QoS 常见问题解答
目录
简介
本文档解答了与服务质量 (QoS) 有关的最常见问题 (FAQ)。
常规
问:什么是服务质量(QoS)?
答:QoS是指网络通过各种底层技术(包括帧中继、异步传输模式(ATM)、以太网和802.1网络、SONET和IP路由网络)为所选网络流量提供更好服务的能力。
QoS 是一组技术,借助这些技术,应用可以在数据吞吐能力(带宽)、时延变化(抖动)和延迟方面请求并接收可预测的服务级别。特别是,QoS 功能通过以下方法提供更好、更便于预测的网络服务:
支持专用带宽。
改进损失特性。
避免和管理网络拥塞。
对网络流量进行整形。
设置网络中的流量优先级。
互联网工程任务组 (IETF) 定义了以下两种 QoS 架构:
集成服务 (IntServ)
差分服务 (DiffServ)
IntServ 沿着网络端到端路径上的设备,使用资源预留协议 (RSVP) 明确发出应用流量的 QoS 需求信令。如果路径中的每个网络设备可以保留必要的带宽,则始发应用可以开始传输。RSVP 的定义请参阅征求意见 (RFC) 2205,IntServ 的定义请参阅 RFC 1633 。
DiffServ 集中关注聚合的设置 QoS。DiffServ 使用 IP 报头中的差分服务代码点 (DSCP) 来表示所需的 QoS 级别,而不是发送应用的 QoS 需求信令。Cisco IOS® 软件版本 12.1(5)T 引入了针对 Cisco 路由器的 DiffServ 标准。有关更多信息,请参阅下列文档:
问:什么是拥塞、延迟和抖动?
A.接口出现流量超过其可处理流量时会发生拥塞。网络拥塞点是服务质量 (QoS) 机制的强大候选。下面是一个典型拥塞点的示例:

网络拥塞会导致延迟。网络以及网络设备引入几种延迟,如了解数据包语音网络中的延迟中所述。根据“了解分组语音网络中的抖动”(Cisco IOS平台)中的解释,延迟变化就是抖动。 延迟和抖动都需要受到控制并减至最小,以支持实时和交互式流量。

问:什么是MQC?
A. MQC代表模块化服务质量(QoS)命令行界面(CLI)。 它旨在通过定义跨平台 QoS 行为的通用命令语法和结果集,来简化思科路由器和交换机上的 QoS 配置。此模型取代了之前为每个 QoS 功能和每个平台定义特定语法的模型。
MQC 包含以下三个步骤:
通过发出 class-map 命令定义一个流量类。
通过发出 policy-map 命令将流量类与一个或多个 QoS 功能相关联来创建流量策略。
通过发出 service-policy 命令将流量策略附加到接口、子接口或虚拟电路 (VC)。
注意:您可以使用MQC语法实施DiffServ的流量调节功能,例如标记和整形。
有关更多信息,请参阅模块化服务质量命令行界面。
问:仅在启用DCEF的VIP接口上支持service-policy消息意味着什么?
A.在Cisco 7500系列的通用接口处理器(VIP)上,仅支持分布式服务质量(QoS)功能,如Cisco IOS 12.1(5)T、12.1(5)E和12.0(14)S。启用分布式思科快速转发 (dCEF) 将自动启用分布式 QoS。
非 VIP 接口(称为传统接口处理器 (IP))支持在路由交换处理器 (RSP) 上启用集中式 QoS 功能。 有关更多信息,请参阅下列文档:
问:服务质量(QoS)策略支持多少类?
答:在Cisco IOS 12.2之前的版本中,最多只能定义256个类,如果相同的类被重用于不同的策略,则每个策略中最多可以定义256个类。如果有两个策略,则两个策略中的类总数不应超过256。如果策略包括基于类的加权公平队列(CBWFQ)(意味着它在任何类中都包含bandwidth [或优先级]语句),则支持的类总数为64。
思科 IOS 版本 12.2(12)、12.2(12)T 和 12.2(12)S 已经更改了 256 个全局类映射的限制,现在可以配置多达 1024 个全局类映射并在同一个策略映射内使用 256 个类映射。
问:应用服务策略时,如何处理路由更新和点对点协议(PPP)/高级数据链路控制(HDLC)保持连接?
