Esta lista é composta dos alertas pré-configurados do CallManager.
- BeginThrottlingCallListBLFSubscriptions
- TentativaChamadaBloqueadaPorPolítica
- CallProcessingNodeCpuPegging
- MecanismoCARDIrítico
- CARIDSEngineFailure
- FalhaNoTrabalhoDoAgendadorCARS
- Falha de CDRAgentSendFile
- CDRFileDeliveryFailed
- CDRHighWaterMarkExceeded
- CDRMaximumDiskSpaceExceeded
- CódigoAmarelo
- FalhaNotificaçãoAlteraçãoDBC
- DBReplicationFailure
- DBReplicationTableOutofSync
- DDRBlockPrevention
- DDRDown
- EMCCFailedInLocalCluster
- EMCCFailedInRemoteCluster
- RelatóriosQualidadeVozExcessiva
- IMEDistributedCacheInative
- IMEOverCota
- AlertadeQualidadeIME
- IdentificadoresDeFallbackInsuficientes
- StatusServiçoMI
- Credenciais Inválidas
- BaixaTaxaDePulsaçãoDoServidorTFTP
- RastreamentodeChamadaMal-intencionado
- MediaListExausted
- MgcpDChannelOutOfService
- NúmeroDeDispositivosRegistradosExcedido
- NúmeroDeGatewaysRegistradosDiminuídos
- NúmeroDeGatewaysRegistradosAumentados
- NúmeroDeDispositivosDeMídiaRegistradosDiminuídos
- NúmeroDeDispositivosDeMídiaRegistradosAumentado
- NúmeroDeTelefonesRegistradosIgnorados
- RouteListExhausted
- SDLLinkOutOfService
- TCPSetupToIMEFailed
- TLSConnectionToIMEFailed
- FalhaEntradaUsuário
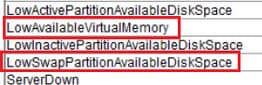
LowAvailableVirtualMemory e LowSwapPartitionAvailableDiskSpace
Os servidores Linux tendem a ‘não limpar’ o uso de memória virtual durante um período de tempo e foi observado que ela se acumula e, portanto, esses alertas.
O Linux opera de forma um pouco diferente como um sistema operacional.
Uma vez alocada a memória para um processo, ela não será recuperada pelo processador, a menos que algum outro processo solicite mais memória do que a memória disponível.
Isso causa alta memória virtual.
Uma solicitação de aumento no limite para o alarme nas versões superiores do gerenciador de chamadas foi documentada no defeito; https://bst.cloudapps.cisco.com/bugsearch/bug/CSCuq75767/?reffering_site=dumpcr
Para partições de troca, esse alerta indica que a partição de troca foi deixada com pouco espaço disponível e é usada intensamente pelo sistema. A partição de permuta é normalmente usada para estender a capacidade de RAM física quando necessário. Em condições normais, se a RAM for suficiente, a troca não deve ser usada em excesso.
Além disso, eles podem ser lançar alertas RTMT causados por uma compilação de arquivos temporários, uma reinicialização do servidor é recomendada para limpar todos os arquivos temporários desnecessários.
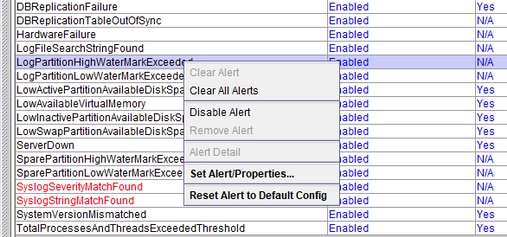
LogPartitionHighWaterMarkExceeded e LogPartitionLowWaterMarkExceeded
Ao executar show status na CLI de um servidor CUCM, um valor que especifica o percentual livre e ocupado da partição de registro no espaço em disco do CUCM é mostrado. Também conhecido como partição comum, esses valores especificam o espaço ocupado pelos logs/rastreamentos e pelos arquivos CDR no servidor, que, embora sejam inofensivos, podem causar problemas no procedimento de instalação/atualização devido à falta de espaço ao longo do tempo. Esses alertas servem como um aviso ao administrador para limpar os logs que podem ter sido acumulados ao longo do tempo no cluster/servidor.
