Ultra-M UCS 240M4 escolhe a falha HDD - Procedimento quente da troca - vEPC
Opções de download
Linguagem imparcial
O conjunto de documentação deste produto faz o possível para usar uma linguagem imparcial. Para os fins deste conjunto de documentação, a imparcialidade é definida como uma linguagem que não implica em discriminação baseada em idade, deficiência, gênero, identidade racial, identidade étnica, orientação sexual, status socioeconômico e interseccionalidade. Pode haver exceções na documentação devido à linguagem codificada nas interfaces de usuário do software do produto, linguagem usada com base na documentação de RFP ou linguagem usada por um produto de terceiros referenciado. Saiba mais sobre como a Cisco está usando a linguagem inclusiva.
Sobre esta tradução
A Cisco traduziu este documento com a ajuda de tecnologias de tradução automática e humana para oferecer conteúdo de suporte aos seus usuários no seu próprio idioma, independentemente da localização. Observe que mesmo a melhor tradução automática não será tão precisa quanto as realizadas por um tradutor profissional. A Cisco Systems, Inc. não se responsabiliza pela precisão destas traduções e recomenda que o documento original em inglês (link fornecido) seja sempre consultado.
Índice
Introdução
Este original descreve as etapas exigidas para substituir a movimentação defeituosa da unidade de disco rígido (HDD) no server em um Ultra-M setup que a rede virtual de StarOS dos anfitriões funciona (VNFs).
Informações de Apoio
Ultra-M é uma solução móvel virtualizada pré-embalada e validada do núcleo do pacote projetada simplificar o desenvolvimento de VNFs. OpenStack é o gerente virtualizado da infraestrutura (VIM) para Ultra-M e consiste nestes tipos de nó:
- Cálculo
- Disco do armazenamento do objeto - Cálculo (OSD - Cálculo)
- Controlador
- Plataforma de OpenStack - Diretor (OSPD)
A arquitetura de nível elevado de Ultra-M e os componentes envolvidos são descritos nesta imagem:
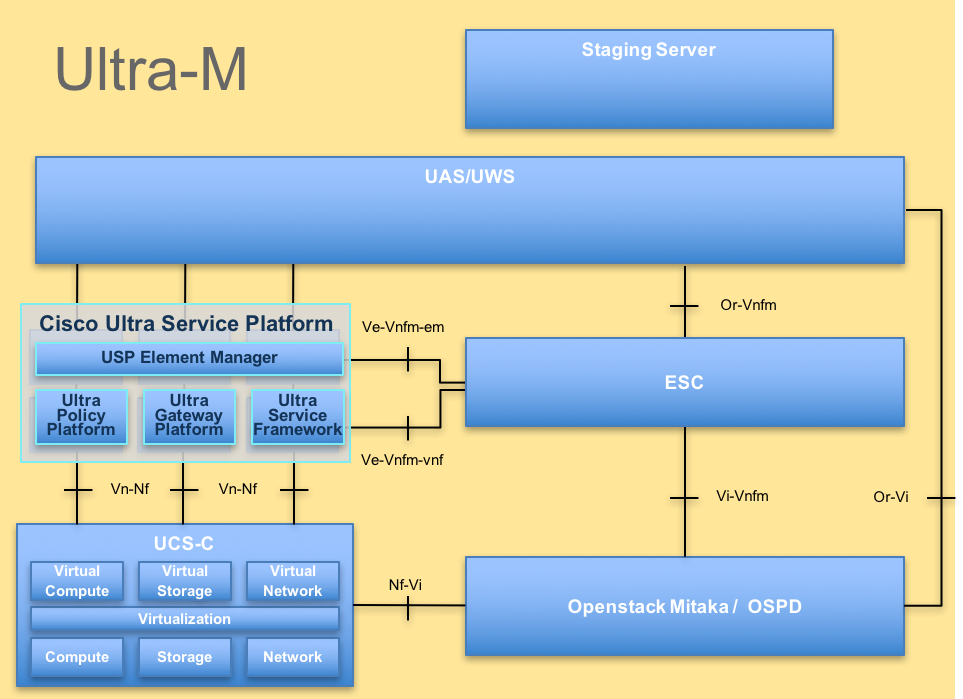 O original de UltraM ArchitectureThis é pretendido para os Ciscos personnel que são familiares com a plataforma de Cisco Ultra-M e detalha as etapas exigidas ser realizado em OpenStack em nível na altura da substituição do server OSPD.
