Remplacement du serveur OSPD UCS 240M4 - vEPC
Options de téléchargement
-
ePub (1.0 MB)
Consulter à l’aide de différentes applications sur iPhone, iPad, Android ou Windows Phone -
Mobi (Kindle) (555.1 KB)
Consulter sur un appareil Kindle ou à l’aide d’une application Kindle sur plusieurs appareils
Langage exempt de préjugés
Dans le cadre de la documentation associée à ce produit, nous nous efforçons d’utiliser un langage exempt de préjugés. Dans cet ensemble de documents, le langage exempt de discrimination renvoie à une langue qui exclut la discrimination en fonction de l’âge, des handicaps, du genre, de l’appartenance raciale de l’identité ethnique, de l’orientation sexuelle, de la situation socio-économique et de l’intersectionnalité. Des exceptions peuvent s’appliquer dans les documents si le langage est codé en dur dans les interfaces utilisateurs du produit logiciel, si le langage utilisé est basé sur la documentation RFP ou si le langage utilisé provient d’un produit tiers référencé. Découvrez comment Cisco utilise le langage inclusif.
À propos de cette traduction
Cisco a traduit ce document en traduction automatisée vérifiée par une personne dans le cadre d’un service mondial permettant à nos utilisateurs d’obtenir le contenu d’assistance dans leur propre langue. Il convient cependant de noter que même la meilleure traduction automatisée ne sera pas aussi précise que celle fournie par un traducteur professionnel.
Table des matières
Introduction
Ce document décrit les étapes requises pour remplacer un serveur défaillant qui héberge OpenStack Platform Director (OSPD) dans une configuration Ultra-M.
Informations générales
Ultra-M est une solution de coeur de réseau de paquets mobile virtualisée préemballée et validée, conçue pour simplifier le déploiement des VNF. OpenStack est le gestionnaire d'infrastructure virtualisée (VIM) pour Ultra-M et se compose des types de noeuds suivants :
- Calculer
- Disque de stockage d'objets - Calcul (OSD - Calcul)
- Contrôleur
- OSPD
L'architecture de haut niveau d'Ultra-M et les composants impliqués sont représentés dans cette image :
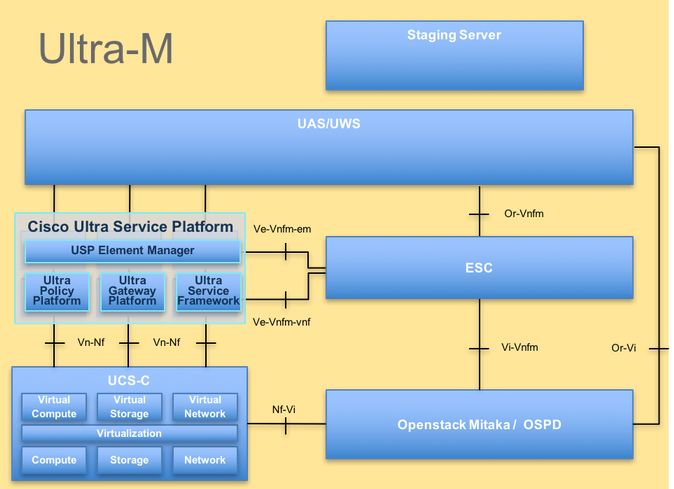 Architecture UltraM
Architecture UltraM
Ce document s'adresse au personnel de Cisco qui connaît la plate-forme Cisco Ultra-M et détaille les étapes requises pour être exécuté au niveau OpenStack au moment du remplacement du serveur OSPD.
Remarque : La version Ultra M 5.1.x est prise en compte afin de définir les procédures dans ce document.
