Surveillance et dépannage de l'utilisation élevée du CPU dans Cisco Unified Communications Manager 6.0 à l'aide de l'outil RTMT (Real Time Monitoring Tool)
Table des matières
Introduction
Ce document fournit des étapes pour aider à la surveillance et au dépannage des problèmes liés à l'utilisation élevée du processeur sur Cisco Unified Communications Manager 6.0 avec RTMT.
Conditions préalables
Exigences
Cisco recommande que vous ayez une connaissance de ce sujet :
-
Solutions Cisco Unified Communications Manager
Composants utilisés
Les renseignements contenus dans le présent document sont fondés sur les points suivants de l'ordre du jour :
-
Heure système, Heure utilisateur, IOWait, IRQ logicielle et IRQ
-
Code jaune, mais l'utilisation totale du processeur est de seulement 25 % - Pourquoi ?
Les informations contenues dans ce document sont basées sur Cisco Unified Communications Manager 6.0.
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. If your network is live, make sure that you understand the potential impact of any command.
Conventions
Pour plus d'informations sur les conventions utilisées dans ce document, reportez-vous à Conventions relatives aux conseils techniques Cisco.
Heure système, Heure utilisateur, IOWait, IRQ logicielle et IRQ
L'utilisation de RTMT pour isoler les problèmes potentiels avec le CPU peut être une étape de dépannage très utile.
Ces termes représentent l'utilisation des rapports de page RTMT CPU et Memory :
-
%Système : Le pourcentage d'utilisation du CPU qui s'est produit lors de l'exécution au niveau du système (noyau)
-
%Utilisateur : Le pourcentage d'utilisation du CPU qui s'est produit lors de l'exécution au niveau utilisateur (application)
-
%IOWait : Pourcentage de temps pendant lequel le processeur était inactif en attendant une demande d'E/S de disque en attente
-
%SoftIRQ : Le pourcentage de temps pendant lequel le processeur exécute le traitement IRQ différé (par exemple, le traitement des paquets réseau)
-
%IRQ Pourcentage de temps pendant lequel le processeur exécute la requête d'interruption, qui est attribuée aux périphériques pour l'interruption, ou envoie un signal à l'ordinateur lorsqu'il a terminé le traitement
Alertes d'identification de CPU
Les alertes CPUPegging/CallProcessNodeCPUPegging surveillent l'utilisation du processeur en fonction des seuils configurés :
Remarque : %CPU est calculé comme %system + %user + %nice + %iowait + %softirq + %irq
Les messages d'alerte sont les suivants :
-
%system, %user, %nice, %iowait, %softirq et %irq
-
Le processus qui utilise le plus de CPU
-
Les processus qui attendent la mise en veille du disque non interruptible
Les alertes d'identification de l'origine des besoins du processeur peuvent apparaître dans RTMT en raison d'une utilisation du processeur supérieure à ce qui est défini comme le niveau du filigrane. Étant donné que l'enregistrement des détails des appels est une application gourmande en ressources processeur lors du chargement, vérifiez si vous recevez les alertes au cours de la même période que lorsque l'enregistrement des détails des appels est configuré pour exécuter des rapports. Dans ce cas, vous pouvez avoir besoin d'augmenter les valeurs de seuil sur RTMT. Référez-vous à Alertes pour plus d'informations sur les alertes RTMT.
Identification du processus qui utilise le plus de CPU
Si %system et/ou %user est suffisamment élevé pour générer une alerte CpuPegging, consultez le message d'alerte pour voir quels processus utilisent le plus de CPU.
Remarque : accédez à la page Processus RTMT et effectuez un tri par %CPU pour identifier les processus à CPU élevé.
