はじめに
このドキュメントでは、データ損失防止(DLP)データ分類で誤検出を減らすためにデータ一致除外を使用する方法について説明します。
概要
データ一致除外では、特定の一致したデータを除外できます。これにより、DLPデータ分類を微調整し、誤検出を大幅に削減できます。この機能を使用すると、既知の非機密データや無関係な一致をDLPスキャンから除外できるため、より正確なデータ保護が可能になります。
除外されたデータと一致する場合に誤検出を最小限に抑える方法
組み込み識別子とカスタム識別子は、キーワードまたはパターンが非機密データと一致する場合に誤検出を生成する可能性があります。例:
- 数値ベースの識別子:
米国社会保障番号(SSN)などの識別子は、内部アカウントIDなど、他の9桁の番号と一致する場合があります。既知のアカウントIDを除外することで、これらの誤検出を減らすことができます。
- テキストベース識別子:
HIPAAに準拠したデータ分類を使用している医療機関のお客様は、「がん寄付機関」などの非患者コンテキストで「がん」という用語を検出する可能性があります。 このような誤ったアラートを防ぐために、特定の用語を除外することができます。
データ一致除外を使用すると、用語または正規表現パターンを指定でき、これらに一致した場合にデータ違反イベントがトリガーされないようにできます。これにより、DLPアラートを正確に制御できます。
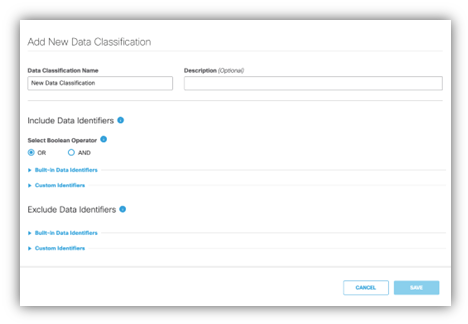
データ一致除外の使用方法
-
Umbrellaダッシュボードで、データの分類ページに移動します。
-
[データ識別子の除外]セクションで、除外するカスタム識別子または組み込み識別子を選択します。
-
除外する特定の用語または正規表現パターンを入力します。
- 除外は、特定の一致したコンテンツにのみ適用され、ドキュメント全体には適用されません。
- たとえば、「Cancer Donation Organization」を除外すると、その用語だけが違反から除外され、残りのドキュメントは引き続きスキャンされます。
-
同じデータIDが同じ分類に含まれ、同じ分類から除外される場合は、除外が優先されます。
関連するリソース
詳細な手順については、Umbrellaのドキュメント「データ分類の作成」を参照してください。
 フィードバック
フィードバック