更換OSD-Compute UCS 240M4 - vEPC
下載選項
無偏見用語
本產品的文件集力求使用無偏見用語。針對本文件集的目的,無偏見係定義為未根據年齡、身心障礙、性別、種族身分、民族身分、性別傾向、社會經濟地位及交織性表示歧視的用語。由於本產品軟體使用者介面中硬式編碼的語言、根據 RFP 文件使用的語言,或引用第三方產品的語言,因此本文件中可能會出現例外狀況。深入瞭解思科如何使用包容性用語。
關於此翻譯
思科已使用電腦和人工技術翻譯本文件,讓全世界的使用者能夠以自己的語言理解支援內容。請注意,即使是最佳機器翻譯,也不如專業譯者翻譯的內容準確。Cisco Systems, Inc. 對這些翻譯的準確度概不負責,並建議一律查看原始英文文件(提供連結)。
目錄
簡介
本文檔介紹在託管StarOS虛擬網路功能(VNF)的Ultra-M設定中替換故障對象儲存磁碟(OSD)-Compute伺服器所需的步驟。
背景資訊
Ultra-M是經過預打包和驗證的虛擬化移動資料包核心解決方案,旨在簡化VNF的部署。 OpenStack是適用於Ultra-M的虛擬化基礎架構管理器(VIM),包含以下節點型別:
- 計算
- OSD — 計算
- 控制器
- OpenStack平台 — 導向器(OSPD)
Ultra-M的高級體系結構及涉及的元件如下圖所示:
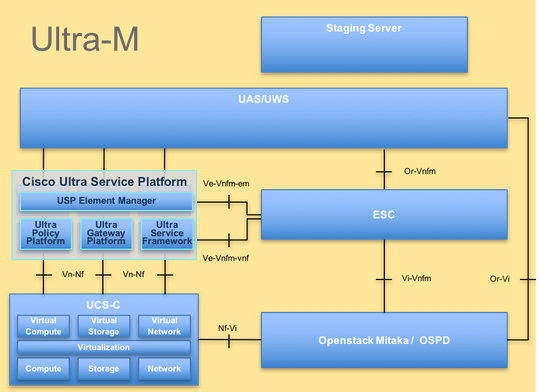
本文檔面向熟悉Cisco Ultra-M平台的思科人員,詳細介紹在進行計算伺服器更換時,在OpenStack和StarOS VNF級別需要執行的步驟。
附註:Ultra M 5.1.x版本用於定義本文檔中的過程。
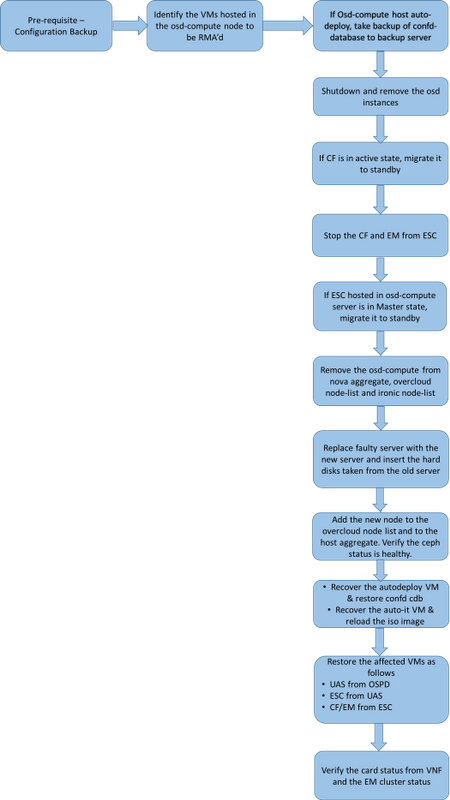
MoP的工作流程
縮寫
| VNF | 虛擬網路功能 |
| CF | 控制功能 |
| SF | 服務功能 |
| ESC | 彈性服務控制器 |
| 澳門幣 | 程式方法 |
| OSD | 對象儲存磁碟 |
| HDD | 硬碟驅動器 |
| 固態硬碟 | 固態驅動器 |
| VIM | 虛擬基礎架構管理員 |
| 虛擬機器 | 虛擬機器 |
| EM | 元素管理器 |
| UAS | Ultra自動化服務 |
| UUID | 通用唯一ID識別符號 |
必要條件
備份OSPD
在替換OSD-Compute節點之前,請務必檢查Red Hat OpenStack平台環境的當前狀態。建議您檢查當前狀態,以避免在計算替換過程開啟時出現複雜情況。通過這種更換流程可以實現這一點。
在進行恢復時,思科建議您使用以下步驟對OSPD資料庫(DB)進行備份:
[root@director ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql
[root@director ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql
/etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack
tar: Removing leading `/' from member names
此過程可確保在不影響任何例項的可用性的情況下替換節點。此外,建議備份StarOS配置,尤其是當要替換的計算節點承載CF VM時。
確定OSD計算節點中託管的VM
確定託管在計算伺服器上的VM。可能發生兩種情況:
OSD-Compute伺服器包含VM的EM/UAS/自動部署/自動IT組合:
[stack@director ~]$ nova list --field name,host | grep osd-compute-0
| c6144778-9afd-4946-8453-78c817368f18 | AUTO-DEPLOY-VNF2-uas-0 | pod1-osd-compute-0.localdomain |
| 2d051522-bce2-4809-8d63-0c0e17f251dc | AUTO-IT-VNF2-uas-0 | pod1-osd-compute-0.localdomain |
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-osd-compute-0.localdomain |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-osd-compute-0.localdomain |
計算伺服器包含虛擬機器的CF/ESC/EM/UAS組合:
[stack@director ~]$ nova list --field name,host | grep osd-compute-1
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-compute-8.localdomain |
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229 | pod1-compute-8.localdomain |
| 75528898-ef4b-4d68-b05d-882014708694 | VNF2-ESC-ESC-0 | pod1-compute-8.localdomain |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-compute-8.localdomain |
附註:此處顯示的輸出中,第一列與UUID相對應,第二列是VM名稱,第三列是存在VM的主機名。此輸出的引數將在後續章節中使用。
驗證Ceph是否具有可用容量,以允許刪除單個OSD伺服器:
[root@pod1-osd-compute-1 ~]# sudo ceph df
GLOBAL:
SIZE AVAIL RAW USED %RAW USED
13393G 11804G 1589G 11.87
POOLS:
NAME ID USED %USED MAX AVAIL OBJECTS
rbd 0 0 0 3876G 0
metrics 1 4157M 0.10 3876G 215385
images 2 6731M 0.17 3876G 897
backups 3 0 0 3876G 0
volumes 4 399G 9.34 3876G 102373
vms 5 122G 3.06 3876G 31863
驗證OSD-Compute伺服器上的ceph osd樹狀態是否為up:
[heat-admin@pod1-osd-compute-1 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod1-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-3 4.35999 host pod1-osd-compute-2
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
-4 4.35999 host pod1-osd-compute-1
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
Ceph進程在OSD-Compute伺服器上處於活動狀態:
[root@pod1-osd-compute-1 ~]# systemctl list-units *ceph*
UNIT LOAD ACTIVE SUB DESCRIPTION
var-lib-ceph-osd-ceph\x2d11.mount loaded active mounted /var/lib/ceph/osd/ceph-11
var-lib-ceph-osd-ceph\x2d2.mount loaded active mounted /var/lib/ceph/osd/ceph-2
var-lib-ceph-osd-ceph\x2d5.mount loaded active mounted /var/lib/ceph/osd/ceph-5
var-lib-ceph-osd-ceph\x2d8.mount loaded active mounted /var/lib/ceph/osd/ceph-8
ceph-osd@11.service loaded active running Ceph object storage daemon
ceph-osd@2.service loaded active running Ceph object storage daemon
ceph-osd@5.service loaded active running Ceph object storage daemon
ceph-osd@8.service loaded active running Ceph object storage daemon
system-ceph\x2ddisk.slice loaded active active system-ceph\x2ddisk.slice
system-ceph\x2dosd.slice loaded active active system-ceph\x2dosd.slice
ceph-mon.target loaded active active ceph target allowing to start/stop all ceph-mon@.service instances at once
ceph-osd.target loaded active active ceph target allowing to start/stop all ceph-osd@.service instances at once
ceph-radosgw.target loaded active active ceph target allowing to start/stop all ceph-radosgw@.service instances at once
ceph.target loaded active active ceph target allowing to start/stop all ceph*@.service instances at once
禁用並停止每個Ceph例項,從OSD中刪除每個例項並解除安裝目錄。對每個Ceph例項重複以下操作:
[root@pod1-osd-compute-1 ~]# systemctl disable ceph-osd@11
[root@pod1-osd-compute-1 ~]# systemctl stop ceph-osd@11
[root@pod1-osd-compute-1 ~]# ceph osd out 11
marked out osd.11.
