About Faults
 Note |
For detailed reference information about faults, events, errors, and system messages, see the Cisco ACI System Messages Reference Guide or the Cisco APIC Management Information Model Reference, which is a web-based application. |
The Application Policy Infrastructure Controller (APIC) maintains a comprehensive, up-to-date run-time representation of the administrative and operational state of the ACI fabric system in a collection of managed objects (MOs). In this model, a fault is represented as a mutable, stateful, and persistent MO. When a specific condition occurs, such as a component failure or an alarm, the system creates a fault MO as a child object to the MO that is primarily associated with the fault. For a fault object class, the fault conditions are defined by the fault rules of the parent object class. An MO class can have multiple defined faults, each of which has a different fault code and a different fault rule. The fault code uniquely identifies a fault definition, and a fault rule uniquely identifies the fault conditions. For a given fault code, a parent MO instance can have only one fault MO.
In most cases, a fault MO is automatically created, escalated, de-escalated, and deleted by the system as specific conditions are detected. If the same condition is detected multiple times while the corresponding fault MO is active, the properties of the fault MO are updated, and no additional instances of the fault MO are created. A fault MO contains an “occur” property to record how many times a fault condition occurs. This property is useful for detecting fault flapping.
The creation of a fault MO can be triggered by internal processes such as finite state machine (FSM) transitions or detected component failures, or by conditions specified by various fault policies, some of which are user configurable. For example, you can set fault thresholds on statistical measurements such as health scores, data traffic, or temperatures.
A fault MO remains in the system after the fault condition is cleared until it is deleted from the system by one of the following circumstances:
-
When the parent MO is deleted.
-
When a cleared fault is acknowledged by the user.
-
When a cleared fault has existed longer than the retention interval.
Fault Objects and Records
In the Cisco APIC Management Information Model Reference, the fault package contains the fault-related object classes.
Fault Objects
A fault object is represented by one of the following two classes:
-
fault:Inst—When a fault occurs in an MO, a fault instance MO (fault:Inst) is created under the MO that experienced the fault condition. -
fault:Delegate—Many MOs are used internally by the system and are not presented conspicuously in the APIC GUI. In order to improve the visibility of a fault that might otherwise go unnoticed, for some faults a corresponding fault delegate MO (fault:Delegate) is created and attached to a logical MO that has higher visibility in the APIC. A fault delegate MO is an identical copy of the original fault MO (fault:Inst). The identity of the original MO that experienced the fault condition is stored in thefault:Delegate:affectedproperty of the fault delegate MO.As an example, if the system attempts to deploy the configuration for an endpoint group to multiple nodes and encounters issues on one of the nodes, the system raises a fault (
fault:InstMO) on the node object affected by the issue and also raises a corresponding fault delegate on the object that represents the endpoint group. The fault delegate allows the user to see all the faults related to the endpoint group in a single place, regardless of where they were triggered.
Fault Records
A fault record records the history of a state transition for a fault instance object. For every fault state change, a fault
record object (fault:Record) is created in the fault log. A fault record is an immutable object that cannot be modified either by the user or by the
system. Record creation is triggered by fault instance MO creation or deletion or by modification of key properties (for example,
severity, life cycle, or acknowledgment) of the fault instance object. All properties of the record are set at the time the
record object is created.
A record object
contains a complete snapshot of the fault instance object and is logically
organized as a flat list under a single container. The record object contains
properties from the corresponding instance object (fault:Inst) such as
severity (original, highest, and previous), acknowledgment, occurrence, and
life cycle as well as inherited properties that provide a snapshot of the fault
instance and the nature and time of its change. The record is meant to be
queried using time-based filters or property filters for severity, affected DN,
or other criteria.
The object creation can also trigger the export of record details to an external destination by syslog. To analyze how a fault object is created and deleted, inspect the fault records.
Fault record objects are purged only when the maximum capacity of fault record objects is reached and space is needed for
new fault records. Depending on the space availability, a fault record can be retained long after the fault object itself
has been deleted. The retention and purge behavior is specified in the fault record retention policy (fault:ARetP) object. For information about configuring the retention policy, see Log Retention Policies.