A. Cisco IOS路由器使用以下两种机制确定控制数据包的优先级:
IP 优先级
pak_priority
两种机制都旨在确保出站接口出现拥塞时,路由器和队列系统不会丢弃或最后丢弃关键控制数据包。有关详细信息,请参阅了解如何在具有 QoS 服务策略的接口上对路由更新和控制数据包进行排队。
问:配置了集成路由和桥接(IRB)的接口是否支持服务质量(QoS)?
答:不。当接口配置为IRB时,您无法配置QoS功能。
分类和标记
问:什么是服务质量(QoS)预分类?
答:QoS预分类使您能够匹配和分类进行隧道封装和/或加密的数据包的原始IP报头内容。此功能未说明将服务类型 (ToS) 字节的初始值从原始数据包报头复制到隧道报头的过程。有关更多信息,请参阅下列文档:
问:哪些数据包报头字段可以重新标记?可用的值有哪些?
答:基于类的标记功能允许您设置或标记数据包的第2层、第3层或多协议标签交换(MPLS)报头。有关更多信息,请参阅下列文档:
问:我是否可以根据URL确定流量的优先级?
答:是的。网络应用识别 (NBAR) 可以让您通过匹配应用层的字段来对数据包进行分类。在引入 NBAR 之前,最精细的分类是第 4 层传输控制协议 (TCP) 和用户数据报协议 (UDP) 端口号。有关更多信息,请参阅下列文档:
问:哪些平台和Cisco IOS软件版本支持基于网络的应用识别(NBAR)?
A.以下版本的Cisco IOS软件引入了对NBAR的支持:
Platform 最低 Cisco IOS 软件版本 7200 12.1(5)T 7100 12.1(5)T 3660 12.1(5)T 3640 12.1(5)T 3620 12.1(5)T 2600 12.1(5)T 1700 12.2(2)T 注意:您需要启用思科快速转发(CEF)才能使用NBAR。
以下平台提供分布式 NBAR (DNBAR):
Platform 最低 Cisco IOS 软件版本 7500 12.2(4)T、12.1(6)E FlexWAN 12.1(6)E 注意:Catalyst 6000多层交换功能卡(MSFC)VLAN接口、Cisco 12000系列或Catalyst 5000系列的路由交换模块(RSM)不支持NBAR。如果未在上表中看到特定的平台,请联系思科技术代表。
排队和拥塞管理
问:排队的作用是什么?
A.队列设计为通过将超额数据包存储在缓冲区直至带宽可用来适应网络设备接口上的临时拥塞。思科 IOS 路由器支持多种排队方法,以满足不同应用的各种带宽、抖动和延迟要求。
大多数接口上的默认机制为先进先出 (FIFO)。 有些流量类型具有更高的延迟/抖动需求。因此,应配置或默认启用以下备用排队机制之一:
加权公平队列 (WFQ)
基于类的加权公平队列 (CBWFQ)
低延迟队列 (LLQ),实际上是具有优先级队列 (PQ) 的 CBWFQ(称为 PQCBWFQ)
优先级队列 (PQ)
自定义队列 (CQ)
通常仅在出站接口出现排队。路由器对从接口出站的数据包进行排队。可以对入站流量实施管制,但通常无法对入站流量进行排队(思科 7500 系列路由器的接收端缓冲是例外情况,该路由器使用分布式思科快速转发 (dCEF) 将数据包从入口转发到出口接口);有关更多信息,请参阅了解使用率为 99% 的 VIP CPU 和 Rx 端缓冲。在思科 7500 和 12000 系列等高端分布式平台上,入站接口可能会根据自身的交换决定,使用自身的数据包缓冲区来存储交换到拥塞出站接口的超额流量。在极少数情况下(通常是在入站接口馈送较慢的出站接口的情况下),入站接口在数据包内存用尽时,会遇到不断递增的已忽略错误。过度拥塞可能导致输出队列丢弃。大部分时间,输入队列丢弃都具有另外的根本原因。有关丢弃故障排除的更多信息,请参阅以下文档:
有关更多信息,请参阅下列文档:
问:加权公平队列(WFQ)和基于类的加权公平队列(CBWFQ)如何运行?
