はじめに
このドキュメントでは、コールフロー関連の問題をトラブルシューティングするために、Cisco SMFでGrafana/Prometheusを使用してカスタムクエリを作成する方法について説明します。
略語
| SMF |
セッション管理機能 |
| UDM |
統合データ管理 |
| AMF |
アクセスおよびモビリティ機能 |
| PDU |
プロトコル データ ユニット |
SMFコールフローの問題をトラブルシューティングするためにクエリーをカスタマイズする理由
組み込みのダッシュボードは、重要なKPIとノードの健全性統計に関する優れたグラフを提供しますが、PromQLクエリとgrafanaの潜在能力を最大限に活用して通常の問題のシナリオをトラブルシューティングするには、カスタムクエリが重要な役割を果たします。カスタムpromqlクエリとグラフにより、特定の障害を特定するための汎用性と利便性が向上します。
組み込みダッシュボードの利点:
- Grafanaは、SMF統計情報を参照するための使いやすいグラフィカルインターフェイスを提供します。
- ほとんどのKPIと統計を確認できる組み込みのGrafanaダッシュボードがあります。
例:
5G SMFダッシュボード
- 5G PDU作成失敗/成功率
- 4G PDN作成失敗/成功率
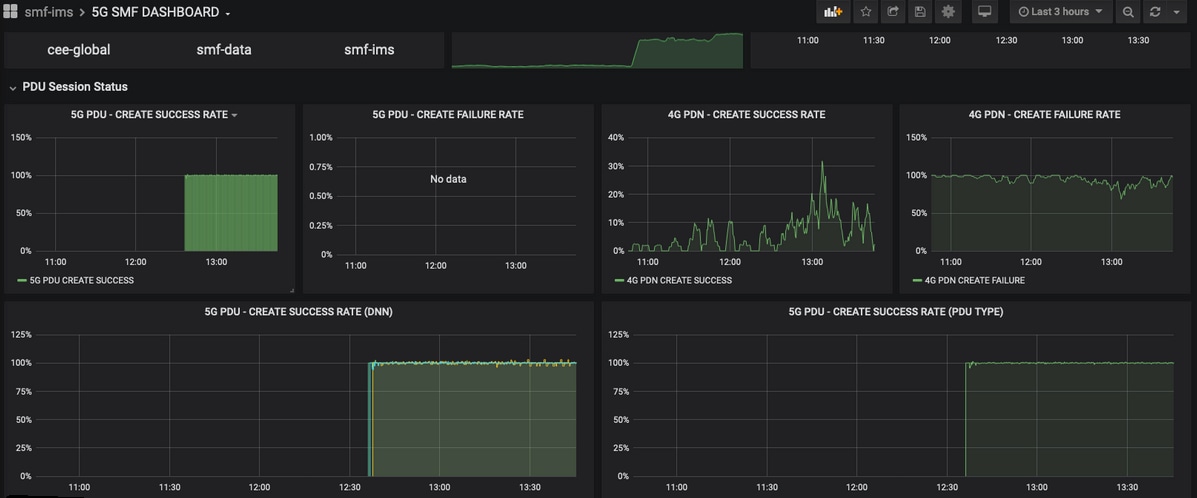

- プロシージャごとの失敗原因の割合。
- 切断理由の割合。
- HTTP要求および対応する応答原因割合。
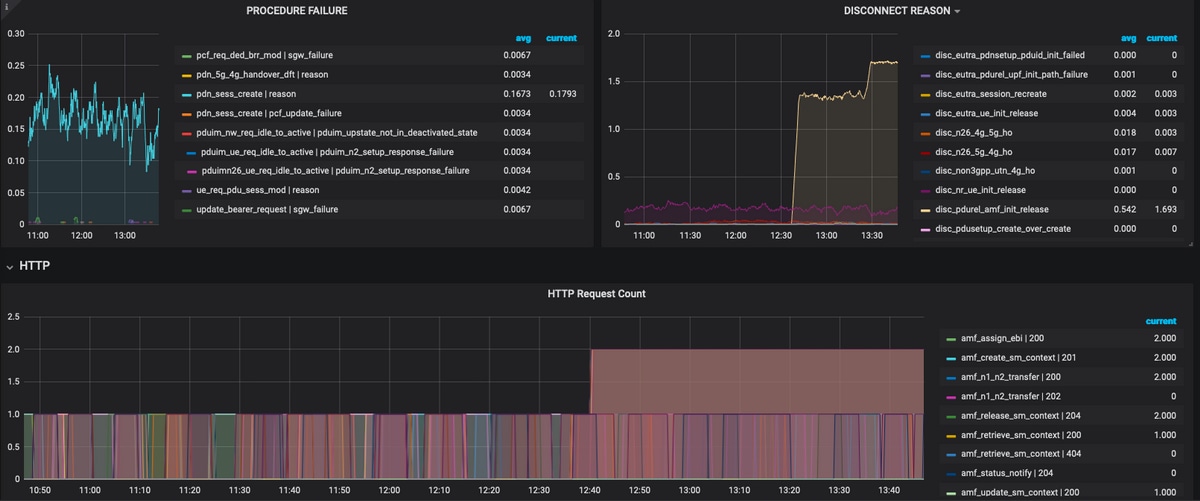
さらにトラブルシューティングを行うには:
- 利用可能なダッシュボードとパネルは、主にパーセンテージとKPIに関するものです。さらに調査する際には、この障害を引き起こした特定のシナリオとメッセージを特定するために、詳細を確認する必要がある場合があります。
