컴퓨팅 서버 UCS C240 M4 교체 - CPAR
다운로드 옵션
편견 없는 언어
본 제품에 대한 문서 세트는 편견 없는 언어를 사용하기 위해 노력합니다. 본 설명서 세트의 목적상, 편견 없는 언어는 나이, 장애, 성별, 인종 정체성, 민족 정체성, 성적 지향성, 사회 경제적 지위 및 교차성에 기초한 차별을 의미하지 않는 언어로 정의됩니다. 제품 소프트웨어의 사용자 인터페이스에서 하드코딩된 언어, RFP 설명서에 기초한 언어 또는 참조된 서드파티 제품에서 사용하는 언어로 인해 설명서에 예외가 있을 수 있습니다. 시스코에서 어떤 방식으로 포용적인 언어를 사용하고 있는지 자세히 알아보세요.
이 번역에 관하여
Cisco는 전 세계 사용자에게 다양한 언어로 지원 콘텐츠를 제공하기 위해 기계 번역 기술과 수작업 번역을 병행하여 이 문서를 번역했습니다. 아무리 품질이 높은 기계 번역이라도 전문 번역가의 번역 결과물만큼 정확하지는 않습니다. Cisco Systems, Inc.는 이 같은 번역에 대해 어떠한 책임도 지지 않으며 항상 원본 영문 문서(링크 제공됨)를 참조할 것을 권장합니다.
목차
소개
이 문서에서는 Ultra-M 설정에서 결함이 있는 컴퓨팅 서버를 교체하는 데 필요한 단계에 대해 설명합니다.
이 절차는 ESC(Elastic Services Controller)가 CPAR(Cisco Prime Access Registrar)을 관리하지 않고 CPAR이 Openstack에 구축된 VM에 직접 설치되는 NEWTON 버전을 사용하는 Openstack 환경에 적용됩니다.
배경 정보
Ultra-M은 VNF의 구축을 간소화하도록 설계된 사전 패키지 및 검증된 가상 모바일 패킷 코어 솔루션입니다. OpenStack은 Ultra-M용 VIM(Virtualized Infrastructure Manager)이며 다음 노드 유형으로 구성됩니다.
- 컴퓨팅
- 개체 스토리지 디스크 - 컴퓨팅(OSD - 컴퓨팅)
- 컨트롤러
- OpenStack 플랫폼 - 디렉터(OSPD)
이 그림에는 Ultra-M의 고급 아키텍처와 관련 구성 요소가 나와 있습니다.
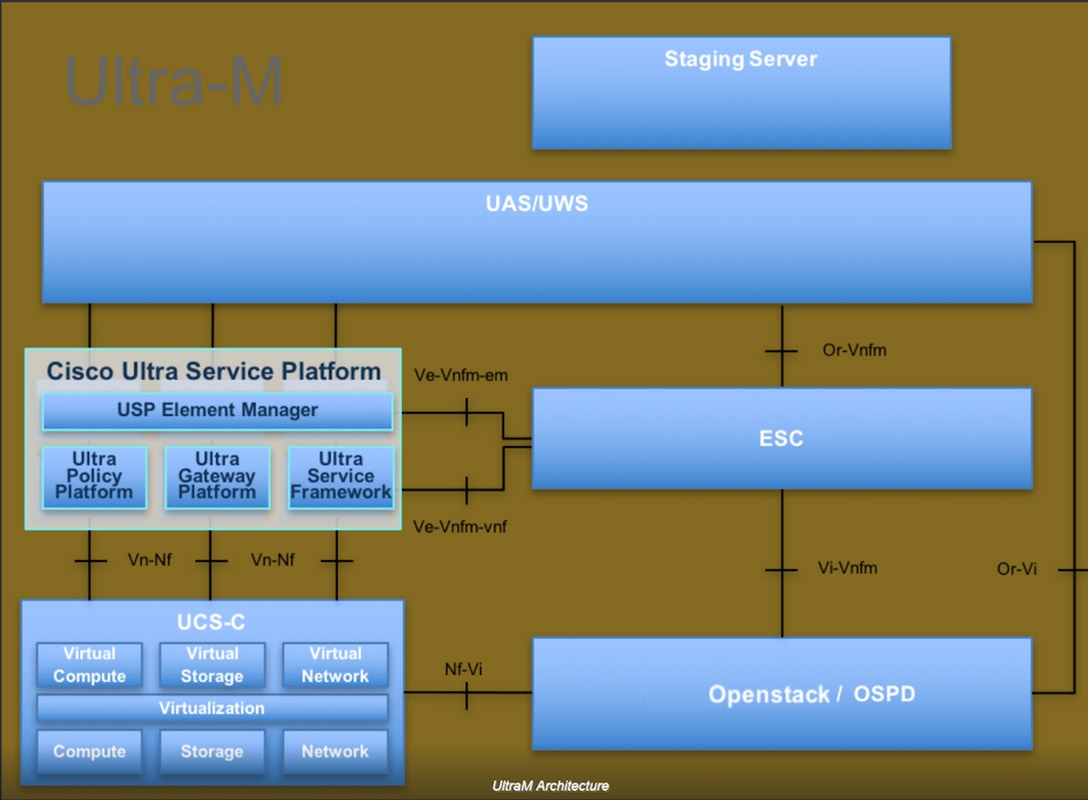
이 문서는 Cisco Ultra-M 플랫폼에 대해 잘 알고 있는 Cisco 직원을 대상으로 하며 OpenStack 및 Redhat OS에서 수행해야 하는 단계에 대해 자세히 설명합니다.
참고: 이 문서의 절차를 정의하기 위해 Ultra M 5.1.x 릴리스가 고려됩니다.
약어
| 자루걸레 | 절차 방법 |
| OSD | 개체 스토리지 디스크 |
| OSPD | OpenStack 플랫폼 디렉터 |
| HDD | 하드 디스크 드라이브 |
| SSD | SSD(Solid State Drive) |
| 빔 | 가상 인프라 관리자 |
| VM | 가상 머신 |
| 엠 | 요소 관리자 |
| UAS | Ultra Automation 서비스 |
| UUID | 보편적으로 고유한 식별자 |
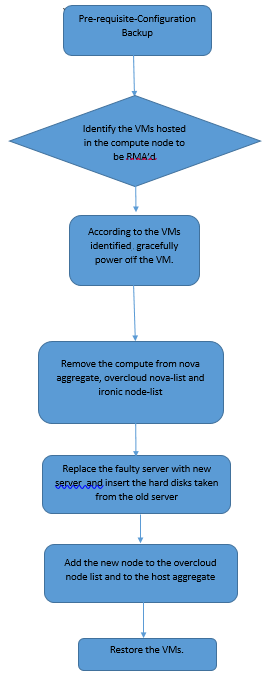
MoP의 워크플로
사전 요구 사항
백업
컴퓨팅 노드를 교체하기 전에 Red Hat OpenStack Platform 환경의 현재 상태를 확인하는 것이 중요합니다. 컴퓨팅 교체 프로세스가 켜져 있을 때 복잡성을 피하기 위해 현재 상태를 확인하는 것이 좋습니다. 이러한 교체 흐름으로 달성할 수 있습니다.
복구의 경우 다음 단계를 사용하여 OSPD 데이터베이스를 백업하는 것이 좋습니다.
[root@ al03-pod2-ospd ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql [root@ al03-pod2-ospd ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql /etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack tar: Removing leading `/' from member names
이 프로세스를 통해 인스턴스의 가용성에 영향을 주지 않고 노드를 교체할 수 있습니다.
참고: 필요한 경우 VM을 복원할 수 있도록 인스턴스의 스냅샷이 있는지 확인합니다. VM의 스냅샷을 만드는 방법은 아래 절차를 따르십시오.
컴퓨팅 노드에서 호스팅되는 VM 식별
컴퓨팅 서버에서 호스팅되는 VM을 식별합니다.
