Ultra-M Isolatie en vervanging van mislukte schijf uit Ceph/Storage Cluster - vEPC
Downloadopties
Inclusief taalgebruik
De documentatie van dit product is waar mogelijk geschreven met inclusief taalgebruik. Inclusief taalgebruik wordt in deze documentatie gedefinieerd als taal die geen discriminatie op basis van leeftijd, handicap, gender, etniciteit, seksuele oriëntatie, sociaaleconomische status of combinaties hiervan weerspiegelt. In deze documentatie kunnen uitzonderingen voorkomen vanwege bewoordingen die in de gebruikersinterfaces van de productsoftware zijn gecodeerd, die op het taalgebruik in de RFP-documentatie zijn gebaseerd of die worden gebruikt in een product van een externe partij waarnaar wordt verwezen. Lees meer over hoe Cisco gebruikmaakt van inclusief taalgebruik.
Over deze vertaling
Cisco heeft dit document vertaald via een combinatie van machine- en menselijke technologie om onze gebruikers wereldwijd ondersteuningscontent te bieden in hun eigen taal. Houd er rekening mee dat zelfs de beste machinevertaling niet net zo nauwkeurig is als die van een professionele vertaler. Cisco Systems, Inc. is niet aansprakelijk voor de nauwkeurigheid van deze vertalingen en raadt aan altijd het oorspronkelijke Engelstalige document (link) te raadplegen.
Inhoud
Inleiding
In dit document worden de stappen beschreven die moeten worden uitgevoerd om OSD-schijf te isoleren en te vervangen van een Ceph/Storage-cluster dat wordt gehost op Object Storage Disk (OSD)-computing in een Ultra-M-installatie.
Achtergrondinformatie
Ultra-M is een voorverpakte en gevalideerde gevirtualiseerde mobiele packet-core-oplossing die ontworpen is om de implementatie van VNF's te vereenvoudigen. OpenStack is de gevirtualiseerde Infrastructuurbeheerder (VIM) voor Ultra-M en bestaat uit deze knooppunten:
- Computeren
- OSD - computing
- Controller
- OpenStack-platform - Director (OSPD)
De hoogwaardige architectuur van Ultra-M en de betrokken componenten worden in dit beeld weergegeven:
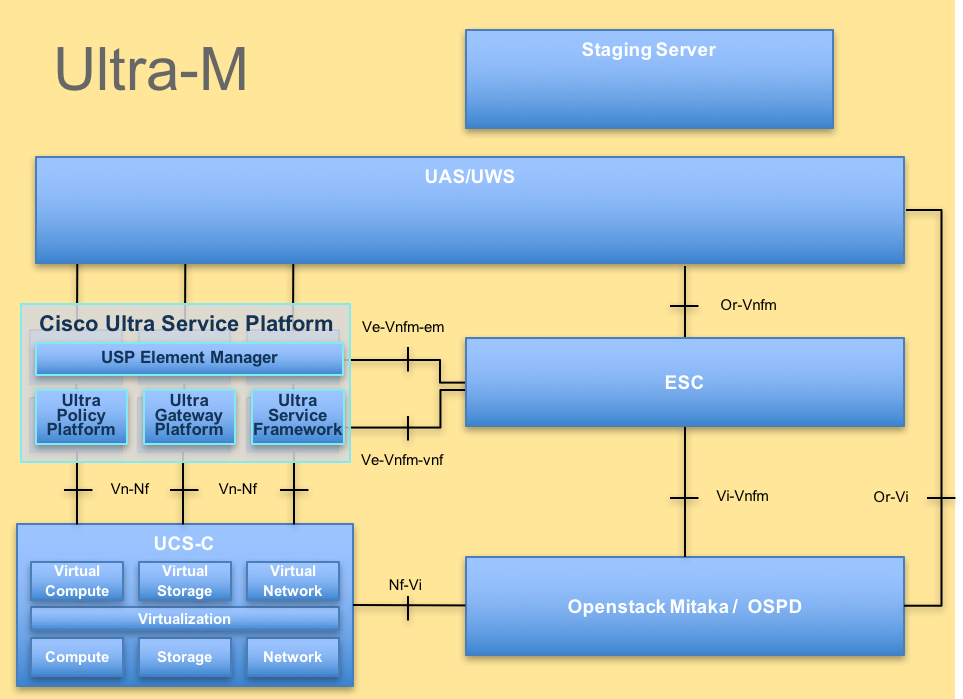 UltraM-architectuurDit document is bedoeld voor het Cisco-personeel dat bekend is met Cisco Ultra-M platform en bevat een gedetailleerd overzicht van de stappen die op OpenStack-niveau moeten worden uitgevoerd op het moment van de OSPD-serververvanging.
