Cisco SDWAN Manager 3 Node Cluster Disaster Recovery
Available Languages
Download Options
Bias-Free Language
The documentation set for this product strives to use bias-free language. For the purposes of this documentation set, bias-free is defined as language that does not imply discrimination based on age, disability, gender, racial identity, ethnic identity, sexual orientation, socioeconomic status, and intersectionality. Exceptions may be present in the documentation due to language that is hardcoded in the user interfaces of the product software, language used based on RFP documentation, or language that is used by a referenced third-party product. Learn more about how Cisco is using Inclusive Language.
Contents
Introduction
This document describes the stateful nature of Cisco vManage and its primary/secondary Designated Router (DR), enabling manual fail-over with auto data replication.
Prerequisites
Requirements
Cisco recommends that you have knowledge of vManage 3-node clusters.
Two separate vManage 3-node clusters must be configured and operational in order to proceed with disaster recovery. On the active cluster you must have validators and controllers onboarded. In case you have validator and controllers on the DR site, they must also be onboarded on the active cluster and not on the DR vManage cluster.
Cisco recommends that before registering disaster recovery, these requirements must be met:
- Ensure that the primary and the secondary node are reachable by HTTPS on a transport VPN (VPN 0).
- Ensure that Cisco vSmart Controllers and Cisco vBond Orchestrators on the secondary setup are connected to the primary setup.
- Ensure that the Cisco vManage primary node and secondary node are running the same Cisco vManage version.
- Out-of-band cluster interface in VPN 0:
- For each vManage instance within a cluster, a third interface (cluster link) is required besides the interfaces used for VPN 0 (transport) and VPN 512 (management).
- This interface is used for communication and syncing between the vManage servers within the cluster.
- This interface must be at least 1 Gbps and have a latency of 4ms or less. A 10 Gbps interface is recommended.
- Both vManage nodes must be able to reach each other through this interface: be it a layer 2 segment or through layer 3 routing.
- In each vManage, this interface must be configured in the GUI as a cluster interface(Administration>Cluster Management– indicate own out-of-band cluster interface IP address, user and password).
- In order to allow Cisco vManage nodes to communicate with each other across data centers, enable TCP ports 8443 and 830 on your data center firewalls.
- Ensure that all services (application-server, configuration-db, messaging server, coordination server, and statistics-db) are enabled on both Cisco vManage nodes.
- Distribute all controllers, including Cisco vBond Orchestrators, across both primary and secondary data centers. Ensure that these controllers are reachable by Cisco vManage nodes that are distributed across these data centers. The controllers connect only to the primary Cisco vManage node.
- Ensure that no other operations are in process in the active (primary) and the standby (secondary) Cisco vManage node. For example, ensure that no servers are in the process of upgrading or attaching templates to devices.
- Disable the Cisco vManage HTTP/HTTPS proxy server if it is enabled. See HTTP/HTTPS Proxy Server for Cisco vManage Communication with External Servers. If you do not disable the proxy server, Cisco vManage attempts to establish disaster recovery communication through the proxy IP address, even if Cisco vManage out-of-band cluster IP addresses are directly reachable. You can re-enable the Cisco vManage HTTP/HTTPS proxy server after disaster recovery registration completes.
- Before you start the disaster recovery registration process, navigate to the Tools > Rediscover Network window on the primary Cisco vManage node and rediscover the Cisco vBond Orchestrators.
Components Used
The information in this document is based on these software versions:
- Manager: 20.12.5
- Validator: 20.12.5
- Controller: 20.12.5
- cEdge: 17.12.5
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. If your network is live, ensure that you understand the potential impact of any command.
Background Information
Disaster recovery provides an administrator-triggered failover process. When disaster recovery is registered, data is replicated automatically between the primary and secondary Cisco vManage clusters. You manually perform a failover to the secondary cluster if needed.
Configure
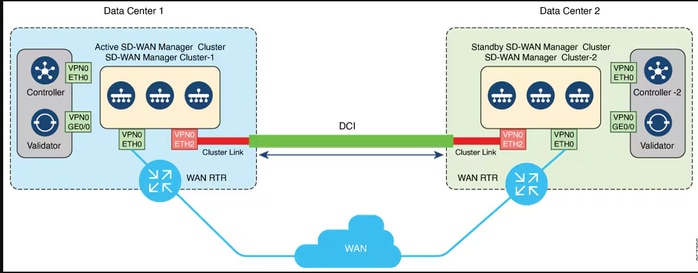
Network Diagram
This figure illustrates the high-level architecture of the disaster recovery solution with a three node cluster.
