings class.
This solution demonstrates the deployment of a complex RAG pipeline on a single Cisco UCS X-Series node powered by 5th Gen Intel® Xeon® processors. By utilizing OpenVINO’s advanced optimizations, including the Intel NNCF for weight compression, organizations can further boost the speed and efficiency of AI applications on Intel AMX-accelerated Intel Xeon Scalable Processors.
This architecture can seamlessly execute AI-driven chatbot applications alongside both traditional and modern workloads within the same Cisco UCS X-Series modular chassis, delivering outstanding performance, scalability, and efficiency. Cisco UCS X-Series stands out as an ideal platform for handling diverse, high-demand workloads without compromise.
This solution supports the deployment of AI models across various environments—on-premise or at the edge—while leveraging CPU-based inferencing for optimized performance. By utilizing Intel® Xeon® Scalable processors, the solution ensures that businesses can efficiently run AI-driven workloads with high-performance capabilities, meeting the demands of next-generation AI applications. The use of CPU-based inferencing provides several advantages, including lower operational costs compared to GPU-based solutions, simplified infrastructure management, and a more cost-effective approach for a wide range of AI applications. Intel AMX powered Processors on Cisco UCS infrastructure enables organizations to optimize their AI operations while ensuring scalability, reliability, and cost-efficiency. With the flexibility to scale based on workload requirements and the ability to deploy on existing infrastructure, this solution offers a practical, high-performance option for businesses seeking to drive AI innovation while maintaining cost control.
Sindhu Sudhir, Technical Marketing Engineer, Cisco Systems, Inc.
Sindhu is a Technical Marketing Engineer at Cisco, specializing in UCS data center solutions. Her expertise revolves around software-defined architectures, particularly with a focus on container-based solutions. Sindhu possesses a strong passion for open-source technologies, cloud-native solutions, and infrastructure automation for the Cisco UCS platform.
Abirami Prabhakaran, Principal Engineer, Intel Corporation
Abirami (Abi) Prabhakaran is currently focusing on delivering optimized Enterprise AI reference architectures with OEMs. Working across Intel and with OEM/ISV partners, she defines and delivers Xeon solutions for Enterprise AI, optimizing performance across use-cases on a distributed HW/SW stack. Abi holds a master’s degree in computer engineering from George Mason University, Virginia.
Rodrigo Escobar, Cloud Systems and Solutions Engineer - AI Software Performance Tech Lead, Intel Corporation
Rodrigo Escobar, Ph.D., is a Systems and Cloud Solutions Engineer and AI Systems Performance Tech Lead in Intel’s Data Center and AI (DCAI) organization where he works with industry partners to fine-tune workloads and enhance overall system performance. His interests are in the area of industry standard benchmarks, performance analysis and optimization of AI and large-scale data analytics applications. Rodrigo is an active member of the Transaction Processing Performance Council (TPC) and serves as the Chairman of the data analytics TPCx-BB benchmark.
Acknowledgements
For their support and contribution to the design, validation and review of this Cisco Validated Design, the authors would like to thank:
● Babu Mahadevan, Cisco Systems, Inc.
● Mishali Naik, Intel Corporation
● Sankalp Ramanujam, Intel Corporation
For more information about Cisco UCS X-Series modular system, Cisco Intersight, Intel AMX and OpenVINO GenAI repository, go to the following links:
● Cisco UCS X- Series modular system: https://www.cisco.com/c/en/us/products/collateral/servers-unified-computing/ucs-x-series-modular-system/solution-overview-c22-2432175.html?ccid=cc002456&oid=sowcsm025665
● Cisco Intersight configuration: https://www.cisco.com/c/en/us/td/docs/unified_computing/Intersight/b_Intersight_Managed_Mode_Configuration_Guide.html
● Intel AMX: https://www.intel.com/content/www/us/en/products/docs/accelerator-engines/what-is-intel-amx.html
● OpenVINO GenAI repository: https://github.com/openvinotoolkit/openvino.genai/
● LLM chatbot demo notebook example: https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/notebooks/llm-chatbot/llm-chatbot.ipynb
This appendix provides all the sample python files required for implementing RAG model using OpenVINO and running performance validations as mentioned in the sections Implementation of RAG-enhanced question-answering applications using OpenVINO and Run Performance Tests on OpenVINO RAG Pipeline. Code samples provided here is not intended to be run on production systems as is, as it may contain references to older versions of Python modules that may have included additional optimizations in later releases.
To implement RAG-enhanced Q&A with OpenVINO and run performance tests, you need to install the required Python modules listed on the requirements.txt file. The sample requirements file used for this solution is:
### requirements.txt
about-time==4.2.1
accelerate==1.1.1
aiohttp==3.9.3
aiosignal==1.3.1
alive-progress==3.1.5
annotated-types==0.6.0
anyio==4.3.0
appdirs==1.4.4
argon2-cffi==23.1.0
argon2-cffi-bindings==21.2.0
arrow==1.3.0
asgiref==3.8.1
asttokens==2.4.1
async-lru==2.0.4
async-timeout==4.0.3
attrs==23.2.0
autograd==1.7.0
Babel==2.15.0
backoff==2.2.1
bcrypt==4.1.2
beautifulsoup4==4.12.3
bert-score==0.3.13
bleach==6.1.0
build==1.1.1
cachetools==5.3.3
certifi==2024.2.2
cffi==1.16.0
chardet==5.2.0
charset-normalizer==3.3.2
chroma-hnswlib==0.7.6
chromadb==0.5.20
click==8.1.7
cma==3.2.2
coloredlogs==15.0.1
comm==0.2.2
contourpy==1.3.1
cryptography==42.0.5
cycler==0.12.1
dataclasses-json==0.6.4
dataclasses-json-speakeasy==0.5.11
datasets==3.1.0
debugpy==1.8.1
decorator==5.1.1
defusedxml==0.7.1
Deprecated==1.2.14
diffusers==0.31.0
dill==0.3.8
diskcache==5.6.3
distro==1.9.0
emoji==2.10.1
exceptiongroup==1.2.0
executing==2.0.1
faiss-cpu==1.9.0
fastapi==0.110.0
fastjsonschema==2.19.1
feedparser==6.0.11
filelock==3.13.1
filetype==1.2.0
FlashRank==0.2.9
flatbuffers==24.3.25
fonttools==4.50.0
fqdn==1.5.1
frozenlist==1.4.1
fsspec==2024.2.0
future==1.0.0
google-auth==2.29.0
googleapis-common-protos==1.63.0
grapheme==0.6.0
greenlet==3.0.3
grpcio==1.62.1
grpcio-tools==1.62.1
h11==0.14.0
h2==4.1.0
hpack==4.0.0
httpcore==1.0.4
httptools==0.6.1
httpx==0.27.0
huggingface-hub==0.25.1
humanfriendly==10.0
hyperframe==6.0.1
idna==3.6
importlib-metadata==6.11.0
importlib_resources==6.4.0
ipykernel==6.29.4
ipython==8.22.2
ipywidgets==8.1.2
iso8601==2.1.0
isoduration==20.11.0
jedi==0.19.1
Jinja2==3.1.3
joblib==1.3.2
json5==0.9.25
jsonpatch==1.33
jsonpath-python==1.0.6
jsonpointer==2.4
jsonschema==4.21.1
jsonschema-specifications==2023.12.1
jstyleson==0.0.2
jupyter-events==0.10.0
jupyter-lsp==2.2.5
jupyter_client==8.6.1
jupyter_core==5.7.2
jupyter_server==2.14.0
jupyter_server_terminals==0.5.3
jupyterlab==4.2.1
jupyterlab_pygments==0.3.0
jupyterlab_server==2.27.2
jupyterlab_widgets==3.0.10
kiwisolver==1.4.5
kubernetes==29.0.0
langchain==0.3.7
langchain-community==0.3.7
langchain-core==0.3.19
langchain-openai==0.2.9
langchain-text-splitters==0.3.2
langchainhub==0.1.21
langdetect==1.0.9
langsmith==0.1.125
llama_cpp_python==0.2.67
lxml==5.1.0
markdown-it-py==3.0.0
MarkupSafe==2.1.5
marshmallow==3.20.2
matplotlib==3.8.3
matplotlib-inline==0.1.6
mdurl==0.1.2
mistune==3.0.2
mmh3==4.1.0
monotonic==1.6
mpmath==1.3.0
multidict==6.0.5
multiprocess==0.70.16
mypy-extensions==1.0.0
natsort==8.4.0
nbclient==0.10.0
nbconvert==7.16.3
nbformat==5.10.3
nest-asyncio==1.6.0
networkx==3.1
ninja==1.10.2.4
nltk==3.8.1
nncf==2.9.0
notebook==7.2.0
notebook_shim==0.2.4
numpy==1.26.4
oauthlib==3.2.2
onnx==1.15.0
onnxruntime==1.17.1
openai==1.54.4
opentelemetry-api==1.23.0
opentelemetry-exporter-otlp-proto-common==1.23.0
opentelemetry-exporter-otlp-proto-grpc==1.23.0
opentelemetry-instrumentation==0.44b0
opentelemetry-instrumentation-asgi==0.44b0
opentelemetry-instrumentation-fastapi==0.44b0
opentelemetry-proto==1.23.0
opentelemetry-sdk==1.23.0
opentelemetry-semantic-conventions==0.44b0
opentelemetry-util-http==0.44b0
openvino==2024.4.0
openvino-telemetry==2024.1.0
optimum==1.23.3
