Problemas comuns do CUCM na plataforma UCS: Núcleo, CPU alta - E/S, estado suspenso
Opções de download
Linguagem imparcial
O conjunto de documentação deste produto faz o possível para usar uma linguagem imparcial. Para os fins deste conjunto de documentação, a imparcialidade é definida como uma linguagem que não implica em discriminação baseada em idade, deficiência, gênero, identidade racial, identidade étnica, orientação sexual, status socioeconômico e interseccionalidade. Pode haver exceções na documentação devido à linguagem codificada nas interfaces de usuário do software do produto, linguagem usada com base na documentação de RFP ou linguagem usada por um produto de terceiros referenciado. Saiba mais sobre como a Cisco está usando a linguagem inclusiva.
Sobre esta tradução
A Cisco traduziu este documento com a ajuda de tecnologias de tradução automática e humana para oferecer conteúdo de suporte aos seus usuários no seu próprio idioma, independentemente da localização. Observe que mesmo a melhor tradução automática não será tão precisa quanto as realizadas por um tradutor profissional. A Cisco Systems, Inc. não se responsabiliza pela precisão destas traduções e recomenda que o documento original em inglês (link fornecido) seja sempre consultado.
Contents
Introduction
Este documento descreve como solucionar cinco cenários de problemas comuns encontrados com o Cisco Unified Communications Manager (CUCM) na plataforma Unified Computing System (UCS).
- Cenário 1: Alta utilização da CPU devido ao problema de espera de E/S
- Cenário 2: reinicialização periódica do CUCM
- Cenário 3: Travamentos do CUCM
- Cenário 4: Travamentos do CUCM
- Cenário 5: o CUCM está no modo somente leitura
Algumas das causas comuns são:
- Falha no disco rígido
- Falha do controlador RAID (Redundant Array of Independent Disks)
- Falha na unidade de backup de bateria (BBU)
Cenário 1: Alta utilização da CPU devido ao problema de espera de E/S
Sintomas
Os serviços Cisco Call Manager (CCM) e Computer Telephony Integration (CTI) são reiniciados devido ao núcleo do CCM CTI.
Como verificar
Rastreamentos de CUCM
Use estes comandos CLI para coletar rastreamentos CUCM:
- show process using-maioria cpu
- show status
- lista ativa do núcleo do utils
- util core analyt output <latest , last two output>
Examine estes registros da Real-Time Monitoring Tool (RTMT):
- CCM detalhado
- CTI detalhada
- PerfMonLogs do coletor de dados do servidor de informações em tempo real (RIS)
- Registros do aplicativo Visualizador de eventos
- Registros do sistema do Visualizador de Eventos
Saída de exemplo
Aqui estão alguns exemplos de saída:
admin:utils core active list
Size Date Core File Name
===============================================
355732 KB 2014-X-X 11:27:29 core.XXX.X.ccm.XXXX
110164 KB 2014-X-X 11:27:25 core.XXX.X.CTIManager.XXXX
admin:util core analyze output
====================================
CCM service backtrace
===================================
#0 0x00df6206 in raise () from /lib/libc.so.6
#1 0x00df7bd1 in abort () from /lib/libc.so.6
#2 0x084349cb in IntentionalAbort (reason=0xb0222f8 "CallManager unable to process
signals. This may be due to CPU or blocked function. Attempting to restart
CallManager.") at ProcessCMProcMon.cpp:80
#3 0x08434a8c in CMProcMon::monitorThread () at ProcessCMProcMon.cpp:530
#4 0x00a8fca7 in ACE_OS_Thread_Adapter::invoke (this=0xb2b04270) at OS_Thread_
Adapter.cpp:94
#5 0x00a45541 in ace_thread_adapter (args=0xb2b04270) at Base_Thread_Adapter.cpp:137
#6 0x004aa6e1 in start_thread () from /lib/libpthread.so.0
#7 0x00ea2d3e in clone () from /lib/libc.so.6
====================================
====================================
CTI Manager backtrace
===================================
#0 0x00b3e206 in raise () from /lib/libc.so.6
#1 0x00b3fbd1 in abort () from /lib/libc.so.6
#2 0x08497b11 in IntentionalAbort (reason=0x86fe488 "SDL Router Services declared
dead. This may be due to high CPU usage or blocked function. Attempting to restart
CTIManager.") at ProcessCTIProcMon.cpp:65
#3 0x08497c2c in CMProcMon::verifySdlTimerServices () at ProcessCTIProcMon.cpp:573
#4 0x084988d8 in CMProcMon::callManagerMonitorThread (cmProcMon=0x93c9638) at Process
CTIProcMon.cpp:330
#5 0x007bdca7 in ACE_OS_Thread_Adapter::invoke (this=0x992d710) at OS_Thread_
Adapter.cpp:94
#6 0x00773541 in ace_thread_adapter (args=0x992d710) at Base_Thread_Adapter.cpp:137
#7 0x0025d6e1 in start_thread () from /lib/libpthread.so.0
#8 0x00bead3e in clone () from /lib/li
====================================
No PerfMonLogs do coletor de dados RIS, é possível ver o alto nível de E/S de disco durante o tempo do núcleo.
