- Finding Feature Information
- Prerequisites for NSF SSO--MPLS TE and RSVP Graceful Restart
- Restrictions for NSF SSO--MPLS TE and RSVP Graceful Restart
- Information About NSF SSO--MPLS TE and RSVP Graceful Restart
- How to Configure NSF SSO--MPLS TE and RSVP Graceful Restart
- Configuration Examples for NSF SSO--MPLS TE and RSVP Graceful Restart
- Additional References
- Feature Information for NSF SSO--MPLS TE and RSVP Graceful Restart
- Glossary
NSF SSO--MPLS TE and RSVP Graceful Restart
The NSF/SSO--MPLS TE and RSVP Graceful Restart feature allows a Route Processor (RP) to recover from disruption in control plane service without losing its Multiprotocol Label Switching (MPLS) forwarding state.
Cisco nonstop forwarding (NSF) with stateful switchover (SSO) provides continuous packet forwarding, even during a network processor hardware or software failure. In a redundant system, the secondary processor recovers control plane service during a critical failure in the primary processor. SSO synchronizes the network state information between the primary and the secondary processor.
In Cisco IOS Release 12.2(33)SRE, SSO can co-exist with traffic engineering (TE) primary tunnels, backup tunnels, and automesh tunnels.
- Finding Feature Information
- Prerequisites for NSF SSO--MPLS TE and RSVP Graceful Restart
- Restrictions for NSF SSO--MPLS TE and RSVP Graceful Restart
- Information About NSF SSO--MPLS TE and RSVP Graceful Restart
- How to Configure NSF SSO--MPLS TE and RSVP Graceful Restart
- Configuration Examples for NSF SSO--MPLS TE and RSVP Graceful Restart
- Additional References
- Feature Information for NSF SSO--MPLS TE and RSVP Graceful Restart
- Glossary
Finding Feature Information
Your software release may not support all the features documented in this module. For the latest caveats and feature information, see Bug Search Tool and the release notes for your platform and software release. To find information about the features documented in this module, and to see a list of the releases in which each feature is supported, see the feature information table at the end of this module.
Use Cisco Feature Navigator to find information about platform support and Cisco software image support. To access Cisco Feature Navigator, go to www.cisco.com/go/cfn. An account on Cisco.com is not required.
Prerequisites for NSF SSO--MPLS TE and RSVP Graceful Restart
If you have many tunnels/LSPs (100 or more) or if you have a large-scale network, the following configuration is recommended:
ip rsvp signalling refresh reduction ip rsvp signalling rate-limit period 50 burst 16 maxsize 3000 limit 37 ip rsvp signalling patherr state-removal ip rsvp signalling initial-retransmit-delay 15000
Additional info about these RSVP commands can be found in the Cisco IOS Quality of Service Command Reference .
- Configure RSVP graceful restart on all interfaces of the neighbor that you want to be restart-capable.
- Configure the redundancy mode as SSO. See Stateful Switchover .
- Enable NSF on the routing protocols running among the provider routers (P), provider edge (PE) routers, and customer edge (CE) routers. The routing protocols are as follows:
For more information, see Information about Cisco Nonstop Forwarding .
Restrictions for NSF SSO--MPLS TE and RSVP Graceful Restart
- RSVP graceful restart supports node failure only.
- Unnumbered interfaces are not supported.
- You cannot enable RSVP fast reroute (FRR) hello messages and RSVP graceful restart on the same router.
- Configure this feature on Cisco 7600 series routers with dual RPs only.
- For releases prior to Cisco IOS Release 12.2(33)SRE, you cannot enable primary one-hop autotunnels, backup autotunnels, or autotunnel mesh groups on a router that is also configured with SSO and Route Processor Redundancy Plus (RPR+). This restriction does not prevent an MPLS TE tunnel that is automatically configured by TE autotunnel from being successfully recovered if any midpoint router along the label-switched path (LSP) of the router experiences an SSO. For Cisco IOS Release 12.2(33)SRE, go to the MPLS TE Autotunnel and SSO Coexistence.
- MPLS TE LSPs that are fast reroutable cannot be successfully recovered if the LSPs are FRR active and the Point of Local Repair (PLR) router experiences an SSO.
- When you configure RSVP graceful restart, you must use the neighbor's interface IP address.
- When SSO (stateful switchover) occurs on a router, the switchover process must complete before FRR (fast reroute) can complete successfully. In a testing environment, allow approximately 2 minutes for TE SSO recovery to complete before manually triggering FRR. To check the TE SSO status, use the show ip rsvp high-availability summary command. Note the status of the HA state field.
