Vervanging moederbord in Ultra-MUCS 240M4-server - CPAR
Downloadopties
Inclusief taalgebruik
De documentatie van dit product is waar mogelijk geschreven met inclusief taalgebruik. Inclusief taalgebruik wordt in deze documentatie gedefinieerd als taal die geen discriminatie op basis van leeftijd, handicap, gender, etniciteit, seksuele oriëntatie, sociaaleconomische status of combinaties hiervan weerspiegelt. In deze documentatie kunnen uitzonderingen voorkomen vanwege bewoordingen die in de gebruikersinterfaces van de productsoftware zijn gecodeerd, die op het taalgebruik in de RFP-documentatie zijn gebaseerd of die worden gebruikt in een product van een externe partij waarnaar wordt verwezen. Lees meer over hoe Cisco gebruikmaakt van inclusief taalgebruik.
Over deze vertaling
Cisco heeft dit document vertaald via een combinatie van machine- en menselijke technologie om onze gebruikers wereldwijd ondersteuningscontent te bieden in hun eigen taal. Houd er rekening mee dat zelfs de beste machinevertaling niet net zo nauwkeurig is als die van een professionele vertaler. Cisco Systems, Inc. is niet aansprakelijk voor de nauwkeurigheid van deze vertalingen en raadt aan altijd het oorspronkelijke Engelstalige document (link) te raadplegen.
Inhoud
Inleiding
In dit document worden de stappen beschreven die nodig zijn om een defect moederbord van een server te vervangen in een Ultra-M-configuratie.
Deze procedure is van toepassing op een Openstack-omgeving met NEWTON-versie waarbij ESC geen CPAR beheert en CPAR rechtstreeks op de VM is geïnstalleerd die op Openstack is geïmplementeerd.
Achtergrondinformatie
Ultra-M is een voorverpakte en gevalideerde gevirtualiseerde mobiele packet core-oplossing die is ontworpen om de implementatie van VNF's te vereenvoudigen. OpenStack is de Virtualized Infrastructure Manager (VIM) voor Ultra-M en bestaat uit deze knooppunttypen:
- berekenen
- Object Storage Disk - Compute (OSD - Compute)
- controleur
- OpenStack Platform - Directeur (OSPD)
De hoogstaande architectuur van Ultra-M en de betrokken componenten worden in deze afbeelding weergegeven:
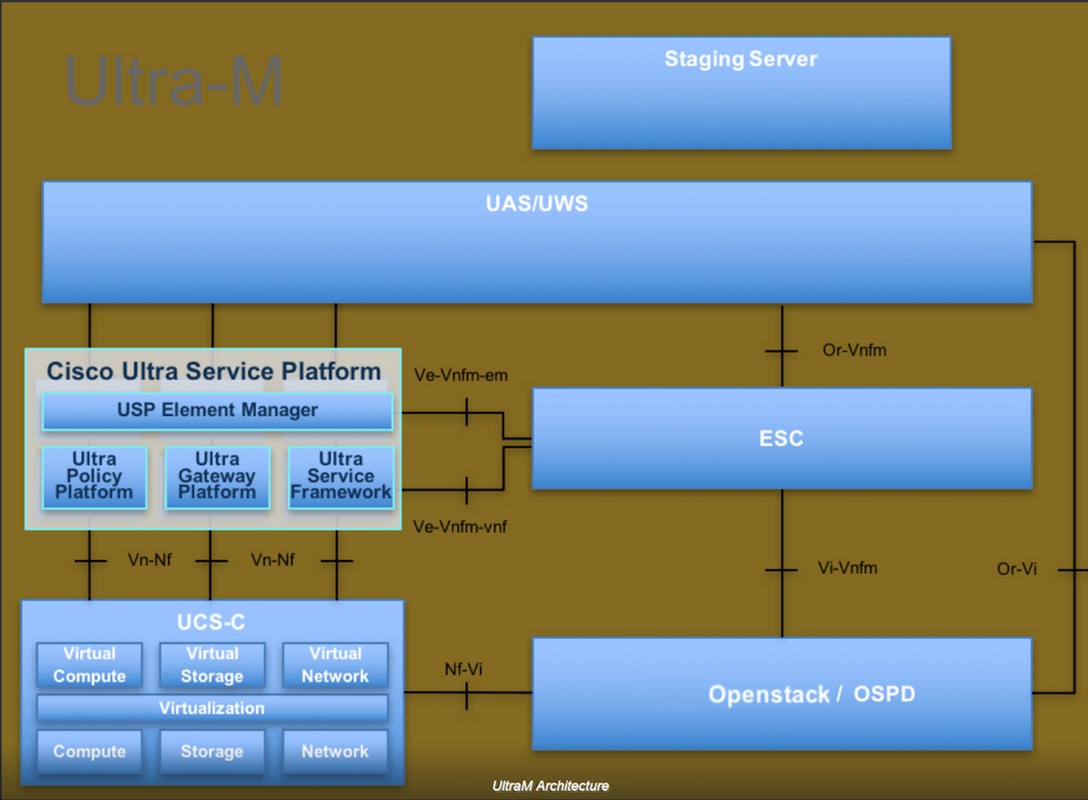
Dit document is bedoeld voor Cisco-personeel dat bekend is met het Cisco Ultra-M-platform en het beschrijft de stappen die moeten worden uitgevoerd bij OpenStack en Redhat OS.
Opmerking: Ultra M 5.1.x release wordt overwogen om de procedures in dit document te definiëren.
Afkortingen
| DWEILEN | Methode van procedure |
| OSD | Object Storage-schijven |
| OSPD | OpenStack Platform Director |
| HARDE SCHIJF | harde schijf |
| SSD | Solid State-harde schijf |
| VIM | Virtual Infrastructure Manager |
| VM | virtuele machine |
| EM | Elementbeheer |
| UAS | Ultra Automation Services |
| UUID | Universally Unique IDentifier |
Workflow van het MoP
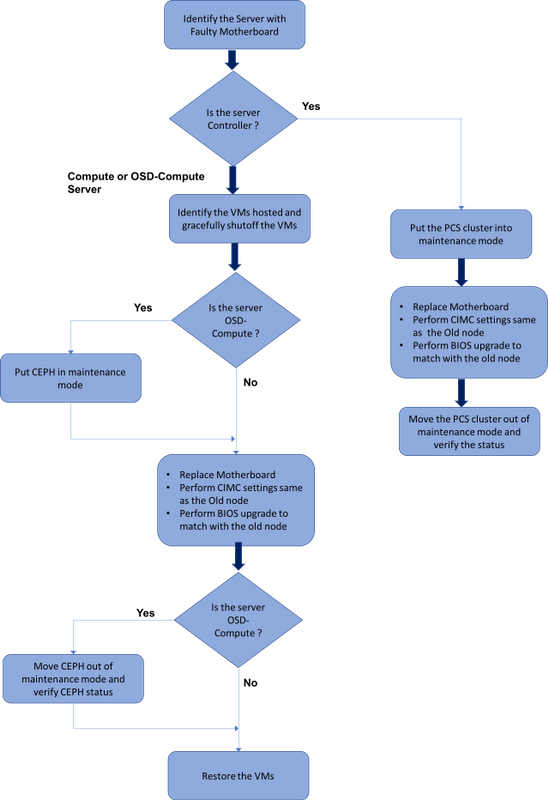
Moederbord vervangen in Ultra-M-configuratie
In een Ultra-M-configuratie kunnen er scenario's zijn waarbij een moederbordvervanging vereist is voor de volgende servertypen: Compute, OSD-Compute en Controller.
Opmerking: De opstartdiskettes met de openstack-installatie worden vervangen na de vervanging van het moederbord. Er is dus geen vereiste om de node terug te voegen naar overcloud. Zodra de server is ingeschakeld na de vervangingsactiviteit, zou deze zichzelf opnieuw inschrijven in de overcloud-stack.
Voorwaarden
Voordat u een Compute node vervangt, is het belangrijk om de huidige status van uw Red Hat OpenStack Platform-omgeving te controleren. Het wordt aanbevolen om de huidige status te controleren om complicaties te voorkomen wanneer het vervangingsproces voor Compute is ingeschakeld. Dit kan worden bereikt door deze stroom van vervanging.
In het geval van herstel raadt Cisco aan om een back-up van de OSPD-database te maken met behulp van de volgende stappen:
[root@director ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql [root@director ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql /etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack tar: Removing leading `/' from member names
Dit proces zorgt ervoor dat een node kan worden vervangen zonder de beschikbaarheid van instanties te beïnvloeden.
Opmerking: zorg ervoor dat u de momentopname van de instantie hebt, zodat u de VM kunt herstellen wanneer dat nodig is. Volg deze procedure voor het maken van een momentopname van de VM.
Moederbord vervangen in computerknooppunt
Voordat de activiteit wordt uitgevoerd, worden de VM's die in de Compute-node worden gehost, sierlijk afgesloten. Nadat het moederbord is vervangen, worden de VM's teruggezet.
De VM's identificeren die in de computernode worden gehost
[stack@al03-pod2-ospd ~]$ nova list --field name,host +--------------------------------------+---------------------------+----------------------------------+ | ID | Name | Host | +--------------------------------------+---------------------------+----------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | pod2-stack-compute-4.localdomain | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | pod2-stack-compute-3.localdomain | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | pod2-stack-compute-3.localdomain | +--------------------------------------+---------------------------+----------------------------------+
Opmerking: in de hier weergegeven uitvoer komt de eerste kolom overeen met de Universally Unique IDentifier (UUID), de tweede kolom is de VM-naam en de derde kolom is de hostnaam waar de VM aanwezig is. De parameters van deze uitvoer worden gebruikt in de volgende secties.
back-up: momentopnameproces
Stap 1. CPAR-toepassing wordt afgesloten.
Stap 1.Open een ssh-client die is aangesloten op het netwerk en maak verbinding met de CPAR-instantie.
Het is belangrijk om niet alle 4 AAA-instanties binnen één site tegelijkertijd af te sluiten, doe het een voor een.
Stap 2.Sluit de CPAR-toepassing af met deze opdracht:
/opt/CSCOar/bin/arserver stop A Message stating “Cisco Prime Access Registrar Server Agent shutdown complete.” Should show up
Als een gebruiker een CLI-sessie heeft geopend, werkt de opdracht voor het stoppen van de server niet en wordt dit bericht weergegeven:
ERROR: You can not shut down Cisco Prime Access Registrar while the CLI is being used. Current list of running CLI with process id is: 2903 /opt/CSCOar/bin/aregcmd –s
In dit voorbeeld moet de gemarkeerde proces-id 2903 worden beëindigd voordat CPAR kan worden stopgezet. Als dit het geval is, beëindig dan dit proces met deze opdracht:
kill -9 *process_id*
Herhaal dan stap 1.
Stap 3.Controleer of de CPAR-toepassing inderdaad is afgesloten door de opdracht uit te geven:
/opt/CSCOar/bin/arstatus
Deze berichten moeten worden weergegeven:
Cisco Prime Access Registrar Server Agent not running Cisco Prime Access Registrar GUI not running
VM Snapshot-taak
Stap 1.Voer de Horizon GUI-website in die overeenkomt met de site (stad) waaraan momenteel wordt gewerkt.
Bij het openen van Horizon wordt dit scherm waargenomen:
Stap 2.Navigeer naar Project > Instanties, zoals weergegeven in de afbeelding.
