Dans le volet de navigation, choisissez Troubleshoot > Cluster Status.
L'état du cluster indique l'état de tous les serveurs dans le rack Cisco Secure Workload. Un serveur en fonctionnement peut afficher l'état Commandé et l'état Actif, comme indiqué ici.
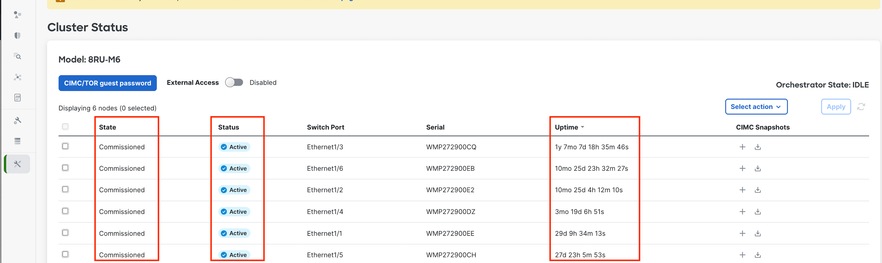

Mise en garde : Si vous remarquez un noeud marqué comme inactif sur la page d'état du cluster, générez un instantané CIMC et soulevez un cas TAC, y compris l'instantané.
Si l'état est Inactif, cela signifie généralement que le serveur est éteint ou peut être arrêté en raison d'un problème matériel, de câble ou de connectivité.
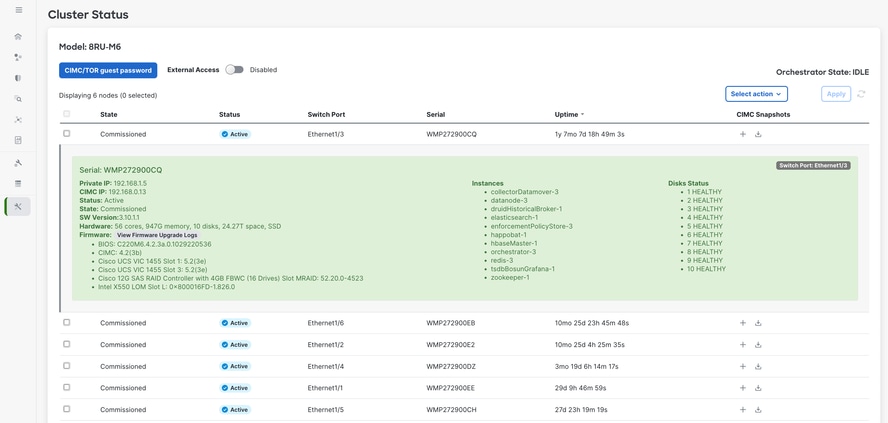
Lorsque vous cliquez sur un serveur dans la liste, vous voyez plus de détails, tels que
· Les machines virtuelles (instances) exécutées sur ce serveur physique
· Adresse IP privée du serveur au sein du cluster
· L’adresse IP CIMC (de gestion)
· Versions actuelles du microprogramme pour le BIOS, CIMC, la carte VIC, la carte LOM et le contrôleur RAID
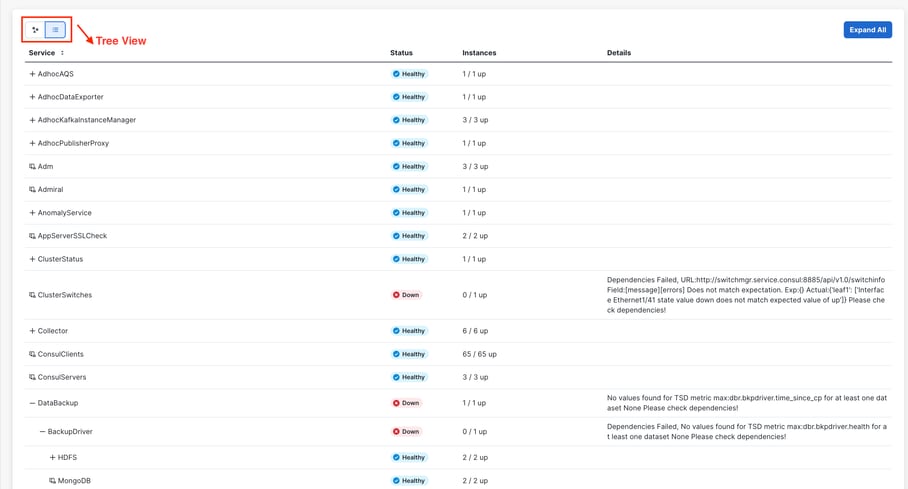
État du service
La page État du service se trouve dans le volet de navigation de gauche sous > .
page État du affiche l'état de tous les services utilisés dans votre cluster de charge de travail CiscoSecure, ainsi que leurs dépendances.
