Sustitución del servidor OSPD UCS 240M4: vEPC
Opciones de descarga
-
ePub (1.0 MB)
Visualice en diferentes aplicaciones en iPhone, iPad, Android, Sony Reader o Windows Phone -
Mobi (Kindle) (554.8 KB)
Visualice en dispositivo Kindle o aplicación Kindle en múltiples dispositivos
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Contenido
Introducción
Este documento describe los pasos necesarios para reemplazar un servidor defectuoso que aloja OpenStack Platform Director (OSPD) en una configuración Ultra-M.
Antecedentes
Ultra-M es una solución de núcleo de paquetes móviles virtualizados previamente empaquetada y validada que se ha diseñado para simplificar la implementación de VNF. OpenStack es el Virtualized Infrastructure Manager (VIM) para Ultra-M y consta de los siguientes tipos de nodos:
- Informática
- Disco de almacenamiento de objetos - Informática (OSD - Informática)
- Controlador
- OSPD
La arquitectura de alto nivel de Ultra-M y los componentes implicados se muestran en esta imagen:
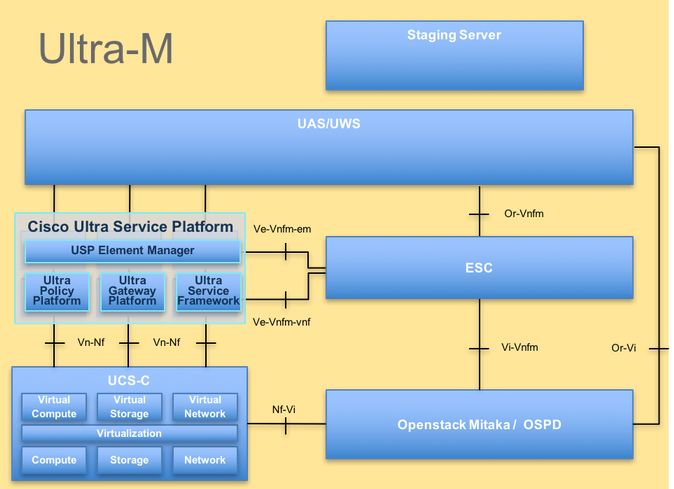 Arquitectura UltraM
Arquitectura UltraM
Este documento está dirigido al personal de Cisco que está familiarizado con la plataforma Ultra-M de Cisco y detalla los pasos que se requieren para que se lleven a cabo en el nivel OpenStack en el momento de la sustitución del servidor OSPD.
Nota: Se considera la versión Ultra M 5.1.x para definir los procedimientos en este documento.
Abreviaturas
| VNF | Función de red virtual |
| CF | Función de control |
| SF | Función de servicio |
| ESC | Controlador de servicio elástico |
| FREGAR | Método de procedimiento |
| OSD | Discos de almacenamiento de objetos |
| HDD | Disco duro |
| SSD | Unidad de estado sólido |
| VIM | Administrador de infraestructura virtual |
| VM | Máquina virtual |
| EM | Administrador de elementos |
| UAS | Servicios de ultra automatización |
| UUID | Identificador único universal |
Flujo de trabajo del MOP
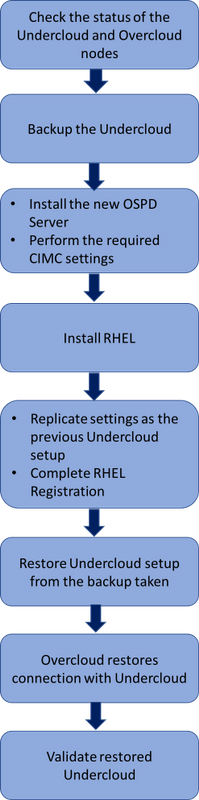 Flujo de trabajo de alto nivel del procedimiento de sustitución
Flujo de trabajo de alto nivel del procedimiento de sustitución
Prerequisites
Comprobación de estado
Antes de reemplazar un servidor OSPD, es importante verificar el estado actual del entorno Red Hat OpenStack Platform y asegurarse de que esté en buen estado para evitar complicaciones cuando el proceso de reemplazo esté activado.