LogPartitionLowWaterMarkExceeded: este alerta é gerado quando o espaço preenchido atinge os valores de limite configurados para o alerta. Este alerta serve como um indicador de pré-verificação para o uso do disco.
LogPartitionHighWaterMarkExceeded: este alerta é gerado quando o espaço preenchido atinge os valores de limite configurados para o alerta. Uma vez que o alerta é gerado, o servidor começa a limpar automaticamente os logs mais antigos para reduzir o espaço ao valor menos que o limite de HighWaterMark.
A prática recomendada seria limpar os logs manualmente assim que o alerta LogPartitionLowWaterMarkExceeded for recebido.
As etapas para fazer isso são:
Etapa 1. Inicie o RTMT.
Etapa 2. Selecione Alert Central e execute estas tarefas:
Selecione LogPartitionHighWaterMarkExceeded, anote seu valor e altere seu valor de limite para 60%.
Selecione LogPartitionLowWaterMarkExceeded, anote seu valor e altere seu valor de limite para 50%.
A pesquisa ocorre a cada 5 minutos, portanto aguarde de 5 a 10 minutos e verifique se o espaço em disco necessário está disponível. Para liberar mais espaço em disco na partição comum, altere os valores de thread LogPartitionHighWaterMarkExceeded e LogPartitionLowWaterMarkExceeded para reduzir os valores (por exemplo, 30% e 20%) novamente.
Dê de 15 a 20 minutos para limpar o espaço na partição comum. Você pode monitorar a diminuição no uso do disco com o comando show status da CLI.
Isso derrubaria a partição comum.
CpuPegging
O alerta CpuPegging monitora o uso da CPU com base no limite configurado.
Quando o alerta de pegging da CPU é recebido, o processo que ocupa a CPU mais alta pode ser ocupado indo para a Gaveta do Sistema à esquerda, ou seja, Processo.
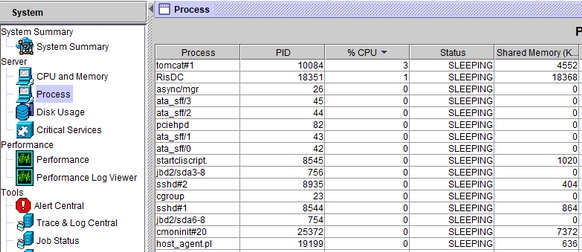
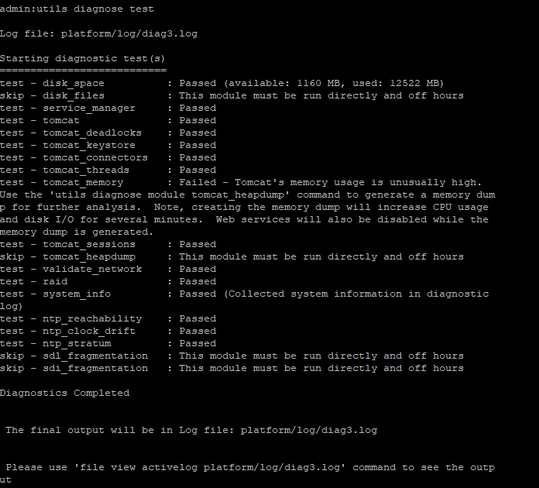
A partir do CLI do servidor em questão, essas saídas fornecerão algumas informações.
- utils diagnose test
- show process load cpu sorted
- show status
- lista ativa principal de utils
É recomendável observar se o pico de CPU acontece em um momento específico ou aleatoriamente. Se ocorrer aleatoriamente, os rastreamentos detalhados necessários do CUCM, bem como os registros de desempenho do RisDC, verificarão o que está disparando o pico na CPU. Se os alertas estiverem ocorrendo em uma hora específica do dia, pode ser devido a alguma atividade agendada, como o backup do Sistema de Recuperação de Desastres (DRS), carregamento de CDR etc.
Além disso, com base nas informações sobre qual processo ocupa mais CPU, logs específicos são tomados para uma investigação mais detalhada. Por exemplo: se o responsável for o Tomcat, os registros relacionados ao Tomcat serão necessários.
 Feedback
Feedback