Abréviations
| VNF | Fonction de réseau virtuel |
| CF | Fonction De Commande |
| SF | Fonction de service |
| ESC | Contrôleur de service élastique |
| SERPILLIÈRE | Méthode de procédure |
| OSD | Disques de stockage d'objets |
| HDD | Disque dur |
| SSD | Disque dur SSD |
| VIM | Gestionnaire d'infrastructure virtuelle |
| VM | Machine virtuelle |
| EM | Gestionnaire d'éléments |
| SAMU | Services d’automatisation ultra |
| UUID | Identificateur Universally Unique |
Flux de travail de la musique d'attente
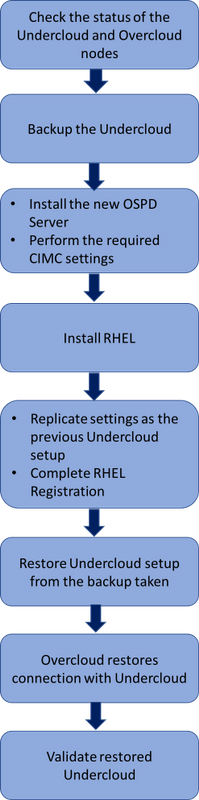 Workflow de haut niveau de la procédure de remplacement
Workflow de haut niveau de la procédure de remplacement
Conditions préalables
Vérification du statut
Avant de remplacer un serveur OSPD, il est important de vérifier l'état actuel de l'environnement Red Hat OpenStack Platform et de s'assurer qu'il est sain afin d'éviter des complications lorsque le processus de remplacement est activé.
Vérifiez l'état de la pile OpenStack et la liste des noeuds :
[stack@director ~]$ source stackrc
[stack@director ~]$ openstack stack list --nested
[stack@director ~]$ ironic node-list
[stack@director ~]$ nova list
Assurez-vous que tous les services sous-cloud sont à l'état chargé, actif et en cours d'exécution à partir du noeud OSP-D :
[stack@director ~]$ systemctl list-units "openstack*" "neutron*" "openvswitch*"
UNIT LOAD ACTIVE SUB DESCRIPTION
neutron-dhcp-agent.service loaded active running OpenStack Neutron DHCP Agent
neutron-openvswitch-agent.service loaded active running OpenStack Neutron Open vSwitch Agent
neutron-ovs-cleanup.service loaded active exited OpenStack Neutron Open vSwitch Cleanup Utility
neutron-server.service loaded active running OpenStack Neutron Server
openstack-aodh-evaluator.service loaded active running OpenStack Alarm evaluator service
openstack-aodh-listener.service loaded active running OpenStack Alarm listener service
openstack-aodh-notifier.service loaded active running OpenStack Alarm notifier service
openstack-ceilometer-central.service loaded active running OpenStack ceilometer central agent
openstack-ceilometer-collector.service loaded active running OpenStack ceilometer collection service
openstack-ceilometer-notification.service loaded active running OpenStack ceilometer notification agent
openstack-glance-api.service loaded active running OpenStack Image Service (code-named Glance) API server
openstack-glance-registry.service loaded active running OpenStack Image Service (code-named Glance) Registry server
openstack-heat-api-cfn.service loaded active running Openstack Heat CFN-compatible API Service
openstack-heat-api.service loaded active running OpenStack Heat API Service
openstack-heat-engine.service loaded active running Openstack Heat Engine Service
openstack-ironic-api.service loaded active running OpenStack Ironic API service
openstack-ironic-conductor.service loaded active running OpenStack Ironic Conductor service
openstack-ironic-inspector-dnsmasq.service loaded active running PXE boot dnsmasq service for Ironic Inspector
openstack-ironic-inspector.service loaded active running Hardware introspection service for OpenStack Ironic
openstack-mistral-api.service loaded active running Mistral API Server
openstack-mistral-engine.service loaded active running Mistral Engine Server
openstack-mistral-executor.service loaded active running Mistral Executor Server
openstack-nova-api.service loaded active running OpenStack Nova API Server
openstack-nova-cert.service loaded active running OpenStack Nova Cert Server
openstack-nova-compute.service loaded active running OpenStack Nova Compute Server
openstack-nova-conductor.service loaded active running OpenStack Nova Conductor Server
openstack-nova-scheduler.service loaded active running OpenStack Nova Scheduler Server
openstack-swift-account-reaper.service loaded active running OpenStack Object Storage (swift) - Account Reaper
openstack-swift-account.service loaded active running OpenStack Object Storage (swift) - Account Server
openstack-swift-container-updater.service loaded active running OpenStack Object Storage (swift) - Container Updater
openstack-swift-container.service loaded active running OpenStack Object Storage (swift) - Container Server
openstack-swift-object-updater.service loaded active running OpenStack Object Storage (swift) - Object Updater
openstack-swift-object.service loaded active running OpenStack Object Storage (swift) - Object Server
openstack-swift-proxy.service loaded active running OpenStack Object Storage (swift) - Proxy Server
openstack-zaqar.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server
openstack-zaqar@1.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server Instance 1
openvswitch.service loaded active exited Open vSwitch
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
37 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
Sauvegarde
Assurez-vous que vous disposez d'un espace disque suffisant avant d'effectuer le processus de sauvegarde. Cette archive tar devrait être d'au moins 3,5 Go.
