CNC升級案例研究
目錄
簡介
本文檔介紹固定無線網路從Cisco CNC 4.1到7.1通過升降和移動進行複雜大規模遷移的案例研究。
摘要
本文介紹了大規模固定無線網路從Cisco Crosswork Network Controller(CNC)版本4.1遷移到7.1版本的詳細案例研究。由於沒有就地升級機制,該遷移需要完全升降和移位部署,在2000多個網路裝置和多個相互依賴的系統上帶來了顯著的架構、操作和整合複雜性。該研究分析了在多個領域遇到的挑戰。
一項重要成果強調了自動化在確保可擴充性、準確性和操作決定性(尤其是對於高容量工作流程)方面的重要作用。結果進一步表明,生產環境明顯偏離受控實驗室條件,需要適應性故障排除、迭代驗證以及與TAC和業務部門工程團隊的持續接觸。此工作提供實用的見解、經驗證的方法以及建議的最佳實踐,作為未來CNC升級和大規模協調平台過渡的參考藍圖。
背景
5G網路的激增、連線裝置的快速採用以及企業和消費者環境的數位化已導致流量顯著增加,而且必須大規模安全可靠地交付多種服務。通訊服務提供商(CSP)現在運行高度動態的網路,傳統孤立運營工具通常導致複雜性、降低使用者體驗和增加運營成本(OpEx)。
為了保持競爭力,運營商越來越多地採用建立在自動化、虛擬化、SDN原則以及分析驅動的自我最佳化網路基礎上的現代化運營模式。
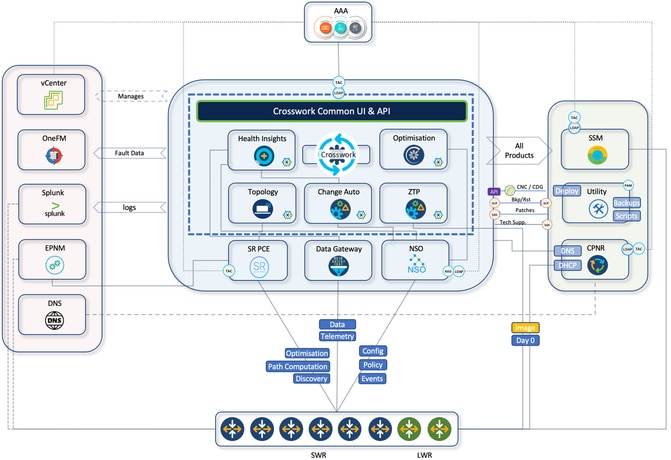
Cisco Crosswork Network Controller(CNC)旨在通過簡化運營工作流、降低總擁有成本(TCO)以及跨多供應商傳輸網路實現基於意圖的自動化來支援這種轉型。CNC為服務調配、網路運行狀況監控和即時最佳化提供統一平台,為運營商提供單一平台,以便更主動、更高效地管理大型IP網路。
底層Crosswork基礎架構提供了可恢復的、可擴展的群集框架,所有CNC應用程式都運行在該群集框架上。對於CNC 7.1,此模組包括最佳化引擎、主動拓撲、變更自動化、運行狀況洞察、元素管理功能(EMF)、服務運行狀況和Crosswork Workflow Manager(CWM)等模組,每個模組都有助於端到端協調和保證。
然而,升級CNC帶來了獨特的挑戰。CNC不支援就地升級,需要完全升降和輪班部署,其中新環境與現有環境並行構建,所有資料和服務都遷移到新版本。本案例研究考察了一個大型的從CNC 4.1到CNC 7.1的升級,該升級針對的是一個支援為所有其他服務提供商提供骨幹服務的澳洲主要服務聚合器。
由於多個自定義的變更自動化行動手冊、自定義的Health Insight KPI、L2/L3 VPN服務協調要求以及安全ZTP的需要,因此遷移特別複雜。
由於內部架構和行為上的變化,很難預測新版本中現有使用案例的表現,因此大版本跳躍帶來了額外的不確定性。這就需要跨所有使用案例進行全面驗證和協調。
在確定最佳資源分配方面進行了大量規劃,包括混合/工作人員節點計數、CDG分配和PCE規模確定,以及您的現有資源足跡是否可以保留。
CNC 7.1的初始部署和驗證在內部的CALO實驗室中進行,為實驗、改進配置和建立信心提供了安全的環境。其次是在內部測試環境中部署,該環境密切地反映了生產情況。最後階段包括在生產中部署CNC 7.1,應用裝置級配置更改,以及執行所有裝置及相關服務到新控制器的分階段遷移。
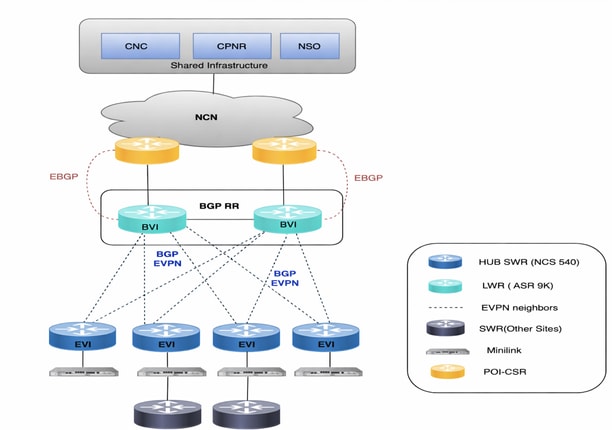
生產網路
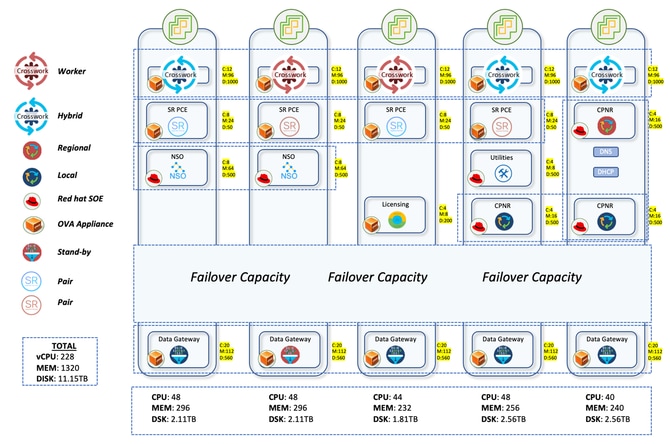
氣隙生產網路遍佈澳洲大片地區。在NCS到ASR9Ks的2K+裝置出現後,CNC通過即時拓撲檢視管理所有這些裝置。大約2000台裝置是運行IOS-XR 24.3.2的NCS540(本地稱為SWR(小型無線路由器)),30台是ASR-9Ks(版本7.5.2)本地稱為LWR(大型無線路由器)。
Crosswork設定由3個混合節點和2個工作節點組成。裝置共有5個CDG,其中4個為活動節點,1個為備用節點。這提供了有限的保護,因為池只有1個待命CDG。但是考慮到你的需求,這個決定成功了。由於所有虛擬機器都位於單個資料中心上,因此只需一個備用伺服器就可以更輕鬆地做出決策。
CDG是處理通過SNMP、CLI和GNMI等各種協定從裝置收集資料的元件。CDG收集的資料通過內部kafka暴露於Crosswork。連線到Crosswork的裝置必須連線到CDG,這可以使資料網關連線到該裝置並獲得裝置資料。
對CDG的器件分佈也進行了大量研究。早期的部署在CDG之間隨機分配了裝置。這導致了非常不均衡的分佈,一些CDG承載更多的裝置,而有1-2個CDG的裝置非常少。這導致某些CDG過度消耗和過度負擔,而另一些中央集權的配置不足。
此處的升級流程是將700個SWR分別分配到4個活動CDG。前三個CDG中容納了2100個SWR。 介面前端LWR非常重,因此為第四個CDG預留了。儘管它們數量很小,數量為30,但此分配確保了即使從這些裝置完成更多收集,也不會對CDG造成過重的負荷。任何後續的SWR入職也將轉至第四CDG。這確保了前三個CDG的均勻分佈,而第四個CDG有更多可以容納新裝置的空間。
SR-PCE以2對的方式部署,這意味著有4個VM分佈在不同主機上。一對管理7個POI站點,另一對管理其餘8個POI站點。CNC GUI上的拓撲更新通過SR-PCE來實現。它通過與其他LWR路由器的BGP-LS對等來瞭解網路拓撲。此元件還用於所有流量工程使用案例,其中它扮演控制器角色,將流量引導至不同的路徑。
要處理所有服務調配和裝置配置使用案例,NSO需要與CNC配合使用。對於生產網路,部署了兩個6.4.1.1版的NSO,以在高可用性模式下協同工作。SR-PCE(Segment Routing Path Computing Element)是為CNC提供拓撲更新和處理即時流量工程使用案例所需的元件。此處部署了四個版本為25.2.1的SR-PCE,每個PCE與兩個不同的LWR對等。
從CNC 4.1到CNC 7.1的遷移工作流程
對於CNC部署,首選方法是使用基於docker的CNC。但是,由於客戶端未批准在其內部部署docker,因此沒有其他選項,只能使用vCenter進行手動部署。與基於指令碼的部署相比,這要花費更長的時間,因為它要求我們在vCenter GUI中提供多次輸入。
完成CNC部署後,所有需要的應用都與BU一起部署,BU提供了自動操作安裝檔案,該檔案可一次性上傳和啟用應用,從而減少了手動執行所需的時間。部署了主要層,其中包括Crosswork最佳化引擎、活動拓撲、服務運行狀況、元素管理功能、Crosswork工作流管理器。此外,還設定了包括Change Automation和Health Insight的附加包。
CWM和SH沒有任何使用案例。但是它們還是被部署了,因為他們對這些應用程式在下一版本中提供的某些使用情形很感興趣。
安裝應用程式後,下一步是遷移舊版CNC中的資料。這主要包括憑證配置檔案、提供者、標籤、自定義手冊、自定義KPI、角色、sZTP憑證和任何其他資料。CNC為可以使用並匯入到新CNC的所有選項提供匯出選項。
