Ultra-M UCS 240M4 escoge el error del HDD - Procedimiento caliente del intercambio - vEPC
Opciones de descarga
-
ePub (251.0 KB)
Visualice en diferentes aplicaciones en iPhone, iPad, Android, Sony Reader o Windows Phone -
Mobi (Kindle) (239.2 KB)
Visualice en dispositivo Kindle o aplicación Kindle en múltiples dispositivos
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Contenido
Introducción
Este documento describe los pasos requeridos para substituir la unidad defectuosa de la unidad de disco duro (HDD) en el servidor en un Ultra-M puesto que funciona la red virtual de StarOS de los host (VNFs).
Antecedentes
Ultra-M es una solución móvil virtualizada preembalada y validada de la base del paquete diseñada para simplificar el despliegue de VNFs. OpenStack es el administrador virtualizado de la infraestructura (VIM) para Ultra-M y consiste en estos tipos de nodo:
- Cálculo
- Disco del almacenamiento del objeto - Cálculo (OSD - Cálculo)
- Regulador
- Plataforma de OpenStack - Director (OSPD)
La arquitectura de alto nivel de Ultra-M y los componentes implicados se representan en esta imagen:
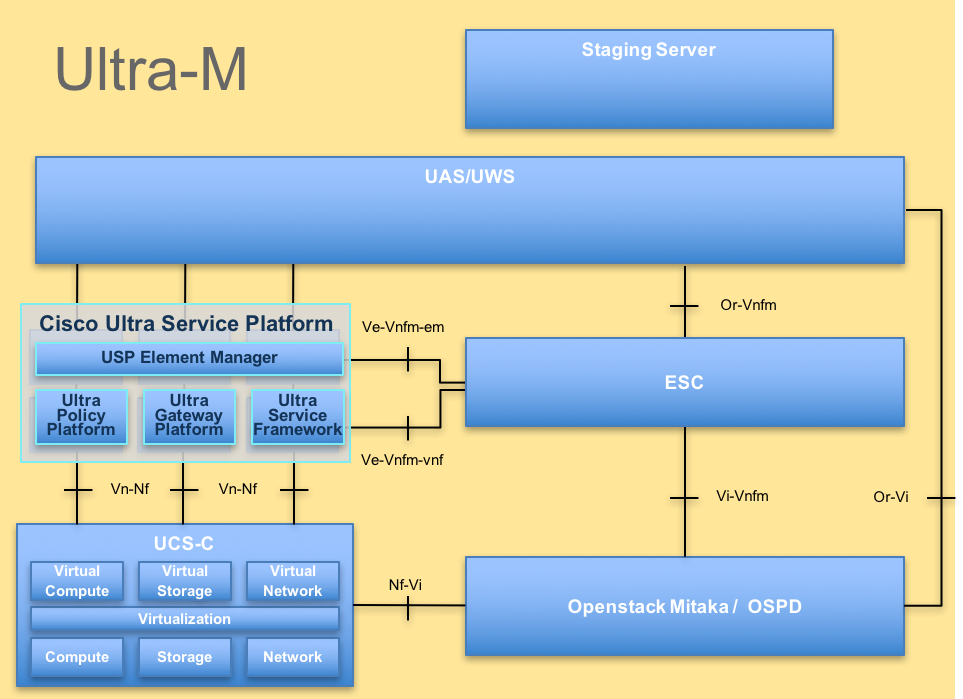 El documento de UltraM ArchitectureThis se piensa para el personal de Cisco que es familiar con la plataforma de Cisco Ultra-M y detalla los pasos requeridos ser realizado en OpenStack llano a la hora del reemplazo del servidor OSPD.
El documento de UltraM ArchitectureThis se piensa para el personal de Cisco que es familiar con la plataforma de Cisco Ultra-M y detalla los pasos requeridos ser realizado en OpenStack llano a la hora del reemplazo del servidor OSPD.
Note: Ultra la versión M 5.1.x se considera para definir los procedimientos en este documento.
