Dépannage du CPU élevé sur les routeurs de la gamme ASR1000
Options de téléchargement
-
ePub (423.4 KB)
Consulter à l’aide de différentes applications sur iPhone, iPad, Android ou Windows Phone -
Mobi (Kindle) (290.2 KB)
Consulter sur un appareil Kindle ou à l’aide d’une application Kindle sur plusieurs appareils
Langage exempt de préjugés
Dans le cadre de la documentation associée à ce produit, nous nous efforçons d’utiliser un langage exempt de préjugés. Dans cet ensemble de documents, le langage exempt de discrimination renvoie à une langue qui exclut la discrimination en fonction de l’âge, des handicaps, du genre, de l’appartenance raciale de l’identité ethnique, de l’orientation sexuelle, de la situation socio-économique et de l’intersectionnalité. Des exceptions peuvent s’appliquer dans les documents si le langage est codé en dur dans les interfaces utilisateurs du produit logiciel, si le langage utilisé est basé sur la documentation RFP ou si le langage utilisé provient d’un produit tiers référencé. Découvrez comment Cisco utilise le langage inclusif.
À propos de cette traduction
Cisco a traduit ce document en traduction automatisée vérifiée par une personne dans le cadre d’un service mondial permettant à nos utilisateurs d’obtenir le contenu d’assistance dans leur propre langue. Il convient cependant de noter que même la meilleure traduction automatisée ne sera pas aussi précise que celle fournie par un traducteur professionnel.
Contenu
Introduction
Ce document décrit comment dépanner les problèmes de CPU élevés sur un routeur de la gamme ASR1000.
Prérequis
Conditions requises
Cisco vous recommande de comprendre l'architecture ASR1000 pour interpréter et utiliser ce document.
Description
Le CPU élevé sur un routeur Cisco peut être défini comme la condition dans laquelle l'utilisation du CPU sur le routeur est supérieure à l'utilisation normale. Dans certains scénarios, l'utilisation accrue du processeur est prévue, tandis que dans d'autres, elle peut indiquer un problème. Une utilisation élevée et transitoire du processeur sur le routeur en raison d'une modification du réseau ou de la configuration peut être ignorée et le comportement est attendu.
Cependant, un routeur qui connaît une utilisation élevée du CPU pendant de longues périodes sans aucune modification du réseau ou de la configuration est inhabituel et doit être analysé. Par conséquent, lorsqu'il est utilisé de manière excessive, le processeur ne peut pas traiter activement tous les autres processus, ce qui entraîne une lenteur de la ligne de commande, une latence du plan de contrôle, des pertes de paquets et la défaillance des services.
Les causes de l'utilisation élevée du processeur sont les suivantes :
- Le processeur du plan de contrôle reçoit trop de trafic de pointillés
- Processus qui se comporte de manière inattendue et qui entraîne une surexploitation du processeur
- Le processeur du plan de données est surutilisé/surabonné
- Trop d'interruptions de processeur
Le CPU élevé n'est pas toujours un problème de routeur de la gamme ASR1000, car l'utilisation du CPU du routeur est directement proportionnelle à la charge sur le routeur. Par exemple, en cas de modification du réseau, le trafic du plan de contrôle sera important lorsque le réseau reconvergera. Par conséquent, nous devons déterminer la cause première de la surexploitation du processeur pour déterminer s'il s'agit d'un comportement attendu ou d'un problème.