Compruebe el estado de la pila de OpenStack y la lista de nodos:
[stack@director ~]$ source stackrc
[stack@director ~]$ openstack stack list --nested
[stack@director ~]$ ironic node-list
[stack@director ~]$ nova list
Asegúrese de que todos los servicios en la nube estén cargados, activos y en ejecución desde el nodo OSP-D:
[stack@director ~]$ systemctl list-units "openstack*" "neutron*" "openvswitch*"
UNIT LOAD ACTIVE SUB DESCRIPTION
neutron-dhcp-agent.service loaded active running OpenStack Neutron DHCP Agent
neutron-openvswitch-agent.service loaded active running OpenStack Neutron Open vSwitch Agent
neutron-ovs-cleanup.service loaded active exited OpenStack Neutron Open vSwitch Cleanup Utility
neutron-server.service loaded active running OpenStack Neutron Server
openstack-aodh-evaluator.service loaded active running OpenStack Alarm evaluator service
openstack-aodh-listener.service loaded active running OpenStack Alarm listener service
openstack-aodh-notifier.service loaded active running OpenStack Alarm notifier service
openstack-ceilometer-central.service loaded active running OpenStack ceilometer central agent
openstack-ceilometer-collector.service loaded active running OpenStack ceilometer collection service
openstack-ceilometer-notification.service loaded active running OpenStack ceilometer notification agent
openstack-glance-api.service loaded active running OpenStack Image Service (code-named Glance) API server
openstack-glance-registry.service loaded active running OpenStack Image Service (code-named Glance) Registry server
openstack-heat-api-cfn.service loaded active running Openstack Heat CFN-compatible API Service
openstack-heat-api.service loaded active running OpenStack Heat API Service
openstack-heat-engine.service loaded active running Openstack Heat Engine Service
openstack-ironic-api.service loaded active running OpenStack Ironic API service
openstack-ironic-conductor.service loaded active running OpenStack Ironic Conductor service
openstack-ironic-inspector-dnsmasq.service loaded active running PXE boot dnsmasq service for Ironic Inspector
openstack-ironic-inspector.service loaded active running Hardware introspection service for OpenStack Ironic
openstack-mistral-api.service loaded active running Mistral API Server
openstack-mistral-engine.service loaded active running Mistral Engine Server
openstack-mistral-executor.service loaded active running Mistral Executor Server
openstack-nova-api.service loaded active running OpenStack Nova API Server
openstack-nova-cert.service loaded active running OpenStack Nova Cert Server
openstack-nova-compute.service loaded active running OpenStack Nova Compute Server
openstack-nova-conductor.service loaded active running OpenStack Nova Conductor Server
openstack-nova-scheduler.service loaded active running OpenStack Nova Scheduler Server
openstack-swift-account-reaper.service loaded active running OpenStack Object Storage (swift) - Account Reaper
openstack-swift-account.service loaded active running OpenStack Object Storage (swift) - Account Server
openstack-swift-container-updater.service loaded active running OpenStack Object Storage (swift) - Container Updater
openstack-swift-container.service loaded active running OpenStack Object Storage (swift) - Container Server
openstack-swift-object-updater.service loaded active running OpenStack Object Storage (swift) - Object Updater
openstack-swift-object.service loaded active running OpenStack Object Storage (swift) - Object Server
openstack-swift-proxy.service loaded active running OpenStack Object Storage (swift) - Proxy Server
openstack-zaqar.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server
openstack-zaqar@1.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server Instance 1
openvswitch.service loaded active exited Open vSwitch
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
37 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
Respaldo
Asegúrese de que dispone de suficiente espacio en disco antes de realizar el proceso de copia de seguridad. Se espera que este tarball tenga al menos 3,5 GB.
[stack@director ~]$df -h
Ejecute este comando como usuario root para realizar una copia de seguridad de los datos del nodo de la nube inferior en un archivo denominado undercloud-backup-[timestamp].tar.gz.
