AI Inferencing on Cisco UCS X-Series with Intel AMX for Medical Image Analysis
Available Languages
Bias-Free Language
The documentation set for this product strives to use bias-free language. For the purposes of this documentation set, bias-free is defined as language that does not imply discrimination based on age, disability, gender, racial identity, ethnic identity, sexual orientation, socioeconomic status, and intersectionality. Exceptions may be present in the documentation due to language that is hardcoded in the user interfaces of the product software, language used based on RFP documentation, or language that is used by a referenced third-party product. Learn more about how Cisco is using Inclusive Language.
- US/Canada 800-553-2447
- Worldwide Support Phone Numbers
- All Tools
 Feedback
Feedback
 Feedback
Feedback

In partnership with:

About the Cisco Validated Design Program
The Cisco Validated Design (CVD) program consists of systems and solutions designed, tested, and documented to facilitate faster, more reliable, and more predictable customer deployments. For more information, go to: http://www.cisco.com/go/designzone.
"AI everywhere" is more than just an IT buzzword; it’s a fundamental shift that every organization is experiencing through the transformative effects of AI workloads on their operations. The main AI challenge in healthcare lies in ensuring the accuracy, reliability, and interpretability of AI-driven models, particularly in high-stake areas like medical diagnostics. While AI has the potential to improve efficiency and decision-making, its adoption is hindered by concerns around data privacy, model transparency, and bias in training datasets. Additionally, integrating AI into existing healthcare workflows and systems can be complex, requiring seamless collaboration between technology and healthcare professionals. Overcoming these challenges is crucial to ensuring AI's effectiveness in improving patient outcomes and supporting clinical decision-making.
The integration of Cisco UCS X-Series servers with Red Hat OpenShift, powered by 5th Generation Intel Xeon Scalable Processors and managed through Cisco Intersight, offers a comprehensive solution for optimizing AI workloads, particularly those requiring intensive inferencing capabilities. This cohesive ecosystem simplifies management through Cisco Intersight’s intuitive interface, enabling efficient operations and streamlining the deployment and scaling of AI workloads. Leveraging the computational power of AMX accelerated 5th Gen Intel Xeon processors, organizations can handle complex AI tasks with improved speed, scalability, and reliability, making it an ideal infrastructure for high-demand applications across industries.
This Cisco validated design document covers Intel AMX accelerated medical diagnosis solution for assessment of pneumonia using chest x-rays, built on Red Hat Validated Patterns and the GitOps framework. By leveraging advanced machine learning capabilities, this approach enhances both accuracy and operational efficiency, while enabling proactive solutions across healthcare industries. Adopting this framework can lead to improved performance, reduced risks, and better outcomes, not only in healthcare but also in sectors like public safety, security, and manufacturing quality control.
This chapter contains the following:
● Audience
This section provides a rationale for the selection of the hardware and software stack utilized in this solution, spanning from the infrastructure layer to the software layer.
In healthcare industries, current detection process for many types of medical conditions, including pneumonia assessment, skin cancers, and so on involves imaging. For example, collecting images of the suspect or at-risk patches is becoming common to be able to check their development over time.
AI lends itself to being effectively a medical assistant in medical imaging in a variety of ways, including:
● Automating tasks: AI can be used to automate tasks such as image segmentation, which is the process of identifying and isolating different parts of an image. This can free up radiologists to focus on more complex tasks, such as interpreting images.
● Detecting abnormalities: AI can be used to detect abnormalities in medical images that may be invisible to the human eye. This is especially useful for detecting small or subtle changes that can be early signs of disease.
● Personalizing treatment: AI can be used to personalize treatment for patients based on their individual medical imaging data. This can help to ensure that patients receive the most effective treatment possible.
● Providing clinical decision support: AI can be used to provide clinical decision support to radiologists and other healthcare professionals. This can help them to make more informed decisions about patient care.
There are challenges to using AI in this manner such as the ability to explain the results, the use of training data while maintaining confidentiality, and algorithm validation. Nonetheless, AI has the potential to make a significant impact on medical imaging. As the technology continues to develop, we can expect to see even more innovative and beneficial applications of AI in this field.
Solution Value
In collaboration with Red Hat, Intel has showcased how straightforward it is to leverage particular hardware features embedded in 5th Generation Intel® Xeon® Scalable processors when utilizing Red Hat validated patterns. Features like Intel® Advanced Matrix Extensions (Intel® AMX) are specifically engineered to enhance AI performance and strengthen security across a diverse array of applications, all of which are seamlessly integrated with OpenShift.
The validated pattern discussed in this solution is an adapted version of the Medical Diagnosis pattern, specifically enhanced to highlight the capabilities of 5th Generation Intel Xeon Scalable Processors, particularly Intel AMX, which accelerates AI workloads. It is based on a demo implementation of an automated data pipeline for analyzing chest X-rays that Red Hat had previously developed. While it retains the same functionality as the original demo, this version employs the GitOps framework for deployment, incorporating Operators, namespace creation, and cluster configuration.
This model should be able to scale up or down on-demand in a real-time basis. Scalability in healthcare industries can be possible only with automation and cloud native architecture, where all interactions are in a disconnected mode. Disconnected mode refers to establishing communication between the solution components over a network. Validated pattern’s automated deployment approach can enhance these cloud native architectures to scale on-demand.
The solution outlined in this guide aims to tackle the afore mentioned challenges encountered by organizations when adopting Generative AI models. The combination of Cisco UCS X-Series Modular System featuring 5th Gen Intel Xeon Scalable processors with Red Hat OpenShift, supplemented by Red Hat® validated patterns encompass all the necessary code and Red Hat® OpenShift® components to deploy specific AI use cases. This reference architecture highlights the following features.
● Optimal performance: Cisco UCS with Intel Xeon Scalable processors with specialized AI accelerators and optimized software frameworks significantly improves inferencing performance and scalability. Cisco Nex-us 9000 switches provide high bandwidth, low latency, congestion management mechanisms, and telemetry to meet the demanding networking requirements of AI/ML applications.
● Balanced architecture: Cisco UCS excels in both Deep Learning and non-Deep Learning compute, critical for the entire inference pipeline. This balanced approach leads to better overall performance and resource utilization.
● Scalability on demand: Cisco UCS seamlessly scales with your AI inferencing needs. Add or remove servers, adjust memory capacities, and configure resources in an automated manner as your models evolve and workloads grow using Cisco Intersight®.
● Faster inferencing with cost efficiency: Intel® AMX brings a range of efficiency improvements, leading to cost reduction, boosts deep learning task performance by optimizing inference, lower total cost of owner-ship (TCO), and progress towards sustainability objectives.
● Adoptability: Red Hat® OpenShift® AI offers a versatile and scalable platform equipped with tools for building, deploying, and managing AI-driven applications. Red Hat Validated Patterns consist of distributed patterns constructed within a GitOps framework that aim to streamline the testing and deployment of complex setups and showcase business value through the integration of real-world workloads and use cases.
This document is intended for, but not limited to, sales engineers, technical consultants, solution architecture and enterprise IT, and machine learning teams interested in design, deployment, and life cycle management of generative AI systems.
This document outlines a reference architecture featuring Red Hat OpenShift Baremetal deployed on Cisco UCS X210c M7 Compute Nodes equipped with 5th Gen Intel Xeon Scalable processors for demonstrating Pneumonia assessment data pipeline built using Intel AMX accelerated Red Hat Validated Patterns. This solution not only illustrates AI adaption in healthcare industry but also discusses the ease with which this demo pipeline can be considered as a foundational framework and further enhanced/extended for analyzing many other health risks and also utilized in other industries which uses image-based analysis.
The Cisco UCS X-Series Modular System supports 5th Gen Intel Xeon Scalable Processors so that you have the option to run inferencing in the data center or at the edge. The Cisco UCS X-Series Modular System, powered by Intersight, is a versatile and forward-looking solution designed to streamline IT operations and keep pace with software-driven innovations.
● By consolidating onto this platform, you can benefit from the density and efficiency of blade servers combined with the scalability of rack servers.
● Embrace emerging technologies and mitigate risks with a system engineered to seamlessly support future advancements, with management delivered through Software as a Service (SaaS).
● Adapt to the demands of your business with agility and scalability, shaping the Cisco UCS X-Series to match your workload requirements using Cisco Intersight.
5th Gen Intel Xeon processors are engineered to seamlessly handle demanding AI workloads, including inference and fine-tuning on models containing up to 20 billion parameters, without an immediate need for additional hardware. Furthermore, the compatibility of 5th Gen with 4th Gen Intel Xeon processors facilitates a smooth upgrade process for existing solutions, minimizing the need for extensive testing and validation.
Intel Xeon processors are equipped with:
● Intel Advanced Matrix Extensions (Intel AMX) accelerator, an AI accelerator, is built into each core to significantly speed up deep-learning applications when 8-bit integer (INT8) or 16-bit float (bfloat16) datatypes are used.
● Higher core frequency, larger last-level cache, and faster memory with DDR5 speed up compute processing and memory access.
● Improved cost-effectiveness is provided by combining the latest-generation AI hardware with software optimizations, which potentially lowers TCO by enabling the use of built-in accelerators to scale-out inferencing performance rather than relying on discrete accelerators, making generative AI more accessible and affordable.
● DeepSpeed provides high-performance inference support for large transformer-based models with billions of parameters, through enablement of multi-CPU inferencing. It automatically partitions models across the specified number of CPUs and inserts necessary communications to run multi-CPU inferencing for the model.
Red Hat Validated patterns empower developers with:
● Quick Environment Setup: Red Hat Validated Patterns enable developers to rapidly create a fully operational environment on OpenShift.
● Streamlined AI Workflow Management: These patterns facilitate reliable and easy management of AI workflows without the complexity of configuration details.
● Integration with Red Hat® OpenShift® AI: Developers can utilize validated patterns, including those enhanced by Intel, to optimize AI workflow development.
● Accelerated Workflow Creation: This solution allows developers and data scientists to build more dependable AI workflows faster than ever.
● Comprehensive AI Lifecycle Support: OpenShift AI covers the entire AI lifecycle, including data acquisition and preparation, model training and fine-tuning, as well as model serving and monitoring.
● Continuous Testing and Updates: Validated patterns come with all the necessary code and are regularly tested for updates, security, and reliability, promoting continuous integration.
● Automated Builds and Tests: This enables frequent updates to the application stack, enhancing software quality and significantly reducing validation and release times.
The reference architecture outlined in this guide presents a systematic approach to deploying an enterprise-ready Red Hat OpenShift Baremetal solution tailored for AI/ML workloads on Cisco UCS infrastructure. Cisco UCS X-Series servers are engineered to swiftly adapt to evolving business demands, facilitating the on-demand deployment of new computing resources to enhance business outcomes. With Cisco UCS, organizations can fine-tune their environments to accommodate the specific requirements of each application, consolidating all server workloads under the centralized management of Cisco Intersight.
Cisco UCS offers the versatility of both nonvirtualized and virtualized systems in a manner unmatched by other server architectures, leading to cost reductions and improved return on investment (ROI). Recognized for its commitment to sustainability, Cisco UCS X-Series earned the 2023 SEAL Sustainable Product Award for products that are “purpose-built” for a sustainable future.
Managed through Cisco Intersight and powered by Intel Xeon Scalable Processors, Cisco UCS X-Series servers integrated with the leading container platform Red Hat OpenShift offer a compelling solution to address these challenges and optimize generative AI performance. Here are some of the benefits:
● Streamlined Management: Cisco Intersight provides centralized management for Cisco UCS X-Series servers, simplifying operations and enhancing efficiency.
● Powerful Processing: Leveraging Intel Xeon Scalable Processors, the Cisco UCS X-Series servers deliver robust computational power, enabling accelerated AI model training and inference.
● Containerized Environment: Red Hat OpenShift offers a containerized platform that enhances scalability, flexibility, and resource utilization for AI workloads.
● Enhanced Performance: By combining Cisco UCS X-Series servers with Red Hat OpenShift, organizations can achieve improved performance for generative AI tasks, ensuring faster insights and decision-making.
● Scalability and Agility: The solution offers scalability to accommodate growing AI workloads and agility to adapt to evolving business requirements seamlessly.
● Integrated Ecosystem: Cisco UCS X-Series servers, Cisco Intersight, Intel Xeon Scalable processors, and Red Hat OpenShift form an integrated ecosystem, providing a cohesive infrastructure for AI-driven applications.
The solution aims to educate on the primary objectives of the Validated Patterns development process, focusing on creating modular and customizable demonstrations. The Medical Diagnosis pattern serves as an example of how AI/ML workloads designed for object detection and classification can be executed on OpenShift clusters.
Consider your workloads and how they can best utilize the pattern framework. Determine whether your users require on-demand or near real-time responses when using your application. Assess whether your application processes images or data protected by Government Privacy Laws or HIPAA. The Medical Diagnosis pattern effectively meets these requirements by leveraging OpenShift Serverless and OpenShift Data Foundation.
This chapter contains the following:
● Cisco UCS X-Series Modular System
● Cisco UCS 6500 Series Fabric Interconnect
● Intel Xeon Scalable Processor Family
● Red Hat OpenShift Container Platform
Cisco UCS X-Series Modular System
The Cisco Unified Computing System X-Series (Cisco UCSX) is a modular, next-generation data center platform that builds upon the unique architecture and advantages of the previous Cisco UCS 5108 system. The Cisco UCS X-Series is a standards-based open system designed to be deployed and automated quickly in a hybrid cloud environment. The following key enhancements in Cisco UCS X-Series simplify IT operations:
● Cloud-managed infrastructure: With Cisco UCS X-Series, the management of the network infrastructure is moved to the cloud, making it easier and simpler for IT teams to respond quickly and at scale to meet the needs of your business. The Cisco Intersight cloud-operations platform allows you to adapt the resources of the Cisco UCS X-Series Modular System to meet the specific requirements of a workload. Additionally, you can seamlessly integrate third-party devices such as Pure Storage and VMware vCenter. This integration also enables global visibility, monitoring, optimization, and orchestration for all your applications and infrastructure.
● Adaptable system designed for modern applications: Today's cloud-native and hybrid applications are dynamic and unpredictable. Application and DevOps teams frequently deploy and redeploy resources to meet evolving requirements. To address this, the Cisco UCS X-Series provides an adaptable system that doesn't lock you into a fixed set of resources. It combines the density, manageability, and efficiency of blade servers with the expandability of rack servers, allowing you to consolidate multiple workloads onto a single platform. This consolidation results in improved performance, automation, and efficiency for both hybrid and traditional data center applications.
● Platform engineered for the future: The Cisco UCS X-Series is designed to adapt to emerging technologies with minimal risk. It is a modular system that can support future generations of processors, storage, nonvolatile memory, accelerators, and interconnects. This eliminates the need to purchase, configure, maintain, power, and cool separate management modules and servers. Cloud-based management through Intersight ensures automatic updates and access to new capabilities delivered through a software-as-a-service model.
● Broad support for diverse workloads: The Cisco UCS X-Series supports a broad range of workloads, reducing the need for different products which lowers support costs, training costs, and gives you more flexibility in your data center environment.
The Cisco UCS X-Series chassis is engineered to be adaptable and flexible. With a midplane-free design, I/O connectivity for the Cisco UCS X9508 chassis is accomplished with front-loading vertically oriented computing nodes that intersect with horizontally oriented I/O connectivity modules in the rear of the chassis. A unified Ethernet fabric is supplied with the Cisco UCS 9108 IFMs. Cisco UCS X9508 Chassis’ superior packaging enables larger compute nodes, thereby providing more space for actual compute components, such as memory, GPU, drives, and accelerators. Improved airflow through the chassis enables support for higher power components, and more space allows for future thermal solutions (such as liquid cooling) without limitations.
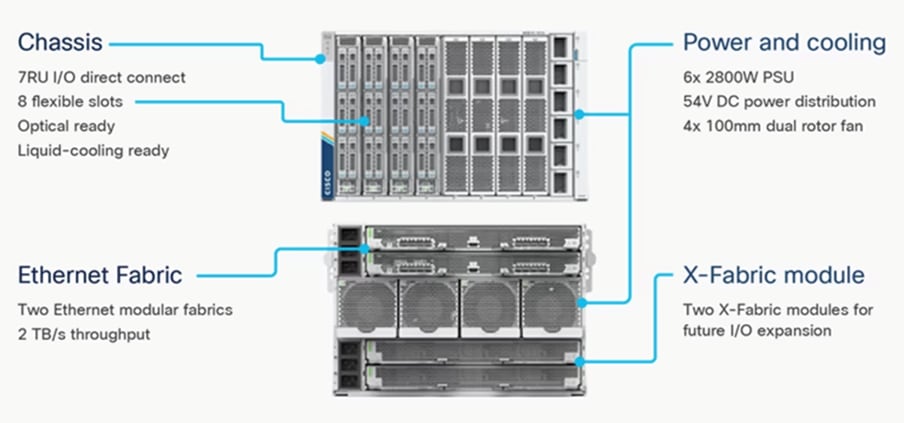
The Cisco UCS X9508 Chassis (Figure 1) provides the following features and benefits:
● The 7RU chassis has 8 front-facing flexible slots. These slots can house a combination of computing nodes and a pool of future I/O resources, which may include graphics processing unit (GPU) accelerators, disk storage, and nonvolatile memory.
● Two Cisco UCS 9108 IFMs at the top of the chassis connect the chassis to upstream Cisco UCS 6400 Series Fabric Interconnects (FIs). Each IFM offers these features:
◦ The module provides up to 100 Gbps of unified fabric connectivity per computing node.
◦ The module provides eight 25-Gbps Small Form-Factor Pluggable 28 (SFP28) uplink ports.
◦ The unified fabric carries management traffic to the Cisco Intersight cloud-operations platform, Fibre Channel over Ethernet (FCoE) traffic, and production Ethernet traffic to the fabric interconnects.
● At the bottom of the chassis are slots used to house Cisco UCS X9416 X-Fabric Modules which enables GPU connectivity to the Cisco UCS X210c Compute Nodes.
● Six 2800-watt (W) power supply units (PSUs) provide 54 volts (V) of power to the chassis with N, N+1, and N+N redundancy. A higher voltage allows efficient power delivery with less copper wiring needed and reduced power loss.
● Efficient, 4 x 100-mm, dual counter-rotating fans deliver industry-leading airflow and power efficiency. Optimized thermal algorithms enable different cooling modes to best support the network environment. Cooling is modular, so future enhancements can potentially handle open- or closed-loop liquid cooling to support even higher-power processors.
