Best Practices für Catalyst Switches der Serien 4500/4000, 5500/5000 und 6500/6000 mit CatOS-Konfiguration und -Verwaltung
Inhalt
Einleitung
In diesem Dokument wird die Implementierung von Switches der Cisco Catalyst Serie in Ihrem Netzwerk, insbesondere der Plattformen Catalyst 4500/4000, 5500/5000 und 6500/6000, erläutert. Konfigurationen und Befehle werden unter der Annahme besprochen, dass Sie Catalyst OS (CatOS) General Deployment Software 6.4(3) oder höher ausführen. Obwohl einige Überlegungen zum Design vorgestellt werden, wird in diesem Dokument nicht das Campus-Design insgesamt behandelt.
Voraussetzungen
Anforderungen
In diesem Dokument wird davon ausgegangen, dass Sie mit der Catalyst 6500 Befehlsreferenz 7.6 vertraut sind.
Obwohl Verweise auf öffentliches Online-Material für die weitere Lektüre im gesamten Dokument enthalten sind, handelt es sich hierbei um andere grundlegende und informative Verweise:
-
Cisco ISP Essentials: Essenzielle IOS-Funktionen, die jeder ISP berücksichtigen sollte.
-
Cisco Richtlinien für die Netzwerküberwachung und Ereigniskorrelation
Verwendete Komponenten
Dieses Dokument ist nicht auf bestimmte Software- und Hardware-Versionen beschränkt.
Konventionen
Weitere Informationen zu Dokumentkonventionen finden Sie unter Cisco Technical Tips Conventions (Technische Tipps von Cisco zu Konventionen).
Hintergrundinformationen
Diese Lösungen zeichnen sich durch jahrelange praktische Erfahrung von Cisco Technikern aus, die mit vielen unserer größten Kunden und komplexen Netzwerken zusammenarbeiten. Daher werden in diesem Dokument reale Konfigurationen hervorgehoben, die Netzwerke erfolgreich machen. Dieses Whitepaper bietet folgende Lösungen:
-
Lösungen, die statistisch gesehen die größte Feldbelastung und damit das geringste Risiko aufweisen.
-
Einfache Lösungen, die Flexibilität gegen deterministische Ergebnisse eintauschen.
-
Lösungen, die von den Netzwerkbetriebsteams einfach verwaltet und konfiguriert werden können
-
Lösungen, die hohe Verfügbarkeit und hohe Stabilität fördern.
Dieses Dokument ist in die folgenden vier Abschnitte unterteilt:
-
Basiskonfiguration - Funktionen, die von den meisten Netzwerken wie Spanning Tree Protocol (STP) und Trunking verwendet werden.
-
Managementkonfiguration - Designüberlegungen sowie System- und Ereignisüberwachung mithilfe von Simple Network Management Protocol (SNMP), Remote Monitoring (RMON), Syslog, Cisco Discovery Protocol (CDP) und Network Time Protocol (NTP).
-
Sicherheitskonfiguration - Kennwörter, Port-Sicherheit, physische Sicherheit und Authentifizierung mit TACACS+.
-
Konfigurations-Checkliste: Zusammenfassung der vorgeschlagenen Konfigurationsvorlagen
Basiskonfiguration
In diesem Abschnitt werden die Funktionen erläutert, die mit den meisten Catalyst-Netzwerken bereitgestellt werden.
Catalyst-Protokolle der Kontrollebene
In diesem Abschnitt werden die Protokolle vorgestellt, die im normalen Betrieb zwischen Switches ausgeführt werden. Ein grundlegendes Verständnis dieser Protokolle ist bei der Behandlung jedes Abschnitts hilfreich.
Supervisor-Datenverkehr
Die meisten in einem Catalyst-Netzwerk aktivierten Funktionen erfordern zwei oder mehr Switches zur Zusammenarbeit. Daher muss ein kontrollierter Austausch von Keepalive-Nachrichten, Konfigurationsparametern und Managementänderungen möglich sein. Unabhängig davon, ob es sich bei diesen Protokollen um proprietäre Protokolle von Cisco wie CDP oder standardbasierte Protokolle wie IEEE 802.1d (STP) handelt, alle Protokolle weisen bei Implementierung auf der Catalyst-Serie gewisse Gemeinsamkeiten auf.
Bei der grundlegenden Frame-Weiterleitung stammen Benutzerdaten-Frames von Endsystemen, und ihre Quell- und Zieladresse werden nicht in allen Layer-2 (L2)-Switched-Domänen geändert. Die Lookup-Tabellen für den Content Addressable Memory (CAM) auf jeder Supervisor Engine des Switches werden durch einen Lernprozess für die Quelladresse ausgefüllt und geben an, welcher Ausgangsport jeden empfangenen Frame weiterleiten muss. Wenn der Adressenlernprozess unvollständig ist (das Ziel unbekannt ist oder der Frame für eine Broadcast- oder Multicast-Adresse bestimmt ist), wird er über alle Ports in diesem VLAN weitergeleitet (geflutet).
Der Switch muss auch erkennen, welche Frames durch das System geschaltet werden sollen und welche an die Switch-CPU selbst (auch als Network Management Processor [NMP] bezeichnet) weitergeleitet werden müssen.
Die Catalyst-Kontrollebene wird mithilfe spezieller Einträge in der CAM-Tabelle erstellt, die als Systemeinträge bezeichnet werden, um Datenverkehr an den NMP auf einem internen Switch-Port zu empfangen und zu leiten. Durch die Verwendung von Protokollen mit bekannten MAC-Zieladressen kann der Steuerungsebenen-Datenverkehr somit vom Datenverkehr getrennt werden. Führen Sie den Befehl show CAM system (CAM-System anzeigen) auf einem Switch aus, um dies zu bestätigen, wie dargestellt:
>show cam system * = Static Entry. + = Permanent Entry. # = System Entry. R = Router Entry. X = Port Security Entry VLAN Dest MAC/Route Des [CoS] Destination Ports or VCs / [Protocol Type] ---- ------------------ ----- ------------------------------------------- 1 00-d0-ff-88-cb-ff # 1/3 !--- NMP internal port. 1 01-00-0c-cc-cc-cc # 1/3 !--- CDP and so on. 1 01-00-0c-cc-cc-cd # 1/3 !--- Cisco STP. 1 01-80-c2-00-00-00 # 1/3 !--- IEEE STP. 1 01-80-c2-00-00-01 # 1/3 !--- IEEE flow control. 1 00-03-6b-51-e1-82 R# 15/1 !--- Multilayer Switch Feature Card (MSFC) router. ...
Cisco verfügt wie dargestellt über einen reservierten Bereich von Ethernet-MAC- und Protokolladressen. Jede dieser Komponenten wird später in diesem Dokument behandelt. Aus Gründen der Übersichtlichkeit wird in dieser Tabelle jedoch eine Zusammenfassung dargestellt.
| Funktion | SNAP HDLC-Protokolltyp | Ziel-Multicast-MAC |
|---|---|---|
| Port Aggregation Protocol (PAgP) | 0 x 1004 | 01-00-0c-cc-cc-cc |
| Spanning Tree PVSTP+ | 0 x 100 B | 01-00-0c-cc-cc-cd |
| VLAN-Bridge | 0 x 100 cm | 01-00-0c-cd-cd-ce |
| Unidirectional Link Detection (UDLD) | 0 x 1011 | 01-00-0c-cc-cc-cc |
| Cisco Discovery Protocol | 0x2000 | 01-00-0c-cc-cc-cc |
| Dynamic Trunking (DTP) | 0 x 2004 | 01-00-0c-cc-cc-cc |
| Schneller STP-Uplink | 0x200a | 01-00-0c-cd-cd-cd |
| IEEE Spanning Tree 802.1d | K/A - DSAP 42 SSAP 42 | 01-80-c2-00-00-00 |
| Inter Switch Link (ISL) | – | 01-00-0c-00-00-00 |
| VLAN-Trunking (VTP) | 0 x 2003 | 01-00-0c-cc-cc-cc |
| IEEE-Pause, 802.3x | K/A - DSAP 81 SSAP 80 | 01-80-C2-00-00-00>0F |
Die meisten Cisco Steuerungsprotokolle verwenden eine IEEE 802.3 SNAP-Kapselung, einschließlich LLC 0xAAAA03, OUI 0x00000C, die in einem LAN-Analyzer-Trace zu sehen ist. Weitere allgemeine Eigenschaften dieser Protokolle sind:
-
Diese Protokolle setzen Punkt-zu-Punkt-Verbindungen voraus. Beachten Sie, dass die bewusste Verwendung von Multicast-Zieladressen es zwei CatalystInnen ermöglicht, transparent über Switches von anderen Anbietern zu kommunizieren, da Geräte, die die Frames nicht verstehen und abfangen, diese einfach überfluten. Point-to-Multipoint-Verbindungen über heterogene Umgebungen können jedoch zu inkonsistentem Verhalten führen und müssen generell vermieden werden.
-
Diese Protokolle enden auf Layer-3-Routern (L3-Routern). funktionieren sie nur innerhalb einer Switch-Domäne.
-
Diese Protokolle erhalten durch die ASIC-Verarbeitung (Application-Specific Integrated Circuit) und -Planung eine Priorisierung von Benutzerdaten.
Nach der Einführung der Steuerprotokoll-Zieladressen muss der Vollständigkeit halber auch die Quelladresse beschrieben werden. Switch-Protokolle verwenden eine MAC-Adresse, die aus einer Reihe von verfügbaren Adressen stammt, die von einem EPROM auf dem Chassis bereitgestellt werden. Führen Sie den Befehl show module aus, um die für die einzelnen Module verfügbaren Adressbereiche anzuzeigen, wenn Datenverkehr wie STP Bridge Protocol Data Units (BPDUs) oder ISL-Frames generiert wird.
>show module
...
Mod MAC-Address(es) Hw Fw Sw
--- -------------------------------------- ------ ---------- -----------------
1 00-01-c9-da-0c-1e to 00-01-c9-da-0c-1f 2.2 6.1(3) 6.1(1d)
00-01-c9-da-0c-1c to 00-01-c9-da-0c-1
00-d0-ff-88-c8-00 to 00-d0-ff-88-cb-ff
!--- MACs for sourcing traffic.
...
VLAN 1
VLAN 1
VLAN 1 hat eine besondere Bedeutung in Catalyst-Netzwerken.
Die Catalyst Supervisor Engine verwendet immer das Standard-VLAN, VLAN 1, um beim Trunking eine Reihe von Steuerungs- und Managementprotokollen zu kennzeichnen, z. B. CDP, VTP und PAgP. Alle Ports, einschließlich der internen sc0-Schnittstelle, sind standardmäßig als Mitglieder von VLAN 1 konfiguriert. Alle Trunks übertragen standardmäßig VLAN 1, und in CatOS-Softwareversionen vor 5.4 war es nicht möglich, Benutzerdaten in VLAN 1 zu blockieren.
Diese Definitionen werden benötigt, um einige häufig verwendete Begriffe in Catalyst-Netzwerken zu verdeutlichen:
-
Das Management-VLAN befindet sich an der Position sc0. kann dieses VLAN geändert werden.
-
Das native VLAN ist das VLAN, zu dem ein Port zurückkehrt, wenn kein Trunking erfolgt, und ist das nicht markierte VLAN auf einem 802.1Q-Trunk. Standardmäßig ist VLAN 1 das native VLAN.
-
Um das native VLAN zu ändern, geben Sie den Befehl set vlan vlan-id mod/port ein.
Hinweis: Erstellen Sie das VLAN, bevor Sie es als natives VLAN des Trunks festlegen.
Es gibt eine Reihe guter Gründe, ein Netzwerk zu optimieren und das Verhalten der Ports in VLAN 1 zu ändern:
-
Wenn der Durchmesser von VLAN 1 wie bei allen anderen VLANs groß genug wird, um ein Risiko für die Stabilität darzustellen (insbesondere aus STP-Sicht), muss das VLAN zurückgenommen werden. Dies wird im Abschnitt In-Band-Management dieses Dokuments genauer beschrieben.
-
Die Daten auf der Kontrollebene von VLAN 1 müssen von den Benutzerdaten getrennt gehalten werden, um die Fehlerbehebung zu vereinfachen und die verfügbaren CPU-Zyklen zu maximieren.
-
L2-Schleifen in VLAN 1 müssen vermieden werden, wenn Multilayer-Campus-Netzwerke ohne STP konzipiert wurden und Trunking zum Access Layer weiterhin erforderlich ist, wenn mehrere VLANs und IP-Subnetze vorhanden sind. Deaktivieren Sie dazu VLAN 1 manuell von den Trunk-Ports.
Beachten Sie zusammenfassend die folgenden Informationen zu Trunks:
-
CDP-, VTP- und PAgP-Updates werden immer auf Trunks mit einem VLAN 1-Tag weitergeleitet. Dies ist auch dann der Fall, wenn VLAN 1 von den Trunks gelöscht wird und nicht das native VLAN ist. Wenn VLAN 1 für Benutzerdaten gelöscht wird, hat dies keine Auswirkungen auf den Steuerungsebenen-Datenverkehr, der weiterhin über VLAN 1 gesendet wird.
-
Auf einem ISL-Trunk werden DTP-Pakete über VLAN1 gesendet. Dies ist auch dann der Fall, wenn VLAN 1 vom Trunk gelöscht wird und nicht mehr das native VLAN ist. Auf einem 802.1Q-Trunk werden DTP-Pakete über das native VLAN gesendet. Dies ist auch dann der Fall, wenn das native VLAN vom Trunk gelöscht wird.
-
In PVST+ werden die 802.1Q IEEE-BPDUs für die Interoperabilität mit anderen Anbietern ohne Tagging an das gemeinsame Spanning Tree-VLAN 1 weitergeleitet, es sei denn, VLAN 1 wird vom Trunk gelöscht. Dies gilt unabhängig von der nativen VLAN-Konfiguration. Cisco PVST+-BPDUs werden für alle anderen VLANs gesendet und gekennzeichnet. Weitere Informationen finden Sie im Abschnitt Spanning Tree Protocol in diesem Dokument.
-
802.1s MST-BPDUs (Multiple Spanning Tree) werden immer im VLAN 1 sowohl auf ISL- als auch auf 802.1Q-Trunks gesendet. Dies gilt auch dann, wenn VLAN 1 von den Trunks gelöscht wird.
-
Deaktivieren oder deaktivieren Sie VLAN 1 nicht auf Trunks zwischen MST Bridges und PVST+ Bridges. Falls VLAN 1 deaktiviert ist, muss die MST-Bridge jedoch Root werden, damit alle VLANs vermeiden, dass die MST-Bridge ihre Boundary-Ports in den Root-inkonsistenten Zustand versetzt. Weitere Informationen finden Sie unter Understanding Multiple Spanning Tree Protocol (802.1s).
Empfehlungen
Damit ein VLAN im Betriebs-/Aktivierungszustand bleibt, ohne dass Clients oder Hosts mit diesem VLAN verbunden sind, muss mindestens ein physisches Gerät mit diesem VLAN verbunden sein. Andernfalls hat das VLAN den Status "up/down". Derzeit gibt es keinen Befehl zum Einrichten einer VLAN-Schnittstelle bzw. zum Hochfahren, wenn der Switch keine aktiven Ports für dieses VLAN enthält.
Wenn Sie kein Gerät anschließen möchten, schließen Sie einen Loopback-Stecker an einem beliebigen Port für dieses VLAN an. Alternativ können Sie ein Crossover-Kabel verwenden, das zwei Ports in diesem VLAN auf demselben Switch verbindet. Diese Methode erzwingt die Aktivierung des Ports. Weitere Informationen finden Sie im Abschnitt zu Loopback-Steckern im Abschnitt zu Loopback-Tests für T1/56K-Leitungen.
Wenn ein Netzwerk für mehrere Dienstanbieter bestimmt ist, fungiert es als Transit-Netzwerk zwischen zwei Dienstanbietern. Wenn die in einem Paket empfangene VLAN-Nummer übersetzt oder geändert werden muss, wenn sie von einem Service Provider an einen anderen Service Provider übergeben wird, ist es ratsam, die QinQ-Funktion zu verwenden, um die VLAN-Nummer zu übersetzen.
VLAN-Trunking-Protokoll
Bevor Sie VLANs erstellen, müssen Sie den VTP-Modus für das Netzwerk festlegen. VTP ermöglicht die zentrale Durchführung von VLAN-Konfigurationsänderungen auf einem oder mehreren Switches. Diese Änderungen werden automatisch an alle anderen Switches in der Domäne weitergeleitet.
Betriebsübersicht
VTP ist ein L2-Messaging-Protokoll, das die Konsistenz der VLAN-Konfiguration aufrechterhält. VTP verwaltet das Hinzufügen, Löschen und Umbenennen von VLANs auf netzwerkweiter Basis. VTP minimiert Fehlkonfigurationen und Konfigurationsinkonsistenzen, die zu einer Reihe von Problemen führen können, z. B. doppelte VLAN-Namen, falsche VLAN-Spezifikationen und Sicherheitsverletzungen. Die VLAN-Datenbank ist eine Binärdatei, die separat von der Konfigurationsdatei im NVRAM auf VTP-Servern gespeichert wird.
Das VTP-Protokoll kommuniziert zwischen Switches über eine Ethernet-Multicast-MAC-Zieladresse (01-00-0c-cc-cc-cc) und den SNAP HDLC-Protokolltyp Ox2003. Es funktioniert nicht über Nicht-Trunk-Ports (VTP ist eine Nutzlast von ISL oder 802.1Q), daher können Nachrichten nicht gesendet, bis der Trunk über DTP online ist.
Die Nachrichtentypen umfassen alle fünf Minuten zusammenfassende Meldungen, Teilwerbesendungen und Anforderungsmeldungen bei Änderungen sowie Joins bei aktivierter VTP-Bereinigung. Die VTP-Konfigurationsrevisionsnummer wird bei jeder Änderung auf einem Server um eins erhöht, wodurch die neue Tabelle über die Domäne verteilt wird.
Wenn ein VLAN gelöscht wird, werden Ports, die zuvor zu diesem VLAN gehörten, in den inaktiven Status versetzt. Wenn ein Switch im Client-Modus beim Start die VTP-VLAN-Tabelle nicht empfangen kann (entweder von einem VTP-Server oder einem anderen VTP-Client), werden alle Ports in VLANs außer dem Standard-VLAN 1 deaktiviert.
Diese Tabelle enthält eine Zusammenfassung des Funktionsvergleichs für verschiedene VTP-Modi:
| Funktion | Server | Kunde | Transparent | Aus1 |
|---|---|---|---|---|
| Quell-VTP-Nachrichten | Ja | Ja | Nein | Nein |
| Abhören von VTP-Nachrichten | Ja | Ja | Nein | Nein |
| VTP-Nachrichten weiterleiten | Ja | Ja | Ja | Nein |
| VLANs erstellen | Ja | Nein | Ja (nur lokal bedeutsam) | Ja (nur lokal bedeutsam) |
| Speichern von VLANs | Ja | Nein | Ja (nur lokal bedeutsam) | Ja (nur lokal bedeutsam) |
Im VTP-transparenten Modus werden VTP-Updates ignoriert (die VTP-Multicast-MAC-Adresse wird aus dem System-CAM entfernt, der normalerweise zur Übernahme von Steuerungs-Frames und deren Weiterleitung an die Supervisor Engine verwendet wird). Wenn das Protokoll eine Multicast-Adresse verwendet, flutet ein Switch im transparenten Modus (oder ein Switch eines anderen Anbieters) einfach den Frame zu anderen Cisco Switches in der Domäne.
1 In CatOS Softwareversion 7.1 wird die Option zur Deaktivierung von VTP über den Aus-Modus eingeführt. Im VTP-Aus-Modus verhält sich der Switch ähnlich wie im VTP-Transparent-Modus. Der Aus-Modus unterdrückt jedoch auch die Weiterleitung von VTP-Updates.
Diese Tabelle bietet eine Zusammenfassung der Erstkonfiguration:
| Funktion | Standardwert |
|---|---|
| VTP-Domänenname | Null |
| VTP-Modus | Server |
| VTP-Version | Version 1 ist aktiviert. |
| VTP-Kennwort | None |
| VTP-Bereinigung | Deaktiviert |
VTP-Version 2 (VTPv2) bietet diese flexible Funktion. Es ist jedoch nicht mit VTP-Version 1 (VTPv1) kompatibel:
-
Token-Ring-Unterstützung
-
Unterstützung nicht erkannter VTP-Informationen; -Schalter propagieren jetzt Werte, die sie nicht parsen können.
-
Versionsabhängiger transparenter Modus; Der transparente Modus überprüft den Domänennamen nicht mehr. Dies ermöglicht die Unterstützung von mehr als einer Domäne in einer transparenten Domäne.
-
Verbreitung der Versionsnummer; Wenn VTPv2 auf allen Switches möglich ist, können alle Switches über die Konfiguration eines einzelnen Switches aktiviert werden.
Weitere Informationen finden Sie unter Understanding and Configuring VLAN Trunk Protocol (VTP).
VTP-Version 3
Mit der CatOS Softwareversion 8.1 wird die Unterstützung von VTP Version 3 (VTPv3) eingeführt. VTPv3 bietet gegenüber den vorhandenen Versionen Verbesserungen. Diese Verbesserungen ermöglichen:
-
Unterstützung erweiterter VLANs
-
Unterstützung für die Erstellung und Ankündigung privater VLANs
-
Unterstützung für VLAN-Instanzen und MST-Zuordnungs-Propagierungs-Instanzen (die in CatOS 8.3 unterstützt werden)
-
Verbesserte Serverauthentifizierung
-
Schutz vor versehentlichem Einfügen der "falschen" Datenbank in eine VTP-Domäne
-
Interaktion mit VTPv1 und VTPv2
-
Die Möglichkeit zur Konfiguration auf Port-Basis
Einer der Hauptunterschiede zwischen der VTPv3-Implementierung und der früheren Version ist die Einführung eines primären VTP-Servers. Im Idealfall darf es in einer VTPv3-Domäne nur einen primären Server geben, wenn die Domäne nicht partitioniert ist. Alle Änderungen, die Sie an der VTP-Domäne vornehmen, müssen auf dem primären VTP-Server ausgeführt werden, damit sie an die VTP-Domäne propagiert werden. In einer VTPv3-Domäne können mehrere Server vorhanden sein, die auch als sekundäre Server bezeichnet werden. Wenn ein Switch als Server konfiguriert ist, wird er standardmäßig zum sekundären Server. Der sekundäre Server kann die Konfiguration der Domäne speichern, jedoch nicht ändern. Ein sekundärer Server kann mit einer erfolgreichen Übernahme vom Switch zum primären Server werden.
Switches, auf denen VTPv3 ausgeführt wird, akzeptieren nur VTP-Datenbanken mit einer höheren Revisionsnummer als der aktuelle primäre Server. Dieser Prozess unterscheidet sich erheblich von VTPv1 und VTPv2, bei denen ein Switch immer eine überlegene Konfiguration von einem Nachbarn in derselben Domäne akzeptiert. Diese Änderung bei VTPv3 bietet Schutz. Ein neuer Switch, der mit einer höheren VTP-Revisionsnummer in das Netzwerk eingeführt wird, kann die VLAN-Konfiguration der gesamten Domäne nicht überschreiben.
Mit VTPv3 wird auch die Art und Weise, wie VTP mit Passwörtern umgeht, optimiert. Wenn Sie die Konfigurationsoption für ausgeblendete Passwörter verwenden, um ein Passwort als "ausgeblendet" zu konfigurieren, treten die folgenden Elemente auf:
-
Das Kennwort wird in der Konfiguration nicht im Nur-Text-Format angezeigt. Das geheime Hexadezimalformat des Kennworts wird in der Konfiguration gespeichert.
-
Wenn Sie versuchen, den Switch als primären Server zu konfigurieren, werden Sie zur Eingabe des Kennworts aufgefordert. Wenn Ihr Kennwort mit dem geheimen Kennwort übereinstimmt, wird der Switch zum primären Server, auf dem Sie die Domäne konfigurieren können.
Hinweis: Beachten Sie, dass der primäre Server nur erforderlich ist, wenn Sie die VTP-Konfiguration für eine Instanz ändern müssen. Eine VTP-Domäne kann ohne aktiven primären Server betrieben werden, da die sekundären Server die Persistenz der Konfiguration über Neuladevorgänge sicherstellen. Der Status des primären Servers wird aus den folgenden Gründen beendet:
-
Ein Switch wird neu geladen
-
Hochverfügbarkeits-Switchover zwischen der aktiven und der redundanten Supervisor Engine
-
Übernahme von einem anderen Server
-
Eine Änderung der Moduskonfiguration
-
Alle Konfigurationsänderungen der VTP-Domäne, z. B.:
-
Version
-
Domänenname
-
Domänenkennwort
-
VTPv3 ermöglicht den Switches außerdem die Teilnahme an mehreren VTP-Instanzen. In diesem Fall kann derselbe Switch der VTP-Server für eine Instanz und ein Client für eine andere Instanz sein, da die VTP-Modi für verschiedene VTP-Instanzen spezifisch sind. Beispielsweise kann ein Switch im transparenten Modus für eine MST-Instanz betrieben werden, während der Switch im Servermodus für eine VLAN-Instanz konfiguriert wird.
Was die Interaktion mit VTPv1 und VTPv2 angeht, ist das Standardverhalten bei allen VTP-Versionen, dass die früheren VTP-Versionen die neuen Versionsupdates einfach verwerfen. Wenn sich die Switches VTPv1 und VTPv2 nicht im transparenten Modus befinden, werden alle VTPv3-Updates verworfen. Nachdem VTPv3-Switches jedoch einen Legacy-VTPv1- oder VTPv2-Frame auf einem Trunk empfangen haben, übergeben sie eine verkleinerte Version ihrer Datenbankaktualisierung an die VTPv1- und VTPv2-Switches. Dieser Informationsaustausch ist jedoch unidirektional, da die VTPv3-Switches keine Updates von VTPv1- und VTPv2-Switches akzeptieren. Bei Trunk-Verbindungen senden VTPv3-Switches weiterhin skalierte Updates sowie umfassende VTPv3-Updates, um das Vorhandensein von VTPv2- und VTPv3-Nachbarn auf den Trunk-Ports zu gewährleisten.
Um VTPv3 für erweiterte VLANs zu unterstützen, wird das Format der VLAN-Datenbank geändert, in der das VTP 70 Byte pro VLAN zuweist. Die Änderung ermöglicht nur die Codierung von Nicht-Standardwerten, anstatt unveränderte Felder für die Legacy-Protokolle zu übertragen. Aufgrund dieser Änderung entspricht die VLAN-Unterstützung für 4.000 der Größe der resultierenden VLAN-Datenbank.
Empfehlung
Es gibt keine spezifische Empfehlung zur Verwendung des VTP-Client/Server-Modus oder des VTP-transparenten Modus. Einige Kunden bevorzugen die einfache Verwaltung des VTP-Client-/Server-Modus, auch wenn dies später noch erwähnt wurde. Aus Redundanzgründen wird in jeder Domäne die Verwendung von zwei Servermodus-Switches empfohlen, in der Regel die beiden Distribution-Layer-Switches. Für die übrigen Switches in der Domäne muss der Client-Modus festgelegt werden. Wenn Sie den Client/Server-Modus mit VTPv2 implementieren, achten Sie darauf, dass eine höhere Revisionsnummer immer in derselben VTP-Domäne akzeptiert wird. Wenn ein Switch, der entweder im VTP-Client- oder im Server-Modus konfiguriert ist, in die VTP-Domäne eingeführt wird und eine höhere Revisionsnummer als die vorhandenen VTP-Server hat, wird die VLAN-Datenbank in der VTP-Domäne überschrieben. Wenn die Konfigurationsänderung nicht beabsichtigt ist und VLANs gelöscht werden, kann das Überschreiben zu einem schwerwiegenden Netzwerkausfall führen. Um sicherzustellen, dass Client- oder Server-Switches immer eine Konfigurationsrevisionsnummer haben, die niedriger ist als die des Servers, ändern Sie den Client-VTP-Domänennamen in einen anderen Namen als den Standardnamen. Kehren Sie dann zum Standard zurück. Mit dieser Aktion wird die Konfigurationsrevision auf dem Client auf 0 gesetzt.
Die VTP-Fähigkeit, Änderungen in einem Netzwerk einfach durchzuführen, hat Vor- und Nachteile. Viele Unternehmen bevorzugen aus folgenden Gründen den vorsichtigen Ansatz des VTP-transparenten Modus:
-
Dies fördert eine gute Änderungskontrolle, da die Anforderung zum Ändern eines VLAN auf einem Switch oder Trunk-Port jeweils als ein Switch betrachtet werden muss.
-
Sie begrenzt das Risiko eines Administratorfehlers, der sich auf die gesamte Domäne auswirkt, z. B. das zufällige Löschen eines VLAN.
-
Es besteht kein Risiko, dass ein neuer Switch mit einer höheren VTP-Revisionsnummer die gesamte VLAN-Konfiguration der Domäne überschreiben kann.
-
Er fordert dazu auf, VLANs von Trunks zu trennen, die zu Switches führen, die keine Ports in diesem VLAN haben. Dadurch wird Frame-Flooding bandbreiteneffizienter. Das manuelle Bereinigen ist ebenfalls von Vorteil, da es den Spanning Tree-Durchmesser reduziert (siehe DTP-Abschnitt dieses Dokuments). Bevor Sie nicht verwendete VLANs auf Port-Channel-Trunks entfernen, stellen Sie sicher, dass alle mit IP-Telefonen verbundenen Ports als Zugriffsports mit Sprach-VLAN konfiguriert werden.
-
Der erweiterte VLAN-Bereich in CatOS 6.x und CatOS 7.x, Nummern 1025 bis 4094, kann nur auf diese Weise konfiguriert werden. Weitere Informationen finden Sie im Abschnitt zur Reduzierung erweiterter VLAN- und MAC-Adressen in diesem Dokument.
-
Der transparente VTP-Modus wird in Campus Manager 3.1, einer Komponente von Cisco Works 2000, unterstützt. Die alte Einschränkung, die mindestens einen Server in einer VTP-Domäne erforderte, wurde entfernt.
| Beispiele für VTP-Befehle | Kommentare |
|---|---|
| vtp-Domänenname festlegen Kennwort x | CDP überprüft Namen, um Fehlkabelungen zwischen den Domänen festzustellen. Ein einfaches Passwort ist eine hilfreiche Vorsichtsmaßnahme gegen unbeabsichtigte Änderungen. Achten Sie beim Einfügen auf die Groß- und Kleinschreibung. |
| VTP-Modus transparent festlegen | |
| set vlan vlan nummer name name | Pro Switch mit Ports im VLAN. |
| Trunk-Modus/Port-VLAN-Bereich festlegen | Ermöglicht, dass Trunks bei Bedarf VLANs übertragen - der Standard ist "all VLANs". |
| Klären des Trunk-Modus/Port-VLAN-Bereichs | Beschränkt den STP-Durchmesser durch manuelles Abschneiden, z. B. auf Trunks vom Distribution Layer zum Access Layer, auf denen das VLAN nicht vorhanden ist. |
Hinweis: Bei Angabe von VLANs mit dem Befehl set werden nur VLANs hinzugefügt und nicht gelöscht. Mit dem Befehl set trunk x/y 1-10 wird beispielsweise die zulässige Liste nicht auf die VLANs 1-10 festgelegt. Geben Sie den Befehl clear trunk x/y 11-1005 ein, um das gewünschte Ergebnis zu erzielen.
Obwohl das Token-Ring-Switching nicht in diesem Dokument behandelt wird, wird für TR-ISL-Netzwerke kein transparenter VTP-Modus empfohlen. Die Grundlage für Token-Ring-Switching ist, dass die gesamte Domäne eine einzelne verteilte Multi-Port-Bridge bildet, sodass jeder Switch über die gleichen VLAN-Informationen verfügen muss.
Weitere Optionen
VTPv2 ist eine Anforderung in Token-Ring-Umgebungen, in denen der Client-/Server-Modus dringend empfohlen wird.
VTPv3 ermöglicht die Implementierung einer strengeren Authentifizierung und Konfigurationsrevisionskontrolle. VTPv3 bietet im Wesentlichen den gleichen Funktionsumfang, jedoch mit verbesserter Sicherheit, wie er im VTPv1/VTPv2-transparenten Modus verfügbar ist. Darüber hinaus ist VTPv3 teilweise mit den älteren VTP-Versionen kompatibel.
In diesem Dokument werden die Vorteile einer Bereinigung von VLANs empfohlen, um unnötiges Frame-Flooding zu reduzieren. Mit dem Befehl set vtp pruning enable werden VLANs automatisch bereinigt, wodurch das ineffiziente Flooding von Frames dort gestoppt wird, wo sie nicht benötigt werden. Im Gegensatz zum manuellen VLAN-Pruning schränkt das automatische Pruning den Spanning Tree-Durchmesser nicht ein.
Ab CatOS 5.1 können die Catalyst Switches ISL-VLAN-Nummern 802.1Q VLAN-Nummern größer als 1000 zuordnen. In CatOS 6.x unterstützen Catalyst 6500/6000-Switches 4096 VLANs gemäß dem IEEE 802.1Q-Standard. Diese VLANs sind in drei Bereiche unterteilt, von denen nur einige mithilfe von VTP auf andere Switches im Netzwerk verteilt werden:
-
VLANs mit normaler Reichweite: 1–1001
-
VLANs mit erweiterten Bereichen: 1025-4094 (kann nur von VTPv3 propagiert werden)
-
VLANs mit reserviertem Bereich: 0, 1002-1024, 4095
Das IEEE hat eine standardbasierte Architektur erstellt, um ähnliche Ergebnisse wie VTP zu erzielen. Als Mitglied des 802.1Q Generic Attribute Registration Protocol (GARP) ermöglicht das Generic VLAN Registration Protocol (GVRP) die VLAN-Management-Interoperabilität zwischen Anbietern, wird jedoch nicht in diesem Dokument behandelt.
Hinweis: CatOS 7.x führt die Option ein, VTP in den Aus-Modus zu versetzen, ein Modus, der transparent sehr ähnlich ist. Der Switch leitet jedoch keine VTP-Frames weiter. Dies kann in einigen Designs nützlich sein, wenn Sie das Trunking zu Switches außerhalb Ihrer administrativen Kontrolle durchführen.
Erweiterte Reduzierung von VLAN- und MAC-Adressen
Die Funktion zur Reduzierung der MAC-Adressen ermöglicht die Identifizierung von VLANs mit erweiterten Bereichen. Durch die Aktivierung der MAC-Adressreduzierung wird der Pool der MAC-Adressen deaktiviert, die für den VLAN Spanning Tree verwendet werden. Es verbleibt nur eine MAC-Adresse. Diese MAC-Adresse identifiziert den Switch. Mit der CatOS Softwareversion 6.1(1) wird die Unterstützung von MAC-Adressreduktion für Catalyst 6500/6000- und Catalyst 4500/4000-Switches eingeführt, um 4096 VLANs gemäß IEEE 802.1Q-Standard zu unterstützen.
Übersicht über den Betrieb
Switch-Protokolle verwenden eine MAC-Adresse, die aus einer Reihe verfügbarer Adressen entnommen wird, die ein EPROM im Chassis als Teil der Bridge-IDs für VLANs bereitstellt, die unter PVST+ ausgeführt werden. Catalyst Switches der Serien 6500/6000 und 4500/4000 unterstützen je nach Chassis-Typ entweder 1024- oder 64-MAC-Adressen.
Catalyst Switches mit 1024 MAC-Adressen ermöglichen standardmäßig keine Reduzierung der MAC-Adressen. MAC-Adressen werden sequenziell zugewiesen. Die erste MAC-Adresse des Bereichs wird VLAN 1 zugewiesen. Die zweite MAC-Adresse des Bereichs wird VLAN 2 zugewiesen usw. Dadurch können die Switches 1.024 VLANs unterstützen, wobei jedes VLAN eine eindeutige Bridge-ID verwendet.
| Chassis-Typ | Chassis-Adresse |
|---|---|
| WS-C4003-S1, WS-C4006-S2 | 1024 |
| WS-C4503, WS-C4506 | 641 |
| WS-C6509-E, WS-C6509, WS-C6509-NEB, WS-C6506-E, WS-C6506, WS-C6009, WS-C6006, OSR-7600 9-AC, OSR-7609-DC | 1024 |
| WS-C6513, WS-C6509-NEB-A, WS-C6504-E, WS-C6503-E, WS-C6503, CISCO 7603, CISCO 7606, CISCO 76 09, CISCO 7613 | 641 |
1 Die Reduzierung der MAC-Adressen ist für Switches mit 64 MAC-Adressen standardmäßig aktiviert und kann nicht deaktiviert werden.
Bei Switches der Catalyst-Serie mit 1024 MAC-Adressen können durch die Aktivierung der MAC-Adressenreduzierung 4.096 VLANs mit PVST+- oder 16 MISTP-Instanzen (Multiple Instance STP) mit eindeutigen IDs unterstützt werden, ohne dass die Anzahl der für den Switch erforderlichen MAC-Adressen steigt. Durch die Reduzierung der MAC-Adressen wird die Anzahl der vom STP benötigten MAC-Adressen von einer pro VLAN- oder MISTP-Instanz auf eine pro Switch reduziert.
Die Abbildung zeigt, dass die Reduzierung der Bridge-ID-MAC-Adresse nicht aktiviert ist. Die Bridge-ID besteht aus einer 2-Byte-Bridge-Priorität und einer 6-Byte-MAC-Adresse:

Durch die Reduzierung der MAC-Adresse wird der Teil der STP-Bridge-ID der BPDU geändert. Das ursprüngliche 2-Byte-Prioritätsfeld wird in zwei Felder unterteilt. Diese Aufteilung ergibt ein 4-Bit-Bridge-Prioritätsfeld und eine 12-Bit-System-ID-Erweiterung, die eine VLAN-Nummerierung von 0 bis 4095 ermöglicht.

Wenn Sie die Reduzierung der MAC-Adressen auf Catalyst-Switches aktiviert haben, um VLANs mit erweiterten Bereichen zu nutzen, aktivieren Sie die Reduzierung der MAC-Adressen auf allen Switches innerhalb derselben STP-Domäne. Dieser Schritt ist erforderlich, damit die STP-Root-Berechnungen auf allen Switches konsistent bleiben. Wenn Sie die Reduzierung der MAC-Adressen aktiviert haben, erhält die Root-Bridge-Priorität ein Vielfaches von 4096 plus der VLAN-ID. Die Switches ohne MAC-Adressenreduzierung können ungewollt Root beanspruchen, da diese Switches eine feinere Granularität bei der Auswahl der Bridge-ID aufweisen.
Konfigurationsrichtlinien
Beim Konfigurieren des erweiterten VLAN-Bereichs müssen Sie bestimmte Richtlinien befolgen. Der Switch kann einen VLAN-Block aus dem erweiterten Bereich für interne Zwecke zuweisen. Beispielsweise kann der Switch die VLANs für die gerouteten Ports oder Flex-WAN-Module zuweisen. Die Zuweisung des VLAN-Blocks beginnt immer mit VLAN 1006 und nimmt zu. Wenn VLANs innerhalb des für das FlexWAN-Modul erforderlichen Bereichs vorhanden sind, werden nicht alle erforderlichen VLANs zugewiesen, da die VLANs nie aus dem VLAN-Bereich des Benutzers zugewiesen werden. Führen Sie den Befehl show vlan oder den Befehl show vlan summary auf einem Switch aus, um die vom Benutzer zugewiesenen und internen VLANs anzuzeigen.
>show vlan summary Current Internal Vlan Allocation Policy - Ascending Vlan status Count Vlans ------------- ----- ------------------------------------------ VTP Active 7 1,17,174,1002-1005 Internal 7 1006-1011,1016 !--- These are internal VLANs. >show vlan ---- -------------------------------- --------- ------- -------- 1 default active 7 4/1-48 !--- Output suppressed. 1006 Online Diagnostic Vlan1 active 0 internal 1007 Online Diagnostic Vlan2 active 0 internal 1008 Online Diagnostic Vlan3 active 0 internal 1009 Voice Internal Vlan active 0 internal 1010 Dtp Vlan active 0 internal 1011 Private Vlan Internal Vlan suspend 0 internal 1016 Online SP-RP Ping Vlan active 0 internal !--- These are internal VLANs.