optimum-intel==1.20.1
orjson==3.9.15
overrides==7.7.0
packaging==23.2
pandas==2.1.4
pandocfilters==1.5.1
parso==0.8.3
pdfminer.six==20231228
pexpect==4.9.0
pillow==10.2.0
platformdirs==4.2.0
portalocker==2.8.2
posthog==3.5.0
prometheus_client==0.20.0
prompt-toolkit==3.0.43
protobuf==4.25.3
psutil==5.9.8
ptyprocess==0.7.0
pulsar-client==3.4.0
pure-eval==0.2.2
pyarrow==15.0.2
pyarrow-hotfix==0.6
pyasn1==0.5.1
pyasn1-modules==0.3.0
pycparser==2.21
pydantic==2.9.2
pydantic_core==2.23.4
pydot==2.0.0
Pygments==2.17.2
pymoo==0.6.1.1
PyMuPDF==1.24.5
PyMuPDFb==1.24.3
pyparsing==3.1.2
PyPika==0.48.9
pyproject_hooks==1.0.0
python-dateutil==2.8.2
python-docx==1.1.0
python-dotenv==1.0.1
python-iso639==2024.2.7
python-json-logger==2.0.7
python-magic==0.4.27
pytz==2024.1
PyYAML==6.0.1
pyzmq==25.1.2
qdrant-client==1.8.0
rapidfuzz==3.6.1
reader==3.12
referencing==0.34.0
regex==2023.12.25
requests==2.32.3
requests-oauthlib==2.0.0
rfc3339-validator==0.1.4
rfc3986-validator==0.1.1
rich==13.7.1
rpds-py==0.18.0
rsa==4.9
safetensors==0.4.5
scikit-learn==1.4.1.post1
scipy==1.12.0
Send2Trash==1.8.3
sentence-transformers==3.3.1
sentencepiece==0.2.0
sgmllib3k==1.0.0
six==1.16.0
sniffio==1.3.1
soupsieve==2.5
SQLAlchemy==2.0.28
stack-data==0.6.3
starlette==0.36.3
sympy==1.13.1
tabulate==0.9.0
tenacity==8.2.3
terminado==0.18.1
texttable==1.7.0
threadpoolctl==3.4.0
tiktoken==0.7.0
tinycss2==1.2.1
tokenizers==0.20.3
tomli==2.0.1
tonic-validate==6.2.0
torch==2.5.1+cpu
tornado==6.4
tqdm==4.67.0
traitlets==5.14.2
transformers==4.46.3
typer==0.10.0
types-python-dateutil==2.9.0.20240316
types-requests==2.31.0.6
types-urllib3==1.26.25.14
typing-inspect==0.9.0
typing_extensions==4.11.0
tzdata==2024.1
unstructured==0.13.4
unstructured-client==0.18.0
uri-template==1.3.0
urllib3==1.26.18
uvicorn==0.29.0
uvloop==0.19.0
watchfiles==0.21.0
wcwidth==0.2.13
webcolors==1.13
webencodings==0.5.1
websocket-client==1.7.0
websockets==12.0
Werkzeug==3.0.1
widgetsnbextension==4.0.10
wrapt==1.16.0
xxhash==3.4.1
yarl==1.9.4
zipp==3.18.1
The benchmark script “benchmark_OV_noOV.py” is the main script that implements the RAG pipeline and runs benchmark tests on a RAG pipeline using various machine learning models and tools. The pipeline integrates LLMs for Q&A tasks, utilizes embedding models for document retrieval, and compresses models to different precisions (BFloat16, INT8, or INT4) using OpenVINO or PyTorch. The script loads datasets, processes them into documents, and splits them into chunks for efficient indexing. It uses a vector database (Qdrant or ChromaDB) for document retrieval and incorporates reranking models to improve search results. The RAG pipeline is used to generate answers to input prompts, and the performance is measured, including the time taken for inference and token generation. The user can specify the model, precision, datastore, and framework (OpenVINO or PyTorch) via command-line arguments, and the script also provides detailed performance metrics and optional hooks for monitoring latencies.
The following steps outline the structure of the script:
● The LLM model is compressed if required depending on the value provided in the command line through the -p parameter.
● The LLM and its Tokenizer are instantiated.
● Instrumentation hooks are added dynamically to report the TTFT and TPOT measurements.
● The text generation arguments are defined and a Langchain pipeline is created for text generation.
● A prompt template and RAG pipeline are defined.
● The input .txt files from the path specified in the command line through the -f parameter are read, split into chunks, and stored in the vector database. Subsequently, the vector database is set up as a document retriever to select a set of top_k documents relevant to each query.
● A re-ranker is created that selects a subset of documents from the initial set of top_k documents retrieved from the vector database for each query.
● A set of pre-defined questions is loaded and sent through the RAG pipeline for its processing.
● The answer text and latencies of the results are printed out.
### benchmark_OV_noOV.py
######Sample run Command line arguments########
#python benchmark-OV_noOV.py -p INT4 -l llama-2-chat-7b -e all-mpnet-base-v2 --dataset_path /fastdata/01/mini_wikipedia/raw_data/text_data -ds qdrant --hooks yes -f OV
import argparse, torch, nncf, logging, shutil, re
from argparse import ArgumentParser
import time, gc, sys, getpass, os, warnings
#sys.path.insert (0, '/home/openvino-rag/ov-rag/utils/llm_bench_utils')
from pathlib import Path
from datetime import datetime
import openvino as ov
import utils.llm_bench_utils.hook_greedy_search
import utils.llm_bench_utils.hook_beam_search
#import utils.llm_bench_utils.hook_greedy_search_hfpatch
from optimum.intel import OVQuantizer
from optimum.intel.openvino import OVModelForCausalLM
from converter import converters
from ov_embedding_model import OVEmbeddings
from typing import List
from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter, MarkdownTextSplitter
from langchain.document_loaders import (
CSVLoader,
EverNoteLoader,
PDFMinerLoader,
TextLoader,
PyPDFLoader,
UnstructuredEPubLoader,
UnstructuredHTMLLoader,
UnstructuredMarkdownLoader,
UnstructuredODTLoader,
UnstructuredPowerPointLoader,
UnstructuredWordDocumentLoader, )
from langchain.indexes import VectorstoreIndexCreator
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain_community.document_loaders import TextLoader, DirectoryLoader
from langchain_community.vectorstores import Qdrant
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import CrossEncoderReranker
from langchain_community.cross_encoders import HuggingFaceCrossEncoder
from reader import Feed
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQA
from langchain.docstore.document import Document
from threading import Event, Thread
from uuid import uuid4
from ov_llm_model import model_classes
from models import template, SUPPORTED_EMBEDDING_MODELS, SUPPORTED_LLM_MODELS, DEFAULT_RAG_PROMPT
from precision import convert_to_Bfloat16, convert_to_int8, convert_to_int4
#show warning once not repeated
warnings.filterwarnings("ignore")
from transformers import (
AutoModelForCausalLM,
AutoModel,
AutoTokenizer,
AutoConfig,
TextIteratorStreamer,
pipeline,
StoppingCriteria,
StoppingCriteriaList,
)
from langchain.llms import HuggingFacePipeline
from transformers import (
StoppingCriteria,
StoppingCriteriaList,
)
import subprocess
def convert_to_precision(model_dir,precision,pt_model_id):
if (model_dir / "openvino_model.xml").exists():
return
cmd = "optimum-cli export openvino --model {model_id} --weight-format {precision} {output_dir}".format(model_id=pt_model_id, precision=precision, output_dir=model_dir)
subprocess.check_call(cmd.split())
return
def main(args):
#Default device selected is CPU by default
embedding_device = "CPU"
llm_device = "CPU"
print(f"LLM model will be loaded to {llm_device} device for response generation")
#Select llm model from the list of llm models for compression
llm_model_id = args.llm
llm_model_configuration = SUPPORTED_LLM_MODELS[llm_model_id]
nncf.set_log_level(logging.ERROR)
#Set model id and model type
pt_model_id = llm_model_configuration["model_id"]
pt_model_name = llm_model_id.split("-")[0] ### no required
model_type = AutoConfig.from_pretrained(pt_model_id, trust_remote_code=True).model_type
llm_prompt_template = llm_model_configuration["prompt_template"]
QA_answer_extract_fn = llm_model_configuration["QA_answer_extract_fn"]
#path to model directories and respective compressions directors for various precisions - These will be created if they don't exist and are required.
bfloat16_model_dir = Path(llm_model_id) / "BFloat16"
int8_model_dir = Path(llm_model_id) / "INT8_compressed_weights"
int4_model_dir = Path(llm_model_id) / "INT4_compressed_weights"
bfloat16_weights = bfloat16_model_dir / "openvino_model.bin"
int8_weights = int8_model_dir / "openvino_model.bin"
int4_weights = int4_model_dir / "openvino_model.bin"
precision=args.precision
if precision in ['BFloat16','INT8','INT4']:
try:
model_dir = int4_model_dir if precision == "INT4" else int8_model_dir if precision == "INT8" else bfloat16_model_dir
convert_to_precision(model_dir,precision.lower(),pt_model_id)
except subprocess.CalledProcessError as e:
print("An error ocurred when trying to convert the model.")
