はじめに
このドキュメントでは、RCMの/dev/vda3ファイルシステムの高いディスク領域使用率の問題をトラブルシューティングする方法について説明します。
前提条件
要件
以下について十分に理解しておくことをお勧めします。
- StarOS Control and User Plane Separation(CUPS)システムのアーキテクチャと管理
- ファイルシステムおよびディスクの使用状況を監視するための基本的なLinux/Unixコマンド。
使用するコンポーネント
このドキュメントの内容は、特定のソフトウェアやハードウェアのバージョンに限定されるものではありません。
このドキュメントの情報は、特定のラボ環境にあるデバイスに基づいて作成されました。このドキュメントで使用するすべてのデバイスは、クリアな(デフォルト)設定で作業を開始しています。本稼働中のネットワークでは、各コマンドによって起こる可能性がある影響を十分確認してください。
概要
コントロールプレーンとユーザプレーンの分離(CUPS)を使用したCisco Ultra Packet Core(UPC)の導入では、冗長コントロールマネージャ(RCM)がコントロールプレーンの運用と管理において重要な役割を果たします。ロギング、モニタリング、およびサブスクライバセッション管理を円滑に機能させるには、RCMノードでファイルシステムを安定して使用することが重要です。
ルートファイルシステム(/dev/vda3)でディスク領域の使用率が高いと、システムが不安定になったり、ログの書き込みに失敗したり、チェックを外した状態でサービスが再起動したりする可能性があります。この記事では、RCMノードでの高いディスク使用率に対処するための分析、トラブルシューティングの手順、および予防策について説明します。
分析と観察
監視中、RCMノードのルートファイルシステムでの使用率が72 %に達していることがわかりました。
ディスク使用率のスナップショット
df -kh
Filesystem Size Used Avail Use% Mounted on
tmpfs 6.3G 9.7M 6.3G 1% /run
/dev/vda3 39G 27G 11G 72% /
tmpfs 32G 4.0K 32G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/vda2 488M 48K 452M 1% /var/tmp
/dev/vda1 488M 76K 452M 1% /tmp
さらに調査すると、/var/log/journal/の下のジャーナルログが大幅に増加していることが判明しました。7月だけで生成されるログの容量は約3 GBです。
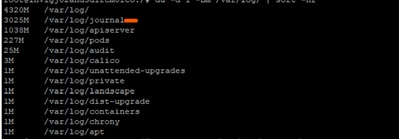
トラブルシューティングプロセス
ディスク使用率を制御するために、必要な変更実装手順が適用されました。
ステップ1: Journalctl Vacuumを使用して古いログをクリーンアップします
過去2週間のログのみを保持:
sudo journalctl --vacuum-time=2weeks
または、ジャーナルのサイズを制限します(たとえば、600 MBのみを保持します)。
sudo journalctl --vacuum-size=600M
ステップ2:将来の防止のためにジャーナリング保持を設定します
ジャーナリング設定の編集:
vi /etc/systemd/journald.conf
パラメータの追加/変更:
MaxRetentionSec=2week
設定を適用します。
sudo systemctl restart systemd-journald
オプションのステップ3:再起動エラーの解決
ステップ2でsystemd-journaldサービスを再起動するときに、関連するエラーが発生する場合があります。
Error : Failed to allocate directory watch: Too many open files
-
systemd-journald はinotifyを使用して、ログディレクトリの変更を監視します。
-
watchまたはmonitorはそれぞれ、特定のカーネル制限に対するカウントを設定します。
問題のあるRCMで定義されている現在の制限は次のとおりです。
cat /proc/sys/fs/inotify/max_user_watches
501120
cat /proc/sys/fs/inotify/max_user_instances
128
ulimit -n
1024
収集した出力から、次の内容を確認します。
- 最大識別腕時計: 501120
- 最大inotify インスタンス数:128
journaldのオープンファイル記述子の制限: 1024
出力値の制限のいずれか(またはすべて)がヒットし、エラーが発生した可能性があります。そこで、現在使用されている値を収集し、収集した出力制限と比較しました。
sudo lsof -p $(pidof systemd-journald) | wc -l
65
echo "Root inotify instances: $(sudo find /proc/*/fd -user root -type l -lname 'anon_inode:inotify' 2>/dev/null | wc -l) / $(cat /proc/sys/fs/inotify/max_user_instances)"
Root inotify instances: 126 / 128
-
現在のinotifyインスタンス数:126
-
現在開いているファイル記述子: 65
128個の許可されたinotifyインスタンスのうち126個をルートがすでに使用しているようです。 そのため、journaldの再起動時には、新しいinotifyインスタンスを作成する余地がほとんどなくなります。
このエラーを解決するには、max_user_instancesの値を増やしてからサービスを再起動します。
# Temporarily increase the limit (until next reboot)
echo 256 > /proc/sys/fs/inotify/max_user_instances
sudo systemctl restart systemd-journald
# Temporarily increase the limit (until next reboot)
echo 256 > /proc/sys/fs/inotify/max_user_instances
sudo systemctl restart systemd-journald
変更後の検証
変更を適用すると、ディスク使用率が61 %に下がり、ノードが通常の動作状態に復元されました。
df -kh
Filesystem Size Used Avail Use% Mounted on
tmpfs 6.3G 9.7M 6.3G 1% /run
/dev/vda3 39G 23G 15G 61% /
tmpfs 32G 4.0K 32G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/vda2 488M 48K 452M 1% /var/tmp
/dev/vda1 488M 76K 452M 1% /tmp
推奨事項
-
導入環境内のすべてのRCMノードに同じ設定を実装し、安全な制限内でディスクの使用率を維持します。
-
ライブトラフィックへの影響を避けるために、変更を実行する前に必ずターゲットRCMをスタンバイモードにします。
-
/dev/vda3使用率とjournaldログの増加を、予防的なシステム健全性チェックの一環として定期的に監視します。
 フィードバック
フィードバック