Vervanging van Controller Server UCS C240 M4 - CPAR
Downloadopties
Inclusief taalgebruik
De documentatie van dit product is waar mogelijk geschreven met inclusief taalgebruik. Inclusief taalgebruik wordt in deze documentatie gedefinieerd als taal die geen discriminatie op basis van leeftijd, handicap, gender, etniciteit, seksuele oriëntatie, sociaaleconomische status of combinaties hiervan weerspiegelt. In deze documentatie kunnen uitzonderingen voorkomen vanwege bewoordingen die in de gebruikersinterfaces van de productsoftware zijn gecodeerd, die op het taalgebruik in de RFP-documentatie zijn gebaseerd of die worden gebruikt in een product van een externe partij waarnaar wordt verwezen. Lees meer over hoe Cisco gebruikmaakt van inclusief taalgebruik.
Over deze vertaling
Cisco heeft dit document vertaald via een combinatie van machine- en menselijke technologie om onze gebruikers wereldwijd ondersteuningscontent te bieden in hun eigen taal. Houd er rekening mee dat zelfs de beste machinevertaling niet net zo nauwkeurig is als die van een professionele vertaler. Cisco Systems, Inc. is niet aansprakelijk voor de nauwkeurigheid van deze vertalingen en raadt aan altijd het oorspronkelijke Engelstalige document (link) te raadplegen.
Inhoud
Inleiding
In dit document worden de stappen beschreven die nodig zijn om een defecte controllerserver in een Ultra-M-configuratie te vervangen.
Deze procedure is van toepassing op een Openstack-omgeving met NEWTON-versie waarbij Elastic Services Controller (ESC) de Cisco Prime Access Registrar (CPAR) niet beheert en CPAR rechtstreeks op de VM wordt geïnstalleerd die op Openstack is geïmplementeerd.
Achtergrondinformatie
Ultra-M is een voorverpakte en gevalideerde gevirtualiseerde mobiele packet core-oplossing die is ontworpen om de implementatie van VNF's te vereenvoudigen. OpenStack is de Virtualized Infrastructure Manager (VIM) voor Ultra-M en bestaat uit deze knooppunttypen:
- berekenen
- Object Storage Disk - Compute (OSD - Compute)
- controleur
- OpenStack Platform - Directeur (OSPD)
De high-level architectuur van Ultra-M en de betrokken componenten worden getoond in deze afbeelding:
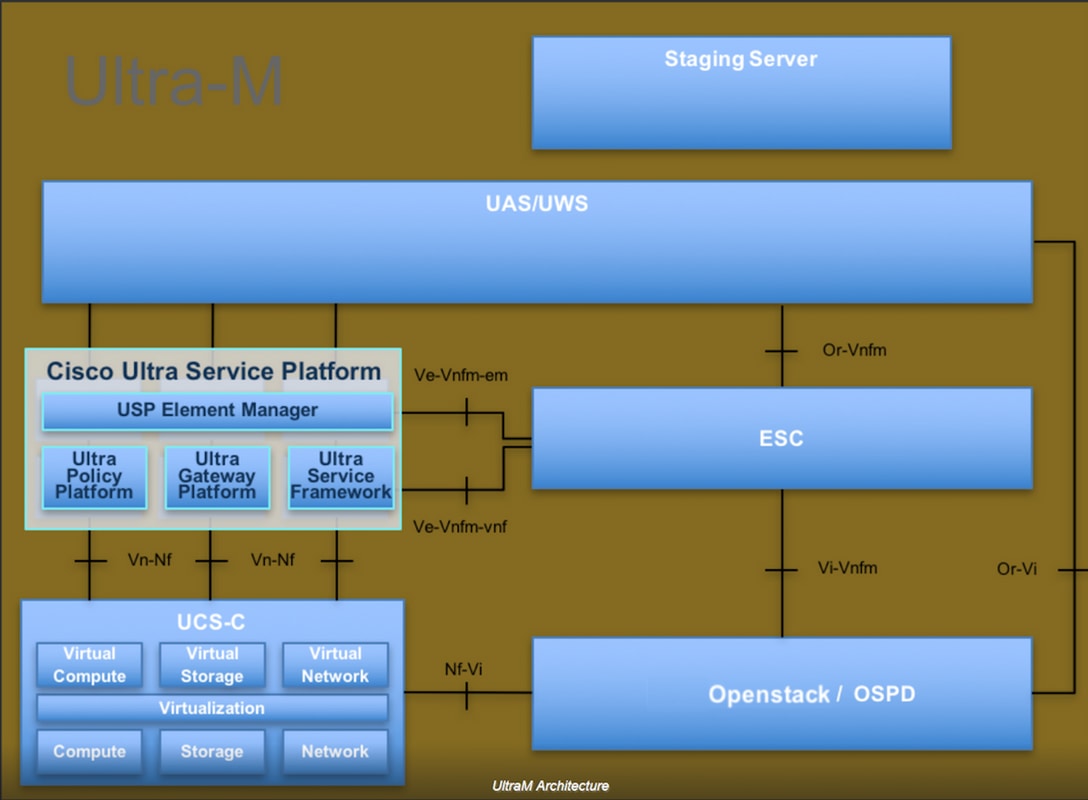
Dit document is bedoeld voor Cisco-personeel dat bekend is met het Cisco Ultra-M-platform en het beschrijft de stappen die moeten worden uitgevoerd bij OpenStack en Redhat OS.
Opmerking: Ultra M 5.1.x release wordt overwogen om de procedures in dit document te definiëren.
Afkortingen
| DWEILEN | Methode van procedure |
| OSD | Object Storage-schijven |
| OSPD | OpenStack Platform - Directeur |
| HARDE SCHIJF | harde schijf |
| SSD | Solid State-harde schijf |
| VIM | Virtual Infrastructure Manager |
| VM | virtuele machine |
| EM | Elementbeheer |
| UAS | Ultra Automation Services |
| UUID | Universally Unique IDentifier |
Workflow van het MoP
Deze afbeelding toont de workflow op hoog niveau van de vervangingsprocedure.

Voorwaarden
back-up
In het geval van herstel raadt Cisco aan om een back-up van de OSPD-database (DB) te maken met behulp van de volgende stappen:
[root@director ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql
[root@director ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql
/etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack
tar: Removing leading `/' from member names
Voorlopige statuscontrole
Het is belangrijk om de huidige status van de OpenStack-omgeving en -services te controleren en ervoor te zorgen dat deze gezond is voordat u doorgaat met de vervangingsprocedure. Het kan helpen complicaties te voorkomen op het moment van het vervangingsproces van de controller.
Stap 1. Controleer de status van OpenStack en de knooppuntenlijst:
[stack@director ~]$ source stackrc
[stack@director ~]$ openstack stack list --nested
[stack@director ~]$ ironic node-list
[stack@director ~]$ nova list
Stap 2. Controleer de status van de pacemaker op de controllers:
Meld u aan bij een van de actieve controllers en controleer de status van de pacemaker. Alle services moeten worden uitgevoerd op de beschikbare controllers en worden gestopt op de defecte controller.
