Ceph/ストレージクラスタからの障害ディスクのUltra-M分離と交換 – vEPC
ダウンロード オプション
偏向のない言語
この製品のドキュメントセットは、偏向のない言語を使用するように配慮されています。このドキュメントセットでの偏向のない言語とは、年齢、障害、性別、人種的アイデンティティ、民族的アイデンティティ、性的指向、社会経済的地位、およびインターセクショナリティに基づく差別を意味しない言語として定義されています。製品ソフトウェアのユーザインターフェイスにハードコードされている言語、RFP のドキュメントに基づいて使用されている言語、または参照されているサードパーティ製品で使用されている言語によりドキュメントに例外が存在する場合があります。シスコのインクルーシブ ランゲージの取り組みの詳細は、こちらをご覧ください。
翻訳について
シスコは世界中のユーザにそれぞれの言語でサポート コンテンツを提供するために、機械と人による翻訳を組み合わせて、本ドキュメントを翻訳しています。ただし、最高度の機械翻訳であっても、専門家による翻訳のような正確性は確保されません。シスコは、これら翻訳の正確性について法的責任を負いません。原典である英語版(リンクからアクセス可能)もあわせて参照することを推奨します。
内容
はじめに
このドキュメントでは、Ultra-MセットアップのObject Storage Disk(OSD)-ComputeでホストされるCeph/StorageクラスタからOSDディスクを分離して交換するために実行する必要のある手順について説明します。
背景説明
Ultra-Mは、VNFの導入を簡素化するように設計された、パッケージ済みで検証済みの仮想化モバイルパケットコアソリューションです。 OpenStackは、Ultra-M向けの仮想化インフラストラクチャマネージャ(VIM)であり、次のノードタイプで構成されています。
- 計算
- OSD – コンピューティング
- コントローラ
- OpenStackプラットフォーム – ディレクタ(OSPD)
Ultra-Mの高度なアーキテクチャと関連するコンポーネントを次の図に示します。
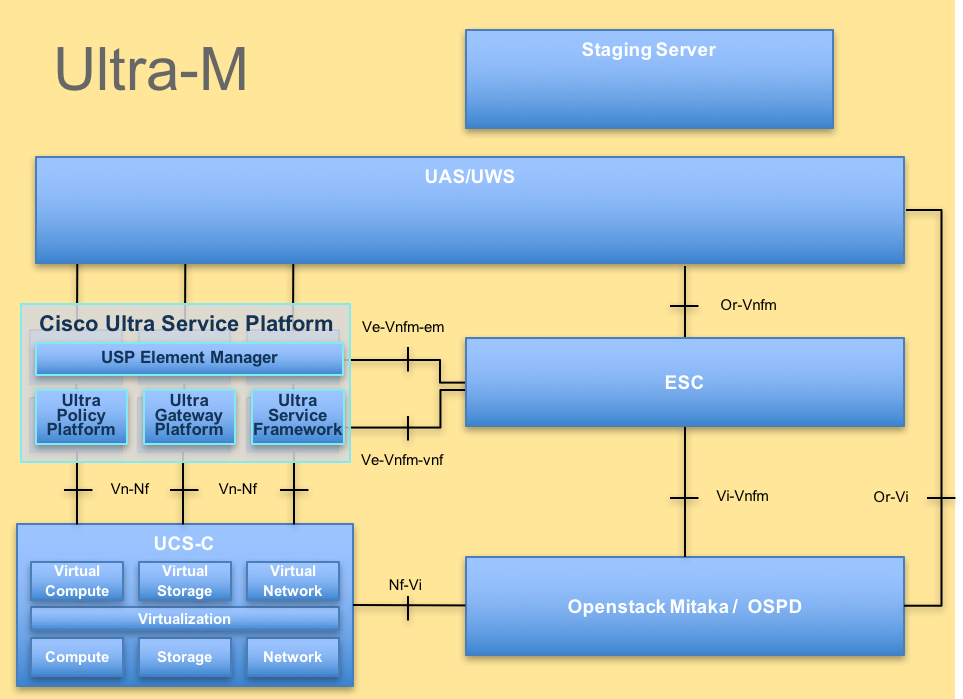 UltraMアーキテクチャこのドキュメントは、Cisco Ultra-Mプラットフォームに精通しているシスコの担当者を対象とし、OSPDサーバ交換時にOpenStackレベルで実行する必要のある手順について詳しく説明しています。
UltraMアーキテクチャこのドキュメントは、Cisco Ultra-Mプラットフォームに精通しているシスコの担当者を対象とし、OSPDサーバ交換時にOpenStackレベルで実行する必要のある手順について詳しく説明しています。
注:このドキュメントでは、手順を定義するためにUltra M 5.1.xリリースを考慮しています。
略語
| VNF | 仮想ネットワーク機能 |
| CF | 制御機能 |
| SF | サービス機能 |
| ESC | 柔軟なサービスコントローラ |
| MOP | 手順の方法 |
| OSD | オブジェクトストレージディスク |
| HDD | ハードディスクドライブ |
| SSD | ソリッドステートドライブ |
| VIM | 仮想インフラストラクチャマネージャ |
| 仮想マシン | 仮想マシン |
| エム | エレメント マネージャ |
| UAS | Ultra 自動化サービス |
| UUID | ユニバーサル一意識別子 |
MoPのワークフロー

前提条件となるヘルスチェック
1. Ceph-disk listコマンドを使用して、OSDのJournalへのマッピングを理解し、分離して交換するディスクを識別します。
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph-disk list
/dev/sda :
/dev/sda1 other, iso9660
/dev/sda2 other, xfs, mounted on /
/dev/sdb :
/dev/sdb1 ceph journal, for /dev/sdc1
