Ultra-M AutoVNFクラスタ障害の回復手順 – vEPC
ダウンロード オプション
偏向のない言語
この製品のドキュメントセットは、偏向のない言語を使用するように配慮されています。このドキュメントセットでの偏向のない言語とは、年齢、障害、性別、人種的アイデンティティ、民族的アイデンティティ、性的指向、社会経済的地位、およびインターセクショナリティに基づく差別を意味しない言語として定義されています。製品ソフトウェアのユーザインターフェイスにハードコードされている言語、RFP のドキュメントに基づいて使用されている言語、または参照されているサードパーティ製品で使用されている言語によりドキュメントに例外が存在する場合があります。シスコのインクルーシブ ランゲージの取り組みの詳細は、こちらをご覧ください。
翻訳について
シスコは世界中のユーザにそれぞれの言語でサポート コンテンツを提供するために、機械と人による翻訳を組み合わせて、本ドキュメントを翻訳しています。ただし、最高度の機械翻訳であっても、専門家による翻訳のような正確性は確保されません。シスコは、これら翻訳の正確性について法的責任を負いません。原典である英語版(リンクからアクセス可能)もあわせて参照することを推奨します。
内容
はじめに
このドキュメントでは、StarOS Virtual Network Functions(VNF)をホストするUltra-MセットアップでUltra Automation Services(UAS)またはAutoVNFクラスタの障害を回復するために必要な手順について説明します。
背景説明
Ultra-Mは、VNFの導入を簡素化するために設計された、パッケージ済みで検証済みの仮想化モバイルパケットコアソリューションです。
Ultra-Mソリューションは、メンタリングされた仮想マシン(VM)タイプで構成されます。
- 自動IT
- 自動展開
- UASまたはAutoVNF
- エレメントマネージャ(EM)
- Elastic Services Controller(ESC)
- 制御機能(CF)
- セッション機能(SF)
Ultra-Mの高度なアーキテクチャと関連するコンポーネントを次の図に示します。
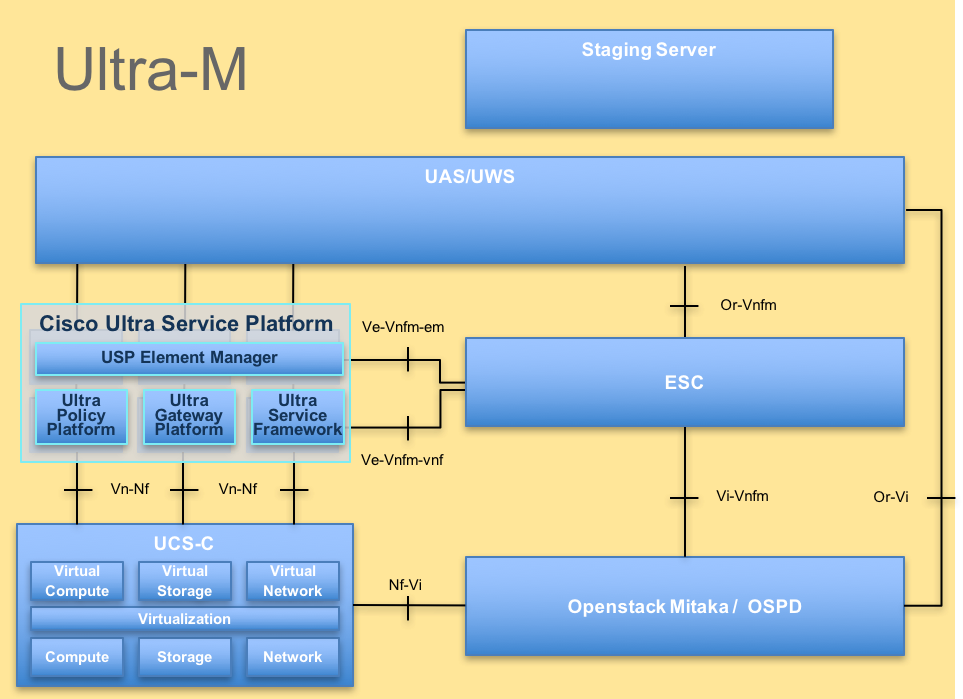 UltraMアーキテクチャ
UltraMアーキテクチャ
このドキュメントは、Cisco Ultra-Mプラットフォームに精通しているシスコの担当者を対象としています。
注:このドキュメントでは、手順を定義するためにUltra M 5.1.xリリースを考慮しています。
略語
| VNF | 仮想ネットワーク機能 |
| CF | 制御機能 |
| SF | サービス機能 |
| ESC | 柔軟なサービスコントローラ |
| MOP | 手順の方法 |
| OSD | オブジェクトストレージディスク |
| HDD | ハードディスクドライブ |
| SSD | ソリッドステートドライブ |
| VIM | 仮想インフラストラクチャマネージャ |
| 仮想マシン | 仮想マシン |
| エム | エレメント マネージャ |
| UAS | Ultra 自動化サービス |
| UUID | ユニバーサル一意識別子 |
MoPのワークフロー
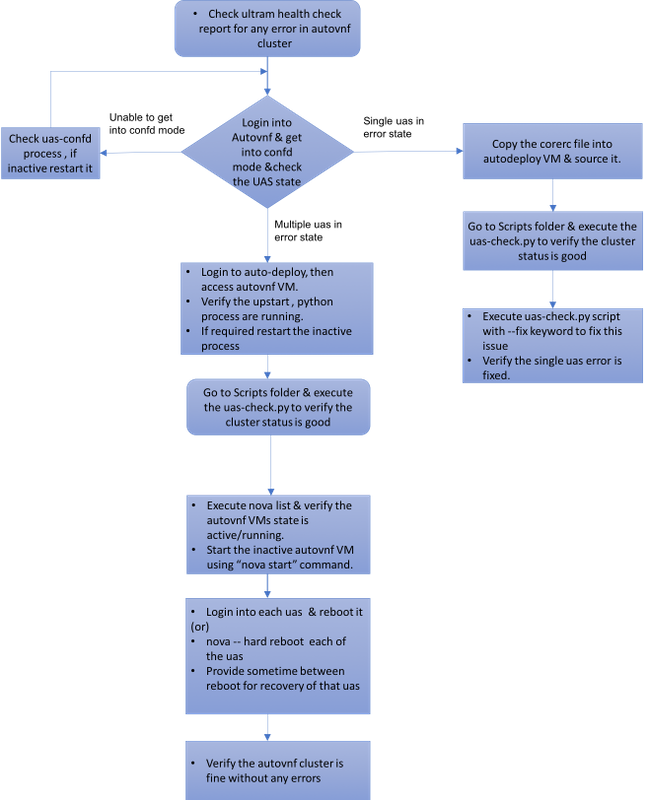
Case 1.UASクラスタの単一障害の回復
ステータスチェック
1. Ultra-M Managerは、Ultra-Mノードのヘルスチェックを実行します。 reports /var/log/cisco/ultram-health/ディレクトリに移動し、UASレポートをgrepします。
-
[stack@pod1-ospd ultram-health]$ more ultram_health_uas.report
---------------------------------------------------------------------------------------------------------
VNF ID | UAS Node | Status | Error Info, if any
---------------------------------------------------------------------------------------------------------
172.21.201.122 | autovnf | XXX | AutoVNF Cluster FAILED : Node: 172.16.180.12, Status: error, Role: NA
172.21.201.122 | vnf-em | :-) |
172.21.201.122 | esc | :-) |
---------------------------------------------------------------------------------------------------------
2. UASクラスタの予想されるステータスは、3つのUASすべてが稼働している図のようになります。
[stack@pod1-ospd ~]# ssh ubuntu@10.1.1.1
password:
ubuntu@autovnf1-uas:~$ ncs_cli -u admin -C
autovnf1-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