[root@director ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql
[root@director ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql
/etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack
tar: Removing leading `/' from member names
Instalación del nuevo nodo OSPD
Instalación del servidor UCS
Los pasos para instalar un nuevo servidor UCS C240 M4, así como los pasos de configuración inicial, se pueden consultar en la Guía de instalación y servicio del servidor Cisco UCS C240 M4.
Inicie sesión en el servidor con el uso de la IP de CIMC.
Realice la actualización del BIOS si el firmware no es de la versión recomendada utilizada anteriormente. A continuación se indican los pasos para actualizar el BIOS: Guía de actualización del BIOS del servidor de montaje en bastidor Cisco UCS C-Series.
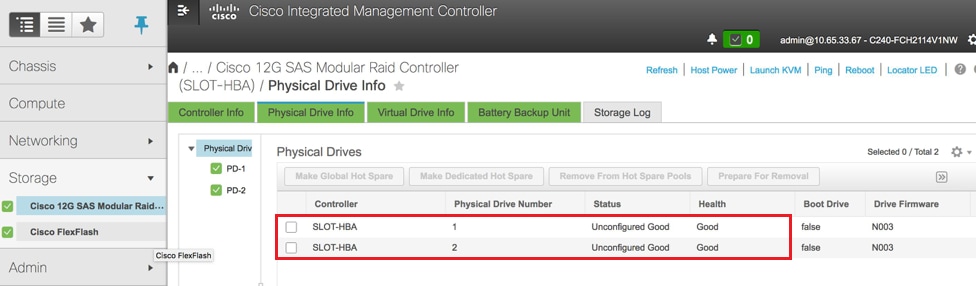
Verifique el estado de las unidades físicas. Debe ser Unconfigured Good:
Vaya a Almacenamiento > Controlador RAID modular Cisco 12G SAS (SLOT-HBA) > Información de unidad física, como se muestra aquí en la imagen.
Cree una unidad virtual a partir de las unidades físicas con RAID de nivel 1:
Vaya a Storage > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Controller Info > Create Virtual Drive from Unused Physical Drives como se muestra en la imagen.
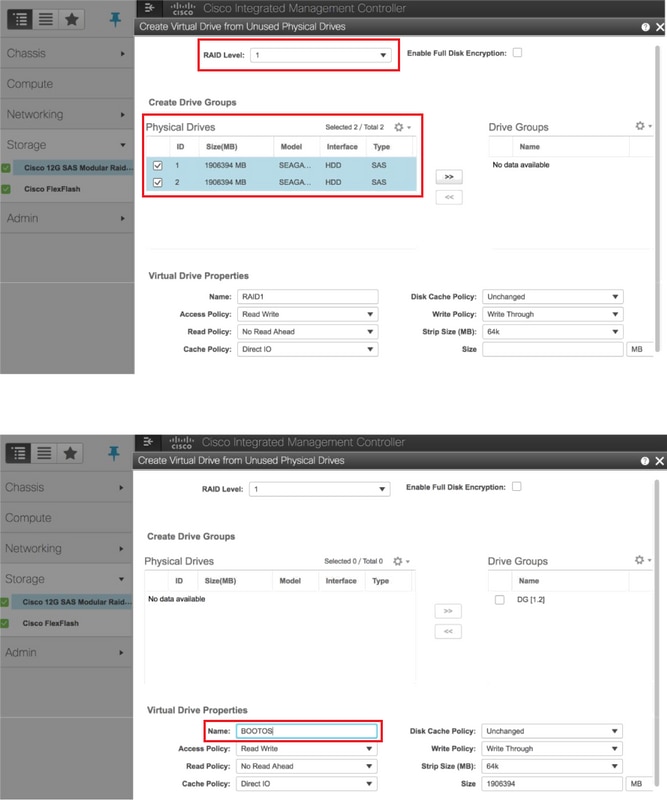
Seleccione el VD y configure Set as Boot Drive como se muestra en la imagen.