/dev/sdb3 ceph journal, for /dev/sdd1
/dev/sdb2 ceph journal, for /dev/sde1
/dev/sdb4 ceph journal, for /dev/sdf1
/dev/sdc :
/dev/sdc1 ceph data, active, cluster ceph, osd.1, journal /dev/sdb1
/dev/sdd :
/dev/sdd1 ceph data, active, cluster ceph, osd.7, journal /dev/sdb3
/dev/sde :
/dev/sde1 ceph data, active, cluster ceph, osd.4, journal /dev/sdb2
/dev/sdf :
/dev/sdf1 ceph data, active, cluster ceph, osd.10, journal /dev/sdb4
2. 特定されたOSDディスクの分離に進む前に、Ceph健全性とOSDツリーマッピングを確認します。
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
1 mons down, quorum 0,1 pod1-controller-0,pod1-controller-1
monmap e1: 3 mons at {pod1-controller-0=11.118.0.10:6789/0,pod1-controller-1=11.118.0.11:6789/0,pod1-controller-2=11.118.0.12:6789/0}
election epoch 28, quorum 0,1 pod1-controller-0,pod1-controller-1
osdmap e709: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v941813: 704 pgs, 6 pools, 490 GB data, 163 kobjects
1470 GB used, 11922 GB / 13393 GB avail
704 active+clean
client io 58580 B/s wr, 0 op/s rd, 7 op/s wr
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod1-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-3 0 host pod1-osd-compute-1
-4 4.35999 host pod1-osd-compute-2
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
-5 4.35999 host pod1-osd-compute-3
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
障害のあるOSDディスクのクラスタからの切り分けと取り外し
1. OSDプロセスを無効化および停止します。
[heat-admin@pod1-osd-compute-3 ~]$ sudo systemctl disable ceph-osd@7
[heat-admin@pod1-osd-compute-3 ~]$ sudo systemctl stop ceph-osd@7
2. OSDに印を付けます。
[heat-admin@pod1-osd-compute-3 ~]$ sudo su
[root@pod1-osd-compute-3 heat-admin]# ceph osd set noout
set noout
[root@pod1-osd-compute-3 heat-admin]# ceph osd set norebalance
set norebalance
[root@pod1-osd-compute-3 heat-admin]# ceph osd out 7
marked out osd.7.