Configurations
For more information on vManage Disaster Recovery, refer to this link.
The two separate 3-node-clusters are already created, assuming each SD-WAN manager has bare minimum configuration and certification part is completed.

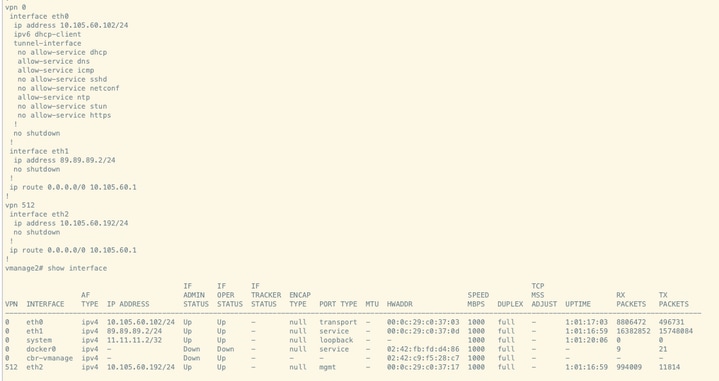
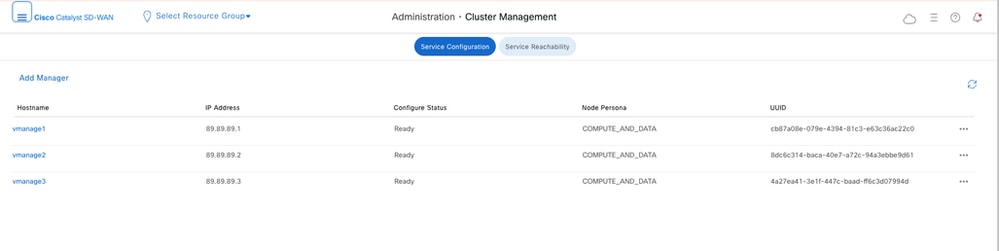
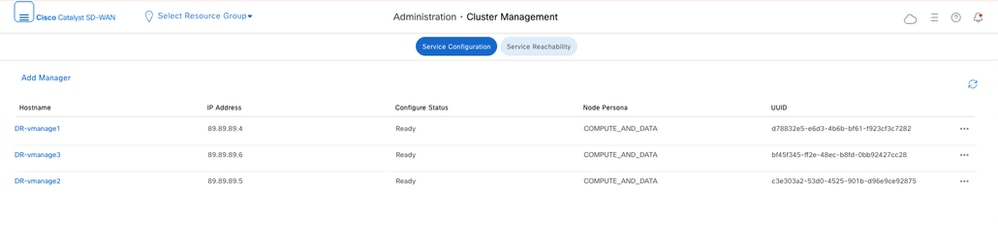
- Navigate to Administration > Cluster Management on both clusters and verify all nodes are in ready state.
DC vManage:
DR-vManage:
- Navigate to Administration>Disaster Recovery. Click Manage Disaster Recovery.
- In the pop-up window, fill the details for both primary and secondary vManage.
The IP addresses to be indicated are the out-of-band cluster interfaces IP addresses.
The credentials must be those of a netadmin user and they must not be changed once the DR is configured, unless it is deleted.
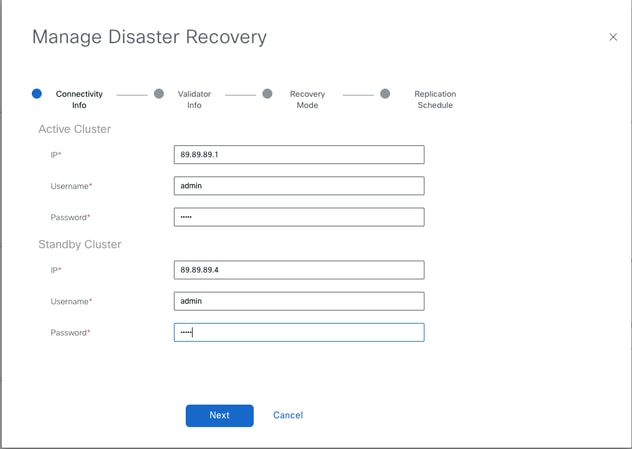
Once filled, click Next.
- Fill the vBond controllers’ details.
The vBond controllers must be reachable in the specified IP address via Netconf.