UltraM-architectuurDit document is bedoeld voor het Cisco-personeel dat bekend is met Cisco Ultra-M platform en bevat een gedetailleerd overzicht van de stappen die op OpenStack-niveau moeten worden uitgevoerd op het moment van de OSPD-serververvanging.
Opmerking: Ultra M 5.1.x release wordt overwogen om de procedures in dit document te definiëren.
Afkortingen
| VNF | Virtuele netwerkfunctie |
| CF | Bedieningsfunctie |
| SF | Servicefunctie |
| ESC | Elastic-servicecontroller |
| MOP | Werkwijze |
| OSD | Schijven voor objectopslag |
| HDD | Harde schijf |
| SSD | Solid state drive |
| VIM | Virtual Infrastructure Manager |
| VM | Virtuele machine |
| EM | Element Manager |
| UAS | Ultra-automatiseringsservices |
| UUID | Universele unieke IDentifier |
Werkstroom van de MoP

Voorafgaande gezondheidscontroles
1. Gebruik de opdracht Ceph-disk list om de koppeling van OSD naar Journal te begrijpen en de schijf te identificeren die moet worden geïsoleerd en vervangen.
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph-disk list
/dev/sda :
/dev/sda1 other, iso9660
/dev/sda2 other, xfs, mounted on /
/dev/sdb :
/dev/sdb1 ceph journal, for /dev/sdc1
/dev/sdb3 ceph journal, for /dev/sdd1
/dev/sdb2 ceph journal, for /dev/sde1
/dev/sdb4 ceph journal, for /dev/sdf1
/dev/sdc :
/dev/sdc1 ceph data, active, cluster ceph, osd.1, journal /dev/sdb1
/dev/sdd :
/dev/sdd1 ceph data, active, cluster ceph, osd.7, journal /dev/sdb3
/dev/sde :
/dev/sde1 ceph data, active, cluster ceph, osd.4, journal /dev/sdb2
/dev/sdf :
/dev/sdf1 ceph data, active, cluster ceph, osd.10, journal /dev/sdb4
2. Controleer de Ceph-status en OSD-boomtoewijzing voordat u doorgaat met de geïdentificeerde OSD-schijfinisolatie.
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
1 mons down, quorum 0,1 pod1-controller-0,pod1-controller-1
monmap e1: 3 mons at {pod1-controller-0=11.118.0.10:6789/0,pod1-controller-1=11.118.0.11:6789/0,pod1-controller-2=11.118.0.12:6789/0}
election epoch 28, quorum 0,1 pod1-controller-0,pod1-controller-1
osdmap e709: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v941813: 704 pgs, 6 pools, 490 GB data, 163 kobjects
1470 GB used, 11922 GB / 13393 GB avail
704 active+clean
client io 58580 B/s wr, 0 op/s rd, 7 op/s wr
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod1-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-3 0 host pod1-osd-compute-1
-4 4.35999 host pod1-osd-compute-2
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
-5 4.35999 host pod1-osd-compute-3
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
Isolatie en verwijdering van defecte OSD-schijf uit het cluster
1. Schakel het OSD-proces uit en stop het.
[heat-admin@pod1-osd-compute-3 ~]$ sudo systemctl disable ceph-osd@7
[heat-admin@pod1-osd-compute-3 ~]$ sudo systemctl stop ceph-osd@7
2. Markeer de OSD.
[heat-admin@pod1-osd-compute-3 ~]$ sudo su
[root@pod1-osd-compute-3 heat-admin]# ceph osd set noout
set noout
[root@pod1-osd-compute-3 heat-admin]# ceph osd set norebalance
set norebalance
[root@pod1-osd-compute-3 heat-admin]# ceph osd out 7
marked out osd.7.
Opmerking: Wacht op het opnieuw in balans brengen van gegevens te voltooien en alle PG's terug te keren naar active+clean om problemen te voorkomen.