注:問題を回避するために、データの再調整が完了し、すべてのPGがactive+cleanに戻るのを待ちます。
3. OSDがマークされていることを確認し、Cephリバランスが先に進むのを待ちます。
[root@pod1-osd-compute-3 heat-admin]# watch -n1 ceph -s
95 active+undersized+degraded+remapped+wait_backfill
28 active+recovery_wait+degraded
2 active+undersized+degraded+remapped+backfilling
1 active+recovering+degraded
2 active+undersized+degraded+remapped+backfilling
1 active+recovering+degraded
2 active+undersized+degraded+remapped+backfilling
67 active+undersized+degraded+remapped+wait_backfill
3 active+undersized+degraded+remapped+backfilling
24 active+undersized+degraded+remapped+wait_backfill
22 active+undersized+degraded+remapped+wait_backfill
1 active+undersized+degraded+remapped+backfilling
8 active+undersized+degraded+remapped+wait_backfill
4. OSDの認証キーを削除します。
[root@pod1-osd-compute-3 heat-admin]# ceph auth del osd.7
updated
5. OSD.7のキーがリストされていないことを確認します。
[root@pod1-osd-compute-3 heat-admin]# ceph auth list
installed auth entries:
osd.0
key: AQCgpB5blV9dNhAAzDN1SVdnuJyTN2f7PAdtFw==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.1
key: AQBdwyBbbuD6IBAAcvG+oQOz5vk62faOqv/CEw==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.10
key: AQCwwyBb7xvHJhAAZKPprXWT7UnvnAXBV9W2rg==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.11
key: AQDxpB5b9/rGFRAAkcCEkpSN1YZVDdeW+Bho7w==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.2
key: AQCppB5btekoNBAAACoWpDz0VL9bZfyIygDpBQ==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.3
key: AQC4pB5bBaUlORAAhi3KPzetwvWhYGnerAkAsg==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.4
key: AQB1wyBbvMIQLRAAXefFVnZxMX6lVtObQt9KoA==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.5
