Sustitución de OSD-Compute UCS 240M4 - vEPC
Opciones de descarga
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Contenido
Introducción
Este documento describe los pasos necesarios para reemplazar un servidor de computación de disco de almacenamiento de objetos (OSD) defectuoso en una configuración Ultra-M que aloja funciones de red virtual (VNF) de StarOS.
Antecedentes
Ultra-M es una solución de núcleo de paquetes móviles virtualizados previamente empaquetada y validada diseñada para simplificar la implementación de VNF. OpenStack es Virtualized Infrastructure Manager (VIM) para Ultra-M y consta de los siguientes tipos de nodos:
- Informática
- OSD - Informática
- Controlador
- Plataforma OpenStack - Director (OSPD)
La arquitectura de alto nivel de Ultra-M y los componentes implicados se muestran en esta imagen:
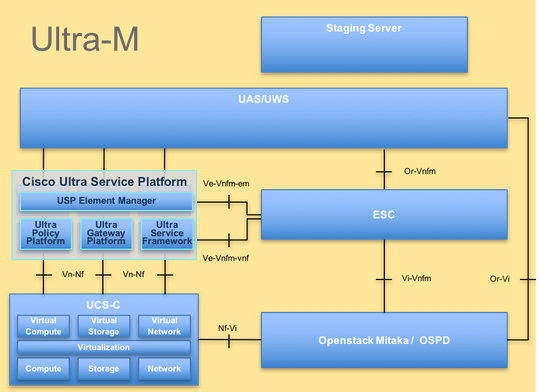
Este documento está dirigido al personal de Cisco que está familiarizado con la plataforma Ultra-M de Cisco y detalla los pasos que se deben llevar a cabo en el nivel OpenStack y StarOS VNF en el momento de la sustitución del servidor de computación.
Nota: Se considera la versión Ultra M 5.1.x para definir los procedimientos en este documento.
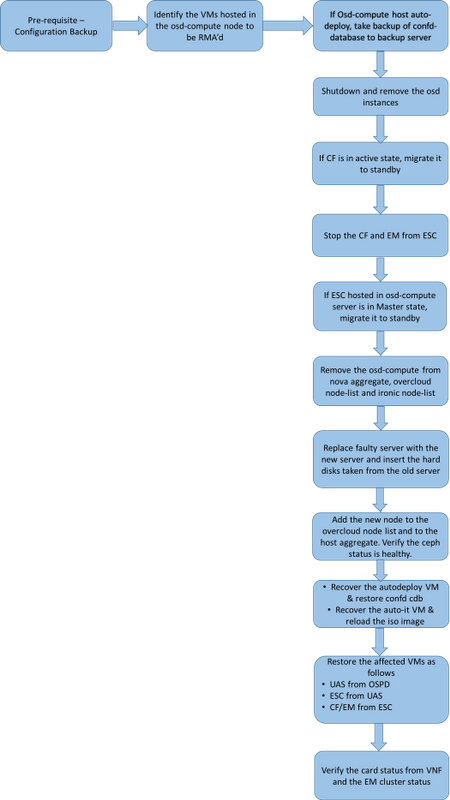
Flujo de trabajo del MOP
Abreviaturas
| VNF | Función de red virtual |
| CF | Función de control |
| SF | Función de servicio |
| ESC | Controlador de servicio elástico |
| FREGAR | Método de procedimiento |
| OSD | Discos de almacenamiento de objetos |
| HDD | Disco duro |
| SSD | Unidad de estado sólido |
| VIM | Administrador de infraestructura virtual |
| VM | Máquina virtual |
| EM | Administrador de elementos |
| UAS | Servicios de ultra automatización |
| UUID | Identificador único universal |
Prerequisites
OSPD de backup
Antes de reemplazar un nodo OSD-Compute, es importante verificar el estado actual de su entorno Red Hat OpenStack Platform. Se recomienda que verifique el estado actual para evitar complicaciones cuando el proceso de reemplazo de Compute esté activado. Se puede lograr con este flujo de reemplazo.
En caso de recuperación, Cisco recomienda realizar una copia de seguridad de la base de datos OSPD (DB) mediante estos pasos:
[root@director ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql
[root@director ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql
/etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack
tar: Removing leading `/' from member names
Este proceso garantiza que un nodo se pueda sustituir sin afectar a la disponibilidad de las instancias. Además, se recomienda realizar una copia de seguridad de la configuración de StarOS, especialmente si el nodo de cálculo que se va a sustituir aloja la máquina virtual CF.
Identificar las VM alojadas en el nodo OSD-Compute
Identifique las VM alojadas en el servidor de computación. Puede haber dos posibilidades:
El servidor OSD-Compute contiene una combinación de VM EM/UAS/Auto-Deploy/Auto-IT:
[stack@director ~]$ nova list --field name,host | grep osd-compute-0
| c6144778-9afd-4946-8453-78c817368f18 | AUTO-DEPLOY-VNF2-uas-0 | pod1-osd-compute-0.localdomain |
| 2d051522-bce2-4809-8d63-0c0e17f251dc | AUTO-IT-VNF2-uas-0 | pod1-osd-compute-0.localdomain |
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-osd-compute-0.localdomain |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-osd-compute-0.localdomain |
El servidor de computación contiene la combinación CF/ESC/EM/UAS de VM:
[stack@director ~]$ nova list --field name,host | grep osd-compute-1
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-compute-8.localdomain |
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229 | pod1-compute-8.localdomain |
| 75528898-ef4b-4d68-b05d-882014708694 | VNF2-ESC-ESC-0 | pod1-compute-8.localdomain |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-compute-8.localdomain |
Nota: En el resultado que se muestra aquí, la primera columna corresponde al UUID, la segunda columna es el nombre de la VM y la tercera columna es el nombre del host donde está presente la VM. Los parámetros de esta salida se utilizarán en las secciones siguientes.
Verifique que Ceph tenga capacidad disponible para permitir que se elimine un solo servidor OSD:
[root@pod1-osd-compute-1 ~]# sudo ceph df
GLOBAL:
SIZE AVAIL RAW USED %RAW USED
13393G 11804G 1589G 11.87
POOLS:
NAME ID USED %USED MAX AVAIL OBJECTS
rbd 0 0 0 3876G 0
metrics 1 4157M 0.10 3876G 215385
images 2 6731M 0.17 3876G 897
backups 3 0 0 3876G 0
volumes 4 399G 9.34 3876G 102373
vms 5 122G 3.06 3876G 31863
Verifique que el estado del árbol ceph osd esté activo en el servidor OSD-Compute:
[heat-admin@pod1-osd-compute-1 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod1-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-3 4.35999 host pod1-osd-compute-2
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
-4 4.35999 host pod1-osd-compute-1
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
Los procesos Ceph están activos en el servidor OSD-Compute:
[root@pod1-osd-compute-1 ~]# systemctl list-units *ceph*
UNIT LOAD ACTIVE SUB DESCRIPTION
var-lib-ceph-osd-ceph\x2d11.mount loaded active mounted /var/lib/ceph/osd/ceph-11
var-lib-ceph-osd-ceph\x2d2.mount loaded active mounted /var/lib/ceph/osd/ceph-2
var-lib-ceph-osd-ceph\x2d5.mount loaded active mounted /var/lib/ceph/osd/ceph-5
var-lib-ceph-osd-ceph\x2d8.mount loaded active mounted /var/lib/ceph/osd/ceph-8
ceph-osd@11.service loaded active running Ceph object storage daemon
ceph-osd@2.service loaded active running Ceph object storage daemon
ceph-osd@5.service loaded active running Ceph object storage daemon
ceph-osd@8.service loaded active running Ceph object storage daemon
system-ceph\x2ddisk.slice loaded active active system-ceph\x2ddisk.slice
system-ceph\x2dosd.slice loaded active active system-ceph\x2dosd.slice
ceph-mon.target loaded active active ceph target allowing to start/stop all ceph-mon@.service instances at once
ceph-osd.target loaded active active ceph target allowing to start/stop all ceph-osd@.service instances at once
ceph-radosgw.target loaded active active ceph target allowing to start/stop all ceph-radosgw@.service instances at once
ceph.target loaded active active ceph target allowing to start/stop all ceph*@.service instances at once
Inhabilite y detenga cada instancia de Ceph, quite cada instancia de OSD y desmonte el directorio. Repita este procedimiento para cada instancia de Ceph:
[root@pod1-osd-compute-1 ~]# systemctl disable ceph-osd@11
[root@pod1-osd-compute-1 ~]# systemctl stop ceph-osd@11
[root@pod1-osd-compute-1 ~]# ceph osd out 11
marked out osd.11.