3. Bevestig of de OSD is uitgetekend en wacht tot de Ceph rebalance om verder te gaan.
[root@pod1-osd-compute-3 heat-admin]# watch -n1 ceph -s
95 active+undersized+degraded+remapped+wait_backfill
28 active+recovery_wait+degraded
2 active+undersized+degraded+remapped+backfilling
1 active+recovering+degraded
2 active+undersized+degraded+remapped+backfilling
1 active+recovering+degraded
2 active+undersized+degraded+remapped+backfilling
67 active+undersized+degraded+remapped+wait_backfill
3 active+undersized+degraded+remapped+backfilling
24 active+undersized+degraded+remapped+wait_backfill
22 active+undersized+degraded+remapped+wait_backfill
1 active+undersized+degraded+remapped+backfilling
8 active+undersized+degraded+remapped+wait_backfill
4. Verwijder de verificatiesleutel voor de OSD.
[root@pod1-osd-compute-3 heat-admin]# ceph auth del osd.7
updated
5. Bevestig dat de sleutels voor OSD.7 niet in de lijst staan.
[root@pod1-osd-compute-3 heat-admin]# ceph auth list
installed auth entries:
osd.0
key: AQCgpB5blV9dNhAAzDN1SVdnuJyTN2f7PAdtFw==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.1
key: AQBdwyBbbuD6IBAAcvG+oQOz5vk62faOqv/CEw==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.10
key: AQCwwyBb7xvHJhAAZKPprXWT7UnvnAXBV9W2rg==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.11
key: AQDxpB5b9/rGFRAAkcCEkpSN1YZVDdeW+Bho7w==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.2
key: AQCppB5btekoNBAAACoWpDz0VL9bZfyIygDpBQ==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.3
key: AQC4pB5bBaUlORAAhi3KPzetwvWhYGnerAkAsg==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.4
key: AQB1wyBbvMIQLRAAXefFVnZxMX6lVtObQt9KoA==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.5
key: AQDBpB5buKHqOhAAW1Q861qoYqW6fAYHlOxsLg==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.6
key: AQDQpB5b1BveFxAAfCLM3tvDUSnYneutyTmaEg==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.8
key: AQDZpB5bd4nlGRAAkkzbmGPnEDAWV0dUhrhE6w==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.9
key: AQDopB5bKCZPGBAAfYtp1GLA7QIi/YxJa8O1yw==
caps: [mon] allow profile osd
caps: [osd] allow *
client.admin
key: AQDpmx5bAAAAABAA3hLK8O2tGgaAK+X2Lly5Aw==
caps: [mds] allow *
caps: [mon] allow *
caps: [osd] allow *
client.bootstrap-mds
key: AQBDpB5bjR1GJhAAB6CKKxXulve9WIiC6ZGXgA==
caps: [mon] allow profile bootstrap-mds
client.bootstrap-osd
key: AQDpmx5bAAAAABAA3hLK8O2tGgaAK+X2Lly5Aw==
caps: [mon] allow profile bootstrap-osd
client.bootstrap-rgw
key: AQBDpB5b7OWXHBAAlATmBAOX/QWW+2mLxPqlkQ==
caps: [mon] allow profile bootstrap-rgw
client.openstack
key: AQDpmx5bAAAAABAAULxfs9cYG1wkSVTjrtiaDg==
caps: [mon] allow r
caps: [osd] allow class-read object_prefix rbd_children, allow rwx pool=volumes, allow rwx pool=backups, allow rwx pool=vms, allow rwx pool=images, allow rwx pool=metrics