設定這些裝置後,開始裝置遷移是明智之舉。在升級的情況下,如果新CNC部署在新子網中,而舊子網部署在新子網中,則需要在裝置上執行ACL更改,以提供與新CNC的可達性。這是一個非常耗時的過程,因為它需要手動登入到每台裝置並更改配置。
完成這些ACL更改後,下一步是將裝置匯入新CNC並將其連線到CDG。如果可達性正確,且SSH和SNMP憑證正確,則裝置在CNC上顯示為可達狀態,並且還可以註冊到NSO(Network Services Orchestrator)。
在NSO前端,所有必需的軟體包必須就位且運行正常,以確保CNC可以與NSO通訊,反之亦然。例如,要從CNC自動將裝置安裝到NSO,必須使用DLM功能包。同樣,如果有任何要求NSO在裝置上配置MDT感測器路徑,則必須在NSO上部署TM-TC包。要點是,根據使用案例,相關產品包必須部署在NSO上。
我們開發了一個用於調配的自動指令碼,而不是採用手動方法部署這些所需的包,特別是傳輸SDN包。隨著CNC 7.1的升級,TSDN軟體包也進行了更新。這些更新的軟體包用於在NSO伺服器上部署,以確保在升級的環境中繼續支援L2/L3調配。該指令碼自動安裝更新的TSDN包並將必要的後設資料載入到NSO中,使其能夠根據需要調配服務。
Cisco Smart Software Manager(SSM)許可伺服器的一個例項和Cisco Prime Network Registrar(CPNR)的3個例項也部署在不同主機上。
CNC體系結構及其與其他元件的整合
CNC通過統一的UI為調配、最佳化和視覺化部署的服務提供了單一平台。這裡簡要總結了駐留在CNC平台套件中的CNC內部元件及其使用案例。
- Crosswork主動拓撲(CAT):
- 分佈在CNC VM節點上的內部元件應用
- 提供已協調庫存的即時端到端可視性
- 將來自多個資料來源的庫存資訊整合到單個顯示器中
- 傳輸網路路徑計算
- 拓撲發現
- Crosswork最佳化引擎(COE):
- 分佈在CNC VM節點上的內部元件應用
- 即時網路最佳化
- 即時拓撲視覺化
- SR-TE視覺化和調配
- RSVP-TE視覺化和調配
- 按需頻寬
- Crosswork健康狀況洞察(CHI):
- 分佈在CNC VM節點上的內部元件應用
- KPI監控
- 警報控制面板
- Crosswork變更自動化(CCA):
- 分佈在CNC VM節點上的內部元件應用
- 具有開箱即用的實戰手冊的開發操作工具
- 安排在所需時間運行播放的功能
- HI KPI警報作為補救措施與建議的重頭戲進行拼接
架構圖表
網路圖表
CNC 4.1 → 7.1詳細遷移工作流程
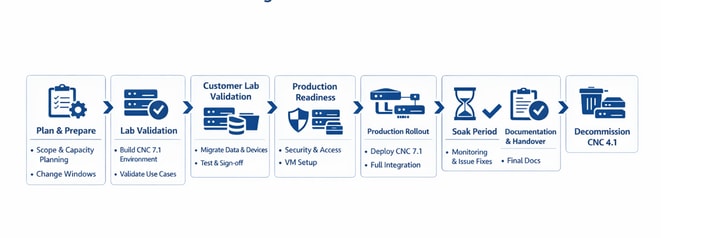
從傳統CNC 4.1到CNC 7.1的端到端分階段遷移(無論版本如何,任何CNC升級都可以遵循相同的流程)
| 計畫 |
' |
實驗 |
' |
客戶實驗室 |
' |
生產就緒 |
' |
生產推廣 |
' |
浸泡期 |
' |
交接 |
' |
停用 |
| 第1階段 1 計畫和準備
|
|||||
| ▼ |
|||||
| 第2階段 2 Internal Lab Validation
|
|||||
| ▼ |
|||||
| 第3階段 3 Customer Lab Validation
|
|||||
| ✓在實驗室中執行ATP並獲得簽核 |
|||||
| ▼ |
|||||
| 第4階段 4生產就緒性
|
|||||
| ▼ |
|||||
| 第5階段 5生產轉移 ↻在生產環境中重複第3階段的所有步驟
|
|||||
| ✓生產推廣 |
|||||
| ▼ |
|||||
| 第6階段 6浸透期
|
|||||
| ▼ |
|||||
| 第7階段 7 文檔和交接
|
|||||
| ▼ |
|||||
| 第8階段 8 停用舊版CNC 4.1
|
|||||
使用案例
L2VPN(基於EVPN)服務布建
L2VPN服務跨多個SWR提供第2層乙太網連線,某些服務錨定在LWR上。CNC活動拓撲用於服務調配,而所有特定於環境的邏輯都通過NSO自定義模板實現。
L2VPN調配被視為Day2配置活動,需要運營商提供的服務屬性。
自定義NSO模板
建立了一些自定義模板,以便與特定於環境的命名約定和介面行為保持一致:
- CT-l2vpn-swr-hub-and-lwr
處理SWR集線器和LWR上的集線器端命名差異(或網橋組和網橋域)。 - CT-l2vpn-swr-nonhub-100 / 101 / 102 / 105
從每個VLAN特定EVI的預設EVPN網橋組和網橋域中刪除ZTP上行鏈路介面。
這些模板確保整個網路中的EVPN配置一致,並消除硬體級別的差異。
L3VPN(基於VRF)服務布建
L3VPN使用案例支援作為終端跨多個SWR的第3層服務交付。調配通過CNC活動拓撲執行,使用自定義NSO模板實施特定於環境的需求。
與L2VPN一樣,這是第2天的配置操作,需要操作員輸入。
自定義NSO模板
- CT-l3vpn-swr
收集特定於VRF的引數(AS編號、VRF名稱、字首集、路由策略名稱、路由區分器),並構建必要的BGP匯入/匯出策略,包括使用使用者定義的路由策略重新分發連線的路由。
流量工程
CNC套件的Crosswork最佳化引擎(COE)應用有助於根據期望的意圖控制網路中的流量流。
有兩種流量型別需要不同的用途(SLA指標):
- TC1流量 — 延遲敏感SLA,確保流量位於最低延遲路徑上。
- TC4流量 — 最小頻寬SLA,確保專用頻寬始終可用於TC4流量
TC1流量(最低延遲)
要確保TC1流量始終採用最低延遲路徑,必須在頭端SWR上建立分段路由(SR)策略,並將路徑計算標準作為延遲。
這可以通過使用CNC為特定顏色1001定義每個頭端SWR上的按需下一跳(ODN)配置來實現,從而便於建立SR策略。
TC4流量(承諾頻寬)
要確保始終在具有專用頻寬的路徑上承載TC4流量,必須在頭端SWR上建立SR策略,並將路徑計算標準作為頻寬。
這通過以下方式實現:
- CNC上的按需頻寬(BoD)功能包
- 使用這些配置建立CNC SR策略,在每台頭端SWR上為特定顏色1004定義On Demand Next Hop(ODN)配置
BoD函式包用於計算SR策略的路徑,SR策略將頻寬作為路徑計算的標準。它跟蹤承諾用於策略的頻寬,並在策略的生命週期中持續監控其當前路徑。
在任何時間點,如果當前BWOD策略的補丁沒有足夠的可用容量來滿足提交的頻寬,它將重新計算BWOD策略路徑並將策略重新路由到新路徑。此BWOD策略重新路由是一個持續的過程,無需手動干預。
在某種程度上,BWOD可以像SR-PCE那樣即時最佳化頻寬。
使用sZTP啟動裝置
在以往的傳統安裝和支援模式中,安裝新裝置的過程需要安裝者具備一定水準的專業知識,以便安裝、配置新元件並對實施進行故障排除。在異地預準備裝置也可能是一個漫長的過程,由處理解決方案不同部分的許多人員來支持。
對於計畫在您的環境中部署的新SWR裝置,通過安全CNC的ZTP(零接觸調配)應用,裝置自動啟動過程。
ZTP工作流程在首次裝置啟動時觸發,它將下載需要應用的計畫平台映像和初始配置,而無需任何手動干預。
該裝置還自動裝入CNC以進行進一步協調。
