
Cisco unveils AI Networking for the agentic era
Network intelligence that propels AI


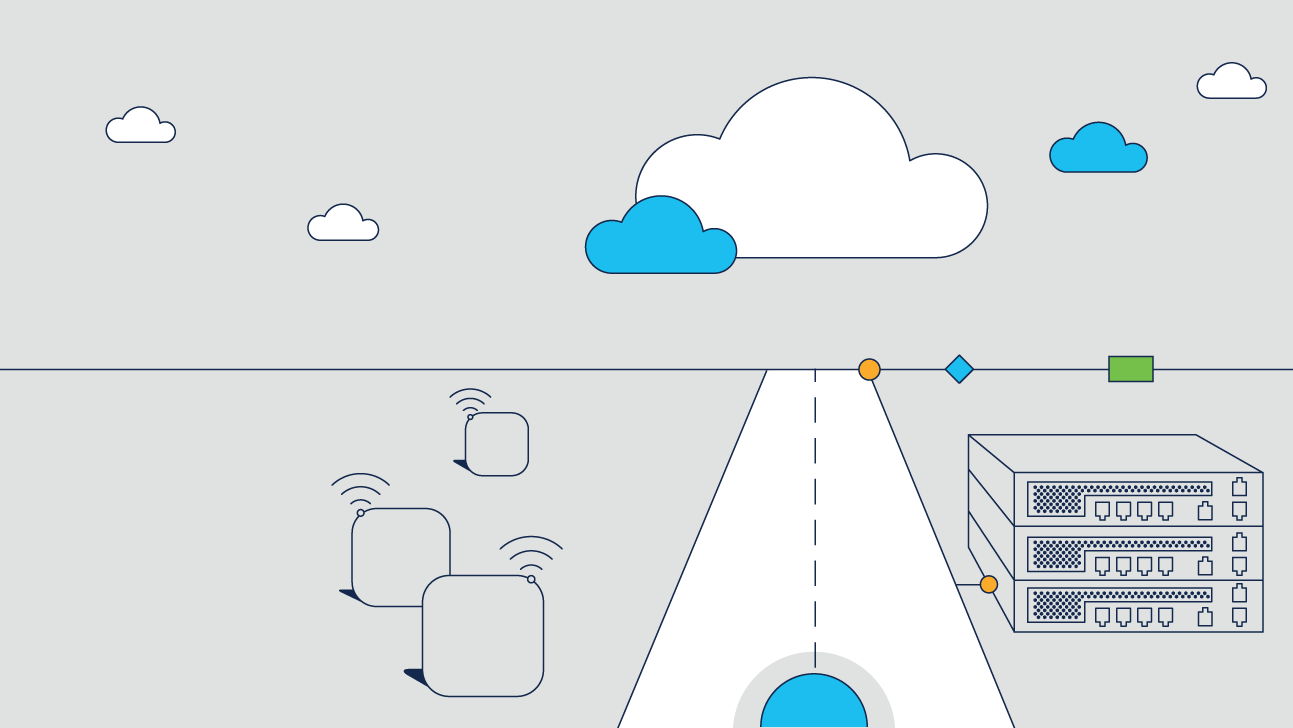
Keep users happy and business running smoothly with software and hardware that work best together. Automation, analytics, and security work hard for you, so you don't have to.
Simplify onboarding and provisioning
Use automated workflows to quickly configure and provision new devices on the network according to your network policies.
Control access with ease
Use artificial intelligence and machine learning (AI/ML) to identify and classify endpoints, implement security policies, and display the most critical alerts for action.
Maintain network health
Use telemetry data and simple management tools to see client, network, service, and application health insights.
Scale your network to match demand
Simplify scalability with flexible router-port configuration to meet demand dynamically. And with Cisco Smart Licensing, it's easy to activate ports when and where you need them.
Find what you're looking for

Access software for switching
Benefit from the latest switching and management innovations as soon as they're released.
Switches
Build a network with multigigabit switches that constantly learn, adapt, and protect.
Access software for wireless
Get continual feature innovations delivered by subscription.
Cisco wireless
Build future-proof workspaces with intelligent, secure, and assured Wi-Fi 7.
Routers
Simplify your WAN architecture and make it easier to deploy, manage, and operate.
Edge platforms
Enhance multicloud application experiences across your cloud, data center, and WAN edge.
Data center and cloud software
Expand your hybrid cloud operations without increasing your management complexity.
Data center switches and infrastructure
Build for scale, industry-leading automation, programmability, and real-time visibility.
Service provider software
Enable automation, assurance, subscriber management, and telco cloud solutions for the services edge.
Service provider routers, wireless, and infrastructure
Break free from proprietary mobile technologies with infrastructure designed for open systems.
Industrial software
Unlock the full value of your industrial infrastructure with Cisco DNA Software subscriptions.
Industrial switching
Digitize your operations with ruggedized, purpose-built switches for your industrial network.
Industrial wireless
Enjoy reliable and secure connectivity for mission-critical, low-latency, and low-power IoT devices.
Industrial routers
Connect your industrial edge securely and at scale to external users and applications.
Industrial security
Gain OT visibility, extend zero-trust security, and develop a converged IT/OT security strategy.
Silicon
Deploy industry-leading silicon that unifies high-performance routing and switching networks.
Optics
Increase capacity, reach, and speed with optical transceivers for your network connections.
Platforms to control your network

Cisco Crosswork Network Automation
Simplify services management and operations with advanced automation for service providers.
Cisco Catalyst Center
Automate, secure, and optimize your wireless and switching access networks.
Cisco Meraki platform
Scale and secure your entire network with the Meraki cloud networking platform.
Cisco Catalyst SD-WAN Manager
Centrally manage your SD-WAN for optimized security, application experience, and cloud connectivity.
Cisco Nexus Dashboard
Configure, operate, and analyze—all from one place—across data center and public cloud.
IoT Control Center
Deliver innovation at scale with our industry-leading IoT cellular connectivity platform.

Network-enabled business outcomes
Services and support
Cisco Professional Services
Move your business forward
Your team. Our expertise. With your desired business outcomes as the compass, let's optimize and transform your IT environment—all while demonstrating measurable success
Cisco Services
Drive results with an optimized network
Deploy faster, help enable NetOps excellence, and improve security and visibility.