------------------------------------
172.16.180.3 alive CONFD-MASTER
172.16.180.7 alive CONFD-SLAVE
172.16.180.12 alive NA
UASに接続しようとするとConfdサーバに接続できない
1. 場合によっては、confdサーバに接続できません。
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ confd_cli -u admin -C
Failed to connect to server
2. uas-confdプロセスのステータスをチェックします。
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ sudo initctl status uas-confd
uas-confd stop/waiting
3. confdサーバが実行されていない場合は、サービスを再起動します。
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ sudo initctl start uas-confd
uas-confd start/running, process 7970
ubuntu@autovnf1-uas-0:/opt/cisco/usp/uas/manager$ confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 172.16.180.9 using ssh on autovnf1-uas-0
エラー状態からのUASの回復
1. クラスタ内の1つのAutoVNFに障害が発生した場合、UASクラスタはUASの1つをエラー状態として示します(UASクラスタ内の各UASのステータスがUASクラスタ内の各UASのステータスに応じて異なります)。
[stack@pod1-ospd ~]# ssh ubuntu@10.1.1.1
password:
ubuntu@autovnf1-uas:~$ ncs_cli -u admin -C
autovnf1-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
------------------------------------
172.16.180.3 alive CONFD-MASTER
172.16.180.7 alive CONFD-SLAVE
172.16.180.12 alive error
2. OSPDサーバの/home/stackからAutoDeployにcorercファイル(vnfのrcファイル)をコピーし、ソースにします。
3. uas-check.pyスクリプトを使用して、UAS/AutoVNFのステータスを確認します。autovnf1はAutoVNF名です。
ubuntu@auto-deploy-iso-590-uas-0:~$ /opt/cisco/usp/apps/auto-it/scripts/uas-check.py auto-vnf autovnf1
2017-11-17 14:52:20,186 - INFO: Check of AutoVNF cluster started
2017-11-17 14:52:22,172 - INFO: Found 2 AutoVNF instance(s), 3 expected
2017-11-17 14:52:22,172 - INFO: Instance 'autovnf1-uas-2' is missing
2017-11-17 14:52:22,172 - INFO: Check completed, AutoVNF cluster has recoverable errors
4. uas-check.pyスクリプトを使用してUASを回復し、—fixキーワードを追加します。
ubuntu@auto-deploy-iso-590-uas-0:~$ /opt/cisco/usp/apps/auto-it/scripts/uas-check.py auto-vnf autovnf1 --fix
2017-11-17 14:52:27,493 - INFO: Check of AutoVNF cluster started
2017-11-17 14:52:29,215 - INFO: Found 2 AutoVNF instance(s), 3 expected
2017-11-17 14:52:29,215 - INFO: Instance 'autovnf1-uas-2' is missing
2017-11-17 14:52:29,215 - INFO: Check completed, AutoVNF cluster has recoverable errors
2017-11-17 14:52:29,386 - INFO: Creating instance 'autovnf1-uas-2' and attaching volume 'autovnf1-uas-vol-2'
2017-11-17 14:52:47,600 - INFO: Created instance 'autovnf1-uas-2'
5. 新しく作成されたUASが機能しており、クラスタの一部であることがわかります。
