Remplacement du serveur de calcul UCS C240 M4 - CPAR
Options de téléchargement
Langage exempt de préjugés
Dans le cadre de la documentation associée à ce produit, nous nous efforçons d’utiliser un langage exempt de préjugés. Dans cet ensemble de documents, le langage exempt de discrimination renvoie à une langue qui exclut la discrimination en fonction de l’âge, des handicaps, du genre, de l’appartenance raciale de l’identité ethnique, de l’orientation sexuelle, de la situation socio-économique et de l’intersectionnalité. Des exceptions peuvent s’appliquer dans les documents si le langage est codé en dur dans les interfaces utilisateurs du produit logiciel, si le langage utilisé est basé sur la documentation RFP ou si le langage utilisé provient d’un produit tiers référencé. Découvrez comment Cisco utilise le langage inclusif.
À propos de cette traduction
Cisco a traduit ce document en traduction automatisée vérifiée par une personne dans le cadre d’un service mondial permettant à nos utilisateurs d’obtenir le contenu d’assistance dans leur propre langue. Il convient cependant de noter que même la meilleure traduction automatisée ne sera pas aussi précise que celle fournie par un traducteur professionnel.
Table des matières
Introduction
Ce document décrit les étapes nécessaires au remplacement d'un serveur informatique défectueux dans une configuration Ultra-M.
Cette procédure s'applique à un environnement Openstack utilisant la version NEWTON où Elastic Services Controller (ESC) ne gère pas Cisco Prime Access Registrar (CPAR) et CPAR est installé directement sur la machine virtuelle déployée sur Openstack.
Informations générales
Ultra-M est une solution de coeur de réseau de paquets mobile virtualisée préemballée et validée, conçue pour simplifier le déploiement des VNF. OpenStack est le gestionnaire d'infrastructure virtualisée (VIM) pour Ultra-M et se compose des types de noeuds suivants :
- Calculer
- Disque de stockage d'objets - Calcul (OSD - Calcul)
- Contrôleur
- Plate-forme OpenStack - Director (OSPD)
L'architecture de haut niveau d'Ultra-M et les composants impliqués sont représentés dans cette image :
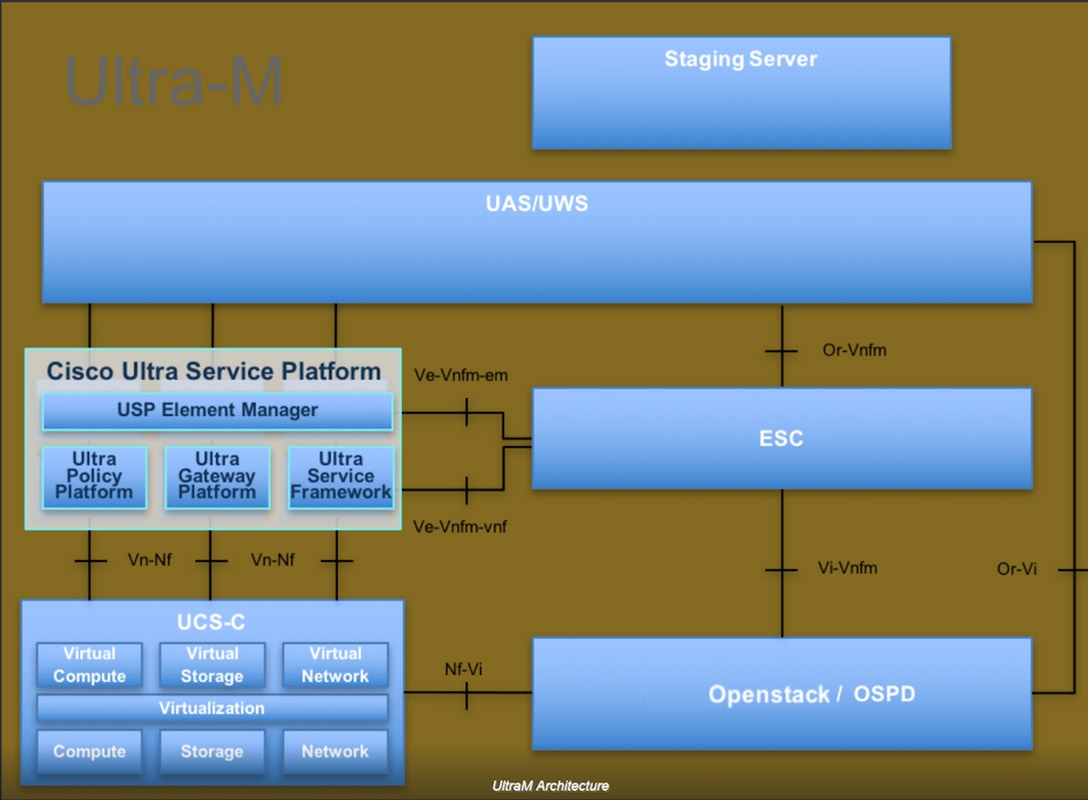
Ce document s'adresse au personnel Cisco qui connaît bien la plate-forme Cisco Ultra-M et détaille les étapes à suivre sur OpenStack et Redhat OS.
Remarque : La version Ultra M 5.1.x est prise en compte afin de définir les procédures dans ce document.
Abréviations
| SERPILLIÈRE | Méthode de procédure |
| OSD | Disques de stockage d'objets |
| OSPD | OpenStack Platform Director |
| HDD | Disque dur |
| SSD | Disque dur SSD |
| VIM | Gestionnaire d'infrastructure virtuelle |
| VM | Machine virtuelle |
| EM | Gestionnaire d'éléments |
| SAMU | Services d’automatisation ultra |
| UUID | Identificateur Universally Unique |
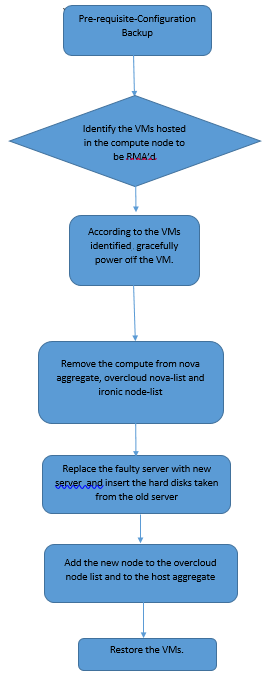
Flux de travail de la musique d'attente
Conditions préalables
Sauvegarde
Avant de remplacer un noeud Compute, il est important de vérifier l'état actuel de votre environnement Red Hat OpenStack Platform. Il est recommandé de vérifier l'état actuel afin d'éviter des complications lorsque le processus de remplacement Compute est activé. Il peut être réalisé par ce flux de remplacement.
En cas de récupération, Cisco recommande d'effectuer une sauvegarde de la base de données OSPD en procédant comme suit :
[root@ al03-pod2-ospd ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql [root@ al03-pod2-ospd ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql /etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack tar: Removing leading `/' from member names
Ce processus garantit qu'un noeud peut être remplacé sans affecter la disponibilité des instances.
Remarque : Assurez-vous de disposer du snapshot de l'instance afin de pouvoir restaurer la VM en cas de besoin. Suivez la procédure ci-dessous pour prendre un instantané de la machine virtuelle.
Identifier les machines virtuelles hébergées dans le noeud de calcul
Identifiez les machines virtuelles qui sont hébergées sur le serveur de calcul.
[stack@al03-pod2-ospd ~]$ nova list --field name,host +--------------------------------------+---------------------------+----------------------------------+ | ID | Name | Host | +--------------------------------------+---------------------------+----------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | pod2-stack-compute-4.localdomain | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | pod2-stack-compute-3.localdomain | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | pod2-stack-compute-3.localdomain | +--------------------------------------+---------------------------+----------------------------------+
Remarque : Dans le résultat affiché ici, la première colonne correspond à l'identifiant unique universel (UUID), la deuxième colonne correspond au nom de la machine virtuelle et la troisième colonne correspond au nom d'hôte où la machine virtuelle est présente. Les paramètres de cette sortie seront utilisés dans les sections suivantes.
