エラーコード"424-Geo-replication Checksum Mismatch";を使用したラック間レプリケーション障害のトラブルシューティング
ダウンロード オプション
偏向のない言語
この製品のドキュメントセットは、偏向のない言語を使用するように配慮されています。このドキュメントセットでの偏向のない言語とは、年齢、障害、性別、人種的アイデンティティ、民族的アイデンティティ、性的指向、社会経済的地位、およびインターセクショナリティに基づく差別を意味しない言語として定義されています。製品ソフトウェアのユーザインターフェイスにハードコードされている言語、RFP のドキュメントに基づいて使用されている言語、または参照されているサードパーティ製品で使用されている言語によりドキュメントに例外が存在する場合があります。シスコのインクルーシブ ランゲージの取り組みの詳細は、こちらをご覧ください。
翻訳について
シスコは世界中のユーザにそれぞれの言語でサポート コンテンツを提供するために、機械と人による翻訳を組み合わせて、本ドキュメントを翻訳しています。ただし、最高度の機械翻訳であっても、専門家による翻訳のような正確性は確保されません。シスコは、これら翻訳の正確性について法的責任を負いません。原典である英語版(リンクからアクセス可能)もあわせて参照することを推奨します。
内容
はじめに
このドキュメントでは、ローカルラックとリモートラック間のgeoレプリケーションチェックサム(GEO)の不一致をトラブルシューティングするためのさまざまな調査方法について説明します。
前提条件
要 件
次の項目に関する知識があることが推奨されます。
- セッション管理機能(SMF)の地理的冗長性
- SMF
- 伝送制御プロトコル(TCP)接続の終了
使用するコンポーネント
このドキュメントの内容は、特定のソフトウェアやハードウェアのバージョンに限定されるものではありません。
このドキュメントの情報は、特定のラボ環境にあるデバイスに基づいて作成されたものです。このドキュメントで使用するすべてのデバイスは、クリアな(デフォルト)設定で作業を開始しています。本稼働中のネットワークでは、各コマンドによって起こる可能性がある影響を十分確認してください。
バックグラウンド情報
SMFの地理的冗長性とは何ですか。
-
SMFは、アクティブ – アクティブモードで地理的冗長性(Geo)をサポートします。
-
GRセットアップは、スタンバイラックへの
etcd/cacheデータのレプリケーションも行います。 -
SMFは、プライマリ/スタンバイの冗長性をサポートします。プライマリ/スタンバイ冗長性では、プライマリからスタンバイインスタンスにデータが複製されます。
-
プライマリ・インスタンスに障害が発生すると、スタンバイ・インスタンスがプライマリになり、オペレーションを引き継ぎます。
-
GRを実現するには、2つのプライマリ/スタンバイペアを設定します。各サイトでトラフィックをアクティブに処理し、スタンバイはリモートサイトのバックアップとして機能します。
Geoレプリケーションポッド
-
geoレプリケーションポッドは、ラック/サイト間の通信およびラック内のPOD/BFDの監視に導入されています。
-
各ラック/サイトで2つのGR-PODインスタンスを実行
-
2つのGR PODがアクティブ/スタンバイモードで機能
-
GR PODはProtoノード/VMで生成されます。
-
GR PODは2つの仮想IPアドレス(VIP)を使用します
-
内部VIP:ポッド間通信(ラック内)
-
ラック/サイト間のGR PODコミュニケーション用の外部VIP
-
GR POD用に設定されたVIPは、Protoノード/VMのいずれかでアクティブにできます。
-
アクティブGR PODが再起動すると、VIPは別のProtoノード/VMに切り替わり、別のProtoノード/VMで実行されているスタンバイGR PODはアクティブになります
GRポッドリファレンスの設定:
smf# show running-config instance instance-id 1 endpoint geo
Thu Oct 20 06:25:25.319 UTC+00:00
instance instance-id 1
endpoint geo
replicas 1
nodes 2
interface geo-internal
vip-ip a.b.c.d vip-port 7001
exit
interface geo-external
vip-ip Y.Y.Y.Y vip-port 7002
exit
exit
exit
アクティブなGeo PodとスタンバイGeo Podの特定
アクティブなGeoポッドを特定するには、Geoポッドログでエラーまたはイベントを確認する必要があります。
アクティブポッド:
user@smf-ims-master-1:~$ kubectl logs georeplication-pod-0 -n smf-smfix1|tail -3
[ERROR] [grcacachepod.go:339] [gr_deferred_sync.application.app] Periodic Sync: Total time taken to sync IPAM cache pod data: 500.563723ms”
[ERROR] [GeoAdminStreamClient.go:276] [gr_pod.geo_admin_client.app] no one waiting for received response for txnID:CP0XXXOKCP0XXX-SMF-IMS-smfix1111163550 of host=geo-admin-pod2
スタンバイポッド:
user@cp0xxx-smf-ims-master-1:~$ kubectl logs georeplication-pod-1 -n smf-smfix1|tail -3