[stack@al03-pod2-ospd ~]$ nova list --field name,host +--------------------------------------+---------------------------+----------------------------------+ | ID | Name | Host | +--------------------------------------+---------------------------+----------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | pod2-stack-compute-4.localdomain | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | pod2-stack-compute-3.localdomain | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | pod2-stack-compute-3.localdomain | +--------------------------------------+---------------------------+----------------------------------+
참고: 여기에 표시된 출력에서 첫 번째 열은 UUID(Universally Unique IDentifier)에 해당하고, 두 번째 열은 VM 이름이며, 세 번째 열은 VM이 있는 호스트 이름입니다. 이 출력의 매개변수는 후속 섹션에서 사용됩니다.
스냅샷 프로세스
CPAR 애플리케이션 종료
1단계. 네트워크에 연결된 SSH 클라이언트를 열고 CPAR 인스턴스에 연결합니다.
한 사이트 내에 있는 4개의 AAA 인스턴스를 모두 동시에 종료하지 않고, 하나씩 차례로 수행하는 것이 중요합니다.
2단계. 다음 명령을 사용하여 CPAR 애플리케이션을 종료합니다.
/opt/CSCOar/bin/arserver stop
"Cisco Prime Access Registrar Server Agent shutdown complete"라는 메시지가 표시됩니다. 나타나야 합니다
참고: 사용자가 CLI 세션을 열어 둔 경우 arserver stop 명령이 작동하지 않으며 다음 메시지가 표시됩니다.
ERROR: You can not shut down Cisco Prime Access Registrar while the
CLI is being used. Current list of running
CLI with process id is:
2903 /opt/CSCOar/bin/aregcmd –s
이 예에서, 하이라이트된 프로세스 ID(2903)는 CPAR이 중단될 수 있기 전에 종료될 필요가 있다. 이 경우 다음 명령을 사용하여 프로세스를 종료합니다.
kill -9 *process_id*
그런 다음 1단계를 반복합니다.
3단계. 다음 명령을 사용하여 CPAR 애플리케이션이 실제로 종료되었는지 확인합니다.
/opt/CSCOar/bin/arstatus
다음 메시지가 표시됩니다.
Cisco Prime Access Registrar Server Agent not running Cisco Prime Access Registrar GUI not running
VM 스냅샷 작업
1단계. 현재 작업 중인 사이트(도시)에 해당하는 Horizon GUI 웹 사이트를 입력합니다. Horizon에 액세스하면 이미지에 표시된 화면이 관찰됩니다.
2단계. 이미지에 표시된 대로 Project > Instances로 이동합니다.
사용한 사용자가 cpar인 경우 이 메뉴에는 4개의 AAA 인스턴스만 표시됩니다.
3단계. 한 번에 하나의 인스턴스만 종료하고 이 문서의 전체 프로세스를 반복합니다. VM을 종료하려면 Actions(작업) > Shut Off Instance(인스턴스 종료)로 이동하여 선택 사항을 확인합니다.

4단계 Status = Shutoff 및 Power State = Shut Down을 통해 인스턴스가 실제로 종료되었는지 확인합니다.
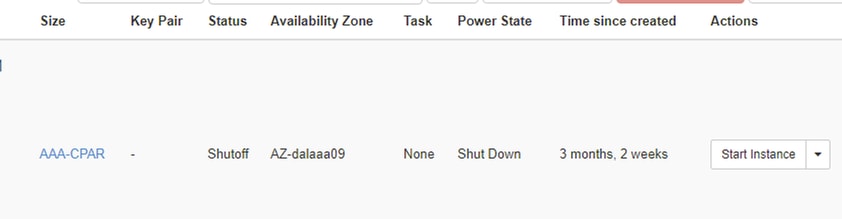
이 단계에서는 CPAR 종료 프로세스를 종료합니다.
VM 스냅샷
CPAR VM이 다운되면 독립 컴퓨터에 속하므로 스냅샷을 병렬로 만들 수 있습니다.
4개의 QCOW2 파일이 병렬로 생성됩니다.
각 AAA 인스턴스의 스냅샷을 만듭니다(25분 -1시간)(qcow 이미지를 소스로 사용한 인스턴스는 25분, 원시 이미지를 소스로 사용한 인스턴스는 1시간).
1단계. POD의 Openstack Horizon GUI에 로그인합니다.
2단계. 로그인했으면 상단 메뉴의 Project > Compute > Instances 섹션으로 이동하여 AAA 인스턴스를 찾습니다.
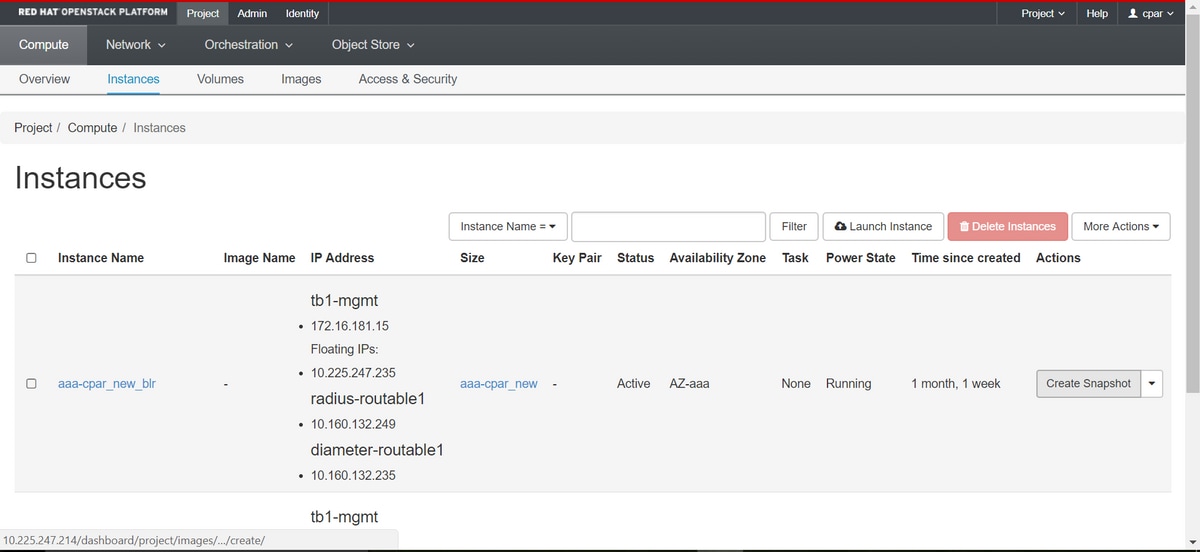
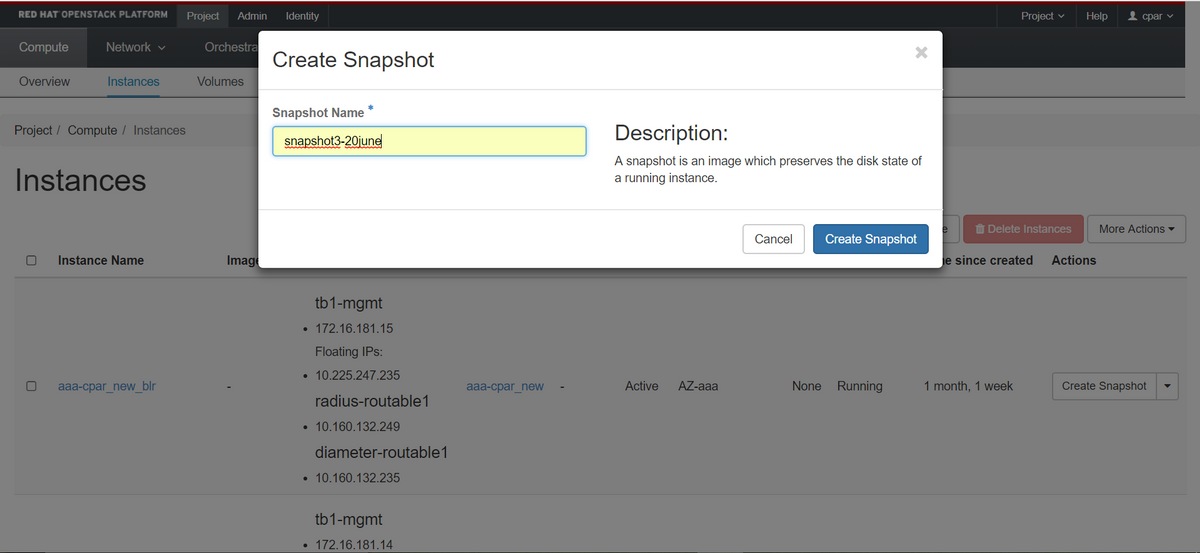
3단계. 스냅샷 생성을 계속하려면 Create Snapshot(스냅샷 생성)을 클릭합니다(이 작업은 해당 AAA 인스턴스에서 실행되어야 함).