[root@pod1-osd-compute-1 ~]# ceph osd crush remove osd.11
removed item id 11 name 'osd.11' from crush map
[root@pod1-osd-compute-1 ~]# ceph auth del osd.11
updated
[root@pod1-osd-compute-1 ~]# ceph osd rm 11
removed osd.11
[root@pod1-osd-compute-1 ~]# umount /var/lib/ceph.osd/ceph-11
[root@pod1-osd-compute-1 ~]# rm -rf /var/lib/ceph.osd/ceph-11
或
可以使用clean.sh指令碼來執行此任務:
[heat-admin@pod1-osd-compute-0 ~]$ sudo ls /var/lib/ceph/osd
ceph-11 ceph-3 ceph-6 ceph-8
[heat-admin@pod1-osd-compute-0 ~]$ /bin/sh clean.sh
[heat-admin@pod1-osd-compute-0 ~]$ cat clean.sh
#!/bin/sh
set -x
CEPH=`sudo ls /var/lib/ceph/osd`
for c in $CEPH
do
i=`echo $c |cut -d'-' -f2`
sudo systemctl disable ceph-osd@$i || (echo "error rc:$?"; exit 1)
sleep 2
sudo systemctl stop ceph-osd@$i || (echo "error rc:$?"; exit 1)
sleep 2
sudo ceph osd out $i || (echo "error rc:$?"; exit 1)
sleep 2
sudo ceph osd crush remove osd.$i || (echo "error rc:$?"; exit 1)
sleep 2
sudo ceph auth del osd.$i || (echo "error rc:$?"; exit 1)
sleep 2
sudo ceph osd rm $i || (echo "error rc:$?"; exit 1)
sleep 2
sudo umount /var/lib/ceph/osd/$c || (echo "error rc:$?"; exit 1)
sleep 2
sudo rm -rf /var/lib/ceph/osd/$c || (echo "error rc:$?"; exit 1)
sleep 2
done
sudo ceph osd tree
在所有OSD進程都進行了遷移/刪除之後,節點可以從超雲中刪除。
註:刪除Ceph後,VNF HD RAID將進入「已降級」狀態,但HD磁碟必須仍然可以訪問。
正常斷電
案例1. OSD計算節點主機CF/ESC/EM/UAS
將CF卡遷移至備用狀態
登入到StarOS VNF並確定與CF VM對應的卡。使用識別OSD-Compute節點中託管的VM部分中標識的CF VM的UUID,並查詢與UUID對應的卡。
[local]VNF2# show card hardware
Tuesday might 08 16:49:42 UTC 2018
<snip>
Card 2:
Card Type : Control Function Virtual Card
CPU Packages : 8 [#0, #1, #2, #3, #4, #5, #6, #7]
CPU Nodes : 1
CPU Cores/Threads : 8
Memory : 16384M (qvpc-di-large)
UUID/Serial Number : F9C0763A-4A4F-4BBD-AF51-BC7545774BE2
<snip>
檢查卡的狀態:
[local]VNF2# show card table
Tuesday might 08 16:52:53 UTC 2018
Slot Card Type Oper State SPOF Attach
----------- -------------------------------------- ------------- ---- ------
1: CFC Control Function Virtual Card Standby -
2: CFC Control Function Virtual Card Active No
3: FC 4-Port Service Function Virtual Card Active No
4: FC 4-Port Service Function Virtual Card Active No
5: FC 4-Port Service Function Virtual Card Active No
6: FC 4-Port Service Function Virtual Card Active No
7: FC 4-Port Service Function Virtual Card Active No
8: FC 4-Port Service Function Virtual Card Active No
9: FC 4-Port Service Function Virtual Card Active No
10: FC 4-Port Service Function Virtual Card Standby -
如果卡處於活動狀態,請將卡移至備用狀態:
[local]VNF2# card migrate from 2 to 1
從ESC關閉CF和EM虛擬機器
登入到與VNF對應的ESC節點並檢查VM的狀態:
[admin@VNF2-esc-esc-0 ~]$ cd /opt/cisco/esc/esc-confd/esc-cli
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229</vm_name>
<state>VM_ALIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c3_0_3e0db133-c13b-4e3d-ac14-
<state>VM_ALIVE_STATE</state>
<deployment_name>VNF2-DEPLOYMENT-em</deployment_name>
<vm_id>507d67c2-1d00-4321-b9d1-da879af524f8</vm_id>
<vm_id>dc168a6a-4aeb-4e81-abd9-91d7568b5f7c</vm_id>
<vm_id>9ffec58b-4b9d-4072-b944-5413bf7fcf07</vm_id>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea</vm_name>
<state>VM_ALIVE_STATE</state>
<snip>
使用其VM名稱逐一停止CF和EM VM。VM名稱(在識別OSD-Compute節點中託管的VM)部分中註明。
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli vm-action STOP VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli vm-action STOP VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea
停止後,VM必須進入SHUTOFF狀態:
[admin@VNF2-esc-esc-0 ~]$ cd /opt/cisco/esc/esc-confd/esc-cli
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229</vm_name>
<state>VM_SHUTOFF_STATE</state>
<vm_name>VNF2-DEPLOYM_c3_0_3e0db133-c13b-4e3d-ac14-
<state>VM_ALIVE_STATE</state>
<deployment_name>VNF2-DEPLOYMENT-em</deployment_name>
<vm_id>507d67c2-1d00-4321-b9d1-da879af524f8</vm_id>
<vm_id>dc168a6a-4aeb-4e81-abd9-91d7568b5f7c</vm_id>
<vm_id>9ffec58b-4b9d-4072-b944-5413bf7fcf07</vm_id>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea</vm_name>
VM_SHUTOFF_STATE
<snip>
將ESC遷移到備用模式
登入到計算節點中託管的ESC並檢查它是否處於主狀態。如果是,將ESC切換到備用模式:
[admin@VNF2-esc-esc-0 esc-cli]$ escadm status
0 ESC status=0 ESC Master Healthy
[admin@VNF2-esc-esc-0 ~]$ sudo service keepalived stop
Stopping keepalived: [ OK ]
[admin@VNF2-esc-esc-0 ~]$ escadm status
1 ESC status=0 In SWITCHING_TO_STOP state. Please check status after a while.
[admin@VNF2-esc-esc-0 ~]$ sudo reboot
Broadcast message from admin@vnf1-esc-esc-0.novalocal
(/dev/pts/0) at 13:32 ...
The system is going down for reboot NOW!