The Cisco UCS X210 M7 server is a high-performance and highly scalable server designed for data centers and enterprise environments. Some of the key benefits of this server are:
● Performance: The Cisco UCS X210 M7 server is built to deliver exceptional performance. It features the latest Intel Xeon Scalable processors, providing high processing power for demanding workloads such as virtualization, database management, and analytics. The server's architecture is designed to optimize performance across a wide range of applications.
● Scalability: The Cisco UCS X210 M7 server offers excellent scalability options, allowing organizations to easily scale their computing resources as their needs grow. With support for up to eight CPUs and up to 112 DIMM slots, the server can accommodate large memory configurations and high core counts, enabling it to handle resource-intensive applications and virtualization environments.
● Memory Capacity: The server supports a large memory footprint, making it suitable for memory-intensive workloads. It can accommodate a vast amount of DDR4 DIMMs, providing a high memory capacity for applications that require significant data processing and analysis.
● Enhanced Virtualization Capabilities: The Cisco UCS X210 M7 server is designed to optimize virtualization performance. It includes features such as Intel Virtualization Technology (VT-x) and Virtual Machine Device Queues (VMDq), which improve virtual machine density and network performance in virtualized environments. These capabilities enable organizations to consolidate their workloads and achieve efficient resource utilization.
● Simplified Management: The Cisco Unified Computing System (Cisco UCS) management software provides a unified and streamlined approach to server management. The Cisco UCS Manager software allows administrators to manage multiple servers from a single interface, simplifying operations and reducing management complexity. Additionally, the server integrates with Cisco's ecosystem of management tools, providing enhanced visibility, automation, and control.
● High Availability and Reliability: The Cisco UCS X210 M7 server is built with redundancy and fault tolerance in mind. It includes features such as hot-swappable components, redundant power supplies, and redundant fans, ensuring high availability and minimizing downtime. The server's architecture is designed to support mission-critical applications that require continuous operation.
● Energy Efficiency: Cisco UCS servers are designed to be energy-efficient. The Cisco UCS X210 M7 server incorporates power management features that optimize power usage and reduce energy consumption. This not only helps organizations reduce their carbon footprint but also lowers operating costs over time.

Cisco UCS Virtual Interface Cards (VICs)
● Cisco UCS X210c M7 Compute Nodes support multiple Cisco UCS VIC cards. This design uses the Cisco UCS VIC 15000 adapter.
● Cisco UCS X210c M7 Compute Nodes support the following Cisco UCS VIC cards:
◦ Cisco UCS VIC 15231
Cisco UCS VIC 15231 fits the mLOM slot in the Cisco UCS X210c Compute Node and enables up to 100 Gbps of unified fabric connectivity to each of the chassis IFMs for a total of 200 Gbps of connectivity per server. Cisco UCS VIC 15231 connectivity to the IFM and up to the fabric interconnects is delivered through 100Gbps. Cisco UCS VIC 15231 supports 512 virtual interfaces (both FCoE and Ethernet) along with the latest networking innovations such as NVMeoF over FC or TCP, VxLAN/NVGRE offload, and so forth.
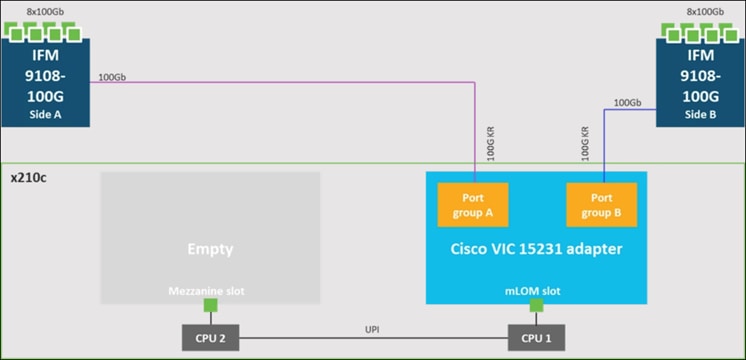
Cisco UCS VIC 15420
Cisco UCS VIC 15420 fits the mLOM slot in the Cisco UCS X210c Compute Node and enables up to 50 Gbps of unified fabric connectivity to each of the chassis IFMs for a total of 100 Gbps of connectivity per server. Cisco UCS VIC 15420 connectivity to the IFM and up to the fabric interconnects is delivered through 4x 25-Gbps connections, which are configured automatically as 2x 50-Gbps port channels. Cisco UCS VIC 15420 supports 512 virtual interfaces (both Fibre Channel and Ethernet) along with the latest networking innovations such as NVMeoF over RDMA (ROCEv2), VxLAN/NVGRE offload, and so on.
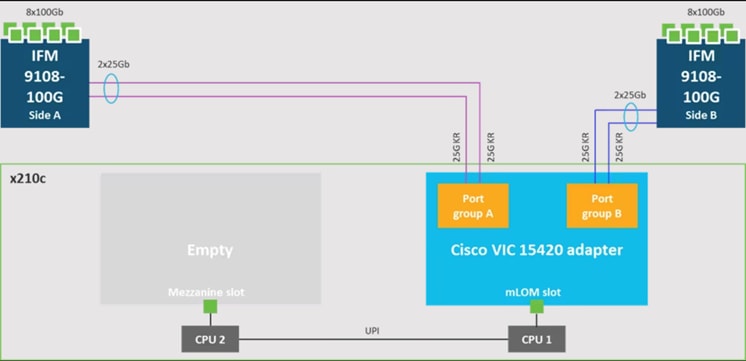
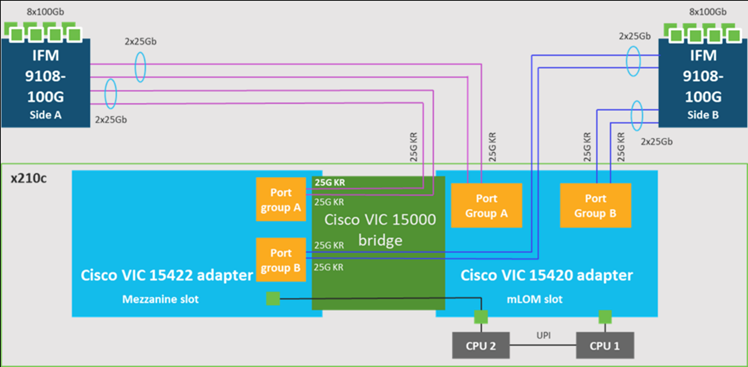
Cisco UCS VIC 15422
The optional Cisco UCS VIC 15422 fits the mezzanine slot on the server. A bridge card (UCSX-V5-BRIDGE) extends this VIC’s 2x 50 Gbps of network connections up to the mLOM slot and out through the mLOM’s IFM connectors, bringing the total bandwidth to 100 Gbps per fabric for a total bandwidth of 200 Gbps per server.
Cisco UCS 6500 Series Fabric Interconnect
The Cisco UCS Fabric Interconnects (FIs) provide a single point of connectivity and management for the entire Cisco UCS system. Typically deployed as an active/active pair, the system’s FIs integrate all components into a single, highly available management domain controlled by the Cisco UCS Manager or Cisco Intersight. Cisco UCS FIs provide a single unified fabric for the system, with low-latency, lossless, cut-through switching that supports LAN, SAN, and management traffic using a single set of cables.
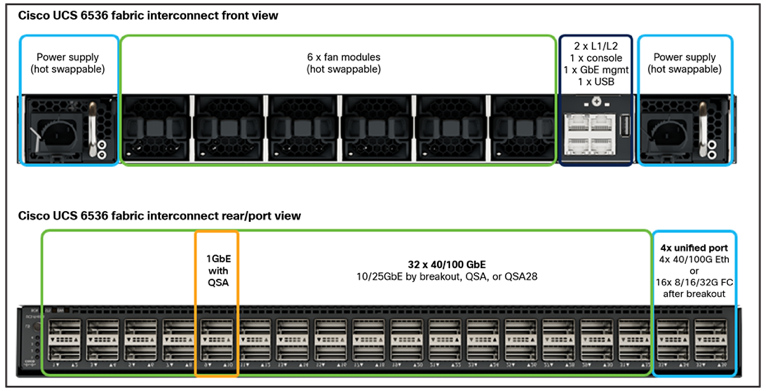
The Cisco UCS 6536 Fabric Interconnect utilized in the current design is a One-Rack-Unit (1RU) 1/10/25/40/100 Gigabit Ethernet, FCoE, and Fibre Channel switch offering up to 7.42 Tbps throughput and up to 36 ports. The switch has 32 40/100-Gbps Ethernet ports and 4 unified ports that can support 40/100-Gbps Ethernet ports or 16 Fiber Channel ports after breakout at 8/16/32-Gbps FC speeds. The 16 FC ports after breakout can operate as an FC uplink or FC storage port. The switch also supports two ports at 1-Gbps speed using QSA, and all 36 ports can breakout for 10- or 25-Gbps Ethernet connectivity. All Ethernet ports can support FCoE.
The Cisco UCS 6536 Fabric Interconnect (FI) is a core part of the Cisco Unified Computing System, providing both network connectivity and management capabilities for the system. The Cisco UCS 6536 Fabric Interconnect offers line-rate, low-latency, lossless 10/25/40/100 Gigabit Ethernet, Fibre Channel, NVMe over Fabric, and Fibre Channel over Ethernet (FCoE) functions.
The Cisco UCS 6536 Fabric Interconnect provides the communication backbone and management connectivity for the Cisco UCS X-Series compute nodes, Cisco UCS X9508 X-series chassis, Cisco UCS B-Series blade servers, Cisco UCS 5108 B-Series server chassis, and Cisco UCS C-Series rack servers. All servers attached to a Cisco UCS 6536 Fabric Interconnect become part of a single, highly available management domain. In addition, by supporting a unified fabric, Cisco UCS 6536 Fabric Interconnect provides both LAN and SAN connectivity for all servers within its domain.
From a networking perspective, the Cisco UCS 6536 uses a cut-through architecture, supporting deterministic, low-latency, line-rate 10/25/40/100 Gigabit Ethernet ports, a switching capacity of 7.42 Tbps per FI and 14.84 Tbps per unified fabric domain, independent of packet size and enabled services. It enables 1600Gbps bandwidth per X9508 chassis with X9108-IFM-100G in addition to enabling end-to-end 100G ethernet and 200G aggregate bandwidth per X210c compute node. With the X9108-IFM-25G and the IOM 2408, it enables 400Gbps bandwidth per chassis per FI domain. The product family supports Cisco low-latency, lossless 10/25/40/100 Gigabit Ethernet unified network fabric capabilities, which increases the reliability, efficiency, and scalability of Ethernet networks. The Cisco UCS 6536 Fabric Interconnect supports multiple traffic classes over a lossless Ethernet fabric from the server through the fabric interconnect. Significant TCO savings come from the Unified Fabric optimized server design in which network interface cards (NICs), Host Bus Adapters (HBAs), cables, and switches can be consolidated.
As applications and data become more distributed from core data center and edge locations to public clouds, a centralized management platform is essential. IT agility will be struggle without a consolidated view of the infrastructure resources and centralized operations. Cisco Intersight provides a cloud-hosted, management and analytics platform for all Cisco UCS and other supported third-party infrastructure across the globe. It provides an efficient way of deploying, managing, and upgrading infrastructure in the data center, ROBO, edge, and co-location environments.
Cisco Intersight API can help you to programmatically:
● Simplify the way they manage their infrastructure.
● Automate configurations and provision for their data center.
● Save long provisioning time.
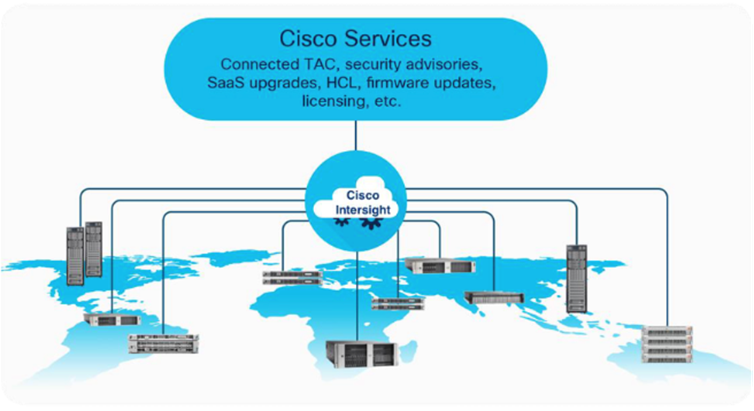
The main benefits of Cisco Intersight infrastructure services follow:
● Simplify daily operations by automating many daily manual tasks.
● Combine the convenience of a SaaS platform with the capability to connect from anywhere and manage infrastructure through a browser or mobile app.
● Stay ahead of problems and accelerate trouble resolution through advanced support capabilities.
● Gain global visibility of infrastructure health and status along with advanced management and support capabilities.
● Upgrade to add workload optimization when needed.
Intel Xeon Scalable Processor Family
The Intel® Xeon® Scalable processors come with built-in accelerators and featured technologies that help optimize workload-specific performance, accelerate AI capabilities, reduce data center latency, reduce data bottlenecks, and balance resource consumption. Intel® Accelerator Engines are purpose-built integrated accelerators on Intel® Xeon® Scalable processors that deliver performance and power efficiency advantages across today’s fastest-growing workloads.
Intel Xeon Scalable processors are designed to meet your organization's computing needs whether it is empowering solid foundations for AI innovation and HPC, supporting critical workloads at the edge, building a secure cloud. They offer optimized performance, scale, and efficiency across a broad range of data center, edge, and workstation workloads.
5th Gen Intel Xeon Scalable Processors
5th Gen Intel Xeon Scalable processors are designed to help boost performance, reduce costs, and improve power efficiency for today’s demanding workloads, enabling you to achieve greater business outcomes.
These processors deliver impressive performance-per-watt gains across all workloads, with higher performance and lower total cost of ownership (TCO) for AI, databases, networking, storage, and high-performance computing (HPC). They offer more compute, larger shared last-level cache, and faster memory at the same power envelope as the previous generation. They are also software- and platform compatible with the 4th Gen Intel Xeon processors, so you can minimize testing and validation when deploying new systems for AI and other workloads.

Some of the key features of 5th Gen Intel Xeon Scalable processors include[1]:
● Built-in AI accelerators on every core, Intel® Advanced Matrix Extensions (Intel®AMX) for a big leap in DL inference and training performance.
● Intel AI software suite of optimized open-source frameworks and tools.
● Out-of-the-box AI performance and E2E productivity with 300+ DL models validated.
● The 5th Gen Intel Xeon processor provides higher core count, better scalability for training and inferencing parallel tasks.
● 5th Gen Intel Xeon processor supports 5600MT/s DDR5 memory speed -16% increase over 4th Gen.
● Boost performance for memory-bound and latency-sensitive workloads with faster memory.
● With up to 320 MB last-level cache shared across all cores — an up to 2.7x increase in last-level cache[2].
Intel Advanced Matrix Extensions (Intel AMX)
Intel Advanced Matrix Extensions (Intel AMX) enables Intel Xeon processors to boost the performance of deep-learning training and inferencing workloads by balancing inference, which is the most prominent use case for a CPU in AI applications, with more capabilities for training. Customers can experience up to 14x better training and inference versus 3rd Gen Intel Xeon processors[3].
Primary benefits of Intel AMX include:
● Improved performance
CPU-based acceleration can improve power and resource utilization efficiencies, giving you better performance for the same price.
For example, 5th Gen Intel Xeon Platinum 8592+ with Intel AMX BF16 has shown up to 10.7x higher real-time speech recognition inference performance (RNN-T) and 7.9x higher performance/watt vs. 3rd Gen Intel Xeon processors with FP32.4.
● Reduced Total Cost of Ownership (TCO)
Intel Xeon processors with Intel AMX enable a range of efficiency improvements that help with decreasing costs, lowering TCO, and advancing sustainability goals.
As an integrated accelerator on Intel Xeon processors, Intel AMX enables you to maximize the investments you have already made and get more from your CPU, removing the cost and complexity typically associated with the addition of a discrete accelerator.
Intel Xeon processors with Intel AMX can also provide a more cost-efficient server architecture compared to other available options, delivering both power and emission reduction benefits.
● Reduced development time
To simplify the process of developing deep-learning applications, Intel works closely with the open-source community, including the TensorFlow and PyTorch projects, to optimize frameworks for Intel hardware, upstreaming Intel’s newest optimizations and features so they are immediately available to developers. This enables you to take advantage of the performance benefits of Intel AMX with the addition of a few lines of code, reducing overall development time.
For more information, see: https://www.intel.com/content/www/us/en/products/docs/accelerator-engines/advanced-matrix-extensions/overview.html
Red Hat OpenShift Container Platform
The Red Hat OpenShift Container Platform (OCP) is a container application platform that brings together CRI-O and Kubernetes and provides an API and web interface to manage these services. CRI-O is a lightweight implementation of the Kubernetes CRI (Container Runtime Interface) to enable using Open Container Initiative (OCI) compatible runtimes including runc, crun, and Kata containers.
OCP allows you to create and manage containers. Containers are standalone processes that run within their own environment, independent of the operating system and the underlying infrastructure. OCP helps develop, deploy, and manage container-based applications. It provides a self-service platform to create, modify, and deploy applications on demand, thus enabling faster development and release life cycles. OCP has a microservices-based architecture of smaller, decoupled units that work together and is powered by Kubernetes with data about the objects stored in etcd, a reliable clustered key-value store.
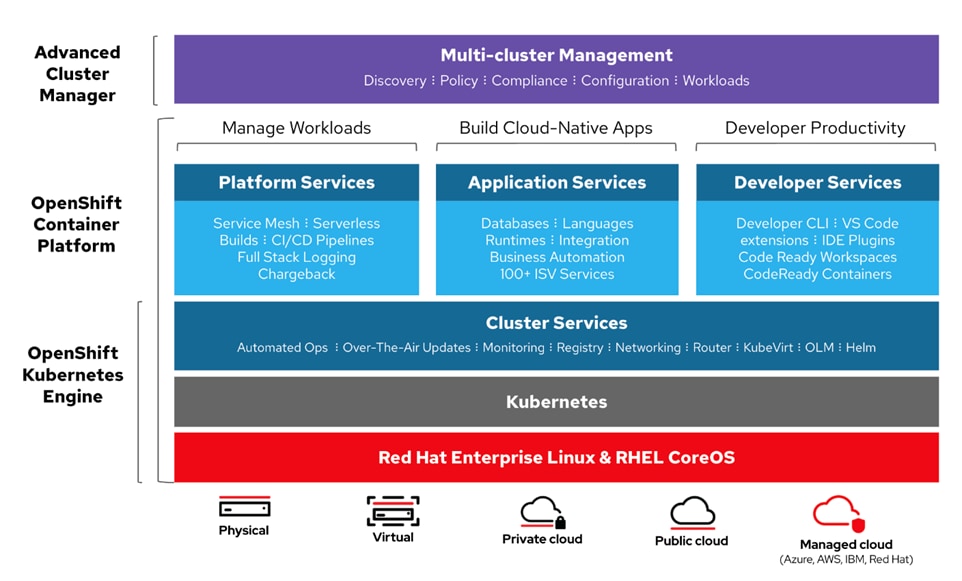
Red Hat OpenShift is an application platform that drives innovation, anywhere. It empowers organizations to modernize their applications and infrastructure, build new cloud-native applications, accelerate their digital transformation, and fuel growth. AI/ML workloads typically run as docker containers or on Linux virtual machines. Red Hat OpenShift AI leverages OpenShift’s capabilities in application development and container infrastructure management to enable a robust, scalable, and secure environment for model delivery and MLOps. OpenShift Administrators manage all aspects of the underlying infrastructure, from GPU resources to storage to user access. This eases the operational burden on ML engineers and data scientists, enabling them to focus on model delivery and less on managing the infrastructure. This operational benefit is a key advantage of using OpenShift AI such as the underlying infrastructure is administered by IT teams that currently manage OpenShift. The provisioned resources (for example - CPUs, GPUs), and other aspects such as identity management and user access are seamlessly available and integrated into OpenShift AI, making it significantly easier to use the platform.