4단계. 스냅샷이 실행되면 Images(이미지) 메뉴로 이동하여 완료되었고 문제가 없는지 확인합니다.
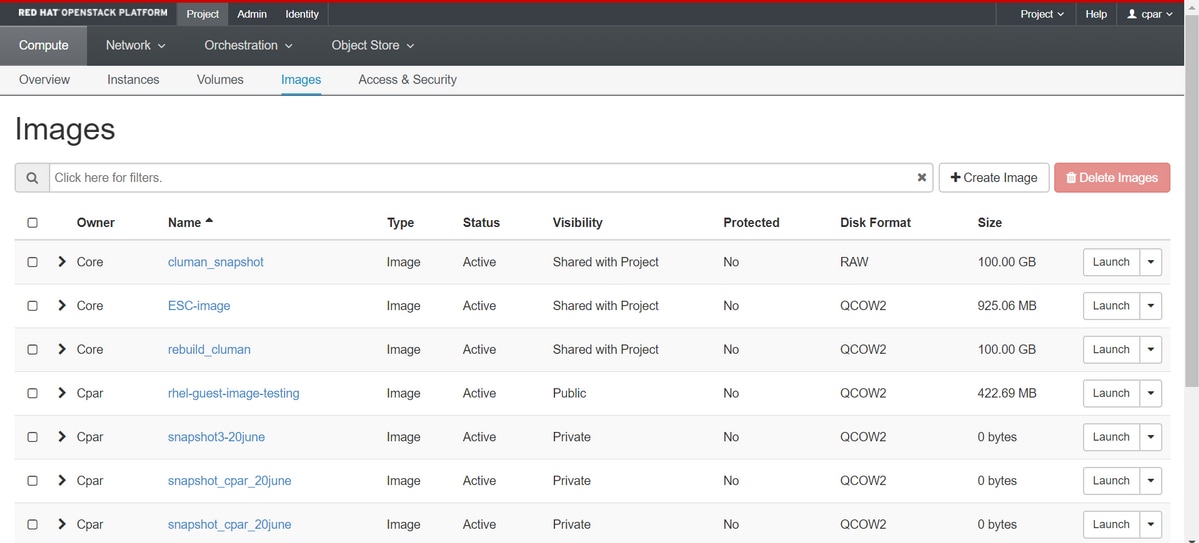
5단계. 다음 단계는 이 프로세스 중에 OSPD가 손실될 경우 QCOW2 형식으로 스냅샷을 다운로드하고 원격 엔티티로 전송하는 것입니다. 이를 위해 OSPD 레벨에서 이 명령 glance image-list를 사용하여 스냅샷을 식별합니다
[root@elospd01 stack]# glance image-list +--------------------------------------+---------------------------+ | ID | Name | +--------------------------------------+---------------------------+ | 80f083cb-66f9-4fcf-8b8a-7d8965e47b1d | AAA-Temporary | | 22f8536b-3f3c-4bcc-ae1a-8f2ab0d8b950 | ELP1 cluman 10_09_2017 | | 70ef5911-208e-4cac-93e2-6fe9033db560 | ELP2 cluman 10_09_2017 | | e0b57fc9-e5c3-4b51-8b94-56cbccdf5401 | ESC-image | | 92dfe18c-df35-4aa9-8c52-9c663d3f839b | lgnaaa01-sept102017 | | 1461226b-4362-428b-bc90-0a98cbf33500 | tmobile-pcrf-13.1.1.iso | | 98275e15-37cf-4681-9bcc-d6ba18947d7b | tmobile-pcrf-13.1.1.qcow2 | +--------------------------------------+---------------------------+
6단계. 다운로드할 스냅샷을 식별하면(이 경우 녹색으로 표시된 스냅샷임), 여기에 표시된 대로 이 glance image-download 명령을 통해 QCOW2 형식으로 다운로드됩니다.
[root@elospd01 stack]# glance image-download 92dfe18c-df35-4aa9-8c52-9c663d3f839b --file /tmp/AAA-CPAR-LGNoct192017.qcow2 &
- "&"가 프로세스를 백그라운드로 전송합니다. 이 작업을 완료하는 데 시간이 다소 걸리며, 작업이 완료되면 이미지가 /tmp 디렉토리에 위치할 수 있습니다.
- 프로세스가 백그라운드로 전송될 때 연결이 끊기면 프로세스도 중지됩니다.
- disown -h 명령을 실행하여 SSH(Secure Shell) 연결이 끊긴 경우에도 OSPD에서 프로세스가 계속 실행되고 종료되도록 합니다.
7단계. 다운로드 프로세스가 완료되면 운영 체제에서 처리하는 프로세스, 작업 및 임시 파일로 인해 스냅샷이 0으로 채워질 수 있으므로 압축 프로세스를 실행해야 합니다. 파일 압축에 사용할 명령은 virt-sparsify입니다.
[root@elospd01 stack]# virt-sparsify AAA-CPAR-LGNoct192017.qcow2 AAA-CPAR-LGNoct192017_compressed.qcow2
이 프로세스에는 약간의 시간(약 10-15분)이 소요됩니다. 완료되면 결과 파일은 다음 단계에서 지정한 대로 외부 엔티티로 전송해야 하는 파일입니다.
파일 무결성을 검증해야 합니다. 이를 위해 다음 명령을 실행하고 출력의 끝에서 손상된 특성을 찾습니다.
[root@wsospd01 tmp]# qemu-img info AAA-CPAR-LGNoct192017_compressed.qcow2 image: AAA-CPAR-LGNoct192017_compressed.qcow2 file format: qcow2 virtual size: 150G (161061273600 bytes) disk size: 18G cluster_size: 65536 Format specific information: compat: 1.1 lazy refcounts: false refcount bits: 16 corrupt: false
OSPD가 손실되는 문제를 방지하기 위해 최근에 생성된 QCOW2 형식의 스냅샷을 외부 엔터티로 전송해야 합니다. 파일 전송을 시작하기 전에 대상에 사용 가능한 디스크 공간이 충분한지 여부를 확인해야 합니다. 메모리 공간을 확인하려면 df -kh 명령을 사용합니다. 다른 사이트의 OSPD로 임시로 전송하는 것이 좋습니다. SFTP sftp root@x.x.x.x을 통해 다른 사이트의 OSPD로 전송하는 것이 좋습니다. 여기서 x.x.x.x는 원격 OSPD의 IP입니다. 전송 속도를 높이기 위해 대상을 여러 OSPD로 전송할 수 있습니다. 같은 방법으로 scp *name_of_the_file*.qcow2 root@ x.x.x.x:/tmp(여기서 x.x.x.x.x는 원격 OSPD의 IP임)를 사용하여 파일을 다른 OSPD로 전송할 수 있습니다.
정상 전원 끄기
노드 전원 끄기
- 인스턴스 전원을 끄려면 nova stop <INSTANCE_NAME>
- 이제 상태 차단과 함께 인스턴스 이름이 표시됩니다.
[stack@director ~]$ nova stop aaa2-21 Request to stop server aaa2-21 has been accepted. [stack@director ~]$ nova list +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | ID | Name | Status | Task State | Power State | Networks | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | ACTIVE | - | Running | tb1-mgmt=172.16.181.14, 10.225.247.233; radius-routable1=10.160.132.245; diameter-routable1=10.160.132.231 | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | SHUTOFF | - | Shutdown | diameter-routable1=10.160.132.230; radius-routable1=10.160.132.248; tb1-mgmt=172.16.181.7, 10.225.247.234 | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | ACTIVE | - | Running | diameter-routable1=10.160.132.233; radius-routable1=10.160.132.244; tb1-mgmt=172.16.181.10 | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+
컴퓨팅 노드 삭제
이 섹션에서 설명하는 단계는 컴퓨팅 노드에서 호스팅되는 VM에 관계없이 공통적인 단계입니다.