Processus de snapshot
Arrêt de l'application CPAR
Étape 1 : ouverture de tout client SSH connecté au réseau et connexion à l’instance CPAR
Il est important de ne pas arrêter les 4 instances AAA au sein d'un site en même temps, et ce de manière individuelle.
Étape 2. Arrêtez l’application CPAR à l’aide de cette commande :
/opt/CSCOar/bin/arserver stop
Un message indique « Arrêt de l'agent du serveur Cisco Prime Access Registrar terminé ». Je devrais venir.
Remarque : Si un utilisateur a laissé une session CLI ouverte, la commande arserver stop ne fonctionnera pas et le message suivant s'affichera :
ERROR: You can not shut down Cisco Prime Access Registrar while the
CLI is being used. Current list of running
CLI with process id is:
2903 /opt/CSCOar/bin/aregcmd –s
Dans cet exemple, l'ID de processus mis en évidence 2903 doit être arrêté avant que le CPAR puisse être arrêté. Si c'est le cas, terminez le processus avec cette commande :
kill -9 *process_id*
Répétez ensuite l'étape 1.
Étape 3. Vérifiez que l’application CPAR a bien été arrêtée par cette commande :
/opt/CSCOar/bin/arstatus
Ces messages doivent s'afficher :
Cisco Prime Access Registrar Server Agent not running Cisco Prime Access Registrar GUI not running
Tâche de snapshot de VM
Étape 1. Accédez au site Web Horizon GUI correspondant au site (ville) en cours de traitement. Lorsque vous accédez à Horizon, l'écran représenté sur l'image s'affiche :
Étape 2. Comme le montre l’image, accédez à Project > Instances.
Si l'utilisateur utilisé était cpar, seules les 4 instances AAA apparaîtront dans ce menu.
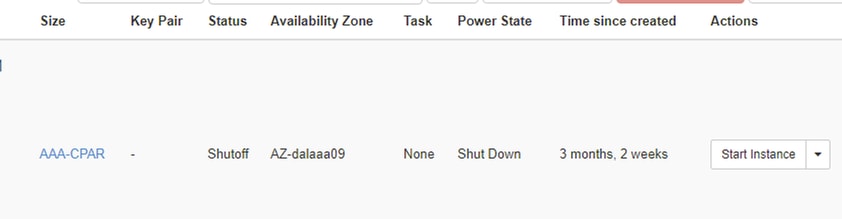
Étape 3. Arrêtez une seule instance à la fois et répétez l'ensemble du processus dans ce document. Afin d'arrêter la VM, accédez à Actions > Shut Off Instance et confirmez votre sélection.

Étape 4 Vérifiez que l'instance a bien été arrêtée en sélectionnant Status = Shutoff et Power State = Shut Down.
Cette étape met fin au processus d'arrêt du CPAR.
Snapshot VM
Une fois les machines virtuelles CPAR désactivées, les instantanés peuvent être pris en parallèle, car ils appartiennent à des ordinateurs indépendants.
Les quatre fichiers QCOW2 sont créés en parallèle.
Prenez un instantané de chaque instance AAA (25 minutes -1 heure) (25 minutes pour les instances qui ont utilisé une image qcow comme source et 1 heure pour les instances qui utilisent une image brute comme source).
Étape 1 : connexion à l'interface utilisateur graphique Horizon d'Openstack de POD.
Étape 2. Une fois connecté, accédez à la section Project > Compute > Instances du menu supérieur et recherchez les instances AAA.
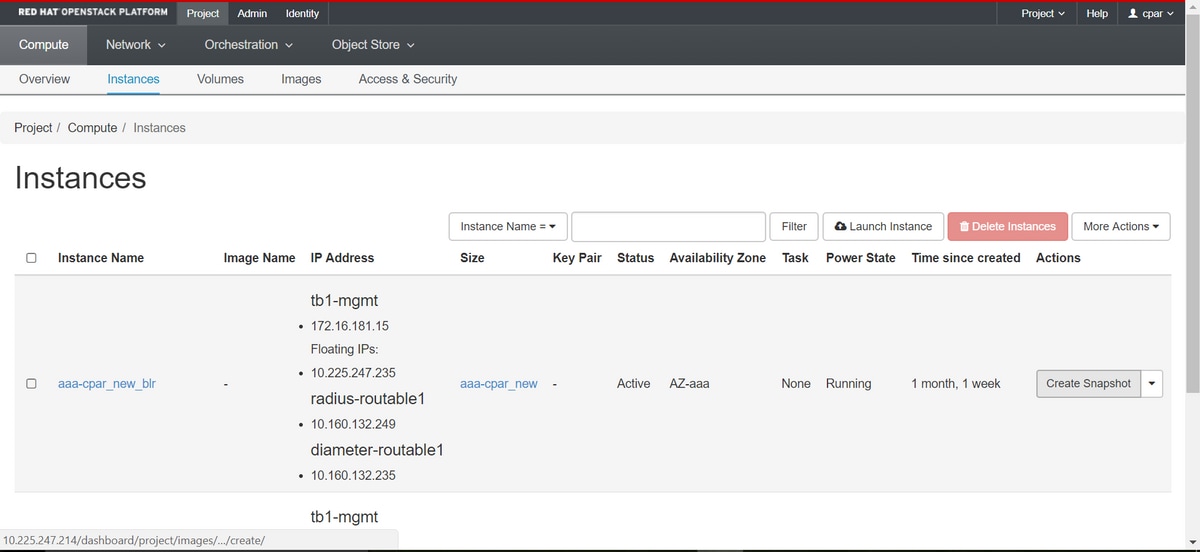
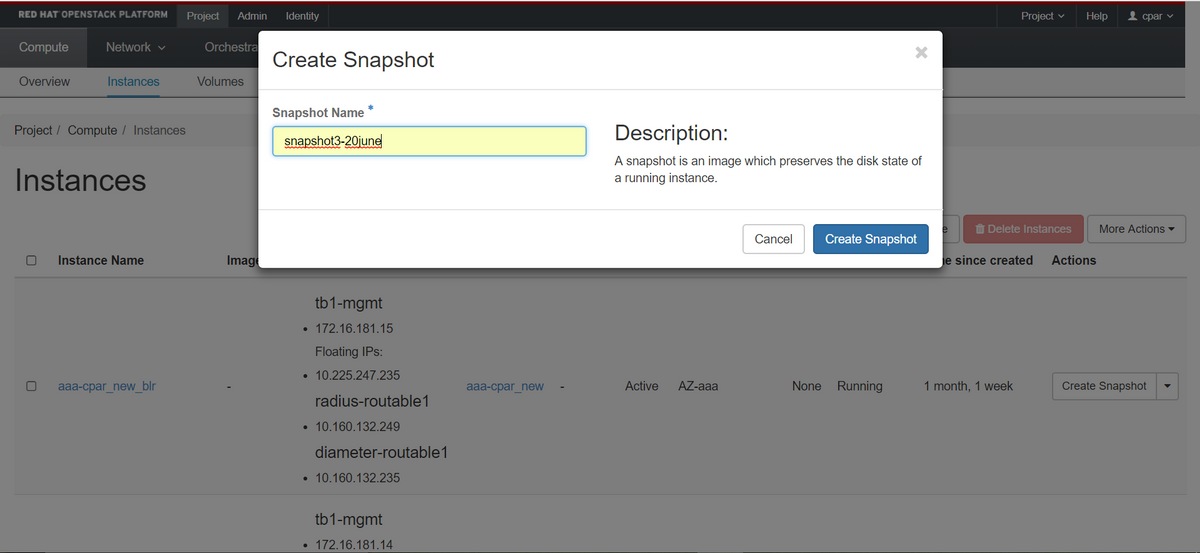
Étape 3. Cliquez sur Create Snapshot pour poursuivre la création du snapshot (cette opération doit être exécutée sur l'instance AAA correspondante).