autovnf1-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
------------------------------------
172.16.180.3 alive CONFD-MASTER
172.16.180.7 alive CONFD-SLAVE
172.16.180.13 alive NA
Case 2.3つのUAS(AutoVNF)はすべてエラー状態です
1. Ultra-M Managerは、Ultra-Mノードのヘルスチェックを実行します。
[stack@pod1-ospd ultram-health]$ more ultram_health_uas.report
---------------------------------------------------------------------------------------------------------
VNF ID | UAS Node | Status | Error Info, if any
---------------------------------------------------------------------------------------------------------
172.21.201.122 | autovnf | XXX | AutoVNF Cluster FAILED : Node: 172.16.180.12, Status: error, Role: NA,Node: 172.16.180.9, Status: error, Role: NA,Node: 172.16.180.10, Status: error, Role: NA
172.21.201.122 | vnf-em | :-) |
172.21.201.122 | esc | :-) |
---------------------------------------------------------------------------------------------------------
2. 出力に示されているように、Ultra-MマネージャはAutoVNFに障害があり、クラスタの3つのUASがすべてError状態であることを示しています。
uas-check.pyスクリプトによるUASの健全性の確認
1. Auto-Deployにログインし、AutoVNF UASにアクセスしてステータスを取得できるかどうかを確認します。
ubuntu@auto-deploy-iso-590-uas-0:~$ /opt/cisco/usp/apps/auto-it/scripts$ ./uas-check.py auto-vnf autovnf1 --os-tenant-name core
2017-12-05 11:41:09,834 - INFO: Check of AutoVNF cluster started
2017-12-05 11:41:11,342 - INFO: Found 3 ACTIVE AutoVNF instances
2017-12-05 11:41:11,343 - INFO: Check completed, AutoVNF cluster is fine
2. Auto-DeployからAutoVNFノードにセキュアシェル(SSH)で接続し、confdモードに入ります。show uasを使用してステータスを確認します。
ubuntu@auto-deploy-iso-590-uas-0:~$ ssh ubuntu@172.16.180.9
password:
autovnf1-uas-1#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.16.181.101
INSTANCE IP STATE ROLE
----------------------------
172.16.180.9 error NA
172.16.180.10 error NA
172.16.180.12 error NA
3. 3つのUASノードすべてでステータスを確認することをお勧めします。
OpenStackレベルでのVMの状態の確認
NovaリストでAutoVNF VMのステータスを確認します。必要に応じて、nova start を実行してシャットオフVMを開始します。
[stack@pod1-ospd ultram-health]$ nova list | grep autovnf
| 83870eed-b4e9-47b3-976d-cc3eddecf866 | autovnf1-uas-0 | ACTIVE | - | Running | orchestr=172.16.180.12; mgmt=172.16.181.6
| 201d9ce5-538c-42f7-a46c-fc8cdef1eabf | autovnf1-uas-1 | ACTIVE | - | Running | orchestr=172.16.180.10; mgmt=172.16.181.5
| 6c6d25cd-21b6-42b9-87ff-286220faa2ff | autovnf1-uas-2 | ACTIVE | - | Running | orchestr=172.16.180.9; mgmt=172.16.181.13
Zookeeperビューの確認
1. リーダーとしてのモードを確認するために飼育員の状態を確認します。
