监控QvPC-DI上的iftask和NPU性能
下载选项
非歧视性语言
此产品的文档集力求使用非歧视性语言。在本文档集中,非歧视性语言是指不隐含针对年龄、残障、性别、种族身份、族群身份、性取向、社会经济地位和交叉性的歧视的语言。由于产品软件的用户界面中使用的硬编码语言、基于 RFP 文档使用的语言或引用的第三方产品使用的语言,文档中可能无法确保完全使用非歧视性语言。 深入了解思科如何使用包容性语言。
关于此翻译
思科采用人工翻译与机器翻译相结合的方式将此文档翻译成不同语言,希望全球的用户都能通过各自的语言得到支持性的内容。 请注意:即使是最好的机器翻译,其准确度也不及专业翻译人员的水平。 Cisco Systems, Inc. 对于翻译的准确性不承担任何责任,并建议您总是参考英文原始文档(已提供链接)。
简介
本文档介绍如何在QvPC-DI上监控iftask/NPU的性能。
它还提供了有关iftask的一些关键概念的详细信息。
使用的组件
本文档中的信息基于QvPC-DI。
本文档中的信息都是基于特定实验室环境中的设备编写的。本文档中使用的所有设备最初均采用原始(默认)配置。如果您的网络处于活动状态,请确保您了解所有命令的潜在影响。
Iftask体系结构
iftask是QvPC-DI中的一个进程。它为DI网络端口和服务端口启用服务功能虚拟卡(SF)和控制功能虚拟卡(CF)上的数据平面开发套件(DPDK)功能。DPDK是处理虚拟化环境中的输入/输出的更有效方式。
高性能网络接口控制器(NIC)的设备驱动程序现在被移至userspace,从而避免了昂贵的情景交换机(userspace/kernelspace)。
驱动程序在用户空间中以不可中断模式运行,线程可以直接访问这些NIC驱动程序中的HW队列/环缓冲区。
有关架构的文档,请访问:
Ultra Gateway Platform System Administration Guide中的Ultra Services Platform(USP)简介。
深入的iftask体系结构(适用于SF)如下图所示:
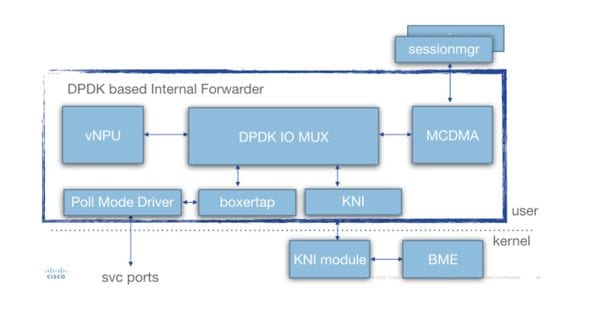
存在各种组件:
轮询模式驱动程序(PMD):此功能持续轮询来自网卡的HW队列(对于SR-IOV)或SW环缓冲区(对于virtio/vmxnet类型的接口)。 这就是与这些PMD关联的CPU持续以100%的速率进行追溯的原因。
在部署期间,可以通过param.cfg文件静态分配分配分配给iftask和iftask内各种功能的CPU数量。
Boxertap:根据数据包的来源将staros元数据(MEH报头)附加到数据包(例如:Di端口/服务端口),以及发送位置(例如:本地vNPU)
IOMUX:具有包含所有目标(sessmgr/ports/vNPU/..)的BIA库。 此功能主要是根据数据包的BIA路由数据包
vNPU:-flow分类/查找。这与基于硬件的系统(ASR5000/ASR5500)中的NPU相当。
vNPU中的流仍由NPUmgr(从demuxmgr/sessmgr等获取其信息)编程到可由vNPU访问的共享内存中。
— 此外,还创建了一个API,以便npumgr/sessmgr可以轮询vNPU以获取统计信息/配置
MCDMA:发往sessmgr的数据包将写入MCDMA接口(通过可用的各种MCDMA核心/线程)。 然后,通过DMA将这些数据包提供给sessmgr。由于内核仅以有限的方式参与,因此这确实可以提高性能。这将在本文中进一步说明。
MCDMA还提供批处理功能(在一个系统调用中处理多个数据包)。
KNI:需要进入linux内核的数据包的接口(DI控制/ARP/icmp/路由/..)