[ERROR] [gr_pod.geo_replication_client_stream] Counters => not an active geo pod
[ERROR] [gr_pod.geo_replication_client_stream] Counters => not an active geo pod
[ERROR] [gr_pod.geo_replication_client_stream] Counters => not an active geo pod
GR PODの機能
GRポッドがサイト全体でETCDおよびキャッシュポッドデータを複製
ETCDおよびキャッシュポッドデータのレプリケーションの詳細を表示するには、CLIを使用します。
[cp0xxx-smf-ims/smfix1] smf# show georeplication checksum instance-id 1
Thu Oct 20 07:11:52.409 UTC+00:00
checksum-details
-- ---- --------
ID Type Checksum
-- ---- -------
1 ETCD 1666249907
IPAM CACHE 1666249907
NRFMgmt CACHE 1666249907
ETCDでのサイトローカルインスタンスロールの管理
[ERROR] [gr_pod.gradmin] updateEntryInEtcd: Updating etcd entries for keys : Instance.2, with role as PRIMARY
[ERROR] [gr_pod.gradmin] updateEntryInEtcd: Updating etcd entries for keys : Instance.1, with role as STANDBY
ローカルサイトのステータスのモニタ(PODステータス/BFDステータス)
[cp0xxx-smf-ims/smfix1] smf# show running-config geomonitor podmonitor pods smf-service
Thu Oct 20 07:36:41.280 UTC+00:00
geomonitor podmonitor pods smf-service
retryCount 2
retryInterval 900
retryFailOverInterval 500
failedReplicaPercent 60
サイトロール
PRIMARY:サイトは準備が整っており、特定のインスタンスのトラフィックをアクティブに取得します。
STANDBY:サイトはスタンバイ状態で、トラフィックを受け入れる準備ができていますが、特定のインスタンスのトラフィックを受け入れません。
STANDBY_ERROR:サイトに問題があり、アクティブではなく、特定のインスタンスのトラフィックを受け入れる準備ができていません。
FAILOVER_INIT:サイトはフェールオーバーを開始し、アプリケーションがアクティビティを完了するためにトラフィックのバッファタイムを2秒にする状態ではありません。
FAILOVER_COMPLETE:サイトはフェールオーバーを完了し、特定のインスタンスのフェールオーバーについてピアサイトに通知しようとしました。バッファ時間は2秒です。
FAILBACK_STARTED:特定のインスタンスに対して、リモートサイトからの遅延によって手動フェールオーバーがトリガーされます。

注:キャッシュ/ETCDレプリケーションとCDLレプリケーションはすべてのロールでも実行されます。GRリンクがダウンするか、定期的なハートビートに障害が発生すると、GRトリガーが中断されます。
GRトリガー
ラック上のGRインスタンスロールを確認するCLI
Show role instance id 1
Show role instance id 2
CLIを使用してロールをスタンバイエラーからスタンバイエラーにリセットする
Geo reset-role instance-id <1/2> role standby
CLIからスタンバイロールへの切り替えエラー
Geo switch-role instance-id <1/2> role standby failback-interval 0
CLIでロールをスタンバイからプライマリに切り替え
このスイッチロールを開始するには、インスタンスの1つをプライマリとするラックからCLIをトリガーする必要があります。
Geo switch-role instance-id <1/2> role standby failback-interval 0
注:晴れの日のシナリオ:Rack1-Instance1-Primary、Instance2-Standby、Rack2-Instance1-StandBy、Instance2-Primary。
雨の日のシナリオ:Rack1-Instance 1およびInstance 2-Primary、Rack2-Instance 1およびInstance 2-StandBy。
TCP接続の終了
TCPプロトコルはコネクション型プロトコルです。つまり、両端のアプリケーションプログラムがメッセージ交換を終了するまで、接続が確立され、維持されます。TCPはインターネットプロトコル(IP)で動作します。
TCPハンドシェイクは、3ウェイハンドシェイクとも呼ばれます。クライアントマシンからサーバマシンへの接続が開始されると、クライアントとサーバはデータを送信する前にSYNパケットとACKパケットを交換します。
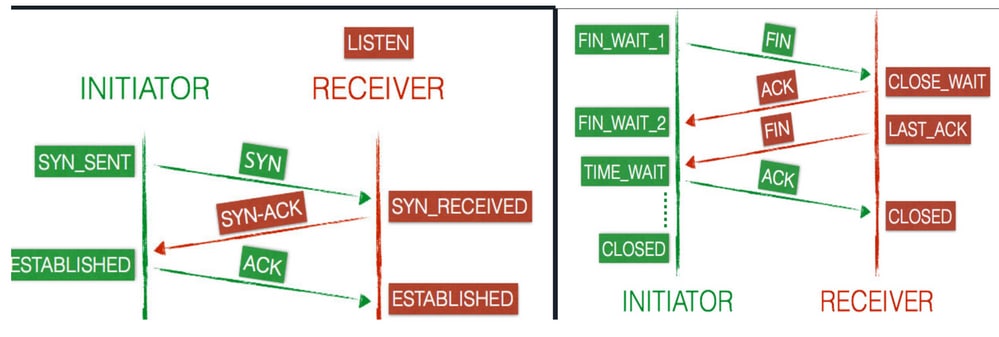 Transmission Control Protocol(TCP;伝送制御プロトコル):クライアントとサーバの接続状態