서비스 목록에서 컴퓨팅 노드 삭제
서비스 목록에서 컴퓨팅 서비스를 삭제합니다.
[stack@director ~]$ openstack compute service list |grep compute-3 | 138 | nova-compute | pod2-stack-compute-3.localdomain | AZ-aaa | enabled | up | 2018-06-21T15:05:37.000000 |
openstack compute service delete <ID>
[stack@director ~]$ openstack compute service delete 138
중성자 에이전트 삭제
이전 관련 중성자 에이전트를 삭제하고 컴퓨팅 서버용 vswitch 에이전트를 엽니다.
[stack@director ~]$ openstack network agent list | grep compute-3 | 3b37fa1d-01d4-404a-886f-ff68cec1ccb9 | Open vSwitch agent | pod2-stack-compute-3.localdomain | None | True | UP | neutron-openvswitch-agent |
openstack 네트워크 에이전트 <ID> 삭제
[stack@director ~]$ openstack network agent delete 3b37fa1d-01d4-404a-886f-ff68cec1ccb9
Ironic 데이터베이스에서 삭제
아이러니한 데이터베이스에서 노드를 삭제하고 확인합니다.
nova show <compute-node> | grep 하이퍼바이저
[root@director ~]# source stackrc [root@director ~]# nova show pod2-stack-compute-4 | grep hypervisor | OS-EXT-SRV-ATTR:hypervisor_hostname | 7439ea6c-3a88-47c2-9ff5-0a4f24647444
아이러니한 노드 삭제 <ID>
[stack@director ~]$ ironic node-delete 7439ea6c-3a88-47c2-9ff5-0a4f24647444 [stack@director ~]$ ironic node-list
삭제된 노드는 이제 ironic node-list에 나열되지 않아야 합니다.
오버클라우드에서 삭제
1단계. 표시된 내용과 함께 delete_node.sh라는 스크립트 파일을 생성합니다. 언급된 템플릿이 스택 구축에 사용되는 deploy.sh 스크립트에 사용된 템플릿과 동일한지 확인합니다.
delete_node.sh
openstack overcloud node delete --templates -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml -e /home/stack/custom-templates/layout.yaml --stack <stack-name> <UUID>
[stack@director ~]$ source stackrc [stack@director ~]$ /bin/sh delete_node.sh + openstack overcloud node delete --templates -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml -e /home/stack/custom-templates/layout.yaml --stack pod2-stack 7439ea6c-3a88-47c2-9ff5-0a4f24647444 Deleting the following nodes from stack pod2-stack: - 7439ea6c-3a88-47c2-9ff5-0a4f24647444 Started Mistral Workflow. Execution ID: 4ab4508a-c1d5-4e48-9b95-ad9a5baa20ae real 0m52.078s user 0m0.383s sys 0m0.086s
2단계. OpenStack 스택 작업이 COMPLETE 상태로 전환될 때까지 기다립니다.
[stack@director ~]$ openstack stack list +--------------------------------------+------------+-----------------+----------------------+----------------------+ | ID | Stack Name | Stack Status | Creation Time | Updated Time | +--------------------------------------+------------+-----------------+----------------------+----------------------+ | 5df68458-095d-43bd-a8c4-033e68ba79a0 | pod2-stack | UPDATE_COMPLETE | 2018-05-08T21:30:06Z | 2018-05-08T20:42:48Z | +--------------------------------------+------------+-----------------+----------------------+----------------------+
새 컴퓨팅 노드 설치
새 UCS C240 M4 서버를 설치하는 단계 및 초기 설정 단계는 Cisco UCS C240 M4 서버 설치 및 서비스 가이드에서 참조할 수 있습니다
1단계. 서버 설치 후 하드 디스크를 이전 서버로 각 슬롯에 삽입합니다.
2단계. CIMC IP를 사용하여 서버에 로그인합니다.
3단계. 펌웨어가 이전에 사용한 권장 버전에 따라 다르면 BIOS 업그레이드를 수행합니다. BIOS 업그레이드 단계는 다음과 같습니다. Cisco UCS C-Series 랙 마운트 서버 BIOS 업그레이드 가이드
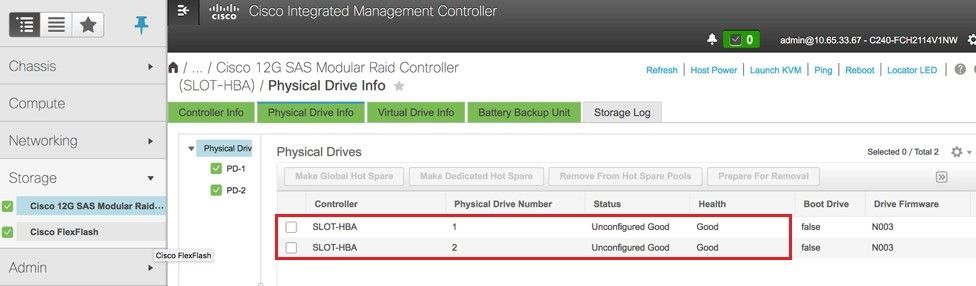
4단계. 물리적 드라이브의 상태가 Unconfigured Good(구성되지 않음, 정상)인지 확인하려면 Storage(스토리지) > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Physical Drive Info(물리적 드라이브 정보)로 이동합니다.
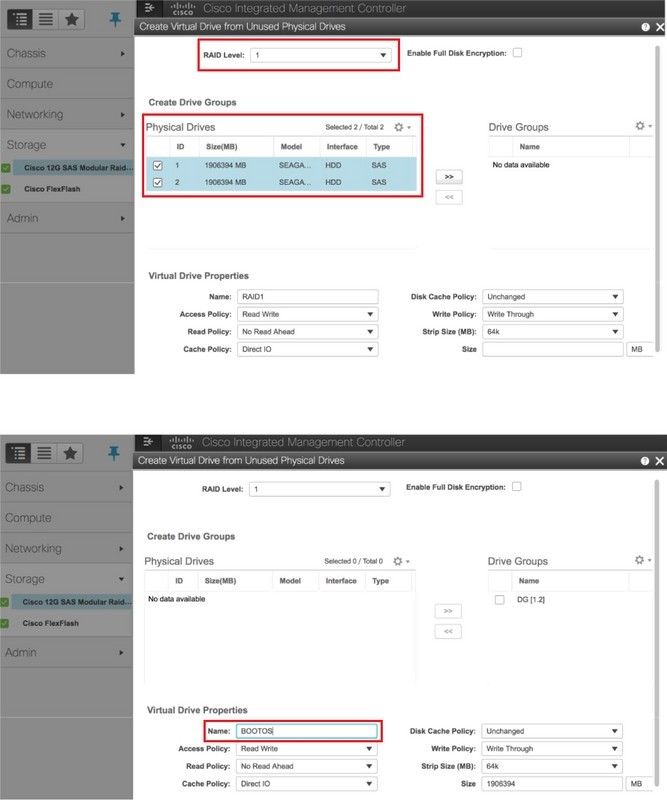
5단계. RAID 레벨 1의 물리적 드라이브에서 가상 드라이브를 생성하려면 Storage(스토리지) > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Controller Info(컨트롤러 정보) > Create Virtual Drive from Unused Physical Drives(사용되지 않은 물리적 드라이브에서 가상 드라이브 만들기)로 이동합니다.
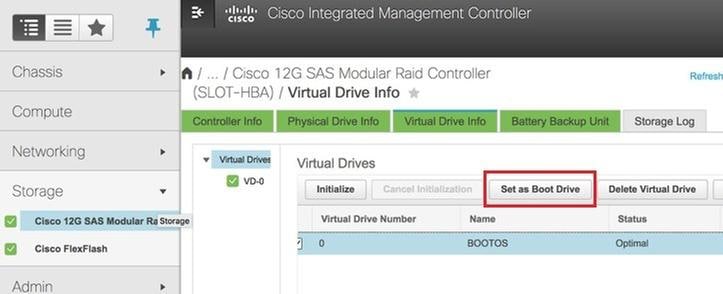
6단계. VD를 선택하고 이미지에 나와 있는 것처럼 Set as Boot Drive(부트 드라이브로 설정)를 구성합니다.
