简介
本文档介绍在托管StarOS虚拟网络功能(VNF)的Ultra-M设置中替换服务器中的两个故障HDD所需的步骤。
背景信息
Ultra-M是经过预先打包和验证的虚拟化移动数据包核心解决方案,旨在简化VNF的部署。OpenStack是适用于Ultra-M的虚拟化基础设施管理器(VIM),由以下节点类型组成:
- 计算
- 对象存储磁盘 — 计算(OSD — 计算)
- 控制器
- OpenStack平台 — 导向器(OSPD)
Ultra-M的高级体系结构和涉及的组件如下图所示:
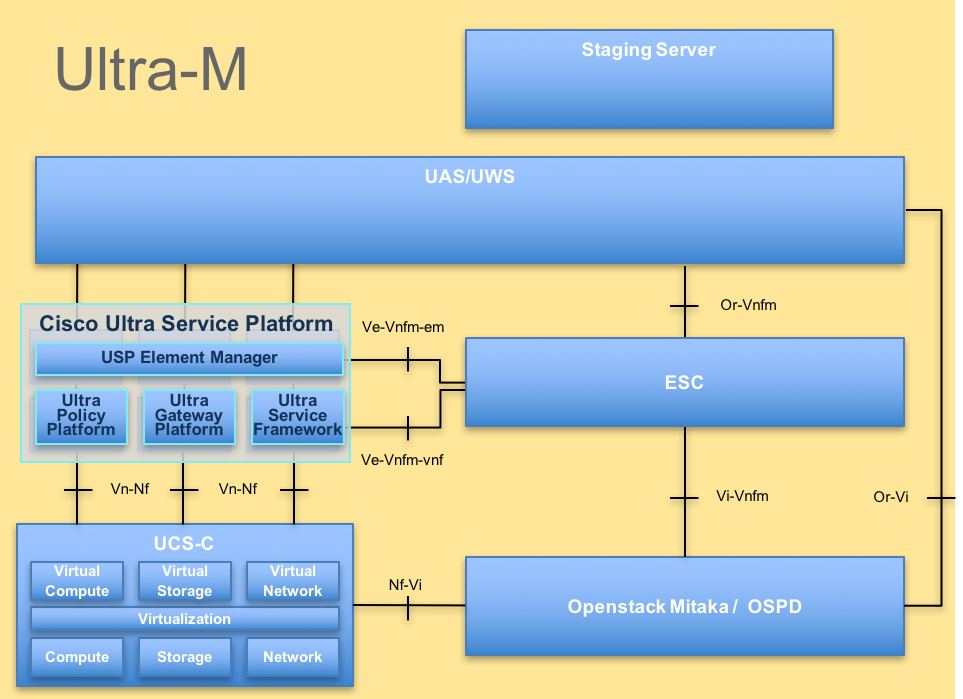 UltraM体系结构
UltraM体系结构
本文档面向熟悉Cisco Ultra-M平台的思科人员,详细介绍在更换控制器服务器时,在OpenStack和StarOS VNF级别需要执行的步骤。
注意:Ultra M 5.1.x版本用于定义本文档中的过程。
缩写
| VNF |
虚拟网络功能 |
| CF |
控制功能 |
| 旧金山 |
服务功能 |
| ESC |
弹性服务控制器 |
| MOP |
程序方法 |
| OSD |
对象存储磁盘 |
| HDD |
硬盘驱动器 |
| SSD |
固态驱动器 |
| VIM |
虚拟基础设施管理器 |
| VM |
虚拟机 |
| EM |
元素管理器 |
| UAS |
超自动化服务 |
| UUID |
通用唯一ID标识符 |
两个HDD故障
每个裸机服务器将调配两个HDD驱动器,以在Raid 1配置中充当BOOT DISK。如果出现单HDD故障,由于存在RAID 1级冗余,故障的HDD可以热插拔。但是,当两个HDD均发生故障时,服务器将关闭,您将失去对服务器的访问权限。要恢复对服务器和服务的访问,需要执行此步骤 更换两个HDD并将服务器添加到现有的超云堆栈。
更换UCS C240 M4服务器上故障组件的过程可参见 更换服务器组件。
如果两个HDD均出现故障,在同一UCS 240M4服务器中仅更换这两个有故障的HDD。更换新磁盘后不需要执行BIOS升级过程。
在基于OpenStack的Ultra-M解决方案中,UCS 240M4裸机服务器可以承担以下角色之一:计算、OSD计算、控制器或OSPD。以下各节介绍处理这些服务器角色中的两个HDD故障所需的步骤。
注意:在UCS 240M4服务器中,如果两个HDD都正常,但某些其他硬件出现故障,则用新硬件替换UCS 240M4,但重复使用相同的HDD。在这种情况下,只有HDD出现故障,因此重新使用相同的UCS 240M4并用新的HDD更换故障的HDD。
计算服务器上的两个HDD故障
如果两个HDD的故障在充当计算节点的UCS 240M4中观察到,请按照Compute Server Replacement Procedure中指定的更换过程执行。
控制器服务器上的两个HDD故障
如果两个HDD均出现故障时在UCS 240M4(充当控制器节点)中,请按照中所述的更换步骤进行操作。
由于观察两个HDD故障的控制器服务器将无法通过安全外壳(SSH)访问,请登录另一个控制器节点以执行上述链接中列出的正常关闭过程。
OSD计算服务器上的两个HDD故障
如果在充当OSD-Compute节点的UCS 240M4中观察到两个HDD出现故障,请按照中所述的更换步骤进行操作。
在此提到的步骤中,无法执行Ceph存储正常关闭,因为这两个故障都会导致服务器无法访问。因此,忽略这些步骤。
OSPD服务器上的两个HDD故障
如果在UCS 240M4(充当sn OSPD节点)中发现两个HDD均出现故障,请按照中所述的更换步骤进行操作。
在这种情况下,需要以前存储的OSPD备份,以在HDD磁盘更换后进行恢复,否则将像完成堆栈重新部署一样。
 反馈
反馈