[stack@director ~]$df -h
Exécutez cette commande en tant qu'utilisateur racine afin de sauvegarder les données du noeud sous-cloud dans un fichier nommé undercloud-backup-[timestamp].tar.gz.
[root@director ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql
[root@director ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql
/etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack
tar: Removing leading `/' from member names
Installation du nouveau noeud OSPD
Installation du serveur UCS
Les étapes d'installation d'un nouveau serveur UCS C240 M4 ainsi que les étapes de configuration initiale peuvent être consultées dans le Guide d'installation et de maintenance du serveur Cisco UCS C240 M4.
Connectez-vous au serveur à l'aide de l'adresse IP CIMC.
Procédez à la mise à niveau du BIOS si le micrologiciel n'est pas conforme à la version recommandée utilisée précédemment. Les étapes de mise à niveau du BIOS sont indiquées ici : Guide de mise à niveau du BIOS du serveur rack Cisco UCS série C.
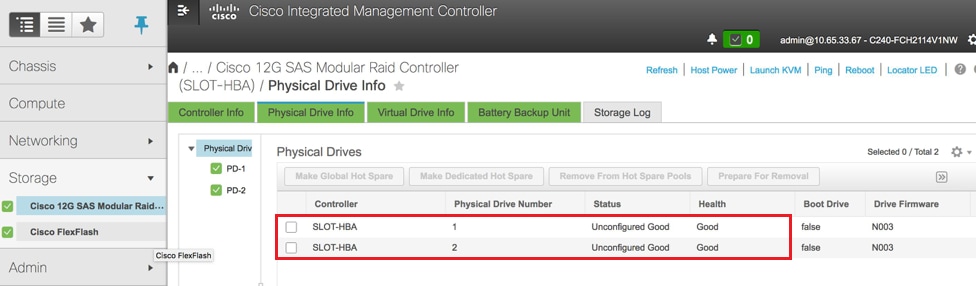
Vérifiez l'état des lecteurs physiques. Il doit être Unconfigured Good :
Accédez à Storage > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Physical Drive Info comme indiqué ici dans l'image.
Créez un disque virtuel à partir des disques physiques avec le niveau RAID 1 :
Accédez à Storage > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Controller Info > Create Virtual Drive from Unused Physical Drives comme indiqué dans l'image.
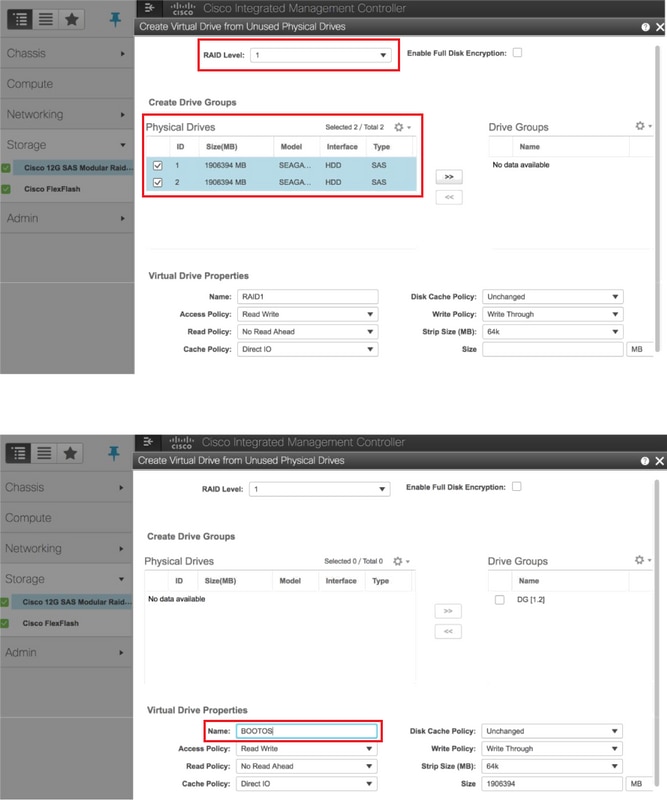
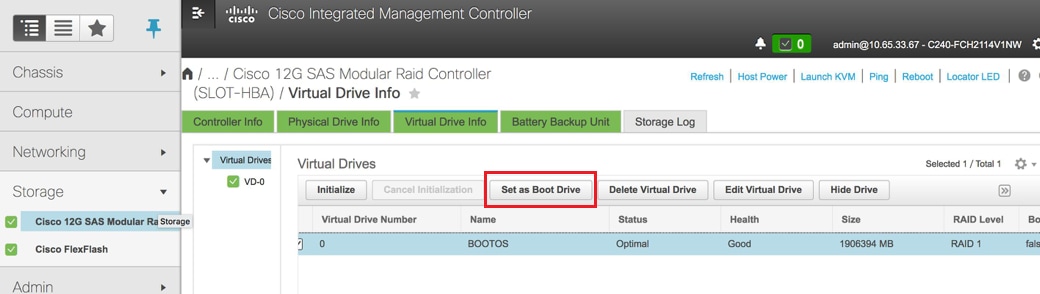
Sélectionnez le VD et configurez Set as Boot Drive comme indiqué dans l'image.