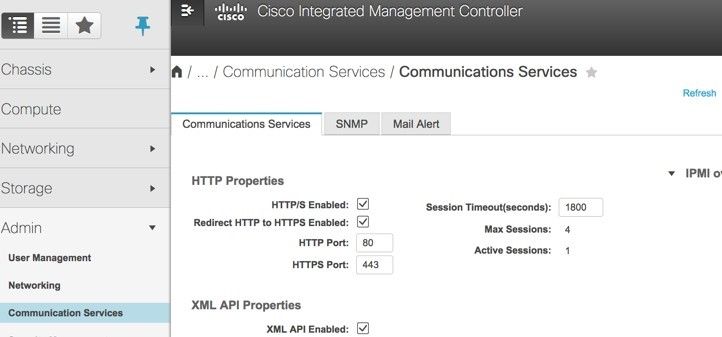
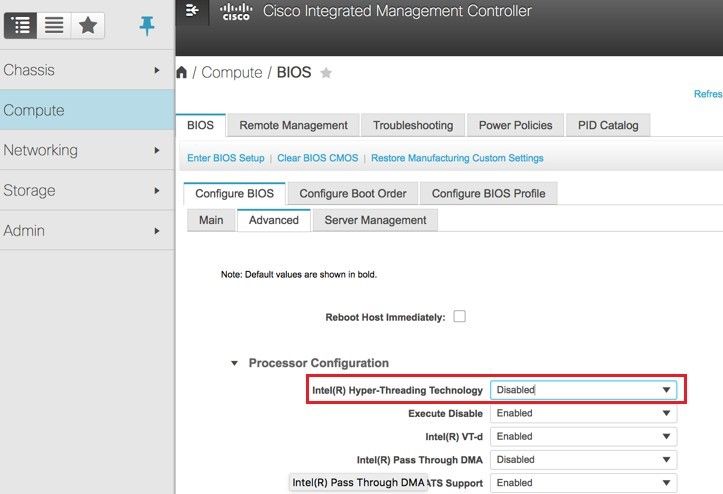
7단계. IPMI over LAN을 활성화하려면 그림과 같이 Admin(관리) > Communication Services(통신 서비스) > Communication Services(통신 서비스)로 이동합니다.
8단계. 하이퍼스레딩을 비활성화하려면 Compute(컴퓨팅) > BIOS > Configure BIOS(BIOS 구성) > Advanced(고급) > Processor Configuration(프로세서 컨피그레이션)으로 이동합니다.
참고: 여기에 표시된 이미지 및 이 섹션에서 설명한 컨피그레이션 단계는 펌웨어 버전 3.0(3e)을 참조하며, 다른 버전에서 작업하는 경우 약간의 차이가 있을 수 있습니다.
오버클라우드에 새 컴퓨팅 노드 추가
이 섹션에서 설명하는 단계는 컴퓨팅 노드가 호스팅하는 VM에 관계없이 공통적인 단계입니다.
1단계. 다른 인덱스로 컴퓨팅 서버 추가
추가할 새 컴퓨팅 서버의 세부 정보만 포함된 add_node.json 파일을 생성합니다. 새 컴퓨팅 서버의 인덱스 번호가 이전에 사용되지 않았는지 확인합니다. 일반적으로 다음으로 높은 컴퓨팅 값을 증가시킵니다.
예: 가장 높은 우선은 compute-17이었고, 따라서 2-vnf 시스템의 경우 compute-18이 생성되었습니다.
참고: json 형식에 유의하십시오.
[stack@director ~]$ cat add_node.json
{
"nodes":[
{
"mac":[
"<MAC_ADDRESS>"
],
"capabilities": "node:compute-18,boot_option:local",
"cpu":"24",
"memory":"256000",
"disk":"3000",
"arch":"x86_64",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"<PASSWORD>",
"pm_addr":"192.100.0.5"
}
]
}
2단계. json 파일을 가져옵니다.
[stack@director ~]$ openstack baremetal import --json add_node.json Started Mistral Workflow. Execution ID: 78f3b22c-5c11-4d08-a00f-8553b09f497d Successfully registered node UUID 7eddfa87-6ae6-4308-b1d2-78c98689a56e Started Mistral Workflow. Execution ID: 33a68c16-c6fd-4f2a-9df9-926545f2127e Successfully set all nodes to available.
3단계. 이전 단계에서 기록한 UUID를 사용하여 노드 자체 검사를 실행합니다.
[stack@director ~]$ openstack baremetal node manage 7eddfa87-6ae6-4308-b1d2-78c98689a56e [stack@director ~]$ ironic node-list |grep 7eddfa87 | 7eddfa87-6ae6-4308-b1d2-78c98689a56e | None | None | power off | manageable | False | [stack@director ~]$ openstack overcloud node introspect 7eddfa87-6ae6-4308-b1d2-78c98689a56e --provide Started Mistral Workflow. Execution ID: e320298a-6562-42e3-8ba6-5ce6d8524e5c Waiting for introspection to finish... Successfully introspected all nodes. Introspection completed. Started Mistral Workflow. Execution ID: c4a90d7b-ebf2-4fcb-96bf-e3168aa69dc9 Successfully set all nodes to available. [stack@director ~]$ ironic node-list |grep available | 7eddfa87-6ae6-4308-b1d2-78c98689a56e | None | None | power off | available | False |
4단계. 오버클라우드 스택에 새 computenode를 추가하기 위해 이전에 스택 구축에 사용되었던 deploy.sh 스크립트를 실행합니다.
[stack@director ~]$ ./deploy.sh ++ openstack overcloud deploy --templates -r /home/stack/custom-templates/custom-roles.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml --stack ADN-ultram --debug --log-file overcloudDeploy_11_06_17__16_39_26.log --ntp-server 172.24.167.109 --neutron-flat-networks phys_pcie1_0,phys_pcie1_1,phys_pcie4_0,phys_pcie4_1 --neutron-network-vlan-ranges datacentre:1001:1050 --neutron-disable-tunneling --verbose --timeout 180 … Starting new HTTP connection (1): 192.200.0.1 "POST /v2/action_executions HTTP/1.1" 201 1695 HTTP POST http://192.200.0.1:8989/v2/action_executions 201 Overcloud Endpoint: http://10.1.2.5:5000/v2.0 Overcloud Deployed clean_up DeployOvercloud: END return value: 0 real 38m38.971s user 0m3.605s sys 0m0.466s
5단계. openstack 스택 상태가 Complete(완료)가 될 때까지 기다립니다.
[stack@director ~]$ openstack stack list +--------------------------------------+------------+-----------------+----------------------+----------------------+ | ID | Stack Name | Stack Status | Creation Time | Updated Time | +--------------------------------------+------------+-----------------+----------------------+----------------------+ | 5df68458-095d-43bd-a8c4-033e68ba79a0 | ADN-ultram | UPDATE_COMPLETE | 2017-11-02T21:30:06Z | 2017-11-06T21:40:58Z | +--------------------------------------+------------+-----------------+----------------------+----------------------+
6단계. 새 컴퓨팅 노드가 활성 상태인지 확인합니다.
[root@director ~]# nova list | grep pod2-stack-compute-4 | 5dbac94d-19b9-493e-a366-1e2e2e5e34c5 | pod2-stack-compute-4 | ACTIVE | - | Running | ctlplane=192.200.0.116 |
VM 복원
스냅샷을 통해 인스턴스 복구
복구 프로세스:
이전 단계에서 생성한 스냅샷으로 이전 인스턴스를 재구축할 수 있습니다.
1단계[선택 사항]. 사용 가능한 이전 VMsnapshot이 없는 경우 백업이 전송된 OSPD 노드에 연결하고 백업을 원래 OSPD 노드로 다시 sftp합니다. sftp root@x.x.x.x을 통해 x.x.x.x는 원래 OSPD의 IP입니다. 스냅샷 파일을 /tmp 디렉토리에 저장합니다.
2단계. 인스턴스가 재배포되는 OSPD 노드에 연결합니다.