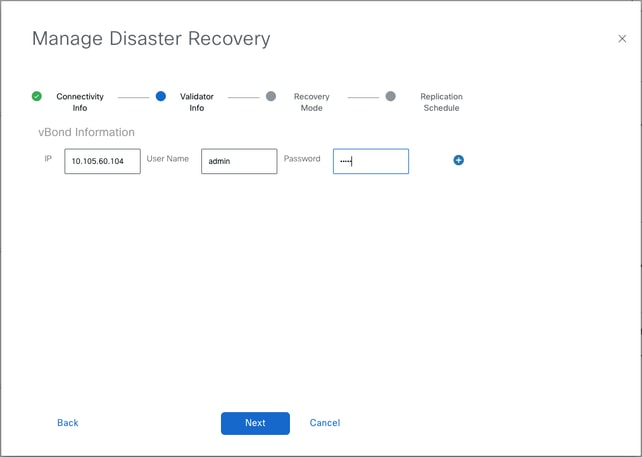
Once filled, click Next.
- In the Recovery Mode, choose Manual. The Automation mode is deprecated. Click Next.
- Fill the vBond controllers’ details.
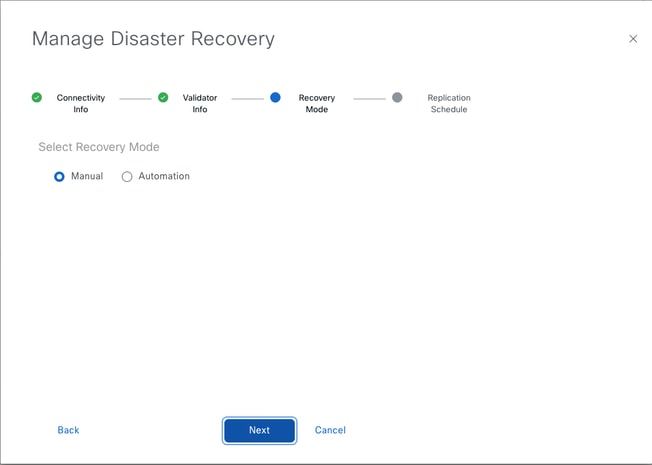
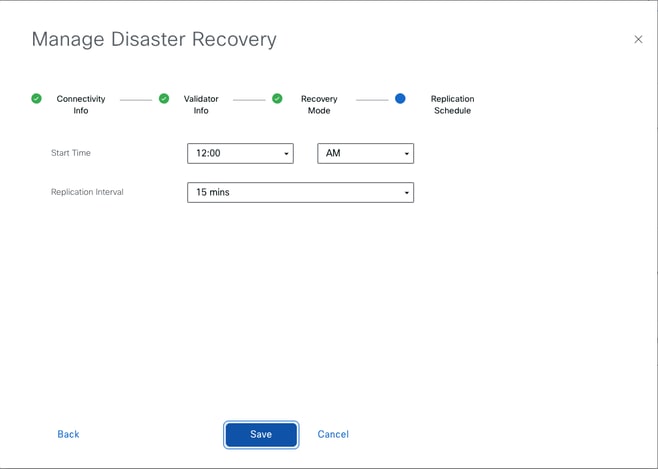
Set the value and click Save.
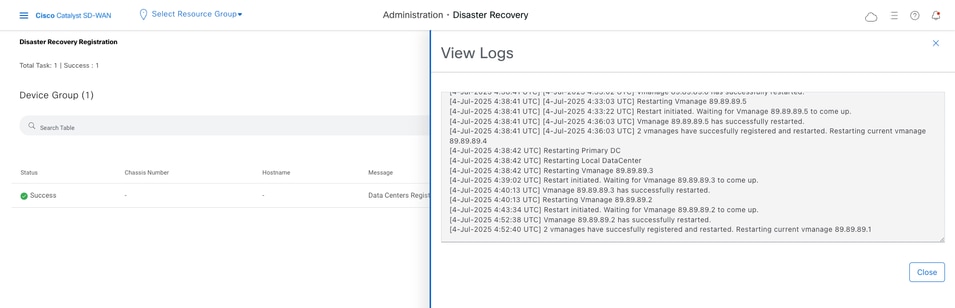
- The DR Registration starts now. Click the refresh button to manually refresh the state and the progress logs. This process can take up to 20-30 minutes.