從新星聚合清單中刪除OSD-Compute節點
列出nova聚合,並根據其託管的VNF確定與計算伺服器對應的聚合。通常,其格式為<VNFNAME>-EM-MGMT<X>和<VNFNAME>-CF-MGMT<X>:
[stack@director ~]$ nova aggregate-list
+----+-------------------+-------------------+
| Id | Name | Availability Zone |
+----+-------------------+-------------------+
| 29 | POD1-AUTOIT | mgmt |
| 57 | VNF1-SERVICE1 | - |
| 60 | VNF1-EM-MGMT1 | - |
| 63 | VNF1-CF-MGMT1 | - |
| 66 | VNF2-CF-MGMT2 | - |
| 69 | VNF2-EM-MGMT2 | - |
| 72 | VNF2-SERVICE2 | - |
| 75 | VNF3-CF-MGMT3 | - |
| 78 | VNF3-EM-MGMT3 | - |
| 81 | VNF3-SERVICE3 | - |
+----+-------------------+-------------------+
在這種情況下,OSD-Compute伺服器屬於VNF2。因此,相應的聚合將是VNF2-CF-MGMT2和VNF2-EM-MGMT2。
從標識的聚合中刪除OSD-Compute節點:
nova aggregate-remove-host
[stack@director ~]$ nova aggregate-remove-host VNF2-CF-MGMT2 pod1-osd-compute-0.localdomain
[stack@director ~]$ nova aggregate-remove-host VNF2-EM-MGMT2 pod1-osd-compute-0.localdomain
[stack@director ~]$ nova aggregate-remove-host POD1-AUTOIT pod1-osd-compute-0.localdomain
驗證是否已從聚合中刪除OSD-Compute節點。現在,確保主機未列在聚合下:
nova aggregate-show
[stack@director ~]$ nova aggregate-show VNF2-CF-MGMT2
[stack@director ~]$ nova aggregate-show VNF2-EM-MGMT2
[stack@director ~]$ nova aggregate-show POD1-AUTOIT
案例2. OSD計算節點託管自動部署/自動IT/EM/UAS
備份自動部署的CDB
定期或在每次啟用/取消啟用後備份autodeploy confd cdb資料,並將檔案儲存到備份伺服器。自動部署不是冗餘的,如果此資料丟失,則很難停用部署。
登入到Auto-Deploy VM並備份confd cdb目錄:
ubuntu@auto-deploy-iso-2007-uas-0:~$sudo -i
root@auto-deploy-iso-2007-uas-0:~#service uas-confd stop
uas-confd stop/waiting
root@auto-deploy-iso-2007-uas-0:~# cd /opt/cisco/usp/uas/confd-6.3.1/var/confd
root@auto-deploy-iso-2007-uas-0:/opt/cisco/usp/uas/confd-6.3.1/var/confd#tar cvf autodeploy_cdb_backup.tar cdb/
cdb/
cdb/O.cdb
cdb/C.cdb
cdb/aaa_init.xml
cdb/A.cdb
root@auto-deploy-iso-2007-uas-0:~# service uas-confd start
uas-confd start/running, process 13852
附註:將autodeploy_cdb_backup.tar複製到備份伺服器。
從自動IT備份system.cfg
將system.cfg檔案備份到backup-server:
Auto-it = 10.1.1.2
Backup server = 10.2.2.2
[stack@director ~]$ ssh ubuntu@10.1.1.2
ubuntu@10.1.1.2's password:
Welcome to Ubuntu 14.04.3 LTS (GNU/Linux 3.13.0-76-generic x86_64)
* Documentation: https://help.ubuntu.com/
System information as of Wed Jun 13 16:21:34 UTC 2018
System load: 0.02 Processes: 87
Usage of /: 15.1% of 78.71GB Users logged in: 0
Memory usage: 13% IP address for eth0: 172.16.182.4
Swap usage: 0%
Graph this data and manage this system at:
https://landscape.canonical.com/
Get cloud support with Ubuntu Advantage Cloud Guest:
http://www.ubuntu.com/business/services/cloud
Cisco Ultra Services Platform (USP)
Build Date: Wed Feb 14 12:58:22 EST 2018
Description: UAS build assemble-uas#1891
sha1: bf02ced
ubuntu@auto-it-vnf-uas-0:~$ scp -r /opt/cisco/usp/uploads/system.cfg root@10.2.2.2:/home/stack
root@10.2.2.2's password:
system.cfg 100% 565 0.6KB/s 00:00
ubuntu@auto-it-vnf-uas-0:~$
註:對OSD-Compute-0上託管的EM/UAS執行正常關閉的步驟在這兩種情況下都相同。請參考案例1。
OSD計算節點刪除
不論計算節點中託管的VM,本節中提到的步驟都是通用的。
從服務清單中刪除OSD計算節點
從服務清單中刪除計算服務:
[stack@director ~]$ source corerc
[stack@director ~]$ openstack compute service list | grep osd-compute-0
| 404 | nova-compute | pod1-osd-compute-0.localdomain | nova | enabled | up | 2018-05-08T18:40:56.000000 |
openstack compute service delete
[stack@director ~]$ openstack compute service delete 404
刪除Neutron代理
刪除舊關聯的中子代理並開啟計算伺服器的vswitch代理:
[stack@director ~]$ openstack network agent list | grep osd-compute-0
| c3ee92ba-aa23-480c-ac81-d3d8d01dcc03 | Open vSwitch agent | pod1-osd-compute-0.localdomain | None | False | UP | neutron-openvswitch-agent |
| ec19cb01-abbb-4773-8397-8739d9b0a349 | NIC Switch agent | pod1-osd-compute-0.localdomain | None | False | UP | neutron-sriov-nic-agent |
openstack network agent delete
[stack@director ~]$ openstack network agent delete c3ee92ba-aa23-480c-ac81-d3d8d01dcc03
[stack@director ~]$ openstack network agent delete ec19cb01-abbb-4773-8397-8739d9b0a349
從Nova和Ironic資料庫中刪除
從nova清單和諷刺資料庫刪除一個節點並對其進行驗證:
[stack@director ~]$ source stackrc
[stack@al01-pod1-ospd ~]$ nova list | grep osd-compute-0
| c2cfa4d6-9c88-4ba0-9970-857d1a18d02c | pod1-osd-compute-0 | ACTIVE | - | Running | ctlplane=192.200.0.114 |