Als de gebruiker CPAR heeft gebruikt, worden alleen de 4 AAA-instanties in dit menu weergegeven.
Stap 3.Sluit slechts één instantie tegelijk af. Herhaal het hele proces in dit document.
Om de VM af te sluiten, gaat u naar Acties > instantie uitschakelen en bevestigt u uw selectie.

Stap 4.Valideer dat de instantie inderdaad is afgesloten door de status = Shutoff en Power State = Shut Down te controleren.
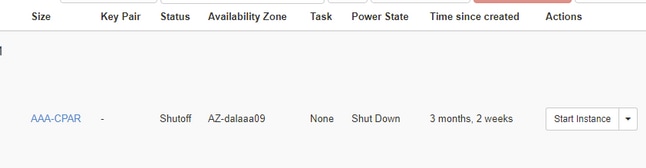
Met deze stap wordt het afsluitproces van de CPAR beëindigd.
VM-momentopname
Zodra de CPAR-VM's zijn uitgeschakeld, kunnen de momentopnamen parallel worden gemaakt, omdat ze behoren tot onafhankelijke computers.
De vier QCOW2-bestanden worden parallel gemaakt.
Een momentopname maken van elke AAA-instantie (25 minuten -1 uur) (25 minuten voor instanties die een qcow-afbeelding als bron hebben gebruikt en 1 uur voor instanties die een onbewerkte afbeelding als bron hebben gebruikt)
Stap 1. Aanmelden bij POD's OpenStack's HorizonGUI.
Stap 2. Nadat u bent ingelogd, gaat u naar de sectie Project > Berekenen > Instanties in het bovenste menu en zoekt u naar de AAA-instanties.
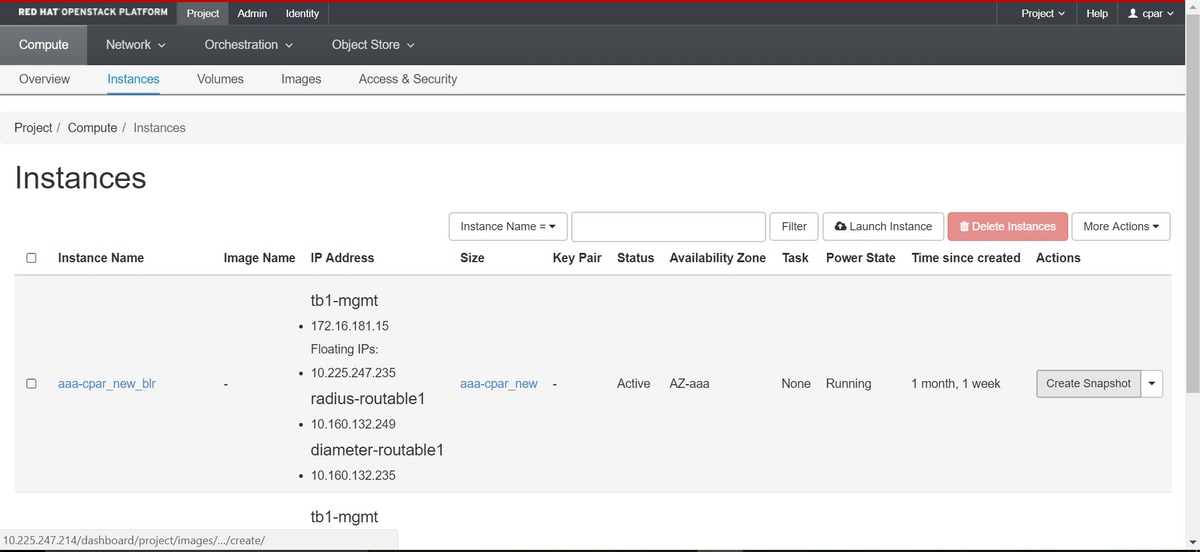
Stap 3. Klik op de knop Momentopname maken om verder te gaan met het maken van momentopnamen (dit moet worden uitgevoerd op de corresponderende AAA-instantie).
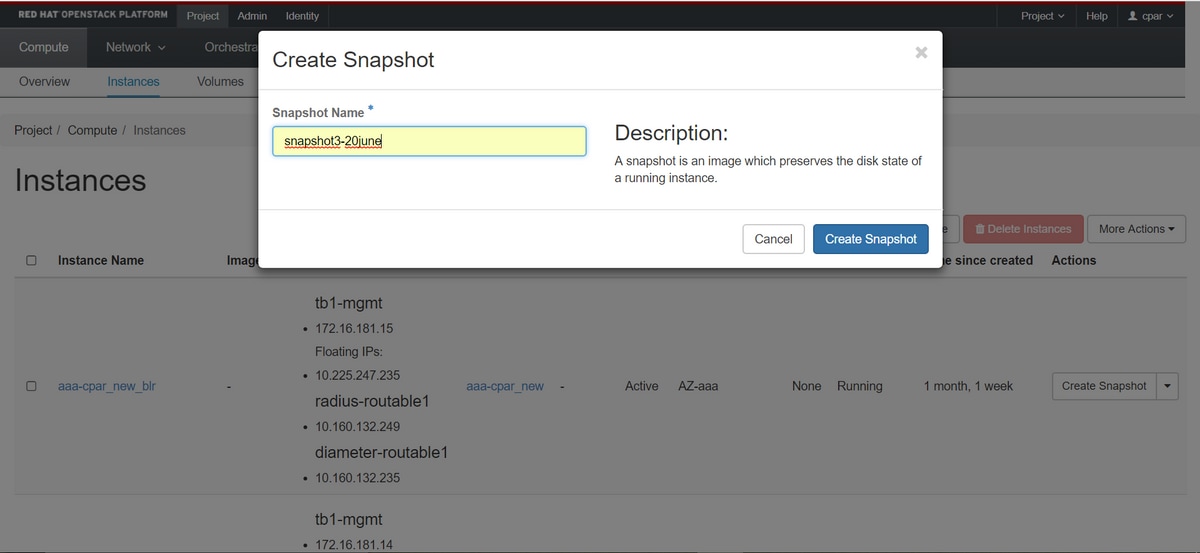
Stap 4. Zodra de momentopname is uitgevoerd, navigeert u naar het menu AFBEELDINGEN en controleert u of alle foto's zijn voltooid en geen problemen zijn gemeld.
Stap 5. De volgende stap is het downloaden van de momentopname in een QCOW2-indeling en het overbrengen naar een externe entiteit in het geval dat de OSPD tijdens dit proces verloren gaat. Om dit te bereiken, identificeert u de momentopname met deze opdracht om de afbeeldingslijst op OSPD-niveau te bekijken.
[root@elospd01 stack]# glance image-list +--------------------------------------+---------------------------+ | ID | Name | +--------------------------------------+---------------------------+ | 80f083cb-66f9-4fcf-8b8a-7d8965e47b1d | AAA-Temporary | | 22f8536b-3f3c-4bcc-ae1a-8f2ab0d8b950 | ELP1 cluman 10_09_2017 | | 70ef5911-208e-4cac-93e2-6fe9033db560 | ELP2 cluman 10_09_2017 | | e0b57fc9-e5c3-4b51-8b94-56cbccdf5401 | ESC-image | | 92dfe18c-df35-4aa9-8c52-9c663d3f839b | lgnaaa01-sept102017 | | 1461226b-4362-428b-bc90-0a98cbf33500 | tmobile-pcrf-13.1.1.iso | | 98275e15-37cf-4681-9bcc-d6ba18947d7b | tmobile-pcrf-13.1.1.qcow2 | +--------------------------------------+---------------------------+
Stap 6. Zodra u hebt vastgesteld welke momentopname moet worden gedownload (in dit geval wordt deze hierboven in het groen gemarkeerd), downloadt u deze in een QCOW2-indeling met behulp van de opdracht Glance image-download zoals hier wordt weergegeven.
[root@elospd01 stack]# glance image-download 92dfe18c-df35-4aa9-8c52-9c663d3f839b --file /tmp/AAA-CPAR-LGNoct192017.qcow2 &
- De "&" stuurt het proces naar de achtergrond. Het zal enige tijd duren om deze actie te voltooien, als het eenmaal is gedaan, kan het beeld zich bevinden in /tmp directory.
- Bij het verzenden van het proces naar de achtergrond, als de connectiviteit verloren gaat, wordt het proces ook gestopt.
- Voer de opdracht "dispwn -h" uit, zodat in het geval dat de SSH-verbinding verloren gaat, het proces nog steeds wordt uitgevoerd en voltooid op de OSPD.
Stap 7. Zodra het downloadproces is voltooid, moet een compressieproces worden uitgevoerd, omdat die momentopname kan worden gevuld met ZEROES vanwege processen, taken en tijdelijke bestanden die door het besturingssysteem worden afgehandeld. De opdracht voor bestandscompressie is virt-sparsify.
[root@elospd01 stack]# virt-sparsify AAA-CPAR-LGNoct192017.qcow2 AAA-CPAR-LGNoct192017_compressed.qcow2
Dit proces duurt enige tijd (ongeveer 10-15 minuten). Als het bestand klaar is, moet het worden overgedragen naar een externe entiteit zoals gespecificeerd in de volgende stap.
Verificatie van de bestandsintegriteit is vereist, om dit te bereiken, voert u de volgende opdracht uit en zoekt u naar het attribuut "corrupt" aan het einde van de uitvoer.
[root@wsospd01 tmp]# qemu-img info AAA-CPAR-LGNoct192017_compressed.qcow2 image: AAA-CPAR-LGNoct192017_compressed.qcow2 file format: qcow2 virtual size: 150G (161061273600 bytes) disk size: 18G cluster_size: 65536 Format specific information: compat: 1.1 lazy refcounts: false refcount bits: 16 corrupt: false
Om een probleem te voorkomen waarbij de OSPD verloren gaat, moet de onlangs gemaakte momentopname op QCOW2-formaat worden overgedragen aan een externe entiteit. Voordat we de bestandsoverdracht starten, moeten we controleren of de bestemming voldoende beschikbare schijfruimte heeft, gebruik de opdracht "df –kh" om de geheugenruimte te verifiëren. Ons advies is om het tijdelijk over te dragen naar de OSPD van een andere site door SFTP "sftproot@x.x.x.x" te gebruiken waar x.x.x.x het IP van een externe OSPD is. Om de overdracht te versnellen, kan de bestemming naar meerdere OSPD's worden verzonden. Op dezelfde manier kunnen we de volgende opdracht gebruiken: scp *name_of_the_file*.qcow2 root@ x.x.x.x:/tmp (waarbij x.x.x.x het IP van een externe OSPD is) om het bestand over te zetten naar een andere OSPD.
sierlijke uitschakeling
Power off Node
- De instantie uitschakelen: nova stop <INSTANCE_NAME>
- Nu ziet u de instantienaam met de status Shutoff.
[stack@director ~]$ nova stop aaa2-21 Request to stop server aaa2-21 has been accepted. [stack@director ~]$ nova list +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | ID | Name | Status | Task State | Power State | Networks | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | ACTIVE | - | Running | tb1-mgmt=172.16.181.14, 10.225.247.233; radius-routable1=10.160.132.245; diameter-routable1=10.160.132.231 | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | SHUTOFF | - | Shutdown | diameter-routable1=10.160.132.230; radius-routable1=10.160.132.248; tb1-mgmt=172.16.181.7, 10.225.247.234 | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | ACTIVE | - | Running | diameter-routable1=10.160.132.233; radius-routable1=10.160.132.244; tb1-mgmt=172.16.181.10 | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+
Moederbord vervangen
De stappen voor het vervangen van het moederbord in een UCS C240 M4-server kunnen worden doorverwezen vanaf de installatie- en servicegids voor Cisco UCS C240 M4-servers
- Meld u aan bij de server met behulp van de CIMC IP.