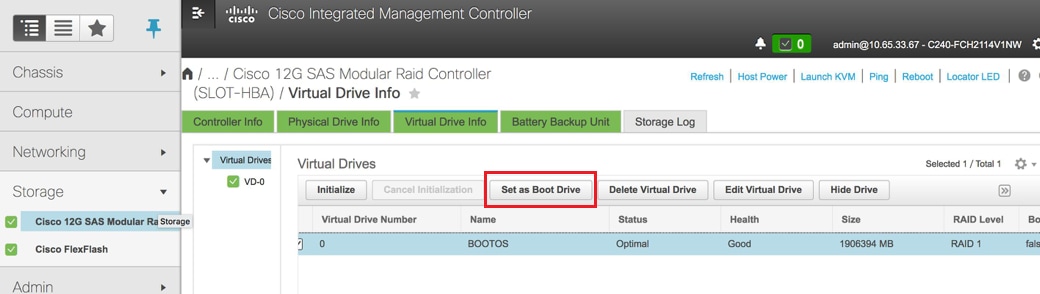
Habilitar IPMI sobre LAN:
Vaya a Admin > Communication Services > Communication Services como se muestra en la imagen.
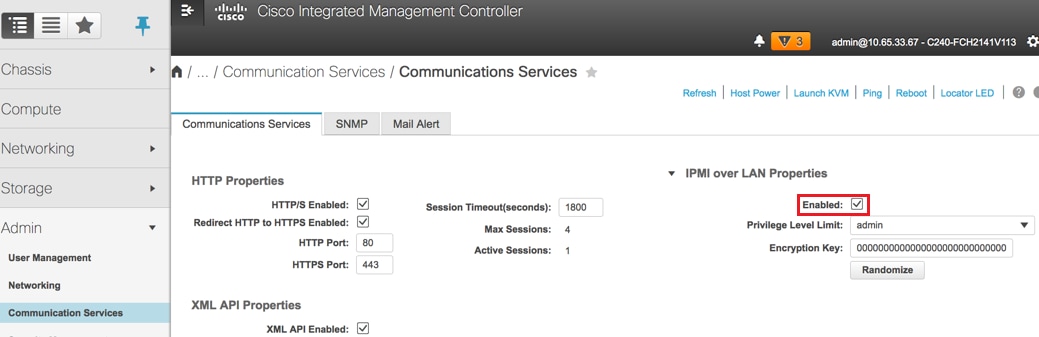
Deshabilitar hiperprocesamiento:
Vaya a Compute > BIOS > Configure BIOS > Advanced > Processor Configuration como se muestra en la imagen.
Nota: La imagen que se muestra aquí y los pasos de configuración mencionados en esta sección hacen referencia a la versión de firmware 3.0(3e) y puede haber ligeras variaciones si trabaja en otras versiones.
Instalación de Red Hat
Montaje de la imagen ISO de Red Hat
1. Inicie sesión en el servidor OSP-D.
2. Inicie la consola KVM.
3. Acceda a Medios virtuales > Activar dispositivos virtuales. Acepte la sesión y active la opción de recordar su configuración para conexiones futuras.
4. Seleccione Medios virtuales > CD/DVD de mapasy asigne la imagen ISO de Red Hat.
5. Seleccione Alimentación > Reinicio del sistema (arranque en caliente) para reiniciar el sistema.
6. Al reiniciar, pulse F6y seleccione vDVD1.22 asignado a vKVM de Ciscoy pulse Escriba.
Instalación de Red Hat Enterprise Linux
Nota: El procedimiento de esta sección representa una versión simplificada del proceso de instalación que identifica el número mínimo de parámetros que se deben configurar.
1. Seleccione la opción para instalar Red Hat Enterprise Linux (RHEL) para comenzar la instalación.
2. Seleccione Selección de Software > Sólo Instalación Mínima.
3. Configure las interfaces de red (eno1 y eno2).
4. Haga clic en Red y Hostname.
- Seleccione la interfaz que se utilizará para la comunicación externa (eno1 o eno2)
- Haga clic en Configure (Configurar)
- Seleccione la ficha Configuración IPv4, seleccione el método Manual y haga clic en Agregar
- Establezca estos parámetros como se utilizaron anteriormente: Address, Netmask, Gateway, DNS server
5. Seleccione Fecha y hora y especifique la región y la ciudad.
6. Habilite Network Time y configure servidores NTP.
7. Seleccione Installation Destination y utilice el sistema de archivos ext4 .
Nota: Suprima /home/ y reasigne la capacidad bajo root /.