Kubernetes Infrastructure
Within OpenShift Container Platform, Kubernetes manages containerized applications across a set of CRI-O runtime hosts and provides mechanisms for deployment, maintenance, and application scaling. The CRI-O service packages, instantiates, and runs containerized applications.
A Kubernetes cluster consists of one or more control plane nodes and a set of worker nodes. This solution design includes HA functionality at the hardware as well as the software stack. An OCP cluster is designed to run in HA mode with 3 control plane nodes and a minimum of 2 worker nodes to help ensure that the cluster has no single point of failure.
Kubernetes Operator
AI/ML workloads, like many modern applications, are using containers and Kubernetes (K8S) orchestration as the de facto development environment for model development and AI-enabled applications. Kubernetes offer several benefits, but one key attribute is its extensibility. Kubernetes provides an Operator framework that vendors and open-source communities can use to develop and deploy self-contained operators that extend the capabilities of the K8s cluster. These operators generally require minimum provisioning and are usually self-managed with automatic updates (unless disabled) and handle life-cycle management. Kubernetes operators are probably the closest thing to an easy-button in infrastructure provisioning (short of IaC). In the Red Hat OpenShift environment that this solution uses, it is even easier to deploy and use operators. Red Hat OpenShift provides an embedded OperatorHub, directly accessible from the cluster console. The Red Hat OperatorHub has hundreds of Red Hat and community certified operators that can be deployed with a few clicks.
To support AI/ML workloads and OpenShift AI, the following Red Hat OpenShift operators are deployed in this solution to enable CPU, storage, and other resources:
● Red Hat Node Feature Discovery Operator to identify and label hardware resources (for example, NVIDIA GPUs)
● Red Hat Data OpenShift AI Operator deploys OpenShift AI on any OpenShift cluster
● OpenShift Pipelines for automating model pipelines in OpenShift AI
For more information on Red Hat OpenShift Operators, see: https://www.redhat.com/en/technologies/cloud-computing/openshift/what-are-openshift-operators.
Red Hat Hybrid Cloud Console
Red Hat Hybrid Cloud Console is a centralized SaaS-based management console for deploying and managing multiple OCP clusters. It is used in this solution to provide consistent container management across a hybrid environment. The SaaS model enables Enterprises to develop, deploy, and innovate faster across multiple infrastructures and quickly take advantage of new capabilities without the overhead of managing the tool. The console gives Enterprises more control and visibility as environments grow and scale. The Hybrid Cloud Console also provides tools to proactively address issues, open and manage support cases, manage cloud costs, subscriptions, and more.
For more information, see: Red Hat Hybrid Cloud Console product page on redhat.com.
Installation Options
Red Hat Enterprise Linux CoreOS (RHCOS) is deployed automatically using configurations in the ignition files. The OCP installer creates the Ignition configuration files necessary to deploy the OCP cluster with RHCOS. The configuration is based on the user provided responses to the installer. These files and images are downloaded and installed on the underlying infrastructure by the installer.
● Openshift-install is a command line utility for installing openshift in cloud environments and on-prem. It collects information from the user, generates manifests, and uses terraform to provision and configure infrastructure that will compose a cluster.
● Assisted Installer is a cloud-hosted installer available at https://console.redhat.com as both an API and a guided web UI. After defining a cluster, the user downloads a custom “discovery ISO” and boots it on the systems that will be provisioned into a cluster, at which point each system connects to console.redhat.com for coordination. Assisted installer offers great flexibility and customization while ensuring success by running an extensive set of validations prior to installation.
● Agent-based installer is a command line utility that delivers the functionality of the Assisted Installer in a stand-alone format that can be run in disconnected and air-gapped environments, creating a cluster without requiring any other running systems besides a container registry.
● Red Hat Advanced Cluster Management for Kubernetes (see the section below) includes the Assisted Installer running on-premises behind a Kubernetes API in addition to a web UI. OpenShift’s baremetal platform features, especially the baremetal-operator, can be combined with the Assisted Installer to create an integrated end-to-end provisioning flow that uses Redfish Virtual Media to automatically boot the discovery ISO on managed systems.
For more information on installation options, see: https://console.redhat.com/openshift/create/datacenter
Red Hat Enterprise Linux CoreOS (RHCOS)
RHCOS is a lightweight operating system specifically designed for running containerized workloads. It is based on the secure, enterprise-grade Red Hat Enterprise Linux (RHEL). RHCOS is the default operating system on all Red Hat OCP cluster nodes. RHCOS is tightly controlled, allowing only a few system settings to be modified using the Ignition configuration files. RHCOS is designed to be installed as part of an OCP cluster installation process with minimal user configuration. Once the cluster is deployed, the cluster will fully manage the RHCOS subsystem configuration and upgrades.
RHCOS includes:
● Ignition – for initial bootup configuration and disk related tasks on OCP cluster nodes
Ignition serves as a first boot system configuration utility for initially bringing up and configuring the nodes in the OCP cluster. Starting from a tightly-controlled OS image, the complete configuration of each system is expressed and applied using ignition. It also creates and formats disk partitions, writes files, creates file systems and directories, configures users, and so on. During a cluster install, the control plane nodes get their configuration file from the temporary bootstrap machine used during install, and the worker nodes get theirs from the control plane nodes. After an OCP cluster is installed, subsequent configuration of nodes is done using the Machine Config Operator to manage and apply ignition.
● CRI-O – Container Engine running on OCP cluster nodes
CRI-O is a stable, standards-based, lightweight container engine for Kubernetes that runs and manages the containers on each node. CRI-O implements the Kubernetes Container Runtime Interface (CRI) for running Open Container Initiative (OCI) compliant runtimes. OCP’s default container runtime is runc. CRI-O has a small footprint and a small attack surface, with an emphasis on security and simplicity. CRI-O is a Cloud Native Computing Foundation (CNCF) incubating project.
● Kubelet – Kubernetes service running on OCP cluster nodes
Kubelet is a Kubernetes service running on every node in the cluster. It communicates with the control plane components and processes requests for running, stopping, and managing container workloads.
● Set of container tools
Container Tools: RHCOS includes a set of container tools (including podman, skopeo, and crictl) for managing containers and container image actions such as start, stop, run, list, remove, build, sign, push, and pull.
● rpm-ostree combines RPM package management with libostree’s immutable content-addressable operating system image management. RHCOS is installed and updated using libostree, guaranteeing that the installed OS is in a known state, with transactional upgrades and support for rollback.
Note: RHCOS was used on all control planes and worker nodes to support the automated OCP 4 deployment.
Red Hat OpenShift AI
Red Hat OpenShift AI (previously known as Red Hat OpenShift Data Science or RHODS) is a flexible and scalable platform for MLOps using Red Hat OpenShift as the foundation. Along with OpenShift AI, all AI/ML workloads, including ML models and AI-enabled applications can be hosted on OpenShift. IT operations teams that manage Kubernetes cluster resources for existing application environments, can continue to do the same for OpenShift AI and AI/ML workloads. Once provisioned, the resources will be directly accessible from the OpenShift AI console for AI/ML teams to use.
Figure 10 illustrates how the model operation life cycle integrates with the initial offering of OpenShift Data Science as a common platform. It provides a core data science workflow as a Red Hat managed service, with the opportunity for increased capabilities and collaboration through ISV-certified software. Models are either hosted on OpenShift cloud service or exported for integration into an intelligent application.
Core tools and capabilities provided with OpenShift AI offer a solid foundation:
● Jupyter notebooks. Data scientists can conduct exploratory data science in JupyterLab with access to core AI/ML libraries and frameworks, including TensorFlow and PyTorch.
● Source-to-image (S2I). Models can be published as endpoints via S2I for integration into intelligent applications and can be rebuilt and redeployed based on changes to the source notebook.
● Optimized inference. Deep learning models can be converted into optimized inference engines to accelerate experiments.
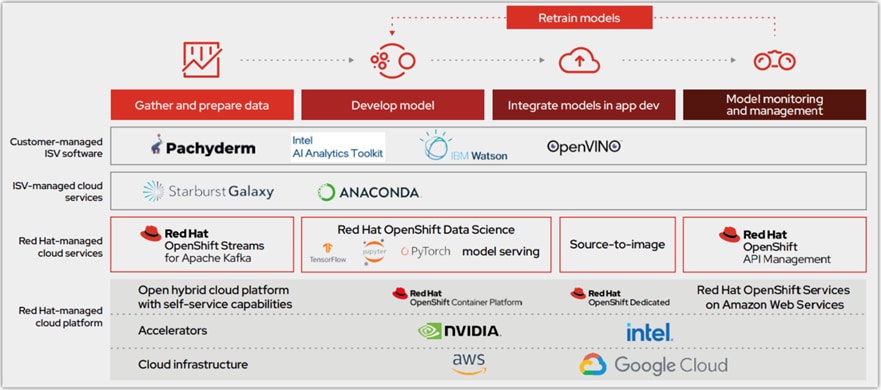
Red Hat OpenShift AI includes key capabilities to accelerate the delivery of AI/ML models and applications in a seamless, consistent manner, at scale. The platform provides the development environment, tools, and frameworks that data scientists and machine learning teams need to build, deploy, and maintain AI/ML models in production. OpenShift AI streamlines the ML model delivery process from development to production deployment (model serving) with efficient life cycle management and pipeline automation. From the OpenShift AI console, AI teams can select from a pre-integrated, Red Hat supported set of tools and technologies or custom components that are enterprise managed, providing the flexibility that teams need to innovate and operate with efficiency. OpenShift AI also makes it easier for multiple teams to collaborate on one or more efforts in parallel.
Red Hat OpenShift ODF
Red Hat OpenShift Data Foundation is a highly integrated collection of cloud storage and data services for Red Hat OpenShift Container Platform. It is available as part of the Red Hat OpenShift Container Platform Service Catalog, packaged as an operator to facilitate simple deployment and management.
Red Hat OpenShift Data Foundation services are primarily made available to applications by way of storage classes that represent the following components:
● Block storage devices, catering primarily to database workloads. Prime examples include Red Hat OpenShift Container Platform logging and monitoring, and PostgreSQL.
● Shared and distributed file system, catering primarily to software development, messaging, and data aggregation workloads. Examples include Jenkins build sources and artifacts, Wordpress uploaded content, Red Hat OpenShift Container Platform registry, and messaging using JBoss AMQ.
● Multicloud object storage, featuring a lightweight S3 API endpoint that can abstract the storage and retrieval of data from multiple cloud object stores.
● On premises object storage, featuring a robust S3 API endpoint that scales to tens of petabytes and billions of objects, primarily targeting data intensive applications. Examples include the storage and access of row, columnar, and semi-structured data with applications like Spark, Presto, Red Hat AMQ Streams (Kafka), and even machine learning frameworks like TensorFlow and PyTorch.
Red Hat OpenShift Data Foundation version 4.x integrates a collection of software projects, including:
● Ceph, providing block storage, a shared and distributed file system, and on-premises object storage
● Ceph CSI, to manage provisioning and lifecycle of persistent volumes and claims
● NooBaa, providing a Multicloud Object Gateway
● OpenShift Data Foundation, Rook-Ceph, and NooBaa operators to initialize and manage OpenShift Data Foundation services.
Red Hat Validated Patterns
Red Hat’s validated patterns are tools for simplifying and replicating your deployments. They are predefined configurations that comprehensively describe a full edge computing and hybrid cloud stack, from services to supporting infrastructure.
Unlike a reference architecture, validated patterns are based on actual customer deployments and are actively maintained over time. They are also validated not only through continuous integration (CI), but with the support of product teams and solutions architects. By using GitOps to deliver configuration as code, validated patterns leverage upstream repositories for open collaboration.
Validated patterns are reliable and less risky because they are maintained and deployed in the real world. They provide a quick proof of concept (PoC) for deploying complex workloads and can be quickly implemented into your streamlined GitOps framework. They have many opportunities for customization and innovation and include a demo to show an example workload use case.
At a high level, a validated pattern uses helmcharts to create templates of the code architecture for a given use case. This template is a well-defined workflow that contains “values” and “secrets” files that manage overrides, making the deployment specific to your use case. Sub-patterns are then applied to multiple layers of the architecture, helping to deploy the components reliably and according to best practices.
Deploying the pattern will follow these general steps:
1. Find a pattern for a use case that fits your needs and fork the pattern repository.
2. Change secrets and/or values files in the local clone to specify overrides for your use case.
3. Deploy the pattern workflow, which will first deploy Red Hat OpenShift® GitOps. OpenShift GitOps will deploy the application(s) and make sure all the components of the pattern are working correctly, including operators and application code.
4. Most patterns will also have a Red Hat Advanced Cluster Management operator deployed so that multi-cluster deployments can be managed.
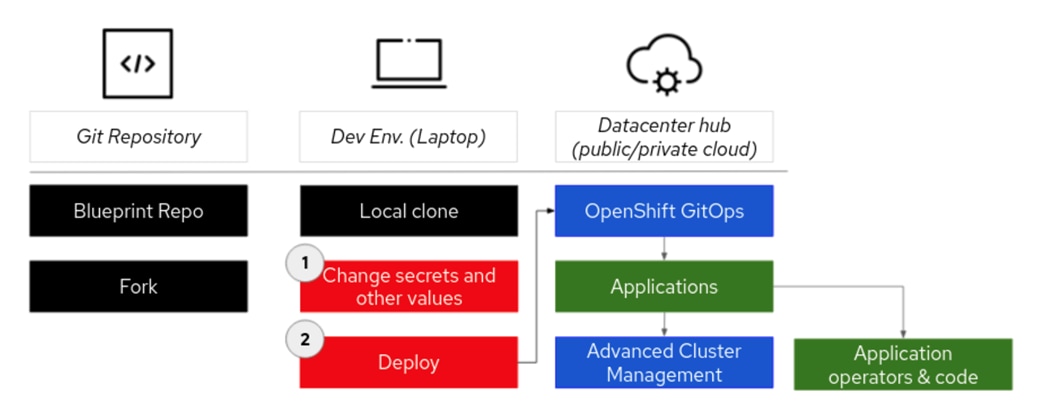
The validated pattern workflow begins with the pattern’s git repository which is then cloned and updated via changes to values files. The pattern operator then deploys all the needed operators for the workload using OpenShift GitOps.
Red Hat OpenShift GitOps
Red Hat® OpenShift® GitOps is an operator that provides a workflow that integrates git repositories, continuous integration/continuous delivery (CI/CD) tools, and Kubernetes to realize faster, more secure, scalable software development, without compromising quality.
OpenShift GitOps enables customers to build and integrate declarative git driven CD workflows directly into their application development platform.
There’s no single tool that converts a development pipeline to "DevOps". By implementing a GitOps framework, updates and changes are pushed through declarative code, automating infrastructure and deployment requirements, and CI/CD.
ArgoCD
Implemented as a Kubernetes controller, ArgoCD continually monitors running applications to verify that the live state matches the desired state, as defined in Git. If an application’s live state deviates from the desired state, ArgoCD reports the differences and allows the live state to be automatically synced to match the desired state. Additionally, any changes made to the “single source of truth” can automatically be applied to the target environments.
Put simply, ArgoCD is an easy-to-use tool that allows development teams to deploy and manage applications without having to learn a lot about Kubernetes, and without needing full access to the Kubernetes system. This hugely simplifies the process of running applications in Kubernetes, leading to better security and increased developer productivity.
Red Hat Advanced Cluster Management for Kubernetes
Red Hat® Advanced Cluster Management for Kubernetes controls clusters and applications from a single console, with built-in security policies. Extend the value of Red Hat OpenShift® by deploying apps, managing multiple clusters, and enforcing policies across multiple clusters at scale. Red Hat’s solution ensures compliance, monitors usage, and maintains consistency.
This chapter contains the following:
● Hardware and Software Components
The Cisco UCS X-Series Modular System, powered by 5th Gen Intel Xeon Scalable processors with Red Hat OpenShift AI solution, is designed to achieve the following objectives:
● Simplify and Streamline Operations for AI/ML: The solution aims to simplify operations for AI/ML tasks while ensuring seamless integration into existing deployments and processes.
● Flexible Design: With a flexible design, the solution offers options for various tools, technologies, and individual components, enabling easy modifications in terms of network, compute, and storage to accommodate evolving needs.
● Modular Architecture: The solution features a modular design where subsystem components such as links, interfaces, models, and platforms can be expanded or upgraded as required, providing scalability and adaptability.
● Scalability: As the deployment scales, compute resources can be effortlessly scaled up or out to meet growing demands, ensuring optimal performance and resource utilization.
● Resilient Infrastructure: The solution is built with a resilient design across all layers of the infrastructure, eliminating single points of failure and enhancing reliability and availability for critical AI/ML workloads.
The following sections explains the solution architecture and design that meets these design requirements.
This solution is based on Red Hat validated pattern is built upon a demo implementation of an automated data pipeline for chest X-ray analysis originally developed by Red Hat. Additionally, this solution distinguishes itself by utilizing the GitOps framework for deployment, which encompasses the management of Operators, the creation of namespaces, and overall cluster configuration. By leveraging GitOps, the pattern enables efficient continuous deployment.
The workflow begins with the ingestion of chest X-rays from a simulated X-ray machine, which are then stored in an object store powered by Ceph Object Store. This object store subsequently sends notifications to a Kafka topic, where a KNative Eventing listener is triggered. This listener activates a KNative Serving function that runs a machine learning model within a container, performing risk assessments for pneumonia on the incoming images. Additionally, a Grafana dashboard visualizes the entire pipeline in real-time, displaying incoming images, processed data, anonymization results, and comprehensive metrics collected by Prometheus.