- Voer een BIOS-upgrade uit als de firmware niet overeenkomt met de aanbevolen versie die eerder is gebruikt. Stappen voor BIOS-upgrade worden hier gegeven: Cisco UCS C-Series Rack-Mount Server BIOS Upgrade Guide
De VM's herstellen
Een instantie herstellen via Snapshot
herstelproces
Het is mogelijk om de vorige instantie opnieuw in te zetten met de momentopname die in eerdere stappen is gemaakt.
Stap 1 [OPTIONEEL].Als er geen eerdere VMsnapshot beschikbaar is, maakt u verbinding met de OSPD-node waar de back-up is verzonden en voert u de back-up terug naar de oorspronkelijke OSPD-node. Gebruik van "sftproot@x.x.x.x" waarbij x.x.x.x het IP van het oorspronkelijke OSPD is. Sla het momentopnamebestand op in de map /tmp.
Stap 2.Verbinding maken met de OSPD-node waar de instantie opnieuw wordt geïmplementeerd.
 Bron de omgevingsvariabelen met deze opdracht:
Bron de omgevingsvariabelen met deze opdracht:
# source /home/stack/pod1-stackrc-Core-CPAR
Stap 3.Om de momentopname als afbeelding te gebruiken, is het noodzakelijk om deze als zodanig naar de horizon te uploaden. Gebruik de volgende opdracht om dit te doen.
#glance image-create -- AAA-CPAR-Date-snapshot.qcow2 --container-format bare --disk-format qcow2 --name AAA-CPAR-Date-snapshot
Het proces is te zien aan de horizon.

Stap 4.Navigeer in Horizon naar Project > Instanties en klik op Instantie starten.

Stap 5.Vul de instantienaam in en kies de beschikbaarheidszone.
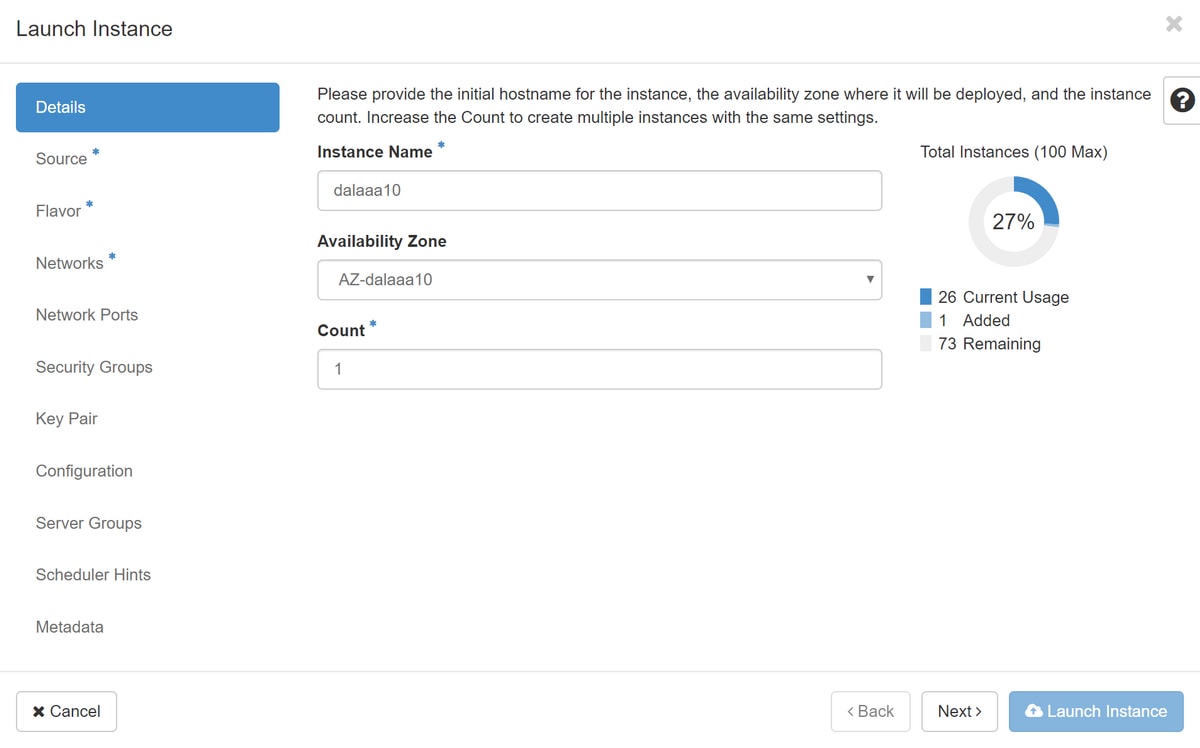
Stap 6.Kies op het tabblad Bron de afbeelding om de instantie te maken. In het menu Select Boot Source select image, wordt hier een lijst met afbeeldingen weergegeven en kies degene die eerder is geüpload terwijl u op +teken klikt.
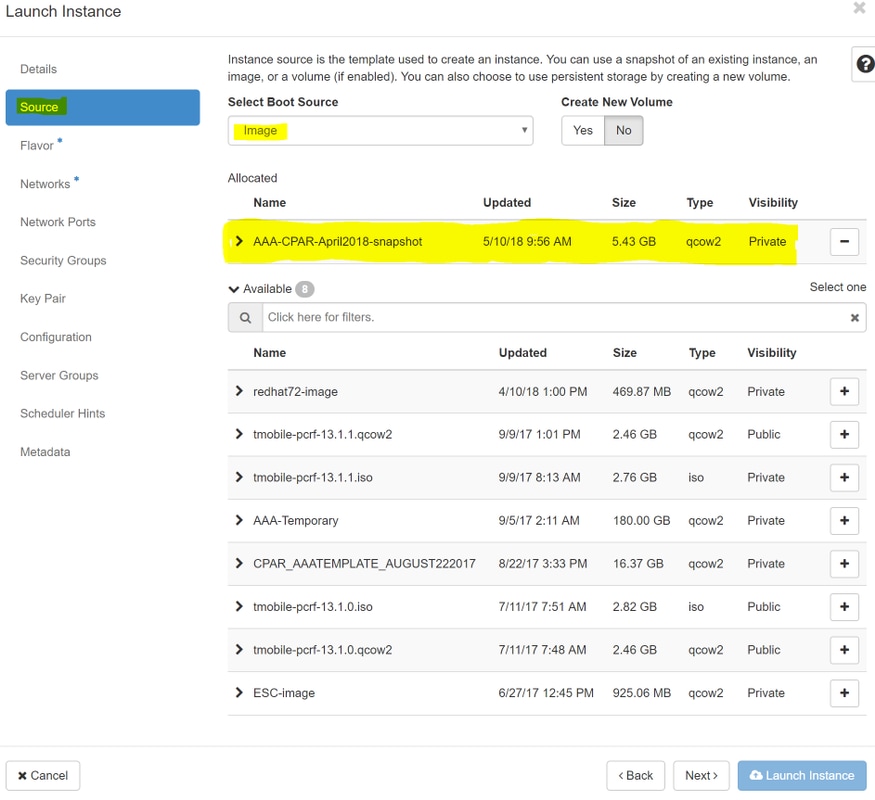
Stap 7.Kies op het tabblad Smaak de AAA-smaak terwijl u op +teken klikt.
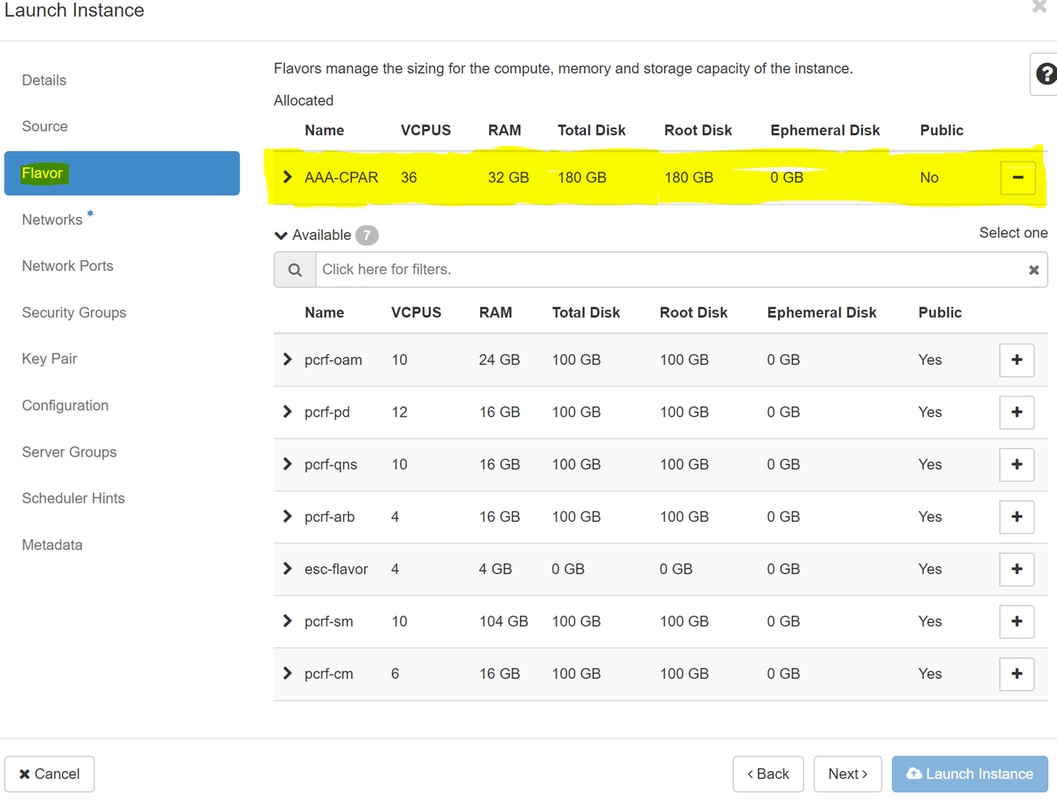
Stap 8.Tot slot, navigeer naar het tabblad netwerk en kies de netwerken die de instantie nodig heeft als u klikt op + ondertekenen. Selecteer in dit geval Diameter-soutable1, Radius-routable1 en tb1-mgmt.