8. Inhabilite Kdump.
9. Establezca la contraseña raíz solamente.
10. Inicie la instalación .
Restauración de la nube subyacente
Preparación de la instalación en la nube basada en copia de seguridad
Una vez que la máquina se haya instalado con RHEL 7.3 y esté en un estado limpio, vuelva a habilitar todas las suscripciones/repositorios necesarios para instalar y ejecutar director.
Configuración del nombre de host:
[root@director ~]$sudo hostnamectl set-hostname <FQDN_hostname>
[root@director ~]$sudo hostnamectl set-hostname --transient <FQDN_hostname>
Editar archivo /etc/hosts:
[root@director ~]$ vi /etc/hosts
<ospd_external_address> <server_hostname> <FQDN_hostname>
10.225.247.142 pod1-ospd pod1-ospd.cisco.com
Validar nombre de host:
[root@director ~]$ cat /etc/hostname
pod1-ospd.cisco.com
Validar configuración DNS:
[root@director ~]$ cat /etc/resolv.conf
#Generated by NetworkManager
nameserver <DNS_IP>
Modifique la interfaz nic de aprovisionamiento:
[root@director ~]$ cat /etc/sysconfig/network-scripts/ifcfg-eno1
DEVICE=eno1
ONBOOT=yes
HOTPLUG=no
NM_CONTROLLED=no
PEERDNS=no
DEVICETYPE=ovs
TYPE=OVSPort
OVS_BRIDGE=br-ctlplane
BOOTPROTO=none
MTU=1500
Complete el registro en Red Hat
Descargue este paquete para configurar subscription-manager para utilizar rh-satelite:
[root@director ~]$ rpm -Uvh http:///pub/katello-ca-consumer-latest.noarch.rpm
[root@director ~]$ subscription-manager config
Regístrese con el satélite rh con el uso de esta clave de activación para RHEL 7.3.
[root@director ~]$subscription-manager register --org="<ORG>" --activationkey="<KEY>"
Para ver la suscripción:
[root@director ~]$ subscription-manager list –consumed
Habilite los repositorios similares a los antiguos repos de OSPD:
[root@director ~]$ sudo subscription-manager repos --disable=*
[root@director ~]$ subscription-manager repos --enable=rhel-7-server-rpms --enable=rhel-7-server-extras-rpms --enable=rh
el-7-server-openstack-10-rpms --enable=rhel-7-server-rh-common-rpms --enable=rhel-ha-for-rhel-7-server-rpm
Realice una actualización en su sistema para asegurarse de que tiene los últimos paquetes básicos del sistema y reinicie el sistema:
[root@director ~]$sudo yum update -y
[root@director ~]$sudo reboot
Restauración de Undercloud
Después de habilitar la suscripción, importe la copia de seguridad en el archivo .tar de la nube bajo cloud-backup-date +%F`.tar.gz al nuevo directorio raíz del servidor OSP-D /root.
Instale el servidor mariadb:
[root@director ~]$ yum install -y mariadb-server
Extraiga el archivo de configuración MariaDB y la copia de seguridad de la base de datos (DB). Realice esta operación como usuario raíz.
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz etc/my.cnf.d/server.cnf
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz root/undercloud-all-databases.sql
Edite /etc/my.cnf.d/server.cnf y comente la entrada bind-address si está presente:
[root@tb3-ospd ~]# vi /etc/my.cnf.d/server.cnf
Inicie el servicio MariaDB y actualice temporalmente la configuración max_allowed_packet:
[root@director ~]$ systemctl start mariadb
[root@director ~]$ mysql -uroot -e"set global max_allowed_packet = 16777216;"
Limpiar ciertos permisos (para volver a crearlos más tarde):
[root@director ~]$ for i in ceilometer glance heat ironic keystone neutron nova;do mysql -e "drop user $i";done
[root@director ~]$ mysql -e 'flush privileges'
Nota: Si el servicio de ceilómetro se ha desactivado previamente en la configuración, ejecute este comando y elimine ceilómetro.
