Database Migration Utilities
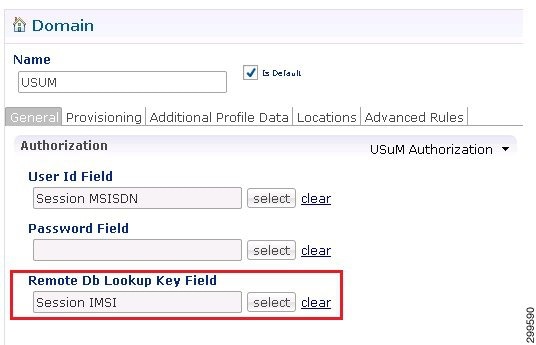
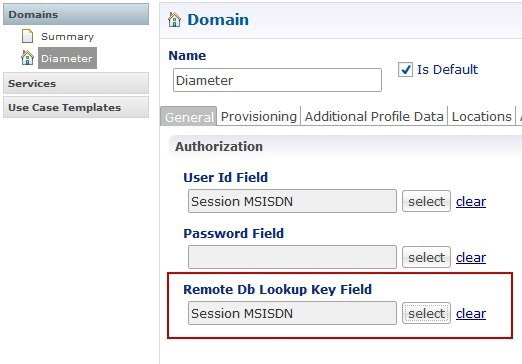
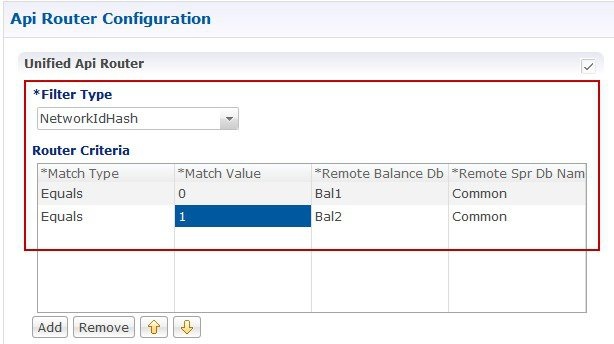
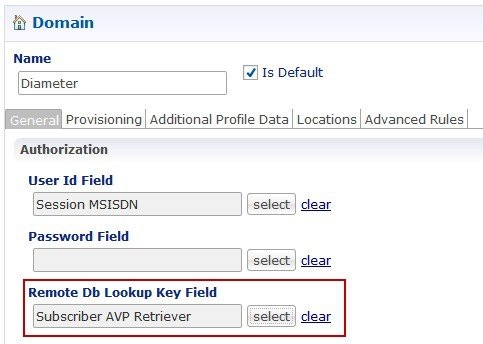
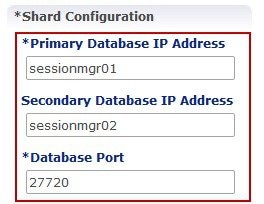
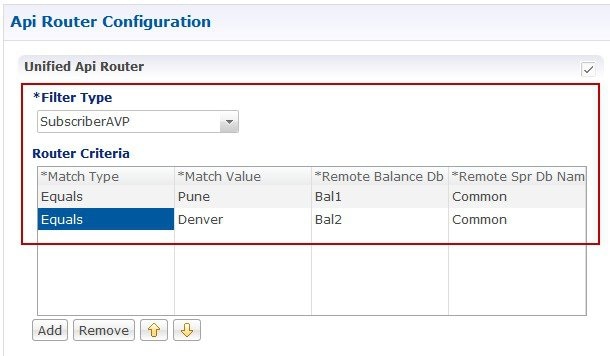
The database migration utilities can be used to migrate a customer from Active/Standby Geographic Redundancy (GR) environment to Active/Active Geographic Redundancy environment. Currently, the migration utilities support doing remote database lookup based on NetworkId (i.e. MSISDN, IMSI, and so on). The user needs to split the SPR and balance databases from Active/Standby GR model i.e. one for each site in Active/Active GR model.