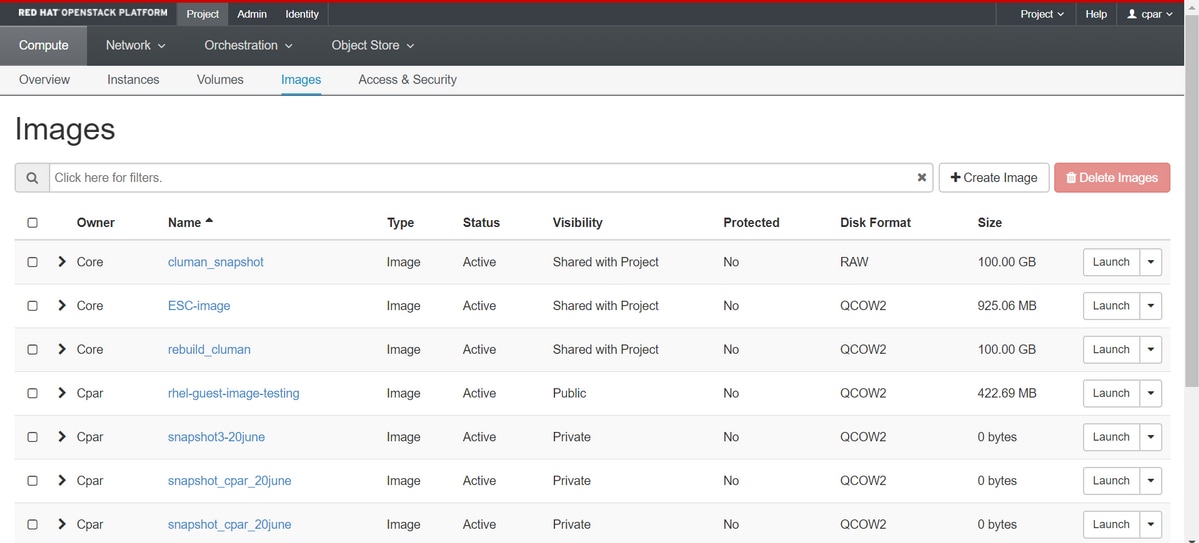
Étape 4. Une fois le cliché exécuté, accédez au menu Images et vérifiez qu'il se termine et qu'il ne signale aucun problème.
Étape 5. L’étape suivante consiste à télécharger le cliché au format QCOW2 et à le transférer à une entité distante au cas où le protocole OSPD serait perdu au cours de ce processus. Pour ce faire, identifiez l'instantané avec cette commande glance image-list au niveau OSPD
[root@elospd01 stack]# glance image-list +--------------------------------------+---------------------------+ | ID | Name | +--------------------------------------+---------------------------+ | 80f083cb-66f9-4fcf-8b8a-7d8965e47b1d | AAA-Temporary | | 22f8536b-3f3c-4bcc-ae1a-8f2ab0d8b950 | ELP1 cluman 10_09_2017 | | 70ef5911-208e-4cac-93e2-6fe9033db560 | ELP2 cluman 10_09_2017 | | e0b57fc9-e5c3-4b51-8b94-56cbccdf5401 | ESC-image | | 92dfe18c-df35-4aa9-8c52-9c663d3f839b | lgnaaa01-sept102017 | | 1461226b-4362-428b-bc90-0a98cbf33500 | tmobile-pcrf-13.1.1.iso | | 98275e15-37cf-4681-9bcc-d6ba18947d7b | tmobile-pcrf-13.1.1.qcow2 | +--------------------------------------+---------------------------+
Étape 6. Une fois identifié le cliché à télécharger (dans ce cas, il s’agira de celui marqué en vert ci-dessus), il est téléchargé au format QCOW2 à l’aide de la commande glance image-download comme indiqué ici.
[root@elospd01 stack]# glance image-download 92dfe18c-df35-4aa9-8c52-9c663d3f839b --file /tmp/AAA-CPAR-LGNoct192017.qcow2 &
- Le « & » envoie le processus en arrière-plan. Cette action prend un certain temps. Une fois terminée, l'image peut être localisée dans le répertoire /tmp.
- Lorsque le processus est envoyé en arrière-plan, si la connectivité est perdue, le processus est également arrêté.
- Exécutez la commande disown -h afin qu'en cas de perte de connexion Secure Shell (SSH), le processus continue à s'exécuter et se termine sur l'OSPD.
Étape 7. Une fois le processus de téléchargement terminé, un processus de compression doit être exécuté car ce snapshot peut être rempli de ZÉROS en raison des processus, des tâches et des fichiers temporaires traités par le système d'exploitation. La commande à utiliser pour la compression de fichiers est virt-sparsify.
[root@elospd01 stack]# virt-sparsify AAA-CPAR-LGNoct192017.qcow2 AAA-CPAR-LGNoct192017_compressed.qcow2
Ce processus prend un certain temps (environ 10-15 minutes). Une fois terminé, le fichier résultant est celui qui doit être transféré à une entité externe comme spécifié à l'étape suivante.
La vérification de l'intégrité du fichier est nécessaire. Pour ce faire, exécutez la commande suivante et recherchez l'attribut corrompu à la fin de sa sortie.
[root@wsospd01 tmp]# qemu-img info AAA-CPAR-LGNoct192017_compressed.qcow2 image: AAA-CPAR-LGNoct192017_compressed.qcow2 file format: qcow2 virtual size: 150G (161061273600 bytes) disk size: 18G cluster_size: 65536 Format specific information: compat: 1.1 lazy refcounts: false refcount bits: 16 corrupt: false
Afin d'éviter un problème de perte de l'OSPD, l'instantané récemment créé sur le format QCOW2 doit être transféré à une entité externe. Avant de commencer le transfert de fichiers, nous devons vérifier si la destination a suffisamment d'espace disque disponible, utilisez la commande df -kh, afin de vérifier l'espace mémoire. Il est conseillé de le transférer temporairement vers l'OSPD d'un autre site via SFTP sftp root@x.x.x.x où x.x.x.x est l'IP d'un OSPD distant. Afin d'accélérer le transfert, la destination peut être envoyée à plusieurs OSPD. De la même manière, cette commande peut être utilisée scp *name_of_the_file*.qcow2 root@ x.x.x.x:/tmp (où x.x.x.x est l'IP d'un OSPD distant) pour transférer le fichier vers un autre OSPD.
Mise hors tension progressive
Mettre le noeud hors tension
- Pour mettre l'instance hors tension : nova stop <NOM_INSTANCE>
- Vous voyez maintenant le nom de l'instance avec l'état shutdown.
[stack@director ~]$ nova stop aaa2-21 Request to stop server aaa2-21 has been accepted. [stack@director ~]$ nova list +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | ID | Name | Status | Task State | Power State | Networks | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | ACTIVE | - | Running | tb1-mgmt=172.16.181.14, 10.225.247.233; radius-routable1=10.160.132.245; diameter-routable1=10.160.132.231 | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | SHUTOFF | - | Shutdown | diameter-routable1=10.160.132.230; radius-routable1=10.160.132.248; tb1-mgmt=172.16.181.7, 10.225.247.234 | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | ACTIVE | - | Running | diameter-routable1=10.160.132.233; radius-routable1=10.160.132.244; tb1-mgmt=172.16.181.10 | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+
Suppression du noeud de calcul
Les étapes mentionnées dans cette section sont courantes, quelles que soient les machines virtuelles hébergées dans le noeud de calcul.