此圖顯示裝置啟動時安全ZTP進程的工作流:
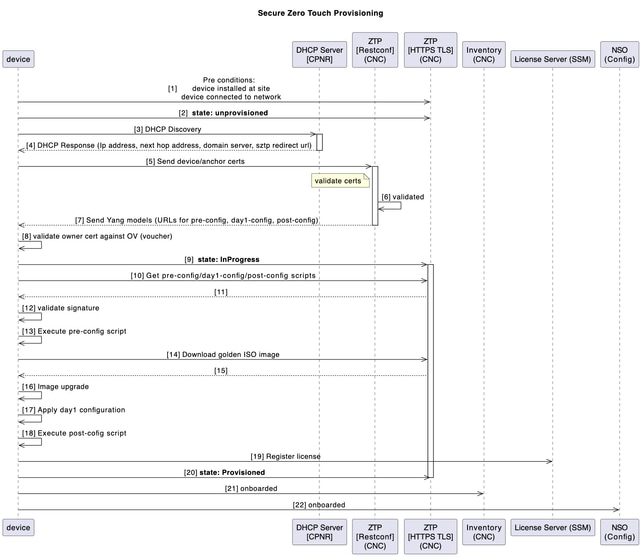
ZTP後協調(自動化驅動)
實用程式主機上的Python自動化使用結構化Excel輸入(按鏈)協調和稽核端到端流程:
- 生成第1天和配置後工件並將其上傳到CNC。
- 建立CPNR保留(繫結到SWR串列的DHCP條目)。
- 在EPNM中新增裝置(用於可視性/保證)。
- CNC中ZTP後內務處理:
- 將SWR分配給CDG(遙測目的地)
- 附加到裝置組和標籤
- 更新緯度/經度以進行拓撲視覺化
- 附加BNM KPI配置檔案以啟用遙測流
CNC中頻寬通知報文(BNM)處理
SWR可以從同地MiniLink交換機接收BNM,該交換機對應於WAN埠的頻寬。這些通知消息是基於標準的CFM消息,包括當前運行的記錄頻寬(RBW)和最大配置頻寬(也稱為額定頻寬(NBW))。
當前頻寬是微波WAN鏈路的實際運行頻寬,基於各個微波鏈路的聚合頻寬及其運行QAM級別。標稱頻寬是配置的最大可能廣域網頻寬,基於每個單個微波鏈路上配置的最大QAM的聚合頻寬。
頻寬最佳化基於以下情況進行:
臨時(稍縱即逝的事件)更改
- 當侷限於SWR的網路/鏈路發生短暫的降級或中斷(例如,由於不利天氣事件,導致微波無線電路徑衰落,並且由於調制方案的改變導致可用頻寬減少),則流量整形校正發生在受影響的網路介面的本地SWR。
- 這可確保受影響傳輸路徑上的資料包丟失最小。
當在CNC中啟用BNM KPI作為後sZTP活動的一部分時,CNC會將遙測配置推送到SWR中。
BNM MDT
遙測模型驅動
destination-group <DGName>
vrf VRF-OMSWR-<AreaCode>1
address-family ipv4 <CDG IPv4Address>埠9010
編碼自描述gpb
protocol tcp
!
!
sensor-group <GroupName>
sensor-path Cisco-IOS-XR-ethernet-cfm-oper:cfm/nodes/node/bandwidth-notifications/bandwidth-notification
!
CNC處理通過遙測接收的這些BNM消息,並在需要時採取補救行動。下面是CNC涉及的兩個元件:
- Health insight(HI):CNC應用程式用於通過自定義KPI接收BNM通知,該自定義KPI可監控BNM消息的特定感測器路徑。Health Insight能夠針對頻寬變化較大的情況發出警報。
- 變更自動化(CA):CNC應用程式用於處理導致HI警報的BNM消息流。部署了2個自定義行動手冊,以便在受影響的介面上進行這些更改:
- 將QoS整形器設定為新RBW
- 正在將介面容量設定為新的RBW值。
開發了一個自定義Python指令碼,以便在違反HI KPI時自動執行自定義邏輯和執行CA手冊。
該劇本觸發指令碼基於以下演算法運行:
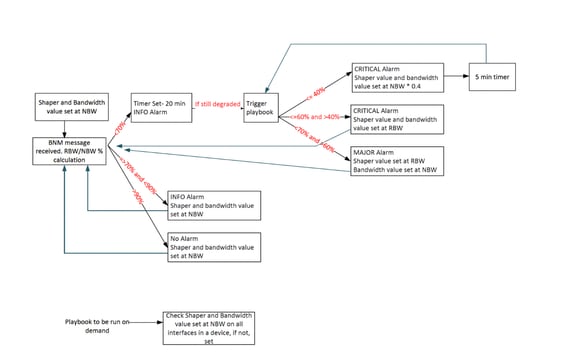
下表說明根據頻寬下降程度設定的自定義警報級別:
報告頻寬= RBW
額定頻寬= NBW
| 警報間隔值 |
通知級別 |
| (RBW/NBW)*100 >=70 |
資訊 |
| (RBW/NBW)*100 <70和>60 |
警告 |
| (RBW/NBW)*100 <=60 |
嚴重 |
此感測器路徑由CNC監控:
Cisco-IOS-XR-ethernet-cfm-oper:cfm/nodes/node/bandwidth-notifications/bandwidth-notification
在CNC中建立自定義KPI以監控BNM感測器路徑。此KPI將新增到配置了120秒順序和警報閾值的KPI配置檔案中。將SWR連線到此配置檔案會自動通過NSO將所需的遙測配置推送到裝置。
啟用後,裝置將按配置的時間間隔將RBW/NBW資料流式傳輸到分配的CDG。Health Insight(HI)計算RBW÷NBW比率並在超過閾值時引發警報;操作員可以在HI和Grafana控制面板中監視這些事件。
CNC中的警報提供器將這些警報轉發到承載Python自動化的混合節點。該指令碼解析裝置/介面/RBW/NBW詳細資訊並觸發相應的Change Automation行動手冊:整形器調整、頻寬更新,或兩者都基於定義的決策邏輯。
以下是工作流程中使用的2個行動手冊:
1.改變整形器價值的攻略
2.更改介面頻寬的手冊
如前所述,該指令碼將啟動Web伺服器作為提供者,使用REST API與CNC通訊。此處捕獲我們獲取的POST請求的任何響應。警報以JSON的形式捕獲,然後轉換為字典以提取必要的引數。
通過自定義自動化行動手冊實現第2天網路運營標準化
定製變更自動化(CA)行動手冊旨在簡化和標準化整個網路生命週期中的第2天關鍵操作。這些功能包括捆綁包以太調配、管理介面描述更新、CFM菊花鏈協調、無縫鏈路容量擴展、eNodeB停用以及高效迷你鏈路自註冊。通過將操作最佳做法嵌入到可重複使用的工作流中,這些操作手冊顯著增強了執行一致性,最大限度地減少了人為錯誤風險,並減少對手動干預的依賴。在思科CNC升級中,此自動化框架在加速運營轉變、確保服務連續性和實現符合現代網路轉型目標的可擴展、可重複流程方面扮演著關鍵角色。
思科CNC 7.1升級中的TACACS+整合連續性
作為Cisco CNC 4.1到7.1升級的一部分,現有的TACACS+整合被謹慎保留,以確保集中式身份驗證、授權的連續性。升級過程驗證並複製了Cisco CNC 7.1中的TACACS+配置,保持與既定的企業安全策略和基於角色的訪問控制(RBAC)機制保持一致。
CNC和CDG系統日誌轉發到Splunk
系統日誌轉發設定為將警報/事件/系統日誌轉發到Splunk伺服器。利用CNC開箱設定系統日誌伺服器的能力來實現這一點。
警報轉發到OneFM
CNC警報也使用CNC restconf連線導向的API轉發到OneFM等北向系統:
curl -L --request GET \
--url https://{server_ip}:30603/crosswork/notification/restconf/streams/v2/alarm.json \
--header 'Accept: application/txt'). This API must be used over a websocket connection config.日常CNC備份自動化
自動指令碼利用CNC備份API進行CNC的完全備份,並將備份檔案儲存在實用程式主機中。此操作每天完成。
挑戰
Crosswork版本中的大跳躍
從Cross work 4.4升級到7.1是一個重大的版本飛躍,而不是例行的增量更新。如此大的跳躍,為多個應用引入了大量新功能,以及實質性的改進和架構變更。因此,CNC升級不僅僅是簡單的版本替換,它需要徹底驗證以確保所有整合元件的相容性、穩定性和適當的功能。擴展的功能集和基礎改進意味著現有的工作流程、配置和整合需要進行仔細的驗證,這使得全面的測試和驗證對升級的成功至關重要。
無就地升級