- 特定の正規表現を使用してカスタマイズされたクエリは、これらの統計情報を関連付け、トリガーを切り分けるのに役立ちます。
- これらのクエリは、SMF grafanaまたはtac-debugパッケージのmetrics dumpを使用したoffline grafanaでグラフをプロットするために使用できます。
- さまざまなサービスに関連付けられているメトリックの範囲を使用できます。また、ラベルキー/値ペアを使用してフィルタリングし、特定のシナリオをトラブルシューティングすることもできます。
GrafanaおよびPrometheus
グラファナ
「Grafanaはオープンソースの可視化および分析ソフトウェアです。どこに保存されているかに関係なく、メトリックのクエリ、視覚化、アラートのオン、および調査を行うことができます。」
Cisco SMFは、組み込みのgrafanaを使用して、アプリケーションコンテナからのリアルタイム統計データをプロットします。
プロメテウス
Prometheusは、メトリック名とキー/値のペアで識別される時系列データを含む多次元データモデルと、これらのデータにアクセスするためのPromQLという柔軟なクエリ言語を提供します。
Prometheusは、マイクロサービスから統計情報やカウンタを収集するために使用されます。
メトリック:時系列統計の識別子。
ラベル:メトリックはラベルで構成されます。基本的にキーと値のペアはどれですか。特定のメトリックのラベルの組合せにより、時系列データの特定のインスタンスが識別されます
例: 
緑色で強調表示されているメトリック「smf_service_stats」には、黄色で強調表示されている多数のラベルがあります。
これらのラベルキー/値ペアを使用して、特定のデータ系列を選択できます。
PromQLクエリ