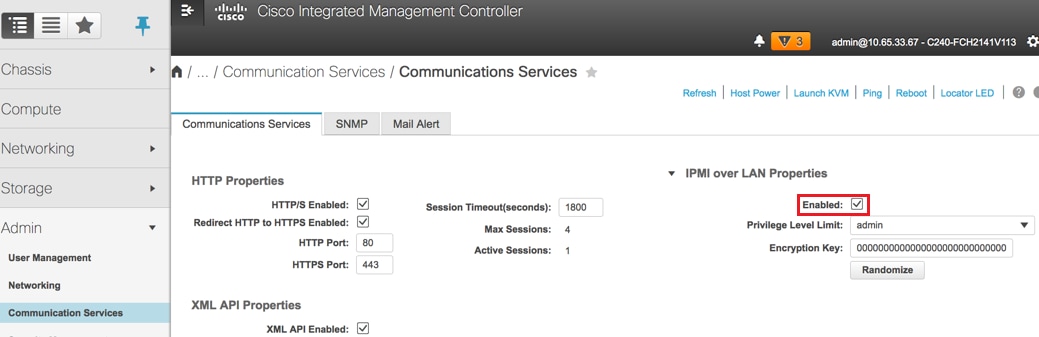
Activer IPMI sur LAN :
Accédez à Admin > Communication Services > Communication Services comme indiqué dans l'image.
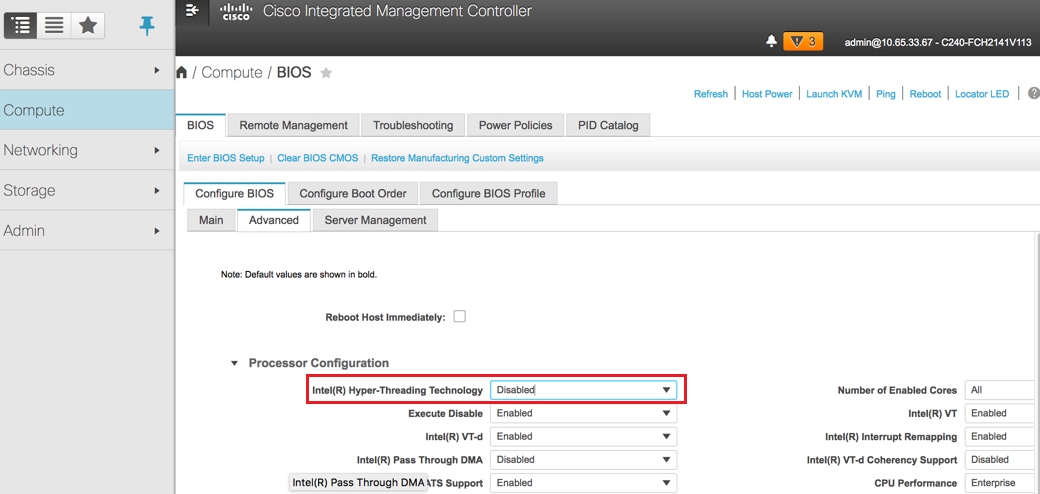
Désactiver l'hyperthreading :
Accédez à Compute > BIOS > Configure BIOS > Advanced > Processor Configuration comme indiqué dans l'image.
Remarque : L'image illustrée ici et les étapes de configuration mentionnées dans cette section font référence à la version 3.0(3e) du micrologiciel et il peut y avoir de légères variations si vous travaillez sur d'autres versions.