- When SSO is in the process of completing, this field will display 'Recovering'.
- When the SSO process has completed, this field will display 'Active'.
Information About NSF SSO--MPLS TE and RSVP Graceful Restart
- Overview of MPLS TE and RSVP Graceful Restart
- MPLS TE Autotunnel and SSO Coexistence
- Benefits of MPLS TE and RSVP Graceful Restart
Overview of MPLS TE and RSVP Graceful Restart
RSVP graceful restart allows RSVP TE-enabled nodes to recover gracefully following a node failure in the network such that the RSVP state after the failure is restored as quickly as possible. The node failure may be completely transparent to other nodes in the network.
RSVP graceful restart preserves the label values and forwarding information and works with third-party or Cisco routers seamlessly.
RSVP graceful restart depends on RSVP hello messages to detect that a neighbor went down. Hello messages include Hello Request or Hello Acknowledgment (ACK) objects between two neighbors.
A node hello is transmitted when Graceful Restart is globally configured and the first LSP to the neighbor is created.
Interface Hello is an optional configuration. If the Graceful Restart Hello command is configured on an interface, the interface hello is considered to be an additional hello instance with the neighbor.
An interface hello for Graceful Restart is transmitted when all of the following conditions are met:
- Graceful Restart is configured globally.
- Graceful restart is configured on the interface.
- An LSP to the neighbor is created and goes over the interface.
Cisco recommends that you use node hellos if the neighbor supports node hellos, and configure interface hellos only if the neighbor router does not support node hellos.
Interface hellos differ from node hellos. as follows:
- Interface hello --The source address in the IP header of the hello message has an IP address that matches the interface that the Hello message sent out. The destination address in the IP header is the interface address of the neighbor on the other side of the link. A TTL of 1 is used for per-interface hellos as it is destined for the directly-connected neighbor.
- Node hello --The source address in the IP header of the Hello message includes the TE router ID of the sending router. The destination address of the IP header has the router ID of the neighbor to which this message is sent. A TTL of more than 1 is used.
As shown in the figure below, the RSVP graceful restart extension to these messages adds an object called Hello Restart_Cap, which tells neighbors that a node may be capable of recovering if a failure occurs.
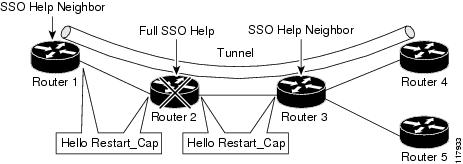
The Hello Restart_Cap object has two values: the restart time, which is the sender's time to restart the RSVP_TE component and exchange hello messages after a failure; and the recovery time, which is the desired time that the sender wants the receiver to synchronize the RSVP and MPLS databases.
In the figure above, RSVP graceful restart help neighbor support is enabled on Routers 1 and 3 so that they can help a neighbor recover after a failure, but they cannot perform self recovery. Router 2 has full SSO help support enabled, meaning it can perform self recovery after a failure or help its neighbor to recover. Router 2 has two RPs, one that is active and one that is standby (backup). A TE LSP is signaled from Router 1 to Router 4.
Router 2 performs checkpointing; that is, it copies state information from the active RP to the standby RP, thereby ensuring that the standby RP has the latest information. If an active RP fails, the standby RP can take over.
Routers 2 and 3 exchange periodic graceful restart hello messages every 10,000 milliseconds (ms) (10 seconds), and so do Routers 2 and 1 and Routers 3 and 4. Assume that Router 2 advertises its restart time = 60,000 ms (60 seconds) and its recovery time = 60,000 ms (60 seconds) as shown in the following example:
23:33:36: Outgoing Hello: 23:33:36: version:1 flags:0000 cksum:883C ttl:255 reserved:0 length:32 23:33:36: HELLO type HELLO REQUEST length 12: 23:33:36: Src_Instance: 0x6EDA8BD7, Dst_Instance: 0x00000000 23:33:36: RESTART_CAP type 1 length 12: 23:33:36: Restart_Time: 0x0000EA60, Recovery_Time: 0x0000EA60
Router 3 records this into its database. Also, both neighbors maintain the neighbor status as UP. However, Router 3's control plane fails at some point (for example, a primary RP failure). As a result, RSVP and TE lose their signaling information and states although data packets continue to be forwarded by the line cards.
When Router 3 declares communication with Router 2 lost, Router 3 starts the restart time to wait for the duration advertised in Router 2's restart time previously recorded (60 seconds). Routers 1 and 2 suppress all RSVP messages to Router 3 except hellos. Router 3 keeps sending the RSVP PATH and RESV refresh messages to Routers 4 and 5 so that they do not expire the state for the LSP; however, Routers 1 and 3 suppress these messages for Router 2.