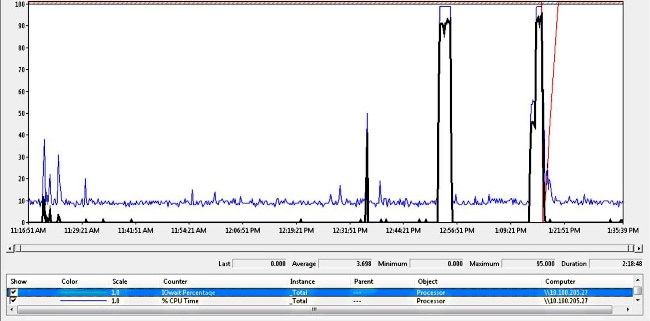
O backtrace corresponde ao bug da Cisco ID CSCua79544 : Núcleos de processo CCM frequentes devido a E/S de disco alta. Este bug descreve um problema de hardware e explica como isolar ainda mais o problema.
Habilitar relatório de E/S de arquivos (FIOR):
Use estes comandos para ativar o FIOR:
utils fior start
utils fior enable
Em seguida, aguarde a próxima ocorrência. Aqui está o comando CLI para coletar a saída: arquivo get ativelog platform/io-stats. Insira estes comandos para desabilitar o FIOR:
utils fior stop
utils fior disable
Aqui está um exemplo de saída de log FIOR:
kern 4 kernel: fio_syscall_table address set to c0626500 based on user input
kern 4 kernel: fiostats: address of do_execve set to c048129a
kern 6 kernel: File IO statistics module version 0.99.1 loaded.
kern 6 kernel: file reads > 265000 and writes > 51200 will be logged
kern 4 kernel: fiostats: enabled.
kern 4 kernel: fiostats[25487] started.
Solução
A I/O WAIT é geralmente um problema com a plataforma UCS e seu armazenamento.
O registro do UCS é necessário para isolar o local da causa. Consulte a seção Como coletar registros do UCS para obter instruções sobre como coletar os rastreamentos.
Cenário 2: reinicialização periódica do CUCM
Sintomas
O CUCM é reinicializado devido a um travamento do ESXI, mas o problema subjacente é que a máquina do UCS perde energia.
Como verificar
Examine estes rastreamentos do CUCM:
- PerfMonLog do coletor de dados RIS da Cisco
- Visualizador de eventos - Log de aplicativos
- Visualizador de Eventos - Registro do Sistema
- CCM detalhado
Não há nada relevante nos rastreamentos do CUCM. O CUCM é interrompido antes do incidente e isso é seguido de uma reinicialização normal do serviço. Isso elimina o CUCM e indica que a causa está em outro lugar.
A plataforma UCS onde o CUCM é executado tem o problema. A plataforma UCS tem muitas instâncias de máquina virtual (VM) executadas nela. Se alguma VM encontrar um erro, ela será vista nos registros do UCS.
O log do UCS é necessário para isolar o local da causa. Consulte a seção Como coletar registros do UCS para obter instruções sobre como coletar os rastreamentos.
Exemplo de saída do Cisco Integrated Management Controller (CIMC)
Aqui estão alguns exemplos de saída:
5:2014 May 11 13:10:48:BMC:kernel:-:<5>[lpc_reset_isr_handler]:79:LPC Reset ISR ->
ResetState: 1
5:2014 May 11 13:10:48:BMC:kernel:-:<5>drivers/bmc/usb/usb1.1/se_pilot2_udc_usb1_1.c:
2288:USB FS: VDD Power WAKEUP- Power Good = OFF
5:2014 May 11 13:10:48:BMC:kernel:-:<5>[se_pilot2_wakeup_interrupt]:2561:USB HS:
VDD Power = OFF
5:2014 May 11 13:10:48:BMC:BIOSReader:1176: BIOSReader.c:752:File Close :
/var/nuova/BIOS/BiosTech.txt
5:2014 May 11 13:10:48:BMC:kernel:-:<5>[block_transfer_fetch_host_request_for_app]:
1720:block_transfer_fetch_host_request_for_app : BT_FILE_CLOSE : HostBTDescr = 27 :
FName = BiosTech.txt
5:2014 May 11 13:10:48:BMC:IPMI:1357: Pilot2SrvPower.c:466:Blade Power Changed To:
[ OFF ]
5:2014 May 11 13:10:49:BMC:lv_dimm:-: lv_dimm.c:126:[lpc_reset_seen]LPC Reset Count
is Different [0x1:0x2] Asserted LPC Reset Seen
Solução
Quando você encontrar este erro, Pilot2SrvPower.c:466:Blade Power foi alterado para: [ DESLIGADO ] - Problema de alimentação, significa que a máquina do UCS perde energia. Portanto, você deve garantir que a máquina UCS receba energia suficiente.