[root@pod1-osd-compute-1 ~]# ceph osd crush remove osd.11
removed item id 11 name 'osd.11' from crush map
[root@pod1-osd-compute-1 ~]# ceph auth del osd.11
updated
[root@pod1-osd-compute-1 ~]# ceph osd rm 11
removed osd.11
[root@pod1-osd-compute-1 ~]# umount /var/lib/ceph.osd/ceph-11
[root@pod1-osd-compute-1 ~]# rm -rf /var/lib/ceph.osd/ceph-11
or
Se puede utilizar la secuencia de comandos Clean.sh para realizar esta tarea:
[heat-admin@pod1-osd-compute-0 ~]$ sudo ls /var/lib/ceph/osd
ceph-11 ceph-3 ceph-6 ceph-8
[heat-admin@pod1-osd-compute-0 ~]$ /bin/sh clean.sh
[heat-admin@pod1-osd-compute-0 ~]$ cat clean.sh
#!/bin/sh
set -x
CEPH=`sudo ls /var/lib/ceph/osd`
for c in $CEPH
do
i=`echo $c |cut -d'-' -f2`
sudo systemctl disable ceph-osd@$i || (echo "error rc:$?"; exit 1)
sleep 2
sudo systemctl stop ceph-osd@$i || (echo "error rc:$?"; exit 1)
sleep 2
sudo ceph osd out $i || (echo "error rc:$?"; exit 1)
sleep 2
sudo ceph osd crush remove osd.$i || (echo "error rc:$?"; exit 1)
sleep 2
sudo ceph auth del osd.$i || (echo "error rc:$?"; exit 1)
sleep 2
sudo ceph osd rm $i || (echo "error rc:$?"; exit 1)
sleep 2
sudo umount /var/lib/ceph/osd/$c || (echo "error rc:$?"; exit 1)
sleep 2
sudo rm -rf /var/lib/ceph/osd/$c || (echo "error rc:$?"; exit 1)
sleep 2
done
sudo ceph osd tree
Después de que todos los procesos OSD se hayan migrado/eliminado, el nodo se puede eliminar de la nube.
Nota: Cuando se elimina Ceph, VNF HD RAID entrará en el estado Degradado, pero el disco HD debe seguir estando accesible.
Graceful Power Off
Caso 1. OSD-Compute Node Hosts CF/ESC/EM/UAS
Migrar tarjeta CF al estado en espera
Inicie sesión en el VNF de StarOS e identifique la tarjeta que corresponde a la VM de CF. Utilice el UUID de la máquina virtual CF identificado en la sección Identifique las máquinas virtuales alojadas en el nodo OSD-Compute y busque la tarjeta que corresponde al UUID.
[local]VNF2# show card hardware
Tuesday might 08 16:49:42 UTC 2018
<snip>
Card 2:
Card Type : Control Function Virtual Card
CPU Packages : 8 [#0, #1, #2, #3, #4, #5, #6, #7]
CPU Nodes : 1
CPU Cores/Threads : 8
Memory : 16384M (qvpc-di-large)
UUID/Serial Number : F9C0763A-4A4F-4BBD-AF51-BC7545774BE2
<snip>
Compruebe el estado de la tarjeta:
[local]VNF2# show card table
Tuesday might 08 16:52:53 UTC 2018
Slot Card Type Oper State SPOF Attach
----------- -------------------------------------- ------------- ---- ------
1: CFC Control Function Virtual Card Standby -
2: CFC Control Function Virtual Card Active No
3: FC 4-Port Service Function Virtual Card Active No
4: FC 4-Port Service Function Virtual Card Active No
5: FC 4-Port Service Function Virtual Card Active No
6: FC 4-Port Service Function Virtual Card Active No
7: FC 4-Port Service Function Virtual Card Active No
8: FC 4-Port Service Function Virtual Card Active No
9: FC 4-Port Service Function Virtual Card Active No
10: FC 4-Port Service Function Virtual Card Standby -
Si la tarjeta está en estado activo, muévala al estado en espera:
[local]VNF2# card migrate from 2 to 1
Apagar CF y EM VM desde ESC
Inicie sesión en el nodo ESC que corresponde a la VNF y verifique el estado de las VM:
[admin@VNF2-esc-esc-0 ~]$ cd /opt/cisco/esc/esc-confd/esc-cli
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229</vm_name>
<state>VM_ALIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c3_0_3e0db133-c13b-4e3d-ac14-
<state>VM_ALIVE_STATE</state>
<deployment_name>VNF2-DEPLOYMENT-em</deployment_name>
<vm_id>507d67c2-1d00-4321-b9d1-da879af524f8</vm_id>
<vm_id>dc168a6a-4aeb-4e81-abd9-91d7568b5f7c</vm_id>
<vm_id>9ffec58b-4b9d-4072-b944-5413bf7fcf07</vm_id>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea</vm_name>
<state>VM_ALIVE_STATE</state>
<snip>
Detenga la máquina virtual CF y EM una a una con el uso de su nombre de máquina virtual. Nombre de VM anotado en la sección Identifique las VM alojadas en el nodo OSD-Compute.
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli vm-action STOP VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli vm-action STOP VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea
Después de que se detiene, las VM deben entrar en el estado SHUTOFF:
[admin@VNF2-esc-esc-0 ~]$ cd /opt/cisco/esc/esc-confd/esc-cli
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229</vm_name>
<state>VM_SHUTOFF_STATE</state>
<vm_name>VNF2-DEPLOYM_c3_0_3e0db133-c13b-4e3d-ac14-
<state>VM_ALIVE_STATE</state>
<deployment_name>VNF2-DEPLOYMENT-em</deployment_name>
<vm_id>507d67c2-1d00-4321-b9d1-da879af524f8</vm_id>
<vm_id>dc168a6a-4aeb-4e81-abd9-91d7568b5f7c</vm_id>
<vm_id>9ffec58b-4b9d-4072-b944-5413bf7fcf07</vm_id>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea</vm_name>
VM_SHUTOFF_STATE
<snip>
Migrar ESC al modo de espera
Inicie sesión en la ESC alojada en el nodo de cálculo y compruebe si está en el estado maestro. En caso afirmativo, cambie el ESC al modo de espera:
[admin@VNF2-esc-esc-0 esc-cli]$ escadm status
0 ESC status=0 ESC Master Healthy
[admin@VNF2-esc-esc-0 ~]$ sudo service keepalived stop
Stopping keepalived: [ OK ]
[admin@VNF2-esc-esc-0 ~]$ escadm status
1 ESC status=0 In SWITCHING_TO_STOP state. Please check status after a while.
[admin@VNF2-esc-esc-0 ~]$ sudo reboot
Broadcast message from admin@vnf1-esc-esc-0.novalocal
(/dev/pts/0) at 13:32 ...
The system is going down for reboot NOW!
Elimine el nodo OSD-Compute de la lista de agregación de Nova
Enumera los agregados nova e identifica el agregado que corresponde al servidor Compute basado en el VNF alojado por él. Normalmente, tendría el formato <VNFNAME>-EM-MGMT<X> y <VNFNAME>-CF-MGMT<X>:
[stack@director ~]$ nova aggregate-list
+----+-------------------+-------------------+
| Id | Name | Availability Zone |
+----+-------------------+-------------------+
| 29 | POD1-AUTOIT | mgmt |
| 57 | VNF1-SERVICE1 | - |
| 60 | VNF1-EM-MGMT1 | - |
| 63 | VNF1-CF-MGMT1 | - |
| 66 | VNF2-CF-MGMT2 | - |
| 69 | VNF2-EM-MGMT2 | - |
| 72 | VNF2-SERVICE2 | - |
| 75 | VNF3-CF-MGMT3 | - |
| 78 | VNF3-EM-MGMT3 | - |
| 81 | VNF3-SERVICE3 | - |
+----+-------------------+-------------------+
En este caso, el servidor OSD-Compute pertenece a VNF2. Por lo tanto, los agregados que corresponden serían VNF2-CF-MGMT2 y VNF2-EM-MGMT2.