[stack@pod2-stack-controller-0 ~]# pcs status <snip> Online: [ pod2-stack-controller-0 pod2-stack-controller-1 ] Offline: [ pod2-stack-controller-2 ] Full list of resources: ip-11.120.0.109 (ocf::heartbeat:IPaddr2): Started pod2-stack-controller-0 ip-172.25.22.109 (ocf::heartbeat:IPaddr2): Started pod2-stack-controller-1 ip-192.200.0.107 (ocf::heartbeat:IPaddr2): Started pod2-stack-controller-0 Clone Set: haproxy-clone [haproxy] Started: [ pod2-stack-controller-0 pod2-stack-controller-1 ] Stopped: [ pod2-stack-controller-2 ] Master/Slave Set: galera-master [galera] Masters: [ pod2-stack-controller-0 pod2-stack-controller-1 ] Stopped: [ pod2-stack-controller-2 ] ip-11.120.0.110 (ocf::heartbeat:IPaddr2): Started pod2-stack-controller-0 ip-11.119.0.110 (ocf::heartbeat:IPaddr2): Started pod2-stack-controller-1 Clone Set: rabbitmq-clone [rabbitmq] Started: [ pod2-stack-controller-0 pod2-stack-controller-1 ] Stopped: [ pod2-stack-controller-2 ] Master/Slave Set: redis-master [redis] Masters: [ pod2-stack-controller-0 ] Slaves: [ pod2-stack-controller-1 ] Stopped: [ pod2-stack-controller-2 ] ip-11.118.0.104 (ocf::heartbeat:IPaddr2): Started pod2-stack-controller-1 openstack-cinder-volume (systemd:openstack-cinder-volume): Started pod2-stack-controller-0 my-ipmilan-for-controller-6 (stonith:fence_ipmilan): Started pod2-stack-controller-1 my-ipmilan-for-controller-4 (stonith:fence_ipmilan): Started pod2-stack-controller-0 my-ipmilan-for-controller-7 (stonith:fence_ipmilan): Started pod2-stack-controller-0 Failed Actions: Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled
In dit voorbeeld is Controller-2 offline. Daarom wordt het vervangen. Controller-0 en Controller-1 zijn operationeel en voeren de clusterservices uit.
Stap 3. Controleer de MariaDB-status in de actieve controllers:
[stack@director] nova list | grep control
| b896c73f-d2c8-439c-bc02-7b0a2526dd70 | pod2-stack-controller-0 | ACTIVE | - | Running | ctlplane=192.200.0.113 |
| 2519ce67-d836-4e5f-a672-1a915df75c7c | pod2-stack-controller-1 | ACTIVE | - | Running | ctlplane=192.200.0.105 |
[stack@director ~]$ for i in 192.200.0.113 192.200.0.105 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local_state_comment'\" ; sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_cluster_size'\""; done
*** 192.200.0.113 ***
Variable_nameValue
wsrep_local_state_comment Synced
Variable_nameValue
wsrep_cluster_size 2
*** 192.200.0.105 ***
Variable_nameValue
wsrep_local_state_comment Synced
Variable_nameValue
wsrep_cluster_size 2
Controleer of deze lijnen aanwezig zijn voor elke actieve controller:
wsrep_local_state_comment: Gesynchroniseerd
wsrep_cluster_size: 2
Steo 4. Controleer de status van de konijnen in de actieve controllers. De defecte controller mag niet worden weergegeven in de lijst van de knooppunten die worden uitgevoerd.
[heat-admin@pod2-stack-controller-0 ~] sudo rabbitmqctl cluster_status
Cluster status of node 'rabbit@pod2-stack-controller-0' ...
[{nodes,[{disc,['rabbit@pod2-stack-controller-0','rabbit@pod2-stack-controller-1',
'rabbit@pod2stack-controller-2']}]},
{running_nodes,['rabbit@pod2-stack-controller-1',
'rabbit@pod2-stack-controller-0']},
{cluster_name,<<"rabbit@pod2-stack-controller-2.localdomain">>},
{partitions,[]},
{alarms,[{'rabbit@pod2-stack-controller-1',[]},
{'rabbit@pod2-stack-controller-0',[]}]}]
[heat-admin@pod2-stack-controller-1 ~] sudo rabbitmqctl cluster_status
Cluster status of node 'rabbit@pod2-stack-controller-1' ...
[{nodes,[{disc,['rabbit@pod2-stack-controller-0','rabbit@pod2-stack-controller-1',
'rabbit@pod2-stack-controller-2']}]},
{running_nodes,['rabbit@pod2-stack-controller-0',
'rabbit@pod2-stack-controller-1']},
{cluster_name,<<"rabbit@pod2-stack-controller-2.localdomain">>},
{partitions,[]},
{alarms,[{'rabbit@pod2-stack-controller-0',[]},
{'rabbit@pod2-stack-controller-1',[]}]}]
Stap 5. Controleer of alle undercloud-services geladen, actief en actief zijn vanaf de OSP-D-node.
[stack@director ~]$ systemctl list-units "openstack*" "neutron*" "openvswitch*"
UNIT LOAD ACTIVE SUB DESCRIPTION
neutron-dhcp-agent.service loaded active running OpenStack Neutron DHCP Agent
neutron-openvswitch-agent.service loaded active running OpenStack Neutron Open vSwitch Agent
neutron-ovs-cleanup.service loaded active exited OpenStack Neutron Open vSwitch Cleanup Utility
neutron-server.service loaded active running OpenStack Neutron Server
openstack-aodh-evaluator.service loaded active running OpenStack Alarm evaluator service
openstack-aodh-listener.service loaded active running OpenStack Alarm listener service
openstack-aodh-notifier.service loaded active running OpenStack Alarm notifier service
openstack-ceilometer-central.service loaded active running OpenStack ceilometer central agent
openstack-ceilometer-collector.service loaded active running OpenStack ceilometer collection service
openstack-ceilometer-notification.service loaded active running OpenStack ceilometer notification agent
openstack-glance-api.service loaded active running OpenStack Image Service (code-named Glance) API server
openstack-glance-registry.service loaded active running OpenStack Image Service (code-named Glance) Registry server
openstack-heat-api-cfn.service loaded active running Openstack Heat CFN-compatible API Service
openstack-heat-api.service loaded active running OpenStack Heat API Service
openstack-heat-engine.service loaded active running Openstack Heat Engine Service
openstack-ironic-api.service loaded active running OpenStack Ironic API service
openstack-ironic-conductor.service loaded active running OpenStack Ironic Conductor service
openstack-ironic-inspector-dnsmasq.service loaded active running PXE boot dnsmasq service for Ironic Inspector
openstack-ironic-inspector.service loaded active running Hardware introspection service for OpenStack Ironic
openstack-mistral-api.service loaded active running Mistral API Server
openstack-mistral-engine.service loaded active running Mistral Engine Server
openstack-mistral-executor.service loaded active running Mistral Executor Server
openstack-nova-api.service loaded active running OpenStack Nova API Server
openstack-nova-cert.service loaded active running OpenStack Nova Cert Server
openstack-nova-compute.service loaded active running OpenStack Nova Compute Server
openstack-nova-conductor.service loaded active running OpenStack Nova Conductor Server
openstack-nova-scheduler.service loaded active running OpenStack Nova Scheduler Server
openstack-swift-account-reaper.service loaded active running OpenStack Object Storage (swift) - Account Reaper
openstack-swift-account.service loaded active running OpenStack Object Storage (swift) - Account Server
openstack-swift-container-updater.service loaded active running OpenStack Object Storage (swift) - Container Updater
openstack-swift-container.service loaded active running OpenStack Object Storage (swift) - Container Server
openstack-swift-object-updater.service loaded active running OpenStack Object Storage (swift) - Object Updater
openstack-swift-object.service loaded active running OpenStack Object Storage (swift) - Object Server
openstack-swift-proxy.service loaded active running OpenStack Object Storage (swift) - Proxy Server
openstack-zaqar.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server
openstack-zaqar@1.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server Instance 1
openvswitch.service loaded active exited Open vSwitch
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
37 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
Hekwerk in het controllercluster uitschakelen
[root@pod2-stack-controller-0 ~]# sudo pcs property set stonith-enabled=false
[root@pod2-stack-controller-0 ~]# pcs property show
Cluster Properties:
cluster-infrastructure: corosync
cluster-name: tripleo_cluster
dc-version: 1.1.15-11.el7_3.4-e174ec8
have-watchdog: false
maintenance-mode: false
redis_REPL_INFO: pod2-stack-controller-2
stonith-enabled: false
Node Attributes:
pod2-stack-controller-0: rmq-node-attr-last-known-rabbitmq=rabbit@pod2-stack-controller-0
pod2-stack-controller-1: rmq-node-attr-last-known-rabbitmq=rabbit@pod2-stack-controller-1
pod2-stack-controller-2: rmq-node-attr-last-known-rabbitmq=rabbit@pod2-stack-controller-2
Installeer de nieuwe controllernode
De stappen voor het installeren van een nieuwe UCS C240 M4-server en de eerste installatiestappen kunnen worden doorverwezen vanaf: Installatie- en servicegids voor de Cisco UCS C240 M4-server
Stap 1. Meld u aan bij de server met behulp van de CIMC IP.