Transmission Control Protocol(TCP;伝送制御プロトコル):クライアントとサーバの接続状態
接続は、そのライフタイム全体を通じて一連の状態を遷移します。状態は、LISTEN、SYN-SENT、SYN-RECEIVED、ESTABLISHED、FIN-WAIT-1、FIN-WAIT-2、CLOSE-WAIT、CLOSING、LAST-ACK、TIME-WAIT、および架空のCLOSEDです。
- 新しいTCP接続が開かれると、クライアント(イニシエータ)はサーバ(レシーバ)に
SYNパケットを送信し、その状態をSYN-SENTに更新します。 - 次にサーバはクライアントに応答として
SYN-ACKを送信し、クライアントは接続状態をSYN-RECEIVEDに変更します。
- クライアントは
ACKで応答し、接続は両方のエンドポイントでESTABLISHEDとしてマークされます。これで、クライアントとサーバはデータを転送する準備が整いました。
- クライアントはサーバに
FINパケットを送信し、その状態をFIN-WAIT-1に更新します。 - サーバはクライアントから終了要求を受信し、
ACKで応答します。応答の後、サーバはCLOSE-WAIT状態になります。 - クライアントはサーバから応答を受信するとすぐに、
FIN-WAIT-2状態に移行します。 - サーバはまだ
CLOSE-WAIT状態で、独立してFINとともに動作し、FINによって状態がLAST-ACKに更新されます。 - ここで、クライアントは終了要求を受信し、
ACKで応答します。これにより、TIME-WAIT状態になります。 - サーバが終了し、接続がすぐに
CLOSEDに設定されます。 - クライアントは、接続が
CLOSEDになるまでの最大4分間、TIME-WAIT状態に留まります。
問題
シナリオ 1. インスタンスId 1のGeoレプリケーションチェックサムにIPAMキャッシュがあり、NRFMgmtキャッシュチェックサムが一致しません
smfix1/smfix2geoレプリケーションステータスが失敗しました(リモートサイトへのラック間レプリケーションが失敗しました)。
エラー:管理コマンドがコード424で失敗しました[pod internal-gr-pod-1, URL http://X.X.0.0:15290/commands]。メッセージ障害:レプリケーションチェックサムが一致しません。
この問題は、8月23日の00:36:19に「Inter rack replication failed」として観測されました。
From CEE alerts:
Inter_Rack_Replication 9ca45362a049 critical 08-23T00:36:19 System
Inter rack replication to Remote Site failed
このCLI出力では、instance-id 1にIP Address Management(IPAM)とNRFキャッシュのチェックサム不一致があることが確認できます。
[cp0xxx-smf-ims/smfix1] smf# show georeplication checksum instance-id 1
Mon Sep 5 08:38:27.762 UTC+00:00
checksum-details
-- --- --------
ID Type Checksum
-- ---- --------
1 ETCD 1662367102
IPAM CACHE 1662367102
NRFMgmtCACHE 1662367102
[cp0xxx-smf-ims/smfix2] smf# show georeplication checksum instance-id 1
Mon Sep 5 08:38:30.767 UTC+00:00
checksum-details
-- ---- --------
ID Type Checksum
-- ---- --------
1 ETCD 1662367102
IPAM CACHE 1661214831
NRFMgmtCACHE 1661214831
シナリオ 2. インスタンスId 2のGeoレプリケーションチェックサムのETCDチェックサムが一致しません
[cp0xxx-smf-ims/smfix1] smf# show georeplication checksum instance-id 2
Mon Sep 5 08:38:37.852 UTC+00:00
checksum-details
-- ---- --------
ID Type Checksum
-- ---- --------
2 ETCD 1661214828
IPAM CACHE 1662367107
NRFMgmtCACHE 1662367107
[cp0xxx-smf-ims/smfix2] smf# show georeplication checksum instance-id 2
Mon Sep 5 08:38:39.118 UTC+00:00
checksum-details
-- ---- -------
ID Type Checksum
-- ---- --------
2 ETCD 1662367107
IPAM CACHE 1662367107
NRFMgmtCACHE 1662367107
シナリオ 3. リモートサイトでのTCP接続確立の失敗
Rack1-smfix1-logs:
GRポッドログから、「Update cache pod checkpoint is stopped, immediate Replication failed and No remote host is available.」が観察できます。