CNC不支援就地升級模式。相反,升級必須採用逐層升級的方法,即保留現有部署,同時使用目標版本從頭開始構建一個全新的環境。安裝新系統後,必須仔細遷移和驗證配置、資料和整合,才能停用較舊的環境。
此方法帶來了幾個操作挑戰:
- 並行環境:新舊數控環境必須同時運行,直到完全完成遷移和驗證。
- 硬體資源壓力:並行運行兩個完整環境會顯著增加對計算、儲存和網路資源的需求,這可能會使可用基礎架構變得緊張。
- 擴展的驗證工作:必須在新版本中驗證所有遷移的資料、配置、策略和整合,以確保它們完全按照預期運行。
- 資料遷移複雜性:歷史資料、應用程式配置和操作設定的傳輸需要仔細規劃,以避免不一致或資料丟失。
- 延遲停用:在新部署被證明穩定之前,不能刪除舊系統及其VM,從而延長了資源使用率和運營開銷。
- 業務協調:團隊必須在過渡期間管理兩個環境之間的同步,以防止配置漂移或運營中斷。
- 閉環自動化衝突:CNC支援閉環自動化用例,這些用例基於即時網路條件動態觸發動作。當舊控制器和新控制器在轉換期間都處於活動狀態時,兩個控制器可能會執行相同的自動化邏輯,這可能導致網路中的重複配置更改或衝突操作。這需要在遷移時段內仔細控制自動化策略。
- 由於缺少本機匯出功能,舊版運算元據(包括歷史警報、事件、故障記錄和審計資訊)不會遷移到新環境中。因此,此歷史資料在升級的系統中不可用,遷移後必須被視作不可恢復。
由於這些因素,升擋模式使數控升級與標準就地升級相比,資源更密集,操作更複雜。
無回滾選項的部署缺陷
CNC中的某些部署和部署後配置錯誤沒有補救路徑,並且需要完整的群集拆卸和重新部署。例如,為Crosswork資料VIP配置的FQDN不正確(對於sZTP使用情形是必需的),導致sZTP無法正常工作。由於這一價值無法在部署後予以更正,因此需要進行全部重新部署。
同樣,部署後無法糾正Change Automation中裝置覆蓋憑據的錯誤配置,導致重建另一個群集。其他錯誤(如網關IP配置錯誤或子網定義)也標識為不可恢復。
這些情景突出表明,在初始部署期間驗證所有不可變引數至關重要。精心規劃和輸入驗證對於避免代價高昂的返工和進度影響至關重要。
部署後診斷驗證的約束
CNC提供診斷實用程式來評估VM級別的運行狀況引數,如磁碟讀/寫延遲、IOPS、同步延遲、網路介面速度和CPU時脈頻率。該實用程式根據預期閾值報告測量值,並將每次檢查標籤為通過或失敗。但是,這些診斷只能在部署群集後執行,因此沒有機制在部署之前驗證基礎架構準備情況。
安裝期間,「忽略診斷檢查」標誌預設設定為false。實際上,如果任何一次檢查失敗,安裝程式就會停止,從而阻止部署繼續進行。結果,現場工程師常常被迫啟用此標籤並完全繞過診斷,因為即使生產級環境也經常無法通過一次或多次檢查。這造成了一個操作難題:各團隊必須選擇,是執行阻止部署的嚴格驗證,還是在不確保底層基礎設施滿足建議的效能基準的情況下繼續操作。
HI自定義KPI建立過程更改
在Health Insight 4.1中,自定義KPI建立依賴於Tick指令碼邏輯,其中KPI定義和處理邏輯使用Tick框架中的指令碼來實施。但是,在7.1版中,這一方法被用於定義和管理KPI的基於檔案的跟蹤框架所取代。
由於此架構更改,現有自定義KPI無法直接重複使用,需要重新處理才能與新跟蹤器檔案格式保持一致。這需要大量時間和精力:
- 瞭解新框架:該團隊必須研究7.1中引入的基於跟蹤器檔案的KPI定義模型的結構、語法和操作行為。
- 重新設計現有邏輯:之前在刻度線指令碼中實現的邏輯必須被翻譯並改編成跟蹤器檔案格式。
- 重新建立BNM KPI:必須使用新框架重新建立自定義BNM KPI,以確保它們產生與以前相同的結果和見解。
- 驗證KPI準確性:需要進行廣泛的驗證,以確認新的實施與以前的版本相比產生了一致和正確的指標。
- 測試和調整:新模型還要求測試實際網路條件下的效能和行為,並根據需要進行調整。
- 缺少支援:新的跟蹤器檔案實現不再支援以前使用tick指令碼的一些功能。因此,必須做出一些妥協。
KPI建立機制的這一更改顯著增加了升級期間所需的工作,因為這涉及學習新系統和重新實施現有自定義監控邏輯以確保運營洞察的連續性。
BNM行動手冊觸發器指令碼中的API超時
通過與CNC API互動的自定義指令碼觸發BNM手冊。在升級和驗證過程中,發現並解決了與API身份驗證和響應處理相關的幾個問題。
CNC API令牌的有效期為8小時,但原始指令碼不包含用於在令牌過期後刷新令牌的正確邏輯。因此,雖然CNC 4.4中的KPI警報功能正常,但在令牌過期後,觸發手冊的指令碼停止執行。此問題在很長一段時間內未引起注意,這意味著自動化指令碼實際上已運行了一年多。此問題僅在CNC 7.1中的遷移和驗證活動中可見。
因此,需要作出一些改進和改進:
- 令牌刷新邏輯:實現了正確的邏輯來檢測令牌到期並自動刷新API令牌,從而確保指令碼的不間斷執行。
- API響應更改:CNC版本之間的差異導致了其他問題。在CNC 4.1中,過期的令牌響應通常包含消息「expired」,而在CNC 7.1中,響應返回「Key not authorized」。 指令碼邏輯必須更新,才能正確解釋7.1中的新響應模式。
- 全域性令牌處理:以前,令牌在函式內進行本地儲存和使用。這樣會建立這樣的場景:令牌在輸入函式時有效,但在後續API呼叫之前過期。該實現被修改為使用全域性令牌處理,以確保所有功能的一致性和正確刷新。
- 改進了錯誤處理:在某些情況下,NSO「check sync」 API返回的響應不完整或與預期結構不同。這導致KeyError異常,從而暫停了指令碼執行。引入了其他異常處理和驗證邏輯,這樣即使收到意外的API響應,指令碼也可以繼續運行。
- 指令碼穩定性增強功能:新增了額外的保護和檢查以確保API故障、臨時響應問題或令牌刷新事件不會導致指令碼意外終止。
這些改進不僅解決了升級期間發現的問題,而且還顯著增強了BNM行動手冊自動化框架的可靠性、可復原性和可維護性。
BNM處理和手冊觸發器設計更改
BNM自動化邏輯是事件驅動的,並依賴CNC內Health Insight應用程式中的KPI生成的警報。整體工作流程如下:
- CNC從裝置讀取NB(標稱頻寬)和RBW(實際頻寬)值。
- 它使用這些值計算頻寬比率(BW%)。
- Health Insight KPI根據預定義的警報閾值評估此比率。
- 當產生警報時,BNM手冊觸發指令碼檢測該警報並執行相應的糾正手冊
原始警報設計中的限制
配置的警報閾值為:
- BW% < 60 → Critical
- 60 ≤ BW% ≤ 70 → 警
- BW% > 90 → Info
此設計在識別頻寬降級方面效果不錯,但在頻寬恢複方案期間產生了一個功能缺口。具體來說,70-90%範圍沒有定義警報級別。
這導致了以下行為:
- 當BW%下降至70%以下時,將生成嚴重或警告警報,觸發調整整形器和頻寬值的行動手冊。
- 但是,當頻寬恢復且BW%增長到70%以上時,KPI不會生成警報,因為值會降到70-90%的範圍內,並且沒有關聯的警報級別。
- 由於BNM自動化指令碼完全依賴警報生成來觸發操作,因此它沒有機會讀取更新的NBW/RBW值或啟動恢復操作。
- 因此,即使有足夠的頻寬可用,也不會自動恢復頻寬。在原始設計中也沒有恢復邏輯。