print(str(e))
sys.exit(1)
if bfloat16_weights.exists():
print(f"Size of BFloat16 model is {bfloat16_weights.stat().st_size / 1024 / 1024:.2f} MB")
# Print size of compressed/quantized models
for precision, compressed_weights in zip([8, 4], [int8_weights, int4_weights]):
if compressed_weights.exists():
print(f"Size of model with INT{precision} compressed weights is {compressed_weights.stat().st_size / 1024 / 1024:.2f} MB"
)
if compressed_weights.exists() and bfloat16_weights.exists():
print(f"Compression rate for INT{precision} model: {bfloat16_weights.stat().st_size / compressed_weights.stat().st_size:.3f}")
#select embedding model from the list of supported embedding models
embedding_model_id_list = list(SUPPORTED_EMBEDDING_MODELS)
embedding_model_id = args.embedding
embedding_model_configuration = SUPPORTED_EMBEDDING_MODELS[embedding_model_id]
print(f"Selected {embedding_model_id} model")
embedding_model_dir = embedding_model_configuration["model_id"]
#Load tokenizer model
start_init = time.perf_counter()
model_name = llm_model_configuration["model_id"]
stop_tokens = llm_model_configuration.get("stop_tokens")
class_key = llm_model_id.split("-")[0]
tok = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
#Load LLM model
start = time.perf_counter()
if args.framework=="OV":
ov_config = {"PERFORMANCE_HINT": "LATENCY", "NUM_STREAMS": "1", "CACHE_DIR": ""}
model = OVModelForCausalLM.from_pretrained(
model_dir,
device=llm_device,
ov_config=ov_config,
config=AutoConfig.from_pretrained(model_dir, trust_remote_code=True),
trust_remote_code=True,
)
elif args.framework=="PT":
model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype=torch.float16)
end = time.perf_counter()
print('Load model:',end-start)
# add instrumentation hooks to transformers
bench_hook = utils.llm_bench_utils.hook_greedy_search.GreedySearchHook()
bench_hook.new_forward(model) #, model_type)
#Define streamer
streamer = TextIteratorStreamer(
tok, timeout=30.0, skip_prompt=True, skip_special_tokens=True
)
if args.framework=="OV":
generate_kwargs = dict(
model=model,
tokenizer=tok,
max_new_tokens=256,
streamer=streamer,
do_sample=False,
)
elif args.framework=="PT":
generate_kwargs = dict(
model=model,
tokenizer=tok,
max_new_tokens=256,
streamer=streamer,
do_sample=False,
)
#Create Langchain text-generation pipeline
pipe = pipeline("text-generation", **generate_kwargs)
llm = HuggingFacePipeline(pipeline=pipe)
#from langchain_community.embeddings import OpenVINOEmbeddings
if args.framework=="OV":
embedding_ov_config = {"PERFORMANCE_HINT": "LATENCY", "NUM_STREAMS": "1", "CACHE_DIR": ""}
model_kwargs_ov = {'device': 'cpu', 'ov_config':embedding_ov_config}
encode_kwargs_ov = {"mean_pooling": True, 'normalize_embeddings': True}
embedding = OpenVINOEmbeddings(
model_name_or_path=str(embedding_model_dir),
model_kwargs=model_kwargs_ov,
encode_kwargs=encode_kwargs_ov,
)
elif args.framework=="PT":
embedding = HuggingFaceEmbeddings(model_name=str(embedding_model_dir))
## load data and split in chunks
docs = load_documents(args.dataset_path,"*.txt")
from datastore import qdrantdatastore
#######Compute Offline time###########################################
start_vectordb = time.perf_counter()
if args.datastore=='qdrant':
datastore = qdrantdatastore(docs, embedding)
retriever = datastore.as_retriever(search_kwargs={"k": args.topK_retriever_docs})
end_vectordb = time.perf_counter()
print("perf_time(VectorDB_create(s)]:",end_vectordb-start_vectordb)
#################Compute Offline time#################################
reranker_model = HuggingFaceCrossEncoder(model_name="BAAI/bge-reranker-base")
reranker = CrossEncoderReranker(model=reranker_model, top_n=args.topN_retriever_docs)
reranking_retriever = ContextualCompressionRetriever(
base_compressor=reranker, base_retriever=retriever
)
# Create prompt and RAG pipeline
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context", "question"], template=llm_prompt_template)
chain_type_kwargs = {"prompt": QA_CHAIN_PROMPT}
rag_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=reranking_retriever,
chain_type_kwargs=chain_type_kwargs,
)
end_init = time.perf_counter()
print("perf_time[total_init(s)]:",end_init-start_init)
### Load a set of prompts to run through the RAG pipeline
questions_subset = load_prompt_list()
### Run RAG pipeline with the previously loaded prompts
chain_run_times=list()
time_infer_set = list()
helpful_answers_set = list()
start = time.perf_counter()
for (i,q) in enumerate(questions_subset):
istart=time.perf_counter()
ans= rag_chain.run(q)
iend=time.perf_counter()
chain_run_times.append(iend-istart)
tm_infer_list = bench_hook.get_time_infer_list()
time_infer_set.append(tm_infer_list[:])
bench_hook.clear_time_infer_list()
helpful_answers_set.append(ans)
print(q+":\n")
if args.print=="yes":
print("Retrieved docs:\n")
print(pretty_format_docs(retriever.invoke(q)))
print("\n\nReranker docs:\n")
print("\n\n")
print(pretty_format_docs(reranking_retriever.invoke(q)))
print("\n\nAnswer:")
print(QA_answer_extract_fn(ans))
print("\n\n")
end = time.perf_counter()
print("perf_time[avg_response(s)]:", (sum(chain_run_times)/len(questions_subset)))
print("perf_time[total_response(s)]:",sum(chain_run_times))
if args.hooks=="yes":
hooks(len(questions_subset),chain_run_times,time_infer_set)
def load_prompt_list():
questions_subset = list()
questions_subset.append("What was one of the many species described in Linnaeus's 18th-century work, Systema Naturae?")
questions_subset.append("Who is Daffy Duck?")
questions_subset.append("What economic uses to ducks have?")
questions_subset.append("What is Canada's national unemployment rate?")
questions_subset.append("What fraternity was Coolidge a member of?")
questions_subset.append("Who suggested Lincoln grow a beard?")
questions_subset.append("Did Lincoln beat John C. Breckinridge in the 1860 election?")
questions_subset.append("Who determined the dependence of the boiling of water with atmospheric pressure?")
return questions_subset
def hooks(num_prompts,chain_run_times,time_infer_set):
print("\nFirst token latencies (s):",[r[0] for r in time_infer_set])
print("perf_time[avg(1st_token_latency(s))]:",sum([r[0] for r in time_infer_set])/len(time_infer_set))
print("perf_time[avg(2nd_token_latency(s))]:",sum([sum(r[1:])/len(r[1:]) for r in time_infer_set])/len(time_infer_set))
for t in range(num_prompts):
print("q"+str(t)+":",chain_run_times[t],"-",sum(time_infer_set[t]),"=",chain_run_times[t]-sum(time_infer_set[t]),"Total tokens",len(time_infer_set[t]))
def join_prompt(sys_prompt,question_prompt):
return f"""<s>[INST]<<SYS>> {sys_prompt} <</SYS>> {question_prompt} [/INST]"""
def pretty_format_docs(docs):
return f"\n{'-' * 100}\n".join([f"Document {i+1}:\n\n" + d.page_content for i, d in enumerate(docs)])
def pretty_print_docs(docs):
print(
f"\n{'-' * 100}\n".join(
[f"Document {i+1}:\n\n" + d.page_content for i, d in enumerate(docs)]
)
)
def load_documents(dataset_path,glob_str,chunk_size=1000, chunk_overlap=100):
#Read the input files from dataset_path
start_load_data = time.perf_counter()
loader = DirectoryLoader(dataset_path, glob_str, show_progress=True ,use_multithreading=True,loader_cls=TextLoader)
documents = loader.load()
end_load_data = time.perf_counter()
print("perf_time[data_read(s)]:",end_load_data - start_load_data)
# Split input files in chunks and create Document data structure
start_split_chunk_data = time.perf_counter()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
docs = text_splitter.split_documents(documents)
print("Will be working on",len(docs),"documents")
end_split_chunk_data = time.perf_counter()
print("perf_time[doc_create(s)]:",end_split_chunk_data - start_split_chunk_data)
return docs
def read_embedding_model():
if not (embedding_model_dir / "openvino_model.xml").exists():
model = AutoModel.from_pretrained(embedding_model_configuration["model_id"])
converters[embedding_model_id](model, embedding_model_dir)
tokenizer = AutoTokenizer.from_pretrained(embedding_model_configuration["model_id"])
tokenizer.save_pretrained(embedding_model_dir)
del model
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# supported precision
parser.add_argument('-p','--precision',choices=[ 'BFloat16', 'INT8', 'INT4'], default="BFloat16",type=str)
# supported list of llm models
parser.add_argument('-l','--llm',choices=['llama-3-8b-instruct','tiny-llama-1b-chat','llama-2-chat-7b', 'Llama-2-7b-chat-hf', 'mistral-7b'],default="llama-2-chat-7b", type=str)
# supported list of embedding models
parser.add_argument('-e','--embedding',choices=['all-mpnet-base-v2', 'text2vec-large-chinese', 'bge-large-en-v1.5'],default="all-mpnet-base-v2", type=str)
# path to the dataset
parser.add_argument("--dataset_path", type=Path)
# supported list of vectordbs
parser.add_argument('-ds','--datastore',choices=[ 'qdrant', 'chromadb'], default="qdrant", type=str)
# hooks helps to enable and capture token latencies
parser.add_argument("--hooks", type=str, choices=['yes','no'],default="no")
#preint retriever documents
parser.add_argument("--print","--print_retriever_doc", type=str, choices=['yes','no'], default="yes")
# top n retriever document. default set to 3
parser.add_argument("-n","--topN_retriever_docs", type=int, default="3")
#top k retriever document. default set to 10
parser.add_argument("-k","--topK_retriever_docs", type=int, default="10")
#Supported frameworks are OpenVINO (OV) and Pytorch(PT)
parser.add_argument("-f", "--framework", type=str, choices=['OV','PT'],default="OV")
args = parser.parse_args()
print(f"Selected LLM model: {args.llm}")
print(f"Selected Embedding model: {args.embedding}")
if (args.dataset_path.exists()==True):
print(f"Dataset Path: {args.dataset_path}")
elif (args.dataset_path.exists()==False) :
print("Enter valid dataset path")
sys.exit(1)
# Call main function
main(args)
The following python files are required to run the main benchmark script. These files can be copied into a folder where you have the benchmark script before running it.