2022/08/23 00:34:00.035 [ERROR] [grreplicationclient.go:201] [gr_pod.geo_replication_client_stream.app] HandleImmediateReplication failed: [RPCNoRemoteHostAvailable] No remote host available for this request
2022/08/23 00:34:02.086 [ERROR] [grreplicationclient.go:466] [gr_pod.geo_replication_client_stream.app] Stream disconnected, closing logQueueCounter=0xc0093b08b0
2022/08/23 00:34:04.124 [ERROR] [GeoAdminStreamClient.go:215] [gr_pod.geo_admin_client.app] ADMIN(geo-admin-pod2) : exit outgoing request loop stream closed
2022/08/23 00:34:43.623 [ERROR] [grreplicationclient.go:270] [gr_pod.geo_replication_client_stream.app] Update etcd checkpointing stopped for grinstance: 1
Rack2-smfix2-logs:
GRポッドログから、Stream disconnectedエラーおよびCACHEチェックサムの違いが予想よりも多いことが確認できます。
2022/08/23 00:34:06.497 [ERROR] [grreplicationserver.go:62] [gr_pod.geo_replication_server_stream.app] Stream disconnected, closing logQueueCounter=0xc001b85d08
2022/08/23 00:34:06.497 [ERROR] [grreplicationserver.go:314] [gr_pod.geo_replication_server_stream.app] handleCachePodSyncRequests : Stream closed of connection=0xc002ee08f0
2022/08/23 00:34:56.751 [ERROR] [grpodcommands.go:455] [gr_pod.cli_command.app] compareChecksumData: CACHE checksum difference is more then expected, local checksum [1661214831] remote checksum [1661214892]
2022/08/23 00:34:56.678 [ERROR] [etcdAuditReplHandler.go:196] [gr_pod.application.app] SyncETCDData periodic sync : For ETCD [C.GR.1.] key, the remote site data size is: [10833]
2022/08/23 00:36:56.757 [ERROR] [grpodcommands.go:455] [gr_pod.cli_command.app] compareChecksumData: CACHE checksum difference is more then expected, local checksum [1661214831] remote checksum [1661215012]
シナリオ 4.マスターノードをホストするサーバで発生するDIMMエラー
ストリームの接続解除エラーとほぼ同時に、geo-replication-pod-0をホストするマスター1ノードでECCエラーが発生します。
CP0XXX-Server9-02# scope sel
CP0XXX-Server9-02 /sel # show entries
Time Severity Description
----------------------- ------------- ----------------------------------------
2022-08-23 00:33:59 UTC Informational "DDR4_P1_E1_ECC: Memory sensor, read 1 correctable ECC errors on CPU1 DIMM E1 was asserted"
2022-08-22 22:59:45 UTC Informational "DDR4_P1_E1_ECC: Memory sensor, read 1 correctable ECC errors on CPU1 DIMM E1 was asserted"
- Rack1のGeo-replication-podとRack2のGeo-replication-podの間の通信が切断されています。
-
マスターノードの1つでDIMMエラーが発生し、Rack1とRack2の間のストリーム接続がダウンしました。
-
Rack1からGeo-replication-podはRack2に要求を複製または送信できず、エラー「Remote Host not available」が表示されます。
-
7002ポートのRack1およびRack2でのnetstatコマンドの出力から、Rack1ソケットがFIN_WAIT1状態でスタックしており、Rack2ソケットがSYN_RECV状態でスタックしていることがわかります。
-
サーバ側、つまりRack2では、ソケットがSYNC_RECV状態のままになり、新しく作成された接続もSYNC_RECV状態になり、相互に通信できなくなります。
-