Außerdem müssen Sie vor der Verwendung der VLANs mit erweiterten Bereichen alle vorhandenen 802.1Q-zu-ISL-Zuordnungen löschen. Außerdem müssen Sie in früheren Versionen als VTPv3 das erweiterte VLAN auf jedem Switch statisch konfigurieren und den VTP-transparenten Modus verwenden. Weitere Informationen finden Sie im Abschnitt Richtlinien zur Konfiguration von VLANs mit erweiterten Bereichen.
Hinweis: Bei Software, die älter als die Softwareversion 8.1(1) ist, können Sie den VLAN-Namen nicht für VLANs mit erweiterten Bereichen konfigurieren. Diese Funktion ist unabhängig von jeder VTP-Version oder jedem VTP-Modus.
Empfehlung
Versuchen Sie, eine konsistente MAC-Adressreduktionskonfiguration innerhalb derselben STP-Domäne aufrechtzuerhalten. Die Durchsetzung einer Reduzierung der MAC-Adressen auf allen Netzwerkgeräten kann jedoch unpraktisch sein, wenn neue Chassis mit 64 MAC-Adressen in die STP-Domäne eingeführt werden. Die Reduzierung der MAC-Adressen ist für Switches mit 64 MAC-Adressen standardmäßig aktiviert und kann nicht deaktiviert werden. Wenn zwei Systeme mit derselben Spanning-Tree-Priorität konfiguriert werden, hat das System ohne Reduzierung der MAC-Adressen eine bessere Spanning-Tree-Priorität. Führen Sie diesen Befehl aus, um die Reduzierung der MAC-Adressen zu aktivieren oder zu deaktivieren:
set spantree macreduction enable | disable
Die Zuweisung der internen VLANs erfolgt in aufsteigender Reihenfolge und beginnt bei VLAN 1006. Weisen Sie die Benutzer-VLANs so nahe wie möglich an VLAN 4094 zu, um Konflikte zwischen den Benutzer-VLANs und den internen VLANs zu vermeiden. Auf Catalyst Switches der Serie 6500, auf denen die Cisco IOS®-Systemsoftware ausgeführt wird, können Sie die interne VLAN-Zuweisung in absteigender Reihenfolge konfigurieren. Die Befehlszeilenschnittstellen-Entsprechung (CLI, Command Line Interface) für CatOS-Software wird offiziell nicht unterstützt.
Autonegotiation
Ethernet/Fast-Ethernet
Autonegotiation ist eine optionale Funktion des IEEE Fast Ethernet (FE)-Standards (802.3u), mit der Geräte automatisch Informationen über Geschwindigkeit und Duplex-Fähigkeiten über eine Verbindung austauschen können. Die Autonegotiation wird auf Layer 1 (L1) ausgeführt und zielt auf Access Layer-Ports ab, an denen vorübergehende Benutzer wie PCs eine Verbindung mit dem Netzwerk herstellen.
Betriebsübersicht
Die häufigste Ursache für Leistungsprobleme bei 10/100-Mbit/s-Ethernet-Verbindungen tritt auf, wenn ein Port der Verbindung mit Halbduplex und der andere mit Vollduplex arbeitet. Dies tritt gelegentlich auf, wenn ein oder beide Ports einer Verbindung zurückgesetzt werden und der Autoübertragung-Prozess nicht dazu führt, dass beide Verbindungspartner die gleiche Konfiguration haben. Dies geschieht auch, wenn Administratoren eine Seite eines Links neu konfigurieren und die andere Seite nicht neu konfigurieren. Die typischen Symptome hierfür sind zunehmende FCS (Frame Check Sequence), CRC (Cyclic Redundancy Check), Alignment oder Laufzähler auf dem Switch.
Die Autonegotiation wird in diesen Dokumenten ausführlich behandelt. Diese Dokumente enthalten Erläuterungen zur Funktionsweise der Autoübertragung sowie Konfigurationsoptionen.
-
Konfiguration und Fehlerbehebung bei Ethernet 10/100Mb Halb-/Vollduplex-Auto-Negotiation
-
Behebung von Kompatibilitätsproblemen zwischen Cisco Catalyst Switches und NICs
Ein weit verbreitetes Missverständnis bei der Autoübertragung ist, dass es möglich ist, einen Verbindungspartner manuell für 100-Mbit/s-Vollduplex zu konfigurieren und mit dem anderen Verbindungspartner automatisch auf Vollduplex zu verhandeln. Ein Versuch, dies zu tun, führt zu einer Duplexungleichheit. Dies ist darauf zurückzuführen, dass ein Verbindungspartner Autoübertragung durchführt, keine Autoübertragung vom anderen Verbindungspartner erkennt und standardmäßig auf Halbduplex umschaltet.
Die meisten Catalyst Ethernet-Module unterstützen 10/100 Mbit/s und Halb-/Vollduplex. Der Befehl show port abilities mod/port bestätigt dies jedoch.
FEFI
Far-End-Fehleranzeige (FEFI) schützt 100BASE-FX- (Glasfaser) und Gigabit-Schnittstellen, während Autoübertragung 100BASE-TX (Kupfer) vor Störungen schützt, die durch die physische Schicht oder Signalisierung verursacht werden.
Ein Fernfehler ist ein Fehler in der Verbindung, den eine Station erkennen kann, während die andere nicht erkennen kann, z. B. eine abgetrennte TX-Leitung. In diesem Beispiel könnte die sendende Station weiterhin gültige Daten empfangen und anhand des Link-Integritäts-Monitors feststellen, dass die Verbindung einwandfrei ist. Er erkennt nicht, dass seine Übertragung nicht von der anderen Station empfangen wird. Eine 100BASE-FX-Station, die einen solchen Fernfehler erkennt, kann ihren übertragenen IDLE-Stream so modifizieren, dass er ein spezielles Bitmuster (das so genannte FEFI-IDLE-Muster) sendet, um den Nachbarn über den Fernfehler zu informieren. Das FEFI-IDLE-Muster löst anschließend ein Herunterfahren des Remote-Ports aus (errdisable). Weitere Informationen zum Fehlerschutz finden Sie im Abschnitt UDLD dieses Dokuments.
FEFI wird von dieser Hardware und den folgenden Modulen unterstützt:
-
Catalyst 5500/5000: WS-X5201R, WS-X5305, WS-X5236, WS-X5237, WS-U5538 und WS-U5539
-
Catalyst 6500/6000 und 4500/4000: Alle 100BASE-FX-Module und GE-Module
Empfehlung
Ob die Autoübertragung auf 10/100-Verbindungen oder auf Hard-Code-Geschwindigkeit und Duplex konfiguriert werden soll, hängt letztlich vom Verbindungspartner- oder Endgerätetyp ab, den Sie mit einem Catalyst Switch-Port verbunden haben. Die automatische Aushandlung zwischen Endgeräten und Catalyst Switches funktioniert im Allgemeinen gut, und Catalyst Switches entsprechen der IEEE 802.3u-Spezifikation. Probleme können jedoch auftreten, wenn NICs oder Switches anderer Anbieter nicht exakt übereinstimmen. Hardwareinkompatibilität und andere Probleme können auch das Ergebnis anbieterspezifischer erweiterter Funktionen sein, wie z. B. automatische Polarität oder Kabelintegrität, die in der IEEE 802.3u-Spezifikation für 10/100-Mbit/s-Autoübertragung nicht beschrieben werden. Siehe Problemhinweis: Leistungsproblem bei Intel Pro/1000T NICs, die mit CAT4K/6K verbunden sind, um ein Beispiel dafür zu geben.
Gehen Sie davon aus, dass in bestimmten Situationen die Einstellung von Host, Portgeschwindigkeit und Duplex erforderlich sein wird. Im Allgemeinen befolgen Sie die folgenden grundlegenden Schritte zur Fehlerbehebung:
-
Stellen Sie sicher, dass entweder die Autoübertragung auf beiden Seiten der Verbindung oder die feste Codierung auf beiden Seiten konfiguriert ist.
-
Informationen zu gängigen Vorbehalten finden Sie in den Versionshinweisen von CatOS.
-
Überprüfen Sie die derzeit ausgeführte Version des Netzwerkkartentreibers oder Betriebssystems, da häufig der neueste Treiber oder Patch benötigt wird.
Versuchen Sie in der Regel zuerst, Autoübertragung für jeden Verbindungspartner zu verwenden. Die Konfiguration der Autoübertragung für Übergangsgeräte wie Laptops bietet offensichtliche Vorteile. Im Idealfall funktioniert die Autoübertragung auch mit Geräten, die keine vorübergehenden Vorgänge unterstützen, wie z. B. Server und feste Workstations, oder von Switch zu Switch und Switch zu Router. Aus einigen der genannten Gründe können sich Verhandlungsfragen ergeben. Befolgen Sie in diesen Fällen die grundlegenden Schritte zur Fehlerbehebung, die in den bereitgestellten TAC-Links beschrieben sind.
Wenn die Portgeschwindigkeit auf einem 10/100 Mbit/s Ethernet-Port auf Auto eingestellt ist, werden sowohl Geschwindigkeit als auch Duplex automatisch ausgehandelt. Führen Sie diesen Befehl aus, um den Port auf "auto" zu setzen:
set port speed port range auto
!--- This is the default.
Wenn Sie den Port fest codieren, geben Sie die folgenden Konfigurationsbefehle ein:
set port speed port range 10 | 100 set port duplex port range full | half
In CatOS 8.3 und höher hat Cisco das optionale Schlüsselwort auto-10-100 eingeführt. Verwenden Sie das Schlüsselwort auto-10-100 für Ports, die Geschwindigkeiten von 10/100/1000 Mbit/s unterstützen, aber eine automatische Aushandlung auf 1000 Mbit/s unerwünscht ist. Bei Verwendung des Schlüsselworts auto-10-100 verhält sich der Port genauso wie ein 10/100-Mbit/s-Port, dessen Geschwindigkeit auf auto festgelegt ist. Über Geschwindigkeit und Duplex wird nur für Ports mit 10/100 Mbit/s verhandelt, und die Geschwindigkeit von 1000 Mbit/s wird nicht verhandelt.
set port speed port_range auto-10-100
Weitere Optionen
Wenn keine Autoübertragung zwischen Switches verwendet wird, kann die L1-Fehleranzeige bei bestimmten Problemen ebenfalls verloren gehen. Es ist hilfreich, L2-Protokolle zu verwenden, um die Ausfallerkennung zu verbessern, z. B. aggressives UDLD.
Gigabit Ethernet
Gigabit Ethernet (GE) verfügt über ein Autoübertragung-Verfahren (IEEE 802.3z), das umfassender ist als das für 10/100 Mbit/s Ethernet und zum Austausch von Flusssteuerungsparametern, Remote-Fehlerinformationen und Duplexinformationen verwendet wird (obwohl GE-Ports der Catalyst-Serie nur den Vollduplex-Modus unterstützen).
Hinweis: 802.3z wurde durch IEEE 802.3:2000-Spezifikationen ersetzt. Weitere Informationen finden Sie unter IEEE Standards On Line LAN/MAN Standards Subscription: Archiv für weitere Informationen.
Betriebsübersicht
GE-Port-Negotiation ist standardmäßig aktiviert, und die Ports an beiden Enden einer GE-Verbindung müssen die gleiche Einstellung haben. Anders als bei FE wird die GE-Verbindung nicht aktiviert, wenn sich die Einstellungen für die Autoübertragung an den Ports an den einzelnen Enden der Verbindung unterscheiden. Die einzige Bedingung, die für eine Verbindung eines Ports, der die Autoübertragung deaktiviert hat, erfüllt sein muss, ist ein gültiges Gigabit-Signal vom anderen Ende. Dieses Verhalten ist unabhängig von der Auto-Negotiation-Konfiguration der Gegenstelle. Angenommen, es gibt zwei Geräte, A und B. Für jedes Gerät kann die Autoübertragung aktiviert oder deaktiviert sein. Diese Tabelle enthält eine Liste möglicher Konfigurationen und der jeweiligen Verbindungsstatus:
| Verhandlung | B aktiviert | B deaktiviert |
|---|---|---|
| A Aktiviert | oben auf beiden Seiten | A unten, B oben |
| Eine deaktivierte | A oben, B unten | oben auf beiden Seiten |
In GE werden Synchronisierung und Autoübertragung (wenn sie aktiviert sind) beim Verbindungsstart mithilfe einer speziellen Sequenz von reservierten Verbindungscodewörtern durchgeführt.
Hinweis: Es gibt ein Wörterbuch mit gültigen Wörtern, und nicht alle möglichen Wörter sind in GE gültig.
Die Lebensdauer einer GE-Verbindung kann wie folgt charakterisiert werden:

Ein Verlust der Synchronisierung bedeutet, dass die MAC einen Verbindungsausfall erkennt. Der Synchronisierungsverlust tritt ein, wenn die Autoübertragung aktiviert oder deaktiviert ist. Die Synchronisierung geht unter bestimmten fehlerhaften Bedingungen verloren, z. B. wenn drei ungültige Wörter nacheinander empfangen werden. Wenn diese Bedingung 10 ms lang andauert, wird die Bedingung "sync fail" bestätigt, und die Verbindung wird in den Zustand "link_down" geändert. Nach dem Verlust der Synchronisation sind weitere drei aufeinander folgende gültige Inaktivitäten erforderlich, um die Synchronisation erneut durchzuführen. Andere katastrophale Ereignisse, wie ein Verlust des Empfangssignals (Rx), verursachen einen Verbindungsabbruch.
Die Autonegotiation ist Teil des Linkup-Prozesses. Wenn die Verbindung aktiv ist, ist die Autoübertragung vorbei. Der Switch überwacht jedoch weiterhin den Status der Verbindung. Wenn Autoübertragung auf einem Port deaktiviert ist, ist die "Autoübertragung"-Phase keine Option mehr.
Die GE-Kupferspezifikation (1000BASE-T) unterstützt die automatische Aushandlung über einen Next Page Exchange. Next Page Exchange ermöglicht die automatische Aushandlung für Geschwindigkeiten von 10/100/1000 Mbit/s an Kupferports.
Hinweis: Die GE-Glasfaserspezifikation enthält nur Bestimmungen für die Aushandlung von Duplex, Flusssteuerung und Remote-Fehlererkennung. GE-Glasfaserports handeln die Portgeschwindigkeit nicht aus. Weitere Informationen zur Autoübertragung finden Sie in den Abschnitten 28 und 37 der IEEE 802.3-2002-Spezifikation.
Die Synchronisierungsneustartverzögerung ist eine Softwarefunktion, die die Gesamtdauer der Autoübertragung steuert. Wenn die Autoübertragung innerhalb dieser Zeit nicht erfolgreich ist, startet die Firmware die Autoübertragung erneut, falls ein Deadlock auftritt. Der Befehl set port sync-restart-delay wirkt sich nur aus, wenn AutoNegotiation auf enable gesetzt ist.
Empfehlung
In einer GE-Umgebung ist die Aktivierung der Autoübertragung wesentlich wichtiger als in einer 10/100-Umgebung. Die Autoübertragung darf nur an Switch-Ports deaktiviert werden, die mit Geräten verbunden sind, die die Aushandlung nicht unterstützen, oder wenn aufgrund von Interoperabilitätsproblemen Verbindungsprobleme auftreten. Cisco empfiehlt, dass die Gigabit-Aushandlung auf allen Switch-to-Switch-Verbindungen und generell auf allen GE-Geräten aktiviert ist (Standard). Führen Sie diesen Befehl aus, um die Autoübertragung zu aktivieren:
set port negotiation port range enable
!--- This is the default.
Eine bekannte Ausnahme ist, wenn eine Verbindung zu einem Gigabit Switch Router (GSR) besteht, auf dem Cisco IOS-Software vor Version 12.0(10)S ausgeführt wird, der Version, die Flusssteuerung und Autoübertragung hinzugefügt hat. Deaktivieren Sie in diesem Fall diese beiden Funktionen, oder der Switch-Port meldet keine Verbindung, und der GSR meldet Fehler. Dies ist eine Beispiel-Befehlssequenz:
set port flowcontrol receive port range off set port flowcontrol send port range off set port negotiation port range disable
Switch-to-Server-Verbindungen müssen von Fall zu Fall geprüft werden. Cisco Kunden stießen bei Sun-, HP- und IBM-Servern auf Probleme mit Gigabit-Aushandlungen.
Weitere Optionen
Die Flusssteuerung ist optionaler Bestandteil der 802.3x-Spezifikation und muss bei Verwendung ausgehandelt werden. Geräte können PAUSE-Frames (bekannte MAC-Adresse 01-80-C2-00-00-00 0F) senden und/oder darauf reagieren. Außerdem können sie der Flusskontrollanforderung des entfernten Nachbarn nicht zustimmen. Ein Port mit einem Eingangspuffer, der sich füllt, sendet einen PAUSE-Frame an seinen Verbindungspartner, der die Übertragung stoppt, und hält alle zusätzlichen Frames in den Ausgangspuffern des Verbindungspartners auf. Dies löst kein Problem mit Überbelegung im Steady-State, vergrößert den Eingangspuffer jedoch effektiv um einen Bruchteil des Ausgangspuffers des Partners bei Bursts.
Diese Funktion eignet sich am besten für Verbindungen zwischen Access-Ports und End-Hosts, bei denen der Host-Ausgabepuffer potenziell so groß ist wie der virtuelle Arbeitsspeicher. Die Vorteile einer Switch-to-Switch-Implementierung sind begrenzt.
Führen Sie die folgenden Befehle aus, um dies an den Switch-Ports zu steuern:
set port flowcontrol mod/port receive | send off |on | desired
>show port flowcontrol
Port Send FlowControl Receive FlowControl RxPause TxPause
admin oper admin oper
----- -------- -------- -------- -------- ------- -------
6/1 off off on on 0 0
6/2 off off on on 0 0
6/3 off off on on 0 0
Hinweis: Alle Catalyst-Module reagieren auf einen PAUSE-Frame, wenn dieser ausgehandelt wird. Einige Module (z. B. WS-X5410, WS-X4306) senden niemals PAUSE-Frames, selbst wenn sie dies aushandeln, da sie nicht blockieren.
Dynamic Trunking Protocol
Kapselungstyp
Trunks erweitern VLANs zwischen Geräten, indem sie die ursprünglichen Ethernet-Frames vorübergehend identifizieren und (verbindungslokal) mit Tags versehen. So können sie über eine einzige Verbindung gemultiplext werden. Dadurch wird auch sichergestellt, dass die separaten VLAN-Broadcast- und Sicherheitsdomänen zwischen den Switches beibehalten werden. In den CAM-Tabellen wird die Frame-zu-VLAN-Zuordnung innerhalb der Switches beibehalten.
Trunking wird auf verschiedenen L2-Medien unterstützt, darunter ATM LANE, FDDI 802.10 und Ethernet, obwohl hier nur Letzteres dargestellt wird.
ISL - Betriebsübersicht
Das proprietäre Identifizierungs- oder Tagging-Schema von Cisco, ISL, wird seit vielen Jahren verwendet. Der IEEE-Standard 802.1Q ist ebenfalls verfügbar.
Durch die vollständige Kapselung des ursprünglichen Frames in einem zweistufigen Tagging-Schema ist ISL im Grunde ein Tunneling-Protokoll und hat den zusätzlichen Vorteil, dass Nicht-Ethernet-Frames transportiert werden. Es fügt einen 26-Byte-Header und einen 4-Byte-FCS zum Standard-Ethernet-Frame hinzu. Die größeren Ethernet-Frames werden von Ports erwartet und verarbeitet, die als Trunks konfiguriert sind. ISL unterstützt 1024 VLANs.
ISL-Frame-Format
| 40 Bit | 4 Bit | 4 Bit | 48 Bit | 16 Bit | 24 Bit | 24 Bit | 15 Bit | Bit | 16 Bit | 16 Bit | Variable Länge | 32 Bit |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ziel Adr | Typ | BENUTZER | SA | LEN | SNAP LLC | HSA | VLAN | BPDU | INDEX | Rücklage | Gekapselter Rahmen | FCS |
| 01-00-0c-00-00 | AAAA03 | 00000C |
Weitere Informationen finden Sie unter InterSwitch Link und IEEE 802.1Q Frame Format.
802.1Q - Betriebsübersicht
Der IEEE 802.1Q-Standard definiert weitaus mehr als nur Kapselungstypen, einschließlich Spanning Tree-Erweiterungen, GARP (siehe VTP-Abschnitt dieses Dokuments) und 802.1p Quality of Service (QoS)-Tagging.
Das 802.1Q-Frame-Format behält die ursprüngliche Ethernet-Quelladresse und Zieladresse bei, aber Switches müssen jetzt auch mit Babygigant-Frames rechnen, selbst auf Access-Ports, auf denen Hosts Tagging verwenden können, um die 802.1p-Benutzerpriorität für die QoS-Signalisierung auszudrücken. Der Tag ist 4 Byte, also sind 802.1Q Ethernet v2-Frames 1522 Byte, eine Leistung der IEEE 802.3ac-Arbeitsgruppe. 802.1Q unterstützt außerdem den Nummernraum für 4096 VLANs.
Alle übertragenen und empfangenen Daten-Frames sind mit 802.1Q gekennzeichnet, mit Ausnahme der Frames im nativen VLAN (es gibt ein implizites Tag, das auf der Konfiguration des Eingangs-Switch-Ports basiert). Frames auf dem nativen VLAN werden immer unmarkiert übertragen und erhalten in der Regel unmarkiert. Sie können jedoch auch getaggt empfangen werden.
Weitere Informationen finden Sie unter VLAN Standardization via IEEE 802.10 und Get IEEE 802 (VLAN-Standardisierung über IEEE 802.10).
802.1Q/801.1p-Frame-Format
| Tag-Header | ||||||||
|---|---|---|---|---|---|---|---|---|
| TPID | TCI | |||||||
| 48 Bit | 48 Bit | 16 Bit | 3 Bit | 1 Bit | 12 Bit | 16 Bit | Variable Länge | 32 Bit |
| DA | SA | TPID | Priorität | CFI | VLAN-ID | Länge/Typ | Daten mit PAD | FCS |
| 0 x 8100 | 0-7 | 0-1 | 0-4095 | |||||
Empfehlung
Da alle neueren Hardwarekomponenten 802.1Q unterstützen (einige davon nur 802.1Q, z. B. die Catalyst 4500/4000-Serie und CSS 11000), empfiehlt Cisco, dass alle neuen Implementierungen dem IEEE 802.1Q-Standard folgen und ältere Netzwerke schrittweise von ISL migrieren.
Der IEEE-Standard ermöglicht Anbieterinteroperabilität. Dies ist in allen Cisco Umgebungen von Vorteil, da neue Host 802.1p-fähige NICs und Geräte verfügbar werden. Obwohl sowohl ISL- als auch 802.1Q-Implementierungen ausgereift sind, wird der IEEE-Standard letztendlich eine höhere Feldbelastung und eine bessere Unterstützung durch Drittanbieter aufweisen, wie z. B. die Unterstützung für Netzwerkanalysen. Der im Vergleich zu ISL geringere Overhead durch die Kapselung von 802.1Q ist ebenfalls ein kleiner Vorteil von 802.1Q.
Da der Kapselungstyp zwischen Switches mithilfe von DTP ausgehandelt wird, wobei ISL standardmäßig als Gewinner ausgewählt wird, wenn beide Seiten ihn unterstützen, muss dieser Befehl ausgeführt werden, um dot1q anzugeben:
set trunk mod/port mode dot1q
Wenn VLAN 1 von einem Trunk gelöscht wird, wie im Abschnitt In-Band-Management dieses Dokuments beschrieben, obwohl keine Benutzerdaten übertragen oder empfangen werden, übergibt der NMP weiterhin Steuerungsprotokolle wie CDP und VTP an VLAN 1.
Wie im Abschnitt zu VLAN 1 dieses Dokuments beschrieben, werden CDP-, VTP- und PAgP-Pakete beim Trunking immer über VLAN 1 gesendet. Bei Verwendung der dot1q-Kapselung werden diese Steuerungs-Frames mit VLAN 1 gekennzeichnet, wenn das native VLAN des Switches geändert wird. Wenn das dot1q-Trunking zu einem Router aktiviert ist und das native VLAN auf dem Switch geändert wird, ist eine Subschnittstelle in VLAN 1 erforderlich, um die getaggten CDP-Frames zu empfangen und CDP-Nachbartransparenz auf dem Router bereitzustellen.
Hinweis: Bei dot1q besteht ein potenzielles Sicherheitsrisiko, das durch das implizite Tagging des nativen VLANs verursacht wird, da Frames von einem VLAN auf ein anderes ohne Router gesendet werden können. Siehe Gibt es Schwachstellen in VLAN-Implementierungen? für weitere Informationen. Die Problemumgehung besteht darin, eine VLAN-ID für das native VLAN des Trunks zu verwenden, das nicht für den Endbenutzerzugriff verwendet wird. Die Mehrheit der Cisco Kunden belässt VLAN 1 als natives VLAN auf einem Trunk und weist zu diesem Zweck Zugriffsports zu anderen VLANs als VLAN 1 zu.
Trunking-Modus
DTP ist die zweite Generation von Dynamic ISL (DISL) und wird eingesetzt, um sicherzustellen, dass die verschiedenen Parameter für das Senden von ISL- oder 802.1Q-Frames, wie der konfigurierte Kapselungstyp, das native VLAN und die Hardwarefunktionen, von den Switches an beiden Enden eines Trunks vereinbart werden. Dies trägt auch zum Schutz vor Nicht-Trunk-Ports bei, die markierte Frames überfluten - ein potenziell schwerwiegendes Sicherheitsrisiko -, indem sichergestellt wird, dass sich die Ports und ihre Nachbarn in einem konsistenten Zustand befinden.
Betriebsübersicht
DTP ist ein L2-Protokoll, das Konfigurationsparameter zwischen einem Switch-Port und seinem Nachbarn aushandelt. Es wird eine andere Multicast-MAC-Adresse (01-00-0c-cc-cc-cc) und der SNAP-Protokolltyp 0x2004 verwendet. Diese Tabelle enthält eine Zusammenfassung der Konfigurationsmodi:
| Modus | Funktion | DTP-Frames übertragen | Endgültiger Status (lokaler Port) |
|---|---|---|---|
| auto (Standard) | Macht den Port bereit, den Link in einen Trunk zu konvertieren. Der Port wird zum Trunk-Port, wenn der benachbarte Port eingeschaltet oder in den gewünschten Modus versetzt wird. | Ja, periodisch. | Trunking |
| On | Stellt den Port in den permanenten Trunk-Modus und versucht über Aushandlungen, den Link in einen Trunk umzuwandeln. Der Port wird selbst dann zu einem Trunk-Port, wenn der benachbarte Port der Änderung nicht zustimmt. | Ja, periodisch. | Trunking, bedingungslos. |
| nonegotiate (Keine Aushandlung) | Stellt den Port in den permanenten Trunking-Modus, verhindert jedoch, dass DTP-Frames vom Port generiert werden. Sie müssen den benachbarten Port manuell als Trunk-Port konfigurieren, um eine Trunk-Verbindung herzustellen. Dies ist nützlich für Geräte, die DTP nicht unterstützen. | Nein | Trunking, bedingungslos. |
| Desirable (gewünscht) | Der Port versucht aktiv, den Link in einen Trunk-Link umzuwandeln. Der Port wird zum Trunk-Port, wenn der benachbarte Port auf "Ein", "Erwünscht" oder "Auto" eingestellt ist. | Ja, periodisch. | Er befindet sich nur dann im Trunking-Zustand, wenn der Remote-Modus aktiviert, automatisch oder erwünscht ist. |
| Aus | Stellt den Port in den permanenten Nicht-Trunk-Modus um und versucht über Aushandlungen, den Link in einen Nicht-Trunk-Link umzuwandeln. Der Port wird selbst dann zu einem Nicht-Trunk-Port, wenn der benachbarte Port der Änderung nicht zustimmt. | Nein im eingeschwungenen Zustand, wird aber übertragen, um die Remote-End-Erkennung nach dem Wechsel von vorne zu beschleunigen. | Nicht-Trunking |
Hier einige der wichtigsten Punkte des Protokolls:
-
DTP setzt eine Punkt-zu-Punkt-Verbindung voraus, und Cisco Geräte unterstützen nur 802.1Q-Trunk-Ports, die Punkt-zu-Punkt sind.
-
Während der DTP-Aushandlung nehmen die Ports nicht am STP teil. Erst wenn der Port zu einem der drei DTP-Typen (Zugriff, ISL oder 802.1Q) wird, wird er zu STP hinzugefügt. Andernfalls wird PAgP (sofern konfiguriert) als nächster Prozess ausgeführt, bevor der Port am STP teilnimmt.
-
Wenn sich der Port im ISL-Modus befindet, werden DTP-Pakete über VLAN 1 gesendet. Andernfalls (für 802.1Q-Trunking- oder Nicht-Trunking-Ports) werden sie über das native VLAN gesendet.
-
Im erwünschten Modus übertragen DTP-Pakete den VTP-Domänennamen (der übereinstimmen muss, damit ein ausgehandelter Trunk verfügbar ist) sowie die Trunk-Konfiguration und den Admin-Status.
-
Nachrichten werden jede Sekunde während der Verhandlung gesendet, und danach alle 30 Sekunden.
-
Achten Sie darauf, dass die Modi Ein, Nicht verhandeln und Aus explizit angeben, in welchem Zustand der Port endet. Eine fehlerhafte Konfiguration kann zu einem gefährlichen/inkonsistenten Zustand führen, in dem eine Seite Trunking verwendet, die andere nicht.
-
Ein Port im Ein-, Auto- oder Erwünscht-Modus sendet DTP-Frames regelmäßig. Wenn ein Port im automatischen oder erwünschten Modus in fünf Minuten kein DTP-Paket erkennt, wird es auf "non-trunk" (Nicht-Trunk) gesetzt.
Weitere Informationen zu ISL finden Sie unter Configuring ISL Trunking on Catalyst 5500/5000 and 6500/6000 Family Switches (Konfigurieren von ISL-Trunking auf Catalyst 5500/5000-Switches). Weitere Details zu 802.1Q finden Sie unter Trunking zwischen Catalyst Switches der Serien 4500/4000, 5500/5000 und 6500/6000 mit 802.1Q-Kapselung mit Cisco CatOS-Systemsoftware.
Empfehlung
Cisco empfiehlt eine explizite Trunk-Konfiguration von wünschenswert an beiden Enden. In diesem Modus können Netzwerkbetreiber Syslog- und Befehlszeilenstatusmeldungen als vertrauenswürdig einstufen, wenn ein Port aktiv ist und Trunking ausführt. Im Gegensatz zum On-Modus, bei dem ein Port angezeigt wird, obwohl der Nachbar falsch konfiguriert ist. Darüber hinaus bietet ein wünschenswerter Modus-Trunk Stabilität in Situationen, in denen eine Seite des Links nicht zu einem Trunk werden kann oder den Trunk-Status verwirft. Führen Sie diesen Befehl aus, um den gewünschten Modus festzulegen:
set trunk mod/port desirable ISL | dot1q
Hinweis: Deaktivieren Sie den Trunk für alle Nicht-Trunk-Ports. Dadurch entfällt die verschwendete Verhandlungszeit beim Hochfahren der Host-Ports. Dieser Befehl wird auch ausgeführt, wenn der Befehl set port host verwendet wird. Weitere Informationen finden Sie im Abschnitt zu STP. Führen Sie diesen Befehl aus, um einen Trunk auf verschiedenen Ports zu deaktivieren:
set trunk port range off
!--- Ports are not trunking; part of the set port host command.
Weitere Optionen
Eine andere gängige Kundenkonfiguration verwendet den erwünschten Modus nur auf dem Distribution Layer und die einfachste Standardkonfiguration (Auto-Modus) auf dem Access Layer.
Einige Switches, z. B. ein Catalyst 2900XL, Cisco IOS-Router oder Geräte anderer Anbieter, unterstützen derzeit keine Trunk-Aushandlung über DTP. Sie können den Non-Negotiate-Modus auf Catalyst Switches der Serien 4500/4000, 5500/5000 und 6500/6000 verwenden, um einen Port für den uneingeschränkten Zugriff auf diese Geräte einzurichten. Dies trägt zur Standardisierung einer einheitlichen Einstellung auf dem gesamten Campus bei. Außerdem können Sie den Nicht-Verhandlungsmodus implementieren, um die "gesamte" Verbindungsinitialisierungszeit zu reduzieren.
Hinweis: Faktoren wie der Channel-Modus und die STP-Konfiguration können sich ebenfalls auf die Initialisierungszeit auswirken.
Führen Sie diesen Befehl aus, um den Nicht-Verhandlungsmodus festzulegen:
set trunk mod/port nonegotiate ISL | dot1q
Cisco empfiehlt, nicht zu verhandeln, wenn eine Verbindung zu einem Cisco IOS-Router besteht, da beim Bridging einige DTP-Frames, die aus dem On-Modus empfangen werden, wieder in den Trunk-Port gelangen können. Beim Empfang des DTP-Frames versucht der Switch-Port, unnötigerweise eine Neuverhandlung durchzuführen (bzw. den Trunk herunter- und herzufahren). Wenn die Option "Nicht verhandeln" aktiviert ist, sendet der Switch keine DTP-Frames.
Spanning Tree Protocol
Grundlegende Überlegungen
Spanning Tree Protocol (STP) hält eine schleifenfreie L2-Umgebung in redundanten Switching- und Bridge-Netzwerken aufrecht. Ohne STP werden Frames auf unbestimmte Zeit geschleift und/oder multipliziert, was zu einem Netzwerkzusammenbruch führt, da alle Geräte in der Broadcast-Domäne ständig durch hohen Datenverkehr unterbrochen werden.
Obwohl STP in mancher Hinsicht ein ausgereiftes Protokoll ist, das ursprünglich für langsame softwarebasierte Bridge-Spezifikationen (IEEE 802.1d) entwickelt wurde, kann es komplex sein, es in großen Switch-Netzwerken mit vielen VLANs, vielen Switches in einer Domäne, Unterstützung mehrerer Anbieter und neueren IEEE-Erweiterungen gut zu implementieren.
Als zukünftige Referenz übernimmt CatOS 6.x weiterhin die neue STP-Entwicklung, wie MISTP, Loop-Guard, Root-Guards und BPDU-Erkennung von Verzerrungen bei der Ankunftszeit. Darüber hinaus sind in CatOS 7.x weitere standardisierte Protokolle verfügbar, wie z. B. IEEE 802.1s Shared Spanning Tree und IEEE 802.1w Rapid Convergence Spanning Tree.
Betriebsübersicht
Die Root-Bridge-Auswahl pro VLAN wird vom Switch mit der niedrigsten Root-Bridge-ID (BID) gewonnen. Die BID ist die Bridge-Priorität in Kombination mit der Switch-MAC-Adresse.
Zunächst werden BPDUs von allen Switches gesendet. Sie enthalten die BID jedes Switches und die Pfadkosten zum Erreichen dieses Switches. Dadurch können die Root-Bridge und der kostengünstigste Pfad zum Root bestimmt werden. Zusätzliche Konfigurationsparameter, die in BPDUs vom Root übertragen werden, setzen diejenigen außer Kraft, die lokal konfiguriert sind, sodass das gesamte Netzwerk konsistente Timer verwendet.
Anschließend wird die Topologie mithilfe der folgenden Schritte konvergiert:
-
Für die gesamte Spanning Tree-Domäne wird eine einzelne Root-Bridge ausgewählt.
-
Für jede Nicht-Root-Bridge wird ein Root-Port (zur Root-Bridge hin) ausgewählt.
-
Für die BPDU-Weiterleitung in jedem Segment wird ein designierter Port ausgewählt.
-
Nicht designierte Ports werden blockiert.
Weitere Informationen finden Sie unter Configuring Spanning Tree (Konfigurieren von Spanning Tree).
| Grundlegende Timer-Standardwerte (Sekunden) | Name | Funktion |
|---|---|---|
| 2 | Hello | Steuert das Senden von BPDUs. |
| 15 | Weiterleitungsverzögerung (Fwddelay) | Steuert, wie lange ein Port im Überwachungs- und Lernstatus verbringt und beeinflusst den Topologieänderungsprozess (siehe nächster Abschnitt). |
| 20 | Maxage | Steuert, wie lange der Switch die aktuelle Topologie aufrechterhält, bevor er nach einem alternativen Pfad sucht. Nach den Maxage-Sekunden gilt eine BPDU als veraltet, und der Switch sucht aus dem Pool der blockierenden Ports nach einem neuen Root-Port. Wenn kein blockierter Port verfügbar ist, behauptet er, der Root selbst an den designierten Ports zu sein. |
| Port-Status | Bedeutung | Standardzeit für den nächsten Status |
|---|---|---|
| Deaktiviert | Verwaltungstechnisch nicht verfügbar. | – |
| Blocking | Empfangen von BPDUs und Beenden von Benutzerdaten. | Überwachung des Empfangs von BPDUs Warten Sie 20 Sekunden auf den Ablauf der Maxima oder die sofortige Änderung, wenn ein direkter/lokaler Verbindungsausfall erkannt wurde. |
| Listening | Senden oder Empfangen von BPDUs, um zu prüfen, ob eine Rückkehr zur Blockierung erforderlich ist | Fwddelay timer (15 Sekunden warten) |
| Learning | Gebäudetopologie/CAM-Tabelle. | Fwddelay timer (15 Sekunden warten) |
| Forwarding | Daten senden/empfangen. | |
| Vollständige grundlegende Topologieänderung: | 20 + 2 (15) = 50 Sekunden, wenn auf das Ablaufen von Max. gewartet wird, oder 30 Sekunden, wenn die direkte Verbindung ausfällt |
Die beiden Arten von BPDUs in STP sind Konfigurations-BPDUs und TCN-BPDUs (Topology Change Notification).
Konfiguration des BPDU-Flusses
Die Konfigurations-BPDUs werden in jedem Hello-Intervall von jedem Port der Root-Bridge bezogen und fließen anschließend zu allen Leaf-Switches, um den Status des Spanning Tree aufrecht zu erhalten. Im eingeschwungenen Zustand verläuft der BPDU-Fluss unidirektional: Root-Ports und blockierende Ports empfangen nur Konfigurations-BPDUs, während designierte Ports nur Konfigurations-BPDUs senden.
Für jede BPDU, die ein Switch vom Root empfängt, wird vom zentralen Catalyst NMP ein neues BPDU verarbeitet und mit den Root-Informationen versendet. Mit anderen Worten: Wenn die Root-Bridge verloren geht oder alle Pfade zur Root-Bridge verloren gehen, werden keine BPDUs mehr empfangen (bis der maximale Timer erneut ausgewählt wird).
TCN-BPDU-Fluss
TCN-BPDUs stammen von Leaf-Switches und fließen zur Root-Bridge, wenn im Spanning Tree eine Topologieänderung erkannt wird. Root-Ports senden nur TCNs, und designierte Ports empfangen nur TCNs.
Die TCN-BPDU wird in Richtung der Root-Bridge übertragen und bei jedem Schritt bestätigt. Dies ist ein zuverlässiger Mechanismus. Sobald die Root-Bridge bei der Root-Bridge eintrifft, benachrichtigt sie die gesamte Domäne, dass eine Änderung aufgetreten ist, indem Konfigurations-BPDUs mit dem TCN-Flag für die MAXAGE + FWD-Verzögerungszeit (standardmäßig 35 Sekunden) bezogen werden. Dadurch ändern alle Switches ihre normale CAM-Alterungszeit von fünf Minuten (standardmäßig) in das Intervall, das mit fwddelay (standardmäßig 15 Sekunden) festgelegt wurde. Weitere Informationen finden Sie unter Understanding Spanning Tree Protocol Topology Changes.
Spanning-Tree-Modi
Es gibt drei verschiedene Möglichkeiten, VLANs mit Spanning Tree zu korrelieren:
-
Ein einzelner Spanning Tree für alle VLANs oder ein Spanning Tree Protocol wie IEEE 802.1Q
-
Spanning Tree pro VLAN oder Shared Spanning Tree wie Cisco PVST
-
Ein Spanning Tree pro VLAN-Satz oder mehrere Spanning Tree, z. B. Cisco MISTP und IEEE 802.1s
Ein Mono-Spanning-Tree für alle VLANs ermöglicht nur eine aktive Topologie und somit keinen Lastenausgleich. Ein STP blockiert einen Port für alle VLANs und überträgt keine Daten.