Elimine el nodo OSD-Compute del agregado identificado:
nova aggregate-remove-host
[stack@director ~]$ nova aggregate-remove-host VNF2-CF-MGMT2 pod1-osd-compute-0.localdomain
[stack@director ~]$ nova aggregate-remove-host VNF2-EM-MGMT2 pod1-osd-compute-0.localdomain
[stack@director ~]$ nova aggregate-remove-host POD1-AUTOIT pod1-osd-compute-0.localdomain
Verifique si el nodo OSD-Compute se ha eliminado de los agregados. Ahora, asegúrese de que el host no aparezca en la lista de agregados:
nova aggregate-show
[stack@director ~]$ nova aggregate-show VNF2-CF-MGMT2
[stack@director ~]$ nova aggregate-show VNF2-EM-MGMT2
[stack@director ~]$ nova aggregate-show POD1-AUTOIT
Caso 2. OSD-Compute Node Hosts Auto-Deploy/Auto-IT/EM/UAS
Copia de seguridad de la CDB de implementación automática
Realice copias de seguridad de los datos de autodeploy confd cdb periódicamente o después de cada activación/desactivación y guarde el archivo en un servidor de copia de seguridad.La implementación automática no es redundante y, si se pierden estos datos, será difícil desactivar la implementación.
Inicie sesión en el directorio Auto-Deploy VM and backup confd cdb:
ubuntu@auto-deploy-iso-2007-uas-0:~$sudo -i
root@auto-deploy-iso-2007-uas-0:~#service uas-confd stop
uas-confd stop/waiting
root@auto-deploy-iso-2007-uas-0:~# cd /opt/cisco/usp/uas/confd-6.3.1/var/confd
root@auto-deploy-iso-2007-uas-0:/opt/cisco/usp/uas/confd-6.3.1/var/confd#tar cvf autodeploy_cdb_backup.tar cdb/
cdb/
cdb/O.cdb
cdb/C.cdb
cdb/aaa_init.xml
cdb/A.cdb
root@auto-deploy-iso-2007-uas-0:~# service uas-confd start
uas-confd start/running, process 13852
Nota: Copie autodeploy_cdb_backup.tar en el servidor de respaldo.
Copia de seguridad de system.cfg desde Auto-IT
Lleve la copia de seguridad del archivo system.cfg al servidor de copia de seguridad:
Auto-it = 10.1.1.2
Backup server = 10.2.2.2
[stack@director ~]$ ssh ubuntu@10.1.1.2
ubuntu@10.1.1.2's password:
Welcome to Ubuntu 14.04.3 LTS (GNU/Linux 3.13.0-76-generic x86_64)
* Documentation: https://help.ubuntu.com/
System information as of Wed Jun 13 16:21:34 UTC 2018
System load: 0.02 Processes: 87
Usage of /: 15.1% of 78.71GB Users logged in: 0
Memory usage: 13% IP address for eth0: 172.16.182.4
Swap usage: 0%
Graph this data and manage this system at:
https://landscape.canonical.com/
Get cloud support with Ubuntu Advantage Cloud Guest:
http://www.ubuntu.com/business/services/cloud
Cisco Ultra Services Platform (USP)
Build Date: Wed Feb 14 12:58:22 EST 2018
Description: UAS build assemble-uas#1891
sha1: bf02ced
ubuntu@auto-it-vnf-uas-0:~$ scp -r /opt/cisco/usp/uploads/system.cfg root@10.2.2.2:/home/stack
root@10.2.2.2's password:
system.cfg 100% 565 0.6KB/s 00:00
ubuntu@auto-it-vnf-uas-0:~$
Nota: Los procedimientos que se deben realizar para un apagado correcto de EM/UAS alojado en OSD-Compute-0 son los mismos en ambos casos. Consulte el Caso 1 para obtener información sobre lo mismo.
OSD-Eliminación de nodos de computación
Los pasos mencionados en esta sección son comunes independientemente de las VM alojadas en el nodo de cálculo.
Eliminar nodo de cálculo de OSD de la lista de servicios
Elimine el servicio Informática de la lista de servicios:
[stack@director ~]$ source corerc
[stack@director ~]$ openstack compute service list | grep osd-compute-0
| 404 | nova-compute | pod1-osd-compute-0.localdomain | nova | enabled | up | 2018-05-08T18:40:56.000000 |
openstack compute service delete
[stack@director ~]$ openstack compute service delete 404
Eliminar agentes de neutrones
Elimine el antiguo agente neutrón asociado y abra el agente vswitch para el servidor Compute:
[stack@director ~]$ openstack network agent list | grep osd-compute-0
| c3ee92ba-aa23-480c-ac81-d3d8d01dcc03 | Open vSwitch agent | pod1-osd-compute-0.localdomain | None | False | UP | neutron-openvswitch-agent |
| ec19cb01-abbb-4773-8397-8739d9b0a349 | NIC Switch agent | pod1-osd-compute-0.localdomain | None | False | UP | neutron-sriov-nic-agent |
openstack network agent delete
[stack@director ~]$ openstack network agent delete c3ee92ba-aa23-480c-ac81-d3d8d01dcc03
[stack@director ~]$ openstack network agent delete ec19cb01-abbb-4773-8397-8739d9b0a349
Eliminar de la base de datos Nova e Ironic
Elimine un nodo de la lista nova y de la base de datos irónica y compruébelo:
[stack@director ~]$ source stackrc
[stack@al01-pod1-ospd ~]$ nova list | grep osd-compute-0
| c2cfa4d6-9c88-4ba0-9970-857d1a18d02c | pod1-osd-compute-0 | ACTIVE | - | Running | ctlplane=192.200.0.114 |
[stack@al01-pod1-ospd ~]$ nova delete c2cfa4d6-9c88-4ba0-9970-857d1a18d02c
nova show| grep hypervisor
[stack@director ~]$ nova show pod1-osd-compute-0 | grep hypervisor
| OS-EXT-SRV-ATTR:hypervisor_hostname | 4ab21917-32fa-43a6-9260-02538b5c7a5a
ironic node-delete
[stack@director ~]$ ironic node-delete 4ab21917-32fa-43a6-9260-02538b5c7a5a
[stack@director ~]$ ironic node-list (node delete must not be listed now)
Eliminar de nube excesiva
Cree un archivo de script denominado delete_node.sh con el contenido como se muestra. Asegúrese de que las plantillas mencionadas son las mismas que las utilizadas en el archivo de comandos deploy.sh utilizado para la implementación de pila:
delete_node.sh
openstack overcloud node delete --templates -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml -e /home/stack/custom-templates/layout.yaml --stack
[stack@director ~]$ source stackrc
[stack@director ~]$ /bin/sh delete_node.sh
+ openstack overcloud node delete --templates -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml -e /home/stack/custom-templates/layout.yaml --stack pod1 49ac5f22-469e-4b84-badc-031083db0533
Deleting the following nodes from stack pod1:
- 49ac5f22-469e-4b84-badc-031083db0533
Started Mistral Workflow. Execution ID: 4ab4508a-c1d5-4e48-9b95-ad9a5baa20ae
real 0m52.078s
user 0m0.383s
sys 0m0.086s
Espere a la operación de pila de OpenStack para pasar al estado COMPLETE:
[stack@director ~]$ openstack stack list
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| ID | Stack Name | Stack Status | Creation Time | Updated Time |
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| 5df68458-095d-43bd-a8c4-033e68ba79a0 | pod1 | UPDATE_COMPLETE | 2018-05-08T21:30:06Z | 2018-05-08T20:42:48Z |
+--------------------------------------+------------+-----------------+----------------------+----------------------
Instalación del nuevo nodo de cálculo
- Los pasos para instalar un nuevo servidor UCS C240 M4 y los pasos de configuración iniciales se pueden consultar en:
Guía de instalación y servicio del servidor Cisco UCS C240 M4
- Después de la instalación del servidor, inserte los discos duros en las ranuras respectivas como el servidor antiguo
- Inicie sesión en el servidor con el uso de la IP de CIMC
- Realice la actualización del BIOS si el firmware no es de la versión recomendada utilizada anteriormente. A continuación se indican los pasos para actualizar la BIOS:
Guía de actualización del BIOS del servidor de montaje en bastidor Cisco UCS C-Series
- Verifique el estado de las unidades físicas. Debe ser bueno sin confeccionar
- Cree una unidad virtual a partir de las unidades físicas con RAID de nivel 1
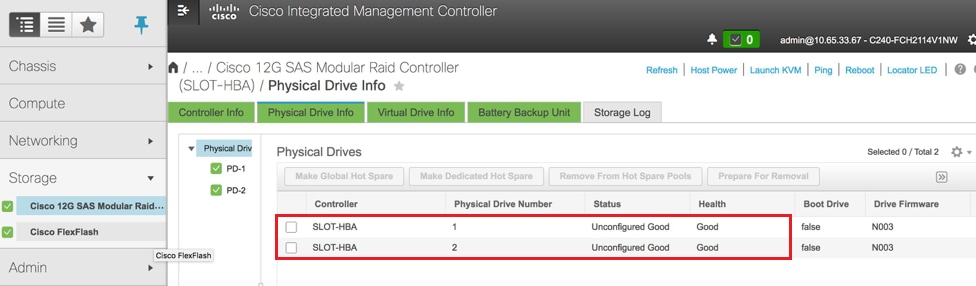 Almacenamiento > Controlador RAID modular Cisco SAS 12G (SLOT-HBA) > Información de la unidad física
Almacenamiento > Controlador RAID modular Cisco SAS 12G (SLOT-HBA) > Información de la unidad física
Nota: Esta imagen es solo para fines ilustrativos, en real, OSD-Compute CIMC verá siete unidades físicas en ranuras (1,2,3,7,8,9,10) en estado bueno sin configurar ya que no se crea ninguna unidad virtual a partir de ellos.
