Viewing Resiliency Status in HX Connect
Independent and Non-Simultaneous Failure Scenarios
The Dashboard page in HX Connect displays the status summary of your HX storage cluster. Click Information ( ) to access the resiliency status. Resiliency status is the data resiliency health status and the ability of the storage cluster
to tolerate failures.
) to access the resiliency status. Resiliency status is the data resiliency health status and the ability of the storage cluster
to tolerate failures.
To access the resiliency status in HX Connect:
-
Log into HX Connect.
-
Enter the HX Storage Cluster management IP address in a browser. Navigate to https://<storage-cluster-management-ip>.
-
Enter the administrative username and password. Click Login.
-
-
On the left navigation pane, click Dashboard.
-
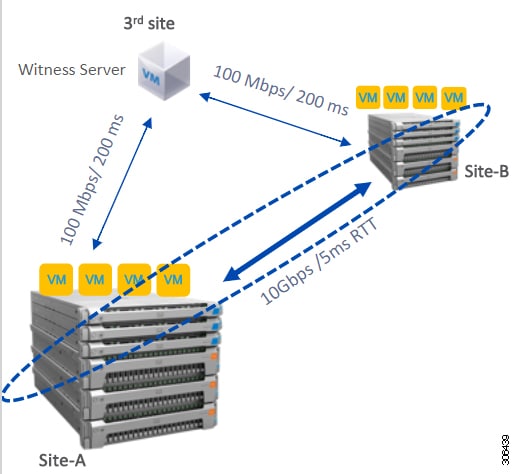
On the Dashboard page, you can view the resiliency status for the HyperFlex Stretch Cluster:
Color coding and icons are used to indicate various status states. Click an icon to display additional information, such as reason messages that explain what is contributing to the current state. The various Resiliency Status states are:
-
Healthy—The cluster is healthy with respect to data and availability.
-
Warning—Either the data or the cluster availability is being adversely affected.
-
Unknown—A transitional state while the cluster is coming online.
 Important |
The disk failures that are mentioned below are for the converged nodes only (the witness VM or Invisible Cloud Witness node and the compute nodes do not have disks hosting user data). |
|
Failure Scenario |
Expected Behavior |
Resiliency Status in HX Connect |
||
|---|---|---|---|---|
|
One node failure |
VMs will failover to the remaining nodes on the same site as long as those nodes can accommodate the VM resources. |
Warning—Cluster shows status of unhealthy until the cluster recovers. |
||
|
All node failure on any one site |
User VMs failover to other site.
|
Warning—HX Connect shows the site failure details. Cluster shows status of unhealthy until the cluster recovers. |
||
|
One disk failure |
Cluster recovers after failover. |
Warning—Cluster shows status of unhealthy until the cluster recovers. |
||
|
Two disk failure on a single site (one disk on each node) simultaneously |
Same as one disk failure. |
Warning—Cluster shows status of unhealthy until the cluster recovers. Same as one disk failure. |
||
|
Witness VM or Invisible Cloud Witness failure |
Cluster remains online. |
Witness VM :No visible indication. Invisible Cloud Witness: Online/Offline/Unknown is shown on the System Information Page |
||
|
vCenter failure (platform impact) |
Cluster remains online. |
No visible indication. |
||
|
Network isolation between a given site and a witness VM or Invisible Cloud Witness |
Cluster remains online. |
No visible indication. |
||
|
Network isolation between sites |
All user VMs from one site will fail over to the other site. The VMs from the other site will continue to run.
|
Warning—HX Connect shows the site failure details. Cluster shows status of unhealthy until the cluster recovers. |
Failure Scenarios with witness VM or Invisible Cloud Witness Failure
|
Failure Scenario |
Expected Behavior |
Visible Indications in HX Connect |
|---|---|---|
|
Disk failure |
Cluster remains online. |
Warning—Cluster shows status of unhealthy until the cluster recovers. |
|
Single node failure |
Cluster remains online. Cluster becomes unhealthy. |
Warning—Cluster shows status of unhealthy until the cluster recovers. |
|
Link failure |
Cluster halts resulting in All Path Down on both sites, until either the second failure is healed or the witness VM or Invisible Cloud Witness is restored. |
Warning—Cluster shows status of unhealthy until the cluster recovers. |
|
Either fabric interconnect pair failure |
Cluster halts resulting in All Path Down on both sites, until either the second failure is healed or the witness VM or Invisible Cloud Witness is restored. |
Warning—Cluster shows status of unhealthy until the cluster recovers. |
|
Switch failure |
Cluster halts resulting in All Path Down on both sites, until either the second failure is healed or the witness VM or Invisible Cloud Witness is restored. |
Warning—Cluster shows status of unhealthy until the cluster recovers. |
|
Site power failure |
Cluster halts resulting in All Path Down on both sites, until either the second failure is healed or the witness VM or Invisible Cloud Witness is restored. |
Warning—Cluster shows status of unhealthy until the cluster recovers. |
 Feedback
Feedback