Iftask数据包流
下图说明了控制平面数据包的数据包流。示例:GTPv2创建会话请求
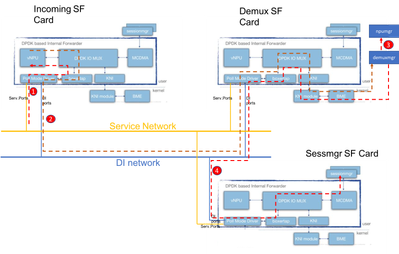
步骤 1:GTPv2 CSR数据包将通过任何可用SF的服务端口进入。它将被放入服务接口NIC的Rx队列中,并由任务流程的一个PMD核心接收。Boxertap将放入MEH报头,数据包将通过IOMux转发到本地vNPU以进行流量查找。
由于这是一个新会话,因此vNPU没有为此编程的特定流,它必须将数据包路由到解复用器卡上的demuxmgr。
步骤 2:vNPU更改MEH报头(为相关解复用器进程使用新的BIA)。IOMUX知道它必须通过DI网络将此信息发送到解复用器卡。如果Demux卡上的任务进程将处理传入的数据包,IOMux会将其路由到KNI模块(指向内核的接口)。 通过内核,它最终将进入demuxmgr进程(在本例中为egtpinmgr)。
步骤 3:Demuxmgr将执行其任务。选择一个sessmgr,并为后续GTPv2数据包使用流编程npumgr
所有卡的vNPU将能够访问npumgr用于对这些流进行编程的共享内存。
步骤 4:GTPv2 CSR现在转发到所选的sessmgr。MEH再次更改,然后从Demux卡转发到DI网络上的Sessmgr SF卡。该卡上的IOMUX进程将通过MCDMA接口将数据包转发到所选的sessmgr。从现在起,sessmgr将处理此会话的所有GTPv2流量。协商GTPU TEID后,它将通过NPUmgr对流进行编程,以便后续GTPU数据包也可以直接从传入SF卡传输到sessmgr SF卡。
vCPU在iftask
在部署期间,将一定数量的虚拟中央处理器(vCPU)静态分配给iftask进程。这减少了用户空间应用(sessmgr等)的核心数量,但大大提高了I/O的性能。
此分配是通过部署期间与每个SF/CF关联的param.cfg模板中的以下参数完成的:
- IFTASK_CORES(要与iftask一起分配的可用内核的百分比)
- (IFTASK_CRYPTO_CORES — (为EPDG分配的)要分配给加密处理的可用内核的百分比)
- (IFTASK_MCDMA_CORES — (进一步调整分配给MCDMA功能的内核数量)
- 在SF上,iftask进程在内部将其分配的内核分配到:
- 轮询模式驱动程序(PMD)vCPU(执行tx/rx/vnpu活动)
- MCDMA vCPU,执行从iftask到sessmgr和背面的数据包传输
- 在CF上,不需要MCDMA vCPU,因为SF不托管sessmgr进程。
命令show cloud hardware iftask提供有关您的QVPC-DI部署的详细信息:
[local]UGP# show cloud hardware iftask Card 1: Total number of cores on VM: 8 Number of cores for PMD only: 0 Number of cores for VNPU only: 0 Number of cores for PMD and VNPU: 2 <-- CF: 2 out of 8 cores are assigned to iftask PMD/VNPU Number of cores for MCDMA: 0 <-- CF: no cores allocated to MCDMA as there is no sessmgr process on CF Number of cores for Crypto: 0 Hugepage size: 2048 kB Total hugepages: 3670016 kB NPUSHM hugepages: 0 kB CPU flags: avx sse sse2 ssse3 sse4_1 sse4_2 Poll CPU's: 1 2 KNI reschedule interval: 5 us ... Card 3: Total number of cores on VM: 8 Number of cores for PMD only: 0 Number of cores for VNPU only: 0 Number of cores for PMD and VNPU: 2 <-- SF: 2 out of 8 core are assigned to iftask PMD/VNPU
Number of cores for MCDMA: 1 <-- SF: 1 out of 8 cores is assigned to iftak MCDMA
Number of cores for Crypto: 0
Hugepage size: 2048 kB
Total hugepages: 4718592 kB
NPUSHM hugepages: 0 kB
CPU flags: avx sse sse2 ssse3 sse4_1 sse4_2
Poll CPU's: 1 2 3
KNI reschedule interval: 5 us
命令show cloud configuration将提供有关所用参数的更多详细信息:
[local]UGP# show cloud configuration Card 1: Config Disk Params: ------------------------- CARDSLOT=1 CPUID=0 CARDTYPE=0x40010100 DI_INTERFACE=BOND:TYPE:ixgbevf-1,TYPE:ixgbevf-2 DI_INTERFACE_VLANID=2111 VNFM_INTERFACE=MAC:fa:16:3e:23:aa:e9 VNFM_PROXY_ADDRS=172.16.180.3,172.16.180.5,172.16.180.6 MGMT_INTERFACE=MAC:fa:16:3e:87:23:9b VNFM_IPV4_ENABLE=true VNFM_IPV4_DHCP_ENABLE=true Local Params: ------------------------- CARDSLOT=1 CARDTYPE=0x40010100 CPUID=0 ... Card 3: Config Disk Params: ------------------------- CARDSLOT=3 CPUID=0 CARDTYPE=0x42030100 DI_INTERFACE=BOND:TYPE:ixgbevf-1,TYPE:ixgbevf-2 SERVICE1_INTERFACE=BOND:TYPE:ixgbevf-3,TYPE:ixgbevf-4 SERVICE2_INTERFACE=BOND:TYPE:ixgbevf-5,TYPE:ixgbevf-6 DI_INTERFACE_VLANID=2111 VNFM_INTERFACE=MAC:fa:16:3e:29:c6:b7 IFTASK_CORES=30 VNFM_IPV4_ENABLE=true VNFM_IPV4_DHCP_ENABLE=true Local Params: ------------------------- CARDSLOT=3 CARDTYPE=0x42010100 CPUID=0
设计注意事项:
将vCPU分配给iftask时,必须考虑许多因素。
-SF可用的vCPU总数与iftask vCPU的总数:默认配置指定通过param.cfg文件中的IFTASK_CORES参数与iftask关联的vCPU的30%。但这可能会因应用而异(MME与SPGW与ePDG) — >咨询工程部。
-分配给PMD的iftask vCPU与分配给MCDMA的iftask vCPU。要验证是否平衡,请参阅下面的“iftask performance”部分。
-iftask MCDMA vCPU与所有应用程序的剩余vCPU的比较。通常,将iftask MCDMA vCPU的分布与用于应用的剩余vCPU(sessmgr/aaamgr/..)进行1/x比较是好的。
示例:
可供SF使用的核心总数38个:
-14个分配给iftask(6个PMD,8个MCDMA)
— 剩余24个分配给其他进程
这意味着每个3个应用vCPU有1个MCDMA vCPU。
这有助于确保每个MCDMA vCPU的负载相等。
监控文件性能
可以通过多种方式监控任务流程。
Consolidate的show命令列表:
show subscribers data-rate show npumgr dinet utilization pps show npumgr dinet utilization pps show cloud monitor di-network summary show cloud hardware iftask show cloud configuration show iftask stats summary show port utilization table show npu utilization table show npumgr utilization information show processes cpu
命令 #show cpu info verbose不会提供有关iftask内核的信息。它们将始终以100%的利用率列出。
在下面的示例中,核心1、2、3与iftask关联,并且按100%利用率列出,这是预期结果。
Card 3, CPU 0:
Status : Standby, Kernel Running, Tasks Running
Load Average : 3.12, 3.12, 3.13 (3.95 max)
Total Memory : 16384M
Kernel Uptime : 4D 21H 56M
Last Reading:
CPU Usage All : 1.9% user, 0.3% sys, 0.0% io, 0.0% irq, 97.8% idle
Core 0 : 5.8% user, 0.2% sys, 0.0% io, 0.0% irq, 94.0% idle
Core 1 : Not Averaged (Poll CPU)
Core 2 : Not Averaged (Poll CPU)
Core 3 : Not Averaged (Poll CPU)
Core 4 : 2.2% user, 0.2% sys, 0.0% io, 0.0% irq, 97.6% idle
Core 5 : 0.8% user, 0.5% sys, 0.0% io, 0.0% irq, 98.7% idle
Core 6 : 0.4% user, 0.5% sys, 0.0% io, 0.0% irq, 99.1% idle