Stap 2. Voer een BIOS-upgrade uit als de firmware niet overeenkomt met de aanbevolen versie die eerder is gebruikt. Stappen voor BIOS-upgrade worden hier gegeven: Cisco UCS C-Series Rack-Mount Server BIOS Upgrade Guide
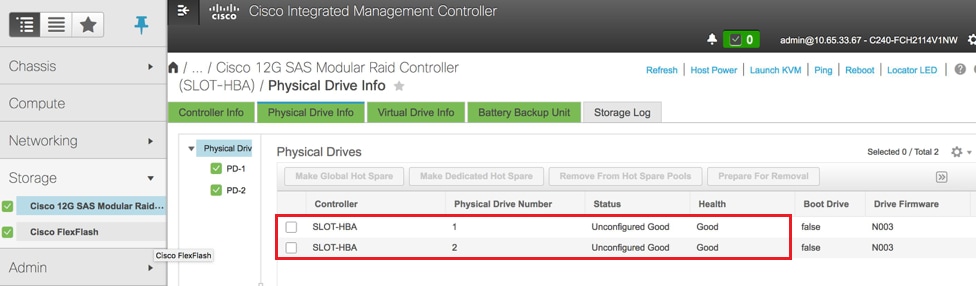
Stap 3. Om de status van fysieke stations te controleren, die niet goed is, gaat u naar Opslag > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Informatie over fysieke stations, zoals weergegeven in de afbeelding.
Stap 4. Als u een virtueel station wilt maken van de fysieke stations met RAID-niveau 1, gaat u naar Opslag > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Controllerinfo > Virtuele schijf maken van ongebruikte fysieke stations.
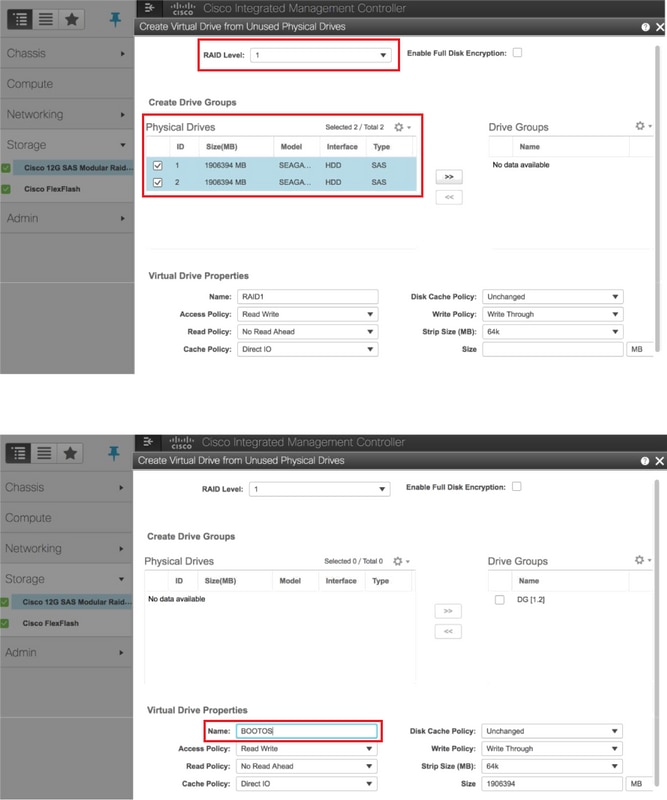
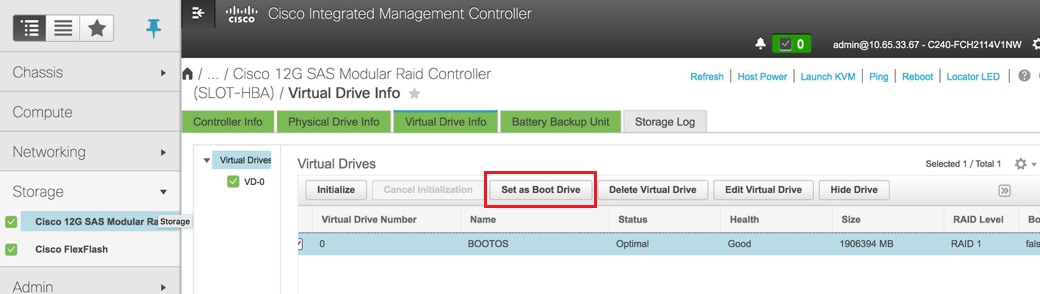
- Selecteer de VD en configureSet as Boot Drive:
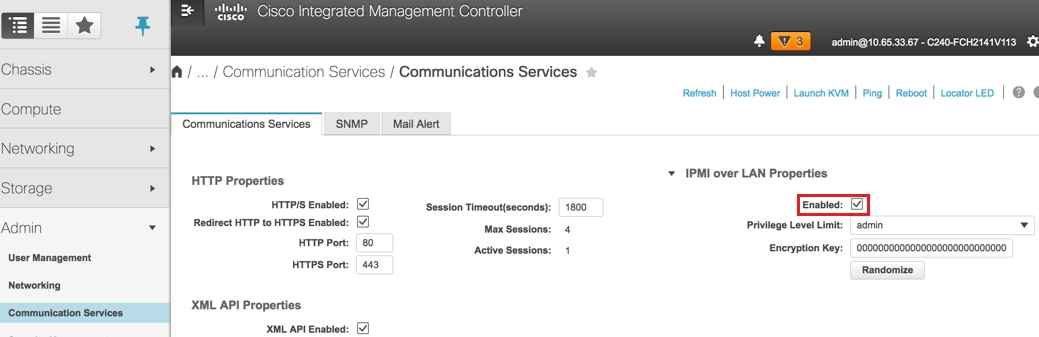
Stap 5. Als u IPMI via LAN wilt inschakelen, gaat u naar Beheer > Communicatiediensten > Communicatiediensten.
Stap 6. Als u hyperthreading wilt uitschakelen, gaat u naar Berekenen > BIOS > BIOS configureren > Geavanceerd > Processorconfiguratie.
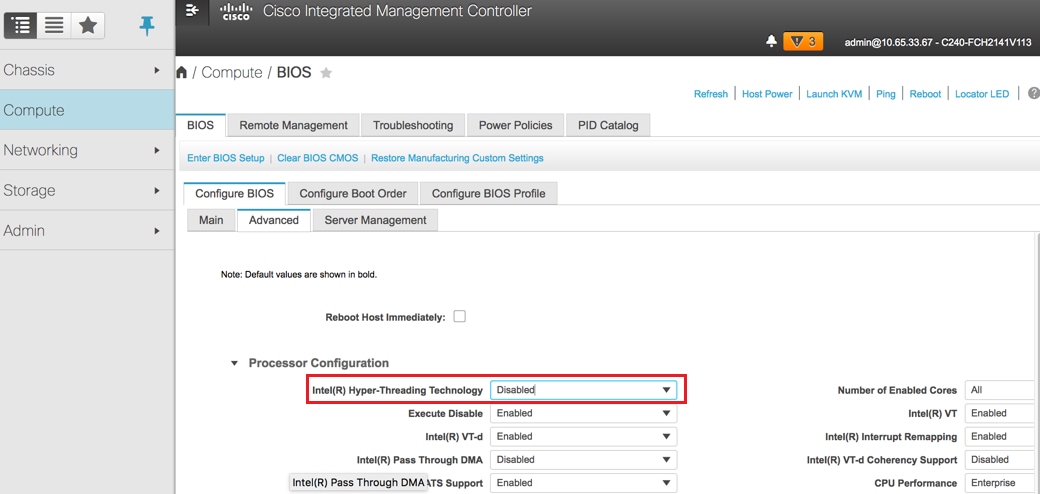
Opmerking: de afbeelding die hier wordt weergegeven en de configuratiestappen die in deze sectie worden vermeld, hebben betrekking op de firmwareversie 3.0 (3e) en er kunnen kleine variaties zijn als u aan andere versies werkt.