Verification
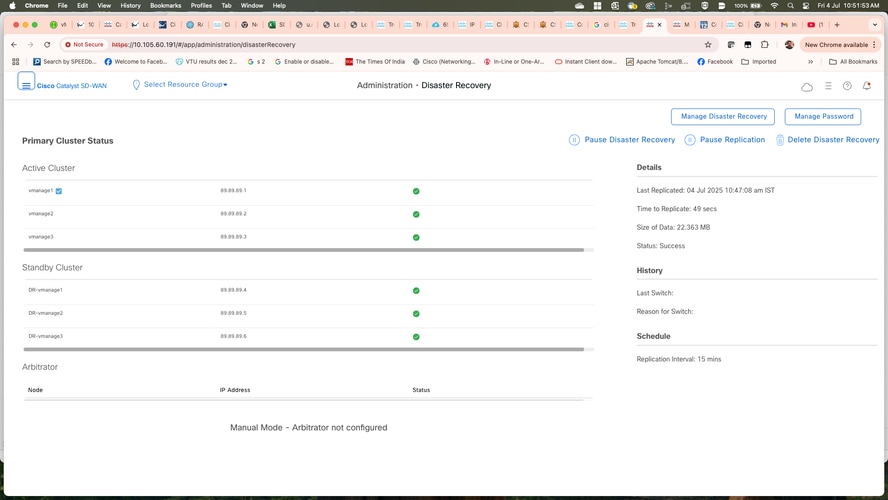
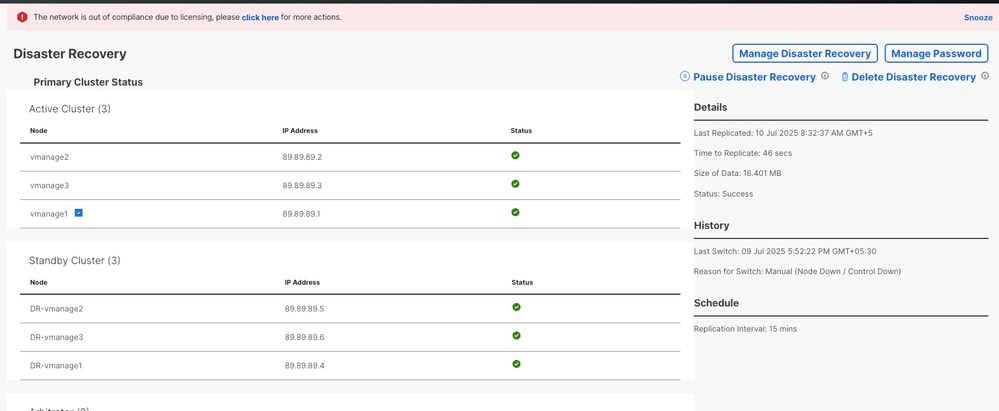
- Navigate to Administration>Disaster Recovery in order to see the Disaster Recovery status and when the data was replicated last time.

Note: In this scenario, replication took only 49 seconds because the lab environment has a small database. However, replication can take several hours depending on the database size. Additionally, it can require a few cycles to achieve successful replication.
Verify disaster recovery log in both clusters.
DC-vmanage (9a15f979-d613-4d75-97bf-f7d4124bc687 is export ID)
vmanage1:/var/log/nms$ cat vmanage-disaster_recovery.log | grep 9a15f979-d613-4d75-97bf-f7d4124bc687
04-Jul-2025 05:17:08,297 UTC INFO [] [] [DataReplicationManager] (pool-232-thread-1) || Export ID Generated: 9a15f979-d613-4d75-97bf-f7d4124bc687
04-Jul-2025 05:17:58,431 UTC INFO [] [] [DisasterRecoveryAlarmsDAO] (pool-232-thread-1) || AlarmsDAO::addAlarm() - Adding alarm {suppressed=false, component=["Disaster Recovery"], severity="Info", eventname="EXPORT_DATA", message="Primary Successfully Exported", acknowledged=false, active=true, type="Disaster_Recovery", rule_name_display="Disaster_Recovery", uuid="ec133314-7205-4afc-bee3-a4b080fc42f0", update_time=1751606278431, entry_time=1751606278431, values=[{host-name="vmanage1", system-ip="11.11.11.1", dcPersonality="primary", exportSize="22.363 MB", exportDuration="49 secs", exportID="9a15f979-d613-4d75-97bf-f7d4124bc687"}], values_short_display=[{host-name="vmanage1", system-ip="11.11.11.1", dcPersonality="primary", exportSize="22.363 MB", exportDuration="49 secs", exportID="9a15f979-d613-4d75-97bf-f7d4124bc687"}], devices=[{host-name="vmanage1", system-ip="11.11.11.1", dcPersonality="primary", exportSize="22.363 MB", exportDuration="49 secs", exportID="9a15f979-d613-4d75-97bf-f7d4124bc687"}], receive_time=1751606278431}
04-Jul-2025 05:17:58,722 UTC INFO [] [] [DataReplicationManager] (pool-232-thread-1) || Sending the import request to remote server 89.89.89.4 for exportID: 9a15f979-d613-4d75-97bf-f7d4124bc687.