A.公平排队试图在活动会话或IP流之间分配接口带宽的公平份额。它根据 IP 报头的多个字段和数据包长度,使用散列算法将数据包分成多个子队列,子队列通过会话识别号来识别。下面是权重的计算方法:
W = K / (优先级+1)
对于 Cisco IOS 12.0(4)T 和更低版本,K = 4096;对于 12.0(5)T 和更高版本,K = 32384。
权重越低,优先级和带宽份额越高。除权重外,还要考虑数据包的长度。
CBWFQ 允许您定义一个流量类并为其分配最低带宽保证。这种机制背后的算法是 WFQ,也是其名称的由来。要配置 CBWFQ,可在 map-class 语句中定义特定的类。然后为策略映射中的每个类分配一个策略。此策略映射随后将出站附加到某个接口。有关更多信息,请参阅下列文档:
问:如果基于类的加权公平队列(CBWFQ)中的某个类未使用其带宽,其他类能否使用该带宽?
答:是的。尽管已使用“保留”和“预留带宽”等字样来描述带宽保证(通过发出 bandwidth 和 priority 命令实现),但这两个命令都没有实现真正的带宽预留。这意味着,如果某个流量类未使用为其配置的带宽,则可以与其他类共享任何未使用的带宽。
如果是优先级类,排队系统将强行对此规则实施一种重要例外。如上所述,优先级类的流入负载由数据流监察器测量。在出现拥塞时,优先级类不能使用任何额外的带宽。有关更多信息,请参阅 Qos 服务策略的 bandwidth 和 priority 命令的比较。
问:子接口是否支持基于类的加权公平队列(CBWFQ)?
答:Cisco IOS逻辑接口本身不支持拥塞状态,也不支持应用排队方法的服务策略的直接应用。相反,首先需要使用通用流量整形 (GTS) 或基于类的整形将整形应用于子接口。有关更多信息,请参阅将 QoS 功能应用于以太网子接口。
问:策略映射中的priority和bandwidth语句有何区别?
答:priority和bandwidth命令在功能以及它们通常支持的应用方面有所不同。下表总结了这些区别:
功能 bandwidth 命令 priority 命令 最小带宽保证 Yes Yes 最大带宽保证 无 Yes 内置监察器 无 Yes 提供低延迟 无 Yes 有关更多信息,请参阅 Qos 服务策略的 bandwidth 和 priority 命令的比较。
问:如何计算FlexWAN和通用接口处理器(VIP)上的队列限制?
A.假设VIP或FlexWAN上有足够的SRAM,则队列限制根据最大延迟500毫秒计算,平均数据包大小为250字节。下面是一个具有 1 Mbps 带宽的类的示例:
队列限制 = 1000000 / (250 x 8 x 2) = 250
随着可用数据包内存的减少以及大量虚拟电路 (VCS) 的出现,系统会分配较小的队列限制值。
在以下示例中,PA-A3 安装在思科 7600 系列的 FlexWAN 卡中,其支持多个具有 2 MB 永久虚拟电路 (PVC) 的子接口。 服务策略应用于每个 VC。
class-map match-any XETRA-CLASS match access-group 104 class-map match-any SNA-CLASS match access-group 101 match access-group 102 match access-group 103 policy-map POLICY-2048Kbps class XETRA-CLASS bandwidth 320 class SNA-CLASS bandwidth 512 interface ATM6/0/0 no ip address no atm sonet ilmi-keepalive no ATM ilmi-keepalive ! interface ATM6/0/0.11 point-to-point mtu 1578 bandwidth 2048 ip address 22.161.104.101 255.255.255.252 pvc ABCD class-vc 2048Kbps-PVC service-policy out POLICY-2048Kbps异步传输模式 (ATM) 接口获取整个接口的队列限制。该限制取决于总可用缓冲区、FlexWAN 上的物理接口数以及接口上允许的最大排队延迟。每个 PVC 根据自己的持续信元速率 (SCR) 或最小信元速率 (MCR) 获得接口限制的一部分,并且每个类根据其带宽分配获得 PVC 限制的一部分。
show policy-map interface 命令的以下输出示例派生自具有 3687 个全局缓冲区的 FlexWAN。发出 show buffer 命令可查看此值。基于 2 Mbps 的 PVC 带宽,为每条 2 Mbps PVC 分配 50 个数据包 (2047/149760 x 3687 = 50)。 然后为每个类分配 50 的一部分,如以下输出所示:
service-policy output: POLICY-2048Kbps class-map: XETRA-CLASS (match-any) 687569 packets, 835743045 bytes 5 minute offered rate 48000 bps, drop rate 6000 BPS match: access-group 104 687569 packets, 835743045 bytes 5 minute rate 48000 BPS queue size 0, queue limit 7 packets output 687668, packet drops 22 tail/random drops 22, no buffer drops 0, other drops 0 bandwidth: kbps 320, weight 15 class-map: SNA-CLASS (match-any) 2719163 packets, 469699994 bytes 5 minute offered rate 14000 BPS, drop rate 0 BPS match: access-group 101 1572388 packets, 229528571 bytes 5 minute rate 14000 BPS match: access-group 102 1146056 packets, 239926212 bytes 5 minute rate 0 BPS match: access-group 103 718 packets, 