다음 명령을 사용하여 환경 변수를 소싱합니다.
# source /home/stack/pod1-stackrc-Core-CPAR
3단계. 이미지를 사용하여 스냅샷을 horizon에 업로드해야 합니다. 다음 명령을 사용하여 이 작업을 수행합니다.
#glance image-create -- AAA-CPAR-Date-snapshot.qcow2 --container-format bare --disk-format qcow2 --name AAA-CPAR-Date-snapshot
그 과정은 지평선 안에서 볼 수 있다.

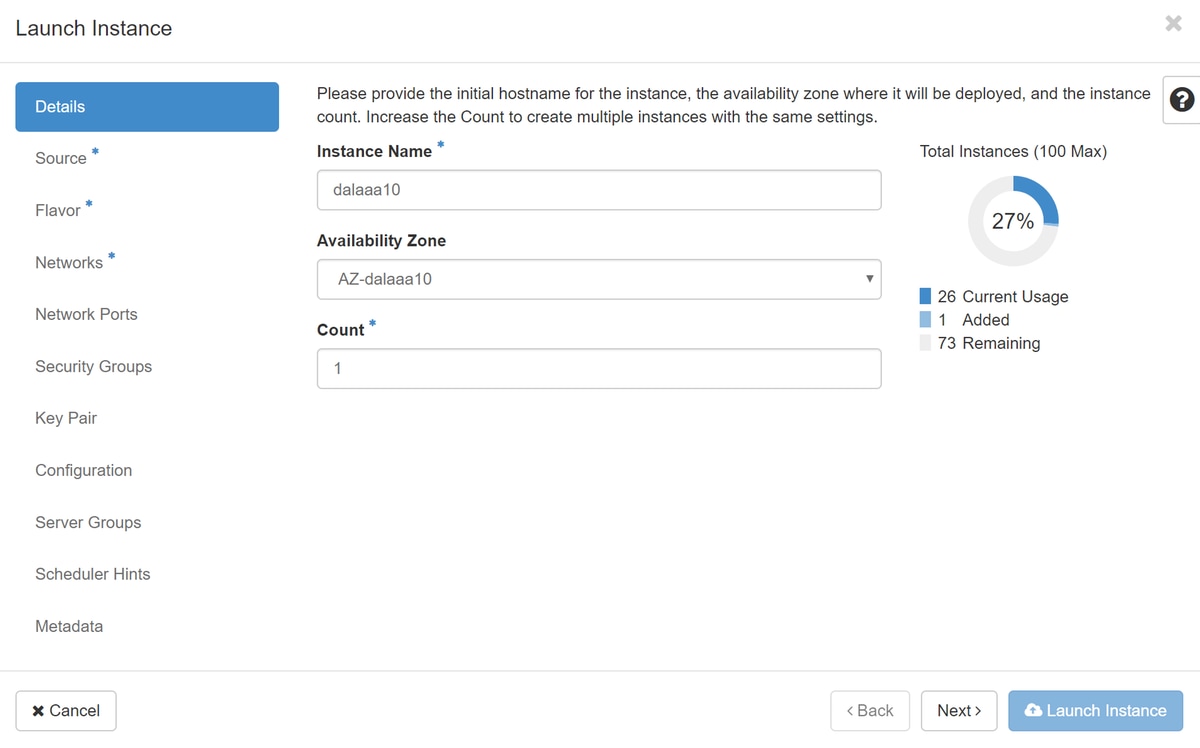
4단계. Horizon에서 그림과 같이 Project(프로젝트) > Instances(인스턴스)로 이동하고 Launch Instance(인스턴스 시작)를 클릭합니다.

5단계. Instance Name(인스턴스 이름)을 입력하고 Availability Zone(가용성 영역)을 선택합니다(이미지 참조).
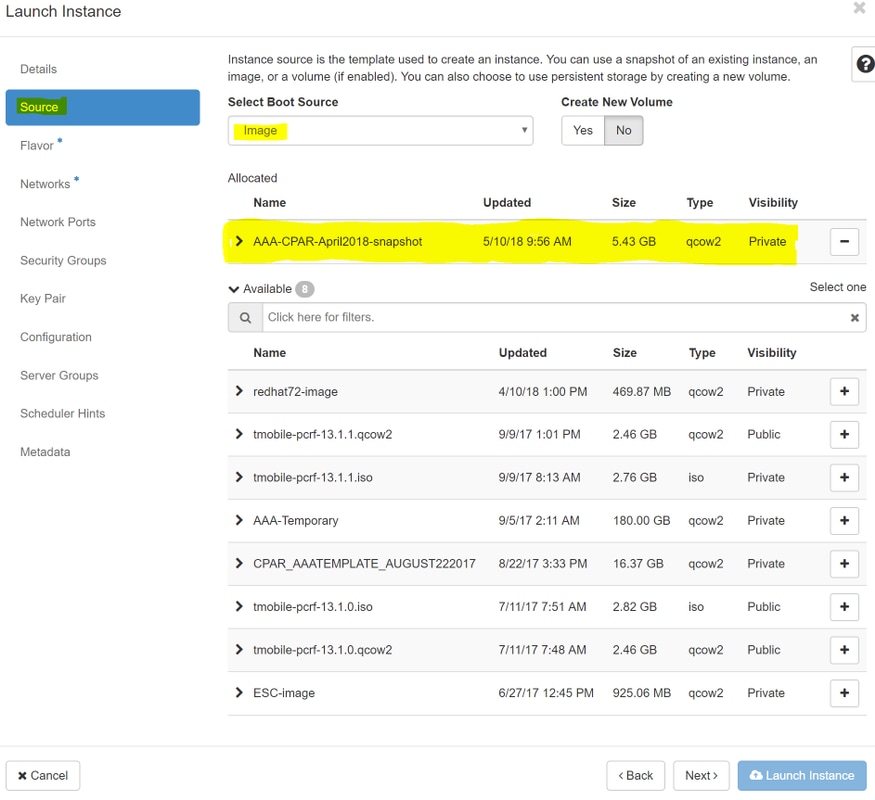
6단계. Source(소스) 탭에서 인스턴스를 생성할 이미지를 선택합니다. Select Boot Source(부팅 소스 선택) 메뉴 이미지 선택에서 이미지 목록이 여기에 표시되며, + 기호를 클릭할 때 이전에 업로드한 이미지를 선택합니다.
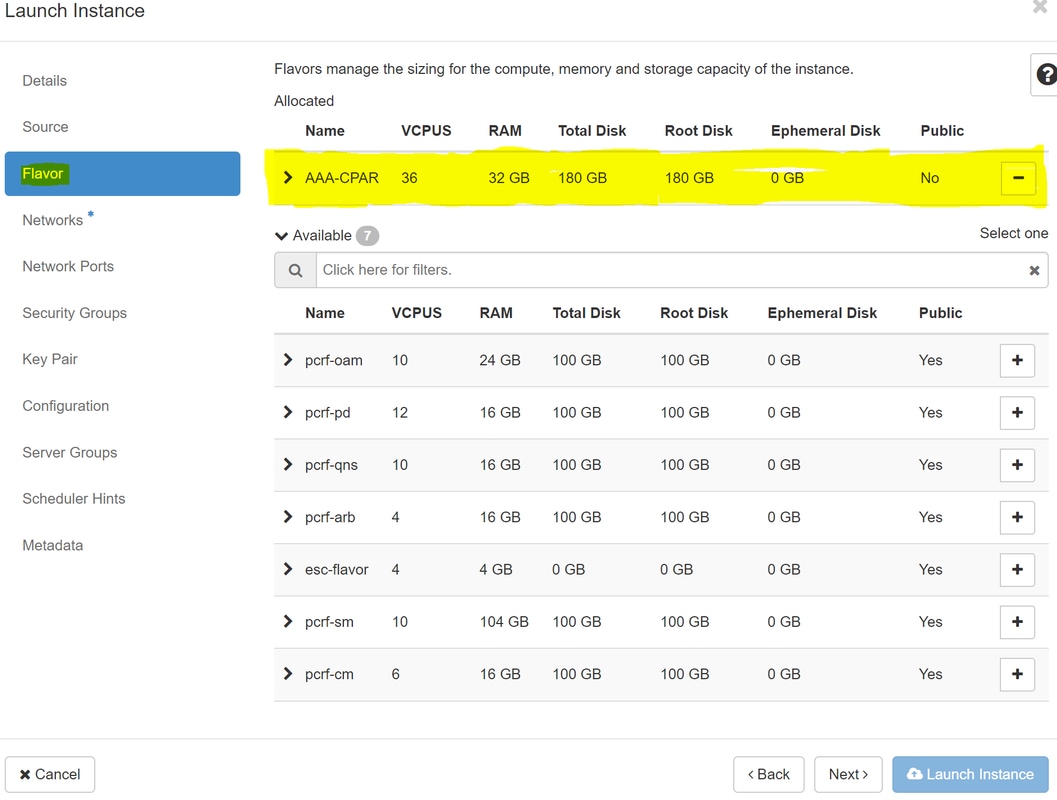
7단계. Flavor(flavor) 탭에서 이미지에 표시된 대로 + 기호를 클릭할 때 AAA 풍미를 선택합니다.