Controllerknooppunt vervangen in Overcloud
Dit gedeelte behandelt de stappen die nodig zijn om de defecte controller te vervangen door de nieuwe in de overcloud. Hiervoor zou het script deploy.s dat werd gebruikt om de stapel naar voren te brengen opnieuw worden gebruikt. Op het moment van de implementatie, in de controllerknooppunten na implementatie, zou de update mislukken vanwege enkele beperkingen in de poppenmodules. Handmatige interventie is vereist voordat u het implementatiescript opnieuw start.
Voorbereiden op het verwijderen van een defecte controllernode
Stap 1. Identificeer de index van de defecte controller. De index is het numerieke achtervoegsel op de controllernaam in de uitvoer van de OpenStack-serverlijst. In dit voorbeeld is de index 2:
[stack@director ~]$ nova list | grep controller
| b896c73f-d2c8-439c-bc02-7b0a2526dd70 | pod2-stack-controller-0 | ACTIVE | - | Running | ctlplane=192.200.0.113 |
| 2519ce67-d836-4e5f-a672-1a915df75c7c | pod2-stack-controller-1 | ACTIVE | - | Running | ctlplane=192.200.0.105 |
| e19b9625-5635-4a52-a369-44310f3e6a21 | pod2-stack-controller-2 | ACTIVE | - | Running | ctlplane=192.200.0.120 |
Stap 2. Maak een Yaml-bestand~sjablonen/remove-controller.yaml dat de te verwijderen node zou definiëren. Gebruik de index in de vorige stap voor het item in de resourcelijst:
[stack@director ~]$ cat templates/remove-controller.yaml
parameters:
ControllerRemovalPolicies:
[{'resource_list': [‘2’]}]
parameter_defaults:
CorosyncSettleTries: 5
Stap 3. Maak een kopie van het implementatiescript dat wordt gebruikt om de overcloud te installeren en plaats een regel om de eerder gemaakte verwijdercontroller.yamlfile op te nemen:
[stack@director ~]$ cp deploy.sh deploy-removeController.sh
[stack@director ~]$ cat deploy-removeController.sh
time openstack overcloud deploy --templates \
-r ~/custom-templates/custom-roles.yaml \
-e /home/stack/templates/remove-controller.yaml \
-e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml \
-e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml \
-e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml \
-e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml \
-e ~/custom-templates/network.yaml \
-e ~/custom-templates/ceph.yaml \
-e ~/custom-templates/compute.yaml \
-e ~/custom-templates/layout-removeController.yaml \
-e ~/custom-templates/rabbitmq.yaml \
--stack pod2-stack \
--debug \
--log-file overcloudDeploy_$(date +%m_%d_%y__%H_%M_%S).log \
--neutron-flat-networks phys_pcie1_0,phys_pcie1_1,phys_pcie4_0,phys_pcie4_1 \
--neutron-network-vlan-ranges datacentre:101:200 \
--neutron-disable-tunneling \
--verbose --timeout 180
Stap 4. Identificeer de ID van de controller die moet worden vervangen, met behulp van de hier genoemde opdrachten en verplaats deze naar de onderhoudsmodus:
[stack@director ~]$ nova list | grep controller
| b896c73f-d2c8-439c-bc02-7b0a2526dd70 | pod2-stack-controller-0 | ACTIVE | - | Running | ctlplane=192.200.0.113 |
| 2519ce67-d836-4e5f-a672-1a915df75c7c | pod2-stack-controller-1 | ACTIVE | - | Running | ctlplane=192.200.0.105 |
| e19b9625-5635-4a52-a369-44310f3e6a21 | pod2-stack-controller-2 | ACTIVE | - | Running | ctlplane=192.200.0.120 |
[stack@director ~]$ openstack baremetal node list | grep e19b9625-5635-4a52-a369-44310f3e6a21
| e7c32170-c7d1-4023-b356-e98564a9b85b | None | e19b9625-5635-4a52-a369-44310f3e6a21 | power off | active | False |
[stack@b10-ospd ~]$ openstack baremetal node maintenance set e7c32170-c7d1-4023-b356-e98564a9b85b
[stack@director~]$ openstack baremetal node list | grep True
| e7c32170-c7d1-4023-b356-e98564a9b85b | None | e19b9625-5635-a369-44310f3e6a21 | power off | active | True |
Stap 5. Om ervoor te zorgen dat de DB op het moment van de vervangingsprocedure wordt uitgevoerd, verwijdert u Galera van pacemakerbesturing en voert u deze opdracht uit op een van de actieve controllers:
[root@pod2-stack-controller-0 ~]# sudo pcs resource unmanage galera
[root@pod2-stack-controller-0 ~]# sudo pcs status Cluster name: tripleo_cluster Stack: corosync Current DC: pod2-stack-controller-0 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum Last updated: Thu Nov 16 16:51:18 2017 Last change: Thu Nov 16 16:51:12 2017 by root via crm_resource on pod2-stack-controller-0 3 nodes and 22 resources configured Online: [ pod2-stack-controller-0 pod2-stack-controller-1 ] OFFLINE: [ pod2-stack-controller-2 ] Full list of resources: ip-11.120.0.109 (ocf::heartbeat:IPaddr2): Started pod2-stack-controller-0 ip-172.25.22.109 (ocf::heartbeat:IPaddr2): Started pod2-stack-controller-1 ip-192.200.0.107 (ocf::heartbeat:IPaddr2): Started pod2-stack-controller-0 Clone Set: haproxy-clone [haproxy] Started: [ pod2-stack-controller-0 pod2-stack-controller-1 ] Stopped: [ pod2-stack-controller-2 ] Master/Slave Set: galera-master [galera] (unmanaged) galera (ocf::heartbeat:galera): Master pod2-stack-controller-0 (unmanaged) galera (ocf::heartbeat:galera): Master pod2-stack-controller-1 (unmanaged) Stopped: [ pod2-stack-controller-2 ] ip-11.120.0.110 (ocf::heartbeat:IPaddr2): Started pod2-stack-controller-0 ip-11.119.0.110 (ocf::heartbeat:IPaddr2): Started pod2-stack-controller-1 <snip>
Voorbereiden op het toevoegen van een nieuwe controllernode
Stap 1. Maak een controllerRMA.jsonfile met alleen de nieuwe controller details. Controleer of het indexnummer op de nieuwe controller niet eerder is gebruikt. Doorgaans wordt dit verhoogd naar het volgende hoogste controllernummer.
Voorbeeld: Hoogste prior was Controller-2, dus maak Controller-3.
Let op: let op het json-formaat.
[stack@director ~]$ cat controllerRMA.json
{
"nodes": [
{
"mac": [
<MAC_ADDRESS>
],
"capabilities": "node:controller-3,boot_option:local",
"cpu": "24",
"memory": "256000",
"disk": "3000",
"arch": "x86_64",
"pm_type": "pxe_ipmitool",
"pm_user": "admin",
"pm_password": "<PASSWORD>",
"pm_addr": "<CIMC_IP>"
}
]
}
Stap 2. Importeer de nieuwe node met behulp van het json-bestand dat in de vorige stap is gemaakt:
[stack@director ~]$ openstack baremetal import --json controllerRMA.json
Started Mistral Workflow. Execution ID: 67989c8b-1225-48fe-ba52-3a45f366e7a0
Successfully registered node UUID 048ccb59-89df-4f40-82f5-3d90d37ac7dd
Started Mistral Workflow. Execution ID: c6711b5f-fa97-4c86-8de5-b6bc7013b398
Successfully set all nodes to available.
[stack@director ~]$ openstack baremetal node list | grep available
| 048ccb59-89df-4f40-82f5-3d90d37ac7dd | None | None | power off | available | False
Stap 3. Stel de node in om de status te beheren:
[stack@director ~]$ openstack baremetal node manage 048ccb59-89df-4f40-82f5-3d90d37ac7dd
[stack@director ~]$ openstack baremetal node list | grep off
| 048ccb59-89df-4f40-82f5-3d90d37ac7dd | None | None | power off | manageable | False |
Stap 4. Introspectie uitvoeren:
[stack@director ~]$ openstack overcloud node introspect 048ccb59-89df-4f40-82f5-3d90d37ac7dd --provide
Started Mistral Workflow. Execution ID: f73fb275-c90e-45cc-952b-bfc25b9b5727
Waiting for introspection to finish...