key: AQDBpB5buKHqOhAAW1Q861qoYqW6fAYHlOxsLg==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.6
key: AQDQpB5b1BveFxAAfCLM3tvDUSnYneutyTmaEg==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.8
key: AQDZpB5bd4nlGRAAkkzbmGPnEDAWV0dUhrhE6w==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.9
key: AQDopB5bKCZPGBAAfYtp1GLA7QIi/YxJa8O1yw==
caps: [mon] allow profile osd
caps: [osd] allow *
client.admin
key: AQDpmx5bAAAAABAA3hLK8O2tGgaAK+X2Lly5Aw==
caps: [mds] allow *
caps: [mon] allow *
caps: [osd] allow *
client.bootstrap-mds
key: AQBDpB5bjR1GJhAAB6CKKxXulve9WIiC6ZGXgA==
caps: [mon] allow profile bootstrap-mds
client.bootstrap-osd
key: AQDpmx5bAAAAABAA3hLK8O2tGgaAK+X2Lly5Aw==
caps: [mon] allow profile bootstrap-osd
client.bootstrap-rgw
key: AQBDpB5b7OWXHBAAlATmBAOX/QWW+2mLxPqlkQ==
caps: [mon] allow profile bootstrap-rgw
client.openstack
key: AQDpmx5bAAAAABAAULxfs9cYG1wkSVTjrtiaDg==
caps: [mon] allow r
caps: [osd] allow class-read object_prefix rbd_children, allow rwx pool=volumes, allow rwx pool=backups, allow rwx pool=vms, allow rwx pool=images, allow rwx pool=metrics
7. クラスタからOSDを削除します。
[root@pod1-osd-compute-3 heat-admin]# ceph osd rm 7
removed osd.7
8. 交換が必要なOSDディスクをアンマウントします。
[root@pod1-osd-compute-3 heat-admin]# umount /var/lib/ceph/osd/ceph-7
9. noscrubとdeepscrubの設定を解除します。
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset noscrub
unset noscrub
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset nodeep-scrub
unset nodeep-scrub
10. Cephの状態を確認し、health-okとすべてのPGがactive+cleanに戻るのを待ちます。
[root@pod1-osd-compute-3 heat-admin]# ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_WARN