O original de UltraM ArchitectureThis é pretendido para os Ciscos personnel que são familiares com a plataforma de Cisco Ultra-M e detalha as etapas exigidas ser realizado em OpenStack em nível na altura da substituição do server OSPD.
Note: A liberação M 5.1.x é considerada ultra a fim definir os procedimentos neste original.
Abreviaturas
| VNF | Função da rede virtual |
| CF | Função de controle |
| SF | Função de serviço |
| ESC | Controlador elástico do serviço |
| ESPANADOR | Método do procedimento |
| OSD | Discos do armazenamento do objeto |
| HDD | Unidade de disco rígido |
| SSD | Movimentação de circuito integrado |
| VIM | Gerente virtual da infraestrutura |
| VM | Máquina virtual |
| EM | Element Manager |
| UA | Ultra Automation Services |
| UUID | Universalmente identificador exclusivo |
Trabalhos do espanador
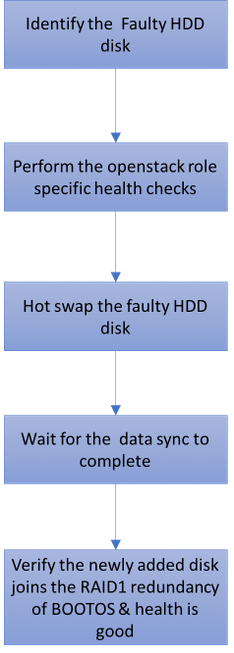
Única falha HDD
1. Cada server de Baremetal será fornecida com duas movimentações HDD atuar como o DISCO DE INICIALIZAÇÃO na configuração da invasão 1. Em caso da única falha HDD, desde que há uma Redundância nivelada RAID 1, a movimentação defeituosa HDD pode estar quente trocada.
2. O procedimento para substituir um componente defeituoso no server UCS C240 M4 pode ser consultado de: Substituindo os componentes de servidor.
3. Em caso da única falha HDD, somente o HDD defeituoso será trocada quente e daqui nenhum procedimento de upgrade BIOS é exigido após ter substituído discos novos.
4. Após ter substituído os discos, espera para a sincronização dos dados entre os discos. Pôde tomar horas para terminar.
5. Em um OpenStack baseado a solução (de Ultra-M), server baremetal UCS 240M4 pode pegar um destes papéis: Cálculo, OSD-cálculo, controlador e OSPD. As etapas exigidas a fim segurar a única falha HDD em cada um destes papéis do servidor são as mesmas e esta seção descreve os exames médicos completos a ser executados antes da troca quente do disco.
Única falha HDD no server do cálculo
1. Se a falha de movimentações HDD é observada no UCS 240M4 que atua como um nó do cálculo, execute estes exames médicos completos antes que você execute finalmente a troca quente do disco defeituoso
2. Identifique os VM que são executado neste server e verifique-os que o estado das funções é bom.
Identifique os VM hospedados no nó do cálculo:
Identifique os VM que são hospedados no server do cálculo e verifique que são ativos e corredor. Pode haver duas possibilidades:
1. O server do cálculo contém somente o SF VM.
[stack@director ~]$ nova list --field name,host | grep compute-10
| 49ac5f22-469e-4b84-badc-031083db0533 | VNF2-DEPLOYM_s8_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d |
pod1-compute-10.localdomain | ACTIVE|
2. O server do cálculo contém a combinação CF/ESC/EM/UAS de VM.
[stack@director ~]$ nova list --field name,host | grep compute-8
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-compute-8.localdomain | ACTIVE |
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c2_0_df4be88d-b4bf-4456-945a-3812653ee229 | pod1-compute-8.localdomain | ACTIVE |
| 75528898-ef4b-4d68-b05d-882014708694 | VNF2-ESC-ESC-0 | pod1-compute-8.localdomain | ACTIVE |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-compute-8.localdomain | ACTIVE |
Note: Na saída mostrada aqui, a primeira coluna corresponde ao UUID, a segunda coluna é o nome VM e a terceira coluna é o hostname onde o VM esta presente.