Supprimer le noeud de calcul de la liste des services
Supprimez le service de calcul de la liste de services :
[stack@director ~]$ openstack compute service list |grep compute-3 | 138 | nova-compute | pod2-stack-compute-3.localdomain | AZ-aaa | enabled | up | 2018-06-21T15:05:37.000000 |
openstack compute service delete <ID>
[stack@director ~]$ openstack compute service delete 138
Supprimer les agents neutroniques
Supprimez l'ancien agent neutron associé et ouvrez vswitch agent pour le serveur informatique :
[stack@director ~]$ openstack network agent list | grep compute-3 | 3b37fa1d-01d4-404a-886f-ff68cec1ccb9 | Open vSwitch agent | pod2-stack-compute-3.localdomain | None | True | UP | neutron-openvswitch-agent |
openstack network agent delete <ID>
[stack@director ~]$ openstack network agent delete 3b37fa1d-01d4-404a-886f-ff68cec1ccb9
Supprimer de la base de données Ironic
Supprimez un noeud de la base de données ironique et vérifiez-le :
nova show <compute-node> | hyperviseur grep
[root@director ~]# source stackrc [root@director ~]# nova show pod2-stack-compute-4 | grep hypervisor | OS-EXT-SRV-ATTR:hypervisor_hostname | 7439ea6c-3a88-47c2-9ff5-0a4f24647444
ironic node-delete <ID>
[stack@director ~]$ ironic node-delete 7439ea6c-3a88-47c2-9ff5-0a4f24647444 [stack@director ~]$ ironic node-list
Le noeud supprimé ne doit pas être répertorié maintenant dans la liste des noeuds ironiques.
Supprimer de Overcloud
Étape 1. Créez un fichier de script nommé delete_node.sh avec le contenu comme indiqué. Assurez-vous que les modèles mentionnés sont les mêmes que ceux utilisés dans le script deploy.sh utilisé pour le déploiement de la pile :
delete_node.sh
openstack overcloud node delete --templates -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml -e /home/stack/custom-templates/layout.yaml --stack <stack-name> <UUID>
[stack@director ~]$ source stackrc [stack@director ~]$ /bin/sh delete_node.sh + openstack overcloud node delete --templates -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml -e /home/stack/custom-templates/layout.yaml --stack pod2-stack 7439ea6c-3a88-47c2-9ff5-0a4f24647444 Deleting the following nodes from stack pod2-stack: - 7439ea6c-3a88-47c2-9ff5-0a4f24647444 Started Mistral Workflow. Execution ID: 4ab4508a-c1d5-4e48-9b95-ad9a5baa20ae real 0m52.078s user 0m0.383s sys 0m0.086s
Étape 2. Attendez que l'opération de pile OpenStack passe à l'état COMPLETE :
[stack@director ~]$ openstack stack list +--------------------------------------+------------+-----------------+----------------------+----------------------+ | ID | Stack Name | Stack Status | Creation Time | Updated Time | +--------------------------------------+------------+-----------------+----------------------+----------------------+ | 5df68458-095d-43bd-a8c4-033e68ba79a0 | pod2-stack | UPDATE_COMPLETE | 2018-05-08T21:30:06Z | 2018-05-08T20:42:48Z | +--------------------------------------+------------+-----------------+----------------------+----------------------+
Installer le nouveau noeud de calcul
Les étapes d'installation d'un nouveau serveur UCS C240 M4 et les étapes de configuration initiale peuvent être consultées dans le Guide d'installation et de maintenance du serveur Cisco UCS C240 M4
Étape 1. Après l’installation du serveur, insérez les disques durs dans les logements respectifs en tant qu’ancien serveur.
Étape 2. Connexion au serveur à l’aide de l’adresse IP CIMC
Étape 3. Effectuez la mise à niveau du BIOS si le micrologiciel n'est pas conforme à la version recommandée utilisée précédemment. Les étapes de la mise à niveau du BIOS sont indiquées ici : Guide de mise à niveau du BIOS du serveur rack Cisco UCS série C
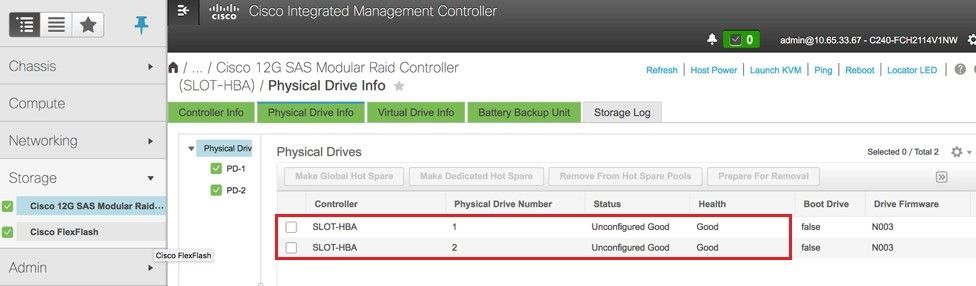
Étape 4. Afin de vérifier l'état des lecteurs physiques, qui est Unconfigured Good, accédez à Storage > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Physical Drive Info.
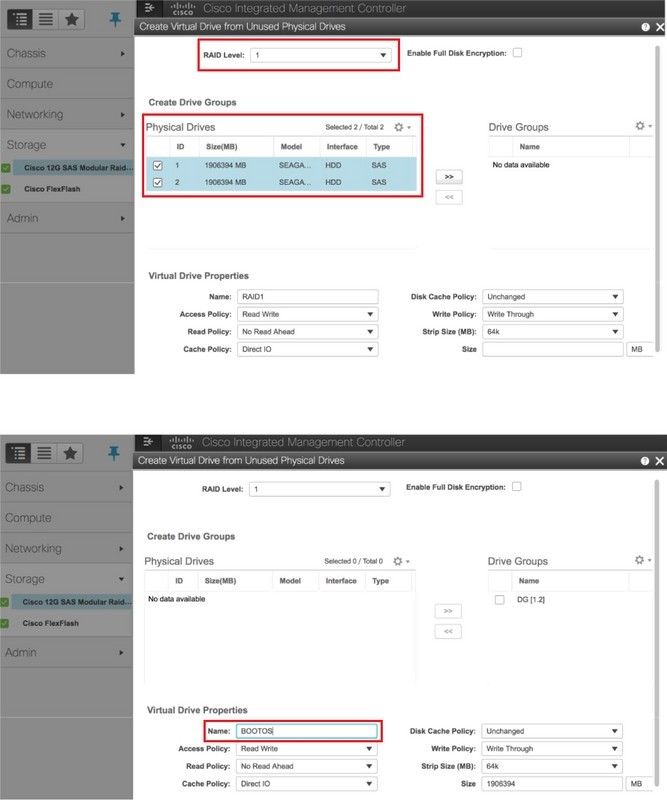
Étape 5. Afin de créer un disque virtuel à partir des disques physiques avec RAID niveau 1, naviguez vers Storage > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Controller Info > Create Virtual Drive from Unused Physical Drives.
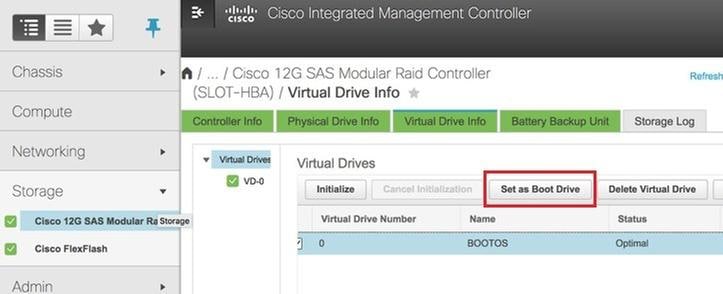
Étape 6. Sélectionnez le VD et configurez Set as Boot Drive, comme illustré dans l'image.