Voici un schéma qui détaille un processus étape par étape pour résoudre un problème de CPU élevé :
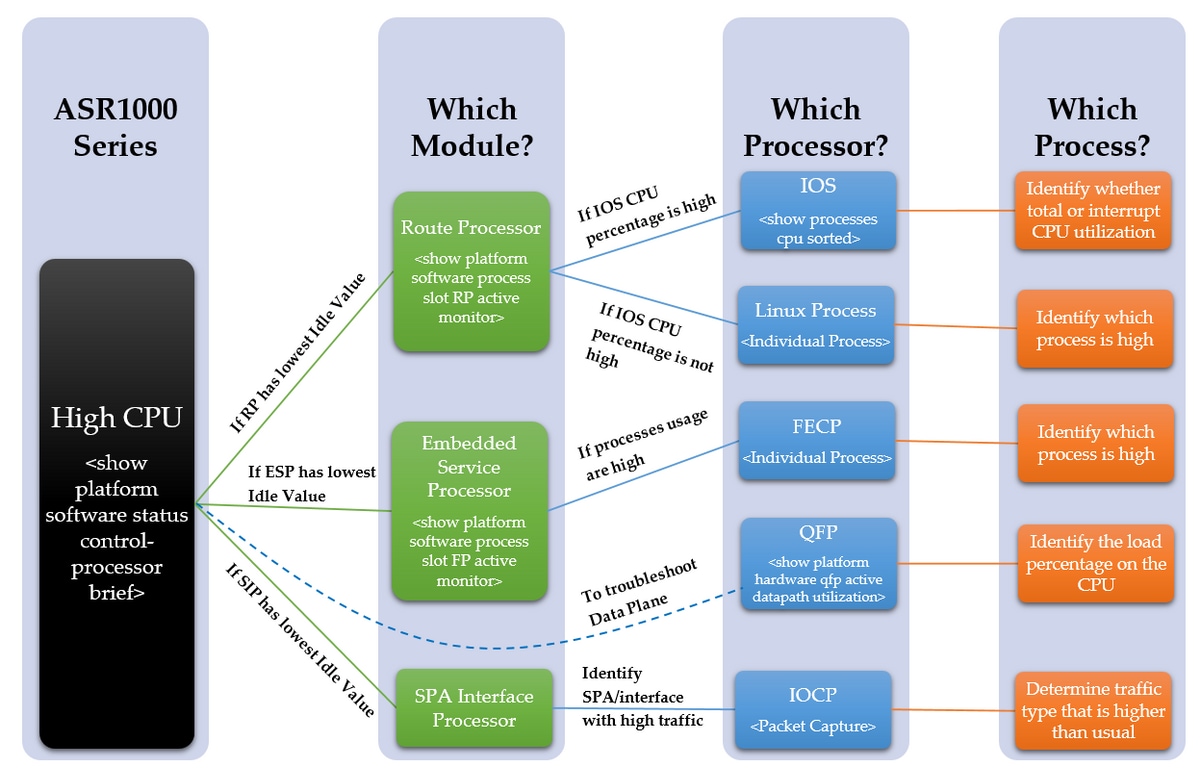
Dépannage des étapes
Étape 1 - Identifiez le module avec un processeur élevé
L'ASR1000 dispose de plusieurs processeurs différents sur les différents modules. Par conséquent, nous devons voir quel module affiche une utilisation supérieure à la normale. Ceci peut être vu à travers la valeur Inactif, car plus la valeur Inactif est faible, plus l'utilisation CPU de ce module est élevée. Ces différents processeurs reflètent tous le plan de contrôle des modules.
Déterminez quel module du périphérique est détecté comme étant doté d'un processeur élevé. Est-ce le RP, ESP ou SIP avec la commande ci-dessous ?
show platform software status control-processor brief
Reportez-vous au résultat ci-dessous pour afficher la colonne mise en surbrillance
Si le RP a une faible valeur d'inactivité, passez à l'étape 2, point 1
Si la valeur d'inactivité du protocole ESP est faible, passez à l'étape 3, point 2.
Si le SIP a une faible valeur d'inactivité, passez à l'étape 4, point 3.
Router#show platform software status control-processor brief
Moyenne charge
État du logement 1 min 5 min 15 min
RP0 Sain 0,00 0,02 0,00
ESP0 Sain 0,01 0,02 0,00
SIP0 sain 0,00 0,01 0,00
Mémoire (kB)
État Du Logement Total Utilisé (Pct) Libre (Pct) Engagé (Pct)
RP0 Santé 2009376 1879196 (94 %) 130180 (6 %) 1432748 (71 %)
ESP0 Santé 2009400 692100 (34 %) 1317300 (66 %) 472536 (24 %)
SIP0 sain 471804 284424 (60 %) 187380 (40 %) 193148 (41 %)
Utilisation du processeur
Système utilisateur UC de logement IOwait Idle inactif IRQ SIRQ
RP0 0 2,59 2,49 0,00 94,80 0,00 0,09 0,00
ESP0 0 2,30 17,90 0,00 79,80 0,00 0,00 0,00
SIP0 0 1,29 4,19 0,00 94,41 0,09 0,00 0,00
Si les valeurs d'inactivité sont toutes relativement élevées, il se peut qu'il ne s'agisse pas d'un problème de plan de contrôle. Pour dépanner le plan de données, le QFP d'ESP doit être observé. Les symptômes d'une ” élevée “ CPU peuvent encore être observés en raison d'un QFP surutilisé, ce qui n'entraînera pas de CPU élevé sur les processeurs du plan de contrôle. Passez à l'étape 6.