Ein Spanning Tree pro VLAN ermöglicht den Lastenausgleich, erfordert jedoch mit zunehmender Anzahl von VLANs eine höhere BPDU-CPU-Verarbeitung. Die CatOS-Versionshinweise enthalten Anleitungen zur Anzahl der für jeden Switch im Spanning Tree empfohlenen logischen Ports. Die Formel für die Catalyst 6500/6000 Supervisor Engine 1 lautet beispielsweise wie folgt:
Anzahl der Ports + (Anzahl der Trunks * Anzahl der VLANs auf Trunks) < 4000
Cisco MISTP und der neue 802.1s-Standard ermöglichen die Definition von nur zwei aktiven STP-Instanzen/Topologien und die Zuordnung aller VLANs zu einem dieser beiden Trees. Mit dieser Technik kann STP auf Tausende von VLANs skaliert werden, während der Lastenausgleich aktiviert ist.
BPDU-Formate
Um den IEEE 802.1Q-Standard zu unterstützen, wurde die vorhandene Cisco STP-Implementierung um PVST+ erweitert, indem Tunneling über eine IEEE 802.1Q mono Spanning Tree-Region unterstützt wurde. PVST+ ist daher sowohl mit dem IEEE 802.1Q MST- als auch dem Cisco PVST-Protokoll kompatibel und erfordert keine zusätzlichen Befehle oder Konfigurationen. Darüber hinaus fügt PVST+ Überprüfungsmechanismen hinzu, um sicherzustellen, dass es bei der Konfiguration von Port-Trunking und VLAN-IDs auf den Switches keine Inkonsistenz gibt.
Nachfolgend sind einige betriebliche Highlights des PVST+-Protokolls aufgeführt:
-
PVST+ arbeitet mit dem 802.1Q-Mono-Spanning-Tree über den so genannten Common Spanning Tree (CST) über einen 802.1Q-Trunk zusammen. Der CST ist immer in VLAN 1, daher muss dieses VLAN auf dem Trunk aktiviert werden, um mit anderen Anbietern kompatibel zu sein. CST-BPDUs werden stets unmarkiert an die IEEE Standard Bridge-Gruppe (MAC-Adresse 01-80-c2-00-00-00, DSAP 42, SSAP 42) übertragen. Der Vollständigkeit halber wird ein paralleler Satz von BPDUs auch an die von Cisco gemeinsam genutzte Spanning Tree-MAC-Adresse für VLAN 1 übertragen.
-
PVST+ tunnelt PVST-BPDUs in 802.1Q-VLAN-Regionen als Multicast-Daten. Cisco Shared Spanning Tree-BPDUs werden an die MAC-Adresse 01-00-0c-cc-cd (SNAP HDLC-Protokolltyp 0x010b) für jedes VLAN auf einem Trunk übertragen. BPDUs sind im nativen VLAN nicht markiert und für alle anderen VLANs markiert.
-
PVST+ überprüft Port- und VLAN-Inkonsistenzen. PVST+ blockiert Ports, die inkonsistente BPDUs empfangen, um Weiterleitungsschleifen zu verhindern. Außerdem werden Benutzer über Syslog-Meldungen über Konfigurationsdiskrepanzen benachrichtigt.
-
PVST+ ist abwärtskompatibel mit bestehenden Cisco Switches, auf denen PVST auf ISL-Trunks ausgeführt wird. ISL-gekapselte BPDUs werden weiterhin mithilfe der IEEE-MAC-Adresse gesendet oder empfangen. Mit anderen Worten: Jeder BPDU-Typ ist Link-Local. Es gibt keine Übersetzungsprobleme.
Empfehlung
Bei allen Catalyst Switches ist STP standardmäßig aktiviert. Dies wird auch dann empfohlen, wenn ein Design ohne L2-Schleifen gewählt wird, sodass STP nicht in dem Sinne aktiviert wird, als es aktiv einen blockierten Port aufrechterhält.
set spantree enable all !--- This is the default.
Cisco empfiehlt, STP aus den folgenden Gründen aktiviert zu lassen:
-
Wenn eine Schleife vorhanden ist (verursacht durch falsche Patches, fehlerhafte Kabel usw.), verhindert STP schädliche Auswirkungen auf das Netzwerk, die durch Multicast- und Broadcast-Daten verursacht werden.
-
Schutz vor dem Ausfall eines EtherChannels.
-
Die meisten Netzwerke sind mit STP konfiguriert, wodurch die maximale Feldeinstrahlung erreicht wird. Eine höhere Belichtung entspricht im Allgemeinen einem stabilen Code.
-
Schutz vor Fehlverhalten von doppelt angeschlossenen NICs (oder Bridging auf Servern aktiviert).
-
Die Software für zahlreiche Protokolle (z. B. PAgP, IGMP-Snooping und Trunking) ist eng mit STP verknüpft. Eine Ausführung ohne STP kann zu unerwünschten Ergebnissen führen.
Ändern Sie die Timer nicht, da dies die Stabilität beeinträchtigen kann. Die meisten der bereitgestellten Netzwerke sind nicht optimiert. Die einfachen STP-Timer, auf die über die Befehlszeile zugegriffen werden kann, wie hello-interval und Maxage, setzen sich ihrerseits aus einer komplexen Reihe anderer angenommener und intrinsischer Timer zusammen. Daher ist es schwierig, Timer abzustimmen und alle Auswirkungen zu berücksichtigen. Außerdem besteht die Gefahr, den UDLD-Schutz zu untergraben.
Im Idealfall sollte der Benutzerdatenverkehr vom Management-VLAN ferngehalten werden. Insbesondere bei älteren Catalyst Switch-Prozessoren ist es am besten, STP-Probleme zu vermeiden, indem das Management-VLAN von den Benutzerdaten getrennt gehalten wird. Bei einer Endstation, die sich daneben benimmt, kann der Supervisor Engine-Prozessor möglicherweise so mit Broadcast-Paketen beschäftigt sein, dass ihm eine oder mehrere BPDUs entgehen können. Neuere Switches mit leistungsfähigeren CPUs und Drosselungssteuerungen entlasten diese Überlegung. Weitere Informationen finden Sie im Abschnitt In-Band-Management in diesem Dokument.
Vermeiden Sie übermäßige Designredundanz. Dies kann zu einem Albtraum bei der Fehlerbehebung führen: Zu viele blockierende Ports beeinträchtigen die langfristige Stabilität. Behalten Sie den gesamten SPT-Durchmesser unter sieben Hops. Versuchen Sie, ein Design nach dem Cisco Multilayer-Modell mit kleineren Switch-Domänen, STP-Dreiecken und deterministischen blockierten Ports (wie im Gigabit Campus Network Design - Principles and Architecture erläutert) zu erstellen.
Sie können Einfluss ausüben und wissen, wo Root-Funktionen und blockierte Ports vorhanden sind, und diese im Topologiediagramm dokumentieren. Die blockierten Ports sind der Ort, an dem die STP-Fehlerbehebung beginnt. Sie wurden daher vom Blockieren zum Weiterleiten umgeschaltet und sind häufig der Hauptbestandteil der Ursachenanalyse. Wählen Sie den Distribution- und Core-Layer als Speicherort des Root-/sekundären Root-Layers, da diese als die stabilsten Teile des Netzwerks gelten. Suchen Sie nach dem optimalen L3- und HSRP-Overlay mit L2-Datenweiterleitungspfaden. Dieser Befehl ist ein Makro, das die Bridge-Priorität konfiguriert. root setzt ihn viel niedriger als der Standard (32768), während root sekundär ihn einigermaßen niedriger als der Standard setzt:
set spantree root secondary vlan range
Hinweis: Dieses Makro setzt die Root-Priorität entweder auf 8192 (standardmäßig), die aktuelle Root-Priorität minus 1 (wenn eine andere Root-Bridge bekannt ist) oder die aktuelle Root-Priorität (wenn die MAC-Adresse niedriger als die des aktuellen Roots ist).
Entfernen Sie nicht benötigte VLANs von den Trunk-Ports (eine bidirektionale Übung). Dadurch wird der STP- und NMP-Verarbeitungsaufwand in Teilen des Netzwerks begrenzt, in denen bestimmte VLANs nicht erforderlich sind. Durch die automatische VTP-Bereinigung wird STP nicht aus einem Trunk entfernt. Weitere Informationen finden Sie im Abschnitt zum VTP in diesem Dokument. Das Standard-VLAN 1 kann mit CatOS 5.4 und höher auch aus Trunks entfernt werden.
Weitere Informationen finden Sie unter Probleme mit dem Spanning Tree Protocol und in den entsprechenden Designüberlegungen.
Weitere Optionen
Cisco hat eine weitere STP, die als VLAN-Bridge bekannt ist. Dieses Protokoll verwendet die MAC-Zieladresse 01-00-0c-cd-cd-ce und den Protokolltyp 0x010c.
Dies ist besonders nützlich, wenn nicht routbare oder ältere Protokolle zwischen VLANs überbrückt werden müssen, ohne die auf diesen VLANs ausgeführten IEEE Spanning Tree-Instanzen zu stören. Wenn VLAN-Schnittstellen für nicht überbrückten Datenverkehr für L2-Datenverkehr blockiert werden (was leicht passieren kann, wenn sie am selben STP teilnehmen wie IP-VLANs), wird der überlagernde L3-Datenverkehr versehentlich ebenfalls abgeschnitten - ein unerwünschter Nebeneffekt. VLAN-Bridge ist daher eine separate STP-Instanz für überbrückte Protokolle, die eine separate Topologie bereitstellt, die geändert werden kann, ohne den IP-Datenverkehr zu beeinträchtigen.
Cisco empfiehlt die Ausführung von VLAN-Bridge, wenn Bridging zwischen VLANs auf Cisco Routern wie MSFC erforderlich ist.
PortFast
PortFast wird verwendet, um den normalen Spanning Tree-Betrieb an Access-Ports zu umgehen, um die Verbindung zwischen Endgeräten und den Diensten zu beschleunigen, mit denen sie nach der Verbindungsinitialisierung eine Verbindung herstellen müssen. Bei einigen Protokollen, wie IPX/SPX, ist es wichtig, den Zugangsport unmittelbar nach dem Erhöhen des Verbindungsstatus im Weiterleitungsmodus anzuzeigen, um GNS-Probleme zu vermeiden.
Weitere Informationen finden Sie unter Verwenden von Portfast und anderen Befehlen zum Beheben von Verbindungsverzögerungen beim Start von Workstations.
Betriebsübersicht
PortFast überspringt den normalen Überwachungs- und Lernstatus von STP, indem ein Port direkt vom Blockierungs- in den Weiterleitungsmodus verschoben wird, nachdem bekannt ist, dass die Verbindung ausgeführt wird. Wenn diese Funktion nicht aktiviert ist, verwirft STP alle Benutzerdaten, bis entschieden wird, dass der Port in den Weiterleitungsmodus versetzt werden kann. Dies kann bis zu doppelt so lange wie die ForwardDelay-Zeit dauern (standardmäßig insgesamt 30 Sekunden).
Der PortFast-Modus verhindert außerdem, dass eine STP-TCN generiert wird, wenn sich der Port-Status vom Lernen zur Weiterleitung ändert. TCNs sind kein Problem für sich allein, aber wenn eine Welle von TCNs die Root Bridge erreicht (in der Regel morgens, wenn die Leute ihre PCs einschalten), kann dies die Konvergenzzeit unnötig verlängern.
STP PortFast ist sowohl in Multicast-CGMP- als auch in Catalyst 5500/5000 MLS-Netzwerken von besonderer Bedeutung. TCNs in diesen Umgebungen können dazu führen, dass die statischen CGMP CAM-Tabelleneinträge veraltet sind, was bis zum nächsten IGMP-Bericht zu Multicast-Paketverlusten führt, und/oder MLS-Cache-Einträge leeren, die dann neu erstellt werden müssen und je nach Größe des Caches zu einem Spitzenwert bei der Router-CPU führen können. (Catalyst 6500/6000 MLS-Implementierungen und Multicast-Einträge, die durch IGMP-Snooping erfasst wurden, sind nicht betroffen.)
Empfehlung
Cisco empfiehlt, STP PortFast für alle aktiven Host-Ports zu aktivieren und für Switch-Switch-Verbindungen und nicht verwendete Ports zu deaktivieren.
Trunking und Channeling müssen außerdem für alle Host-Ports deaktiviert werden. Jeder Access-Port ist standardmäßig für Trunking und Channeling aktiviert, aber Switchnachbarn werden von der Architektur an Host-Ports nicht erwartet. Werden diese Protokolle für Verhandlungen belassen, kann die anschließende Verzögerung bei der Port-Aktivierung zu unerwünschten Situationen führen, in denen anfängliche Pakete von Workstations, wie z. B. DHCP-Anfragen, nicht weitergeleitet werden.
In CatOS 5.2 wurde ein Makrobefehl eingeführt, der den Port-Host-Port-Bereich festlegt, der diese Konfiguration für Access-Ports implementiert und die Leistung von Autoübertragung und Verbindung deutlich verbessert:
set port host port range !--- Macro command for these commands: set spantree portfast port range enable set trunk port range off set port channel port range mode off
Hinweis: PortFast bedeutet nicht, dass Spanning Tree auf diesen Ports überhaupt nicht ausgeführt wird. BPDUs werden weiterhin gesendet, empfangen und verarbeitet.
Weitere Optionen
PortFast BPDU-Guard bietet eine Möglichkeit, Schleifen zu verhindern, indem ein Nicht-Trunk-Port in den Status "errdisable" versetzt wird, wenn ein BPDU an diesem Port empfangen wird.
Ein BPDU-Paket darf auf einem für PortFast konfigurierten Access-Port nie empfangen werden, da Host-Ports nicht an Switches angeschlossen werden dürfen. Wenn ein BPDU festgestellt wird, weist dies auf eine ungültige und möglicherweise gefährliche Konfiguration hin, die eine administrative Maßnahme erfordert. Wenn die BPDU-Guard-Funktion aktiviert ist, deaktiviert Spanning Tree für PortFast konfigurierte Schnittstellen, die BPDUs empfangen, anstatt sie in den STP-Blockierungsstatus zu versetzen.
Der Befehl funktioniert Switch-basiert und nicht Port-basiert, wie dargestellt:
set spantree portfast bpdu-guard enable
Der Netzwerkmanager wird durch eine SNMP-Trap- oder Syslog-Meldung benachrichtigt, wenn der Port ausfällt. Es ist auch möglich, eine automatische Wiederherstellungszeit für fehlerhaft deaktivierte Ports zu konfigurieren. Weitere Informationen finden Sie im Abschnitt UDLD dieses Dokuments. Weitere Informationen finden Sie unter Spanning Tree Portfast BPDU Guard Enhancement.
Hinweis: PortFast für Trunk-Ports wurde in CatOS 7.x eingeführt und hat in früheren Versionen keine Auswirkungen auf Trunk-Ports. PortFast für Trunk-Ports wurde entwickelt, um die Konvergenzzeiten für L3-Netzwerke zu erhöhen. Zusätzlich zu dieser Funktion bietet CatOS 7.x die Möglichkeit, PortFast BPDU-Guard für jeden Port zu konfigurieren.
UplinkFast
UplinkFast bietet eine schnelle STP-Konvergenz nach einem direkten Verbindungsausfall auf der Netzwerkzugriffsschicht. Das STP wird nicht geändert. Sein Zweck besteht darin, die Konvergenzzeit unter bestimmten Umständen auf weniger als drei Sekunden zu beschleunigen, anstatt auf die typische 30-Sekunden-Verzögerung. Weitere Informationen finden Sie unter Understanding and Configuring the Cisco Uplink Fast Feature.
Betriebsübersicht
Wenn der Weiterleitungs-Uplink verloren geht, wird der blockierende Uplink beim Multilayer-Designmodell von Cisco auf dem Access Layer sofort in einen Weiterleitungsstatus verschoben, ohne auf den Zustände "Zuhören" und "Lernen" zu warten.
Eine Uplink-Gruppe besteht aus einer Reihe von Ports pro VLAN, die als Root-Port und Backup-Root-Port ausgelegt werden können. Unter normalen Bedingungen stellen die Root-Ports die Konnektivität vom Zugriff zum Root sicher. Wenn diese primäre Root-Verbindung aus irgendeinem Grund ausfällt, wird die Backup-Root-Verbindung sofort aktiviert, ohne dass eine typische Konvergenzverzögerung von 30 Sekunden durchlaufen werden muss.
Da dadurch der normale Prozess der Bearbeitung von STP-Topologieänderungen (Abhören und Lernen) effektiv umgangen wird, ist ein alternativer Topologiekorrekturmechanismus erforderlich, um Switches in der Domäne zu aktualisieren, sodass lokale Endstationen über einen alternativen Pfad erreichbar sind. Der Access-Layer-Switch, auf dem UplinkFast ausgeführt wird, generiert darüber hinaus Frames für jede MAC-Adresse im CAM für eine Multicast-MAC-Adresse (01-00-0c-cd-cd-cd, HDLC-Protokoll 0x200a), um die CAM-Tabelle in allen Switches in der Domäne mit der neuen Topologie zu aktualisieren.
Empfehlung
Cisco empfiehlt die Aktivierung von UplinkFast für Switches mit blockierten Ports, in der Regel auf Zugriffsebene. Verwenden Sie die Switches nicht ohne die implizierte Topologiekenntnisse einer Backup-Root-Verbindung - in der Regel Distribution- und Core-Switches im Cisco Multilayer-Design. Es kann unterbrechungsfrei zu einem Produktionsnetzwerk hinzugefügt werden. Führen Sie diesen Befehl aus, um UplinkFast zu aktivieren:
set spantree uplinkfast enable
Mit diesem Befehl wird außerdem die Bridge-Priorität hoch gesetzt, um das Risiko zu minimieren, dass dies zu einer Root-Bridge wird, und die Port-Priorität hoch, um zu minimieren, dass sie zu einem designierten Port wird, was die Funktionalität beeinträchtigt. Wenn Sie einen Switch wiederherstellen, auf dem UplinkFast aktiviert war, muss die Funktion deaktiviert, die Uplink-Datenbank mit "clear uplink" gelöscht und die Bridge-Prioritäten manuell wiederhergestellt werden.
Hinweis: Das Schlüsselwort all protocol für den UplinkFast-Befehl wird benötigt, wenn die Funktion zur Protokollfilterung aktiviert ist. Da der CAM bei aktivierter Protokollfilterung den Protokolltyp sowie MAC- und VLAN-Informationen aufzeichnet, muss für jedes Protokoll ein UplinkFast-Frame für jede MAC-Adresse generiert werden. Das Schlüsselwort rate gibt die Pakete pro Sekunde der UplinkFast Topology Update Frames an. Die Standardeinstellung wird empfohlen. Sie müssen BackboneFast nicht mit Rapid STP (RSTP) oder IEEE 802.1w konfigurieren, da der Mechanismus nativ im RSTP enthalten und automatisch aktiviert ist.
BackboneFast
BackboneFast ermöglicht schnelle Konvergenz bei Ausfällen indirekter Verbindungen. Durch die zusätzliche STP-Funktion können die Konvergenzzeiten von standardmäßig 50 Sekunden auf 30 Sekunden reduziert werden.
Betriebsübersicht
Der Mechanismus wird initiiert, wenn ein Root-Port oder blockierter Port auf einem Switch untergeordnete BPDUs von der designierten Bridge empfängt. Dies kann passieren, wenn ein Downstream-Switch seine Verbindung zum Root verloren hat und beginnt, eigene BPDUs zu senden, um einen neuen Root auszuwählen. Eine untergeordnete BPDU identifiziert einen Switch als Root-Bridge und als designierte Bridge.
Unter normalen Spanning Tree-Regeln ignoriert der empfangende Switch untergeordnete BPDUs für die konfigurierte maximale Alterungszeit, standardmäßig 20 Sekunden. Mit BackboneFast erkennt der Switch jedoch die unterlegene BPDU als Signal, dass sich die Topologie geändert haben könnte, und versucht mithilfe von Root Link Query (RLQ)-BPDUs zu ermitteln, ob ein alternativer Pfad zur Root-Bridge vorhanden ist. Durch diese Protokollerweiterung kann ein Switch überprüfen, ob der Root noch verfügbar ist, einen blockierten Port in kürzerer Zeit an die Weiterleitung verschieben und den isolierten Switch, der die untergeordnete BPDU gesendet hat, darüber informieren, dass der Root noch vorhanden ist.
Dies sind einige der wichtigsten Punkte des Protokolls:
-
Ein Switch überträgt das RLQ-Paket nur vom Root-Port (d. h. zur Root-Bridge).
-
Ein Switch, der eine RLQ erhält, kann entweder antworten, wenn er der Root-Switch ist, oder wenn er weiß, dass die Verbindung zum Root-Switch unterbrochen wurde. Wenn es diese Fakten nicht kennt, muss es die Abfrage über seinen Root-Port weiterleiten.
-
Wenn ein Switch die Verbindung zum Root verloren hat, muss er auf diese Abfrage negativ antworten.
-
Die Antwort darf nur über den Port gesendet werden, von dem die Abfrage stammt.
-
Der Root-Switch muss auf diese Anfrage immer positiv antworten.
-
Wenn die Antwort an einem Nicht-Root-Port eingeht, wird sie verworfen.
Die STP-Konvergenzzeiten können daher um bis zu 20 Sekunden verringert werden, da die maximale Dauer (Max.) nicht abgelaufen sein muss.
Weitere Informationen finden Sie unter Understanding and Configuring Backbone Fast on Catalyst Switches.
Empfehlung
Cisco empfiehlt die Aktivierung von BackboneFast auf allen Switches, auf denen STP ausgeführt wird. Es kann unterbrechungsfrei zu einem Produktionsnetzwerk hinzugefügt werden. Führen Sie diesen Befehl aus, um BackboneFast zu aktivieren:
set spantree backbonefast enable
Hinweis: Dieser Befehl auf globaler Ebene muss auf allen Switches in einer Domäne konfiguriert werden, da er dem STP-Protokoll Funktionen hinzufügt, die von allen Switches verstanden werden müssen.
Weitere Optionen
BackboneFast wird auf 2900XLs und 3500s nicht unterstützt. Sie darf nicht aktiviert werden, wenn die Switch-Domäne zusätzlich zu den Catalyst Switches der Serien 4500/4000, 5500/5000 und 6500/6000 auch diese Switches enthält.
Sie müssen BackboneFast nicht mit RSTP oder IEEE 802.1w konfigurieren, da der Mechanismus nativ im RSTP enthalten und automatisch aktiviert ist.
Spanning Tree Loop Guard
Loop Guard ist eine proprietäre STP-Optimierung von Cisco. Loop Guard schützt L2-Netzwerke vor Loops, die durch Folgendes verursacht werden:
-
Fehlerhafte Netzwerkschnittstellen
-
Besetzte CPUs
-
Alle Faktoren, die die normale Weiterleitung von BPDUs verhindern
Eine STP-Schleife tritt auf, wenn ein blockierender Port in einer redundanten Topologie irrtümlicherweise in den Weiterleitungsstatus wechselt. Dieser Übergang erfolgt in der Regel, weil einer der Ports in einer physisch redundanten Topologie (nicht unbedingt der blockierende Port) keine BPDUs mehr empfängt.
Loop Guard ist nur in Switched-Netzwerken nützlich, in denen Switches über Point-to-Point-Verbindungen verbunden sind. Bei den meisten modernen Campus- und Rechenzentrumsnetzwerken handelt es sich um diese Netzwerktypen. Bei einer Point-to-Point-Verbindung kann eine designierte Bridge nur verschwinden, wenn sie eine untergeordnete BPDU sendet oder die Verbindung deaktiviert. Die Funktion zum STP-Loop-Guard wurde in CatOS 6.2(1) für die Plattformen Catalyst 4000 und Catalyst 5000 und in Version 6.2(2) für die Plattform Catalyst 6000 eingeführt.
Weitere Informationen zum Spanning Tree Protocol Enhancements using Loop Guard and BPDU Skew Detection Features (Spanning-Tree-Protokollverbesserungen mit Loop Guard und BPDU-Skew-Erkennungsfunktionen) finden Sie unter Loop Guard.
Betriebsübersicht
Loop Guard überprüft, ob ein Root-Port oder ein alternativer/Backup-Root-Port BPDUs empfängt. Wenn der Port keine BPDUs empfängt, versetzt der Loop Guard den Port in einen inkonsistenten Zustand (Blockierung), bis der Port wieder BPDUs empfängt. Ein Port im inkonsistenten Zustand überträgt keine BPDUs. Wenn ein solcher Port erneut BPDUs empfängt, wird der Port (und die Verbindung) wieder als einsatzfähig eingestuft. Die Loop-Inkonsistenz wird vom Port entfernt, und der STP bestimmt den Port-Status, da eine solche Wiederherstellung automatisch erfolgt.
Loop Guard isoliert den Fehler und ermöglicht die Konvergenz von Spanning Tree in einer stabilen Topologie ohne die fehlerhafte Verbindung oder Bridge. Loop Guard verhindert STP-Loops mit der Geschwindigkeit der verwendeten STP-Version. Es besteht keine Abhängigkeit vom STP selbst (802.1d oder 802.1w) oder von der Abstimmung der STP-Timer. Aus diesen Gründen sollten Sie Loop Guard in Verbindung mit UDLD in Topologien implementieren, die auf STP basieren und in denen die Software die Funktionen unterstützt.
Wenn der Loop Guard einen inkonsistenten Port blockiert, wird diese Meldung protokolliert:
%SPANTREE-2-ROOTGUARDBLOCK: Port 1/1 tried to become non-designated in VLAN 77. Moved to root-inconsistent state.
Wenn die BPDU an einem Port in einem schleifeninkonsistenten STP-Zustand empfangen wird, wechselt der Port in einen anderen STP-Zustand. Entsprechend der empfangenen BPDU erfolgt die Wiederherstellung automatisch, und es ist kein Eingriff erforderlich. Nach der Wiederherstellung wird diese Meldung protokolliert.
SPANTREE-2-LOOPGUARDUNBLOCK: port 3/2 restored in vlan 3.
Interaktion mit anderen STP-Funktionen
-
Root Guard
Root Guard erzwingt, dass ein Port immer festgelegt wird. Loop Guard ist nur wirksam, wenn der Port der Root-Port oder ein alternativer Port ist. Diese Funktionen schließen sich gegenseitig aus. Loop Guard und Root Guard können auf einem Port nicht gleichzeitig aktiviert werden.
-
UplinkFast
Loop Guard ist kompatibel mit UplinkFast. Wenn der Loop Guard einen Root-Port in einen Blockierungsstatus versetzt, versetzt UplinkFast einen neuen Root-Port in den Weiterleitungsstatus. Außerdem wählt UplinkFast keinen schleifeninkonsistenten Port als Root-Port aus.
-
BackboneFast
Loop Guard ist mit BackboneFast kompatibel. Der Empfang einer untergeordneten BPDU, die von einer festgelegten Bridge stammt, löst BackboneFast aus. Da BPDUs von dieser Verbindung empfangen werden, ist Loop Guard nicht aktiviert, sodass BackboneFast und Loop Guard kompatibel sind.
-
PortFast
PortFast wechselt einen Port unmittelbar nach der Verbindung in den designierten Weiterleitungsstatus. Da ein PortFast-fähiger Port kein Root- oder alternativer Port sein kann, schließen sich Loop Guard und PortFast gegenseitig aus.
-
PAgP
Loop Guard verwendet die Ports, die STP bekannt sind. Daher kann Loop Guard von der Abstraktion logischer Ports profitieren, die PAgP bereitstellt. Um jedoch einen Kanal zu bilden, müssen alle physischen Ports, die in einem Kanal gruppiert sind, kompatible Konfigurationen aufweisen. PAgP erzwingt die einheitliche Konfiguration von Loop Guard auf allen physischen Ports, um einen Kanal zu bilden.
Hinweis: Dies sind Vorbehalte beim Konfigurieren von Loop Guard auf einem EtherChannel:
-
STP wählt immer den ersten funktionierenden Port im Kanal aus, um die BPDUs zu senden. Wenn diese Verbindung unidirektional wird, blockiert Loop Guard den Kanal, selbst wenn andere Verbindungen im Kanal ordnungsgemäß funktionieren.
-
Wenn Ports, die bereits durch Loop Guard blockiert sind, gruppiert werden, um einen Kanal zu bilden, verliert STP alle Statusinformationen für diese Ports. Der neue Channel-Port kann den Weiterleitungsstatus mit einer designierten Rolle erreichen.
-
Wenn ein Kanal durch einen Loop Guard blockiert wird und der Kanal unterbrochen wird, verliert STP alle Statusinformationen. Die einzelnen physischen Ports können den Weiterleitungsstatus mit designierter Rolle erreichen, selbst wenn einer oder mehrere der Links, die den Kanal bildeten, unidirektional sind.
In den letzten beiden Fällen in dieser Liste besteht die Möglichkeit einer Schleife, bis UDLD den Fehler erkennt. Der Loop Guard ist jedoch nicht in der Lage, die Loop zu erkennen.
-
Loop Guard und UDLD - Funktionsvergleich
Die Loop Guard- und UDLD-Funktionen überschneiden sich teilweise. Beide bieten Schutz vor STP-Ausfällen, die von unidirektionalen Verbindungen verursacht werden. Diese beiden Funktionen unterscheiden sich jedoch hinsichtlich des Problemansatzes und der Funktionalität. Insbesondere gibt es bestimmte unidirektionale Fehler, die UDLD nicht erkennen kann, z. B. Fehler, die von einer CPU verursacht werden, die keine BPDUs sendet. Darüber hinaus kann die Verwendung aggressiver STP-Timer und des RSTP-Modus zu Schleifen führen, bevor UDLD die Fehler erkennen kann.
Loop Guard funktioniert nicht auf gemeinsam genutzten Verbindungen oder in Situationen, in denen die Verbindung seit der Verbindung unidirektional war. Falls die Verbindung seit dem Linkup unidirektional war, empfängt der Port niemals BPDUs und wird entsprechend konfiguriert. Dieses Verhalten kann normal sein, sodass der Loop Guard diesen speziellen Fall nicht abdeckt. UDLD bietet Schutz vor einem solchen Szenario.
Aktivieren Sie sowohl UDLD als auch Loop Guard, um ein Höchstmaß an Schutz zu bieten. Im Abschnitt Loop Guard vs. Unidirectional Link Detection von Spanning-Tree Protocol Enhancements using Loop Guard and BPDU Skew Detection Features (Schleifenschutz und BPDU-Skew-Erkennung) finden Sie einen Vergleich von Schleifenschutz- und UDLD-Funktionen.
Empfehlung
Cisco empfiehlt, in einem Switch-Netzwerk mit physischen Schleifen Loop Guard global zu aktivieren. Ab Version 7.1(1) der Catalyst-Software können Sie Loop Guard global auf allen Ports aktivieren. Diese Funktion ist auf allen Punkt-zu-Punkt-Verbindungen aktiviert. Der Duplexstatus der Verbindung erkennt die Point-to-Point-Verbindung. Wenn die Duplexeinheit voll ist, gilt die Verbindung als Point-to-Point. Führen Sie diesen Befehl aus, um Global Loop Guard zu aktivieren:
set spantree global-default loopguard enable
Weitere Optionen
Aktivieren Sie bei Switches, die die globale Loop Guard-Konfiguration nicht unterstützen, die Funktion an allen einzelnen Ports, einschließlich Port-Channel-Ports. Obwohl die Aktivierung von Loop Guard auf einem designierten Port keine Vorteile bietet, ist diese Aktivierung kein Problem. Darüber hinaus kann eine gültige Spanning Tree-Rekonvergenz einen designierten Port in einen Root-Port umwandeln, wodurch die Funktion für diesen Port nützlich ist. Führen Sie diesen Befehl aus, um Loop Guard zu aktivieren:
set spantree guard loop mod/port
Netzwerke mit schleifenfreien Topologien können weiterhin vom Schleifenschutz profitieren, wenn Schleifen versehentlich eingeführt werden. Die Aktivierung von Loop Guard in dieser Topologie kann jedoch zu Problemen mit der Netzwerkisolierung führen. Um schleifenfreie Topologien zu erstellen und Probleme mit der Isolierung des Netzwerks zu vermeiden, geben Sie diese Befehle ein, um den Schleifenschutz global oder einzeln zu deaktivieren. Aktivieren Sie Loop Guard nicht auf freigegebenen Links.
-
set spantree global-default loopguard disable !--- This is the global default.
Oder
-
set spantree guard none mod/port !--- This is the default port configuration.
Spanning Tree Root Guard
Mit der Funktion "Root Guard" können Sie die Root Bridge-Platzierung im Netzwerk erzwingen. Root Guard stellt sicher, dass der Port, auf dem Root Guard aktiviert ist, der designierte Port ist. Üblicherweise sind alle Root Bridge-Ports designierte Ports, es sei denn, zwei oder mehr Ports der Root-Bridge sind miteinander verbunden. Wenn die Bridge überlegene STP-BPDUs an einem Port empfängt, der Root Guard aktiviert, verschiebt die Bridge diesen Port in einen Status, der Root-inkonsistent ist. Der Status "Root inkonsistent" entspricht effektiv einem Mithörstatus. Über diesen Port wird kein Verkehr weitergeleitet. Auf diese Weise erzwingt der Root Guard die Position der Root Bridge. Root Guard ist in CatOS für Catalyst 29xx, 4500/4000, 5500/5000 und 6500/6000 ab Softwareversion 6.1.1 verfügbar.
Betriebsübersicht
Root Guard ist ein integrierter STP-Mechanismus. Root Guard verfügt nicht über einen eigenen Timer und ist nur auf den Empfang von BPDU angewiesen. Wenn Root Guard auf einen Port angewendet wird, lässt Root Guard nicht zu, dass ein Port zu einem Root-Port wird. Wenn der Empfang einer BPDU eine Spanning-Tree-Konvergenz auslöst, die dazu führt, dass ein designierter Port zu einem Root-Port wird, wird der Port in einen Root-inkonsistenten Zustand versetzt. Diese Syslog-Meldung zeigt die Aktion an:
%SPANTREE-2-ROOTGUARDBLOCK: Port 1/1 tried to become non-designated in VLAN 77. Moved to root-inconsistent state
Nachdem der Port das Senden besserer BPDUs beendet hat, wird der Port wieder entsperrt. Über STP wechselt der Port vom überwachenden in den lernenden Status und wechselt schließlich in den weiterleitenden Status. Die Erholung erfolgt automatisch, und ein menschliches Eingreifen ist nicht erforderlich. Diese Syslog-Meldung enthält ein Beispiel:
%SPANTREE-2-ROOTGUARDUNBLOCK: Port 1/1 restored in VLAN 77
Root Guard erzwingt die Festlegung eines Ports, und Loop Guard ist nur wirksam, wenn es sich bei dem Port um den Root-Port oder einen alternativen Port handelt. Die beiden Funktionen schließen sich daher gegenseitig aus. Loop Guard und Root Guard können auf einem Port nicht gleichzeitig aktiviert werden.
Weitere Informationen finden Sie unter Spanning Tree Protocol Root Guard Enhancement.
Empfehlung
Cisco empfiehlt, die Root-Guard-Funktion an Ports zu aktivieren, die mit Netzwerkgeräten verbunden sind, die nicht unter direkter administrativer Kontrolle sind. Führen Sie den folgenden Befehl aus, um root guard zu konfigurieren:
set spantree guard root mod/port
EtherChannel
EtherChannel-Technologien ermöglichen das Inverse-Multiplexing mehrerer Kanäle (bis zu acht auf Catalyst 6500/6000) zu einer einzelnen logischen Verbindung. Obwohl sich die Implementierungen der einzelnen Plattformen von denen der nächsten unterscheiden, müssen Sie die allgemeinen Anforderungen kennen:
-
Algorithmus zur statistischen Multiplexierung von Frames über mehrere Kanäle
-
Erstellung eines logischen Ports, sodass eine einzelne STP-Instanz ausgeführt werden kann
-
Ein Channel Management-Protokoll wie PAgP oder Link Aggregation Control Protocol (LACP)
Frame-Multiplexing
EtherChannel umfasst einen Frame-Verteilungsalgorithmus, der Frames effizient über die 10/100- oder Gigabit-Verbindungen der Komponenten multiplexiert. Unterschiede bei den Algorithmen je Plattform ergeben sich aus der Fähigkeit der einzelnen Hardwaretypen, Frame-Header-Informationen zu extrahieren, um die Verteilungsentscheidung zu treffen.
Der Lastverteilungsalgorithmus ist eine globale Option für beide Kanalsteuerungsprotokolle. PAgP und LACP verwenden den Frame-Verteilungsalgorithmus, da der IEEE-Standard keine bestimmten Verteilungsalgorithmen vorschreibt. Jeder Verteilungsalgorithmus stellt jedoch sicher, dass der Algorithmus beim Empfang von Frames nicht zu einer Fehlordnung von Frames führt, die Teil einer bestimmten Konversation oder Duplizierung von Frames sind.
Hinweis: Diese Informationen müssen berücksichtigt werden:
-
Der Catalyst 6500/6000 verfügt über eine neuere Switching-Hardware als der Catalyst 5500/5000 und kann IP Layer 4 (L4)-Informationen mit Leitungsgeschwindigkeit lesen, um eine intelligentere Multiplexing-Entscheidung als einfache MAC L2-Informationen zu treffen.
-
Die Funktionen von Catalyst 5500/5000 hängen vom Vorhandensein eines Ethernet Bundling Chip (EBC) auf dem Modul ab. Der Befehl show port functions mod/port (Portfunktionen anzeigen) bestätigt, was für die einzelnen Ports möglich ist.
In der folgenden Tabelle wird der Frame-Verteilungsalgorithmus für jede aufgelistete Plattform im Detail veranschaulicht:
| Plattform | Channel-Lastenausgleichsalgorithmus |
|---|---|
| Catalyst 5500-/5000-Serie | Ein Catalyst 5500/5000 mit den erforderlichen Modulen ermöglicht das Vorhandensein von zwei bis vier Verbindungen pro FEC1, die sich jedoch im selben Modul befinden müssen. Quell- und Ziel-MAC-Adresspaare bestimmen die für die Frame-Weiterleitung ausgewählte Verbindung. Eine X-OR-Operation wird für die am wenigsten signifikanten zwei Bit der Quell-MAC-Adresse und der Ziel-MAC-Adresse durchgeführt. Dieser Vorgang führt zu einem von vier Ergebnissen: (0 0), (0 1), (1 0) oder (1 1). Jeder dieser Werte verweist auf einen Link im FEC-Paket. Bei einem Fast EtherChannel mit zwei Ports wird im X-OR-Betrieb nur ein Bit verwendet. Es kann vorkommen, dass eine Adresse im Quell-/Zielpaar eine Konstante ist. Das Ziel kann beispielsweise ein Server oder, noch wahrscheinlicher, ein Router sein. In diesem Fall wird statistischer Lastenausgleich verwendet, da die Quelladresse immer unterschiedlich ist. |
| Catalyst 4500-/4000-Serie | Catalyst 4500/4000 EtherChannel verteilt Frames über die Links in einem Kanal (auf einem einzelnen Modul) basierend auf den Bits niedriger Reihenfolge der Quell- und Ziel-MAC-Adressen jedes Frames. Im Vergleich zum Catalyst 5500/5000 ist der Algorithmus komplizierter und verwendet einen deterministischen Hash dieser Felder aus MAC-DA (Byte 3, 5, 6), SA (Byte 3, 5, 6), Eingangsport und VLAN-ID. Die Frame-Verteilungsmethode kann nicht konfiguriert werden. |
| Catalyst 6500-/6000-Serie | Abhängig von der Supervisor Engine-Hardware gibt es zwei Möglichkeiten für Hashing-Algorithmen. Der Hash ist ein in der Hardware implementiertes Polynom 17. Grades, das in allen Fällen die MAC-Adresse, die IP-Adresse oder die IP TCP/UDP2-Portnummer annimmt und den Algorithmus anwendet, um einen Drei-Bit-Wert zu generieren. Dies erfolgt getrennt für Quell- und Zieladressen. Das Ergebnis ist dann XORd, um einen weiteren Drei-Bit-Wert zu generieren, mit dem bestimmt wird, welcher Port im Kanal für die Weiterleitung des Pakets verwendet wird. Die Kanäle beim Catalyst 6500/6000 können zwischen Ports an jedem Modul und bis zu 8 Ports gebildet werden. |
1 FEC = Fast EtherChannel
2 UDP = User Datagram Protocol
Diese Tabelle enthält die von den verschiedenen Catalyst 6500/6000 Supervisor Engine-Modellen unterstützten Verteilungsmethoden und deren Standardverhalten.
| Hardware | Beschreibung | Verteilungsmethoden |
|---|---|---|
| WS-F6020 (L2-Modul) | Early Supervisor Engine 1 | L2-MAC: SA; DA; SA und DA |
| WS-F6020A (L2-Engine) WS-F6K-PFC (L3-Engine) | Später Supervisor Engine 1 und Supervisor Engine 1A/PFC1 | L2-MAC: SA; DA; SA und DA L3-IP: SA; DA; SA und DA (Standard) |
| WS-F6K-PFC2 | Supervisor Engine 2/PFC2 (benötigt CatOS 6.x) | L2-MAC: SA; DA; SA und DA L3-IP: SA; DA; SA und DA (Standard) L4-Sitzung: S-Port; D-Port; S & D-Port (Standard) |
| WS-F6K-PFC3BXL WS-F6K-PFC3B WS-F6K-PFC3A | Supervisor Engine 720/PFC3A (benötigt CatOS 8.1.x) Supervisor Engine 720/Supervisor Engine 32/PFC3B (benötigt CatOS 8.4.x) Supervisor Engine 720/PFC3BXL (benötigt CatOS 8.3.x) | L2-MAC: SA; DA; SA und DA L3-IP: SA; DA; SA und DA (Standard) L4-Sitzung: S-Port; D-Port; S & D-Port IP-VLAN-L4-Sitzung: SA- und VLAN- und S-Port; DA-, VLAN- und D-Port; SA- & DA- & VLAN- & S-Port & D-Port |
Hinweis: Bei der L4-Verteilung verwendet das erste fragmentierte Paket die L4-Verteilung. Alle nachfolgenden Pakete verwenden eine L3-Verteilung.
