简介
本文档讨论思科实时监控工具(RTMT)警报,并演示如何对一些常见警报进行故障排除。
先决条件
要求
Cisco建议您具备Cisco Call Manager Web管理知识。
使用的组件
本文档中的信息基于Cisco CallManager Server 11.0。
本文档中的信息都是基于特定实验室环境中的设备编写的。本文档中使用的所有设备最初均采用原始(默认)配置。如果您使用的是真实网络,请确保您已经了解所有命令的潜在影响。
背景信息
作为客户端应用程序运行的RTMT使用HTTPS和TCP来监控系统性能、设备状态、设备发现、计算机电话集成(CTI)应用程序和语音消息传送端口。RTMT可用于为其监控的群集配置警报。
系统生成警报消息,以便在满足预定义条件(例如激活的服务从上到下)时通知管理员。系统可以将警报作为电子邮件/电子邮件页面发送。
RTMT支持警报定义、设置和查看,包含预配置和用户定义的警报。虽然您可以对这两种类型执行配置任务,但不能删除预配置的警报。
RTMT警报
Unified RTMT在警报中心显示预配置的警报和自定义警报,如图所示。
您还可以通过点击系统抽屉的层次结构树中的Alert Central图标来访问Alert Central。
配置
Unified RTMT在适用的选项卡下组织警报:System、CallManager、Cisco Unity Connection和Custom。
您可以在警报中心启用或禁用预配置和自定义警报;但是,不能删除预配置的警报。
RTMT中的警报分类如下:
系统警报
此列表包括预配置的系统警报:
-
身份验证失败
-
CiscoDRFailure
-
CoreDumpFileFound
-
Cpu追溯
-
CriticalAuditEventGenerated
-
CriticalServiceDown
-
硬件故障
-
LogFileSearchStringFound
-
已超出LogPartitionHighWaterMarkExceeded
-
已超出LogPartitionLowWaterMarkExceeded
-
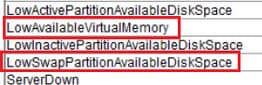
LowActivePartitionAvailableDiskSpace
-
LowAvailableVirtualMemory
-
LowInactivePartitionAvailableDiskSpace
-
LowSwapPartitionAvailableDiskSpace
-
ServerDown(适用于Unified Communications Manager(CUCM)群集)
-
SparePartitionHighWaterMarkExceeded
-
SparePartitionLowWaterMarkExceeded
-
系统日志严重性匹配已找到
-
系统日志字符串匹配已找到
-
系统版本不匹配
-
TotalProcessesAndThreadsExceededThreshold
CallManager警报
此列表包括预配置的CallManager警报。
- BeginThrottlingCallListBLFSsubscriptions
- CallAttemptBlockedByPolicy
- CallProcessingNodeCpuPegging
- CARIDSEngineCritical
- CARIDSEngineFailure
- CARSchedulerJobFailed
- CDRAgentSendFileFailed
- CDRFileDeliveryFailed
- 已超过CDRHighWaterMarkExceeded
- CDRMmaximumDiskSpaceExceeded
- CodeYellow
- DBChangeNotifyFailure
- DBReplicationFailure
- DBReplicationTableOutofSync
- DDRBlockPrevention
- DRDown
- EMCCFailedInLocalCluster
- EMCCFailedInRemoteCluster
- ExcessiveVoiceQualityReports
- IMEDdistributedCacheInactive
- IMEOverQuota
- IMEQualityAlert
- InsufficientFallbackIdentifiers
- IMEServiceStatus
- 凭证无效
- LowTFTPServerHeartbeatRate
- MaliciousCallTrace
- MediaListExhauted
- MgcpDChannelOutOfService
- NumberOfRegisteredDevicesExceeded
- NumberOfRegisteredGatewaysReduced
- NumberOfRegisteredGatewaysIncreated