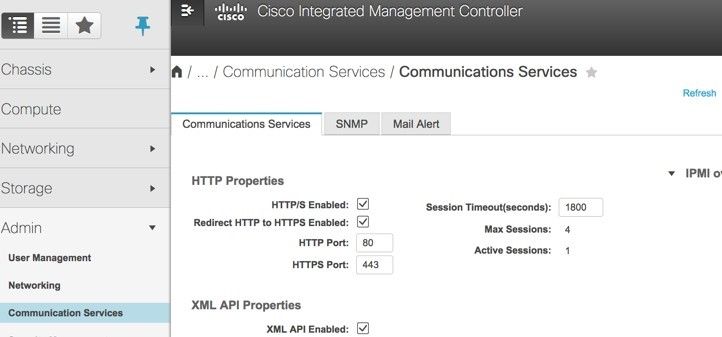
Étape 7. Afin d’activer IPMI sur LAN, naviguez jusqu’à Admin > Communication Services > Communication Services, comme indiqué dans l’image.
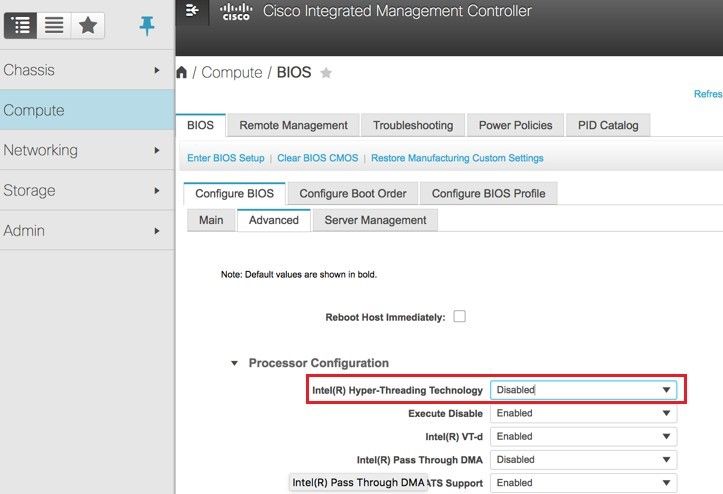
Étape 8. Afin de désactiver l’hyperthreading, accédez à Compute > BIOS > Configure BIOS > Advanced > Processor Configuration.
Remarque : L'image illustrée ici et les étapes de configuration mentionnées dans cette section font référence à la version 3.0(3e) du micrologiciel et il peut y avoir de légères variations si vous travaillez sur d'autres versions.
Ajouter le nouveau noeud de calcul à l'Overcloud
Les étapes mentionnées dans cette section sont courantes quelle que soit la machine virtuelle hébergée par le noeud de calcul.
Étape 1. Ajout d’un serveur de calcul avec un index différent
Créez un fichier add_node.json avec uniquement les détails du nouveau serveur de calcul à ajouter. Assurez-vous que le numéro d'index du nouveau serveur de calcul n'a pas été utilisé auparavant. En général, incrémentez la valeur de calcul immédiatement supérieure.
Exemple : Le plus haut précédent était compute-17, donc, a créé compute-18 dans le cas du système 2-vnf.
Remarque : Gardez à l'esprit le format json.
[stack@director ~]$ cat add_node.json
{
"nodes":[
{
"mac":[
"<MAC_ADDRESS>"
],
"capabilities": "node:compute-18,boot_option:local",
"cpu":"24",
"memory":"256000",
"disk":"3000",
"arch":"x86_64",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"<PASSWORD>",
"pm_addr":"192.100.0.5"
}
]
}
Étape 2 : importation du fichier json
[stack@director ~]$ openstack baremetal import --json add_node.json Started Mistral Workflow. Execution ID: 78f3b22c-5c11-4d08-a00f-8553b09f497d Successfully registered node UUID 7eddfa87-6ae6-4308-b1d2-78c98689a56e Started Mistral Workflow. Execution ID: 33a68c16-c6fd-4f2a-9df9-926545f2127e Successfully set all nodes to available.
Étape 3. Exécutez l’introspection de noeud en utilisant l’UUID noté à l’étape précédente.
[stack@director ~]$ openstack baremetal node manage 7eddfa87-6ae6-4308-b1d2-78c98689a56e [stack@director ~]$ ironic node-list |grep 7eddfa87 | 7eddfa87-6ae6-4308-b1d2-78c98689a56e | None | None | power off | manageable | False | [stack@director ~]$ openstack overcloud node introspect 7eddfa87-6ae6-4308-b1d2-78c98689a56e --provide Started Mistral Workflow. Execution ID: e320298a-6562-42e3-8ba6-5ce6d8524e5c Waiting for introspection to finish... Successfully introspected all nodes. Introspection completed. Started Mistral Workflow. Execution ID: c4a90d7b-ebf2-4fcb-96bf-e3168aa69dc9 Successfully set all nodes to available. [stack@director ~]$ ironic node-list |grep available | 7eddfa87-6ae6-4308-b1d2-78c98689a56e | None | None | power off | available | False |
Étape 4. Exécutez le script deploy.sh qui a été précédemment utilisé pour déployer la pile, afin d'ajouter le nouveau code ordinateur à la pile overcloud :
[stack@director ~]$ ./deploy.sh ++ openstack overcloud deploy --templates -r /home/stack/custom-templates/custom-roles.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml --stack ADN-ultram --debug --log-file overcloudDeploy_11_06_17__16_39_26.log --ntp-server 172.24.167.109 --neutron-flat-networks phys_pcie1_0,phys_pcie1_1,phys_pcie4_0,phys_pcie4_1 --neutron-network-vlan-ranges datacentre:1001:1050 --neutron-disable-tunneling --verbose --timeout 180 … Starting new HTTP connection (1): 192.200.0.1 "POST /v2/action_executions HTTP/1.1" 201 1695 HTTP POST http://192.200.0.1:8989/v2/action_executions 201 Overcloud Endpoint: http://10.1.2.5:5000/v2.0 Overcloud Deployed clean_up DeployOvercloud: END return value: 0 real 38m38.971s user 0m3.605s sys 0m0.466s
Étape 5. Attendez que l'état de la pile openstack soit Terminé.
[stack@director ~]$ openstack stack list +--------------------------------------+------------+-----------------+----------------------+----------------------+ | ID | Stack Name | Stack Status | Creation Time | Updated Time | +--------------------------------------+------------+-----------------+----------------------+----------------------+ | 5df68458-095d-43bd-a8c4-033e68ba79a0 | ADN-ultram | UPDATE_COMPLETE | 2017-11-02T21:30:06Z | 2017-11-06T21:40:58Z | +--------------------------------------+------------+-----------------+----------------------+----------------------+
Étape 6. Vérifiez que le nouveau noeud de calcul est à l’état Actif.
[root@director ~]# nova list | grep pod2-stack-compute-4 | 5dbac94d-19b9-493e-a366-1e2e2e5e34c5 | pod2-stack-compute-4 | ACTIVE | - | Running | ctlplane=192.200.0.116 |
Restaurer les machines virtuelles
Récupérer une instance via un snapshot
Processus de récupération :
Il est possible de redéployer l'instance précédente à l'aide de l'instantané pris lors des étapes précédentes.
Étape 1 [FACULTATIF]. S'il n'y a pas de VMsnapshot précédent disponible alors connectez-vous au noeud OSPD où la sauvegarde a été envoyée et sftp la sauvegarde à son noeud OSPD d'origine. Via sftp root@x.x.x.x où x.x.x.x est l'IP de l'OSPD d'origine. Enregistrez le fichier d'instantané dans le répertoire /tmp.
Étape 2 : connexion au noeud OSPD sur lequel l’instance est redéployée

Utilisez la commande suivante pour créer la source des variables d'environnement :
# source /home/stack/pod1-stackrc-Core-CPAR
Étape 3. Pour utiliser le cliché en tant qu'image, vous devez le télécharger vers l'horizon en tant que tel. Pour ce faire, utilisez la commande suivante.
#glance image-create -- AAA-CPAR-Date-snapshot.qcow2 --container-format bare --disk-format qcow2 --name AAA-CPAR-Date-snapshot
Le processus peut être vu à l'horizon.