Exames médicos completos:
1. Entre ao StarOS VNF e identifique o cartão que corresponde ao SF ou ao CF VM. Use o UUID do SF ou o CF VM identificado da seção “identifica os VM hospedados no nó do cálculo”, e identifica o cartão que corresponde ao UUID.
[local]VNF2# show card hardware
Tuesday might 08 16:49:42 UTC 2018
<snip>
Card 8:
Card Type : 4-Port Service Function Virtual Card
CPU Packages : 26 [#0, #1, #2, #3, #4, #5, #6, #7, #8, #9, #10, #11, #12, #13, #14, #15, #16, #17, #18, #19, #20, #21, #22, #23, #24, #25]
CPU Nodes : 2
CPU Cores/Threads : 26
Memory : 98304M (qvpc-di-large)
UUID/Serial Number : 49AC5F22-469E-4B84-BADC-031083DB0533
<snip>
[local]VNF2# show card hardware
Tuesday might 08 16:49:42 UTC 2018
<snip>
Card 2:
Card Type : Control Function Virtual Card
CPU Packages : 8 [#0, #1, #2, #3, #4, #5, #6, #7]
CPU Nodes : 1
CPU Cores/Threads : 8
Memory : 16384M (qvpc-di-large)
UUID/Serial Number : F9C0763A-4A4F-4BBD-AF51-BC7545774BE2
<snip>
2. Verifique o estado do cartão.
[local]VNF2# show card table
Tuesday might 08 16:52:53 UTC 2018
Slot Card Type Oper State SPOF Attach
----------- -------------------------------------- ------------- ---- ------
1: CFC Control Function Virtual Card Active No
2: CFC Control Function Virtual Card Standby -
3: FC 4-Port Service Function Virtual Card Active No
4: FC 4-Port Service Function Virtual Card Active No
5: FC 4-Port Service Function Virtual Card Active No
6: FC 4-Port Service Function Virtual Card Active No
7: FC 4-Port Service Function Virtual Card Active No
8: FC 4-Port Service Function Virtual Card Active No
9: FC 4-Port Service Function Virtual Card Active No
10: FC 4-Port Service Function Virtual Card Standby -
3. Entre ao ESC hospedado no nó do cálculo e verifique o estado.
[admin@VNF2-esc-esc-0 esc-cli]$ escadm status
0 ESC status=0 ESC Master Healthy
4. Entre ao EM hospedado no nó do cálculo e verifique o estado.
ubuntu@vnfd2deploymentem-1:~$ ncs_cli -u admin -C
admin connected from 10.225.247.142 using ssh on vnfd2deploymentem-1
admin@scm# show ems
EM VNFM
ID SLA SCM PROXY
---------------------
3 up up up
6 up up up
5. Entre aos UA hospedados no nó do cálculo e verifique o estado.
ubuntu@autovnf2-uas-1:~$ sudo su
root@autovnf2-uas-1:/home/ubuntu# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on autovnf2-uas-1
autovnf2-uas-1#show uas ha
uas ha-vip 172.18.181.101
autovnf2-uas-1#
autovnf2-uas-1#
autovnf2-uas-1#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.18.181.101
INSTANCE IP STATE ROLE
-----------------------------------
172.18.180.4 alive CONFD-SLAVE
172.18.180.5 alive CONFD-MASTER
172.18.180.8 alive NA
autovnf2-uas-1#show errors
% No entries found.
6. Se os exames médicos completos são muito bem, continue com procedimento e espera quentes da troca do disco defeituoso para a sincronização dos dados como toma horas para terminar. Refira a substituição dos componentes de servidor.
7. Repita estes procedimentos do exame médico completo a fim confirmar que o estado de saúde dos VM hospedados no nó do cálculo está restaurado.
Escolha a falha HDD no server do controlador
1. Se a falha de movimentações HDD é observada no UCS 240M4 que atua como um nó do controlador, siga os exames médicos completos antes que você execute a troca quente do disco defeituoso.
2. Verifique o estado do pacemaker em controladores.
3. Entre a um dos controladores ativo e verifique o estado do pacemaker. Todos os serviços devem ser executado nos controladores disponíveis e parado na falha no controlador.