Successfully introspected all nodes.
Introspection completed.
Started Mistral Workflow. Execution ID: a892b456-eb15-4c06-b37e-5bc3f6c37c65
Successfully set all nodes to available
[stack@director ~]$ openstack baremetal node list | grep available
| 048ccb59-89df-4f40-82f5-3d90d37ac7dd | None | None | power off | available | False |
Stap 5. Markeer de beschikbare node met de nieuwe eigenschappen van de controller. Zorg ervoor dat u de controller-ID gebruikt die is aangewezen voor de nieuwe controller, zoals gebruikt in het controllerRMA.jsonfile:
[stack@director ~]$ openstack baremetal node set --property capabilities='node:controller-3,profile:control,boot_option:local' 048ccb59-89df-4f40-82f5-3d90d37ac7dd
Stap 6. In het implementatiescript is er een aangepaste sjabloon genaamd layout.yaml, die onder andere aangeeft welke IP-adressen aan de controllers zijn toegewezen voor de verschillende interfaces. Op een nieuwe stapel zijn er 3 adressen gedefinieerd voor Controller-0, Controller-1 en Controller-2. Wanneer u een nieuwe controller toevoegt, moet u ervoor zorgen dat u voor elk subnet een volgend IP-adres achter elkaar toevoegt:
ControllerIPs:
internal_api:
- 11.120.0.10
- 11.120.0.11
- 11.120.0.12
- 11.120.0.13
tenant:
- 11.117.0.10
- 11.117.0.11
- 11.117.0.12
- 11.117.0.13
storage:
- 11.118.0.10
- 11.118.0.11
- 11.118.0.12
- 11.118.0.13
storage_mgmt:
- 11.119.0.10
- 11.119.0.11
- 11.119.0.12
- 11.119.0.13
Stap 7. Voer nu de deploy-removecontroller.shdie eerder is gemaakt uit om de oude node te verwijderen en de nieuwe node toe te voegen.
Opmerking: deze stap zal naar verwachting mislukken in ControllerNodesDeployment_Step1. Op dat moment is handmatige interventie vereist.
[stack@b10-ospd ~]$ ./deploy-addController.sh
START with options: [u'overcloud', u'deploy', u'--templates', u'-r', u'/home/stack/custom-templates/custom-roles.yaml', u'-e', u'/usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml', u'-e', u'/usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml', u'-e', u'/usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml', u'-e', u'/usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml', u'-e', u'/home/stack/custom-templates/network.yaml', u'-e', u'/home/stack/custom-templates/ceph.yaml', u'-e', u'/home/stack/custom-templates/compute.yaml', u'-e', u'/home/stack/custom-templates/layout-removeController.yaml', u'-e', u'/home/stack/custom-templates/rabbitmq.yaml', u'--stack', u'newtonoc', u'--debug', u'--log-file', u'overcloudDeploy_11_15_17__07_46_35.log', u'--neutron-flat-networks', u'phys_pcie1_0,phys_pcie1_1,phys_pcie4_0,phys_pcie4_1', u'--neutron-network-vlan-ranges', u'datacentre:101:200', u'--neutron-disable-tunneling', u'--verbose', u'--timeout', u'180']
:
DeploymentError: Heat Stack update failed
END return value: 1
real 42m1.525s
user 0m3.043s
sys 0m0.614s
De voortgang/status van de implementatie kan worden gecontroleerd met de volgende opdrachten:
[stack@director~]$ openstack stack list --nested | grep -iv complete
+--------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------------+----------------------+----------------------+--------------------------------------+
| ID | Stack Name | Stack Status | Creation Time | Updated Time | Parent |
+--------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------------+----------------------+----------------------+--------------------------------------+
| c1e338f2-877e-4817-93b4-9a3f0c0b3d37 | pod2-stack-AllNodesDeploySteps-5psegydpwxij-ComputeDeployment_Step1-swnuzjixac43 | UPDATE_FAILED | 2017-10-08T14:06:07Z | 2017-11-16T18:09:43Z | e90f00ef-2499-4ec3-90b4-d7def6e97c47 |
| 1db4fef4-45d3-4125-bd96-2cc3297a69ff | pod2-stack-AllNodesDeploySteps-5psegydpwxij-ControllerDeployment_Step1-hmn3hpruubcn | UPDATE_FAILED | 2017-10-08T14:03:05Z | 2017-11-16T18:12:12Z | e90f00ef-2499-4ec3-90b4-d7def6e97c47 |
| e90f00ef-2499-4ec3-90b4-d7def6e97c47 | pod2-stack-AllNodesDeploySteps-5psegydpwxij | UPDATE_FAILED | 2017-10-08T13:59:25Z | 2017-11-16T18:09:25Z | 6c4b604a-55a4-4a19-9141-28c844816c0d |
| 6c4b604a-55a4-4a19-9141-28c844816c0d | pod2-stack | UPDATE_FAILED | 2017-10-08T12:37:11Z | 2017-11-16T17:35:35Z | None |
+--------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------------+----------------------+----------------------+--------------------------------------+
manuele interventie
Stap 1. Voer op de OSP-D-server de opdracht Lijst met OpenStack-servers uit om de beschikbare controllers weer te geven. De nieuw toegevoegde controller moet in de lijst verschijnen:
[stack@director ~]$ openstack server list | grep controller-3
| 3e6c3db8-ba24-48d9-b0e8-1e8a2eb8b5ff | pod2-stack-controller-3 | ACTIVE | ctlplane=192.200.0.103 | overcloud-full |
Stap 2. Maak verbinding met een van de actieve controllers (niet de nieuw toegevoegde controller) en kijk naar het bestand /etc/corosync/corosycn.conf. Zoek het model dat anodeïd toewijst aan elke controller. Zoek de vermelding voor het mislukte knooppunt en noteer de naam:
[root@pod2-stack-controller-0 ~]# cat /etc/corosync/corosync.conf
totem {
version: 2
secauth: off
cluster_name: tripleo_cluster
transport: udpu
token: 10000
}
nodelist {
node {
ring0_addr: pod2-stack-controller-0
nodeid: 5
}
node {
ring0_addr: pod2-stack-controller-1
nodeid: 7
}
node {
ring0_addr: pod2-stack-controller-2
nodeid: 8
}
}
Stap 3. Log in op elk van de actieve controllers. Verwijder de mislukte node en start de service opnieuw op. In dit geval, verwijder pod2-stack-controller-2. Voer deze actie niet uit op de nieuw toegevoegde controller:
[root@pod2-stack-controller-0 ~]# sudo pcs cluster localnode remove pod2-stack-controller-2
pod2-stack-controller-2: successfully removed!
[root@pod2-stack-controller-0 ~]# sudo pcs cluster reload corosync
Corosync reloaded
[root@pod2-stack-controller-1 ~]# sudo pcs cluster localnode remove pod2-stack-controller-2
pod2-stack-controller-2: successfully removed!
[root@pod2-stack-controller-1 ~]# sudo pcs cluster reload corosync
Corosync reloaded
Stap 4. Voer deze opdracht uit vanaf een van de actieve controllers om de mislukte node uit het cluster te verwijderen:
[root@pod2-stack-controller-0 ~]# sudo crm_node -R pod2-stack-controller-2 --force
Stap 5. Voer deze opdracht uit vanaf een van de actieve controllers om de mislukte node uit het abbitmqcluster te verwijderen:
[root@pod2-stack-controller-0 ~]# sudo rabbitmqctl forget_cluster_node rabbit@pod2-stack-controller-2
Removing node 'rabbit@newtonoc-controller-2' from cluster ...