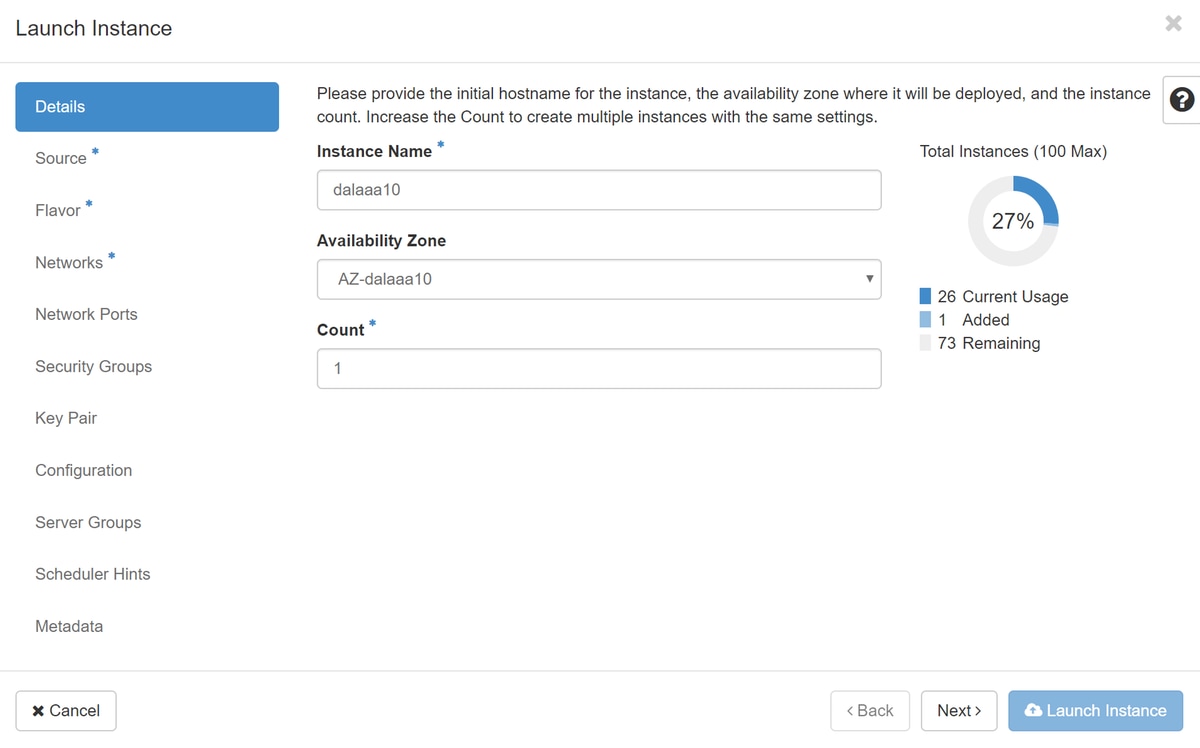
Étape 4. Dans l'horizon, naviguez vers Project > Instances et cliquez sur Launch Instance, comme indiqué dans l'image.

Étape 5. Entrez le nom de l'instance et choisissez la zone de disponibilité, comme indiqué dans l'image.
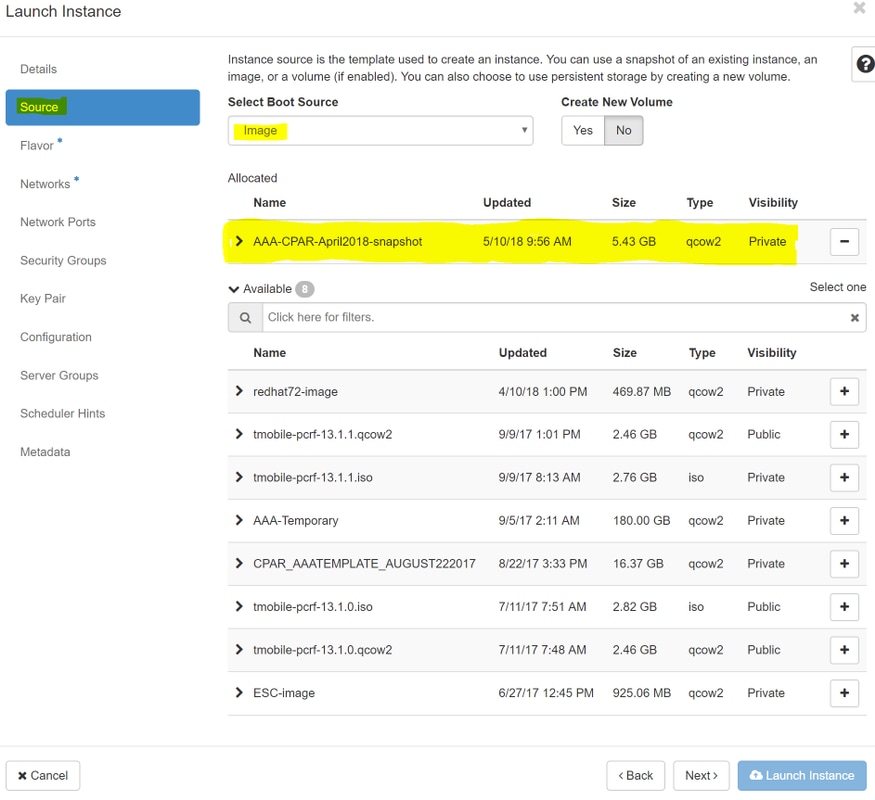
Étape 6. Dans l'onglet Source, choisissez l'image pour créer l'instance. Dans le menu Select Boot Source sélectionnez image, une liste d'images s'affiche ici, choisissez celle qui a été précédemment téléchargée lorsque vous cliquez sur le signe +.
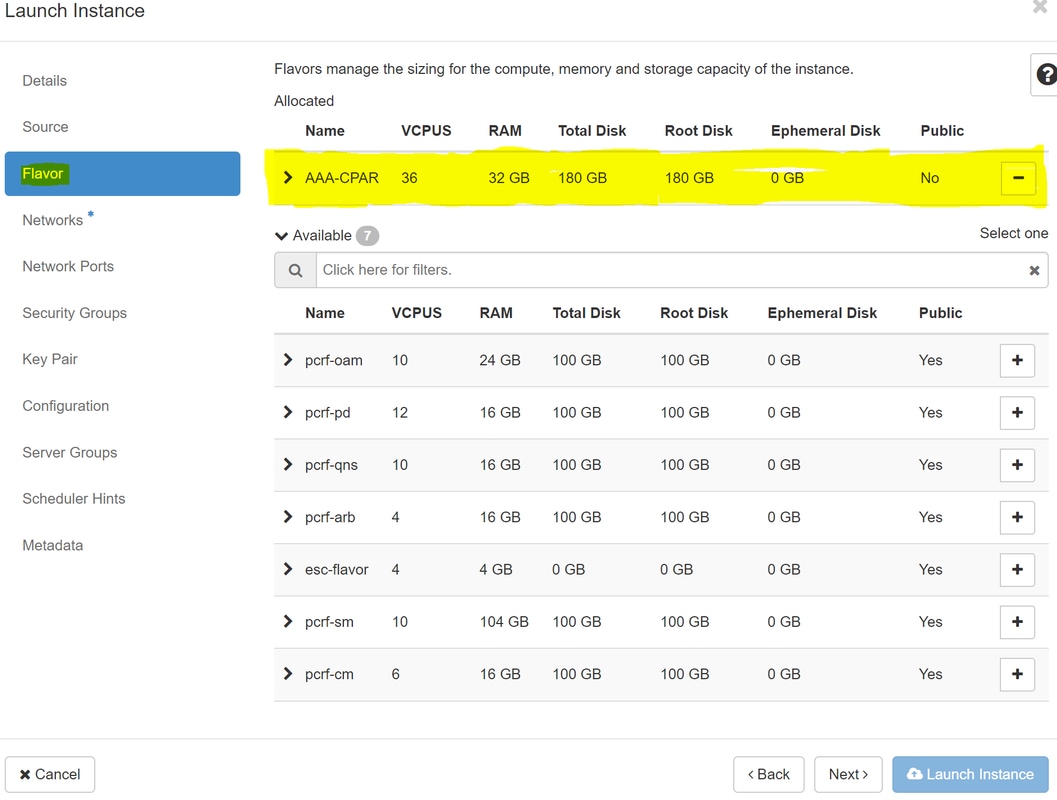
Étape 7. Dans l'onglet Saveur, choisissez la saveur AAA lorsque vous cliquez sur le signe +, comme illustré dans l'image.