Cree la cuenta stackuser:
[root@director ~]$ sudo useradd stack
[root@director ~]$ sudo passwd stack << specify a password
[root@director ~]$ echo "stack ALL=(root) NOPASSWD:ALL" | sudo tee -a /etc/sudoers.d/stack
[root@director ~]$ sudo chmod 0440 /etc/sudoers.d/stack
Restaure el directorio principal del usuario de la pila:
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz home/stack
Instale los paquetes base de swift y glance y, a continuación, restaure sus datos:
[root@director ~]$ yum install -y openstack-glance openstack-swift
[root@director ~]$ tar --xattrs -xzC / -f undercloud-backup-$DATE.tar.gz srv/node var/lib/glance/images
Confirme que los datos son propiedad del usuario correcto:
[root@director ~]$ chown -R swift: /srv/node
[root@director ~]$ chown -R glance: /var/lib/glance/images
Restaure los certificados SSL en la nube (opcional; solo se debe realizar si la configuración utiliza certificados SSL).
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz etc/pki/instack-certs/undercloud.pem
[root@director ~]$ tar -xzC / -f undercloud-backup-$DATE.tar.gz etc/pki/ca-trust/source/anchors/ca.crt.pem
Vuelva a ejecutar la instalación en la nube inferior como usuario de la pila y asegúrese de ejecutarla en el directorio principal del usuario de la pila:
[root@director ~]$ su - stack
[stack@director ~]$ sudo yum install -y python-tripleoclient
Confirme que el nombre de host esté configurado correctamente en /etc/hosts.
Reinstale la nube inferior:
[stack@director ~]$ openstack undercloud install
<snip>
#############################################################################
Undercloud install complete.
The file containing this installation's passwords is at
/home/stack/undercloud-passwords.conf.
There is also a stackrc file at /home/stack/stackrc.
These files are needed to interact with the OpenStack services, and must be
secured.
#############################################################################
Vuelva a conectar la nube inferior restaurada a la nube superior
Una vez completados estos pasos, es de esperar que la nube subyacente restablezca automáticamente su conexión a la nube excesiva. Los nodos continuarán sondeando la orquestación (calor) para las tareas pendientes, con el uso de una simple solicitud HTTP que se emite cada pocos segundos.
Validar la restauración completada
Utilice estos comandos para realizar una comprobación de estado del entorno recién restaurado:
[root@director ~]$ su - stack
Last Log in: Tue Nov 28 21:27:50 EST 2017 from 10.86.255.201 on pts/0
[stack@director ~]$ source stackrc
[stack@director ~]$ nova list
+--------------------------------------+--------------------+--------+------------+-------------+------------------------+
| ID | Name | Status | Task State | Power State | Networks |
+--------------------------------------+--------------------+--------+------------+-------------+------------------------+
| b1f5294a-629e-454c-b8a7-d15e21805496 | pod1-compute-0 | ACTIVE | - | Running | ctlplane=192.200.0.119 |
| 9106672e-ac68-423e-89c5-e42f91fefda1 | pod1-compute-1 | ACTIVE | - | Running | ctlplane=192.200.0.120 |
| b3ed4a8f-72d2-4474-91a1-b6b70dd99428 | pod1-compute-2 | ACTIVE | - | Running | ctlplane=192.200.0.124 |
| 677524e4-7211-4571-ac35-004dc5655789 | pod1-compute-3 | ACTIVE | - | Running | ctlplane=192.200.0.107 |
| 55ea7fe5-d797-473c-83b1-d897b76a7520 | pod1-compute-4 | ACTIVE | - | Running | ctlplane=192.200.0.122 |
| c34c1088-d79b-42b6-9306-793a89ae4160 | pod1-compute-5 | ACTIVE | - | Running | ctlplane=192.200.0.108 |
| 4ba28d8c-fb0e-4d7f-8124-77d56199c9b2 | pod1-compute-6 | ACTIVE | - | Running | ctlplane=192.200.0.105 |
| d32f7361-7e73-49b1-a440-fa4db2ac21b1 | pod1-compute-7 | ACTIVE | - | Running | ctlplane=192.200.0.106 |
| 47c6a101-0900-4009-8126-01aaed784ed1 | pod1-compute-8 | ACTIVE | - | Running | ctlplane=192.200.0.121 |