You need “converter.py” to convert the LLM models. The Optimum command line interface can be used to convert LLMs from Hugging Face to OpenVINO™ IR format. Optimum also uses NNCF to perform BFloat16, INT8, or INT4 weight compression on a model to reduce its memory footprint and inference latency without a significant reduction in response quality.
### converter.py
from functools import wraps
import warnings
import torch
import openvino as ov
from pathlib import Path
from typing import Tuple, Optional
import types
from transformers.modeling_outputs import BaseModelOutputWithPast
try:
from optimum.exporters.openvino.stateful import make_stateful
from optimum.exporters.openvino.stateful import fuse_cache_reorder
except ImportError:
warnings.warn("We recommend to update optimum-intel for getting optimal performance")
make_stateful = None
fuse_cache_reorder = None
def patch_stateful(ov_model, model_type):
key_value_input_names = [
key.get_any_name() for key in ov_model.inputs if any("key_values" in key_name for key_name in key.get_names())
]
key_value_output_names = [
key.get_any_name() for key in ov_model.outputs if any("present" in key_name for key_name in key.get_names())
]
not_kv_inputs = [
input for input in ov_model.inputs if not any(name in key_value_input_names for name in input.get_names())
]
if not key_value_input_names or not key_value_output_names:
return
batch_dim = 1 if model_type == "chatglm" else 0
num_attention_heads = 1
fuse_cache_reorder(ov_model, not_kv_inputs, key_value_input_names, batch_dim)
make_stateful(
ov_model, not_kv_inputs, key_value_input_names, key_value_output_names, batch_dim, num_attention_heads, None
)
def flattenize_inputs(inputs):
"""
Helper function for making nested inputs flattens
"""
flatten_inputs = []
for input_data in inputs:
if input_data is None:
continue
if isinstance(input_data, (list, tuple)):
flatten_inputs.extend(flattenize_inputs(input_data))
else:
flatten_inputs.append(input_data)
return flatten_inputs
def cleanup_torchscript_cache():
"""
Helper for removing cached model representation
"""
torch._C._jit_clear_class_registry()
torch.jit._recursive.concrete_type_store = torch.jit._recursive.ConcreteTypeStore()
torch.jit._state._clear_class_state()
def convert_mpt(pt_model: torch.nn.Module, model_path: Path):
"""
MPT model conversion function
Params:
pt_model: PyTorch model
model_path: path for saving model
Returns:
None
"""
ov_out_path = Path(model_path) / "openvino_model.xml"
pt_model.config.save_pretrained(ov_out_path.parent)
pt_model.config.use_cache = True
outs = pt_model(
input_ids=torch.ones((1, 10), dtype=torch.long),
attention_mask=torch.ones((1, 10), dtype=torch.long),
)
inputs = ["input_ids"]
outputs = ["logits"]
dynamic_shapes = {"input_ids": {0: "batch_size", 1: "seq_len"}, "attention_mask": {0: "batch_size", 1: "seq_len"}}
for idx in range(len(outs.past_key_values)):
inputs.extend([f"past_key_values.{idx}.key", f"past_key_values.{idx}.value"])
dynamic_shapes[inputs[-1]] = {0: "batch_size", 2: "past_sequence + sequence"}
dynamic_shapes[inputs[-2]] = {0: "batch_size", 3: "past_sequence + sequence"}
outputs.extend([f"present.{idx}.key", f"present.{idx}.value"])
inputs.append("attention_mask")
dummy_inputs = {
"input_ids": torch.ones((1, 2), dtype=torch.long),
"past_key_values": outs.past_key_values,
"attention_mask": torch.ones((1, 12), dtype=torch.long),
}
pt_model.config.torchscript = True
orig_forward = pt_model.forward
@wraps(orig_forward)
def ts_patched_forward(
input_ids: torch.Tensor,
past_key_values: Tuple[Tuple[torch.Tensor]],
attention_mask: torch.Tensor,
):
pkv_list = list(past_key_values)
outs = orig_forward(
input_ids=input_ids, past_key_values=pkv_list, attention_mask=attention_mask
)
return (outs.logits, tuple(outs.past_key_values))
pt_model.forward = ts_patched_forward
ov_model = ov.convert_model(pt_model, example_input=dummy_inputs)
pt_model.forward = orig_forward
for inp_name, m_input, input_data in zip(
inputs, ov_model.inputs, flattenize_inputs(dummy_inputs.values())
):
input_node = m_input.get_node()
if input_node.element_type == ov.Type.dynamic:
m_input.get_node().set_element_type(ov.Type.f32)
shape = list(input_data.shape)
if inp_name in dynamic_shapes:
for k in dynamic_shapes[inp_name]:
shape[k] = -1
input_node.set_partial_shape(ov.PartialShape(shape))
m_input.get_tensor().set_names({inp_name})
for out, out_name in zip(ov_model.outputs, outputs):
out.get_tensor().set_names({out_name})
ov_model.validate_nodes_and_infer_types()
if make_stateful is not None:
patch_stateful(ov_model, "mpt")
ov.save_model(ov_model, ov_out_path)
del ov_model
cleanup_torchscript_cache()
del pt_model
def _update_qwen_rotary_embedding_cache(model):
model.transformer.rotary_emb(2048)
def convert_qwen(pt_model: torch.nn.Module, model_path: Path):
"""
Qwen model conversion function
Params:
pt_model: PyTorch model
model_path: path for saving model
Returns:
None
"""
_update_qwen_rotary_embedding_cache(pt_model)
ov_out_path = Path(model_path) / "openvino_model.xml"
pt_model.config.save_pretrained(ov_out_path.parent)
pt_model.config.use_cache = True
outs = pt_model(
input_ids=torch.ones((1, 10), dtype=torch.long),
attention_mask=torch.ones((1, 10), dtype=torch.long),
)
inputs = ["input_ids"]
outputs = ["logits"]
dynamic_shapes = {
"input_ids": {0: "batch_size", 1: "seq_len"},
"attention_mask": {0: "batch_size", 1: "seq_len"},
"token_type_ids": {0: "batch_size", 1: "seq_len"},
}
for idx in range(len(outs.past_key_values)):
inputs.extend([f"past_key_values.{idx}.key", f"past_key_values.{idx}.value"])
dynamic_shapes[inputs[-1]] = {0: "batch_size", 1: "past_sequence + sequence"}
dynamic_shapes[inputs[-2]] = {0: "batch_size", 1: "past_sequence + sequence"}
outputs.extend([f"present.{idx}.key", f"present.{idx}.value"])
inputs += ["attention_mask", "token_type_ids"]
dummy_inputs = {
"input_ids": torch.ones((1, 2), dtype=torch.long),
"past_key_values": outs.past_key_values,
"attention_mask": torch.ones((1, 12), dtype=torch.long),
"token_type_ids": torch.ones((1, 2), dtype=torch.long),
}
pt_model.config.torchscript = True
ov_model = ov.convert_model(pt_model, example_input=dummy_inputs)
for inp_name, m_input, input_data in zip(
inputs, ov_model.inputs, flattenize_inputs(dummy_inputs.values())
):
input_node = m_input.get_node()
if input_node.element_type == ov.Type.dynamic:
m_input.get_node().set_element_type(ov.Type.f32)
shape = list(input_data.shape)
if inp_name in dynamic_shapes:
for k in dynamic_shapes[inp_name]:
shape[k] = -1
input_node.set_partial_shape(ov.PartialShape(shape))
m_input.get_tensor().set_names({inp_name})
for out, out_name in zip(ov_model.outputs, outputs):
out.get_tensor().set_names({out_name})
ov_model.validate_nodes_and_infer_types()
if make_stateful is not None:
patch_stateful(ov_model, "qwen")
ov.save_model(ov_model, ov_out_path)
del ov_model
cleanup_torchscript_cache()
del pt_model
@torch.jit.script_if_tracing
def _chatglm2_get_context_layer(query_layer: torch.Tensor, key_layer: torch.Tensor, value_layer: torch.Tensor):
mask = torch.zeros((query_layer.shape[-2], key_layer.shape[-2]), dtype=query_layer.dtype)
if query_layer.shape[2] == key_layer.shape[2]:
tmp_mask = torch.ones((query_layer.shape[-2], key_layer.shape[-2]), dtype=torch.bool).triu(diagonal=1)
mask.masked_fill_(tmp_mask, float("-inf"))
context_layer = torch.nn.functional.scaled_dot_product_attention(query_layer, key_layer, value_layer, attn_mask=mask)
return context_layer
def _core_attention_forward(self, query_layer, key_layer, value_layer, attention_mask):
query_layer, key_layer, value_layer = [k.permute(1, 2, 0, 3) for k in [query_layer, key_layer, value_layer]]
if attention_mask is None:
context_layer = _chatglm2_get_context_layer(query_layer, key_layer, value_layer)
else:
context_layer = torch.nn.functional.scaled_dot_product_attention(
query_layer, key_layer, value_layer, attention_mask
)
context_layer = context_layer.permute(2, 0, 1, 3)
new_context_layer_shape = context_layer.size()[:-2] + (self.hidden_size_per_partition,)
context_layer = context_layer.reshape(*new_context_layer_shape)
return context_layer
@torch.jit.script_if_tracing
def _get_chatglm_attention_mask(input_ids, past_key):
mask = torch.zeros((input_ids.shape[1], past_key.shape[0] + input_ids.shape[1]), dtype=past_key.dtype)
if past_key.shape[0] == 0:
tmp_mask = torch.ones((input_ids.shape[1], past_key.shape[0] + input_ids.shape[1]), dtype=torch.bool).triu(diagonal=1)
mask.masked_fill_(tmp_mask, float("-inf"))
return mask
def _chatglm_transformer_forward(
self,
input_ids,
position_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.BoolTensor] = None,
full_attention_mask: Optional[torch.BoolTensor] = None,
past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
inputs_embeds: Optional[torch.Tensor] = None,
use_cache: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None
):
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
use_cache = use_cache if use_cache is not None else self.config.use_cache
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
batch_size, seq_length = input_ids.shape
if inputs_embeds is None:
inputs_embeds = self.embedding(input_ids)
if self.pre_seq_len is not None:
if past_key_values is None:
past_key_values = self.get_prompt(batch_size=batch_size, device=input_ids.device,
dtype=inputs_embeds.dtype)
if attention_mask is not None:
attention_mask = torch.cat([attention_mask.new_ones((batch_size, self.pre_seq_len)), attention_mask], dim=-1)
if full_attention_mask is None:
if (attention_mask is not None and not attention_mask.all()) or (past_key_values and seq_length != 1):
full_attention_mask = self.get_masks(input_ids, past_key_values, padding_mask=attention_mask)
elif past_key_values is not None:
full_attention_mask = torch.ones(batch_size, seq_length, seq_length,
device=input_ids.device,
dtype=torch.float) * float("-inf")
full_attention_mask.triu_(diagonal=1)
past_length = 0
if past_key_values:
past_length = past_key_values[0][0].shape[0]
if past_length:
full_attention_mask = torch.cat((torch.zeros(batch_size, seq_length, past_length,
device=input_ids.device), full_attention_mask), dim=-1)
full_attention_mask.unsqueeze_(1)
# Rotary positional embeddings
rotary_pos_emb = self.rotary_pos_emb(self.seq_length)
if position_ids is not None:
rotary_pos_emb = rotary_pos_emb[position_ids]
else:
rotary_pos_emb = rotary_pos_emb[None, :seq_length]
rotary_pos_emb = rotary_pos_emb.transpose(0, 1).contiguous()
# Run encoder.
hidden_states, presents, all_hidden_states, all_self_attentions = self.encoder(
inputs_embeds, full_attention_mask, rotary_pos_emb=rotary_pos_emb,
kv_caches=past_key_values, use_cache=use_cache, output_hidden_states=output_hidden_states
)
if not return_dict:
return tuple(v for v in [hidden_states, presents, all_hidden_states, all_self_attentions] if v is not None)
return BaseModelOutputWithPast(
last_hidden_state=hidden_states,
past_key_values=presents,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
)
def _patch_chatglm_forward(model: "PreTrainedModel"):
model.transformer.forward = types.MethodType(_chatglm_transformer_forward, model.transformer)
for block in model.transformer.encoder.layers:
block.self_attention.core_attention.forward = types.MethodType(
_core_attention_forward, block.self_attention.core_attention
)
def convert_chatglm(pt_model: torch.nn.Module, model_path: Path):
"""
ChatGLM model conversion function
Params:
pt_model: PyTorch model
model_path: path for saving model
Returns:
None
"""
_patch_chatglm_forward(pt_model)
ov_out_path = Path(model_path) / "openvino_model.xml"
pt_model.config.save_pretrained(ov_out_path.parent)
pt_model.config.use_cache = True
outs = pt_model(
input_ids=torch.ones((1, 10), dtype=torch.long),
position_ids=torch.arange(0, 10, dtype=torch.long),
)
inputs = ["input_ids"]
outputs = ["logits"]
dynamic_shapes = {
"input_ids": {0: "batch_size", 1: "seq_len"},
"position_ids": {0: "batch_size", 1: "seq_len"},
"attention_mask": {0: "batch_size", 1: "seq_len"},
}
inputs += ["position_ids", "attention_mask"]
for idx in range(len(outs.past_key_values)):
inputs.extend([f"past_key_values.{idx}.key", f"past_key_values.{idx}.value"])
dynamic_shapes[inputs[-1]] = {0: "past_sequence + sequence", 1: "batch_size"}
dynamic_shapes[inputs[-2]] = {0: "past_sequence + sequence", 1: "batch_size"}
outputs.extend([f"present.{idx}.key", f"present.{idx}.value"])
dummy_inputs = {
"input_ids": torch.ones((1, 1), dtype=torch.long),
"position_ids": torch.tensor([[10]], dtype=torch.long),
"attention_mask": torch.ones((1, 11), dtype=torch.long),
"past_key_values": outs.past_key_values,
}
pt_model.config.torchscript = True
ov_model = ov.convert_model(pt_model, example_input=dummy_inputs)
for inp_name, m_input, input_data in zip(
inputs, ov_model.inputs, flattenize_inputs(dummy_inputs.values())
):
input_node = m_input.get_node()
if input_node.element_type == ov.Type.dynamic:
m_input.get_node().set_element_type(ov.Type.f32)
shape = list(input_data.shape)
if inp_name in dynamic_shapes:
for k in dynamic_shapes[inp_name]:
shape[k] = -1
input_node.set_partial_shape(ov.PartialShape(shape))
m_input.get_tensor().set_names({inp_name})
for out, out_name in zip(ov_model.outputs, outputs):
out.get_tensor().set_names({out_name})
ov_model.validate_nodes_and_infer_types()
if make_stateful is not None:
print("PATCH STATEFUL")
patch_stateful(ov_model, "chatglm")
ov.save_model(ov_model, ov_out_path)
del ov_model
cleanup_torchscript_cache()
del pt_model
def convert_mpnet(pt_model: torch.nn.Module, model_path: Path):
ov_out_path = Path(model_path) / "openvino_model.xml"
dummy_inputs = {"input_ids": torch.ones((1, 10), dtype=torch.long), "attention_mask": torch.ones(
(1, 10), dtype=torch.long)}
ov_model = ov.convert_model(pt_model, example_input=dummy_inputs)
ov.save_model(ov_model, ov_out_path)
def convert_bert(pt_model: torch.nn.Module, model_path: Path):
ov_out_path = Path(model_path) / "openvino_model.xml"
dummy_inputs = {"input_ids": torch.ones((1, 10), dtype=torch.long), "attention_mask": torch.ones(
(1, 10), dtype=torch.long), "token_type_ids": torch.zeros((1, 10), dtype=torch.long)}
ov_model = ov.convert_model(pt_model, example_input=dummy_inputs)
ov.save_model(ov_model, ov_out_path)
converters = {
# LLM models
"mpt": convert_mpt,
"qwen": convert_qwen,
"chatglm3": convert_chatglm,
# embedding models
"all-mpnet-base-v2": convert_mpnet,
"text2vec-large-chinese": convert_bert,
}
● The “datastore.py” script sets up an in-memory Qdrant index that stores a collection of documents (converted into vectors) and prepares it for fast similarity searches:
from langchain.docstore.document import Document
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import Qdrant
def qdrantdatastore(docs, embedding) :
qdrant = Qdrant.from_documents(
docs,
embedding,
location=":memory:", # Local mode with in-memory storage only
collection_name="my_documents",
embedding_dim=768,
similarity="dot_product",
recreate_index=True,
hnsw_config={"m": 16, "ef_construct": 64} )
return qdrant
The “models.py” script sets up a system for interacting with Llama-based models (Llama-2-7b-chat and Llama-3-8b-instruct) and embedding models, enabling question-answering tasks. It processes the text inputs and responses, normalizes embeddings where needed, and extracts helpful answers from the model outputs based on predefined prompts and templates.
