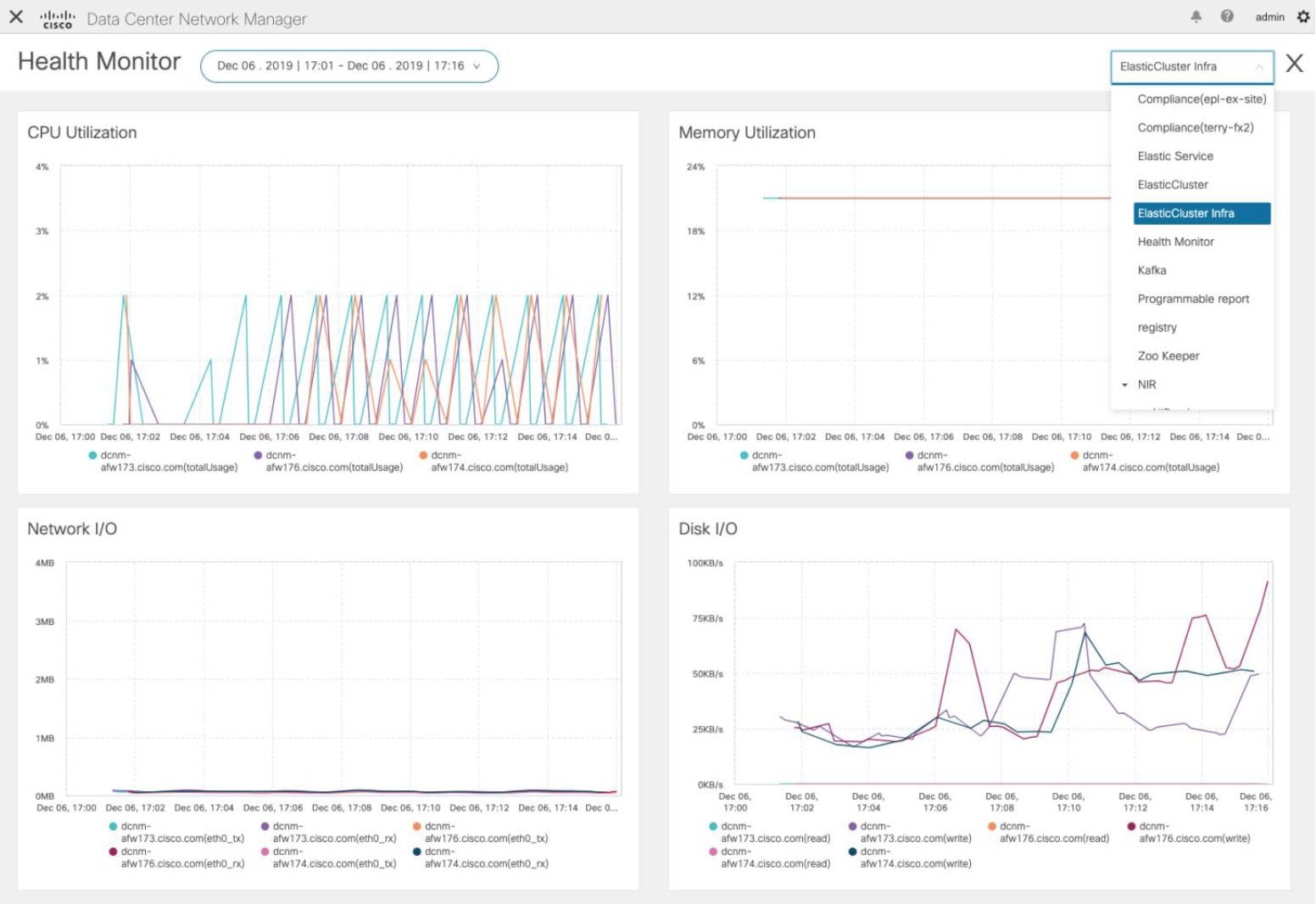
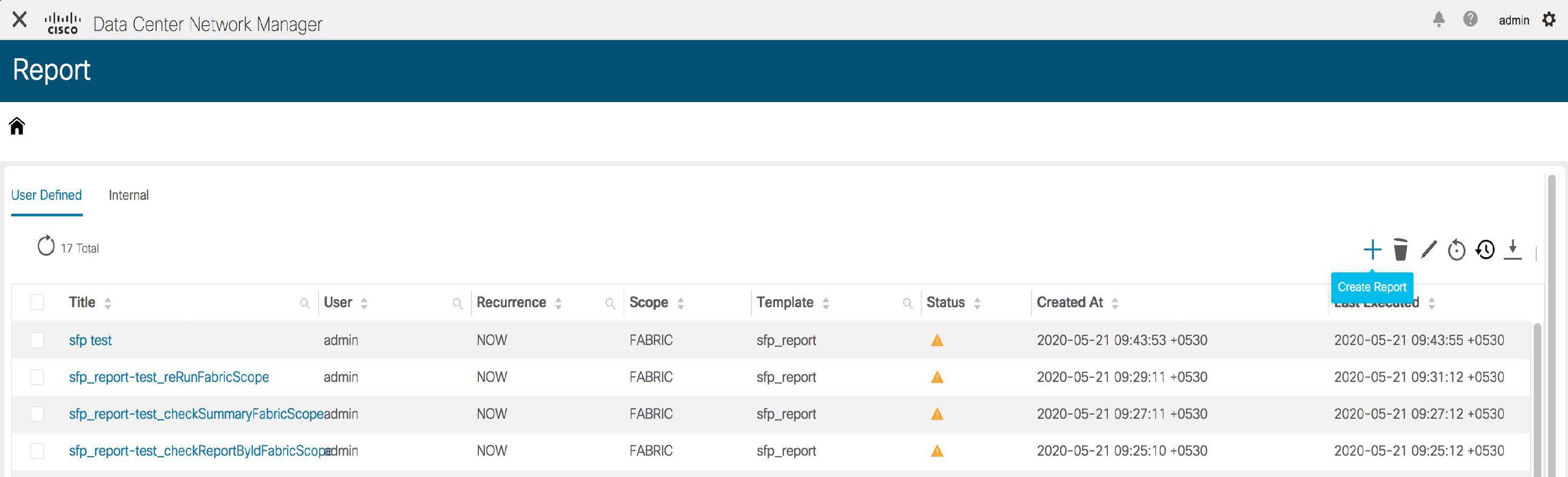
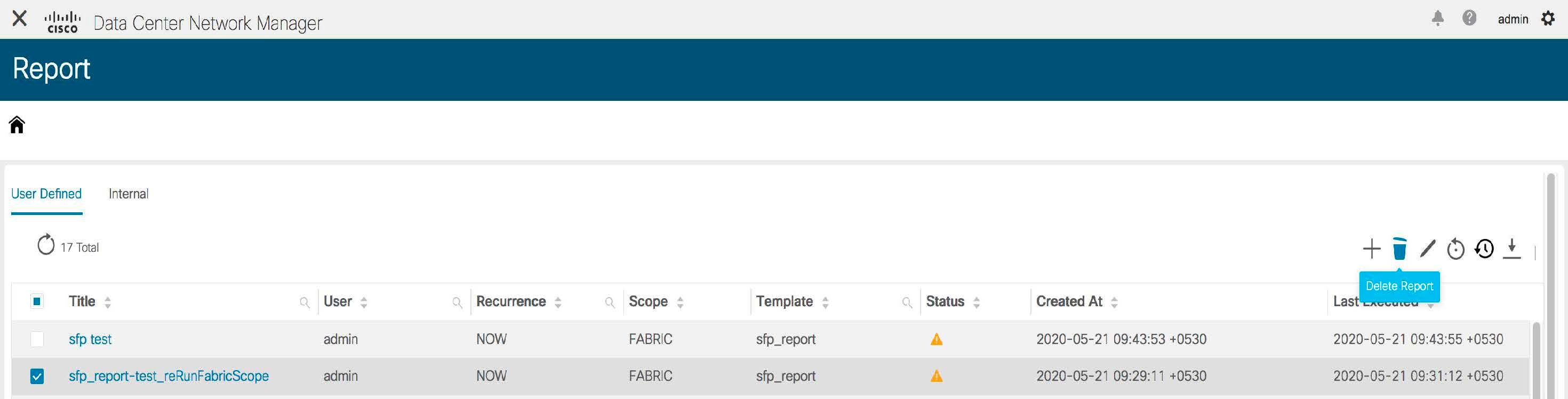
Cisco DCNM in Unclustered Mode
From Cisco DCNM Release 11.0(1), the unclustered mode is the default deployment mode in both Standalone and Native HA environment. In this mode, the Cisco DCNM runs some of its internal services as containers, also.