[stack@al01-pod1-ospd ~]$ nova delete c2cfa4d6-9c88-4ba0-9970-857d1a18d02c
nova show| grep hypervisor
[stack@director ~]$ nova show pod1-osd-compute-0 | grep hypervisor
| OS-EXT-SRV-ATTR:hypervisor_hostname | 4ab21917-32fa-43a6-9260-02538b5c7a5a
ironic node-delete
[stack@director ~]$ ironic node-delete 4ab21917-32fa-43a6-9260-02538b5c7a5a
[stack@director ~]$ ironic node-list (node delete must not be listed now)
從Overcloud中刪除
建立名為delete_node.sh的指令碼檔案,其內容如圖所示。請確保提到的模板與用於堆疊部署的deploy.sh指令碼中使用的模板相同:
delete_node.sh
openstack overcloud node delete --templates -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml -e /home/stack/custom-templates/layout.yaml --stack
[stack@director ~]$ source stackrc
[stack@director ~]$ /bin/sh delete_node.sh
+ openstack overcloud node delete --templates -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml -e /home/stack/custom-templates/layout.yaml --stack pod1 49ac5f22-469e-4b84-badc-031083db0533
Deleting the following nodes from stack pod1:
- 49ac5f22-469e-4b84-badc-031083db0533
Started Mistral Workflow. Execution ID: 4ab4508a-c1d5-4e48-9b95-ad9a5baa20ae
real 0m52.078s
user 0m0.383s
sys 0m0.086s
等待OpenStack堆疊操作以移至COMPLETE狀態:
[stack@director ~]$ openstack stack list
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| ID | Stack Name | Stack Status | Creation Time | Updated Time |
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| 5df68458-095d-43bd-a8c4-033e68ba79a0 | pod1 | UPDATE_COMPLETE | 2018-05-08T21:30:06Z | 2018-05-08T20:42:48Z |
+--------------------------------------+------------+-----------------+----------------------+----------------------
安裝新的計算節點
- 有關安裝新UCS C240 M4伺服器的步驟和初始設定步驟,請參閱:
- 安裝伺服器後,將硬碟插入相應插槽中,作為舊伺服器
- 使用CIMC IP登入到伺服器
- 如果韌體與以前使用的推薦版本不一致,請執行BIOS升級。BIOS升級步驟如下:
- 驗證物理驅動器的狀態。它一定是無限的好東西
- 使用RAID級別1從物理驅動器建立虛擬驅動器
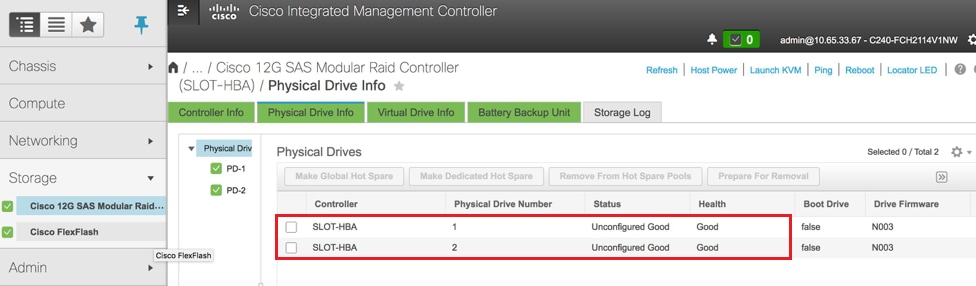 儲存> Cisco 12G SAS模組化Raid控制器(SLOT-HBA)>物理驅動器資訊
儲存> Cisco 12G SAS模組化Raid控制器(SLOT-HBA)>物理驅動器資訊
附註:此映像僅供說明之用,在實際OSD計算CIMC中,您將看到七個物理驅動器位於插槽(1,2,3,7,8,9,10)中,處於未配置的良好狀態,因為沒有從插槽建立虛擬驅動器。
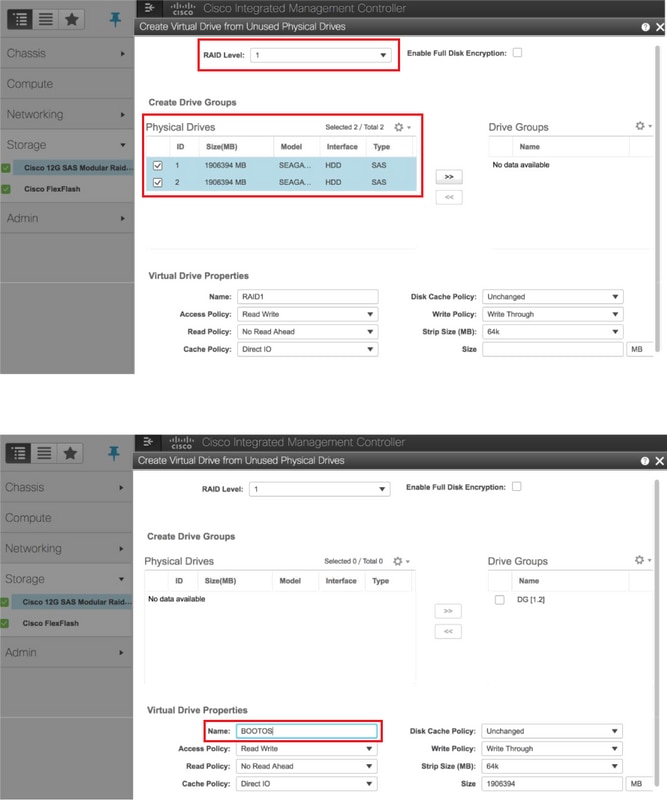 儲存> Cisco 12G SAS模組化Raid控制器(SLOT-HBA)>控制器資訊>從未使用的物理驅動器建立虛擬驅動器
儲存> Cisco 12G SAS模組化Raid控制器(SLOT-HBA)>控制器資訊>從未使用的物理驅動器建立虛擬驅動器
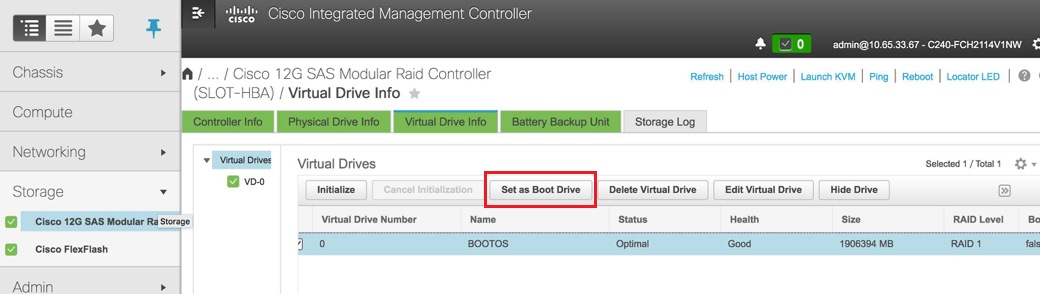 選擇VD並配置「設定為引導驅動器」
選擇VD並配置「設定為引導驅動器」
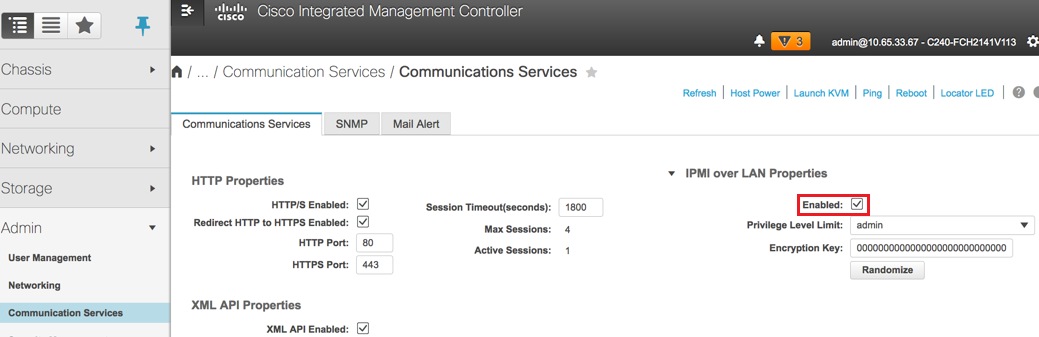 啟用IPMI over LAN:管理>通訊服務>通訊服務
啟用IPMI over LAN:管理>通訊服務>通訊服務
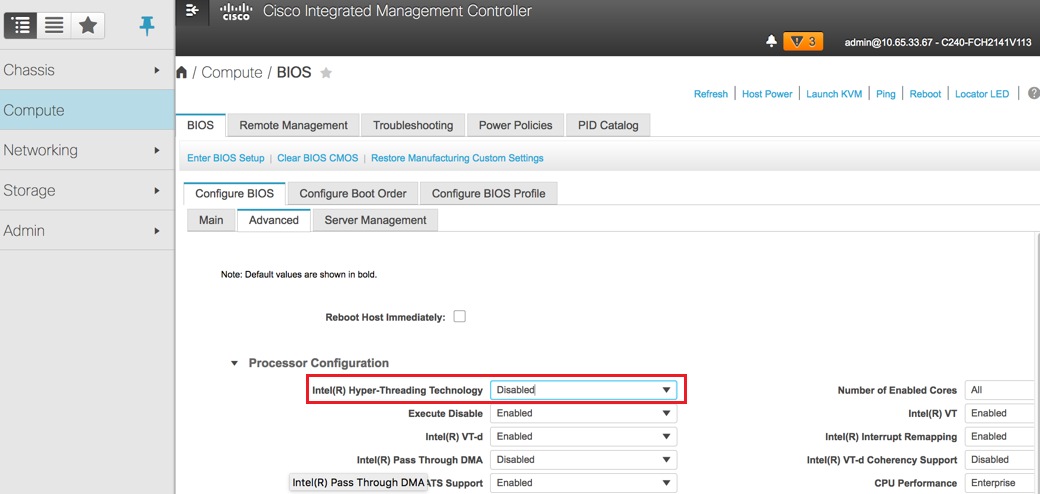 禁用超執行緒:計算> BIOS >配置BIOS >高級>處理器配置
禁用超執行緒:計算> BIOS >配置BIOS >高級>處理器配置
- 與使用物理驅動器1和2建立的BOOTOS VD類似,建立四個虛擬驅動器,作為
JOURNAL > From physical drive number 3
OSD1 >從物理驅動器號7
OSD2 >從物理驅動器號8
OSD3 >從物理驅動器號9
OSD4 >從物理驅動器號10 - 最後,物理驅動器和虛擬驅動器必須類似,如下圖所示:
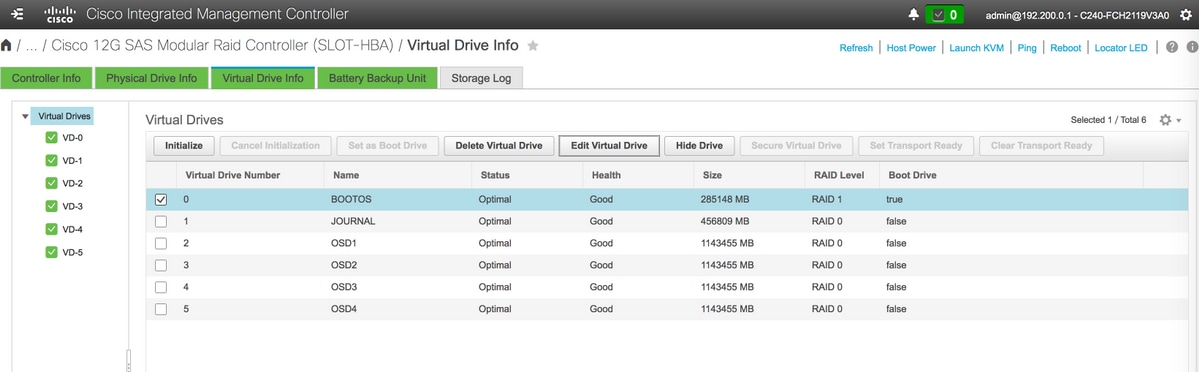 虛擬驅動器
虛擬驅動器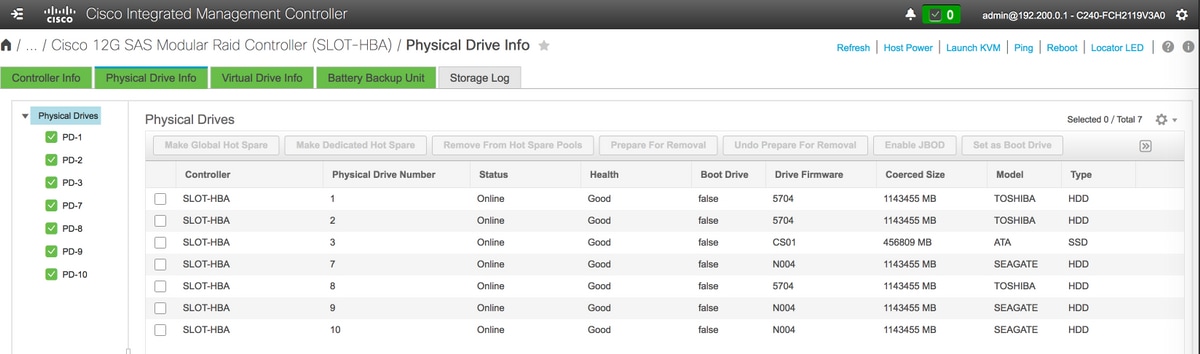 物理驅動器
物理驅動器
附註:此處顯示的影象和本節中提到的配置步驟是參考韌體版本3.0(3e),如果您使用其他版本,可能會有細微的差異。
將新的OSD-Compute節點新增到Overcloud
不論計算節點託管的VM,本節中提到的步驟都是通用的。
新增具有不同索引的計算伺服器。
建立一個add_node.json檔案,其中僅包含要新增的新計算伺服器的詳細資訊。確保以前未使用過新OSD-Compute伺服器的索引號。通常,遞增下一個最高計算值。
範例:最高先驗知識是OSD-Compute-0,因此在2-vnf系統的情況下建立了OSD-Compute-3。
附註:請記住json格式。
[stack@director ~]$ cat add_node.json
{
"nodes":[
{
"mac":[
"<MAC_ADDRESS>"
],
"capabilities": "node:osd-compute-3,boot_option:local",
"cpu":"24",
"memory":"256000",
"disk":"3000",
"arch":"x86_64",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"<PASSWORD>",
"pm_addr":"192.100.0.5"
}
]
}
匯入json檔案:
[stack@director ~]$ openstack baremetal import --json add_node.json
Started Mistral Workflow. Execution ID: 78f3b22c-5c11-4d08-a00f-8553b09f497d
Successfully registered node UUID 7eddfa87-6ae6-4308-b1d2-78c98689a56e
Started Mistral Workflow. Execution ID: 33a68c16-c6fd-4f2a-9df9-926545f2127e
Successfully set all nodes to available.
使用上一步中介紹的UUID運行節點內檢:
[stack@director ~]$ openstack baremetal node manage 7eddfa87-6ae6-4308-b1d2-78c98689a56e
[stack@director ~]$ ironic node-list |grep 7eddfa87
| 7eddfa87-6ae6-4308-b1d2-78c98689a56e | None | None | power off | manageable | False |
[stack@director ~]$ openstack overcloud node introspect 7eddfa87-6ae6-4308-b1d2-78c98689a56e --provide
Started Mistral Workflow. Execution ID: e320298a-6562-42e3-8ba6-5ce6d8524e5c