Core 7 : 0.1% user, 0.3% sys, 0.0% io, 0.0% irq, 99.6% idle
Poll CPUs : 3 (1, 2, 3)
Core 1 : 100.0% user, 0.0% sys, 0.0% io, 0.0% irq, 0.0% idle
Core 2 : 100.0% user, 0.0% sys, 0.0% io, 0.0% irq, 0.0% idle
Core 3 : 100.0% user, 0.0% sys, 0.0% io, 0.0% irq, 0.0% idle
Processes / Tasks : 143 processes / 16 tasks
Network mcdmaN : 0.002 kpps rx, 0.001 mbps rx, 0.002 kpps tx, 0.001 mbps tx
File Usage : 1504 open files, 1627405 available
Memory Usage : 7687M 46.9% used
Memory Details:
Static : 330M kernel, 144M image
System : 10M tmp, 0M buffers, 54M kcache, 79M cache
Process/Task : 6963M (120M small, 684M huge, 6158M other)
Other : 104M shared data
Free : 8696M free
Usable : 5810M usable (8696M free, 0M reclaimable, 2885M reserved by tasks)命令#show npu utilization table将列出与iftask进程关联的每个核心的利用率(在每个卡上)的良好摘要。
注意:这里的重要一点是确定某些内核的利用率是否始终高于其他内核。
[local]UGP# show npu utilization table
-------iftask-------
lcore now 5min 15min
-------- ------ ------ ------
01/0/1 0% 0% 0%
01/0/2 0% 0% 0%
02/0/1 0% 0% 0%
02/0/2 2% 1% 0%
03/0/1 0% 0% 0%
03/0/2 0% 0% 0%
03/0/3 0% 0% 0%
04/0/1 0% 0% 0%
04/0/2 0% 0% 0%
04/0/3 0% 0% 0%
05/0/1 0% 0% 0%
05/0/2 0% 0% 0%
05/0/3 0% 0% 0%命令#show npumgr utilization information(隐藏命令)
此命令可提供有关每个内核的更多信息,以及哪些内核占用了CPU。
注意:PMD核心的CPU消耗在PortRX、PortTX、KNI和密码上。MCDMA核心的CPU被MCDMA占用。
PMD和MCDMA核心应具有相当均匀的负载。
如果不是这种情况,可能需要进行一些调整(例如,分配更多/更少的MDMA核心)。
******** show npumgr utilization information 3/0/0 *******
5-Sec Avg: lcore01| lcore02| lcore03| lcore04| lcore05| lcore06| lcore07| lcore08| lcore09| lcore10| lcore11| lcore12| lcore13| lcore14| lcore15| lcore16|
Idle: 31%| 37%| 32%| 35%| 41%| 48%| 47%| 38%| 57%| 56%| 55%| 56%| 46%| 56%| 54%| 52%|
PortRX: 28%| 26%| 27%| 26%| 0%| 0%| 0%| 0%| 12%| 14%| 11%| 11%| 0%| 0%| 0%| 0%|
PortTX: 5%| 5%| 6%| 5%| 8%| 8%| 8%| 14%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%|
KniRX: 6%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%|
Kni: 1%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%| 0%|
McdmaRX: 0%| 0%| 0%| 0%| 34%| 29%| 29%| 32%| 0%| 0%| 0%| 0%| 35%| 28%| 28%| 28%|
Mcdma: 0%| 0%| 0%| 0%| 11%| 7%| 4%| 6%| 0%| 0%| 0%| 0%| 14%| 7%| 7%| 7%|
Vnpu: 28%| 29%| 28%| 32%| 0%| 0%| 0%| 0%| 30%| 28%| 33%| 28%| 0%| 0%| 0%| 0%|
McdmaFlush: 0%| 0%| 0%| 0%| 6%| 8%| 12%| 10%| 0%| 0%| 0%| 0%| 6%| 10%| 11%| 14%|