Installation de Red Hat
Montage de l'image ISO Red Hat
1. Connectez-vous au serveur OSP-D.
2. Lancez la console KVM.
3. Accédez à Virtual Media > Activation des périphériques virtuels. Acceptez la session et activez la mémorisation de vos paramètres pour les connexions futures.
4. Sélectionnez Virtual Media > Carte CD/DVDet mappez l'image ISO Red Hat.
5. Sélectionnez Alimentation > Réinitialiser le système (démarrage à chaud) pour redémarrer le système.
6. Au redémarrage, appuyez sur F6et sélectionnez vDVD1.22 mappé sur Cisco vKVMet appuyez sur Saisissez .
Installer Red Hat Enterprise Linux
Remarque : La procédure de cette section représente une version simplifiée du processus d'installation qui identifie le nombre minimum de paramètres à configurer.
1. Sélectionnez l'option d'installation de Red Hat Enterprise Linux (RHEL) afin de commencer l'installation.
2. Sélectionnez Software Selection > Minimum Install Only.
3. Configurez les interfaces réseau (eno1 et eno2).
4. Cliquez sur Réseau et Nom de l'hôte.
- Sélectionnez l'interface qui serait utilisée pour la communication externe (eno1 ou eno2)
- Cliquez sur Configurer
- Sélectionnez l'onglet IPv4 Settings, sélectionnez la méthode Manual et cliquez sur Add
- Définissez ces paramètres comme précédemment : Address, Netmask, Gateway, DNS server
5. Sélectionnez Date et heure et indiquez votre région et votre ville.
6. Activez Network Time et configurez les serveurs NTP.
7. Sélectionnez Installation Destination et utilisez le système de fichiers ext4 .
Remarque : Supprimez /home/ et réallouez la capacité sous root /.
8. Désactivez Kdump.
9. Définir le mot de passe racine uniquement.
10. Commencez l'installation .
Restaurer le sous-cloud
Préparation de l'installation sous cloud basée sur la sauvegarde
Une fois la machine installée avec RHEL 7.3 et dans un état propre, réactivez tous les abonnements/référentiels nécessaires pour installer et exécuter Director.
Configuration du nom d'hôte :
[root@director ~]$sudo hostnamectl set-hostname <FQDN_hostname>
[root@director ~]$sudo hostnamectl set-hostname --transient <FQDN_hostname>
Modifier le fichier /etc/hosts :
[root@director ~]$ vi /etc/hosts
<ospd_external_address> <server_hostname> <FQDN_hostname>
10.225.247.142 pod1-ospd pod1-ospd.cisco.com
Valider le nom d'hôte :
[root@director ~]$ cat /etc/hostname
pod1-ospd.cisco.com
Valider la configuration DNS :
[root@director ~]$ cat /etc/resolv.conf
#Generated by NetworkManager
nameserver <DNS_IP>
Modifiez l'interface de la carte réseau de provisioning :
[root@director ~]$ cat /etc/sysconfig/network-scripts/ifcfg-eno1
DEVICE=eno1
ONBOOT=yes
HOTPLUG=no
NM_CONTROLLED=no
PEERDNS=no
DEVICETYPE=ovs
TYPE=OVSPort
OVS_BRIDGE=br-ctlplane
BOOTPROTO=none
MTU=1500
Terminer l'enregistrement Red Hat
Téléchargez ce package afin de configurer subscription-manager afin d'utiliser rh-satellite :
[root@director ~]$ rpm -Uvh http:///pub/katello-ca-consumer-latest.noarch.rpm
[root@director ~]$ subscription-manager config
Enregistrez-vous avec rh-satellite en utilisant cette clé d'activation pour RHEL 7.3.
[root@director ~]$subscription-manager register --org="<ORG>" --activationkey="<KEY>"
Pour afficher l'abonnement :
[root@director ~]$ subscription-manager list –consumed
Activez les référentiels similaires à l'ancien repos OSPD :
[root@director ~]$ sudo subscription-manager repos --disable=*
[root@director ~]$ subscription-manager repos --enable=rhel-7-server-rpms --enable=rhel-7-server-extras-rpms --enable=rh
el-7-server-openstack-10-rpms --enable=rhel-7-server-rh-common-rpms --enable=rhel-ha-for-rhel-7-server-rpm
Effectuez une mise à jour de votre système afin de vous assurer que vous disposez des derniers packages système de base et redémarrez le système :
[root@director ~]$sudo yum update -y
[root@director ~]$sudo reboot
Restauration Sous Le Nuage
Après avoir activé l'abonnement, importez le fichier tar sous-cloud sauvegardé undercloud-backup-date +%F`.tar.gz dans le nouveau répertoire racine /racine du serveur OSP-D.