For more information on the workflow of the validated pattern-based data pipeline that helps in Pneumonia assessment, see Functionality of the Pneumonia Assessment Data Pipeline.
Solution Topology
As shown in Figure 12, we deployed Red Hat OpenShift on Cisco UCS X210c compute nodes powered by 5th Gen Intel Xeon Scalable processors.
This solution is an enterprise-ready Red Hat OpenShift architecture with 3x control-plane nodes for HA. There is a 1x worker node configured specifically to run pneumonia assessment. A Cisco UCS 9508 chassis with 4x Cisco UCS X210 M7 servers are connected using 100GbE IFM modules to Cisco UCS Fabric Interconnects, deployed in Intersight Managed Mode (IMM). 4 x 100GbE links from each IFM connect are bundled in a port-channel and connected to each Fabric Interconnect to provide an aggregate bandwidth of 800Gbps to the chassis with up to 8 Cisco UCS compute servers. Cisco Nexus Switches ensure high-bandwidth and lossless communication. Two Cisco Nexus 9000 Series Switches in Cisco NX-OS mode provide top-of-rack switching. The fabric interconnects use multiple 100GbE links to connect to the Nexus switches in a VPC configuration. At least two 100 Gigabit Ethernet ports from each FI, in a port-channel configuration are connected to each Nexus 9000 Series Switch. The high-performance servers are deployed as OpenShift compute nodes and booted using the Assisted Installer deployed RHCOS image on local M.2 boot drives in a RAID1 configuration. Persistent storage volumes for running Red Hat Validated Patterns based Medical Diagnosis solution are created by utilizing local NVMe drives available on 4x Cisco UCS X210c compute nodes, facilitated by Red Hat OpenShift Data Foundation. Each Cisco UCS X210 M7 compute node is equipped with a Cisco UCS VIC 15231 that provides 2 x 100GbE ports for 200Gbps of bandwidth from each server to the chassis.
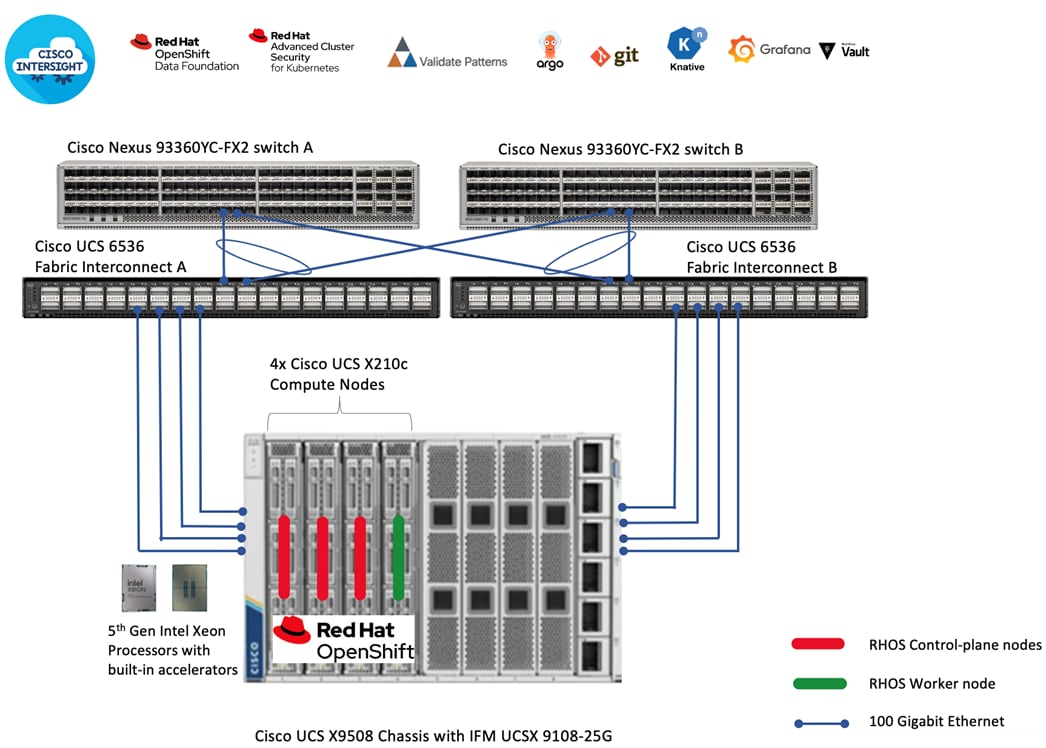
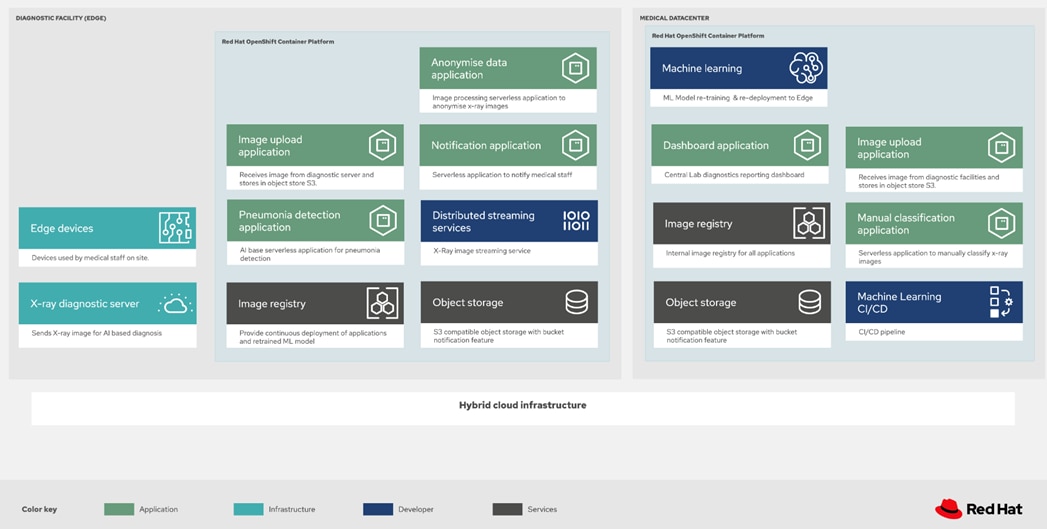
The solution helps you understand the following:
● How to use a GitOps approach to keep in control of configuration and operations
● How to deploy AI/ML technologies for medical diagnosis using GitOps
The Medical Diagnosis pattern uses the following products and technologies:
● Red Hat OpenShift Container Platform for container orchestration
● Red Hat OpenShift GitOps, a GitOps continuous delivery (CD) solution
● Red Hat AMQ, an event streaming platform based on the Apache Kafka
● Red Hat OpenShift Serverless for event-driven applications
● Red Hat OpenShift Data Foundation for cloud native storage capabilities
● Grafana Operator to manage and share Grafana dashboards, data sources, and so on
● Node Feature Discovery Operator to label nodes with Intel AMX capabilities
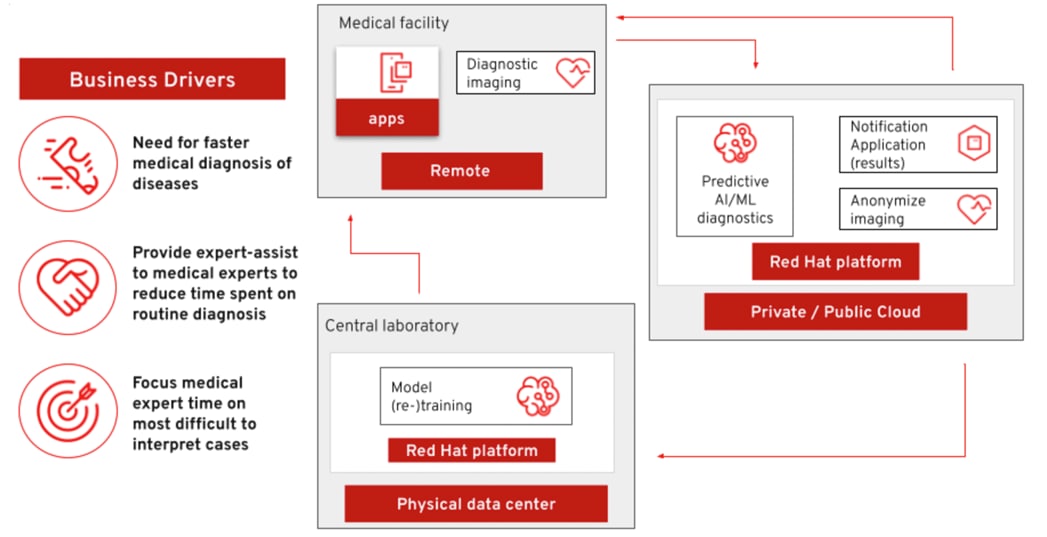
The solution shown in Figure 14 has two distinct locations: the diagnostic facility where the medical staff and the edge x-ray devices are located and the medical data center where development and monitoring of the solution takes place.
Initial images are sent into the diagnostic facility image receiver and an event is registered to start the processing for automated diagnosis. These images are stored locally, anonymized, and automatically evaluated for possible disease detection. A notification is generated for the medical staff, whether automated detection, non-detection, or an edge case requiring qualified medical staff review. (In many cases, medical staff will want to give at least a quick review of detection and non-detection cases as well.)
In the process of image capture and processing, the images are sent back to the medical data center to be added to the collection used for model training and development. The applications, machine learning models, data science development, and dashboards for monitoring the processes are all in constant evolution. Developers and operations teams maintain code and infrastructure manifests for full GitOps deployment of the architectural elements.
Note: The Intel AMX accelerated Medical Diagnosis pattern currently does not include an edge component. Plans for integrating edge deployment capabilities are in place for a future release of the pattern architecture. As a result, both image generation and processing are currently performed within the data center.
Hardware and Software Components
Table 1 lists the details about the hardware and software components used in this solution.
Table 1. Hardware and Software components
| Component name |
Details |
Image version |
Quantity |
| Computing |
Cisco UCS X-Series blade chassis can host combination of Cisco UCS X210c M7 compute nodes and a pool of IO resources that include GPU accelerators, disk storage and non-volatile memory. The Chassis has UCS 9108 100G IFM proving 100G connectivity to the compute nodes on each side of the Fabric. |
|
1 |
| Cisco UCS X210c M7 compute node |
Each node is equipped with 2x Intel 5th Gen Intel Xeon Scalable processors 8568Y+ each with 48 cores running at 2.3GHz base frequency. Each node has 16x 64G memory (total of 1024GB) running at 4800 MTs. Each compute node has one Cisco UCS VIC 15231 providing 100Gbps connectivity on each side of the Fabric. |
5.2(1.240010) |
4 |
| Cisco UCS 6536 Fabric Interconnect |
Cisco UCS 6536 Fabric Interconnect providing both network connectivity and management capabilities for the system. |
4.3(2.230117) |
2 |
| Cisco Nexus Switch |
Cisco Nexus 93360YC-FX2 for high-bandwidth lossless connectivity |
NXOS version 10.2(5) |
2 |
| Red Hat OpenShift |
Red Hat OpenShift Container Platform 4.16 |
4.16 |
1 |
This chapter contains the following:
● Configure Cisco UCS X-Series Servers using Cisco Intersight
● Deploy Red Hat OpenShift Baremetal
● Prepare Red Hat OpenShift Cluster to Deploy Medical Diagnosis
● Deploy Intel AMX Accelerated Medical Diagnosis Pattern
This chapter provides insight into the deployment process. The infrastructure proposed in this solution incorporates Cisco UCS M7 Platform X-Series servers. We deployed Red Hat OpenShift Baremetal on 4x X210c M7 blade servers powered by Intel Xeon 5th Gen platinum processors (48 cores – 8568Y+). Pneumonia detection implementation discussed in this paper is based on Red Hat Validated Pattern extended to showcase 5th Generation Intel Xeon Scalable Processors capabilities, especially Intel AMX that speeds up AI workloads. This demo pipeline is developed using Red Hat OpenShift validated pattern approach. Validated Pattern consist of distributed patterns constructed within a GitOps framework. These patterns aim not only to streamline the testing and deployment of complex setups but also to showcase business value through the integration of real-world workloads and use cases. The validated pattern uses Node Feature Discovery Operator, whose task is to detect hardware features and expose them as labels for the baremetal nodes. It also used Red Hat OpenShift Serverless component, which is modified to assign AI workload to nodes with available Intel AMX feature. Red Hat OpenShift Data Foundation is software-defined storage for containers and have leveraged NVMe drives residing in 4x X210c nodes to deploy Red Hat OpenShift Data Foundation.
The model used for the Pneumonia assessment pipeline is Keras-Neural Network from Kaggle. This model is a simple Neural Network model for binary classification. The code needed to train such NN can be found here: https://www.kaggle.com/code/kosovanolexandr/keras-nn-x-ray-predict-pneumonia-86-54. Intel has used Intel's Neural Compressor (https://github.com/intel/neural-compressor) to quantize the model from fp32 to int8 precision. This allows to use Intel AMX operations to speed up inference without much drop in accuracy.
Configure Cisco UCS X-Series Servers using Cisco Intersight
Cisco UCS X-Series Configuration - Cisco Intersight Managed Mode is shown in this configuration diagram:
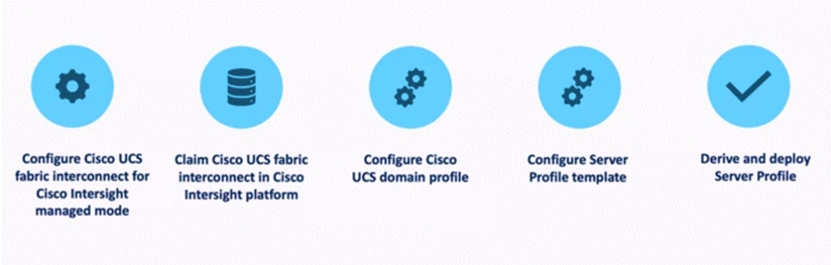
The stages are as follows:
1. Set Up Cisco UCS Fabric Interconnect for Cisco Intersight Managed Mode.
During the initial configuration, for the management mode the configuration wizard enables customers to choose whether to manage the fabric interconnect through Cisco UCS Manager or the Cisco Intersight platform. Customers can switch the management mode for the fabric interconnects between Cisco Intersight and Cisco UCS Manager at any time; however, Cisco UCS FIs must be set up in Intersight Managed Mode (IMM) for configuring the Cisco UCS X-Series system.
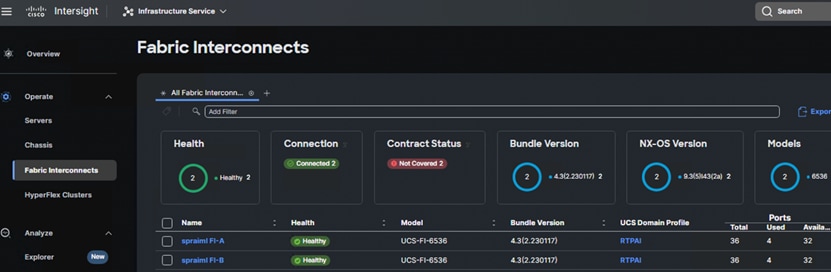
2. Claim a Cisco UCS Fabric Interconnect in the Cisco Intersight Platform.
After setting up the Cisco UCS 6536 Fabric Interconnect for Cisco Intersight Managed Mode, FIs can be claimed to a new or an existing Cisco Intersight account. When a Cisco UCS Fabric Interconnect is successfully added to Cisco Intersight, all future configuration steps are completed in the Cisco Intersight portal.
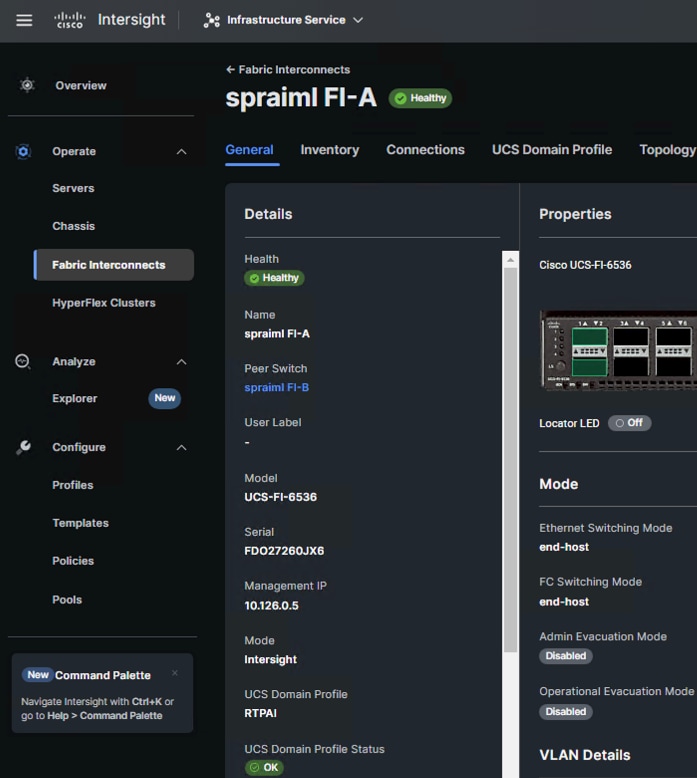
You can verify whether a Cisco UCS Fabric Interconnect is in Cisco UCS Manager managed mode or Cisco Intersight Managed Mode by clicking on the fabric interconnect name and looking at the detailed information screen for the FI.
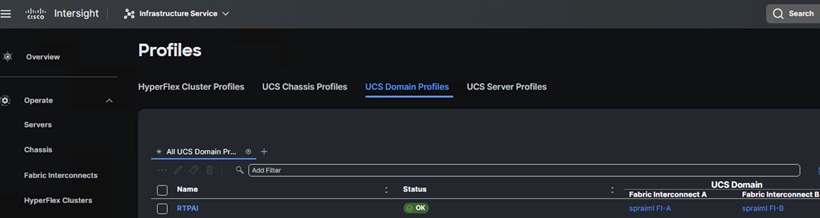
3. Cisco UCS Domain Profile.
A Cisco UCS domain profile configures a fabric interconnect pair through reusable policies, allows configuration of the ports and port channels, and configures the VLANs and VSANs to be used in the network. It defines the characteristics of and configures the ports on the fabric interconnects. One Cisco UCS domain profile can be assigned to one fabric interconnect domain.
