はじめに
このドキュメントでは、UCSサーバでメモリエラーを処理するためのトラブルシューティング手順について説明します。
前提条件
要 件
次のトピックに関する知識を身に付けておくことをお勧めします。
- UCSの基本的な知識。
- メモリアーキテクチャの基本知識。
使用するコンポーネント
このドキュメントの情報は、次のソフトウェアとハードウェアのバージョンに基づいています。
- UCSファミリサーバM5、M6、M7以降
- UCS マネージャ
- Cisco インテグレーテッド マネージメント コントローラ(CIMC)
- Cisco Intersightマネージドモード(IMM)
このドキュメントの情報は、特定のラボ環境にあるデバイスに基づいて作成されたものです。このドキュメントで使用するすべてのデバイスは、クリアな(デフォルト)設定で作業を開始しています。本稼働中のネットワークでは、各コマンドによって起こる可能性がある影響を十分確認してください。
バックグラウンド情報
メモリ エラー
メモリエラーは、メモリの場所を読み取ろうとしたときに発生します。メモリから読み取られた値が、そこにあるはずの値と一致しません。これらのエラーは、次の2つのタイプに分類されます。
1. ソフトエラー
ソフトエラーは一時的なもので、繰り返し発生し続けることはありません。これらは一時的なものであり、読み取りを再試行するか、メモリの場所を書き換えることで修正できることがよくあります。
2. ハードエラー
永続的な物理不具合が原因で発生します。 メモリの場所を書き換えて読み取りアクセスを再試行しても、ハードエラーは解消されません。その結果、このメモリエラーは修正不可能となり、エラーが繰り返し発生するため、メモリを交換する必要があります。