Abreviaturas
| VNF | Función de la red virtual |
| CF | Función de control |
| SF | Función de servicio |
| ESC | Regulador elástico del servicio |
| FREGONA | Método de procedimiento |
| OSD | Discos del almacenamiento del objeto |
| HDD | Unidad de disco duro |
| SSD | Unidad de estado sólido |
| VIM | Administrador virtual de la infraestructura |
| VM | Máquina virtual |
| EM | Element Manager |
| UA | Servicios de ultra automatización |
| UUID | Universal Identificador único |
Flujo de trabajo de la fregona
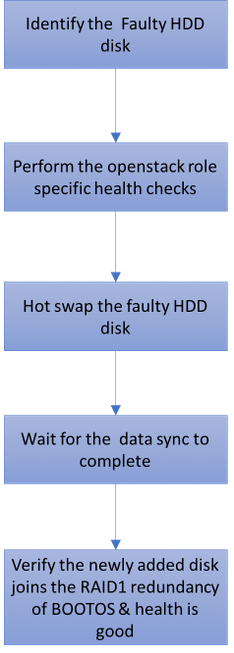
Solo error del HDD
1. Cada servidor de Baremetal será aprovisionado con dos unidades del HDD a actuar como DISCO DE ARRANQUE en configuración de la incursión 1. En caso del solo error del HDD, puesto que hay Redundancia llana RAID 1, la unidad defectuosa del HDD puede ser caliente intercambiada.
2. El procedimiento para substituir a un componente defectuoso en el servidor UCS C240 M4 se puede referir de: Reemplazo de los componentes del servidor.
3. En caso del solo error del HDD, solamente el HDD defectuoso será haber intercambiado caliente y por lo tanto no se requiere ningún procedimiento de actualización BIOS después de substituir los nuevos discos.
4. Después de substituir los discos, espera para la Sincronización de datos entre los discos. Puede ser que tarde las horas para completar.
5. En un OpenStack basado la solución (de Ultra-M), servidor baremetal UCS 240M4 puede tomar uno de estos papeles: Cálculo, OSD-cálculo, regulador y OSPD. Los pasos requeridos para manejar el solo error del HDD en cada uno de estas Funciones del servidor son lo mismo y esta sección describe las revisiones médicas que se realizarán antes del intercambio caliente del disco.
Solo error del HDD en el servidor del cálculo
1. Si observan al error de unidades del HDD en el UCS 240M4 que actúa como nodo del cálculo, realice estas revisiones médicas antes de que usted finalmente realice el intercambio caliente del disco defectuoso
2. Identifique los VM que se ejecutan en este servidor y verifique el estatus de las funciones son bueno.
Identifique los VM recibidos en el nodo del cálculo:
Identifique los VM que se reciben en el servidor del cálculo y verifiquelos que son activos y funcionamiento. Puede haber dos posibilidades:
1. El servidor del cálculo contiene solamente el SF VM.
[stack@director ~]$ nova list --field name,host | grep compute-10
| 49ac5f22-469e-4b84-badc-031083db0533 | VNF2-DEPLOYM_s8_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d |
pod1-compute-10.localdomain | ACTIVE|
2. El servidor del cálculo contiene la combinación CF/ESC/EM/UAS de VM.
[stack@director ~]$ nova list --field name,host | grep compute-8
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-compute-8.localdomain | ACTIVE |
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c2_0_df4be88d-b4bf-4456-945a-3812653ee229 | pod1-compute-8.localdomain | ACTIVE |
| 75528898-ef4b-4d68-b05d-882014708694 | VNF2-ESC-ESC-0 | pod1-compute-8.localdomain | ACTIVE |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-compute-8.localdomain | ACTIVE |
Note: En la salida mostrada aquí, la primera columna corresponde al UUID, la segunda columna es el nombre VM y la tercera columna es el nombre de host donde está presente el VM.
Revisiones médicas:
1. Inicie sesión al StarOS VNF e identifique el indicador luminoso LED amarillo de la placa muestra gravedad menor que corresponde al SF o al CF VM. Utilice el UUID del SF o el CF VM identificado de la sección “identifica los VM recibidos en el nodo del cálculo”, e identifica el indicador luminoso LED amarillo de la placa muestra gravedad menor que corresponde al UUID.