Some of the characteristics of the Cisco UCS domain profile are:
● A single domain profile is created for the pair of Cisco UCS fabric interconnects.
● Unique port policies are defined for the two fabric interconnects.
● The VLAN configuration policy is common to the fabric interconnect pair because both fabric interconnects are configured for the same set of VLANs.
● The Network Time Protocol (NTP), network connectivity, and system Quality-of-Service (QoS) policies are common to the fabric interconnect pair.
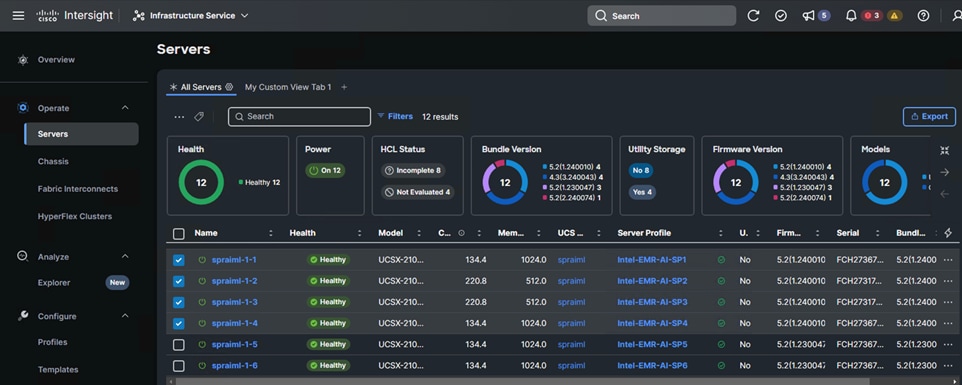
The Cisco UCS X9508 Chassis and Cisco UCS X210c M7 Compute Nodes are automatically discovered when the ports are successfully configured using the domain profile as shown below:
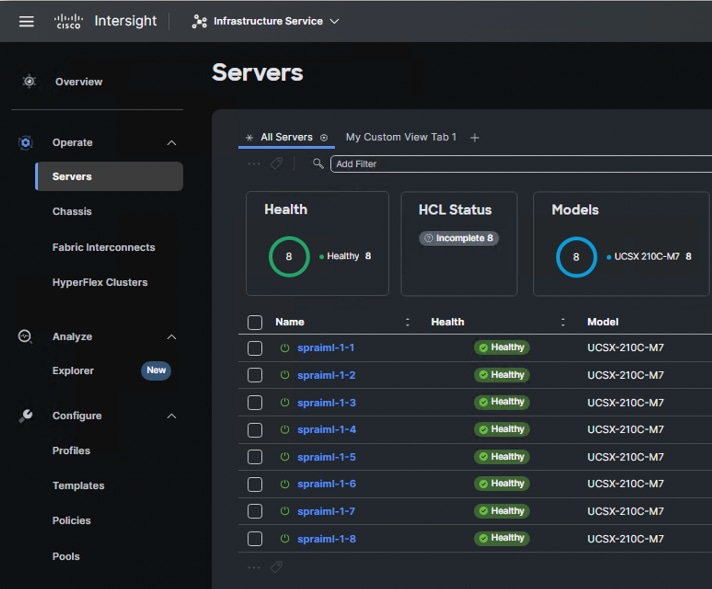
For this solution, the first 4 Cisco UCS x210c Compute nodes were used.
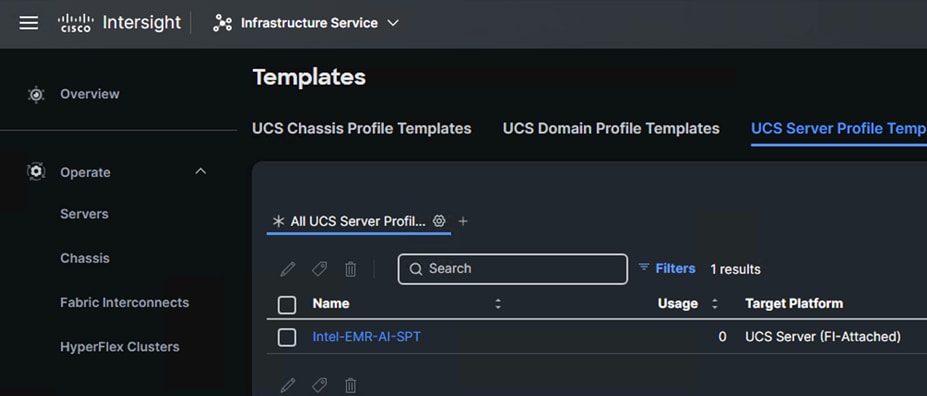
4. Server Profile Template.
A server profile template enables resource management by simplifying policy alignment and server configuration. A server profile template is created using the server profile template wizard.
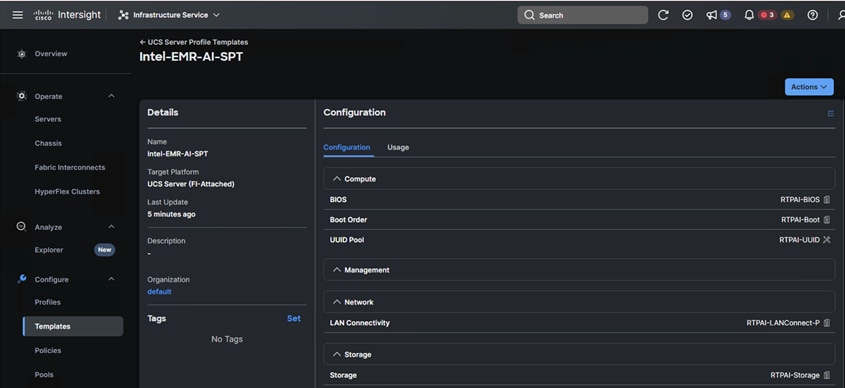
The server profile template wizard groups the server policies into the following four categories to provide a quick summary view of the policies that are attached to a profile:
● Compute policies: BIOS, boot order, and virtual media policies.
● Network policies: adapter configuration and LAN connectivity. The LAN connectivity policy requires you to create Ethernet network policy, Ethernet adapter policy, and Ethernet QoS policy.
● Storage policies: configuring local storage for application.
● Management policies: device connector, Intelligent Platform Management Interface (IPMI) over LAN, Lightweight Directory Access Protocol (LDAP), local user, network connectivity, Simple Mail Transfer Protocol (SMTP), Simple Network Management Protocol (SNMP), Secure Shell (SSH) and so on.
Some of the characteristics of the server profile template for our solution are:
● BIOS policy is created to specify various server parameters in accordance with the solution best practices.
● Boot order policy defines virtual media (KVM mapper DVD), local storage and UEFI Shell.
● IMC access policy defines the management IP address pool for KVM access.
● Local user policy is used to enable KVM-based user access.
● LAN connectivity policy is used to create virtual network interface cards (vNICs) — Various policies and pools are also created for the vNIC configuration.
5. Derive and deploy Server Profiles.
Server profiles are derived from server-profile templates and applied on baremetal UCS servers that are claimed in Cisco Intersight. When the server profiles are applied successfully, you can see the profile status as shown in the screenshot below.
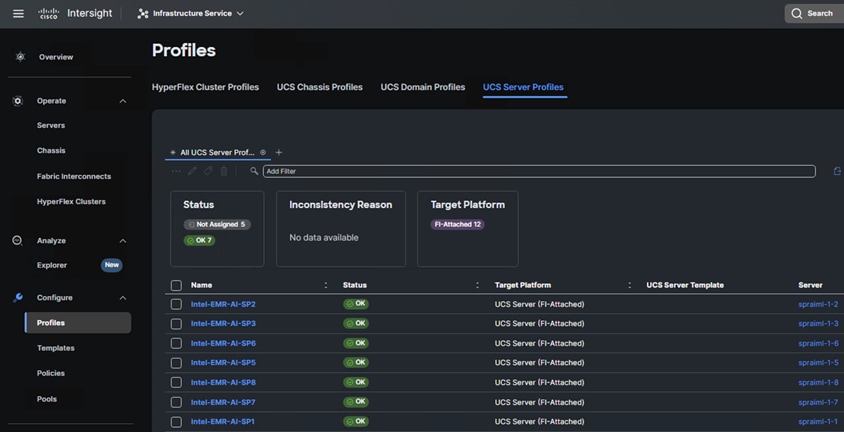
Once the server profiles are successfully applied, you can proceed with Red OpenShift Baremetal deployment.
Deploy Red Hat OpenShift Baremetal
Red Hat offers multiple options for deploying OpenShift clusters, including both on-premises and SaaS solutions for connected and disconnected environments. These deployments can be managed using Advanced Cluster Management (ACM) or the cloud-based Red Hat Hybrid Cloud Console (HCC).
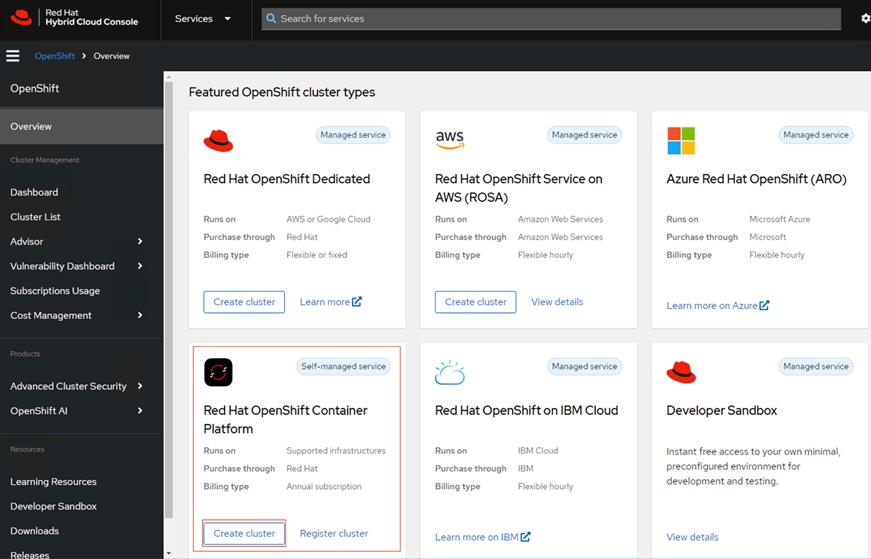
Procedure 1. Create a Red Hat OpenShift cluster
Step 1. From HCC select Red Hat OpenShift Container Platform and click Create Cluster.
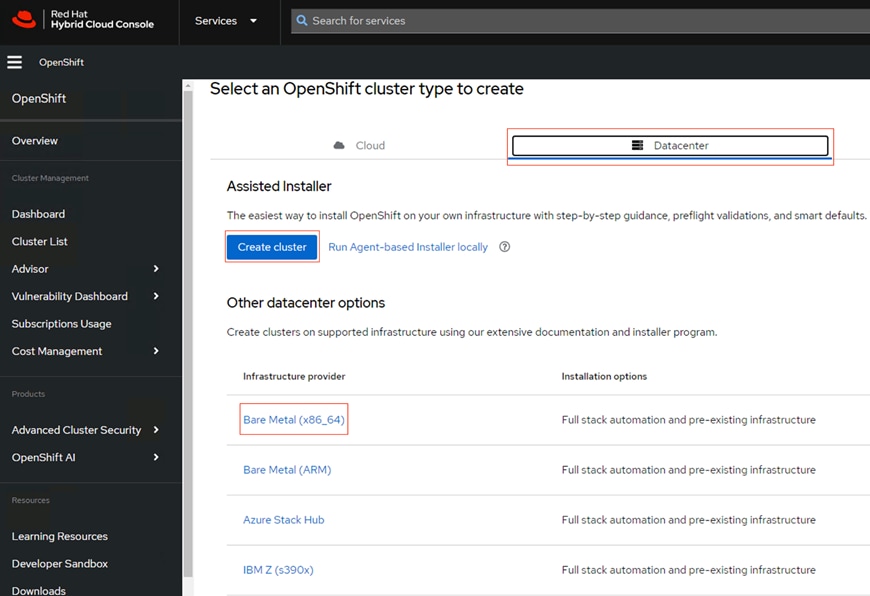
Step 2. In the next prompted page click Datacenter tab > Bare Metal (x86_64) > Create cluster.
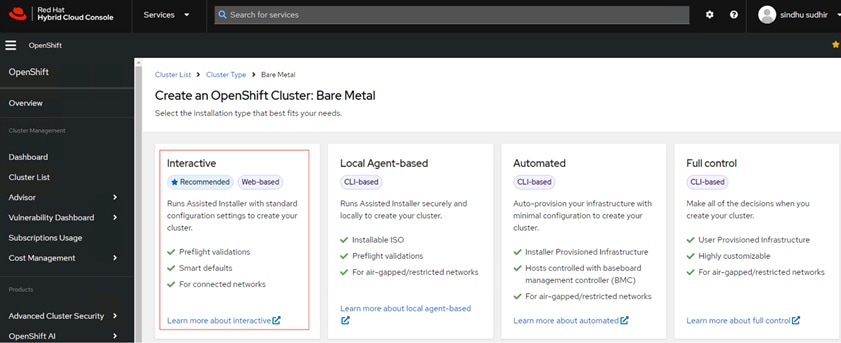
Step 3. In the next page select Interactive. In this solution, Red Hat OpenShift is deployed as a self-managed service using the Red Hat-recommended Assisted Installer from the Hybrid Cloud Console. Note that the Assisted Installer requires a connected environment for on-premises deployments.
Step 4. Fill in the cluster details with cluster name, OpenShift version you intent to install, base domain, network choices, DNS details etc. Make sure you have setup a private DNS, create necessary PTR records, DHCP server (optional - if DHCP IP assignment is preferred), configured NTP, Web Proxy server etc. For further clarifications on infrastructure setup for OpenShift and troubleshooting see: https://docs.redhat.com/en/documentation/assisted_installer_for_openshift_container_platform/2024/html-single/installing_openshift_container_platform_with_the_assisted_installer/index#prerequisites
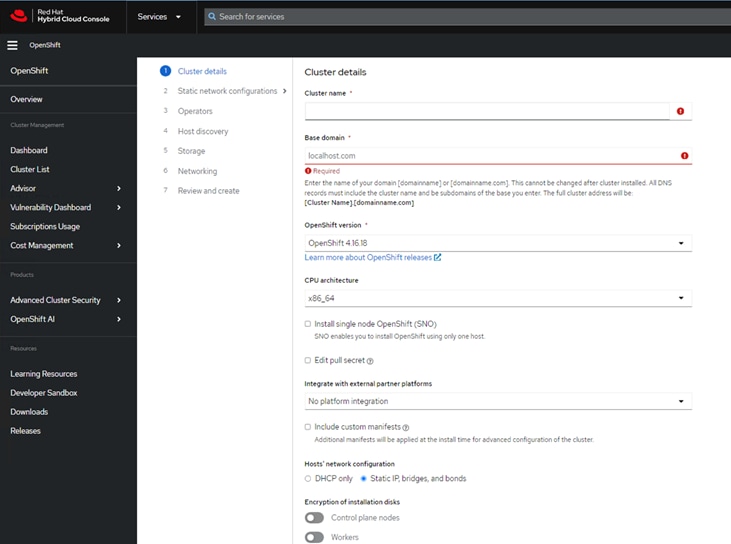
Step 5. OpenShift is deployed on Cisco UCS-X baremetal servers, which are also managed from the cloud using Cisco Intersight. Red Hat Assisted Installer provides a discovery image that must be downloaded and installed on the baremetal servers using virtual media (vKVM, CIMC) or iPXE. When downloading the discovery ISO, you can select either a minimal image or a full image.
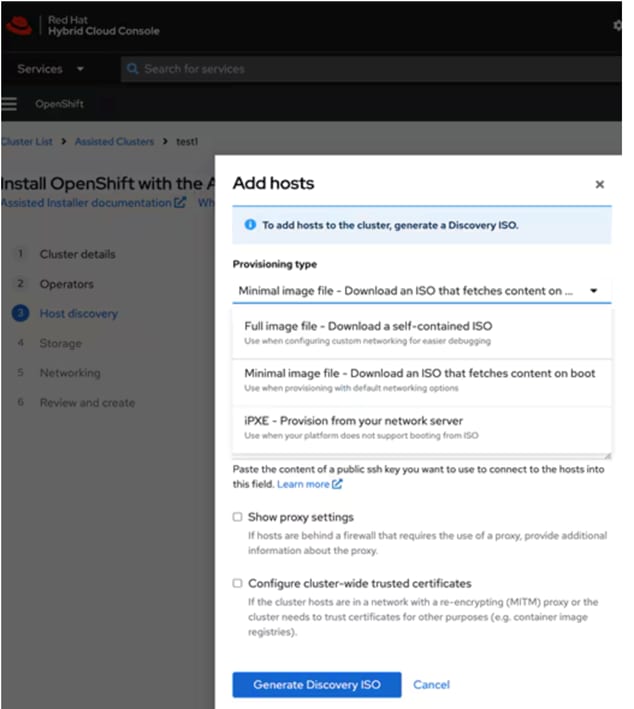
Note: Make sure you provide the SSH public key of the client node for password-less cluster node access.
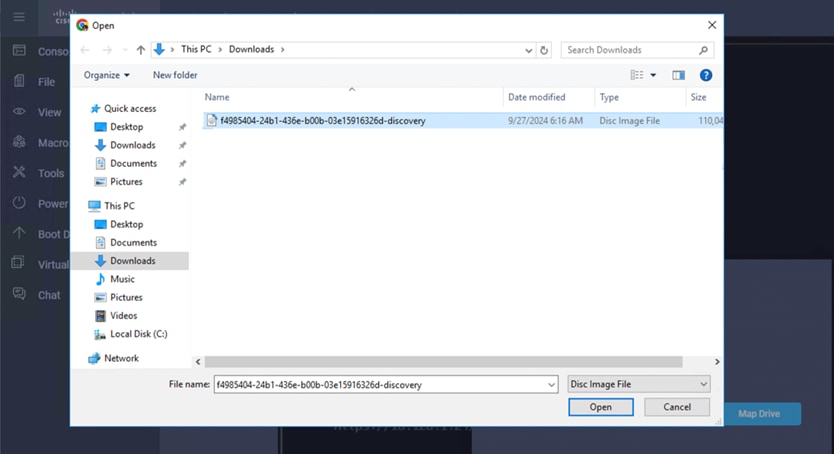
Step 6. Mount the downloaded ISO as KVM-Mapped DVD on Cisco UCS-X baremetal servers.
