Document Conventions
This document uses the following conventions:
| Convention | Description |
|---|---|
| ^ or Ctrl |
Both the ^ symbol and Ctrl represent the Control (Ctrl) key on a keyboard. For example, the key combination ^D or Ctrl-D means that you hold down the Control key while you press the D key. (Keys are indicated in capital letters but are not case sensitive.) |
| bold font |
Commands and keywords and user-entered text appear in bold font. |
| Italic font |
Document titles, new or emphasized terms, and arguments for which you supply values are in italic font. |
Courier font
|
Terminal
sessions and information the system displays appear in
|
Bold Courier font
|
Bold Courier font indicates text that the user must enter. |
| [x] |
Elements in square brackets are optional. |
| ... |
An ellipsis (three consecutive nonbolded periods without spaces) after a syntax element indicates that the element can be repeated. |
| | |
A vertical line, called a pipe, indicates a choice within a set of keywords or arguments. |
| [x | y] |
Optional alternative keywords are grouped in brackets and separated by vertical bars. |
| {x | y} |
Required alternative keywords are grouped in braces and separated by vertical bars. |
| [x {y | z}] |
Nested set of square brackets or braces indicate optional or required choices within optional or required elements. Braces and a vertical bar within square brackets indicate a required choice within an optional element. |
| string |
A nonquoted set of characters. Do not use quotation marks around the string or the string will include the quotation marks. |
| < > |
Nonprinting characters such as passwords are in angle brackets. |
| [ ] |
Default responses to system prompts are in square brackets. |
| !, # |
An exclamation point (!) or a pound sign (#) at the beginning of a line of code indicates a comment line. |
Reader Alert Conventions
This document uses the following conventions for reader alerts:
 Note |
Means reader take note. Notes contain helpful suggestions or references to material not covered in the manual. |
 Tip |
Means the following information will help you solve a problem. |
 Caution |
Means reader be careful. In this situation, you might do something that could result in equipment damage or loss of data. |
 Timesaver |
Means the described action saves time. You can save time by performing the action described in the paragraph. |
 Warning |
Means reader be warned. In this situation, you might perform an action that could result in bodily injury. |
|
IMPORTANT SAFETY INSTRUCTIONS This warning symbol means danger. You are in a situation that could cause bodily injury. Before you work on any equipment, be aware of the hazards involved with electrical circuitry and be familiar with standard practices for preventing accidents. Use the statement number provided at the end of each warning to locate its translation in the translated safety warnings that accompanied this device. Statement 1071 SAVE THESE INSTRUCTIONS |
|
| Waarschuwing |
BELANGRIJKE VEILIGHEIDSINSTRUCTIES Dit waarschuwingssymbool betekent gevaar. U verkeert in een situatie die lichamelijk letsel kan veroorzaken. Voordat u aan enige apparatuur gaat werken, dient u zich bewust te zijn van de bij elektrische schakelingen betrokken risico's en dient u op de hoogte te zijn van de standaard praktijken om ongelukken te voorkomen. Gebruik het nummer van de verklaring onderaan de waarschuwing als u een vertaling van de waarschuwing die bij het apparaat wordt geleverd, wilt raadplegen. BEWAAR DEZE INSTRUCTIES |
| Varoitus |
TÄRKEITÄ TURVALLISUUSOHJEITA Tämä varoitusmerkki merkitsee vaaraa. Tilanne voi aiheuttaa ruumiillisia vammoja. Ennen kuin käsittelet laitteistoa, huomioi sähköpiirien käsittelemiseen liittyvät riskit ja tutustu onnettomuuksien yleisiin ehkäisytapoihin. Turvallisuusvaroitusten käännökset löytyvät laitteen mukana toimitettujen käännettyjen turvallisuusvaroitusten joukosta varoitusten lopussa näkyvien lausuntonumeroiden avulla. SÄILYTÄ NÄMÄ OHJEET |
| Attention |
IMPORTANTES INFORMATIONS DE SÉCURITÉ Ce symbole d'avertissement indique un danger. Vous vous trouvez dans une situation pouvant entraîner des blessures ou des dommages corporels. Avant de travailler sur un équipement, soyez conscient des dangers liés aux circuits électriques et familiarisez-vous avec les procédures couramment utilisées pour éviter les accidents. Pour prendre connaissance des traductions des avertissements figurant dans les consignes de sécurité traduites qui accompagnent cet appareil, référez-vous au numéro de l'instruction situé à la fin de chaque avertissement. CONSERVEZ CES INFORMATIONS |
| Warnung |
WICHTIGE SICHERHEITSHINWEISE Dieses Warnsymbol bedeutet Gefahr. Sie befinden sich in einer Situation, die zu Verletzungen führen kann. Machen Sie sich vor der Arbeit mit Geräten mit den Gefahren elektrischer Schaltungen und den üblichen Verfahren zur Vorbeugung vor Unfällen vertraut. Suchen Sie mit der am Ende jeder Warnung angegebenen Anweisungsnummer nach der jeweiligen Übersetzung in den übersetzten Sicherheitshinweisen, die zusammen mit diesem Gerät ausgeliefert wurden. BEWAHREN SIE DIESE HINWEISE GUT AUF. |
| Avvertenza |
IMPORTANTI ISTRUZIONI SULLA SICUREZZA Questo simbolo di avvertenza indica un pericolo. La situazione potrebbe causare infortuni alle persone. Prima di intervenire su qualsiasi apparecchiatura, occorre essere al corrente dei pericoli relativi ai circuiti elettrici e conoscere le procedure standard per la prevenzione di incidenti. Utilizzare il numero di istruzione presente alla fine di ciascuna avvertenza per individuare le traduzioni delle avvertenze riportate in questo documento. CONSERVARE QUESTE ISTRUZIONI |
| Advarsel |
VIKTIGE SIKKERHETSINSTRUKSJONER Dette advarselssymbolet betyr fare. Du er i en situasjon som kan føre til skade på person. Før du begynner å arbeide med noe av utstyret, må du være oppmerksom på farene forbundet med elektriske kretser, og kjenne til standardprosedyrer for å forhindre ulykker. Bruk nummeret i slutten av hver advarsel for å finne oversettelsen i de oversatte sikkerhetsadvarslene som fulgte med denne enheten. TA VARE PÅ DISSE INSTRUKSJONENE |
| Aviso |
INSTRUÇÕES IMPORTANTES DE SEGURANÇA Este símbolo de aviso significa perigo. Você está em uma situação que poderá ser causadora de lesões corporais. Antes de iniciar a utilização de qualquer equipamento, tenha conhecimento dos perigos envolvidos no manuseio de circuitos elétricos e familiarize-se com as práticas habituais de prevenção de acidentes. Utilize o número da instrução fornecido ao final de cada aviso para localizar sua tradução nos avisos de segurança traduzidos que acompanham este dispositivo. GUARDE ESTAS INSTRUÇÕES |
| ¡Advertencia! |
INSTRUCCIONES IMPORTANTES DE SEGURIDAD Este símbolo de aviso indica peligro. Existe riesgo para su integridad física. Antes de manipular cualquier equipo, considere los riesgos de la corriente eléctrica y familiarícese con los procedimientos estándar de prevención de accidentes. Al final de cada advertencia encontrará el número que le ayudará a encontrar el texto traducido en el apartado de traducciones que acompaña a este dispositivo. GUARDE ESTAS INSTRUCCIONES |
| Varning! |
VIKTIGA SÄKERHETSANVISNINGAR Denna varningssignal signalerar fara. Du befinner dig i en situation som kan leda till personskada. Innan du utför arbete på någon utrustning måste du vara medveten om farorna med elkretsar och känna till vanliga förfaranden för att förebygga olyckor. Använd det nummer som finns i slutet av varje varning för att hitta dess översättning i de översatta säkerhetsvarningar som medföljer denna anordning. SPARA DESSA ANVISNINGAR |