28 pgs backfill_wait
4 pgs backfilling
5 pgs degraded
5 pgs recovery_wait
83 pgs stuck unclean
recovery 1697/516881 objects degraded (0.328%)
recovery 76428/516881 objects misplaced (14.786%)
noout,norebalance,sortbitwise,require_jewel_osds flag(s) set
1 mons down, quorum 0,1 pod1-controller-0,pod1-controller-1
monmap e1: 3 mons at {pod1-controller-0=11.118.0.10:6789/0,pod1-controller-1=11.118.0.11:6789/0,pod1-controller-2=11.118.0.12:6789/0}
election epoch 28, quorum 0,1 pod1-controller-0,pod1-controller-1
osdmap e877: 11 osds: 11 up, 11 in; 193 remapped pgs
flags noout,norebalance,sortbitwise,require_jewel_osds
pgmap v942974: 704 pgs, 6 pools, 490 GB data, 163 kobjects
1470 GB used, 10806 GB / 12277 GB avail
1697/516881 objects degraded (0.328%)
76428/516881 objects misplaced (14.786%)
511 active+clean
156 active+remapped
28 active+remapped+wait_backfill
5 active+recovery_wait+degraded+remapped
4 active+remapped+backfilling
client io 331 kB/s wr, 0 op/s rd, 56 op/s wr
OSDディスクの交換と新しいVDの作成
1. 問題のあるドライブを取り外し、新しいドライブに交換する:『Cisco UCS C240 M4サーバインストレーション/サービスガイド』
2. OSD-ComputeのCIMCへのログインを確認し、OSDが交換され、良好な状態で表示されているスロットをチェックします。
3. 新しいHDDの仮想ドライブを作成します。メタデータのない新しいHDDである必要があります。
4. 新しく追加されたディスクがUnconimaged Good状態であることを確認します。
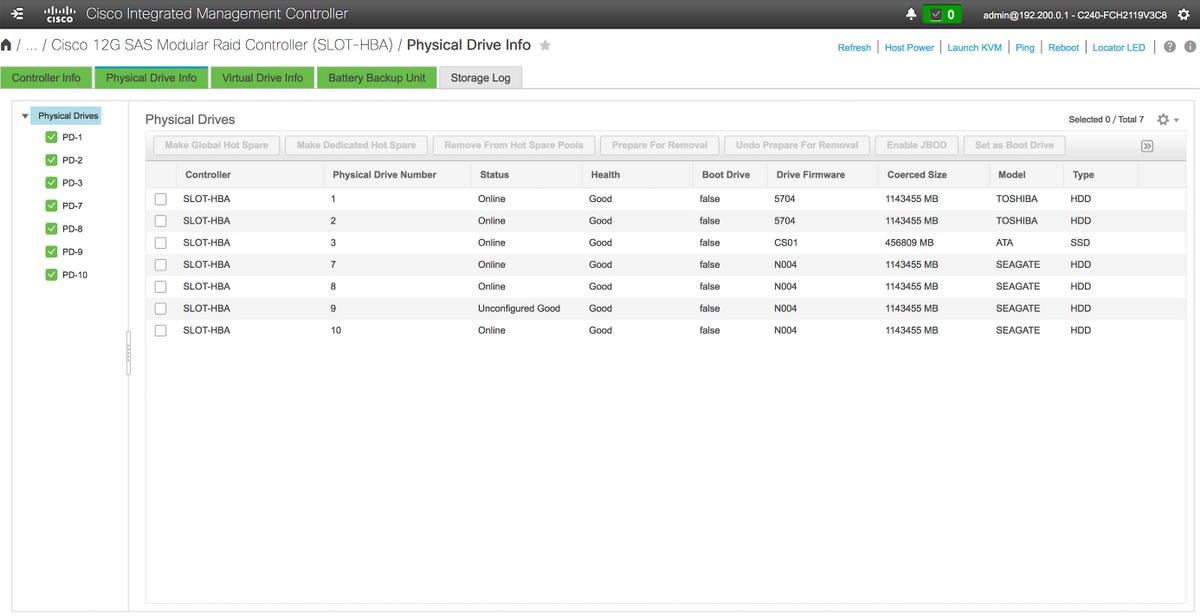 ストレージ> Cisco 12G SASモジュラRaidコントローラ(SLOT-HBA) >物理ドライブ情報
ストレージ> Cisco 12G SASモジュラRaidコントローラ(SLOT-HBA) >物理ドライブ情報
5. Create Virtual Drive from Unused Physical Drivesオプションを選択して、VDを作成します。
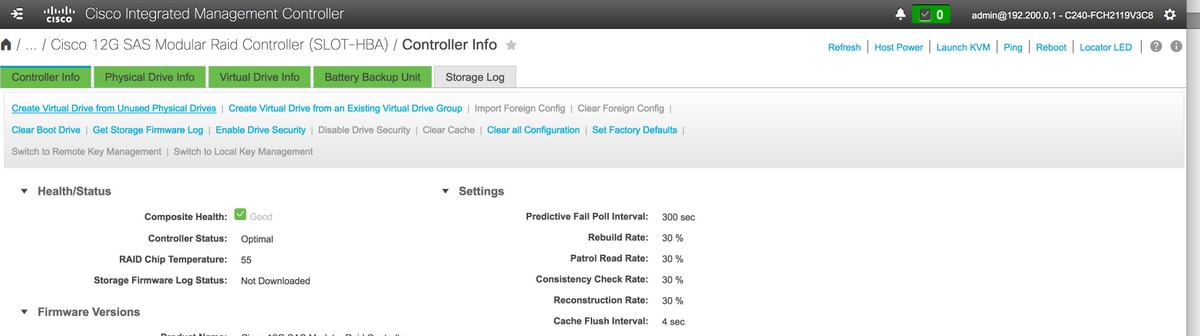 ストレージ> Cisco 12G SASモジュラRaidコントローラ(SLOT-HBA)
ストレージ> Cisco 12G SASモジュラRaidコントローラ(SLOT-HBA)
