Utiliser la classification de documents basée sur XML pour une gestion efficace des politiques DLP
Table des matières
Introduction
Ce document décrit comment utiliser la classification de documents basée sur ML (Conçue avec Meta Lama 3) pour simplifier et améliorer la gestion des politiques de prévention des pertes de données (DLP).
Aperçu
La classification de documents XML améliore la correspondance de contenu et facilite la gestion des stratégies DLP. Vous pouvez faire votre choix parmi des types de documents prédéfinis et préformés, ce qui vous évite d'avoir à créer de toutes pièces des classifications de données complexes basées sur des termes et des modèles.
Utilisation de la classification de documents basée sur ML
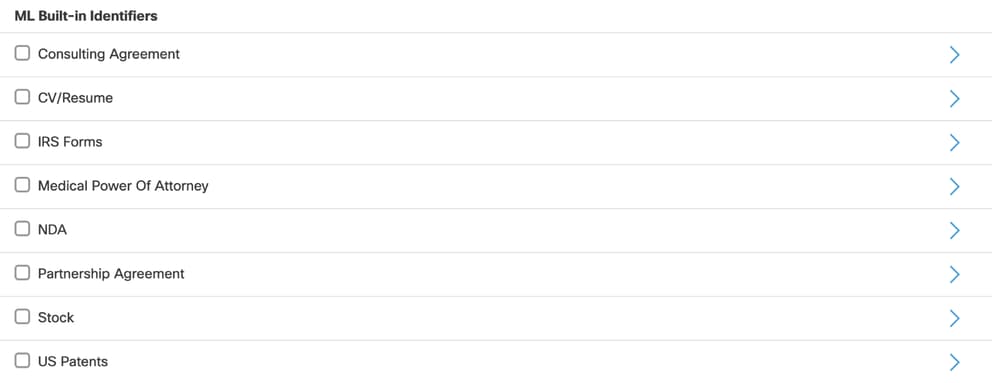
- La classification de documents basée sur XML est disponible en tant qu'identificateur intégré lorsque vous créez une classification de données.
- Tous les identificateurs ML pris en charge apparaissent dans la section Identificateurs intégrés ML pendant la configuration de la classification des données.
 26221783199892
26221783199892
Types de documents pris en charge
Vous pouvez utiliser la classification basée sur ML pour ces types de documents :
- Contrats de conseil
- CV et CV
- formulaires du fisc
- Procuration médicale
- Accords de non-divulgation (ACD)
- Accords de partenariat
- Stock et brevets américains
Langues et régions prises en charge
La version initiale prend uniquement en charge les documents en anglais américain. La prise en charge d'autres langues et régions est prévue pour les futures mises à jour.
Prise en charge DLP multimode
La classification de documents basée sur XML fonctionne avec les DLP Realtime et SaaS API DLP. Il est compatible avec tous les types de fichiers DLP pris en charge.
Ressources connexes
Reportez-vous à la documentation Secure Access and Umbrella pour obtenir des instructions sur l'utilisation des identificateurs de données basés sur ML dans les classifications de données et les règles DLP :
- Accès sécurisé : Identificateurs de données intégrés
- Parapluie : Identificateurs de données intégrés
Historique de révision
| Révision | Date de publication | Commentaires |
|---|---|---|
2.0 |
20-Jul-2026
|
Première publication |
1.0 |
21-Oct-2025
|
Première publication |
 Commentaires
Commentaires