Cipher: 1%| 2%| 6%| 2%| 0%| 0%| 0%| 0%| 1%| 2%| 1%| 5%| 0%| 0%| 0%| 0%|
rx kbits/sec: 728563| 736103| 647535| 626595| 811362| 698724| 717147| 799281| 617199| 595268| 623670| 633132| 819270| 672732| 790849| 719498|
rx frames/sec: 94409| 95586| 91107| 84997| 109526| 97466| 98557| 107690| 81122| 82076| 86959| 87960| 114114| 96198| 108108| 100259|
tx kbits/sec: 715038| 722181| 634227| 614221| 827124| 712740| 731329| 814782| 605373| 583318| 611001| 620328| 835692| 686575| 806395| 733924|
tx frames/sec: 94310| 95491| 90969| 84896| 109526| 97466| 98557| 107690| 81002| 81986| 86858| 87859| 114114| 96198| 108108| 100259|
5-Min Avg: ...
15-Min Avg: ...更详细的解释:
对于通过服务端口或DI端口传入的iftask进程的数据包,CPU的入帐方式如下。
Vnpu查找是最占用大量cpu的部分。
如果Vnpu查找之后:
— 数据包被发送到MCDMA核心,CPU时间将记在相关MCDMA核心的McdmaRx上。
— 数据包被发送到另一个iftask核心,CPU时间将记入Vnpu
— 数据包在同一个iftask核心上发出,CPU时间将记入PortRx
— 数据包在同一内核上发送,CPU时间将记入KniRx下方
PortRx还包括大量一般开销,用于将数据包从接收队列中拉出,并将其调度/排队到需要到达的位置
#show npumgr dinet utilization pps、#show npumgr dinet utilization bps和#show port utilization table命令
它们提供有关DI端口和服务端口上的负载的信息。
实际性能取决于NIC/CPU和CPU分配给iftask。
[local]UGP# show npumgr dinet utilization pps
------ Average DINet Port Utilization (in kpps) ------
Port Type Current 5min 15min
Rx Tx Rx Tx Rx Tx
----- ------------------------ ------- ------- ------- ------- ------- -------
1/0 Virtual Ethernet 0 0 0 0 0 0
2/0 Virtual Ethernet 0 0 0 0 0 0
3/0 Virtual Ethernet 0 0 0 0 0 0
4/0 Virtual Ethernet 0 0 0 0 0 0
5/0 Virtual Ethernet 0 0 0 0 0 0
[local]UGP# show npumgr dinet utilization bps
------ Average DINet Port Utilization (in mbps) ------
Port Type Current 5min 15min
Rx Tx Rx Tx Rx Tx
----- ------------------------ ------- ------- ------- ------- ------- -------
1/0 Virtual Ethernet 1 1 1 1 1 1
2/0 Virtual Ethernet 1 0 1 0 1 0
3/0 Virtual Ethernet 0 0 0 0 0 0
4/0 Virtual Ethernet 0 0 0 0 0 0
5/0 Virtual Ethernet 0 0 0 0 0 0
[local]UGP# show port utilization table
------ Average Port Utilization (in mbps) ------
Port Type Current 5min 15min
Rx Tx Rx Tx Rx Tx
----- ------------------------ ------- ------- ------- ------- ------- -------
1/1 Virtual Ethernet 0 0 0 0 0 0
2/1 Virtual Ethernet 0 0 0 0 0 0
3/10 Virtual Ethernet 0 0 0 0 0 0
3/11 Virtual Ethernet 0 0 0 0 0 0
4/10 Virtual Ethernet 0 0 0 0 0 0
4/11 Virtual Ethernet 0 0 0 0 0 0
5/10 Virtual Ethernet 0 0 0 0 0 0
5/11 Virtual Ethernet 0 0 0 0 0 0命令#show cloud monitor di-network summary