04-Jul-2025 05:17:59,081 UTC INFO [a17a50ae-e6d3-401c-9d34-7c9423a5dd5a] [vmanage1] [DisasterRecoveryRestfulResource] (default task-32) |default| Received request from 89.89.89.1, for token: 9a15f979-d613-4d75-97bf-f7d4124bc687, and file: default_1751001428297.tar.gz
04-Jul-2025 05:21:06,515 UTC INFO [a456da19-9868-42e1-b3e7-9cb7ef3bdb81] [vmanage1] [DisasterRecoveryRestfulResource] (default task-31) |default| Replication status for exportID: 9a15f979-d613-4d75-97bf-f7d4124bc687, is Success
vmanage1:/var/log/nms$
DR-Vmanage
DR-vmanage1:/var/log/nms$ cat vmanage-disaster_recovery.log | grep 9a15f979-d613-4d75-97bf-f7d4124bc687
04-Jul-2025 05:15:23,296 UTC INFO [] [] [DataReplicationManager] (Thread-366) || Payload received for data replication: {replicationDir="/opt/data/disaster_recovery/", filename="default_1751001428297.tar.gz", exportID="9a15f979-d613-4d75-97bf-f7d4124bc687", deviceIP="89.89.89.1", exportTime="1751606278229", exportDuration="49 secs", exportSize="22.363 MB", SwitchOverHistoryNode={lastSwitch=0, reasonForSwitch=null, updatedPrimary="89.89.89.1"}, startTime="1751606228297", sha256sum="06363770a967beec4667f29e5b033de4a538523f34e36d9952ffc893fb0557db"}
04-Jul-2025 05:15:23,298 UTC INFO [] [] [DataReplicationManager] (Thread-366) || destinationURL dataservice/disasterrecovery/download/9a15f979-d613-4d75-97bf-f7d4124bc687/default_1751001428297.tar.gz Saved to File /opt/data/disaster_recovery/default_1751001428297.tar.gz
04-Jul-2025 05:15:24,040 UTC INFO [] [] [DisasterRecoveryAlarmsDAO] (Thread-366) || AlarmsDAO::addAlarm() - Adding alarm {suppressed=false, component=["Disaster Recovery"], severity="Info", eventname="DOWNLOAD_DATA", message="Replication payload successfully downloaded by secondary", acknowledged=false, active=true, type="Disaster_Recovery", rule_name_display="Disaster_Recovery", uuid="94ab4c3a-26d9-4d99-b631-d380313d7f08", update_time=1751606124040, entry_time=1751606124040, values=[{host-name="DR-vmanage1", system-ip="12.12.12.1", dcPersonality="secondary", exportSize="22.363 MB", downloadDuration="00 secs", exportID="9a15f979-d613-4d75-97bf-f7d4124bc687"}], values_short_display=[{host-name="DR-vmanage1", system-ip="12.12.12.1", dcPersonality="secondary", exportSize="22.363 MB", downloadDuration="00 secs", exportID="9a15f979-d613-4d75-97bf-f7d4124bc687"}], devices=[{host-name="DR-vmanage1", system-ip="12.12.12.1", dcPersonality="secondary", exportSize="22.363 MB", downloadDuration="00 secs", exportID="9a15f979-d613-4d75-97bf-f7d4124bc687"}], receive_time=1751606124040}
04-Jul-2025 05:15:24,170 UTC INFO [] [] [DataReplicationManager] (Thread-366) || Downloaded replication file size 23449259 for token 9a15f979-d613-4d75-97bf-f7d4124bc687
04-Jul-2025 05:15:24,171 UTC INFO [] [] [DisasterRecoveryManager] (Thread-366) || Sending rpc message to copyReplicationFile for token 9a15f979-d613-4d75-97bf-f7d4124bc687