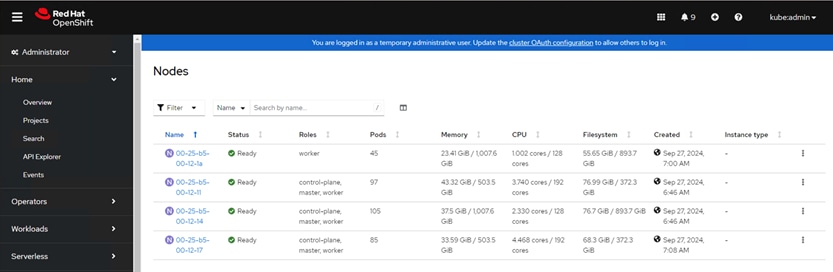
Step 7. Once the cluster is created, from the console you can view the node details.
Step 8. To access the cluster from the client node, you need to install OpenShift CLI (OC) client package on the node. For more information on how to install OpenShift CLI, see: https://docs.openshift.com/container-platform/4.16/cli_reference/openshift_cli/getting-started-cli.html
Step 9. Once the OC client package is installed, export the Kubeconfig that is available as a downloadable file after the OpenShift Cluster installation. Run the oc login command with username and password to log into the cluster.
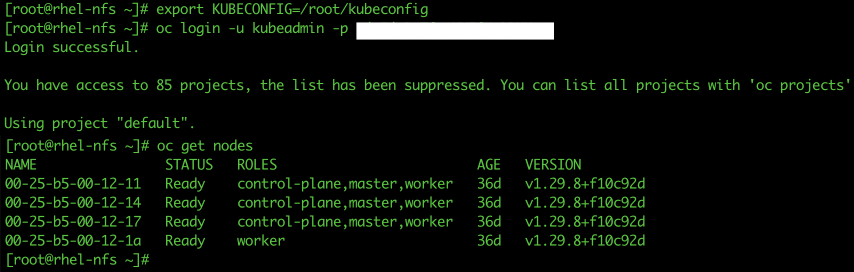
Prepare Red Hat OpenShift Cluster to Deploy Medical Diagnosis
Procedure 1. Deploy validated patterns for medical diagnosis
Step 1. Install the Local Storage Operator from Operators > OperatorHub from your new installed OpenShift cluster console. Local Storage volumes should be created before installing Red Hat OpenShift Data Foundation. You can proceed to create with the default settings.
Step 2. Install Red Hat OpenShift Data Foundation operator from Operators > OperatorHub.
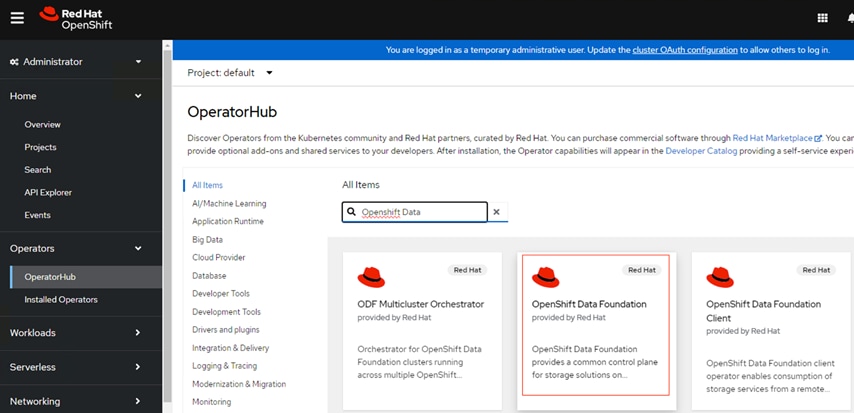
Step 3. Once the ODF Operator is installed on the baremetal cluster nodes, click Create StorageSystems. In Backing Storage page, make sure the following is selected:
● “Full Deployment” for the Deployment type option.
● “Create a new StorageClass using the local devices” option.
● “Use Ceph RBD as the default StorageClass”.
● In the Create local volume set page, “Disks on all nodes” option.
Note: The options/fields that are not mentioned explicitly can be left at the default settings or can be changed as per your requirements.
Once the StorageSystems is created you can see the status, raw capacity, and so on, as shown below:
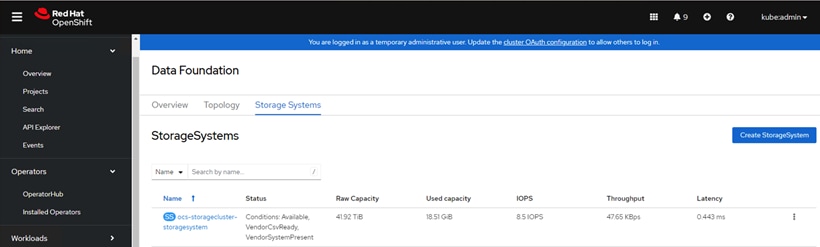
Step 4. You can see the StoageClasses form the Storage > StorageClasses page:
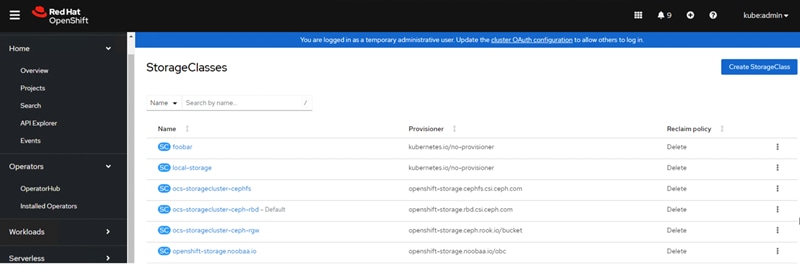
Step 5. For installing Hashicorp Vault, “ocs-storagecluster-cephfs” should be set as default storageclass. Run the following command to patch the storageclass as default:
oc patch storageclass ocs-storagecluster-cephfs -p '{"metadata": {"annotations": {"storageclass.kubernetes.io/is-default-class": "true"}}}'
Step 6. OpenShift Container Platform Cluster must have an Image Registry configured. To set up an image registry, run the following:
cat <<EOF | oc apply -f -
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: registry-storage-pvc
namespace: openshift-image-registry
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 100Gi
storageClassName: ocs-storagecluster-cephfs
EOF
Deploy Intel AMX Accelerated Medical Diagnosis Pattern
Procedure 1. Deploy the Intel AMX accelerated Medical Diagnosis pattern
Step 1. Fork the repository medical-diagnosis on GitHub. You must fork the repository because your fork will be updated as part of the GitOps and DevOps processes.
Step 2. Clone the forked copy of this repository.
Step 3. Create a local copy of the Helm values file that can safely include your credentials.
Note: Do not commit this file so that you don’t accidently push personal credentials to GitHub.
Step 4. Run the following commands to add your credentials:
cp values-secret.yaml.template ~/values-secret-medical-diagnosis.yaml
Step 5. Edit the “values-secret-medical-diagnosis.yaml” to update your credentials:
vi ~/values-secret-medical-diagnosis.yaml
Step 6. (Optional) by default Vault password policy generated the passwords and you can choose to keep them as is. The yaml file looks like this:
version "2.0"
secrets:
# NEVER COMMIT THESE VALUES TO GIT
# Database login credentials and configuration
- name: xraylab
fields:
- name: database-user
value: xraylab
- name: database-host
value: xraylabdb
- name: database-db
value: xraylabdb
- name: database-master-user
value: xraylab
- name: database-password
onMissingValue: generate
vaultPolicy: validatedPatternDefaultPolicy
- name: database-root-password
onMissingValue: generate
vaultPolicy: validatedPatternDefaultPolicy
- name: database-master-password
onMissingValue: generate
vaultPolicy: validatedPatternDefaultPolicy
# Grafana Dashboard admin user/password
- name: grafana
fields:
- name: GF_SECURITY_ADMIN_USER:
value: root
- name: GF_SECURITY_ADMIN_PASSWORD:
onMissingValue: generate
vaultPolicy: validatedPatternDefaultPolicy
Note: When setting a custom password for database users, it’s best to avoid using the special character “$” since it may be interpreted by the shell, potentially leading to an incorrect password configuration.
Step 7. To customize the deployment for your cluster, update the “values-global.yaml” file by running the following commands:
git checkout -b my-branch
vi values-global.yaml
# Yaml file sample to show the bucketsource location
...omitted
datacenter:
cloudProvider: PROVIDE_CLOUDPROVIDER # Not required for on-prem
storageClassName: "ocs-storagecluster-cephfs" # Default filesystem storage used on on-prem cluster, can be changed by user
region: PROVIDE_REGION # Not required for on-prem
clustername: "" # Not required for on-prem, pattern uses on-prem cluster value instead
domain: "" # Not required for on-prem, pattern uses on-prem cluster value instead
s3:
# Values for S3 bucket access
# bucketSource: "provide s3 bucket name where images are stored"
bucketSource: "PROVIDE_BUCKET_SOURCE"
# Bucket base name used for image-generator and image-server applications.
bucketBaseName: "xray-source"
Note: Replace the 'bucketSource' value. Users can specify any bucket name that includes only letters, numbers, and hyphens ('-').
Step 8. Once the yaml file is updated. Run the following command commit and push to your branch:
# git add values-global.yaml
# git commit values-global.yaml
# git push origin my-branch
Step 9. To preview the changes that will be implemented to the Helm charts, run the following command:
./pattern.sh make show
Step 10. Log into your cluster by running the following commands:
export KUBECONFIG=<path-to-kubeconfig>
oc login -u kubeadmin -p <your cluster password>
Step 11. Run the install script, which invokes ansible playbook to install the Validated Pattern:
./pattern.sh make install
Step 12. If the installation fails, you review the instructions and make updates, if required. To continue the installation, run the following command:
./pattern.sh make update
Step 13. This step might take some time, especially for the OpenShift Data Foundation Operator components to install and synchronize. The ./pattern.sh make install command provides some progress updates during the installation process. It can take up to twenty minutes. Compare your ./pattern.sh make install run progress with the following screenshots that shows a successful installation.
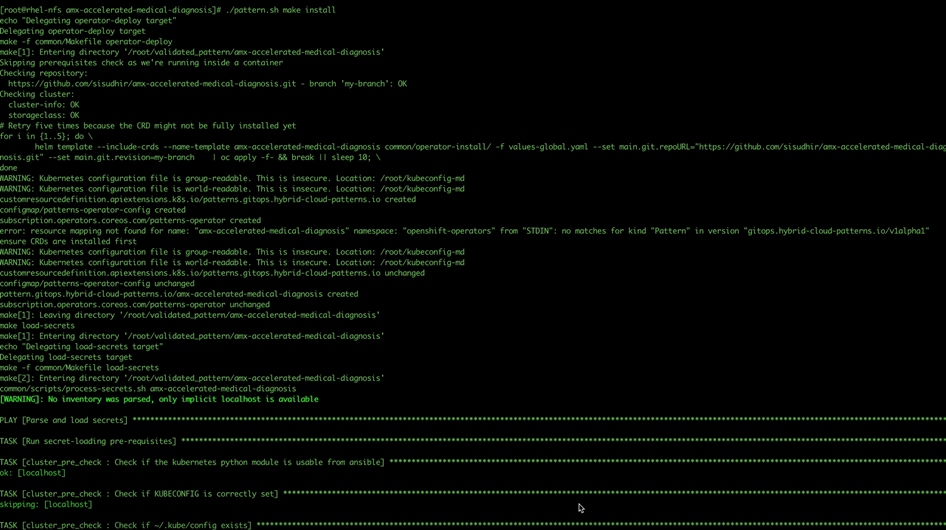


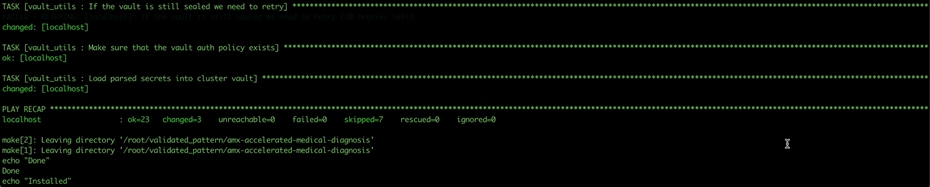
Step 14. Verify that the Operators have been installed. From the web console of your cluster navigate to Operators > Installed Operators page.
Step 15. Check that the Operator is installed in the “openshift-operators” namespace and its status is Succeeded. Make sure the OpenShift Data Foundation is listed in the list of installed Operators.
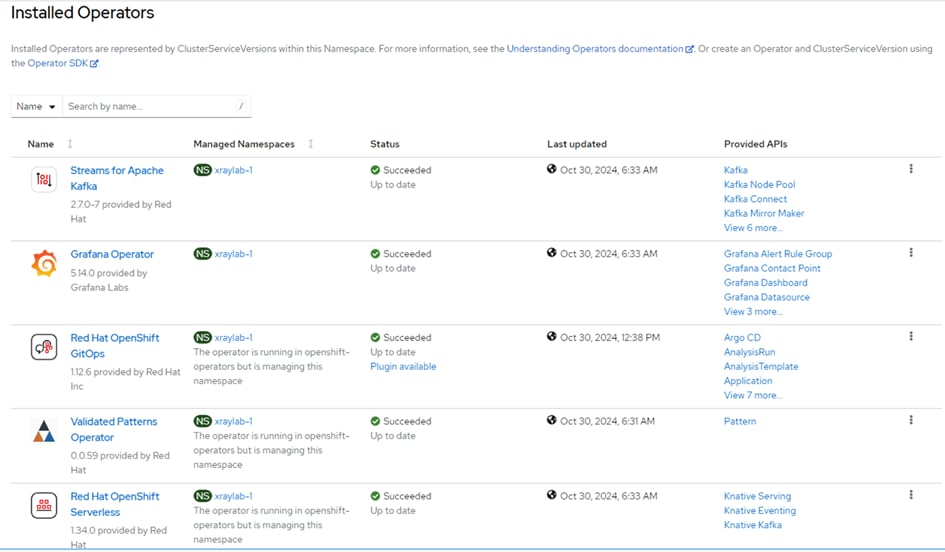
Step 16. (Optional) To add secret into Vault manually, you need to log into the Vault using the root token. To fetch the root token, run the command and copy the root token:
oc -n vault get route vault -ojsonpath='{.spec.host}'
Step 17. Root token secret to vault can be obtained by running the following command:
oc -n imperative get secrets vaultkeys -ojsonpath='{.data.vault_data_json}' | base64 -d
Note: Vault maintains all the secrets required for this pattern. For example, to access mariadb – a small db for storing anonymized images, the password should be fetched from here. Similarly, to access Grafana dashboard we need to copy the password from here.
Step 18. To check the various applications that are being deployed, you can view the progress of the OpenShift GitOps Operator. The URLs and login credentials for ArgoCD change depending on the pattern name and the site names they control. Follow the instructions below to find them, however you choose to deploy the pattern. Display the fully qualified domain names, and matching login credentials, for all ArgoCD instances:
ARGO_CMD=`oc get secrets -A -o jsonpath='{range .items[*]}{"oc get -n "}{.metadata.namespace}{" routes; oc -n "}{.metadata.namespace}{" extract secrets/"}{.metadata.name}{" --to=-\\n"}{end}' | grep gitops-cluster`
CMD=`echo $ARGO_CMD | sed 's|- oc|-;oc|g'`
eval $CMD

Step 19. Examine the medical-diagnosis-hub ArgoCD instance from the web console of your cluster.
Step 20. You can track all the applications for the pattern in this instance as shown in the screenshots below. Check that all applications are synchronized. There are thirteen different ArgoCD applications that are deployed as part of this pattern.
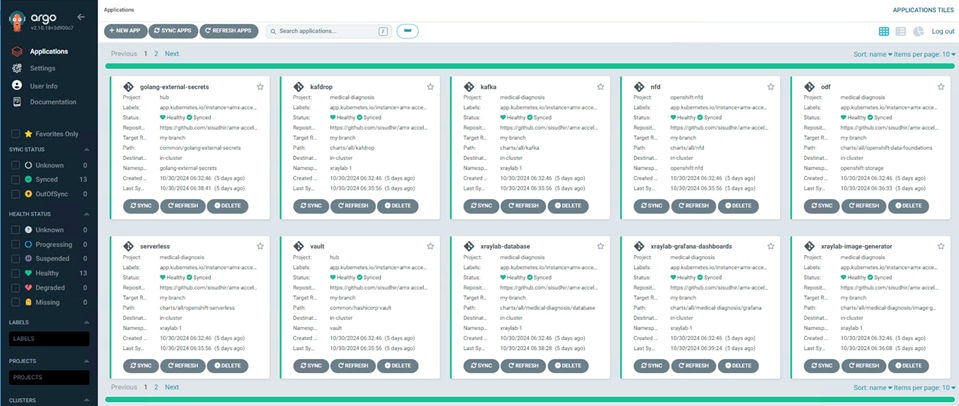
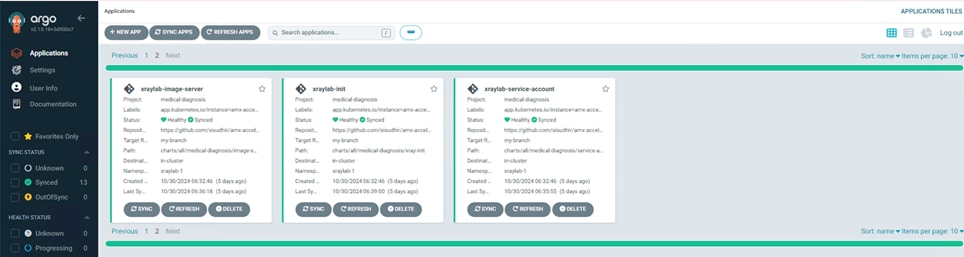
Note: The Medical Diagnosis pattern requires on-premises object storage. Instead of AWS S3 or other cloud alternatives, you can set up Ceph RGW object storage. To interact with its API, you can utilize the AWS CLI. For installation instructions, please refer to the AWS CLI installation manual here: https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html#getting-started-install-instructions
Step 21. Set up local S3 object storage only after ODF is properly deployed by validated pattern.
Step 22. You can extract CEPH_RGW_ENDPOINT by running the command:
oc -n openshift-storage get route s3-rgw -ojsonpath='{.spec.host}'
Step 23. You can fetch AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY of RGW object store by running the following commands:
oc -n xraylab-1 get secret s3-secret-bck -ojsonpath='{.data.AWS_ACCESS_KEY_ID}' | base64 -d
oc -n xraylab-1 get secret s3-secret-bck -ojsonpath='{.data.AWS_SECRET_ACCESS_KEY}' | base64 -d
Note: These values are required to set up object storage properly, if the URL is not accessible (you will get an error while retrieving them). This could be an indicator that ODF is not working properly. Firstly, check if s3-rgw is accessible. You can navigate to ArgoCD dashboard and then click ODF application to resync the s3-rgw component. Secondly, click on “xraylab-init” application and check if the job bucket-init and create-s3-secret are complete. If not resync the application.