7. Verwijder de OSD uit het cluster.
[root@pod1-osd-compute-3 heat-admin]# ceph osd rm 7
removed osd.7
8. Koppel de OSD-schijf los die moet worden vervangen.
[root@pod1-osd-compute-3 heat-admin]# umount /var/lib/ceph/osd/ceph-7
9. Stel de noscrub en deepscrub los.
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset noscrub
unset noscrub
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset nodeep-scrub
unset nodeep-scrub
10. Controleer de gezondheid van de Ceph en wacht op gezondheid-ok en alle PG's om terug te komen op active+clean.
[root@pod1-osd-compute-3 heat-admin]# ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_WARN
28 pgs backfill_wait
4 pgs backfilling
5 pgs degraded
5 pgs recovery_wait
83 pgs stuck unclean
recovery 1697/516881 objects degraded (0.328%)
recovery 76428/516881 objects misplaced (14.786%)
noout,norebalance,sortbitwise,require_jewel_osds flag(s) set
1 mons down, quorum 0,1 pod1-controller-0,pod1-controller-1
monmap e1: 3 mons at {pod1-controller-0=11.118.0.10:6789/0,pod1-controller-1=11.118.0.11:6789/0,pod1-controller-2=11.118.0.12:6789/0}
election epoch 28, quorum 0,1 pod1-controller-0,pod1-controller-1
osdmap e877: 11 osds: 11 up, 11 in; 193 remapped pgs
flags noout,norebalance,sortbitwise,require_jewel_osds
pgmap v942974: 704 pgs, 6 pools, 490 GB data, 163 kobjects
1470 GB used, 10806 GB / 12277 GB avail
1697/516881 objects degraded (0.328%)
76428/516881 objects misplaced (14.786%)
511 active+clean
156 active+remapped
28 active+remapped+wait_backfill
5 active+recovery_wait+degraded+remapped
4 active+remapped+backfilling
client io 331 kB/s wr, 0 op/s rd, 56 op/s wr
Vervang de OSD-schijf en maak een nieuwe VD
1. Verwijder het defecte station en vervang het door een nieuw station: Cisco UCS C240 M4 Server Installatie- en servicegids.
2. Controleer inloggen bij CIMC van de OSD-computing en controleer de sleuf waar OSD is vervangen en in goede gezondheid is weergegeven.
3. Maak een virtuele drive voor een nieuwe HDD, moet het een verse HDD zonder enige metadata zijn.
4. Controleer of de nieuwe schijf zich in de toestand Onverbonden goed bevindt.
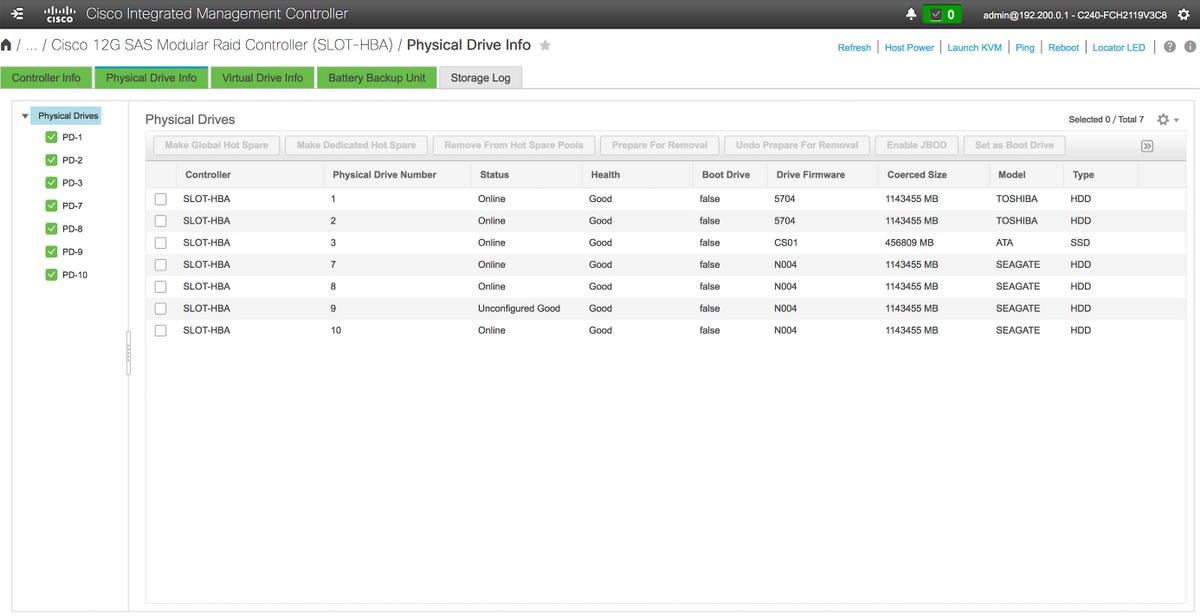 Opslag > Cisco 12G SAS modulaire Raid-controller (SLEUF-HBA) > Informatie over fysieke schijf
Opslag > Cisco 12G SAS modulaire Raid-controller (SLEUF-HBA) > Informatie over fysieke schijf