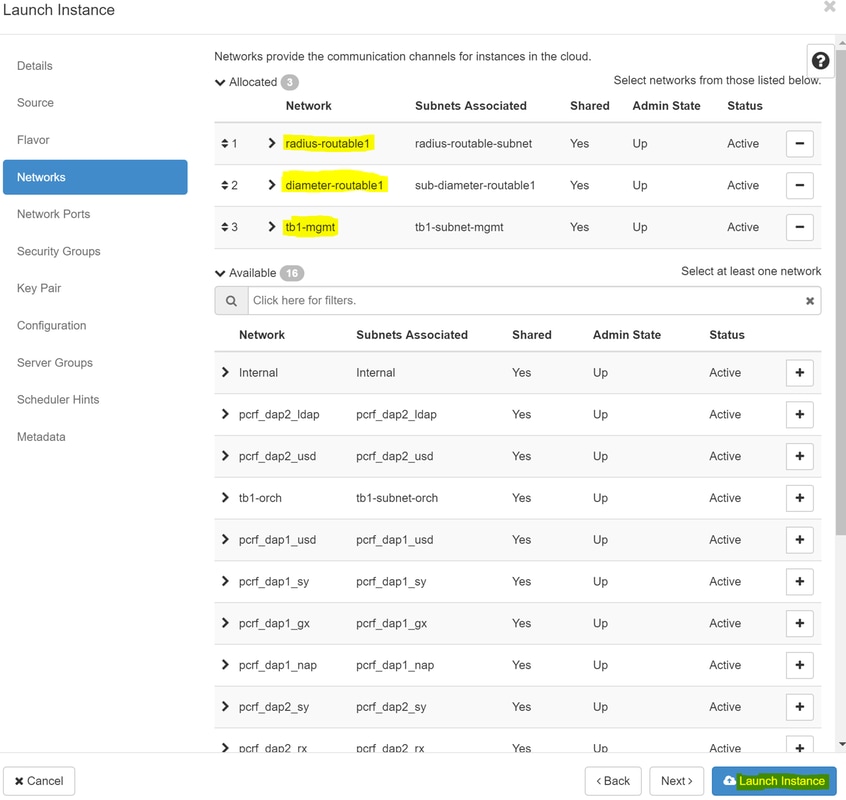
Stap 9. Klik ten slotte op de instantie Launch om deze te maken. De voortgang kan worden gemonitord in Horizon:
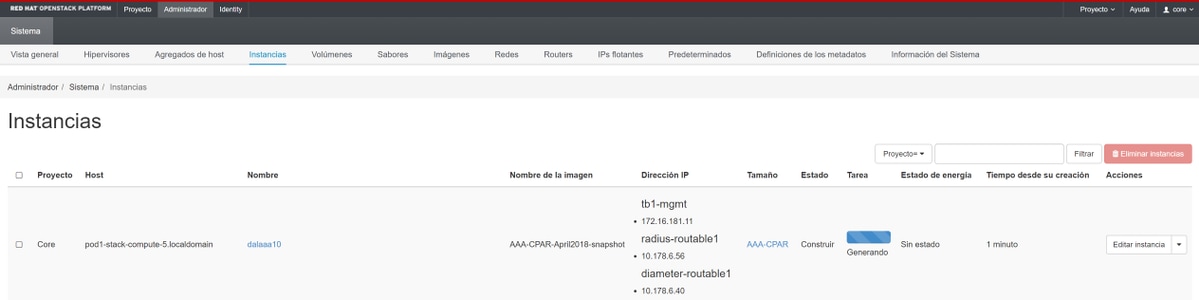
Na een paar minuten is de installatie volledig geïmplementeerd en klaar voor gebruik.

Een zwevend IP-adres maken en toewijzen
Een zwevend IP-adres is een routeerbaar adres, wat betekent dat het bereikbaar is vanaf de buitenkant van de Ultra M / Openstack-architectuur en dat het in staat is om te communiceren met andere knooppunten van het netwerk.
Stap 1.Navigeer in het hoofdmenu van Horizon naar Beheer > Zwevende IP's.
Stap 2. Klik op de knopIP toewijzen aan project.
Stap 3. Selecteer in het venster Drijvende IP toewijzen de groep waaruit het nieuwe drijvende IP-adres behoort, het project waaraan het wordt toegewezen en het nieuwe drijvende IP-adres zelf.
Voorbeeld:
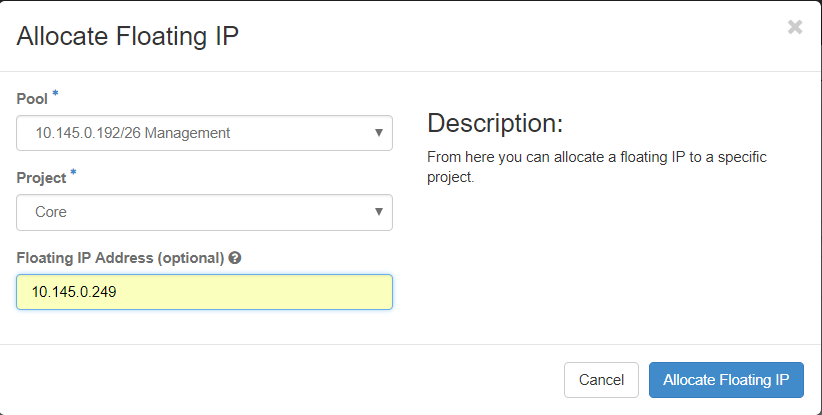
Stap 4. Klik opAllocateFloating IPbutton.
Stap 5. Navigeer in het hoofdmenu van Horizon naar Project > Instanties.
Stap 6.In de kolom Actie klikt u op de pijl die naar beneden wijst in de knop Maak momentopname, een menu moet worden weergegeven. Selecteer Floating IPoption koppelen.
Stap 7. Selecteer het corresponderende drijvende IP-adres dat moet worden gebruikt in het veld IP-adres en kies de corresponderende beheerinterface (eth0) in het nieuwe exemplaar waarin dit drijvende IP zal worden toegewezen in de poort die moet worden gekoppeld. Zie de volgende afbeelding als voorbeeld van deze procedure.
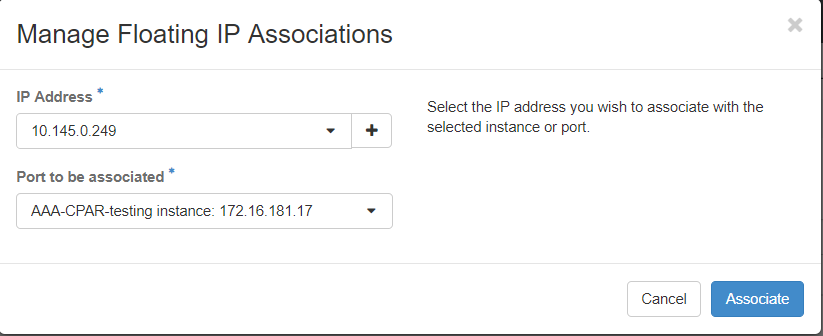
Stap 8. Klik ten slotte op de knop Associate.
SSH inschakelen
Stap 1.Navigeer in het hoofdmenu van Horizon naar Project > Instanties.
Stap 2.Klik op de naam van de instantie/VM die is gemaakt in sectieEen nieuwe instantie starten.
Stap 3. Klik op Consoletab. Hiermee wordt de opdrachtregelinterface van de VM weergegeven.
Stap 4.Als de CLI eenmaal is weergegeven, voert u de juiste aanmeldingsreferenties in:
Gebruikersnaam:root
Wachtwoord:cisco123
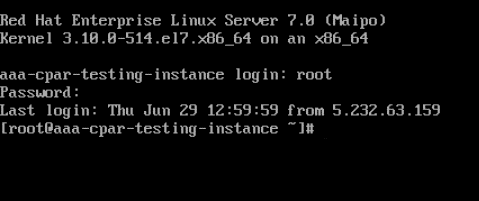
Stap 5.Voer in de CLI het commando /etc/ssh/sshd_configto edit ssh configuration in.
Stap 6. Zodra het ssh-configuratiebestand is geopend, drukt u op Ito om het bestand te bewerken. Zoek vervolgens naar het onderstaande gedeelte en wijzig de eerste regel van PasswordAuthentication notoPasswordAuthentication yes.

Stap 7.Druk op ESCen voer:wq! in om wijzigingen in het bestand sshd_config op te slaan.
Stap 8. Voer de commandservice uit die opnieuw moet worden gestart.
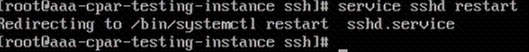
Stap 9.Om te testen of SSH-configuratiewijzigingen correct zijn toegepast, opent u een SSH-client en probeert u een externe beveiligde verbinding tot stand te brengen met behulp van de drijvende IP die aan de instantie is toegewezen (d.w.z. 10.145.0.249) en de gebruikersroot.
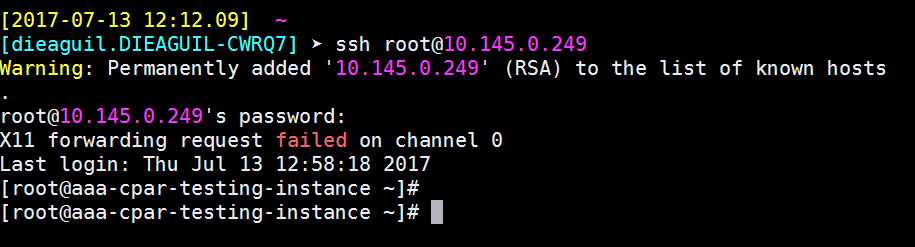
Een SSH-sessie instellen
Open een SSH-sessie met het IP-adres van de corresponderende VM/server waarop de toepassing is geïnstalleerd.

CPAR-instantie starten
Volg de onderstaande stappen zodra de activiteit is voltooid en de CPAR-services opnieuw kunnen worden ingesteld op de site die is afgesloten.
- Als u zich opnieuw wilt aanmelden bij Horizon, gaat u naar Project > Instantie > Start.
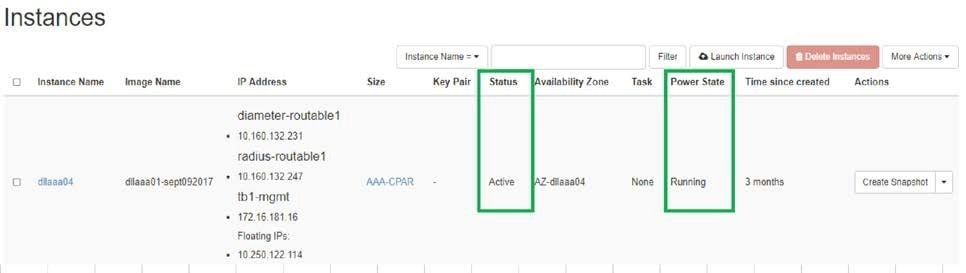
- Controleer of de status van de instantie actief is en of de energiestatus actief is:
Gezondheidscontrole na activiteit
Stap 1.Voer de opdracht /opt/CSCOar/bin/arstatus op OS-niveau uit.
[root@aaa04 ~]# /opt/CSCOar/bin/arstatus Cisco Prime AR RADIUS server running (pid: 24834) Cisco Prime AR Server Agent running (pid: 24821) Cisco Prime AR MCD lock manager running (pid: 24824) Cisco Prime AR MCD server running (pid: 24833) Cisco Prime AR GUI running (pid: 24836) SNMP Master Agent running (pid: 24835) [root@wscaaa04 ~]#
Stap 2.Voer de opdracht /opt/CSCOar/bin/aregcmd uit op OS-niveau en voer de beheerdersreferenties in. Controleer of CPAR Health 10 van de 10 is en verlaat de CPAR CLI.