6. Physical Drive 9を使用して新しいVDを作成し、OSD3という名前を付けます。
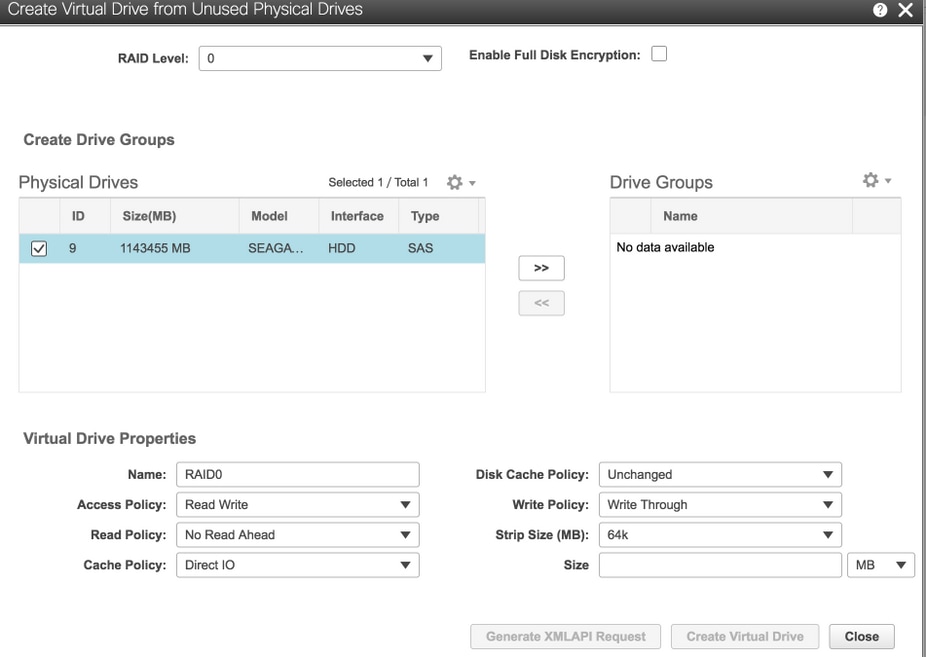 [ストレージ]>[Cisco 12G SASモジュラRaidコントローラ(SLOT-HBA)]>[コントローラ情報]>[未使用の物理ドライブから仮想ドライブを作成]
[ストレージ]>[Cisco 12G SASモジュラRaidコントローラ(SLOT-HBA)]>[コントローラ情報]>[未使用の物理ドライブから仮想ドライブを作成]
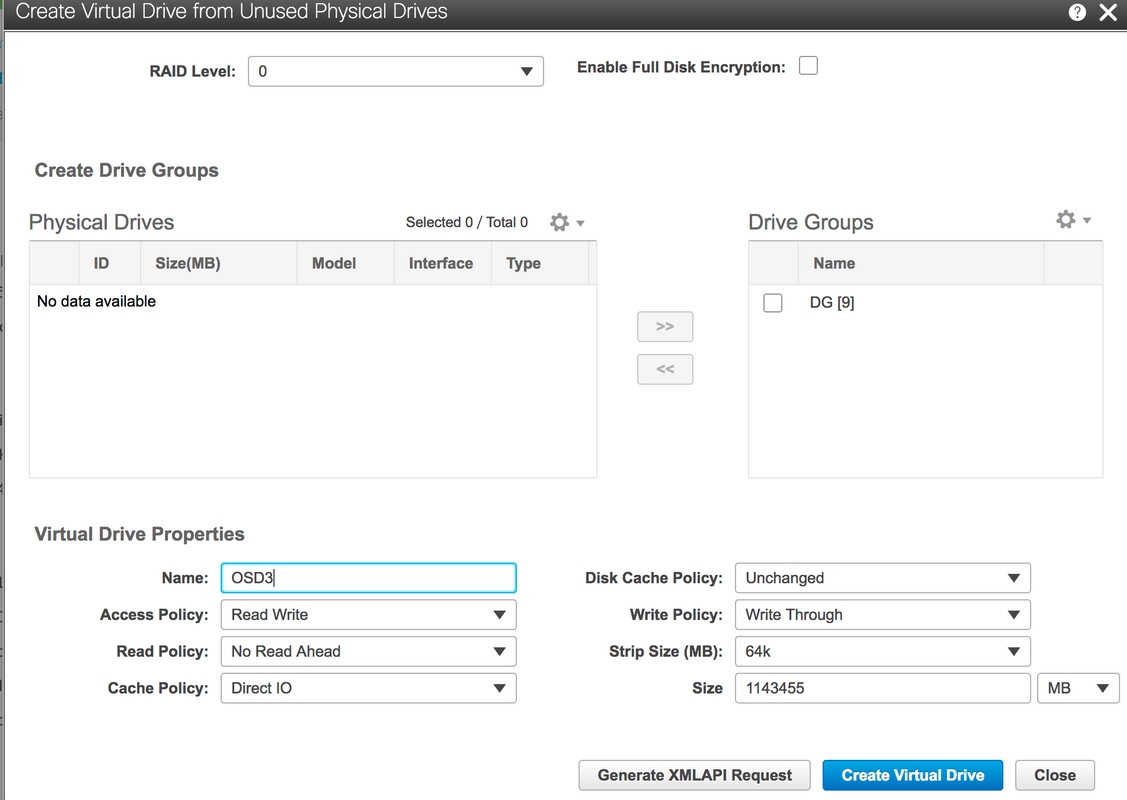 [ストレージ]>[Cisco 12G SASモジュラRaidコントローラ(SLOT-HBA)]>[コントローラ情報]>[未使用の物理ドライブから仮想ドライブを作成]
[ストレージ]>[Cisco 12G SASモジュラRaidコントローラ(SLOT-HBA)]>[コントローラ情報]>[未使用の物理ドライブから仮想ドライブを作成]
7. IPMI over LANを有効にします: Admin > Communication Services > Communication Services。
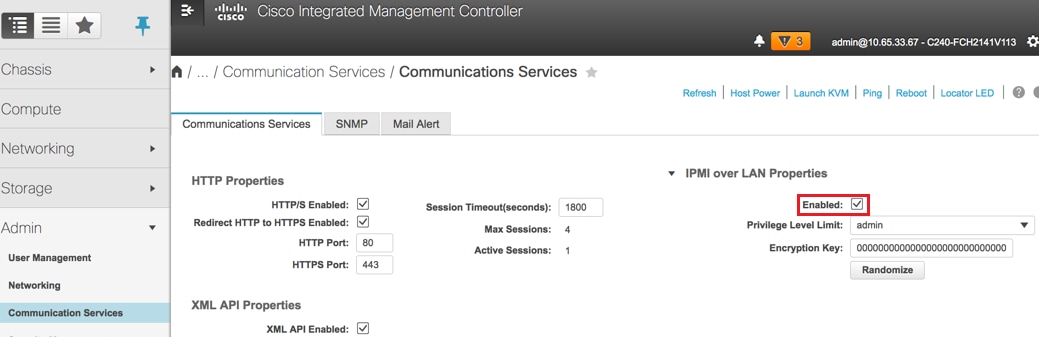 IPMI over LANの有効化: Admin > Communication Services > Communication Services
IPMI over LANの有効化: Admin > Communication Services > Communication Services
8. ハイパースレッディングを無効にする:コンピューティング> BIOS > Conimage BIOS >アドバンスド>プロセッサ設定。
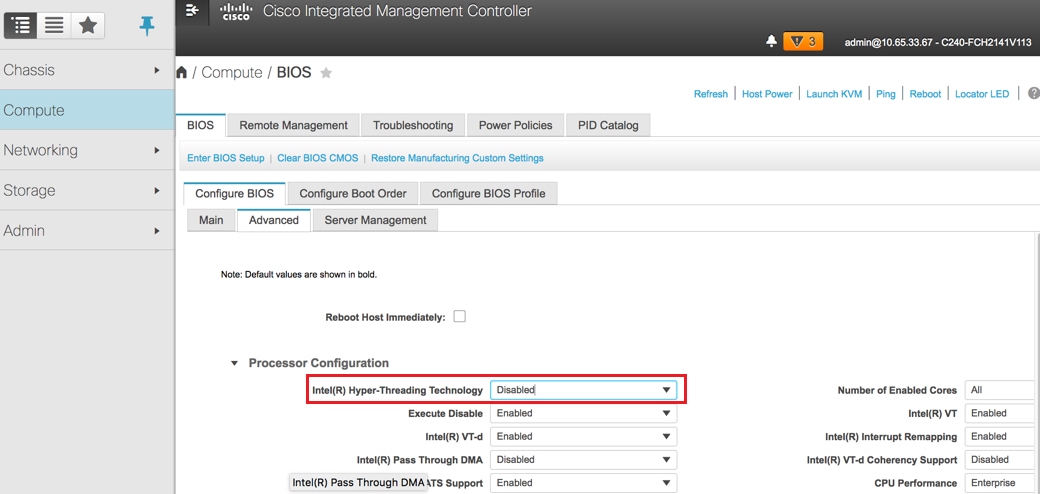 ハイパースレッディングの無効化:コンピューティング> BIOS > BIOSの設定> Advanced > Processor Configuration
ハイパースレッディングの無効化:コンピューティング> BIOS > BIOSの設定> Advanced > Processor Configuration
注:ここに示すイメージとこのセクションで説明する設定手順はファームウェアバージョン3.0(3e)を基準としているため、他のバージョンを操作する場合は多少バリエーションがある可能性があります。
OSDをクラスタに追加し直す
1. 新しいディスクを交換した後、partprobeを実行して新しいデバイスを検出します。
[root@pod1-osd-compute-3 heat-admin]# partprobe
[root@pod1-osd-compute-3 heat-admin]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 278.5G 0 disk
|
-sda1 8:1 0 1M 0 part
-sda2 8:2 0 278.5G 0 part /
sdb 8:16 0 446.1G 0 disk
|
-sdb1 8:17 0 107G 0 part
-sdb2 8:18 0 107G 0 part
-sdb3 8:19 0 107G 0 part
-sdb4 8:20 0 107G 0 part
sdc 8:32 0 1.1T 0 disk
|
-sdc1 8:33 0 1.1T 0 part /var/lib/ceph/osd/ceph-1
sdd 8:48 0 1.1T 0 disk
|
-sdd1 8:49 0 1.1T 0 part