5. Selecteer de optie Virtuele schijf maken van ongebruikte fysieke stations om de VD te maken.
 Opslag > Cisco 12G SAS modulaire Raid-controller (SLEUF-HBA)
Opslag > Cisco 12G SAS modulaire Raid-controller (SLEUF-HBA)
6. Gebruik Physical Drive 9 om een nieuwe VD te maken en noem het OSD3.
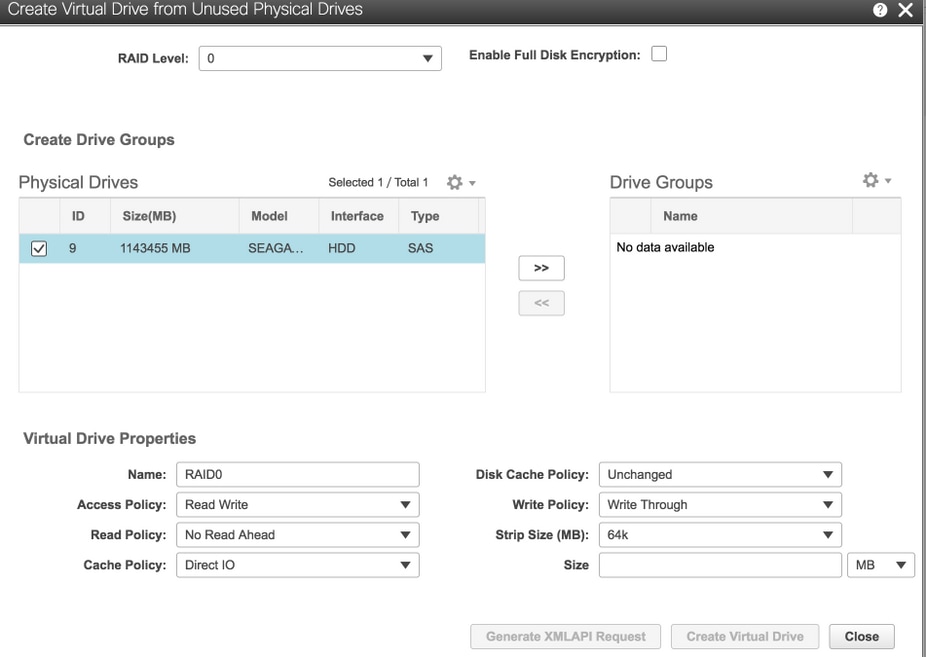 Opslag > Cisco 12G SAS modulaire Raid-controller (SLEUF-HBA) > Controller-informatie > Virtuele schijf maken van ongebruikte fysieke schijven
Opslag > Cisco 12G SAS modulaire Raid-controller (SLEUF-HBA) > Controller-informatie > Virtuele schijf maken van ongebruikte fysieke schijven