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod1-controller-0 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Thu Jun 28 07:53:06 2018 Last change: Wed Jan 17 11:38:00 2018 by root via cibadmin on pod1-controller-0
3 nodes and 22 resources conimaged
Online: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Full list of resources:
ip-10.2.2.2 (ocf::heartbeat:IPaddr2): Started pod1-controller-0
ip-11.120.0.42 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-11.119.0.42 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
ip-11.120.0.50 (ocf::heartbeat:IPaddr2): Started pod1-controller-0
ip-11.118.0.48 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-192.200.0.102 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: haproxy-clone [haproxy]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: redis-master [redis]
Masters: [ pod1-controller-0 ]
Slaves: [ pod1-controller-1 pod1-controller-2 ]
openstack-cinder-volume (systemd:openstack-cinder-volume): Started pod1-controller-0
my-ipmilan-for-controller-0 (stonith:fence_ipmilan): Started pod1-controller-1
my-ipmilan-for-controller-1 (stonith:fence_ipmilan): Started pod1-controller-2
my-ipmilan-for-controller-2 (stonith:fence_ipmilan): Started pod1-controller-0
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
4. Verifique o estado de MariaDB nos controladores ativo.
[stack@director] nova list | grep control
| 4361358a-922f-49b5-89d4-247a50722f6d | pod1-controller-0 | ACTIVE | - | Running | ctlplane=192.200.0.102 |
| d0f57f27-93a8-414f-b4d8-957de0d785fc | pod1-controller-1 | ACTIVE | - | Running | ctlplane=192.200.0.110 |
[stack@director ~]$ for i in 192.200.0.102 192.200.0.110 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local_state_comment'\" ; sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_cluster_size'\""; done
*** 192.200.0.152 ***
Variable_name Value
wsrep_local_state_comment Synced
Variable_name Value
wsrep_cluster_size 2
*** 192.200.0.154 ***
Variable_name Value
wsrep_local_state_comment Synced
Variable_name Value
wsrep_cluster_size 2
5. Verifique que estas linhas estam presente para cada controlador ativo:
wsrep_local_state_comment: Synced
wsrep_cluster_size: 2
6. Verifique o estado de Rabbitmq nos controladores ativo.
[heat-admin@pod1-controller-0 ~]$ sudo rabbitmqctl cluster_status
Cluster status of node 'rabbit@pod1-controller-0' ...
[{nodes,[{disc,['rabbit@pod1-controller-0','rabbit@pod1-controller-1',
'rabbit@pod1-controller-2']}]},
{running_nodes,['rabbit@pod1-controller-2',
'rabbit@pod1-controller-1',
'rabbit@pod1-controller-0']},
{cluster_name,<<"rabbit@pod1-controller-0.localdomain">>},
{partitions,[]},
{alarms,[{'rabbit@pod1-controller-2',[]},
{'rabbit@pod1-controller-1',[]},
{'rabbit@pod1-controller-0',[]}]}]
7. Se os exames médicos completos são muito bem, continue com procedimento e espera quentes da troca do disco defeituoso para a sincronização dos dados como toma horas para terminar. Refira a substituição dos componentes de servidor.
8. Repita estes procedimentos do exame médico completo a fim confirmar o estado de saúde do controlador é restaurado.
Escolha a falha HDD no server do OSD-cálculo
Se a falha de movimentações HDD é observada no UCS 240M4 que atua como o nó do OSD-cálculo do sn, execute estes exames médicos completos antes que você execute a troca quente do disco defeituoso.
Identifique os VM hospedados no nó do OSD-cálculo:
Identifique os VM que são hospedados no server do cálculo. Pode haver duas possibilidades:
1. O server do OSD-cálculo contém a combinação EM/UAS/Auto-Deploy/Auto-IT de VM.
[stack@director ~]$ nova list --field name,host | grep osd-compute-0
| c6144778-9afd-4946-8453-78c817368f18 | AUTO-DEPLOY-VNF2-uas-0 | pod1-osd-compute-0.localdomain | ACTIVE |
| 2d051522-bce2-4809-8d63-0c0e17f251dc | AUTO-IT-VNF2-uas-0 | pod1-osd-compute-0.localdomain | ACTIVE |
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-osd-compute-0.localdomain | ACTIVE |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-osd-compute-0.localdomain | ACTIVE |
2. O server do cálculo contém a combinação CF/ESC/EM/UAS de VM.
[stack@director ~]$ nova list --field name,host | grep osd-compute-1
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-compute-8.localdomain | ACTIVE |
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229 | pod1-compute-8.localdomain | ACTIVE |
| 75528898-ef4b-4d68-b05d-882014708694 | VNF2-ESC-ESC-0 | pod1-compute-8.localdomain | ACTIVE |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-compute-8.localdomain | ACTIVE |
Note: Na saída mostrada aqui, a primeira coluna corresponde ao UUID, a segunda coluna é o nome VM e a terceira coluna é o hostname onde o VM esta presente.