Installez le serveur mariadb :
[root@director ~]$ yum install -y mariadb-server
Extrayez le fichier de configuration MariaDB et la sauvegarde de base de données (DB). Effectuez cette opération en tant qu'utilisateur racine.
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz etc/my.cnf.d/server.cnf
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz root/undercloud-all-databases.sql
Modifiez /etc/my.cnf.d/server.cnf et commentez l'entrée bind-address si elle est présente :
[root@tb3-ospd ~]# vi /etc/my.cnf.d/server.cnf
Démarrez le service MariaDB et mettez à jour temporairement le paramètre max_allowed_packet :
[root@director ~]$ systemctl start mariadb
[root@director ~]$ mysql -uroot -e"set global max_allowed_packet = 16777216;"
Nettoyer certaines autorisations (à recréer ultérieurement) :
[root@director ~]$ for i in ceilometer glance heat ironic keystone neutron nova;do mysql -e "drop user $i";done
[root@director ~]$ mysql -e 'flush privileges'
Remarque : si le service de ceilomètre a été précédemment désactivé dans la configuration, exécutez cette commande et supprimez le ceilomètre.
Créez le compte stackuser :
[root@director ~]$ sudo useradd stack
[root@director ~]$ sudo passwd stack << specify a password
[root@director ~]$ echo "stack ALL=(root) NOPASSWD:ALL" | sudo tee -a /etc/sudoers.d/stack
[root@director ~]$ sudo chmod 0440 /etc/sudoers.d/stack
Restaurer le répertoire d'accueil utilisateur de la pile :
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz home/stack
Installez les packages de base swift et glance, puis restaurez leurs données :
[root@director ~]$ yum install -y openstack-glance openstack-swift
[root@director ~]$ tar --xattrs -xzC / -f undercloud-backup-$DATE.tar.gz srv/node var/lib/glance/images
Vérifiez que les données appartiennent à l'utilisateur approprié :
[root@director ~]$ chown -R swift: /srv/node
[root@director ~]$ chown -R glance: /var/lib/glance/images
Restaurer les certificats SSL sous-cloud (facultatif - à effectuer uniquement si la configuration utilise des certificats SSL).
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz etc/pki/instack-certs/undercloud.pem
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz etc/pki/ca-trust/source/anchors/ca.crt.pem
Exécutez à nouveau l'installation sous-cloud en tant qu'utilisateur de la pile et assurez-vous de l'exécuter dans le répertoire d'accueil de l'utilisateur de la pile :
[root@director ~]$ su - stack
[stack@director ~]$ sudo yum install -y python-tripleoclient
Vérifiez que le nom d'hôte est correctement défini dans /etc/hosts.
Réinstallez le sous-cloud :
[stack@director ~]$ openstack undercloud install
<snip>
#############################################################################
Undercloud install complete.
The file containing this installation's passwords is at
/home/stack/undercloud-passwords.conf.
There is also a stackrc file at /home/stack/stackrc.
These files are needed to interact with the OpenStack services, and must be
secured.
#############################################################################
Reconnecter le sous-nuage restauré au sous-nuage
Une fois que vous avez terminé ces étapes, le sous-nuage peut être censé restaurer automatiquement sa connexion au surnuage. Les noeuds continueront à interroger l'orchestration (chaleur) pour les tâches en attente, à l'aide d'une simple requête HTTP émise toutes les quelques secondes.