Étape 2 - Analysez le module
- Processeur de routage
Confirmez au sein du RP quel processeur est observé avec une utilisation élevée du CPU à l'aide de la commande ci-dessous. Est-ce le processus Linux ou l'IOS ?
show platform software process slot RP active monitor
Si le pourcentage de CPU IOS est élevé (linux_iosd-imag), il s'agit de l'IOS RP. Passez à l'étape 3
Si le pourcentage de CPU des autres processus est élevé, alors il est probable qu'il s'agit du processus Linux. Passez à l'étape 4
- Processeur de services intégré
Confirmez au sein de l'ESP si le processeur du plan de contrôle est considéré comme ayant une utilisation élevée du CPU. Est-ce la FECP ?
show platform process slot FP active monitor
Si les processus sont élevés, il s'agit du FECP, puis passez à l'ÉTAPE 5
S'il ne s'agit pas de la FECP, il ne s'agit pas d'un problème lié aux processus du plan de contrôle dans ESP. Si des symptômes tels que la latence du réseau ou les pertes de file d'attente sont toujours observés, il peut être nécessaire de revoir le plan de données pour déterminer s'il est surutilisé. Passez à l'étape 6
- Processeur d'interface SPA
Si le SIP est considéré comme ayant une utilisation élevée de la CPU, l'IOCP est considéré comme ayant une CPU élevée. Déterminez le ou les processus de l'IOCP qui ont une utilisation élevée du CPU.
Effectuez une capture de paquets et identifiez le trafic le plus élevé et les processus associés à ce type de trafic. Passez à l'étape 7
Étape 3 - Processus IOS
Reportez-vous au résultat ci-dessous, le premier pourcentage correspond à l'utilisation totale du CPU et le second pourcentage à l'utilisation du CPU d'interruption, qui correspond à la quantité de CPU utilisée pour traiter les paquets punis.
Si le pourcentage d'interruption est élevé, cela signifie qu'une grande quantité de trafic est acheminée au RP (ceci peut être confirmé par la commande show platform software infrastructure punt)
Si le pourcentage d'interruption est faible, mais que le CPU total est élevé, un ou plusieurs processus seront observés pour utiliser le CPU pendant une longue période.
Confirmez au sein de l’IOS quel(s) processus(s) est(sont) observé(s) à une utilisation élevée du CPU avec la commande ci-dessous.
show processes cpu trié
Identifiez le pourcentage élevé (processeur total ou processeur d'interruption), puis, si nécessaire, identifiez le processus/processus individuel. Passez à l'étape 7
Router#show processes cpu trié
Utilisation du CPU pour cinq secondes: 0% / 0%; one minute: 1%; cinq minutes: 1%
Exécution du PID (ms) processus TTY 5 min 5 s Secs appelé
Exécution du PID (ms) processus TTY 5 min 5 s Secs appelé
188 8143 434758 18 0,15 % 0,18 % 0,19 % 0 Ethernet Msec Ti
515 380 7050 53 0,07 % 0,00 % 0,00 % 0 Processus principal SBC
3 2154 215 10018 0,07 % 0,00 % 0,19 % 0 Exec
380 1783 55002 32 0,07% 0,06% 0,06% 0 MMA DB TIMER
63 3132 11143 281 0,07 % 0,07 % 0,07 % 0 tâche IOSD ipc
5 1 2 500 0,00% 0,00% 0,00% 0 IPC ISSU Dispatc
6 19 12 1583 0,00 % 0,00 % 0,00 % 0 RF Esclave Principal
8 0 1 0 0,00 % 0,00 % 0,00 % 0 Minuteurs de notification RO
7 0 1 0 0,00 % 0,00 % 0,00 % 0 EDDRI_MAIN
10 6 75 80 0,00 % 0,00 % 0,00 % 0 Gestionnaire de pool
9 5671 538 10540 0,00 % 0,14 % 0,12 % 0 Tas de chèque
Étape 4 - Processus Linux
Si l'on observe que l'IOS a surutilisé le processeur, nous devons observer l'utilisation du processeur pour le processus Linux individuel. Ces processus sont les autres processus listés dans la commande show platform software process slot RP active monitor. Identifiez le ou les processus observés pour lesquels le CPU est élevé, puis passez à l'ÉTAPE 7.