-
Dump the mongoDB data from active site of active/standby system using
mongodumpcommand. -
Run the Split Script on SPR and balance database files collected using
mongodumpcommand. -
Restore the mongo database for each site with
mongorestorecommand using files collected from running Split Script.
After the database splitting is done, you can audit the data by running the Audit Script on each set of site-specific database files separately.
The Split Script is a python script to split SPR and balance database into two site specific parts. The file split.csv is the input file which should have the Network Id regex strings for each site. The Audit Script is a tool to do auditing on the split database files to check for any missing/orphaned records.
To extract the database migration utility, execute the following command:
tar -zxvf
/mnt/iso/app/install/xxx.tar.gz -C /tmp/release-train-directory
where, xxx is the release train version.
This command will extract release train into /tmp/release-train-directory.
Split Script
The split script first splits the SPR database into two site-specific
SPR databases based on the
network_id_key field. Then it loops through the
balance database to check which site each balance record correlates to based on
the
subscriberId field and puts the balance record into
one of two site-specific balance databases. If there is no match, then it is
considered as
Orphaned balance record and added to
nositebal.json.
Here are the usage details of the split script:
Usage
python split.py split.csv > output.txt
Prerequisite
The prerequisite to run the script is
python-pymongo module. To install python-pymongo on
CPS VMs, run the command
yum install python-pymongo.
System Requirements
-
RAM: Minimum 1 GB of free memory. The script is memory-intensive and it needs at least 1 GB of RAM to work smoothly.
-
vCPUs: Minimum 4 vCPUs. The script is CPU intensive.
-
Persistent Storage: Free storage is required which should be at least as much as the Active/Standby database file sizes. SSD storage type is preferred (for faster runtimes) but not required.
Input Files
-
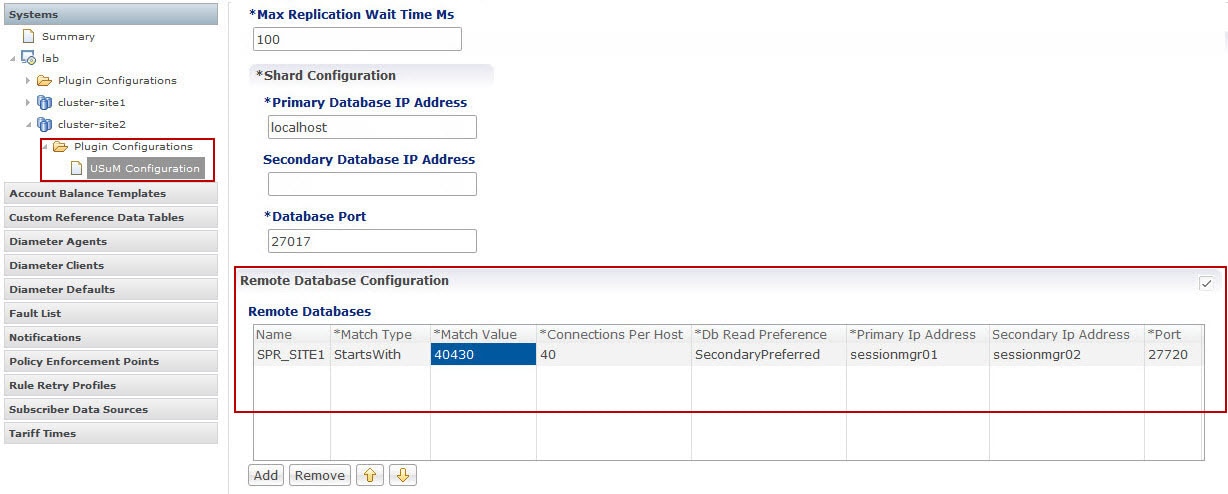
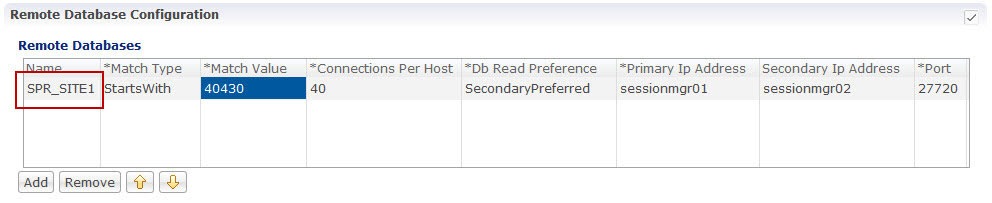
The command line argument split.csv is a CSV file that will have network ID regex strings listed per site. The format of each line is site-name, one or more comma-separated regex strings. The regex format is python regex.