- NumberOfRegisteredMediaDevicesDecreated
- NumberOfRegisteredMediaDevicesIncreated
- NumberOfRegisteredPhoneDropped
- 路由列表已用尽
- SDLLinkOutOfService
- TCPSetupToIMEilled
- TLSConnectionToIMEFilled
- UserInputFailure
LowAvailableVirtualMemory和LowSwapPartitionAvailableDiskSpace
Linux服务器倾向于在一段时间内“不清除”虚拟内存的使用情况,并且发现会积累这些警报,从而产生这些警报。
作为操作系统,Linux的运行方式略有不同。
内存分配给进程后,处理器将不会收回内存,除非其它进程请求内存大于可用内存。
这会导致高虚拟内存。
缺陷中记录了在Call Manager的更高版本中增加警报阈值的请求;https://bst.cloudapps.cisco.com/bugsearch/bug/CSCuq75767/?reffering_site=dumpcr
对于交换分区,此警报表示交换分区可用空间不足,且被系统大量使用。交换分区通常用于在需要时扩展物理RAM容量。在正常情况下,如果RAM足够,则不应过度使用交换。
此外,这些警报可能会因临时文件的累积而引发RTMT警报,建议重新启动服务器以清除任何不必要的临时文件。
LogPartitionHighWaterMarkExceeded和LogPartitionLowWaterMarkExceeded
在CUCM服务器的CLI上运行show status时,将显示一个值,该值指定在CUCM磁盘空间中日志记录分区的已用和空闲百分比。这些值也称为公共分区,指定服务器中的日志/跟踪和CDR文件所占用的空间,即使这些空间是无害的,也可能会导致安装/升级过程出现问题,因为随着时间推移缺少空间。这些警报对管理员起到警告作用,以清除群集/服务器中随时间累积的日志。
LogPartitionLowWaterMarkExceeded:当填充空间达到为警报配置的阈值时生成此警报。此警报用作磁盘使用情况的预检查指示器。
LogPartitionHighWaterMarkExceeded:当填充空间达到为警报配置的阈值时生成此警报。生成警报后,服务器开始自动清除最旧的日志,以便将空间缩小到可忽略HighWaterMark阈值的值。
最佳做法是在收到LogPartitionLowWaterMarkExceeded警报后立即手动清除日志。
具体步骤如下:
步骤1.启动RTMT。
步骤2.选择Alert Central,然后执行以下任务:
选择LogPartitionHighWaterMarkExceeded,记下其值并将其阈值更改为60%。
选择LogPartitionLowWaterMarkExceeded,注意其值,并将其阈值更改为50%。
轮询每5分钟执行一次,因此请等待5-10分钟,然后验证所需的磁盘空间是否可用。如果要释放公共分区中的更多磁盘空间,请再次将LogPartitionHighWaterMarkExceeded和LogPartitionLowWaterMarkExceeded线程值更改为较低的值(例如,30%和20%)。
给它一个15到20分钟的时间来清除公共分区中的空间。您可以使用CLI命令show status监控磁盘使用量的减少。
那会把共同的分区拆下来。
Cpu追溯
CpuPegging警报根据配置的阈值监控CPU使用情况。
收到CPU追溯警报后,可以转至左侧的“系统抽屉”(即“进程”)来占用最高CPU的进程。
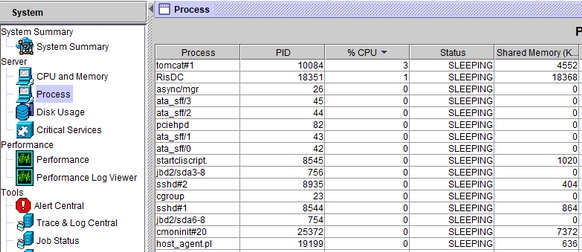
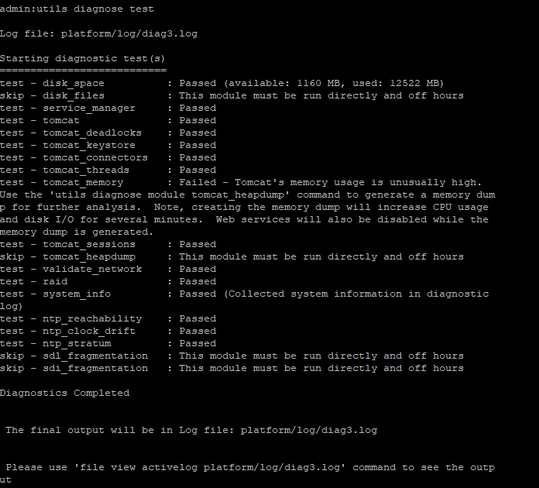
从相关服务器的CLI中,这些输出将提供一些见解。
- utils诊断测试
- show process load cpu sorted
- show status
- utils core active list
建议观察CPU峰值是在特定时间还是随机发生的。如果它随机发生,则所需的详细CUCM跟踪以及RisDC perfmon日志检查CPU中触发峰值的原因。如果在一天中的特定时间发出警报,则可能是由于某些计划活动(如灾难恢复系统(DRS)备份、CDR负载等)所致。
此外,根据哪个进程占用CPU最多的信息,将采用特定日志进行进一步调查。例如如果罪魁祸首是Tomcat,则需要Tomcat相关日志。
验证
使用本部分可确认配置能否正常运行。
如果您在遵循此处建议的变通方法后未解除警报,或者警报似乎对服务有直接影响,请与Cisco TAC联系,以了解有关呼叫管理器版本、集群中的节点数、警报时间和持续时间以及CPU追溯时所需的进程缩窄的必要详细信息。
故障排除
目前没有针对此配置的故障排除信息。
 反馈
反馈