La vue du graphique montre l'intégrité du service, chaque noeud du graphique montre l'intégrité du service et une périphérie représente la dépendance par rapport aux autres services. Les services défectueux sont marqués en rouge lorsque le service n'est pas disponible et en orange lorsque le service est dégradé mais disponible. Une couleur verte ou bleu ciel indique que le service est sain. Pour plus d'informations sur le débogage de ces noeuds, utilisez l'arborescence qui contient le bouton Développer tout pour afficher tous les noeuds enfants dans l'arborescence des dépendances. Down, indique que le service n'est pas fonctionnel, et Unhealth, indique que le service n'est pas entièrement fonctionnel.
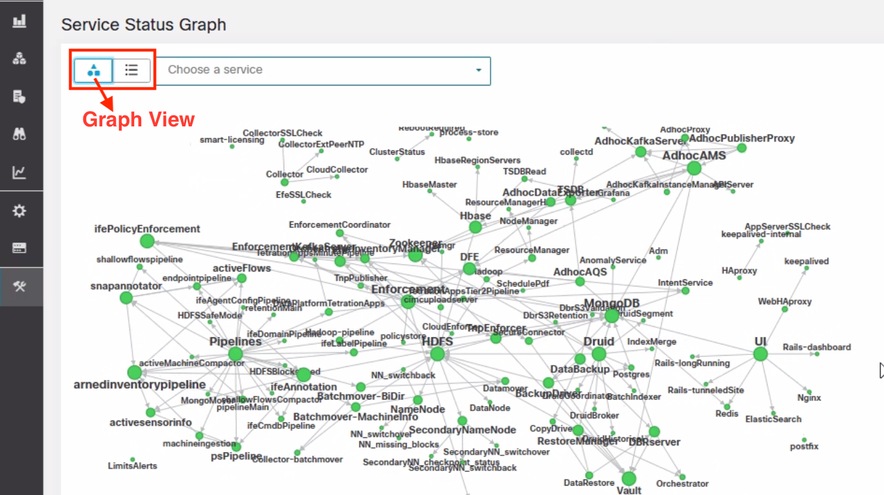

Remarque : À partir de la version 3.10.2.11 du correctif, la page d'état du service s'affiche en bleu ciel. Une couleur verte ou bleu ciel indique que le service est sain.
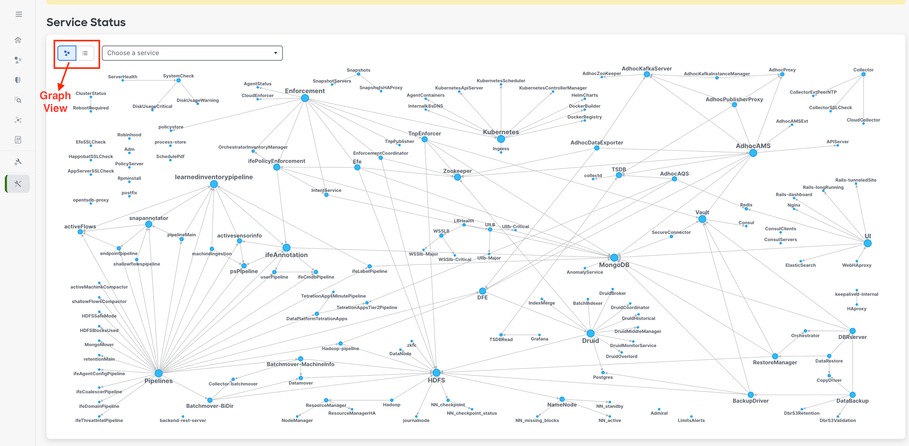
Par défaut, la page État du service affiche les fonctions et les dépendances du cluster dans une vue graphique. Si les icônes sont toutes vertes ou bleu ciel, aucune erreur n'est détectée.
Si un service s'affiche en rouge ou en orange, l'arborescence affiche la liste des services et vous permet d'effectuer une hiérarchisation vers le bas sur les dépendances du service ainsi que sur d'autres détails détectés par la fonction État du service. Ces informations d'erreur de dépendance sont particulièrement importantes à noter et à capturer lors de l'ouverture d'un dossier auprès du TAC.