修正可能なエラー
エラーが検出されて修正されると、修正可能と見なされます。これは、読み取りを再試行するか、またはエラー訂正コード(ECC)データを使用して正しいメモリ内容を計算し、適切なデータをメモリに書き戻すことで実現できます。エラーが検出されて修正されると、Cisco Integrated Management Controller(IMC)によってイベントがシステムイベントログに記録されます。
通常、修正可能なエラーは、ソフトエラーの結果です。修正可能なエラーが同じメモリの場所で長期間続く場合は、潜在的なハードエラーを示している可能性があります。
適応型ダブルデバイスデータ修正(ADDDC)
ADDDCスペアリングは、同じ領域に存在する場合、連続する2つのDRAM障害を修正できます。ADDDCは、障害ビットからスペアメモリに動的にデータを移動し、修正可能なエラーが修正不能になるのを防ぎます。このメカニズムをトリガーするには、修正可能なECCエラーのしきい値が必要です。
ADDDCは、修正可能なECCエラーが修正不可能なECCエラーの前に存在する場合に役立ちます。
ポストパッケージ修復(PPR)
Post Package Repair(PPR)では、冗長DRAM列を活用することで、DIMM内の障害が発生したメモリ領域を永続的に修復できます。この修理は現場で行われ、DIMMを交換しなくてもハードエラーから迅速に回復できます。修復を実行するには、システムでADDDCイベントが発生し、少なくとも1回のリブートサイクルが実行される必要があります。この修復アクティビティは、パフォーマンスやOSで使用可能な総メモリに影響を与えません。