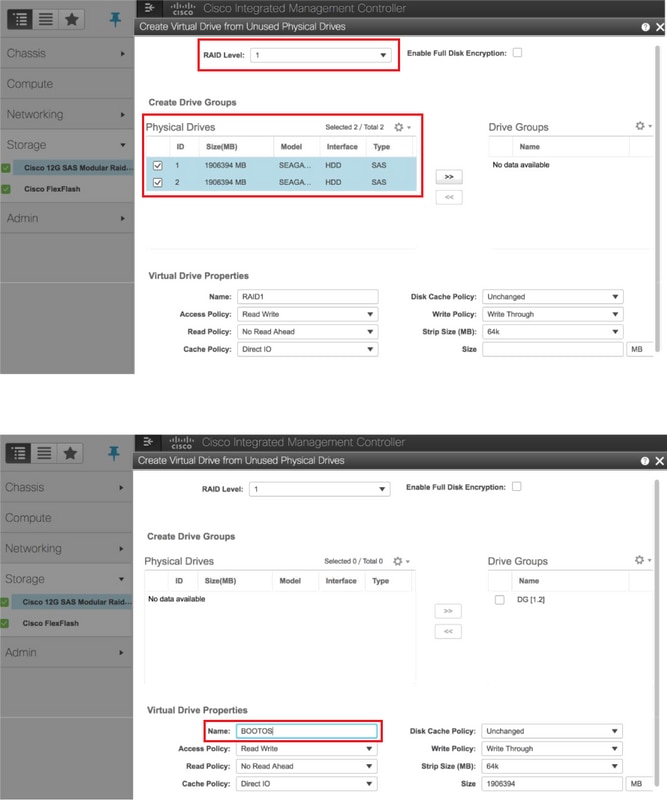 Almacenamiento > Controlador RAID modular SAS de 12 GB de Cisco (SLOT-HBA) > Información del controlador > Crear unidad virtual a partir de unidades físicas no utilizadas
Almacenamiento > Controlador RAID modular SAS de 12 GB de Cisco (SLOT-HBA) > Información del controlador > Crear unidad virtual a partir de unidades físicas no utilizadas
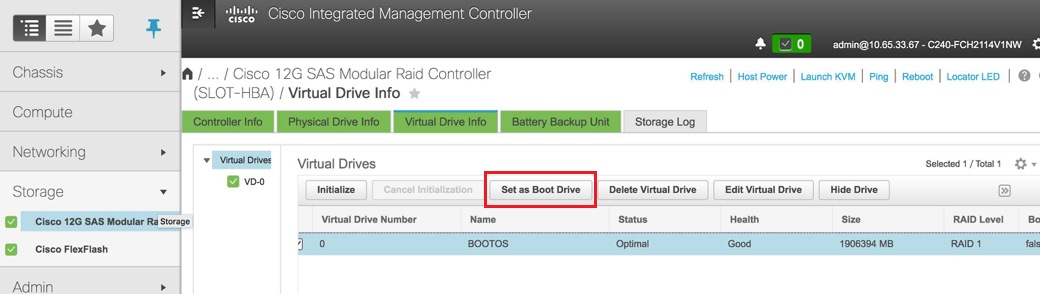 Seleccione el DVD y configure "Set as Boot Drive" (Establecer como unidad de arranque)
Seleccione el DVD y configure "Set as Boot Drive" (Establecer como unidad de arranque)
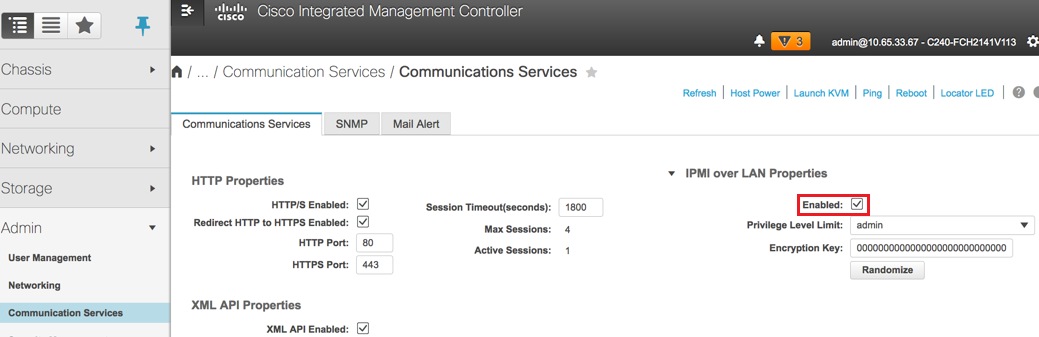 Habilitar IPMI sobre LAN: Admin > Communication Services > Communication Services
Habilitar IPMI sobre LAN: Admin > Communication Services > Communication Services
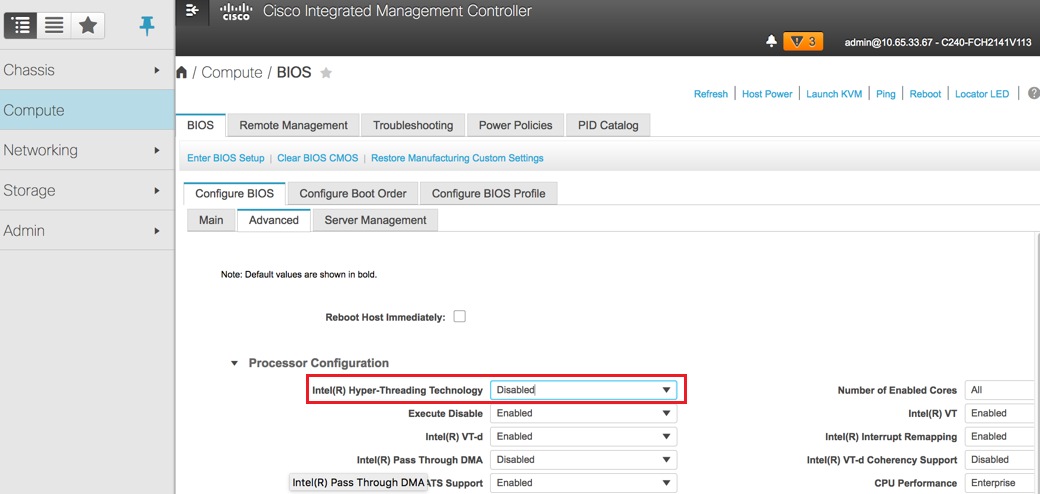 Deshabilitar hiperprocesamiento: Compute > BIOS > Configure BIOS > Advanced > Processor Configuration
Deshabilitar hiperprocesamiento: Compute > BIOS > Configure BIOS > Advanced > Processor Configuration
- Al igual que BOOTOS VD creado con las unidades físicas 1 y 2, crear cuatro unidades virtuales más como
JOURNAL > Desde la unidad física número 3
OSD1 > Desde la unidad física número 7
OSD2 > Desde la unidad física número 8
OSD3 > Desde la unidad física número 9
OSD4 > Desde la unidad física número 10 - Al final, las unidades físicas y las unidades virtuales deben ser similares a como se muestra en la imagen:
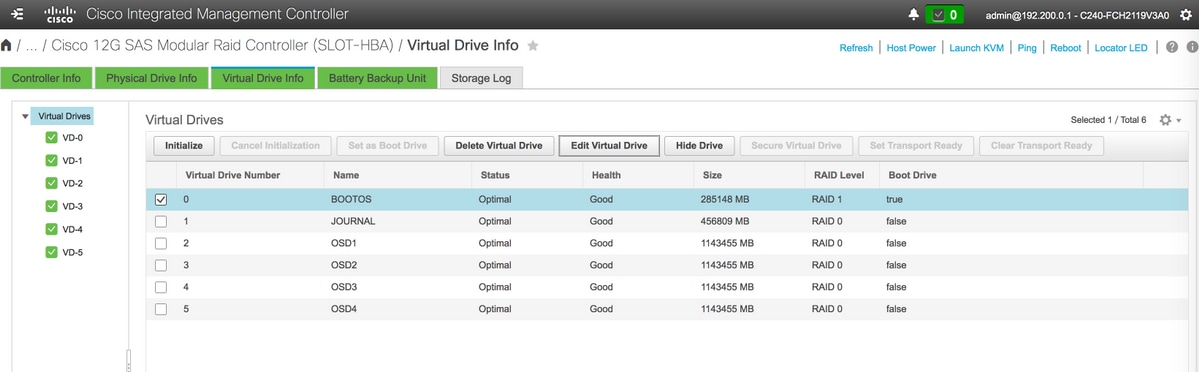 unidades virtuales
unidades virtuales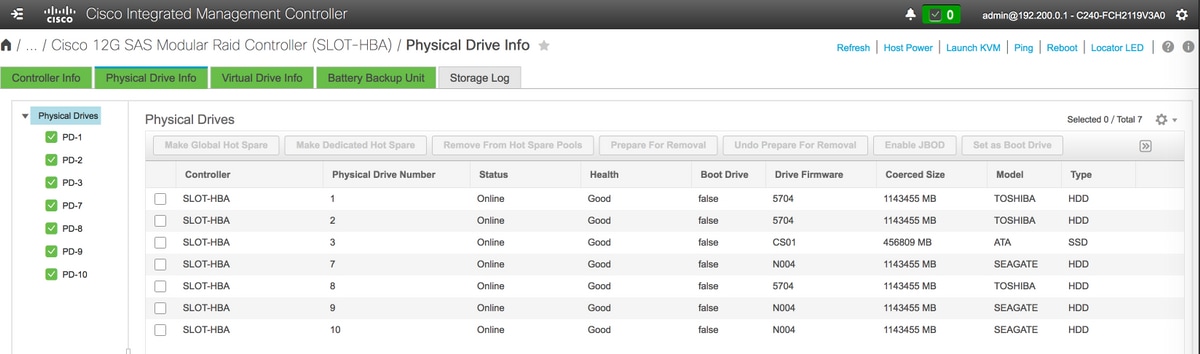 Unidades físicas
Unidades físicas
Nota: La imagen que se muestra aquí y los pasos de configuración mencionados en esta sección hacen referencia a la versión de firmware 3.0(3e) y puede haber ligeras variaciones si trabaja en otras versiones.
Agregar el nuevo nodo de computación OSD a la nube excesiva
Los pasos mencionados en esta sección son comunes independientemente de la máquina virtual alojada por el nodo informático.
Agregue un servidor de computación con un índice diferente.
Cree un archivo add_node.json sólo con los detalles del nuevo servidor de computación que se agregará. Asegúrese de que el número de índice del nuevo servidor OSD-Compute no se haya utilizado antes. Normalmente, se incrementa el siguiente valor de cálculo más alto.
Ejemplo: La más alta anterior fue OSD-Compute-0, por lo que creó OSD-Compute-3 en el caso de un sistema 2-vnf.
Nota: Tenga en cuenta el formato json.
[stack@director ~]$ cat add_node.json
{
"nodes":[
{
"mac":[
"<MAC_ADDRESS>"
],
"capabilities": "node:osd-compute-3,boot_option:local",
"cpu":"24",
"memory":"256000",
"disk":"3000",
"arch":"x86_64",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"<PASSWORD>",
"pm_addr":"192.100.0.5"
}
]
}
Importe el archivo json:
[stack@director ~]$ openstack baremetal import --json add_node.json
Started Mistral Workflow. Execution ID: 78f3b22c-5c11-4d08-a00f-8553b09f497d
Successfully registered node UUID 7eddfa87-6ae6-4308-b1d2-78c98689a56e
Started Mistral Workflow. Execution ID: 33a68c16-c6fd-4f2a-9df9-926545f2127e
Successfully set all nodes to available.
Ejecute la introspección de nodos con el uso del UUID indicado en el paso anterior:
[stack@director ~]$ openstack baremetal node manage 7eddfa87-6ae6-4308-b1d2-78c98689a56e
[stack@director ~]$ ironic node-list |grep 7eddfa87
| 7eddfa87-6ae6-4308-b1d2-78c98689a56e | None | None | power off | manageable | False |
[stack@director ~]$ openstack overcloud node introspect 7eddfa87-6ae6-4308-b1d2-78c98689a56e --provide
Started Mistral Workflow. Execution ID: e320298a-6562-42e3-8ba6-5ce6d8524e5c
Waiting for introspection to finish...
Successfully introspected all nodes.
Introspection completed.
Started Mistral Workflow. Execution ID: c4a90d7b-ebf2-4fcb-96bf-e3168aa69dc9
Successfully set all nodes to available.
[stack@director ~]$ ironic node-list |grep available
| 7eddfa87-6ae6-4308-b1d2-78c98689a56e | None | None | power off | available | False |
Agregue direcciones IP a custom-templates/layout.yml en OsdComputeIPs. En este caso, cuando reemplace OSD-Compute-0, agregue esa dirección al final de la lista para cada tipo:
OsdComputeIPs:
internal_api:
- 11.120.0.43
- 11.120.0.44
- 11.120.0.45
- 11.120.0.43 <<< take osd-compute-0 .43 and add here
tenant:
- 11.117.0.43
- 11.117.0.44
- 11.117.0.45
- 11.117.0.43 << and here