Étape 5 - Processus FECP
Si un ou plusieurs processus sont élevés, il est probable que ce sont les processus au sein du FECP qui sont responsables de l'utilisation élevée du CPU, passez à l'ÉTAPE 7.
Étape 6 - Utilisation de QFP
Le processeur de flux Quantum est l'ASIC de transfert. Pour déterminer la charge sur le moteur de transfert, le QFP peut être surveillé. La commande ci-dessous répertorie les paquets d'entrée et de sortie (priorité et non priorité) en paquets par seconde et en bits par seconde. La dernière ligne affiche le volume total de la charge CPU due au transfert de paquets en pourcentage.
show platform hardware qfp active datapath use
Identifiez si l'entrée ou la sortie est élevée, affichez la charge du processus, puis passez à l'ÉTAPE 7.
Router#show platform hardware qfp active datapath utilisation
RPC 0 : Subdev 0 5 s 1 min 5 min 60 min
Entrée: Priorité (pps) 0 0 0 0
(bps) 208 176 176 176
Non prioritaire (pps) 0 2 2 2
(bps) 64 784 784 784
Total (pps) 0 2 2 2
(bps) 272 960 960 960
Sortie : Priorité (pps) 0 0 0 0
(bps) 192 160 160 160
Non prioritaire (pps) 0 1 1 1
(bps) 0 6488 6496 6488
Total (pps) 0 1 1 1
(bps) 192 6648 6656 6648
Traitement : Charge (pct) 0 0 0 0
Étape 7 - Déterminez la cause première et identifiez la correction
Avec le ou les processus qui ont été observés pour avoir surutilisé le processeur identifié, il y a une image plus claire des raisons pour lesquelles un CPU élevé s'est produit. Pour continuer, recherchez les fonctions exécutées par le processus identifié. Cela aidera à déterminer un plan d'action sur la façon d'aborder le problème. Par exemple - Si le processus est responsable d'un protocole particulier, vous pouvez examiner la configuration associée à ce protocole.
Si vous rencontrez toujours des problèmes liés au processeur, il est recommandé de contacter le centre d'assistance technique pour permettre à un ingénieur de vous aider à dépanner davantage. Les étapes ci-dessus pour le dépannage aideront l'ingénieur à isoler le problème plus efficacement.
Exemple de dépannage
Dans cet exemple, nous allons exécuter le processus de dépannage et essayer d'identifier au mieux une cause racine possible pour le CPU élevé du routeur. Pour commencer, déterminez quel module est observé pour connaître le CPU élevé, nous avons la sortie suivante :
Router#show platform software status control-processor brief
Moyenne charge
État du logement 1 min 5 min 15 min
RP0 Santé 0,66 0,15 0,05
ESP0 Sain 0,00 0,00 0,00
SIP0 sain 0,00 0,00 0,00
Mémoire (kB)
État Du Logement Total Utilisé (Pct) Libre (Pct) Engagé (Pct)
RP0 Santé 2009376 1879196 (94 %) 130180 (6 %) 1432756 (71 %)
ESP0 Santé 2009400 692472 (34 %) 1316928 (66 %) 472668 (24 %)
SIP0 sain 471804 284556 (60 %) 187248 (40 %) 193148 (41 %)
Utilisation du processeur
Système utilisateur UC de logement Idle IRQ SIRQ IOwait
RP0 0 57,11 14,42 0,00 0 0,00 28,25 0,19 0,00
ESP0 0 2,10 17,91 0,00 79,97 0,00 0,00 0,00
SIP0 0 1,20 6,00 0,00 92,80 0,00 0,00 0,00
Comme la quantité d'inactivité dans RP0 est très faible, elle suggère un problème de CPU élevé dans le processeur de routage. Par conséquent, pour dépanner plus loin, nous allons identifier quel processeur dans le RP est observé pour faire face à un CPU élevé.