[local]VNF2# show card hardware
Tuesday might 08 16:49:42 UTC 2018
<snip>
Card 8:
Card Type : 4-Port Service Function Virtual Card
CPU Packages : 26 [#0, #1, #2, #3, #4, #5, #6, #7, #8, #9, #10, #11, #12, #13, #14, #15, #16, #17, #18, #19, #20, #21, #22, #23, #24, #25]
CPU Nodes : 2
CPU Cores/Threads : 26
Memory : 98304M (qvpc-di-large)
UUID/Serial Number : 49AC5F22-469E-4B84-BADC-031083DB0533
<snip>
[local]VNF2# show card hardware
Tuesday might 08 16:49:42 UTC 2018
<snip>
Card 2:
Card Type : Control Function Virtual Card
CPU Packages : 8 [#0, #1, #2, #3, #4, #5, #6, #7]
CPU Nodes : 1
CPU Cores/Threads : 8
Memory : 16384M (qvpc-di-large)
UUID/Serial Number : F9C0763A-4A4F-4BBD-AF51-BC7545774BE2
<snip>
2. Verifique el estatus del indicador luminoso LED amarillo de la placa muestra gravedad menor.
[local]VNF2# show card table
Tuesday might 08 16:52:53 UTC 2018
Slot Card Type Oper State SPOF Attach
----------- -------------------------------------- ------------- ---- ------
1: CFC Control Function Virtual Card Active No
2: CFC Control Function Virtual Card Standby -
3: FC 4-Port Service Function Virtual Card Active No
4: FC 4-Port Service Function Virtual Card Active No
5: FC 4-Port Service Function Virtual Card Active No
6: FC 4-Port Service Function Virtual Card Active No
7: FC 4-Port Service Function Virtual Card Active No
8: FC 4-Port Service Function Virtual Card Active No
9: FC 4-Port Service Function Virtual Card Active No
10: FC 4-Port Service Function Virtual Card Standby -
3. Inicie sesión al ESC recibido en el nodo del cálculo y marque el estatus.
[admin@VNF2-esc-esc-0 esc-cli]$ escadm status
0 ESC status=0 ESC Master Healthy
4. Inicie sesión al EM recibido en el nodo del cálculo y marque el estatus.
ubuntu@vnfd2deploymentem-1:~$ ncs_cli -u admin -C
admin connected from 10.225.247.142 using ssh on vnfd2deploymentem-1
admin@scm# show ems
EM VNFM
ID SLA SCM PROXY
---------------------
3 up up up
6 up up up
5. Inicie sesión a los UA recibidos en el nodo del cálculo y marque el estatus.
ubuntu@autovnf2-uas-1:~$ sudo su
root@autovnf2-uas-1:/home/ubuntu# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on autovnf2-uas-1
autovnf2-uas-1#show uas ha
uas ha-vip 172.18.181.101
autovnf2-uas-1#
autovnf2-uas-1#
autovnf2-uas-1#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.18.181.101
INSTANCE IP STATE ROLE
-----------------------------------
172.18.180.4 alive CONFD-SLAVE
172.18.180.5 alive CONFD-MASTER
172.18.180.8 alive NA
autovnf2-uas-1#show errors
% No entries found.
6. Si las revisiones médicas están muy bien, proceda con el procedimiento y la espera calientes del intercambio del disco defectuoso para la Sincronización de datos como tarda las horas para completar. Refiera a substituir a los componentes del servidor.
7. Relance estos procedimientos de la revisión médica para confirmar que el estado de salud de los VM recibidos en el nodo del cálculo está restablecido.
Escoja el error del HDD en el servidor del regulador
1. Si observan al error de unidades del HDD en el UCS 240M4 que actúa como nodo del regulador, siga las revisiones médicas antes de que usted realice el intercambio caliente del disco defectuoso.
2. Marque el estatus de los marcapasos en los reguladores.
3. Inicie sesión a uno de los controladores activos y marque el estatus de los marcapasos. Todos los servicios deben ejecutarse en los reguladores disponibles y parado en el controlador con fallas.