-
Endpoint Locator is running as a container application, from Cisco DCNM Release 11.1(1).
-
Configuration Compliance service is a container application, from Cisco DCNM Release 11.0(1).
-
Virtual Machine Manager (VMM) is also a container application, from Cisco DCNM Release 11.0(1)
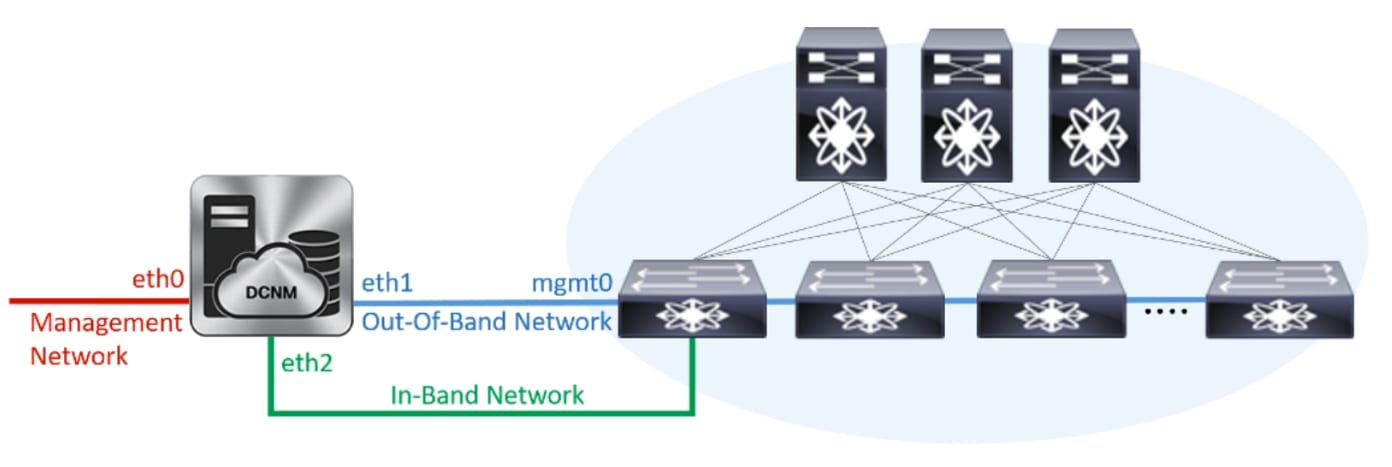
Cisco DCNM leverages resources from the Standby node for running some containers applications. The Cisco DCNM Active and Standby nodes work together to extend resources to the overall functionality and deployment of DCNM and its applications. However, it has limited resources to run some of the advanced applications and to extend the system to deploy more applications delivered through the Cisco AppCenter. For example, you cannot deploy the Network Insights applications that are downloaded from the Cisco AppCenter, for production, in unclustered mode.
To install and deploy applications, see Installing and Deploying Applications.
For best practices and recommended deployments for IP address configurations of all interfaces of the Cisco DCNM and Compute nodes, see Best Practices for Deploying Cisco DCNM and Computes in Cisco DCNM Installation Guide, for your deployment type.

















 Feedback
Feedback