Router#show processes cpu trié
Utilisation du CPU pour cinq secondes: 84% / 36%; one minute: 34%; cinq minutes: 9%
Exécution du PID (ms) processus TTY 5 min 5 s Secs appelé
107 303230 50749 5975 46,69% 18,12% 4,45% 0 IOSXE-RP Punt Se
63 105617 540091 195 0,23 % 0,10 % 0,08 % 0 tâche IOSD ipc
159 74792 2645991 28 0,15 % 0,06 % 0,06 % 0 VRRS Thread principal
116 53685 169683 316 0,15 % 0,05 % 0,01 % 0 Par seconde Emploi
9 305547 26511 11525 0,15 % 0,28 % 0,16 % 0 Tas de chèque
188 362507 20979154 17 0,15 % 0,15 % 0,19 % 0 Ethernet Msec Ti
3 147 186 790 0,07 % 0,08 % 0,02 % 0 Exec
2 32126 33935 946 0,07 % 0,03 % 0,00 % 0 Compteur de charge
446 416 33932 12 0,07 % 0,00 % 0,00 % 0 processus VDC
164 59945 5261819 11 0,07% 0,04% 0,02% 0 IP ARP Age de nouvelle tentative
43 1703 16969 100 0,07% 0,00% 0,00% 0 IPC Maintien en vie M
À partir de ce résultat, on peut observer que le pourcentage total de CPU et le pourcentage d'interruption sont plus élevés que prévu. Le processus supérieur qui utilise le CPU est le “ IOSXE-RP Punt Se ” qui est le processus qui gère le trafic pour le CPU RP, donc nous pouvons regarder plus loin dans ce trafic qui est pointé vers le RP.
Router#show platform software infrastructure punt
Statistiques internes de l'interface LSMPI :
activé=0, désactivé=0, limité=0, non limité=0, état prêt
Tampons d'entrée = 90100722
Tampons de sortie = 100439
rxdone count = 90100722
txdone count = 100436
Rx aucun nombre de types de particules = 0
Tx no particule type count = 0
Txbuf à partir du nombre d'ombres = 0
Aucun début de paquet = 0
Aucune extrémité du paquet = 0
Statistiques de suppression de pointes :
Version 0 incorrecte
Type 0 incorrect
En-tête de fonction 0
En-tête de plate-forme 0
En-tête de fonction manquant 0
Incompatibilité d'en-tête commune 0
Longueur totale incorrecte 0
Longueur de paquet incorrecte 0
Décalage réseau incorrect 0
En-tête 0 non pointu
Type de liaison inconnu 0
Pas de swidb 1
En-tête de fonction ESS incorrect 0
Pas de fonction ESS 0
Aucune fonctionnalité SSLVPN 0
Punt For Us type inconnu 0
Cause de poinçonnage hors limites 0
Causes du paquet de point IOSXE-RP :
62 210226 Contrôle de couche 2 et paquets hérités
147 Paquets de requête ou de réponse ARP
27801234 Paquets de données For-us
Paquets de keepalive 84426 RP<->QFP
6 Paquets de contiguïté allégés
1647 Paquets de contrôle For-us
FOR_US Control IPv4 stats :
1647 Paquets OSPF
histogramme de paquet (500 octets/bin), taille moyenne en 92, sur 56 :
Nombre De Dépassements De Taille De Pak
0+ : 90097805 98790
+ de 500 : 0 7
À partir de ce résultat, nous pouvons voir qu'il y a une grande quantité de paquets dans le ” de données “ For-us qui indique le trafic dirigé vers le routeur, ce compteur a été confirmé avoir été incrémenté à partir de l'observation de la commande plusieurs fois sur plusieurs minutes. Cela confirme que le processeur est surutilisé par une grande quantité de trafic pointé, qui est souvent le trafic du plan de contrôle. Le trafic du plan de contrôle peut inclure ARP, SSH, SNMP, les mises à jour de route (BGP, EIGRP, OSPF), etc. À partir de ces informations, nous sommes en mesure d'identifier la cause potentielle du CPU élevé et cela aide à dépanner la cause première. Par exemple, une capture de paquets ou un moniteur de trafic différent pourrait être mis en oeuvre pour voir le trafic exact pointé vers le RP, ce qui permettrait d'identifier et de résoudre la cause première pour éviter un problème similaire à l'avenir.