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod1-controller-0 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Thu Jun 28 07:53:06 2018 Last change: Wed Jan 17 11:38:00 2018 by root via cibadmin on pod1-controller-0
3 nodes and 22 resources conimaged
Online: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Full list of resources:
ip-10.2.2.2 (ocf::heartbeat:IPaddr2): Started pod1-controller-0
ip-11.120.0.42 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-11.119.0.42 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
ip-11.120.0.50 (ocf::heartbeat:IPaddr2): Started pod1-controller-0
ip-11.118.0.48 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-192.200.0.102 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: haproxy-clone [haproxy]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: redis-master [redis]
Masters: [ pod1-controller-0 ]
Slaves: [ pod1-controller-1 pod1-controller-2 ]
openstack-cinder-volume (systemd:openstack-cinder-volume): Started pod1-controller-0
my-ipmilan-for-controller-0 (stonith:fence_ipmilan): Started pod1-controller-1
my-ipmilan-for-controller-1 (stonith:fence_ipmilan): Started pod1-controller-2
my-ipmilan-for-controller-2 (stonith:fence_ipmilan): Started pod1-controller-0
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
4. Estatus de MariaDB del control en los controladores activos.
[stack@director] nova list | grep control
| 4361358a-922f-49b5-89d4-247a50722f6d | pod1-controller-0 | ACTIVE | - | Running | ctlplane=192.200.0.102 |
| d0f57f27-93a8-414f-b4d8-957de0d785fc | pod1-controller-1 | ACTIVE | - | Running | ctlplane=192.200.0.110 |
[stack@director ~]$ for i in 192.200.0.102 192.200.0.110 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_local_state_comment'\" ; sudo mysql --exec=\"SHOW STATUS LIKE 'wsrep_cluster_size'\""; done
*** 192.200.0.152 ***
Variable_name Value
wsrep_local_state_comment Synced
Variable_name Value
wsrep_cluster_size 2
*** 192.200.0.154 ***
Variable_name Value
wsrep_local_state_comment Synced
Variable_name Value
wsrep_cluster_size 2
5. Verifique que estas líneas estén presentes para cada controlador activo:
wsrep_local_state_comment: Synced
wsrep_cluster_size: 2
6. Marque el estatus de Rabbitmq en los controladores activos.
[heat-admin@pod1-controller-0 ~]$ sudo rabbitmqctl cluster_status
Cluster status of node 'rabbit@pod1-controller-0' ...
[{nodes,[{disc,['rabbit@pod1-controller-0','rabbit@pod1-controller-1',
'rabbit@pod1-controller-2']}]},
{running_nodes,['rabbit@pod1-controller-2',
'rabbit@pod1-controller-1',
'rabbit@pod1-controller-0']},
{cluster_name,<<"rabbit@pod1-controller-0.localdomain">>},
{partitions,[]},
{alarms,[{'rabbit@pod1-controller-2',[]},
{'rabbit@pod1-controller-1',[]},
{'rabbit@pod1-controller-0',[]}]}]
7. Si las revisiones médicas están muy bien, proceda con el procedimiento y la espera calientes del intercambio del disco defectuoso para la Sincronización de datos como tarda las horas para completar. Refiera a substituir a los componentes del servidor.
8. Relance estos procedimientos de la revisión médica para confirmar el estado de salud del regulador se restablece.
Escoja el error del HDD en el servidor del OSD-cálculo
Si observan al error de unidades del HDD en el UCS 240M4 que actúa como nodo del OSD-cálculo del sn, realice estas revisiones médicas antes de que usted realice el intercambio caliente del disco defectuoso.
Identifique los VM recibidos en el nodo del OSD-cálculo:
Identifique los VM que se reciben en el servidor del cálculo. Puede haber dos posibilidades:
1. El servidor del OSD-cálculo contiene la combinación EM/UAS/Auto-Deploy/Auto-IT de VM.
[stack@director ~]$ nova list --field name,host | grep osd-compute-0
| c6144778-9afd-4946-8453-78c817368f18 | AUTO-DEPLOY-VNF2-uas-0 | pod1-osd-compute-0.localdomain | ACTIVE |
| 2d051522-bce2-4809-8d63-0c0e17f251dc | AUTO-IT-VNF2-uas-0 | pod1-osd-compute-0.localdomain | ACTIVE |
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-osd-compute-0.localdomain | ACTIVE |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-osd-compute-0.localdomain | ACTIVE |
2. El servidor del cálculo contiene la combinación CF/ESC/EM/UAS de VM.
[stack@director ~]$ nova list --field name,host | grep osd-compute-1
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-compute-8.localdomain | ACTIVE |
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229 | pod1-compute-8.localdomain | ACTIVE |
| 75528898-ef4b-4d68-b05d-882014708694 | VNF2-ESC-ESC-0 | pod1-compute-8.localdomain | ACTIVE |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-compute-8.localdomain | ACTIVE |
Note: En la salida mostrada aquí, la primera columna corresponde al UUID, la segunda columna es el nombre VM y la tercera columna es el nombre de host donde está presente el VM.