04-Jul-2025 05:15:24,216 UTC INFO [] [] [DisasterRecoveryManager] (Thread-366) || Sending message to destinations [Endpoint{ip='89.89.89.5', uuid='c3e303a2-53d0-4525-901b-d96e9ce92875'}, Endpoint{ip='89.89.89.6', uuid='bf45f345-ff2e-48ec-b8fd-0bb92427cc28'}] for token 9a15f979-d613-4d75-97bf-f7d4124bc687
04-Jul-2025 05:15:24,245 UTC INFO [] [] [DisasterRecoveryManager] (Thread-366) || Waiting for copyReplicationFile to complete for token 9a15f979-d613-4d75-97bf-f7d4124bc687
04-Jul-2025 05:18:19,545 UTC INFO [] [] [DataReplicationWorker] (Thread-366) || Successfully Deleted Imported Data Directory /opt/data/disaster_recovery/9a15f979-d613-4d75-97bf-f7d4124bc687
04-Jul-2025 05:18:19,643 UTC INFO [] [] [DisasterRecoveryAlarmsDAO] (Thread-366) || AlarmsDAO::addAlarm() - Adding alarm {suppressed=false, component=["Disaster Recovery"], severity="Info", eventname="IMPORT_DATA", message="Secondary Successfully Imported", acknowledged=false, active=true, type="Disaster_Recovery", rule_name_display="Disaster_Recovery", uuid="1fc80500-f621-4d45-9395-4ed949ddda68", update_time=1751606299643, entry_time=1751606299643, values=[{host-name="DR-vmanage1", system-ip="12.12.12.1", dcPersonality="secondary", exportSize="22.363 MB", importDuration="02 mins 45 secs", exportID="9a15f979-d613-4d75-97bf-f7d4124bc687"}], values_short_display=[{host-name="DR-vmanage1", system-ip="12.12.12.1", dcPersonality="secondary", exportSize="22.363 MB", importDuration="02 mins 45 secs", exportID="9a15f979-d613-4d75-97bf-f7d4124bc687"}], devices=[{host-name="DR-vmanage1", system-ip="12.12.12.1", dcPersonality="secondary", exportSize="22.363 MB", importDuration="02 mins 45 secs", exportID="9a15f979-d613-4d75-97bf-f7d4124bc687"}], receive_time=1751606299643}
04-Jul-2025 05:18:19,707 UTC INFO [] [] [DataReplicationManager] (Thread-366) || Successfully imported data from exportID 9a15f979-d613-4d75-97bf-f7d4124bc687
04-Jul-2025 05:18:19,716 UTC INFO [] [] [DisasterRecoveryManager] (Thread-366) || Sending rpc message to deleteReplicationFile for token 9a15f979-d613-4d75-97bf-f7d4124bc687
04-Jul-2025 05:18:19,849 UTC INFO [] [] [DisasterRecoveryManager] (Thread-366) || Sending message to destinations [Endpoint{ip='89.89.89.5', uuid='c3e303a2-53d0-4525-901b-d96e9ce92875'}, Endpoint{ip='89.89.89.6', uuid='bf45f345-ff2e-48ec-b8fd-0bb92427cc28'}] for token 9a15f979-d613-4d75-97bf-f7d4124bc687
How to verify replication leader node?
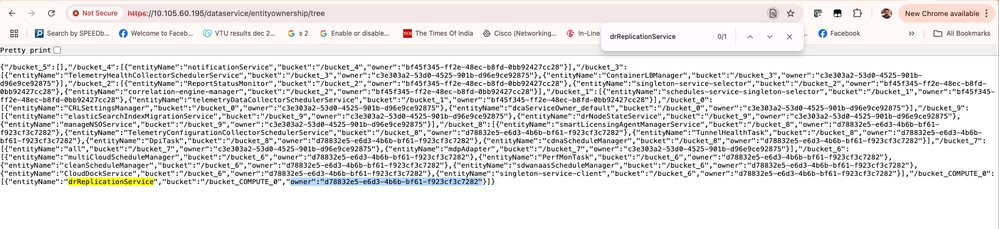
- Use the next API in order to findout replication leader node on both clusters:
https://<vmanage-ip>/data service/entity ownership/tree.
For DC cluster:
Replication node is cb87a08e-079e-4394-81c3-e63c36ac22c0 which is node1, verify it from show control local-properties.

Similarly for DR-vManage, replication node is d78832e5-e6d3-4b6b-bf61-f923cf3c7282.
Validator (vBond) Password Update After Disaster Recovery Registration
If you change the vBond password after disaster recovery registration is complete, a switchover fails because the vBond password is not updated on the secondary cluster, which still retains the old vBond password.