245211 bytes 5 minute rate 0 BPS queue size 0, queue limit 12 packets output 2719227, packet drops 0 tail/random drops 0, no buffer drops 0, other drops 0 bandwidth: kbps 512, weight 25 queue-limit 100 class-map: class-default (match-any) 6526152 packets, 1302263701 bytes 5 minute offered rate 44000 BPS, drop rate 0 BPS match: any 6526152 packets, 1302263701 bytes 5 minute rate 44000 BPS queue size 0, queue limit 29 packets output 6526840, packet drops 259 tail/random drops 259, no buffer drops 0, other drops 0如果流量流使用较大的数据包大小,则 show policy-map interface 命令输出可能会报告 no bufferdrops 字段的递增值,因为在达到队列限制之前可能会用尽缓冲区。在这种情况下,请尝试将非优先级类的队列限制手动调低。有关详细信息,请参阅了解 IP 到 ATM CoS 的传输队列限制。
问:如何验证队列限制值?
A.在非分布式平台上,默认情况下队列限制为64个数据包。以下示例输出是在 Cisco 3600 系列路由器上捕获的:
november# show policy-map interface s0 Serial0 Service-policy output: policy1 Class-map: class1 (match-all) 0 packets, 0 bytes 5 minute offered rate 0 BPS, drop rate 0 BPS Match: ip precedence 5 Weighted Fair Queueing Output Queue: Conversation 265 Bandwidth 30 (kbps) Max Threshold 64 (packets) !--- Max Threshold is the queue-limit. (pkts matched/bytes matched) 0/0 (depth/total drops/no-buffer drops) 0/0/0 Class-map: class2 (match-all) 0 packets, 0 bytes 5 minute offered rate 0 BPS, drop rate 0 BPS Match: ip precedence 2 Match: ip precedence 3 Weighted Fair Queueing Output Queue: Conversation 266 Bandwidth 24 (kbps) Max Threshold 64 (packets) (pkts matched/bytes matched) 0/0 (depth/total drops/no-buffer drops) 0/0/0 Class-map: class-default (match-any) 0 packets, 0 bytes 5 minute offered rate 0 BPS, drop rate 0 BPS Match: any
问:能否在类内启用公平队列?
答:具有分布式服务质量(QoS)的Cisco 7500系列支持每类公平队列。其他平台(包括思科 7200 系列和思科 2600/3600 系列)支持在 class-default 类中执行加权公平队列 (WFQ);所有带宽类均采用先进先出 (FIFO) 机制。
问:可以使用哪些命令来监控排队?
A.使用以下命令监控排队:
show queue {interface}{interface number} - 在思科 7500 系列以外的思科 IOS 平台上,此命令用于显示活动队列或会话。如果接口或虚拟电路 (VC) 未拥塞,则不会列出任何队列。Cisco 7500 系列不支持 show queue 命令。
show queueing interface interface-number [vc [[vpi/] vci] - 此命令用于显示接口或 VC 的队列统计信息。即使没有拥塞,仍然可以在此处看到一些命中数,因为无论是否存在拥塞,始终都会对进程切换数据包进行计数。除非存在拥塞,否则不会计入思科快速转发 (CEF) 和快速交换数据包。优先级队列 (PQ)、自定义队列 (CQ) 和加权公平队列 (WFQ) 等传统排队机制不提供分类统计信息。只有高于 12.0(5)T 的映像中基于模块化服务质量命令行界面 (MQC) 的功能提供这些统计数据。
show policy interface {interface}{interface number} - packets 计数器计算与类条件匹配的数据包数量。无论接口是否发生拥塞,此计数器都会增加。packets matched 计数器表示当接口拥塞时与类条件匹配的数据包数量。有关数据包计数器的更多信息,请参阅下列文档:
思科基于类的 QoS 配置和统计信息 MIB - 提供简单网络管理协议 (SNMP) 监控功能。
Q. RSVP可以与基于类的加权公平队列(CBWFQ)结合使用。 为接口同时配置资源预留协议 (RSVP) 和 CBWFQ 时,RSVP 和 CBWFQ 是否独立工作,如同各自单独运行时的表现一样?RSVP 的行为看起来就像 CBWFQ 没有针对带宽可用性、评估和分配进行配置一样。
A.在Cisco IOS软件版本12.1(5)T及更高版本中使用RSVP和CB-WFQ时,路由器可以运行,使RSVP流和CBWFQ类共享接口或PVC上的可用带宽,而无需超订用。
IOS 软件版本 12.2(1)T 及更高版本允许 RSVP 使用自己的“ip rsvp 带宽”池进行准入控制,而 CBWFQ 则对 RSVP 数据包进行分类、管制和调度。这里假定数据包由发送方预先标记,而且非 RSVP 数据包的标记有所不同。
拥塞避免加权随机早期检测 (WRED)
问:是否可以同时启用加权随机早期检测(WRED)和低延迟队列(LLQ)或基于类的加权公平队列(CBWFQ)?