PPRとADDDCはデフォルトで有効になっていますが、設定可能です。PPRでは、ADDDCスペアリングRASモードも有効にする必要があります。RAS設定がADDDCスペアリングまたはプラットフォームデフォルト以外の場合、PPRは動作しません。唯一サポートされているPPRモードはハードPPRです。これは、修復が永続的であることを意味します。
部分キャッシュラインスペアリング(PCLS)
メモリコントローラにはエラー防止メカニズムがあります。これは、メモリ内のデータの欠陥のある小さな部分を特定することによって機能します。これらの障害のある場所は、代替となる可能性のあるバックアップデータとともに特別なディレクトリに記録されます。メモリにアクセスする際、これらの障害スポットにエラーが発生した場合、コントローラはディレクトリからのバックアップデータを使用して、すべてがスムーズに動作するようにします。
注:これらの機能は、サーバで実行されているCPUアーキテクチャとファームウェアのバージョンによって異なります。メモリエラーをより適切に処理するために、最新の推奨バージョンであることを確認してください。
RAS障害のトラブルシューティング
UCS マネージャ
通常、UCS Managerでは、これらの障害はRASイベントとして表示されます。
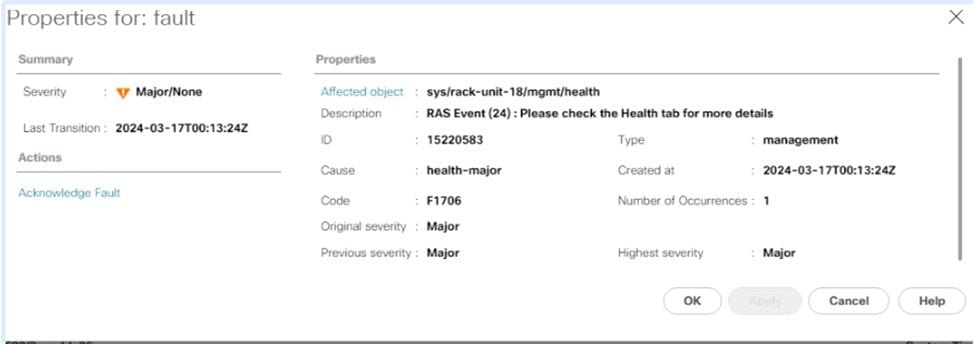
正常性の概要では、PCLSまたはPPRがトリガーされたかどうかなど、エラーに関する詳細情報を確認できます。
PCLSの例
M6以降のサーバでは、エラー防止メカニズムであるBIOSオプションとして部分キャッシュラインスペアリング(PCLS)を有効にするオプションがあります。PPRを起動してDIMMを修復するには、サーバをできるだけ早くリブートする必要があります。サーバがリブートしたら、同じDIMMに対してUCS Managerの追加の障害を監視します。