Stap 6. Verwijder de mislukte node uit de MongoDB. Om dit te doen, moet u de actieve Mongo-node vinden. Usenetstatt om het IP-adres van de host te vinden:
[root@pod2-stack-controller-0 ~]# sudo netstat -tulnp | grep 27017
tcp 0 0 11.120.0.10:27017 0.0.0.0:* LISTEN 219577/mongod
Stap 7. Meld u aan bij de node en controleer of deze de master is met behulp van het IP-adres en het poortnummer van de vorige opdracht:
[heat-admin@pod2-stack-controller-0 ~]$ echo "db.isMaster()" | mongo --host 11.120.0.10:27017
MongoDB shell version: 2.6.11
connecting to: 11.120.0.10:27017/test
{
"setName" : "tripleo",
"setVersion" : 9,
"ismaster" : true,
"secondary" : false,
"hosts" : [
"11.120.0.10:27017",
"11.120.0.12:27017",
"11.120.0.11:27017"
],
"primary" : "11.120.0.10:27017",
"me" : "11.120.0.10:27017",
"electionId" : ObjectId("5a0d2661218cb0238b582fb1"),
"maxBsonObjectSize" : 16777216,
"maxMessageSizeBytes" : 48000000,
"maxWriteBatchSize" : 1000,
"localTime" : ISODate("2017-11-16T18:36:34.473Z"),
"maxWireVersion" : 2,
"minWireVersion" : 0,
"ok" : 1
}
Als de node niet de master is, meldt u zich aan bij de andere actieve controller en voert u dezelfde stap uit.
Stap 1. Geef in het stramien een lijst van de beschikbare knooppunten met het gebruik van de opdracht others.status(). Zoek de oude / niet-reagerende node en identificeer de naam van de mongo-node.
[root@pod2-stack-controller-0 ~]# mongo --host 11.120.0.10
MongoDB shell version: 2.6.11
connecting to: 11.120.0.10:27017/test
<snip>
tripleo:PRIMARY> rs.status()
{
"set" : "tripleo",
"date" : ISODate("2017-11-14T13:27:14Z"),
"myState" : 1,
"members" : [
{
"_id" : 0,
"name" : "11.120.0.10:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 418347,
"optime" : Timestamp(1510666033, 1),
"optimeDate" : ISODate("2017-11-14T13:27:13Z"),
"electionTime" : Timestamp(1510247693, 1),
"electionDate" : ISODate("2017-11-09T17:14:53Z"),
"self" : true
},
{
"_id" : 2,
"name" : "11.120.0.12:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 418347,
"optime" : Timestamp(1510666033, 1),
"optimeDate" : ISODate("2017-11-14T13:27:13Z"),
"lastHeartbeat" : ISODate("2017-11-14T13:27:13Z"),
"lastHeartbeatRecv" : ISODate("2017-11-14T13:27:13Z"),
"pingMs" : 0,
"syncingTo" : "11.120.0.10:27017"
},
{
"_id" : 3,
"name" : "11.120.0.11:27017
"health" : 0,
"state" : 8,
"stateStr" : "(not reachable/healthy)",
"uptime" : 0,
"optime" : Timestamp(1510610580, 1),
"optimeDate" : ISODate("2017-11-13T22:03:00Z"),
"lastHeartbeat" : ISODate("2017-11-14T13:27:10Z"),
"lastHeartbeatRecv" : ISODate("2017-11-13T22:03:01Z"),
"pingMs" : 0,
"syncingTo" : "11.120.0.10:27017"
}
],
"ok" : 1
}
Stap 2. Verwijder de mislukte node uit de master met behulp van de opdracht others. remove. Sommige fouten worden gezien wanneer u deze opdracht uitvoert, maar controleer de status nogmaals om te zien dat de node is verwijderd:
[root@pod2-stack-controller-0 ~]$ mongo --host 11.120.0.10
<snip>
tripleo:PRIMARY> rs.remove('11.120.0.12:27017')
2017-11-16T18:41:04.999+0000 DBClientCursor::init call() failed
2017-11-16T18:41:05.000+0000 Error: error doing query: failed at src/mongo/shell/query.js:81
2017-11-16T18:41:05.001+0000 trying reconnect to 11.120.0.10:27017 (11.120.0.10) failed
2017-11-16T18:41:05.003+0000 reconnect 11.120.0.10:27017 (11.120.0.10) ok
tripleo:PRIMARY> rs.status()
{
"set" : "tripleo",
"date" : ISODate("2017-11-16T18:44:11Z"),
"myState" : 1,
"members" : [
{
"_id" : 3,
"name" : "11.120.0.11:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 187,
"optime" : Timestamp(1510857848, 3),
"optimeDate" : ISODate("2017-11-16T18:44:08Z"),
"lastHeartbeat" : ISODate("2017-11-16T18:44:11Z"),
"lastHeartbeatRecv" : ISODate("2017-11-16T18:44:09Z"),
"pingMs" : 0,
"syncingTo" : "11.120.0.10:27017"
},
{
"_id" : 4,
"name" : "11.120.0.10:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 89820,
"optime" : Timestamp(1510857848, 3),
"optimeDate" : ISODate("2017-11-16T18:44:08Z"),
"electionTime" : Timestamp(1510811232, 1),
"electionDate" : ISODate("2017-11-16T05:47:12Z"),
"self" : true
}
],
"ok" : 1
}
tripleo:PRIMARY> exit
bye
Stap 3. Voer deze opdracht uit om de lijst met actieve controllernodes bij te werken. Neem de nieuwe controllernode op in deze lijst:
[root@pod2-stack-controller-0 ~]# sudo pcs resource update galera wsrep_cluster_address=gcomm://pod2-stack-controller-0,pod2-stack-controller-1,pod2-stack-controller-2
Stap 4. Kopieer deze bestanden van een controller die al bestaat naar de nieuwe controller:
/etc/sysconfig/clustercheck
/root/.my.cnf
On existing controller:
[root@pod2-stack-controller-0 ~]# scp /etc/sysconfig/clustercheck stack@192.200.0.1:/tmp/.
[root@pod2-stack-controller-0 ~]# scp /root/.my.cnf stack@192.200.0.1:/tmp/my.cnf
On new controller:
[root@pod2-stack-controller-3 ~]# cd /etc/sysconfig
[root@pod2-stack-controller-3 sysconfig]# scp stack@192.200.0.1:/tmp/clustercheck .
[root@pod2-stack-controller-3 sysconfig]# cd /root
[root@pod2-stack-controller-3 ~]# scp stack@192.200.0.1:/tmp/my.cnf .my.cnf
Stap 5. Voer de opdracht clusternode add uit vanaf een van de controllers die al bestaat:
[root@pod2-stack-controller-1 ~]# sudo pcs cluster node add pod2-stack-controller-3
Disabling SBD service...
pod2-stack-controller-3: sbd disabled
pod2-stack-controller-0: Corosync updated
pod2-stack-controller-1: Corosync updated
Setting up corosync...
pod2-stack-controller-3: Succeeded
Synchronizing pcsd certificates on nodes pod2-stack-controller-3...
pod2-stack-controller-3: Success
Restarting pcsd on the nodes in order to reload the certificates...
pod2-stack-controller-3: Success
Stap 6. Meld u aan bij elke controller en bekijk het bestand /etc/corosync/corosync.conf. Zorg ervoor dat de nieuwe controller wordt vermeld en dat de code die aan die controller is toegewezen, het volgende nummer in de reeks is dat niet eerder is gebruikt. Zorg ervoor dat deze wijziging op alle 3 de controllers wordt uitgevoerd:
[root@pod2-stack-controller-1 ~]# cat /etc/corosync/corosync.conf
totem {
version: 2
secauth: off
cluster_name: tripleo_cluster
transport: udpu
token: 10000
}
nodelist {
node {
ring0_addr: pod2-stack-controller-0
nodeid: 5
}
node {
ring0_addr: pod2-stack-controller-1
nodeid: 7
}
node {
ring0_addr: pod2-stack-controller-3
nodeid: 6
}
}
quorum {
provider: corosync_votequorum
}
logging {
to_logfile: yes
logfile: /var/log/cluster/corosync.log
to_syslog: yes
}
Bijvoorbeeld/etc/corosync/corosync.confafter modification:
totem {
version: 2
secauth: off
cluster_name: tripleo_cluster
transport: udpu
token: 10000
}
nodelist {
node {
ring0_addr: pod2-stack-controller-0
nodeid: 5
}
node {
ring0_addr: pod2-stack-controller-1
nodeid: 7
}
node {
ring0_addr: pod2-stack-controller-3
nodeid: 9
}
}
quorum {
provider: corosync_votequorum
}
logging {
to_logfile: yes
logfile: /var/log/cluster/corosync.log
to_syslog: yes
}
Stap 7. Herstart corosyncon met de actieve controllers. Start corosyncon niet op de nieuwe controller:
[root@pod2-stack-controller-0 ~]# sudo pcs cluster reload corosync
[root@pod2-stack-controller-1 ~]# sudo pcs cluster reload corosync
Stap 8. Start de nieuwe controllernode vanaf een van de werkende controllers:
[root@pod2-stack-controller-1 ~]# sudo pcs cluster start pod2-stack-controller-3
Stap 9. Start Galera opnieuw op vanaf een van de werkende controllers:
[root@pod2-stack-controller-1 ~]# sudo pcs cluster start pod2-stack-controller-3
pod2-stack-controller-0: Starting Cluster...