storage:
- 11.118.0.43
- 11.118.0.44
- 11.118.0.45
- 11.118.0.43 << and here
storage_mgmt:
- 11.119.0.43
- 11.119.0.44
- 11.119.0.45
- 11.119.0.43 << and here
Ejecute el script deploy.sh que se utilizó anteriormente para implementar la pila, para agregar el nuevo nodo de computación a la pila de nube excesiva:
[stack@director ~]$ ./deploy.sh
++ openstack overcloud deploy --templates -r /home/stack/custom-templates/custom-roles.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml --stack ADN-ultram --debug --log-file overcloudDeploy_11_06_17__16_39_26.log --ntp-server 172.24.167.109 --neutron-flat-networks phys_pcie1_0,phys_pcie1_1,phys_pcie4_0,phys_pcie4_1 --neutron-network-vlan-ranges datacentre:1001:1050 --neutron-disable-tunneling --verbose --timeout 180
…
Starting new HTTP connection (1): 192.200.0.1
"POST /v2/action_executions HTTP/1.1" 201 1695
HTTP POST http://192.200.0.1:8989/v2/action_executions 201
Overcloud Endpoint: http://10.1.2.5:5000/v2.0
Overcloud Deployed
clean_up DeployOvercloud:
END return value: 0
real 38m38.971s
user 0m3.605s
sys 0m0.466s
Espere a que el estado de la pila de OpenStack sea COMPLETE:
[stack@director ~]$ openstack stack list
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| ID | Stack Name | Stack Status | Creation Time | Updated Time |
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| 5df68458-095d-43bd-a8c4-033e68ba79a0 | pod1 | UPDATE_COMPLETE | 2017-11-02T21:30:06Z | 2017-11-06T21:40:58Z |
+--------------------------------------+------------+-----------------+----------------------+----------------------+
Verifique que el nuevo nodo OSD-Compute esté en el estado Activo:
[stack@director ~]$ source stackrc
[stack@director ~]$ nova list |grep osd-compute-3
| 0f2d88cd-d2b9-4f28-b2ca-13e305ad49ea | pod1-osd-compute-3 | ACTIVE | - | Running | ctlplane=192.200.0.117 |
[stack@director ~]$ source corerc
[stack@director ~]$ openstack hypervisor list |grep osd-compute-3
| 63 | pod1-osd-compute-3.localdomain |
Inicie sesión en el nuevo servidor OSD-Compute y compruebe los procesos de Ceph. Inicialmente, el estado será HEALTH_WARN cuando Ceph se recupere:
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_WARN
223 pgs backfill_wait
4 pgs backfilling
41 pgs degraded
227 pgs stuck unclean
41 pgs undersized
recovery 45229/1300136 objects degraded (3.479%)
recovery 525016/1300136 objects misplaced (40.382%)
monmap e1: 3 mons at {Pod1-controller-0=11.118.0.40:6789/0,Pod1-controller-1=11.118.0.41:6789/0,Pod1-controller-2=11.118.0.42:6789/0}
election epoch 58, quorum 0,1,2 Pod1-controller-0,Pod1-controller-1,Pod1-controller-2
osdmap e986: 12 osds: 12 up, 12 in; 225 remapped pgs
flags sortbitwise,require_jewel_osds
pgmap v781746: 704 pgs, 6 pools, 533 GB data, 344 kobjects
1553 GB used, 11840 GB / 13393 GB avail
45229/1300136 objects degraded (3.479%)
525016/1300136 objects misplaced (40.382%)
477 active+clean
186 active+remapped+wait_backfill
37 active+undersized+degraded+remapped+wait_backfill
4 active+undersized+degraded+remapped+backfilling
Pero después de un corto período (20 minutos), Ceph vuelve a un estado HEALTH_OK:
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph -s
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
monmap e1: 3 mons at {Pod1-controller-0=11.118.0.40:6789/0,Pod1-controller-1=11.118.0.41:6789/0,Pod1-controller-2=11.118.0.42:6789/0}
election epoch 58, quorum 0,1,2 Pod1-controller-0,Pod1-controller-1,Pod1-controller-2
osdmap e1398: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v784311: 704 pgs, 6 pools, 533 GB data, 344 kobjects
1599 GB used, 11793 GB / 13393 GB avail
704 active+clean
client io 8168 kB/s wr, 0 op/s rd, 32 op/s wr
[heat-admin@pod1-osd-compute-3 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 0 host pod1-osd-compute-0
-3 4.35999 host pod1-osd-compute-2
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
-4 4.35999 host pod1-osd-compute-1
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
-5 4.35999 host pod1-osd-compute-3
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
Configuración de sustitución de postservidor
Después de agregar el servidor a la nube, consulte el enlace siguiente para aplicar la configuración que estaba presente anteriormente en el servidor antiguo:
Restauración de las VM
Caso 1. OSD-Compute Node Hosting CF, ESC, EM y UAS
Adición a la lista de Nova Aggregate