アラートで説明しているように、修正不可能なエラーが発生して予期しないサーバのダウンタイムが発生するリスクが伴うため、できるだけ早い時期にサーバをリブートすることを推奨します。
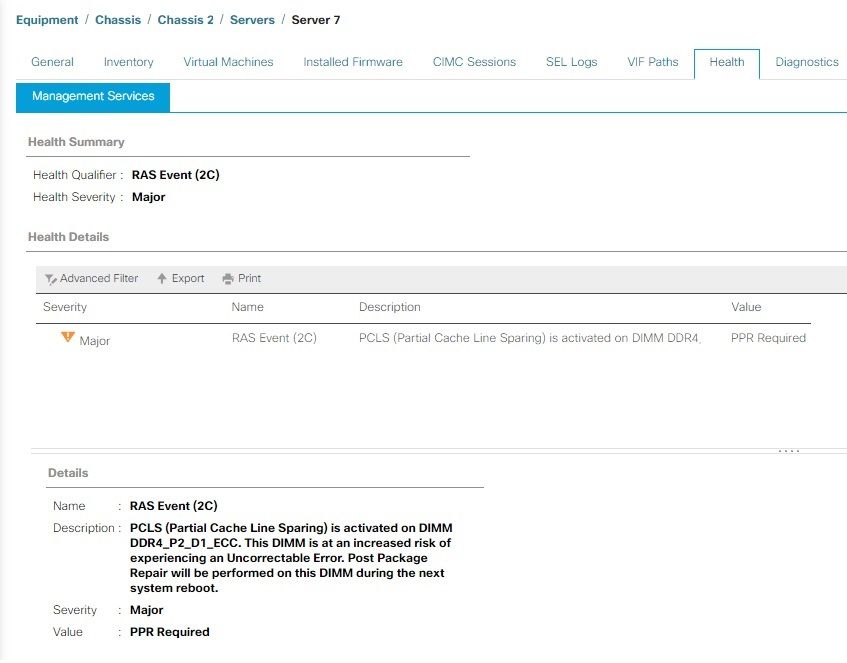
PPRの例
サーバーでADDDCおよびPPRが有効になっており、RASイベントが発生しました。この障害は、DIMMを修復するためにPPRをリブートすることを示唆しています。PPRを起動してDIMMを修復するには、できるだけ早くサーバをリブートする必要があります。
サーバがリブートしたら、同じDIMMに対してUCS Managerの追加の障害を監視します。
アラートで説明しているように、修正不可能なエラーが発生して予期しないサーバのダウンタイムが発生するリスクが伴うため、できるだけ早い時期にサーバをリブートすることを推奨します。
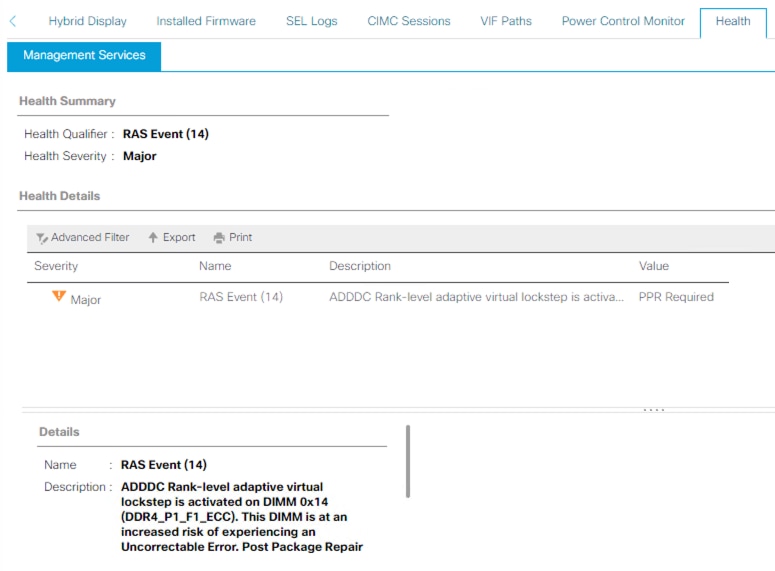
Intersight 管理モード
サーバでADDDCが有効になっていて、BANK VLSイベントが発生し、表示される障害が発生しました。このシナリオでは、次のステップとして、できるだけ早くサーバをリブートしてPPRを実行します。

Cisco インテグレーテッド マネージメント コントローラ(CIMC)
Cisco Integrated Management Controllerを使用している場合、障害は次のように表示されます。サーバにADDDCがあり、VLSイベントが発生した場合、これは修正不可能なエラーを防ぐために設計された通りに動作しています。
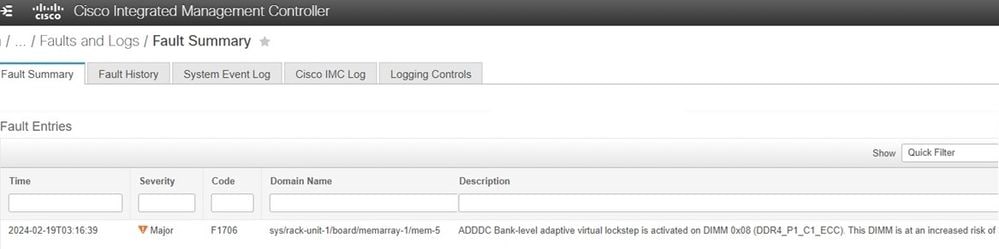