[root@aaa02 logs]# /opt/CSCOar/bin/aregcmd Cisco Prime Access Registrar 7.3.0.1 Configuration Utility Copyright (C) 1995-2017 by Cisco Systems, Inc. All rights reserved. Cluster: User: admin Passphrase: Logging in to localhost [ //localhost ] LicenseInfo = PAR-NG-TPS 7.2(100TPS:) PAR-ADD-TPS 7.2(2000TPS:) PAR-RDDR-TRX 7.2() PAR-HSS 7.2() Radius/ Administrators/ Server 'Radius' is Running, its health is 10 out of 10 --> exit
Stap 3.Voer de opdracht netstat | grep diameter uit en controleer of alle DRA-verbindingen tot stand zijn gebracht.
De hieronder genoemde output is voor een omgeving waar Diameter links worden verwacht. Als er minder koppelingen worden weergegeven, betekent dit dat de verbinding met de DRA wordt verbroken en moet worden geanalyseerd.
[root@aa02 logs]# netstat | grep diameter tcp 0 0 aaa02.aaa.epc.:77 mp1.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:36 tsa6.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:47 mp2.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:07 tsa5.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:08 np2.dra01.d:diameter ESTABLISHED
Stap 4. Controleer of het TPS-logboek aangeeft welke verzoeken door CPAR worden verwerkt. De gemarkeerde waarden vertegenwoordigen de TPS en dat zijn de waarden waar we aandacht aan moeten besteden.
De waarde van TPS mag niet hoger zijn dan 1500.
[root@wscaaa04 ~]# tail -f /opt/CSCOar/logs/tps-11-21-2017.csv 11-21-2017,23:57:35,263,0 11-21-2017,23:57:50,237,0 11-21-2017,23:58:05,237,0 11-21-2017,23:58:20,257,0 11-21-2017,23:58:35,254,0 11-21-2017,23:58:50,248,0 11-21-2017,23:59:05,272,0 11-21-2017,23:59:20,243,0 11-21-2017,23:59:35,244,0 11-21-2017,23:59:50,233,0
Stap 5.Zoek naar "error" of "alarm" berichten in name_radius_1_log
[root@aaa02 logs]# grep -E "error|alarm" name_radius_1_log
Stap 6.Controleer de hoeveelheid geheugen die het CPAR-proces gebruikt door de volgende opdracht uit te voeren:
Bovenkant | GREP radius
[root@sfraaa02 ~]# top | grep radius 27008 root 20 0 20.228g 2.413g 11408 S 128.3 7.7 1165:41 radius
Deze gemarkeerde waarde moet lager zijn dan: 7Gb, wat het maximaal toegestane is op toepassingsniveau.
Moederbordvervanging in OSD-computerknooppunt
Vóór de activiteit worden de VM's die in de Compute-node worden gehost, sierlijk afgesloten en wordt de CEPH in de onderhoudsmodus gezet. Nadat het moederbord is vervangen, worden de VM's hersteld en wordt CEPH uit de onderhoudsmodus gehaald.
Identificeer de VM's die in de OSD-Compute Node worden gehost
Identificeer de VM's die op de OSD-computerserver worden gehost.
[stack@director ~]$ nova list --field name,host | grep osd-compute-0 | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | pod2-stack-compute-4.localdomain |
back-up: momentopnameproces
CPAR-toepassing afsluiten
Stap 1.Open een ssh-client die is aangesloten op het netwerk en maak verbinding met de CPAR-instantie.
Het is belangrijk om niet alle 4 AAA-instanties binnen één site tegelijkertijd af te sluiten, doe het een voor een.
Stap 2.Sluit de CPAR-toepassing af met deze opdracht:
/opt/CSCOar/bin/arserver stop A Message stating “Cisco Prime Access Registrar Server Agent shutdown complete.” Should show up
Opmerking: als een gebruiker een CLI-sessie heeft geopend, werkt de opdracht voor het stoppen van de server niet en wordt het volgende bericht weergegeven:
ERROR: You can not shut down Cisco Prime Access Registrar while the CLI is being used. Current list of running CLI with process id is: 2903 /opt/CSCOar/bin/aregcmd –s
In dit voorbeeld moet de gemarkeerde proces-id 2903 worden beëindigd voordat CPAR kan worden stopgezet. Als dit het geval is, beëindig dan dit proces met deze opdracht:
kill -9 *process_id*
Herhaal dan stap 1.
Stap 3.Controleer of de CPAR-toepassing inderdaad is afgesloten met deze opdracht:
/opt/CSCOar/bin/arstatus
Deze berichten verschijnen:
Cisco Prime Access Registrar Server Agent not running Cisco Prime Access Registrar GUI not running
VM Snapshot-taak
Stap 1.Voer de Horizon GUI-website in die overeenkomt met de site (stad) waaraan momenteel wordt gewerkt.
Bij het openen van Horizon wordt de getoonde afbeelding waargenomen:
Stap 2. Navigeer naar Project > Instanties, zoals weergegeven in de afbeelding.
Als de gebruiker CPAR heeft gebruikt, worden alleen de 4 AAA-instanties in dit menu weergegeven.
Stap 3.Sluit slechts één instantie tegelijk af. Herhaal het hele proces in dit document.
Om de VM af te sluiten, gaat u naar Acties > instantie uitschakelen en bevestigt u uw selectie.

Stap 4.Valideer dat de instantie inderdaad is afgesloten door de status = Shutoff en Power State = Shut Down te controleren.
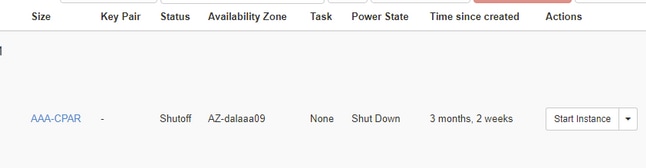
Met deze stap wordt het afsluitproces van de CPAR beëindigd.
VM-momentopname
Zodra de CPAR-VM's zijn uitgeschakeld, kunnen de momentopnamen parallel worden gemaakt, omdat ze behoren tot onafhankelijke computers.
De vier QCOW2-bestanden worden parallel gemaakt.
Maak een momentopname van elke AAA-instantie (25 minuten -1 uur) (25 minuten voor instanties die een Qcow-afbeelding als bron hebben gebruikt en 1 uur voor instanties die een onbewerkte afbeelding als bron hebben gebruikt)
Stap 1. Meld u aan bij de HorizonGUI van POD's Openstack.
Stap 2. Nadat u bent ingelogd, gaat u naar de sectie Project > Berekenen > Instanties in het bovenste menu en zoekt u naar de AAA-instanties.
Stap 3. Klik op de knop Momentopname maken om verder te gaan met het maken van momentopnamen (dit moet worden uitgevoerd op de corresponderende AAA-instantie).
Stap 4. Zodra de momentopname is uitgevoerd, navigeert u naar het menu AFBEELDINGEN en controleert u of alle foto's zijn voltooid en geen problemen zijn gemeld.
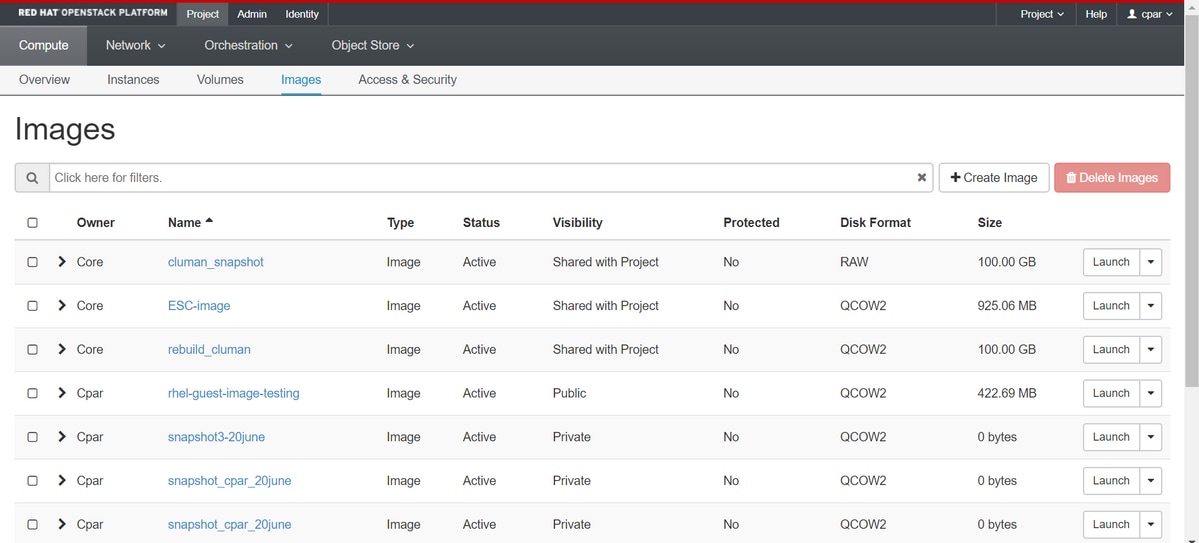
Stap 5. De volgende stap is het downloaden van de momentopname in een QCOW2-indeling en het overbrengen naar een externe entiteit in het geval dat de OSPD tijdens dit proces verloren gaat. Om dit te bereiken, identificeert u de momentopname met deze opdracht om de afbeeldingslijst op OSPD-niveau te bekijken.
[root@elospd01 stack]# glance image-list +--------------------------------------+---------------------------+ | ID | Name | +--------------------------------------+---------------------------+ | 80f083cb-66f9-4fcf-8b8a-7d8965e47b1d | AAA-Temporary | | 22f8536b-3f3c-4bcc-ae1a-8f2ab0d8b950 | ELP1 cluman 10_09_2017 | | 70ef5911-208e-4cac-93e2-6fe9033db560 | ELP2 cluman 10_09_2017 | | e0b57fc9-e5c3-4b51-8b94-56cbccdf5401 | ESC-image | | 92dfe18c-df35-4aa9-8c52-9c663d3f839b | lgnaaa01-sept102017 | | 1461226b-4362-428b-bc90-0a98cbf33500 | tmobile-pcrf-13.1.1.iso | | 98275e15-37cf-4681-9bcc-d6ba18947d7b | tmobile-pcrf-13.1.1.qcow2 | +--------------------------------------+---------------------------+
Stap 6. Zodra u hebt vastgesteld dat de momentopname moet worden gedownload (in dit geval wordt deze hierboven in het groen gemarkeerd), downloadt u deze nu op een QCOW2-formaat met deze opdracht Glance image-download zoals hier wordt weergegeven.
[root@elospd01 stack]# glance image-download 92dfe18c-df35-4aa9-8c52-9c663d3f839b --file /tmp/AAA-CPAR-LGNoct192017.qcow2 &
- De "&" stuurt het proces naar de achtergrond. Het zal enige tijd duren om deze actie te voltooien, als het eenmaal is gedaan, kan het beeld zich bevinden in /tmp directory.
- Bij het verzenden van het proces naar de achtergrond, als de connectiviteit verloren gaat, wordt het proces ook gestopt.
- Voer de opdracht "dispwn -h" uit, zodat in het geval dat de SSH-verbinding verloren gaat, het proces nog steeds wordt uitgevoerd en voltooid op de OSPD.
7. Zodra het downloadproces is voltooid, moet een compressieproces worden uitgevoerd, omdat die momentopname kan worden gevuld met NULLEN vanwege processen, taken en tijdelijke bestanden die door het besturingssysteem worden afgehandeld. De opdracht voor bestandscompressie is virt-sparsify.