Weitere Informationen zur EtherChannel-Unterstützung auf anderen Plattformen sowie zur Konfiguration und Fehlerbehebung finden Sie in den folgenden Dokumenten:
-
Grundlegendes zu EtherChannel Load Balancing und Redundanz auf Catalyst Switches
-
Konfigurieren von LACP (802.3ad) zwischen einem Catalyst 6500/6000 und einem Catalyst 4500/4000
Empfehlung
Catalyst Switches der Serien 6500/6000 führen standardmäßig Load Balancing nach IP-Adresse durch. Dies wird in CatOS 5.5 empfohlen, vorausgesetzt, dass IP das dominierende Protokoll ist. Führen Sie diesen Befehl aus, um den Lastenausgleich festzulegen:
set port channel all distribution ip both !--- This is the default.
Die Frame-Verteilung der Catalyst Serien 4500/4000 und 5500/5000 nach L2-MAC-Adresse ist in den meisten Netzwerken akzeptabel. Dieselbe Verbindung wird jedoch für den gesamten Datenverkehr verwendet, wenn nur zwei Hauptgeräte über einen Kanal kommunizieren (da SMAC und DMAC konstant sind). Dies kann in der Regel ein Problem bei der Serversicherung und anderen Übertragungen großer Dateien oder bei einem Übertragungssegment zwischen zwei Routern sein.
Obwohl der logische Aggregat-Port (Aggregat-Port) von SNMP als separate Instanz verwaltet werden kann und aggregierte Durchsatzstatistiken erfasst werden, empfiehlt Cisco dennoch, jede der physischen Schnittstellen separat zu verwalten, um zu überprüfen, wie die Frame-Verteilungsmechanismen funktionieren und ob ein statistischer Lastenausgleich erreicht wird.
Ein neuer Befehl, der Befehl show channel traffic , in CatOS 6.x kann Statistiken zur prozentualen Verteilung einfacher anzeigen, als wenn Sie einzelne Port-Zähler mit dem Befehl show counters mod/port oder dem Befehl show mac mod/port in CatOS 5.x überprüfen. Mit dem neuen Befehl show channel hash in CatOS 6.x können Sie basierend auf dem Verteilungsmodus überprüfen, welcher Port als ausgehender Port für bestimmte Adressen und/oder Portnummern ausgewählt wird. Die entsprechenden Befehle für LACP-Kanäle sind der Befehl show lacp-channel traffic und der Befehl show lacp-channel hash.
Weitere Optionen
Wenn die relativen Einschränkungen von MAC-basierten Algorithmen auf Catalyst 4500/4000 oder Catalyst 5500/5000 ein Problem darstellen und kein guter statistischer Lastenausgleich erreicht wird, sind die folgenden Schritte möglich:
-
Catalyst 6500/6000 Switches mit Point-Bereitstellung
-
Erhöhen Sie die Bandbreite ohne Channeling, indem Sie beispielsweise von mehreren FE-Ports zu einem GE-Port oder von mehreren GE-Ports zu einem 10 GE-Port wechseln.
-
Paare von Endstationen mit großen Volumenströmen neu adressieren
-
Bereitstellung dedizierter Verbindungen/VLANs für Geräte mit hoher Bandbreite
Richtlinien und Einschränkungen für die EtherChannel-Konfiguration
EtherChannel überprüft die Port-Eigenschaften aller physischen Ports, bevor kompatible Ports zu einem einzelnen logischen Port zusammengeführt werden. Konfigurationsrichtlinien und -einschränkungen variieren je nach Switch-Plattform. Befolgen Sie die Richtlinien, um Bündelungsprobleme zu vermeiden. Wenn beispielsweise QoS aktiviert ist, bilden sich bei der Bündelung der Catalyst Switching-Module der Serien 6500/6000 mit unterschiedlichen QoS-Funktionen keine EtherChannels. In Cisco IOS Software können Sie die QoS-Portattributüberprüfung für den EtherChannel im Paket mit dem Schnittstellenbefehl no mls qos channel-consistency port-channel deaktivieren. Ein entsprechender Befehl zum Deaktivieren der QoS-Port-Attributprüfung ist in CatOS nicht verfügbar. Sie können den Befehl show port ability mod/port ausführen, um die QoS-Portfunktion anzuzeigen und festzustellen, ob die Ports kompatibel sind.
Befolgen Sie diese Richtlinien für verschiedene Plattformen, um Konfigurationsprobleme zu vermeiden:
-
Der Abschnitt EtherChannel-Konfigurationsrichtlinien zur Konfiguration von EtherChannel (Catalyst 6500/6000)
-
Im Abschnitt Konfigurationsrichtlinien und -beschränkungen für den EtherChannel der Konfiguration von Fast EtherChannel und Gigabit EtherChannel (Catalyst 4500/4000)
-
Im Abschnitt Konfigurationsrichtlinien und -beschränkungen für den EtherChannel der Konfiguration von Fast EtherChannel und Gigabit EtherChannel (Catalyst 5000)
Hinweis: Die maximale Anzahl von Port-Channels, die vom Catalyst 4000 unterstützt werden, beträgt 126. Bei Softwareversionen 6.2(1) und früher unterstützen die Catalyst Switches der Serie 6500 mit sechs oder neun Steckplätzen maximal 128 EtherChannels. In Softwareversion 6.2(2) und höheren Versionen verarbeitet die Spanning Tree-Funktion die Port-ID. Aus diesem Grund beträgt die maximale Anzahl unterstützter EtherChannels 126 für ein Chassis mit sechs oder neun Steckplätzen und 63 für ein Chassis mit 13 Steckplätzen.
Port-Aggregationsprotokoll
PAgP ist ein Verwaltungsprotokoll, das die Parameterkonsistenz an beiden Enden der Verbindung prüft und den Kanal bei der Anpassung an einen Verbindungsausfall oder eine Verbindungserweiterung unterstützt. Beachten Sie folgende Fakten zum PAgP:
-
PAgP erfordert, dass alle Ports im Kanal zum gleichen VLAN gehören oder als Trunk-Ports konfiguriert sind. (Da dynamische VLANs die Änderung eines Ports in ein anderes VLAN erzwingen können, sind sie nicht in der EtherChannel-Teilnahme enthalten.)
-
Wenn ein Paket bereits vorhanden ist und die Konfiguration eines Ports geändert wird (z. B. durch Ändern des VLAN- oder Trunking-Modus), werden alle Ports im Paket entsprechend dieser Konfiguration geändert.
-
PAgP gruppiert keine Ports, die mit unterschiedlichen Geschwindigkeiten oder Portduplex betrieben werden. Wenn Geschwindigkeit und Duplex geändert werden, sobald ein Paket vorhanden ist, ändert PAgP die Portgeschwindigkeit und die Duplexfunktion für alle Ports im Paket.
Betriebsübersicht
Der PAgP-Port steuert alle zu gruppierenden physischen (oder logischen) Ports. PAgP-Pakete werden mit derselben Multicast-Gruppen-MAC-Adresse gesendet, die auch für CDP-Pakete verwendet wird: 01-00-0c-cc-cc-cc. Der Protokollwert ist 0x0104. Dies ist eine Zusammenfassung der Protokolloperation:
-
Solange der physische Port aktiv ist, werden während der Erkennung jede Sekunde und im Dauerbetrieb alle 30 Sekunden PAgP-Pakete übertragen.
-
Das Protokoll wartet auf PAgP-Pakete, die bestätigen, dass der physische Port eine bidirektionale Verbindung zu einem anderen PAgP-fähigen Gerät hat.
-
Wenn Datenpakete, aber keine PAgP-Pakete empfangen werden, wird davon ausgegangen, dass der Port mit einem nicht PAgP-fähigen Gerät verbunden ist.
-
Sobald zwei PAgP-Pakete an einer Gruppe physischer Ports empfangen wurden, versucht das System, einen aggregierten Port zu bilden.
-
Wenn PAgP-Pakete für einen bestimmten Zeitraum angehalten werden, wird der PAgP-Status deaktiviert.
Normale Verarbeitung
Diese Konzepte müssen definiert werden, um das Protokollverhalten besser zu verstehen:
-
Agport - ein logischer Port, der sich aus allen physischen Ports in derselben Aggregation zusammensetzt und durch einen eigenen SNMP ifIndex identifiziert werden kann. Daher enthält ein Port keine nicht betriebsbereiten Ports.
-
Kanal: eine Aggregation, die die Bildungskriterien erfüllt; Es könnte daher nicht betriebsfähige Ports enthalten (Ports sind eine Untergruppe von Kanälen). Protokolle wie STP und VTP, jedoch mit Ausnahme von CDP und DTP, werden oberhalb von PAgP über die Ports ausgeführt. Keines dieser Protokolle kann Pakete senden oder empfangen, bis PAgP seine AgPorts an einen oder mehrere physische Ports anfügt.
-
Gruppenkapazität: Jeder physische Port und Agport verfügt über einen Konfigurationsparameter, der als Gruppenkapazität bezeichnet wird. Ein physischer Port kann nur dann mit einem anderen physischen Port aggregiert werden, wenn diese dieselben Gruppenfunktionen aufweisen.
-
Aggregationsverfahren - Wenn ein physischer Port den UpData- oder UpPAgP-Status erreicht, wird er an einen geeigneten Aggregationsvorgang angeschlossen. Wenn es einen dieser Staaten in einen anderen Staat verlässt, wird es vom Hafen getrennt.
Die Definitionen der Zustände und die Erstellungsverfahren sind in dieser Tabelle enthalten:
| Status | Bedeutung |
|---|---|
| UpData | Es wurden keine PAgP-Pakete empfangen. PAgP-Pakete werden gesendet. Der physische Port ist der einzige, der mit seinem Port verbunden ist. Nicht-PAgP-Pakete werden zwischen dem physischen Port und einem Port hin- und hergeleitet. |
| BiDir | Es wurde genau ein PAgP-Paket empfangen, das belegt, dass zu genau einem Nachbarn eine bidirektionale Verbindung besteht. Der physische Port ist mit keinem Port verbunden. PAgP-Pakete werden gesendet und können empfangen werden. |
| Nach obenPAgP | Dieser physische Port ist, möglicherweise in Verbindung mit anderen physischen Ports, mit einem Port verbunden. PAgP-Pakete werden über den physischen Port gesendet und empfangen. Nicht-PAgP-Pakete werden zwischen dem physischen Port und einem Port hin- und hergeleitet. |
Beide Enden beider Verbindungen müssen sich auf die Gruppierung einigen, d. h. die größte Gruppe von Ports im Port, die von beiden Enden der Verbindung zugelassen wird.
Wenn ein physischer Port den UpPAgP-Status erreicht, wird er dem Port zugewiesen, der über physische Mitglieds-Ports verfügt, die den Gruppenfunktionen des neuen physischen Ports entsprechen und sich im BiDir- oder UpPAgP-Status befinden. (Alle BiDir-Ports werden gleichzeitig in den UpPAgP-Status verschoben.) Wenn es keinen Agport gibt, dessen physische Port-Parameter mit dem neu einsatzbereiten physischen Port kompatibel sind, wird er einem Agport mit geeigneten Parametern zugewiesen, dem keine physischen Ports zugeordnet sind.
Ein PAgP-Timeout kann bei dem letzten Nachbarn auftreten, der auf dem physischen Port bekannt ist. Das Port-Timing-Out wird aus dem Port entfernt. Gleichzeitig werden alle physischen Ports im selben Port entfernt, deren Timer ebenfalls abgelaufen sind. Auf diese Weise kann ein Hafen, dessen anderes Ende verendet ist, auf einmal abgerissen werden, und nicht auf einmal.
Verhalten bei Fehlern
Wenn eine Verbindung in einem vorhandenen Kanal ausfällt (z. B. Port nicht angeschlossen, Gigabit Interface Converter [GBIC] entfernt oder Glasfaserverbindung unterbrochen), wird der Agport aktualisiert, und der Datenverkehr wird innerhalb einer Sekunde über die verbleibenden Verbindungen gehasht. Datenverkehr, der nach dem Ausfall nicht neu gestartet werden muss (Datenverkehr, der weiterhin über dieselbe Verbindung sendet), hat keinen Verlust. Die Wiederherstellung der ausgefallenen Verbindung löst eine weitere Aktualisierung des Ports aus, und der Datenverkehr wird erneut gehasht.
Hinweis: Das Verhalten bei einem Verbindungsausfall in einem Kanal aufgrund einer Abschaltung oder des Entfernens eines Moduls kann unterschiedlich sein. Ein Kanal muss per Definition zwei physische Ports aufweisen. Wenn in einem Channel mit zwei Ports ein Port aus dem System verloren geht, wird der logische Agport heruntergefahren und der ursprüngliche physische Port in Bezug auf Spanning Tree neu initialisiert. Das bedeutet, dass Datenverkehr verworfen werden kann, bis er für Daten über STP wieder verfügbar ist.
Es gibt eine Ausnahme zu dieser Regel für den Catalyst 6500/6000. In früheren Versionen als CatOS 6.3 wird ein Port während des Modulentfernens nicht heruntergefahren, wenn der Kanal nur aus Ports auf den Modulen 1 und 2 besteht.
Dieser Unterschied zwischen den beiden Fehlermodi ist wichtig, wenn die Wartung eines Netzwerks geplant ist, da eine STP-TCN berücksichtigt werden kann, wenn ein Modul online entfernt oder eingefügt wird. Wie bereits erwähnt, ist es wichtig, jede physische Verbindung im Kanal mit dem NMS zu verwalten, da ein Ausfall zu Unterbrechungen führen kann.
Um unerwünschte Topologieänderungen auf dem Catalyst 6500/6000 zu vermeiden, werden folgende Schritte vorgeschlagen:
-
Wird ein einzelner Port pro Modul verwendet, um einen Kanal zu bilden, müssen drei oder mehr Module verwendet werden (drei oder mehr Ports insgesamt).
-
Wenn der Kanal zwei Module umfasst, müssen zwei Ports auf jedem Modul verwendet werden (insgesamt vier Ports).
-
Wenn für zwei Karten ein Kanal mit zwei Ports erforderlich ist, verwenden Sie nur die Ports der Supervisor Engine.
-
Führen Sie ein Upgrade auf CatOS 6.3 durch, das das Entfernen von Modulen ohne STP-Neuberechnung für auf Module aufgeteilte Kanäle behandelt.
Konfigurationsoptionen
EtherChannels können in verschiedenen Modi konfiguriert werden, wie in der folgenden Tabelle zusammengefasst:
| Modus | Konfigurierbare Optionen |
|---|---|
| On | PAgP ist nicht in Betrieb. Der Port kanalisiert, unabhängig davon, wie der Nachbar-Port konfiguriert ist. Wenn der Nachbarport-Modus aktiviert ist, wird ein Kanal gebildet. |
| Aus | Der Port kanalisiert nicht, unabhängig davon, wie der Nachbar konfiguriert ist. |
| auto (Standard) | Die Aggregation erfolgt über das PAgP-Protokoll. Versetzt einen Port in einen passiven Verhandlungsstatus, und an der Schnittstelle werden keine PAgP-Pakete gesendet, bis mindestens ein PAgP-Paket empfangen wird, das anzeigt, dass der Sender im gewünschten Modus arbeitet. |
| Desirable (gewünscht) | Die Aggregation erfolgt über das PAgP-Protokoll. Versetzt einen Port in einen aktiven Verhandlungsstatus, in dem der Port Verhandlungen mit anderen Ports durch Senden von PAgP-Paketen initiiert. Ein Kanal wird mit einer anderen Port-Gruppe entweder im erwünschten oder im automatischen Modus gebildet. |
| Non-Silent (Standard für Catalyst 5500/5000 Glasfaser-FE- und GE-Ports) | Ein auto- oder erwünschter Modus-Schlüsselwort. Wenn auf der Schnittstelle keine Datenpakete empfangen werden, ist die Schnittstelle niemals an einen Port angeschlossen und kann nicht für Daten verwendet werden. Diese Prüfung der Bidirektionalität wurde für bestimmte Catalyst 5500/5000-Hardware durchgeführt, da bei einigen Verbindungsfehlern der Kanal unterbrochen wird. Da der Non-Silent-Modus aktiviert ist, darf ein sich erholender Nachbar-Port nie wieder hochfahren und den Kanal unnötig auseinanderbrechen. Flexiblere Paketangebote und verbesserte Prüfungen der Bidirektionalität sind bei Hardware der Catalyst Serien 4500/4000 und 6500/6000 standardmäßig enthalten. |
| Silent (Standard für alle Catalyst 6500/6000- und 4500/4000-Ports und 5500/5000-Kupfer-Ports) | Ein auto- oder erwünschter Modus-Schlüsselwort. Werden an der Schnittstelle keine Datenpakete empfangen, so ist die Schnittstelle nach einer 15-sekündigen Zeitüberschreitung selbstständig an einen Aport angeschlossen und kann somit zur Datenübertragung genutzt werden. Der Silent-Modus ermöglicht auch einen Channel-Betrieb, wenn der Partner ein Analyzer oder Server sein kann, der niemals PAgP sendet. |
Die Einstellungen silent/non-silent beeinflussen, wie Ports auf Situationen reagieren, die unidirektionalen Datenverkehr verursachen, oder wie sie einen Failover erreichen. Wenn ein Port nicht senden kann (z. B. aufgrund eines ausgefallenen physischen Sublayers [PHY] oder aufgrund einer defekten Glasfaser oder eines defekten Kabels), kann dies dazu führen, dass der benachbarte Port weiterhin betriebsbereit ist. Der Partner überträgt weiterhin Daten, aber Daten gehen verloren, da kein Datenrückverkehr empfangen werden kann. Spanning Tree-Schleifen können sich auch aufgrund der unidirektionalen Natur der Verbindung bilden.
Einige Glasfaserports haben die gewünschte Fähigkeit, den Port in einen betriebsunfähigen Zustand zu versetzen, wenn das Empfangssignal (FEFI) verloren geht. Dies führt dazu, dass der Partner-Port nicht mehr funktionsfähig ist und die Ports an beiden Enden der Verbindung effektiv ausfallen.
Wenn Geräte verwendet werden, die Daten übertragen (z. B. BPDUs) und unidirektionale Bedingungen nicht erkennen können, muss der Non-Silent-Modus verwendet werden, damit die Ports so lange nicht betriebsbereit sind, bis Empfangsdaten vorliegen und die Verbindung auf bidirektionale Verbindungen überprüft wurde. Die Zeit, die PAgP benötigt, um eine unidirektionale Verbindung zu erkennen, beträgt etwa 3,5 x 30 Sekunden = 105 Sekunden, wobei 30 Sekunden die Zeit zwischen zwei aufeinander folgenden PAgP-Nachrichten sind. UDLD wird als schnellerer Detektor für unidirektionale Verbindungen empfohlen.
Wenn Geräte verwendet werden, die keine Daten übertragen, muss der unbeaufsichtigte Modus verwendet werden. Dies zwingt den Port, eine Verbindung herzustellen und den Betrieb aufzunehmen, unabhängig davon, ob empfangene Daten vorhanden sind oder nicht. Darüber hinaus wird für Ports, die unidirektionale Zustände erkennen können, z. B. neuere Plattformen, die L1 FEFI und UDLD verwenden, standardmäßig der stille Modus verwendet.
Verifizierung
In der Tabelle ist eine Zusammenfassung aller möglichen PAgP-Channeling-Modus-Szenarien zwischen zwei direkt verbundenen Switches (Switch-A und Switch-B) dargestellt. Einige dieser Kombinationen können dazu führen, dass STP die Ports auf der Channeling-Seite in den deaktivierten Zustand versetzt (d. h., einige der Kombinationen deaktivieren die Ports auf der Channeling-Seite).
| Channel-Modus von Switch-A | Channel-Modus von Switch-B | Channel-Status |
|---|---|---|
| On | On | Kanal (nicht PAgP) |
| On | Aus | Not Channel (errdisable) |
| On | Auto (automatisch) | Not Channel (errdisable) |
| On | Desirable (gewünscht) | Not Channel (errdisable) |
| Aus | On | Not Channel (errdisable) |
| Aus | Aus | Not Channel |
| Aus | Auto (automatisch) | Not Channel |
| Aus | Desirable (gewünscht) | Not Channel |
| Auto (automatisch) | On | Not Channel (errdisable) |
| Auto (automatisch) | Aus | Not Channel |
| Auto (automatisch) | Auto (automatisch) | Not Channel |
| Auto (automatisch) | Desirable (gewünscht) | PAgP-Kanal |
| Desirable (gewünscht) | On | Not Channel (errdisable) |
| Desirable (gewünscht) | Aus | Not Channel |
| Desirable (gewünscht) | Auto (automatisch) | PAgP-Kanal |
| Desirable (gewünscht) | Desirable (gewünscht) | PAgP-Kanal |
Empfehlung
Cisco empfiehlt, PAgP für alle Switch-to-Switch-Kanalverbindungen zu aktivieren, sodass der Ein-Modus vermieden wird. Die bevorzugte Methode besteht darin, den gewünschten Modus an beiden Enden einer Verbindung festzulegen. Es wird außerdem empfohlen, das Schlüsselwort silent/non-silent standardmäßig beizubehalten - silent auf Catalyst 6500/6000- und 4500/4000-Switches, non-silent auf Catalyst 5500/5000-Glasfaserports.
Wie in diesem Dokument beschrieben, ist die explizite Konfiguration des Channeling-Off-Zugriffs auf allen anderen Ports für eine schnelle Datenweiterleitung hilfreich. Es muss vermieden werden, auf einen Port, der nicht für das Channeling verwendet werden soll, bis zur Zeitüberschreitung für PAgP mit 15 Sekunden zu warten, zumal der Port dann an STP übergeben wird, das selbst 30 Sekunden für die Datenweiterleitung benötigen kann, plus möglicherweise 5 Sekunden für DTP für insgesamt 50 Sekunden. Der Befehl set port host wird im STP-Abschnitt dieses Dokuments genauer beschrieben.
set port channel port range mode desirable set port channel port range mode off !--- Ports not channeled; part of the set port hostcommand.
Mit diesem Befehl wird Channels eine Admin-Gruppennummer zugewiesen, wie mit dem Befehl show channel group angezeigt. Das Hinzufügen und Entfernen von Channeling-Ports zum gleichen Port kann dann bei Bedarf über die Administratornummer verwaltet werden.
Weitere Optionen
Eine weitere gängige Konfiguration für Kunden, die ein Modell mit minimalem Administrationsaufwand auf dem Access Layer haben, besteht darin, den Modus auf dem Distribution Layer und dem Core Layer auf den gewünschten Modus zu setzen und die Access Layer-Switches auf der automatischen Standardkonfiguration zu belassen.
Beim Channeling zu Geräten, die PAgP nicht unterstützen, muss der Kanal eingeschaltet sein. Dies gilt für Geräte wie Server, Local Director, Content-Switches, Router, Switches mit älterer Software, Catalyst XL-Switches und Catalyst 8540s. Führen Sie folgenden Befehl aus,
set port channel port range mode on
Der neue 802.3ad IEEE LACP-Standard, der in CatOS 7.x verfügbar ist, wird PAgP wahrscheinlich langfristig ersetzen, da er die Vorteile der plattform- und anbieterübergreifenden Interoperabilität bietet.
Link Aggregation Control Protocol
LACP ist ein Protokoll, das es Ports mit ähnlichen Eigenschaften ermöglicht, durch dynamische Aushandlung mit angrenzenden Switches einen Kanal zu bilden. PAgP ist ein proprietäres Protokoll von Cisco, das nur auf Cisco Switches und Switches ausgeführt werden kann, die von lizenzierten Anbietern bereitgestellt werden. Das in IEEE 802.3ad definierte LACP ermöglicht es Cisco Switches jedoch, das Ethernet-Channeling mit Geräten zu verwalten, die der 802.3ad-Spezifikation entsprechen. Mit den Softwareversionen von CatOS 7.x wurde die LACP-Unterstützung eingeführt.
In funktioneller Hinsicht gibt es zwischen LACP und PAgP nur einen sehr geringen Unterschied. Beide Protokolle unterstützen maximal acht Ports in jedem Kanal, und vor der Bündelung werden die gleichen Port-Eigenschaften überprüft. Zu diesen Port-Eigenschaften gehören:
-
Geschwindigkeit
-
Duplex
-
Natives VLAN
-
Trunking-Typ
Die wichtigsten Unterschiede zwischen LACP und PAgP sind:
-
LACP kann nur auf Vollduplex-Ports ausgeführt werden, und LACP unterstützt keine Halbduplex-Ports.
-
LACP unterstützt Hot-Standby-Ports. LACP versucht immer, die maximale Anzahl kompatibler Ports in einem Kanal zu konfigurieren, bis zu der maximalen Anzahl, die die Hardware zulässt (acht Ports). Wenn LACP nicht in der Lage ist, alle kompatiblen Ports zu aggregieren, werden alle Ports, die nicht aktiv in den Kanal eingebunden werden können, in den Hot-Standby-Status versetzt und nur verwendet, wenn einer der verwendeten Ports ausfällt. Ein Beispiel für eine Situation, in der LACP nicht alle kompatiblen Ports aggregieren kann, ist, wenn das Remote-System restriktivere Hardware-Einschränkungen aufweist.
Hinweis: In CatOS kann ein Verwaltungsschlüssel maximal acht Ports zugewiesen werden. In der Cisco IOS Software versucht LACP, die maximale Anzahl kompatibler Ports in einem EtherChannel zu konfigurieren, und zwar bis zu der maximalen Anzahl, die die Hardware zulässt (acht Ports). Weitere acht Ports können als Hot-Standby-Ports konfiguriert werden.
Betriebsübersicht
Das LACP steuert jeden einzelnen physischen (oder logischen) Port, der gebündelt werden soll. LACP-Pakete werden unter Verwendung der Multicast-Gruppen-MAC-Adresse 01-80-c2-00-00-02 gesendet. Der Typ-/Feldwert ist 0x8809 mit dem Subtyp 0x01. Es folgt eine Zusammenfassung des Protokollvorgangs:
-
Das Protokoll setzt voraus, dass die Geräte ihre Aggregationsfunktionen und Statusinformationen melden. Die Übertragungen werden regelmäßig über jede "aggregierbare" Verbindung gesendet.
-
Solange der physische Port aktiv ist, werden die LACP-Pakete während der Erkennung jede Sekunde und im Dauerzustand alle 30 Sekunden übertragen.
-
Die Partner eines "aggregierbaren" Links hören sich die Informationen an, die innerhalb des Protokolls gesendet werden, und entscheiden, welche Maßnahmen sie ergreifen möchten.
-
Kompatible Ports werden in einem Kanal konfiguriert, bis zu der maximalen Anzahl, die die Hardware zulässt (acht Ports).
-
Die Aggregationen werden durch den regelmäßigen, rechtzeitigen Austausch aktueller Zustandsinformationen zwischen den Link-Partnern verwaltet. Wenn sich die Konfiguration ändert (z. B. aufgrund eines Verbindungsausfalls), setzen die Protokollpartner eine Zeitüberschreitung durch und ergreifen auf Basis des neuen Systemstatus die entsprechenden Maßnahmen.
-
Neben periodischen LACP Data Unit (LACPDU)-Übertragungen überträgt das Protokoll bei einer Änderung der Zustandsinformationen eine ereignisgesteuerte LACPDU an den Partner. Die Partner des Protokolls treffen die geeigneten Maßnahmen auf der Grundlage des neuen Zustands des Systems.
LACP-Parameter
Damit LACP bestimmen kann, ob eine Gruppe von Links mit demselben System verbunden ist und ob diese Links hinsichtlich der Aggregation kompatibel sind, müssen die folgenden Parameter festgelegt werden:
-
Eine global eindeutige Kennung für jedes System, das an der Link-Aggregation teilnimmt
Jedem System, auf dem LACP ausgeführt wird, muss eine Priorität zugewiesen werden, die entweder automatisch oder vom Administrator ausgewählt werden kann. Die Standard-Systempriorität ist 32768. Die Systempriorität wird hauptsächlich in Verbindung mit der MAC-Adresse des Systems verwendet, um die Systemkennung zu bilden.
-
Ein Mittel zur Identifizierung der Funktionen, die jedem Port und jedem Aggregator zugeordnet sind, sofern ein bestimmtes System sie versteht
Jedem Port im System muss entweder automatisch oder vom Administrator eine Priorität zugewiesen werden. Der Standardwert ist 128. Die Priorität wird zusammen mit der Portnummer verwendet, um die Port-ID zu bilden.
-
Mittel zur Identifizierung einer Verbindungsaggregationsgruppe und ihr zugehöriger Aggregator
Die Aggregationsfähigkeit eines Ports mit einem anderen wird durch einen einfachen 16-Bit-Ganzzahlparameter zusammengefasst, der strikt größer als Null ist. Dieser Parameter wird als "Schlüssel" bezeichnet. Die einzelnen Schlüsselfaktoren werden durch unterschiedliche Faktoren bestimmt, z. B.:
-
Die physischen Merkmale des Ports, darunter:
-
Datenrate
-
Duplexität
-
Point-to-Point- oder gemeinsam genutztes Medium
-
-
Konfigurationsbeschränkungen, die der Netzwerkadministrator festlegt
Jedem Port sind zwei Schlüssel zugeordnet:
-
Ein administrativer Schlüssel - Dieser Schlüssel ermöglicht die Manipulation von Schlüsselwerten durch die Verwaltung. Ein Benutzer kann diesen Schlüssel auswählen.
-
Ein Betriebsschlüssel - Das System verwendet diesen Schlüssel, um Aggregationen zu bilden. Ein Benutzer kann diesen Schlüssel nicht auswählen oder direkt ändern.
Die Gruppe von Ports in einem System, die denselben Betriebsschlüsselwert nutzen, gehört derselben Schlüsselgruppe an.
-
Wenn Sie zwei Systeme und eine Gruppe von Ports mit demselben Verwaltungsschlüssel haben, versucht jedes System, die Ports zu aggregieren. Jedes System startet am Port mit der höchsten Priorität im System mit der höchsten Priorität. Dieses Verhalten ist möglich, da jedes System seine eigene Priorität, die entweder vom Benutzer oder vom System zugewiesen wurde, und seine Partnerpriorität kennt, die durch LACP-Pakete erkannt wurde.
Verhalten bei Fehlern
Das Fehlerverhalten für LACP entspricht dem für PAgP. Wenn eine Verbindung in einem vorhandenen Kanal ausfällt, wird der Agport aktualisiert, und der Datenverkehr wird innerhalb einer Sekunde über die verbleibenden Verbindungen gehasht. Ein Link kann aus diesen und anderen Gründen fehlschlagen:
-
Ein Port ist nicht angeschlossen.
-
Ein GBIC wird entfernt.
-
Eine Glasfaser ist defekt.
-
Hardwarefehler (Schnittstelle oder Modul)
Datenverkehr, der nach dem Ausfall nicht neu gestartet werden muss (Datenverkehr, der weiterhin über dieselbe Verbindung sendet), hat keinen Verlust. Die Wiederherstellung der ausgefallenen Verbindung löst eine weitere Aktualisierung des Ports aus, und der Datenverkehr wird erneut gehasht.
Konfigurationsoptionen
LACP-EtherChannels können in verschiedenen Modi konfiguriert werden, wie in der folgenden Tabelle zusammengefasst:
| Modus | Konfigurierbare Optionen |
|---|---|
| On | Die Verbindungsaggregation muss ohne LACP-Aushandlung gebildet werden. Der Switch sendet weder das LACP-Paket noch verarbeitet er ein eingehendes LACP-Paket. Wenn der Nachbarport-Modus aktiviert ist, wird ein Kanal gebildet. |
| Aus | Der Port kanalisiert nicht, unabhängig von der Konfiguration des Nachbarn. |
| Passiv (Standard) | Dies ist mit dem Modus auto bei PAgP vergleichbar. Der Switch initiiert den Kanal nicht, versteht jedoch eingehende LACP-Pakete. Der Peer (im aktiven Zustand) initiiert die Aushandlung durch Senden eines LACP-Pakets. Der Switch empfängt und beantwortet das Paket und bildet schließlich den Aggregationskanal mit dem Peer. |
| Aktiv | Dies ähnelt dem erwünschten Modus in PAgP. Der Switch initiiert die Verhandlung, um eine AgLink-Verbindung zu bilden. Das Verbindungsaggregat wird gebildet, wenn das andere Ende im aktiven oder passiven LACP-Modus ausgeführt wird. |
Überprüfung (LACP und LACP)
Die Tabelle in diesem Abschnitt zeigt eine Übersicht über alle möglichen LACP-Channeling-Modus-Szenarien zwischen zwei direkt verbundenen Switches (Switch-A und Switch-B). Einige dieser Kombinationen können dazu führen, dass STP die Ports auf der Channeling-Seite in den errdisable-Status versetzt. Das bedeutet, dass einige der Kombinationen die Ports auf der Channeling-Seite schließen.
| Channel-Modus von Switch-A | Channel-Modus von Switch-B | Switch-A Channel-Status | Switch-B Channel-Status |
|---|---|---|---|
| On | On | Kanal (ohne LACP) | Kanal (ohne LACP) |
| On | Aus | Not Channel (errdisable) | Not Channel |
| On | Passive | Not Channel (errdisable) | Not Channel |
| On | Aktiv | Not Channel (errdisable) | Not Channel |
| Aus | Aus | Not Channel | Not Channel |
| Aus | Passive | Not Channel | Not Channel |
| Aus | Aktiv | Not Channel | Not Channel |
| Passive | Passive | Not Channel | Not Channel |
| Passive | Aktiv | LACP-Kanal | LACP-Kanal |
| Aktiv | Aktiv | LACP-Kanal | LACP-Kanal |
Verifizierung (LACP und PAgP)
Die Tabelle in diesem Abschnitt zeigt eine Zusammenfassung aller möglichen Szenarien für den LACP-zu-PAgP-Channeling-Modus zwischen zwei direkt verbundenen Switches (Switch-A und Switch-B). Einige dieser Kombinationen können dazu führen, dass STP die Ports auf der Channeling-Seite in den errdisable-Status versetzt. Das bedeutet, dass einige der Kombinationen die Ports auf der Channeling-Seite schließen.
| Channel-Modus von Switch-A | Channel-Modus von Switch-B | Switch-A Channel-Status | Switch-B Channel-Status |
|---|---|---|---|
| On | On | Kanal (ohne LACP) | Kanal (nicht PAgP) |
| On | Aus | Not Channel (errdisable) | Not Channel |
| On | Auto (automatisch) | Not Channel (errdisable) | Not Channel |
| On | Desirable (gewünscht) | Not Channel (errdisable) | Not Channel |
| Aus | On | Not Channel | Not Channel (errdisable) |
| Aus | Aus | Not Channel | Not Channel |
| Aus | Auto (automatisch) | Not Channel | Not Channel |
| Aus | Desirable (gewünscht) | Not Channel | Not Channel |
| Passive | On | Not Channel | Not Channel (errdisable) |
| Passive | Aus | Not Channel | Not Channel |
| Passive | Auto (automatisch) | Not Channel | Not Channel |
| Passive | Desirable (gewünscht) | Not Channel | Not Channel |
| Aktiv | On | Not Channel | Not Channel (errdisable) |
| Aktiv | Aus | Not Channel | Not Channel |
| Aktiv | Auto (automatisch) | Not Channel | Not Channel |
| Aktiv | Desirable (gewünscht) | Not Channel | Not Channel |
Empfehlung
Cisco empfiehlt, PAgP für Kanalverbindungen zwischen Cisco Switches zu aktivieren. Wenn Sie Geräte anschließen, die PAgP nicht unterstützen, aber LACP unterstützen, aktivieren Sie LACP durch die Konfiguration von LACP, das auf beiden Enden der Geräte aktiv ist. Wenn LACP oder PAgP von beiden Endgeräten nicht unterstützt werden, müssen Sie den Kanal fest auf on programmieren.
-
set channelprotocol lacp module
Auf Switches mit CatOS verwenden alle Ports auf einem Catalyst 4500/4000 und einem Catalyst 6500/6000 standardmäßig das Kanalprotokoll PAgP und führen daher kein LACP aus. Damit die Ports für die Verwendung von LACP konfiguriert werden können, müssen Sie das Kanalprotokoll auf den Modulen auf LACP festlegen. LACP und PAgP können nicht auf Switches ausgeführt werden, die CatOS ausführen.
-
set port lacp-channel port_range admin-key
Im LACP-Paket wird ein Parameter für den Admin-Schlüssel (Administrator-Schlüssel) ausgetauscht. Zwischen Ports mit demselben Administratorschlüssel wird nur ein Kanal gebildet. Der Befehl set port lacp-channel port_range admin-key weist den Kanälen eine Admin-Schlüsselnummer zu. Der Befehl show lacp-channel group zeigt die Nummer an. Der Befehl set port lacp-channel port_range admin-key weist allen Ports im Port-Bereich denselben Admin-Schlüssel zu. Der Administrator-Schlüssel wird nach dem Zufallsprinzip zugewiesen, wenn kein bestimmter Schlüssel konfiguriert wurde. Anschließend können Sie bei Bedarf auf den Admin-Schlüssel zurückgreifen, um das Hinzufügen und Entfernen von Channeling-Ports zum gleichen Port zu verwalten.
-
set port lacp-channel port_range mode activeMit dem Befehl set port lacp-channel port_range mode active wird der Channel-Modus für eine Reihe von Ports, denen zuvor derselbe Admin-Schlüssel zugewiesen wurde, in aktiv geändert.
Darüber hinaus verwendet LACP einen 30-Sekunden-Intervalltimer (Slow_Periodic_Time), nachdem die LACP-EtherChannels eingerichtet wurden. Die Anzahl der Sekunden vor der Ungültigerklärung empfangener LACPDU-Informationen unter Verwendung langer Zeitüberschreitungen (3 x Slow_Periodic_Time) beträgt 90. Verwenden Sie UDLD, das ein schnellerer Detektor unidirektionaler Verbindungen ist. Die LACP-Timer können nicht angepasst werden. Derzeit ist es nicht möglich, die Switches so zu konfigurieren, dass sie die schnelle PDU-Übertragung (jede Sekunde) verwenden, um den Kanal nach der Kanalbildung aufrechtzuerhalten.