這一限制在生產網路中可見,在此網路中,以前經過頻寬縮減的鏈路即使在條件改善後仍保持受限狀態。
KPI框架更改的影響
CNC 7.1中引入的框架更改進一步加劇了這一問題。在Health Insight 4.1中,基於Tick的KPI實現支援多達5個警報級別,允許更精細地控制閾值範圍,並使恢復邏輯更易於實施。
然而,在CNC 7.1中,基於tracker檔案的KPI框架僅支援三個警報級別,這降低了定義多個恢復閾值的靈活性,並且需要重新設計警報邏輯以適合這些限制。
過度觸發Playbook
在原始實現中發現的另一個問題是劇本執行頻率極高。自動化邏輯不包括任何保持時間或穩定視窗。CNC從滿足報警條件的裝置讀取值後:
- 警報立即引發。
- 自動化指令碼立即觸發了糾正行動手冊。
由於即時網路中的遙測值頻繁波動,因此每小時都會觸發數百個手冊,從網路穩定性和應用效能角度來看,這樣做並不理想。
重新設計的自動化邏輯
為了克服這些限制,對BNM自動化設計進行了一些改進:
- 修訂警報閾值邏輯:為了確保恢復頻段在三個警報級別內被捕獲,對邏輯進行了修改,將任何大於70%的BW%現在都視為INFO級別警報,取代了之前僅將大於90%的值歸類為INFO的做法。這確保了70-90%的恢復頻段受到主動監控,使恢復行動手冊可以在頻寬條件改善時觸發。
- 暫停時間簡介:引入了20分鐘的保持時間機制,確保在觸發行動手冊之前頻寬條件在定義的持續時間內保持穩定。這可防止自動化對短期波動的反應。
- 受控實戰手冊執行:使用修訂後的邏輯和保持時間,劇本執行的頻率會顯著降低,從而阻止不必要的自動化操作。
- 嚴重退化的助推器機制:對於頻寬嚴重下降的情況,引入了增強方法。在這些情況下,自動化會主動將流量整形器和頻寬分配調整到NBW的40%,從而更快地從擁塞中恢復。
- 提高自動化穩定性:重新設計的工作流程可確保有效地處理頻寬減少和頻寬恢複方案,即使在基於跟蹤器的KPI框架的限制範圍內也是如此。
結果
通過這些設計更改,再加上以前在API處理、令牌管理和指令碼魯棒性方面的改進,BNM自動化框架現在以一種更加穩定、高效和可預測的方式運行。該系統可以正確響應擁塞和恢復條件,同時避免執行過多的手冊執行,並確保可靠的網路頻寬最佳化。
裝置警報抑制
在CNC 4.1中,警報通過RESTCONF API轉發到北向系統OneFM。由於CNC 4.1堆疊不包括EMF功能,該平台僅生成系統級警報。這些警報是在上游轉發的,與警報分類無關。
隨著CNC 7.1的部署,EMF的應用被引入,大大擴展了告警模型。警報現在分為三種型別:
- 系統警報 — 與CNC平台和應用運行狀況相關
- 網路警報 — 與網路服務條件相關
- 裝置警報 — 直接從網路裝置生成並通過CNC轉發
但是,已經有一個負責收集和管理裝置級警報的EPNM。如果CNC也將這些警報轉發給OneFM,則會導致兩個系統收到重複警報。因此,要求從CNC中排除裝置警報,同時仍轉發系統和網路警報。
主要挑戰在於用於向OneFM轉發警報的RESTCONF北向API的限制。API不支援根據警報類別過濾警報。如果能夠進行此類過濾,解決方案將非常簡單:只需在API級別排除裝置警報,然後將其轉發到北向系統。
對幾種可能的解決方案進行了評估和討論:
- 在源位置停止裝置陷阱:防止裝置向CNC傳送陷阱。
- 在北向系統(OneFM)上過濾警報:允許CNC在OneFM內傳送所有警報,但過濾裝置警報。
- 在轉發警報之前在CNC內進行過濾。
在裝置級別停止陷阱不可行,因為CNC依靠這些陷阱來檢測裝置事件並保持對網路條件的操作感知。禁用陷阱會顯著降低CNC響應網路問題的能力。
該解決方案最終利用了內建CNC功能,稱為「裝置警報抑制」。此功能使管理員能夠根據裝置組抑制特定型別的裝置警報,從而防止這些警報被處理或進一步向上游轉發。
通過配置裝置警報抑制策略,系統能夠:
- 在CNC內抑制裝置生成的警報。
- 繼續處理和轉發系統和網路警報。
- 防止重複的裝置警報到達OneFM系統。
該方法在不影響CNC從裝置接收陷阱能力的情況下,提供了清潔且可擴展的解決方案。因此,流向OneFM的警報流得到了簡化,從而確保僅轉發相關的系統和網路警報,同時避免與EPNM的裝置警報管理重複。
帶外更改
在現有設定中,操作團隊經常依賴直接基於CLI的指令碼將配置更新推送到網路裝置,特別是用於ACL修改和調試活動等任務。儘管這種方法在短期內有效,但會導致配置漂移,因為系統不會跟蹤在NSO以外進行的更改。因此,NSO的調配工作流程因目標(建模)狀態和實際裝置配置之間的不一致而受到影響,導致故障和運營效率低下。
L2/L3 VPN協調
由於帶外配置更改:網路團隊更新了CNC/NSO和TSDN工作流程之外的裝置上的VPN相關配置。因此,NSO中儲存的狀態(從CNC 4.1時代)並不總是與裝置上的狀態相匹配。
這些差異導致了多次協調失敗和不一致。在若干情況下,NSO包含裝置上不再存在的VPN服務資料(或者以NSO未反映的方式修改的)。 為了使NSO與網路保持一致,必須刪除僅存在於NSO中而不是裝置上的VPN服務條目,並更正由帶外更改造成的其他不匹配。
日程影響
解決這些問題需要在最初的核對計畫之外再執行大約兩週的時間。額外的時間用於識別不匹配、驗證裝置狀態以及安全地清除或糾正NSO CDB資料。
意見
- 配置授權:對VPN(或任何受TSDN管理的)配置的帶外更改會導致NSO與網路之間的漂移,使協調複雜化。
- 遷移前基線:在遷移之前,NC/NSO管理的狀態與僅裝置狀態的明確基線將使差異更易於檢測和解決。
- 自動化和轉換:負載轉換指令碼和特定於使用者的自定義對於以一致的方式處理4.1和7.1之間的格式和模型差異至關重要。
類似升級的建議
- 在協調視窗期間,對VPN(和其他TSDN管理的)服務實施變更凍結,只有通過受控流程例外。
- 運行協調前稽核,將NSO CDB與裝置配置進行比較,以便在開始協調之前量化並列出差異。
- 記錄並交代VPN更改必須經過CNC/NSO TSDN升級後才能避免帶外漂移的重複發生。
- 保留轉換和對賬指令碼,以便在將來的升級中重複使用或進行故障排除。
CNC備份因維護模式依賴性而失敗
CNC備份機制要求平台在啟動備份操作之前被置於維護模式。根據設計,備份API實施此前提條件;如果CNC無法轉換到維護模式,備份過程將自動中止。
在實踐中,由於持續的系統活動,進入維護模式經常失敗,包括:
- 主動變更自動化行動手冊(MOP)執行
- 持續的sZTP工作流程
- DLM服務操作
- KPI配置檔案附加或分離活動
- 隨選showtech產品系列
- 後台協調任務
任何此類活動的存在都會阻止CNC進入維護模式,從而導致備份操作在執行之前失敗。
運營影響
所需的每日CNC備份,以確保合規性和操作保障。然而,頻繁的自動化活動,特別是BNM觸發的攻略,意味著系統經常無法進入維護模式。結果,備份故障重複發生,造成了巨大的操作風險,需要手動干預。
緩解策略
1.備份計畫最佳化:確定了系統活動最小的維護視窗。根據流量和自動化分析,備份作業安排在上午5:00(AEST),此時協調和實戰手冊執行最不可能處於活動狀態。
2.備份前活動驗證:在呼叫備份API之前引入了自動預檢查:
- 該指令碼查詢CNC API以檢測正在運行的Change Automation MOP作業。
- 如果任何作業報告為Running,指令碼將等待5秒並重試。
- 此循環一直持續,直到系統報告無活動作業為止。
- 只有在確認環境為空閒後,指令碼才會嘗試啟用維護模式並觸發備份。
這阻止了系統處於繁忙操作狀態時的不必要的備份嘗試。
3.重試和復原機制:為適應暫態系統狀態,增加了額外的保障措施:
- 如果備份API返回失敗,則最多嘗試三次重試
- 重試之間的短延遲間隔
- 平穩的錯誤處理,避免指令碼終止
結果和結果
組合緩解顯著提高了備份可靠性:
- 備份故障顯著減少
- 實施後,只觀察到兩個故障,它們都是由於指令碼控制之外的sZTP進程停滯所致。
- 在BNM行動手冊自動化中引入的執行延遲進一步減少了與維護模式的爭用。
將系統日誌轉發到Splunk
系統日誌目標在CNC中配置為通過TLS將日誌轉發到Splunk。但是,一旦收到日誌,Splunk端將無法讀取。由於此問題源自Splunk環境,因此選擇返回到UDP傳輸,在此之後成功處理日誌。
裝置分組遷移問題
使用者之前在CNC 4.1中建立了18個裝置組;但是,該版本未提供任何基於UI或API驅動的機制來匯出或匯入裝置組。因此,將這些組遷移到CNC 7.1需要採用非標準方法。確定了兩個內部CNC API:一個顯示裝置組分層結構,另一個列出對映到每個分層結構節點的裝置。使用這些API,提取所有裝置組及其相關裝置並將其儲存為JSON輸出。然後,開發了一個自定義指令碼來分析響應並僅從每個組中提取裝置主機名。
CNC 7.1引入了裝置組的本地匯入/匯出功能,包括基於CSV的匯入模板。在從舊系統中提取主機名後,建立了第二個自動化指令碼以所需格式填充CSV模板,從而確保可以準確且獨立地匯入每個裝置組。這種自動化至關重要;如果沒有它,將裝置組遷移到CNC 7.1將會非常耗時且操作複雜。
隔離嚴重頻寬降級的裝置
儘管實施了BNM使用案例來自動修復低RBW/NBW比率,但裝置子集仍長時間處於嚴重降級狀態。儘管整形器和頻寬調整行動手冊通常會在降級事件後不久恢復裝置,但仍有幾個裝置持續處於嚴重狀態超過一週,因此需要手動干預。但是,識別這些裝置是一個挑戰。雖然CNC UI提供警報和頻寬指標的清晰視覺化,但它不容易顯示僅在較長間隔內處於「嚴重」狀態的裝置。
為了解決這一操作缺口,開發了一個API驅動的解決方案。CNC提供一個API,用於檢索可配置時間視窗(例如,7天,一個月)內頂級警報生成裝置的清單。 通過獲取此資料並篩選在選定時間段內僅生成嚴重警報的裝置,該團隊能夠快速隔離需要手動補救的裝置。這種自動化方法顯著提高了故障排除效率,並減少了識別持續退化情況所需的時間。
裝置遙測配置刪除
在CNC 4.1中,當裝置與Health Insight(HI)KPI配置檔案關聯時,會自動應用通過tm-tcfunction pack從NSO推送的遙測配置。但是,這些配置(包括CDG VIP引用)在稍後分離KPI配置檔案時未刪除。因此,隨著時間的推移,裝置積累了陳舊和冗餘的遙測條目。
這一問題在升級到CNC 7.1期間變得更加明顯。裝置經常保留來自CNC 4.1的舊式CDG VIP遙測配置,以及CNC 7.1生成的新條目,導致超過2000個裝置上的多個衝突遙測配置。由於只有CNC 7.1 CDG VIP配置必須保持活動狀態,因此對運行影響和配置衛生提出了擔憂。
為了解決這個問題,開發了一個自動指令碼,用於識別並從每個裝置的遙測配置中刪除過時的CDG VIP引用。此解決方案消除了配置不一致,恢復了與預期的7.1遙測模型的一致性,並避免了大型裝置群中數天的手動清除工作。
排除MDT集合故障
在CNC 7.1中,大多數健康洞察(HI)KPI集合依賴於模型驅動遙測(MDT)。 在裝置上啟用KPI配置檔案時,NSO會自動對所需的感測器路徑進行程式設計,並將CDG VIP配置為遙測目標。應用此配置後,將建立相應的CDG收集作業以跟蹤裝置的遙測狀態。
在驗證期間,據報有100多台裝置缺少遙測配置。通過CNC使用者介面識別這些裝置已被證明是不切實際的,因為UI僅支援每個裝置的過濾,不能有效地擴展超過2,000個裝置的機群。這就需要一種自動的方法來確定哪些裝置缺少遙測配置和所需的KPI重新啟用。
為了解決此問題,我們利用BNM標籤在每次啟用KPI配置檔案時分配給裝置。首先,生成帶有BNM標籤的所有裝置的輸出。然後開發一個Python指令碼與CNC收集API互動,並加入分頁邏輯以檢索完整集合作業(每個API呼叫最多返回100個條目)。 該指令碼從收集作業資料提取主機名,並將其與匯出的BNM標籤裝置清單進行比較。
此比較產生了已標籤但未出現在BNM收集作業中的裝置的清單,表明尚未應用MDT遙測配置。然後在這些裝置上重新啟用KPI配置檔案,驗證確認已正確建立所有相應的收集作業。
此自動化顯著簡化了故障排除流程,使團隊能夠在一天內識別和修復所有受影響的裝置,而通過手動檢查無法實現這一目的。
NSO 6.4.1.1中HA行為變化與一致性演算法調整
在Cisco CNC 7.1轉換過程中,從Cisco NSO 5.7.5.1升級到6.4.1.1期間,由於更新NSO版本中隱式啟用了consensus演算法,因此高可用性(HA)行為發生了顯著的變化。這不是NSO 5.7.5.1中的預設行為,導致升級後故障切換特性發生改變。具體來說,當主節點關閉時,輔助節點轉換為只讀狀態,阻止其處理調配活動。同樣,當輔助節點關閉時,主節點從活動主節點狀態移動到「無」狀態,從而影響服務的連續性。
為了恢復與先前部署一致的預期HA行為,NSO 6.4.1.1中明確禁用了一致性演算法。此調整確保主節點和輔助節點在故障轉移場景中恢復其預期角色,允許不間斷調配,並保持與早期NSO版本一致的操作穩定性。
NSO版本升級和程式包相容性增強功能
作為從Cisco CNC 4.1到7.1過渡的一部分,基礎的Cisco NSO版本從5.7.5.1升級到6.4.1.1。此版本升級導致現有NSO包中的XML模板結構發生變化,導致某些依賴於舊模板行為的回歸測試用例失敗。
為了彌補這些相容性差距,對受影響的NSO軟體包模板進行了分析和更新,以與NSO 6.4.1.1的修訂方案和處理要求保持一致。這些增強確保了所有的自動化工作流程和服務模式繼續按預期運行,恢復回歸穩定,並在升級後的CNC環境中保持一致性。
大規模實施KPI的問題
CNC提供開箱即用的UI機制,用於在裝置上啟用KPI配置檔案。儘管這種方法對小型艦隊非常有效,但在大規模上卻變得效率低下和不可靠。在此部署中,超過2,000個SWR裝置需要啟用KPI,而UI沒有提供批次選擇或處理裝置的有效方法。
最初,嘗試了一種基於標籤的方法:所有SWR裝置都分配了一個SWR標籤,並且使用標籤選擇而不是手動裝置選擇執行KPI啟用。但是,在單一工作流程中處理2,000多台裝置會導致重大的操作挑戰。該作業運行了三個多小時,並且失敗了數百次。雖然所有裝置都包括在目的中,但只有~750個裝置成功獲得KPI支援,重複嘗試只能產生遞增的進度。事實證明,這種方法既不可擴展,也不可重複。它顯示了負載的嚴重問題。
第二個挑戰來自NSO裝置同步問題。許多故障表明NSO未與相應的裝置同步。嘗試手動同步操作後進行KPI重新啟用是不切實際的,需要操作員投入大量精力。