[root@elospd01 stack]# virt-sparsify AAA-CPAR-LGNoct192017.qcow2 AAA-CPAR-LGNoct192017_compressed.qcow2
Dit proces duurt enige tijd (ongeveer 10-15 minuten). Als het bestand klaar is, moet het worden overgedragen naar een externe entiteit zoals gespecificeerd in de volgende stap.
Verificatie van de bestandsintegriteit is vereist, om dit te bereiken, voert u de volgende opdracht uit en zoekt u naar het attribuut "corrupt" aan het einde van de uitvoer.
[root@wsospd01 tmp]# qemu-img info AAA-CPAR-LGNoct192017_compressed.qcow2 image: AAA-CPAR-LGNoct192017_compressed.qcow2 file format: qcow2 virtual size: 150G (161061273600 bytes) disk size: 18G cluster_size: 65536 Format specific information: compat: 1.1 lazy refcounts: false refcount bits: 16 corrupt: false
Om een probleem te voorkomen waarbij de OSPD verloren gaat, moet de onlangs gemaakte momentopname op QCOW2-formaat worden overgedragen aan een externe entiteit. Voordat we de bestandsoverdracht starten, moeten we controleren of de bestemming voldoende beschikbare schijfruimte heeft, gebruik de opdracht "df –kh" om de geheugenruimte te verifiëren. Ons advies is om het tijdelijk over te dragen naar de OSPD van een andere site door SFTP "sftproot@x.x.x.x" te gebruiken waar x.x.x.x het IP van een externe OSPD is. Om de overdracht te versnellen, kan de bestemming naar meerdere OSPD's worden verzonden. Op dezelfde manier kunnen we de volgende opdracht gebruiken: scp *name_of_the_file*.qcow2 root@ x.x.x.x:/tmp (waarbij x.x.x.x het IP van een externe OSPD is) om het bestand over te zetten naar een andere OSPD.
CEPH in onderhoudsmodus zetten
Stap 1. Controleer of de status van de cephosd-structuur in de server is ingesteld
[heat-admin@pod2-stack-osd-compute-0 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod2-stack-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-3 4.35999 host pod2-stack-osd-compute-1
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
-4 4.35999 host pod2-stack-osd-compute-2
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
Stap 2. Meld u aan bij de OSD Compute-node en zet CEPH in de onderhoudsmodus.
[root@pod2-stack-osd-compute-0 ~]# sudo ceph osd set norebalance
[root@pod2-stack-osd-compute-0 ~]# sudo ceph osd set noout
[root@pod2-stack-osd-compute-0 ~]# sudo ceph status
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_WARN
noout,norebalance,sortbitwise,require_jewel_osds flag(s) set
monmap e1: 3 mons at {pod2-stack-controller-0=11.118.0.10:6789/0,pod2-stack-controller-1=11.118.0.11:6789/0,pod2-stack-controller-2=11.118.0.12:6789/0}
election epoch 10, quorum 0,1,2 pod2-stack-controller-0,pod2-stack-controller-1,pod2-stack-controller-2
osdmap e79: 12 osds: 12 up, 12 in
flags noout,norebalance,sortbitwise,require_jewel_osds
pgmap v22844323: 704 pgs, 6 pools, 804 GB data, 423 kobjects
2404 GB used, 10989 GB / 13393 GB avail
704 active+clean
client io 3858 kB/s wr, 0 op/s rd, 546 op/s wr
Opmerking: wanneer CEPH wordt verwijderd, gaat VNF HD RAID in de gedegradeerde staat, maar de hd-schijf moet nog steeds toegankelijk zijn
sierlijke uitschakeling
Power off Node
- De instantie uitschakelen: nova stop <INSTANCE_NAME>
- U ziet de instantienaam met de status Shutoff.
[stack@director ~]$ nova stop aaa2-21 Request to stop server aaa2-21 has been accepted. [stack@director ~]$ nova list +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | ID | Name | Status | Task State | Power State | Networks | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | ACTIVE | - | Running | tb1-mgmt=172.16.181.14, 10.225.247.233; radius-routable1=10.160.132.245; diameter-routable1=10.160.132.231 | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | SHUTOFF | - | Shutdown | diameter-routable1=10.160.132.230; radius-routable1=10.160.132.248; tb1-mgmt=172.16.181.7, 10.225.247.234 | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | ACTIVE | - | Running | diameter-routable1=10.160.132.233; radius-routable1=10.160.132.244; tb1-mgmt=172.16.181.10 | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+
Moederbord vervangen
De stappen voor het vervangen van het moederbord in een UCS C240 M4-server kunnen worden doorverwezen vanaf de installatie- en servicegids voor Cisco UCS C240 M4-servers
- Meld u aan bij de server met behulp van de CIMC IP.
- Voer een BIOS-upgrade uit als de firmware niet overeenkomt met de aanbevolen versie die eerder is gebruikt. Stappen voor BIOS-upgrade worden hier gegeven: Cisco UCS C-Series Rack-Mount Server BIOS Upgrade Guide
CEPH uit onderhoudsmodus verplaatsen
Meld u aan bij de OSD Compute-node en verplaats CEPH uit de onderhoudsmodus.
[root@pod2-stack-osd-compute-0 ~]# sudo ceph osd unset norebalance
[root@pod2-stack-osd-compute-0 ~]# sudo ceph osd unset noout
[root@pod2-stack-osd-compute-0 ~]# sudo ceph status
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
monmap e1: 3 mons at {pod2-stack-controller-0=11.118.0.10:6789/0,pod2-stack-controller-1=11.118.0.11:6789/0,pod2-stack-controller-2=11.118.0.12:6789/0}
election epoch 10, quorum 0,1,2 pod2-stack-controller-0,pod2-stack-controller-1,pod2-stack-controller-2
osdmap e81: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v22844355: 704 pgs, 6 pools, 804 GB data, 423 kobjects
2404 GB used, 10989 GB / 13393 GB avail
704 active+clean
client io 3658 kB/s wr, 0 op/s rd, 502 op/s wr
De VM's herstellen
Een instantie herstellen via Snapshot
Herstelproces:
Het is mogelijk om de vorige instantie opnieuw in te zetten met de momentopname die in eerdere stappen is gemaakt.
Stap 1 [OPTIONEEL].Als er geen eerdere VMsnapshot beschikbaar is, maakt u verbinding met de OSPD-node waar de back-up is verzonden en voert u de back-up terug naar de oorspronkelijke OSPD-node. Gebruik van "sftproot@x.x.x.x" waarbij x.x.x.x het IP van het oorspronkelijke OSPD is. Sla het momentopnamebestand op in de map /tmp.
Stap 2.Verbinding maken met de OSPD-node waar de instantie opnieuw wordt geïmplementeerd.

Bron de omgevingsvariabelen met deze opdracht:
# source /home/stack/pod1-stackrc-Core-CPAR
Stap 3.Om de momentopname als afbeelding te gebruiken, is het noodzakelijk om deze als zodanig naar de horizon te uploaden. Gebruik de volgende opdracht om dit te doen.
#glance image-create -- AAA-CPAR-Date-snapshot.qcow2 --container-format bare --disk-format qcow2 --name AAA-CPAR-Date-snapshot
Het proces is te zien aan de horizon.

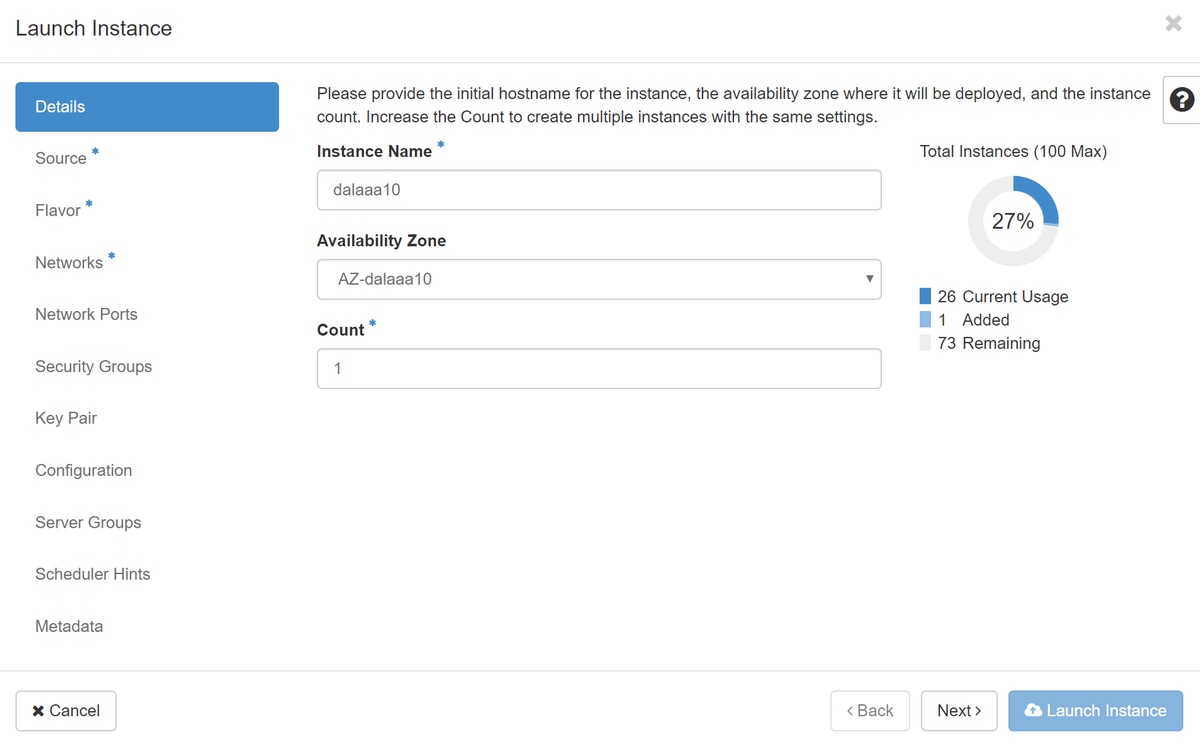
Stap 4.Navigeer in Horizon naar Project > Instanties en klik op Instantie starten.

Stap 5.Vul de instantienaam in en kies de beschikbaarheidszone.
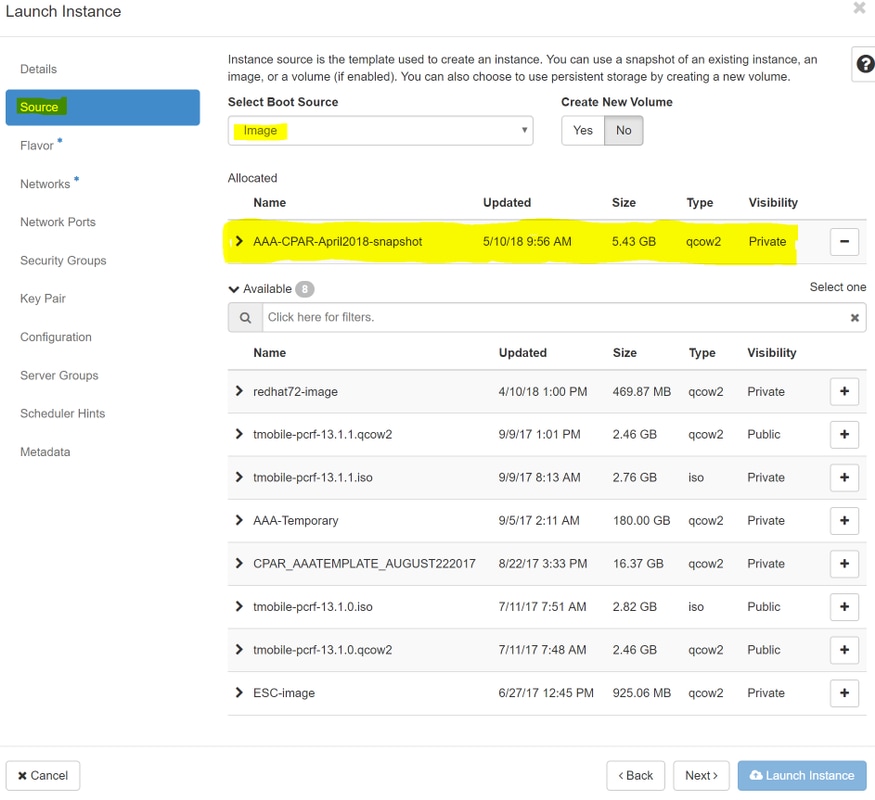
Stap 6.Kies op het tabblad Bron de afbeelding om de instantie te maken. Selecteer in het menu Select Boot Source (Opstartbron selecteren) image (Afbeelding selecteren), een lijst met afbeeldingen wordt hier weergegeven en kies degene die eerder is geüpload terwijl u op +teken klikt.