Weitere Optionen
Wenn Sie ein Modell mit minimalem Verwaltungsaufwand auf dem Access-Layer haben, ist es eine gängige Konfiguration, den Modus auf dem Distribution- und Core-Layer aktiv zu setzen. Belassen Sie die Access-Layer-Switches bei der passiven Standardkonfiguration.
Unidirektionale Verbindungserkennung
UDLD ist ein proprietäres, schlankes Protokoll von Cisco, das entwickelt wurde, um Instanzen unidirektionaler Kommunikation zwischen Geräten zu erkennen. Obwohl es andere Methoden wie FEFI gibt, um den bidirektionalen Zustand von Übertragungsmedien zu erfassen, gibt es bestimmte Fälle, in denen die L1-Erkennungsmechanismen nicht ausreichen. Diese Szenarien können zu einem der folgenden Ereignisse führen:
-
Der unvorhersehbare Betrieb von STP
-
Falsches oder übermäßiges Flooding von Paketen
-
Das schwarze Loch im Verkehr
Die UDLD-Funktion soll diese Fehlerbedingungen an Glasfaser- und Kupfer-Ethernet-Schnittstellen beheben:
-
Überwachen Sie die physischen Kabelkonfigurationen, und deaktivieren Sie alle falsch verdrahteten Ports als errdisable.
-
Schutz vor unidirektionalen Links. Wenn aufgrund einer Medien- oder Port-/Schnittstellenfehlfunktion eine unidirektionale Verbindung erkannt wird, wird der betroffene Port als errdisable deaktiviert und eine entsprechende Syslog-Meldung generiert.
-
Darüber hinaus prüft der aggressive UDLD-Modus, ob eine Verbindung, die zuvor als bidirektional galt, während einer Überlastung nicht die Verbindung verliert und unbrauchbar wird. UDLD führt fortlaufende Verbindungstests für die Verbindung durch. Der Hauptzweck des aggressiven UDLD-Modus besteht darin, unter bestimmten Fehlerbedingungen ein Blackholing des Datenverkehrs zu vermeiden.
Spanning Tree mit seinem gleichmäßigen, unidirektionalen BPDU-Fluss litt akut an diesen Ausfällen. Es ist leicht einzusehen, wie ein Port plötzlich keine BPDUs mehr übertragen kann, was dazu führt, dass der STP-Status beim Nachbarn von Blockierung zu Weiterleitung wechselt. Diese Änderung erzeugt eine Schleife, da der Port immer noch empfangen kann.
Betriebsübersicht
UDLD ist ein L2-Protokoll, das oberhalb der LLC-Schicht funktioniert (Ziel-MAC 01-00-0c-cc-cc, SNAP HDLC-Protokolltyp 0x0111). Wenn UDLD in Kombination mit FEFI- und Autoübertragung-L1-Mechanismen ausgeführt wird, ist es möglich, die physische (L1) und logische (L2) Integrität einer Verbindung zu validieren.
UDLD bietet Funktionen und Schutz, die FEFI und Autoübertragung nicht leisten können. Dazu gehören die Erkennung und Zwischenspeicherung von Nachbarinformationen, die Möglichkeit zum Herunterfahren falsch angeschlossener Ports und die Erkennung von Fehlfunktionen oder Fehlern logischer Schnittstellen/Ports auf Links, die nicht Point-to-Point-Verbindungen sind (Verbindungen, die Medienkonverter oder Hubs durchlaufen).
UDLD verwendet zwei grundlegende Mechanismen: Er lernt die Nachbarn kennen, hält die Informationen in einem lokalen Cache auf dem neuesten Stand und sendet eine Reihe von UDLD-Sonden-/Echo-Nachrichten, wenn ein neuer Nachbar erkannt wird oder ein Nachbar eine erneute Synchronisierung des Caches anfordert.
UDLD sendet kontinuierlich Prüfnachrichten an alle Ports, auf denen UDLD aktiviert ist. Immer wenn eine bestimmte "Trigger"-UDLD-Nachricht an einem Port empfangen wird, beginnt eine Erkennungsphase und ein Validierungsprozess. Wenn am Ende dieses Prozesses alle gültigen Bedingungen erfüllt sind, wird der Port-Status nicht geändert. Um diese Bedingungen zu erfüllen, muss der Port bidirektional und korrekt verkabelt sein. Andernfalls wird der Port errdisable gesetzt, und eine Syslog-Meldung wird angezeigt. Die Syslog-Meldung ähnelt der folgenden Meldung:
-
UDLD-3-DISABLE: Unidirektionale Verbindung an Port [dec]/[dec] erkannt. Port deaktiviert
-
UDLD-4-ONEWAYPATH: Eine unidirektionale Verbindung von Port [dec]/[dec] zu Port
[dec]/[dec] von Gerät [chars] wurde erkannt
Unter Messages and Recovery Procedures (Catalyst series switches, 7.6) (Nachrichten und Wiederherstellungsverfahren) finden Sie eine vollständige Liste der Systemmeldungen nach Einrichtung, die UDLD-Ereignisse enthält.
Nachdem eine Verbindung hergestellt und als bidirektional klassifiziert wurde, kündigt UDLD in einem Standardintervall von 15 Sekunden weiterhin Sonden-/Echo-Meldungen an. Diese Tabelle stellt gültige UDLD-Verbindungsstatus dar, wie in der Ausgabe des Befehls show udld port angegeben:
| Hafenstaat | Kommentar |
|---|---|
| Unbestimmt | Erkennung wird durchgeführt, oder eine benachbarte UDLD-Einheit wurde deaktiviert oder ihre Übertragung wurde blockiert. |
| Nicht zutreffend | UDLD wurde deaktiviert. |
| Herunterfahren | Eine unidirektionale Verbindung wurde erkannt, und der Port wurde deaktiviert. |
| Bidirektional | Bidirektionale Verbindung wurde erkannt. |
-
Neighbor Cache Maintenance (Wartung des Nachbar-Caches): UDLD sendet regelmäßig Hello-Probe/Echo-Pakete an jede aktive Schnittstelle, um die Integrität des UDLD-Nachbar-Caches zu gewährleisten. Wenn eine Hello-Nachricht empfangen wird, wird sie zwischengespeichert und für einen maximalen Zeitraum, der als Haltezeit definiert wird, im Speicher gespeichert. Nach Ablauf der Haltezeit ist der entsprechende Cache-Eintrag veraltet. Wenn innerhalb der Haltezeit eine neue Hello-Nachricht eingeht, wird der ältere Eintrag durch den neuen ersetzt und der entsprechende Time-to-Live-Timer zurückgesetzt.
-
Um die Integrität des UDLD-Caches aufrechtzuerhalten, werden bei jeder Deaktivierung einer UDLD-fähigen Schnittstelle oder beim Zurücksetzen eines Geräts alle vorhandenen Cache-Einträge für die von der Konfigurationsänderung betroffenen Schnittstellen gelöscht und UDLD sendet mindestens eine Nachricht, um die jeweiligen Nachbarn zu informieren, dass die entsprechenden Cache-Einträge geleert werden.
-
Echo Detection Mechanism (Echo-Erkennungsmechanismus): Der Echomechanismus bildet die Grundlage des Erkennungsalgorithmus. Immer wenn ein UDLD-Gerät von einem neuen Nachbarn erfährt oder eine Resynchronisierungsanforderung von einem nicht synchronisierten Nachbarn empfängt, startet es das Erkennungsfenster auf seiner Seite der Verbindung und sendet daraufhin eine Flut von Echo-Nachrichten. Da dieses Verhalten bei allen Nachbarn gleich sein muss, erwartet der Echo-Sender, dass er als Antwort Echos erhält. Wenn das Erkennungsfenster endet und keine gültige Antwortnachricht eingegangen ist, wird die Verbindung als unidirektional betrachtet, und ein Vorgang zur Wiederherstellung oder zum Abschalten der Verbindung kann ausgelöst werden.
Konvergenzzeit
Um STP-Schleifen zu vermeiden, reduzierte CatOS 5.4(3) das UDLD-Standard-Nachrichtenintervall von 60 Sekunden auf 15 Sekunden, um eine unidirektionale Verbindung zu beenden, bevor ein blockierter Port in den Weiterleitungsstatus übergehen konnte.
Hinweis: Der Wert für das Nachrichtenintervall bestimmt die Rate, mit der ein Nachbar nach der Verbindungs- oder Erkennungsphase UDLD-Tests sendet. Das Nachrichtenintervall muss nicht an beiden Enden einer Verbindung übereinstimmen, obwohl eine konsistente Konfiguration nach Möglichkeit wünschenswert ist. Wenn UDLD-Nachbarn eingerichtet sind, wird das konfigurierte Nachrichtenintervall gesendet, und das Zeitüberschreitungsintervall für diesen Peer wird mit (3 * message_interval) berechnet. Aus diesem Grund wird eine Peer-Beziehung abgebrochen, nachdem drei aufeinander folgende Hellos (oder Sonden) verpasst wurden. Da sich die Nachrichtenintervalle auf jeder Seite unterscheiden, ist dieser Timeoutwert auf jeder Seite unterschiedlich.
Die ungefähre Zeit, die UDLD benötigt, um einen unidirektionalen Fehler zu erkennen, beträgt etwa (2,5 * message_interval + 4 Sekunden) oder etwa 41 Sekunden bei Verwendung des Standard-Nachrichtenintervalls von 15 Sekunden. Dies liegt deutlich unter den 50 Sekunden, die normalerweise für die Wiederkonvergierung von STP erforderlich sind. Wenn die NMP-CPU über Ersatzzyklen verfügt und Sie den Auslastungsgrad sorgfältig überwachen, können Sie das Nachrichtenintervall (gerade) auf das Minimum von 7 Sekunden reduzieren. Dieses Nachrichtenintervall beschleunigt die Erkennung um einen wesentlichen Faktor.
Aus diesem Grund ist UDLD von standardmäßigen Spanning Tree-Timern abhängig. Wenn Sie STP so einstellen, dass die Konvergenz schneller als bei UDLD erfolgt, sollten Sie einen alternativen Mechanismus in Betracht ziehen, z. B. die CatOS 6.2-Funktion zum Loop Guard. Wenn Sie RSTP (IEEE 802.1w) implementieren, sollten Sie auch einen alternativen Mechanismus in Betracht ziehen, da das RSTP über Konvergenzeigenschaften in Millisekunden verfügt, die von der Topologie abhängen. Verwenden Sie in diesen Fällen Loop Guard in Verbindung mit UDLD, das den besten Schutz bietet. Loop Guard verhindert STP-Loops mit der Geschwindigkeit der verwendeten STP-Version, und UDLD erkennt unidirektionale Verbindungen auf einzelnen EtherChannel-Verbindungen oder in Fällen, in denen BPDUs nicht entlang der unterbrochenen Richtung fließen.
Hinweis: UDLD erfasst nicht alle STP-Fehlersituationen, z. B. Fehler, die von einer CPU verursacht werden, die keine BPDUs über einen Zeitraum sendet, der länger ist als (2 * FwdDelay + Maxage). Aus diesem Grund empfiehlt Cisco, UDLD in Verbindung mit Loop Guard (eingeführt in CatOS 6.2) in Topologien zu implementieren, die auf STP basieren.
 Achtung: Vorsicht vor früheren UDLD-Versionen, die ein nicht konfigurierbares Standard-Nachrichtenintervall von 60 Sekunden verwenden. Diese Versionen sind anfällig für Spanning-Tree-Loop-Bedingungen.
Achtung: Vorsicht vor früheren UDLD-Versionen, die ein nicht konfigurierbares Standard-Nachrichtenintervall von 60 Sekunden verwenden. Diese Versionen sind anfällig für Spanning-Tree-Loop-Bedingungen.
Aggressiver UDLD-Modus
Aggressive UDLD wurde speziell für die (wenigen) Fälle entwickelt, in denen ein fortlaufender Test der bidirektionalen Konnektivität erforderlich ist. Daher bietet der aggressive Modus in diesen Situationen einen besseren Schutz vor gefährlichen unidirektionalen Verbindungsbedingungen:
-
Wenn der Verlust von UDLD-PDUs symmetrisch ist und an beiden Enden eine Zeitüberschreitung auftritt, wird keiner der Ports deaktiviert.
-
Auf einer Seite einer Verbindung ist der Port angeklemmt (beide übertragen [Tx] und Rx).
-
Eine Seite eines Links bleibt aktiv, während die andere Seite des Links heruntergegangen ist.
-
Die Autoübertragung oder ein anderer L1-Fehlererkennungsmechanismus ist deaktiviert.
-
Die Abhängigkeit von L1-FEFI-Mechanismen sollte reduziert werden.
-
Maximaler Schutz vor Fehlern unidirektionaler Verbindungen auf Punkt-zu-Punkt-FE/GE-Verbindungen ist erforderlich. Insbesondere wenn kein Ausfall zwischen zwei Nachbarn zulässig ist, können UDLD-aggressive Sonden als "Herzschlag" angesehen werden, dessen Vorhandensein die Integrität der Verbindung garantiert.
Der häufigste Fall für eine Implementierung von aggressivem UDLD besteht darin, die Konnektivitätsprüfung für ein Mitglied eines Pakets durchzuführen, wenn die Autoübertragung oder ein anderer L1-Fehlererkennungsmechanismus deaktiviert oder nicht verwendbar ist. Dies gilt insbesondere für EtherChannel-Verbindungen, da PAgP/LACP selbst bei Aktivierung keine sehr niedrigen Hello-Timer im Steady-State verwenden. In diesem Fall bietet das aggressive UDLD den zusätzlichen Vorteil, dass mögliche Spanning-Tree-Schleifen verhindert werden.
Die Umstände, die zum symmetrischen Verlust von UDLD-Sondenpaketen beitragen, sind schwieriger zu charakterisieren. Sie müssen wissen, dass normales UDLD eine Prüfung auf eine unidirektionale Verbindung ausführt, auch nachdem eine Verbindung den bidirektionalen Status erreicht hat. Mit UDLD sollen L2-Probleme erkannt werden, die STP-Schleifen verursachen. Diese Probleme verlaufen in der Regel unidirektional, da BPDUs im Steady-State nur in eine Richtung fließen. Daher ist der Einsatz von normalem UDLD in Verbindung mit Autoübertragung und Loop Guard (für Netzwerke, die auf STP basieren) fast immer ausreichend. Der aggressive UDLD-Modus ist jedoch vorteilhaft in Situationen, in denen Überlastungen in beide Richtungen gleichermaßen betroffen sind, was zum Verlust von UDLD-Sonden in beide Richtungen führt. Dieser Verlust an UDLD-Tests kann beispielsweise auftreten, wenn die CPU-Auslastung an jedem Ende der Verbindung erhöht ist. Weitere Beispiele für einen bidirektionalen Verbindungsverlust sind die Fehler eines der folgenden Geräte:
-
DWDM-Transponder (Dense Wavelength Division Multiplexing)
-
Ein Medienkonverter
-
Hub
-
Weiteres L1-Gerät
Hinweis: Der Fehler kann nicht durch Autoübertragung erkannt werden.
Aggressive UDLD error (Aggressiver UDLD-Fehler) deaktiviert den Port in diesen Fehlersituationen. Berücksichtigen Sie die Auswirkungen sorgfältig, wenn Sie den aggressiven UDLD-Modus auf Links aktivieren, die nicht Point-to-Point sind. Links zu Medienkonvertern, Hubs oder ähnlichen Geräten sind nicht Point-to-Point-Verbindungen. Zwischengeschaltete Geräte können die Weiterleitung von UDLD-Paketen verhindern und ein unnötiges Abschalten einer Verbindung erzwingen.
Nachdem alle Nachbarn eines Ports veraltet sind, startet der aggressive UDLD-Modus (sofern aktiviert) die Verbindungssequenz neu, um eine Resynchronisierung mit potenziell nicht synchronisierten Nachbarn durchzuführen. Dieser Aufwand erfolgt entweder in der Werbe- oder in der Detektionsphase. Wenn die Verbindung nach einer schnellen Abfolge von Nachrichten (acht fehlgeschlagene Wiederholungen) immer noch als "unbestimmt" gilt, wird der Port in den errdisable-Status versetzt.
Hinweis: Einige Switches sind nicht aggressiv UDLD-fähig. Derzeit verfügen der Catalyst 2900XL und der Catalyst 3500XL über hartcodierte Nachrichtenintervalle von 60 Sekunden. Dieses Intervall gilt nicht als ausreichend schnell, um vor potenziellen STP-Schleifen zu schützen (unter Verwendung der STP-Standardparameter).
UDLD auf gerouteten Links
Für diese Erläuterung ist eine geroutete Verbindung einer von zwei Verbindungstypen:
-
Point-to-Point zwischen zwei Router-Knoten
Dieser Link ist mit einer 30-Bit-Subnetzmaske konfiguriert.
-
Ein VLAN mit mehreren Ports, das jedoch nur geroutete Verbindungen unterstützt
Ein Beispiel ist eine geteilte L2-Core-Topologie.
Jedes Interior Gateway Routing Protocol (IGRP) weist eindeutige Merkmale im Hinblick auf den Umgang mit Nachbarbeziehungen und Routenkonvergenz auf. Die in diesem Abschnitt beschriebenen Merkmale sind relevant, wenn Sie zwei der heute verwendeten gängigeren Routing-Protokolle gegenüberstellen, das Open Shortest Path First (OSPF) Protocol und das Enhanced IGRP (EIGRP).
Beachten Sie zunächst, dass ein L1- oder L2-Ausfall in einem Point-to-Point-gerouteten Netzwerk zu einem beinahe sofortigen Ausfall der L3-Verbindung führt. Da der einzige Switch-Port in diesem VLAN bei einem L1/L2-Ausfall in den Status "Nicht verbunden" wechselt, synchronisiert die MSFC-Funktion für den automatischen Zustand den Status der L2- und L3-Ports in etwa zwei Sekunden. Durch diese Synchronisierung wird die L3-VLAN-Schnittstelle in den Status "up/down" (aktiv/inaktiv) versetzt.
Annehmen von Timer-Standardwerten. OSPF sendet alle 10 Sekunden Hello-Nachrichten und hat ein Dead-Intervall von 40 Sekunden (4 * Hello). Diese Timer sind für OSPF-Punkt-zu-Punkt- und Broadcast-Netzwerke konsistent. Da OSPF eine bidirektionale Kommunikation benötigt, um eine Adjacency zu bilden, beträgt die Failover-Zeit im ungünstigsten Fall 40 Sekunden. Dieses Failover ist auch dann der Fall, wenn der L1/L2-Fehler nicht bei einer Punkt-zu-Punkt-Verbindung auftritt, sodass ein Szenario mit halbem Betrieb übrig bleibt, mit dem sich das L3-Protokoll befassen muss. Da die Erkennungszeit von UDLD der Zeit eines ablaufenden OSPF-Dead-Timers (etwa 40 Sekunden) sehr ähnlich ist, sind die Vorteile der Konfiguration des UDLD-Normalmodus auf einer OSPF-L3-Point-to-Point-Verbindung begrenzt.
In vielen Fällen lässt sich EIGRP schneller konvergieren als OSPF. Sie müssen jedoch beachten, dass keine bidirektionale Kommunikation erforderlich ist, damit Nachbarn Routing-Informationen austauschen können. In sehr spezifischen Szenarien mit halb-betrieblichen Ausfällen ist EIGRP anfällig für das Black Holing von Datenverkehr, das so lange andauert, bis ein anderes Ereignis die Routen über diesen Nachbarn "aktiv" macht. Der UDLD-Normalmodus kann die in diesem Abschnitt beschriebenen Umstände mildern. Der normale UDLD-Modus erkennt den unidirektionalen Verbindungsausfall, und der Fehler deaktiviert den Port.
Für L3-geroutete Verbindungen, die ein beliebiges Routing-Protokoll verwenden, bietet UDLD normal weiterhin Schutz vor Problemen bei der anfänglichen Verbindungsaktivierung. Zu diesen Problemen gehören fehlerhafte Verkabelung oder Hardware. Darüber hinaus bietet der aggressive UDLD-Modus die folgenden Vorteile bei L3-Router-Verbindungen:
-
Verhindert das unnötige Blackholing von Datenverkehr
Hinweis: In einigen Fällen sind Mindest-Timer erforderlich.
-
Versetzt einen flapping-Link in den errdisable-Status
-
Schutz vor Schleifen, die sich aus L3-EtherChannel-Konfigurationen ergeben
Standardverhalten von UDLD
UDLD ist global deaktiviert und standardmäßig in Bereitschaft auf Glasfaser-Ports aktiviert. Da UDLD ein Infrastrukturprotokoll ist, das nur zwischen Switches erforderlich ist, ist UDLD an Kupfer-Ports standardmäßig deaktiviert. Für den Host-Zugriff werden in der Regel Kupfer-Ports verwendet.
Hinweis: UDLD muss global und auf Schnittstellenebene aktiviert werden, bevor Nachbarn bidirektionalen Status erhalten können. In CatOS 5.4(3) und höher beträgt das Standard-Nachrichtenintervall 15 Sekunden und kann zwischen 7 und 90 Sekunden konfiguriert werden.
Wiederherstellung deaktivieren ist standardmäßig global deaktiviert. Wenn ein Port global aktiviert wird und in den errdisable-Status wechselt, wird er nach einem ausgewählten Zeitintervall automatisch erneut aktiviert. Die Standardzeit beträgt 300 Sekunden. Dies ist ein globaler Timer, der für alle Ports in einem Switch aufrechterhalten wird. Sie können die erneute Aktivierung eines Ports manuell verhindern, wenn Sie das Zeitlimit für errdisable für diesen Port deaktivieren. Führen Sie den Befehl set port errdisable-timeout mod/port disable aus.
Hinweis: Die Verwendung dieses Befehls hängt von der Softwareversion ab.
Die Funktion "errdisable timeout" sollte verwendet werden, wenn Sie den aggressiven UDLD-Modus ohne Out-of-Band-Netzwerkverwaltungsfunktionen implementieren, insbesondere im Access Layer oder auf einem Gerät, das im Falle einer errdisable-Situation vom Netzwerk isoliert werden kann.
Weitere Informationen zur Konfiguration einer Zeitüberschreitung für Ports im errdisable-Status finden Sie unter Configuring Ethernet, Fast Ethernet, Gigabit Ethernet und 10-Gigabit Ethernet Switching.
Empfehlung
UDLD im Normalmodus ist in den allermeisten Fällen ausreichend, wenn Sie es ordnungsgemäß und in Verbindung mit den entsprechenden Funktionen und Protokollen verwenden. Zu diesen Funktionen/Protokollen gehören:
-
FEFI
-
Autonegotiation
-
Loop Guard
Bei der Bereitstellung von UDLD sollten Sie berücksichtigen, ob ein fortlaufender Test der bidirektionalen Konnektivität (aggressiver Modus) erforderlich ist. Wenn die Autoübertragung aktiviert ist, ist normalerweise kein aggressiver Modus erforderlich, da die Autoübertragung die Fehlererkennung an L1 kompensiert.
Cisco empfiehlt die Aktivierung des UDLD-Normalmodus auf allen Point-to-Point FE/GE-Verbindungen zwischen Cisco Switches, bei denen das UDLD-Nachrichtenintervall auf den Standardwert von 15 Sekunden eingestellt ist. Bei dieser Konfiguration wird der Standard-Spanning-Tree-Timer 802.1d vorausgesetzt. Darüber hinaus können Sie UDLD in Verbindung mit Loop Guard in Netzwerken verwenden, die STP für Redundanz und Konvergenz verwenden. Diese Empfehlung gilt für Netzwerke, in denen ein oder mehrere Ports in der Topologie den STP-Blockierungsstatus aufweisen.
Führen Sie die folgenden Befehle aus, um UDLD zu aktivieren:
set udld enable
!--- After global enablement, all FE and GE fiber !--- ports have UDLD enabled by default.
set udld enable port range
!--- This is for additional specific ports and copper media, if needed.
Sie müssen Ports manuell aktivieren, die aufgrund von Symptomen für unidirektionale Verbindungen aufgrund eines Fehlers deaktiviert wurden. Geben Sie den Befehl set port enable ein.
Weitere Informationen finden Sie unter Verstehen und Konfigurieren der Funktion des Unidirectional Link Detection Protocol (UDLD).
Weitere Optionen
Für maximalen Schutz gegen Symptome, die von unidirektionalen Links herrühren, konfigurieren Sie den aggressiven Modus UDLD:
set udld aggressive-mode enable port_range
Darüber hinaus können Sie den Wert für das UDLD-Nachrichtenintervall zwischen 7 und 90 Sekunden an jedem Ende einstellen (sofern unterstützt), um eine schnellere Konvergenz zu erreichen:
set udld interval time
Ziehen Sie die Funktion "errdisable" in Betracht, die auf jedem Gerät verwendet wird, das im Falle einer errdisable-Situation vom Netzwerk isoliert werden kann. Dies gilt in der Regel für den Access Layer und bei der Implementierung des aggressiven UDLD-Modus ohne Out-of-Band-Netzwerkmanagement-Funktionen.
Wenn ein Port in den errdisable-Status versetzt wird, bleibt er standardmäßig inaktiv. Sie können den folgenden Befehl ausführen, mit dem Ports nach einem Zeitüberschreitungsintervall erneut aktiviert werden:
Hinweis: Das Zeitüberschreitungsintervall beträgt standardmäßig 300 Sekunden.
>set errdisable-timeout enable ? bpdu-guard !--- This is BPDU port-guard. channel-misconfig !--- This is a channel misconfiguration. duplex-mismatch udld other !--- These are other reasons. all !--- Apply errdisable timeout to all reasons.
Wenn das Partnergerät nicht UDLD-fähig ist, z. B. ein End-Host oder -Router, führen Sie das Protokoll nicht aus. Führen Sie folgenden Befehl aus,
set udld disable port_range
Test und Überwachung von UDLD
UDLD lässt sich nur mit einer wirklich fehlerhaften/unidirektionalen Komponente im Labor, z. B. einem defekten GBIC, testen. Das Protokoll wurde entwickelt, um seltenere Fehlerszenarien zu erkennen als die Szenarien, die normalerweise in einer Übung verwendet werden. Wenn Sie z. B. einen einfachen Test durchführen und einen Strang einer Glasfaser entfernen, um den gewünschten errdisable-Status anzuzeigen, müssen Sie die L1-Autoübertragung deaktiviert haben. Andernfalls fällt der physische Port aus, wodurch die UDLD-Nachrichtenkommunikation zurückgesetzt wird. Das Remote-Ende wechselt in den unbestimmten Status der UDLD-Normalität. Wenn Sie den aggressiven UDLD-Modus verwenden, wechselt das Remote-Ende in den Status errdisable.
Es gibt eine zusätzliche Testmethode, um den PDU-Verlust von Nachbarn für UDLD zu simulieren. Verwenden Sie MAC-Layer-Filter, um die UDLD/CDP-Hardwareadresse zu blockieren, aber das Passieren anderer Adressen zu ermöglichen.
Führen Sie die folgenden Befehle aus, um UDLD zu überwachen:
>show udld UDLD : enabled Message Interval : 15 seconds >show udld port 3/1 UDLD : enabled Message Interval : 15 seconds Port Admin Status Aggressive Mode Link State -------- ------------ --------------- ---------------- 3/1 enabled disabled bidirectional
Außerdem können Sie im privilegierten Modus den Befehl "hidden show udld neighbor" ausführen, um den UDLD-Cache-Inhalt zu überprüfen (wie CDP dies tut). Ein Vergleich des UDLD-Cache mit dem CDP-Cache, um zu überprüfen, ob eine protokollspezifische Anomalie vorliegt, ist häufig nützlich. Wenn auch CDP betroffen ist, sind in der Regel alle PDUs/BPDUs betroffen. Überprüfen Sie daher auch STP. Überprüfen Sie beispielsweise, ob sich die Root-Identität oder die Root/designierte Port-Platzierung geändert hat.
>show udld neighbor 3/1 Port Device Name Device ID Port-ID OperState ----- --------------------- ------------ ------- ---------- 3/1 TSC07117119M(Switch) 000c86a50433 3/1 bidirectional
Darüber hinaus können Sie den UDLD-Status und die Konsistenz der Konfiguration mithilfe der Cisco UDLD SNMP MIB-Variablen überwachen.
Jumbo-Frame
Die standardmäßige Maximum Transmission Unit (MTU)-Frame-Größe beträgt 1518 Byte für alle Ethernet-Ports, einschließlich GE und 10 GE. Die Jumbo Frame-Funktion ermöglicht Schnittstellen das Umschalten von Frames, die größer als die standardmäßige Ethernet-Frame-Größe sind. Diese Funktion ist nützlich, um die Server-zu-Server-Leistung zu optimieren und Anwendungen wie Multi-Protocol Label Switching (MPLS), 802.1Q-Tunneling und L2 Tunneling Protocol Version 3 (L2TPv3) zu unterstützen, die die Größe der ursprünglichen Frames erhöhen.
Betriebsübersicht
Die IEEE 802.3-Standardspezifikation definiert eine maximale Ethernet-Frame-Größe von 1518 Byte für reguläre Frames und 1522 Byte für 802.1Q-gekapselte Frames. Die 802.1Q-gekapselten Rahmen werden manchmal als "Babyriesen" bezeichnet. Im Allgemeinen werden Pakete als riesige Frames klassifiziert, wenn die Pakete die für eine bestimmte Ethernet-Verbindung festgelegte maximale Länge überschreiten. Riesenpakete werden auch als Jumbo Frames bezeichnet.
Es gibt verschiedene Gründe, warum die MTU-Größe bestimmter Frames 1518 Byte überschreiten kann. Hier einige Beispiele:
-
Herstellerspezifische Anforderungen - Anwendungen und bestimmte NICs können eine MTU-Größe angeben, die außerhalb der standardmäßigen 1500 Byte liegt. Die Tendenz zur Angabe solcher MTU-Größen beruht auf durchgeführten Studien, die belegen, dass eine Vergrößerung eines Ethernet-Frames den durchschnittlichen Durchsatz erhöhen kann.
-
Trunking: Um VLAN-ID-Informationen zwischen Switches oder anderen Netzwerkgeräten zu übertragen, wurde Trunking verwendet, um den Standard-Ethernet-Frame zu ergänzen. Heute sind die beiden gebräuchlichsten Formen des Trunking die proprietäre ISL-Kapselung von Cisco und IEEE 802.1Q.
-
MPLS: Nachdem MPLS für eine Schnittstelle aktiviert wurde, besteht die Möglichkeit, die Frame-Größe eines Pakets zu erhöhen. Diese Erweiterung hängt von der Anzahl der Labels im Label-Stack für ein mit MPLS markiertes Paket ab. Die Gesamtgröße eines Labels beträgt 4 Bytes. Die Gesamtgröße eines Label-Stacks beträgt n x 4 Bytes. Wenn ein Label-Stack gebildet wird, können die Frames die MTU überschreiten.
-
802.1Q-Tunneling: 802.1Q-Tunneling-Pakete enthalten zwei 802.1Q-Tags, von denen in der Regel jeweils nur ein Tag auf einmal für die Hardware sichtbar ist. Aus diesem Grund addiert das interne Tag 4 Byte zum MTU-Wert (Payload-Größe).
-
Universal Transport Interface (UTI)/L2TPv3 - UTI/L2TPv3 kapselt L2-Daten, die über das IP-Netzwerk weitergeleitet werden sollen. Die Kapselung kann die ursprüngliche Frame-Größe um bis zu 50 Byte erhöhen. Der neue Frame enthält einen neuen IP-Header (20 Byte), einen L2TPv3-Header (12 Byte) und einen neuen L2-Header. Die L2TPv3-Nutzlast besteht aus dem vollständigen L2-Frame, der den L2-Header enthält.
Die Fähigkeit der verschiedenen Catalyst Switches, verschiedene Frame-Größen zu unterstützen, hängt von vielen Faktoren ab, unter anderem von der Hardware und Software. Bestimmte Module können größere Frame-Größen als andere unterstützen, selbst wenn sie sich auf derselben Plattform befinden.
-
Die Catalyst 5500/5000-Switches unterstützen Jumbo Frames in der CatOS 6.1-Version. Wenn die Jumbo Frames-Funktion auf einem Port aktiviert ist, steigt die MTU-Größe auf 9.216 Byte. Auf UTP-basierten Line Cards (Unshielded Twisted Pair) mit 10/100 Mbit/s wird eine Frame-Größe von maximal 8.092 Byte unterstützt. Diese Einschränkung ist eine ASIC-Einschränkung. Die Aktivierung der Jumbo Frame-Größe-Funktion unterliegt in der Regel keinen Einschränkungen. Sie können diese Funktion für Trunking/Non-Trunking und Channeling/Non-Channeling verwenden.
-
Die Catalyst Switches der Serie 4000 (Supervisor Engine 1 [WS-X4012] und Supervisor Engine 2 [WS-X4013]) unterstützen aufgrund einer ASIC-Einschränkung keine Jumbo Frames. Die Ausnahme ist jedoch 802.1Q-Trunking.
-
Die Plattform der Catalyst 6500-Serie unterstützt Jumbo Frame-Größen in CatOS 6.1(1) und höher. Diese Unterstützung hängt jedoch vom verwendeten Linecard-Typ ab. Die Aktivierung der Jumbo Frame-Größe-Funktion unterliegt in der Regel keinen Einschränkungen. Sie können diese Funktion für Trunking/Non-Trunking und Channeling/Non-Channeling verwenden. Die MTU-Standardgröße beträgt 9.216 Byte, nachdem die Jumbo-Frame-Unterstützung für den einzelnen Port aktiviert wurde. Die Standard-MTU kann nicht mit CatOS konfiguriert werden. In Version 12.1(13)E der Cisco IOS Software wurde jedoch der Befehl system jumbomtu eingeführt, um die Standard-MTU zu überschreiben.
Weitere Informationen finden Sie unter Jumbo/Giant Frame-Unterstützung bei Catalyst Switches - Konfigurationsbeispiel.
In dieser Tabelle werden die MTU-Größen beschrieben, die von verschiedenen Linecards für Catalyst Switches der 6500-/6000-Serie unterstützt werden:
Hinweis: Die MTU-Größe oder Paketgröße bezieht sich nur auf die Ethernet-Nutzlast.
| Line Card | MTU-Größe |
|---|---|
| Standard | 9216 Byte |
| WS-X6248-RJ-45, WS-X6248A-RJ-45 WS-X6248-TEL, WS-X6248A-TEL WS-X6348-RJ-45(V), WS-X6348-V RJ-21(V) | 8.092 Byte (begrenzt durch den PHY-Chip) |
| WS-X6148-RJ-45(V), WS-X6148-RJ-21(V) WS-X6148-45AF, WS-X6148-21AF | 9.100 Byte (@ 100 Mbit/s) 9.216 Byte (@ 10 Mbit/s) |
| WS-X6148A-RJ-45, WS-X6148A-45AF, WS-X6148-FE-SFP | 9216 Byte |
| WS-X6324-100FX-MM, -SM, WS-X6024-10FL-MT | 9216 Byte |
| WS-X6548-RJ-45, WS-X6548-RJ-21, WS-X6524-100FX-MM WS-X6148X2-RJ-45, WS-X6148X2-45AF WS-X6196-RJ-21, WS-X6196-21AF WS-X6408-GBIC, WS-X6316-GE-TX , WS-X6416-GBIC WS-X6516-GBIC, WS-X 6516A-GBIC, WS-X6816-GBIC Uplinks der Supervisor Engine 1, 2, 32 und 720 | 9216 Byte |
| WS-X6516-GE-TX | 8.092 Byte (@ 100 Mbit/s) 9.216 Byte (@ 10 oder 1.000 Mbit/s) |
| WS-X6148-GE-TX, WS-X6148V-GE-TX, WS-X6148-GE-45AF, WS-X6548-GE-TX, WS-X6548V-GE-TX, WS-X6548 GE-45AF | 1500 Byte (Jumbo-Frame nicht unterstützt) |
| WS-X6148A-GE-TX, WS-X6148A-GE-45AF, WS-X6502-10GE, WS-X67xx Serie | 9216 Byte |
| OSM ATM (OC12c) | 9180 Byte |
| OSM CHOC3, CHOC12, CHOC48, CT3 | 9.216 Byte (OCx und DS3) 7.673 Byte (T1/E1) |
| Flex-WAN | 7673 Byte (CT3 T1/DS0) 9216 Byte (OC3c POS) 7673 Byte (T1) |
| CSM (WS-X606-SLB-APC) | 9.216 Byte (Stand: CSM 3.1(5) und 3.2(1)) |
| OSM POS OC3c, OC12c, OC48c OSM DPT OC48c, OSM GE WAN | 9216 Byte |
Unterstützung von Layer-3-Jumbo Frames
Mit CatOS, das auf der Supervisor Engine ausgeführt wird, und Cisco IOS-Software, die auf MSFC ausgeführt wird, bieten die Catalyst 6500/6000-Switches auch L3-Jumbo Frame-Unterstützung in Cisco IOS® Softwareversion 12.1(2)E und höher unter Verwendung von PFC/MSFC2, PFC2/MSFC2 oder neuerer Hardware. Wenn sowohl Eingangs- als auch Ausgangs-VLANs für Jumbo Frames konfiguriert sind, werden alle Pakete mit Leitungsgeschwindigkeit von der PFC hardwaregesteuert. Wenn das Eingangs-VLAN für Jumbo Frames konfiguriert ist und das Ausgangs-VLAN nicht konfiguriert ist, gibt es zwei Szenarien:
-
Ein Jumbo Frame, der vom End-Host mit dem Don't Fragment (DF)-Bit gesendet wird (für die MTU-Pfaderkennung) - Das Paket wird verworfen, und ein Internet Control Message Protocol (ICMP), das nicht erreichbar ist, wird mit dem erforderlichen Nachrichtencodefragment und festgelegtem DF an den End-Host gesendet.
-
Ein Jumbo Frame, der vom End-Host gesendet wird, ohne dass das DF-Bit festgelegt ist - Pakete werden auf MSFC2/MSFC3 durchgestellt, um fragmentiert und in der Software weitergeschaltet zu werden.
Diese Tabelle fasst die L3-Jumbo-Unterstützung für verschiedene Plattformen zusammen:
| L3-Switch oder -Modul | Maximale L3-MTU-Größe |
|---|---|
| Catalyst Serie 2948G-L3/4908G-L3 | Jumbo Frames werden nicht unterstützt. |
| Catalyst 5000 RSM1/RSFC2 | Jumbo Frames werden nicht unterstützt. |
| Catalyst 6500 MSFC1 | Jumbo Frames werden nicht unterstützt. |
| Catalyst 6500 MSFC2 und höher | Cisco IOS Software-Version 12.1(2)E: 9216 Byte |
1 RSM = Route Switch Module
2 RSFC = Route Switch Feature Card
Überlegungen zur Netzwerkleistung
Die Leistung von TCP über WANs (das Internet) wurde eingehend untersucht. Diese Gleichung erläutert, warum der TCP-Durchsatz eine Obergrenze hat, die auf Folgendem basiert:
-
Die maximale Segmentgröße (Maximum Segment Size, MSS), die die MTU-Länge abzüglich der Länge der TCP/IP-Header angibt
-
Die Round-Trip-Zeit (RTT)
-
Der Paketverlust
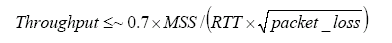
Gemäß dieser Formel ist der maximal erreichbare TCP-Durchsatz direkt proportional zur MSS. Bei konstantem RTT und Paketverlust kann der TCP-Durchsatz verdoppelt werden, wenn die Paketgröße verdoppelt wird. Wenn Sie Jumbo Frames anstelle von 1518-Byte-Frames verwenden, kann eine sechsfache Vergrößerung eine potenzielle sechsfache Verbesserung des TCP-Durchsatzes einer Ethernet-Verbindung ergeben.