Agregue el nodo OSD-Compute a los hosts agregados y verifique si el host ha sido agregado. En este caso, el nodo OSD-Compute debe agregarse a los agregados de host CF y EM.
nova aggregate-add-host
[stack@director ~]$ nova aggregate-add-host VNF2-CF-MGMT2 pod1-osd-compute-3.localdomain
[stack@director ~]$ nova aggregate-add-host VNF2-EM-MGMT2 pod1-osd-compute-3.localdomain
[stack@direcotr ~]$ nova aggregate-add-host POD1-AUTOIT pod1-osd-compute-3.localdomain
nova aggregate-show
[stack@director ~]$ nova aggregate-show VNF2-CF-MGMT2
[stack@director ~]$ nova aggregate-show VNF2-EM-MGMT2
[stack@director ~]$ nova aggregate-show POD1-AUTOITT
Recuperación de UAS VM
Verifique el estado de la máquina virtual UAS en la lista nova y elimínela:
[stack@director ~]$ nova list | grep VNF2-UAS-uas-0
| 307a704c-a17c-4cdc-8e7a-3d6e7e4332fa | VNF2-UAS-uas-0 | ACTIVE | - | Running | VNF2-UAS-uas-orchestration=172.168.11.10; VNF2-UAS-uas-management=172.168.10.3
[stack@director ~]$ nova delete VNF2-UAS-uas-0
Request to delete server VNF2-UAS-uas-0 has been accepted.
Para recuperar la VM autovnf-uas, ejecute el script uas-check para verificar el estado. Debe informar de un ERROR. Luego ejecute nuevamente con la opción —fix para recrear la VM de UAS que falta:
[stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts/
[stack@director scripts]$ ./uas-check.py auto-vnf VNF2-UAS
2017-12-08 12:38:05,446 - INFO: Check of AutoVNF cluster started
2017-12-08 12:38:07,925 - INFO: Instance 'vnf1-UAS-uas-0' status is 'ERROR'
2017-12-08 12:38:07,925 - INFO: Check completed, AutoVNF cluster has recoverable errors
[stack@director scripts]$ ./uas-check.py auto-vnf VNF2-UAS --fix
2017-11-22 14:01:07,215 - INFO: Check of AutoVNF cluster started
2017-11-22 14:01:09,575 - INFO: Instance VNF2-UAS-uas-0' status is 'ERROR'
2017-11-22 14:01:09,575 - INFO: Check completed, AutoVNF cluster has recoverable errors
2017-11-22 14:01:09,778 - INFO: Removing instance VNF2-UAS-uas-0'
2017-11-22 14:01:13,568 - INFO: Removed instance VNF2-UAS-uas-0'
2017-11-22 14:01:13,568 - INFO: Creating instance VNF2-UAS-uas-0' and attaching volume ‘VNF2-UAS-uas-vol-0'
2017-11-22 14:01:49,525 - INFO: Created instance ‘VNF2-UAS-uas-0'
Inicie sesión en autovnf-uas. Espere unos minutos y UAS debe volver al estado correcto:
VNF2-autovnf-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.17.181.101
INSTANCE IP STATE ROLE
-----------------------------------
172.17.180.6 alive CONFD-SLAVE
172.17.180.7 alive CONFD-MASTER
172.17.180.9 alive NA
Nota: Si uas-check.py —fix falla, es posible que necesite copiar este archivo y ejecutarlo nuevamente.
[stack@director ~]$ mkdir –p /opt/cisco/usp/apps/auto-it/common/uas-deploy/
[stack@director ~]$ cp /opt/cisco/usp/uas-installer/common/uas-deploy/userdata-uas.txt /opt/cisco/usp/apps/auto-it/common/uas-deploy/
Recuperación de la máquina virtual ESC
Verifique el estado de la máquina virtual ESC de la lista nova y elimínela:
stack@director scripts]$ nova list |grep ESC-1
| c566efbf-1274-4588-a2d8-0682e17b0d41 | VNF2-ESC-ESC-1 | ACTIVE | - | Running | VNF2-UAS-uas-orchestration=172.168.11.14; VNF2-UAS-uas-management=172.168.10.4 |
[stack@director scripts]$ nova delete VNF2-ESC-ESC-1
Request to delete server VNF2-ESC-ESC-1 has been accepted.
En AutoVNF-UAS, busque la transacción de implementación de ESC y en el registro de la transacción busque la línea de comandos boot_vm.py para crear la instancia de ESC:
ubuntu@VNF2-uas-uas-0:~$ sudo -i
root@VNF2-uas-uas-0:~# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on VNF2-uas-uas-0
VNF2-uas-uas-0#show transaction
TX ID TX TYPE DEPLOYMENT ID TIMESTAMP STATUS
-----------------------------------------------------------------------------------------------------------------------------
35eefc4a-d4a9-11e7-bb72-fa163ef8df2b vnf-deployment VNF2-DEPLOYMENT 2017-11-29T02:01:27.750692-00:00 deployment-success
73d9c540-d4a8-11e7-bb72-fa163ef8df2b vnfm-deployment VNF2-ESC 2017-11-29T01:56:02.133663-00:00 deployment-success
VNF2-uas-uas-0#show logs 73d9c540-d4a8-11e7-bb72-fa163ef8df2b | display xml
<config xmlns="http://tail-f.com/ns/config/1.0">
<logs xmlns="http://www.cisco.com/usp/nfv/usp-autovnf-oper">
<tx-id>73d9c540-d4a8-11e7-bb72-fa163ef8df2b</tx-id>
<log>2017-11-29 01:56:02,142 - VNFM Deployment RPC triggered for deployment: VNF2-ESC, deactivate: 0
2017-11-29 01:56:02,179 - Notify deployment
..