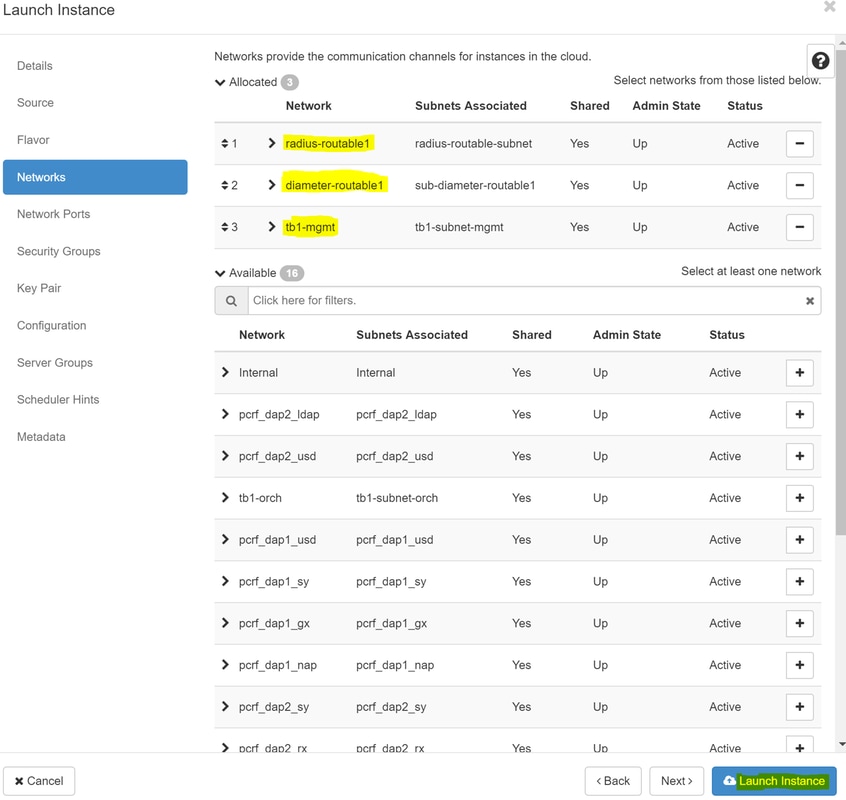
Étape 8. Accédez à l'onglet Networks et sélectionnez les réseaux dont l'instance a besoin lorsque vous cliquez sur le signe +. Dans ce cas, sélectionnez diameter-soutable1, radius-routable1 et tb1-mgmt, comme indiqué dans l'image.
Étape 9. Cliquez sur Launch instance pour le créer. La progression peut être suivie dans Horizon :
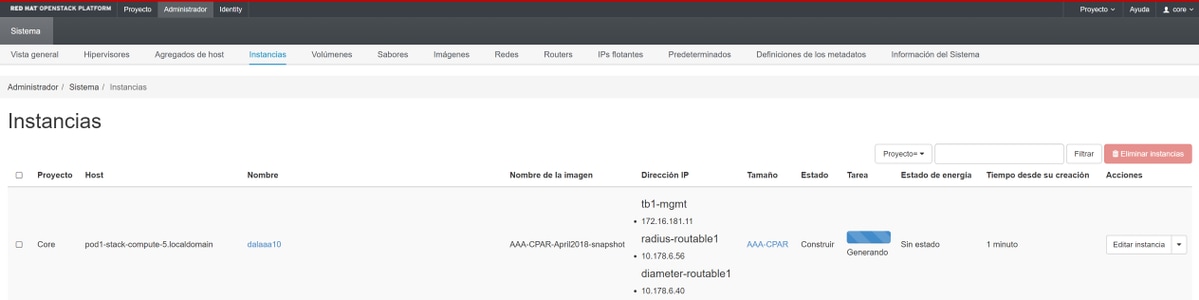
Au bout de quelques minutes, l'instance sera entièrement déployée et prête à l'emploi.

Créer et attribuer une adresse IP flottante
Une adresse IP flottante est une adresse routable, ce qui signifie qu'elle est accessible depuis l'extérieur de l'architecture Ultra M/Openstack et qu'elle peut communiquer avec d'autres noeuds à partir du réseau.
Étape 1. Dans le menu supérieur d’Horizon, accédez à Admin > Floating IPs.
Étape 2. Cliquez sur le bouton Allocate IP to Project.
Étape 3. Dans la fenêtre Allocate Floating IP, sélectionnez le pool à partir duquel la nouvelle adresse IP flottante appartient, le projet auquel elle va être attribuée et la nouvelle adresse IP flottante elle-même.
Exemple :
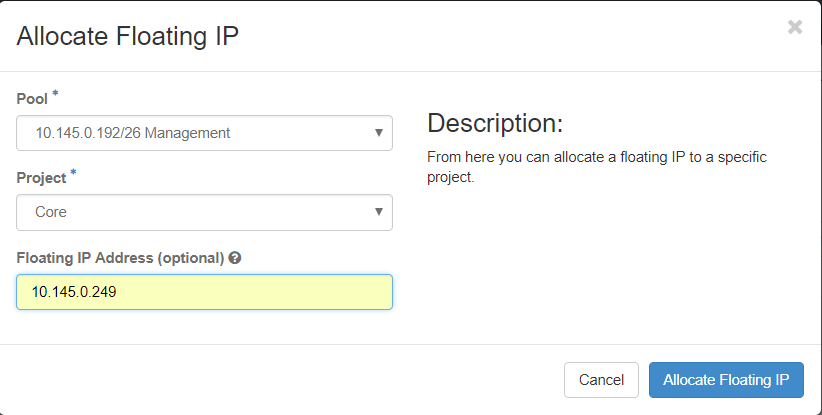
Étape 4. Cliquez sur le bouton Allocate Floating IP.
Étape 5. Dans le menu supérieur Horizon, accédez à Projet > Instances.
Étape 6. Dans la colonne Action, cliquez sur la flèche qui pointe vers le bas dans le Créer un cliché bouton, un menu doit être affiché. Sélectionnez l'option Associer IP flottante.
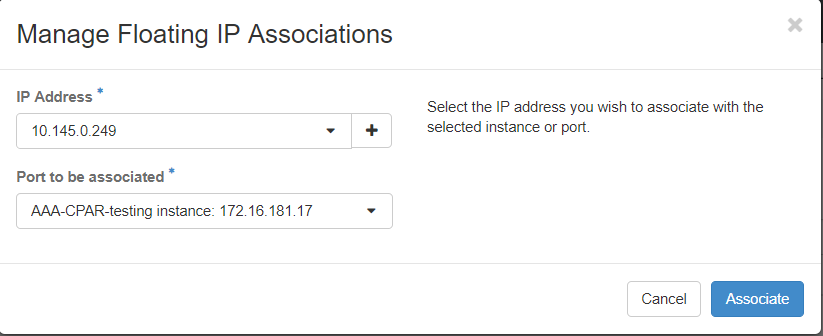
Étape 7. Sélectionnez l’adresse IP flottante correspondante destinée à être utilisée dans le champ IP Address et choisissez l’interface de gestion correspondante (eth0) à partir de la nouvelle instance où cette adresse IP flottante va être attribuée dans le port à associer. Reportez-vous à l'image suivante comme exemple de cette procédure.