Prometheusは、PromQLと呼ばれる機能クエリ言語を提供しています。組み込み関数はPromQlで利用可能です(例えばSum(), by(), count()など)を使用すると、グラフ形式または表形式で特定の時系列データを選択できます。
例:
sum(smf_service_stats{status="success"}) by (procedure_type)
この例では、smf_service_statsメトリックからprocedure_typeによってデータを選択します。ここで、status = "success"
sum(次元の合計を計算)
by(出力をラベル別にグループ化します)
Labelキー/値ペアを使用してsum内でフィルタを使用すると、グラフをさらにフィルタできます。
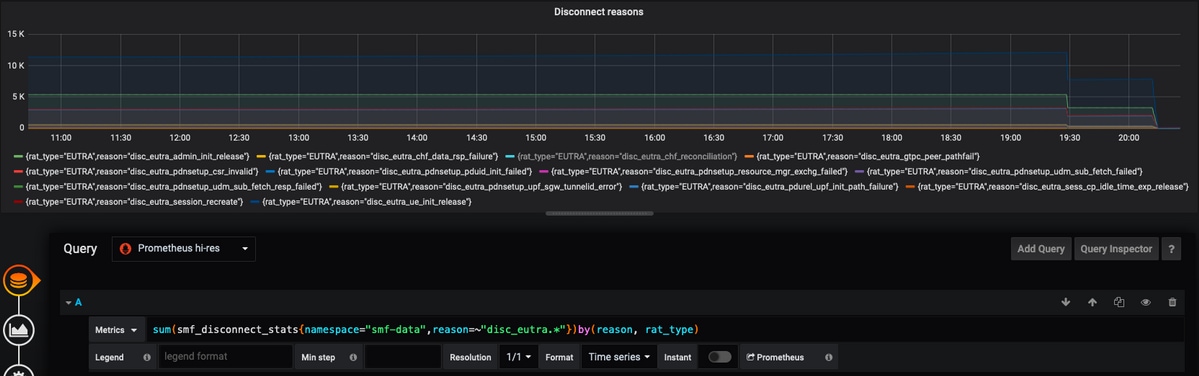
例 1:
sum(smf_disconnect_stats{namespace="smf-data",reason=~"disc_eutra.*"})by(reason, rat_type)
ここで名前空間smf-dataが選択され、理由としてdisk_eutraで始まるすべての切断理由(すなわち、4G切断理由)が考慮されます。
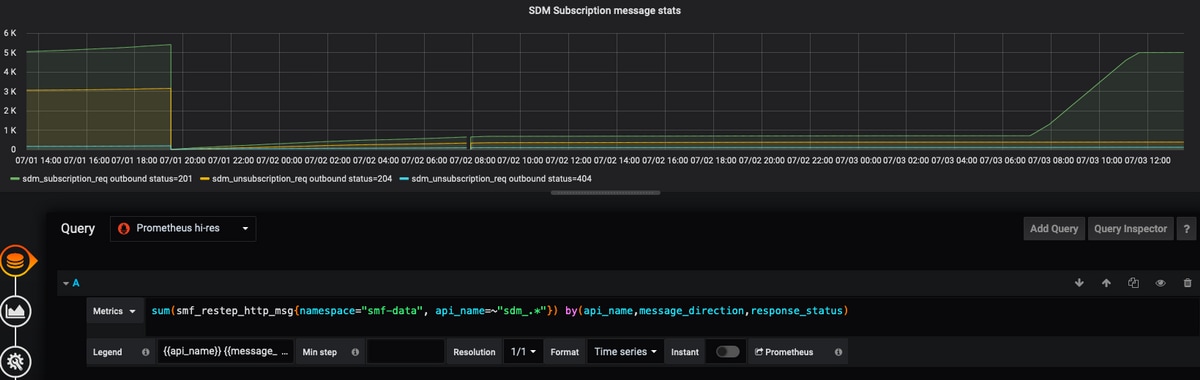
例 2:
sum(smf_restep_http_msg{namespace="smf-data", api_name=~"sdm_.*"}) by(api_name,message_direction,response_status,response_cause)
このクエリは、SMF - UDM sdm-subscriptionメッセージを応答原因とともに出力します。
ダッシュボードとパネルの作成方法