答:是的。排队定义了数据包离开队列的顺序。这意味着,它定义了一种数据包调度机制。它还可以用于提供公平带宽分配和最低带宽保证。相反,征求意见 (RFC) 2475 将丢包定义为“基于指定的规则丢弃数据包的过程。” 默认丢包机制为尾部丢弃,即接口在队列已满时丢弃数据包。随机早期检测 (RED) 和思科 WRED 为备用丢包机制,该机制在队列已满之前就开始随机丢包,并寻求保持一致的平均队列深度。WRED 使用数据包的 IP 优先级值做出有区别的丢弃决策。有关详细信息,请参阅加权随机早期探测 (WRED)。
问:如何监控加权随机早期检测(WRED),并确保其真正生效?
A. WRED监控平均队列深度,并在计算值超过最小阈值时开始丢弃数据包。发出 show policy-map interface 命令,并监控平均队列深度值,如以下示例所示:
Router# show policy interface s2/1 Serial2/1 output : p1 Class c1 Weighted Fair Queueing Output Queue: Conversation 265 Bandwidth 20 (%) (pkts matched/bytes matched) 168174/41370804 (pkts discards/bytes discards/tail drops) 20438/5027748/0 mean queue depth: 39 Dscp Random drop Tail drop Minimum Maximum Mark (Prec) pkts/bytes pkts/bytes threshold threshold probability 0(0) 2362/581052 1996/491016 20 40 1/10 1 0/0 0/0 22 40 1/10 2 0/0 0/0 24 40 1/10 [output omitted]
管制和整形
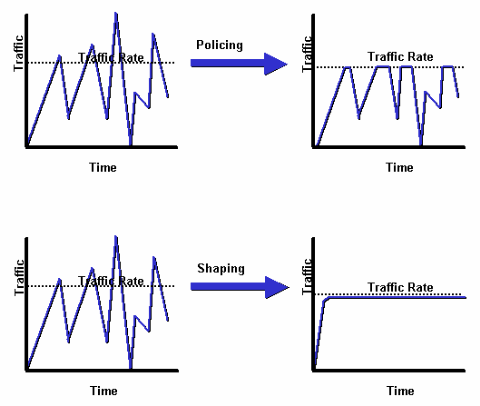
监管和整形有什么区别?
A.以下图表说明了主要区别。流量整形在队列中保留额外的数据包,然后对额外的数据包进行调度,以便随时间的增加稍后传输。流量整形的结果是一个平滑的数据包输出速率。相反,流量监察传播突发流量。当流量速率达到所配置的最大速率时,将丢弃(或重新标记)超额流量。 其结果是,输出速率显示为带有波峰和波谷的锯齿状。
有关更多信息,请参阅监察和整形概述。

问:什么是令牌桶?算法如何工作?
A.令牌桶本身没有丢弃或优先级策略。下面是令牌桶工作原理的示例:
以一定速率将令牌添加到令牌桶中。
每个令牌是源发送一定数量的位的权限。
要发送数据包,流量管制器必须能够从令牌桶中删除与所代表的数据包大小相等的若干令牌。
如果令牌桶中没有足够的令牌来发送数据包,数据包会等待直至令牌桶中有足够的令牌(适用于整形器),或者数据包会被丢弃或标记(适用于管制器)。
桶本身具有指定的容量。如果令牌桶容量已满,新到达的令牌会被丢弃,后续数据包无法使用令牌桶。因此,在任何时刻,源能够发送到网络中的最大突发流量都大致与令牌桶的大小成正比。令牌桶允许突变流量,但会对其进行限制。
问:对于基于类的策略管制之类的流量管制器,承诺突发量(BC)和超额突发量(Be)意味着什么?我应如何选择这些值?