ubuntu@autovnf1-uas-0:/var/log/upstart$ /opt/cisco/usp/packages/zookeeper/current/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/cisco/usp/packages/zookeeper/current/bin/../conf/zoo.cfg
Mode: leader
2. 飼育員は通常は起きておくべきです。
AutoVNFのトラブルシューティング:プロセスとタスク
1. ノードのエラー状態の理由を特定します。AutoVNFを実行するには、次に示すように一連のプロセスを起動して実行する必要があります。
AutoVNF
uws-ae
uas-confd
cluster_manager
uas_manager
ubuntu@autovnf1-uas-0:~$ sudo initctl list | grep uas
uas-confd stop/waiting ====> this is not good, the uas-confd process is not running
uas_manager start/running, process 2143
root@autovnf1-uas-1:/home/ubuntu# sudo initctl list
....
uas-confd start/running, process 1780
....
autovnf start/running, process 1908
....
....
uws-ae start/running, process 1909
....
....
cluster_manager start/running, process 1827
....
.....
uas_manager start/running, process 1697
......
......
2. 次のPythonプロセスが実行されていることを確認します。
uas_manager.py
cluster_manager.py
usp_autovnf.py
root@autovnf1-uas-1:/home/ubuntu# ps -aef | grep pyth
root 1819 1697 0 Jun13 ? 00:00:50 python /opt/cisco/usp/uas/manager/uas_manager.py
root 1858 1827 0 Jun13 ? 00:09:21 python /opt/cisco/usp/uas/manager/cluster_manager.py
root 1908 1 0 Jun13 ? 00:01:00 python /opt/cisco/usp/uas/autovnf/usp_autovnf.py
root 25662 24750 0 13:16 pts/7 00:00:00 grep --color=auto pyth
3. 予期されたプロセスのいずれかがstart/running状態でない場合は、プロセスを再起動してステータスを確認します。それでもError状態が表示される場合は、次の項で説明する手順に従ってこの問題を解決してください。
エラー状態の複数のUASに対する修正
1. nova —ospdからhard reboot <vmの名前>。次のUASに進む前に、このVMのリカバリに少し時間を取ってください。すべてのUAS VMで実行します。
または
2. 各UASにログインし、sudo rebootを使用します。 リカバリが完了するまで待ってから、他のUAS VMに進みます。
トランザクションログの場合は、次の項目を確認します。
/var/log/upstart/autovnf.log
show logs xxx | display xml
これにより問題が修正され、UASがエラー状態から回復します。
1. ultram_health_checkレポートを使用して同じことを確認します。
[stack@pod1-ospd ultram-health]$ more ultram_health_uas.report
---------------------------------------------------------------------------------------------------------
VNF ID | UAS Node | Status | Error Info, if any
---------------------------------------------------------------------------------------------------------
172.21.201.122 | autovnf | :-) |
172.21.201.122 | vnf-em | :-) |
172.21.201.122 | esc | :-) |
---------------------------------------------------------------------------------------------------------
シスコ エンジニア提供
- パルテエバンラジャゴパルシスコアドバンスドサービス
- パドマラージラマヌードジャムシスコアドバンスドサービス
 フィードバック
フィードバックシスコに問い合わせ
- サポート ケースをオープン

- (シスコ サービス契約が必要です。)