Zweitens erfordern die ständig steigenden Leistungsanforderungen von Serverfarmen ein effizienteres Mittel, um höhere Datenraten mit NFS-UDP-Datagrammen (Network File System) zu gewährleisten. NFS ist der am weitesten verbreitete Datenspeicherungsmechanismus für die Übertragung von Dateien zwischen UNIX-basierten Servern und verfügt über 8400-Byte-Datagramme. Bei einer erweiterten Ethernet-MTU von 9 KB ist ein einzelner Jumbo Frame groß genug, um ein 8-KB-Anwendungsdatagramm (z. B. NFS) plus den Paket-Header-Overhead zu übertragen. Diese Funktion ermöglicht außerdem effizientere DMA-Übertragungen (Direct Memory Access) auf den Hosts, da die Software nicht mehr benötigt, um NFS-Blöcke in separate UDP-Datagramme zu fragmentieren.
Empfehlung
Wenn Sie Jumbo-Frames unterstützen möchten, beschränken Sie die Verwendung von Jumbo-Frames auf Bereiche des Netzwerks, in denen alle Switch-Module (L2) und Schnittstellen (L3) Jumbo-Frames unterstützen. Diese Konfiguration verhindert die Fragmentierung im Pfad. Die Konfiguration von Jumbo Frames, die größer als die unterstützte Frame-Länge im Pfad sind, eliminiert alle Vorteile, die durch die Verwendung der Funktion erzielt werden, da eine Fragmentierung erforderlich ist. Wie die Tabellen in diesem Jumbo Frame-Abschnitt zeigen, können verschiedene Plattformen und Linecards in Bezug auf die maximal unterstützten Paketgrößen variieren.
Konfigurieren Sie Jumbo Frame-fähige Host-Geräte mit einer MTU-Größe, die dem von der Netzwerkhardware unterstützten gemeinsamen kleinsten Nenner entspricht, für das gesamte L2-VLAN, in dem sich das Host-Gerät befindet. Führen Sie den folgenden Befehl aus, um die Jumbo Frame-Unterstützung für Module mit Jumbo Frame-Unterstützung zu aktivieren:
set port jumbo mod/port enable
Wenn Sie darüber hinaus Jumbo Frame-Unterstützung über L3-Grenzen hinweg wünschen, konfigurieren Sie den größten verfügbaren MTU-Wert von 9.216 Byte auf allen entsprechenden VLAN-Schnittstellen. Führen Sie den Befehl mtu unter den VLAN-Schnittstellen aus:
interface vlan vlan#
mtu 9216
Durch diese Konfiguration wird sichergestellt, dass die von den Modulen unterstützte Layer-2-Jumbo-Frame-MTU immer kleiner oder gleich dem Wert ist, der für die Layer-3-Schnittstellen konfiguriert ist, die vom Datenverkehr durchlaufen werden. Dadurch wird eine Fragmentierung verhindert, wenn Datenverkehr vom VLAN über die L3-Schnittstelle geroutet wird.
Managementkonfiguration
In diesem Abschnitt werden Überlegungen zur Steuerung, Bereitstellung und Fehlerbehebung eines Catalyst-Netzwerks erläutert.
Netzwerkdiagramme
Übersichtliche Netzwerkdiagramme sind ein wesentlicher Bestandteil des Netzwerkbetriebs. Sie werden bei der Fehlerbehebung kritisch und stellen das wichtigste Medium für die Informationsweitergabe dar, wenn sie bei einem Ausfall an Lieferanten und Partner eskaliert werden. Ihre Vorbereitung, Bereitschaft und Zugänglichkeit dürfen nicht unterschätzt werden.
Empfehlung
Cisco empfiehlt, die folgenden drei Diagramme zu erstellen:
-
Gesamtdiagramm: Selbst für die größten Netzwerke ist ein Diagramm wichtig, das die durchgängige physische und logische Konnektivität zeigt. Unternehmen, die ein hierarchisches Design implementiert haben, dokumentieren jede Ebene separat. Bei der Planung und Problemlösung kommt es jedoch häufig auf eine gute Kenntnis der Verknüpfung der Domänen an.
-
Physisches Diagramm - zeigt die gesamte Switch- und Router-Hardware und -Verkabelung. Trunks, Verbindungen, Geschwindigkeiten, Channel-Gruppen, Port-Nummern, Steckplätze, Chassis-Typen, Software, VTP-Domänen, Root Bridge, Backup Root Bridge-Priorität, MAC-Adresse und blockierte Ports pro VLAN müssen gekennzeichnet werden. Es ist oft klarer, interne Geräte wie den Catalyst 6500/6000 MSFC als Router auf einem Stick darzustellen, der über einen Trunk verbunden ist.
-
Logisches Diagramm - zeigt nur L3-Funktionalität (Router als Objekte, VLANs als Ethernet-Segmente). IP-Adressen, Subnetze, sekundäre Adressierung, HSRP Aktiv und Standby, Access-Core-Distribution-Layer und Routing-Informationen müssen gekennzeichnet werden.


In-Band-Management
Je nach Konfiguration muss die In-Band-Managementschnittstelle (intern) des Switches (bekannt als sc0) möglicherweise diese Daten verarbeiten:
-
Switch-Managementprotokolle wie SNMP, Telnet, Secure Shell Protocol (SSH) und Syslog
-
Benutzerdaten wie Broadcasts und Multicasts
-
Switch-Steuerungsprotokolle wie STP BPDUs, VTP, DTP, CDP usw.
Im Multilayer-Design von Cisco ist es gängige Praxis, ein Management-VLAN zu konfigurieren, das eine Switched-Domäne umspannt und alle sc0-Schnittstellen enthält. Auf diese Weise wird der Verwaltungsverkehr vom Benutzerverkehr getrennt und die Sicherheit der Switch-Verwaltungsschnittstellen erhöht. In diesem Abschnitt werden die Bedeutung und die potenziellen Probleme beschrieben, die die Verwendung des Standard-VLAN 1 und die Ausführung des Management-Datenverkehrs zum Switch im selben VLAN wie der Benutzerdatenverkehr mit sich bringen.
Betriebsübersicht
Das Hauptproblem bei der Verwendung von VLAN 1 für Benutzerdaten ist, dass der Supervisor Engine NMP im Allgemeinen nicht durch einen Großteil des von Endgeräten generierten Multicast- und Broadcast-Verkehrs unterbrochen werden muss. Ältere Catalyst 5500/5000-Hardware, insbesondere die Supervisor Engine I und die Supervisor Engine II, verfügen nur über begrenzte Ressourcen für die Verarbeitung dieses Datenverkehrs, obwohl das Prinzip für alle Supervisor Engines gilt. Wenn die Supervisor Engine-CPU, der Puffer oder der In-Band-Kanal zur Backplane voll ausgelastet ist und auf unnötigen Datenverkehr hört, können Steuerungs-Frames möglicherweise übersehen werden. Im schlimmsten Fall kann dies zu einem Spanning Tree-Loop oder einem EtherChannel-Ausfall führen.
Wenn die Befehle show interface und show ip stats auf dem Catalyst ausgegeben werden, können sie einen Hinweis auf den Anteil des Broadcast- zum Unicast-Datenverkehr und den Anteil des IP- zum Nicht-IP-Datenverkehrs geben (der in der Regel nicht in Management-VLANs zu finden ist).
Eine weitere Integritätsprüfung für ältere Catalyst 5500/5000-Hardware besteht darin, die Ausgabe von show inband zu überprüfen. | biga (versteckter Befehl) für Ressourcenfehler (RscrcErrors), ähnlich wie Buffer-Drops in einem Router. Wenn diese Ressourcenfehler kontinuierlich auftreten, steht möglicherweise aufgrund eines hohen Broadcast-Datenverkehrs im Management-VLAN kein Speicher für den Empfang von Systempaketen zur Verfügung. Ein einzelner Ressourcenfehler kann bedeuten, dass die Supervisor Engine ein Paket wie BPDUs nicht verarbeiten kann. Dies kann schnell zu einem Problem werden, da Protokolle wie Spanning Tree verpasste BPDUs nicht erneut senden.
Empfehlung
Wie im Abschnitt "Cat Control" dieses Dokuments hervorgehoben, ist VLAN 1 ein spezielles VLAN, das den Großteil des Steuerungsebenen-Datenverkehrs kennzeichnet und verarbeitet. VLAN 1 ist standardmäßig auf allen Trunks aktiviert. Bei größeren Campus-Netzwerken muss der Durchmesser der VLAN 1 STP-Domäne berücksichtigt werden. Eine Instabilität in einem Teil des Netzwerks könnte sich auf VLAN 1 auswirken und somit die Stabilität der Kontrollebene und damit die STP-Stabilität aller anderen VLANs beeinflussen. In CatOS 5.4 und höher konnte VLAN 1 mithilfe des folgenden Befehls darauf beschränkt werden, Benutzerdaten zu übertragen und STP auszuführen:
clear trunk mod/port vlan 1
Dies verhindert nicht, dass Kontrollpakete von Switch zu Switch in VLAN 1 gesendet werden, wie dies bei einem Netzwerkanalyser der Fall ist. Es werden jedoch keine Daten weitergeleitet, und STP wird nicht über diese Verbindung ausgeführt. Daher kann dieses Verfahren verwendet werden, um VLAN 1 in kleinere Failure-Domains aufzuteilen.
Anmerkung: Derzeit ist es nicht möglich, VLAN 1-Trunks auf 3500s und 2900XLs zu löschen.
Selbst wenn beim Campus-Design darauf geachtet wurde, dass die Benutzer-VLANs auf relativ kleine Switch-Domänen und entsprechend kleine Fehler-/L3-Grenzen beschränkt sind, sind einige Kunden immer noch versucht, das Management-VLAN anders zu behandeln und das gesamte Netzwerk mit einem einzigen Management-Subnetz zu bedecken. Es gibt keinen technischen Grund dafür, dass eine zentrale NMS-Anwendung an L2-Geräte angrenzen muss, und dieses Argument ist auch nicht sicherheitsrelevant. Cisco empfiehlt, den Durchmesser der Management-VLANs auf die gleiche geroutete Domänenstruktur wie Benutzer-VLANs zu beschränken und eine Out-of-Band-Verwaltung und/oder CatOS 6.x SSH-Unterstützung in Betracht zu ziehen, um die Sicherheit des Netzwerkmanagements zu erhöhen.
Weitere Optionen
In einigen Topologien gibt es jedoch Designaspekte, die bei der Umsetzung dieser Cisco Empfehlungen zu berücksichtigen sind. So ist beispielsweise ein wünschenswertes und gängiges Cisco Multilayer-Design ein Design, bei dem die Verwendung eines aktiven Spanning Tree vermieden wird. Dazu müssen Sie jedes IP-Subnetz/VLAN auf einen einzelnen Access-Layer-Switch oder Switch-Cluster beschränken. Bei diesen Designs kann kein Trunking bis zum Access-Layer konfiguriert werden.
Es gibt keine einfache Antwort auf die Frage, ob ein separates Management-VLAN erstellt und Trunking aktiviert werden soll, um das VLAN zwischen dem L2-Access- und dem L3-Distribution-Layer zu übertragen. Bei der Design-Prüfung mit Ihrem Cisco Techniker stehen zwei Optionen zur Auswahl:
-
Option 1: zwei oder drei eindeutige VLANs vom Distribution Layer bis zu jedem Access Layer-Switch zu verbinden. Dies ermöglicht beispielsweise ein Daten-VLAN, ein Sprach-VLAN und ein Management-VLAN und hat weiterhin den Vorteil, dass STP inaktiv ist. (Beachten Sie, dass ein zusätzlicher Konfigurationsschritt erforderlich ist, wenn VLAN 1 von den Trunks gelöscht wird.) Bei dieser Lösung sind außerdem Design-Punkte zu berücksichtigen, um ein vorübergehendes Blackholing des gerouteten Datenverkehrs während der Wiederherstellung nach Ausfällen zu vermeiden: STP PortFast für Trunks (CatOS 7.x und höher) oder VLAN Autostate-Synchronisierung mit STP-Weiterleitung (später als CatOS 5.5[9]).
-
Option 2: Ein einzelnes VLAN für Daten und Management ist möglicherweise ausreichend. Mit neuerer Switch-Hardware, wie z. B. leistungsfähigeren CPUs und Steuerungsebenen zur Ratenbegrenzung, sowie einem Design mit relativ kleinen Broadcast-Domänen, wie es vom Multilayer-Design empfohlen wird, ist die Realität für viele Kunden, dass die Trennung der sc0-Schnittstelle von den Benutzerdaten weniger problematisch ist als früher. Eine abschließende Entscheidung sollte wahrscheinlich am besten durch eine Analyse des Broadcast-Datenverkehrsprofils für dieses VLAN und eine Besprechung der Funktionen der Switch-Hardware mit Ihrem Cisco Techniker gefällt werden. Wenn das Management-VLAN tatsächlich alle Benutzer an diesem Access-Layer-Switch enthält, wird die Verwendung von IP-Eingangsfiltern dringend empfohlen, um den Switch vor Benutzern zu schützen. Dies wird im Abschnitt zur Sicherheitskonfiguration dieses Dokuments beschrieben.
Out-of-Band-Management
Wenn wir die Argumente des vorherigen Abschnitts noch einen Schritt weiter gehen, kann das Netzwerkmanagement durch den Aufbau einer separaten Verwaltungsinfrastruktur im Produktionsnetzwerk besser verfügbar gemacht werden, sodass Geräte unabhängig von den Ereignissen auf Datenverkehr- oder Steuerungsebene immer remote erreichbar sind. Diese beiden Ansätze sind typisch:
-
Out-of-Band-Management mit einem exklusiven LAN
-
Out-of-Band-Management mit Terminalservern
Betriebsübersicht
Jeder Router und Switch im Netzwerk kann mit einer Out-of-Band-Ethernet-Managementschnittstelle in einem Management-VLAN ausgestattet werden. Ein Ethernet-Port an jedem Gerät wird im Management-VLAN konfiguriert und außerhalb des Produktionsnetzwerks über die sc0-Schnittstelle mit einem separaten Switch-Managementnetzwerk verkabelt. Beachten Sie, dass Catalyst 4500/4000-Switches über eine spezielle me1-Schnittstelle auf der Supervisor Engine verfügen, die nur für das Out-of-Band-Management und nicht als Switch-Port verwendet wird.
Darüber hinaus kann die Terminalserveranbindung durch die Konfiguration eines Cisco 2600 oder 3600 mit RJ-45-zu-seriellen Kabeln für den Zugriff auf den Konsolen-Port jedes Routers und Switches in der Anordnung erreicht werden. Ein Terminalserver vermeidet außerdem die Notwendigkeit der Konfiguration von Backup-Szenarien, wie z. B. Modems auf AUX-Ports für jedes Gerät. Ein einzelnes Modem kann am AUX-Port des Terminalservers konfiguriert werden, um den anderen Geräten während eines Netzwerkverbindungsausfalls einen Einwahldienst bereitzustellen.
Empfehlung
Durch diese Anordnung sind neben zahlreichen In-Band-Pfaden zwei Out-of-Band-Pfade zu jedem Switch und Router möglich, wodurch ein hochverfügbares Netzwerkmanagement ermöglicht wird. Out-of-Band ist verantwortlich für:
-
Out-of-Band trennt den Management-Datenverkehr von den Benutzerdaten.
-
Out-of-Band hat die Management-IP-Adresse in einem separaten Subnetz, VLAN und Switch für eine höhere Sicherheit.
-
Out-of-Band bietet eine höhere Sicherheit für die Bereitstellung von Managementdaten bei Netzwerkausfällen.
-
Out-of-Band hat kein aktives Spanning Tree im Management-VLAN. Redundanz ist nicht kritisch.
Systemtests
Systemstart-Diagnose
Während eines Systemstarts werden eine Reihe von Prozessen durchgeführt, um sicherzustellen, dass eine zuverlässige und betriebsbereite Plattform zur Verfügung steht, sodass fehlerhafte Hardware das Netzwerk nicht stört. Die Catalyst Boot-Diagnose wird zwischen Power-On Self Test (POST) und Online-Diagnose aufgeteilt.
Betriebsübersicht
Je nach Plattform- und Hardwarekonfiguration werden beim Booten und beim Hot-Swap einer Karte im Chassis unterschiedliche Diagnosen durchgeführt. Eine höhere Diagnosestufe führt zu einer größeren Anzahl erkannter Probleme, jedoch zu einem längeren Bootzyklus. Diese drei Ebenen der POST-Diagnose können ausgewählt werden (alle Tests überprüfen DRAM, RAM und Cache-Vorhandensein und -Größe und initialisieren sie):
| Betriebsübersicht | |||
|---|---|---|---|
| Umgehung | – | 3 | Nicht verfügbar für die 4500/4000-Serie mit CatOS 5.5 oder früher. |
| Minimal | Musterschreibtests werden nur auf der ersten MB DRAM durchgeführt. | 30 | Standard für die Serien 5500/5000 und 6500/6000; nicht verfügbar für die 4500/4000-Serie. |
| Abschließen | Musterschreibtests für den gesamten Speicher. | 60 | Standardeinstellung für die Serien 4500/4000. |
Online-Diagnose
Bei diesen Tests werden die Paketpfade intern im Switch überprüft. Es ist wichtig zu beachten, dass Online-Diagnosen daher systemweite Tests sind und nicht nur Port-Tests. Auf Catalyst Switches der Serien 5500/5000 und 6500/6000 werden die Tests zunächst von der Supervisor Engine im Standby-Modus und anschließend von der primären Supervisor Engine aus durchgeführt. Die Länge der Diagnose hängt von der Systemkonfiguration (Anzahl der Steckplätze, Module, Ports) ab. Es gibt drei Kategorien von Tests:
-
Loopback-Test - Pakete vom Supervisor Engine NMP werden an jeden Port gesendet, dann an den NMP zurückgesendet und auf Fehler untersucht.
-
Bündelungstest - Es werden Kanäle mit bis zu acht Ports erstellt und Loopback-Tests am Aggregat-Port durchgeführt, um das Hashing für bestimmte Verbindungen zu überprüfen (weitere Informationen finden Sie im EtherChannel-Abschnitt dieses Dokuments).
-
EARL-Test (Enhanced Address Recognition Logic): Sowohl die zentrale Supervisor Engine als auch die L3-Umschreibmodule des Inline-Ethernet-Moduls wurden getestet. Hardware-Weiterleitungseinträge und geroutete Ports werden vor dem Senden von Beispielpaketen (für jeden Protokollkapselungstyp) vom NMP über die Switching-Hardware jedes Moduls und zurück an den NMP erstellt. Dies gilt für Catalyst 6500/6000 PFC-Module und neuere Versionen.
Die Online-Diagnose kann etwa zwei Minuten dauern. Minimale Diagnosen führen keine Bündel- oder Umschreibtests für andere Module als die Supervisor Engine durch und können etwa 90 Sekunden in Anspruch nehmen.
Wird bei einem Speichertest eine Differenz zwischen dem zurückgelesenen und dem geschriebenen Muster festgestellt, wechselt der Portstatus zu Faulty. Die Ergebnisse dieser Tests sind sichtbar, wenn der Befehl show test ausgegeben wird, gefolgt von der zu überprüfenden Modulnummer:
>show test 9
Diagnostic mode: complete (mode at next reset: complete)
!--- Configuration setting.
Module 9 : 4-port Multilayer Switch
Line Card Status for Module 9 : PASS
Port Status :
Ports 1 2 3 4
-----------------
. . . .
Line Card Diag Status for Module 9 (. = Pass, F = Fail, N = N/A)
Loopback Status [Reported by Module 1] :
Ports 1 2 3 4
-----------------
. . F .
!--- Faulty.
Channel Status :
Ports 1 2 3 4
-----------------
. . . .
Empfehlung
Cisco empfiehlt, für alle Switches eine vollständige Diagnose festzulegen, um eine maximale Fehlererkennung zu gewährleisten und Ausfälle während des normalen Betriebs zu vermeiden.
Hinweis: Diese Änderung tritt erst beim nächsten Start des Geräts in Kraft. Führen Sie diesen Befehl aus, um die vollständige Diagnose festzulegen:
set test diaglevel complete
Weitere Optionen
In einigen Situationen kann eine schnelle Systemstart-Zeit besser sein als das Warten auf die Ausführung einer vollständigen Diagnose. Es gibt weitere Faktoren und Zeitpunkte, die bei der Aktivierung eines Systems eine Rolle spielen. Insgesamt ergeben sich aus dem POST-Test und der Online-Diagnose jedoch wieder etwa ein Drittel der Zeit. Bei Tests mit einem vollständig bestückten Supervisor Engine-Chassis mit neun Steckplätzen und einem Catalyst 6509 betrug die Gesamtstartzeit bei vollständiger Diagnose etwa 380 Sekunden, bei minimaler Diagnose etwa 300 Sekunden und bei umgehender Diagnose nur 250 Sekunden. Geben Sie den folgenden Befehl ein, um die Umgehung zu konfigurieren:
set test diaglevel bypass
Hinweis: Catalyst 4500/4000 akzeptiert die Konfiguration für minimale Diagnosen. Dies führt jedoch weiterhin zu einem vollständigen Test. Der Minimalmodus könnte zukünftig auf dieser Plattform unterstützt werden.
Ausführen der Zeitdiagnose
Sobald das System betriebsbereit ist, führt die Supervisor Engine des Switches verschiedene Überwachungsaufgaben für die anderen Module durch. Wenn ein Modul nicht über die Verwaltungsnachrichten erreichbar ist (Serial Control Protocol [SCP], das über den Out-of-Band-Managementbus ausgeführt wird), versucht die Supervisor Engine, die Karte neu zu starten oder ggf. andere Maßnahmen zu ergreifen.
Betriebsübersicht
Die Supervisor Engine führt verschiedene Überwachungsfunktionen automatisch aus. Dafür ist keine Konfiguration erforderlich. Bei Catalyst 5500/5000 und 6500/6000 werden die folgenden Komponenten des Switches überwacht:
-
NMP über einen Watchdog
-
Verbesserte EARL-Chipfehler
-
Inband-Kanal von der Supervisor Engine zur Backplane
-
Module über Keepalive über Out-of-Band-Channel (Catalyst 6500/6000)
-
Die aktive Supervisor Engine wird von der Standby-Supervisor Engine auf ihren Status überwacht (Catalyst 6500/6000)
System- und Hardware-Fehlererkennung
Betriebsübersicht
In CatOS 6.2 und höher wurden weitere Funktionen hinzugefügt, um kritische Komponenten auf System- und Hardwareebene zu überwachen. Diese drei Hardwarekomponenten werden unterstützt:
-
Inband
-
Port-Zähler
-
Arbeitsspeicher
Wenn die Funktion aktiviert ist und ein Fehler erkannt wird, generiert der Switch eine Syslog-Meldung. Die Meldung informiert den Administrator, dass ein Problem vorliegt, bevor eine spürbare Leistungsminderung auftritt. In CatOS-Versionen 6.4(16), 7.6(12), 8.4(2) und höher wurde der Standardmodus für alle drei Komponenten von "deaktiviert" in "aktiviert" geändert.
Inband
Wenn ein In-Band-Fehler erkannt wird, werden Sie in einer Syslog-Meldung darauf hingewiesen, dass ein Problem vorliegt, bevor es zu einer spürbaren Leistungsminderung kommt. Der Fehler zeigt die Art des Auftretens eines In-Band-Fehlers an. Hier einige Beispiele:
-
In-Band stecken
-
Ressourcenfehler
-
Inband-Fehler beim Hochfahren
Wenn ein In-Band-Ping-Fehler erkannt wird, meldet die Funktion außerdem eine zusätzliche Syslog-Meldung mit einem Snapshot der aktuellen Tx- und Rx-Rate für die In-Band-Verbindung, die CPU und die Backplane-Last des Switches. Mit dieser Meldung können Sie genau feststellen, ob der In-Band-Verkehr blockiert (kein Tx/Rx) oder überlastet (übermäßig Tx/Rx) ist. Anhand dieser zusätzlichen Informationen können Sie die Ursache von In-Band-Ping-Fehlern ermitteln.
Port-Zähler
Wenn Sie dieses Feature aktivieren, wird ein Prozess zum Debuggen von Portzählern erstellt und gestartet. Der Port-Zähler überwacht regelmäßig ausgewählte interne Port-Fehlerzähler. Die Architektur der Linecard, insbesondere die ASICs auf dem Modul, bestimmt, welche Zähler für die Funktionsabfragen verwendet werden. Der technische Support von Cisco oder ein Entwicklungsingenieur kann diese Informationen verwenden, um Probleme zu beheben. Diese Funktion fragt keine Fehlerindikatoren ab, z. B. FCS, CRC, Alignment und Läufe, die direkt mit der Verbindungspartnerverbindung verknüpft sind. Informationen zur Integration dieser Funktion finden Sie im Abschnitt Behandlung von EtherChannel-/Verbindungsfehlern dieses Dokuments.
Polling wird alle 30 Minuten ausgeführt und im Hintergrund ausgewählter Fehlerindikatoren ausgeführt. Wenn die Anzahl zwischen zwei aufeinander folgenden Abfragen auf demselben Port ansteigt, wird der Vorfall in einer Syslog-Meldung gemeldet, die Details zum Modul/Port und zum Fehlerzähler enthält.
Die Port-Zähleroption wird auf der Catalyst 4500/4000-Plattform nicht unterstützt.
Arbeitsspeicher
Bei Aktivierung dieser Funktion wird die Hintergrundüberwachung und Erkennung von DRAM-Beschädigungen durchgeführt. Zu diesen Speicherbeschädigungsbedingungen gehören:
-
Zuweisung
-
Freisetzung
-
Außerhalb des zulässigen Bereichs
-
Falsche Ausrichtung
Empfehlung
Aktivieren Sie alle Fehlererkennungsfunktionen, einschließlich In-Band, Port-Zähler und Speicher, sofern diese unterstützt werden. Durch die Aktivierung dieser Funktionen wird eine verbesserte proaktive System- und Hardware-Warndiagnose für die Catalyst Switch-Plattform erreicht. Führen Sie die folgenden Befehle aus, um alle drei Fehlererkennungsfunktionen zu aktivieren:
set errordetection inband enable !--- This is the default in CatOS 6.4(16), 7.6(12), 8.4(2), and later. set errordetection portcounters enable !--- This is the default in CatOS 6.4(16), 7.6(12), 8.4(2), and later. set errordetection memory enable !--- This is the default in CatOS 6.4(16), 7.6(12), 8.4(2), and later.
Geben Sie den folgenden Befehl ein, um zu bestätigen, dass die Fehlererkennung aktiviert ist:
>show errordetection Inband error detection: enabled Memory error detection: enabled Packet buffer error detection: errdisable Port counter error detection: enabled Port link-errors detection: disabled Port link-errors action: port-failover Port link-errors interval: 30 seconds
Fehlerbehandlung bei EtherChannel/Verbindung
Betriebsübersicht
In CatOS 8.4 und höher wurde eine neue Funktion eingeführt, um ein automatisches Failover für den Datenverkehr von einem Port in einem EtherChannel zu einem anderen Port im selben EtherChannel bereitzustellen. Port-Failover tritt auf, wenn einer der Ports im Channel innerhalb des angegebenen Intervalls einen konfigurierbaren Fehlerschwellenwert überschreitet. Der Port-Failover erfolgt nur, wenn im EtherChannel noch ein betriebsbereiter Port vorhanden ist. Wenn der ausgefallene Port der letzte Port im EtherChannel ist, wechselt der Port nicht in den Port-Failover-Status. Über diesen Port wird weiterhin Datenverkehr weitergeleitet, unabhängig von der Art der Fehler, die aufgetreten sind. Einzelne, nicht-Channeling-Ports gelangen nicht in den Port-Failover-Status. Diese Ports wechseln in den errdisable-Status, wenn der Fehlerschwellenwert innerhalb des angegebenen Intervalls überschritten wird.
Diese Funktion ist nur wirksam, wenn Sie Portindikatoren zur Fehlererkennung festlegen aktivieren. Die zu überwachenden Verbindungsfehler basieren auf drei Zählern:
-
Fehler
-
RxCRCs (CRCAlignErrors)
-
TxCRCs
Führen Sie den Befehl show counters auf einem Switch aus, um die Anzahl der Fehlerzähler anzuzeigen. Hier ein Beispiel:
>show counters 4/48 ....... 32 bit counters 0 rxCRCAlignErrors = 0 ....... 6 ifInErrors = 0 ....... 12 txCRC = 0
Diese Tabelle enthält eine Liste möglicher Konfigurationsparameter und der entsprechenden Standardkonfiguration:
| Parameter | Standard |
|---|---|
| Global | Deaktiviert |
| Portmonitor für RxCRC | Deaktiviert |
| Portmonitor für InErrors | Deaktiviert |
| Portmonitor für TxCRC | Deaktiviert |
| Aktion | Port-Failover |
| Intervall | 30 Sekunden |
| Stichprobenanzahl | 3 aufeinander folgende |
| Niedriger Schwellenwert | 1000 |
| Hoher Grenzwert | 1001 |
Wenn die Funktion aktiviert ist und die Fehleranzahl eines Ports den hohen Wert des konfigurierbaren Grenzwerts innerhalb des angegebenen Sampling-Zählzeitraums erreicht, kann die konfigurierbare Aktion entweder auf "error disable" oder "port failover" gesetzt werden. Die Aktion error disable setzt den Port in den Status errdisable. Wenn Sie die Port-Failover-Aktion konfigurieren, wird der Port-Channel-Status berücksichtigt. Der Port wird nur dann aufgrund eines Fehlers deaktiviert, wenn sich der Port in einem Kanal befindet, dieser Port jedoch nicht der letzte betriebsbereite Port im Kanal ist. Wenn die konfigurierte Aktion "Port-Failover" lautet und der Port ein einzelner oder ein nicht kanalisierter Port ist, wird der Port in den Status "errdisable" versetzt, wenn die Anzahl der Port-Fehler den hohen Wert des Grenzwerts erreicht.
Das Intervall ist eine Timer-Konstante zum Lesen der Port-Fehlerzähler. Der Standardwert für das Intervall für Verbindungsfehler ist 30 Sekunden. Der zulässige Bereich liegt zwischen 30 und 1800 Sekunden.
Es besteht die Gefahr, dass ein Port aufgrund eines unerwarteten einmaligen Ereignisses versehentlich aufgrund eines Fehlers deaktiviert wird. Um dieses Risiko zu minimieren, werden nur dann Maßnahmen an einem Port ergriffen, wenn der Zustand durch diese aufeinander folgende Probenahme wiederholt anhält. Der Standard-Abtastwert ist 3, und der zulässige Bereich liegt zwischen 1 und 255.
Der Schwellenwert ist eine absolute Zahl, die basierend auf dem Intervall zwischen Verbindungsfehlern überprüft werden muss. Der niedrige Standardwert für "link-error" ist 1000 und der zulässige Bereich ist 1 bis 65.535. Der hohe Standardwert für "link-error" ist 1001. Wenn die aufeinander folgende Anzahl von Abtastvorgängen den unteren Grenzwert erreicht, wird ein Syslog gesendet. Wenn die aufeinander folgenden Abtastzeitpunkte den hohen Grenzwert erreichen, wird ein Syslog gesendet und eine Fehlerdeaktivierungs- oder Port-Failover-Aktion ausgelöst.
Hinweis: Verwenden Sie für alle Ports in einem Kanal dieselbe Konfiguration zur Port-Fehlererkennung. Weitere Informationen finden Sie in den folgenden Abschnitten des Software-Konfigurationsleitfadens für die Catalyst Serie 6500:
-
Im Abschnitt Configuring EtherChannel/Link Error Handling (Konfigurieren der EtherChannel/Link-Fehlerbehandlung) unter Checking Status and Connectivity (Status- und Verbindungsüberprüfung)
-
Der Abschnitt Configuring Port Error Detection unter Configuring Ethernet, Fast Ethernet, Gigabit Ethernet, and 10-Gigabit Ethernet Switching
Empfehlungen
Da die Funktion SCP-Nachrichten zum Aufzeichnen und Vergleichen der Daten verwendet, kann eine hohe Anzahl aktiver Ports CPU-intensiv sein. Dieses Szenario ist noch CPU-intensiver, wenn das Schwellenwertintervall auf einen sehr kleinen Wert festgelegt wird. Aktivieren Sie diese Funktion mit Diskretion für Ports, die als kritische Verbindungen festgelegt sind und Datenverkehr für sensible Anwendungen übertragen. Führen Sie diesen Befehl aus, um die globale Erkennung von Verbindungsfehlern zu aktivieren:
set errordetection link-errors enable
Beginnen Sie außerdem mit den Standardparametern für Grenzwert, Intervall und Sampling. Verwenden Sie die Standardaktion "Port-Failover".
Führen Sie die folgenden Befehle aus, um die globalen Parameter für Verbindungsfehler auf einzelne Ports anzuwenden:
set port errordetection mod/port inerrors enable set port errordetection mod/port rxcrc enable set port errordetection mod/port txcrc enable
Sie können die folgenden Befehle ausgeben, um die Konfiguration der Verbindungsfehler zu überprüfen:
show errordetection
show port errordetection {mod | mod/port}
Catalyst 6500/6000 - Paketpuffer-Diagnose
In CatOS-Versionen 6.4(7), 7.6(5) und 8.2(1) wurde die Paketpufferdiagnose für Catalyst 6500/6000 eingeführt. Die Paketpufferdiagnose, die standardmäßig aktiviert ist, erkennt Paketpufferfehler, die durch vorübergehende statische RAM-Fehler (SRAM) verursacht werden. Die Erkennung erfolgt über diese 48-Port-10/100-Mbit/s-Leitungsmodule:
-
WS-X6248-RJ45
-
WS-X6248-RJ21
-
WS-X6348-RJ45
-
WS-X6348-RJ21
-
WS-X6148-RJ45
-
WS-X6148-RJ21
Wenn der Fehler auftritt, bleiben 12 der 48 10/100-Mbit/s-Ports weiterhin verbunden und es kann zu zufälligen Verbindungsproblemen kommen. Die einzige Möglichkeit zur Wiederherstellung besteht darin, das Leitungsmodul aus- und wieder einzuschalten.
Betriebsübersicht
Die Paketpufferdiagnose überprüft die Daten, die in einem bestimmten Abschnitt des Paketpuffers gespeichert sind, um festzustellen, ob sie durch vorübergehende SRAM-Fehler beschädigt sind. Wenn der Prozess etwas Anderes als das zurückliest, was er geschrieben hat, führt er zwei mögliche konfigurierbare Wiederherstellungsoptionen aus:
-
Standardmäßig werden die Line Card-Ports, die von einem Pufferfehler betroffen sind, aufgrund eines Fehlers deaktiviert.
-
Die zweite Option besteht darin, die Linecard aus- und wieder einzuschalten.
Es wurden zwei Syslog-Meldungen hinzugefügt. Die Meldungen enthalten eine Warnung zur Fehlerdeaktivierung der Ports oder zum Aus- und Einschalten des Moduls aufgrund von Paketpufferfehlern:
%SYS-3-PKTBUFFERFAIL_ERRDIS:Packet buffer failure detected. Err-disabling port 5/1. %SYS-3-PKTBUFFERFAIL_PWRCYCLE: Packet buffer failure detected. Power cycling module 5.
Bei älteren CatOS-Versionen als 8.3 und 8.4 beträgt die Ein- und Ausschaltzeit der Linecards zwischen 30 und 40 Sekunden. Eine Rapid Boot-Funktion wurde in CatOS 8.3 und 8.4 eingeführt. Die Funktion lädt die Firmware während des ersten Bootvorgangs automatisch auf die installierten Linecards herunter, um die Bootdauer zu minimieren. Die Rapid Boot-Funktion reduziert die Ein-/Ausschaltzeit auf ca. 10 Sekunden.
Empfehlung
Cisco empfiehlt die Standardoption errdisable. Diese Aktion hat die geringsten Auswirkungen auf den Netzwerkservice während der Produktionszeiten. Wenn möglich, verschieben Sie die Verbindung, die von den deaktivierten Ports betroffen ist, auf andere verfügbare Switch-Ports, um den Service wiederherzustellen. Planen Sie ein manuelles Ein- und Ausschalten der Linecard während des Wartungsfensters. Führen Sie den Befehl reset module mod aus, um eine vollständige Wiederherstellung nach dem beschädigten Paketpuffer zu ermöglichen.
Hinweis: Wenn die Fehler auch nach dem Zurücksetzen des Moduls auftreten, versuchen Sie, das Modul wieder einzusetzen.
Führen Sie diesen Befehl aus, um die Option errdisable zu aktivieren:
set errordetection packet-buffer errdisable !--- This is the default.
Andere Option
Da ein Aus- und Einschalten der Linecard erforderlich ist, um alle Ports wiederherzustellen, bei denen ein SRAM-Fehler aufgetreten ist, besteht eine alternative Wiederherstellungsaktion in der Konfiguration der Aus- und Wiedereinschalt-Option. Diese Option ist unter Umständen nützlich, in denen ein Ausfall von Netzwerkdiensten, der zwischen 30 und 40 Sekunden dauern kann, hinnehmbar ist. Diese Zeitspanne ist die Zeit, die ein Leitungsmodul benötigt, um sich ohne die Rapid Boot-Funktion vollständig neu zu starten und wieder in Betrieb zu nehmen. Die Rapid Boot-Funktion kann die Ausfallzeit der Netzwerkdienste mit der Ein-/Ausschaltoption auf 10 Sekunden reduzieren. Führen Sie den folgenden Befehl aus, um die Ein-/Ausschaltoption zu aktivieren:
set errordetection packet-buffer power-cycle
Paketpuffer-Diagnose
Dieser Test gilt nur für Catalyst 5500/5000 Switches. Mit diesem Test wird die fehlerhafte Hardware von Catalyst 5500/5000-Switches ermittelt, die Ethernet-Module mit spezieller Hardware verwenden, die eine 10/100-Mbit/s-Verbindung zwischen Benutzerports und der Switch-Rückwandplatine bereitstellen. Da sie keine CRC-Prüfung für Bündel durchführen können, können Pakete beschädigt werden und CRC-Fehler verursachen, wenn ein Port-Paketpuffer zur Laufzeit defekt wird. Leider kann dies zur Ausbreitung fehlerhafter Frames weiter in das Catalyst 5500/5000 ISL-Netzwerk führen, was im schlimmsten Fall zu Störungen auf der Kontrollebene und Broadcast-Stürmen führen kann.
Neuere Catalyst 5500/5000-Module und andere Plattformen verfügen über eine integrierte Überprüfung auf Hardwarefehler und benötigen keine Paketpuffertests. Daher gibt es keine Möglichkeit, diese zu konfigurieren.
Die Leitungsmodule, für die eine Paketpufferdiagnose erforderlich ist, sind WS-X5010, WS-X5011, WS-X5013, WS-X5020, WS-X5111, WS-X5113, WS-X5114 und WS-X5. WS-X5203, WS-X5213/a, WS-X5223, WS-X5224, WS-X5506, WS-X5509, WS-U5531, WS-U555 33 und WS-U5535.
Betriebsübersicht
Bei dieser Diagnose wird überprüft, ob Daten, die in einem bestimmten Abschnitt des Paketpuffers gespeichert sind, nicht versehentlich durch fehlerhafte Hardware beschädigt wurden. Wenn der Prozess etwas Anderes als geschrieben zurückliest, wird der Port im fehlgeschlagenen Modus heruntergefahren, da dieser Port Daten beschädigen kann. Es ist kein Schwellenwert für Fehler erforderlich. Fehlgeschlagene Ports können erst wieder aktiviert werden, nachdem das Modul zurückgesetzt (oder ersetzt) wurde.
Es gibt zwei Modi für Paketpuffertests: geplanten und On-Demand. Zu Beginn eines Tests werden Syslog-Meldungen generiert, um die erwartete Länge des Tests (auf die nächste Minute aufgerundet) und den Beginn des Tests anzugeben. Die genaue Länge des Tests variiert je nach Port-Typ, Größe des Puffers und Art des Testlaufs.