When Routers 1 and 3 receive the hello message from Router 2, Routers 1 and 3 check the recovery time value in the message. If the recovery time is 0, Router 3 knows that Router 2 was not able to preserve its forwarding information, and Routers 1 and 3 delete all RSVP state that they had with Router 2.
If the recovery time is greater than 0, Router 1 sends Router 2 PATH messages for each LSP that it had previously sent through Router 2. If these messages were previously refreshed in summary messages, they are sent individually during the recovery time. Each of these PATH messages includes a Recovery_Label object containing the label value received from Router 2 before the failure.
When Router 3 receives a PATH message from Router 2, Router 3 sends a RESV message upstream. However, Router 3 suppresses the RESV message until it receives a PATH message. When Router 2 receives the RESV message, it installs the RSVP state and reprograms the forwarding entry for the LSP.
MPLS TE Autotunnel and SSO Coexistence
In Cisco IOS 12.2(33)SRE and later releases, MPLS TE primary tunnels, backup tunnels, and automesh tunnels can coexist with SSO; that is, they can be configured together. However, there are the following functional differences:
- Headend autotunnels created on the active RP are not checkpointed and created on the standby RP.
- After the SSO switchover, the new active RP recreates all the headend autotunnels and signals their LSPs. The LSP ID is different from the LSP ID used before the SSO switchover. Tunnel traffic may be dropped during the signaling of new autotunnel LSPs.
- SSO coexistence does not affect TE autotunnels in the midpoint or tailend routers along the LSPs from being checkpointed and recovered.
Benefits of MPLS TE and RSVP Graceful Restart
State Information Recovery
RSVP graceful restart allows a node to perform self recovery or to help its neighbor recover state information when there is an RP failure or the device has undergone an SSO.
Session Information Recovery
RSVP graceful restart allows session information recovery with minimal disruption to the network.
Increased Availability of Network Services
A node can perform a graceful restart to help itself or a neighbor recover its state by keeping the label bindings and state information, thereby providing a faster recovery of the failed node and not affecting currently forwarded traffic.
How to Configure NSF SSO--MPLS TE and RSVP Graceful Restart
- Enabling RSVP Graceful Restart Globally
- Enabling RSVP Graceful Restart on an Interface
- Setting a DSCP Value
- Setting a Value to Control the Hello Refresh Interval
- Setting a Value to Control the Missed Refresh Limit
- Verifying the RSVP Graceful Restart Configuration
Enabling RSVP Graceful Restart Globally
DETAILED STEPS
Note
If you have many tunnels/LSPs (100 or more) or if you have a large-scale network, the following configuration is recommended:
ip rsvp signalling refresh reduction ip rsvp signalling rate-limit period 50 burst 16 maxsize 3000 limit 37 ip rsvp signalling patherr state-removal ip rsvp signalling initial-retransmit-delay 15000
Enabling RSVP Graceful Restart on an Interface
 Note |
You must repeat this procedure for each of the neighbor router's interfaces. |
DETAILED STEPS
Setting a DSCP Value
DETAILED STEPS
| Command or Action | Purpose | |
|---|---|---|
|
|
Example: Router> enable |
Enables privileged EXEC mode.
|
|
|
Example: Router# configure terminal |
Enters global configuration mode. |
|
|
Example: Router(config)# ip rsvp signalling hello graceful-restart dscp 30 |
Sets a DSCP value on a router with RSVP graceful restart enabled. |
|
|
Example: Router(config)# exit |
(Optional) Returns to privileged EXEC mode. |
Setting a Value to Control the Hello Refresh Interval
DETAILED STEPS
| Command or Action | Purpose | |||
|---|---|---|---|---|
|
|
Example: Router> enable |
Enables privileged EXEC mode.
|
||
|
|
Example: Router# configure terminal |
Enters global configuration mode. |
||
|
|
Example: Router(config)# ip rsvp signalling hello graceful-restart refresh interval 5000 |
Sets the value to control the request interval in graceful restart hello messages. This interval represents the frequency at which RSVP hello messages are sent to a neighbor; for example, one hello message is sent per each interval.
|
||
|
|
Example: Router(config)# exit |
(Optional) Returns to privileged EXEC mode. |
Setting a Value to Control the Missed Refresh Limit
DETAILED STEPS
| Command or Action | Purpose | |||
|---|---|---|---|---|
|
|
Example: Router> enable |
Enables privileged EXEC mode.