[04-July-2025 6:47:35 UTC] Unshut control tunnel on the standby vManage.
[04-July-2025 6:47:36 UTC] Sleeping for 10 seconds to ensure control tunnel is fully up and functional on the vmanage.
[04-July-2025 6:47:55 UTC] Failed to activate the cluster. Vbond is unreachable
================
04-July-2025 06:47:55,206 UTC ERROR [89b008fa-2c1b-4f78-b093-ed1fa1f06b71] [vManage20-14-DR] [DisasterRecoveryManager] (dr_activate) |default| IP credentials are not reachable through given ip and authentication creds com.viptela.vmanage.server.device.common.NetConfClientException: java.io.IOException: Unable to authenticate for deviceIP 10.66.91.163. With session Nio2Session[local=/10.66.91.173:56704, remote=/10.66.91.163:830]!
at com.viptela.vmanage.server.device.common.NetConfClient.connect(NetConfClient.java:255) ~[vmanage-server-1.0.0-SNAPSHOT.jar:?]
at com.viptela.vmanage.server.device.common.NetConfClient.<init>(NetConfClient.java:114) ~[vmanage-server-1.0.0-SNAPSHOT.jar:?]Update Validator (vbond) Password
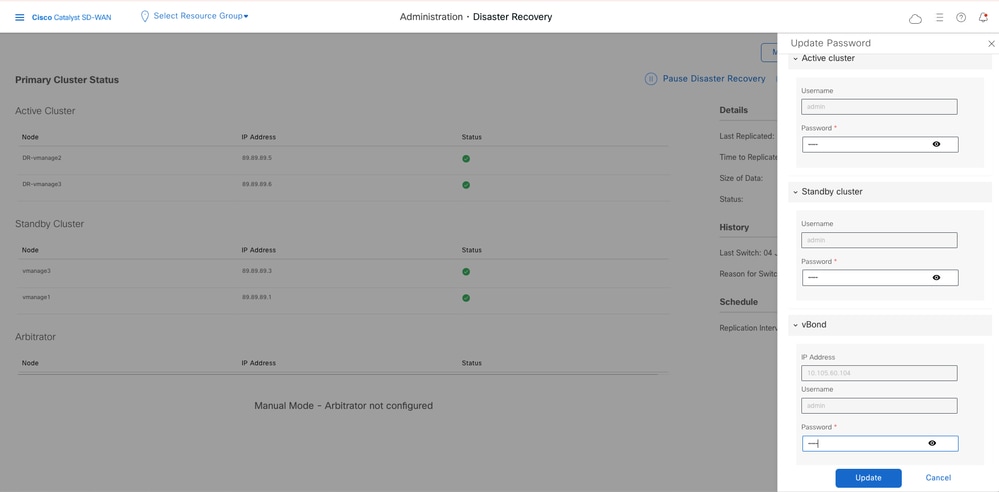
Ensure to update the new vBond password on both the Disaster Recovery page and under Manage Password:
Administration > Disaster Recovery > Manage Password > Update vBond password.
Ensure replication is successful after updating the password. Attempt a failover only after confirming successful replication.
caveat: https://bst.cloudapps.cisco.com/bugsearch/bug/CSCwn19224.
Adding New Validator (vBond) to Overlay After Disaster Recovery Registration
Adding a new validator to the SD-WAN overlay after disaster recovery registration is not supported, as the disaster recovery setup is not aware of this new validator information since it was not updated during registration.
Although you can add the validator, a switchover fails.
If you need to add a new validator, observe these steps:
1. Delete the disaster recovery setup.
2. Add the new validator to the SD-WAN overlay.
3. Reconfigure disaster recovery.
Upgrade Disaster Recovery Overlays
Before You Begin
-
Use the CLI method to upgrade both the active and standbyCisco SD-WAN Managers.
-
Ensure that the replication status on theAdministration > Disaster Recoverypage is stable and not in a transient state such asImport Pending,Export Pending, orDownload Pending. It must be in the Success state before pausing disaster recovery.
-
Pause the disaster recovery usingPause Disaster Recovery under Administration > Disaster Recoverypage.
Upgrade Process
In this case you are upgrading vManage cluster from 20.12.5 to 20.15.2. Use the CLI method in order to upgrade the cluster.