3. Los procesos de Ceph son activos en el servidor del OSD-cálculo.
[root@pod1-osd-compute-1 ~]# systemctl list-units *ceph*
UNIT LOAD ACTIVE SUB DESCRIPTION
var-lib-ceph-osd-ceph\x2d11.mount loaded active mounted /var/lib/ceph/osd/ceph-11
var-lib-ceph-osd-ceph\x2d2.mount loaded active mounted /var/lib/ceph/osd/ceph-2
var-lib-ceph-osd-ceph\x2d5.mount loaded active mounted /var/lib/ceph/osd/ceph-5
var-lib-ceph-osd-ceph\x2d8.mount loaded active mounted /var/lib/ceph/osd/ceph-8
ceph-osd@11.service loaded active running Ceph object storage daemon
ceph-osd@2.service loaded active running Ceph object storage daemon
ceph-osd@5.service loaded active running Ceph object storage daemon
ceph-osd@8.service loaded active running Ceph object storage daemon
system-ceph\x2ddisk.slice loaded active active system-ceph\x2ddisk.slice
system-ceph\x2dosd.slice loaded active active system-ceph\x2dosd.slice
ceph-mon.target loaded active active ceph target allowing to start/stop all ceph-mon@.service instances at once
ceph-osd.target loaded active active ceph target allowing to start/stop all ceph-osd@.service instances at once
ceph-radosgw.target loaded active active ceph target allowing to start/stop all ceph-radosgw@.service instances at once
ceph.target loaded active active ceph target allowing to start/stop all ceph*@.service instances at once
4. Verifique que la asignación de OSD (disco del HDD) a meter en diario (SSD) sea buena.
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph-disk list
/dev/sda :
/dev/sda1 other, iso9660
/dev/sda2 other, xfs, mounted on /
/dev/sdb :
/dev/sdb1 ceph journal, for /dev/sdc1
/dev/sdb3 ceph journal, for /dev/sdd1
/dev/sdb2 ceph journal, for /dev/sde1
/dev/sdb4 ceph journal, for /dev/sdf1
/dev/sdc :
/dev/sdc1 ceph data, active, cluster ceph, osd.1, journal /dev/sdb1
/dev/sdd :
/dev/sdd1 ceph data, active, cluster ceph, osd.7, journal /dev/sdb3
/dev/sde :
/dev/sde1 ceph data, active, cluster ceph, osd.4, journal /dev/sdb2
/dev/sdf :
/dev/sdf1 ceph data, active, cluster ceph, osd.10, journal /dev/sdb4
5. Verifique que la salud de Ceph y la asignación del árbol OSD sea buenas.
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
1 mons down, quorum 0,1 pod1-controller-0,pod1-controller-1
monmap e1: 3 mons at {pod1-controller-0=11.118.0.10:6789/0,pod1-controller-1=11.118.0.11:6789/0,pod1-controller-2=11.118.0.12:6789/0}
election epoch 28, quorum 0,1 pod1-controller-0,pod1-controller-1
osdmap e709: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v941813: 704 pgs, 6 pools, 490 GB data, 163 kobjects
1470 GB used, 11922 GB / 13393 GB avail
704 active+clean
client io 58580 B/s wr, 0 op/s rd, 7 op/s wr
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod1-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-4 4.35999 host pod1-osd-compute-2
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
-5 4.35999 host pod1-osd-compute-3
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
6. Si las revisiones médicas están muy bien, proceda con el procedimiento y la espera calientes del intercambio del disco defectuoso para la Sincronización de datos como tarda las horas para completar. Refiera a substituir a los componentes del servidor.
7. Relance estos procedimientos de la revisión médica para confirmar el estado de salud de los VM recibidos en el nodo del OSD-cálculo se restablecen.