|
||
|
|
Example: Router# configure terminal |
Enters global configuration mode. |
||
|
|
Example: Router(config)# ip rsvp signalling hello graceful-restart refresh misses 5 |
Specifies how many sequential RSVP TE graceful restart hello acknowledgments (ACKs) a node can miss before the node considers communication with its neighbor lost.
|
||
|
|
Example: Router(config)# exit |
(Optional) Returns to privileged EXEC mode. |
Verifying the RSVP Graceful Restart Configuration
DETAILED STEPS
| Command or Action | Purpose | |
|---|---|---|
|
|
Example: Router> enable |
(Optional) Enables privileged EXEC mode.
|
|
|
Example: Router# show ip rsvp hello graceful-restart |
Displays information about the status of RSVP graceful restart and related parameters. |
|
|
Example: Router# exit |
(Optional) Returns to user EXEC mode. |
Configuration Examples for NSF SSO--MPLS TE and RSVP Graceful Restart
- Configuring NSF SSO--MPLS TE and RSVP Graceful Restart Example
- Verifying the NSF SSO--MPLS TE and RSVP Graceful Restart Configuration Example
Configuring NSF SSO--MPLS TE and RSVP Graceful Restart Example
In the following example, RSVP graceful restart is enabled globally and on a neighbor router's interfaces as shown in the figure below. Related parameters, including a DSCP value, a refresh interval, and a missed refresh limit are set.
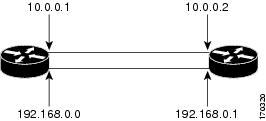
enable configure terminal ip rsvp signalling hello graceful-restart mode full interface POS 1/0/0 ip rsvp signalling hello graceful-restart neighbor 10.0.0.1 ip rsvp signalling hello graceful-restart neighbor 10.0.0.2 exit ip rsvp signalling hello graceful-restart dscp 30 ip rsvp signalling hello graceful-restart refresh interval 50000 ip rsvp signalling hello graceful-restart refresh misses 5 exit
Verifying the NSF SSO--MPLS TE and RSVP Graceful Restart Configuration Example
The following example verifies the status of RSVP graceful restart and the configured parameters:
Router# show ip rsvp hello graceful-restart
Graceful Restart: Enabled (full mode)
Refresh interval: 10000 msecs
Refresh misses: 4
DSCP:0x30
Advertised restart time: 30000 msecs
Advertised recovery time: 120000 msecs
Maximum wait for recovery: 3600000 msecs
Additional References
Related Documents
| Related Topic |
Document Title |
|---|---|
| RSVP commands: complete command syntax, command mode, defaults, usage guidelines, and examples |
Cisco IOS Quality of Service Solutions Command Reference |
| Quality of service (QoS) classification |
Classification Overview |
| QoS signalling |
Signalling Overview |
| QoS congestion management |
Congestion Management Overview |
| Stateful switchover |
Stateful Switchover |
| Cisco nonstop forwarding |
Information about Cisco Nonstop Forwarding |
| RSVP hello state timer |
MPLS Traffic Engineering: RSVP Hello State Timer |
Standards
| Standard |
Title |
|---|---|
| No new or modified standards are supported by this feature, and support for existing standards has not been modified by this feature. |
-- |
MIBs
| MIB |
MIBs Link |
|---|---|
| No new or modified MIBS are supported by this feature, and support for existing MIBs has not been modified by this feature. |
To locate and download MIBs for selected platforms, Cisco IOS releases, and feature sets, use Cisco MIB Locator found at the following URL: |
RFCs
| RFC |
Title |
|---|---|
| RFC 3209 |
RSVP-TE: Extensions to RSVP for LSP Tunnels |
| RFC 3473 |
Generalized Multi-Protocol Label Switching (GMPLS) Signaling Resource Reservation Protocol-Traffic Engineering (RSVP-TE) Extensions |
| RFC 4558 |
Node-ID Based Resource Reservation Protocol (RSVP) Hello: A Clarification Statement |
Technical Assistance
| Description |
Link |
|---|---|
| The Cisco Support website provides extensive online resources, including documentation and tools for troubleshooting and resolving technical issues with Cisco products and technologies. To receive security and technical information about your products, you can subscribe to various services, such as the Product Alert Tool (accessed from Field Notices), the Cisco Technical Services Newsletter, and Really Simple Syndication (RSS) Feeds. Access to most tools on the Cisco Support website requires a Cisco.com user ID and password. |
Feature Information for NSF SSO--MPLS TE and RSVP Graceful Restart
The following table provides release information about the feature or features described in this module. This table lists only the software release that introduced support for a given feature in a given software release train. Unless noted otherwise, subsequent releases of that software release train also support that feature.