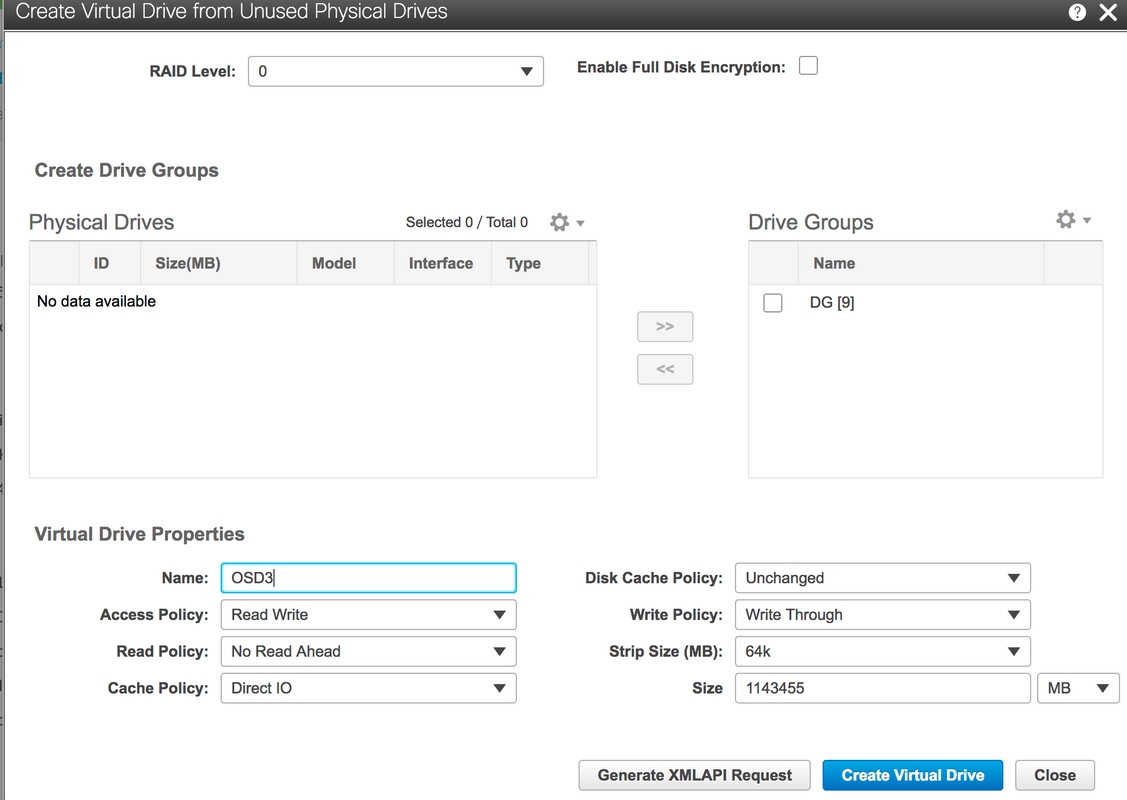 Opslag > Cisco 12G SAS modulaire Raid-controller (SLEUF-HBA) > Controller-informatie > Virtuele schijf maken van ongebruikte fysieke schijven
Opslag > Cisco 12G SAS modulaire Raid-controller (SLEUF-HBA) > Controller-informatie > Virtuele schijf maken van ongebruikte fysieke schijven
7. IPMI over LAN inschakelen: Beheerder > Communicatiediensten > Communicatiediensten.
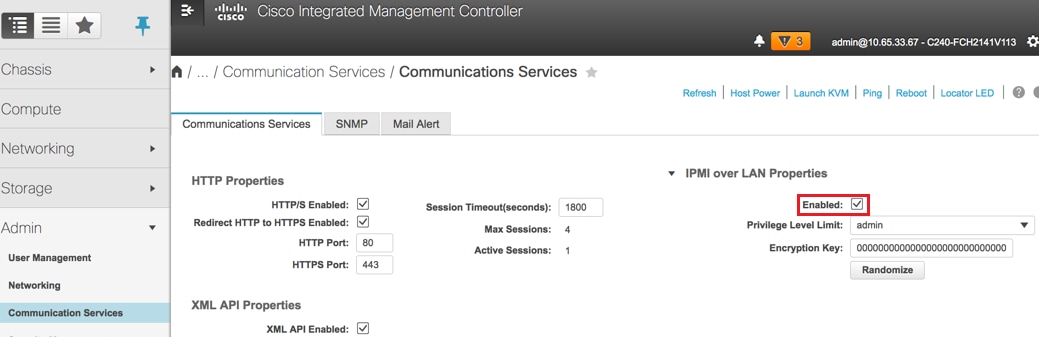 IPMI over LAN inschakelen: Beheerder > Communicatiediensten > Communicatiediensten
IPMI over LAN inschakelen: Beheerder > Communicatiediensten > Communicatiediensten