Waiting for introspection to finish...
Successfully introspected all nodes.
Introspection completed.
Started Mistral Workflow. Execution ID: c4a90d7b-ebf2-4fcb-96bf-e3168aa69dc9
Successfully set all nodes to available.
[stack@director ~]$ ironic node-list |grep available
| 7eddfa87-6ae6-4308-b1d2-78c98689a56e | None | None | power off | available | False |
在OsdComputeIPs下將IP地址新增到custom-templates/layout.yml。在這種情況下,當您替換OSD-Compute-0時,會將該地址新增到每個型別的清單末尾:
OsdComputeIPs:
internal_api:
- 11.120.0.43
- 11.120.0.44
- 11.120.0.45
- 11.120.0.43 <<< take osd-compute-0 .43 and add here
tenant:
- 11.117.0.43
- 11.117.0.44
- 11.117.0.45
- 11.117.0.43 << and here
storage:
- 11.118.0.43
- 11.118.0.44
- 11.118.0.45
- 11.118.0.43 << and here
storage_mgmt:
- 11.119.0.43
- 11.119.0.44
- 11.119.0.45
- 11.119.0.43 << and here
運行以前用於部署堆疊的deploy.sh指令碼,以便將新的計算節點新增到超雲堆疊:
[stack@director ~]$ ./deploy.sh
++ openstack overcloud deploy --templates -r /home/stack/custom-templates/custom-roles.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml --stack ADN-ultram --debug --log-file overcloudDeploy_11_06_17__16_39_26.log --ntp-server 172.24.167.109 --neutron-flat-networks phys_pcie1_0,phys_pcie1_1,phys_pcie4_0,phys_pcie4_1 --neutron-network-vlan-ranges datacentre:1001:1050 --neutron-disable-tunneling --verbose --timeout 180
…
Starting new HTTP connection (1): 192.200.0.1
"POST /v2/action_executions HTTP/1.1" 201 1695
HTTP POST http://192.200.0.1:8989/v2/action_executions 201
Overcloud Endpoint: http://10.1.2.5:5000/v2.0
Overcloud Deployed
clean_up DeployOvercloud:
END return value: 0
real 38m38.971s
user 0m3.605s
sys 0m0.466s
等待OpenStack堆疊狀態變為COMPLETE:
[stack@director ~]$ openstack stack list
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| ID | Stack Name | Stack Status | Creation Time | Updated Time |
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| 5df68458-095d-43bd-a8c4-033e68ba79a0 | pod1 | UPDATE_COMPLETE | 2017-11-02T21:30:06Z | 2017-11-06T21:40:58Z |
+--------------------------------------+------------+-----------------+----------------------+----------------------+
檢查新的OSD-Compute節點是否處於活動狀態:
[stack@director ~]$ source stackrc
[stack@director ~]$ nova list |grep osd-compute-3
| 0f2d88cd-d2b9-4f28-b2ca-13e305ad49ea | pod1-osd-compute-3 | ACTIVE | - | Running | ctlplane=192.200.0.117 |
[stack@director ~]$ source corerc
[stack@director ~]$ openstack hypervisor list |grep osd-compute-3
| 63 | pod1-osd-compute-3.localdomain |
登入新的OSD-Compute伺服器並檢查Ceph進程。最初,當Ceph恢復時,狀態將為HEALTH_WARN:
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_WARN
223 pgs backfill_wait
4 pgs backfilling
41 pgs degraded
227 pgs stuck unclean
41 pgs undersized
recovery 45229/1300136 objects degraded (3.479%)
recovery 525016/1300136 objects misplaced (40.382%)
monmap e1: 3 mons at {Pod1-controller-0=11.118.0.40:6789/0,Pod1-controller-1=11.118.0.41:6789/0,Pod1-controller-2=11.118.0.42:6789/0}
election epoch 58, quorum 0,1,2 Pod1-controller-0,Pod1-controller-1,Pod1-controller-2
osdmap e986: 12 osds: 12 up, 12 in; 225 remapped pgs
flags sortbitwise,require_jewel_osds
pgmap v781746: 704 pgs, 6 pools, 533 GB data, 344 kobjects
1553 GB used, 11840 GB / 13393 GB avail
45229/1300136 objects degraded (3.479%)
525016/1300136 objects misplaced (40.382%)
477 active+clean
186 active+remapped+wait_backfill
37 active+undersized+degraded+remapped+wait_backfill
4 active+undersized+degraded+remapped+backfilling
但是在短時間後(20分鐘),Ceph會返回到HEALTH_OK狀態:
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
monmap e1: 3 mons at {Pod1-controller-0=11.118.0.40:6789/0,Pod1-controller-1=11.118.0.41:6789/0,Pod1-controller-2=11.118.0.42:6789/0}
election epoch 58, quorum 0,1,2 Pod1-controller-0,Pod1-controller-1,Pod1-controller-2
osdmap e1398: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v784311: 704 pgs, 6 pools, 533 GB data, 344 kobjects
1599 GB used, 11793 GB / 13393 GB avail
704 active+clean
client io 8168 kB/s wr, 0 op/s rd, 32 op/s wr
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 0 host pod1-osd-compute-0
-3 4.35999 host pod1-osd-compute-2
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