3. Os processos de Ceph são ativos no server do OSD-cálculo.
[root@pod1-osd-compute-1 ~]# systemctl list-units *ceph*
UNIT LOAD ACTIVE SUB DESCRIPTION
var-lib-ceph-osd-ceph\x2d11.mount loaded active mounted /var/lib/ceph/osd/ceph-11
var-lib-ceph-osd-ceph\x2d2.mount loaded active mounted /var/lib/ceph/osd/ceph-2
var-lib-ceph-osd-ceph\x2d5.mount loaded active mounted /var/lib/ceph/osd/ceph-5
var-lib-ceph-osd-ceph\x2d8.mount loaded active mounted /var/lib/ceph/osd/ceph-8
ceph-osd@11.service loaded active running Ceph object storage daemon
ceph-osd@2.service loaded active running Ceph object storage daemon
ceph-osd@5.service loaded active running Ceph object storage daemon
ceph-osd@8.service loaded active running Ceph object storage daemon
system-ceph\x2ddisk.slice loaded active active system-ceph\x2ddisk.slice
system-ceph\x2dosd.slice loaded active active system-ceph\x2dosd.slice
ceph-mon.target loaded active active ceph target allowing to start/stop all ceph-mon@.service instances at once
ceph-osd.target loaded active active ceph target allowing to start/stop all ceph-osd@.service instances at once
ceph-radosgw.target loaded active active ceph target allowing to start/stop all ceph-radosgw@.service instances at once
ceph.target loaded active active ceph target allowing to start/stop all ceph*@.service instances at once
4. Verifique que o mapeamento de OSD (disco HDD) a girar (SSD) é bom.
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph-disk list
/dev/sda :
/dev/sda1 other, iso9660
/dev/sda2 other, xfs, mounted on /
/dev/sdb :
/dev/sdb1 ceph journal, for /dev/sdc1
/dev/sdb3 ceph journal, for /dev/sdd1
/dev/sdb2 ceph journal, for /dev/sde1
/dev/sdb4 ceph journal, for /dev/sdf1
/dev/sdc :
/dev/sdc1 ceph data, active, cluster ceph, osd.1, journal /dev/sdb1
/dev/sdd :
/dev/sdd1 ceph data, active, cluster ceph, osd.7, journal /dev/sdb3
/dev/sde :
/dev/sde1 ceph data, active, cluster ceph, osd.4, journal /dev/sdb2
/dev/sdf :
/dev/sdf1 ceph data, active, cluster ceph, osd.10, journal /dev/sdb4
5. Verifique que a saúde de Ceph e o mapeamento da árvore OSD são bons.
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
1 mons down, quorum 0,1 pod1-controller-0,pod1-controller-1
monmap e1: 3 mons at {pod1-controller-0=11.118.0.10:6789/0,pod1-controller-1=11.118.0.11:6789/0,pod1-controller-2=11.118.0.12:6789/0}
election epoch 28, quorum 0,1 pod1-controller-0,pod1-controller-1
osdmap e709: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v941813: 704 pgs, 6 pools, 490 GB data, 163 kobjects
1470 GB used, 11922 GB / 13393 GB avail
704 active+clean
client io 58580 B/s wr, 0 op/s rd, 7 op/s wr
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod1-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-4 4.35999 host pod1-osd-compute-2
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
-5 4.35999 host pod1-osd-compute-3
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
6. Se os exames médicos completos são muito bem, continue com procedimento e espera quentes da troca do disco defeituoso para a sincronização dos dados como toma horas para terminar. Refira a substituição dos componentes de servidor.
7. Repita estes procedimentos do exame médico completo a fim confirmar o estado de saúde dos VM hospedados no nó do OSD-cálculo são restaurados.