[root@pod2-stack-controller-1 ~]# sudo pcs resource cleanup galera
Cleaning up galera:0 on pod2-stack-controller-0, removing fail-count-galera
Cleaning up galera:0 on pod2-stack-controller-1, removing fail-count-galera
Cleaning up galera:0 on pod2-stack-controller-3, removing fail-count-galera
* The configuration prevents the cluster from stopping or starting 'galera-master' (unmanaged)
Waiting for 3 replies from the CRMd... OK
[root@pod2-stack-controller-1 ~]#
[root@pod2-stack-controller-1 ~]# sudo pcs resource manage galera
Stap 10. Het cluster bevindt zich in de onderhoudsmodus. Schakel de onderhoudsmodus uit om de services te starten:
[root@pod2-stack-controller-2 ~]# sudo pcs property set maintenance-mode=false --wait
Stap 11. Controleer de status van de pc's voor Galera totdat alle drie de controllers als master in Galera worden vermeld:
Opmerking: voor grote instellingen kan het enige tijd duren om DB's te synchroniseren.
[root@pod2-stack-controller-1 ~]# sudo pcs status | grep galera -A1
Master/Slave Set: galera-master [galera]
Masters: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-3 ]
Stap 12. Switch het cluster naar onderhoudsmodus:
[root@pod2-stack-controller-1~]# sudo pcs property set maintenance-mode=true --wait
[root@pod2-stack-controller-1 ~]# pcs cluster status
Cluster Status:
Stack: corosync
Current DC: pod2-stack-controller-0 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Thu Nov 16 19:17:01 2017 Last change: Thu Nov 16 19:16:48 2017 by root via cibadmin on pod2-stack-controller-1
*** Resource management is DISABLED ***
The cluster will not attempt to start, stop or recover services
PCSD Status:
pod2-stack-controller-3: Online
pod2-stack-controller-0: Online
pod2-stack-controller-1: Online
Stap 13. Voer het implementatiescript dat u eerder hebt uitgevoerd, opnieuw uit. Dit keer moet het lukken.
[stack@director ~]$ ./deploy-addController.sh
START with options: [u'overcloud', u'deploy', u'--templates', u'-r', u'/home/stack/custom-templates/custom-roles.yaml', u'-e', u'/usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml', u'-e', u'/usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml', u'-e', u'/usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml', u'-e', u'/usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml', u'-e', u'/home/stack/custom-templates/network.yaml', u'-e', u'/home/stack/custom-templates/ceph.yaml', u'-e', u'/home/stack/custom-templates/compute.yaml', u'-e', u'/home/stack/custom-templates/layout-removeController.yaml', u'--stack', u'newtonoc', u'--debug', u'--log-file', u'overcloudDeploy_11_14_17__13_53_12.log', u'--neutron-flat-networks', u'phys_pcie1_0,phys_pcie1_1,phys_pcie4_0,phys_pcie4_1', u'--neutron-network-vlan-ranges', u'datacentre:101:200', u'--neutron-disable-tunneling', u'--verbose', u'--timeout', u'180']
options: Namespace(access_key='', access_secret='***', access_token='***', access_token_endpoint='', access_token_type='', aodh_endpoint='', auth_type='', auth_url='https://192.200.0.2:13000/v2.0', authorization_code='', cacert=None, cert='', client_id='', client_secret='***', cloud='', consumer_key='', consumer_secret='***', debug=True, default_domain='default', default_domain_id='', default_domain_name='', deferred_help=False, discovery_endpoint='', domain_id='', domain_name='', endpoint='', identity_provider='', identity_provider_url='', insecure=None, inspector_api_version='1', inspector_url=None, interface='', key='', log_file=u'overcloudDeploy_11_14_17__13_53_12.log', murano_url='', old_profile=None, openid_scope='', os_alarming_api_version='2', os_application_catalog_api_version='1', os_baremetal_api_version='1.15', os_beta_command=False, os_compute_api_version='', os_container_infra_api_version='1', os_data_processing_api_version='1.1', os_data_processing_url='', os_dns_api_version='2', os_identity_api_version='', os_image_api_version='1', os_key_manager_api_version='1', os_metrics_api_version='1', os_network_api_version='', os_object_api_version='', os_orchestration_api_version='1', os_project_id=None, os_project_name=None, os_queues_api_version='2', os_tripleoclient_api_version='1', os_volume_api_version='', os_workflow_api_version='2', passcode='', password='***', profile=None, project_domain_id='', project_domain_name='', project_id='', project_name='admin', protocol='', redirect_uri='', region_name='', roles='', timing=False, token='***', trust_id='', url='', user='', user_domain_id='', user_domain_name='', user_id='', username='admin', verbose_level=3, verify=None)
Auth plugin password selected
Starting new HTTPS connection (1): 192.200.0.2
"POST /v2/action_executions HTTP/1.1" 201 1696
HTTP POST https://192.200.0.2:13989/v2/action_executions 201
Overcloud Endpoint: http://172.25.22.109:5000/v2.0
Overcloud Deployed
clean_up DeployOvercloud:
END return value: 0
real 54m17.197s
user 0m3.421s
sys 0m0.670s
Overcloud-services controleren in de controller
Zorg ervoor dat alle beheerde services correct worden uitgevoerd op de knooppunten van de controller.
[heat-admin@pod2-stack-controller-2 ~]$ sudo pcs status
De L3 Agent-routers voltooien
Controleer de routers om ervoor te zorgen dat L3-agents correct worden gehost. Zorg ervoor dat u het overcloudrc-bestand ophaalt wanneer u deze controle uitvoert.
Stap 1. Zoek de naam van de router op:
[stack@director~]$ source corerc
[stack@director ~]$ neutron router-list
+--------------------------------------+------+-------------------------------------------------------------------+-------------+------+
| id | name | external_gateway_info | distributed | ha |
+--------------------------------------+------+-------------------------------------------------------------------+-------------+------+
| d814dc9d-2b2f-496f-8c25-24911e464d02 | main | {"network_id": "18c4250c-e402-428c-87d6-a955157d50b5", | False | True |
In dit voorbeeld is de naam van de router de belangrijkste.