接続はSYN_RECV状態です。これは、カーネルがポート(つまりリスニングモード)のSYNパケットを受信したが、相手側がACKで応答しなかったためです。
smfix2-Master-2にはgeo外部VIP (Y.Y.Y.Y:7002)がインストールされていますが、リモートホスト(SMFIX1)のTCP接続状態がESTABLISHED状態ではなくSYN_RECV状態でスタックしています。a.b.c.dとa.b.c.eは、smfix1 (Rack1)のMaster-1と2 IPです。
user@cp0xxx-smf-ims-master-2:~$ netstat -anp | grep 7002
tcp 0 0 Y.Y.Y.Y:7002 0.0.0.0:* LISTEN -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.e:35542 SYN_RECV -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.d:47046 SYN_RECV -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.e:36248 SYN_RECV -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.d:42686 SYN_RECV -
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.e:38248 SYN_RECV -
リモートピアのsmfix1(Rack1)上の外部Geo VIP TCP接続ステータスがFIN-WAIT1状態である。
user@cp0xxx-smf-ims-master-1:~$ netstat -anp | grep 7002
tcp 0 0 a.b.c.d 0.0.0.0:* LISTEN -
tcp 0 1 a.b.c.d:60866 Y.Y.Y.Y:7002 FIN_WAIT1 -
tcp 0 1 a.b.c.d:52274 Y.Y.Y.Y:7002 FIN_WAIT1 -
tcp 0 1 a.b.c.d:59674 Y.Y.Y.Y:7002 FIN_WAIT1 -
tcp 0 1 a.b.c.d:47926 Y.Y.Y.Y:7002 FIN_WAIT1 -
ソリューション
ラック1:
-
まず、スタンバイGeoポッドを削除し、ポッドが回復するまで待ってから、アクティブGeoポッドを削除します。 マスターVIPにログインし、GRポッドを削除します。
kubectl delete pod-n
ラック2:
- まず、スタンバイGeoポッドを削除し、ポッドが回復するまで待ってから、アクティブGeoポッドを削除します。
-
CLIからGeoレプリケーションステータスを確認し、Geoポッドの削除をポストします。
show georeplication-status
- Rack1とRack2でGeoポッドの削除を行うと、外部Geo VIP IP:TCPポートがESTABLISHED状態に移行することがわかります。
- GeoRepliacationのステータスが「Pass」です。
- ラック間のレプリケーションステータスでチェックサムの不一致は見られない。
smfix2 (ラック2):
user@cp0xxx-smf-ims-master-1:~$ sudo netstat -anp | grep 7002 | grep -v aa
tcp 0 0 Y.Y.Y.Y:7002 0.0.0.0:* LISTEN 36854
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.d:46402 ESTABLISHED 36854/grpod
tcp 0 0 Y.Y.Y.Y:7002 1a.b.c.e:54708 ESTABLISHED 36854/grpod
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.d:55152 ESTABLISHED 36854/grpod
tcp 0 0 Y.Y.Y.Y:7002 a.b.c.e:46530 ESTABLISHED 36854/grpod
tcp 0 0 10.59.0.0:7002 10.59.0.0:46532 ESTABLISHED 36854/grpod
smfix1 (ラック1):
user@cp0xxx-smf-ims-master-1:~$ sudo netstat -anp | grep 7002 | grep -v aa
tcp 0 0 a.b.c.d 0.0.0.0:* LISTEN 53932/grpod
tcp 0 0 a.b.c.d:46530 Y.Y.Y.Y:7002 ESTABLISHED 53932/grpod
tcp 0 0 a.b.c.d:46402 Y.Y.Y.Y:7002 ESTABLISHED 53932/grpod
tcp 0 17 a.b.c.d:46532 Y.Y.Y.Y:7002 ESTABLISHED 53932/grpod
2.geoレプリケーションのステータス:
[okcp0xx-smf-ims/smfix1] smf# show georeplication-status
result "pass"
[okcp0xx-smf-ims/smfix2] smf# show georeplication-status
result "pass"
更新履歴
| 改定 | 発行日 | コメント |
|---|---|---|
1.0 |
05-Dec-2022
|
初版 |
シスコ エンジニア提供
- マナサGカンビCisco TACエンジニア
- クリシュナキショレD Vシスコのテクニカルリーダー
 フィードバック
フィードバックシスコに問い合わせ
- サポート ケースをオープン

- (シスコ サービス契約が必要です。)