sde 8:64 0 1.1T 0 disk
|
-sde1 8:65 0 1.1T 0 part /var/lib/ceph/osd/ceph-4
sdf 8:80 0 1.1T 0 disk
|
-sdf1 8:81 0 1.1T 0 part /var/lib/ceph/osd/ceph-10
2. サーバー上で利用可能なデバイスを見つけます。
[root@pod1-osd-compute-3 heat-admin]# fdisk -l
Disk /dev/sda: 299.0 GB, 298999349248 bytes, 583983104 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x000b5e87
Device Boot Start End Blocks Id System
/dev/sda1 2048 4095 1024 83 Linux
/dev/sda2 * 4096 583983070 291989487+ 83 Linux
WARNING: fdisk GPT support is currently new, and therefore in an experimental phase. Use at your own discretion.
Disk /dev/sdb: 479.0 GB, 478998953984 bytes, 935544832 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disk label type: gpt
# Start End Size Type Name
1 2048 224462847 107G unknown ceph journal
2 224462848 448923647 107G unknown ceph journal
3 448923648 673384447 107G unknown ceph journal
4 673384448 897845247 107G unknown ceph journal
WARNING: fdisk GPT support is currently new, and therefore in an experimental phase. Use at your own discretion.
Disk /dev/sdd: 1199.0 GB, 1198999470080 bytes, 2341795840 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: gpt
# Start End Size Type Name
1 2048 2341795806 1.1T unknown ceph data
WARNING: fdisk GPT support is currently new, and therefore in an experimental phase. Use at your own discretion.
Disk /dev/sdc: 1199.0 GB, 1198999470080 bytes, 2341795840 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: gpt
# Start End Size Type Name
1 2048 2341795806 1.1T unknown ceph data
WARNING: fdisk GPT support is currently new, and therefore in an experimental phase. Use at your own discretion.