Stap 2. Lijst van alle L3-agents om UUID van de mislukte node en de nieuwe node te vinden:
[stack@director ~]$ neutron agent-list | grep "neutron-l3-agent"
| 70242f5c-43ab-4355-abd6-9277f92e4ce6 | L3 agent | pod2-stack-controller-0.localdomain | nova | :-) | True | neutron-l3-agent |
| 8d2ffbcb-b6ff-42cd-b5b8-da31d8da8a40 | L3 agent | pod2-stack-controller-2.localdomain | nova | xxx | True | neutron-l3-agent |
| a410a491-e271-4938-8a43-458084ffe15d | L3 agent | pod2-stack-controller-3.localdomain | nova | :-) | True | neutron-l3-agent |
| cb4bc1ad-ac50-42e9-ae69-8a256d375136 | L3 agent | pod2-stack-controller-1.localdomain | nova | :-) | True | neutron-l3-agent |
In dit voorbeeld moet L3-agent die overeenkomt met pod2-stack-controller-2.localdomain van de router worden verwijderd en degene die overeenkomt met pod2-stack-controller-3.localdomain moet aan de router worden toegevoegd:
[stack@director ~]$ neutron l3-agent-router-remove 8d2ffbcb-b6ff-42cd-b5b8-da31d8da8a40 main
Removed router main from L3 agent
[stack@director ~]$ neutron l3-agent-router-add a410a491-e271-4938-8a43-458084ffe15d main
Added router main to L3 agent
Stap 3. Controleer de bijgewerkte lijst met L3-agents:
[stack@director ~]$ neutron l3-agent-list-hosting-router main
+--------------------------------------+-----------------------------------+----------------+-------+----------+
| id | host | admin_state_up | alive | ha_state |
+--------------------------------------+-----------------------------------+----------------+-------+----------+
| 70242f5c-43ab-4355-abd6-9277f92e4ce6 | pod2-stack-controller-0.localdomain | True | :-) | standby |
| a410a491-e271-4938-8a43-458084ffe15d | pod2-stack-controller-3.localdomain | True | :-) | standby |
| cb4bc1ad-ac50-42e9-ae69-8a256d375136 | pod2-stack-controller-1.localdomain | True | :-) | active |
+--------------------------------------+-----------------------------------+----------------+-------+----------+
Stap 4. Geef een lijst van alle services die worden uitgevoerd vanaf de verwijderde controllernode en verwijder deze:
[stack@director ~]$ neutron agent-list | grep controller-2
| 877314c2-3c8d-4666-a6ec-69513e83042d | Metadata agent | pod2-stack-controller-2.localdomain | | xxx | True | neutron-metadata-agent |
| 8d2ffbcb-b6ff-42cd-b5b8-da31d8da8a40 | L3 agent | pod2-stack-controller-2.localdomain | nova | xxx | True | neutron-l3-agent |
| 911c43a5-df3a-49ec-99ed-1d722821ec20 | DHCP agent | pod2-stack-controller-2.localdomain | nova | xxx | True | neutron-dhcp-agent |
| a58a3dd3-4cdc-48d4-ab34-612a6cd72768 | Open vSwitch agent | pod2-stack-controller-2.localdomain | | xxx | True | neutron-openvswitch-agent |
[stack@director ~]$ neutron agent-delete 877314c2-3c8d-4666-a6ec-69513e83042d
Deleted agent(s): 877314c2-3c8d-4666-a6ec-69513e83042d
[stack@director ~]$ neutron agent-delete 8d2ffbcb-b6ff-42cd-b5b8-da31d8da8a40
Deleted agent(s): 8d2ffbcb-b6ff-42cd-b5b8-da31d8da8a40
[stack@director ~]$ neutron agent-delete 911c43a5-df3a-49ec-99ed-1d722821ec20
Deleted agent(s): 911c43a5-df3a-49ec-99ed-1d722821ec20
[stack@director ~]$ neutron agent-delete a58a3dd3-4cdc-48d4-ab34-612a6cd72768
Deleted agent(s): a58a3dd3-4cdc-48d4-ab34-612a6cd72768
[stack@director ~]$ neutron agent-list | grep controller-2
[stack@director ~]$
Computerservices voltooien
Stap 1. CheckNova service-items links van de verwijderde node en verwijder ze:
[stack@director ~]$ nova service-list | grep controller-2
| 615 | nova-consoleauth | pod2-stack-controller-2.localdomain | internal | enabled | down | 2017-11-16T16:08:14.000000 | - |
| 618 | nova-scheduler | pod2-stack-controller-2.localdomain | internal | enabled | down | 2017-11-16T16:08:13.000000 | - |
| 621 | nova-conductor | pod2-stack-controller-2.localdomain | internal | enabled | down | 2017-11-16T16:08:14.000000 | -
[stack@director ~]$ nova service-delete 615
[stack@director ~]$ nova service-delete 618
[stack@director ~]$ nova service-delete 621
stack@director ~]$ nova service-list | grep controller-2
Stap 2. Zorg ervoor dat het consoleauthproces op alle controllers wordt uitgevoerd of start het opnieuw op met behulp van deze opdracht: pc-resource herstart openstack-nova-consoleauth:
[stack@director ~]$ nova service-list | grep consoleauth
| 601 | nova-consoleauth | pod2-stack-controller-0.localdomain | internal | enabled | up | 2017-11-16T21:00:10.000000 | - |
| 608 | nova-consoleauth | pod2-stack-controller-1.localdomain | internal | enabled | up | 2017-11-16T21:00:13.000000 | - |
| 622 | nova-consoleauth | pod2-stack-controller-3.localdomain | internal | enabled | up | 2017-11-16T21:00:13.000000 | -
Hekwerk opnieuw starten op de knooppunten van de controller
Stap 1. Controleer alle controllers voor de IP-route naar de undercloud 192.0.0.0/8:
[root@pod2-stack-controller-3 ~]# ip route
default via 10.225.247.203 dev vlan101
10.225.247.128/25 dev vlan101 proto kernel scope link src 10.225.247.212
11.117.0.0/24 dev vlan17 proto kernel scope link src 11.117.0.10
11.118.0.0/24 dev vlan18 proto kernel scope link src 11.118.0.10
11.119.0.0/24 dev vlan19 proto kernel scope link src 11.119.0.10
11.120.0.0/24 dev vlan20 proto kernel scope link src 11.120.0.10
169.254.169.254 via 192.200.0.1 dev eno1
192.200.0.0/24 dev eno1 proto kernel scope link src 192.200.0.113
Stap 2. Controleer de huidige stonithconfiguratie. Verwijder elke verwijzing naar de oude controllernode:
[root@pod2-stack-controller-3 ~]# sudo pcs stonith show --full
Resource: my-ipmilan-for-controller-6 (class=stonith type=fence_ipmilan)
Attributes: pcmk_host_list=pod2-stack-controller-1 ipaddr=192.100.0.1 login=admin passwd=Csco@123Starent lanplus=1
Operations: monitor interval=60s (my-ipmilan-for-controller-6-monitor-interval-60s)
Resource: my-ipmilan-for-controller-4 (class=stonith type=fence_ipmilan)
Attributes: pcmk_host_list=pod2-stack-controller-0 ipaddr=192.100.0.14 login=admin passwd=Csco@123Starent lanplus=1
Operations: monitor interval=60s (my-ipmilan-for-controller-4-monitor-interval-60s)
Resource: my-ipmilan-for-controller-7 (class=stonith type=fence_ipmilan)
Attributes: pcmk_host_list=pod2-stack-controller-2 ipaddr=192.100.0.15 login=admin passwd=Csco@123Starent lanplus=1
Operations: monitor interval=60s (my-ipmilan-for-controller-7-monitor-interval-60s)
[root@pod2-stack-controller-3 ~]# pcs stonith delete my-ipmilan-for-controller-7
Attempting to stop: my-ipmilan-for-controller-7...Stopped
Stap 3. Adstonithconfiguratie voor nieuwe controller:
[root@pod2-stack-controller-3 ~]sudo pcs stonith create my-ipmilan-for-controller-8 fence_ipmilan pcmk_host_list=pod2-stack-controller-3 ipaddr=<CIMC_IP> login=admin passwd=<PASSWORD> lanplus=1 op monitor interval=60s
Stap 4. Herstart het hekwerk vanaf elke controller en controleer de status:
[root@pod2-stack-controller-1 ~]# sudo pcs property set stonith-enabled=true
[root@pod2-stack-controller-3 ~]# pcs status
<snip>
my-ipmilan-for-controller-1 (stonith:fence_ipmilan): Started pod2-stack-controller-3
my-ipmilan-for-controller-0 (stonith:fence_ipmilan): Started pod2-stack-controller-3
my-ipmilan-for-controller-3 (stonith:fence_ipmilan): Started pod2-stack-controller-3
Bijgedragen door Cisco-engineers
- Karthikeyan DachanamoorthyCisco Advanced Services
- Harshita BhardwajCisco Advanced Services
 Feedback
FeedbackContact Cisco
- Een ondersteuningscase openen

- (Vereist een Cisco-servicecontract)