Valider la restauration terminée
Utilisez ces commandes afin d'effectuer un contrôle d'intégrité de l'environnement nouvellement restauré:
[root@director ~]$ su - stack
Last Log in: Tue Nov 28 21:27:50 EST 2017 from 10.86.255.201 on pts/0
[stack@director ~]$ source stackrc
[stack@director ~]$ nova list
+--------------------------------------+--------------------+--------+------------+-------------+------------------------+
| ID | Name | Status | Task State | Power State | Networks |
+--------------------------------------+--------------------+--------+------------+-------------+------------------------+
| b1f5294a-629e-454c-b8a7-d15e21805496 | pod1-compute-0 | ACTIVE | - | Running | ctlplane=192.200.0.119 |
| 9106672e-ac68-423e-89c5-e42f91fefda1 | pod1-compute-1 | ACTIVE | - | Running | ctlplane=192.200.0.120 |
| b3ed4a8f-72d2-4474-91a1-b6b70dd99428 | pod1-compute-2 | ACTIVE | - | Running | ctlplane=192.200.0.124 |
| 677524e4-7211-4571-ac35-004dc5655789 | pod1-compute-3 | ACTIVE | - | Running | ctlplane=192.200.0.107 |
| 55ea7fe5-d797-473c-83b1-d897b76a7520 | pod1-compute-4 | ACTIVE | - | Running | ctlplane=192.200.0.122 |
| c34c1088-d79b-42b6-9306-793a89ae4160 | pod1-compute-5 | ACTIVE | - | Running | ctlplane=192.200.0.108 |
| 4ba28d8c-fb0e-4d7f-8124-77d56199c9b2 | pod1-compute-6 | ACTIVE | - | Running | ctlplane=192.200.0.105 |
| d32f7361-7e73-49b1-a440-fa4db2ac21b1 | pod1-compute-7 | ACTIVE | - | Running | ctlplane=192.200.0.106 |
| 47c6a101-0900-4009-8126-01aaed784ed1 | pod1-compute-8 | ACTIVE | - | Running | ctlplane=192.200.0.121 |
| 1a638081-d407-4240-b9e5-16b47e2ff6a2 | pod1-compute-9 | ACTIVE | - | Running | ctlplane=192.200.0.112 |
<snip>
[stack@director ~]$ ssh heat-admin@192.200.0.107
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod1-controller-0 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
3 nodes and 22 resources configured
Online: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Full list of resources:
ip-10.1.10.10 (ocf::heartbeat:IPaddr2): Started pod1-controller-0
ip-11.120.0.97 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
Clone Set: haproxy-clone [haproxy]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
ip-192.200.0.106 (ocf::heartbeat:IPaddr2): Started pod1-controller-0
ip-11.120.0.95 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-11.119.0.98 (ocf::heartbeat:IPaddr2): Started pod1-controller-0
ip-11.118.0.92 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: redis-master [redis]
Masters: [ pod1-controller-0 ]
Slaves: [ pod1-controller-1 pod1-controller-2 ]
openstack-cinder-volume (systemd:openstack-cinder-volume): Started pod1-controller-0
my-ipmilan-for-controller-0 (stonith:fence_ipmilan): Stopped
my-ipmilan-for-controller-1 (stonith:fence_ipmilan): Stopped
my-ipmilan-for-controller-2 (stonith:fence_ipmilan): Stopped
Failed Actions:
* my-ipmilan-for-controller-0_start_0 on pod1-controller-1 'unknown error' (1): call=190, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:45 2017', queued=0ms, exec=20005ms
* my-ipmilan-for-controller-1_start_0 on pod1-controller-1 'unknown error' (1): call=192, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:53:08 2017', queued=0ms, exec=20005ms
* my-ipmilan-for-controller-2_start_0 on pod1-controller-1 'unknown error' (1): call=188, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:23 2017', queued=0ms, exec=20004ms
* my-ipmilan-for-controller-0_start_0 on pod1-controller-0 'unknown error' (1): call=210, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:53:08 2017', queued=0ms, exec=20005ms
* my-ipmilan-for-controller-1_start_0 on pod1-controller-0 'unknown error' (1): call=207, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:45 2017', queued=0ms, exec=20004ms
* my-ipmilan-for-controller-2_start_0 on pod1-controller-0 'unknown error' (1): call=206, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:45 2017', queued=0ms, exec=20006ms
* ip-192.200.0.106_monitor_10000 on pod1-controller-0 'not running' (7): call=197, status=complete, exitreason='none',
last-rc-change='Wed Nov 22 13:51:31 2017', queued=0ms, exec=0ms
* my-ipmilan-for-controller-0_start_0 on pod1-controller-2 'unknown error' (1): call=183, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:23 2017', queued=1ms, exec=20006ms
* my-ipmilan-for-controller-1_start_0 on pod1-controller-2 'unknown error' (1): call=184, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:23 2017', queued=0ms, exec=20005ms
* my-ipmilan-for-controller-2_start_0 on pod1-controller-2 'unknown error' (1): call=177, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:02 2017', queued=0ms, exec=20005ms
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
[heat-admin@pod1-controller-0 ~]$ sudo ceph status
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
monmap e1: 3 mons at {pod1-controller-0=11.118.0.40:6789/0,pod1-controller-1=11.118.0.41:6789/0,pod1-controller-2=11.118.0.42:6789/0}
election epoch 58, quorum 0,1,2 pod1-controller-0,pod1-controller-1,pod1-controller-2
osdmap e1398: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v1245812: 704 pgs, 6 pools, 542 GB data, 352 kobjects
1625 GB used, 11767 GB / 13393 GB avail
704 active+clean
client io 21549 kB/s wr, 0 op/s rd, 120 op/s wr
Vérifier le fonctionnement du service d'identité (Keystone)
Cette étape valide les opérations Identity Service en interrogeant une liste d'utilisateurs.