Cenário 3: Travamentos do CUCM
Sintomas
A VM do CUCM trava, mas ainda responde aos pings. A tela do console do vSphere exibe estas informações:
*ERROR* %No Memory Available *ERROR* %No Memory Available
Como verificar
Examine estes rastreamentos do CUCM:
- PerfMonLog do coletor de dados RIS da Cisco
- Visualizador de eventos - Log de aplicativos
- Visualizador de Eventos - Registro do Sistema
- CCM detalhado
Não há nada relevante nos rastreamentos do CUCM. O CUCM para antes do incidente e é seguido por uma reinicialização de serviço normal. Isso elimina o CUCM e indica que a causa está em outro lugar.
A plataforma UCS onde o CUCM é executado tem o problema. A plataforma UCS tem muitas instâncias de VM executadas nela. Se alguma VM encontrar um erro, ela será vista nos registros do UCS.
O log do UCS é necessário para isolar o local da causa. Consulte a seção Como coletar registros do UCS para obter instruções sobre como coletar os rastreamentos.
Solução
Desligue a VM e reinicialize-a. Após a reinicialização, o sistema funciona bem.
Cenário 4: Travamentos do CUCM
Sintomas
O servidor CUCM vai para um estado em que trava.
Como verificar
Examine estes rastreamentos do CUCM:
- PerfMonLog do coletor de dados RIS da Cisco
- Visualizador de eventos - Log de aplicativos
- Visualizador de Eventos - Registro do Sistema
- CCM detalhado
Não há nada relevante nos rastreamentos do CUCM. O CUCM para antes do incidente e é seguido por uma reinicialização de serviço normal. Isso elimina o CUCM e indica que a causa está em outro lugar.
A plataforma UCS onde o CUCM é executado tem o problema. A plataforma UCS tem muitas instâncias de VM executadas nela. Se alguma VM encontrar um erro, ela será vista nos registros do UCS.
O log do UCS é necessário para isolar o local da causa. Consulte a seção Como coletar registros do UCS para obter instruções sobre como coletar os rastreamentos.
Solução
Tente reiniciar manualmente para ver se ajuda.
Cenário 5: o CUCM está no modo somente leitura
Sintomas
Você recebe este erro:
The /common file system is mounted read only. Please use Recovery Disk to check the file system using fsck.
Como verificar
O Publisher (PUB) e um Subscriber (SUB) instalados na mesma máquina do UCS mostram o erro de modo somente leitura. O disco de recuperação não corrige o problema.
Não há nada relevante nos rastreamentos do CUCM. O CUCM para antes do incidente e é seguido por uma reinicialização de serviço normal. Isso elimina o CUCM e indica que a causa está em outro lugar.
A plataforma UCS onde o CUCM é executado tem o problema. A plataforma UCS tem muitas instâncias de VM executadas nela. Se alguma VM encontrar um erro, ela será vista nos registros do UCS.
O log do UCS é necessário para isolar o local da causa. Consulte a seção Como coletar registros do UCS para obter instruções sobre como coletar os rastreamentos.
Solução
Após a substituição do hardware, recrie os nós problemáticos.
Como coletar registros do UCS
Esta seção descreve como coletar os rastreamentos necessários para identificar o problema ou fornece links para artigos que fornecem essas informações.