此命令用于监控DI网络的运行状况。这些卡互相发送心跳,失窃被监控。在正常的系统中,不会报告任何损失。
[local]UGP# show cloud monitor di-network summary Card 3 Heartbeat Results: ToCard Health 5MinLoss 60MinLoss 1 Good 0.00% 0.00% 2 Good 0.00% 0.00% 4 Good 0.00% 0.00% 5 Good 0.00% 0.00% Card 4 Heartbeat Results: ToCard Health 5MinLoss 60MinLoss 1 Good 0.00% 0.00% 2 Good 0.00% 0.00% 3 Good 0.00% 0.00% 5 Good 0.00% 0.00% Card 5 Heartbeat Results: ToCard Health 5MinLoss 60MinLoss 1 Good 0.00% 0.00% 2 Good 0.00% 0.00% 3 Good 0.00% 0.00% 4 Good 0.00% 0.00%
命令#show iftask stats summary
如果NPU负载更高,流量可能会被丢弃。
要对此进行评估,可以采用命令#show iftask stats summary输出。
注意:DISCARDS可以是非零值,理想情况下,所有其他计数器应保持为0。
[local]VPC# show iftask stats summary Thursday January 18 16:01:29 IST 2018 ----------------------------------------------------------------------------------------------- Counter SF3 SF4 SF5 SF6 SF7 SF8 SF9 SF10 SF11 SF12 ___TOTAL___ ------------------------------------------------------------------------------------------------ svc_rx 32491861127 16545600654 37041906441 37466889835 32762859630 34931554543 38861410897 16025531220 33566817747 32823851780 312518283874 svc_tx 46024774071 14811663244 40316226774 39926898585 40803541378 48718868048 35252698559 1738016438 4249156512 40356388348 312198231957 di_rx 42307187425 14637310721 40072487209 39584697117 41150445596 44534022642 31867253533 1731310419 4401095653 40711142205 300996952520 di_tx 28420090751 16267050562 36423298668 36758561246 32731606974 30366650898 35201117980 16009902791 33536789041 32815316570 298530385481 __ALL_DROPS__ 1932492 252 17742 790473 11228 627018 844812 60402 0 460830 4745249 svc_tx_drops 0 0 0 0 0 0 0 0 0 0 0 di_rx_drops 0 1 0 0 49 113 579 30200 0 4888 35830 di_tx_drops 0 0 0 0 0 0 0 0 0 0 0 sw_rss_enq_drops 0 0 0 0 0 0 0 0 0 0 0 kni_thread_drops 0 0 0 0 0 0 0 0 0 0 0 kni_drops 0 1 0 0 0 0 124 30200 0 0 30325 mcdma_drops 0 0 0 168 80 194535 758500 0 0 11628 964911 mux_deliver_hop_drops 0 0 0 0 0 0 0 0 0 1019 1019 mux_deliver_drops 0 0 0 0 0 0 0 0 0 0 0 mux_xmit_failure_drops 0 3 0 0 0 0 7 2 0 0 12 mc_dma_thread_enq_drops 0 0 0 0 49 113 580 0 0 3457 4199 sw_tx_egress_enq_drops 1904329 0 0 787971 9004 429214 85022 0 0 429810 3645350 cpeth0_drops 0 0 0 0 0 0 0 0 0 0 0 mcdma_summary_drops 28163 247 17742 2334 2046 3043 0 0 0 10028 63603 fragmentation_err 0 0 0 0 0 0 0 0 0 0 0 reassembly_err 0 0 0 0 0 0 0 0 0 0 0 reassembly_ring_enq_err 0 0 0 0 0 0 0 0 0 0 0 __DISCARDS__ 20331090 9051092 23736055 23882896 23807520 24231716 24116576 8944291 22309474 20135799 20135799