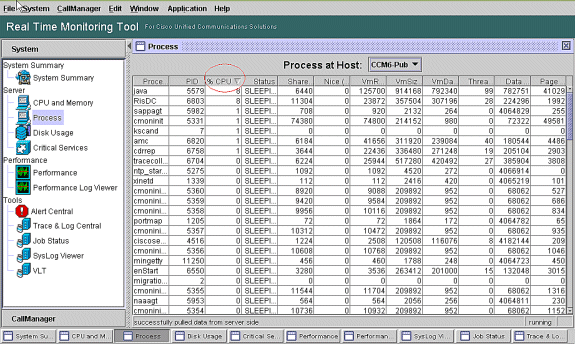
Remarque : pour l'analyse post mortem, le journal PerfMon de dépannage RIS effectue le suivi du processus %utilisation CPU, et il effectue le suivi au niveau du système.
IoWait élevé
High %IOWait indique des activités d'E/S de disque élevées. Considérez les points suivants :
-
IOWait est dû à un échange de mémoire important.
Vérifiez le %CPU Time for Swap Partition pour voir s'il y a un niveau élevé d'activité d'échange de mémoire. Comme Muster dispose d'au moins 2 Go de mémoire vive, un échange de mémoire élevé est probablement dû à une fuite de mémoire.
-
IOWait est dû à l'activité DB.
La base de données est principalement la seule qui accède à la partition active. Si %CPU Time for Active Partition est élevé, il y a probablement beaucoup d'activité de la base de données.
IOWait élevé en raison d'une partition commune
La partition commune (ou partition de journal) est l'emplacement de stockage des fichiers de trace et des fichiers journaux.
Remarque : cochez les cases suivantes :
-
Trace & Log Central : y a-t-il une activité de collecte de trace ? Si le traitement des appels est affecté (c'est-à-dire CodeYellow), ajustez la planification de la collecte de suivi. En outre, si l'option zip est utilisée, désactivez-la.
-
Paramètre de trace : au niveau détaillé, CallManager génère un certain nombre de traces. Si %IOWait et/ou CCM est à l'état CodeYellow et que le paramètre de suivi du service CallManager est défini sur Détaillé, essayez de le modifier en "Erreur".
Identification du processus responsable des E/S de disque
Il n'existe aucun moyen direct de connaître l'utilisation de %IOWait par processus. Actuellement, le meilleur moyen est de vérifier les processus en attente sur le disque.
Si %IOWait est suffisamment élevé pour provoquer une alerte CpuPegging, vérifiez le message d'alerte pour déterminer les processus en attente d'E/S disque.
-
Accédez à la page Processus RTMT et effectuez un tri par état. Recherchez les processus en état de veille du disque non interruptible. Le processus SFTP utilisé par TLC pour la collecte planifiée est dans l'état de veille du disque non interruptible.
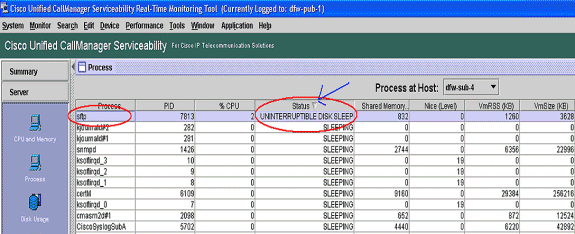
Remarque : le fichier journal PerfMon de dépannage RIS peut être téléchargé pour examiner l'état du processus sur des périodes plus longues.

-
Dans l'outil de surveillance en temps réel, allez à Système > Outils > Trace > Trace & Log Central.
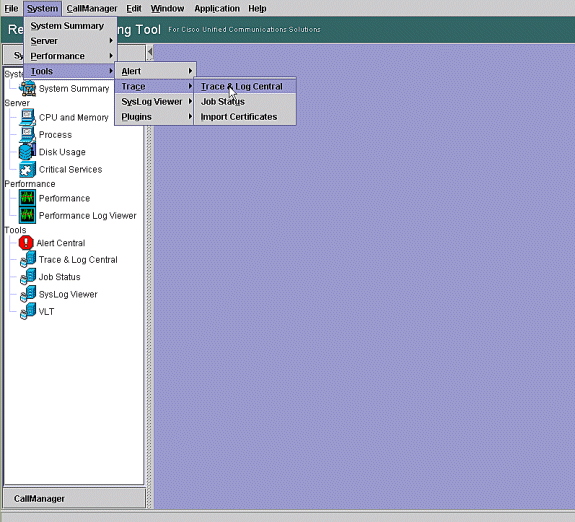
-
Double-cliquez sur Collecter les fichiers et choisissez Suivant.
