





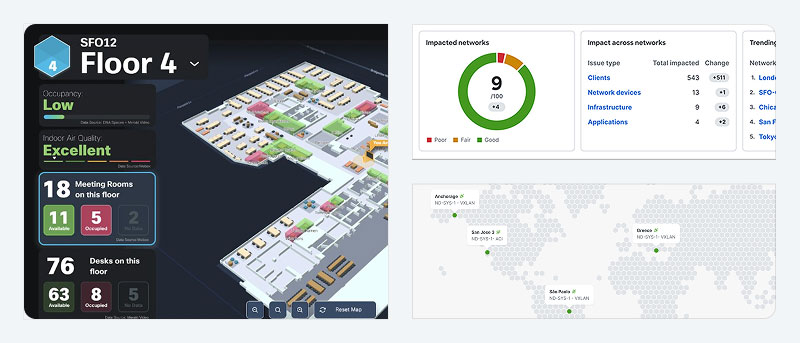
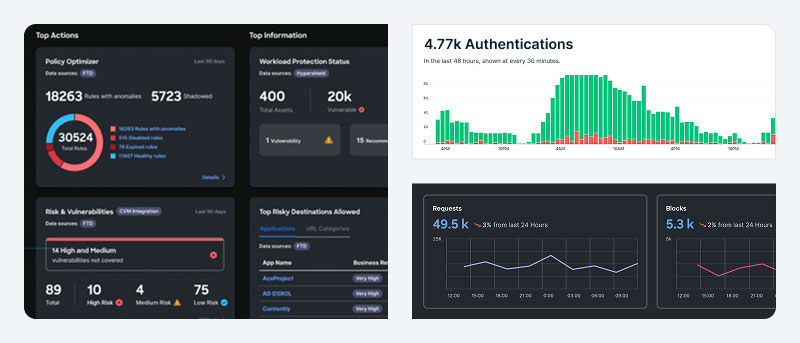
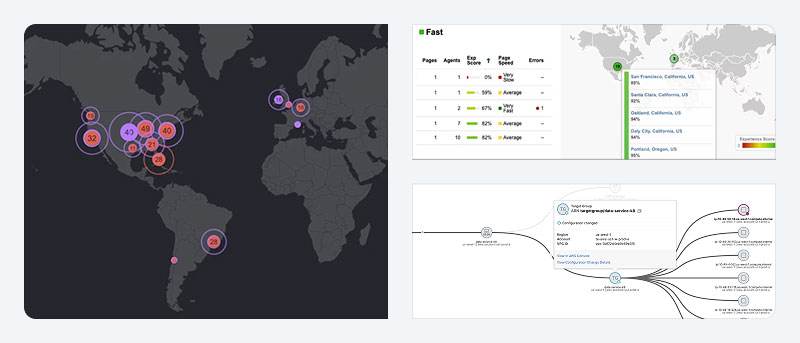

You can find support for Cisco Networking products through the Cisco Support hub, which provides product-specific resources, documentation, downloads, and expert assistance.
The network that only Cisco can deliver
AgenticOps for operational simplicity
From reactive to proactive. Cross-domain agents detect, decide, and act—freeing teams for what matters.
Security fused into the network
Built to withstand what's next, with quantum-ready protection at every layer.
Scalable devices for AI
The network that powers AI. High-performance, low-latency devices for AI-ready enterprises.

What’s new in Cisco Networking
AI Networking
Scale AI with secure, intelligent Ethernet that boosts GPU efficiency.
Secure Campus
Secure, AI-optimized campus networking to simplify operations and scale.
What you can do with Cisco networking
Transform campus and branch
Deliver consistent, secure user experiences across every site—with automated operations and cloud-managed simplicity.
Enforce Zero Trust access
Enforce zero-trust policy and identity-aware access from user to application.
Connect industrial environments
Extend secure, resilient networking to factories, utilities, transportation, and critical infrastructure.
Scale wide-area networking
Secure, high-performance WAN technology connecting branch, campus, and cloud with consistent application experience and security-policy enforcement.
Data center and cloud networking
Silicon to software. Every workload. High-performance data center networking with security built into every layer.
Service provider networking
Scalable networking solutions for service providers to deliver advanced services.

Scalable Infrastructure
From campus switches to branch routers to industrial access—all built on Cisco Silicon One.
Secure Routers
Secure, high-performance routing and SD-WAN infrastructure enabling resilient, scalable enterprise connectivity across campus, branch, and cloud.
Smart Switches
Next-generation switching powered by advanced silicon to deliver deterministic performance, deep telemetry, and secure, scalable connectivity across enterprise and data center networks.
Exceptional Wi-Fi 7
High-performance, secure wireless foundation enabling reliable connectivity and superior application experience across modern enterprise environments.
Industrial networking
Industrial-grade networking bridging IT and OT, built on the same platform as campus and branch, with ruggedized capabilities for factory, harsh, and outdoor environments.
Software/Assurance
Simplified operations, powered by AgenticOps
Network software
Software to automate, monitor, and secure your network.
Network security
Comprehensive security solutions to protect your network from evolving threats.
End-to-end visibility from client to cloud
Assure every digital experience across owned and unowned networks.
Resources
Promotions and trials
Discover limited-time networking discounts and free trials.
Cisco Networking Academy
Build your skills with self-paced or instructor-led courses—several of which are free.
Cisco DevNet
Browse resources for network engineers and developers working on Cisco platforms.
Cisco Networking resources
See a full list of networking communities, webinars, and other resources.
FAQs
The Cisco Community is a hub where you can connect with peers and Cisco specialists to ask for help, share experiences, and build your professional network. The hub includes an area devoted to networking products.
Cisco Services provide expert guidance to help you plan, design, implement, operate, and optimize your IT environment as well as AI-powered and expert-backed support to enable proactive and predictive IT operations.
Cisco offers learning options for a wide range of levels and learning styles. Cisco Networking Academy provides beginner-friendly content and offers online and in-person options. Cisco U. provides product, certification, and skills- training options online for all levels, from associate to expert. The Cisco Learning Partners program provides online and in-person instructor-led training for enterprises and individuals.
We offer such certifications as Cisco Certified Network Associate, Cisco Certified Network Professional, and Cisco Certified Internetwork Expert.
Cisco DevNet provides extensive resources for network engineers and developers working on Cisco platforms. Technical practitioners have access to APIs and API documentation, data models, hands-on Learning Labs, live-tech sandboxes, and developer-focused events.
Yes, the Cisco networking software portfolio provides device management and dashboarding solutions. Our software solutions enable IT teams to transition to a unified, AI-driven platform that simplifies operations, automates tasks, and enhances security across digital infrastructures. The solutions provide flexible, subscription-based licensing, allowing for consistent updates and optimized networking performance across different environments.
The Cisco Networking App Marketplace offers all Cisco-approved integrations with the Cisco Networking platform, featuring more than 350 ready-to-use networking applications developed by technology partners. These applications leverage Cisco APIs and AI to simplify network operations, enhance performance, and provide scalable, secure solutions.
Use technical documents and Cisco Validated design guides to get step-by-step information and best practices for configuring Cisco routers, switches, and wireless access points.
Explore the Cisco end-of-sale and end-of-life products page for the full list of products we no longer sell. You can also seek feedback from the Cisco community about end-of-life topics and options for what to do next.

