Connectivity Refresher
This section serves a simple review of how communication between the pods and the nodes works. This is useful to troubleshoot cluster issues. The following example shows a 2-node Kubernetes deployment and how coredns traffic is reaching the kube-api:
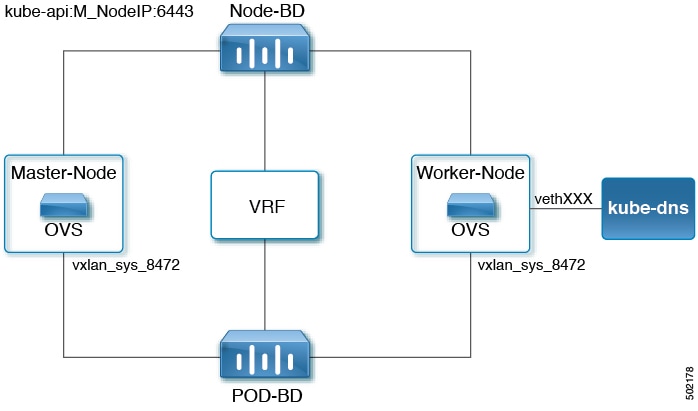
After the coredns pod comes up, the pod tries to initialize services and endpoints from the API server. The API server runs on the master nodes, listen on port 6443, and is accessible by the Node-BD subnet.
You can have multiple masters. By default Kubernetes creates a service IP address to load balance sessions between multiple masters. For example, in a 2-master configuration, you can see the following information:
root@k8s-01:~# kubectl --namespace=default describe service kubernetes
Name: kubernetes
Namespace: default
Labels: component=apiserver provider=kubernetes
Annotations: <none>
Selector: <none>
Type: ClusterIP
IP: 10.37.0.1
Port: https 443/TCP
Endpoints: 10.32.0.11:6443,10.32.0.12:6443
Session Affinity: ClientIP
Events: <none>When coredns tries to connect to the master, coredns tries to connect to kubernetes-service-ip on port 443 (10.37.0.1 is used in the example above). A sniffer trace collected on the coredns vethID would show flows initiated with the KubeDNS IP address directed to the kubernetes-service-ip on port 443.
After the traffic hits the Open vSwitch (OVS), the traffic will be destination network address translated to one of the master node API addresses. A sniffer trace collected on the vxlan_sys_8472 interface shows that the destination IP address has been changed from "kubernetes-service-ip:443" to "Master-IP:6443."
This procedure can be used to troubleshoot most services on the cluster.

 Feedback
Feedback