-4 4.35999 host pod1-osd-compute-1
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
-5 4.35999 host pod1-osd-compute-3
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
更換後伺服器設定
將伺服器新增到重疊雲後,請參閱下面的連結以應用舊伺服器中以前存在的設定:
恢復VM
案例1. OSD-Compute Node Hosting CF、ESC、EM和UAS
新增到Nova聚合清單
將OSD-Compute節點新增到聚合主機並驗證是否已新增主機。在這種情況下,必須將OSD-Compute節點新增到CF和EM主機聚合中。
nova aggregate-add-host
[stack@director ~]$ nova aggregate-add-host VNF2-CF-MGMT2 pod1-osd-compute-3.localdomain
[stack@director ~]$ nova aggregate-add-host VNF2-EM-MGMT2 pod1-osd-compute-3.localdomain
[stack@direcotr ~]$ nova aggregate-add-host POD1-AUTOIT pod1-osd-compute-3.localdomain
nova aggregate-show
[stack@director ~]$ nova aggregate-show VNF2-CF-MGMT2
[stack@director ~]$ nova aggregate-show VNF2-EM-MGMT2
[stack@director ~]$ nova aggregate-show POD1-AUTOITT
恢復UAS VM
檢查UAS VM在新星清單中的狀態並將其刪除:
[stack@director ~]$ nova list | grep VNF2-UAS-uas-0
| 307a704c-a17c-4cdc-8e7a-3d6e7e4332fa | VNF2-UAS-uas-0 | ACTIVE | - | Running | VNF2-UAS-uas-orchestration=172.168.11.10; VNF2-UAS-uas-management=172.168.10.3
[stack@director ~]$ nova delete VNF2-UAS-uas-0
Request to delete server VNF2-UAS-uas-0 has been accepted.
要恢復autovnf-uas VM,請運行uas-check腳本以檢查狀態。它必須報告錯誤。然後使用 — fix選項再次運行,以重新建立缺失的UAS VM:
[stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts/
[stack@director scripts]$ ./uas-check.py auto-vnf VNF2-UAS
2017-12-08 12:38:05,446 - INFO: Check of AutoVNF cluster started
2017-12-08 12:38:07,925 - INFO: Instance 'vnf1-UAS-uas-0' status is 'ERROR'
2017-12-08 12:38:07,925 - INFO: Check completed, AutoVNF cluster has recoverable errors
[stack@director scripts]$ ./uas-check.py auto-vnf VNF2-UAS --fix
2017-11-22 14:01:07,215 - INFO: Check of AutoVNF cluster started
2017-11-22 14:01:09,575 - INFO: Instance VNF2-UAS-uas-0' status is 'ERROR'
2017-11-22 14:01:09,575 - INFO: Check completed, AutoVNF cluster has recoverable errors
2017-11-22 14:01:09,778 - INFO: Removing instance VNF2-UAS-uas-0'
2017-11-22 14:01:13,568 - INFO: Removed instance VNF2-UAS-uas-0'
2017-11-22 14:01:13,568 - INFO: Creating instance VNF2-UAS-uas-0' and attaching volume ‘VNF2-UAS-uas-vol-0'
2017-11-22 14:01:49,525 - INFO: Created instance ‘VNF2-UAS-uas-0'
登入到autovnf-uas。請等待幾分鐘,然後UAS必須返回正常狀態:
VNF2-autovnf-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.17.181.101
INSTANCE IP STATE ROLE
-----------------------------------
172.17.180.6 alive CONFD-SLAVE
172.17.180.7 alive CONFD-MASTER
172.17.180.9 alive NA
附註:如果uas-check.py -fix失敗,您可能需要複製此檔案並再次運行。
[stack@director ~]$ mkdir –p /opt/cisco/usp/apps/auto-it/common/uas-deploy/
[stack@director ~]$ cp /opt/cisco/usp/uas-installer/common/uas-deploy/userdata-uas.txt /opt/cisco/usp/apps/auto-it/common/uas-deploy/
恢復ESC虛擬機器
從新星清單中檢查ESC VM的狀態並將其刪除:
stack@director scripts]$ nova list |grep ESC-1
| c566efbf-1274-4588-a2d8-0682e17b0d41 | VNF2-ESC-ESC-1 | ACTIVE | - | Running | VNF2-UAS-uas-orchestration=172.168.11.14; VNF2-UAS-uas-management=172.168.10.4 |
[stack@director scripts]$ nova delete VNF2-ESC-ESC-1
Request to delete server VNF2-ESC-ESC-1 has been accepted.
在AutoVNF-UAS中查詢ESC部署事務,並在事務的日誌中查詢boot_vm.py命令列以建立ESC例項:
ubuntu@VNF2-uas-uas-0:~$ sudo -i
root@VNF2-uas-uas-0:~# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on VNF2-uas-uas-0
VNF2-uas-uas-0#show transaction
TX ID TX TYPE DEPLOYMENT ID TIMESTAMP STATUS
-----------------------------------------------------------------------------------------------------------------------------
35eefc4a-d4a9-11e7-bb72-fa163ef8df2b vnf-deployment VNF2-DEPLOYMENT 2017-11-29T02:01:27.750692-00:00 deployment-success
73d9c540-d4a8-11e7-bb72-fa163ef8df2b vnfm-deployment VNF2-ESC 2017-11-29T01:56:02.133663-00:00 deployment-success
VNF2-uas-uas-0#show logs 73d9c540-d4a8-11e7-bb72-fa163ef8df2b | display xml
<config xmlns="http://tail-f.com/ns/config/1.0">
<logs xmlns="http://www.cisco.com/usp/nfv/usp-autovnf-oper">
<tx-id>73d9c540-d4a8-11e7-bb72-fa163ef8df2b</tx-id>
<log>2017-11-29 01:56:02,142 - VNFM Deployment RPC triggered for deployment: VNF2-ESC, deactivate: 0
2017-11-29 01:56:02,179 - Notify deployment
..