8. Schakel hyperthreading uit: computing > BIOS > Conimage BIOS > Advanced > Processor Configuration.
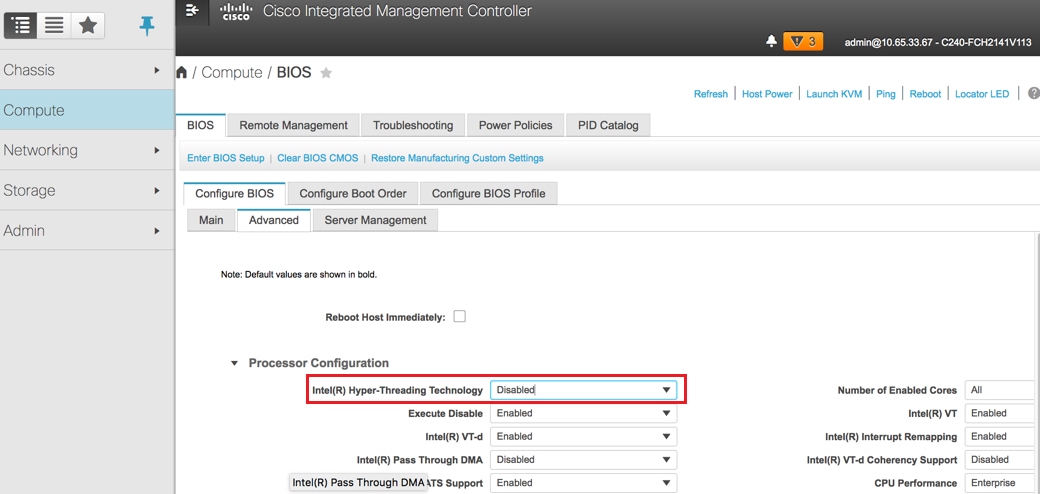 Hyperthreading uitschakelen: Computers > BIOS > Configureren van BIOS > Geavanceerd > Processorconfiguratie
Hyperthreading uitschakelen: Computers > BIOS > Configureren van BIOS > Geavanceerd > Processorconfiguratie
Opmerking: Het hier getoonde beeld en de configuratie stappen die in deze sectie worden vermeld, hebben betrekking op de firmware versie 3.0(3e) en er kunnen kleine variaties optreden als u aan andere versies werkt.
Voeg terug de OSD in de Cluster
1. Nadat een nieuwe schijf is vervangen, voert u partsonde uit om het nieuwe apparaat te ontdekken.
[root@pod1-osd-compute-3 heat-admin]# partprobe
[root@pod1-osd-compute-3 heat-admin]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 278.5G 0 disk
|
-sda1 8:1 0 1M 0 part
-sda2 8:2 0 278.5G 0 part /
sdb 8:16 0 446.1G 0 disk
|
-sdb1 8:17 0 107G 0 part
-sdb2 8:18 0 107G 0 part
-sdb3 8:19 0 107G 0 part
-sdb4 8:20 0 107G 0 part
sdc 8:32 0 1.1T 0 disk
|
-sdc1 8:33 0 1.1T 0 part /var/lib/ceph/osd/ceph-1
sdd 8:48 0 1.1T 0 disk
|
-sdd1 8:49 0 1.1T 0 part
sde 8:64 0 1.1T 0 disk
|
-sde1 8:65 0 1.1T 0 part /var/lib/ceph/osd/ceph-4
sdf 8:80 0 1.1T 0 disk
|
-sdf1 8:81 0 1.1T 0 part /var/lib/ceph/osd/ceph-10
2. Zoek een apparaat dat beschikbaar is op de server.
[root@pod1-osd-compute-3 heat-admin]# fdisk -l
Disk /dev/sda: 299.0 GB, 298999349248 bytes, 583983104 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x000b5e87
Device Boot Start End Blocks Id System
/dev/sda1 2048 4095 1024 83 Linux
/dev/sda2 * 4096 583983070 291989487+ 83 Linux
WARNING: fdisk GPT support is currently new, and therefore in an experimental phase. Use at your own discretion.
Disk /dev/sdb: 479.0 GB, 478998953984 bytes, 935544832 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disk label type: gpt
# Start End Size Type Name
1 2048 224462847 107G unknown ceph journal
2 224462848 448923647 107G unknown ceph journal
3 448923648 673384447 107G unknown ceph journal
4 673384448 897845247 107G unknown ceph journal
WARNING: fdisk GPT support is currently new, and therefore in an experimental phase. Use at your own discretion.
Disk /dev/sdd: 1199.0 GB, 1198999470080 bytes, 2341795840 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: gpt
# Start End Size Type Name
1 2048 2341795806 1.1T unknown ceph data
WARNING: fdisk GPT support is currently new, and therefore in an experimental phase. Use at your own discretion.
Disk /dev/sdc: 1199.0 GB, 1198999470080 bytes, 2341795840 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: gpt
# Start End Size Type Name
1 2048 2341795806 1.1T unknown ceph data
WARNING: fdisk GPT support is currently new, and therefore in an experimental phase. Use at your own discretion.