Disk /dev/sde: 1199.0 GB, 1198999470080 bytes, 2341795840 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: gpt
# Start End Size Type Name
1 2048 2341795806 1.1T unknown ceph data
WARNING: fdisk GPT support is currently new, and therefore in an experimental phase. Use at your own discretion.
Disk /dev/sdf: 1199.0 GB, 1198999470080 bytes, 2341795840 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: gpt
# Start End Size Type Name
1 2048 2341795806 1.1T unknown ceph data
[root@pod1-osd-compute-3 heat-admin]#
3. Ceph-disk listを使用して、ジャーナルディスクパーティションマップを特定します。
[root@pod1-osd-compute-3 heat-admin]# ceph-disk list
/dev/sda :
/dev/sda1 other, iso9660
/dev/sda2 other, xfs, mounted on /
/dev/sdb :
/dev/sdb1 ceph journal, for /dev/sdc1
/dev/sdb3 ceph journal
/dev/sdb2 ceph journal, for /dev/sde1
/dev/sdb4 ceph journal, for /dev/sdf1
/dev/sdc :
/dev/sdc1 ceph data, active, cluster ceph, osd.1, journal /dev/sdb1
/dev/sdd :
/dev/sdd1 other, xfs
/dev/sde :
/dev/sde1 ceph data, active, cluster ceph, osd.4, journal /dev/sdb2
/dev/sdf :
/dev/sdf1 ceph data, active, cluster ceph, osd.10, journal /dev/sdb4
注:ceph-diskリストで、強調表示された出力sde1はsdb2のジャーナルパーティションです。Ceph-disk listの出力を確認し、コマンドのjournal disk partitionをCephの準備にマッピングします。以下のコマンドを実行するとすぐに、OSD.7が起動/インし、データのリバランス(バックフィル/リカバリ)が開始されます。
4. Cephディスクを作成し、クラスタに追加し直します。
[root@pod1-osd-compute-3 heat-admin]# ceph-disk --setuser ceph --setgroup ceph prepare --fs-type xfs /dev/sdd /dev/sdb3
prepare_device: OSD will not be hot-swappable if journal is not the same device as the osd data
Creating new GPT entries.
The operation has completed successfully.
meta-data=/dev/sdd1 isize=2048 agcount=4, agsize=73181055 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=292724219, imaxpct=5
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=142931, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
Warning: The kernel is still using the old partition table.
The new table will be used at the next reboot.
The operation has completed successfully.
#####Hint###
where - sdd is new drive added as OSD
where – sdb3 is journal disk partition number
mapping is sdc1 for sdc, sdd1 for sdd, sde1 for sde
sdf1 for sdf (and so on)
5. Cephディスクをアクティブ化し、noscrubおよびnodeep-scrubフラグの設定を解除します。
[root@pod1-osd-compute-3 heat-admin]# ceph-disk activate-all
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset noout
unset noout
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset norebalance
unset norebalance
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset noscrub
unset noscrub
[root@pod1-osd-compute-3 heat-admin]# ceph osd unset nodeep-scrub
unset nodeep-scrub
6. リバランスが完了するまで待ち、CephとOSDツリーの状態が良好であることを確認します。
[root@pod1-osd-compute-3 heat-admin]# watch -n 3 ceph -s
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
1 mons down, quorum 0,1 pod1-controller-0,pod1-controller-1
monmap e1: 3 mons at {pod1-controller-0=11.118.0.10:6789/0,pod1-controller-1=11.118.0.11:6789/0,pod1-controller-2=11.118.0.12:6789/0}
election epoch 28, quorum 0,1 pod1-controller-0,pod1-controller-1
osdmap e709: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v941813: 704 pgs, 6 pools, 490 GB data, 163 kobjects
1470 GB used, 11922 GB / 13393 GB avail
704 active+clean
client io 58580 B/s wr, 0 op/s rd, 7 op/s wr
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod1-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-4 4.35999 host pod1-osd-compute-2
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
-5 4.35999 host pod1-osd-compute-3
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
シスコ エンジニア提供
- パルテエバンラジャゴパルシスコアドバンスドサービス
- パドマラージラマヌードジャムシスコアドバンスドサービス
 フィードバック
フィードバックシスコに問い合わせ
- サポート ケースをオープン

- (シスコ サービス契約が必要です。)