為了解決這些限制,開發了一個自動化的、批處理驅動的工作流程:
- 匯出完整的CNC清單。
- 批次處理裝置50(通過調整確定為最佳大小)。
- 對於每個批處理,使用裝置UUID觸發自動同步。
- 通過CNC API執行KPI啟用。
- 以程式設計方式監視KPI作業歷史記錄和日誌失敗。
- 通過重複同步和KPI啟用步驟重新處理故障裝置。
- 成功完成批處理後,轉到下一組50台裝置。
該自動化還包括禁用KPI配置檔案、啟用完整生命週期管理的功能。
此解決方案為KPI調配提供了簡化、確定性和高度可擴展的流程。它消除了手動干預,確保了一致的結果,並節省了數天的運營工作。當KPI配置檔案在BNM設計更改後必須禁用和重新啟用時,同樣的自動化被證明是無價的,它可以在整個2,000個裝置群中進行快速且無錯誤的重新配置。
RESTCONF北向API限製為管理員訪問
用於從CNC轉發警報和事件的RESTCONF北向API具有限制,因此只能使用admin帳戶呼叫。嘗試通過服務帳戶訪問API失敗,儘管這些帳戶具有所需的操作角色。作為解決方法,使用者需要使用管理員憑據將警報轉發到北向系統,從而引入操作限制並限制對最低許可權訪問原則的遵守。
自動化作為戰略推動因素
鑑於CNC升級和遷移程式的規模和複雜性,手動執行操作任務很快證明是不可持續的。裝置自註冊、KPI調配、配置協調、協調以及遙測驗證等活動涉及數千個網路元素和重複的工作流,這些元素在手動執行時很容易發生人為錯誤。因此,自動化不僅對於加快執行速度,而且對於確保一致性、降低運營風險以及讓交付團隊從時間密集型重複任務中解放出來都至關重要。
通過指令碼化工作流程和API驅動的操作將這些流程系統化,升級計畫實現了顯著的效率提升。自動化加快了任務完成速度,提高了準確性,並且在所有部分都實現了可預知的結果。由此帶來的節省不僅縮短了整體部署時間,而且使工程師能夠專注於更高價值的驗證和設計工作,而不是日常的運營任務。
有些自動化活動是在升級專案開始前確定的,而有些活動是在出現挑戰時確定的。有些問題也是由於專案過程中出現的問題而有必要的。
此表說明了自動化對整個計畫產生重大影響的領域。
| 任務描述 |
手動工作(天) |
自動化工作(天) |
估計節省額(天) |
| ACL更新(SWR/LWR)(2K+) |
30.0 |
2.0 |
28.0 |
| 裝置遷移和連線至CDG(2K+) |
5 |
1.0 |
4.0 |
| BNM KPI連線到裝置(2K+) |
4.0 |
1.5(平均值) |
2.5 |
| 服務對帳 |
7 |
2.5 |
4.5 |
| 裝置組遷移 |
4 |
0.5 |
3.5 |
| 隔離頻寬嚴重下降的裝置 |
3 |
0.5 |
2.5 |
| MDT集合故障排除 |
3 |
0.5 |
2.5 |
| 合計 |
56天 |
8.5天 |
47.5天 |
經驗教訓
升級並不簡單
CNC不支援就地升級,而升降和換檔模式帶來了巨大的操作複雜性。絕不能假定過程簡單,特別是在版本跳轉較大時。意外問題會出現在應用程式、整合和工作流程中,並且每個問題都需要時間、分析和謹慎的緩解。主要版本的飛躍放大了這一挑戰,使得徹底規劃、驗證和分階段執行變得至關重要。我們不得不在TAC案例和故障排除工作中花費大量額外時間。由於我們沒有為此預留緩衝時間,這變得很有挑戰性。
CX必須完成繁重的工作
期望在部署、整合、遷移和端到端使用案例驗證方面投入大量的CX工作。不要認為在舊版本上驗證的工作流在新版本上表現相同。 — 需要進行大量的故障排除和分析才能使工作順利進行。
自動化工具包勢在必行
升級過程表明,自動化不是可選的便利,而是大規模數控部署的基本要求。我們早就為必要候選者制定了自動化計畫,但人們永遠無法假定這已經足夠了。在專案進行過程中,可以在使用情形中發現問題,使用情形中自動化肯定會增加價值,如前面的章節所示。
避免遷移期間發生雙控制器衝突
在升級過程中,確保舊的和新的CNC環境不能同時處於活動狀態至關重要。儘管驗證需要較短的吸收期,但是將其大幅延長(如本專案中所發生的2個月以上)會導致操作風險。由於兩個CNC都處於活動狀態,時間超過15-20天,所以閉環自動化功能(如按需頻寬)會在整個網路中生成不一致且衝突的操作,因為自動化邏輯同時從兩個控制器運行。
關鍵教訓是在遷移期間實施清晰的護欄。管理性禁用舊數控系統中的裝置、暫停自動化工作流程或限制遙測訂閱等措施可以防止這些衝突。未來的升級必須明確規劃嚴格的控制器隔離,以避免雙控制器干擾並確保可預測的網路行為。
MOP不是神聖不可侵犯的
雖然會針對每個部署、整合和使用案例建立過程方法(MOP)文檔,但假設在實驗室條件下驗證的MOP在生產中行為相同是不現實的。生產環境始終顯示偏差,有的微小,有的顯著,從而突顯了控制測試過程中未能發現的差距。現實中的網路、傳統行為、外部依賴項和即時流量條件都會引入實驗室模擬無法始終複製的變數。
關鍵的學習是,團隊必須在進行生產部署時考慮到遇到意外行為、重大案例和新發現。靈活性、快速故障排除能力以及隨時調整程式的準備程度對於大規模成功執行至關重要。
TAC案例的效力
生產後問題不可避免,而且儘管交付團隊進行初始故障排除很有價值,但僅依靠內部努力可能會導致不必要的延遲。謹慎的做法是將TAC案例作為安全網路平行地開啟,尤其是對於與產品相關的問題或無法立即診斷的複雜行為。TAC調查通常需要花費時間,如果將案例建立時間推遲數天,可能會導致專案動力明顯受損。儘早與TAC接洽,可確保專家在需要時提供幫助,加快根本原因識別,並防止可避免的進度延後。
與CNC業務部門接洽,以獲得有效的知識支援
來自數控業務部門的強大支援在任何數控專案中都極具價值。使用者往往需要詳細的產品見解和澄清,而僅憑交付團隊無法輕鬆獲得這些見解和澄清。在整個專案期間都可聯絡到業務部門聯絡人,可加快問題解決速度,提高技術準確性,並有助於建立更大的信心和使用者關係。
CNC升級的最佳實踐
規劃最佳化升級策略
CNC不支援就地升級,因此並行部署不可避免。將新環境視為全新安裝,並分配足夠的計算、儲存和管理容量來同時運行兩個環境。提前計畫驗證階段、遷移排序和轉換活動。
嚴格的預部署驗證對於不可變的引數尤其重要
許多經驗都強調了在初始部署期間進行盡職調查的重要性。預先驗證所有關鍵輸入,特別是不可變的配置引數,對於防止成本高昂的重新部署和計畫影響至關重要。因此,強烈建議使用結構化的預部署檢查單、對等審查和試運行驗證,以最大程度降低不可逆配置錯誤的風險。
在接觸生產環境之前使用專用驗證環境
在專案早期階段建立內部CALO/測試環境允許團隊進行試驗、驗證工作流程、發現版本特定更改,並在影響生產之前建立信心。這顯著減少了最終推廣期間的未知數。
基於證據的分散式Crosswork元件規模確定
在設計集群、CDG分佈和PCE分配時,決策依據裝置型別、介面規模、拓撲複雜性和收集強度,而不是簡單的裝置計數。均衡的分佈可防止過載,並確保整個群集的可預測效能。
重複性、大量工作的自動化
在重複性、高容量或操作關鍵的啟動任務中建立自動化積壓工作,並在需要自動化的情況下進行投資。首先在SIT環境中驗證和最佳化您的自動化,確保生產不依賴於最後一分鐘的修復。規模增加了手動工作的成本;標準化自動化提高了品質、速度和控制。將結果打包為可重複使用的資產(有文檔記錄的介面、引數化作業、共用庫),這樣團隊就可以在未來的Crosswork升級和相鄰專案中使用相同的自動化,從而減少返工和入職時間。