2017-11-29 01:57:30,385 - Creating VNFM 'VNF2-ESC-ESC-1' with [python //opt/cisco/vnf-staging/bootvm.py VNF2-ESC-ESC-1 --flavor VNF2-ESC-ESC-flavor --image 3fe6b197-961b-4651-af22-dfd910436689 --net VNF2-UAS-uas-management --gateway_ip 172.168.10.1 --net VNF2-UAS-uas-orchestration --os_auth_url http://10.1.2.5:5000/v2.0 --os_tenant_name core --os_username ****** --os_password ****** --bs_os_auth_url http://10.1.2.5:5000/v2.0 --bs_os_tenant_name core --bs_os_username ****** --bs_os_password ****** --esc_ui_startup false --esc_params_file /tmp/esc_params.cfg --encrypt_key ****** --user_pass ****** --user_confd_pass ****** --kad_vif eth0 --kad_vip 172.168.10.7 --ipaddr 172.168.10.6 dhcp --ha_node_list 172.168.10.3 172.168.10.6 --file root:0755:/opt/cisco/esc/esc-scripts/esc_volume_em_staging.sh:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc_volume_em_staging.sh --file root:0755:/opt/cisco/esc/esc-scripts/esc_vpc_chassis_id.py:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc_vpc_chassis_id.py --file root:0755:/opt/cisco/esc/esc-scripts/esc-vpc-di-internal-keys.sh:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc-vpc-di-internal-keys.sh
Guarde la línea boot_vm.py en un archivo de script de shell (esc.sh) y actualice todas las líneas de nombre de usuario ***** y contraseña ***** con la información correcta (normalmente core/<PASSWORD>). También debe quitar la opción -encrypt_key. Para user_pass y user_confd_pass, debe utilizar el formato - username: contraseña (ejemplo - admin:<PASSWORD>).
Busque la URL para evitar que bootvm.py ejecute running-config y envíe el archivo bootvm.py a la máquina virtual autovnf-uas. En este caso, 10.1.2.3 es la dirección IP de la máquina virtual de Auto-IT:
root@VNF2-uas-uas-0:~# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on VNF2-uas-uas-0
VNF2-uas-uas-0#show running-config autovnf-vnfm:vnfm
…
configs bootvm
value http:// 10.1.2.3:80/bundles/5.1.7-2007/vnfm-bundle/bootvm-2_3_2_155.py
!
root@VNF2-uas-uas-0:~# wget http://10.1.2.3:80/bundles/5.1.7-2007/vnfm-bundle/bootvm-2_3_2_155.py
--2017-12-01 20:25:52-- http://10.1.2.3 /bundles/5.1.7-2007/vnfm-bundle/bootvm-2_3_2_155.py
Connecting to 10.1.2.3:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 127771 (125K) [text/x-python]
Saving to: ‘bootvm-2_3_2_155.py’
100%[=====================================================================================>] 127,771 --.-K/s in 0.001s
2017-12-01 20:25:52 (173 MB/s) - ‘bootvm-2_3_2_155.py’ saved [127771/127771]
Cree un archivo /tmp/esc_params.cfg:
root@VNF2-uas-uas-0:~# echo "openstack.endpoint=publicURL" > /tmp/esc_params.cfg
Ejecute la secuencia de comandos del shell para implementar ESC desde el nodo UAS:
root@VNF2-uas-uas-0:~# /bin/sh esc.sh
+ python ./bootvm.py VNF2-ESC-ESC-1 --flavor VNF2-ESC-ESC-flavor --image 3fe6b197-961b-4651-af22-dfd910436689
--net VNF2-UAS-uas-management --gateway_ip 172.168.10.1 --net VNF2-UAS-uas-orchestration --os_auth_url
http://10.1.2.5:5000/v2.0 --os_tenant_name core --os_username core --os_password <PASSWORD> --bs_os_auth_url
http://10.1.2.5:5000/v2.0 --bs_os_tenant_name core --bs_os_username core --bs_os_password <PASSWORD>
--esc_ui_startup false --esc_params_file /tmp/esc_params.cfg --user_pass admin:<PASSWORD> --user_confd_pass
admin:<PASSWORD> --kad_vif eth0 --kad_vip 172.168.10.7 --ipaddr 172.168.10.6 dhcp --ha_node_list 172.168.10.3
172.168.10.6 --file root:0755:/opt/cisco/esc/esc-scripts/esc_volume_em_staging.sh:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc_volume_em_staging.sh
--file root:0755:/opt/cisco/esc/esc-scripts/esc_vpc_chassis_id.py:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc_vpc_chassis_id.py
--file root:0755:/opt/cisco/esc/esc-scripts/esc-vpc-di-internal-keys.sh:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc-vpc-di-internal-keys.sh
Inicie sesión en el nuevo ESC y verifique el estado de la copia de seguridad:
ubuntu@VNF2-uas-uas-0:~$ ssh admin@172.168.11.14
…
####################################################################
# ESC on VNF2-esc-esc-1.novalocal is in BACKUP state.
####################################################################
[admin@VNF2-esc-esc-1 ~]$ escadm status
0 ESC status=0 ESC Backup Healthy
[admin@VNF2-esc-esc-1 ~]$ health.sh
============== ESC HA (BACKUP) ===================================================
ESC HEALTH PASSED
Recuperación de VM CF y EM desde ESC
Verifique el estado de las VM CF y EM de la lista nova. Deben estar en el estado ERROR:
[stack@director ~]$ source corerc
[stack@director ~]$ nova list --field name,host,status |grep -i err
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | None | ERROR|
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229 |None | ERROR
Inicie sesión en el maestro ESC, ejecute recovery-vm-action para cada máquina virtual de EM y CF afectada. Sé paciente. ESC programaría la acción de recuperación y es posible que no se produzca durante unos minutos. Supervise el archivo yangesc.log:
sudo /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli recovery-vm-action DO
[admin@VNF2-esc-esc-0 ~]$ sudo /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli recovery-vm-action DO VNF2-DEPLOYMENT-_VNF2-D_0_a6843886-77b4-4f38-b941-74eb527113a8
[sudo] password for admin:
Recovery VM Action
/opt/cisco/esc/confd/bin/netconf-console --port=830 --host=127.0.0.1 --user=admin --privKeyFile=/root/.ssh/confd_id_dsa --privKeyType=dsa --rpc=/tmp/esc_nc_cli.ZpRCGiieuW
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="1">
<ok/>
</rpc-reply>
[admin@VNF2-esc-esc-0 ~]$ tail -f /var/log/esc/yangesc.log
…
14:59:50,112 07-Nov-2017 WARN Type: VM_RECOVERY_COMPLETE
14:59:50,112 07-Nov-2017 WARN Status: SUCCESS
14:59:50,112 07-Nov-2017 WARN Status Code: 200
14:59:50,112 07-Nov-2017 WARN Status Msg: Recovery: Successfully recovered VM [VNF2-DEPLOYMENT-_VNF2-D_0_a6843886-77b4-4f38-b941-74eb527113a8]
Inicie sesión en el nuevo EM y compruebe que el estado del EM es activo:
ubuntu@VNF2vnfddeploymentem-1:~$ /opt/cisco/ncs/current/bin/ncs_cli -u admin -C
admin connected from 172.17.180.6 using ssh on VNF2vnfddeploymentem-1
admin@scm# show ems
EM VNFM
ID SLA SCM PROXY
---------------------
2 up up up
3 up up up
Inicie sesión en el VNF de StarOS y verifique que la tarjeta CF esté en estado de espera.