| 1a638081-d407-4240-b9e5-16b47e2ff6a2 | pod1-compute-9 | ACTIVE | - | Running | ctlplane=192.200.0.112 |
<snip>
[stack@director ~]$ ssh heat-admin@192.200.0.107
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod1-controller-0 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
3 nodes and 22 resources configured
Online: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Full list of resources:
ip-10.1.10.10 (ocf::heartbeat:IPaddr2): Started pod1-controller-0
ip-11.120.0.97 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
Clone Set: haproxy-clone [haproxy]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
ip-192.200.0.106 (ocf::heartbeat:IPaddr2): Started pod1-controller-0
ip-11.120.0.95 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-11.119.0.98 (ocf::heartbeat:IPaddr2): Started pod1-controller-0
ip-11.118.0.92 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: redis-master [redis]
Masters: [ pod1-controller-0 ]
Slaves: [ pod1-controller-1 pod1-controller-2 ]
openstack-cinder-volume (systemd:openstack-cinder-volume): Started pod1-controller-0
my-ipmilan-for-controller-0 (stonith:fence_ipmilan): Stopped
my-ipmilan-for-controller-1 (stonith:fence_ipmilan): Stopped
my-ipmilan-for-controller-2 (stonith:fence_ipmilan): Stopped
Failed Actions:
* my-ipmilan-for-controller-0_start_0 on pod1-controller-1 'unknown error' (1): call=190, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:45 2017', queued=0ms, exec=20005ms
* my-ipmilan-for-controller-1_start_0 on pod1-controller-1 'unknown error' (1): call=192, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:53:08 2017', queued=0ms, exec=20005ms
* my-ipmilan-for-controller-2_start_0 on pod1-controller-1 'unknown error' (1): call=188, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:23 2017', queued=0ms, exec=20004ms
* my-ipmilan-for-controller-0_start_0 on pod1-controller-0 'unknown error' (1): call=210, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:53:08 2017', queued=0ms, exec=20005ms
* my-ipmilan-for-controller-1_start_0 on pod1-controller-0 'unknown error' (1): call=207, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:45 2017', queued=0ms, exec=20004ms
* my-ipmilan-for-controller-2_start_0 on pod1-controller-0 'unknown error' (1): call=206, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:45 2017', queued=0ms, exec=20006ms
* ip-192.200.0.106_monitor_10000 on pod1-controller-0 'not running' (7): call=197, status=complete, exitreason='none',
last-rc-change='Wed Nov 22 13:51:31 2017', queued=0ms, exec=0ms
* my-ipmilan-for-controller-0_start_0 on pod1-controller-2 'unknown error' (1): call=183, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:23 2017', queued=1ms, exec=20006ms
* my-ipmilan-for-controller-1_start_0 on pod1-controller-2 'unknown error' (1): call=184, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:23 2017', queued=0ms, exec=20005ms
* my-ipmilan-for-controller-2_start_0 on pod1-controller-2 'unknown error' (1): call=177, status=Timed Out, exitreason='none',
last-rc-change='Wed Nov 22 13:52:02 2017', queued=0ms, exec=20005ms
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
[heat-admin@pod1-controller-0 ~]$ sudo ceph status
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
monmap e1: 3 mons at {pod1-controller-0=11.118.0.40:6789/0,pod1-controller-1=11.118.0.41:6789/0,pod1-controller-2=11.118.0.42:6789/0}
election epoch 58, quorum 0,1,2 pod1-controller-0,pod1-controller-1,pod1-controller-2
osdmap e1398: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v1245812: 704 pgs, 6 pools, 542 GB data, 352 kobjects
1625 GB used, 11767 GB / 13393 GB avail
704 active+clean
client io 21549 kB/s wr, 0 op/s rd, 120 op/s wr
Comprobar el funcionamiento de Identity Service (Keystone)
Este paso valida las operaciones de Identity Service consultando una lista de usuarios.