Mise en garde : Si vous constatez que l'un des services n'est pas sain et s'affiche en rouge, contactez le centre d'assistance technique (TAC) pour obtenir de l'aide afin de résoudre ces problèmes. Un engagement rapide auprès du TAC peut aider à restaurer toutes les fonctionnalités.
Hawkeye (Graphiques)
Les tableaux de bord Hawkeye offrent une visibilité sur l'intégrité du cluster de charge de travail sécurisé, ainsi que des indicateurs et des informations pour faciliter le dépannage
La page Hawkeye (Graphiques) se trouve dans le volet de navigation de gauche, sous
Lorsque vous cliquez sur Hawkeye (Graphiques), un nouvel onglet de navigateur s'ouvre automatiquement et affiche le tableau de bord Hawkeye comme illustré ici.
Dans le tableau de bord Hawkeye, cliquez sur l'onglet Spark Pipeline Current pour surveiller l'état du cluster de charge globale sécurisée.
Sur la page Spark Pipeline Current, vérifiez que les valeurs de latence de bout en bout, de latence de couche de desserte, de latence de pipeline principal et de latence de flux active sont toutes inférieures à 10 minutes.
Vérifiez également que les valeurs d'exécution sont inférieures à 1 minute et qu'elles sont présentées en secondes et que l'état HDFS est Bon, comme illustré ci-dessous.
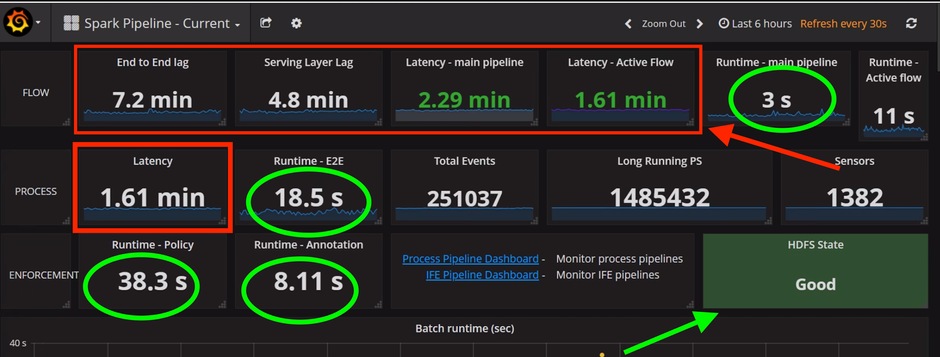
Mise en garde : Si vous observez des valeurs de latence, y compris un décalage de bout en bout ou un décalage de la couche de service, dépassant 6 heures sans montrer de diminution progressive, veuillez contacter le Centre d'assistance technique (TAC).
Prévérifications de mise à niveau
Avant et après les tâches de maintenance, utilisez la vérification préalable de la mise à niveau pour exécuter des vérifications de l'intégrité du cluster ; ce processus garantit que les services, les configurations et les composants matériels sont tous en bon état de fonctionnement
-
Accédez à Upgrade Precheck.
Accédez à l'interface utilisateur TetrationUI et procédez comme suit :
Patientez quelques minutes pour le résultat des vérifications préalables de la mise à niveau. Si tout fonctionne correctement, comme illustré dans cette image, vous pouvez poursuivre les actions suivantes des activités de maintenance du cluster.
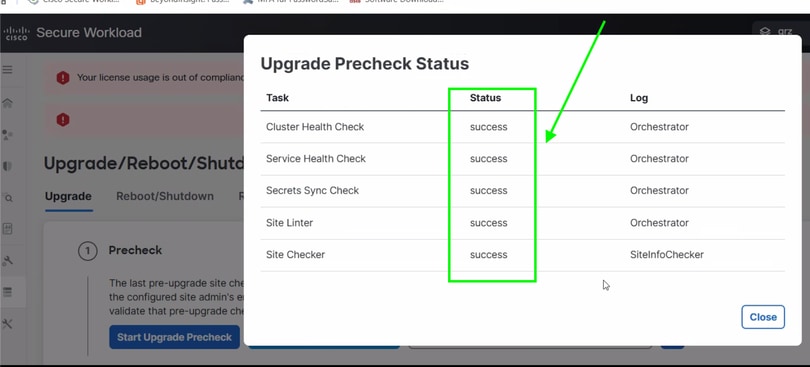
Mise en garde : En cas d'échec de la vérification préalable de la mise à niveau, contactez le centre d'assistance technique (TAC) pour obtenir de l'aide.
|
 Commentaires
Commentaires