[stack@director ~]$ source stackrc
[stack@director ~]$ openstack user list
+----------------------------------+------------------+
| ID | Name |
+----------------------------------+------------------+
| 69ac2b9d89414314b1366590c7336f7d | admin |
| f5c30774fe8f49d0a0d89d5808a4b2cc | glance |
| 3958d852f85749f98cca75f26f43d588 | heat |
| cce8f2b7f1a843a08d0bb295a739bd34 | ironic |
| ce7c642f5b5741b48a84f54d3676b7ee | ironic-inspector |
| a69cd42a5b004ec5bee7b7a0c0612616 | mistral |
| 5355eb161d75464d8476fa0a4198916d | neutron |
| 7cee211da9b947ef9648e8fe979b4396 | nova |
| f73d36563a4a4db482acf7afc7303a32 | swift |
| d15c12621cbc41a8a4b6b67fa4245d03 | zaqar |
| 3f0ed37f95544134a15536b5ca50a3df | zaqar-websocket |
+----------------------------------+------------------+
[stack@director ~]$
[stack@director ~]$ source <overcloudrc>
[stack@director ~]$ openstack user list
+----------------------------------+------------+
| ID | Name |
+----------------------------------+------------+
| b4e7954942184e2199cd067dccdd0943 | admin |
| 181878efb6044116a1768df350d95886 | neutron |
| 6e443967ee3f4943895c809dc998b482 | heat |
| c1407de17f5446de821168789ab57449 | nova |
| c9f64c5a2b6e4d4a9ff6b82adef43992 | glance |
| 800e6b1163b74cc2a5fab4afb382f37d | cinder |
| 4cfa5a2a44c44c678025842f080e5f53 | heat-cfn |
| 9b222eeb8a58459bb3bfc76b8fff0f9f | swift |
| 815f3f25bcda49c290e1b56cd7981d1b | core |
| 07c40ade64f34a64932129175150fa4a | gnocchi |
| 0ceeda0bc32c4d46890e53adef9a193d | aodh |
| f3caab060171468592eab376a94967b8 | ceilometer |
+----------------------------------+------------+
[stack@director ~]$
Télécharger des images pour une présentation ultérieure du noeud
Validez /httpboot et tous ces fichiers Inspector.ipxe, agent.kernel, agent.ramdisk, si ce n'est pas le cas, passez à ces étapes.
[stack@director ~]$ ls /httpboot
inspector.ipxe
[stack@director ~]$ source stackrc
[stack@director ~]$ cd images/
[stack@director images]$ openstack overcloud image upload --image-path /home/stack/images
Image "overcloud-full-vmlinuz" is up-to-date, skipping.
Image "overcloud-full-initrd" is up-to-date, skipping.
Image "overcloud-full" is up-to-date, skipping.
Image "bm-deploy-kernel" is up-to-date, skipping.
Image "bm-deploy-ramdisk" is up-to-date, skipping.
[stack@director images]$ ls /httpboot
agent.kernel agent.ramdisk inspector.ipxe
[stack@director images]$
Redémarrer la délimitation
La délimitation sera à l'état arrêté après la récupération OSPD. Cette procédure active la délimitation.
[heat-admin@pod1-controller-0 ~]$ sudo pcs property set stonith-enabled=true
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
[heat-admin@pod1-controller-0 ~]$sudo pcs stonith show
Informations connexes
Contribution d’experts de Cisco
- Padmaraj RamanoudjamServices avancés Cisco
- Partheeban RajagopalServices avancés Cisco
 Commentaires
CommentairesContacter Cisco
- Ouvrir un dossier d’assistance

- (Un contrat de service de Cisco est requis)