On-Demand-Tests sind aggressiv, um innerhalb weniger Minuten zu beenden. Da diese Tests den Paketspeicher aktiv beeinträchtigen, müssen die Ports vor dem Testen vom Administrator deaktiviert werden. Führen Sie diesen Befehl aus, um die Ports herunterzufahren:
> (enable) test packetbuffer 4/1 Warning: only disabled ports may be tested on demand - 4/1 will be skipped. > (enable) set port disable 4/1 > (enable) test packetbuffer 4/1 Packet buffer test started. Estimated test time: 1 minute. %SYS-5-PKTTESTSTART:Packet buffer test started %SYS-5-PKTTESTDONE:Packet buffer test done. Use 'show test' to see test results
Geplante Tests sind weitaus weniger aufwändig als On-Demand-Tests und werden im Hintergrund ausgeführt. Die Tests werden parallel über mehrere Module, aber jeweils an einem Port pro Modul durchgeführt. Beim Test werden kleine Abschnitte des Paketpufferspeichers beibehalten, geschrieben und gelesen, bevor die Daten des Benutzerpaketpuffers wiederhergestellt werden. Somit werden keine Fehler generiert. Da der Test jedoch in den Pufferspeicher geschrieben wird, blockiert er eingehende Pakete für einige Millisekunden und verursacht einige Verluste bei belegten Verbindungen. Standardmäßig gibt es zwischen jedem Buffer-Write-Test eine Pause von acht Sekunden, um Paketverluste zu minimieren. Dies bedeutet jedoch, dass ein System mit vielen Modulen, die den Paketpuffertest benötigen, über 24 Stunden für den Test benötigen kann. Dieser geplante Test wird standardmäßig aktiviert, um sonntags um 03:30 Uhr in CatOS 5.4 oder höher ausgeführt zu werden. Der Teststatus kann mit dem folgenden Befehl bestätigt werden:
>show test packetbuffer status !--- When test is running, the command returns !--- this information: Current packet buffer test details Test Type : scheduled Test Started : 03:30:08 Jul 20 2001 Test Status : 26% of ports tested Ports under test : 10/5,11/2 Estimated time left : 11 minutes !--- When test is not running, !--- the command returns this information: Last packet buffer test details Test Type : scheduled Test Started : 03:30:08 Jul 20 2001 Test Finished : 06:48:57 Jul 21 2001
Empfehlung
Cisco empfiehlt, die Funktion zum Testen geplanter Paketpuffer für Catalyst 5500/5000-Systeme zu verwenden, da das Erkennen von Problemen an Modulen das Risiko eines geringen Paketverlusts überwiegt.
Anschließend muss eine standardisierte Wochenzeit im gesamten Netzwerk geplant werden, sodass der Kunde Links von fehlerhaften Ports oder RMA-Modulen nach Bedarf ändern kann. Da dieser Test je nach Netzwerkauslastung einen gewissen Paketverlust verursachen kann, muss er für kürzere Netzwerkzeiten geplant werden, z. B. für die Standardeinstellung 3:30 Uhr an einem Sonntagmorgen. Führen Sie diesen Befehl aus, um die Testzeit festzulegen:
set test packetbuffer Sunday 3:30 !--- This is the default.
Nach der Aktivierung (z. B. wenn CatOS zum ersten Mal auf 5.4 und höher aktualisiert wird) besteht die Möglichkeit, dass ein zuvor verborgenes Speicher-/Hardwareproblem erkannt wird und ein Port infolgedessen automatisch abgeschaltet wird. Sie können diese Nachricht sehen:
%SYS-3-PKTBUFBAD:Port 1/1 failed packet buffer test
Weitere Optionen
Wenn es nicht akzeptabel ist, wöchentlich einen geringen Paketverlust pro Port zu riskieren, wird empfohlen, die On-Demand-Funktion bei geplanten Ausfällen zu verwenden. Führen Sie diesen Befehl aus, um diese Funktion manuell für jeden Bereich zu starten (allerdings muss der Port zuvor administrativ deaktiviert werden):
test packetbuffer port range
Systemprotokollierung
Syslog-Meldungen sind Cisco-spezifisch und ein wichtiger Bestandteil des proaktiven Fehlermanagements. Über Syslog wird ein breiteres Spektrum von Netzwerk- und Protokollbedingungen gemeldet, als über standardisiertes SNMP möglich wäre. Verwaltungsplattformen wie Cisco Resource Manager Essentials (RMEs) und das Network Analysis Toolkit (NATkit) nutzen Syslog-Informationen auf leistungsstarke Weise, da sie folgende Aufgaben ausführen:
-
Präsenzanalyse nach Schweregrad, Nachricht, Gerät usw.
-
Filterung der zur Analyse eingehenden Nachrichten aktivieren
-
Auslösung von Warnmeldungen, z. B. Pager, oder Erfassung von Bestands- und Konfigurationsänderungen auf Anforderung
Empfehlung
Ein wichtiger Punkt ist, welche Protokollierungsinformationen lokal generiert und im Switch-Puffer gespeichert werden sollen, anstatt an einen Syslog-Server gesendet zu werden (mit dem Befehl set logging server severity value). Einige Unternehmen protokollieren einen hohen Grad an Informationen zentral, während andere den Switch selbst besuchen, um die detaillierteren Protokolle für ein Ereignis zu überprüfen, oder eine höhere Ebene der Syslog-Erfassung nur während der Fehlerbehebung ermöglichen.
Das Debuggen unterscheidet sich auf CatOS-Plattformen von der Cisco IOS-Software, aber die detaillierte Systemprotokollierung kann auf Sitzungsbasis aktiviert werden, wobei die festgelegte Protokollierungssitzung aktiviert wird, ohne die Standardprotokollierung zu ändern.
Cisco empfiehlt in der Regel, die Spantree- und System-Syslog-Funktionen auf Stufe 6 zu bringen, da dies wichtige Stabilitätsfunktionen sind, die überwacht werden müssen. Darüber hinaus wird für Multicast-Umgebungen empfohlen, die Protokollierungsebene der Multicast-Einrichtung auf 4 zu erhöhen, damit Syslog-Meldungen generiert werden, wenn Router-Ports gelöscht werden. Leider kann dies vor CatOS 5.5(5) dazu führen, dass Syslog-Meldungen für IGMP-Joins und -Links aufgezeichnet werden, was für die Überwachung zu laut ist. Bei Verwendung von IP-Eingabelisten wird eine Protokollierungsebene von mindestens 4 empfohlen, um nicht autorisierte Anmeldeversuche zu erfassen. Führen Sie die folgenden Befehle aus, um die folgenden Optionen festzulegen:
set logging buffer 500
!--- This is the default.
set logging server syslog server IP address
set logging server enable
!--- This is the default.
set logging timestamp enable
set logging level spantree 6 default
!--- Increase default STP syslog level.
set logging level sys 6 default
!--- Increase default system syslog level.
set logging server severity 4
!--- This is the default; !--- it limits messages exported to syslog server.
set logging console disable
Schalten Sie die Konsolenmeldungen aus, um sich vor dem Risiko zu schützen, dass der Switch hängenbleibt, wenn er bei hohem Nachrichtenvolumen auf eine Antwort eines langsamen oder nicht vorhandenen Terminals wartet. Die Konsolenprotokollierung hat unter CatOS eine hohe Priorität und wird hauptsächlich verwendet, um die Abschlussmeldungen lokal bei der Fehlerbehebung oder bei einem Switch-Absturz zu erfassen.
Diese Tabelle enthält die einzelnen Protokollierungsfunktionen, Standardwerte und empfohlenen Änderungen für Catalyst 6500/6000. Jede Plattform verfügt je nach unterstützten Funktionen über etwas andere Funktionen.
| Einrichtung | Standardstufe | Empfohlene Aktion |
|---|---|---|
| ACL | 5 | Lass mich in Ruhe. |
| CDP | 4 | Lass mich in Ruhe. |
| Bullen | 3 | Lass mich in Ruhe. |
| DTP | 8 | Lass mich in Ruhe. |
| Graf | 2 | Lass mich in Ruhe. |
| Ethisch1 | 5 | Lass mich in Ruhe. |
| Dateisysteme | 2 | Lass mich in Ruhe. |
| GVRP | 2 | Lass mich in Ruhe. |
| ip | 2 | Bei Verwendung von IP-Eingabelisten in 4 ändern. |
| Kernel | 2 | Lass mich in Ruhe. |
| 1 Tag | 3 | Lass mich in Ruhe. |
| Mcast | 2 | Bei Verwendung von Multicast auf 4 umstellen (CatOS 5.5[5] und höher) |
| Verwaltung | 5 | Lass mich in Ruhe. |
| MLS | 5 | Lass mich in Ruhe. |
| Seite | 5 | Lass mich in Ruhe. |
| Profil | 2 | Lass mich in Ruhe. |
| Beschneiden | 2 | Lass mich in Ruhe. |
| Privatevlan | 3 | Lass mich in Ruhe. |
| QoS | 3 | Lass mich in Ruhe. |
| radius | 2 | Lass mich in Ruhe. |
| RSVP | 3 | Lass mich in Ruhe. |
| sicherheit | 2 | Lass mich in Ruhe. |
| snmp | 2 | Lass mich in Ruhe. |
| Spanbaum | 2 | Ändern Sie den Wert in 6. |
| sys | 5 | Ändern Sie den Wert in 6. |
| TAC | 2 | Lass mich in Ruhe. |
| tcp | 2 | Lass mich in Ruhe. |
| telnet | 2 | Lass mich in Ruhe. |
| TFTP | 2 | Lass mich in Ruhe. |
| UDLD | 4 | Lass mich in Ruhe. |
| VMPS | 2 | Lass mich in Ruhe. |
| VTP | 2 | Lass mich in Ruhe. |
1 In CatOS 7.x und höher wird der Seiteneinrichtungscode durch den Ethc-Einrichtungscode ersetzt, um die LACP-Unterstützung widerzuspiegeln.
Hinweis: Im Gegensatz zur Cisco IOS Software protokollieren Catalyst Switches derzeit für jeden ausgeführten set- oder clear-Befehl eine Syslog-Meldung zur Konfigurationsänderung. Diese löst die Meldung nur nach dem Beenden des Konfigurationsmodus aus. Wenn RMEs Konfigurationen bei diesem Trigger in Echtzeit sichern müssen, müssen diese Meldungen auch an den RME-Syslog-Server gesendet werden. Für die meisten Kunden sind regelmäßige Konfigurations-Backups für Catalyst Switches ausreichend, und der Schweregrad der Standard-Serverprotokollierung muss nicht geändert werden.
Informationen zum Einstellen von NMS-Warnmeldungen finden Sie im System Message Guide (Handbuch für Systemmeldungen).
Simple Network Management Protocol
SNMP wird zum Abrufen von Statistiken, Zählern und Tabellen verwendet, die in MIBs (Management Information Bases) für Netzwerkgeräte gespeichert sind. Die erfassten Informationen können von NMS (z. B. HP Openview) verwendet werden, um Warnmeldungen in Echtzeit zu generieren, die Verfügbarkeit zu messen, Informationen zur Kapazitätsplanung zu liefern sowie Konfigurations- und Fehlerbehebungsprüfungen durchzuführen.
Betriebsübersicht
Mit einigen Sicherheitsmechanismen kann eine Netzwerkmanagement-Station Informationen in den MIBs mit dem SNMP-Protokoll get abrufen und die nächsten Anfragen abrufen sowie Parameter mit dem Befehl set ändern. Darüber hinaus kann ein Netzwerkgerät so konfiguriert werden, dass es eine Trap-Nachricht für das NMS generiert, die eine Warnung in Echtzeit ausgibt. SNMP Polling verwendet den IP-UDP-Port 161 und SNMP-Traps den Port 162.
Cisco unterstützt die folgenden SNMP-Versionen:
-
SNMPv1: RFC 1157 Internet Standard, mit Klartext-Community String-Sicherheit. Eine IP-Adressenzugriffskontrollliste und ein Kennwort definieren die Community der Manager, die auf die Agenten-MIB zugreifen können.
-
SNMPv2C: eine Kombination aus SNMPv2, einem in den RFCs 1902 bis 1907 definierten Draft-Internetstandard, und SNMPv2C, einem Community-basierten administrativen Framework für SNMPv2, das ein in RFC 1901 definierter experimenteller Entwurf ist. Zu den Vorteilen zählen ein Massenabruffunktionsmechanismus, der das Abrufen von Tabellen und großen Informationsmengen unterstützt, die Anzahl erforderlicher Roundtrips minimiert und die Fehlerbehandlung verbessert.
-
SNMPv3: Der von RFC 2570 vorgeschlagene Entwurf bietet sicheren Zugriff auf Geräte durch die Kombination von Authentifizierung und Verschlüsselung von Paketen über das Netzwerk. Folgende Sicherheitsfunktionen werden in SNMPv3 bereitgestellt:
-
Nachrichtenintegrität: stellt sicher, dass ein Paket während der Übertragung nicht manipuliert wurde
-
Authentifizierung: bestimmt, dass die Nachricht von einer gültigen Quelle stammt
-
Verschlüsselung: verschlüsselt den Inhalt eines Pakets, um zu verhindern, dass es von einer nicht autorisierten Quelle leicht angezeigt wird.
-
In dieser Tabelle sind die Kombinationen von Sicherheitsmodellen aufgeführt:
| Modellebene | Authentifizierung | Verschlüsselung | Ergebnis |
|---|---|---|---|
| V1 | noAuthNoPriv, Community-Zeichenfolge | Nein | Verwendet einen Community-String-Abgleich für die Authentifizierung. |
| v2c | noAuthNoPriv, Community-Zeichenfolge | Nein | Verwendet einen Community-String-Abgleich für die Authentifizierung. |
| V3 | noAuthNoPriv, Benutzername | Nein | Verwendet einen Benutzernamen-Abgleich für die Authentifizierung. |
| V3 | authNoPriv, MD5 oder SHA | NP | Bietet Authentifizierung auf Basis der HMAC-MD5- oder HMAC-SHA-Algorithmen. |
| V3 | authPriv, MD5 oder SHA | DES | Bietet Authentifizierung auf Basis der HMAC-MD5- oder HMAC-SHA-Algorithmen. DES-56-Bit-Verschlüsselung zusätzlich zur Authentifizierung nach CBC-DES (DES-56)-Standard |
Hinweis: Beachten Sie diese Informationen zu SNMPv3-Objekten:
-
Jeder Benutzer gehört zu einer Gruppe.
-
Eine Gruppe definiert die Zugriffsrichtlinie für eine Gruppe von Benutzern.
-
Eine Zugriffsrichtlinie definiert, auf welche SNMP-Objekte zugegriffen werden kann, um sie zu lesen, zu schreiben und zu erstellen.
-
Eine Gruppe bestimmt die Liste der Benachrichtigungen, die ihre Benutzer erhalten können.
-
Eine Gruppe definiert auch das Sicherheitsmodell und die Sicherheitsstufe für ihre Benutzer.
SNMP-Trap-Empfehlung
SNMP stellt die Grundlage für das gesamte Netzwerkmanagement dar und wird in allen Netzwerken aktiviert und verwendet. Der SNMP-Agent auf dem Switch muss so konfiguriert sein, dass er die von der Managementstation unterstützte SNMP-Version verwendet. Da ein Agent mit mehreren Managern kommunizieren kann, ist es möglich, die Software so zu konfigurieren, dass sie die Kommunikation mit einer Managementstation über das SNMPv1-Protokoll und mit einer anderen Station über das SNMPv2-Protokoll unterstützt.
Die meisten NMS-Stationen verwenden SNMPv2C derzeit unter dieser Konfiguration:
set snmp community read-only string !--- Allow viewing of variables only. set snmp community read-write string !--- Allow setting of variables. set snmp community read-write-all string!--- Include setting of SNMP strings.
Cisco empfiehlt, SNMP-Traps für alle verwendeten Funktionen zu aktivieren (nicht verwendete Funktionen können bei Bedarf deaktiviert werden). Wenn ein Trap aktiviert ist, kann er mit dem Test-SNMP-Befehl getestet und die entsprechende Fehlerbehandlung (z. B. eine Pager-Warnung oder ein Popup-Fenster) auf dem NMS eingerichtet werden.
Alle Traps sind standardmäßig deaktiviert und müssen der Konfiguration hinzugefügt werden, entweder einzeln oder über den Parameter all.
set snmp trap enable all
set snmp trap server address read-only community string
Zu den in CatOS 5.5 verfügbaren Traps gehören:
| Trap | Beschreibung |
|---|---|
| verfassen | Authentifizierung |
| bridge | Bridge |
| Chassis | Gehäuse |
| konfig. | Konfiguration |
| Entität | Einheit |
| Unerlaubnis | IP-Genehmigung |
| modul | Modul |
| Repeater | Repeater |
| STPX | Spanning Tree-Erweiterung |
| syslog | Syslog-Benachrichtigung |
| VPNs | VLAN Membership Policy Server |
| VTP | VLAN-Trunk-Protokoll |
Hinweis: Das Syslog-Trap sendet alle vom Switch generierten Syslog-Meldungen auch als SNMP-Trap an das NMS. Wenn Syslog-Warnungen bereits von einem Analysegerät wie Cisco Works 2000 RMEs durchgeführt werden, ist es nicht unbedingt sinnvoll, diese Informationen zweimal zu erhalten.
Im Gegensatz zur Cisco IOS Software sind SNMP-Traps auf Portebene standardmäßig deaktiviert, da Switches über Hunderte von aktiven Schnittstellen verfügen können. Cisco empfiehlt daher, SNMP-Traps auf Portebene für wichtige Ports wie Infrastruktur-Links zu Routern, Switches und Hauptservern zu aktivieren. Andere Ports, wie Benutzer-Host-Ports, sind nicht erforderlich, was die Netzwerkverwaltung vereinfacht.
set port trap port range enable
!--- Enable on key ports only.
SNMP-Polling-Empfehlung
Es wird empfohlen, das Netzwerkmanagement zu überprüfen, um spezifische Anforderungen im Detail zu besprechen. Es werden jedoch einige grundlegende Philosophien von Cisco für die Verwaltung großer Netzwerke aufgelistet:
-
Tun Sie etwas Einfaches, und tun Sie es gut.
-
Reduzieren der Überlastung der Mitarbeiter durch übermäßige Datenabfragen, Erfassung, Tools und manuelle Analysen.
-
Netzwerkmanagement ist mit nur wenigen Tools möglich, z. B. HP Openview als NMS, Cisco RMEs als Konfigurations-, Syslog-, Bestands- und Softwaremanager, Microsoft Excel als NMS-Datenanalysator und CGI als Möglichkeit zur Veröffentlichung im Web.
-
Durch die Veröffentlichung von Berichten im Internet können sich Nutzer, wie z. B. Führungskräfte und Analysten, selbst mit Informationen versorgen, ohne das Betriebspersonal mit vielen speziellen Anfragen zu belasten.
-
Erfahren Sie, was im Netzwerk gut funktioniert, und lassen Sie es in Ruhe. Konzentriere dich auf das, was nicht funktioniert.
In der ersten Phase der NMS-Implementierung muss die Netzwerkhardware als Basis dienen. Aus der einfachen CPU-, Arbeitsspeicher- und Pufferauslastung auf Routern und der NMP-CPU-, Arbeitsspeicher- und Backplane-Auslastung auf Switches lässt sich viel über den Status von Geräten und Protokollen ableiten. Erst nach einer Hardware-Baseline haben L2- und L3-Datenverkehrslast, -spitzen und -durchschnittliche Baselines volle Bedeutung. Baselines werden in der Regel über mehrere Monate erstellt, um die täglichen, wöchentlichen und vierteljährlichen Trends - je nach Geschäftszyklus des Unternehmens - sichtbar zu machen.
In vielen Netzwerken treten aufgrund von Überabfragen Leistungs- und Kapazitätsprobleme des NMS auf. Es wird daher empfohlen, nach Festlegung der Baseline auf den Geräten selbst Alarm- und Ereignis-RMON-Grenzwerte festzulegen, um das NMS über anormale Änderungen zu informieren und so die Abfrage zu unterbinden. Auf diese Weise kann das Netzwerk den Betreibern sagen, wenn etwas nicht normal ist, und nicht ständig abfragen, ob alles normal ist. Schwellenwerte können auf der Grundlage verschiedener Regeln festgelegt werden, z. B. Höchstwert plus ein Prozentsatz oder Standardabweichung vom Mittelwert. Sie sind nicht Gegenstand dieses Dokuments.
In der zweiten Phase der NMS-Implementierung wird mithilfe des SNMP eine detailliertere Abfrage bestimmter Netzwerkbereiche durchgeführt. Dazu gehören Bereiche mit Zweifeln, Bereiche vor einer Änderung oder Bereiche, die als gut funktionierend gekennzeichnet sind. Verwenden Sie die NMS-Systeme als Suchscheinwerfer, um das Netzwerk im Detail zu durchsuchen und Hotspots zu beleuchten (versuchen Sie nicht, das gesamte Netzwerk zu beleuchten).
Die Cisco Network Management Consulting-Gruppe empfiehlt, diese MIBs für zentrale Fehler in Campus-Netzwerken zu analysieren oder zu überwachen. Weitere Informationen finden Sie unter Cisco Network Monitoring and Event Correlation Guidelines (z. B. zu Performance-MIBs für die Abfrage).
| Objektname | Objektbeschreibung | OID | Umfrageintervall | Grenzwert |
|---|---|---|---|---|
| MIB-II | ||||
| sysBetriebszeit | Systembetriebszeit in 1/100 Sekunden | 1.3.6.1.2.1.1.3 | 5 Minuten | < 30000 |
| Objektname | Objektbeschreibung | OID | Umfrageintervall | Grenzwert |
|---|---|---|---|---|
| CISCO-PROZESS-MIB | ||||
| cpmCPUTotal5min | Der prozentuale Gesamtanteil der CPU-Auslastung in den letzten 5 Minuten | 1.3.6.1.4.1.9.9.109.1.1.1.1.5 | 10 Minuten | Grundlinie |
| Objektname | Objektbeschreibung | OID | Umfrageintervall | Grenzwert |
|---|---|---|---|---|
| CISCO-STACK-MIB | ||||
| sysEnableChassisTraps | Gibt an, ob die Traps "chassisAlarmOn" und "chassisAlarmOff" in dieser MIB generiert werden müssen. | 1.3.6.1.4.1.9.5.1.1.24 | 24 h | 1 |
| sysEnableModuleTraps | Gibt an, ob moduleUp- und moduleDown-Traps in dieser MIB generiert werden müssen. | 1.3.6.1.4.1.9.5.1.1.25 | 24 h | 1 |
| sysEnableBridgeTraps | Gibt an, ob neue Root- und TopologyChange-Traps in der BRIDGE-MIB (RFC 1493) generiert werden müssen. | 1.3.6.1.4.1.9.5.1.1.26 | 24 h | 1 |
| sysEnableRepeaterTraps | Gibt an, ob die Traps in REPEATER-MIB (RFC1516) generiert werden müssen. | 1.3.6.1.4.1.9.5.1.1.29 | 24 h | 1 |
| sysEnableIpPermitTraps | Gibt an, ob die IP-Zulassen-Traps in dieser MIB generiert werden müssen. | 1.3.6.1.4.1.9.5.1.1.31 | 24 h | 1 |
| sysAktivierenVmpsTraps | Gibt an, ob der in CISCO- VLAN-MEMBERSHIP-MIB definierte vmVmpsChange-Trap generiert werden muss. | 1.3.6.1.4.1.9.5.1.1.33 | 24 h | 1 |
| sysEnableConfigTraps | Gibt an, ob der sysConfigChange-Trap in dieser MIB generiert werden muss. | 1.3.6.1.4.1.9.5.1.1.35 | 24 h | 1 |
| sysEnableStpxTrap | Gibt an, ob das stpxInconsistencyUpdate-Trap in der CISCO-STP-EXTENSIONS-MIB generiert werden muss. | 1.3.6.1.4.1.9.5.1.1.40 | 24 h | 1 |
| ChassisPs1Status | Status des Netzteils 1. | 1.3.6.1.4.1.9.5.1.2.4 | 10 Minuten | 2 |
| ChassisPs1Testergebnis | Detaillierte Informationen zum Status des Netzteils 1. | 1.3.6.1.4.1.9.5.1.2.5 | Bei Bedarf. | |
| ChassisPS2Status | Status des Netzteils 2. | 1.3.6.1.4.1.9.5.1.2.7 | 10 Minuten | 2 |
| chassisPs2Testergebnis | Detaillierte Informationen zum Status des Netzteils 2 | 1.3.6.1.4.1.9.5.1.2.8 | Bei Bedarf. | |
| ChassisLüfterstatus | Status des Gehäuselüfters | 1.3.6.1.4.1.9.5.1.2.9 | 10 Minuten | 2 |
| ChassisLüfterTestErgebnis | Detaillierte Informationen zum Status des Gehäuselüfters. | 1.3.6.1.4.1.9.5.1.2.10 | Bei Bedarf. | |
| FahrgestellMinorAlarm | Untergeordneter Alarmstatus des Chassis. | 1.3.6.1.4.1.9.5.1.2.11 | 10 Minuten | 1 |
| Großalarm im Chassis | Großer Chassis-Alarmstatus | 1.3.6.1.4.1.9.5.1.2.12 | 10 Minuten | 1 |
| ChassisTempAlarm | Alarmstatus Chassis-Temperatur | 1.3.6.1.4.1.9.5.1.2.13 | 10 Minuten | 1 |
| Modulstatus | Betriebsstatus des Moduls. | 1.3.6.1.4.1.9.5.1.3.1.1.10 | 30 Minuten | 2 |
| ModulTestErgebnis | Detaillierte Informationen zum Zustand der Module. | 1.3.6.1.4.1.9.5.7.3.1.1.11 | Bei Bedarf. | |
| ModulStandbyStatus | Status eines redundanten Moduls. | 1.3.6.1.4.1.9.5.7.3.1.1.21 | 30 Minuten | =1 oder =4 |
| Objektname | Objektbeschreibung | OID | Umfrageintervall | Grenzwert |
|---|---|---|---|---|
| CISCO-MEMORY-POOL-MIB | ||||
| dot1dStpZeitSeitTopologieänderung | Die Zeit (in 1/100 Sekunden) seit der letzten Erkennung einer Topologieänderung durch die Entität. | 1.3.6.1.2.1.17.2.3 | 5 Minuten | < 30000 |
| dot1dStpTopChanges | Die Gesamtzahl der von dieser Bridge erkannten Topologieänderungen seit dem letzten Zurücksetzen oder Initialisieren der Management-Einheit. | 1.3.6.1.2.1.17.2.4 | Bei Bedarf. | |
| dot1dStpPortState [1] | Der aktuelle Status des Ports, der durch die Anwendung des Spanning Tree Protocol definiert wird. Der Rückgabewert kann einer der folgenden Werte sein: deaktiviert (1), blockiert (2), hört (3), lernt (4), leitet weiter (5) oder unterbrochen (6). | 1.3.6.1.2.1.17.2.15.1.3 | Bei Bedarf. | |
| Objektname | Objektbeschreibung | OID | Umfrageintervall | Grenzwert |
|---|---|---|---|---|
| CISCO-MEMORY-POOL-MIB | ||||
| ciscoSpeicherPoolVerwendet | Gibt die Anzahl der Bytes aus dem Speicherpool an, die derzeit von Anwendungen auf dem verwalteten Gerät verwendet werden. | 1.3.6.1.4.1.9.9.48.1.1.1.5 | 30 Minuten | Grundlinie |
| ciscoSpeicherPoolFrei | Gibt die Anzahl der Bytes aus dem Speicherpool an, die auf dem verwalteten Gerät derzeit nicht verwendet werden. Hinweis: Die Summe von ciscoMemoryPoolUsed und ciscoMemoryPoolFree entspricht der gesamten Speicherkapazität im Pool. |
1.3.6.1.4.1.9.9.48.1.1.1.6 | 30 Minuten | Grundlinie |
| ciscoSpeicherPoolGrößterFrei | Zeigt die größte Anzahl zusammenhängender Bytes aus dem Speicherpool an, die auf dem verwalteten Gerät derzeit nicht verwendet werden. | 1.3.6.1.4.1.9.9.48.1.1.1.7 | 30 Minuten | Grundlinie |
Weitere Informationen zur Unterstützung von Cisco MIB finden Sie unter Cisco Network Management Toolkit - MIBs.
Hinweis: Bei einigen Standard-MIBs wird davon ausgegangen, dass eine bestimmte SNMP-Entität nur eine Instanz der MIB enthält. Daher verfügt die Standard-MIB über keinen Index, der Benutzern den direkten Zugriff auf eine bestimmte Instanz der MIB ermöglicht. In diesen Fällen wird eine Community-String-Indizierung bereitgestellt, um auf jede Instanz der Standard-MIB zuzugreifen. Die Syntax lautet [Community-Zeichenfolge]@[Instanznummer], wobei die Instanz in der Regel eine VLAN-Nummer ist.
Weitere Optionen
Aufgrund der Sicherheitsaspekte von SNMPv3 ist zu erwarten, dass SNMPv2 rechtzeitig überholt wird. Cisco empfiehlt den Kunden, sich im Rahmen ihrer NMS-Strategie auf dieses neue Protokoll vorzubereiten. Die Vorteile bestehen darin, dass Daten sicher von SNMP-Geräten erfasst werden können, ohne dass Manipulationen oder Beschädigungen befürchtet werden. Vertrauliche Informationen, wie SNMP set Command Packets, die eine Switch-Konfiguration ändern, können verschlüsselt werden, um zu verhindern, dass ihr Inhalt im Netzwerk verfügbar gemacht wird. Darüber hinaus können verschiedene Benutzergruppen unterschiedliche Berechtigungen haben.
Hinweis: Die Konfiguration von SNMPv3 unterscheidet sich erheblich von der SNMPv2-Befehlszeile, und eine erhöhte CPU-Last auf der Supervisor Engine ist zu erwarten.
Fernüberwachung
RMON ermöglicht die Vorverarbeitung von MIB-Daten durch das Netzwerkgerät selbst, um eine allgemeine Verwendung oder Anwendung dieser Informationen durch den Netzwerkmanager vorzubereiten, z. B. die Bestimmung historischer Baseline und die Analyse von Schwellenwerten.
Die Ergebnisse der RMON-Verarbeitung werden in RMON-MIBs gespeichert, um anschließend von einem NMS erfasst zu werden, wie in RFC 1757 definiert.
Betriebsübersicht
Catalyst Switches unterstützen Mini-RMON in der Hardware an jedem Port, die aus vier grundlegenden RMON-1-Gruppen besteht: Statistiken (Gruppe 1), Verlauf (Gruppe 2), Alarme (Gruppe 3) und Ereignisse (Gruppe 9).
Der stärkste Teil von RMON-1 ist der Schwellwertmechanismus der Alarm- und Ereignisgruppen. Wie bereits erwähnt, ermöglicht die Konfiguration von RMON-Grenzwerten dem Switch das Senden einer SNMP-Trap, wenn eine Anomalie auftritt. Nach der Identifizierung der Schlüsselports kann SNMP verwendet werden, um Zähler oder RMON-Verlaufsgruppen abzufragen und Baselines für die Aufzeichnung der normalen Datenverkehrsaktivität für diese Ports zu erstellen. Als Nächstes können Grenzwerte für steigende und fallende RMON-Werte festgelegt und Alarme konfiguriert werden, wenn eine definierte Abweichung von der Baseline vorliegt.
Die Konfiguration von Schwellenwerten wird am besten mit einem RMON-Managementpaket durchgeführt, da die erfolgreiche Erstellung der Parameterzeilen in Alarm- und Ereignistabellen langwierig ist. Kommerzielle RMON NMS-Pakete, wie z. B. Cisco Traffic Director, Teil von Cisco Works 2000, beinhalten grafische Benutzeroberflächen (GUIs), die die Festlegung von RMON-Grenzwerten erheblich vereinfachen.
Zu Vergleichszwecken stellt die EtherStats-Gruppe einen nützlichen Bereich von L2-Datenverkehrsstatistiken bereit. Die Objekte in dieser Tabelle können zum Abrufen von Statistiken zu Unicast-, Multicast- und Broadcast-Datenverkehr sowie zu verschiedenen L2-Fehlern verwendet werden. Der RMON-Agent auf dem Switch kann auch so konfiguriert werden, dass diese Abtastwerte in der Verlaufsgruppe gespeichert werden. Dieser Mechanismus ermöglicht die Reduzierung der Polling-Menge, ohne die Abtastrate zu reduzieren. RMON-Verläufe können präzise Baselines liefern, ohne dass ein erheblicher Polling-Overhead entsteht. Je mehr Historien erfasst werden, desto mehr Switch-Ressourcen werden genutzt.
Obwohl Switches nur vier grundlegende Gruppen von RMON-1 bereitstellen, dürfen die restlichen RMON-1 und RMON-2 nicht vergessen werden. Alle Gruppen sind in RFC 2021 definiert, einschließlich Benutzerverlauf (Gruppe 18) und Sondenkonfiguration (Gruppe 19). L3- und höhere Informationen können von Switches mit SPAN-Port- oder VLAN-ACL-Umleitungsfunktionen abgerufen werden, mit denen Sie den Datenverkehr zu einem externen RMON SwitchProbe oder einem internen Network Analysis Module (NAM) kopieren können.
NAMs unterstützen alle RMON-Gruppen und können sogar Daten auf Anwendungsebene untersuchen, einschließlich NetFlow-Daten, die von Catalysts exportiert werden, wenn MLS aktiviert ist. Wenn MLS ausgeführt wird, schaltet der Router nicht alle Pakete in einem Flow um. Daher bieten nur NetFlow-Datenexport und keine Schnittstellenzähler eine zuverlässige VLAN-Abrechnung.
Sie können einen SPAN-Port und einen Switch-Prüfpunkt verwenden, um einen Paket-Stream für einen bestimmten Port, Trunk oder ein VLAN zu erfassen und die Pakete hochzuladen, um sie mit einem RMON-Managementpaket zu dekodieren. Der SPAN-Port ist über die SPAN-Gruppe in der CISCO-STACK-MIB per SNMP steuerbar, sodass dieser Prozess leicht zu automatisieren ist. Traffic Director nutzt diese Funktionen zusammen mit der Funktion für mobile Agenten.
Die Abdeckung eines gesamten VLAN birgt jedoch auch einige Vorbehalte. Selbst wenn Sie einen 1-Gbit/s-Test verwenden, kann der gesamte Paket-Stream von einem VLAN oder sogar einem 1-Gbit/s-Vollduplex-Port die Bandbreite des SPAN-Ports überschreiten. Wenn der SPAN-Port kontinuierlich mit voller Bandbreite ausgeführt wird, besteht die Gefahr, dass Daten verloren gehen. Weitere Informationen finden Sie unter Configuring the Catalyst Switched Port Analyzer (SPAN).
Empfehlung
Cisco empfiehlt die Bereitstellung von RMON-Schwellenwerten und Warnmeldungen, um die Netzwerkverwaltung intelligenter zu gestalten als durch SNMP-Abfragen allein. Dadurch wird der Overhead beim Netzwerkmanagement reduziert, und das Netzwerk kann intelligent alarmieren, wenn sich etwas von der Basislinie geändert hat. RMON muss von einem externen Agenten wie Traffic Director gesteuert werden. CLI wird nicht unterstützt. Führen Sie die folgenden Befehle aus, um RMON zu aktivieren:
set snmp rmon enable
set snmp extendedrmon netflow enable mod
!--- For use with NAM module only.
Es ist wichtig, sich vor Augen zu halten, dass die primäre Funktion eines Switches die Weiterleitung von Frames ist und nicht die Funktion eines großen RMON-Tests mit mehreren Ports. Wenn Sie daher Verlaufsdaten und Schwellenwerte für mehrere Ports unter verschiedenen Bedingungen einrichten, sollten Sie berücksichtigen, dass Ressourcen verbraucht werden. Wenn Sie RMON erweitern möchten, sollten Sie ein NAM-Modul in Betracht ziehen. Denken Sie auch an die Regel für kritische Ports: nur Abfragen und Festlegen von Schwellenwerten für die Ports, die in der Planungsphase als wichtig identifiziert wurden.
Speicheranforderungen
Die RMON-Speichernutzung ist auf allen Switch-Plattformen bezüglich Statistiken, Verlaufsdaten, Alarmen und Ereignissen konstant. RMON verwendet einen Bucket, um Verlaufsdaten und Statistiken über den RMON-Agenten (in diesem Fall den Switch) zu speichern. Die Bucket-Größe wird auf der RMON-Anfrage (Switch Probe) oder der RMON-Anwendung (Traffic Director) definiert und dann zur Einstellung an den Switch gesendet. In der Regel gelten Speicherbeschränkungen nur für ältere Supervisor Engines mit weniger als 32 MB DRAM. Beachten Sie die folgenden Richtlinien:
-
Dem NMP-Image wird ca. 450 KB Codebereich hinzugefügt, um Mini-RMON (d. h. vier RMON-Gruppen) zu unterstützen: Statistiken, Verlauf, Alarme und Ereignisse). Der dynamische Speicherbedarf für RMON variiert, da er von der Laufzeitkonfiguration abhängt. Die Laufzeitinformationen zur RMON-Speichernutzung für jede Mini-RMON-Gruppe werden hier erläutert:
-
Ethernet Statistics group (Ethernet-Statistikgruppe): Benötigt 800 Byte für jede Switched Ethernet/FE-Schnittstelle.
-
Verlaufsgruppe - Für die Ethernet-Schnittstelle benötigt jeder konfigurierte Eintrag zur Verlaufssteuerung mit 50 Buckets ca. 3,6 KB Speicherplatz und 56 Byte für jeden zusätzlichen Bucket.
-
Warnungen und Ereignisgruppen: Jede konfigurierte Warnung und die entsprechenden Ereigniseinträge erhalten 2,6 KB.
-
-
Um die RMON-bezogene Konfiguration zu speichern, benötigt das System ca. 20.000 NVRAM an Speicherplatz, wenn die Gesamt-NVRAM-Größe des Systems 256.000 oder mehr beträgt, und 10.000 NVRAM an Speicherplatz, wenn die Gesamt-NVRAM-Größe 128.000 beträgt.
Network Time Protocol
Das NTP, RFC 1305, synchronisiert die Zeiterfassung für eine Reihe von verteilten Zeitservern und Clients und ermöglicht die Korrelation von Ereignissen, wenn Systemprotokolle erstellt werden oder andere zeitspezifische Ereignisse eintreten.
Das NTP bietet Client-Zeitgenauigkeiten, in LANs in der Regel innerhalb einer Millisekunde und in WANs bis zu einigen Zehntel Millisekunden, im Vergleich zu einem mit UTC (Coordinated Universal Time) synchronisierten primären Server. Typische NTP-Konfigurationen nutzen mehrere redundante Server und verschiedene Netzwerkpfade, um eine hohe Genauigkeit und Zuverlässigkeit zu erreichen. Einige Konfigurationen enthalten kryptografische Authentifizierung, um versehentliche oder böswillige Protokollangriffe zu verhindern.
Betriebsübersicht
NTP wurde zuerst in RFC 958 dokumentiert, hat sich aber durch RFC 1119 (NTP-Version 2) weiterentwickelt und befindet sich jetzt in der dritten Version, wie in RFC 1305 definiert. Er läuft über den UDP-Port 123. Für die gesamte NTP-Kommunikation wird UTC verwendet, was der Greenwich Mean Time entspricht.
Zugriff auf Public Time Server
Das NTP-Subnetz umfasst derzeit mehr als 50 öffentliche primäre Server, die über Funk, Satellit oder Modem direkt mit UTC synchronisiert sind. Normalerweise werden Client-Workstations und Server mit einer relativ kleinen Anzahl von Clients nicht mit primären Servern synchronisiert. Es gibt etwa 100 öffentliche sekundäre Server, die mit den primären Servern synchronisiert sind und die Synchronisierung von mehr als 100.000 Clients und Servern im Internet ermöglichen. Die aktuellen Listen werden auf der Seite "Liste der öffentlichen NTP-Server" geführt, die regelmäßig aktualisiert wird. Es gibt zahlreiche private primäre und sekundäre Server, die normalerweise nicht auch für die Öffentlichkeit verfügbar sind. Eine Liste der öffentlichen NTP-Server und Informationen zu ihrer Verwendung finden Sie auf der Website des Zeitsynchronisierungsservers der University of Delaware.
Da es keine Garantie dafür gibt, dass diese öffentlichen Internet-NTP-Server verfügbar sind oder dass sie die richtige Zeit produzieren, wird dringend empfohlen, andere Optionen in Betracht zu ziehen. Dies kann die Verwendung verschiedener eigenständiger GPS-Geräte (Global Positioning Service) umfassen, die direkt mit einer Reihe von Routern verbunden sind.
Eine weitere mögliche Option ist die Verwendung verschiedener Router, die als Stratum 1-Master konfiguriert sind. Dies wird jedoch nicht empfohlen.