Fault Severity
A fault raised by the system can transition through more than one severity during its life cycle. This table describes the possible fault severities in decreasing order of severity:
| Severity | Description |
|---|---|
| critical | A service-affecting condition that requires immediate corrective action. For example, this severity could indicate that the managed object is out of service and its capability must be restored. |
| major | A service-affecting condition that requires urgent corrective action. For example, this severity could indicate a severe degradation in the capability of the managed object and that its full capability must be restored. |
| minor | A nonservice-affecting fault condition that requires corrective action to prevent a more serious fault from occurring. For example, this severity could indicate that the detected alarm condition is not currently degrading the capacity of the managed object. |
| warning | A potential or impending service-affecting fault that currently has no significant effects in the system. An action should be taken to further diagnose, if necessary, and correct the problem to prevent it from becoming a more serious service-affecting fault. |
| info | A basic notification or informational message that is possibly independently insignificant. (Used only for events) |
| cleared | A notification that the condition that caused the fault has been resolved, and the fault has been cleared. |
Note |
There is no 'debug' severity level. |
Fault Types
A fault raised by the system can be one of the types described in this table:
| Type | Description |
|---|---|
| generic |
The system has detected a generic issue. |
| equipment |
The system has detected that a physical component is inoperable or has another functional issue. |
| configuration |
The system is unable to successfully configure a component. |
| connectivity |
The system has detected a connectivity issue, such as an unreachable adapter. |
| environmental |
The system has detected a power issue, thermal issue, voltage issue, or a loss of CMOS settings. |
| management |
The system has detected a serious management issue, such as one of the following:
|
| network |
The system has detected a network issue, such as a link down. |
| operational |
The system has detected an operational issue, such as a log capacity limit or a failed component discovery. |
Fault Properties
The system provides detailed information about each fault raised. This table describes the fault properties:
| Property | Description |
|---|---|
| code | The fault code (for example, F1017). |
| rule id | The identifier of the rule that generated the fault instance. |
| id | The unique identifier assigned to the fault. |
| cause | The probable cause category (for example, equipment-inoperable). |
| type | The type of fault (for example: connectivity or environmental). |
| severity | The current severity level of the fault. |
| created | The day and time when the fault occurred. |
| lastTransition | The day and time on which the severity or life cycle state for the fault last changed. |
| descr | The description of the fault. |
| lc | The life cycle state of the fault (for example, soaking). |
| occur | The number of times the event that raised the fault occurred. |
| origSeverity | The severity assigned to the fault on the first time that it occurred. |
| prevSeverity | If the severity has changed, this is the previous severity. |
| highestSeverity | The highest severity encountered for this issue. |
Fault Life Cycle
APIC fault MOs are stateful, and a fault raised by the APIC transitions through more than one state during its life cycle. In addition, the severity of a fault might change due to its persistence over time, so a change in the state may also cause a change in severity. Each change of state causes the creation of a fault record and, if external reporting is configured, can generate a syslog or other external report.
Only one instance of a given fault MO can exist on each parent MO. If the same fault occurs again while the fault MO is active, the APIC increments the number of occurrences.
The fault life cycle is shown in the following state diagram:
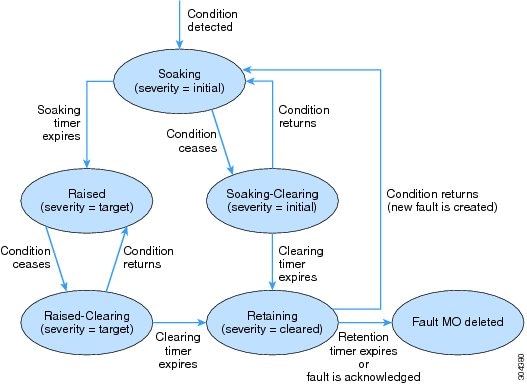
The characteristics of each state are as follows:
-
Soaking—A fault MO is created when a fault condition is detected. The initial state is Soaking, and the initial severity is specified by the fault policy for the fault class. Because some faults are important only if they persist over a period of time, a soaking interval begins, as specified by the fault policy. During the soaking interval, the system observes whether the fault condition persists or whether it is alleviated and reoccurs one or more times. When the soaking interval expires, the next state depends on whether the fault condition remains.
-
Soaking-Clearing— If the fault condition is alleviated during the soaking interval, the fault MO enters the Soaking-Clearing state, retaining its initial severity. A clearing interval begins. If the fault condition returns during the clearing interval, the fault MO returns to the Soaking state. If the fault condition does not return during the clearing interval, the fault MO enters the Retaining state.
-
Raised—If the fault condition persists when the soaking interval expires, the fault MO enters the Raised state. Because a persistent fault might be more serious than a transient fault, the fault is assigned a new severity, the target severity. The target severity is specified by the fault policy for the fault class. The fault remains in the Raised state at the target severity until the fault condition is alleviated.
-
Raised-Clearing—When the fault condition of a Raised Fault is alleviated, the fault MO enters the Raised-Clearing state. The severity remains at the target severity, and a clearing interval begins. If the fault condition returns during the clearing interval, the fault MO returns to the Raised state.
-
Retaining—When the fault condition is absent for the duration of the clearing interval in either the Raised-Clearing or Soaking-Clearing state, the fault MO enters the Retaining state with the severity level cleared. A retention interval begins, during which the fault MO is retained for the length of time that is specified in the fault policy. This interval ensures that the fault reaches the attention of an administrator even if the condition that caused the fault has been alleviated, and that the fault is not deleted prematurely. If the fault condition reoccurs during the retention interval, a new fault MO is created in the Soaking state. If the fault condition has not returned before the retention interval expires, or if the fault is acknowledged by the user, the fault MO is deleted.
The soaking, clearing,
and retention intervals are specified in the fault life cycle profile (fault:LcP) object.
Note |
A fault lifecycle change might not take effect on a switch if the inter-process messaging system is overloaded. For example, overloading can occur when the syslog severity level is set to “debug” or when pushing an extremely large configuration much beyond the scale limit of the switch. |
Configuring the Fault Life Cycle Intervals
The fault lifecycle has three user-configurable parameters.
Procedure
|
Step 1 |
Navigate to Fabric > Fabric Policies > Policies > Monitoring > Common Policy > Fault Lifecycle Policy. |
|
Step 2 |
In the work pane, you can configure the following parameters:
|
|
Step 3 |
To see the nodes and policies that will be affected by changes to this policy, click Show Usage. |
|
Step 4 |
Click Submit. |


 Feedback
Feedback