### models.py
from transformers import (
StoppingCriteria,
StoppingCriteriaList,
)
import torch
def llama3_partial_text_processor(partial_text, new_text):
new_text = new_text.replace("[INST]", "").replace("[/INST]", "")
partial_text += new_text
return partial_text
def llama_partial_text_processor(partial_text, new_text):
new_text = new_text.replace("[INST]", "").replace("[/INST]", "")
partial_text += new_text
return partial_text
def get_helpful_answer_llama3(answer_text):
answer_lines=answer_text.split('\n')
num_lines = len(answer_lines)
for x in range(len(answer_lines)):
line = answer_lines[x]
if line.strip().lower().endswith('<|eot_id|><|start_header_id|>assistant<|end_header_id|>'):
return '\n'.join(answer_lines[x+1:])
return ""
def get_helpful_answer_llama2(answer_text):
answer_lines=answer_text.split('\n')
for line in answer_lines:
if line.strip().upper().startswith('HELPFUL ANSWER:'):
return line[len('HELPFUL ANSWER:'):]
return ""
DEFAULT_SYSTEM_PROMPT = """\
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.\
"""
DEFAULT_RAG_PROMPT = """\
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.\
"""
SUPPORTED_LLM_MODELS = {
"llama-2-chat-7b": {
"model_id": "meta-llama/Llama-2-7b-chat-hf",
"remote": False,
"start_message": f"<s>[INST] <<SYS>>\n{DEFAULT_SYSTEM_PROMPT }\n<</SYS>>\n\n",
"history_template": "{user}[/INST]{assistant}</s><s>[INST]",
"current_message_template": "{user} [/INST]{assistant}",
"tokenizer_kwargs": {"add_special_tokens": False},
"partial_text_processor": llama_partial_text_processor,
"QA_answer_extract_fn": get_helpful_answer_llama2,
"prompt_template": f"""<s>[INST] <<SYS>>\n{DEFAULT_RAG_PROMPT}\n<</SYS>>\n"""
+ """
Question: {question}
Context: {context}
Helpful Answer: [/INST]""",
},
"llama-3-8b-instruct": {
"model_id": "meta-llama/Meta-Llama-3-8B-Instruct",
"remote": False,
"start_message": f"<s>[INST] <<SYS>>\n{DEFAULT_SYSTEM_PROMPT }\n<</SYS>>\n\n",
"history_template": "{user}[/INST]{assistant}</s><s>[INST]",
"current_message_template": "{user} [/INST]{assistant}",
"tokenizer_kwargs": {"add_special_tokens": False},
"partial_text_processor": llama3_partial_text_processor,
"QA_answer_extract_fn": get_helpful_answer_llama3,
"prompt_template": f"""<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{DEFAULT_RAG_PROMPT}<|eot_id|><|start_header_id|>user<|end_header_id|>"""
+ """
Question: {question}
Context: {context}
Answer: <|eot_id|><|start_header_id|>assistant<|end_header_id|>""",
},
}
SUPPORTED_EMBEDDING_MODELS = {
"all-mpnet-base-v2": {
"model_id": "sentence-transformers/all-mpnet-base-v2",
"do_norm": True,
},
"text2vec-large-chinese": {
"model_id": "GanymedeNil/text2vec-large-chinese",
"do_norm": False,
},
"bge-large-en-v1.5":{
"model_id": "BAAI/bge-large-en-v1.5",
"do_norm": True,
},
}
template = """Use the following pieces of context to answer the question at the end. Use three sentences maximum and keep the answer as concise as possible.
{context}
Question: {question}
Helpful Answer:"""
The “ov_embedding_model.py” python script defines a class OVEmbeddings that wraps an OpenVINO-based embedding model, making it compatible with LangChain for embedding tasks. The class uses a Hugging Face tokenizer and OpenVINO for efficient inference on transformer models. Overall, it allows efficient embedding computation using OpenVINO for transformer models while supporting text normalization and batching for faster inference.
### ov_embedding_model.py
from langchain.pydantic_v1 import BaseModel, Extra, Field
from langchain.schema.embeddings import Embeddings
from typing import Optional, Union, Dict, Tuple, Any, List
from sklearn.preprocessing import normalize
from transformers import AutoTokenizer
from pathlib import Path
import openvino as ov
import torch
import numpy as np
class OVEmbeddings(BaseModel, Embeddings):
"""
LangChain compatible model wrapper for embedding model
"""
model: Any #: :meta private:
"""LLM Transformers model."""
model_kwargs: Optional[dict] = None
"""OpenVINO model configurations."""
tokenizer: Any #: :meta private:
"""Huggingface tokenizer model."""
do_norm: bool
"""Whether normlizing the output of model"""
num_stream: int
"""Number of stream."""
encode_kwargs: Dict[str, Any] = Field(default_factory=dict)
"""Keyword arguments to pass when calling the `encode` method of the model."""
@classmethod
def from_model_id(
cls,
model_id: str,
do_norm: bool,
ov_config: Optional[dict],
model_kwargs: Optional[dict],
**kwargs: Any,
):
_model_kwargs = model_kwargs or {}
_ov_config = ov_config or {}
tokenizer = AutoTokenizer.from_pretrained(model_id, **_model_kwargs)
core = ov.Core()
model_path = Path(model_id) / "openvino_model.xml"
model = core.compile_model(model_path, **_ov_config)
num_stream = model.get_property('NUM_STREAMS')
return cls(
model=model,
tokenizer=tokenizer,
do_norm = do_norm,
num_stream=num_stream,
**kwargs,
)
class Config:
"""Configuration for this pydantic object."""
extra = Extra.forbid
def _text_length(self, text: Union[List[int], List[List[int]]]):
"""
Help function to get the length for the input text. Text can be either
a list of ints (which means a single text as input), or a tuple of list of ints
(representing several text inputs to the model).
"""
if isinstance(text, dict): # {key: value} case
return len(next(iter(text.values())))
elif not hasattr(text, '__len__'): # Object has no len() method
return 1
# Empty string or list of ints
elif len(text) == 0 or isinstance(text[0], int):
return len(text)
else:
# Sum of length of individual strings
return sum([len(t) for t in text])
def encode(self, sentences: Union[str, List[str]]):
"""
Computes sentence embeddings
Args:
sentences: the sentences to embed
Returns:
By default, a list of tensors is returned.
"""
all_embeddings = []
length_sorted_idx = np.argsort(
[-self._text_length(sen) for sen in sentences])
sentences_sorted = [sentences[idx] for idx in length_sorted_idx]
nireq = self.num_stream + 1
infer_queue = ov.AsyncInferQueue(self.model, nireq)
def postprocess(request, userdata):
embeddings = request.get_output_tensor(0).data
embeddings = np.mean(embeddings, axis=1)
if self.do_norm:
embeddings = normalize(embeddings, 'l2')
all_embeddings.extend(embeddings)
infer_queue.set_callback(postprocess)
for i, sentence in enumerate(sentences_sorted):
inputs = {}
features = self.tokenizer(
sentence, padding=True, truncation=True, return_tensors='np')
for key in features:
inputs[key] = features[key]
infer_queue.start_async(inputs, i)
infer_queue.wait_all()
all_embeddings = np.asarray(all_embeddings)
return all_embeddings
def embed_documents(self, texts: List[str]) -> List[List[float]]:
"""Compute doc embeddings using a HuggingFace transformer model.
Args:
texts: The list of texts to embed.
Returns:
List of embeddings, one for each text.
"""
texts = list(map(lambda x: x.replace("\n", " "), texts))
embeddings = self.encode(texts, **self.encode_kwargs)
return embeddings.tolist()
def embed_query(self, text: str) -> List[float]:
"""Compute query embeddings using a HuggingFace transformer model.
Args:
text: The text to embed.
Returns:
Embeddings for the text.
"""
return self.embed_documents([text])[0]
The “ov_llm_model.py” script defines wrapper classes for several transformer-based language models, making them compatible with OpenVINO for efficient deployment on Intel hardware. Each class customizes the model's input and output handling for use with OpenVINO, ensuring that the models can handle dynamic input shapes and optimized inference. The classes include methods to reshape inputs, manage past key-value states for autoregressive generation, and run asynchronous inference. Additionally, a class method _from_pretrained allows loading pre-trained models from specified paths and initializing them with the correct configuration. A dictionary model_classes maps model names to their corresponding wrapper classes.
### ov_llm_model.py
from transformers import PretrainedConfig, AutoTokenizer
from optimum.utils import NormalizedTextConfig, NormalizedConfigManager
from optimum.intel.openvino import OVModelForCausalLM
from transformers.modeling_outputs import CausalLMOutputWithPast
from optimum.intel.openvino.utils import OV_XML_FILE_NAME
from pathlib import Path
from typing import Optional, Union, Dict, Tuple, Any, List
from pathlib import Path
import openvino as ov
import torch
import numpy as np
class OVMPTModel(OVModelForCausalLM):
"""
Optimum intel compatible model wrapper for MPT
"""
def __init__(
self,
model: "Model",
config: "PretrainedConfig" = None,
device: str = "CPU",
dynamic_shapes: bool = True,
ov_config: Optional[Dict[str, str]] = None,
model_save_dir: Optional[Union[str, Path]] = None,
**kwargs,
):
NormalizedConfigManager._conf["mpt"] = NormalizedTextConfig.with_args(
num_layers="n_layers", num_attention_heads="n_heads"
)
super().__init__(
model, config, device, dynamic_shapes, ov_config, model_save_dir, **kwargs
)
def _reshape(self, model: "Model", *args, **kwargs):
shapes = {}
for inputs in model.inputs:
shapes[inputs] = inputs.get_partial_shape()
if shapes[inputs].rank.get_length() in [2, 3]:
shapes[inputs][1] = -1
elif shapes[inputs].rank.get_length() == 1:
continue
else:
if ".key" in inputs.get_any_name():
shapes[inputs][3] = -1
else:
shapes[inputs][2] = -1
model.reshape(shapes)
return model
def forward(
self,
input_ids: torch.LongTensor,
attention_mask: Optional[torch.LongTensor] = None,
past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
position_ids: Optional[torch.LongTensor] = None,
**kwargs,
) -> CausalLMOutputWithPast:
self.compile()
if self.use_cache and past_key_values is not None:
input_ids = input_ids[:, -1:]
batch_size = input_ids.shape[0]
inputs = {}
past_len = 0
if not self.stateful:
if past_key_values is not None:
past_len = past_key_values[0][1].shape[-2]
if self._pkv_precision == Type.bf16:
# numpy does not support bf16, pretending f16, should change to bf16
past_key_values = tuple(
Tensor(past_key_value, past_key_value.shape, Type.bf16)
for pkv_per_layer in past_key_values
for past_key_value in pkv_per_layer
)
else:
# Flatten the past_key_values
past_key_values = tuple(
past_key_value for pkv_per_layer in past_key_values for past_key_value in pkv_per_layer
)
# Add the past_key_values to the decoder inputs
inputs = dict(zip(self.key_value_input_names, past_key_values))
# Create empty past_key_values for decoder_with_past first generation step
elif self.use_cache:
for input_name in self.key_value_input_names:
model_inputs = self.model.input(input_name)
shape = model_inputs.get_partial_shape()
if self.config.model_type == 'chatglm':
shape[0] = 0
shape[1] = batch_size
else:
shape[0] = batch_size
if shape[2].is_dynamic:
shape[2] = 0
elif shape.rank.get_length() == 4 and shape[3].is_dynamic:
shape[3] = 0
else:
shape[1] = 0
inputs[input_name] = Tensor(model_inputs.get_element_type(), shape.get_shape())
else:
# past_key_values are not used explicitly, instead they are handled inside the model
if past_key_values is None:
# Need a marker to differentiate the first generate iteration from the others in
# the first condition at the function beginning above.
# It should be something that is not None and it should be True when converted to Boolean.
past_key_values = ((),)
# This is the first iteration in a sequence, reset all states
for state in self.request.query_state():
state.reset()
# Set initial value for the next beam_idx input that will be used at the current iteration
# and will be optionally updated by _reorder_cache at the next iterations if beam_search is used
self.next_beam_idx = np.array(range(batch_size), dtype=int)
inputs["input_ids"] = np.array(input_ids)
# Add the attention_mask inputs when needed
if "attention_mask" in self.input_names or "position_ids" in self.input_names:
if attention_mask is not None:
attention_mask = np.array(attention_mask)
else:
attention_mask = np.ones(
(input_ids.shape[0], input_ids.shape[1] + past_len), dtype=inputs["input_ids"].dtype
)
if "attention_mask" in self.input_names:
inputs["attention_mask"] = attention_mask
if "position_ids" in self.input_names:
if position_ids is not None:
position_ids = np.array(position_ids)
else:
position_ids = np.cumsum(attention_mask, axis=1) - 1
position_ids[attention_mask == 0] = 1
if past_key_values:
position_ids = np.expand_dims(position_ids[:, -1], axis=-1)
inputs["position_ids"] = position_ids
if hasattr(self, 'next_beam_idx'):
inputs['beam_idx'] = self.next_beam_idx
# Run inference
self.request.start_async(inputs, share_inputs=True)
self.request.wait()
logits = torch.from_numpy(self.request.get_tensor("logits").data).to(self.device)
if not self.stateful:
if self.use_cache:
# Tuple of length equal to : number of layer * number of past_key_value per decoder layer (2 corresponds to the self-attention layer)
past_key_values = tuple(self.request.get_tensor(key).data for key in self.key_value_output_names)
# Tuple of tuple of length `n_layers`, with each tuple of length equal to 2 (k/v of self-attention)
past_key_values = tuple(
past_key_values[i : i + self.num_pkv] for i in range(0, len(past_key_values), self.num_pkv)
)
else:
past_key_values = None
return CausalLMOutputWithPast(logits=logits, past_key_values=past_key_values)
@classmethod
def _from_pretrained(
cls,
model_id: Union[str, Path],
config: PretrainedConfig,
use_auth_token: Optional[Union[bool, str, None]] = None,
revision: Optional[Union[str, None]] = None,
force_download: bool = False,
cache_dir: Optional[str] = None,
file_name: Optional[str] = None,
subfolder: str = "",
from_onnx: bool = False,
local_files_only: bool = False,
load_in_8bit: bool = False,
**kwargs,
):
model_path = Path(model_id)
default_file_name = OV_XML_FILE_NAME
file_name = file_name or default_file_name
model_cache_path = cls._cached_file(
model_path=model_path,
use_auth_token=use_auth_token,
revision=revision,
force_download=force_download,
cache_dir=cache_dir,
file_name=file_name,
subfolder=subfolder,
local_files_only=local_files_only,
)
model = cls.load_model(model_cache_path, load_in_8bit=load_in_8bit)
init_cls = OVMPTModel
return init_cls(
model=model, config=config, model_save_dir=model_cache_path.parent, **kwargs
)
class OVCHATGLMModel(OVModelForCausalLM):
"""
Optimum intel compatible model wrapper for CHATGLM2
"""
def _reshape(self, model: "Model", *args, **kwargs):
shapes = {}
for inputs in model.inputs:
shapes[inputs] = inputs.get_partial_shape()
shapes[inputs][0] = -1
input_name = inputs.get_any_name()
if input_name.startswith('beam_idx'):
continue
if input_name.startswith('past_key_values'):
shapes[inputs][1] = -1
shapes[inputs][2] = 2
elif shapes[inputs].rank.get_length() > 1:
shapes[inputs][1] = -1
model.reshape(shapes)
return model
class OVQWENModel(OVModelForCausalLM):
"""
Optimum intel compatible model wrapper for QWEN
"""
def _reshape(self, model: "Model", *args, **kwargs):
shapes = {}
for inputs in model.inputs:
shapes[inputs] = inputs.get_partial_shape()
if inputs.get_any_name().startswith('beam_idx'):
continue
shapes[inputs][1] = -1
model.reshape(shapes)
return model
def forward(
self,
input_ids: torch.LongTensor,
past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
attention_mask: Optional[torch.LongTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
**kwargs,
) -> CausalLMOutputWithPast:
self.compile()
if self.use_cache and past_key_values is not None:
input_ids = input_ids[:, -1:]
batch_size = input_ids.shape[0]
inputs = {}
past_len = 0
if not self.stateful:
if past_key_values is not None:
past_len = past_key_values[0][1].shape[-2]
if self._pkv_precision == Type.bf16:
# numpy does not support bf16, pretending f16, should change to bf16
past_key_values = tuple(
Tensor(past_key_value, past_key_value.shape, Type.bf16)
for pkv_per_layer in past_key_values
for past_key_value in pkv_per_layer
)
else:
# Flatten the past_key_values
past_key_values = tuple(
past_key_value for pkv_per_layer in past_key_values for past_key_value in pkv_per_layer
)
# Add the past_key_values to the decoder inputs
inputs = dict(zip(self.key_value_input_names, past_key_values))
# Create empty past_key_values for decoder_with_past first generation step
elif self.use_cache:
for input_name in self.key_value_input_names:
model_inputs = self.model.input(input_name)
shape = model_inputs.get_partial_shape()
if self.config.model_type == 'chatglm':
shape[0] = 0
shape[1] = batch_size
else:
shape[0] = batch_size
if shape[2].is_dynamic:
shape[2] = 0
elif shape.rank.get_length() == 4 and shape[3].is_dynamic:
shape[3] = 0
else:
shape[1] = 0
inputs[input_name] = Tensor(model_inputs.get_element_type(), shape.get_shape())
else:
# past_key_values are not used explicitly, instead they are handled inside the model
if past_key_values is None:
# Need a marker to differentiate the first generate iteration from the others in
# the first condition at the function beginning above.
# It should be something that is not None and it should be True when converted to Boolean.
past_key_values = ((),)
# This is the first iteration in a sequence, reset all states
for state in self.request.query_state():
state.reset()
# Set initial value for the next beam_idx input that will be used at the current iteration
# and will be optionally updated by _reorder_cache at the next iterations if beam_search is used
self.next_beam_idx = np.array(range(batch_size), dtype=int)
inputs["input_ids"] = np.array(input_ids)
# Add the attention_mask inputs when needed
if "attention_mask" in self.input_names or "token_type_ids" in self.input_names:
if attention_mask is not None:
attention_mask = np.array(attention_mask)
else:
attention_mask = np.ones(
(input_ids.shape[0], input_ids.shape[1] + past_len), dtype=inputs["input_ids"].dtype
)
if "attention_mask" in self.input_names:
inputs["attention_mask"] = attention_mask
if "token_type_ids" in self.input_names:
if token_type_ids is not None:
token_type_ids = np.array(token_type_ids)
else:
token_type_ids = np.zeros(
(input_ids.shape[0], input_ids.shape[1]), dtype=inputs["input_ids"].dtype
)
inputs["token_type_ids"] = token_type_ids
if hasattr(self, 'next_beam_idx'):
inputs['beam_idx'] = self.next_beam_idx
# Run inference
self.request.start_async(inputs, share_inputs=True)
self.request.wait()
logits = torch.from_numpy(self.request.get_tensor("logits").data).to(self.device)
if not self.stateful:
if self.use_cache:
# Tuple of length equal to : number of layer * number of past_key_value per decoder layer (2 corresponds to the self-attention layer)
past_key_values = tuple(self.request.get_tensor(key).data for key in self.key_value_output_names)
# Tuple of tuple of length `n_layers`, with each tuple of length equal to 2 (k/v of self-attention)
past_key_values = tuple(
past_key_values[i : i + self.num_pkv] for i in range(0, len(past_key_values), self.num_pkv)
)
else:
past_key_values = None
return CausalLMOutputWithPast(logits=logits, past_key_values=past_key_values)
model_classes = {
"mpt": OVMPTModel,
"chatglm3": OVCHATGLMModel,
"gemma": OVModelForCausalLM,
"qwen": OVQWENModel,
"baichuan2": OVModelForCausalLM,
}
The “precision.py” script provides functions to convert machine learning models into more efficient formats (bfloat16, int8, and int4) for deployment on Intel hardware using OpenVINO. The convert_to_bfloat16 function converts a model to bfloat16 format if it doesn't already exist. It loads the model, converts its weights to bfloat16, and saves it to a specified directory. The convert_to_int8 function quantizes the bfloat16 model to int8 using OpenVINO's quantizer and saves the result, while convert_to_int4 applies further compression to the model weights, converting them to int4 format using specific compression configurations for different models. Each function ensures that model weights are appropriately compressed for efficient inference without exceeding memory or performance limits.