トラブルシューティングの手順
- たとえば、他のDIMM障害がなく、修正不可能なエラーがあることを確認します。
- メンテナンス時間帯をスケジュールします。
- ホストをメンテナンスモードにしてサーバをリブートし、Post Package Repair(PPR)を使用してDIMMの永続的な修復を試みます。
UCSMのリブート手順
注:OSからサーバをリブートすることもできます。この例では、サーバUIからrebootオプションを使用します。
UCS ManagerのWebインターフェイスに移動します。
ブレードサーバ
Equipment > Chassis > Server Xの順に選択します。
統合サーバ
Equipment > Rack-Mounts > Server Xの順に選択します。
KVM consoleをクリックします。
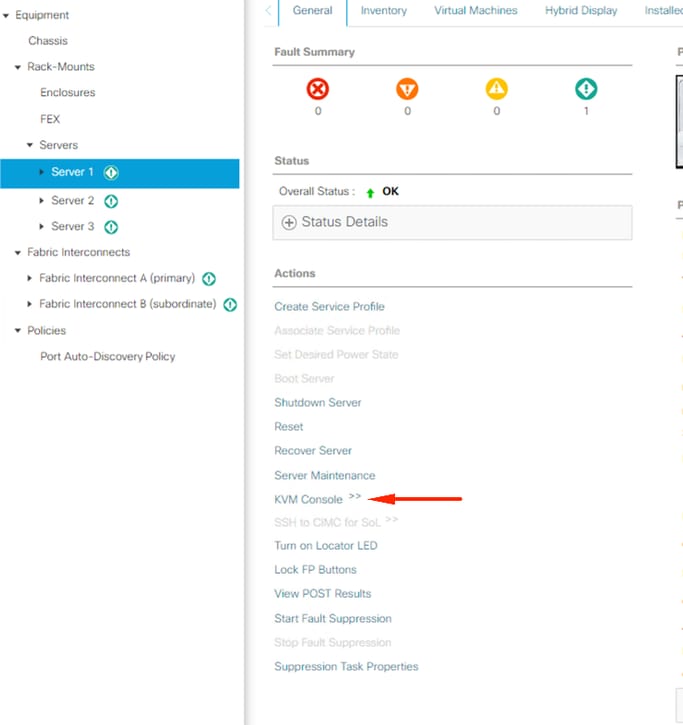
KVMウィンドウで、server actionsをクリックし、Resetを選択してOKをクリックします。
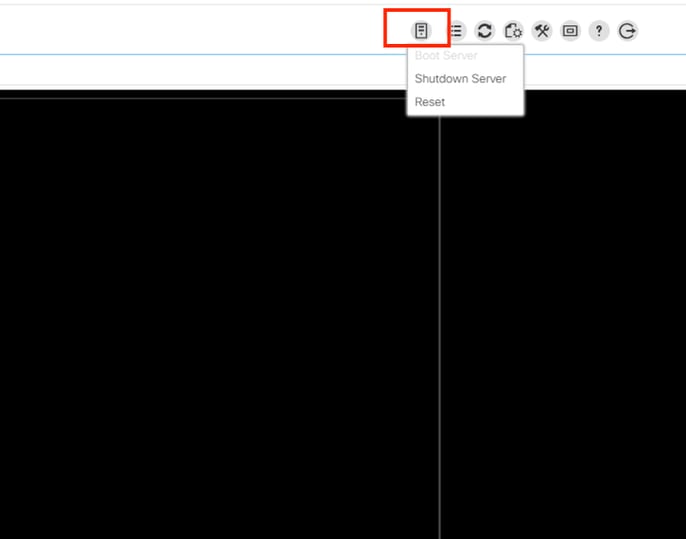
KVMで再起動プロセスを監視し、OSが正しく起動することを確認します。
IMMのリブート手順
Serversタブに移動し、serverを識別して、Action(3つのドット)メニューをクリックします。
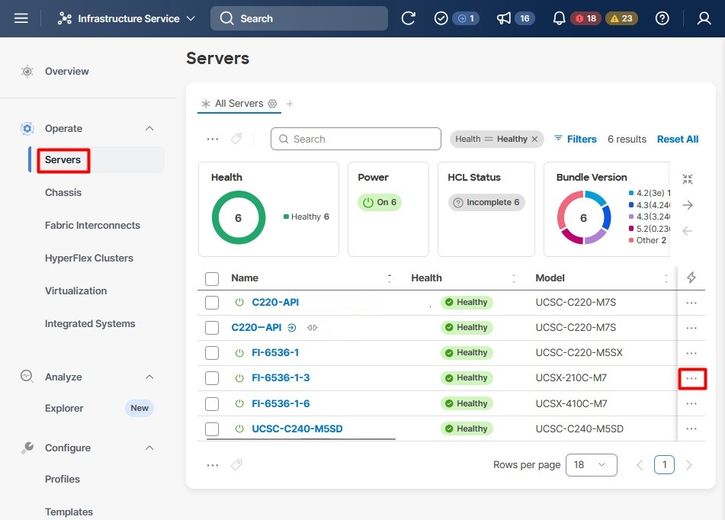
次に、Powerメニューを選択し、次にPower Cycleオプションを選択します。
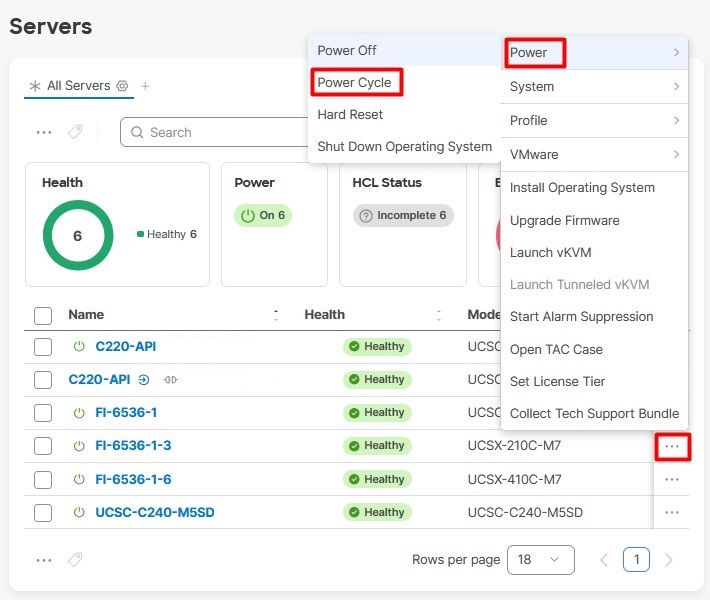
Power Cycleボタンをクリックして、操作を確定します。
