Op ML gebaseerde documentclassificatie gebruiken voor efficiënt DLP-beleidsbeheer
Inhoud
Inleiding
In dit document wordt beschreven hoe u op ML gebaseerde documentclassificatie (Built with Meta Llama 3) kunt gebruiken om het beleid voor het voorkomen van gegevensverlies (DLP) te vereenvoudigen en te verbeteren.
Overzicht
ML-documentclassificatie verbetert de afstemming van inhoud en maakt DLP-beleidsbeheer eenvoudiger. U kunt kiezen uit vooraf gedefinieerde, vooraf getrainde documenttypen, zodat u geen complexe gegevensclassificaties hoeft op te bouwen op basis van termen en patronen.
Hoe te gebruiken ML-Based Document Classification
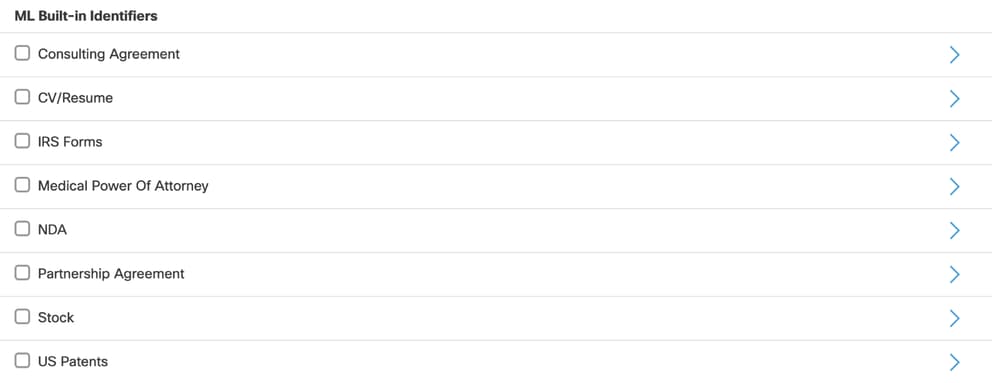
- ML-gebaseerde documentclassificatie is beschikbaar als een ingebouwde id wanneer u een gegevensclassificatie maakt.
- Alle ondersteunde op ML gebaseerde identifiers worden weergegeven in de sectie Ingebouwde identifiers van ML tijdens de configuratie van de gegevensclassificatie.
 26221783199892
26221783199892
Ondersteunde documenttypen
U kunt op ML gebaseerde classificatie gebruiken voor deze documenttypen:
- Consultingovereenkomsten
- CV's en cv's
- IRS-formulieren
- Medische volmacht
- Niet-openbaarmakingsovereenkomsten (NDA)
- Partnerschapsovereenkomsten
- Voorraad en Amerikaanse patenten
Ondersteunde talen en regio's
De eerste versie ondersteunt alleen documenten in het Engels in de VS. Ondersteuning voor extra talen en regio's is gepland voor toekomstige updates.
Multimode DLP-ondersteuning
ML-gebaseerde documentclassificatie werkt met zowel Realtime DLP als SaaS API DLP. Het is compatibel met alle DLP-ondersteunde bestandstypen.
Gerelateerde bronnen
Zie Secure Access en Umbrella-documentatie voor richtlijnen voor het gebruik van op ML gebaseerde data-ID's in gegevensclassificaties en DLP-regels:
- Veilige toegang: ingebouwde data-id's
- Paraplu: ingebouwde data-id's
Revisiegeschiedenis
| Revisie | Publicatiedatum | Opmerkingen |
|---|---|---|
2.0 |
20-Jul-2026
|
Eerste vrijgave |
1.0 |
21-Oct-2025
|
Eerste vrijgave |
 Feedback
FeedbackContact Cisco
- Een ondersteuningscase openen

- (Vereist een Cisco-servicecontract)