A.流量监察器不会缓冲过量的数据包并在稍后传输它们,整形器的情况也是如此。相反,管制器不会缓冲数据包,而是执行简单的发送或不发送策略。在拥塞期间,由于无法缓冲,因此可执行的最佳方案是通过正确配置扩展突发量来减少主动丢包的情况。因此,非常有必要了解管制器如何使用正常突发量和扩展突发量值,来确保达到所配置的承诺信息速率 (CIR)。
路由器的通用缓冲规则中大致模拟了突发参数。此规则建议配置与往返时间比特率相等的缓冲,以便在拥塞时容纳所有连接的未完成传输控制协议 (TCP) 窗口。
下表说明 normal burst 值和 extended burst 值的用途及推荐公式:
突发参数 目的 推荐的公式 normal burst
实现一个标准令牌桶。
设置令牌桶的最大大小(但 Be 大于 BC 时,可以借用令牌)。
确定令牌桶的大小;其原因在于,如果令牌通容量已满,新到达的令牌会被丢弃,后续数据包无法使用令牌桶。
注意:1.5秒是典型的往返时间。
extended burst
实现一个具有扩展突发功能的令牌桶。
通过设置 BC = Be 禁用。
当 BC 等于 Be 时,流量管制器无法借用令牌并在可用令牌不足时直接丢弃数据包。
并非所有平台都使用或支持相同的管制器参数值范围。请参阅以下文档以了解您的特定平台支持的值:
问:承诺接入速率(CAR)或基于类的策略如何决定数据包是否符合或超过承诺信息速率(CIR)?即使合规速率小于所配置的 CIR,路由器还是会丢弃数据包并报告超额速率。
A.流量监察器使用正常突发和扩展突发值来确保达到配置的CIR。要确保较好的吞吐量,设置足够高的突发值十分重要。如果突发量数值配置过低,实现的速率可能远低于所配置的速率。严重的临时突发量会对传输控制协议 (TCP) 流量的吞吐量产生重大不利影响。对于 CAR,发出 show interface rate-limit 命令以监控当前突发量,并确定显示值是否始终接近限制 (BC) 和扩展限制 (Be) 值。
rate-limit 256000 7500 7500 conform-action continue exceed-action drop rate-limit 512000 7500 7500 conform-action continue exceed-action drop router# show interfaces virtual-access 26 rate-limit Virtual-Access26 Cable Customers Input matches: all traffic params: 256000 BPS, 7500 limit, 7500 extended limit conformed 2248 packets, 257557 bytes; action: continue exceeded 35 packets, 22392 bytes; action: drop last packet: 156ms ago, current burst: 0 bytes last cleared 00:02:49 ago, conformed 12000 BPS, exceeded 1000 BPS Output matches: all traffic params: 512000 BPS, 7500 limit, 7500 extended limit conformed 3338 packets, 4115194 bytes; action: continue exceeded 565 packets, 797648 bytes; action: drop last packet: 188ms ago, current burst: 7392 bytes last cleared 00:02:49 ago, conformed 194000 BPS, exceeded 37000 BPS有关更多信息,请参阅下列文档:
问:突发量和队列限制是否相互独立?
A.是,监察器突发量和队列限制是相互独立且独立的。可以将监察器视为允许一定数量数据包(或字节)的门,将队列视为在网络传输之前保留承认数据包的大小为队列限制 的桶。理论上讲,您希望桶的大小足够容纳门(监察器)所承认字节/数据包数的突发流量。
服务质量 (QoS) 帧中继
问:对于承诺信息速率(CIR)、承诺突发量(BC)、超额突发量(Be)和最小CIR(MinCIR),应该选择什么值?
A.通过发出frame-relay traffic-shaping命令启用的帧中继流量整形支持多个可配置的参数。这些参数包括 frame-relay cir、frame-relay mincir 和 frame-relay BC。有关选择这些参数值并了解相关 show 命令的详细信息,请参阅以下文档:
问:在Cisco IOS 12.1中,帧中继主接口上的优先级队列是否起作用?