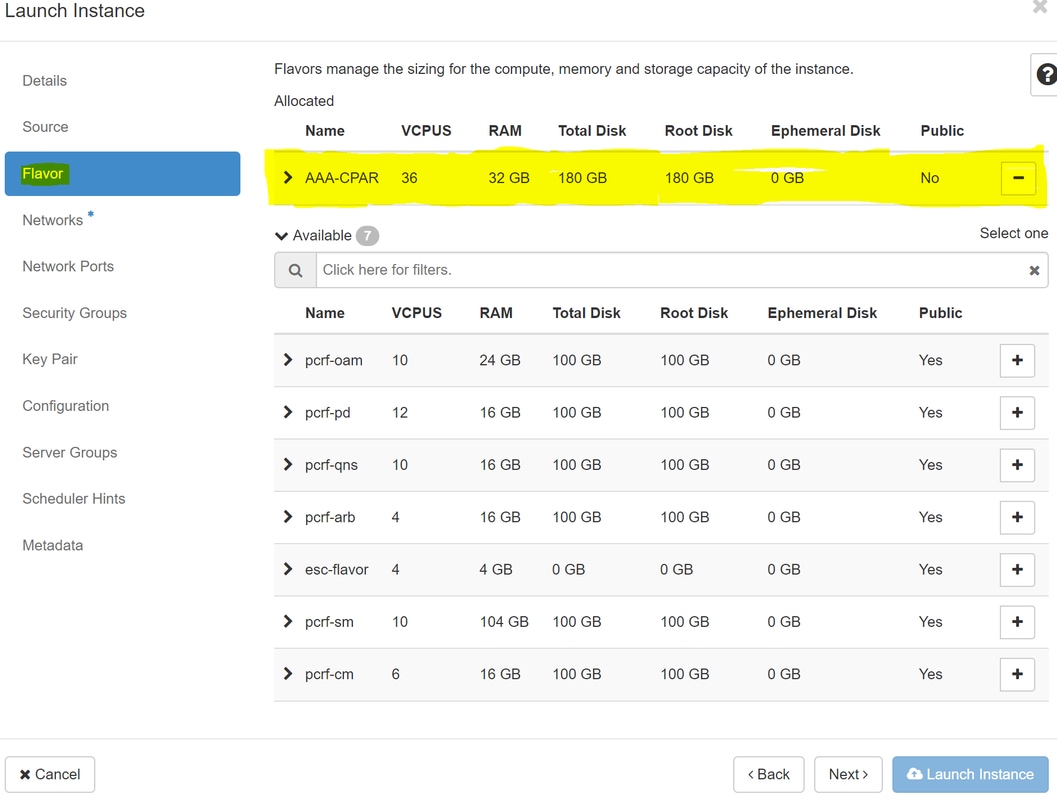
Stap 7.Kies op het tabblad Smaak de AAA-smaak terwijl u op het +-teken klikt.
Stap 8.Ten slotte, navigeert u naar het tabblad netwerk en kiest u de netwerken die de instantie nodig heeft als u op het + teken klikt. Selecteer in dit geval Diameter-soutable1, Radius-routable1 en tb1-mgmt.
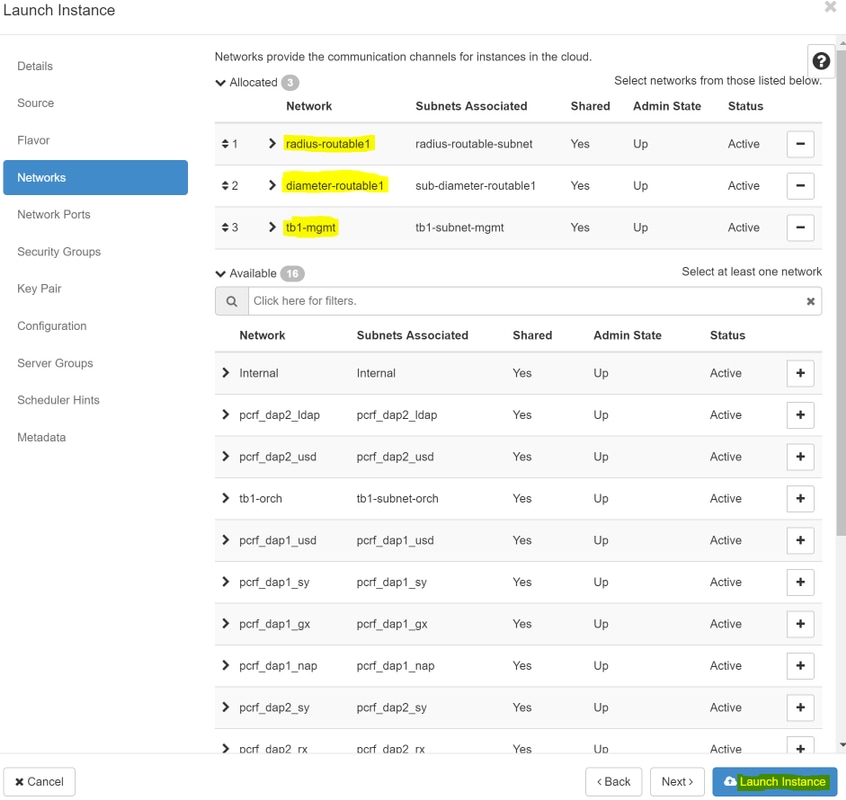
Stap 9. Klik ten slotte op de instantie Launch om deze te maken. De voortgang kan worden gemonitord in Horizon:
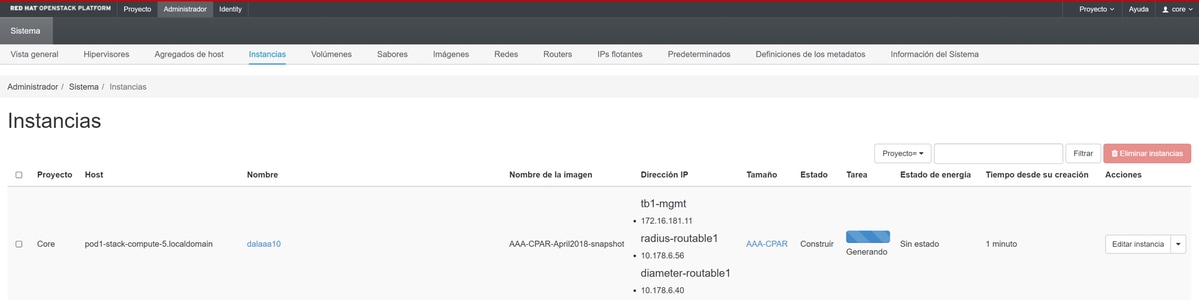
Na een paar minuten is de installatie volledig geïmplementeerd en klaar voor gebruik.

Een zwevend IP-adres maken en toewijzen
Een zwevend IP-adres is een routeerbaar adres, wat betekent dat het bereikbaar is vanaf de buitenkant van de Ultra M / Openstack-architectuur en dat het in staat is om te communiceren met andere knooppunten van het netwerk.
Stap 1.Navigeer in het hoofdmenu van Horizon naar Beheer > Zwevende IP's.
Stap 2.Klik op de knopIP toewijzen aan project.
Stap 3. Selecteer in het venster Drijvende IP toewijzen de groep waaruit het nieuwe drijvende IP-adres behoort, het project waaraan het wordt toegewezen en het nieuwe drijvende IP-adres zelf.
Voorbeeld:
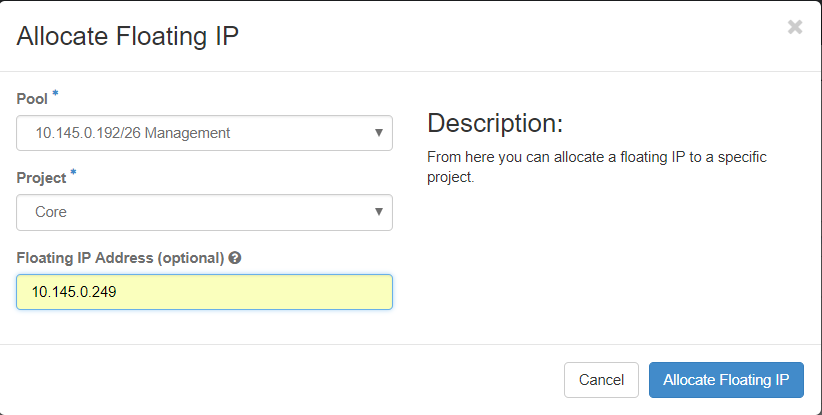
Stap 4. Klik opAllocateFloating IPbutton.
Stap 5. Navigeer in het hoofdmenu van Horizon naar Project > Instanties.
Stap 6. In de kolom Actie klikt u op de pijl die naar beneden wijst in de knop Maak momentopname, een menu moet worden weergegeven. Selecteer Floating IPoption koppelen.
Stap 7. Selecteer het corresponderende drijvende IP-adres dat moet worden gebruikt in het veld IP-adres en kies de corresponderende beheerinterface (eth0) in het nieuwe exemplaar waarin dit drijvende IP zal worden toegewezen in de poort die moet worden gekoppeld. Zie de volgende afbeelding als voorbeeld van deze procedure.
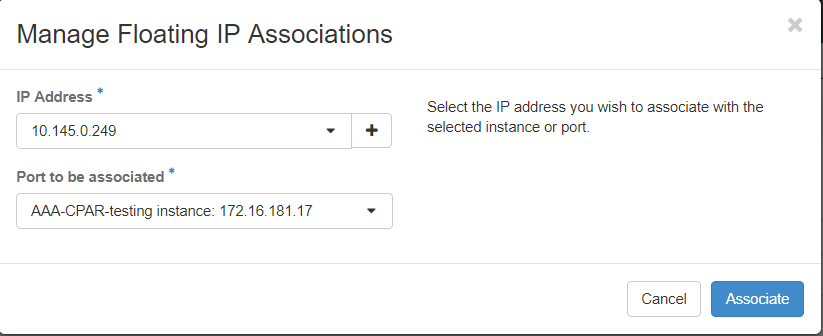
Stap 8.Klik ten slotte op de knop Associëren.