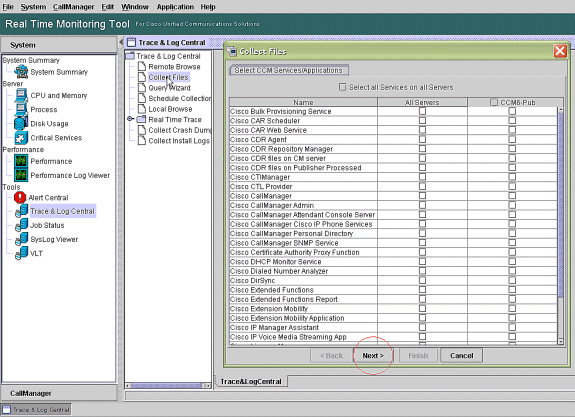
-
Sélectionnez PerfMonLog du collecteur de données Cisco RIS et choisissez Next.
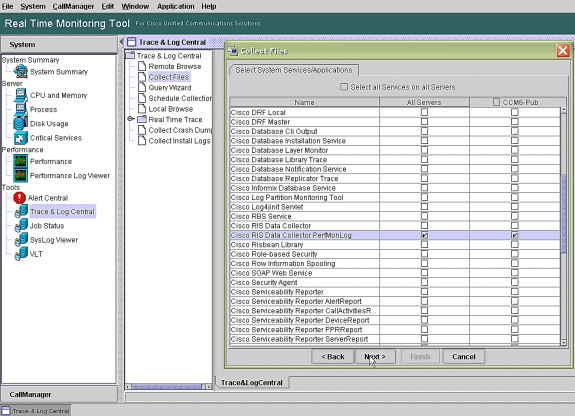
-
Dans le champ Temps de collecte, configurez le temps requis pour afficher les fichiers journaux pour la période en question. Dans le champ Options de fichier de téléchargement, accédez à votre chemin de téléchargement (un emplacement à partir duquel vous pouvez lancer l'Analyseur de performances Windows pour afficher le fichier journal), choisissez Fichiers zip, puis Terminer.
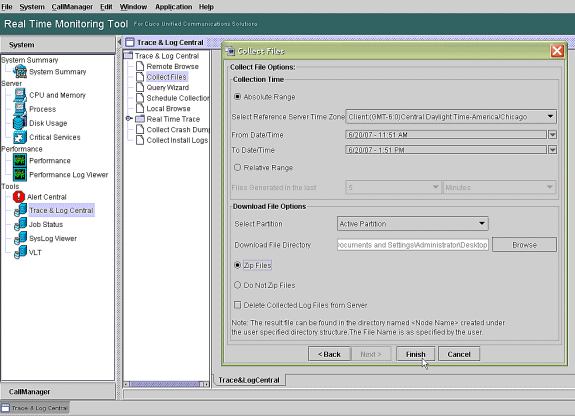
-
Notez la progression de la collecte des fichiers et le chemin de téléchargement. Aucune erreur ne doit être signalée ici.
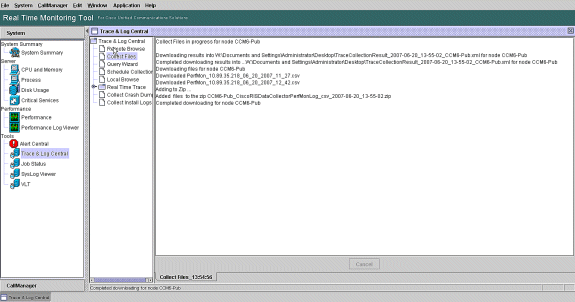
-
Affichez les fichiers journaux de performances à l'aide de l'outil Analyseur de performances Microsoft. Choisissez Démarrer > Paramètres > Panneau de configuration > Outils d'administration > Performances.