Disk /dev/sde: 1199.0 GB, 1198999470080 bytes, 2341795840 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: gpt
# Start End Size Type Name
1 2048 2341795806 1.1T unknown ceph data
WARNING: fdisk GPT support is currently new, and therefore in an experimental phase. Use at your own discretion.
Disk /dev/sdf: 1199.0 GB, 1198999470080 bytes, 2341795840 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: gpt
# Start End Size Type Name
1 2048 2341795806 1.1T unknown ceph data
[root@pod1-osd-compute-3 heat-admin]#
3. Gebruik Ceph-disk lijst om de kaart van de dagboekschijfverdeling te identificeren.
[root@pod1-osd-compute-3 heat-admin]# ceph-disk list
/dev/sda :
/dev/sda1 other, iso9660
/dev/sda2 other, xfs, mounted on /
/dev/sdb :
/dev/sdb1 ceph journal, for /dev/sdc1
/dev/sdb3 ceph journal
/dev/sdb2 ceph journal, for /dev/sde1
/dev/sdb4 ceph journal, for /dev/sdf1
/dev/sdc :
/dev/sdc1 ceph data, active, cluster ceph, osd.1, journal /dev/sdb1
/dev/sdd :
/dev/sdd1 other, xfs
/dev/sde :
/dev/sde1 ceph data, active, cluster ceph, osd.4, journal /dev/sdb2
/dev/sdf :
/dev/sdf1 ceph data, active, cluster ceph, osd.10, journal /dev/sdb4
Opmerking: In ceph-disk lijst, output gemarkeerd sde1 is journal-partitie voor sdb2. Controleer de output van de Ceph-disk lijst en breng de journal-schijf partitie in kaart in opdracht voor Ceph voorbereiding. Zodra u onder bevel OSD.7 kwam omhoog/in lopen en de gegevensherbalancering (backfill/recovery) zal worden begonnen.
4. Maak de Ceph-disk en voeg deze terug toe aan het cluster.
[root@pod1-osd-compute-3 heat-admin]# ceph-disk --setuser ceph --setgroup ceph prepare --fs-type xfs /dev/sdd /dev/sdb3
prepare_device: OSD will not be hot-swappable if journal is not the same device as the osd data
Creating new GPT entries.
The operation has completed successfully.
meta-data=/dev/sdd1 isize=2048 agcount=4, agsize=73181055 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=292724219, imaxpct=5
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=142931, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
Warning: The kernel is still using the old partition table.
The new table will be used at the next reboot.
The operation has completed successfully.
#####Hint###
where - sdd is new drive added as OSD
where – sdb3 is journal disk partition number
mapping is sdc1 for sdc, sdd1 for sdd, sde1 for sde
sdf1 for sdf (and so on)
5. Activeer de Ceph-disks en ontgrendel de noscrub en nodeep-scrub vlaggen.
[root@pod1-osd-compute-3 heat-admin]# ceph-disk activate-all
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset noout
unset noout
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset norebalance
unset norebalance
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset noscrub
unset noscrub
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset nodeep-scrub
unset nodeep-scrub
6. Wacht op de herbalancering om te voltooien en te verifiëren dat de gezondheid van Ceph en OSD boom goed zijn.
[root@pod1-osd-compute-3 heat-admin]# watch -n 3 ceph -s
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
1 mons down, quorum 0,1 pod1-controller-0,pod1-controller-1
monmap e1: 3 mons at {pod1-controller-0=11.118.0.10:6789/0,pod1-controller-1=11.118.0.11:6789/0,pod1-controller-2=11.118.0.12:6789/0}
election epoch 28, quorum 0,1 pod1-controller-0,pod1-controller-1
osdmap e709: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v941813: 704 pgs, 6 pools, 490 GB data, 163 kobjects
1470 GB used, 11922 GB / 13393 GB avail
704 active+clean
client io 58580 B/s wr, 0 op/s rd, 7 op/s wr
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod1-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-4 4.35999 host pod1-osd-compute-2
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
-5 4.35999 host pod1-osd-compute-3
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
Bijgedragen door Cisco-engineers
- Partheban RajagopalCisco geavanceerde services
- Padmaraj RamanoudjamCisco geavanceerde services
 Feedback
FeedbackContact Cisco
- Een ondersteuningscase openen

- (Vereist een Cisco-servicecontract)