Stratum
Jeder NTP-Server nimmt eine Schicht auf, die angibt, wie weit er von einer externen Zeitquelle entfernt ist. Server der Schicht 1 haben Zugriff auf eine externe Zeitquelle, z. B. eine Funkuhr. Server der Schicht 2 beziehen Zeitangaben von einem nominierten Satz von Servern der Schicht 1, Server der Schicht 3 Zeitangaben von Servern der Schicht 2 usw.
Server-Peer-Beziehung
-
Ein Server reagiert auf Client-Anfragen, versucht aber nicht, Datumsinformationen aus einer Client-Zeitquelle einzubinden.
-
Ein Peer reagiert auf Client-Anfragen, versucht jedoch, die Client-Anfragen als potenziellen Kandidaten für eine bessere Zeitquelle zu verwenden und bei der Stabilisierung seiner Taktfrequenz zu helfen.
-
Um ein echter Peer zu sein, müssen beide Seiten der Verbindung eine Peer-Beziehung eingehen, anstatt einen Benutzer als Peer und den anderen Benutzer als Server zu haben. Es wird außerdem empfohlen, dass Peers Schlüssel austauschen, sodass nur vertrauenswürdige Hosts als Peers miteinander kommunizieren.
-
Bei einer Clientanfrage an einen Server beantwortet der Server den Client und vergisst, dass der Client eine Frage gestellt hat. Bei einer Clientanfrage an einen Peer beantwortet der Server den Client und speichert Statusinformationen über den Client, um zu verfolgen, wie gut er bei der Zeiterfassung arbeitet und auf welchem Schicht-Server er ausgeführt wird.
Hinweis: CatOS kann nur als NTP-Client fungieren.
Es ist kein Problem für einen NTP-Server, viele tausend Clients zu verarbeiten. Die Verarbeitung von Hunderten von Peers wirkt sich jedoch auf den Arbeitsspeicher aus, und die Wartung des Status beansprucht mehr CPU-Ressourcen auf der Box sowie mehr Bandbreite.
Umfrage
Das NTP-Protokoll ermöglicht es einem Client, einen Server jederzeit abzufragen. Wenn das NTP zum ersten Mal auf einem Cisco Gerät konfiguriert wird, sendet es in schnellen Abständen von NTP_MINPOLL (24 = 16 Sekunden) acht Abfragen. NTP_MAXPOLL umfasst 214 Sekunden (d. h. 16.384 Sekunden oder 4 Stunden, 33 Minuten, 4 Sekunden). Dies ist die maximale Zeit, die benötigt wird, bevor NTP erneut eine Abfrage für eine Antwort durchführt. Derzeit verfügt Cisco nicht über eine Methode, um die manuelle Festlegung der POLL-Zeit durch den Benutzer zu erzwingen.
Der NTP-Abfragezähler beginnt bei 26 (64) Sekunden und wird um zwei (bei der Synchronisierung der beiden Server) auf 210 erhöht. Das heißt, Sie können erwarten, dass die Synchronisierungsnachrichten in einem Intervall von 64, 128, 256, 512 oder 1024 Sekunden gesendet werden. pro konfiguriertem Server oder Peer. Die Zeit variiert zwischen 64 Sekunden und 1024 Sekunden als Zweierpotenz basierend auf der Phasenregelschleife, die Pakete sendet und empfängt. Wenn in der Zeit viel Jitter auftritt, werden häufiger Umfragen durchgeführt. Wenn die Referenzuhr genau und die Netzwerkverbindung konsistent ist, werden die Abfragezeiten auf 1024 Sekunden zwischen den einzelnen Abfragen konvergiert.
In der Praxis bedeutet dies, dass sich das NTP-Abfrageintervall ändert, wenn sich die Verbindung zwischen dem Client und dem Server ändert. Je besser die Verbindung, desto länger ist das Abfrageintervall, d. h. der NTP-Client hat acht Antworten für seine letzten acht Anfragen erhalten (das Abfrageintervall wird dann verdoppelt). Bei einer einzigen verpassten Antwort wird das Abfrageintervall halbiert. Das Abfrageintervall beginnt bei 64 Sekunden und endet bei maximal 1024 Sekunden. Im besten Fall dauert es etwas mehr als zwei Stunden, bis das Umfrageintervall von 64 Sekunden auf 1024 Sekunden steigt.
Broadcasts
NTP-Broadcasts werden nie weitergeleitet. Der Befehl ntp broadcast veranlasst den Router, NTP-Broadcasts von der Schnittstelle zu starten, für die er konfiguriert ist. Der Befehl ntp broadcast client bewirkt, dass der Router oder Switch NTP-Broadcasts auf der Schnittstelle abhört, auf der er konfiguriert ist.
NTP-Datenverkehrsstufen
Die vom NTP genutzte Bandbreite ist minimal, da das Intervall zwischen den zwischen Peers ausgetauschten Polling-Nachrichten in der Regel alle 17 Minuten (1024 Sekunden) auf maximal eine Nachricht zurückgeregelt wird. Bei sorgfältiger Planung kann dies innerhalb der Routernetzwerke über die WAN-Verbindungen aufrechterhalten werden. Die NTP-Clients müssen eine Peer-Verbindung zu lokalen NTP-Servern herstellen, nicht über das WAN bis zu den Core-Routern am zentralen Standort, die die Layer-2-Server bilden.
Ein konvergenter NTP-Client benötigt etwa 0,6 Bit/Sekunde pro Server.
Empfehlung
Viele Kunden verwenden auf ihren CatOS-Plattformen ein NTP, das im Client-Modus konfiguriert ist und von mehreren zuverlässigen Feeds aus dem Internet oder einer Funkuhr synchronisiert wird. Eine einfachere Alternative zum Servermodus beim Betrieb einer großen Anzahl von Switches ist jedoch die Aktivierung von NTP im Broadcast-Client-Modus auf dem Management-VLAN in einer Switched-Domäne. Dieser Mechanismus ermöglicht es einer ganzen Katalytdomäne, eine Uhr aus einer einzelnen Broadcast-Nachricht zu empfangen. Die Genauigkeit der Zeiterfassung wird jedoch geringfügig reduziert, da der Informationsfluss in eine Richtung erfolgt.
Die Verwendung von Loopback-Adressen als Update-Quelle kann ebenfalls zur Konsistenz beitragen. Sicherheitsbedenken können auf zwei Arten ausgeräumt werden:
-
Filtern von Server-Updates
-
Authentifizierung
Die zeitliche Korrelation von Ereignissen ist in zwei Fällen äußerst wertvoll: Fehlerbehebung und Sicherheitsüberprüfungen. Es muss darauf geachtet werden, die Zeitquellen und Daten zu schützen. Die Verschlüsselung wird empfohlen, damit Schlüsselereignisse nicht absichtlich oder unabsichtlich gelöscht werden.
Cisco empfiehlt folgende Konfigurationen:
| Catalyst-Konfiguration |
|---|
set ntp broadcastclient enable set ntp authentication enable set ntp key key !--- This is a Message Digest 5 (MD5) hash. set ntp timezone |
| Alternative Catalyst Konfiguration |
|---|
!--- This more traditional configuration creates !--- more configuration work and NTP peerings. set ntp client enable set ntp server IP address of time server set timezone zone name set summertime date change details |
| Router-Konfiguration |
|---|
!--- This is a sample router configuration to distribute !--- NTP broadcast information to the Catalyst broadcast clients. ntp source loopback0 ntp server IP address of time server ntp update-calendar clock timezone zone name clock summer-time date change details ntp authentication key key ntp access-group access-list !--- To filter updates to allow only trusted sources of NTP information. Interface to campus/management VLAN containing switch sc0 ntp broadcast |
Cisco Discovery Protocol
CDP tauscht Informationen zwischen benachbarten Geräten über die Sicherungsschicht aus und ist äußerst hilfreich bei der Bestimmung der Netzwerktopologie und der physischen Konfiguration außerhalb der logischen oder IP-Schicht. Unterstützt werden hauptsächlich Switches, Router und IP-Telefone. In diesem Abschnitt werden einige der Verbesserungen von CDP Version 2 gegenüber Version 1 beschrieben.
Betriebsübersicht
CDP verwendet die SNAP-Kapselung mit dem Typcode 2000. Für Ethernet, ATM und FDDI wird die Multicast-Zieladresse 01-00-0c-cc-cc-cc, HDLC-Protokolltyp 0x2000 verwendet. Auf Tokenringen wird die Funktionsadresse c000.0800.0000 verwendet. CDP-Frames werden standardmäßig jede Minute in regelmäßigen Abständen gesendet.
CDP-Nachrichten enthalten eine oder mehrere Unternachrichten, die es den Zielgeräten ermöglichen, Informationen über jedes Nachbargerät zu sammeln und zu speichern.
CDP-Version 1 unterstützt folgende Parameter:
| Parameter | Typ | Beschreibung |
|---|---|---|
| 1 | Geräte-ID | Hostname des Geräts oder Seriennummer der Hardware in ASCII. |
| 2 | Adresse | Die L3-Adresse der Schnittstelle, die das Update gesendet hat. |
| 3 | Port-ID | Der Port, an den das CDP-Update gesendet wurde. |
| 4 | Funktionen | Beschreibt die Funktionen des Geräts: Router: 0 x 10 TB-Bridge: 0x02 SR Bridge: 0x04-Switch: 0x08 (bietet L2- und/oder L3-Switching) Host: 0x10 IGMP-bedingte Filterung: 0x20 Die Bridge oder der Switch leitet keine IGMP-Berichtspakete an Nicht-Router-Ports weiter. Repeater: 0 x 40 |
| 5 | Version | Eine Zeichenfolge, die die Softwareversion enthält (wie in Version anzeigen). |
| 6 | Plattform | Hardwareplattform, z. B. WS-C5000, WS-C6009 oder Cisco RSP |
In der CDP-Version 2 wurden zusätzliche Protokollfelder eingeführt. CDP Version 2 unterstützt alle Felder, die aufgeführten können jedoch in Switched-Umgebungen besonders nützlich sein und werden in CatOS verwendet.
Anmerkung: Wenn ein Switch CDPv1 ausführt, werden v2-Frames verworfen. Wenn ein Switch, auf dem CDPv2 ausgeführt wird, einen CDPv1-Frame über eine Schnittstelle empfängt, beginnt er, CDPv1-Frames von dieser Schnittstelle zusätzlich zu CDPv2-Frames zu senden.
| Parameter | Typ | Beschreibung |
|---|---|---|
| 9 | VTP-Domäne | Die VTP-Domäne, falls auf dem Gerät konfiguriert. |
| 10 | Natives VLAN | Unter dot1q ist dies das nicht gekennzeichnete VLAN. |
| 11 | Voll-/Halbduplex | Dieses Feld enthält die Duplexeinstellung des Sendeports. |
Empfehlung
CDP ist standardmäßig aktiviert und ist für die Transparenz benachbarter Geräte und die Fehlerbehebung unerlässlich. Sie wird auch von Netzwerkmanagementanwendungen zum Erstellen von L2-Topologieübersichten verwendet. Führen Sie die folgenden Befehle aus, um CDP einzurichten:
set cdp enable !--- This is the default. set cdp version v2 !--- This is the default.
In Teilen des Netzwerks, in denen ein hohes Maß an Sicherheit erforderlich ist (z. B. internetseitige DMZs), muss CDP wie folgt deaktiviert werden:
set cdp disable port range
Mit dem Befehl show cdp neighbors wird die lokale CDP-Tabelle angezeigt. Mit einem Stern (*) gekennzeichnete Einträge weisen auf eine VLAN-Diskrepanz hin. Mit einem # gekennzeichnete Einträge weisen auf eine Duplexunstimmigkeit hin. Dies kann eine wertvolle Hilfe bei der Fehlerbehebung sein.
>show cdp neighbors * - indicates vlan mismatch. # - indicates duplex mismatch. Port Device-ID Port-ID Platform ----- ------------------ ------- ------------ 3/1 TBA04060103(swi-2) 3/1 WS-C6506 3/8 TBA03300081(swi-3) 1/1 WS-C6506 15/1 rtr-1-msfc VLAN 1 cisco Cat6k-MSFC 16/1 MSFC1b Vlan2 cisco Cat6k-MSFC
Weitere Optionen
Einige Switches, z. B. der Catalyst 6500/6000, können IP-Telefone über UTP-Kabel mit Strom versorgen. Die über CDP empfangenen Informationen unterstützen die Stromverwaltung am Switch.
Da an IP-Telefone ein PC angeschlossen werden kann und beide Geräte an denselben Port des Catalyst angeschlossen werden, kann der Switch das VoIP-Telefon in ein separates VLAN (das zusätzliche VLAN) versetzen. Auf diese Weise kann der Switch auf einfache Weise eine andere Quality of Service (QoS) für den VoIP-Verkehr anwenden.
Wenn das Hilfs-VLAN geändert wird (z. B. um die Verwendung eines bestimmten VLANs oder einer bestimmten Tagging-Methode zu erzwingen), werden diese Informationen über CDP an das Telefon gesendet.
| Parameter | Typ | Beschreibung |
|---|---|---|
| 14 | Appliance-ID | Ermöglicht die Unterscheidung des VoIP-Datenverkehrs vom anderen Datenverkehr über eine separate VLAN-ID (zusätzliches VLAN). |
| 16 | Stromverbrauch | Die Leistungsaufnahme eines VoIP-Telefons in Milliwatt. |
Hinweis: Catalyst Switches der Serien 2900 und 3500XL unterstützen derzeit CDPv2 nicht.
Sicherheitskonfiguration
Im Idealfall hat der Kunde bereits eine Sicherheitsrichtlinie erstellt, anhand derer festgelegt werden kann, welche Tools und Technologien von Cisco qualifiziert sind.
Hinweis: Die Sicherheit der Cisco IOS Software wird im Gegensatz zu CatOS in vielen Dokumenten behandelt, z. B. Cisco ISP Essentials.
Grundlegende Sicherheitsfunktionen
Passwörter
Konfigurieren Sie ein Kennwort auf Benutzerebene (Anmeldung). Bei Kennwörtern in CatOS 5.x und höheren Versionen wird die Groß-/Kleinschreibung beachtet. Sie können zwischen 0 und 30 Zeichen lang sein, einschließlich Leerzeichen. Legen Sie das Aktivierungskennwort fest:
set password password set enablepass password
Alle Kennwörter müssen für die Anmeldung bestimmte Mindestlängenstandards erfüllen (z. B. mindestens sechs Zeichen, eine Kombination aus Buchstaben und Zahlen sowie Groß- und Kleinbuchstaben) und bei Verwendung Kennwörter aktivieren. Diese Kennwörter werden mit dem MD5-Hashing-Algorithmus verschlüsselt.
Um die Verwaltung der Passwortsicherheit und des Gerätezugriffs flexibler zu gestalten, empfiehlt Cisco die Verwendung eines TACACS+-Servers. Weitere Informationen finden Sie im Abschnitt TACACS+ dieses Dokuments.
Secure Shell
Verwenden Sie die SSH-Verschlüsselung, um Telnet-Sitzungen und andere Remote-Verbindungen zum Switch zu schützen. Die SSH-Verschlüsselung wird nur für Remote-Anmeldungen am Switch unterstützt. Sie können keine Telnet-Sitzungen verschlüsseln, die vom Switch initiiert wurden. SSH Version 1 wird von CatOS 6.1 unterstützt, Version 2 wurde von CatOS 8.3 hinzugefügt. SSH Version 1 unterstützt die Verschlüsselungsmethoden Data Encryption Standard (DES) und Triple-DES (3-DES), und SSH Version 2 unterstützt die Verschlüsselungsmethoden 3-DES und Advanced Encryption Standard (AES). Sie können die SSH-Verschlüsselung mit RADIUS- und TACACS+-Authentifizierung verwenden. Diese Funktion wird von SSH-Images (k9) unterstützt. Weitere Informationen finden Sie unter How to Configure SSH on Catalyst Switches Running CatOS (SSH-Konfiguration auf Catalyst-Switches mit CatOS).
set crypto key rsa 1024
Um den Fallback von Version 1 zu deaktivieren und Verbindungen von Version 2 zu akzeptieren, geben Sie den folgenden Befehl ein:
set ssh mode v2
IP-Berechtigungsfilter
Diese Filter schützen den Zugriff auf die sc0-Managementschnittstelle über Telnet und andere Protokolle. Diese sind besonders wichtig, wenn das für die Verwaltung verwendete VLAN auch Benutzer enthält. Geben Sie die folgenden Befehle ein, um die IP-Adressen- und Port-Filterung zu aktivieren:
set ip permit enable set ip permit IP address mask Telnet|ssh|snmp|all
Wenn der Telnet-Zugriff mit diesem Befehl jedoch eingeschränkt wird, kann der Zugriff auf CatOS-Geräte nur über einige wenige vertrauenswürdige Endgeräte erfolgen. Diese Konfiguration kann bei der Fehlerbehebung ein Hindernis darstellen. Beachten Sie, dass es möglich ist, IP-Adressen zu fälschen und den gefilterten Zugriff zu täuschen, sodass dies nur die erste Schutzschicht ist.
Kanal-Sicherheit
Ziehen Sie die Verwendung der Port-Sicherheit in Betracht, um nur einer oder mehreren bekannten MAC-Adressen die Weiterleitung von Daten an einen bestimmten Port zu ermöglichen (um beispielsweise zu verhindern, dass statische Endstationen ohne Änderungskontrolle gegen neue Stationen ausgetauscht werden). Dies ist durch die Verwendung statischer MAC-Adressen möglich.
set port security mod/port enable MAC address
Dies ist auch möglich, indem eingeschränkte MAC-Adressen dynamisch gelernt werden.
set port security port range enable
Die folgenden Optionen können konfiguriert werden:
-
set port security mod/port age time value - gibt die Dauer an, für die Adressen auf dem Port gesichert werden, bevor eine neue Adresse abgerufen werden kann. Die gültige Zeit in Minuten ist 10 - 1440. Die Standardeinstellung ist no aging.
-
set port securitymod/port maximum value - Schlüsselwort, das die maximale Anzahl von MAC-Adressen angibt, die auf dem Port gesichert werden sollen. Gültige Werte sind 1 (Standard) - 1025.
-
set port security mod/port violpment shutdown - deaktiviert den Port (Standard), wenn eine Verletzung auftritt, sendet Syslog-Meldung (Standard) und verwirft den Datenverkehr.
-
set port security mod/port shutdown time value - Dauer, für die ein Port deaktiviert bleibt. Gültige Werte sind 10 - 1440 Minuten. Standard ist permanent heruntergefahren
Mit CatOS 6.x und höher hat Cisco eine 802.1x-Authentifizierung eingeführt, mit der sich Clients bei einem zentralen Server authentifizieren können, bevor Ports für Daten aktiviert werden können. Diese Funktion befindet sich in der Anfangsphase der Unterstützung für Plattformen wie Windows XP, kann jedoch von vielen Unternehmen als strategische Richtung betrachtet werden. Weitere Informationen zur Konfiguration der Port-Sicherheit auf Switches, die Cisco IOS-Software ausführen, finden Sie unter Konfigurieren der Port-Sicherheit.
Anmeldebanner
Erstellen Sie die entsprechenden Gerätebanner, um die Aktionen anzugeben, die für den nicht autorisierten Zugriff durchgeführt wurden. Werben Sie nicht mit dem Namen des Standorts oder mit Netzwerkdaten, die nicht autorisierten Benutzern Informationen bereitstellen könnten. Diese Banner dienen dazu, bei einer Kompromittierung des Geräts und beim Ergreifen des Täters Rechtsmittel einzulegen:
# set banner motd ^C *** Unauthorized Access Prohibited *** *** All transactions are logged *** ------------- Notice Board ------------- ----Contact Joe Cisco at 1 800 go cisco for access problems---- ^C
Personen- und Gebäudeschutz
Der physische Zugriff auf die Geräte darf nicht ohne die entsprechende Autorisierung erfolgen, sodass die Geräte in einem kontrollierten (abgeschlossenen) Raum untergebracht werden müssen. Um sicherzustellen, dass das Netzwerk funktionsfähig bleibt und nicht durch böswillige Manipulation von Umweltfaktoren beeinträchtigt wird, müssen alle Geräte über eine ordnungsgemäße USV (mit redundanten Quellen, wo möglich) und eine Temperaturkontrolle (Klimaanlage) verfügen. Denken Sie daran, dass eine Person mit böswilliger Absicht den physischen Zugang verletzt und dass eine Unterbrechung durch Kennwortwiederherstellung oder andere Methoden viel wahrscheinlicher ist.
Terminal Access Controller Access Control System
Standardmäßig sind Kennwörter für den nicht privilegierten und den privilegierten Modus global und gelten für jeden Benutzer, der auf den Switch oder Router zugreift, entweder vom Konsolenport oder über eine Telnet-Sitzung im Netzwerk. Ihre Implementierung auf Netzwerkgeräten ist zeitaufwendig und nicht zentralisiert. Außerdem ist es schwierig, Zugriffsbeschränkungen mithilfe von Zugriffslisten zu implementieren, die anfällig für Konfigurationsfehler sein können.
Drei Sicherheitssysteme unterstützen die Kontrolle und Überwachung des Zugriffs auf Netzwerkgeräte. Diese verwenden Client/Server-Architekturen, um alle Sicherheitsinformationen in einer zentralen Datenbank zu speichern. Diese drei Sicherheitssysteme sind:
-
TACACS+
-
RADIUS
-
Kerberos
TACACS+ ist eine gängige Bereitstellung in Cisco Netzwerken und steht im Mittelpunkt dieses Kapitels. Es bietet folgende Funktionen:
-
Authentication (Authentifizierung): Der Identifizierungs- und Verifizierungsprozess für einen Benutzer. Für die Authentifizierung eines Benutzers können verschiedene Methoden verwendet werden. Die gängigste Methode ist jedoch die Kombination aus Benutzername und Kennwort.
-
Autorisierung: Verschiedene Befehle können erteilt werden, sobald ein Benutzer authentifiziert wird.
-
Accounting: Die Aufzeichnung der Aktivitäten oder Aktionen eines Benutzers auf dem Gerät.
Weitere Informationen finden Sie unter Configuring TACACS+, RADIUS, and Kerberos on Cisco Catalyst Switches (Konfigurieren von TACACS+, RADIUS und Kerberos auf Cisco Catalyst-Switches).
Betriebsübersicht
Das Protokoll TACACS+ leitet Benutzernamen und Kennwörter über MD5 One-Way Hashing (RFC 1321) verschlüsselt über das Netzwerk an den zentralen Server weiter. Er verwendet TCP-Port 49 als Transportprotokoll. Dies bietet gegenüber UDP (von RADIUS verwendet) folgende Vorteile:
-
Verbindungsorientierter Transport
-
Separate Bestätigung, dass eine Anforderung empfangen wurde (TCP ACK), unabhängig davon, wie geladen der Backend-Authentifizierungsmechanismus derzeit ist
-
Sofortige Anzeige eines Serverabsturzes (RST-Pakete)
Wenn während einer Sitzung eine zusätzliche Autorisierungsprüfung erforderlich ist, prüft der Switch mit TACACS+, ob dem Benutzer die Berechtigung zur Verwendung eines bestimmten Befehls erteilt wurde. Dies bietet eine bessere Kontrolle über die Befehle, die auf dem Switch ausgeführt werden können, während die Verbindung zum Authentifizierungsmechanismus getrennt wird. Mithilfe der Befehlskontoverwaltung können die Befehle überwacht werden, die ein bestimmter Benutzer ausgegeben hat, während er an ein bestimmtes Netzwerkgerät angeschlossen ist.
Wenn ein Benutzer eine einfache ASCII-Anmeldung versucht, indem er sich bei einem Netzwerkgerät mit TACACS+ authentifiziert, geschieht dieser Vorgang in der Regel:
-
Wenn die Verbindung hergestellt ist, kontaktiert der Switch den TACACS+-Daemon, um eine Aufforderung zur Eingabe des Benutzernamens zu erhalten, die dann dem Benutzer angezeigt wird. Der Benutzer gibt einen Benutzernamen ein, und der Switch kontaktiert den TACACS+-Daemon, um eine Kennwortaufforderung zu erhalten. Der Switch zeigt dem Benutzer die Aufforderung zur Eingabe des Kennworts an, der dann ein Kennwort eingibt, das ebenfalls an den TACACS+-Daemon gesendet wird.
-
Das Netzwerkgerät erhält schließlich eine der folgenden Antworten vom TACACS+-Daemon:
-
ACCEPT (Akzeptieren): Der Benutzer wird authentifiziert, und der Service kann beginnen. Wenn das Netzwerkgerät so konfiguriert ist, dass eine Autorisierung erforderlich ist, beginnt die Autorisierung zu diesem Zeitpunkt.
-
REJECT (Zurückweisen) - Der Benutzer konnte sich nicht authentifizieren. Dem Benutzer kann der weitere Zugriff verweigert werden, oder er wird aufgefordert, die Anmeldesequenz abhängig vom TACACS+-Daemon erneut zu versuchen.
-
FEHLER - Während der Authentifizierung ist ein Fehler aufgetreten. Dies kann entweder am Daemon oder in der Netzwerkverbindung zwischen dem Daemon und dem Switch erfolgen. Wenn eine ERROR-Antwort empfangen wird, versucht das Netzwerkgerät in der Regel, eine alternative Methode zur Authentifizierung des Benutzers zu verwenden.
-
CONTINUE (FORTFAHREN) - Der Benutzer wird zur Eingabe zusätzlicher Authentifizierungsinformationen aufgefordert.
-
-
Die Benutzer müssen zuerst die TACACS+-Authentifizierung erfolgreich abschließen, bevor sie die TACACS+-Autorisierung vornehmen können.
-
Wenn eine TACACS+-Autorisierung erforderlich ist, wird der TACACS+-Daemon erneut kontaktiert und gibt eine ACCEPT- oder REJECT-Autorisierungsantwort zurück. Wenn eine ACCEPT-Antwort zurückgegeben wird, enthält die Antwort Daten in Form von Attributen, die verwendet werden, um die EXEC- oder NETZWERK-Sitzung für diesen Benutzer zu leiten und die Befehle zu bestimmen, auf die der Benutzer zugreifen kann.
Empfehlung
Cisco empfiehlt die Verwendung von TACACS+, da diese problemlos mithilfe von Cisco Secure ACS für NT-, Unix- oder andere Software von Drittanbietern implementiert werden kann. Zu den Funktionen von TACACS+ gehören eine detaillierte Abrechnung, die Statistiken zur Befehls- und Systemnutzung liefert, ein MD5-Verschlüsselungsalgorithmus und die administrative Kontrolle von Authentifizierungs- und Autorisierungsprozessen.
In diesem Beispiel verwenden der Anmelde- und der Aktivierungsmodus den TACACS+-Server für die Authentifizierung und können auf die lokale Authentifizierung zurückgreifen, wenn der Server nicht verfügbar ist. Dies ist eine wichtige Hintertür, die in den meisten Netzwerken zu verlassen ist. Führen Sie die folgenden Befehle aus, um TACACS+ einzurichten:
set tacacs server server IP primary set tacacs server server IP !--- Redundant servers are possible. set tacacs attempts 3 !--- This is the default. set tacacs key key !--- MD5 encryption key. set tacacs timeout 15 !--- Longer server timeout (5 is default). set authentication login tacacs enable set authentication enable tacacs enable set authentication login local enable set authentication enable local enable !--- The last two commands are the default; they allow fallback !--- to local if no TACACS+ server available.
Weitere Optionen
Es ist möglich, die Befehle, die jeder Benutzer oder jede Benutzergruppe auf dem Switch ausführen kann, über die TACACS+-Autorisierung zu steuern. Eine Empfehlung ist jedoch schwierig, da alle Kunden individuelle Anforderungen in diesem Bereich haben. Weitere Informationen finden Sie unter Steuern des Zugriffs auf den Switch über Authentifizierung, Autorisierung und Abrechnung.
Schließlich bieten Accounting-Befehle eine Prüfliste der Eingaben und Konfigurationen der einzelnen Benutzer. Dies ist ein Beispiel, bei dem die Audit-Informationen am Ende des Befehls üblicherweise empfangen werden:
set accounting connect enable start-stop tacacs+ set accounting exec enable start-stop tacacs+ set accounting system enable start-stop tacacs+ set accounting commands enable all start-stop tacacs+ set accounting update periodic 1
Diese Konfiguration bietet folgende Funktionen:
-
Der Befehl connect ermöglicht die Erfassung von ausgehenden Verbindungsereignissen auf dem Switch, z. B. Telnet.
-
Der Befehl exec ermöglicht die Abrechnung von Anmeldesitzungen auf dem Switch, z. B. für Betriebspersonal.
-
Der Systembefehl ermöglicht die Erfassung von Systemereignissen auf dem Switch, z. B. das erneute Laden oder Zurücksetzen.
-
Der Befehl commands (Befehle) ermöglicht die Erfassung der Daten, die auf dem Switch eingegeben wurden, für die Befehle show und configuration.
-
Regelmäßige Aktualisierungen pro Minute am Server sind hilfreich, um festzustellen, ob Benutzer noch angemeldet sind.
Konfigurations-Checkliste
Dieser Abschnitt enthält eine Zusammenfassung der empfohlenen Konfigurationen mit Ausnahme von Sicherheitsdetails.
Es ist äußerst hilfreich, alle Ports zu kennzeichnen. Führen Sie diesen Befehl aus, um die Ports zu beschriften:
set port description descriptive name
Verwenden Sie diese Taste in Verbindung mit den aufgelisteten Command-Tabellen:
| Wichtigste: |
|---|
| Fett gedruckter Text - empfohlene Änderung |
| Normaler Text - Standard, empfohlene Einstellung |
Globale Konfigurationsbefehle
| Command | Kommentar |
|---|---|
| VTP-Domänennamen-Kennwort festlegen | Schutz vor nicht autorisierten VTP-Updates von neuen Switches aus. |
| VTP-Modus transparent festlegen | Wählen Sie den in diesem Dokument heraufgestuften VTP-Modus aus. Weitere Informationen finden Sie im Abschnitt zum VLAN Trunking Protocol in diesem Dokument. |
| set spantree enable all | Stellen Sie sicher, dass STP in allen VLANs aktiviert ist. |
| Spantree Root-VLAN festlegen | Empfohlen wird die Positionierung von Root-Bridges (und sekundären Root-Bridges) pro VLAN. |
| set spantree backbonefest aktivieren | Ermöglichung schneller STP-Konvergenz bei indirekten Ausfällen (nur wenn alle Switches in der Domäne die Funktion unterstützen) |
| Spantree UplinkFast aktivieren | Ermöglichung schneller STP-Konvergenz bei direkten Ausfällen (nur für Access-Layer-Switches) |
| set spantree portfast bpduguard enable | Aktivieren Sie das automatische Herunterfahren des Ports, wenn eine nicht autorisierte Spanning Tree-Erweiterung vorhanden ist. |
| set udld enable | Ermöglichung der unidirektionalen Verbindungserkennung (auch Konfiguration auf Port-Ebene erforderlich) |
| Prüfbild-Sollwert abgeschlossen | Aktivieren Sie die vollständige Diagnose beim Hochfahren (Standard bei Catalyst 4500/4000). |
| set test packetbuffer sun 3:30 | Aktivieren Sie die Port-Pufferfehlerüberprüfung (gilt nur für Catalyst 5500/5000). |
| Protokollierungspuffer festlegen 500 | Maximaler interner Syslog-Puffer |
| IP-Adresse des Protokollierungsservers festlegen | Konfigurieren Sie den Ziel-Syslog-Server für die externe Protokollierung von Systemmeldungen. |
| set logging server aktivieren | Den externen Protokollierungsserver zulassen. |
| Zeitstempel festlegen aktivieren | Zeitstempel für Nachrichten im Protokoll aktivieren. |
| Protokollierungsebene festlegen Spantree 6, Standard | Erhöhung der STP-Syslog-Standardstufe. |
| Protokollierungsebene festlegen sys 6 Standard | Erhöhen Sie die Syslog-Standardstufe des Systems. |
| Schweregrad des Protokollierungsservers festlegen 4 | Nur den Export des Syslog-Protokolls mit dem höheren Schweregrad zulassen. |
| Festlegen, Protokollierungskonsole deaktivieren | Deaktivieren Sie die Konsole, es sei denn, es wird eine Fehlerbehebung durchgeführt. |
| set snmp community schreibgeschützter String | Konfigurieren Sie das Kennwort, um die Remotedatensammlung zu ermöglichen. |
| set snmp community Zeichenfolge mit Lese-/Schreibzugriff | Konfigurieren Sie das Kennwort, um die Remote-Konfiguration zu ermöglichen. |
| set snmp community string mit Lese-/Schreibzugriff | Konfigurieren Sie das Kennwort so, dass eine Remote-Konfiguration möglich ist, einschließlich Kennwörtern. |
| set snmp trap enable all | Aktivieren Sie SNMP-Traps für den NMS-Server, um Fehler- und Ereigniswarnungen zu erhalten. |
| set snmp trap server address string | Konfigurieren der Adresse des NMS-Trap-Empfängers |
| SNMP-RMON aktivieren | Aktivieren Sie RMON für die lokale Statistikerfassung. Weitere Informationen finden Sie im Abschnitt Remote Monitoring in diesem Dokument. |
| set ntp broadcast client enable | Ermöglicht den genauen Empfang der Systemuhr von einem Upstream-Router. |
| set ntp timezone zonenname | Legen Sie die lokale Zeitzone für das Gerät fest. |
| ntp sommertime Datum Änderungsdetails festlegen | Konfigurieren Sie ggf. die Sommerzeit für die Zeitzone. |
| Aktivieren Sie die NTP-Authentifizierung. | Konfigurieren verschlüsselter Zeitinformationen zu Sicherheitszwecken |
| NTP-Schlüssel festlegen | Verschlüsselungsschlüssel konfigurieren. |
| cdp enable festlegen | Stellen Sie sicher, dass die Erkennung von Nachbarn aktiviert ist (standardmäßig ist diese Funktion auch auf Ports aktiviert). |
| set tacacs server IP address primary | Konfigurieren Sie die Adresse des AAA-Servers. |
| TACACS Server-IP-Adresse festlegen | Redundante AAA-Server, sofern möglich |
| set tacacs versuche 3 | Lassen Sie für das AAA-Benutzerkonto drei Kennwortversuche zu. |
| Tasten-Taste festlegen | Legen Sie den Verschlüsselungsschlüssel AAA MD5 fest. |
| set tacacs timeout 15 | Längere Server-Zeitüberschreitung zulassen (Standardeinstellung ist fünf Sekunden). |
| set authentication login tacacs enable | Verwenden Sie AAA für die Authentifizierung für die Anmeldung. |
| set authentication enable tacacs enable | Verwenden Sie AAA für die Authentifizierung für den Aktivierungsmodus. |
| Authentisierung festlegen Anmelden lokal aktivieren | Standard; Ermöglicht Fallback zu lokal, wenn kein AAA-Server verfügbar ist. |
| set authentication enable local aktivieren | Standard; Ermöglicht Fallback zu lokal, wenn kein AAA-Server verfügbar ist. |
Konfigurationsbefehle für Host-Ports
| Command | Kommentar |
|---|---|
| Port-Host-Port-Bereich festlegen | Entfernen Sie nicht benötigte Portverarbeitung. Dieses Makro setzt Spantree PortFast enable, channel off, trunk off. |
| set udld disable Port-Bereich | Entfernen Sie nicht benötigte Port-Verarbeitung (standardmäßig deaktiviert für Kupfer-Port). |
| Portgeschwindigkeit Portbereich einstellen Auto | Verwenden Sie die automatische Aushandlung mit aktuellen Host-Netzwerkkartentreibern. |
| set port trap port range disable | Keine SNMP-Traps für allgemeine Benutzer erforderlich; nur Schlüsselports nachverfolgen. |
Server-Konfigurationsbefehle
| Command | Kommentar |
|---|---|
| Port-Host-Port-Bereich festlegen | Entfernen Sie nicht benötigte Portverarbeitung. Dieses Makro setzt Spantree PortFast enable, channel off, trunk off. |
| set udld disable Port-Bereich | Entfernen Sie nicht benötigte Port-Verarbeitung (standardmäßig deaktiviert für Kupfer-Port). |
| Portgeschwindigkeit Portbereich einstellen 10 | 100 | Normalerweise statische/Server-Ports konfigurieren; Andernfalls verwenden Sie AutoVerhandlung. |
| Port-Duplexportbereich voll festlegen | Hälfte | In der Regel statische Ports/Server-Ports Andernfalls verwenden Sie AutoVerhandlung. |
| Port-Trap-Port-Bereich aktivieren | Wichtige Service-Ports müssen Trap an das NMS senden. |
Konfigurationsbefehle für nicht verwendete Ports
| Command | Kommentar |
|---|---|
| set spantree portfast port range disable | Aktivieren Sie die erforderliche Port-Verarbeitung und den Schutz für STP. |
| Port-Deaktivierungsbereich festlegen | Deaktivieren Sie nicht verwendete Ports. |
| VLAN-Portbereich für ungenutzten Dummy-VLANs festlegen | Leiten Sie nicht autorisierten Datenverkehr an nicht genutztes VLAN, wenn der Port aktiviert ist. |
| den Trunk-Port-Bereich deaktivieren | Deaktivieren Sie "port from trunking", bis administriert. |
| Port-Channel-Port-Bereich ausgeschaltet | Deaktivieren Sie Port vom Channeling bis zum Verwalten. |
Infrastruktur-Ports (Switch, Switch, Router)
| Command | Kommentar |
|---|---|
| set udld enable portbereich | Aktivieren Sie die unidirektionale Verbindungserkennung (nicht standardmäßig an Kupferports). |
| set udld aggressive-mode enable port range | Aktivieren Sie den aggressiven Modus (für Geräte, die diesen unterstützen). |
| Port-Aushandlungs-Port-Bereich festlegenAktivieren | Standardmäßige GE-Autoübertragung von Verbindungsparametern zulassen. |
| Port-Trap-Port-Bereich aktivieren | SNMP-Traps für diese Schlüsselports zulassen. |
| den Trunk-Port-Bereich deaktivieren | Deaktivieren Sie diese Funktion, wenn Sie keine Trunks verwenden. |
| Trunk-Modus/Port festlegen, erwünschte ISL | dot1q | verhandeln | Bei Verwendung von Trunks ist dot1q bevorzugt. |
| Klären des Trunk-Modus/Port-VLAN-Bereichs | Begrenzen Sie den STP-Durchmesser, indem Sie VLANs dort aus Trunks entfernen, wo sie nicht benötigt werden. |
| Port-Channel-Port-Bereich ausgeschaltet | Deaktivieren Sie diese Funktion, wenn Sie keine Kanäle verwenden. |
| Port-Channel-Port-Bereichsmodus erwünscht | Bei Verwendung von Kanälen wird PAgP aktiviert. |
| Port-Channel festlegen alle Verteilungs-IP beide | Bei Verwendung von Kanälen L3-Quell-/Ziel-Lastenausgleich zulassen (Standard bei Catalyst 6500/6000). |
| Trunk-Modus/Port-Nicht-Aushandlung-ISL festlegen | dot1q | Deaktivierung von DTP bei Trunking zu Router, Catalyst 2900XL, 3500 oder einem anderen Anbieter |
| Port-Aushandlung-Modus festlegen/Port deaktivieren | Die Aushandlung kann für einige alte GE-Geräte inkompatibel sein. |
Zugehörige Informationen
- Häufige CatOS-Fehlermeldungen bei Catalyst Switches der Serien 4500/4000
- Häufige CatOS-Fehlermeldungen bei Switches der Catalyst 5000/5500-Serie
- Häufige CatOS-Fehlermeldungen bei Catalyst Switches der Serien 6500/6000
- Produkt-Support für Switches
- Support für LAN-Switching-Technologie
- Technischer Support und Dokumentation für Cisco Systeme
Revisionsverlauf
| Überarbeitung | Veröffentlichungsdatum | Kommentare |
|---|---|---|
1.0 |
10-Dec-2001
|
Erstveröffentlichung |
 Feedback
FeedbackCisco kontaktieren
- Eine Supportanfrage öffnen

- (Erfordert einen Cisco Servicevertrag)