Caso 2. OSD-Compute Node Hosting Auto-IT, Auto-deploy, EM y UAS
Recuperación de VM implementada automáticamente
En OSPD, si la VM implementada automáticamente se vio afectada pero sigue mostrando ACTIVE/Running, primero deberá eliminarla. Si la implementación automática no se vio afectada, diríjase a Recuperación de la VM de Auto-it:
[stack@director ~]$ nova list |grep auto-deploy
| 9b55270a-2dcd-4ac1-aba3-bf041733a0c9 | auto-deploy-ISO-2007-uas-0 | ACTIVE | - | Running | mgmt=172.16.181.12, 10.1.2.7 [stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts
[stack@director ~]$ ./auto-deploy-booting.sh --floating-ip 10.1.2.7 --delete
Una vez eliminada la implementación automática, vuelva a crearla con la misma dirección flotante:
[stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts
[stack@director scripts]$ ./auto-deploy-booting.sh --floating-ip 10.1.2.7
2017-11-17 07:05:03,038 - INFO: Creating AutoDeploy deployment (1 instance(s)) on 'http://10.84.123.4:5000/v2.0' tenant 'core' user 'core', ISO 'default'
2017-11-17 07:05:03,039 - INFO: Loading image 'auto-deploy-ISO-5-1-7-2007-usp-uas-1.0.1-1504.qcow2' from '/opt/cisco/usp/uas-installer/images/usp-uas-1.0.1-1504.qcow2'
2017-11-17 07:05:14,603 - INFO: Loaded image 'auto-deploy-ISO-5-1-7-2007-usp-uas-1.0.1-1504.qcow2'
2017-11-17 07:05:15,787 - INFO: Assigned floating IP '10.1.2.7' to IP '172.16.181.7'
2017-11-17 07:05:15,788 - INFO: Creating instance 'auto-deploy-ISO-5-1-7-2007-uas-0'
2017-11-17 07:05:42,759 - INFO: Created instance 'auto-deploy-ISO-5-1-7-2007-uas-0'
2017-11-17 07:05:42,759 - INFO: Request completed, floating IP: 10.1.2.7
Copie el archivo Autodeploy.cfg, ISO y el archivo confd_backup.tar del servidor de respaldo para implementar automáticamente la VM y restaurar los archivos confd cdb del archivo tar de respaldo:
ubuntu@auto-deploy-iso-2007-uas-0:~# sudo -i
ubuntu@auto-deploy-iso-2007-uas-0:# service uas-confd stop
uas-confd stop/waiting
root@auto-deploy-iso-2007-uas-0:# cd /opt/cisco/usp/uas/confd-6.3.1/var/confd
root@auto-deploy-iso-2007-uas-0:/opt/cisco/usp/uas/confd-6.3.1/var/confd# tar xvf /home/ubuntu/ad_cdb_backup.tar
cdb/
cdb/O.cdb
cdb/C.cdb
cdb/aaa_init.xml
cdb/A.cdb
root@auto-deploy-iso-2007-uas-0~# service uas-confd start
uas-confd start/running, process 2036
Verifique que confd se haya cargado correctamente mediante la comprobación de transacciones anteriores. Actualice el archivo autodeploy.cfg con un nuevo nombre OSD-Compute. Consulte la Sección - Paso final: Actualizar configuración de AutoDeploy:
root@auto-deploy-iso-2007-uas-0:~# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on auto-deploy-iso-2007-uas-0
auto-deploy-iso-2007-uas-0#show transaction
SERVICE SITE
DEPLOYMENT SITE TX AUTOVNF VNF AUTOVNF
TX ID TX TYPE ID DATE AND TIME STATUS ID ID ID ID TX ID
-------------------------------------------------------------------------------------------------------------------------------------
1512571978613 service-deployment tb5bxb 2017-12-06T14:52:59.412+00:00 deployment-success
auto-deploy-iso-2007-uas-0# exit
Recuperación de la máquina virtual de TI automática
Desde OSPD, si la máquina virtual de auto-it se vio afectada pero aún se muestra como ACTIVA/En ejecución, debe eliminarse. Si auto-it no se vio afectado, pase a la siguiente VM:
[stack@director ~]$ nova list |grep auto-it
| 580faf80-1d8c-463b-9354-781ea0c0b352 | auto-it-vnf-ISO-2007-uas-0 | ACTIVE | - | Running | mgmt=172.16.181.3, 10.1.2.8 [stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts
[stack@director ~]$ ./ auto-it-vnf-staging.sh --floating-ip 10.1.2.8 --delete
Ejecute auto-it-vnf staging script y vuelva a crear auto-it:
[stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts
[stack@director scripts]$ ./auto-it-vnf-staging.sh --floating-ip 10.1.2.8
2017-11-16 12:54:31,381 - INFO: Creating StagingServer deployment (1 instance(s)) on 'http://10.84.123.4:5000/v2.0' tenant 'core' user 'core', ISO 'default'
2017-11-16 12:54:31,382 - INFO: Loading image 'auto-it-vnf-ISO-5-1-7-2007-usp-uas-1.0.1-1504.qcow2' from '/opt/cisco/usp/uas-installer/images/usp-uas-1.0.1-1504.qcow2'
2017-11-16 12:54:51,961 - INFO: Loaded image 'auto-it-vnf-ISO-5-1-7-2007-usp-uas-1.0.1-1504.qcow2'
2017-11-16 12:54:53,217 - INFO: Assigned floating IP '10.1.2.8' to IP '172.16.181.9'
2017-11-16 12:54:53,217 - INFO: Creating instance 'auto-it-vnf-ISO-5-1-7-2007-uas-0'
2017-11-16 12:55:20,929 - INFO: Created instance 'auto-it-vnf-ISO-5-1-7-2007-uas-0'
2017-11-16 12:55:20,930 - INFO: Request completed, floating IP: 10.1.2.8
Recargue la imagen ISO. En este caso, la dirección IP de auto-it es 10.1.2.8. Esta operación tardará unos minutos en cargarse:
[stack@director ~]$ cd images/5_1_7-2007/isos
[stack@director isos]$ curl -F file=@usp-5_1_7-2007.iso http://10.1.2.8:5001/isos
{
"iso-id": "5.1.7-2007"
}
to check the ISO image:
[stack@director isos]$ curl http://10.1.2.8:5001/isos
{
"isos": [
{
"iso-id": "5.1.7-2007"
}
]
}
Copie los archivos VNF system.cfg del directorio OSPD Auto-Deploy a auto-it VM:
[stack@director autodeploy]$ scp system-vnf* ubuntu@10.1.2.8:.
ubuntu@10.1.2.8's password:
system-vnf1.cfg 100% 1197 1.2KB/s 00:00
system-vnf2.cfg 100% 1197 1.2KB/s 00:00
ubuntu@auto-it-vnf-iso-2007-uas-0:~$ pwd
/home/ubuntu
ubuntu@auto-it-vnf-iso-2007-uas-0:~$ ls
system-vnf1.cfg system-vnf2.cfg
Nota: El procedimiento de recuperación de EM y UAS VM son iguales en ambos casos. Consulte la sección Case.1 (Caso 1) para obtener información sobre lo mismo.
Gestionar error de recuperación de ESC
En los casos en que ESC no pueda iniciar la máquina virtual debido a un estado inesperado, Cisco recomienda que realice un switchover de ESC reiniciando el ESC maestro. El cambio a ESC tardaría aproximadamente un minuto. Ejecute el script health.sh en el nuevo ESC maestro para verificar si el estado es activo. Maestro ESC para iniciar la VM y fijar el estado de la VM. Esta tarea de recuperación tardará hasta cinco minutos en completarse.
Puede supervisar /var/log/esc/yangesc.log y /var/log/esc/escmanager.log. Si no ve que la VM se recupera después de 5-7 minutos, el usuario tendrá que ir y hacer la recuperación manual de la VM (s) afectada(s).
Actualización de configuración de implementación automática
Desde AutoDeploy VM, edite auto-deploy.cfg y reemplace el antiguo servidor OSD-Compute por el nuevo. A continuación, cargue replace en confd_cli. Este paso es necesario para desactivar la implementación correctamente más adelante.
root@auto-deploy-iso-2007-uas-0:/home/ubuntu# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on auto-deploy-iso-2007-uas-0
auto-deploy-iso-2007-uas-0#config
Entering configuration mode terminal
auto-deploy-iso-2007-uas-0(config)#load replace autodeploy.cfg
Loading. 14.63 KiB parsed in 0.42 sec (34.16 KiB/sec)
auto-deploy-iso-2007-uas-0(config)#commit
Commit complete.
auto-deploy-iso-2007-uas-0(config)#end
Reinicie los servicios uas-confd y Auto-Deploy después del cambio de configuración:
root@auto-deploy-iso-2007-uas-0:~# service uas-confd restart
uas-confd stop/waiting
uas-confd start/running, process 14078
root@auto-deploy-iso-2007-uas-0:~# service uas-confd status
uas-confd start/running, process 14078
root@auto-deploy-iso-2007-uas-0:~# service autodeploy restart
autodeploy stop/waiting
autodeploy start/running, process 14017
root@auto-deploy-iso-2007-uas-0:~# service autodeploy status
autodeploy start/running, process 14017
Habilitación de Syslogs
Para habilitar los registros del sistema para el servidor UCS, los componentes de Openstack y las VM recuperadas, siga las secciones
"Vuelva a habilitar syslog para los componentes de UCS y Openstack" y "Habilite syslog para las VNF" en el enlace siguiente:
Historial de revisiones
| Revisión | Fecha de publicación | Comentarios |
|---|---|---|
1.0 |
10-Jul-2018
|
Versión inicial |
Con la colaboración de ingenieros de Cisco
- Partheeban RajagopalCisco Advanced Services
- Padmaraj RamanoudjamCisco Advanced Services
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)