Une fois la capture de paquets terminée, voici quelques exemples de trafic puni potentiel :
- ARP : Cela peut être dû à un nombre excessif de requêtes ARP, qui se produirait si plusieurs adresses IP envoyaient des requêtes ARP via la configuration d’une route IP vers une interface de diffusion. Cela peut également être dû à des entrées vidées de la table ARP et devra être réappris en fonction des entrées d'adresse MAC qui expirent ou des interfaces qui s'activent/s.
- SSH : Cela peut entraîner une utilisation élevée du CPU en raison d'une commande show importante (show tech-support) ou lorsque beaucoup de commandes debug sont activées, ce qui force beaucoup de CLI à être envoyé sur la session SSH.
- SNMP : Cela peut être dû à l'agent SNMP qui met un long temps à traiter une requête, et qui cause donc un CPU élevé. Souvent deux causes probables sont les MIB interrogées ou les tables de routage et/ou ARP interrogées par le NMS.
- Mises à jour de routage : Souvent, un afflux de mises à jour de route est dû à une reconvergence du réseau ou à des défaillances de liaison. Cela peut indiquer les routes qui s’arrêtent sur le réseau, ou des périphériques entiers qui s’arrêtent, ce qui force le réseau à converger et à recalculer les meilleures routes, qui dépendent du protocole de routage utilisé.
Cela montre comment la cause première peut être isolée en identifiant la cause du CPU élevé, quand il s'agit d'un niveau de processus individuel. À partir de là, le processus ou le protocole individuel peut être analysé isolément pour déterminer s’il s’agit d’un problème de configuration, d’un problème logiciel, d’une conception de réseau ou d’une pratique prévue.
Commandes supplémentaires
Vous trouverez ci-dessous une liste d'autres commandes utiles supplémentaires à utiliser et à trier par processeur auquel elles se rapportent :
Processeur de routage
- <show process cpu history>
- Fournit un graphique de l'historique du processeur au cours des 60 dernières secondes, minutes et 72 heures
- <show process process_ID>
- Informations détaillées sur la mémoire de processus et les allocations de CPU
- <show platform software infrastructure punt>
- Fournit des informations sur tout le trafic qui est pointé vers le RP
- <show platform software status control-processor brief>
- Décrit la charge et l'état du processeur, ainsi que les statistiques de la mémoire et du module.
- <show platform software process slot r0|r1 monitor>
- Détaille les différents processus et leurs allocations de CPU et de mémoire sur le module sélectionné
- <processus logiciel de la plate-forme de surveillance r0|r1>
- Fournit un flux en direct qui met à jour les processus lorsqu'ils utilisent le processeur
- Nécessite que la commande “ terminal-type ” soit entrée en mode de configuration globale pour fonctionner correctement
Processeur de services intégré
- <show platform software process list fp active summary>
- Décrit un résumé de tous les processus exécutés sur le processeur, ainsi que la charge moyenne
- <show platform software process slot f0|f1 monitor>
- Détaille les différents processus et leurs allocations de CPU et de mémoire sur le module sélectionné
- <processus logiciel de la plate-forme de surveillance f0|f1>
- Fournit un flux en direct qui met à jour les processus tels qu'ils utilisent le processeur
- Nécessite que la commande “ terminal-type ” soit entrée en mode de configuration globale pour fonctionner correctement
Contribution d’experts de Cisco
- Chris CourtelisCisco Systems
 Commentaires
CommentairesContacter Cisco
- Ouvrir un dossier d’assistance

- (Un contrat de service de Cisco est requis)