Introduction
Ce document décrit les étapes requises pour remplacer les deux disques durs défectueux dans le serveur dans une configuration Ultra-M qui héberge les fonctions de réseau virtuel (VNF) de StarOS.
Informations générales
Ultra-M est une solution de coeur de réseau de paquets mobile virtualisée préemballée et validée, conçue pour simplifier le déploiement des VNF. OpenStack est le gestionnaire d'infrastructure virtualisée (VIM) pour Ultra-M et se compose des types de noeuds suivants :
- Calculer
- Disque de stockage d'objets - Calcul (OSD - Calcul)
- Contrôleur
- Plate-forme OpenStack - Director (OSPD)
L'architecture de haut niveau d'Ultra-M et les composants impliqués sont représentés dans cette image :
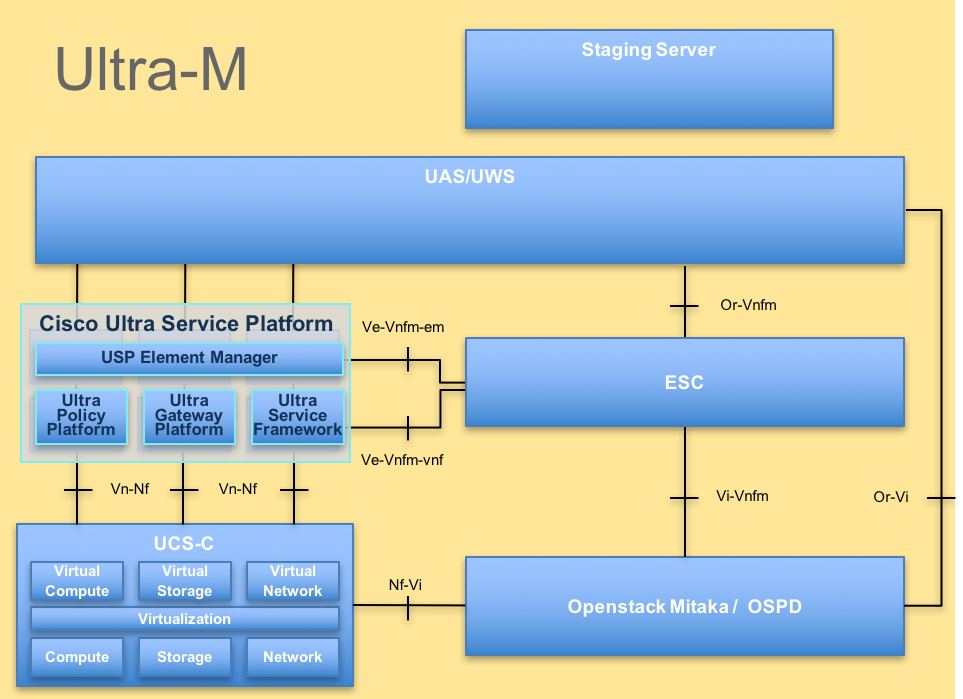 Architecture UltraM
Architecture UltraM
Ce document s'adresse au personnel Cisco familiarisé avec la plate-forme Cisco Ultra-M et détaille les étapes à effectuer au niveau OpenStack et StarOS VNF au moment du remplacement du serveur de contrôleur.
Remarque : La version Ultra M 5.1.x est prise en compte afin de définir les procédures dans ce document.
Abréviations
| VNF |
Fonction de réseau virtuel |
| CF |
Fonction De Commande |
| SF |
Fonction de service |
| ESC |
Contrôleur de service élastique |
| SERPILLIÈRE |
Méthode de procédure |
| OSD |
Disques de stockage d'objets |
| HDD |
Disque dur |
| SSD |
Disque dur SSD |
| VIM |
Gestionnaire d'infrastructure virtuelle |
| VM |
Machine virtuelle |
| EM |
Gestionnaire d'éléments |
| SAMU |
Services d’automatisation ultra |
| UUID |
Identificateur Universally Unique |
Défaillance des deux disques durs
Chaque serveur sans système d'exploitation sera équipé de deux disques durs afin de servir de DISQUE D'AMORÇAGE dans la configuration RAID 1. En cas de défaillance d'un disque dur, étant donné qu'il existe une redondance de niveau RAID 1, le disque dur défectueux peut être remplacé à chaud. Cependant, lorsque les deux disques durs tombent en panne, le serveur est arrêté et vous perdez l'accès au serveur. Afin de restaurer l'accès au serveur et aux services, il est nécessaire pour remplacer les deux disques durs et ajouter le serveur à la pile de surcloud existante.
La procédure de remplacement d'un composant défectueux sur le serveur UCS C240 M4 est disponible à l'adresse suivante : Remplacement des composants du serveur.
En cas de défaillance des deux disques durs, remplacez uniquement ces deux disques durs défectueux sur le même serveur UCS 240M4. La procédure de mise à niveau du BIOS n'est pas requise après le remplacement de nouveaux disques.
Dans la solution Ultra-M basée sur OpenStack, le serveur sans système d'exploitation UCS 240M4 peut assumer l'un des rôles suivants : Compute, OSD-Compute, Controller ou OSPD. Les étapes requises pour gérer les deux pannes de disque dur dans chacun de ces rôles de serveur sont mentionnées dans ces sections.
Remarque : Dans les cas où les deux disques durs sont en bon état, mais où un autre matériel est défectueux sur le serveur UCS 240M4, remplacez le serveur UCS 240M4 par le nouveau matériel. Toutefois, réutilisez les mêmes disques durs. Dans ce cas, seuls les disques durs sont défectueux. Réutilisez donc le même UCS 240M4 et remplacez les disques durs défectueux par de nouveaux disques durs.
Défaillance des deux disques durs sur le serveur de calcul
Si la défaillance des deux disques durs est observée dans l'UCS 240M4 qui agit comme un noeud de calcul, suivez la procédure de remplacement indiquée dans la Procédure de remplacement du serveur de calcul.
Défaillance des deux disques durs sur le serveur contrôleur
Si la défaillance des deux disques durs est observée dans le système UCS 240M4 qui agit comme un noeud contrôleur, suivez la procédure de remplacement indiquée dans la .
Étant donné que le serveur contrôleur qui observe la défaillance des deux disques durs ne sera pas accessible via Secure Shell (SSH), connectez-vous à un autre noeud contrôleur afin d'effectuer la procédure d'arrêt progressif indiquée dans le lien mentionné.
Défaillance des deux disques durs sur le serveur OSD-Compute
Si la défaillance des deux disques durs est observée dans le système UCS 240M4, qui fait office de noeud OSD-Compute, suivez la procédure de remplacement indiquée dans la .
Dans la procédure mentionnée ici, l'arrêt progressif du stockage Ceph ne peut pas être effectué car les deux pannes entraînent l'inaccessibilité du serveur. Par conséquent, ignorez ces étapes.
Défaillance des deux disques durs sur le serveur OSPD
Si la défaillance des deux disques durs est observée dans UCS 240M4, qui agit comme un noeud OSPD, suivez la procédure de remplacement indiquée dans la .
Dans ce cas, la sauvegarde OSPD précédemment stockée est nécessaire pour la restauration après le remplacement du disque dur, sinon elle sera comme un redéploiement complet de la pile.
 Commentaires
Commentaires