8단계. 이제 Networks(네트워크) 탭으로 이동하여 + 기호를 클릭할 때 인스턴스에 필요한 네트워크를 선택합니다. 이 경우 이미지에 표시된 대로 diameter-soutable1, radius-routable1 및 tb1-mgmt를 선택합니다.
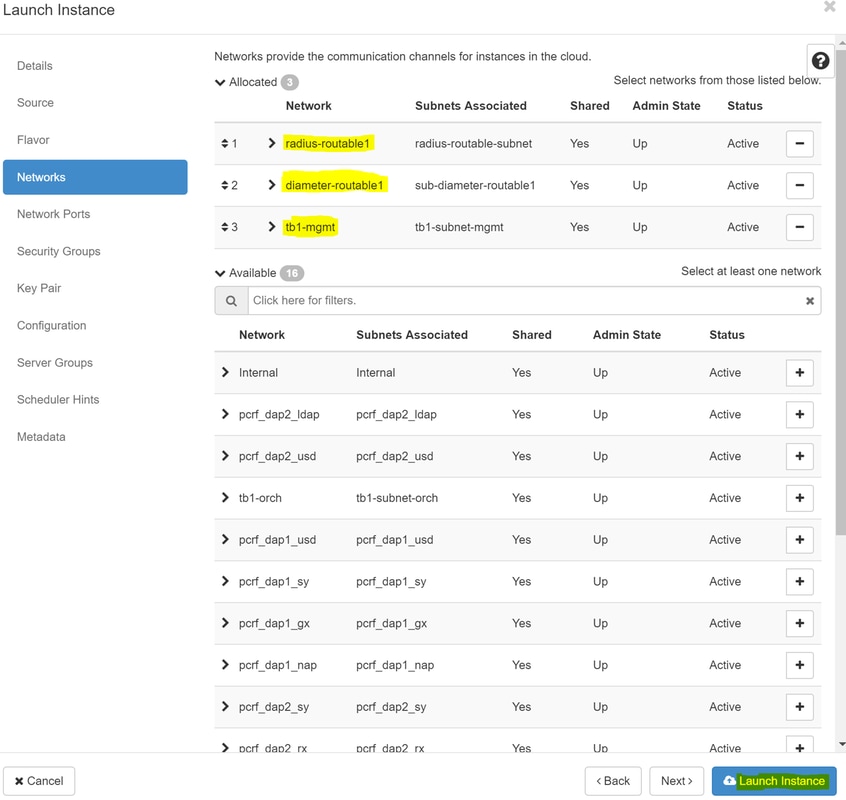
9단계. 인스턴스를 생성하려면 Launch instance(인스턴스 실행)를 클릭합니다. Horizon에서 진행 상황을 모니터링할 수 있습니다.
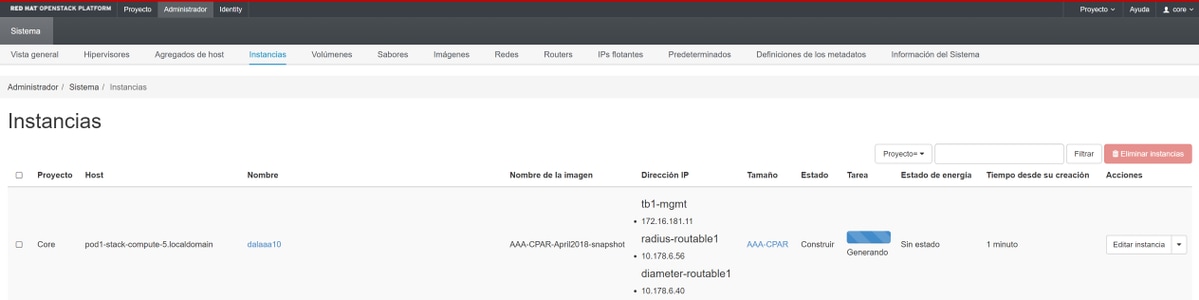
몇 분 후에 인스턴스가 완전히 구축되어 사용할 준비가 됩니다.

부동 IP 주소 생성 및 할당
부동 IP 주소는 라우팅 가능한 주소입니다. 즉 Ultra M/Openstack 아키텍처 외부에서 연결할 수 있고 네트워크의 다른 노드와 통신할 수 있습니다.
1단계. Horizon 상단 메뉴에서 Admin(관리) > Floating IPs(부동 IP)로 이동합니다.
2단계. Allocate IP to Project(프로젝트에 IP 할당) 버튼을 클릭합니다.
3단계. Allocate Floating IP(부동 IP 할당) 창에서 새 부동 IP가 속한 풀, 이 풀이 할당될 프로젝트 및 새 부동 IP 주소 자체를 선택합니다.
예를 들면 다음과 같습니다.
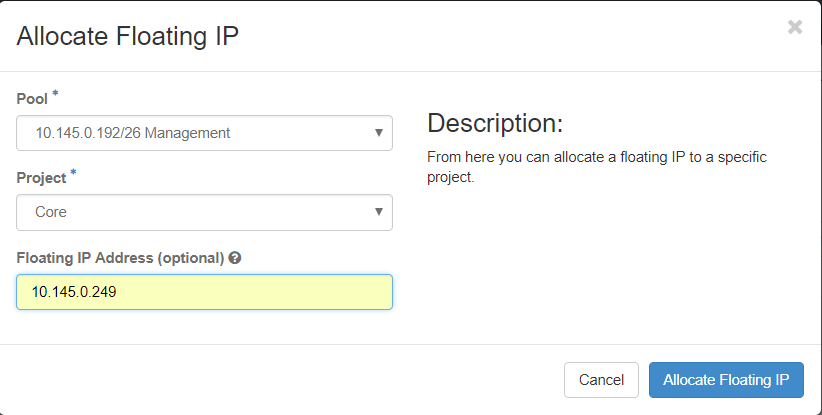
4단계. Allocate Floating IP(부동 IP 할당) 버튼을 클릭합니다.
5단계. Horizon 상단 메뉴에서 Project > Instances로 이동합니다.
6단계. Action(작업) 열에서 Create Snapshot(스냅샷 생성) 버튼을 가리키는 화살표를 클릭하면 메뉴가 표시됩니다. Associate Floating IP(부동 IP 연결) 옵션을 선택합니다.
7단계. IP Address(IP 주소) 필드에서 사용할 해당 유동 IP 주소를 선택하고, 이 유동 IP가 연결될 포트에서 할당될 새 인스턴스에서 해당 관리 인터페이스(eth0)를 선택합니다. 이 절차의 예시로 다음 이미지를 참조하시기 바랍니다.
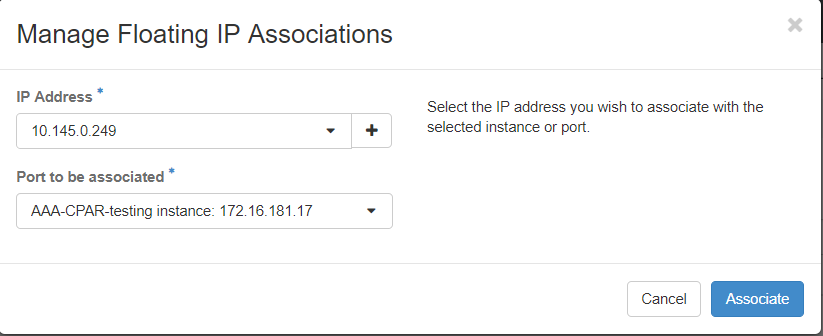
8단계. Associate(연결)를 클릭합니다.