[stack@director ~]$ source stackrc
[stack@director ~]$ openstack user list
+----------------------------------+------------------+
| ID | Name |
+----------------------------------+------------------+
| 69ac2b9d89414314b1366590c7336f7d | admin |
| f5c30774fe8f49d0a0d89d5808a4b2cc | glance |
| 3958d852f85749f98cca75f26f43d588 | heat |
| cce8f2b7f1a843a08d0bb295a739bd34 | ironic |
| ce7c642f5b5741b48a84f54d3676b7ee | ironic-inspector |
| a69cd42a5b004ec5bee7b7a0c0612616 | mistral |
| 5355eb161d75464d8476fa0a4198916d | neutron |
| 7cee211da9b947ef9648e8fe979b4396 | nova |
| f73d36563a4a4db482acf7afc7303a32 | swift |
| d15c12621cbc41a8a4b6b67fa4245d03 | zaqar |
| 3f0ed37f95544134a15536b5ca50a3df | zaqar-websocket |
+----------------------------------+------------------+
[stack@director ~]$
[stack@director ~]$ source <overcloudrc>
[stack@director ~]$ openstack user list
+----------------------------------+------------+
| ID | Name |
+----------------------------------+------------+
| b4e7954942184e2199cd067dccdd0943 | admin |
| 181878efb6044116a1768df350d95886 | neutron |
| 6e443967ee3f4943895c809dc998b482 | heat |
| c1407de17f5446de821168789ab57449 | nova |
| c9f64c5a2b6e4d4a9ff6b82adef43992 | glance |
| 800e6b1163b74cc2a5fab4afb382f37d | cinder |
| 4cfa5a2a44c44c678025842f080e5f53 | heat-cfn |
| 9b222eeb8a58459bb3bfc76b8fff0f9f | swift |
| 815f3f25bcda49c290e1b56cd7981d1b | core |
| 07c40ade64f34a64932129175150fa4a | gnocchi |
| 0ceeda0bc32c4d46890e53adef9a193d | aodh |
| f3caab060171468592eab376a94967b8 | ceilometer |
+----------------------------------+------------+
[stack@director ~]$
Cargar imágenes para una futura introspección de nodos
Valide /httpboot y todos estos archivos inspector.ipxe, agent.kernel, agent.ramdisk, si no continúa con estos pasos.
[stack@director ~]$ ls /httpboot
inspector.ipxe
[stack@director ~]$ source stackrc
[stack@director ~]$ cd images/
[stack@director images]$ openstack overcloud image upload --image-path /home/stack/images
Image "overcloud-full-vmlinuz" is up-to-date, skipping.
Image "overcloud-full-initrd" is up-to-date, skipping.
Image "overcloud-full" is up-to-date, skipping.
Image "bm-deploy-kernel" is up-to-date, skipping.
Image "bm-deploy-ramdisk" is up-to-date, skipping.
[stack@director images]$ ls /httpboot
agent.kernel agent.ramdisk inspector.ipxe
[stack@director images]$
Reiniciar la delimitación
La valla estará en estado detenido después de la recuperación de OSPD. Este procedimiento habilitará la delimitación.
[heat-admin@pod1-controller-0 ~]$ sudo pcs property set stonith-enabled=true
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
[heat-admin@pod1-controller-0 ~]$sudo pcs stonith show
Información Relacionada
Con la colaboración de ingenieros de Cisco
- Padmaraj RamanoudjamCisco Advanced Services
- Partheeban RajagopalCisco Advanced Services
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)