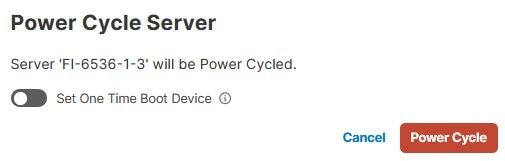
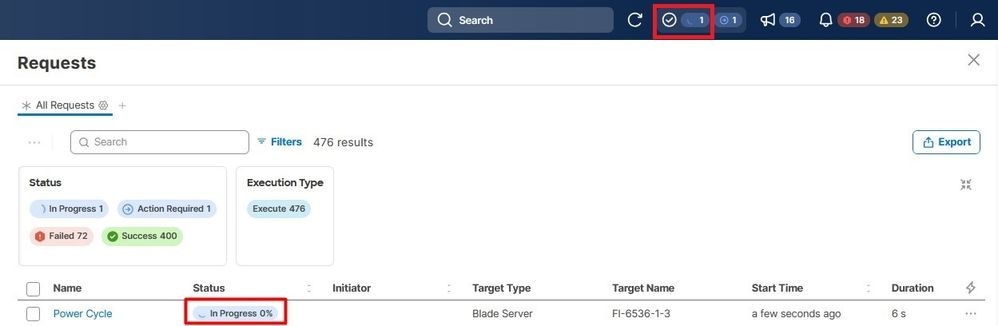
Requestsメニューの下で、進行状況を検証します。
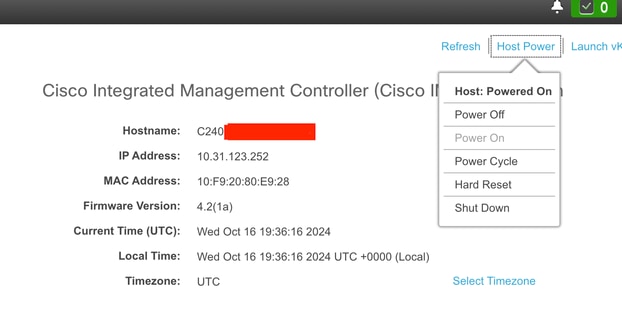
CIMCのリブート手順
Host Powerオプションまで移動し、Power Cycleを選択します。
KVMを起動して再起動プロセスを監視し、OSが正しく起動することを確認します。
新しい障害の監視
リブート後にエラーが発生しない場合、つまりDIMMに関連する他のRASイベントまたは障害がない場合、PPRは成功し、サーバは再び使用できます。
新しいADDDCイベントが発生した場合は、前の手順で説明した再起動プロセスを繰り返して、PPRで追加の永続的な修復を実行します。
修正不可能なエラー、または再起動後に動作不能な障害が発生した場合、その障害はメモリを交換する必要があることを示します。
注:これらの障害が発生した場合は、Cisco TACでケースをオープンし、DIMMを交換してください。
UCS Managerの修正不可能なメモリエラー
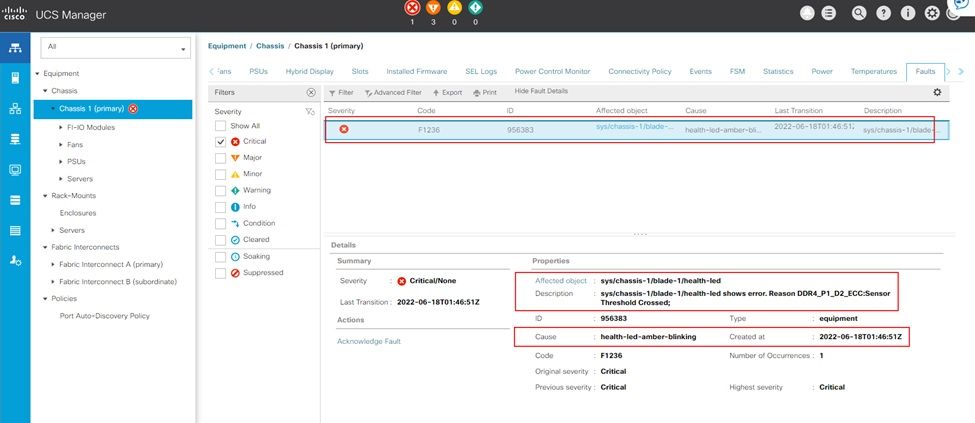
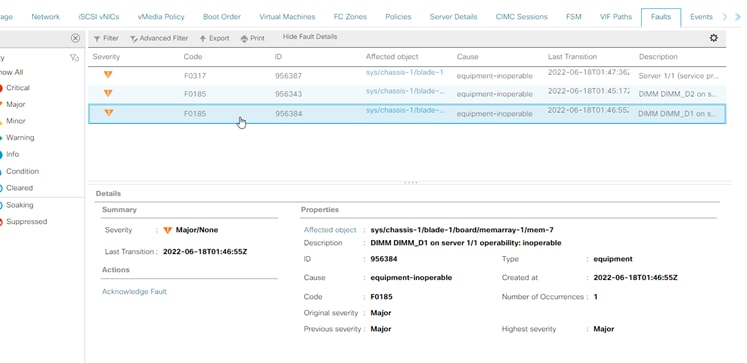
IMMメモリの修正不可能なエラー
修正不可能なエラー障害。この障害は、DIMMに修正不可能なエラーがあり、交換が必要であることを示しています。

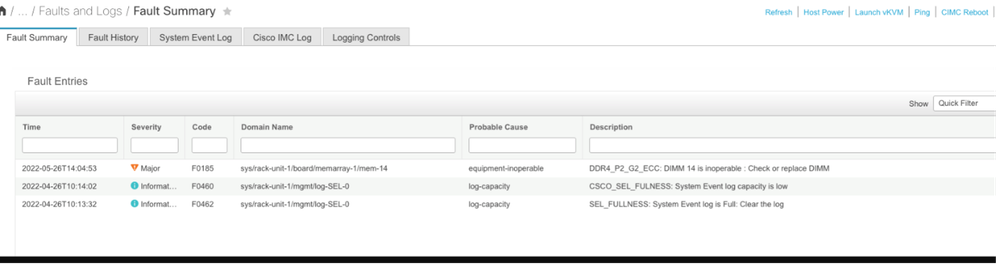
CIMCの修正不可能なメモリエラー
関連情報
 フィードバック
フィードバック