2017-11-29 01:57:30,385 - Creating VNFM 'VNF2-ESC-ESC-1' with [python //opt/cisco/vnf-staging/bootvm.py VNF2-ESC-ESC-1 --flavor VNF2-ESC-ESC-flavor --image 3fe6b197-961b-4651-af22-dfd910436689 --net VNF2-UAS-uas-management --gateway_ip 172.168.10.1 --net VNF2-UAS-uas-orchestration --os_auth_url http://10.1.2.5:5000/v2.0 --os_tenant_name core --os_username ****** --os_password ****** --bs_os_auth_url http://10.1.2.5:5000/v2.0 --bs_os_tenant_name core --bs_os_username ****** --bs_os_password ****** --esc_ui_startup false --esc_params_file /tmp/esc_params.cfg --encrypt_key ****** --user_pass ****** --user_confd_pass ****** --kad_vif eth0 --kad_vip 172.168.10.7 --ipaddr 172.168.10.6 dhcp --ha_node_list 172.168.10.3 172.168.10.6 --file root:0755:/opt/cisco/esc/esc-scripts/esc_volume_em_staging.sh:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc_volume_em_staging.sh --file root:0755:/opt/cisco/esc/esc-scripts/esc_vpc_chassis_id.py:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc_vpc_chassis_id.py --file root:0755:/opt/cisco/esc/esc-scripts/esc-vpc-di-internal-keys.sh:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc-vpc-di-internal-keys.sh
將boot_vm.py行儲存到Shell指令碼檔案(esc.sh),並使用正確的資訊更新所有使用者名稱*****和密碼*****行(通常為core/<PASSWORD>)。 也需要移除-encrypt_key選項。 對於user_pass和user_confd_pass,您需要使用格式 — username:password(示例- admin:<PASSWORD>)。
查詢URL以使bootvm.py不受running-config影響,並將bootvm.py檔案獲取到autovnf-uas VM。在本例中,10.1.2.3是自動IT虛擬機器的IP:
root@VNF2-uas-uas-0:~# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on VNF2-uas-uas-0
VNF2-uas-uas-0#show running-config autovnf-vnfm:vnfm
…
configs bootvm
value http:// 10.1.2.3:80/bundles/5.1.7-2007/vnfm-bundle/bootvm-2_3_2_155.py
!
root@VNF2-uas-uas-0:~# wget http://10.1.2.3:80/bundles/5.1.7-2007/vnfm-bundle/bootvm-2_3_2_155.py
--2017-12-01 20:25:52-- http://10.1.2.3 /bundles/5.1.7-2007/vnfm-bundle/bootvm-2_3_2_155.py
Connecting to 10.1.2.3:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 127771 (125K) [text/x-python]
Saving to: ‘bootvm-2_3_2_155.py’
100%[=====================================================================================>] 127,771 --.-K/s in 0.001s
2017-12-01 20:25:52 (173 MB/s) - ‘bootvm-2_3_2_155.py’ saved [127771/127771]
建立/tmp/esc_params.cfg檔案:
root@VNF2-uas-uas-0:~# echo "openstack.endpoint=publicURL" > /tmp/esc_params.cfg
運行shell指令碼以便從UAS節點部署ESC:
root@VNF2-uas-uas-0:~# /bin/sh esc.sh
+ python ./bootvm.py VNF2-ESC-ESC-1 --flavor VNF2-ESC-ESC-flavor --image 3fe6b197-961b-4651-af22-dfd910436689
--net VNF2-UAS-uas-management --gateway_ip 172.168.10.1 --net VNF2-UAS-uas-orchestration --os_auth_url
http://10.1.2.5:5000/v2.0 --os_tenant_name core --os_username core --os_password <PASSWORD> --bs_os_auth_url
http://10.1.2.5:5000/v2.0 --bs_os_tenant_name core --bs_os_username core --bs_os_password <PASSWORD>
--esc_ui_startup false --esc_params_file /tmp/esc_params.cfg --user_pass admin:<PASSWORD> --user_confd_pass
admin:<PASSWORD> --kad_vif eth0 --kad_vip 172.168.10.7 --ipaddr 172.168.10.6 dhcp --ha_node_list 172.168.10.3
172.168.10.6 --file root:0755:/opt/cisco/esc/esc-scripts/esc_volume_em_staging.sh:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc_volume_em_staging.sh
--file root:0755:/opt/cisco/esc/esc-scripts/esc_vpc_chassis_id.py:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc_vpc_chassis_id.py
--file root:0755:/opt/cisco/esc/esc-scripts/esc-vpc-di-internal-keys.sh:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc-vpc-di-internal-keys.sh
登入到新的ESC並驗證備份狀態:
ubuntu@VNF2-uas-uas-0:~$ ssh admin@172.168.11.14
…
####################################################################
# ESC on VNF2-esc-esc-1.novalocal is in BACKUP state.
####################################################################
[admin@VNF2-esc-esc-1 ~]$ escadm status
0 ESC status=0 ESC Backup Healthy
[admin@VNF2-esc-esc-1 ~]$ health.sh
============== ESC HA (BACKUP) ===================================================
ESC HEALTH PASSED
從ESC恢復CF和EM虛擬機器
從新星清單中檢查CF和EM VM的狀態。它們必須處於ERROR狀態:
[stack@director ~]$ source corerc
[stack@director ~]$ nova list --field name,host,status |grep -i err
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | None | ERROR|
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229 |None | ERROR
登入到ESC主伺服器,為每個受影響的EM和CF VM運行recovery-vm-action。耐心點。ESC會安排恢復操作,並且此操作可能在幾分鐘內不會發生。監控yangesc.log:
sudo /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli recovery-vm-action DO
[admin@VNF2-esc-esc-0 ~]$ sudo /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli recovery-vm-action DO VNF2-DEPLOYMENT-_VNF2-D_0_a6843886-77b4-4f38-b941-74eb527113a8
[sudo] password for admin:
Recovery VM Action
/opt/cisco/esc/confd/bin/netconf-console --port=830 --host=127.0.0.1 --user=admin --privKeyFile=/root/.ssh/confd_id_dsa --privKeyType=dsa --rpc=/tmp/esc_nc_cli.ZpRCGiieuW
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="1">
<ok/>
</rpc-reply>
[admin@VNF2-esc-esc-0 ~]$ tail -f /var/log/esc/yangesc.log
…
14:59:50,112 07-Nov-2017 WARN Type: VM_RECOVERY_COMPLETE
14:59:50,112 07-Nov-2017 WARN Status: SUCCESS
14:59:50,112 07-Nov-2017 WARN Status Code: 200
14:59:50,112 07-Nov-2017 WARN Status Msg: Recovery: Successfully recovered VM [VNF2-DEPLOYMENT-_VNF2-D_0_a6843886-77b4-4f38-b941-74eb527113a8]
登入到新EM並驗證EM狀態是否為up:
ubuntu@VNF2vnfddeploymentem-1:~$ /opt/cisco/ncs/current/bin/ncs_cli -u admin -C
admin connected from 172.17.180.6 using ssh on VNF2vnfddeploymentem-1
admin@scm# show ems
EM VNFM
ID SLA SCM PROXY
---------------------
2 up up up
3 up up up
登入到StarOS VNF並驗證CF卡是否處於備用狀態。
案例2. OSD計算節點託管自動IT、自動部署、EM和UAS
自動部署虛擬機器的恢復
在OSPD中,如果自動部署虛擬機器受影響,但仍顯示活動/正在運行,則需要首先將其刪除。如果自動部署未受影響,請跳至自動it虛擬機器的恢復:
[stack@director ~]$ nova list |grep auto-deploy
| 9b55270a-2dcd-4ac1-aba3-bf041733a0c9 | auto-deploy-ISO-2007-uas-0 | ACTIVE | - | Running | mgmt=172.16.181.12, 10.1.2.7 [stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts
[stack@director ~]$ ./auto-deploy-booting.sh --floating-ip 10.1.2.7 --delete
刪除自動部署後,使用相同的floatingip地址重新創建它:
[stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts
[stack@director scripts]$ ./auto-deploy-booting.sh --floating-ip 10.1.2.7
2017-11-17 07:05:03,038 - INFO: Creating AutoDeploy deployment (1 instance(s)) on 'http://10.84.123.4:5000/v2.0' tenant 'core' user 'core', ISO 'default'
2017-11-17 07:05:03,039 - INFO: Loading image 'auto-deploy-ISO-5-1-7-2007-usp-uas-1.0.1-1504.qcow2' from '/opt/cisco/usp/uas-installer/images/usp-uas-1.0.1-1504.qcow2'
2017-11-17 07:05:14,603 - INFO: Loaded image 'auto-deploy-ISO-5-1-7-2007-usp-uas-1.0.1-1504.qcow2'
2017-11-17 07:05:15,787 - INFO: Assigned floating IP '10.1.2.7' to IP '172.16.181.7'
2017-11-17 07:05:15,788 - INFO: Creating instance 'auto-deploy-ISO-5-1-7-2007-uas-0'
2017-11-17 07:05:42,759 - INFO: Created instance 'auto-deploy-ISO-5-1-7-2007-uas-0'
2017-11-17 07:05:42,759 - INFO: Request completed, floating IP: 10.1.2.7
從備份伺服器複製Autodeploy.cfg檔案、ISO和confd_backup tar檔案以自動部署VM,並從備份tar檔案中還原confd cdb檔案:
ubuntu@auto-deploy-iso-2007-uas-0:~# sudo -i
ubuntu@auto-deploy-iso-2007-uas-0:# service uas-confd stop
uas-confd stop/waiting
root@auto-deploy-iso-2007-uas-0:# cd /opt/cisco/usp/uas/confd-6.3.1/var/confd
root@auto-deploy-iso-2007-uas-0:/opt/cisco/usp/uas/confd-6.3.1/var/confd# tar xvf /home/ubuntu/ad_cdb_backup.tar
cdb/
cdb/O.cdb
cdb/C.cdb
cdb/aaa_init.xml
cdb/A.cdb
root@auto-deploy-iso-2007-uas-0~# service uas-confd start
uas-confd start/running, process 2036
通過檢查早期的事務來驗證confd是否已正確載入。使用新的OSD計算名稱更新autodeploy.cfg。請參閱部分 — 最後步驟:更新自動部署配置:
root@auto-deploy-iso-2007-uas-0:~# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on auto-deploy-iso-2007-uas-0
auto-deploy-iso-2007-uas-0#show transaction
SERVICE SITE
DEPLOYMENT SITE TX AUTOVNF VNF AUTOVNF
TX ID TX TYPE ID DATE AND TIME STATUS ID ID ID ID TX ID
-------------------------------------------------------------------------------------------------------------------------------------
1512571978613 service-deployment tb5bxb 2017-12-06T14:52:59.412+00:00 deployment-success
auto-deploy-iso-2007-uas-0# exit
恢復自動IT虛擬機器
在OSPD中,如果自動轉換虛擬機器受到影響,但仍顯示為活動/正在運行,則需要將其刪除。如果auto-it未受影響,請跳至下一個VM:
[stack@director ~]$ nova list |grep auto-it
| 580faf80-1d8c-463b-9354-781ea0c0b352 | auto-it-vnf-ISO-2007-uas-0 | ACTIVE | - | Running | mgmt=172.16.181.3, 10.1.2.8 [stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts
[stack@director ~]$ ./ auto-it-vnf-staging.sh --floating-ip 10.1.2.8 --delete
運行auto-it-vnf暫存指令碼並重新創建自動it:
[stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts
[stack@director scripts]$ ./auto-it-vnf-staging.sh --floating-ip 10.1.2.8
2017-11-16 12:54:31,381 - INFO: Creating StagingServer deployment (1 instance(s)) on 'http://10.84.123.4:5000/v2.0' tenant 'core' user 'core', ISO 'default'
2017-11-16 12:54:31,382 - INFO: Loading image 'auto-it-vnf-ISO-5-1-7-2007-usp-uas-1.0.1-1504.qcow2' from '/opt/cisco/usp/uas-installer/images/usp-uas-1.0.1-1504.qcow2'
2017-11-16 12:54:51,961 - INFO: Loaded image 'auto-it-vnf-ISO-5-1-7-2007-usp-uas-1.0.1-1504.qcow2'
2017-11-16 12:54:53,217 - INFO: Assigned floating IP '10.1.2.8' to IP '172.16.181.9'
2017-11-16 12:54:53,217 - INFO: Creating instance 'auto-it-vnf-ISO-5-1-7-2007-uas-0'
2017-11-16 12:55:20,929 - INFO: Created instance 'auto-it-vnf-ISO-5-1-7-2007-uas-0'
2017-11-16 12:55:20,930 - INFO: Request completed, floating IP: 10.1.2.8
重新載入ISO映像。在這種情況下,自動IP位址為10.1.2.8。這可能需要幾分鐘才能載入:
[stack@director ~]$ cd images/5_1_7-2007/isos
[stack@director isos]$ curl -F file=@usp-5_1_7-2007.iso http://10.1.2.8:5001/isos
{
"iso-id": "5.1.7-2007"
}
to check the ISO image:
[stack@director isos]$ curl http://10.1.2.8:5001/isos
{
"isos": [
{
"iso-id": "5.1.7-2007"
}
]
}
將VNF system.cfg檔案從OSPD自動部署目錄複製到自動it VM:
[stack@director autodeploy]$ scp system-vnf* ubuntu@10.1.2.8:.
ubuntu@10.1.2.8's password:
system-vnf1.cfg 100% 1197 1.2KB/s 00:00
system-vnf2.cfg 100% 1197 1.2KB/s 00:00
ubuntu@auto-it-vnf-iso-2007-uas-0:~$ pwd
/home/ubuntu
ubuntu@auto-it-vnf-iso-2007-uas-0:~$ ls
system-vnf1.cfg system-vnf2.cfg
附註:兩種情況下EM和UAS VM的恢復過程是相同的。請參考Case.1部分,瞭解相同內容。
處理ESC恢復失敗
如果ESC由於意外狀態而無法啟動VM,Cisco建議您通過重新啟動主ESC執行ESC切換。ESC切換將需要大約一分鐘。在新的Master ESC上運行health.sh指令碼以檢查狀態是否為up。主ESC以啟動VM並修復VM狀態。完成此恢復任務最多需要五分鐘。
您可以監控/var/log/esc/yangesc.log和/var/log/esc/escmanager.log。如果您在5-7分鐘之後沒有看到虛擬機器被恢復,則使用者將需要執行受影響虛擬機器的手動恢復。
自動部署配置更新
在AutoDeploy VM中,編輯auto-deploy.cfg,並用新的OSD-Compute伺服器替換舊伺服器。然後在confd_cli中載入替換。以後成功停用部署需要此步驟。
root@auto-deploy-iso-2007-uas-0:/home/ubuntu# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on auto-deploy-iso-2007-uas-0
auto-deploy-iso-2007-uas-0#config
Entering configuration mode terminal
auto-deploy-iso-2007-uas-0(config)#load replace autodeploy.cfg
Loading. 14.63 KiB parsed in 0.42 sec (34.16 KiB/sec)
auto-deploy-iso-2007-uas-0(config)#commit
Commit complete.
auto-deploy-iso-2007-uas-0(config)#end
在配置更改後重新啟動uas-confd和自動部署服務:
root@auto-deploy-iso-2007-uas-0:~# service uas-confd restart
uas-confd stop/waiting
uas-confd start/running, process 14078
root@auto-deploy-iso-2007-uas-0:~# service uas-confd status
uas-confd start/running, process 14078
root@auto-deploy-iso-2007-uas-0:~# service autodeploy restart
autodeploy stop/waiting
autodeploy start/running, process 14017
root@auto-deploy-iso-2007-uas-0:~# service autodeploy status
autodeploy start/running, process 14017
啟用系統日誌
要為UCS伺服器、Openstack元件和已恢復的VM啟用系統日誌,請按照部分操作
「Re-Enable syslog for UCS and Openstack components(為UCS和Openstack元件重新啟用系統日誌)」和「Enable syslog for the VNFs(為VNF啟用系統日誌)」在下面的連結中:
修訂記錄
| 修訂 | 發佈日期 | 意見 |
|---|---|---|
1.0 |
10-Jul-2018
|
初始版本 |
由思科工程師貢獻
- Partheeban RajagopalCisco Advanced Services
- Padmaraj RamanoudjamCisco Advanced Services
 意見
意見