SSH 사용
1단계. Horizon 상단 메뉴에서 Project > Instances로 이동합니다.
2단계. 새 인스턴스 점심식사 섹션에서 생성한 인스턴스/VM의 이름을 클릭합니다.
3단계. Console(콘솔) 탭을 클릭합니다. VM의 CLI가 표시됩니다.
4단계. CLI가 표시되면 적절한 로그인 자격 증명을 입력합니다.
사용자 이름: 루트
암호: cisco123
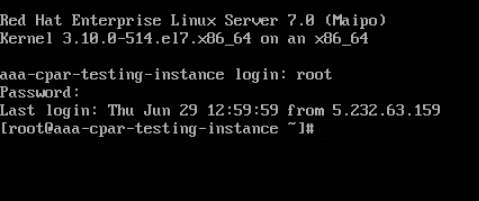
5단계. CLI에서 명령을 vi /etc/ssh/sshd_config로 입력하여 ssh 컨피그레이션을 수정합니다.
6단계. ssh 컨피그레이션 파일이 열리면 I를 눌러 파일을 편집합니다. 그런 다음 아래에 표시된 섹션을 찾아 첫 번째 줄을 PasswordAuthentication no에서 PasswordAuthentication yes로 변경합니다.

7단계. Esc를 누르고 :wq!를 입력합니다. sshd_config 파일 변경 내용을 저장합니다.
8단계. service sshd restart 명령을 실행합니다.
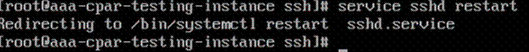
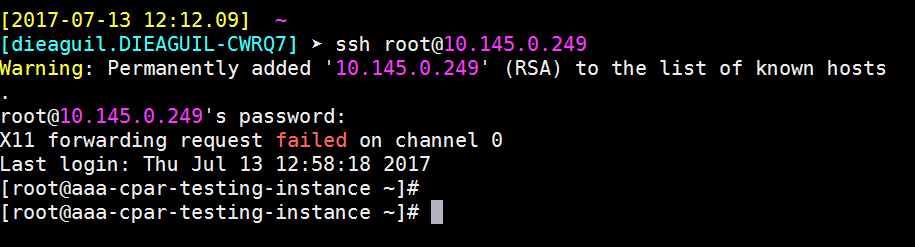
9단계. SSH 컨피그레이션 변경 사항이 올바르게 적용되었는지 테스트하려면 SSH 클라이언트를 열고 인스턴스에 할당된 부동 IP(예: 10.145.0.249) 및 사용자 루트를 사용하여 원격 보안 연결을 설정합니다.
SSH 세션 설정
애플리케이션이 설치된 해당 VM/서버의 IP 주소로 SSH 세션을 엽니다.

CPAR 인스턴스 시작
활동이 완료되고 종료된 사이트에서 CPAR 서비스를 다시 설정할 수 있게 되면 아래 단계를 따르십시오.
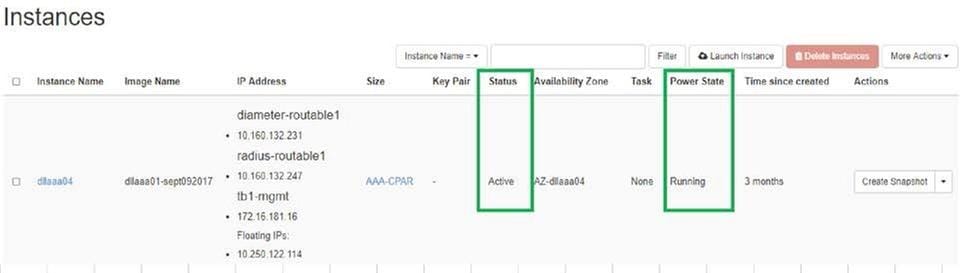
- Horizon에 다시 로그인하려면 Project > Instance > Start Instance로 이동합니다.
- 인스턴스의 상태가 활성 상태이고 전원 상태가 실행 중인지 확인합니다.
작업 후 상태 확인
1단계. OS 레벨에서 명령/opt/CSCOar/bin/arstatus를 실행합니다.
[root@wscaaa04 ~]# /opt/CSCOar/bin/arstatus Cisco Prime AR RADIUS server running (pid: 24834) Cisco Prime AR Server Agent running (pid: 24821) Cisco Prime AR MCD lock manager running (pid: 24824) Cisco Prime AR MCD server running (pid: 24833) Cisco Prime AR GUI running (pid: 24836) SNMP Master Agent running (pid: 24835) [root@wscaaa04 ~]#
2단계. OS 레벨에서 명령/opt/CSCOar/bin/aregcmd를 실행하고 관리자 자격 증명을 입력합니다. CPAR Health(CPAR 상태)가 10개 중 10개인지 확인하고 CPAR CLI를 종료합니다.
[root@aaa02 logs]# /opt/CSCOar/bin/aregcmd
Cisco Prime Access Registrar 7.3.0.1 Configuration Utility
Copyright (C) 1995-2017 by Cisco Systems, Inc. All rights reserved.
Cluster:
User: admin
Passphrase:
Logging in to localhost
[ //localhost ]
LicenseInfo = PAR-NG-TPS 7.2(100TPS:)
PAR-ADD-TPS 7.2(2000TPS:)
PAR-RDDR-TRX 7.2()
PAR-HSS 7.2()
Radius/
Administrators/
Server 'Radius' is Running, its health is 10 out of 10
--> exit
3단계.netstat 명령을 실행합니다. | grep diameter 및 모든 DRA 연결이 설정되었는지 확인합니다.
아래 표시된 출력은 Diameter 링크가 필요한 환경에 대한 것입니다. 표시되는 링크 수가 적을 경우, 이는 분석해야 하는 DRA와의 연결이 끊겼음을 나타냅니다.
[root@aa02 logs]# netstat | grep diameter tcp 0 0 aaa02.aaa.epc.:77 mp1.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:36 tsa6.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:47 mp2.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:07 tsa5.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:08 np2.dra01.d:diameter ESTABLISHED
4단계. TPS 로그에 CPAR에서 처리 중인 요청이 표시되는지 확인합니다. 강조 표시된 값은 TPS를 나타내며 해당 값은 우리가 주목해야 할 값입니다.
TPS의 값은 1500을 초과할 수 없습니다.
[root@wscaaa04 ~]# tail -f /opt/CSCOar/logs/tps-11-21-2017.csv 11-21-2017,23:57:35,263,0 11-21-2017,23:57:50,237,0 11-21-2017,23:58:05,237,0 11-21-2017,23:58:20,257,0 11-21-2017,23:58:35,254,0 11-21-2017,23:58:50,248,0 11-21-2017,23:59:05,272,0 11-21-2017,23:59:20,243,0 11-21-2017,23:59:35,244,0 11-21-2017,23:59:50,233,0
5단계. name_radius_1_log에서 "오류" 또는 "경보" 메시지를 확인합니다.
[root@aaa02 logs]# grep -E "error|alarm" name_radius_1_log
6단계. 다음 명령을 사용하여 CPAR 프로세스가 있는 메모리의 양을 확인합니다.
꼭대기 | grep radius
[root@sfraaa02 ~]# top | grep radius 27008 root 20 0 20.228g 2.413g 11408 S 128.3 7.7 1165:41 radius
이 강조 표시된 값은 다음 값보다 작아야 합니다. 7Gb - 애플리케이션 수준에서 허용되는 최대 용량입니다.
Cisco 엔지니어가 작성
- 카르티케얀 다차나모르티Cisco 고급 서비스
- 하시타 바드와이Cisco 고급 서비스
 피드백
피드백지원 문의
- 지원 케이스 접수

- (시스코 서비스 계약 필요)