|
|

|
|

|
|

|
|

|
|
| Aviso |
INSTRUÇÕES IMPORTANTES DE SEGURANÇA Este símbolo de aviso significa perigo. Você se encontra em uma situação em que há risco de lesões corporais. Antes de trabalhar com qualquer equipamento, esteja ciente dos riscos que envolvem os circuitos elétricos e familiarize-se com as práticas padrão de prevenção de acidentes. Use o número da declaração fornecido ao final de cada aviso para localizar sua tradução nos avisos de segurança traduzidos que acompanham o dispositivo. GUARDE ESTAS INSTRUÇÕES |
| Advarsel |
VIGTIGE SIKKERHEDSANVISNINGER Dette advarselssymbol betyder fare. Du befinder dig i en situation med risiko for legemesbeskadigelse. Før du begynder arbejde på udstyr, skal du være opmærksom på de involverede risici, der er ved elektriske kredsløb, og du skal sætte dig ind i standardprocedurer til undgåelse af ulykker. Brug erklæringsnummeret efter hver advarsel for at finde oversættelsen i de oversatte advarsler, der fulgte med denne enhed. GEM DISSE ANVISNINGER |

|
|

|
|

|
|

|
|

|
|

|
|

|
|

|

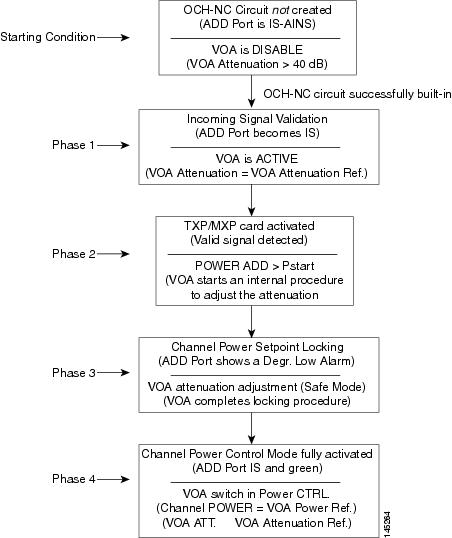
 Feedback
Feedback