SSH inschakelen
Stap 1.Navigeer in het hoofdmenu van Horizon naar Project > Instanties.
Stap 2.Klik op de naam van de instantie/VM die is gemaakt in sectieEen nieuwe instantie starten.
Stap 3.Klik op Consoletab. Hiermee wordt de CLI van de VM weergegeven.
Stap 4. Als de CLI eenmaal is weergegeven, voert u de juiste aanmeldingsreferenties in:
Gebruikersnaam:root
Wachtwoord:cisco123
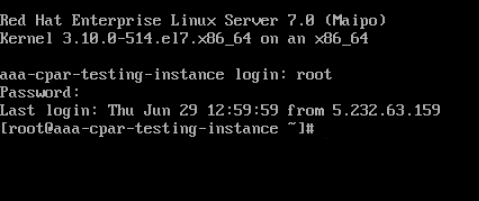
Stap 5.Voer in de CLI het commando /etc/ssh/sshd_configto edit ssh configuration in.
Stap 6. Zodra het ssh-configuratiebestand is geopend, drukt u op Ito om het bestand te bewerken. Zoek vervolgens naar het gedeelte dat hier wordt weergegeven en wijzig de eerste regel van PasswordAuthentication notoPasswordAuthentication yes.

Stap 7.Druk op ESCen voer:wq! in om wijzigingen in het bestand sshd_config op te slaan.
Stap 8. Voer de opdrachtservice sshd restart uit.
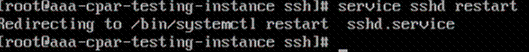
Stap 9.Om te testen of SSH-configuratiewijzigingen correct zijn toegepast, opent u een SSH-client en probeert u een externe beveiligde verbinding tot stand te brengen met behulp van de drijvende IP die aan de instantie is toegewezen (d.w.z. 10.145.0.249) en de gebruikersroot.
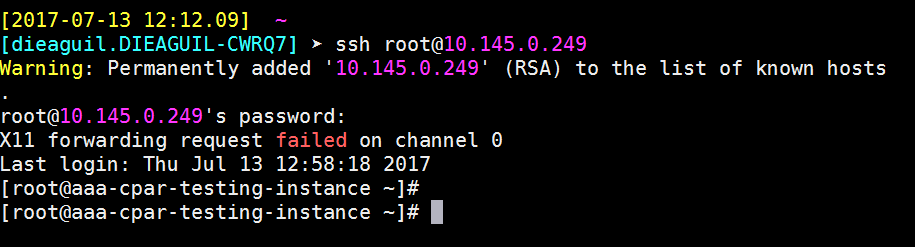
Een SSH-sessie instellen
Open een SSH-sessie met het IP-adres van de corresponderende VM/server waarop de toepassing is geïnstalleerd.

CPAR-instantie starten
Volg deze stappen zodra de activiteit is voltooid en de CPAR-services opnieuw kunnen worden ingesteld op de site die is afgesloten.
- Meld u aan bij Horizon en navigeer naar Project > Instantie > Start.
- Controleer of de status van de instantie actief is en of de energiestatus actief is:
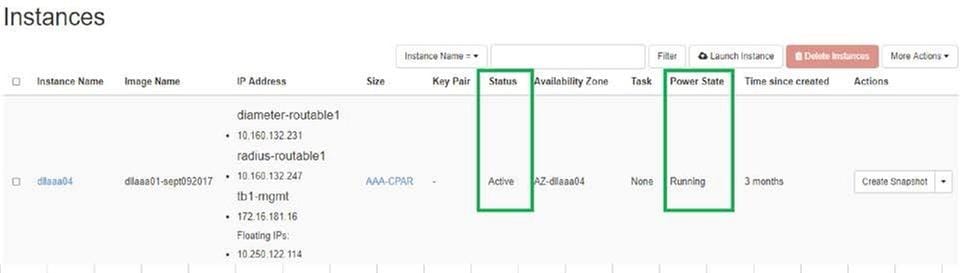
Gezondheidscontrole na activiteit
Stap 1. Voer de opdracht /opt/CSCOar/bin/arstatus uit op besturingssysteemniveau.
[root@aaa04 ~]# /opt/CSCOar/bin/arstatus Cisco Prime AR RADIUS server running (pid: 24834) Cisco Prime AR Server Agent running (pid: 24821) Cisco Prime AR MCD lock manager running (pid: 24824) Cisco Prime AR MCD server running (pid: 24833) Cisco Prime AR GUI running (pid: 24836) SNMP Master Agent running (pid: 24835) [root@wscaaa04 ~]#
Stap 2. Voer de opdracht /opt/CSCOar/bin/aregcmd uit op besturingssysteemniveau en voer de beheerdersreferenties in. Controleer of CPAR Health 10 van de 10 is en verlaat de CPAR CLI.
[root@aaa02 logs]# /opt/CSCOar/bin/aregcmd Cisco Prime Access Registrar 7.3.0.1 Configuration Utility Copyright (C) 1995-2017 by Cisco Systems, Inc. All rights reserved. Cluster: User: admin Passphrase: Logging in to localhost [ //localhost ] LicenseInfo = PAR-NG-TPS 7.2(100TPS:) PAR-ADD-TPS 7.2(2000TPS:) PAR-RDDR-TRX 7.2() PAR-HSS 7.2() Radius/ Administrators/ Server 'Radius' is Running, its health is 10 out of 10 --> exit
Stap 3.Voer de opdracht netstat | grep diameter uit en controleer of alle DRA-verbindingen tot stand zijn gebracht.
De hier genoemde output is voor een omgeving waar Diameter links worden verwacht. Als er minder koppelingen worden weergegeven, betekent dit dat de verbinding met de DRA wordt verbroken en moet worden geanalyseerd.
[root@aa02 logs]# netstat | grep diameter tcp 0 0 aaa02.aaa.epc.:77 mp1.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:36 tsa6.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:47 mp2.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:07 tsa5.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:08 np2.dra01.d:diameter ESTABLISHED
Stap 4. Controleer of het TPS-logboek aangeeft welke verzoeken door CPAR worden verwerkt. De gemarkeerde waarden vertegenwoordigen de TPS en dat zijn de waarden waar we aandacht aan moeten besteden.
De waarde van TPS mag niet hoger zijn dan 1500.
[root@wscaaa04 ~]# tail -f /opt/CSCOar/logs/tps-11-21-2017.csv 11-21-2017,23:57:35,263,0 11-21-2017,23:57:50,237,0 11-21-2017,23:58:05,237,0 11-21-2017,23:58:20,257,0 11-21-2017,23:58:35,254,0 11-21-2017,23:58:50,248,0 11-21-2017,23:59:05,272,0 11-21-2017,23:59:20,243,0 11-21-2017,23:59:35,244,0 11-21-2017,23:59:50,233,0
Stap 5.Zoek naar "error" of "alarm" berichten in name_radius_1_log
[root@aaa02 logs]# grep -E "error|alarm" name_radius_1_log
Stap 6.Controleer de hoeveelheid geheugen die het CPAR-proces gebruikt met deze opdracht:
Bovenkant | GREP radius
[root@sfraaa02 ~]# top | grep radius 27008 root 20 0 20.228g 2.413g 11408 S 128.3 7.7 1165:41 radius
Deze gemarkeerde waarde moet lager zijn dan: 7Gb, wat het maximaal toegestane is op toepassingsniveau.
Vervanging moederbord in knooppunt controller
Controleren van de status van de controller en Cluster in onderhoudsmodus zetten
Vanuit OSPD logt u in bij de controller en controleert u of de pc's in goede staat zijn - alle drie de controllers Online en Galera tonen alle drie de controllers als Master.
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod2-stack-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Fri Jul 6 09:02:52 2018Last change: Mon Jul 2 12:49:52 2018 by root via crm_attribute on pod2-stack-controller-0
3 nodes and 19 resources configured
Online: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Full list of resources:
ip-11.120.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Clone Set: haproxy-clone [haproxy]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-192.200.0.110(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
ip-11.120.0.44(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
ip-11.118.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-10.225.247.214(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Master/Slave Set: redis-master [redis]
Masters: [ pod2-stack-controller-2 ]
Slaves: [ pod2-stack-controller-0 pod2-stack-controller-1 ]
ip-11.119.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
openstack-cinder-volume(systemd:openstack-cinder-volume):Started pod2-stack-controller-1
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Zet het cluster in onderhoudsmodus
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs cluster standby
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod2-stack-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Fri Jul 6 09:03:10 2018Last change: Fri Jul 6 09:03:06 2018 by root via crm_attribute on pod2-stack-controller-0
3 nodes and 19 resources configured
Node pod2-stack-controller-0: standby
Online: [ pod2-stack-controller-1 pod2-stack-controller-2 ]
Full list of resources:
ip-11.120.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Clone Set: haproxy-clone [haproxy]
Started: [ pod2-stack-controller-1 pod2-stack-controller-2 ]
Stopped: [ pod2-stack-controller-0 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-192.200.0.110(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
ip-11.120.0.44(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
ip-11.118.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-10.225.247.214(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Master/Slave Set: redis-master [redis]
Masters: [ pod2-stack-controller-2 ]
Slaves: [ pod2-stack-controller-1 ]
Stopped: [ pod2-stack-controller-0 ]
ip-11.119.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
openstack-cinder-volume(systemd:openstack-cinder-volume):Started pod2-stack-controller-1
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Moederbord vervangen
Procedure voor het vervangen van het moederbord in een UCS C240 M4-server kan worden doorverwezen vanaf de installatie- en servicegids voor Cisco UCS C240 M4-servers
- Meld u aan bij de server met behulp van de CIMC IP.
- Voer een BIOS-upgrade uit als de firmware niet overeenkomt met de aanbevolen versie die eerder is gebruikt. Stappen voor BIOS-upgrade worden hier gegeven:
Cisco UCS C-Series Rack-Mount Server BIOS Upgrade Guide
Clusterstatus herstellen
Meld u aan bij de getroffen controller en verwijder de stand-bymodus door stand-by in te stellen. Verify controller wordt online geleverd met cluster en galera toont alle drie de controllers als Master. Dit kan enkele minuten duren.
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs cluster unstandby
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod2-stack-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Fri Jul 6 09:03:37 2018Last change: Fri Jul 6 09:03:35 2018 by root via crm_attribute on pod2-stack-controller-0
3 nodes and 19 resources configured
Online: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Full list of resources:
ip-11.120.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Clone Set: haproxy-clone [haproxy]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod2-stack-controller-1 pod2-stack-controller-2 ]
Slaves: [ pod2-stack-controller-0 ]
ip-192.200.0.110(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
ip-11.120.0.44(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
ip-11.118.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod2-stack-controller-1 pod2-stack-controller-2 ]
Stopped: [ pod2-stack-controller-0 ]
ip-10.225.247.214(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Master/Slave Set: redis-master [redis]
Masters: [ pod2-stack-controller-2 ]
Slaves: [ pod2-stack-controller-0 pod2-stack-controller-1 ]
ip-11.119.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
openstack-cinder-volume(systemd:openstack-cinder-volume):Started pod2-stack-controller-1
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Bijgedragen door Cisco-engineers
- Karthikeyan DachanamoorthyCisco Advanced Services
- Harshita BhardwajCisco Advanced Services
 Feedback
FeedbackContact Cisco
- Een ondersteuningscase openen

- (Vereist een Cisco-servicecontract)