SW-RSS和HW-RSS
RSS是一项能够将来自NIC的入站流量分布到多个DPDK处理器上的功能。通常,NIC在硬件中支持RSS,使其能够在多个工作负载核心之间分配流量。
Staros中的iftask进程已实施软件版本的rss,在以下情况下可以启用此版本:
-nic不支持硬件rss(因此所有tx/rx流量将停留在单个iftask CPU上)。
-nic没有足够的发送/接收队列(比分配给iftask的可用tx/接收CPU的队列少)。 在这种情况下,SW-RSS(全面)可在分配给rx/tx的所有可用的iftask核心之间正确分配。
此功能仅适用于通过服务端口传入的流量。不考虑DI流量。
存在3种配置模式:
-no iftask sw-rss - sw-rss disabled。系统依赖于HW RSS。
-iftask sw-rss comprehensive — 使用sw rss处理所有流量。软件RSS可以与硬件RSS一起运行。无需禁用硬件RSS。但是,SW RSS将负责对发往iftask核心的SERVICE流量执行实际负载均衡。
-iftask sw-rss补充 — 仅对hw-rss不支持的流量使用软件rss(示例:MPLS流量)
使用硬件和软件RSS时,了解流量如何散列到各种iftask/dpdk处理器非常重要。
硬件RSS:散列取决于硬件。下面是一个示例:
[root@host]# ethtool -n enp10s0f1
4 RX rings available
Total 0 rules
[root@host] # ethtool -n enp10s0f0 rx-flow-hash udp4
UDP over IPV4 flows use these fields for computing Hash flow key:
IP SA
IP DA
软件RSS:从Staros 21.6开始,SW RSS版本散列行为如下:
1. In case of IPV6
we only support L3( IP src/dst ) based hashing (same as the old behaviour).
2. In case of IPV4
a. For TCP we support IP src/dst + tcp ports src/dst
b. For UDP fragmented - only IP src/dst
c. For UDP non-fragmented not gtpu ( I.e. Port !=2152) ? IP src/dst + udp port src/dst
d. For UDP non-fragmented and gtpu ( I.e. Port ==2152) - IP src/dst + udp port src/dst + gtp tunnel id
e. Any other protocol ? we default back to IP src/dst
重要信息:加密DI流量的RSS:
如果没有SW-RSS(补充/综合),则所有加密的DI流量可能会在iftask中散列到单个核心。
这将导致此核心始终比其他核心拥有更高的利用率。
自CSCvi06080  ,现在可以通过以下配置命令缓解此问题:
,现在可以通过以下配置命令缓解此问题:
iftask di-net-encrypt-rss
集成CSCvm41257之后 ,此选项将被设为默认值。
有关软件RSS的更多详细信息:
sw-rss的目的是对PMD核心进行负载均衡,并避免吞吐量限制方案,即一个PMD核心在其它核心拥有大量可用容量时达到最大。
所有服务端口入口数据包都从NIC中拉出,并由为其到达的Rx队列提供服务的PMD核心给予MEH封装。
此时,iftask不知道将数据包发送到何处。数据包必须由VNPU处理才能确定内部目标。这些数据包在传递给VNPU时几乎都会通过IOC/流查找。例外情况与因未配置/禁用vlan或目标MAC无效等原因而放弃有关(还有L3转发场景,但这种情况不常见)。
如果未配置sw-rss,则VNPU IOC/流查找处理会紧随MEH封装发生在同一核心上。如果配置了sw-rss,数据包将排队到核心以根据散列进行VNPU处理。VNPU IOC/流查找操作是单个最昂贵的iftask函数;sw-rss允许我们跨所有PMD核心平衡工作负载。
在VNPU IOC/流查找之后,数据包通过DINet传输传输到另一个SF,或通过MCDMA传输排队到本地应用(同样,也有例外,但我认为它们与本讨论无关)。
发送到另一个SF的数据包直接排队到目标卡上的相应MCDMA通道,然后按照DINet Rx。它们不需要(第二个)VNPU通道。
TX/RX队列
在iftask日志中,我们可以看到如下日志:
Tue May 7 15:26:48 2019 PID:8188 APP: max rx queues supported 16 ...