A.帧中继接口同时支持接口排队机制和每虚电路(VC)排队机制。从思科 IOS 12.0(4)T 开始,只有在配置帧中继流量整形 (FRTS) 时,接口队列才支持先进先出 (FIFO) 或基于接口的优先级排队 (PIPQ)。 因此,如果升级到 Cisco IOS 12.1,将无法再使用以下配置。
interface Serial0/0 frame-relay traffic-shaping bandwidth 256 no ip address encapsulation frame-relay IETF priority-group 1 ! interface Serial0/0.1 point-to-point bandwidth 128 ip address 136.238.91.214 255.255.255.252 no ip mroute-cache traffic-shape rate 128000 7936 7936 1000 traffic-shape adaptive 32000 frame-relay interface-dlci 200 IETF如果未启用 FRTS,可以将备用排队方法(如基于类的加权公平队列 (CBWFQ))应用于主接口,此时主接口的作用类似于单个带宽管道。此外,从思科 IOS 12.1.1(T) 开始,可以在帧中继主接口上启用帧中继永久虚拟电路 (PVC) 优先级接口排队 (PIPQ) 。您可以定义“高”、“中”、“正常”、或“低”四个优先级的 PVC 并在主接口上发出 frame-relay interface-queue priority 命令,如以下示例所示:
interface Serial3/0 description framerelay main interface no ip address encapsulation frame-relay no ip mroute-cache frame-relay traffic-shaping frame-relay interface-queue priority interface Serial3/0.103 point-to-point description frame-relay subinterface ip address 1.1.1.1 255.255.255.252 frame-relay interface-dlci 103 class frameclass map-class frame-relay frameclass frame-relay adaptive-shaping becn frame-relay cir 60800 frame-relay BC 7600 frame-relay be 22800 frame-relay mincir 8000 service-policy output queueingpolicy frame-relay interface-queue priority low
问:帧中继流量整形(FRTS)是否与分布式思科快速转发(dCEF)和基于分布式类的加权公平队列(dCBWFQ)配合使用?
答:从Cisco IOS 12.1(5)T开始,Cisco 7500系列中的VIP仅支持QoS功能的分布式版本。要在帧中继接口上启用流量整形,请使用分布式流量整形 (DTS)。 有关更多信息,请参阅下列文档:
异步传输模式 (ATM) 的服务质量 (QoS)
问:在异步传输模式(ATM)接口上,我应在何处应用具有基于类的加权公平队列(CBWFQ)和低延迟队列(LLQ)的服务策略?
A.从Cisco IOS 12.2开始,ATM接口支持三个级别的服务策略或逻辑接口:主接口、子接口和永久虚拟电路 (PVC)。 应用策略的位置取决于启用服务质量 (QoS) 功能的位置。由于 ATM 接口监控每条虚拟电路 (VC) 的拥塞级别并维护每个 VC 的超额数据包队列,因此应在每条 VC 上应用排队策略。有关更多信息,请参阅下列文档:
问:IP到异步传输模式(ATM)服务类别(COs)队列统计哪些字节?
A.服务策略中配置的带宽和优先级命令分别启用基于类的加权公平队列(CBWFQ)和低延迟队列(LLQ),这些命令使用一个Kbps值,该值将计算与show interface命令输出相同的开销字节。具体来讲,第 3 层排队系统对逻辑链路控制/子网访问协议 (LLC/SNAP) 进行计数。 它不执行下列计数:
ATM 第 5 适配层 (AAL5) 报尾
填充使最后一个信元成为 48 字节的偶数倍
5 字节信元头
问:有多少条虚电路(VCS)可以同时支持服务策略?