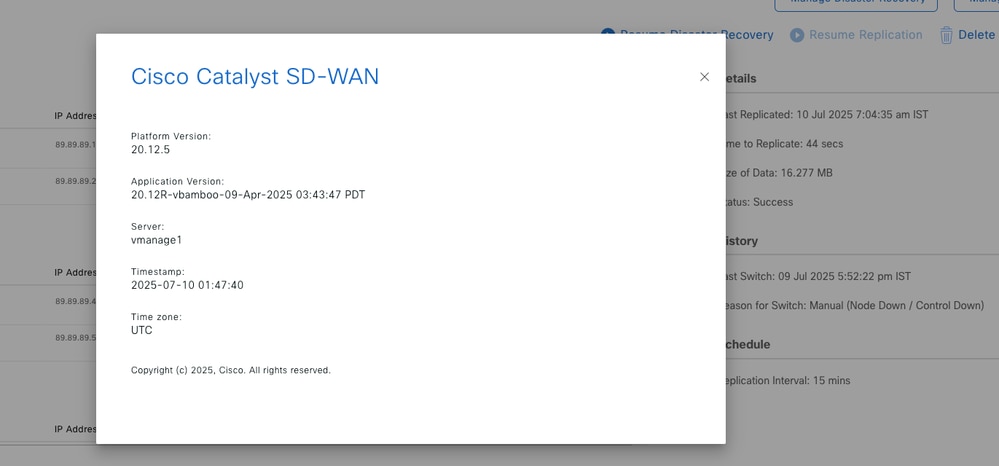
Before you upgrade, verify version and replication status.
Pause disaster recovery:
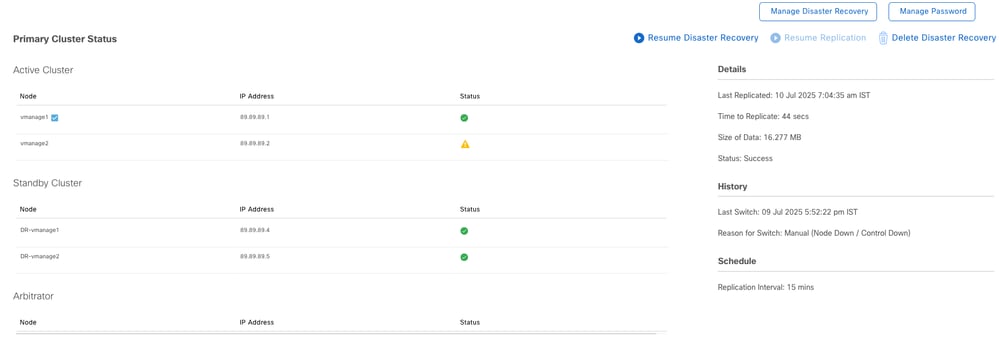
After the upgrade, ensure all services are running and that you can log in to all vManage nodes (DC and DR) using the GUI.
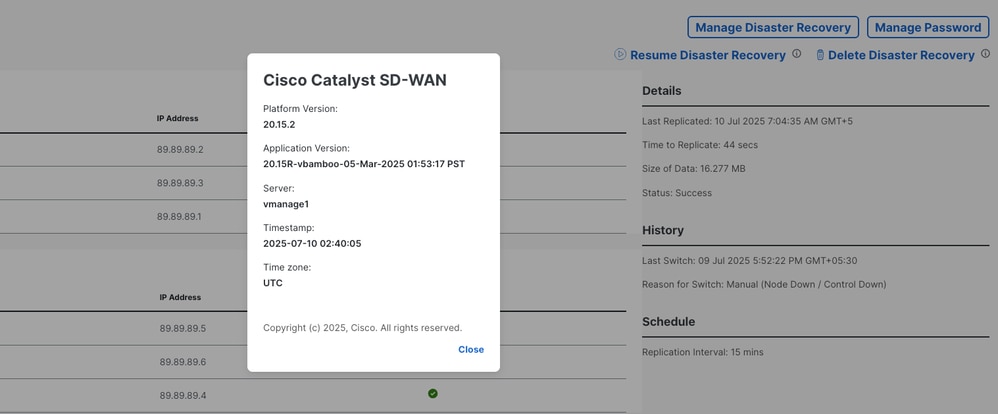
Resume disaster recovery; replication starts, and the replication status must eventually show as success.
Related Information
Revision History
| Revision | Publish Date | Comments |
|---|---|---|
1.0 |
25-Jul-2025
|
Initial Release |
Contributed by Cisco Engineers
- Md Aamir SadiqueCisco TAC Engineer
 Feedback
FeedbackContact Cisco
- Open a Support Case

- (Requires a Cisco Service Contract)