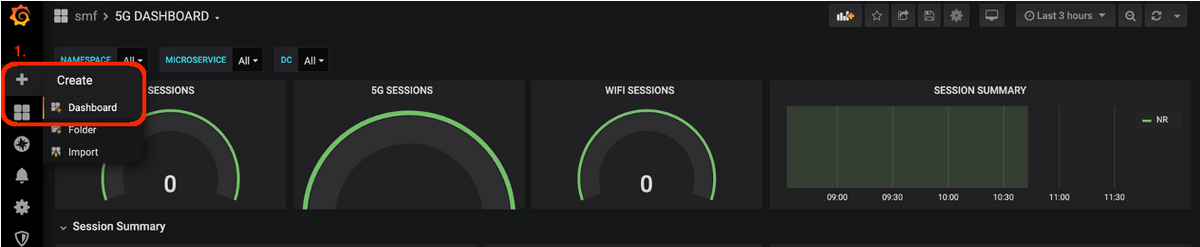
新しいダッシュボードを追加します。
ステップ 1:次の図に示すように、Create > Dashboardの順に移動します。
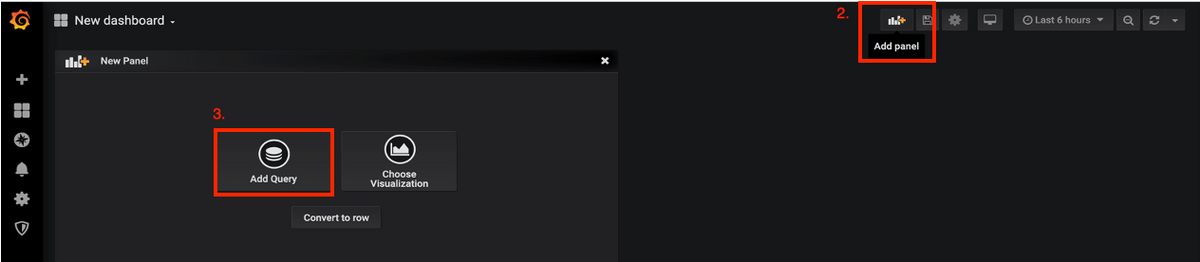
New Panelを追加するには、Add Queryを使用します。
ステップ 2:新しいパネルを追加するには、上部のAdd Panelオプションに移動します。
ステップ 3:Add Queryボタンを選択します。
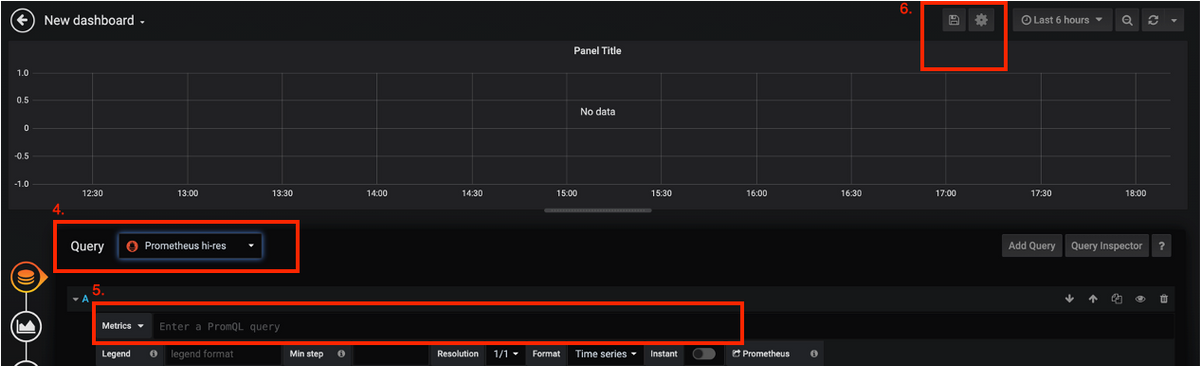
Query Type- Prometheus hi-resを選択します。
ステップ 4:QueryドロップダウンリストからPrometheus hi-resオプションを選択します。
ステップ 5:次に、指定されたボックスにpromqlクエリを追加します。
手順 6:パネルを保存します。
例:カスタマイズされたクエリとグラフを使用したトラブルシューティング
PDUセッション確立の失敗 – N1N2応答障害
ステップ 1:KPI Dip Observation」を参照し、PDUセッションの作成エラーを特定します。

Query: sum by (procedure_type, pdu_type, status, reason) (smf_service_stats{namespace="smf",procedure_type="pdu_sess_create"})
ステップ2:障害の原因は「n1n2_transfer_failure_rsp_code」です。接続解除の理由を確認します。

Query: sum(smf_disconnect_stats{namespace=”smf"}) by (reason)