### precision.py
import sys
import gc
import nncf
import shutil
import openvino as ov
from optimum.intel import OVQuantizer
from optimum.intel.openvino import OVModelForCausalLM
def convert_to_bfloat16(bfloat16_model_dir,llm_model_configuration,pt_model_id):
if (bfloat16_model_dir / "openvino_model.xml").exists():
return
if not llm_model_configuration["remote"]:
ov_model = OVModelForCausalLM.from_pretrained(
pt_model_id, export=True, compile=False, load_in_8bit=False
)
ov_model.half()
ov_model.save_pretrained(bfloat16_model_dir)
del ov_model
else:
model_kwargs = {}
if "revision" in llm_model_configuration:
model_kwargs["revision"] = llm_model_configuration["revision"]
model = AutoModelForCausalLM.from_pretrained(
llm_model_configuration["model_id"],
torch_dtype=torch.float32,
trust_remote_code=True,
**model_kwargs
)
converters[pt_model_name](model, bfloat16_model_dir)
del model
gc.collect()
def convert_to_int8(int8_model_dir,bfloat16_model_dir,llm_model_configuration,pt_model_id):
if (int8_model_dir / "openvino_model.xml").exists():
return
int8_model_dir.mkdir(parents=True, exist_ok=True)
if not llm_model_configuration["remote"]:
if bfloat16_model_dir.exists():
ov_model = OVModelForCausalLM.from_pretrained(bfloat16_model_dir, compile=False, load_in_8bit=False)
else:
ov_model = OVModelForCausalLM.from_pretrained(
pt_model_id, export=True, compile=False
)
ov_model.half()
quantizer = OVQuantizer.from_pretrained(ov_model)
quantizer.quantize(save_directory=int8_model_dir, weights_only=True)
del quantizer
del ov_model
else:
convert_to_bfloat16()
ov_model = ov.Core().read_model(bfloat16_model_dir / "openvino_model.xml")
shutil.copy(bfloat16_model_dir / "config.json", int8_model_dir / "config.json")
configuration_file = bfloat16_model_dir / f"configuration_{model_type}.py"
if configuration_file.exists():
shutil.copy(
configuration_file, int8_model_dir / f"configuration_{model_type}.py"
)
compressed_model = nncf.compress_weights(ov_model)
ov.save_model(compressed_model, int8_model_dir / "openvino_model.xml")
del ov_model
del compressed_model
gc.collect()
def convert_to_int4(int4_model_dir,bfloat16_model_dir,llm_model_configuration,pt_model_id,llm_model_id):
compression_configs = {
"zephyr-7b-beta": {
"mode": nncf.CompressWeightsMode.INT4_SYM,
"group_size": 64,
"ratio": 0.6,
},
"mistral-7b": {
"mode": nncf.CompressWeightsMode.INT4_SYM,
"group_size": 64,
"ratio": 0.6,
},
"notus-7b-v1": {
"mode": nncf.CompressWeightsMode.INT4_SYM,
"group_size": 64,
"ratio": 0.6,
},"PERFORMANCE_HINT": "LATENCY", "NUM_STREAMS": "1",
"neural-chat-7b-v3-1": {
"mode": nncf.CompressWeightsMode.INT4_SYM,
"group_size": 64,
"ratio": 0.6,
},
"llama-2-chat-7b": {
"mode": nncf.CompressWeightsMode.INT4_SYM,
"group_size": 128,
"ratio": 0.8,
},
"chatglm2-6b": {
"mode": nncf.CompressWeightsMode.INT4_SYM,
"group_size": 128,
"ratio": 0.72
},
"qwen-7b-chat": {
"mode": nncf.CompressWeightsMode.INT4_SYM,
"group_size": 128,
"ratio": 0.6
},
'red-pajama-3b-chat': {
"mode": nncf.CompressWeightsMode.INT4_ASYM,
"group_size": 128,
"ratio": 0.5,
},
"default": {
"mode": nncf.CompressWeightsMode.INT4_ASYM,
"group_size": 128,
"ratio": 0.8,
},
}
model_compression_params = compression_configs.get(
llm_model_id, compression_configs["default"]
)
if (int4_model_dir / "openvino_model.xml").exists():
return
int4_model_dir.mkdir(parents=True, exist_ok=True)
if not llm_model_configuration["remote"]:
if not bfloat16_model_dir.exists():
model = OVModelForCausalLM.from_pretrained(
pt_model_id, export=True, compile=False, load_in_8bit=False
).half()
model.config.save_pretrained(int4_model_dir)
ov_model = model._original_model
del model
gc.collect()
else:
ov_model = ov.Core().read_model(bfloat16_model_dir / "openvino_model.xml")
shutil.copy(bfloat16_model_dir / "config.json", int4_model_dir / "config.json")
else:
convert_to_bfloat16()
ov_model = ov.Core().read_model(bfloat16_model_dir / "openvino_model.xml")
shutil.copy(bfloat16_model_dir / "config.json", int4_model_dir / "config.json")
configuration_file = bfloat16_model_dir / f"configuration_{model_type}.py"
if configuration_file.exists():
shutil.copy(
configuration_file, int4_model_dir / f"configuration_{model_type}.py"
)
compressed_model = nncf.compress_weights(ov_model, **model_compression_params)
ov.save_model(compressed_model, int4_model_dir / "openvino_model.xml")
del ov_model
del compressed_model
gc.collect()
Feedback
For comments and suggestions about this guide and related guides, join the discussion on Cisco Community at https://cs.co/en-cvds.
CVD Program
ALL DESIGNS, SPECIFICATIONS, STATEMENTS, INFORMATION, AND RECOMMENDATIONS (COLLECTIVELY, "DESIGNS") IN THIS MANUAL ARE PRESENTED "AS IS," WITH ALL FAULTS. CISCO AND ITS SUPPLIERS DISCLAIM ALL WARRANTIES, INCLUDING, WITHOUT LIMITATION, THE WARRANTY OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT OR ARISING FROM A COURSE OF DEALING, USAGE, OR TRADE PRACTICE. IN NO EVENT SHALL CISCO OR ITS SUPPLIERS BE LIABLE FOR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, OR INCIDENTAL DAMAGES, INCLUDING, WITHOUT LIMITATION, LOST PROFITS OR LOSS OR DAMAGE TO DATA ARISING OUT OF THE USE OR INABILITY TO USE THE DESIGNS, EVEN IF CISCO OR ITS SUPPLIERS HAVE BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
THE DESIGNS ARE SUBJECT TO CHANGE WITHOUT NOTICE. USERS ARE SOLELY RESPONSIBLE FOR THEIR APPLICATION OF THE DESIGNS. THE DESIGNS DO NOT CONSTITUTE THE TECHNICAL OR OTHER PROFESSIONAL ADVICE OF CISCO, ITS SUPPLIERS OR PARTNERS. USERS SHOULD CONSULT THEIR OWN TECHNICAL ADVISORS BEFORE IMPLEMENTING THE DESIGNS. RESULTS MAY VARY DEPENDING ON FACTORS NOT TESTED BY CISCO.
CCDE, CCENT, Cisco Eos, Cisco Lumin, Cisco Nexus, Cisco StadiumVision, Cisco TelePresence, Cisco WebEx, the Cisco logo, DCE, and Welcome to the Human Network are trademarks; Changing the Way We Work, Live, Play, and Learn and Cisco Store are service marks; and Access Registrar, Aironet, AsyncOS, Bringing the Meeting To You, Catalyst, CCDA, CCDP, CCIE, CCIP, CCNA, CCNP, CCSP, CCVP, Cisco, the Cisco Certified Internetwork Expert logo, Cisco IOS, Cisco Press, Cisco Systems, Cisco Systems Capital, the Cisco Systems logo, Cisco Unified Computing System (Cisco UCS), Cisco UCS B-Series Blade Servers, Cisco UCS C-Series Rack Servers, Cisco UCS S-Series Storage Servers, Cisco UCS X-Series, Cisco UCS Manager, Cisco UCS Management Software, Cisco Unified Fabric, Cisco Application Centric Infrastructure, Cisco Nexus 9000 Series, Cisco Nexus 7000 Series. Cisco Prime Data Center Network Manager, Cisco NX-OS Software, Cisco MDS Series, Cisco Unity, Collaboration Without Limitation, EtherFast, EtherSwitch, Event Center, Fast Step, Follow Me Browsing, FormShare, GigaDrive, HomeLink, Internet Quotient, IOS, iPhone, iQuick Study, LightStream, Linksys, MediaTone, MeetingPlace, MeetingPlace Chime Sound, MGX, Networkers, Networking Academy, Network Registrar, PCNow, PIX, PowerPanels, ProConnect, ScriptShare, SenderBase, SMARTnet, Spectrum Expert, StackWise, The Fastest Way to Increase Your Internet Quotient, TransPath, WebEx, and the WebEx logo are registered trade-marks of Cisco Systems, Inc. and/or its affiliates in the United States and certain other countries. (LDW_P1)
All other trademarks mentioned in this document or website are the property of their respective owners. The use of the word partner does not imply a partnership relationship between Cisco and any other company. (0809R)