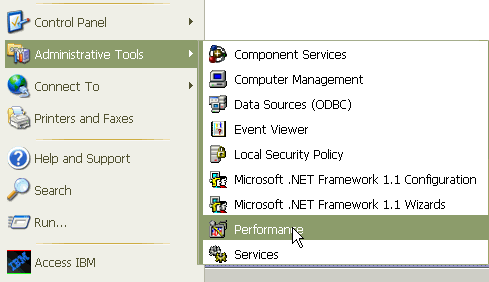
-
Dans la fenêtre de l'application, cliquez avec le bouton droit et choisissez Propriétés.
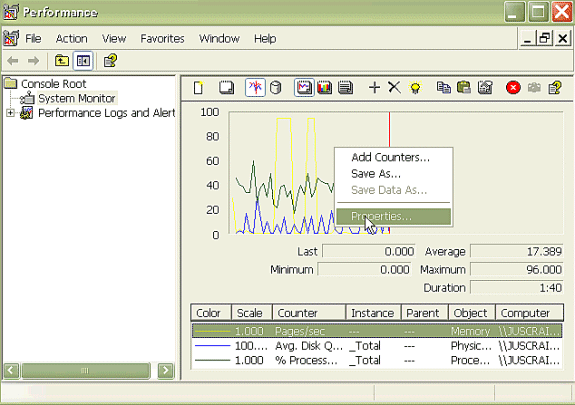
-
Sélectionnez l'onglet Source dans la boîte de dialogue Propriétés du Moniteur système. Choisissez Fichiers journaux : comme source de données, puis cliquez sur le bouton Add.
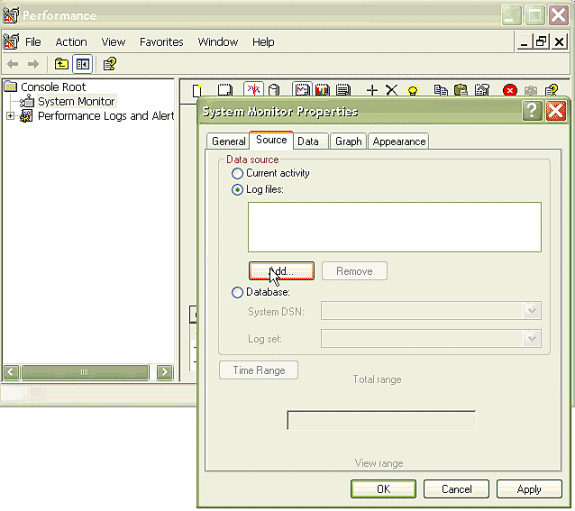
-
Accédez au répertoire dans lequel vous avez téléchargé le fichier journal PerfMon et choisissez le fichier perfmon csv. Le fichier journal inclut la convention d'attribution de noms suivante :
PerfMon_<noeud>_<mois>_<jour>_<année>_<heure>_<minute>.csv ; par exemple, PerfMon_10.89.35.218_6_20_2005_11_27.csv.
-
Cliquez sur Apply.
-
Cliquez sur le bouton Intervalle de temps. Afin de spécifier l'intervalle de temps dans le fichier journal PerfMon que vous souhaitez afficher, faites glisser la barre vers les heures de début et de fin appropriées.
-
Afin d'ouvrir la boîte de dialogue Ajouter des compteurs, cliquez sur l'onglet Données et cliquez sur Ajouter. Dans la liste déroulante Objet de performance, ajoutez Processus. Choisissez Process Status et cliquez sur All instances. Lorsque vous avez terminé les choix de compteurs, cliquez sur Fermer.