Step 24. Clone the repository with x-ray images:
git clone https://github.com/red-hat-data-services/jumpstart-library.git
Step 25. X-ray images are stored in the following path in the repo: https://github.com/red-hat-data-services/jumpstart-library/tree/main/demo1-xray-pipeline/base_elements/containers/image-init/base_images
Step 26. Create and configure the bucket by setting up the environment variables:
export AWS_ACCESS_KEY_ID=$(oc -n xraylab-1 get secret s3-secret-bck -ojsonpath='{.data.AWS_ACCESS_KEY_ID}' | base64 -d)
export AWS_SECRET_ACCESS_KEY=$(oc -n xraylab-1 get secret s3-secret-bck -ojsonpath='{.data.AWS_SECRET_ACCESS_KEY}' | base64 -d)
export CEPH_RGW_ENDPOINT=$(oc -n openshift-storage get route s3-rgw -ojsonpath='{.spec.host}')
export CEPH_BUCKET_NAME="NAME_OF_YOUR_BUCKET"
cd jumpstart-library/demo1-xray-pipeline/base_elements/containers/image-init
aws --endpoint https://${CEPH_RGW_ENDPOINT} --no-verify-ssl s3api create-bucket --bucket ${CEPH_BUCKET_NAME}
aws --endpoint https://${CEPH_RGW_ENDPOINT} --no-verify-ssl s3 cp base_images/ s3://${CEPH_BUCKET_NAME}/ --recursive
Note: The CEPH_BUCKET_NAME value should be the same as the bucketSource: "PROVIDE_BUCKET_SOURCE" value specified in the values-global.yaml file.
Step 27. Ceph RGW bucket needs specific bucket policy to be applied. To apply the policy, run the following commands:
cd amx-accelerated-medical-diagnosis
aws --endpoint https://${CEPH_RGW_ENDPOINT} --no-verify-ssl s3api put-bucket-policy --bucket ${CEPH_BUCKET_NAME} --policy file://./bucket-policy.json
Step 28. Check the routes for the project “openshift-storage”. Navigate to Routes tab in your cluster console. Click the URL “s3-rgw”.
Step 29. Make sure when accessing the s3-rgw URL, you can see some XML and not see the access denied error message.
Note: S3-rgw or the Rados Gateway (RGW), is a component of Ceph that provides Object Storage through an S3-compatible API on all Ceph implementations including OpenShift Data Foundation. RGW, is the Ceph Object Gateway daemon in Ceph Object Storage that uses an HTTP server designed to interact with a Ceph Storage Cluster.
Step 30. In Routes, from the Project drop-down list, change the project to “xraylab-1”.
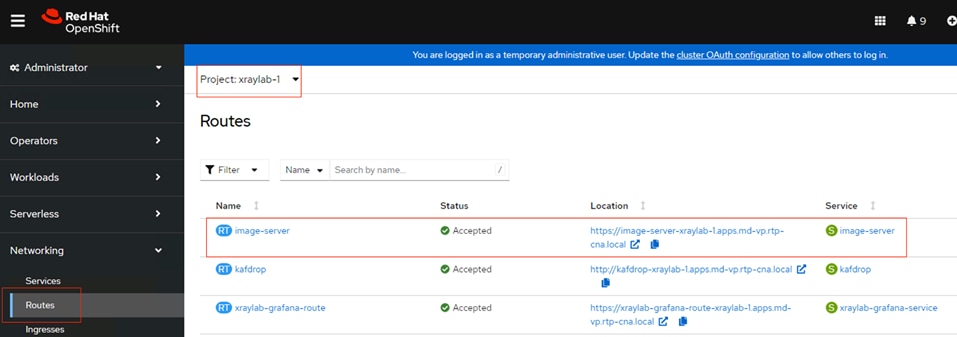
Step 31. Click the URL for the image-server. Ensure that you do not see an access denied error message. You should be able to see a “Hello World” message.

Step 32. Start the image file flow. There are three different ways in which we can start the images to flow, as listed below. Image generator pod will process the x-ray images and will push the processed images to Grafana dashboard.
● From the command-line, after exporting the KUBECONFIG and logging into your cluster. Run the following command:
oc scale deploymentconfig/image-generator --replicas=1 -n xraylab-1
● From your cluster console, you can scale up the image-generator pod by navigating to DeploymentConfigs under Workloads tab.
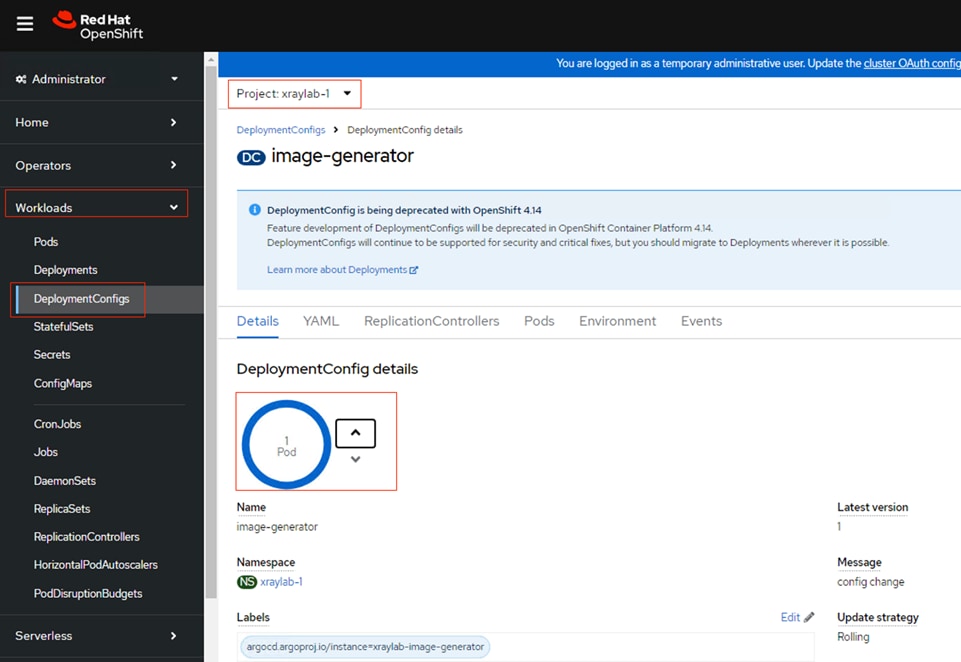
● Alternately, from your cluster console, you can change the view from Administrator to Developer.
● Select Topology tab. Select “xraylab-1” from the Project drop-down list.
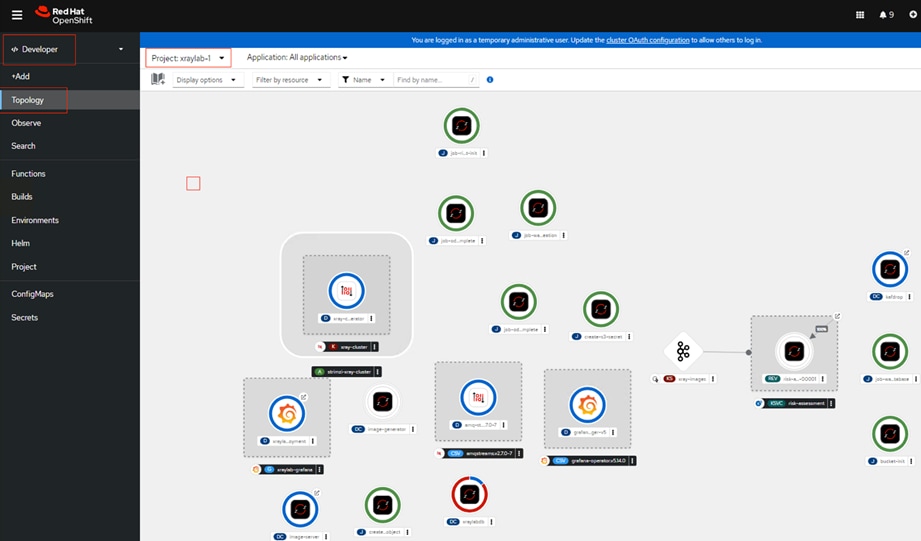
● Right-click the image-generator pod and increase the count on the pop-up window.
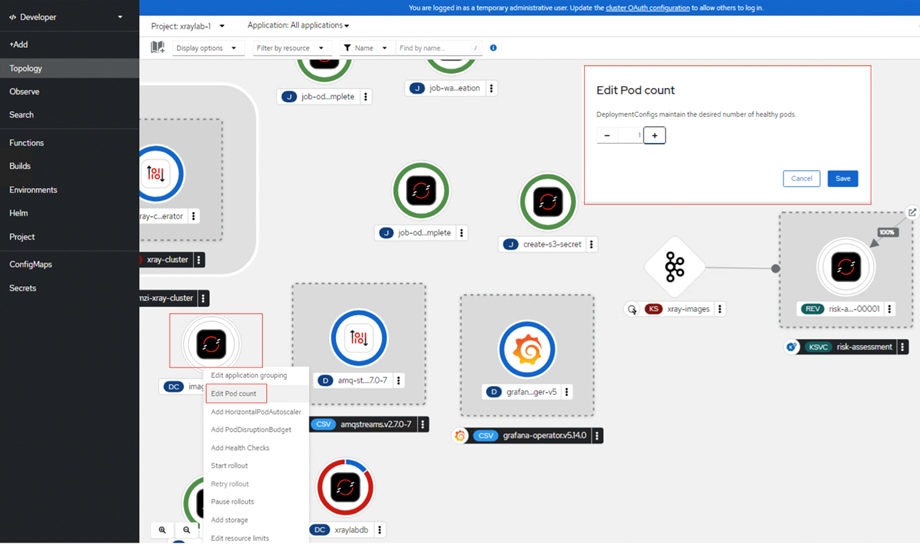
OpenShift GitOps view from Hub AgroCD displays all applications in healthy state:
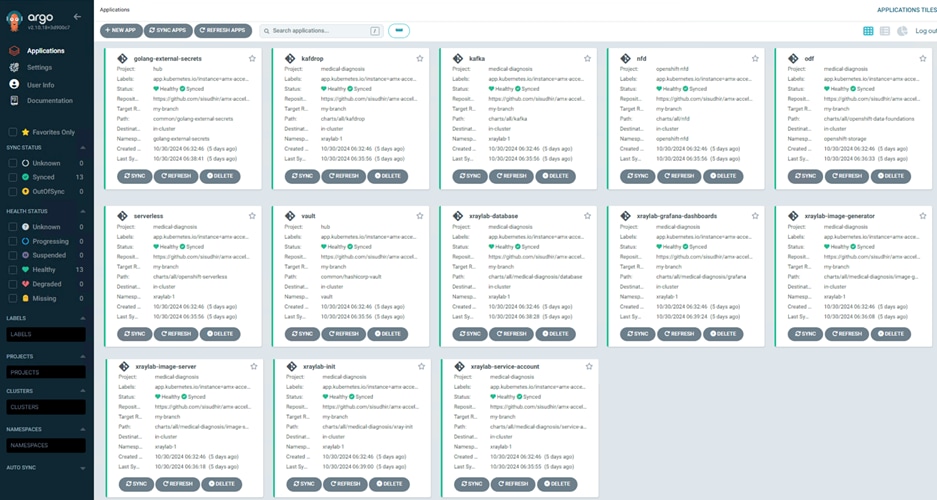
Note: All applications should be healthy for the pattern to work correctly, even if some applications may be OutOfSync. In certain instances, ODF (OpenShift Data Foundation) might show an OutOfSync state, but this typically does not affect functionality. If any application is an 'unhealthy' state, it is important to sync the application bring it to healthy state. For other issues, go to https://validatedpatterns.io/patterns/medical-diagnosis-amx/troubleshooting/
Step 33. Navigate to Routes tab in your cluster console, with xraylab-1 selected from the Project drop-down. Click the URL “xraylab-grafana-route” to access the Grafana dashboard.
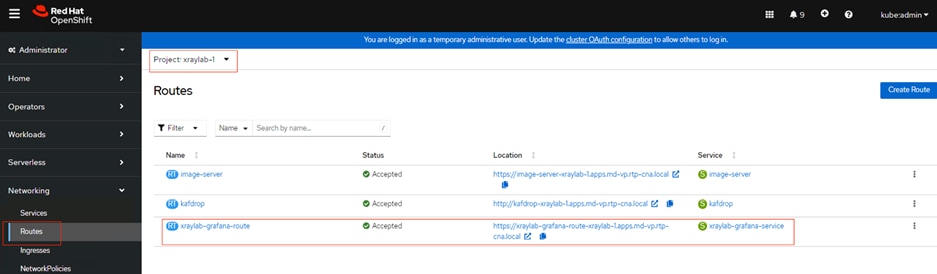
Step 34. Grafana dashboard shows the x-ray images getting processed. You can see that the counters show the numbers images uploaded, number images processed, and you also get to view CPU and memory utilization. Image Anonymization refers to a condition where the pre-trained model is unable to access the x-ray image to classify it as Pneumonia affected. There is a special filter incorporated in the assessment process to enable assessment with a certainty limit set to 80%. If the x-ray images show signs of Pneumonia but less than 80%, they are anonymized and sent to hospitals for manual assessment. However, Pneumonia signs above 80% are classified as Pneumonia affected by the pre-trained model based assessment.
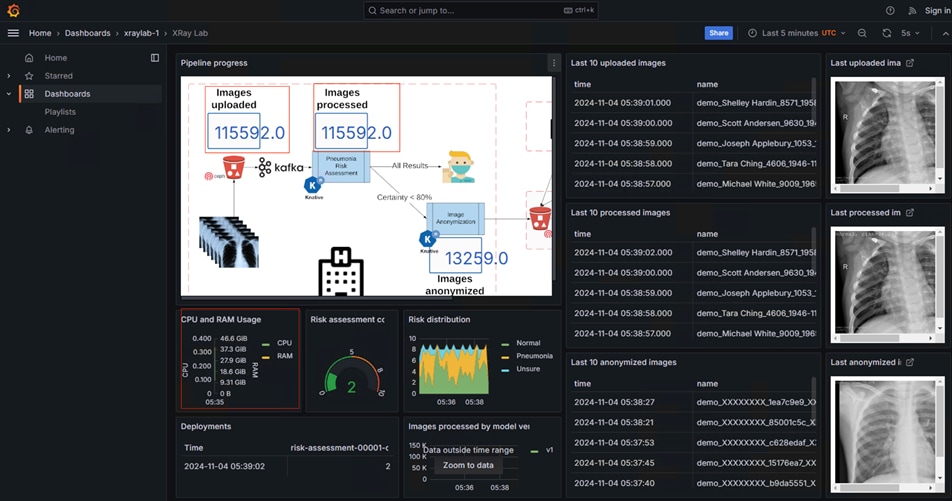
Step 35. When you click the x-ray image, you get an enlarged version which shows the source x-ray image, and the processed images showing whether there is a risk of Pneumonia or not.
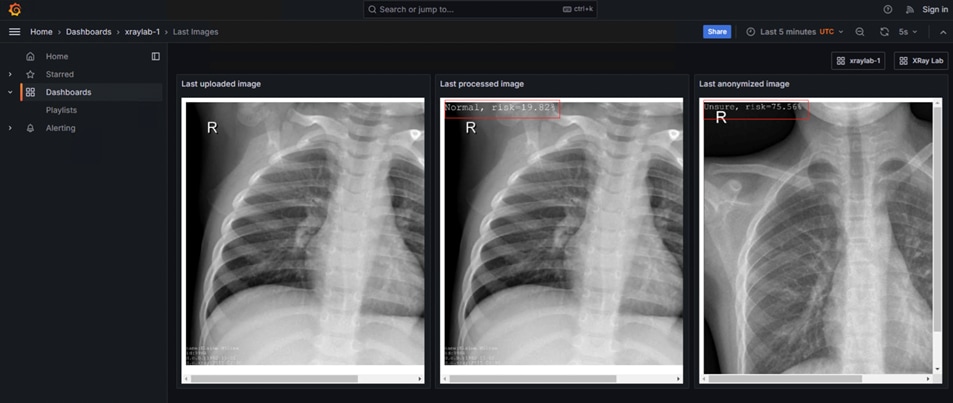
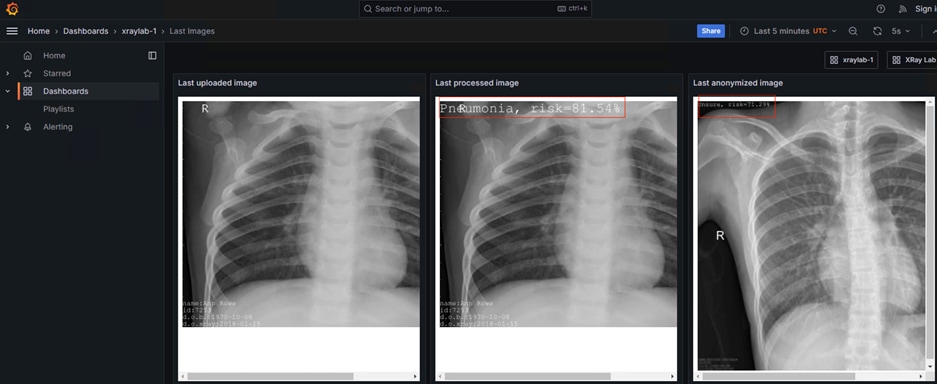
Step 36. Scale the image-generator pod to see the changes in the Grafana dashboard. You can scale the pods and see the CPU utilization increasing drastically. To scale the pods, run the following command from your client.
oc scale deploymentconfig/image-generator --replicas=2
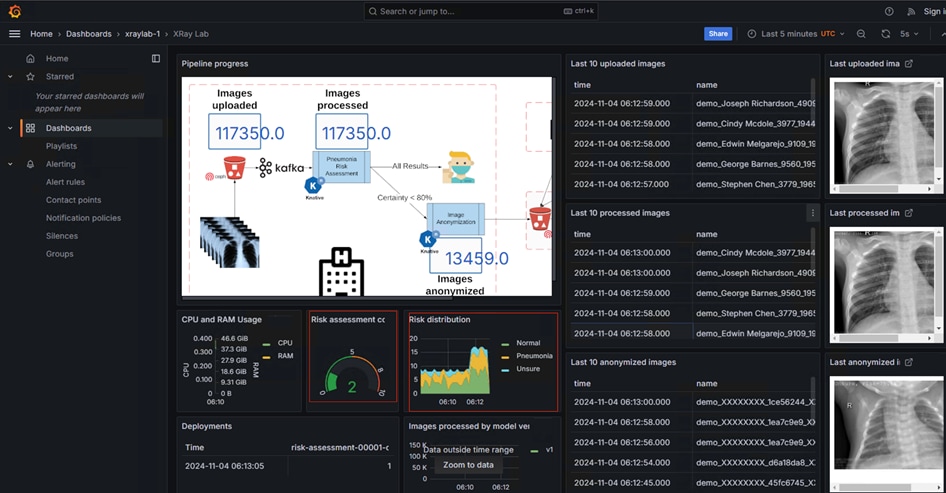
Step 37. By scaling the image-generator pods to 4 replicas, you can see the CPU utilization rise to 95.6% as shown in the screenshot below.
oc scale deploymentconfig/image-generator --replicas=4
Functionality of the Pneumonia Assessment Data Pipeline
This chapter describes the backend functionality of the validated pattern-based data pipeline that helps in Pneumonia assessment.