ステップ 3:切断理由「disk_pdusetup_n1n2_transfer_rsp_failure」は、AMFピアからの否定応答を示しています。SMFとAMFの相互作用はHTTPサービスベースのインターフェイスを介して行われるため、HTTP統計情報をさらに調べる必要があります(メトリック:smf_restep_http_msg)
HTTP統計情報は、障害発生中にSMFがHTTPステータスコード401 - Unauthorized from AMFを受信したことを示します
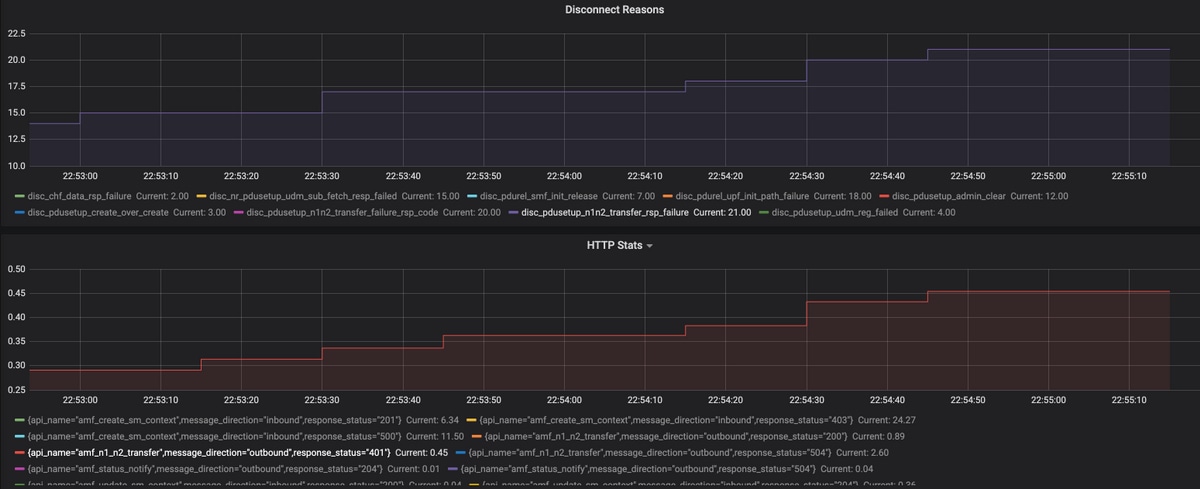
Query: sum(smf_restep_http_msg{namespace="smf"}) by(api_name,message_direction,response_status)
トラブルシューティングの重要なメトリック:
smf_disconnect_stats
smf_proto_pfcp_msg_total
smf_service_stats
smf_restep_http_msg
smf_n1_message_stats
smf_proto_pfcp_msg_total
nodemgr_msg_stats
nodemgr_gtpc_msg_stats
chf_message_stats
policy_msg_processing_status
procedure_protocol_total
procedure_service_total
SMFメトリックの詳細:
これらの例で示すように、特定の障害シナリオで必要に応じて独自のカスタムグラフをプロットして、さまざまなメッセージを関連付け、障害を切り分けることができます。このようなクエリは、Tac_debug_pkgからのメトリックデータがローカルのgrafanaにマウントされた後でも、ローカルシステムで実行できます。
 フィードバック
フィードバック