Tue May 7 15:26:48 2019 PID:8188 APP: max tx queues supported 8 ...
Tue May 7 15:26:48 2019 PID:8188 APP: hw rx requested 2 ...
Tue May 7 15:26:48 2019 PID:8188 APP: hw tx requested tx 5
这与实际硬件支持的rx和tx队列支持的数量以及任务请求的tx/rx队列的数量有关。
iftask的请求与分配给iftask的处理器数量密切相关。
注意:每个驱动因素都不一样。一些查询主机,一些具有硬编码。
hw tx requested count是dpdk正在使用的内核数。这通常比分配给iftask的核心总数多1,因为dpdk包括控制/ipc线程运行的核心。此核心与boxer共享并计划为通用cpu(dpdk控制/ipc线程未使用大量cpu)。
请求的hw rx计数通常是PMD核心的数量。
Iftask为每个端口分配最小值(请求值,最大值),并在核心之间分配它们。分配算法有点复杂。目标是尽可能均匀地分配所有核心的工作负载。
Iftask txbatch
自21.9版起,staros具有以下对批处理(聚合流量)非常重要的默认任务配置选项。 当节点正在测试单个(或几个)用户时,这会对性能产生一些负面影响。
# iftask mcdmatxbatch burst size 32 # iftask mcdmatxbatch latency 200 # iftask txbatch burst size 32 # iftask txbatch latency 200
关于这方面的更多解释见于另一份文件:
批量统计数据
为与iftask/dinet相关的QPVC-DI性能开发了bulkstat方案。这对于从性能/负载角度监控设备、服务端口和npu利用率非常有用:
card schema iftask-dinet format EMS,IFTASKDINET,%date%,%time%,%dinet-rxpkts-curr%,%dinet-txpkts-curr%,%dinet-rxpkts-5minave%,%dinet-txpkts-5minave%,%dinet-rxpkts-15minave%,%dinet-txpkts-15minave%,%dinet-txdrops-curr%,%dinet-txdrops-5minave%,%dinet-txdrops-15minave%,%npuutil-now% file 2 port schema iftask-port format EMS,IFTASKPORT,%date%,%time%,%util-rxpkts-curr%,%util-txpkts-curr%,%util-rxpkts-5min%,%util-txpkts-5min%,%util-rxpkts-15min%,%util-txpkts-15min%,%util-txdrops-curr%,%util-txdrops-5min%,%util-txdrops-15min% file 3 card schema npu-util format EMS,NPUUTIL,%date%,%time%,%npuutil-now%,%npuutil-5minave%,%npuutil-15minave%,%npuutil-rxbytes-5secave%,%npuutil-txbytes-5secave%,%npuutil-rxbytes-5minave%,%npuutil-txbytes-5minave%,%npuutil-rxbytes-15minave%,%npuutil-txbytes-15minave%,%npuutil-rxpkts-5secave%,%npuutil-txpkts-5secave%,%npuutil-rxpkts-5minave%,%npuutil-txpkts-5minave%,%npuutil-rxpkts-15minave%,%npuutil-txpkts-15minave%
修订历史记录
| 版本 | 发布日期 | 备注 |
|---|---|---|
1.0 |
09-Jun-2018
|
初始版本 |
 反馈
反馈