Use Cisco Feature Navigator to find information about platform support and Cisco software image support. To access Cisco Feature Navigator, go to www.cisco.com/go/cfn. An account on Cisco.com is not required.
| Table 1 | Feature Information for NSF/SSO--MPLS TE and RSVP Graceful Restart |
| Feature Name |
Releases |
Feature Information |
|---|---|---|
| NSF/SSO--MPLS TE and RSVP Graceful Restart |
12.0(29)S 12.2(33)SRA 12.2(33)SRB 12.2(33)SXH 12.2(33)SRE |
The NSF/SSO--MPLS TE and RSVP Graceful Restart feature allows an RP or its neighbor to recover from disruption in control plane service without losing its MPLS forwarding state. In Cisco IOS Release 12.0(29)S, this feature was introduced as MPLS Traffic Engineering--RSVP Graceful Restart and allowed a neighboring RP to recover from disruption in control plane service without losing its MPLS forwarding state. In Cisco IOS Release 12.2(33)SRA, this feature was integrated and new commands were added. In Cisco IOS Release 12.2(33)SRB, support was added for ISSU and SSO recovery of LSPs that include loose hops. In Cisco IOS Release 12.2(33)SXH, this feature was integrated. In Cisco IOS Release 12.2(33)SRE, SSO can coexist with primary tunnels, backup tunnels, and mesh tunnels. |
| MPLS TE-- RSVP Graceful Restart and 12.0S--12.2S Interop |
15.2(1)S |
In Cisco IOS Release 15.2(1)S, this feature was integrated. |
| MPLS TE-- Autotunnel/Automesh SSO Coexistence |
15.2(1)S |
In Cisco IOS Release 15.2(1)S, this feature was integrated. |
Glossary
DSCP --differentiated services code point. Six bits in the IP header, as defined by the IETF. These bits determine the class of service provided to the IP packet.
Fast Reroute --A mechanism for protecting MPLS traffic engineering (TE) LSPs from link and node failure by locally repairing the LSPs at the point of failure, allowing data to continue to flow on them while their headend routers attempt to establish end-to-end LSPs to replace them. FRR locally repairs the protected LSPs by rerouting them over backup tunnels that bypass failed links or nodes.
graceful restart --A process for helping an RP restart after a node failure has occurred.
headend --The router that originates and maintains a given LSP. This is the first router in the LSP's path.
hello instance --A mechanism that implements the RSVP hello extensions for a given router interface address and remote IP address. Active hello instances periodically send hello request messages, expecting Hello ACK messages in response. If the expected ACK message is not received, the active hello instance declares that the neighbor (remote IP address) is unreachable (that is, it is lost). This can cause LSPs crossing this neighbor to be fast rerouted.
IGP --Interior Gateway Protocol. Internet protocol used to exchange routing information within an autonomous system. Examples of common Internet IGPs include IGRP, OSPF, and RIP.
ISSU --In Service Software Upgrade. Software upgrade without service interruption.
label --A short, fixed-length data identifier that tells switching nodes how to forward data (packets or cells).
LSP --label switched path. A configured connection between two routers, in which MPLS is used to carry packets.
MPLS --Multiprotocol Label Switching. A method for forwarding packets (frames) through a network. MPLS enables routers at the edge of a network to apply labels to packets (frames). ATM switches or existing routers in the network core can switch packets according to the labels.
RSVP --Resource Reservation Protocol. A protocol that supports the reservation of resources across an IP network. Applications running on IP end systems can use RSVP to indicate to other nodes the nature (bandwidth, jitter, maximum burst, and so on) of the packet streams they want to receive.
state --Information that a router must maintain about each LSP. The information is used for rerouting tunnels.
tailend --The router upon which an LSP is terminated. This is the last router in the LSP's path.
TE --traffic engineering. The techniques and processes used to cause routed traffic to travel through the network on a path other than the one that would have been chosen if standard routing methods had been used.
Cisco and the Cisco logo are trademarks or registered trademarks of Cisco and/or its affiliates in the U.S. and other countries. To view a list of Cisco trademarks, go to this URL: www.cisco.com/go/trademarks. Third-party trademarks mentioned are the property of their respective owners. The use of the word partner does not imply a partnership relationship between Cisco and any other company. (1110R)
Any Internet Protocol (IP) addresses and phone numbers used in this document are not intended to be actual addresses and phone numbers. Any examples, command display output, network topology diagrams, and other figures included in the document are shown for illustrative purposes only. Any use of actual IP addresses or phone numbers in illustrative content is unintentional and coincidental.
 Feedback
Feedback