A.以下文档提供可支持的异步传输模式(ATM)VCS数量的有用指南。已安全部署约 200 至 300 条 VBR-nrt 永久虚拟电路 (PVC) :
另外,请考虑以下事项:
使用功能强大的处理器。例如,VIP4-80 提供的性能远远高于 VIP2-50。
可用的数据包内存量。在 NPE-400 上,为数据包缓冲区预留了高达 32 MB (在 256 MB 的系统中)的空间。在 NPE-200 上,为数据包缓冲区预留了高达 16 MB (在 128 MB 的系统中)的空间。
在多达 200 条 ATM PVC 上同时运行每条 VC 加权随机早期探测 (WRED) 的配置已经过广泛测试。VIP2-50 上可用于每条 VC 的队列的数据包内存数量有限。例如,具有 8-MB SRAM 的 VIP2-50 提供 1085 个数据包缓冲区,可用于 WRED 运行位置的 IP 到 ATM CoS 的每条 VC 排队。如果已配置 100 条 ATM PVC,并且所有 VCS 同时遇到过度拥塞情况(可以在使用非 TCP 流量受控源的测试环境中进行模拟),则平均每条 PVC 约有 10 个数据包可进行缓冲,这对于 WRED 成功运行而言可能太短。因此,如果有大量 ATM PVC 运行每条 VC 的 WRED 并同时面临拥塞,强烈建议在设计中使用具有较大 SRAM 的 VIP2-50 设备。
配置的活动PVC的数量越多,其平均信元速率(SCR)就越低,因此WRED要求的在PVC上运行的队列就越短。因此,与使用 IP 到 ATM 服务类别 (CoS) 第 1 阶段功能的默认 WRED 配置文件的情形一样,在大量低速拥塞 ATM PVC 上激活每条 VC 的 WRED 时,配置较低的 WRED 丢弃阈值可以将 VIP 上缓冲区不足的风险降至最低。VIP 的缓冲短缺不会导致任何故障。如果 VIP 上的缓冲区不足,在缓冲区不足期间,IP 到 ATM CoS 第 1 阶段功能会直接降级为先进先出 (FIFO) 尾部丢弃策略(也就是说,系统将执行与未在 PVC 上激活 IP 到 ATM CoS 功能时相同的丢包策略)。
可以合理支持的同时使用的最大 VCS 数。
问:哪种异步传输模式(ATM)硬件支持IP到ATM服务类别(CO)功能,包括基于类的加权公平队列(CBWFQ)和低延迟队列(LLQ)?
A. IP到ATM CO是指基于每条虚电路(VC)启用的一组功能。根据这一定义,ATM 接口处理器 (AIP)、PA-A1 和 4500 ATM 网络处理器均不支持 IP 到 ATM CoS。根据 PA-A3 和大多数网络模块(ATM-25 除外)给出的定义,这些 ATM 硬件不支持每条 VC 的排队。有关更多信息,请参阅以下文档:
语音和服务质量 (QoS)
问:链路分段和交织(LFI)如何工作?
A.当网络处理大型数据包(例如通过WAN进行的文件传输协议(FTP)传输)时,Telnet和IP语音等交互流量容易出现延迟增加。当 FTP 数据包在较慢的 WAN 链路上排队时,交互式流量的数据包延迟较长。因此我们设计了一种方法,旨在对较大的数据包进行分段并在较大数据包 (FTP) 分段之间对较小的(语音)数据包进行排队。Cisco IOS 路由器支持多种第 2 层分段机制。有关更多信息,请参阅下列文档:
问:我可以使用哪些工具监控IP语音的性能?
答:思科目前提供多种选项,用于使用思科的IP语音解决方案监控网络服务质量(QoS)。这些解决方案不使用感知语音质量测量 (PSQM) 或一些新提出的语音质量测量算法来测量语音质量。Agilent (HP) 和 NetIQ 提供的工具可用于此用途。但是,思科提供的工具可以通过测量延迟、抖动和丢包,来提供您所体验的语音质量。有关更多信息,请参阅使用 Cisco Service Assurance Agent 和 Internetwork Performance Monitor 管理语音 IP (VoIP) 网络的服务质量。
问: Q. %SW_MGR-3-CM_ERROR_FEATURE_CLASS :Connection Manager Feature Error:Class SSS:(QoS) - install error, ignore.
A.观察到的功能安装错误是在将无效配置应用到模板时预期出现的行为。它表明因冲突而没有应用服务策略。一般来讲,不应为分层策略映射中子策略的 class-default 配置整形,而应在接口的父策略中进行配置。结果,此消息将与回溯消息一起打印出来。
使用基于会话的策略,只能在子接口或 PVC 级别执行 class-default 的整形。不支持在物理接口进行整形。如果在物理接口完成配置,显示此错误消息是预料之中的行为。
对于 LNS,另一个可能的原因是启动会话时可通过 RADIUS 服务器设置服务策略。发出 show tech 命令以查看 RADIUS 服务器配置,并查看会话启动或抖动时通过 RADIUS 服务器安装的所有非法服务策略。
相关信息
修订历史记录
| 版本 | 发布日期 | 备注 |
|---|---|---|
1.0 |
11-Apr-2002
|
初始版本 |
 反馈
反馈