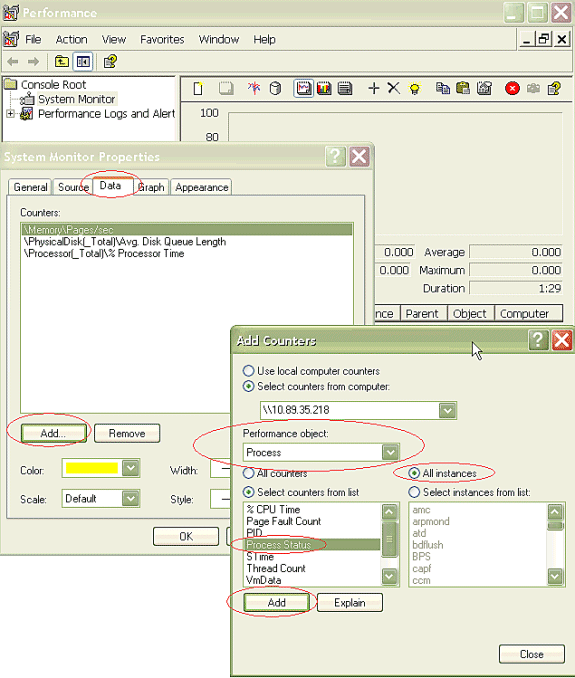
-
Conseils pour l'affichage du journal :
-
Définissez l'échelle verticale du graphique sur Maximum 6.
-
Concentrez-vous sur chaque processus et examinez la valeur maximale de 2 ou plus.
-
Supprimez les processus qui ne sont pas en veille du disque non interruptible.
-
Utilisez l'option de surbrillance.
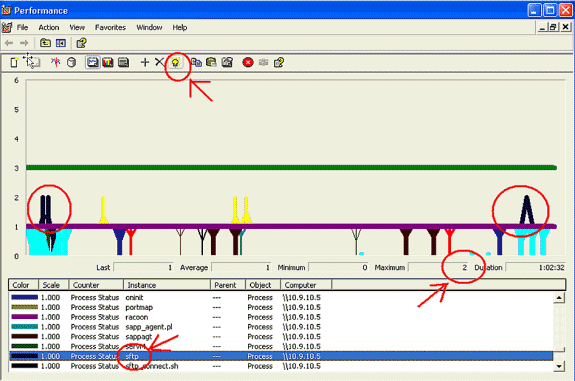
Remarque : état du processus 2 = le disque ininterruptible en veille est suspect. D'autres possibilités d'état sont 0-running, 1-sleep, 2-Uninterruptible disk sleep, 3-Zombie, 4-Traced ou stoppé, 5-Paging, 6-Unknown
-










Code jaune
L'alerte Code Yellow est générée lorsque le service CallManager passe à l'état Code Yellow. Pour plus d'informations sur l'état Code Jaune, référez-vous à Limitation d'appel et à l'état Code Jaune. L'alerte CodeYellow peut être configurée pour télécharger des fichiers de trace à des fins de dépannage.
Le compteur AverageExpectedDelay représente le délai moyen attendu actuel pour traiter un message entrant. Si la valeur est supérieure à la valeur spécifiée dans le paramètre de service « Code Yellow Entry Latency », l'alarme CodeYellow est générée. Ce compteur peut être un indicateur clé des performances de traitement des appels.
CodeYellow, mais l'utilisation totale du processeur est de seulement 25 % - Pourquoi ?
CallManager peut passer à l'état CodeYellow en raison d'un manque de ressources processeur lorsque l'utilisation totale du processeur est seulement d'environ 25 à 35 % dans un boîtier à 4 processeurs virtuels.
Remarque : lorsque l'Hyper-Threading est activé, un serveur doté de deux processeurs physiques comporte quatre processeurs virtuels.
Remarque : de même, sur un serveur à deux processeurs, CodeYellow est possible à environ 50 % d'utilisation totale du processeur.
Alerte : "L'état du service est ARRÊTÉ. Interface de messagerie Cisco."
Si RTMT envoie l'état du service est DOWN. Interface de messagerie Cisco. , vous devez désactiver le service d'interface de messagerie Cisco si CUCM n'est pas intégré à un système de messagerie vocale tiers. Si vous désactivez le service d'interface de messagerie Cisco, il arrête les autres alertes de RTMT.
Informations connexes
Historique de révision
| Révision | Date de publication | Commentaires |
|---|---|---|
1.0 |
22-Jun-2007
|
Première publication |
 Commentaires
CommentairesContacter Cisco
- Ouvrir un dossier d’assistance

- (Un contrat de service de Cisco est requis)