Figure 15 illustrates a high-level workflow diagram that ties important pieces that allows for Pneumonia detection process.
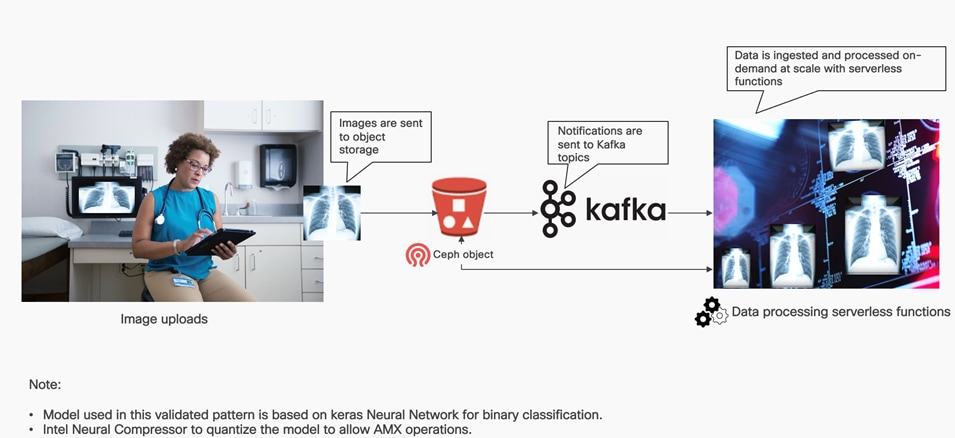
The functionality of the high-level pneumonia assessment workflow can be described as follows:
● Chest X-rays from hospitals are pushed to the in-coming Ceph bucket, created using the Ceph Object gateway in OpenShift. Ceph object gateway is an object storage interface that provides a Restful gateway between application and ceph storage clusters. Bucket notifications provide a mechanism for sending information from the s3-rgw or Rados Gateway (RGW) when certain events are happening on a bucket.
● Ceph sends a notification to Kafka endpoints through bucket notification in OpenShift container Storage. This notification is in the form of a message.
● Kafka will handle this message through a topic that is created.
● This message is be consumed by Knative eventing, which is a serverless deployment in OpenShift.
● The Knative eventing will pass on the fetched message to the Knative Serving service.
● This service will in turn launch an image generating pod called image-generator pod, which will parse the message, retrieve the images and do the assessment.
In a practical scenario where hospitals are transmitting thousands of X-rays for pneumonia assessments from multiple locations, this model must be capable of scaling up or down on demand in real time. Achieving such scalability is only feasible with automation and a cloud-native architecture, enabling all interactions to occur in a disconnected manner over the network. The automated deployment approach of validated patterns can significantly enhance these cloud-native architectures for on-demand scaling. With these patterns, you can automatically deploy a full-stack application using a GitOps-based framework, which facilitates continuous integration for your applications.
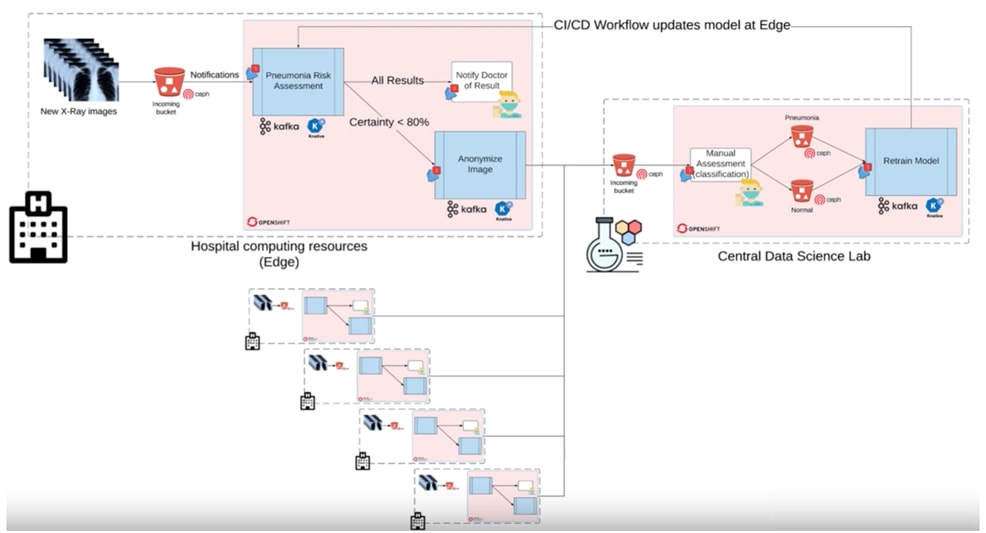
In this pipeline, x-ray images from hospitals are sent to an incoming Ceph bucket initiated by OpenShift Storage. Notifications are dispatched to a Kafka source via a Kafka topic, which are then consumed by Knative eventing and serving—both of which are serverless deployments in OpenShift. The Knative serving spins up a pod that performs pneumonia assessments on the incoming x-ray images.
This pod conducts risk assessments using a pre-trained Keras model that has been quantized for AMX with the Intel Neural Compressor. Based on the percentage of opacification or infiltrates in the chest x-ray, the images are classified as pneumonia-affected, normal, or uncertain. Given that no model can guarantee accuracy, there may be instances when it is unsure about a pneumonia diagnosis. To address this, a filter is incorporated that checks the certainty percentage; if this percentage falls below 80%, the uncertain x-rays are labelled as anonymized images and sent to a separate bucket. These images can then be manually assessed by technicians or doctors, and their evaluations can be used to retrain the model. This process enables the model to continually evolve and improve over time.
Cluster Sizing
To understand the cluster sizing requirements for the Intel AMX accelerated Medical Diagnosis pattern, consider the components listed in Table 2 that the Intel AMX accelerated Medical Diagnosis pattern deploys on the datacenter or the hub OpenShift cluster:
Table 2. Operators and Application deployed by medical Diagnosis pattern
| Name |
Kind |
Namespace |
Description |
| Medical Diagnosis Hub |
Application |
medical-diagnosis-hub |
Hub GitOps management |
| Red Hat OpenShift GitOps |
Operator |
openshift-operators |
OpenShift GitOps |
| Red Hat OpenShift Data Foundation |
Operator |
openshift-storage |
Cloud Native storage solution |
| Red Hat AMQ Streams |
Operator |
openshift-operators |
AMQ Streams provides Apache Kafka access |
| Red Hat OpenShift Serverless |
Operator |
- knative-serving (knative-eventing) |
Provides access to Knative Serving and Eventing functions |
| Node Feature Discovery Operator |
Operator |
openshift-nfd |
Manages the detection and labeling of hardware features and configuration (for example Intel AMX) |
The Intel AMX accelerated Medical Diagnosis pattern also includes the Red Hat Advanced Cluster Management (RHACM) supporting operator that is installed by OpenShift GitOps using Argo CD.
The OpenShift cluster is a standard deployment of three control plane nodes and one or more worker nodes. Three control plane nodes satisfy the high-availability need for the control-plane for an enterprise deployment. The medical diagnosis pattern deployment is based on Red Hat OpenShift Baremetal deployment and is leveraging local NVMe drives within the X-Series nodes to ensure storage persistence for the pattern deployment through distributed storage provided by OpenShift Data Foundation. You can consider deploying three or more worker nodes to create a dedicated distributed storage specifically for the worker nodes. Note that OpenShift Data Foundation deployment requires minimum three nodes.
Table 3. Minimum resource requirement for deploying medical diagnosis pattern
| Node type |
Number of nodes |
CPU |
Memory |
Storage |
| Control Planes |
3 |
2x 5th Generation Intel Xeon Gold 6526Y (16 cores at 2.8 GHz base with Intel AMX) or better |
128 GB (8 x 16 GB DDR5 4800) or more |
NVME SSD 3TB or more |
| Workers |
1-3 |
2x 5th Generation Intel Xeon Gold 6538Y+ (32 cores at 2.2 GHz base with Intel AMX) or better |
256 GB (16 x 16 GB) or 512 GB (16 x 32GB) DDR5-4800 |
NVME SSD 3TB or more |
Note: The above information is intended as guidance, and we recommend running performance tests with expected workloads to avoid any post-deployment challenges.
The pattern was tested in the on-premises environment with the following hardware configuration (per cluster):
Table 4. Resources used for deploying and testing medical diagnosis pattern at Cisco Lab
| Node type |
Number of nodes |
CPU |
Memory |
Storage |
| Control Planes |
3 |
2x 5th Generation Intel Xeon Platinum 8568Y+ (48 cores at 2.3 GHz base with Intel AMX) |
1024 GB (16 x 64 GB) DDR5 4800 |
NVME SSD 3.8TB |
| Workers |
1 |
2x 5th Generation Intel Xeon Platinum 8568Y+ (48 cores at 2.3 GHz base with Intel AMX) |
1024 GB (16 x 64 GB) DDR5-4800 |
NVME SSD 3.8TB |
Customizing Medical Diagnosis Pattern
A primary objective of the Validated Patterns development process is to create modular and customizable demonstrations. The Medical Diagnosis pattern serves as an illustration of how AI and machine learning workloads for object detection and classification can be executed on OpenShift clusters. Reflect on your own workloads to understand: how your workloads can best utilize this pattern framework? Does your solution need on-demand or near real-time responses when interacting with your application? Additionally, is your application handling images or data subject to Government Privacy Laws or HIPAA regulations? The Medical Diagnosis pattern is designed to meet these needs by leveraging OpenShift Serverless and OpenShift Data Foundation.
Extending Medical Diagnosis Pattern for other use cases
Other use cases that benefit from the Medical Diagnosis pattern are as follows:
● In this solution, the Medical Diagnosis pattern analyzes X-ray images to assess the likelihood that a patient has pneumonia. Building on this medical application, the pattern can be adapted for other early detection scenarios involving object detection and classification. For instance, it could be utilized to examine CT images for anomalies such as sepsis, cancer, or benign tumors. Furthermore, it can assist in identifying blood clots, certain heart diseases, and gastrointestinal disorders like Crohn’s disease.
● The Transportation Security Agency (TSA) could enhance its existing scanning capabilities using the Medical Diagnosis pattern to more accurately detect restricted items carried by individuals or concealed in luggage. By implementing Machine Learning Operations (MLOps), the model continually trains and improves its ability to identify dangerous items, including non-metallic threats like firearms or knives, while also recognizing authorized items. This would help minimize unnecessary stops and searches at security checkpoints for passengers.
● Additionally, military organizations could leverage images captured by drones, satellites, or other platforms to identify and assess various objects. For example, the model could be trained to classify types of ships and possibly infer their country of origin and other identifying traits.
● Manufacturing companies could apply this pattern to inspect finished products as they come off the production line. By analyzing images under various lighting conditions, the system can identify defects before packaging and distribution, allowing for items to be redirected to a defect area.
These examples illustrate the versatility of the Medical Diagnosis pattern as a foundational framework for various applications.
Conclusion
The integration of Cisco UCS X-Series servers with Red Hat OpenShift, managed via Cisco Intersight and powered by 5th Generation Intel Xeon Scalable Processors, provides a holistic solution for optimizing inferencing generative AI workloads. This cohesive ecosystem streamlines management through Cisco Intersight, leveraging its user-friendly interface for simplified operations. With the robust computational capabilities of Intel Xeon Scalable Processors, organizations can efficiently handle demanding AI tasks.
The medical diagnosis solution utilizing Red Hat Validated Patterns and the GitOps framework showcases significant versatility and potential beyond its initial healthcare focus. Its capability can be extended to analyze imaging data for early detection of health issues can be adapted to strengthen security protocols for organizations like the TSA, enhance military surveillance, and optimize quality control in manufacturing. By harnessing advanced machine learning operations, this approach not only boosts accuracy and efficiency but also supports proactive measures across various sectors. Implementing such a framework can result in improved operational effectiveness, reduced risks, and ultimately better outcomes for both public safety and product quality.
Sindhu Sudhir, Technical Marketing Engineer, Cisco Systems, Inc.
Sindhu is a Technical Marketing Engineer at Cisco, specializing in UCS data center solutions. Her expertise revolves around software-defined architectures, particularly with a focus on container-based solutions. Sindhu possesses a strong passion for open-source technologies, cloud-native solutions, and infrastructure automation for the Cisco UCS platform.
Igor Marzynski, Cloud Systems and Solutions Engineer, Intel Corporation
Igor is a Cloud Systems and Solutions Engineer at Intel with 5+ years of experience. He is an expert in automation, configuration management and deployment of container-based solutions with emphasis on Red Hat OpenShift environment. Igor is proficient in multiple DevOps tools and highly enthusiastic about open-source solutions and technologies.
Acknowledgements
For their support and contribution to the design, validation and review of this Cisco Validated Design, the authors would like to thank:
● Babu Mahadevan, Cisco Systems, Inc.
● Chris O’Brien, Cisco Systems, Inc.
● Piotr Grabuszynski, Intel Corporation
● Sankalp Ramanujam, Intel Corporation
For more information about Cisco UCS X-Series modular system, Cisco Intersight, Intel AMX and Medical Diagnosis Validated Patterns, go to the following links:
● Cisco UCS X- Series modular system: https://www.cisco.com/c/en/us/products/collateral/servers-unified-computing/ucs-x-series-modular-system/solution-overview-c22-2432175.html?ccid=cc002456&oid=sowcsm025665
● Cisco Intersight configuration: https://www.cisco.com/c/en/us/td/docs/unified_computing/Intersight/b_Intersight_Managed_Mode_Configuration_Guide.html
● Intel AMX: https://www.intel.com/content/www/us/en/products/docs/accelerator-engines/what-is-intel-amx.html
● Validated Patterns GitHub link: https://github.com/validatedpatterns/medical-diagnosis
● Red Hat Validated Pattern Solution for enabling medical Imaging Diagnosis for edge: https://www.redhat.com/architect/portfolio/detail/6-enabling-medical-imaging-diagnostics-with-edge#_edge_medical_diagnosis_with_gitops
For comments and suggestions about this guide and related guides, join the discussion on Cisco Community at https://cs.co/en-cvds.
CVD Program
ALL DESIGNS, SPECIFICATIONS, STATEMENTS, INFORMATION, AND RECOMMENDATIONS (COLLECTIVELY, "DESIGNS") IN THIS MANUAL ARE PRESENTED "AS IS," WITH ALL FAULTS. CISCO AND ITS SUPPLIERS DISCLAIM ALL WARRANTIES, INCLUDING, WITHOUT LIMITATION, THE WARRANTY OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT OR ARISING FROM A COURSE OF DEALING, USAGE, OR TRADE PRACTICE. IN NO EVENT SHALL CISCO OR ITS SUPPLIERS BE LIABLE FOR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, OR INCIDENTAL DAMAGES, INCLUDING, WITHOUT LIMITATION, LOST PROFITS OR LOSS OR DAMAGE TO DATA ARISING OUT OF THE USE OR INABILITY TO USE THE DESIGNS, EVEN IF CISCO OR ITS SUPPLIERS HAVE BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
THE DESIGNS ARE SUBJECT TO CHANGE WITHOUT NOTICE. USERS ARE SOLELY RESPONSIBLE FOR THEIR APPLICATION OF THE DESIGNS. THE DESIGNS DO NOT CONSTITUTE THE TECHNICAL OR OTHER PROFESSIONAL ADVICE OF CISCO, ITS SUPPLIERS OR PARTNERS. USERS SHOULD CONSULT THEIR OWN TECHNICAL ADVISORS BEFORE IMPLEMENTING THE DESIGNS. RESULTS MAY VARY DEPENDING ON FACTORS NOT TESTED BY CISCO.
CCDE, CCENT, Cisco Eos, Cisco Lumin, Cisco Nexus, Cisco StadiumVision, Cisco TelePresence, Cisco WebEx, the Cisco logo, DCE, and Welcome to the Human Network are trademarks; Changing the Way We Work, Live, Play, and Learn and Cisco Store are service marks; and Access Registrar, Aironet, AsyncOS, Bringing the Meeting To You, Catalyst, CCDA, CCDP, CCIE, CCIP, CCNA, CCNP, CCSP, CCVP, Cisco, the Cisco Certified Internetwork Expert logo, Cisco IOS, Cisco Press, Cisco Systems, Cisco Systems Capital, the Cisco Systems logo, Cisco Unified Computing System (Cisco UCS), Cisco UCS B-Series Blade Servers, Cisco UCS C-Series Rack Servers, Cisco UCS S-Series Storage Servers, Cisco UCS X-Series, Cisco UCS Manager, Cisco UCS Management Software, Cisco Unified Fabric, Cisco Application Centric Infrastructure, Cisco Nexus 9000 Series, Cisco Nexus 7000 Series. Cisco Prime Data Center Network Manager, Cisco NX-OS Software, Cisco MDS Series, Cisco Unity, Collaboration Without Limitation, EtherFast, EtherSwitch, Event Center, Fast Step, Follow Me Browsing, FormShare, GigaDrive, HomeLink, Internet Quotient, IOS, iPhone, iQuick Study, LightStream, Linksys, MediaTone, MeetingPlace, MeetingPlace Chime Sound, MGX, Networkers, Networking Academy, Network Registrar, PCNow, PIX, PowerPanels, ProConnect, ScriptShare, SenderBase, SMARTnet, Spectrum Expert, StackWise, The Fastest Way to Increase Your Internet Quotient, TransPath, WebEx, and the WebEx logo are registered trade-marks of Cisco Systems, Inc. and/or its affiliates in the United States and certain other countries. (LDW_P1+)
All other trademarks mentioned in this document or website are the property of their respective owners. The use of the word partner does not imply a partnership relationship between Cisco and any other company. (0809R)