避免並行運行時的雙閉環控制
在共存期間,將閉環自動化視為單寫入器功能:只有一個業務流程路徑可以主動進行補救或策略驅動的配置。在舊堆疊和新堆疊上併發使用CLA可能產生重複觸發和意圖不同的風險,從而破壞裝置狀態的穩定。在功能驗證和最終切換到新控制器之後,將CLA作為後期階段里程碑計畫啟用。
執行結構化的升級影響評估
主要版本跳轉引入新功能,同時淘汰或更改舊功能。在這些變化中考慮這些因素非常重要。很多情況下,升級版本的發行說明中不會記錄此更改,我們到達現場後會彈出此更改。對以下內容進行結構化評估:
- 棄用的API
- KPI框架更改
- 應用級行為差異
- 配置模型偏差
- 警報、拓撲處理和攻略執行更改
測試整個整合表面的相容性和行為
CNC與多個外部系統互動,例如NSO、SSM、CPNR、EPNM、OneFM、Splunk和協調框架。
遷移前:
- 驗證版本相容性
- 測試所有北向/南向整合
- 確認資料模型、陷阱、遙測流
- 檢查SSL/RESTCONF身份驗證行為
遷移後發現的整合故障會造成操作盲點。
制定穩健的遷移前資料匯出策略
在開始遷移之前匯出所有內容:
- 憑據配置檔案
- 提供商
- 標記
- 自定義手冊
- 自定義KPI
- 角色和RBAC
- sZTP憑證
- 裝置組
- 歷史服務後設資料
具有內建驗證門的批處理裝置遷移
在遷移數千台裝置時,按受控批次執行遷移:
- 移動固定隊列中的裝置(例如,按區域、CDG負載或裝置型別)
- 在移至下一批之前驗證遙測、NSO同步狀態和可達性
- 如果出現持續異常,請回滾該批次
這防止在短時間內在CDG和CNC上產生高負荷。
通過NSO整合處理帶外配置更改
為了解決CNC 4.1到7.1升級中的帶外挑戰,實施了向NSO驅動的操作的結構化轉變。運營團隊獲得了對NSO CLI的基於使用者的受控訪問許可權,而裝置CLI的直接管理訪問許可權被限制以防止帶外更改。此外,舊版CLI指令碼被系統性地轉換為基於RESTCONF的自動化並與NSO整合,從而實現了諸如乾式運行驗證和事務回滾等功能。此方法確保所有配置更改都集中管理、可審計且與NSO的服務模型一致,從而有效地消除配置漂移並恢復調配可靠性。
大力強調變更凍結
在關鍵遷移時段內:
- 凍結使用者發起的網路更改
- 限制配置推送
- 與現場團隊和NOC團隊同步
- 規劃一些視窗,以便適應使用CNC/ZTP更換裝置等緊急活動。
這樣可以降低噪音,並確保網路狀態在整個升級過程中保持穩定
結論
從CNC 4.1向CNC 7.1的遷移構成了大規模網路協調平台升級所固有的複雜性的重要案例研究。此專案證明,此類轉換不僅僅是版本改進,而是跨架構層、運營工作流和自動化生態系統的全面轉換。由於缺少就地升級路徑,需要進行完全升降和移位部署,這帶來了並行環境挑戰,並需要在CNC、NSO、SR-PCE、CDG和外部系統整合間進行細緻的協調。由此產生的運營情形強調了強健的遷移方法、詳盡的驗證週期和嚴格控制的轉換過程對於減少生產環境中的風險的重要性。
此次升級進一步表明了自動化作為可擴充性和準確性不可或缺支柱的重要性。該專案擁有2,000多台裝置、廣泛的遙測配置、多個相關元件以及動態閉環自動化工作流程,突出表明在這種規模的環境中,手動操作程式存在侷限性。專門構建的自動化跨越ACL更新、裝置入站、KPI調配、遙測清除和故障隔離,已證明對於確保確定性、減少人為錯誤和實現顯著效率提升至關重要。自動化框架不僅使遷移期間的運營連續性得以實現,還為持續的網路最佳化奠定了可持續發展的基礎。
同樣重要的是認識到生產行為明顯偏離受控實驗室條件。框架更改(例如從基於時間週期的KPI邏輯到基於跟蹤器的定義的轉換)引入了不可預期的行為轉變,需要重新設計、重新測試和迭代細化。同樣,圍繞閉環自動化、遙測可靠性和API行為的運營挑戰也突出表明需要進行自適應故障排除、主動風險評估,並需要與TAC和業務部門主題專家持續接觸。這些因素共同表明,主要版本過渡需要技術深度和組織就緒性。仍有一些未解決的問題有待在下一版crosswork 7.2中解決。
總體而言,此次升級表明,成功的大規模CNC遷移依賴於以下四個基本支柱:嚴格的預部署驗證、系統和可復原的自動化、強大的跨職能協調,以及可預知實驗室和生產環境之間差異的自適應操作狀態。從此次合作中獲得的見解不僅有助於穩定部署CNC 7.1,而且還可為未來的過渡提供藍圖、介紹最佳實踐、加強架構保障,以及增強機構知識,以推進您的網路自動化生態系統的後續發展。
術語表
| 字詞 |
定義 |
| BNM |
頻寬通知消息。 |
| 貓 |
Crosswork主動拓撲 |
| CCA |
Crosswork變更自動化 |
| CDG |
Crosswork資料閘道 |
| CHI |
Crosswork健康狀況洞察 |
| CNC |
Cisco Crosswork網路控制器 |
| COE |
Crosswork最佳化引擎 |
| CPNR |
Cisco Prime Network Registrar |
| CWM |
Crosswork工作流程管理員 |
| EMF |
元素管理功能 |
| KPI |
關鍵績效指標 |
| LWR |
大型無線路由器 |
| MDT |
模型驅動遙測 |
| 澳門幣 |
程式方法 |
| NBW |
額定頻寬 |
| NSO |
網路服務協調器 |
| RBW |
記錄的頻寬 |
| SR-PCE |
分段路由路徑計算元素 |
| SSM |
思科智慧軟體管理員 |
| SWR |
小型無線路由器 |
| TAC |
技術支援中心 |
| TSDN |
傳輸軟體定義網路 |
| ZTP |
零接觸調配 |
| RR |
路由反射器 |
| RP |
路由配置檔案 |
| POI |
互連點 |
| EVPN |
乙太網虛擬專用網路。 |
參考資料
- Cisco Systems, Cisco Crosswork網路控制器版本說明,版本7.1.0
- Cisco Systems, Cisco Crosswork Infrastructure 7.1安裝指南
- Cisco Systems, Cisco Crosswork Infrastructure 7.1管理指南 — 概念概述:
- Cisco Systems, Crosswork網路控制器流量工程和最佳化指南7.1版
- Cisco Systems, Cisco Crosswork健康狀況洞察使用者指南,版本7.1
- Cisco Systems, Crosswork零接觸布建(ZTP)部署指南
- Cisco Systems, Cisco NSO Transport SDN Function Pack套件安裝指南7.1.0版
- Cisco Systems,Cisco SR-PCE配置指南
修訂記錄
| 修訂 | 發佈日期 | 意見 |
|---|---|---|
2.0 |
04-May-2026
|
初始版本、格式、標題、連結、語法、拼寫。 |
1.0 |
30-Apr-2026
|
初始版本 |
 意見
意見