Escolha a falha HDD no server OSPD
1. Se a falha de movimentações HDD é observada no UCS 240M4 que atua como um nó OSPD, execute estes exames médicos completos antes que você inicie a troca quente do disco defeituoso.
2. Verifique o estado da pilha de OpenStack e da lista do nó.
[stack@director ~]$ source stackrc
[stack@director ~]$ openstack stack list --nested
[stack@director ~]$ ironic node-list
[stack@director ~]$ nova list
3. Verifique se todos os serviços de Undercloud estiverem no carregado, estado ativo e running do nó OSP-D.
[stack@director ~]$ systemctl list-units "openstack*" "neutron*" "openvswitch*"
UNIT LOAD ACTIVE SUB DESCRIPTION
neutron-dhcp-agent.service loaded active running OpenStack Neutron DHCP Agent
neutron-openvswitch-agent.service loaded active running OpenStack Neutron Open vSwitch Agent
neutron-ovs-cleanup.service loaded active exited OpenStack Neutron Open vSwitch Cleanup Utility
neutron-server.service loaded active running OpenStack Neutron Server
openstack-aodh-evaluator.service loaded active running OpenStack Alarm evaluator service
openstack-aodh-listener.service loaded active running OpenStack Alarm listener service
openstack-aodh-notifier.service loaded active running OpenStack Alarm notifier service
openstack-ceilometer-central.service loaded active running OpenStack ceilometer central agent
openstack-ceilometer-collector.service loaded active running OpenStack ceilometer collection service
openstack-ceilometer-notification.service loaded active running OpenStack ceilometer notification agent
openstack-glance-api.service loaded active running OpenStack Image Service (code-named Glance) API server
openstack-glance-registry.service loaded active running OpenStack Image Service (code-named Glance) Registry server
openstack-heat-api-cfn.service loaded active running Openstack Heat CFN-compatible API Service
openstack-heat-api.service loaded active running OpenStack Heat API Service
openstack-heat-engine.service loaded active running Openstack Heat Engine Service
openstack-ironic-api.service loaded active running OpenStack Ironic API service
openstack-ironic-conductor.service loaded active running OpenStack Ironic Conductor service
openstack-ironic-inspector-dnsmasq.service loaded active running PXE boot dnsmasq service for Ironic Inspector
openstack-ironic-inspector.service loaded active running Hardware introspection service for OpenStack Ironic
openstack-mistral-api.service loaded active running Mistral API Server
openstack-mistral-engine.service loaded active running Mistral Engine Server
openstack-mistral-executor.service loaded active running Mistral Executor Server
openstack-nova-api.service loaded active running OpenStack Nova API Server
openstack-nova-cert.service loaded active running OpenStack Nova Cert Server
openstack-nova-compute.service loaded active running OpenStack Nova Compute Server
openstack-nova-conductor.service loaded active running OpenStack Nova Conductor Server
openstack-nova-scheduler.service loaded active running OpenStack Nova Scheduler Server
openstack-swift-account-reaper.service loaded active running OpenStack Object Storage (swift) - Account Reaper
openstack-swift-account.service loaded active running OpenStack Object Storage (swift) - Account Server
openstack-swift-container-updater.service loaded active running OpenStack Object Storage (swift) - Container Updater
openstack-swift-container.service loaded active running OpenStack Object Storage (swift) - Container Server
openstack-swift-object-updater.service loaded active running OpenStack Object Storage (swift) - Object Updater
openstack-swift-object.service loaded active running OpenStack Object Storage (swift) - Object Server
openstack-swift-proxy.service loaded active running OpenStack Object Storage (swift) - Proxy Server
openstack-zaqar.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server
openstack-zaqar@1.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server Instance 1
openvswitch.service loaded active exited Open vSwitch
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
37 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
4. Se os exames médicos completos são muito bem, continue com procedimento e espera quentes da troca do disco defeituoso para a sincronização dos dados como toma horas para terminar. Refira a substituição dos componentes de servidor.
5. Repita estes procedimentos do exame médico completo a fim confirmar que o estado de saúde dos Nós OSPD está restaurado.
Colaborado por engenheiros da Cisco
- Partheeban RajagopalServiços avançados de Cisco
- Padmaraj RamanoudjamServiços avançados de Cisco
 Feedback
FeedbackContate a Cisco
- Abrir um caso de suporte

- (É necessário um Contrato de Serviço da Cisco)