Escoja el error del HDD en el servidor OSPD
1. Si observan al error de unidades del HDD en el UCS 240M4 que actúa como nodo OSPD, realice estas revisiones médicas antes de que usted inicie el intercambio caliente del disco defectuoso.
2. Marque el estatus del stack de OpenStack y de la lista del nodo.
[stack@director ~]$ source stackrc
[stack@director ~]$ openstack stack list --nested
[stack@director ~]$ ironic node-list
[stack@director ~]$ nova list
3. Marque si todos los servicios de Undercloud están en cargado, estatus activo y corriente del nodo OSP-D.
[stack@director ~]$ systemctl list-units "openstack*" "neutron*" "openvswitch*"
UNIT LOAD ACTIVE SUB DESCRIPTION
neutron-dhcp-agent.service loaded active running OpenStack Neutron DHCP Agent
neutron-openvswitch-agent.service loaded active running OpenStack Neutron Open vSwitch Agent
neutron-ovs-cleanup.service loaded active exited OpenStack Neutron Open vSwitch Cleanup Utility
neutron-server.service loaded active running OpenStack Neutron Server
openstack-aodh-evaluator.service loaded active running OpenStack Alarm evaluator service
openstack-aodh-listener.service loaded active running OpenStack Alarm listener service
openstack-aodh-notifier.service loaded active running OpenStack Alarm notifier service
openstack-ceilometer-central.service loaded active running OpenStack ceilometer central agent
openstack-ceilometer-collector.service loaded active running OpenStack ceilometer collection service
openstack-ceilometer-notification.service loaded active running OpenStack ceilometer notification agent
openstack-glance-api.service loaded active running OpenStack Image Service (code-named Glance) API server
openstack-glance-registry.service loaded active running OpenStack Image Service (code-named Glance) Registry server
openstack-heat-api-cfn.service loaded active running Openstack Heat CFN-compatible API Service
openstack-heat-api.service loaded active running OpenStack Heat API Service
openstack-heat-engine.service loaded active running Openstack Heat Engine Service
openstack-ironic-api.service loaded active running OpenStack Ironic API service
openstack-ironic-conductor.service loaded active running OpenStack Ironic Conductor service
openstack-ironic-inspector-dnsmasq.service loaded active running PXE boot dnsmasq service for Ironic Inspector
openstack-ironic-inspector.service loaded active running Hardware introspection service for OpenStack Ironic
openstack-mistral-api.service loaded active running Mistral API Server
openstack-mistral-engine.service loaded active running Mistral Engine Server
openstack-mistral-executor.service loaded active running Mistral Executor Server
openstack-nova-api.service loaded active running OpenStack Nova API Server
openstack-nova-cert.service loaded active running OpenStack Nova Cert Server
openstack-nova-compute.service loaded active running OpenStack Nova Compute Server
openstack-nova-conductor.service loaded active running OpenStack Nova Conductor Server
openstack-nova-scheduler.service loaded active running OpenStack Nova Scheduler Server
openstack-swift-account-reaper.service loaded active running OpenStack Object Storage (swift) - Account Reaper
openstack-swift-account.service loaded active running OpenStack Object Storage (swift) - Account Server
openstack-swift-container-updater.service loaded active running OpenStack Object Storage (swift) - Container Updater
openstack-swift-container.service loaded active running OpenStack Object Storage (swift) - Container Server
openstack-swift-object-updater.service loaded active running OpenStack Object Storage (swift) - Object Updater
openstack-swift-object.service loaded active running OpenStack Object Storage (swift) - Object Server
openstack-swift-proxy.service loaded active running OpenStack Object Storage (swift) - Proxy Server
openstack-zaqar.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server
openstack-zaqar@1.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server Instance 1
openvswitch.service loaded active exited Open vSwitch
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
37 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
4. Si las revisiones médicas están muy bien, proceda con el procedimiento y la espera calientes del intercambio del disco defectuoso para la Sincronización de datos como tarda las horas para completar. Refiera a substituir a los componentes del servidor.
5. Relance estos procedimientos de la revisión médica para confirmar que el estado de salud de los Nodos OSPD está restablecido.
Con la colaboración de ingenieros de Cisco
- Partheeban RajagopalAdvanced Services de Cisco
- Padmaraj RamanoudjamAdvanced Services de Cisco
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)