Here is an example of a split.csv file where the networkId regex strings are in the MSISDN Prefix format (i.e. "Starts With" type in Policy Builder configuration).
site1,5699[0-9]*,5697[0-9]*,5695[0-9]*,5693[0-9]*,5691[0-9]*
site2,569[86420][0-9]*
Here is another example where the networkId strings are in the suffix format (i.e. "Ends With" type in Policy Builder configuration).
site1,^.*[0-4]$
site2,^.*[5-9]$ 
Important
Since this is a CSV file, using "," in regex strings would result in unexpected behavior, so avoid using "," in regex strings.
-
The script looks for the file subscriber.bson and one or more account.bson files in current directory. The account.bson files could be in nested folders to support a sharded balance database. The balance database could be compressed or uncompressed (the script does not look into the compressed fields).
Output Files
-
site1-balance-mgmt_account.bson
-
site1_spr_subscriber.bson
-
site2-balance-mgmt_account.bson
-
site2_spr_subscriber.bson
-
errorbal.json
-
errorspr.json
-
nositebal.json
-
nositespr.json
$ time python split.py split.csv > output.txt
real8m44.015s
user8m0.236s
sys0m35.270s
$ more output.txt
Found the following subscriber file
./spr/spr/subscriber.bson
Found the following balance files
./balance_mgmt/balance_mgmt/account.bson
./balance_mgmt_1/balance_mgmt_1/account.bson
./balance_mgmt_2/balance_mgmt_2/account.bson
./balance_mgmt_3/balance_mgmt_3/account.bson
./balance_mgmt_4/balance_mgmt_4/account.bson
./balance_mgmt_5/balance_mgmt_5/account.bson
Site1 regex strings: 5699[0-9]*|5697[0-9]*|5695[0-9]*|5693[0-9]*|5691[0-9]*
Site2 regex strings: 569[86420][0-9]*
Started processing subscriber file
….
….
<snip>Audit Script
The audit script first goes through
the balance database and retrieves a list of IDs. Then it loops through each
record in SPR database and tries to match the
network_id_key or
_id with the ID list from balance database. If there
is no match, they are tagged with the counter for
Subscribers missing balance records.
Here are the usage details for the audit script:
Usage
python audit.py > output.txt
Prerequisite
The prerequisite to run the script is
python-pymongo module. To install python-pymongo on
CPS VMs, run the command
yum install python-pymongo.
System Requirements
-
RAM: Minimum 1 GB of free memory. The script is memory-intensive and it needs at least 1 GB of RAM to work smoothly.
-
vCPUs: Minimum 4 vCPUs. The script is CPU intensive.
Input Files
The script looks for the file subscriber.bson and one or more account.bson files in current directory. The account.bson files could be in nested folders to support a sharded balance database. The balance database could be compressed or uncompressed (the script does not look into the compressed fields).
Output Files
sprbalmissing.bson
Sample console output from script before splitting SPR and balance databases.
Total subscriber exceptions: 0
Total subscriber errors: 0
Total subscriber empty records: 1
Total subscriber records: 6743644
Total subscriber matched records: 6733102
Total subscriber missing records: 10541After running the script on site-specific databases after the split, the user gets the following:
Total subscriber exceptions: 0
Total subscriber errors: 0
Total subscriber empty records: 1
Total subscriber records: 4137817
Total subscriber matched records: 4131978
Total subscriber missing records: 5839Total subscriber exceptions: 0
Total subscriber errors: 0
Total subscriber empty records: 1
Total subscriber records: 2605826
Total subscriber matched records: 2601124
Total subscriber missing records: 4702







 Feedback
Feedback