Como coletar registros CIMC: Show tech
Consulte estes artigos para obter informações sobre como coletar logs do CICM:
Usando a GUI do Cisco CIMC para coletar detalhes do show-tech
Guia visual para coletar arquivos de suporte técnico (séries B e C)
Como coletar registros ESXI: Logs do sistema
Consulte este artigo para obter informações sobre como coletar registros ESXI:
Obtendo informações de diagnóstico para hosts ESXi 5.x usando o vSphere Client
Exemplo de saída de CLI do CIMC
Aqui está um exemplo de saída da CLI do CIMC de uma falha de disco rígido:
ucs-c220-m3 /chassis # show hdd
Name Status LocateLEDStatus
-------------------- -------------------- --------------------
HDD1_STATUS present TurnOFF
HDD2_STATUS present TurnOFF
HDD3_STATUS failed TurnOFF
HDD4_STATUS present TurnOFF
HDD5_STATUS absent TurnOFF
HDD6_STATUS absent TurnOFF
HDD7_STATUS absent TurnOFF
HDD8_STATUS absent TurnOFF
ucs-c220-m3 /chassis # show hdd-pid
Disk Controller Product ID Vendor Model
---- ----------- -------------------- ---------- ------------
1 SLOT-2 A03-D500GC3 ATA ST9500620NS
2 SLOT-2 A03-D500GC3 ATA ST9500620NS
3 SLOT-2 A03-D500GC3 ATA ST9500620NS
4 SLOT-2 A03-D500GC3 ATA ST9500620NS
ucs-c220-m3 /chassis/storageadapter # show physical-drive
Physical Drive Number Controller Health Status Manufacturer Model Predictive
Failure Count Drive Firmware Coerced Size Type
--------------------- ---------- -------------- ---------------------- ------
-------- -------------- ------------------------ -------------- -------------- -----
1 SLOT-2 Good Online ATA ST9500620NS 0 CC03 475883 MB HDD
2 SLOT-2 Good Online ATA ST9500620NS 0 CC03 475883 MB HDD
3 SLOT-2 Severe Fault Unconfigured Bad ATA ST9500620NS 0 CC03 0 MB HDD
4 SLOT-2 Good Online ATA ST9500620NS 0 CC03 475883 MB HDD
Aqui está um exemplo de saída CLI do CICM da falha do controlador RAID:
ucs-c220-m3 /chassis/storageadapter # show virtual-drive
Virtual Drive Health Status Name Size RAID Level Boot Drive
------------- -------------- -------------------- ---------------- ----------
---------- ----------
0 Moderate Fault Degraded 951766 MB RAID 10 true
Exemplo de saída da GUI do CIMC
Aqui está um exemplo de saída da GUI do CIMC de uma falha de disco rígido:
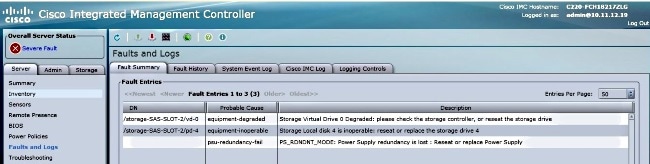
Aqui está um exemplo de saída da GUI do CIMC de um erro de tela roxa:
( Falha no controlador Raid | Defeito: CSCuh86924 Exceção PSOD PF ESXi 14 - Controladora RAID LSI 9266-8i )
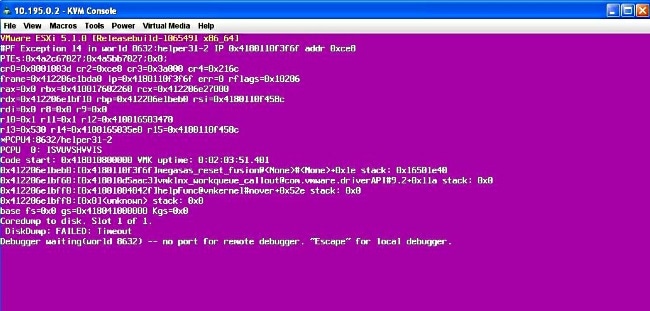
Aqui está um exemplo de saída da GUI do CIMC de uma Falha de BBU:
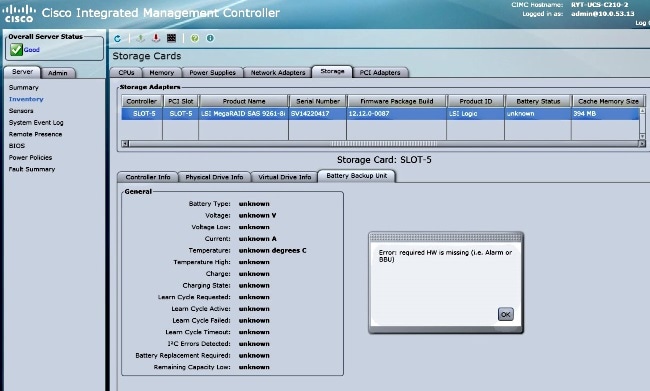
Colaborado por engenheiros da Cisco
- Sivakumar ShanmugamCisco TAC Engineer
 Feedback
FeedbackContate a Cisco
- Abrir um caso de suporte

- (É necessário um Contrato de Serviço da Cisco)