Étape 8. Cliquez sur Associate.
Activer le protocole SSH
Étape 1. Dans le menu supérieur Horizon, accédez à Projet > Instances.
Étape 2. Cliquez sur le nom de l'instance/de la VM créée dans la section Lancer une nouvelle instance.
Étape 3. Cliquez sur l’onglet Console. L'interface de ligne de commande de la VM s'affiche.
Étape 4. Une fois l’interface de ligne de commande affichée, saisissez les informations de connexion appropriées :
username (nom d’utilisateur) : racine
Mot de passe : cisco123
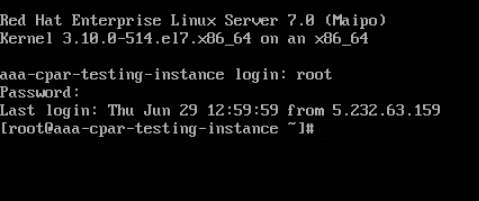
Étape 5. Dans l’ILC, entrez la commande vi /etc/ssh/sshd_config pour modifier la configuration ssh.
Étape 6. Une fois le fichier de configuration ssh ouvert, appuyez sur I pour modifier le fichier. Recherchez ensuite la section affichée ci-dessous et changez la première ligne de PasswordAuthentication no en PasswordAuthentication yes.

Étape 7. Appuyez sur ESC et entrez :wq ! pour enregistrer les modifications apportées au fichier sshd_config.
Étape 8. Exécutez la commande service sshd restart.
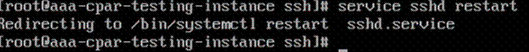
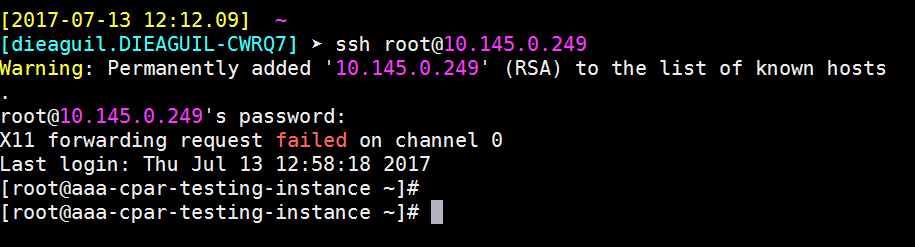
Étape 9. Afin de tester que les modifications de configuration SSH ont été correctement appliquées, ouvrez tout client SSH et essayez d’établir une connexion sécurisée à distance à l’aide de l’adresse IP flottante attribuée à l’instance (c’est-à-dire 10.145.0.249) et à la racine de l’utilisateur.
Établir une session SSH
Ouvrez une session SSH avec l'adresse IP de la machine virtuelle/du serveur correspondant où l'application est installée.

Début de l'instance CPAR
Veuillez suivre les étapes ci-dessous, une fois que l'activité est terminée et que les services CPAR peuvent être rétablis dans le site qui a été fermé.
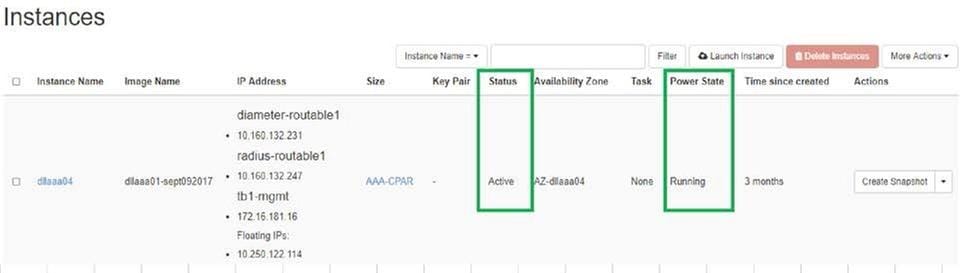
- Pour vous reconnecter à Horizon, accédez à Project > Instance > Start Instance.
- Vérifiez que l'état de l'instance est actif et que l'état d'alimentation est en cours d'exécution :
Contrôle d'intégrité post-activité
Étape 1 : exécution de la commande /opt/CSCOar/bin/arstatus au niveau du système d’exploitation
[root@wscaaa04 ~]# /opt/CSCOar/bin/arstatus Cisco Prime AR RADIUS server running (pid: 24834) Cisco Prime AR Server Agent running (pid: 24821) Cisco Prime AR MCD lock manager running (pid: 24824) Cisco Prime AR MCD server running (pid: 24833) Cisco Prime AR GUI running (pid: 24836) SNMP Master Agent running (pid: 24835) [root@wscaaa04 ~]#
Étape 2. Exécutez la commande /opt/CSCOar/bin/aregcmd au niveau du système d’exploitation et entrez les informations d’identification de l’administrateur. Vérifiez que CPAR Health est 10 sur 10 et quittez CPAR CLI.
[root@aaa02 logs]# /opt/CSCOar/bin/aregcmd
Cisco Prime Access Registrar 7.3.0.1 Configuration Utility
Copyright (C) 1995-2017 by Cisco Systems, Inc. All rights reserved.
Cluster:
User: admin
Passphrase:
Logging in to localhost
[ //localhost ]
LicenseInfo = PAR-NG-TPS 7.2(100TPS:)
PAR-ADD-TPS 7.2(2000TPS:)
PAR-RDDR-TRX 7.2()
PAR-HSS 7.2()
Radius/
Administrators/
Server 'Radius' is Running, its health is 10 out of 10
--> exit
Étape 3.Exécutez la commande netstat | grep diameter et vérifiez que toutes les connexions DRA sont établies.
Le résultat mentionné ci-dessous concerne un environnement dans lequel des liaisons de diamètre sont attendues. Si moins de liens sont affichés, cela représente une déconnexion du DRA qui doit être analysée.
[root@aa02 logs]# netstat | grep diameter tcp 0 0 aaa02.aaa.epc.:77 mp1.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:36 tsa6.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:47 mp2.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:07 tsa5.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:08 np2.dra01.d:diameter ESTABLISHED
Étape 4. Vérifiez que le journal TPS indique les demandes en cours de traitement par CPAR. Les valeurs mises en évidence représentent le TPS et ce sont celles auxquelles nous devons prêter attention.
La valeur de TPS ne doit pas dépasser 1500.
[root@wscaaa04 ~]# tail -f /opt/CSCOar/logs/tps-11-21-2017.csv 11-21-2017,23:57:35,263,0 11-21-2017,23:57:50,237,0 11-21-2017,23:58:05,237,0 11-21-2017,23:58:20,257,0 11-21-2017,23:58:35,254,0 11-21-2017,23:58:50,248,0 11-21-2017,23:59:05,272,0 11-21-2017,23:59:20,243,0 11-21-2017,23:59:35,244,0 11-21-2017,23:59:50,233,0
Étape 5. Recherchez les messages d'erreur ou d'alarme dans name_radius_1_log
[root@aaa02 logs]# grep -E "error|alarm" name_radius_1_log
Étape 6. Vérifiez la quantité de mémoire utilisée par le processus CPAR à l’aide de la commande suivante :
peigné | rayon grep
[root@sfraaa02 ~]# top | grep radius 27008 root 20 0 20.228g 2.413g 11408 S 128.3 7.7 1165:41 radius
Cette valeur mise en surbrillance doit être inférieure à : 7 Go, soit le maximum autorisé au niveau de l'application.
Contribution d’experts de Cisco
- Karthikeyan DachanamoorthyServices avancés Cisco
- Harshita BhardwajServices avancés Cisco
 Commentaires
CommentairesContacter Cisco
- Ouvrir un dossier d’assistance

- (Un contrat de service de Cisco est requis)